Image and Video Analysis and Understanding
Share This Topical Collection
Editors
 Dr. Leonardo Galteri
Dr. Leonardo Galteri
Dr. Leonardo Galteri
E-Mail
Website
Guest Editor
Media Integration and Communication Center, University of Florence, 50134 Florence, Italy
Interests: computer vision; multimedia; machine learning; deep learning; pattern recognition
 Prof. Dr. Stefanos Kollias
Prof. Dr. Stefanos Kollias
Prof. Dr. Stefanos Kollias
E-Mail
Website1
Website2
Guest Editor
School of Computer Science, University of Lincoln, Lincoln LN6 7TS, UK
Interests: image and video processing, analysis, coding, storage, retrieval; multimedia systems; computer graphics and virtual reality; artificial intelligence; neural networks; human–computer interaction; medical imaging
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
The significant recent advancements in research fields such as robotics, autonomous driving, and human-machine interaction have strongly renewed the interest in understanding the physical world through computer vision systems. In addition, the opportunities that arise from new significant technological advances such as deep learning, expert systems, and other intelligent algorithms make it possible to design innovative solutions that can be effectively applied in real case scenarios. The proper development of computer vision techniques can significantly contribute to improving both the effectiveness and efficiency of image and video understanding.
The main aim of this Special Issue is to collect high-quality submissions that focus on image and video understanding and analysis, addressing the new challenges and the major breakthroughs in this field. General topics covered in this Special Issue include, but are not limited to:
- 3D reconstruction from images and videos;
- Image and video segmentation;
- Motion analysis;
- Action recognition;
- Object detection and tracking;
- Image and video enhancement;
- Compressive sensing;
- Face recognition;
- Image captioning;
- Video and image parsing;
- Reinforcement learning;
- Computer vision applications
Dr. Leonardo Galteri
Dr. Claudio Ferrari
Prof. Dr. Stefanos Kollias
Guest Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Electronics is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- computer vision
- image and video analysis
- deep learning
- biometrics multi-modal vision scene understanding
Published Papers (23 papers)
Open AccessArticle
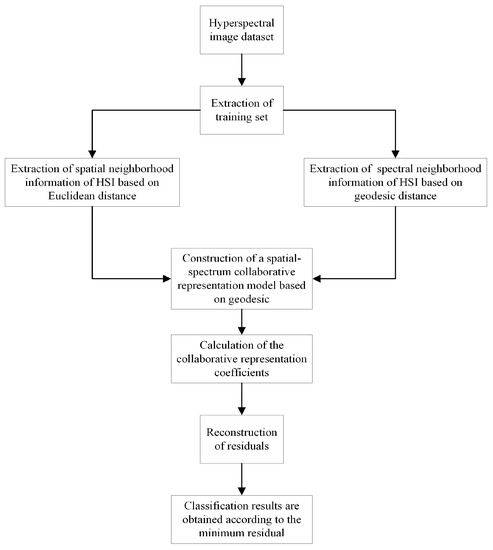
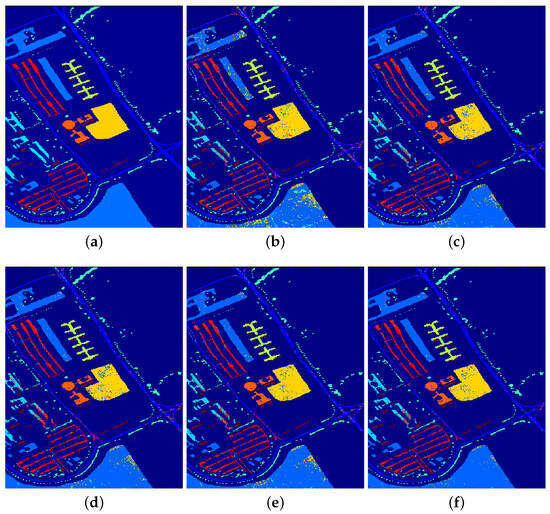
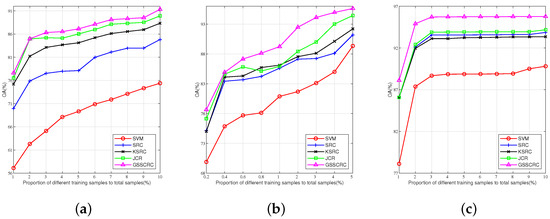
Hyperspectral Image Classification Using Geodesic Spatial–Spectral Collaborative Representation
by
Guifeng Zheng, Xuanrui Xiong, Ying Li, Juan Xi, Tengfei Li and Amr Tolba
Cited by 1 | Viewed by 795
Abstract
With the continuous advancement of remote sensing technology, the information encapsulated within hyperspectral images has become increasingly enriched. The effective and comprehensive utilization of spatial and spectral information to achieve the accurate classification of hyperspectral images presents a significant challenge in the domain
[...] Read more.
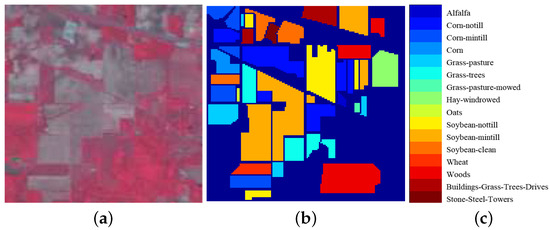
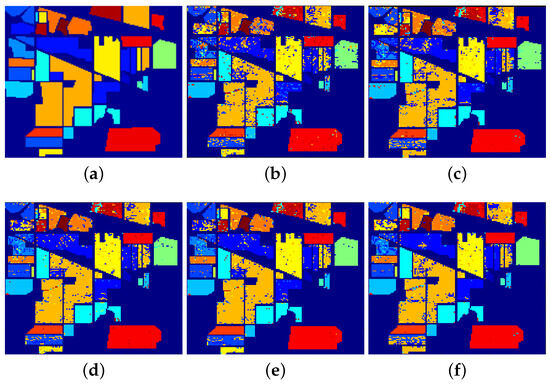
With the continuous advancement of remote sensing technology, the information encapsulated within hyperspectral images has become increasingly enriched. The effective and comprehensive utilization of spatial and spectral information to achieve the accurate classification of hyperspectral images presents a significant challenge in the domain of hyperspectral image processing. To address this, this paper introduces a novel approach to hyperspectral image classification based on geodesic spatial–spectral collaborative representation. It introduces geodesic distance to extract spectral neighboring information from hyperspectral images and concurrently employs Euclidean distance to extract spatial neighboring information. By integrating collaborative representation with spatial–spectral information, the model is constructed. The collaborative representation coefficients are obtained by solving the model to reconstruct the testing samples, leading to the classification results derived from the minimum reconstruction residuals. Finally, with comparative experiments conducted on three classical hyperspectral image datasets, the effectiveness of the proposed method is substantiated. On the Indian Pines dataset, the proposed algorithm achieved overall accuracy (OA) of 91.33%, average accuracy (AA) of 93.81%, and kappa coefficient (Kappa) of 90.13%. In the case of the Salinas dataset, OA was 95.62%; AA was 97.30%; and Kappa was 93.84%. Lastly, on the PaviaU dataset, OA stood at 95.77%; AA was 94.13%; and Kappa was 94.38%.
Full article
►▼
Show Figures
Open AccessArticle
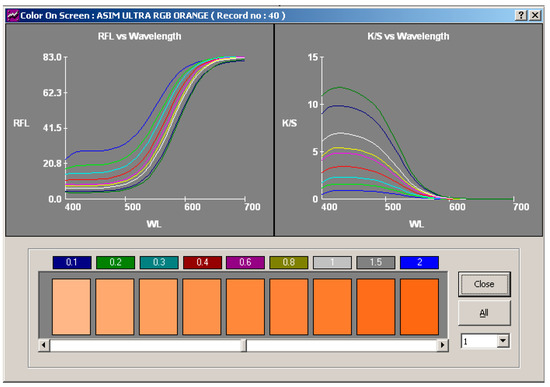
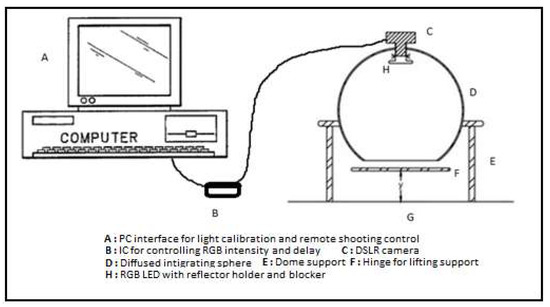
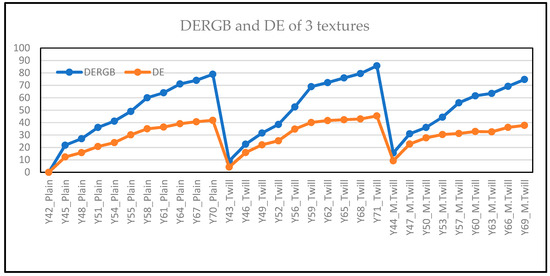
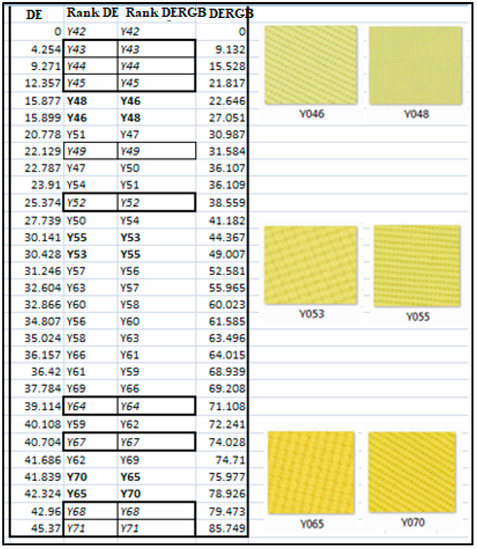
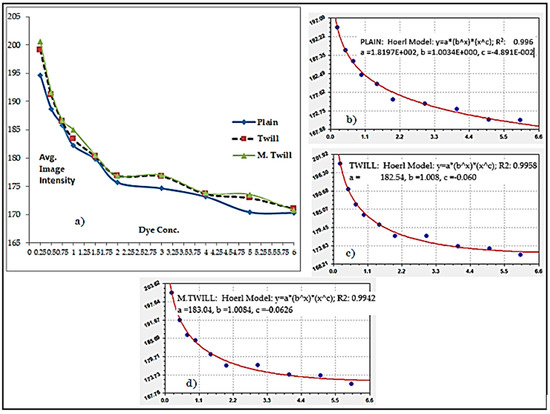
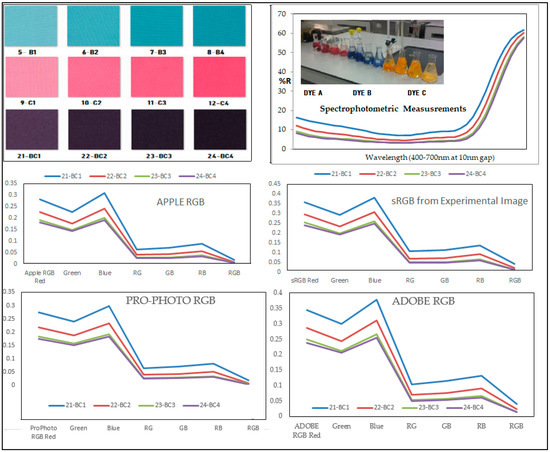
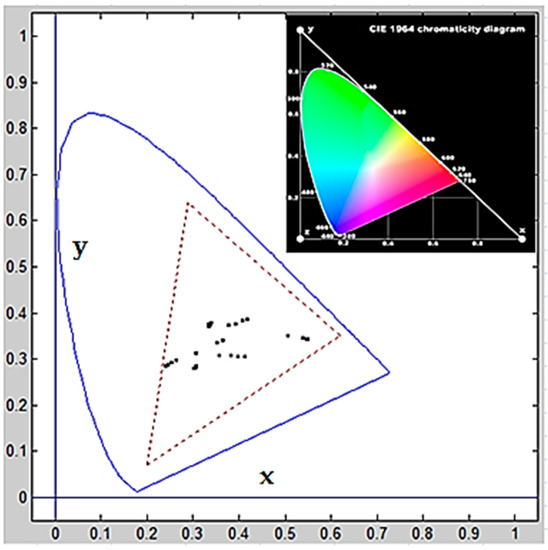
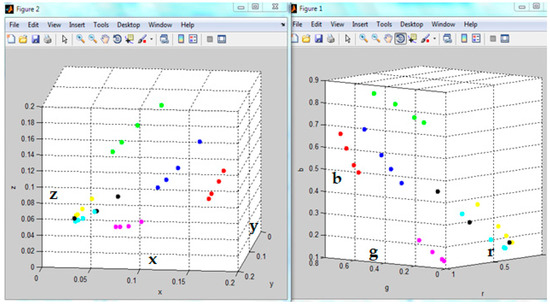
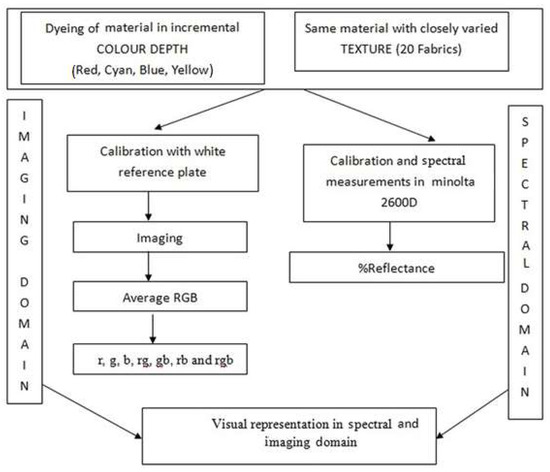
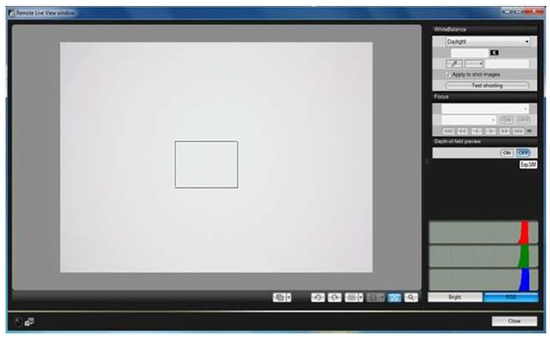
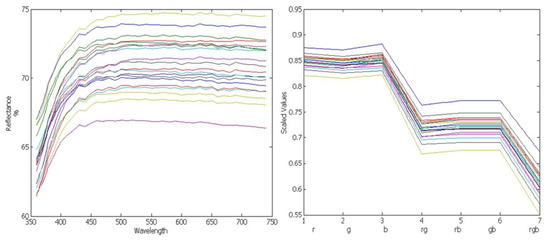
Color and Texture Analysis of Textiles Using Image Acquisition and Spectral Analysis in Calibrated Sphere Imaging System-II
by
Nibedita Rout, Jinlian Hu, George Baciu, Priyabrata Pattanaik, K. Nakkeeran and Asimananda Khandual
Viewed by 1591
Abstract
The extended application of device-dependent systems’ vision is growing exponentially, but these systems face challenges in precisely imitating the human perception models established by the device-independent systems of the Commission internationale de l’éclairage (CIE). We previously discussed the theoretical treatment and experimental validation
[...] Read more.
