1. Introduction
In the last decade, deep learning (DL) algorithms have been capable of generating photo-realistic images and videos, useful in a wide range of applications, such as computer graphics, digital design and art generation. In this context, the scientific community is exploring the possibility of controlling image synthesis by feeding auxiliary inputs, such as category labels, descriptive text, hand-drawn sketches, semantic maps and many others. Generative Adversarial Networks (GANs), first introduced by Goodfellow et al. [
1], represent nowadays the state-of-the-art solution. Despite their success, GANs are affected by training instabilities and are sensitive to hyperparameters configuration. The high-dimensional image space of such networks exacerbates the complexity of generating high-resolution images in opposition to low-resolution and simulated data, such as MNIST [
2], Fashion MNIST [
3] and CoDraw [
4]. Recent models introduced by Zhang et al. [
5,
6] have proven to achieve excellent results exploiting a multi-stage approach, in which several networks cooperate in sequence at different resolutions. Nonetheless, the complexity in the training phase and the limitations in generating multiple objects inside the same image are still key issues.
In order for the image generating system to be effective, bridging the gap between high-level concepts, such as sketches and text descriptions, and pixel-level details is required. Depending on the nature of such constraints, all conditional GAN models can be gathered into three main groups:
Image-to-Image Translation,
Text-to-Image Synthesis and
Style Transfer.
Image-to-Image Translation (I2IT) offers hard spatial constraints exploitation at the expense of color-pattern-level information and an increasing sketch complexity for fine detail generation, resulting in the suppression of chromatic and style variety. Isola et al. [
7] and Wang et al. [
8] represent exhaustive examples of the described behaviors. On the other hand,
Text-to-Image Synthesis (T2IS) employs written captions, which are flexible and informative but hard to handle when coping with detailed shape descriptions. This may lead to high color variations but little or no shape adjustments. In general, this problem is solved using complex cascade networks to capture every possible semantic meaning, e.g., [
9]. However, this scenario results in elaborated models, restraining and limiting the possibilities of generating multiple objects in the same image.
Style Transfer (ST) works in a different context, allowing the network to homogeneously apply a requested style on a given input image. This kind of conditioning lacks fine control over the final generated image, as the model performs a translation rather than a proper generation. An important accomplishment is pictured by Zhu et al. [
10].
Two of the aforementioned categories are prone to be affected by Mode Collapsing. This phenomenon is characterized by the generation of samples containing either the same color and texture patterns (I2IT) or shapes (T2IS), pointing out a major limitation in the mono-conditional generation scenario. On the other hand, ST is virtually unaffected by this issue, although it requires a well-formed image provided as a basis for the translation, limiting the expressiveness of the model.
In aRTIC GAN, we decide to address the
Mode Collapsing problem by creating a multi-conditional scenario in which I2IT and T2IS are combined, contrasting each other’s style suppression. In particular, we proposed as visual input the use of simple and minimal hand-drawn sketches and descriptive captions related to colors and patterns. These two conditioning are both user-friendly and simple to retrieve, differently from previous works that combine text caption only with position [
11] and parts [
12] information. Moreover, the concurrent use of simple sketches and text descriptions takes advantage of non-overlapping information: the illustration imposes hard spatial constraints, making the model able to identify pose and species, while the caption is in charge of pointing out the coloring.
In addition to the initial problem, we explored the possibilities of multi-object generation. One major problem we encountered is represented by different visual defects, such as checkerboard artifacts and the loss of detail, which may characterize the generated image. These issues are derived directly from the output morphology and must be solved by custom adjustments; thus, we opted for a sequential model, as opposed to the more common concurrent approach. The proposed method exploits a recurrent module in conjunction with a third visual conditioning represented by an initial background. In detail, this is used by the first generated object, and the resulted output is provided as a new scene for the following generation step. A visual example of the overall generation procedure is provided in
Figure 1.