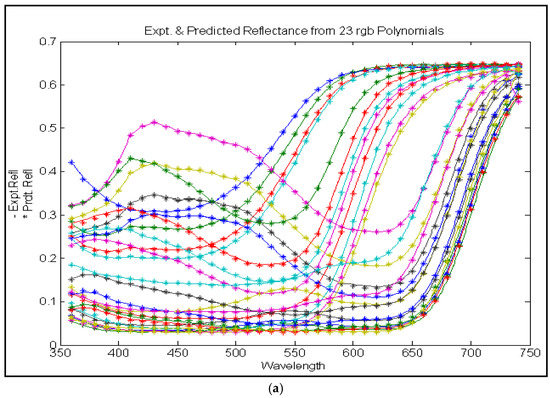
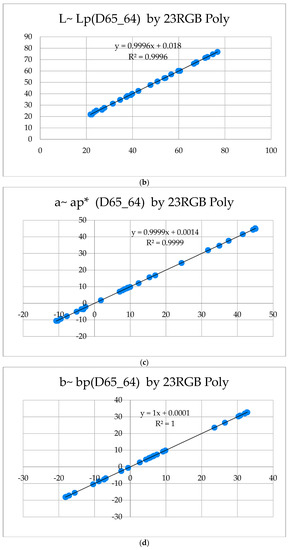
The extended application of device-dependent systems’ vision is growing exponentially, but these systems face challenges in precisely imitating the human perception models established by the device-independent systems of the Commission internationale de l’éclairage (CIE). We previously discussed the theoretical treatment and experimental validation of developing a calibrated integrated sphere imaging system to imitate the visible spectroscopy environment. The RGB polynomial function was derived to obtain a meaningful interpretation of color features. In this study, we dyed three different types of textured materials in the same bath with a yellow reactive dye at incremental concentrations to see how their color difference profiles tested. Three typical cotton textures were dyed with three ultra-RGB remozol reactive dyes and their combinations. The color concentration ranges of 1%, 2%, 3%, and 4% were chosen for each dye, followed by their binary and ternary mixtures. The aim was to verify the fundamental spectral feature mapping in various imaging color spaces and spectral domains. The findings are quite interesting and help us to understand the ground truth behind working in two domains. In addition, the trends of color mixing, CIE color difference, CIExy (chromaticity) color gamut, and RGB gamut and their distinguishing features were verified. Human perception accuracy was also compared in both domains to clarify the influence of texture. These fundamental experiments and observations on human perception and calibrated imaging color space could clarify the expected precision in both domains.
Full article
►▼
Show Figures
Open AccessArticle
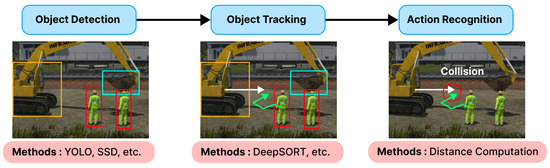
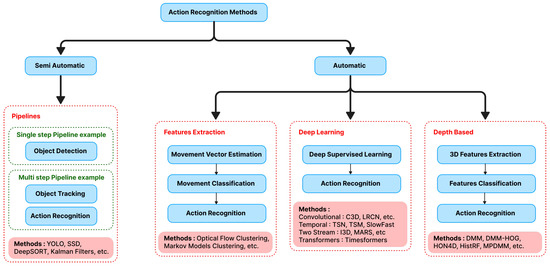
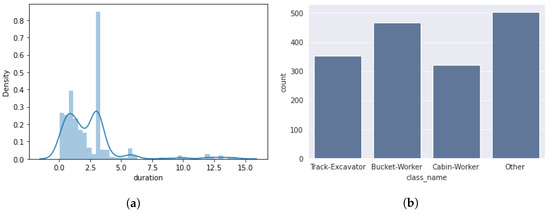
A Review and Comparative Study of Explainable Deep Learning Models Applied on Action Recognition in Real Time
by
Sidi Ahmed Mahmoudi, Otmane Amel, Sédrick Stassin, Margot Liagre, Mohamed Benkedadra and Matei Mancas
Cited by 4 | Viewed by 2407
Abstract
Video surveillance and image acquisition systems represent one of the most active research topics in computer vision and smart city domains. The growing concern for public and workers’ safety has led to a significant increase in the use of surveillance cameras that provide
[...] Read more.
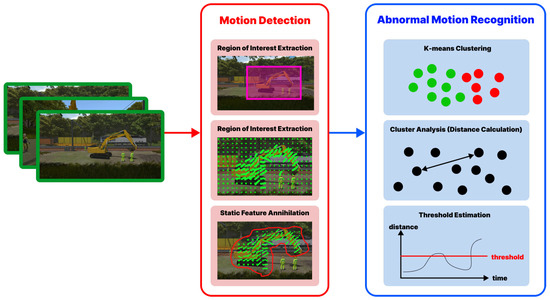
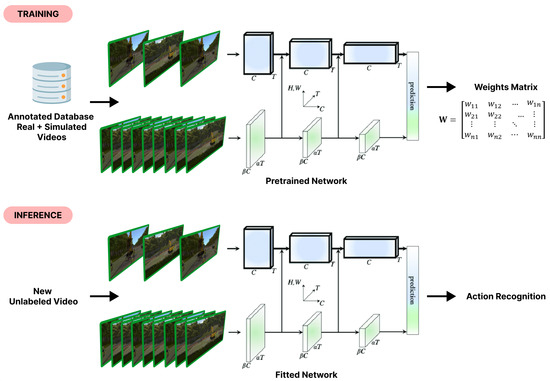
Video surveillance and image acquisition systems represent one of the most active research topics in computer vision and smart city domains. The growing concern for public and workers’ safety has led to a significant increase in the use of surveillance cameras that provide high-definition images and even depth maps when 3D cameras are available. Consequently, the need for automatic techniques for behavior analysis and action recognition is also increasing for several applications such as dangerous actions detection in railway stations or construction sites, event detection in crowd videos, behavior analysis, optimization in industrial sites, etc. In this context, several computer vision and deep learning solutions have been proposed recently where deep neural networks provided more accurate solutions, but they are not so efficient in terms of explainability and flexibility since they remain adapted for specific situations only. Moreover, the complexity of deep neural architectures requires the use of high computing resources to provide fast and real-time computations. In this paper, we propose a review and a comparative analysis of deep learning solutions in terms of precision, explainability, computation time, memory size, and flexibility. Experimental results are conducted within simulated and real-world dangerous actions in railway construction sites. Thanks to our comparative analysis and evaluation, we propose a personalized approach for dangerous action recognition depending on the type of collected data (image) and users’ requirements.
Full article
►▼
Show Figures
Open AccessArticle
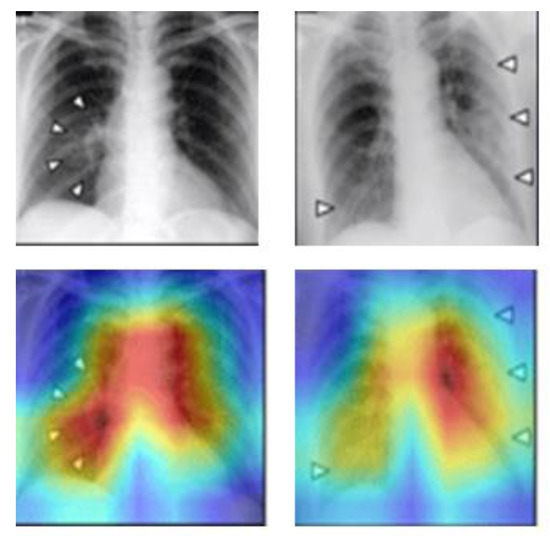
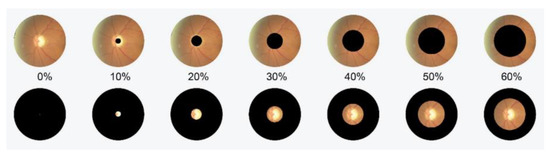
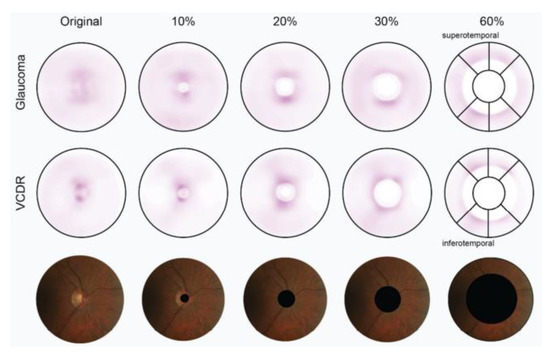
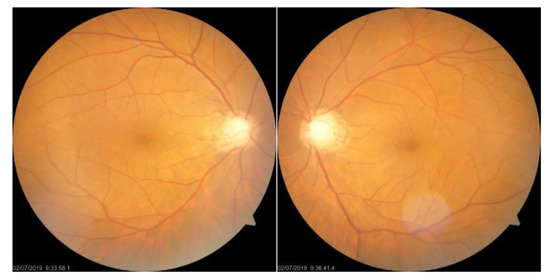
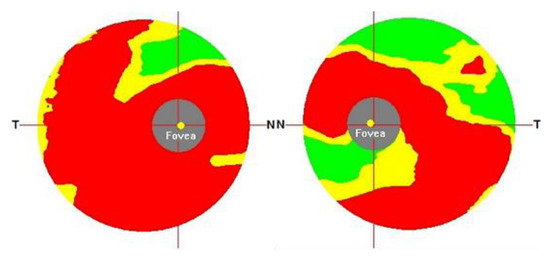
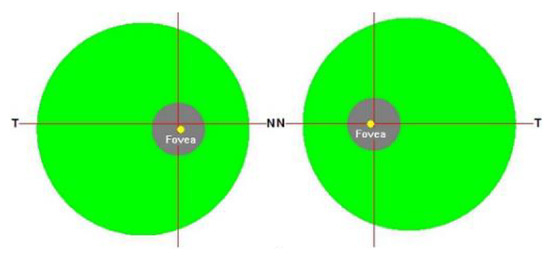
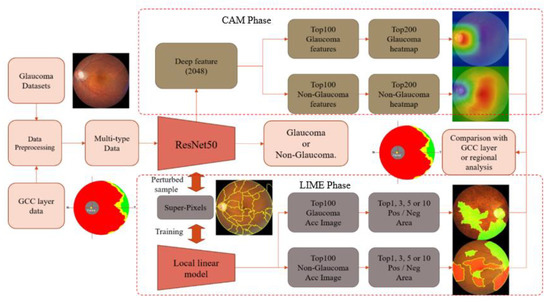
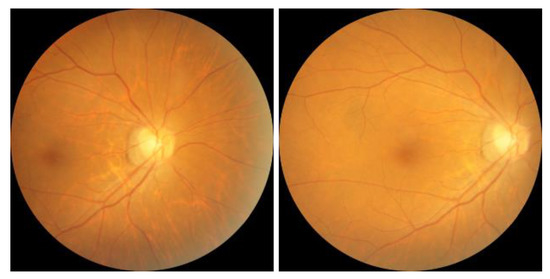
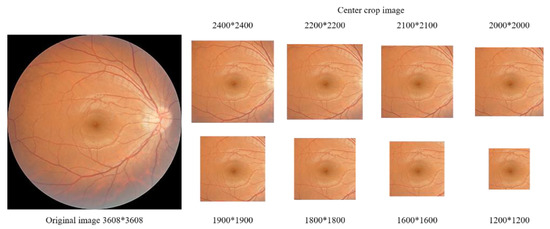
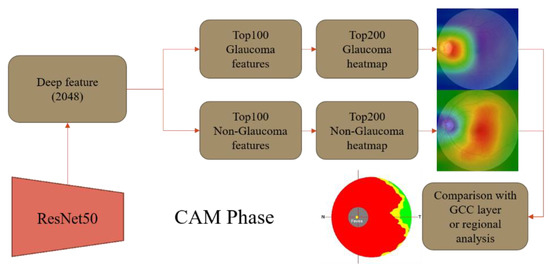
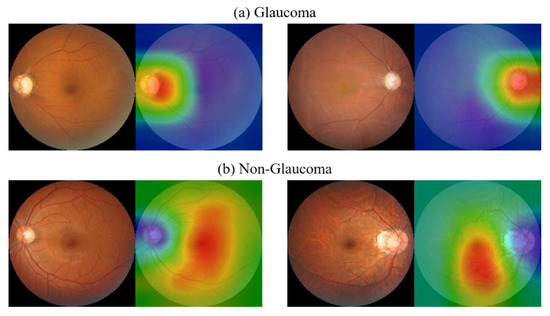
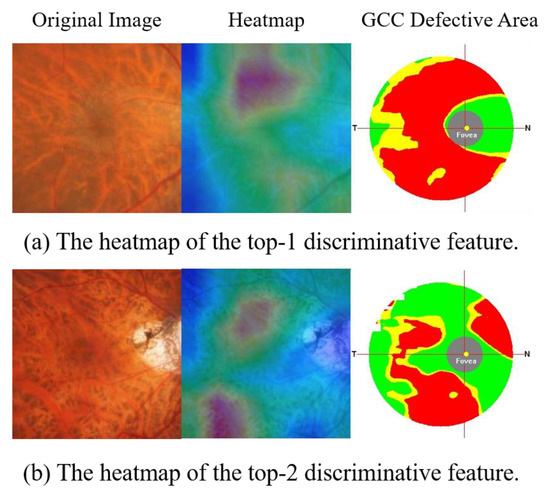
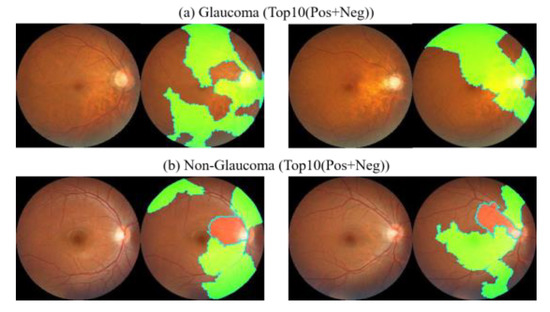
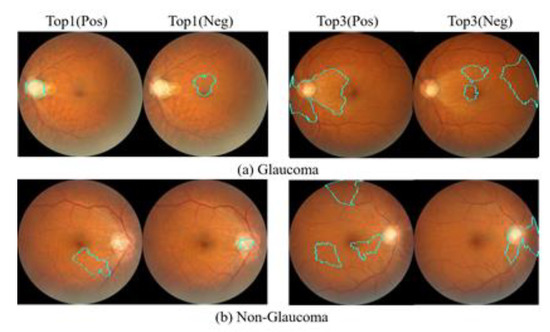
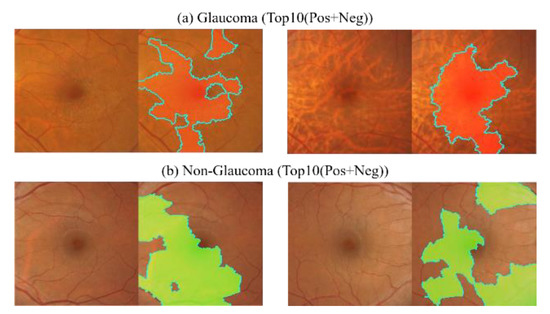
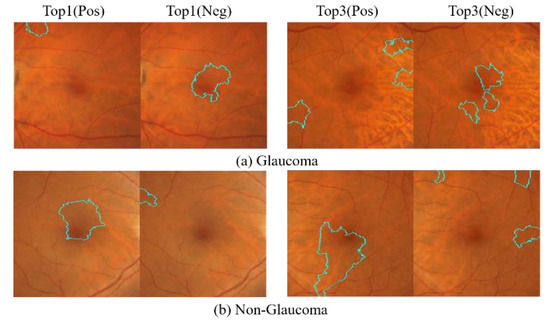
A Study of the Interpretability of Fundus Analysis with Deep Learning-Based Approaches for Glaucoma Assessment
by
Jing-Ming Guo, Yu-Ting Hsiao, Wei-Wen Hsu, Sankarasrinivasan Seshathiri, Jiann-Der Lee, Yan-Min Luo and Peizhong Liu
Cited by 1 | Viewed by 1229
Abstract
Earlier studies focused on training ResNet50 deep learning models on a dataset of fundus images from the National Taiwan University Hospital HsinChu Branch. The study aimed to identify class-specific discriminative areas related to various conditions of ganglion cell complex (GCC) thickness, center focus
[...] Read more.