aRTIC GAN displays a compact design, composed of a set of blocks in charge of capturing the proper semantic, leading to a generation process enriched with detail enhancement or suppression (see
Figure 2). This pipeline forwards the given inputs along a realistic inpainting procedure up to the intermediate and final results. The simplicity of this configuration allows the model to be called recursively over a series of different pairs of sketches and descriptions, while the rendering capabilities enable high levels of realism, limiting the generation possibilities only to the human imagination and artistic touch. The contribution of our method is threefold:
- (i)
aRTIC GAN exploits two specifically designed refinement blocks (
Section 3.2) to deal with image artifacts and fine detail enforcement as opposed to the multi-stage generation approaches. This structure aims to achieve a small parameter count, much lower than the aforesaid counterparts, while still obtaining high-quality performance.
- (ii)
In order to use a unique discriminator for single-stage generation, our discriminator produces different outputs at the same time. This design allows us to simultaneously analyze text consistency and image quality at several levels without weighing down excessively the overall complexity. The model and the novel losses are described, respectively, in
Section 3.3 and
Section 3.4.
- (iii)
The use of sketches and text descriptions improves performance while reducing the
Mode Collapsing effects, since each constraint influences and dampens the variation suppression problem caused by the other input. As an additional effect, the generator appears to better discern elements from multiple domains and to generate them accordingly, boosting even more the all-round realism quality and the detail enhancement (
Section 5.3).
All the introduced novelties have been validated on two well-known datasets containing birds (CUB-200 [
13]) and flowers (Oxford Flower 102 [
14]) images. The correspondent text descriptions together with their embeddings (i.e., their vector representation), outlining attributes such as appearances and colors, are provided in a different dataset collected by Reed et al. [
12].
The paper is organized as follows:
Section 2 presents the state-of-the-art work, describing the main generation approaches;
Section 3 discusses the main novelties of aRTIC GAN with respect to network blocks, losses and architecture;
Section 4 describes the implementation details of the proposed method, from the input preparation to the network setup and training procedure;
Section 5 shows the experiments and results, investigating comparative and ablation studies;
Section 6 draws the conclusions of our work.
2. Related Works
Generating photo-realistic images is a challenging and significant task for many applications, such as computer graphics, digital design and art generation. Over the last few years, great progress has been achieved in this direction with the emergence of deep generative models. Among them, GANs [
1] stood out for their capability to achieve several outstanding results, relentlessly improving as [
15,
16,
17,
18,
19]. Moreover, the efficiency of GAN-based image processing has been proven in many other research areas such as object classification [
20] or signal restoration [
21].
Realistic image generation can be divided into five main categories with respect to conditioning types and modalities:
Image-to-Image Translation has significantly improved over the last years since the development of Pix2Pix by Zhu et al. [
7], where conditional generative adversarial network is explored to learn a mapping from input to output images. CycleGAN was introduced by Zhu et al. [
10] to convert the source domain into a different target domain in the absence of explicit paired example images. Wang et al. [
8] proposed an improvement to generate high-definition images by progressively adding new generators. Chen et al. [
22] presented an alternative approach by exploiting a cascade of refinement blocks. A recent turning point has been reached by Park et al. [
23], who introduced a novel method based on semantic spatially adaptive normalization. Recently, Park et al. [
24] proposed an approach based on patchwise contrastive learning and adversarial learning, while [
25] explored a hierarchical tree structure to organize labels and a new translation process. A peculiar approach was developed by [
26] which exploited a rich dataset collected through Artbreeder [
27] to output a single image from a graph-like structure. Finally, Dai et al. [
28] learned a sequence of invertible mappings which led to a flow-version of popular GANs, such as StarGAN, AGGAN and CyCADA, with similar performances but half of the training parameters.