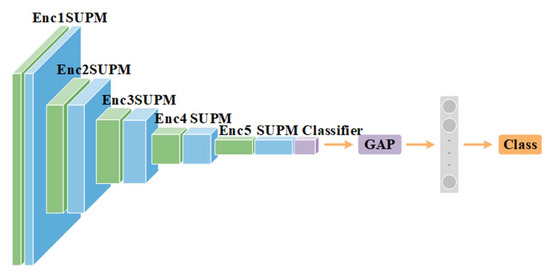
Earlier studies focused on training ResNet50 deep learning models on a dataset of fundus images from the National Taiwan University Hospital HsinChu Branch. The study aimed to identify class-specific discriminative areas related to various conditions of ganglion cell complex (GCC) thickness, center focus areas, cropped patches from the fundus, and dataset partitions. The study utilized two visualization methods to evaluate and explain the areas of interest of the network model and determine if they aligned with clinical diagnostic knowledge. The results of the experiments demonstrated that incorporating GCC thickness information improved the accuracy of glaucoma determination. The deep learning models primarily focused on the optic nerve head (ONH) for glaucoma diagnosis, which was consistent with clinical rules. Nonetheless, the models achieved high prediction accuracy in detecting glaucomatous cases using only cropped images of macular areas. Moreover, the model’s focus on regions with GCC impairment in some cases indicates that deep learning models can identify morphologically detailed alterations in fundus photographs that may be beyond the scope of visual diagnosis by experts. This highlights the significant contribution of deep learning models in the diagnosis of glaucoma.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
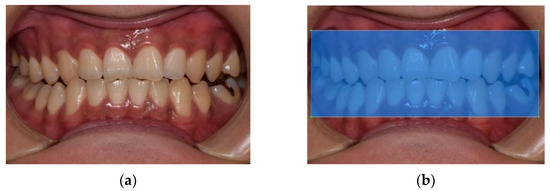
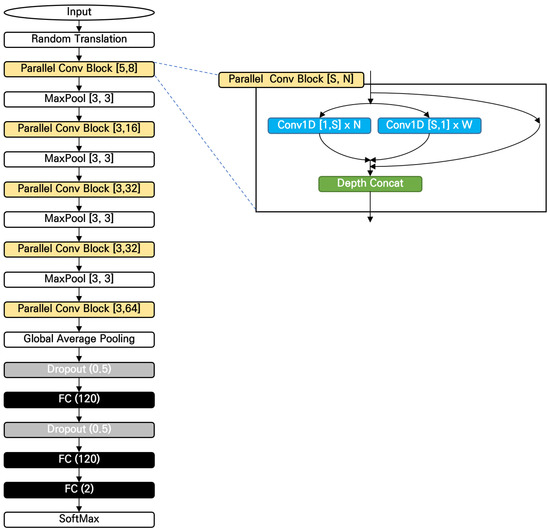
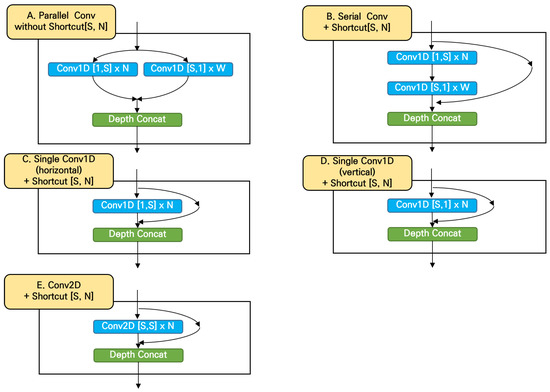
Periodontal Disease Classification with Color Teeth Images Using Convolutional Neural Networks
by
Saron Park, Habibilloh Erkinov, Md. Al Mehedi Hasan, Seoul-Hee Nam, Yu-Rin Kim, Jungpil Shin and Won-Du Chang
Cited by 3 | Viewed by 2479
Abstract
Oral health plays an important role in people’s quality of life as it is related to eating, talking, and smiling. In recent years, many studies have utilized artificial intelligence for oral health care. Many studies have been published on tooth identification or recognition
[...] Read more.
Oral health plays an important role in people’s quality of life as it is related to eating, talking, and smiling. In recent years, many studies have utilized artificial intelligence for oral health care. Many studies have been published on tooth identification or recognition of dental diseases using X-ray images, but studies with RGB images are rarely found. In this paper, we propose a deep convolutional neural network (CNN) model that classifies teeth with periodontal diseases from optical color images captured in front of the mouth. A novel network module with one-dimensional convolutions in parallel was proposed and compared to the conventional models including ResNet152. In results, the proposed model achieved 11.45% higher than ResNet152 model, and it was proved that the proposed structure enhanced the training performances, especially when the amount of training data was insufficient. This paper shows the possibility of utilizing optical color images for the detection of periodontal diseases, which may lead to a mobile oral healthcare system in the future.
Full article
►▼
Show Figures
Open AccessArticle
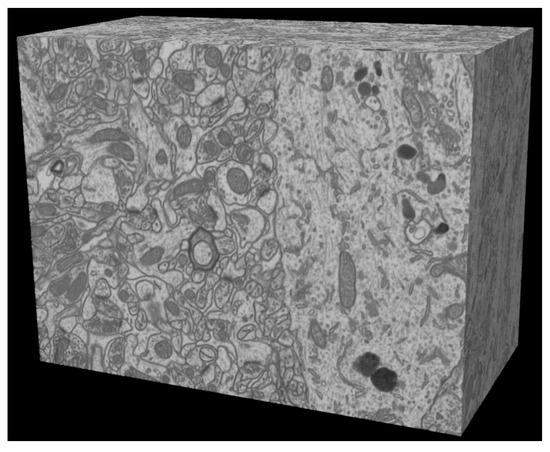
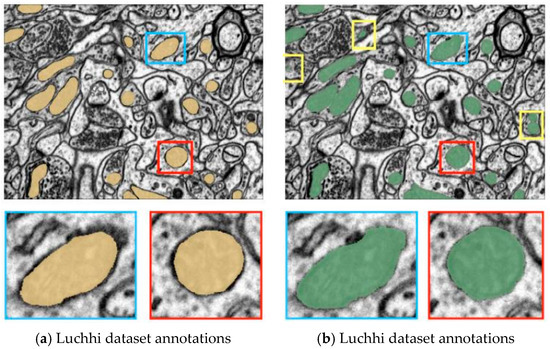
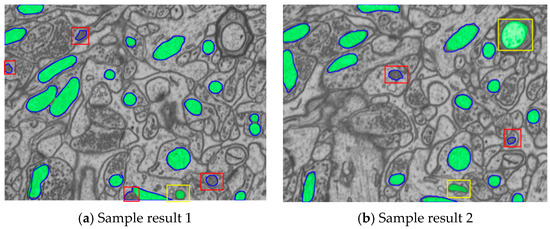
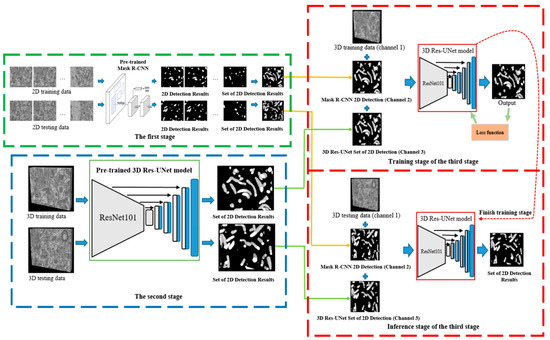
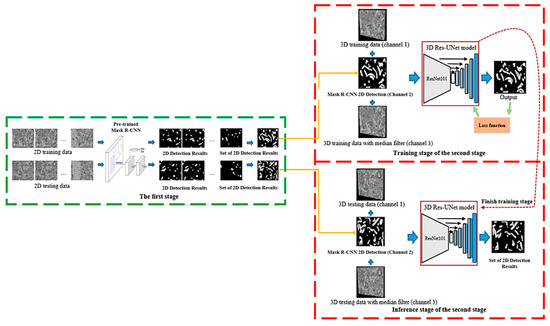
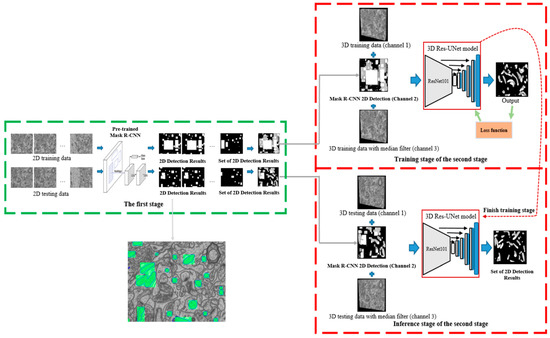
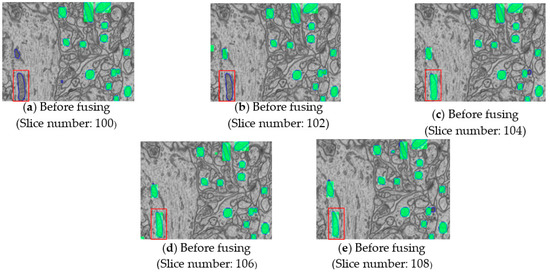
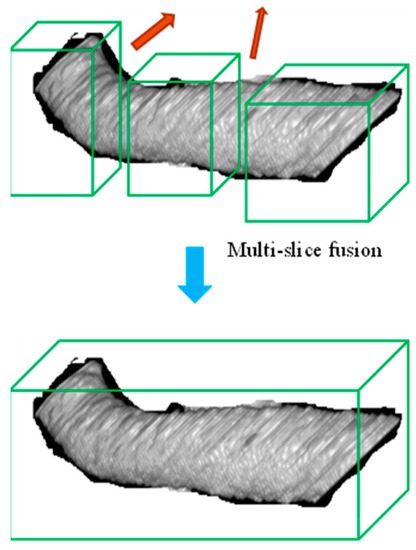
Two-Stage Cascaded CNN Model for 3D Mitochondria EM Segmentation
by
Jing-Ming Guo, Sankarasrinivasan Seshathiri, Jia-Hao Liu and Wei-Wen Hsu
Viewed by 1386
Abstract
Mitochondria are the organelles that generate energy for the cells. Many studies have suggested that mitochondrial dysfunction or impairment may be related to cancer and other neurodegenerative disorders such as Alzheimer’s and Parkinson’s diseases. Therefore, morphologically detailed alterations in mitochondria and 3D reconstruction
[...] Read more.
Mitochondria are the organelles that generate energy for the cells. Many studies have suggested that mitochondrial dysfunction or impairment may be related to cancer and other neurodegenerative disorders such as Alzheimer’s and Parkinson’s diseases. Therefore, morphologically detailed alterations in mitochondria and 3D reconstruction of mitochondria are highly demanded research problems in the performance of clinical diagnosis. Nevertheless, manual mitochondria segmentation over 3D electron microscopy volumes is not a trivial task. This study proposes a two-stage cascaded CNN architecture to achieve automated 3D mitochondria segmentation, combining the merits of top-down and bottom-up approaches. For top-down approaches, the segmentation is conducted on objects’ localization so that the delineations of objects’ contours can be more precise. However, the combinations of 2D segmentation from the top-down approaches are inadequate to perform proper 3D segmentation without the information on connectivity among frames. On the other hand, the bottom-up approach finds coherent groups of pixels and takes the information of 3D connectivity into account in segmentation to avoid the drawbacks of the 2D top-down approach. However, many small areas that share similar pixel properties with mitochondria become false positives due to insufficient information on objects’ localization. In the proposed method, the detection of mitochondria is carried out with multi-slice fusion in the first stage, forming the segmentation cues. Subsequently, the second stage is to perform 3D CNN segmentation that learns the pixel properties and the information of 3D connectivity under the supervision of cues from the detection stage. Experimental results show that the proposed structure alleviates the problems in both the top-down and bottom-up approaches, which significantly accomplishes better performance in segmentation and expedites clinical analysis.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
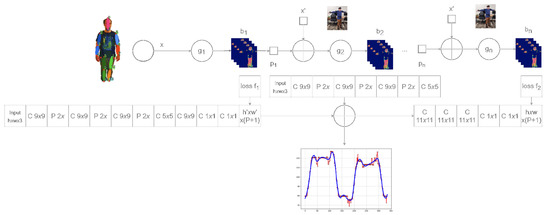
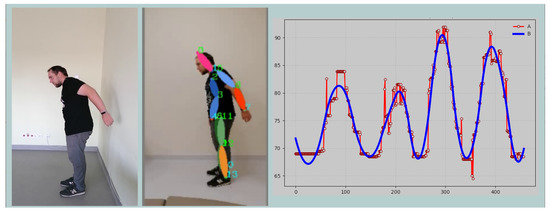
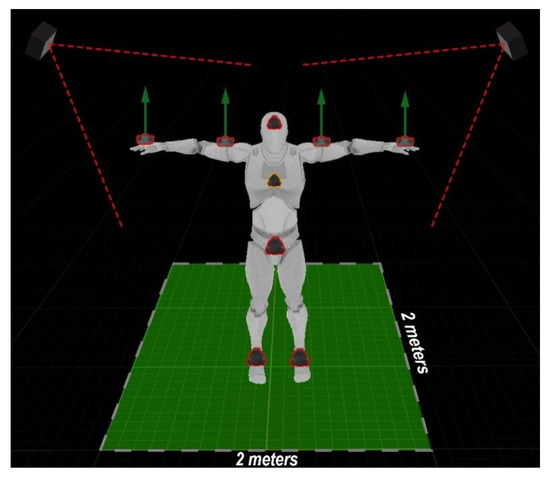
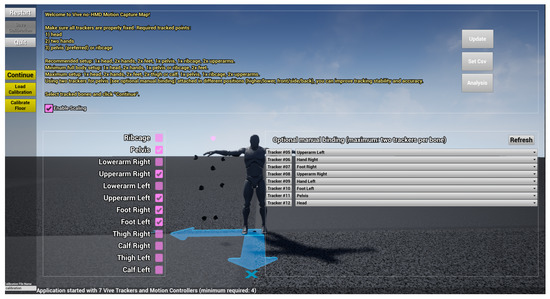
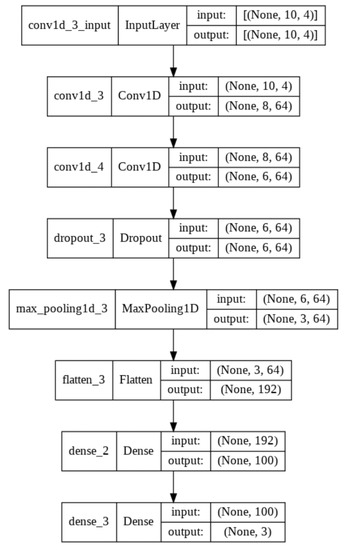
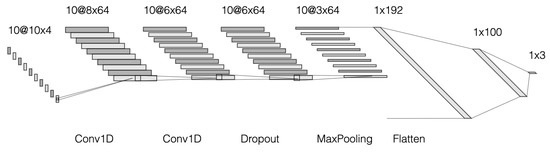
BiomacVR: A Virtual Reality-Based System for Precise Human Posture and Motion Analysis in Rehabilitation Exercises Using Depth Sensors
by
Rytis Maskeliūnas, Robertas Damaševičius, Tomas Blažauskas, Cenker Canbulut, Aušra Adomavičienė and Julius Griškevičius
Cited by 9 | Viewed by 3883
Abstract
Remote patient monitoring is one of the most reliable choices for the availability of health care services for the elderly and/or chronically ill. Rehabilitation requires the exact and medically correct completion of physiotherapy activities. This paper presents BiomacVR, a virtual reality (VR)-based rehabilitation
[...] Read more.
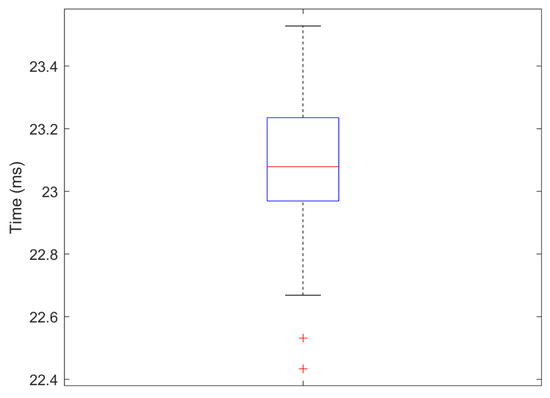
Remote patient monitoring is one of the most reliable choices for the availability of health care services for the elderly and/or chronically ill. Rehabilitation requires the exact and medically correct completion of physiotherapy activities. This paper presents BiomacVR, a virtual reality (VR)-based rehabilitation system that combines a VR physical training monitoring environment with upper limb rehabilitation technology for accurate interaction and increasing patients’ engagement in rehabilitation training. The system utilises a deep learning motion identification model called Convolutional Pose Machine (CPM) that uses a stacked hourglass network. The model is trained to precisely locate critical places in the human body using image sequences collected by depth sensors to identify correct and wrong human motions and to assess the effectiveness of physical training based on the scenarios presented. This paper presents the findings of the eight most-frequently used physical training exercise situations from post-stroke rehabilitation methodology. Depth sensors were able to accurately identify key parameters of the posture of a person performing different rehabilitation exercises. The average response time was 23 ms, which allows the system to be used in real-time applications. Furthermore, the skeleton features obtained by the system are useful for discriminating between healthy (normal) subjects and subjects suffering from lower back pain. Our results confirm that the proposed system with motion recognition methodology can be used to evaluate the quality of the physiotherapy exercises of the patient and monitor the progress of rehabilitation and assess its effectiveness.
Full article
►▼
Show Figures
Open AccessArticle
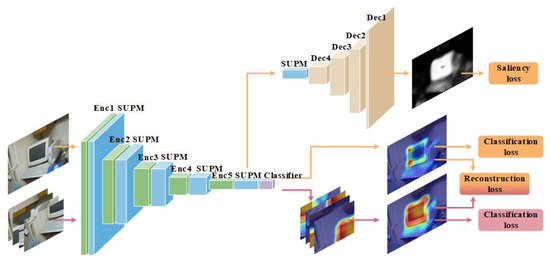
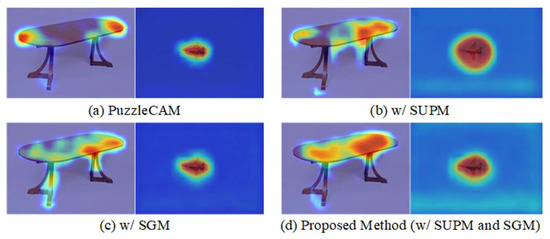
Saliency Guidance and Expansion Suppression on PuzzleCAM for Weakly Supervised Semantic Segmentation
by
Rong-Hsuan Chang, Jing-Ming Guo and Sankarasrinivasan Seshathiri
Cited by 1 | Viewed by 1204
Abstract
The semantic segmentation model usually provides pixel-wise category prediction for images. However, a massive amount of pixel-wise annotation images is required for model training, which is time-consuming and labor-intensive. An image-level categorical annotation is recently popular and attempted to overcome the above issue
[...] Read more.
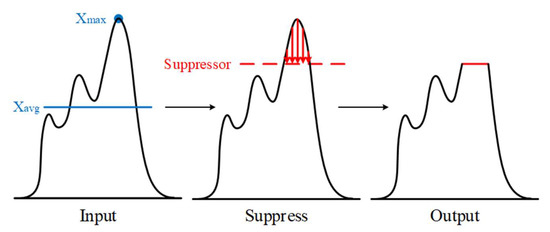
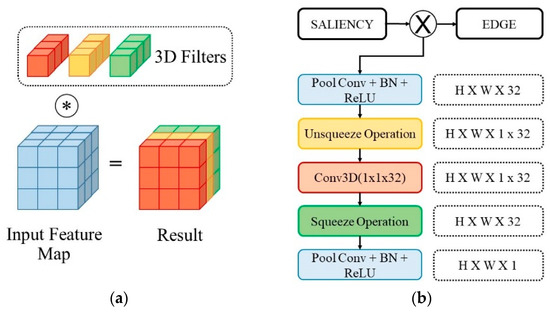
The semantic segmentation model usually provides pixel-wise category prediction for images. However, a massive amount of pixel-wise annotation images is required for model training, which is time-consuming and labor-intensive. An image-level categorical annotation is recently popular and attempted to overcome the above issue in this work. This is also termed weakly supervised semantic segmentation, and the general framework aims to generate pseudo masks with class activation mapping. This can be learned through classification tasks that focus on explicit features. Some major issues in these approaches are as follows: (1) Excessive attention on the specific area; (2) for some objects, the detected range is beyond the boundary, and (3) the smooth areas or minor color gradients along the object are difficult to categorize. All these problems are comprehensively addressed in this work, mainly to overcome the importance of overly focusing on significant features. The suppression expansion module is used to diminish the centralized features and to expand the attention view. Moreover, to tackle the misclassification problem, the saliency-guided module is adopted to assist in learning regional information. It limits the object area effectively while simultaneously resolving the challenge of internal color smoothing. Experimental results show that the pseudo masks generated by the proposed network can achieve 76.0%, 73.3%, and 73.5% in mIoU with the PASCAL VOC 2012 train, validation, and test set, respectively, and outperform the state-of-the-art methods.
Full article
►▼
Show Figures
Open AccessArticle
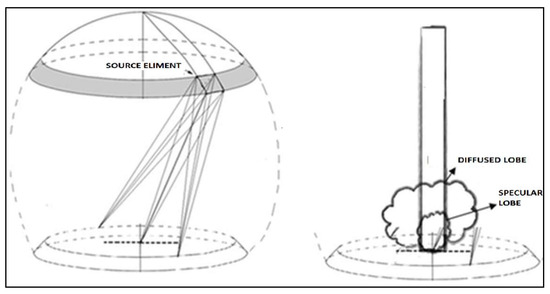
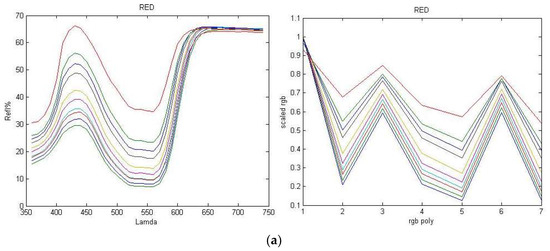
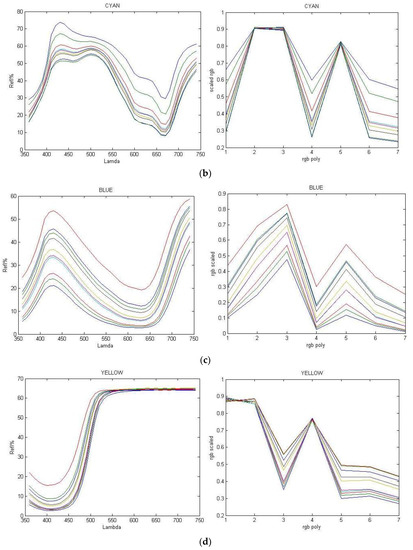
Color and Texture Analysis of Textiles Using Image Acquisition and Spectral Analysis in Calibrated Sphere Imaging System-I
by
Nibedita Rout, George Baciu, Priyabrata Pattanaik, K. Nakkeeran and Asimananda Khandual
Cited by 1 | Viewed by 1309
Abstract
Numerous imaging applications and analyses demand human perception, and color space transformation of device-dependent tri-band color interpretation (RGB) to device-independent CIE color space standards needs human intervention. The imaging acquisition environment, theoretical conversion errors, viewing geometry, well-defined illumination uniformity, and calibration protocols limit
[...] Read more.
Numerous imaging applications and analyses demand human perception, and color space transformation of device-dependent tri-band color interpretation (RGB) to device-independent CIE color space standards needs human intervention. The imaging acquisition environment, theoretical conversion errors, viewing geometry, well-defined illumination uniformity, and calibration protocols limit their precision and applicability. It is unfortunate that in most image processing applications, the spectral data are either unavailable or immeasurable. This study is based on developing a novel integrating sphere imaging system and experimentation with textiles’ controlled variation of texture and color. It proposes a simple calibration technique and describes how unique digital color signatures can be derived from calibrated RGB derivatives to extract the best features for color and texture. Additionally, an alter-ego of reflectance function, missing in the imaging domain, is suggested that could be helpful for visualization, identification, and application for qualitative and quantitative color-texture analysis. Our further investigation revealed promising colorimetric results while validating color characterization and different color combinations over three textures.