Text-to-Image Synthesis was first pursued by Reed et al. [
29], in which embeddings containing visual-relevant features are obtained taking advantage of the popular text embedding technique Char CNN-RNN [
12]. Subsequently, Zhang et al. [
5,
6] introduced StackGAN in which the employment of multiple consecutive generator-discriminator pairs is explored. Xu et al. [
9] developed AttnGAN, a model able to transform text description into spatial attention associating single words with image regions. The usage of a BI-LSTM text encoder rather than Char CNN-RNN allows the model to focus on both the general caption meaning and the single semantic word meaning, obtaining impressive results. The drawback is a very high complexity due to the fact that every semantic aspect part has to be controlled by a different component. Finally, Hong et al. [
30] and Wang et al. [
31] focused on the spatial constraints of the generated image. Other recent notable works are DM-GAN [
32], MirrorGAN [
33] and DF-GAN [
34], using, respectively, a dynamic memory module to refine fuzzy images (DM-GAN), a mirror structure to model T2I and I2T subjects (MirrorGAN) and a single-stage architecture composed of a deep text–image fusion block and a target-aware discriminator (DF-GAN). Finally, Li et al. [
35] proposed a lightweight GAN model with a novel word-level discriminator providing fine-grained training feedback; the corresponding generator is able to correctly focus on specific visual attributes while using a small number of parameters.
Style Transfer aims at transferring the style from one image onto another synthesising a texture from a source image preserving the semantic content of a target image. Gatys et al. [
36] exploited one of the first attempts of texture modeling with deep learning. The multiple-domain transfer problem was widely addressed in [
37,
38,
39,
40], deepening the analysis on cross-domain relations, style merging and translation control, even in non-visual scenarios. This type of approach was explored in more specific fields, such as face modification, resulting, for example, in a family of architectures specialized in
age progression and regression, such as CAAE [
41] and its further development CAAE++ [
42], C-GAN (Contextual GAN) [
43], IPCGAN [
44], idGAN [
45] and CAN-GAN [
46]. Recently, An et al. [
47] explored the content leak issue in state-of-the-art methods and addressed it using neural flows, while [
48] developed an adaptive attention normalization procedure to apply the attention mechanism on a per-point basis. A novel application of Laplacian pyramids was proposed by [
49], which transfers global style patterns with a drafting network and further refines the local details with a revision network by hallucinating the previous output with a residual image.
The
Multi-Conditioned GANs approach, although very demanding, nowadays results fundamentally in dampening the problem of
Mode Collapsing; otherwise, it is much more difficult to deal with the "standard" mono-conditional methods. Reed et al. [
12] proposed an architecture to generate objects from text descriptions and bounding boxes or object part locations. Bounding boxes determine the object region but cannot provide any information about the appropriate pose. On the other hand, the posture can be precisely described by selecting single parts’ locations, although this methodology is significantly unnatural and time-consuming. H.Park et al. [
11] introduced a model improving the generation process by focusing on object masks, while Dean et al. [
50] developed a cascade GAN exploiting both class labels and audio signal inputs. Recently, astonishing results were achieved by T. Park et al. [
23], combining semantic maps in combination with input semantic layouts. This method displays great visual performance, even showing capabilities of concurrent multiple-object generation. However, it lacks fine-detail control over the single object.
Multiple-Object Generation has been mainly addressed via a concurrent approach, characterized by a simultaneous spawning of multiple objects. Examples of concurrent generation are provided by [
23,
51,
52,
53,
54]. Turkoglu et al. [
55] proposed oppositely a sequential generation method based on a recursive approach, in which one single object is generated at a time from a segmentation map to deal with the occlusion artifacts problem. Finally, the model proposed by El et al. [
56] produces sequentially simple shapes in a simulator [
4], inpainting new geometrical objects in the scene.
3. Method
aRTIC GAN, as a Generative adversarial network (GAN), consists of a generator G and a discriminator D competing in a two-player minimax game: the discriminator tries to distinguish real training data from synthetic images, and the generator tries to fool the discriminator. aRTIC GAN takes as input an RGB image containing a background and the inpainted sketch (see
Section 4.2) together with a text description embedding (
Section 4.2.4). When dealing with the task of generating multiple objects, as opposed to multi-stage methods such as [
5,
6,
9], our approach focuses on a single-stage generation process resulting in a much more compact design as shown in
Figure 1. Specifically, at each step, the image produced as output by the generator is merged with the sketch for the consecutive generation process, resulting in a recurrent approach due to the exploitation of the same generator and discriminator.