Full article
►▼
Show Figures
Open AccessArticle
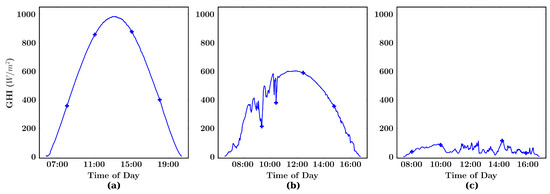
Deep Learning-Based Image Regression for Short-Term Solar Irradiance Forecasting on the Edge
by
Elissaios Alexios Papatheofanous, Vasileios Kalekis, Georgios Venitourakis, Filippos Tziolos and Dionysios Reisis
Cited by 4 | Viewed by 3057
Abstract
Photovoltaic (PV) power production is characterized by high variability due to short-term meteorological effects such as cloud movements. These effects have a significant impact on the incident solar irradiance in PV parks. In order to control PV park performance, researchers have focused on
[...] Read more.
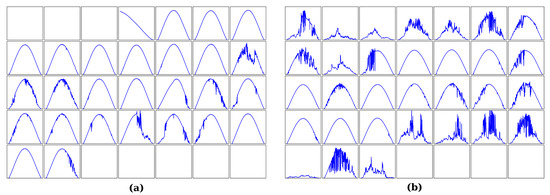
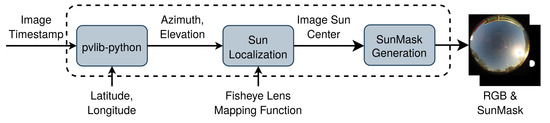
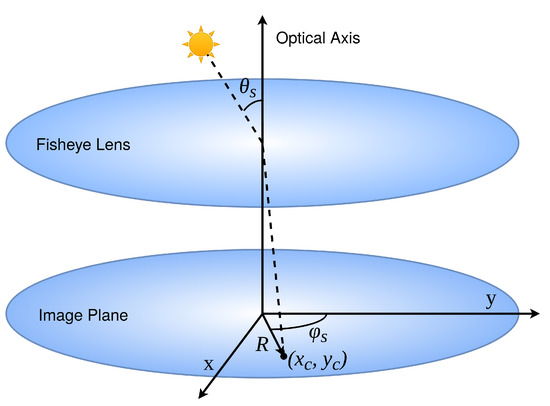
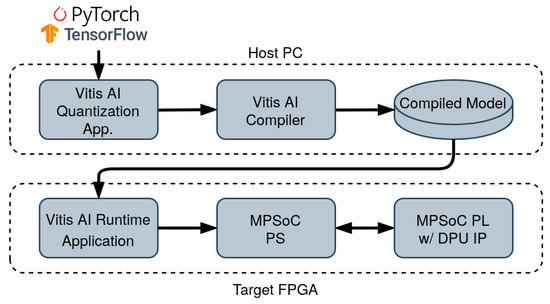
Photovoltaic (PV) power production is characterized by high variability due to short-term meteorological effects such as cloud movements. These effects have a significant impact on the incident solar irradiance in PV parks. In order to control PV park performance, researchers have focused on Computer Vision and Deep Learning approaches to perform short-term irradiance forecasting using sky images. Motivated by the task of improving PV park control, the current work introduces the Image Regression Module, which produces irradiance values from sky images using image processing methods and Convolutional Neural Networks (CNNs). With the objective of enhancing the performance of CNN models on the task of irradiance estimation and forecasting, we propose an image processing method based on sun localization. Our findings show that the proposed method can consistently improve the accuracy of irradiance values produced by all the CNN models of our study, reducing the Root Mean Square Error by up to 10.44 W/m
for the MobileNetV2 model. These findings indicate that future applications which utilize CNNs for irradiance forecasting should identify the position of the sun in the image in order to produce more accurate irradiance values. Moreover, the integration of the proposed models on an edge-oriented Field-Programmable Gate Array (FPGA) towards a smart PV park for the real-time control of PV production emphasizes their advantages.
Full article
►▼
Show Figures
Open AccessArticle
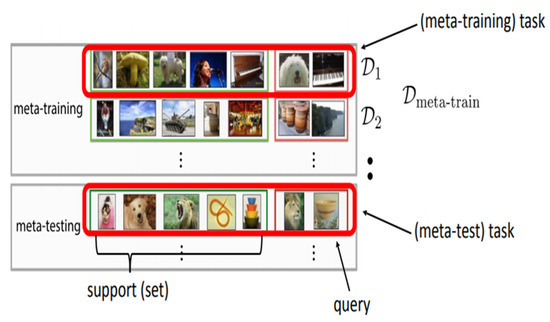
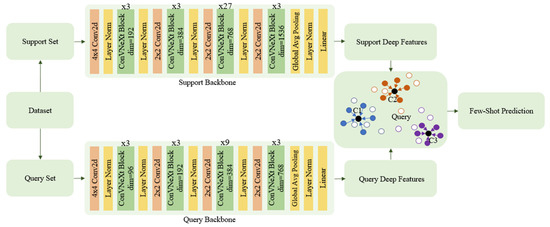
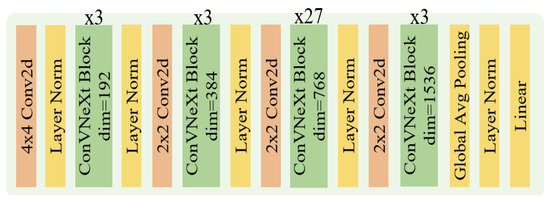
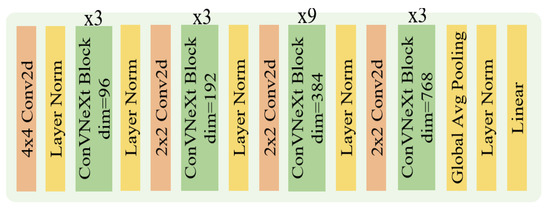
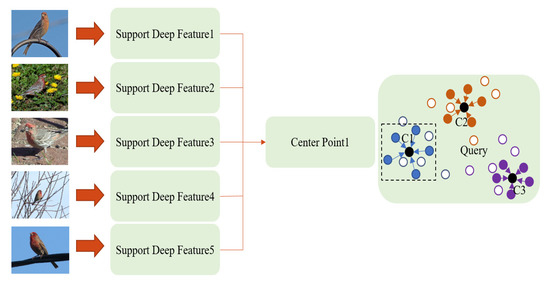
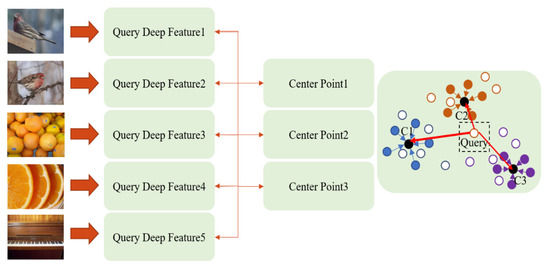
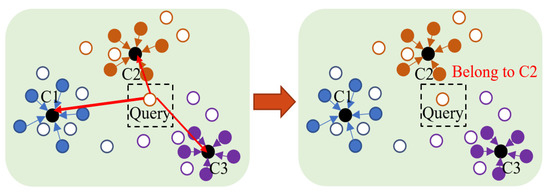
Few-Shot Classification with Dual-Model Deep Feature Extraction and Similarity Measurement
by
Jing-Ming Guo, Sankarasrinivasan Seshathiri and Wen-Hsiang Chen
Cited by 1 | Viewed by 1264
Abstract
From traditional machine learning to the latest deep learning classifiers, most models require a large amount of labeled data to perform optimal training and obtain the best performance. Yet, when limited training samples are available or when accompanied by noisy labels, severe degradation
[...] Read more.
From traditional machine learning to the latest deep learning classifiers, most models require a large amount of labeled data to perform optimal training and obtain the best performance. Yet, when limited training samples are available or when accompanied by noisy labels, severe degradation in accuracy can arise. The proposed work mainly focusses on these practical issues. Herein, standard datasets, i.e., Mini-ImageNet, CIFAR-FS, and CUB 200, are considered, which also have similar issues. The main goal is to utilize a few labeled data in the training stage, extracting image features and then performing feature similarity analysis across all samples. The highlighted aspects of the proposed method are as follows. (1) The main self-supervised learning strategies and augmentation techniques are exploited to obtain the best pretrained model. (2) An improved dual-model mechanism is proposed to train the support and query datasets with multiple training configurations. As examined in the experiments, the dual-model approach obtains superior performance of few-shot classification compared with all of the state-of-the-art methods.
Full article
►▼
Show Figures
Open AccessArticle
Optimized Seam-Driven Image Stitching Method Based on Scene Depth Information
by
Xin Chen, Mei Yu and Yang Song
Cited by 8 | Viewed by 2711
Abstract
It is quite challenging to stitch images with continuous depth changes and complex textures. To solve this problem, we propose an optimized seam-driven image stitching method considering depth, color, and texture information of the scene. Specifically, we design a new energy function to
[...] Read more.
It is quite challenging to stitch images with continuous depth changes and complex textures. To solve this problem, we propose an optimized seam-driven image stitching method considering depth, color, and texture information of the scene. Specifically, we design a new energy function to reduce the structural distortion near the seam and improve the invisibility of the seam. By additionally introducing depth information into the smoothing term of energy function, the seam is guided to pass through the continuous regions of the image with high similarity. The experimental results show that benefiting from the new defined energy function, the proposed method can find the seam that adapts to the depth of the scene, and effectively avoid the seam from passing through the salient objects, so that high-quality stitching results can be achieved. The comparison with the representative image stitching methods proves the effectiveness and generalization of the proposed method.
Full article
►▼
Show Figures
Open AccessArticle
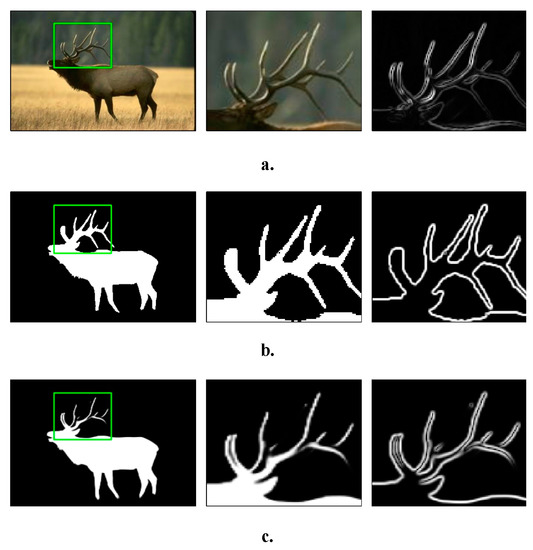
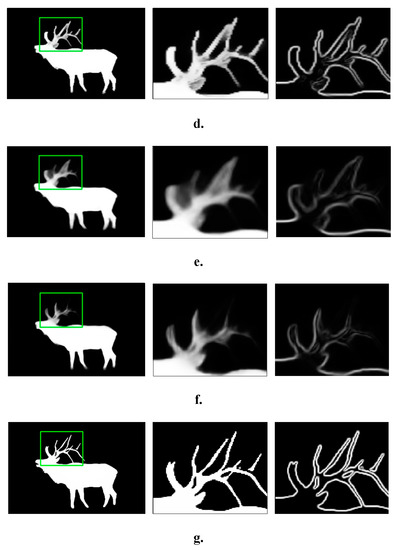
MEAN: Multi-Edge Adaptation Network for Salient Object Detection Refinement
by
Jing-Ming Guo and Herleeyandi Markoni
Viewed by 1407
Abstract
Recent advances in salient object detection adopting deep convolutional neural networks have achieved state-of-the-art performance. Salient object detection is task in computer vision to detect interesting objects. Most of the Convolutional Neural Network (CNN)-based methods produce plausible saliency outputs, yet with extra computational
[...] Read more.
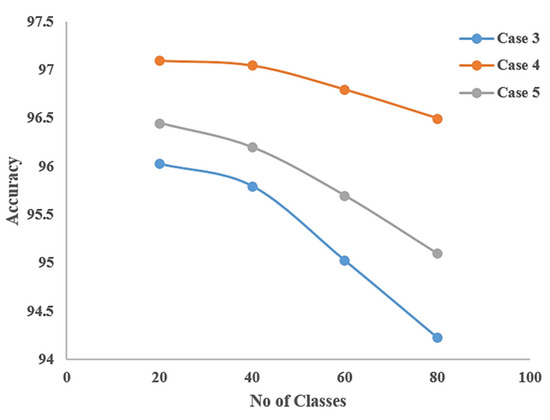
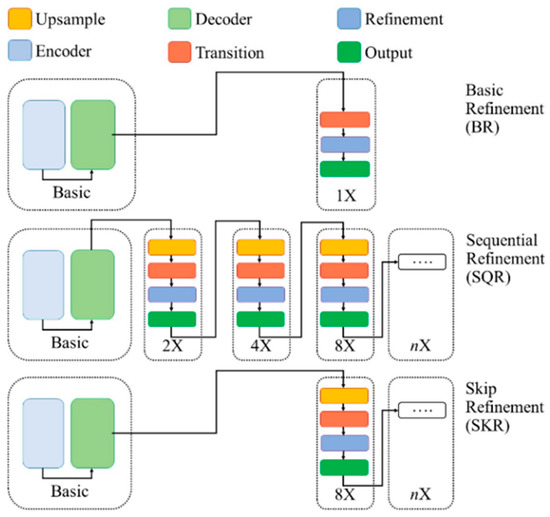
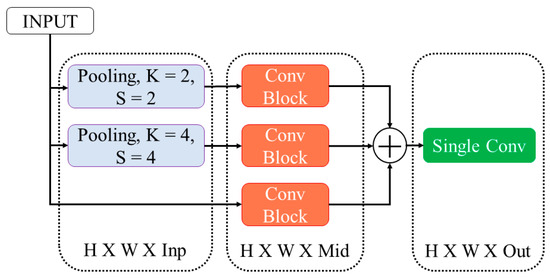
Recent advances in salient object detection adopting deep convolutional neural networks have achieved state-of-the-art performance. Salient object detection is task in computer vision to detect interesting objects. Most of the Convolutional Neural Network (CNN)-based methods produce plausible saliency outputs, yet with extra computational time. However in practical, the low computation algorithm is demanded. One approach to overcome this limitation is to resize the input into a smaller size to reduce the heavy computation in the backbone network. However, this process degrades the performance, and fails to capture the exact details of the saliency boundaries due to the downsampling process. A robust refinement strategy is needed to improve the final result where the refinement computation should be lower than that of the original prediction network. Consequently, a novel approach is proposed in this study using the original image gradient as a guide to detect and refine the saliency result. This approach lowers the computational cost by eliminating the huge computation in the backbone network, enabling flexibility for users in choosing a desired size with a more accurate boundary. The proposed method bridges the benefits of smaller computation and a clear result on the boundary. Extensive experiments have demonstrated that the proposed method is able to maintain the stability of the salient detection performance given a smaller input size with a desired output size and improvise the overall salient object detection result.
Full article
►▼
Show Figures
Open AccessArticle
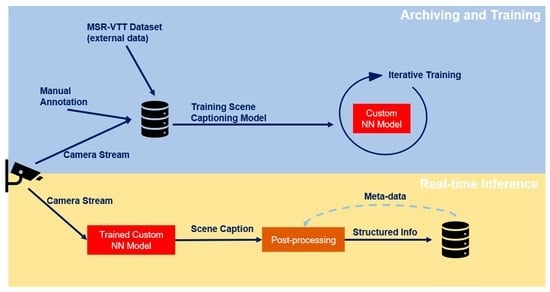
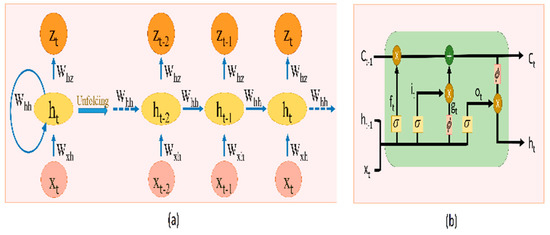
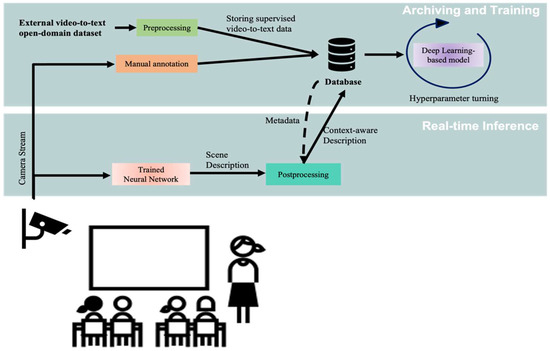
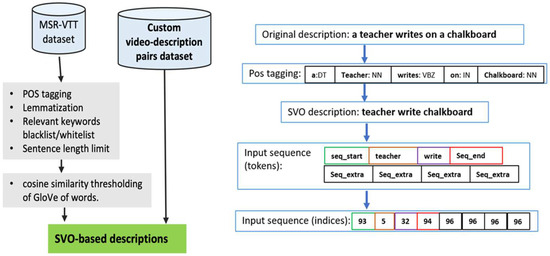
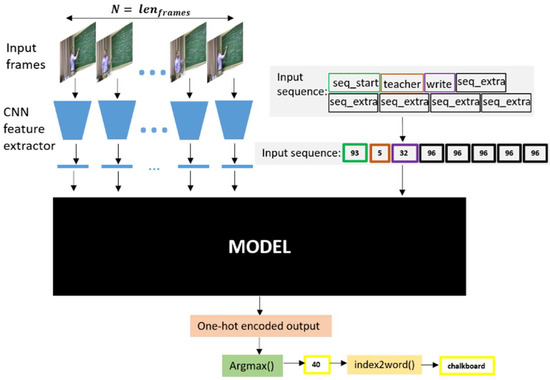
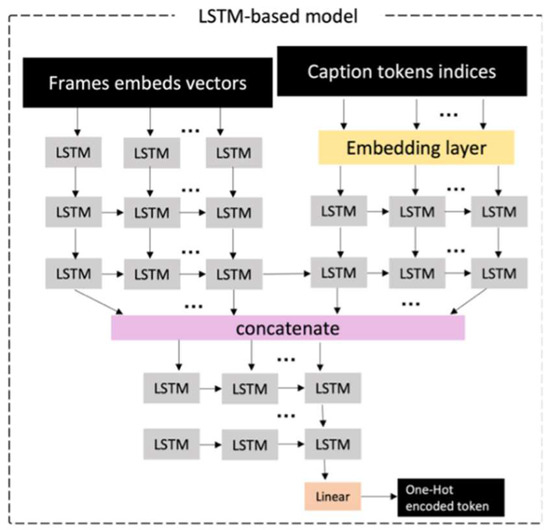
Deep Learning-Based Context-Aware Video Content Analysis on IoT Devices
by
Gad Gad, Eyad Gad, Korhan Cengiz, Zubair Fadlullah and Bassem Mokhtar
Cited by 4 | Viewed by 1980
Abstract
Integrating machine learning with the Internet of Things (IoT) enables many useful applications. For IoT applications that incorporate video content analysis (VCA), deep learning models are usually used due to their capacity to encode the high-dimensional spatial and temporal representations of videos. However,
[...] Read more.
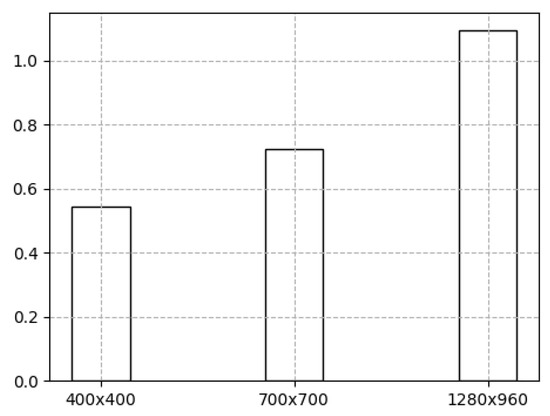
Integrating machine learning with the Internet of Things (IoT) enables many useful applications. For IoT applications that incorporate video content analysis (VCA), deep learning models are usually used due to their capacity to encode the high-dimensional spatial and temporal representations of videos. However, limited energy and computation resources present a major challenge. Video captioning is one type of VCA that describes a video with a sentence or a set of sentences. This work proposes an IoT-based deep learning-based framework for video captioning that can (1) Mine large open-domain video-to-text datasets to extract video-caption pairs that belong to a particular domain. (2) Preprocess the selected video-caption pairs including reducing the complexity of the captions’ language model to improve performance. (3) Propose two deep learning models: A transformer-based model and an LSTM-based model. Hyperparameter tuning is performed to select the best hyperparameters. Models are evaluated in terms of accuracy and inference time on different platforms. The presented framework generates captions in standard sentence templates to facilitate extracting information in later stages of the analysis. The two developed deep learning models offer a trade-off between accuracy and speed. While the transformer-based model yields a high accuracy of 97%, the LSTM-based model achieves near real-time inference.
Full article
►▼
Show Figures
Open AccessArticle
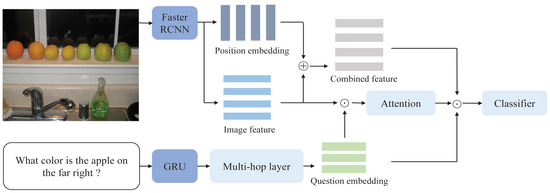
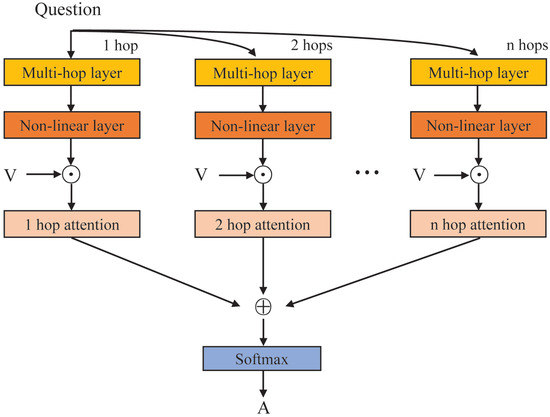
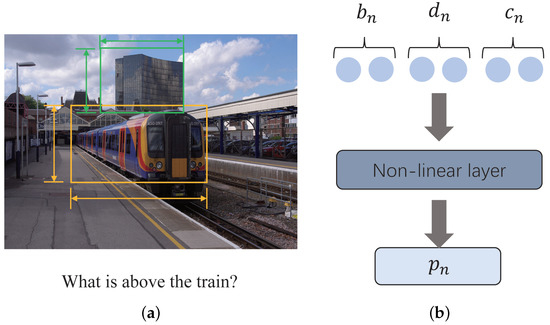
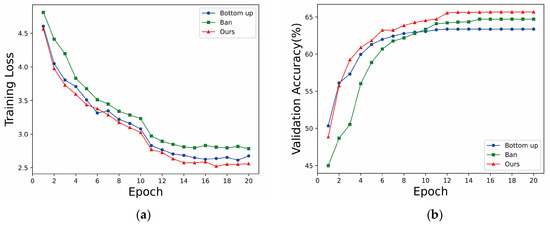
Multi-Modal Alignment of Visual Question Answering Based on Multi-Hop Attention Mechanism
by
Qihao Xia, Chao Yu, Yinong Hou, Pingping Peng, Zhengqi Zheng and Wen Chen
Cited by 4 | Viewed by 1903
Abstract
The alignment of information between the image and the question is of great significance in the visual question answering (VQA) task. Self-attention is commonly used to generate attention weights between image and question. These attention weights can align two modalities. Through the attention
[...] Read more.
The alignment of information between the image and the question is of great significance in the visual question answering (VQA) task. Self-attention is commonly used to generate attention weights between image and question. These attention weights can align two modalities. Through the attention weight, the model can select the relevant area of the image to align with the question. However, when using the self-attention mechanism, the attention weight between two objects is only determined by the representation of these two objects. It ignores the influence of other objects around these two objects. This contribution proposes a novel multi-hop attention alignment method that enriches surrounding information when using self-attention to align two modalities. Simultaneously, in order to utilize position information in alignment, we also propose a position embedding mechanism. The position embedding mechanism extracts the position information of each object and implements the position embedding mechanism to align the question word with the correct position in the image. According to the experiment on the VQA2.0 dataset, our model achieves validation accuracy of 65.77%, outperforming several state-of-the-art methods. The experimental result shows that our proposed methods have better performance and effectiveness.
Full article
►▼
Show Figures
Open AccessArticle
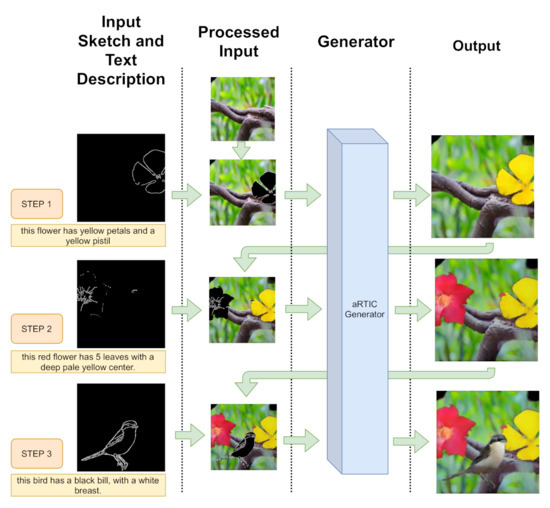
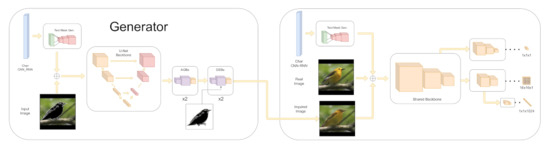
aRTIC GAN: A Recursive Text-Image-Conditioned GAN
by
Edoardo Alati, Carlo Alberto Caracciolo, Marco Costa, Marta Sanzari , Paolo Russo and Irene Amerini
Cited by 2 | Viewed by 2227
Abstract
Generative Adversarial Networks have recently demonstrated the capability to synthesize photo-realistic real-world images. However, they still struggle to offer high controllability of the output image, even if several constraints are provided as input. In this work, we present a Recursive Text-Image-Conditioned GAN (aRTIC
[...] Read more.
Generative Adversarial Networks have recently demonstrated the capability to synthesize photo-realistic real-world images. However, they still struggle to offer high controllability of the output image, even if several constraints are provided as input. In this work, we present a Recursive Text-Image-Conditioned GAN (aRTIC GAN), a novel approach for multi-conditional image generation under concurrent spatial and text constraints. It employs few line drawings and short descriptions to provide informative yet human-friendly conditioning. The proposed scenario is based on accessible constraints with high degrees of freedom: sketches are easy to draw and add strong restrictions on the generated objects, such as their orientation or main physical characteristics. Text on its side is so common and expressive that easily enforces information otherwise impossible to provide with minimal illustrations, such as objects components color, color shades, etc. Our aRTIC GAN is suitable for the sequential generation of multiple objects due to its compact design. In fact, the algorithm exploits the previously generated image in conjunction with the sketch and the text caption, resulting in a recurrent approach. We developed three network blocks to tackle the fundamental problems of catching captions’ semantic meanings and of handling the trade-off between smoothing grid-pattern artifacts and visual detail preservation. Furthermore, a compact three-task discriminator (covering global, local and textual aspects) was developed to preserve a lightweight and robust architecture. Extensive experiments proved the validity of aRTIC GAN and show that the combined use of sketch and description allows us to avoid explicit object labeling.