In this Section we introduce the main novelties of aRTIC GAN, focusing on original network blocks, loss definitions and overall architecture composition.
3.1. Text Mask Generator
The cross-modal input of aRTIC GAN Generator is carried out through the
Text Mask Generator Block (TMG) (shown in
Figure 3), who is in charge of combining sketches and captions. First of all, text descriptions are encoded with the robust embedding method exploited by Reed et al. [
29], whose performances are widely demonstrated in several works [
5,
6,
9,
11]. After that the text embedding is combined with the desired object sketch, represented here as a binary mask (in
Section 4.2.2 are given details regarding the binary mask generation).
The composition of text embedding and object binary mask could in principle be performed by a single fully connected (FC) layer, resulting in a prohibitive parameters number. To overcome this issue and to preserve the separation between text and objects, we propose a series of progressive
upsampling blocks fed at each level with the binary mask describing the desired location and rough shape of the object. Such a mechanism of spatial enforcement is reproduced in the generator and the discriminator so that each text channel is independently trained in both models. In
Section 5.2 we present an overview of the configuration and performance of the TMG Block.
The TMG output is concatenated to the RGB input, i.e., an initial background image in case of the first object, or the previously generated scene in case of the subsequent ones, and fed to the aRTIC GAN Generator successive block (in
Figure 2 is depicted the overall generation process).
3.2. Refinement Blocks
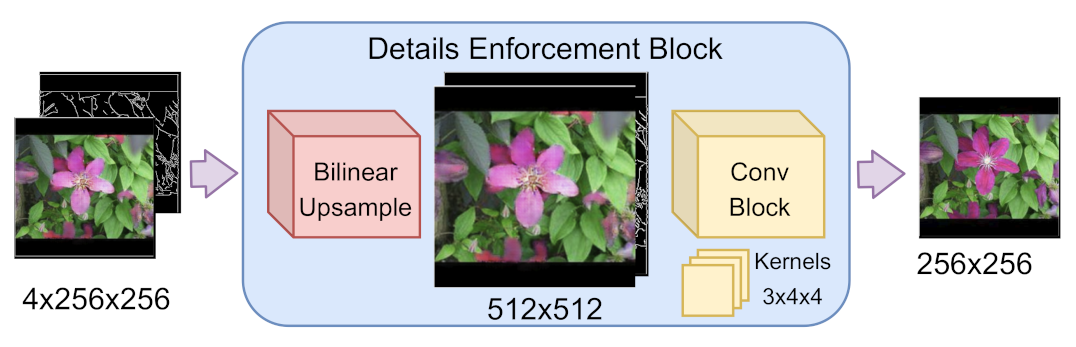
As shown in
Figure 4, we dealt with two main issues to achieve photo-realistic images: large monochromatic areas are affected by grid and checkerboard artifacts, while finer details are insufficiently highlighted. To deal with these undesired effects, the generator is equipped with two refinement modules: the Anti-Grid Block (AGB) and the Detail Enforcement Block (DEB), respectively illustrated in
Figure 5 and
Figure 6. The idea of grid-pattern removal in GANs is not novel [
57,
58], but our approach differs in the development of a specific modular block which can be applied several times in a row (e.g., 2 consecutive ones in the proposed architecture). The contributions of these two modules are further discussed in
Section 5.4.
The
Anti-Grid Block (AGB) is in charge of removing the grid-pattern artifacts due to small dimension kernels during the decoder steps of the generator. Our implementation is inspired by the ones proposed by Odena et al. [
57] and Sugawara et al. [
58]. The model performs an upsample operation by a factor of 2 via a
bilinear function, and then a
convolutional layer composed of three 8 × 8 kernels and a
hyperbolic tangent activation function are employed.
As analyzed in detail in
Section 5.4, the AGB effectively learns a smoothing function with improved performance with respect to classical smoothing algorithms [
59,
60] operating over the whole image and causing an excessive blur effect.