Full article
►▼
Show Figures
Open AccessArticle
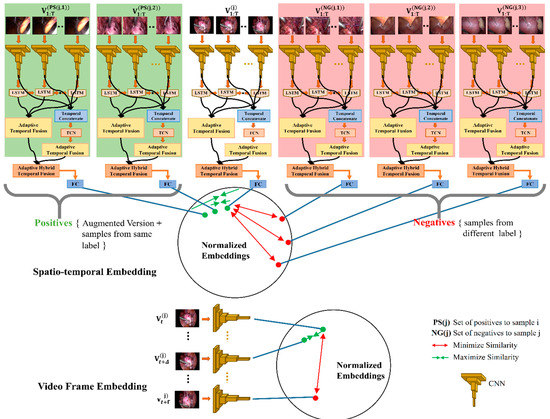
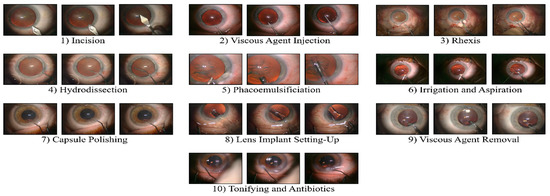
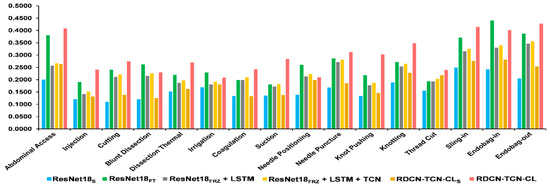
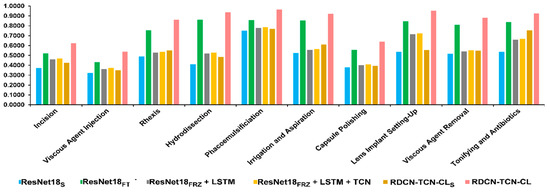
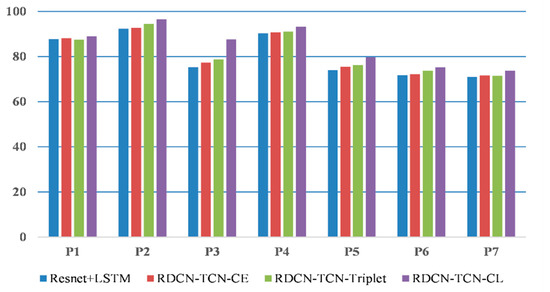
Hybrid Spatiotemporal Contrastive Representation Learning for Content-Based Surgical Video Retrieval
by
Vidit Kumar, Vikas Tripathi, Bhaskar Pant, Sultan S. Alshamrani, Ankur Dumka, Anita Gehlot, Rajesh Singh, Mamoon Rashid, Abdullah Alshehri and Ahmed Saeed AlGhamdi
Cited by 11 | Viewed by 1889
Abstract
In the medical field, due to their economic and clinical benefits, there is a growing interest in minimally invasive surgeries and microscopic surgeries. These types of surgeries are often recorded during operations, and these recordings have become a key resource for education, patient
[...] Read more.
In the medical field, due to their economic and clinical benefits, there is a growing interest in minimally invasive surgeries and microscopic surgeries. These types of surgeries are often recorded during operations, and these recordings have become a key resource for education, patient disease analysis, surgical error analysis, and surgical skill assessment. However, manual searching in this collection of long-term surgical videos is an extremely labor-intensive and long-term task, requiring an effective content-based video analysis system. In this regard, previous methods for surgical video retrieval are based on handcrafted features which do not represent the video effectively. On the other hand, deep learning-based solutions were found to be effective in both surgical image and video analysis, where CNN-, LSTM- and CNN-LSTM-based methods were proposed in most surgical video analysis tasks. In this paper, we propose a hybrid spatiotemporal embedding method to enhance spatiotemporal representations using an adaptive fusion layer on top of the LSTM and temporal causal convolutional modules. To learn surgical video representations, we propose exploring the supervised contrastive learning approach to leverage label information in addition to augmented versions. By validating our approach to a video retrieval task on two datasets, Surgical Actions 160 and Cataract-101, we significantly improve on previous results in terms of mean average precision, 30.012 ± 1.778 vs. 22.54 ± 1.557 for Surgical Actions 160 and 81.134 ± 1.28 vs. 33.18 ± 1.311 for Cataract-101. We also validate the proposed method’s suitability for surgical phase recognition task using the benchmark Cholec80 surgical dataset, where our approach outperforms (with 90.2% accuracy) the state of the art.
Full article
►▼
Show Figures
Open AccessArticle
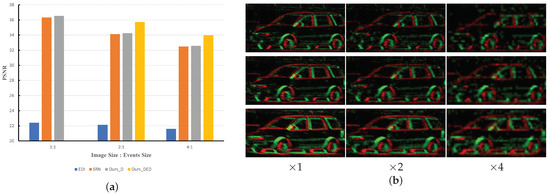
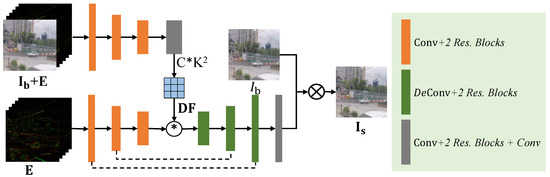
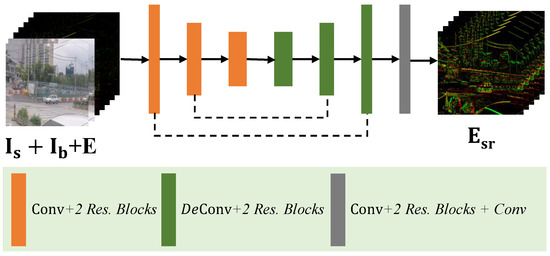
Image Deblurring Aided by Low-Resolution Events
by
Zhouxia Wang, Jimmy Ren, Jiawei Zhang and Ping Luo
Cited by 4 | Viewed by 2056
Abstract
Due to the limitation of event sensors, the spatial resolution of event data is relatively low compared to the spatial resolution of the conventional frame-based camera. However, low-spatial-resolution events recorded by event cameras are rich in temporal information which is helpful for image
[...] Read more.
Due to the limitation of event sensors, the spatial resolution of event data is relatively low compared to the spatial resolution of the conventional frame-based camera. However, low-spatial-resolution events recorded by event cameras are rich in temporal information which is helpful for image deblurring, while intensity images captured by frame cameras are in high resolution and have potential to promote the quality of events. Considering the complementarity between events and intensity images, an alternately performed model is proposed in this paper to deblur high-resolution images with the help of low-resolution events. This model is composed of two components: a DeblurNet and an EventSRNet. It first uses the DeblurNet to attain a preliminary sharp image aided by low-resolution events. Then, it enhances the quality of events with EventSRNet by extracting the structure information in the generated sharp image. Finally, the enhanced events are sent back into DeblurNet to attain a higher quality intensity image. Extensive evaluations on the synthetic GoPro dataset and real RGB-DAVIS dataset have shown the effectiveness of the proposed method.
Full article
►▼
Show Figures
Open AccessArticle
A Light-Weight CNN for Object Detection with Sparse Model and Knowledge Distillation
by
Jing-Ming Guo, Jr-Sheng Yang, Sankarasrinivasan Seshathiri and Hung-Wei Wu
Cited by 9 | Viewed by 3701
Abstract
This study details the development of a lightweight and high performance model, targeting real-time object detection. Several designed features were integrated into the proposed framework to accomplish a light weight, rapid execution, and optimal performance in object detection. Foremost, a sparse and lightweight
[...] Read more.
This study details the development of a lightweight and high performance model, targeting real-time object detection. Several designed features were integrated into the proposed framework to accomplish a light weight, rapid execution, and optimal performance in object detection. Foremost, a sparse and lightweight structure was chosen as the network’s backbone, and feature fusion was performed using modified feature pyramid networks. Recent learning strategies in data augmentation, mixed precision training, and network sparsity were incorporated to substantially enhance the generalization for the lightweight model and boost the detection accuracy. Moreover, knowledge distillation was applied to tackle dropping issues, and a student–teacher learning mechanism was also integrated to ensure the best performance. The model was comprehensively tested using the MS-COCO 2017 dataset, and the experimental results clearly demonstrated that the proposed model could obtain a high detection performance in comparison to state-of-the-art methods, and required minimal computational resources, making it feasible for many real-time deployments.
Full article
►▼
Show Figures
Open AccessArticle
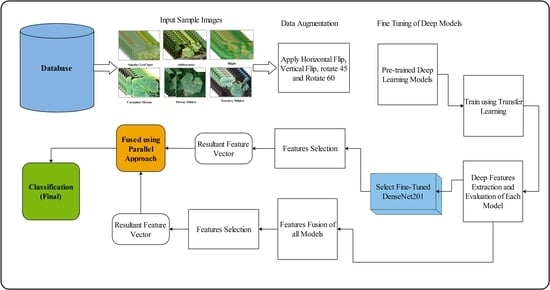
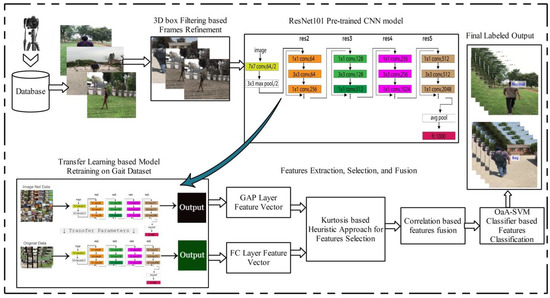
Deep Learning and Kurtosis-Controlled, Entropy-Based Framework for Human Gait Recognition Using Video Sequences
by
Muhammad Imran Sharif, Muhammad Attique Khan, Abdullah Alqahtani, Muhammad Nazir, Shtwai Alsubai, Adel Binbusayyis and Robertas Damaševičius
Cited by 20 | Viewed by 3279
Abstract
Gait is commonly defined as the movement pattern of the limbs over a hard substrate, and it serves as a source of identification information for various computer-vision and image-understanding techniques. A variety of parameters, such as human clothing, angle shift, walking style, occlusion,
[...] Read more.
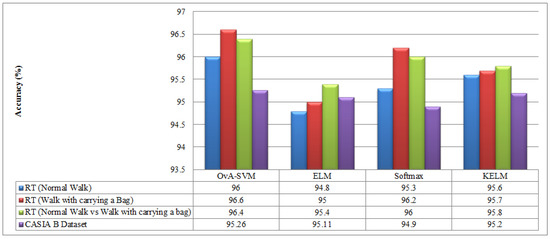
Gait is commonly defined as the movement pattern of the limbs over a hard substrate, and it serves as a source of identification information for various computer-vision and image-understanding techniques. A variety of parameters, such as human clothing, angle shift, walking style, occlusion, and so on, have a significant impact on gait-recognition systems, making the scene quite complex to handle. In this article, we propose a system that effectively handles problems associated with viewing angle shifts and walking styles in a real-time environment. The following steps are included in the proposed novel framework: (a) real-time video capture, (b) feature extraction using transfer learning on the ResNet101 deep model, and (c) feature selection using the proposed kurtosis-controlled entropy (KcE) approach, followed by a correlation-based feature fusion step. The most discriminant features are then classified using the most advanced machine learning classifiers. The simulation process is fed by the CASIA B dataset as well as a real-time captured dataset. On selected datasets, the accuracy is 95.26% and 96.60%, respectively. When compared to several known techniques, the results show that our proposed framework outperforms them all.
Full article
►▼
Show Figures
Open AccessArticle
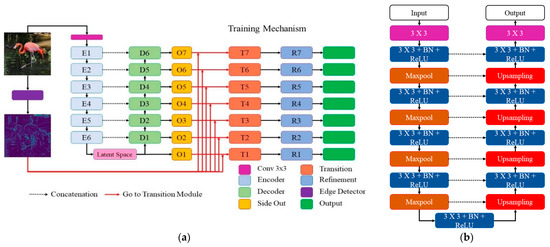
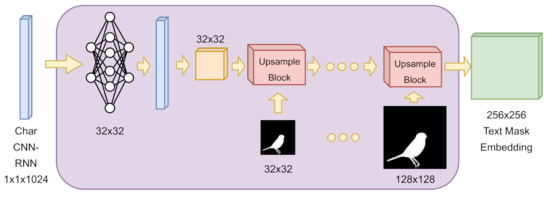
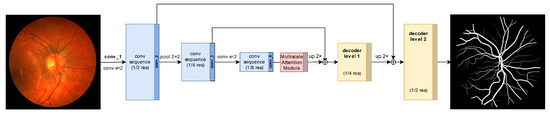
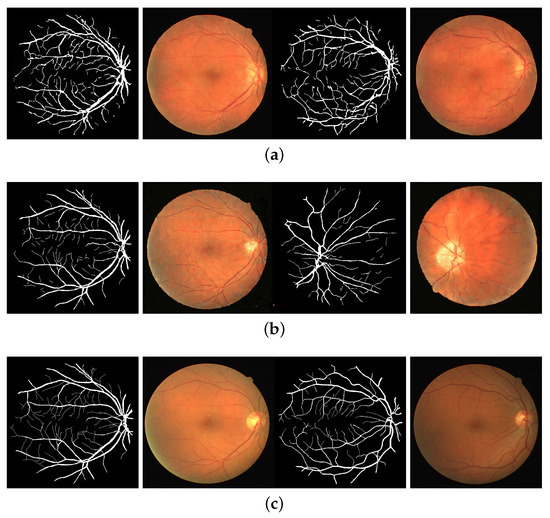
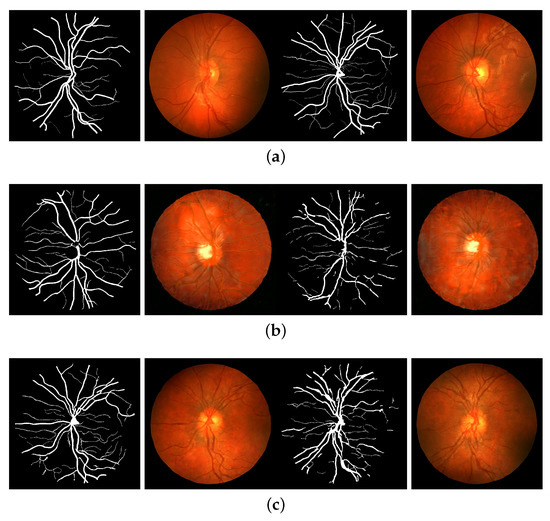
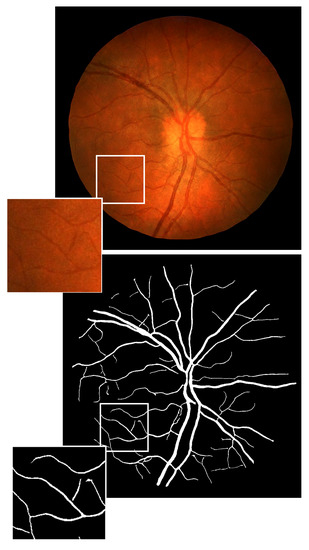
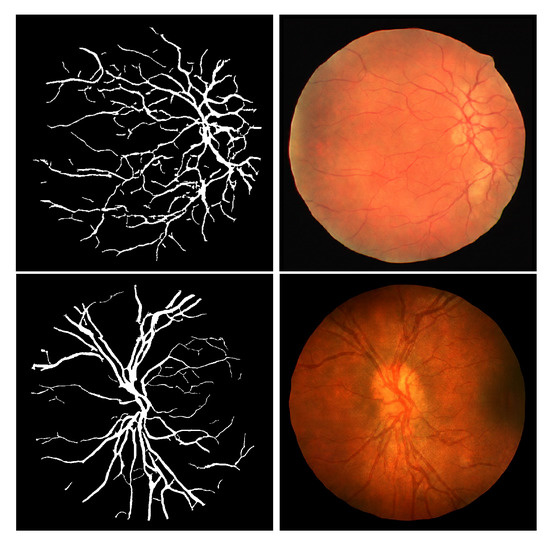
A Two-Stage GAN for High-Resolution Retinal Image Generation and Segmentation
by
Paolo Andreini, Giorgio Ciano, Simone Bonechi, Caterina Graziani, Veronica Lachi, Alessandro Mecocci, Andrea Sodi, Franco Scarselli and Monica Bianchini
Cited by 35 | Viewed by 5216
Abstract
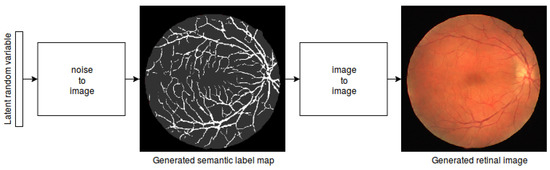
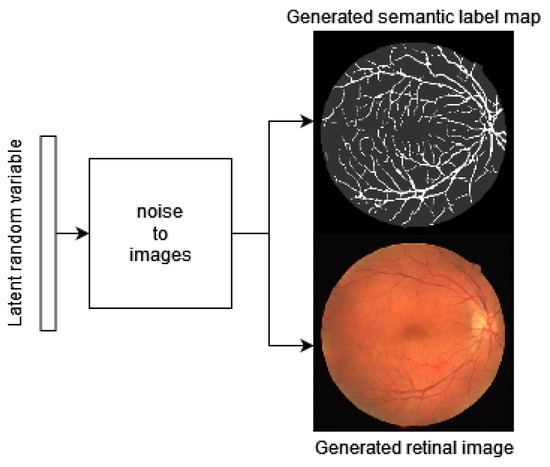
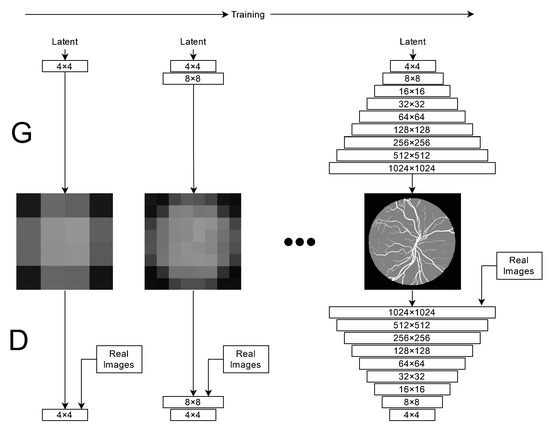
In this paper, we use Generative Adversarial Networks (GANs) to synthesize high-quality retinal images along with the corresponding semantic label-maps, instead of real images during training of a segmentation network. Different from other previous proposals, we employ a two-step approach: first, a progressively
[...] Read more.
In this paper, we use Generative Adversarial Networks (GANs) to synthesize high-quality retinal images along with the corresponding semantic label-maps, instead of real images during training of a segmentation network. Different from other previous proposals, we employ a two-step approach: first, a progressively growing GAN is trained to generate the semantic label-maps, which describes the blood vessel structure (i.e., the vasculature); second, an image-to-image translation approach is used to obtain realistic retinal images from the generated vasculature. The adoption of a two-stage process simplifies the generation task, so that the network training requires fewer images with consequent lower memory usage. Moreover, learning is effective, and with only a handful of training samples, our approach generates realistic high-resolution images, which can be successfully used to enlarge small available datasets. Comparable results were obtained by employing only synthetic images in place of real data during training. The practical viability of the proposed approach was demonstrated on two well-established benchmark sets for retinal vessel segmentation—both containing a very small number of training samples—obtaining better performance with respect to state-of-the-art techniques.
Full article
►▼
Show Figures
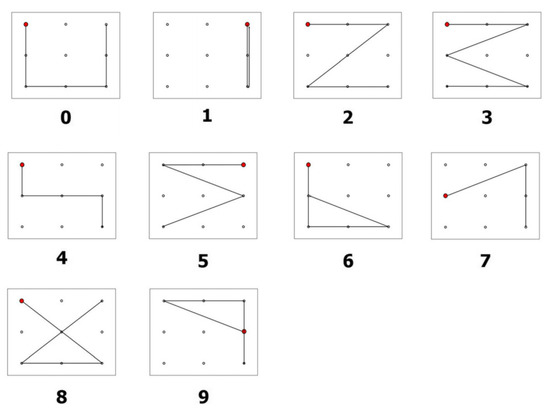
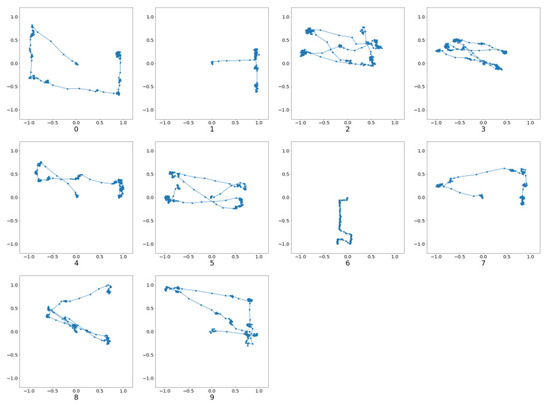
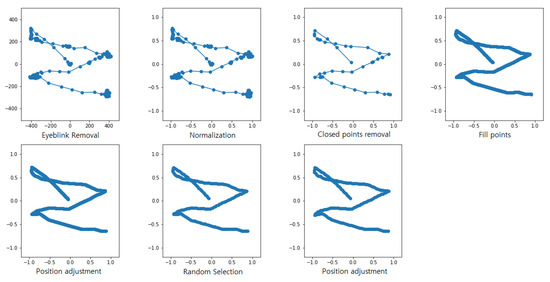
Open AccessArticle
Recognition of Eye-Written Characters with Limited Number of Training Data Based on a Siamese Network
by
Dong-Hyun Kang and Won-Du Chang
Cited by 1 | Viewed by 1612
Abstract
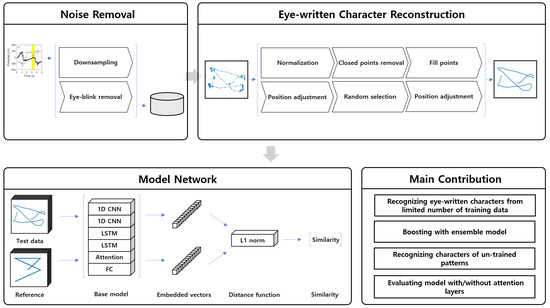
Developing a hum–computer interface (HCI) is essential, especially for those that have spinal cord injuries or paralysis, because of the difficulties associated with the application of conventional devices and systems. Eye-writing is an HCI that uses eye movements for writing characters such that
[...] Read more.
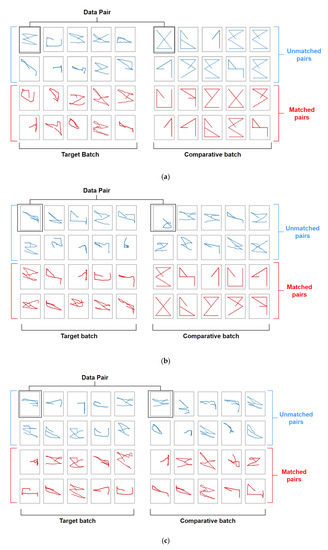
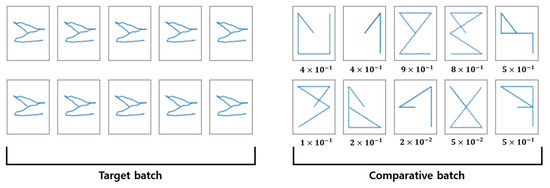
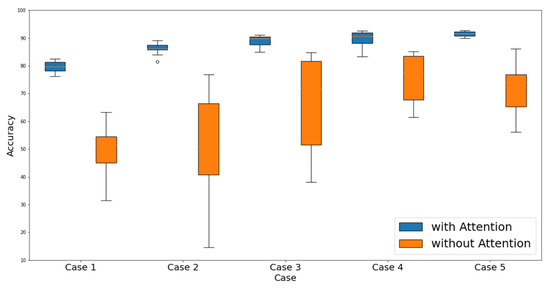
Developing a hum–computer interface (HCI) is essential, especially for those that have spinal cord injuries or paralysis, because of the difficulties associated with the application of conventional devices and systems. Eye-writing is an HCI that uses eye movements for writing characters such that the gaze movements form letters. In addition, it is a promising HCI because it can be utilized even when voices and hands are inaccessible. However, eye-writing HCI has low accuracy and encounters difficulties in obtaining data. This study proposes a method for recognizing eye-written characters accurately and with limited data. The proposed method is constructed using a Siamese network, an attention mechanism, and an ensemble algorithm. In the experiment, the proposed method successfully classified the eye-written characters (Arabic numbers) with high accuracy (92.78%) when the ratio of training to test data was 2:1. In addition, the method was tested as the ratio changed, and 80.80% accuracy was achieved when the number of training data was solely one-tenth of the test data.
Full article
►▼
Show Figures
Open AccessArticle
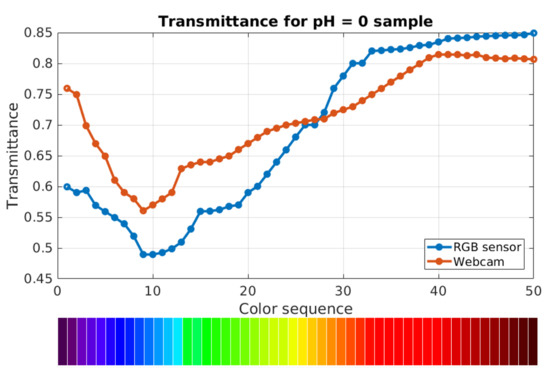
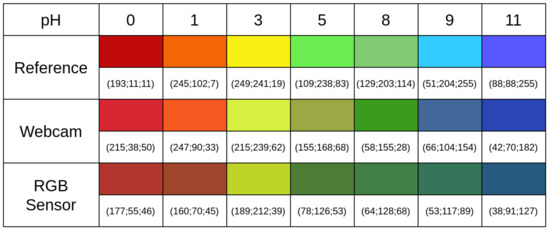
Compact System for Colorimetric Sensor Arrays Characterization Based on Computer Screen Photo-Assisted Technology
by
Giovanni Gugliandolo, Giovanni Pilato and Nicola Donato
Cited by 1 | Viewed by 1812
Abstract
The detection of the spectral fingerprint of chemical sensors through the combined use of an LCD and a webcam is an alternative approach for chemical sensor characterization. This technique allows the development of more compact, cheap, and user-friendly measurement systems compared to the
[...] Read more.
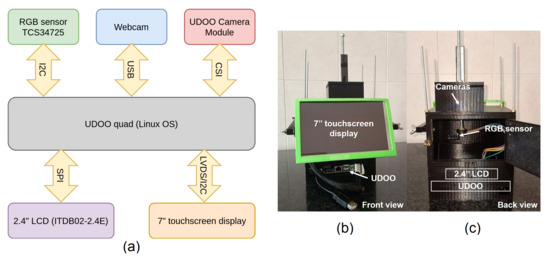
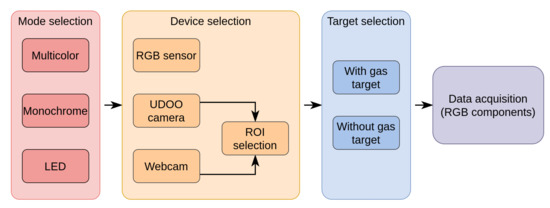
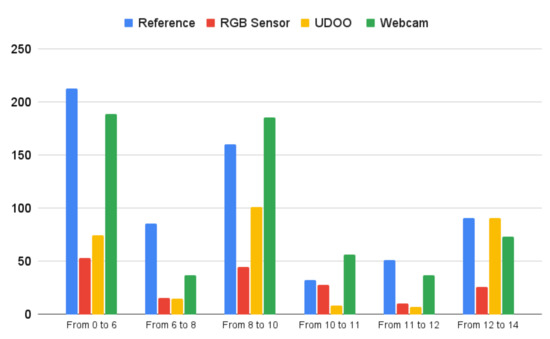
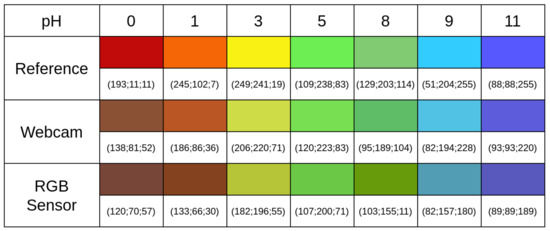
The detection of the spectral fingerprint of chemical sensors through the combined use of an LCD and a webcam is an alternative approach for chemical sensor characterization. This technique allows the development of more compact, cheap, and user-friendly measurement systems compared to the more classic instruments, such as spectrometers and gas chromatography systems. In the Computer Screen Photo-assisted Technique (CSPT), a display acts as a light source, and a conventional camera (e.g., a webcam) plays the role of a detector. The light from the LCD is reflected (or transmitted) by the chemical sensor, and the camera detects it. In the present contribution, we propose a compact and low-cost platform based on CSPT for the characterization of colorimetric sensor arrays. The system can provide spectral information of both reflected and transmitted light from the sample. Further, a 2.4-inch LCD and three different detector’s (a webcam, an RGB sensor, and a camera module) performances have been evaluated and discussed. The developed system includes a UDOO-based single board computer that makes it a stand-alone measurement system.
Full article
►▼
Show Figures












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}