The
Detail Enforcement Block (DEB) plays a key role in object generation by exploiting a bilinear upsampling and a convolutional downscaling combination analogous to the one in the AGB. The DEB input is given by the concatenation of the initial sketch with the AGB output. The objects’ spatial constraints are enforced using
convolutional kernels, obtaining two significant improvements: the avoidance of small detail removal performed by the AGB (e.g., little bird eyes in
Figure 4) and the enhancement of sharper image elements. The latter effect comes from mimicking a well-known behavior exploited in previous works dealing with stacked approaches, in which sharp details are generated by the last G-D pairs [
5,
6,
9,
50].
3.3. Loss Functions
aRTIC GAN loss functions are based on several components to enforce all the constraints defined by TMG, AGB and DEB. Four types of cost functions have been implemented for both the generator and discriminator.
Binary and Patch Losses, introduced by [
1,
7], are widely used in image translation methods. In particular, the Binary Loss states the likelihood of an image, while the Patch Loss associates a confidence with the realism of each image region. aRTIC GAN exploits them together to enforce precise object generation with both fine details and global consistency (e.g., small-scale generated parts placed in a realistic way). Moreover, each of these losses provides a measurement on the image-caption consistency other than the Text Reconstruction Loss (described later in this section). Binary and Patch Losses are defined by applying a Mean Squared Error cost function, as proposed by Mao et al. [
61]:
where
DBin is the binary output of the discriminator,
DPatch is the patch output of the discriminator,
G is the generator output,
y is the ground truth image and
z is the concatenation of the RGB image with the inpainted sketch and the text description embedding.
Double L1 Loss deals with the synthesized object and the recursive generation of multiple elements. aRTIC GAN computes this criterion function twice: the first one is calculated over the whole image to ensure background consistency; the second one is computed on the eroded sketch area, as introduced by [
11], to ensure the visibility of the object.
Double L1 Loss is defined as follows:
where
yMasked is the eroded ground truth and
GMasked is the eroded output of the generator.
Text Reconstruction Loss (TRL) is fundamental for preserving semantic information represented by the text embedding in the discriminator architecture. Without this specific loss, semantic information would be ignored leading to
Mode Collapsing. Since Binary and Patch Losses focus mainly on spatial consistency, TRL ensures coherence between color patterns and referring captions, as shown in
Section 5.4. Text Reconstruction Loss is defined using the Cosine Similarity (CS) as follows:
where
DTRL is the text reconstruction output of the discriminator and
ztext is the input text embedding.
The final
Generator and Discriminator Losses take the following forms:
where
is the Generator Loss,
is the Discriminator Loss and the weight parameters
are defined in
Section 4.3.
3.4. aRTIC GAN Architecture
One of the main advantages of aRTIC GAN is the tight model composed of a single generator–discriminator pair. The discriminator’s multi-head structure balances between the network compactness and the number of constraints given to the model in the previously described loss.
The overall architecture is shown in
Figure 2. The generator G is a mixture of four components: the TMG, the encoder-decoder (E-D) backbone and the two refinement blocks. The output of the Text Mask Generator is fed to the E-D backbone. This core unit has a U-net [
62] structure and is in charge of analyzing features at several scales while feeding the upsampling blocks with the corresponding encoder information. The final output image is given by the two refinement blocks working in pipeline. The discriminator D has been designed to take advantage of two feature-extraction backbones and is composed of 10 convolutional layers. It is able to perform three different tasks in parallel: binary classification, patch classification and text reconstruction.
4. Implementation Details
A detailed overview of the technical aspects is provided here, starting from the datasets employed in our experiments, the input text and sketches preprocessing, the network setup and its training procedure.
4.1. Datasets
The
Caltech-UCSD Birds 200 (CUB-200) [
13] dataset is composed of more than 11,000 images depicting 200 bird species. Images are associated with objects’ bounding boxes, segmentation masks and attributes.
The
Oxford Flowers 102 [
14] dataset is made up of more than 8000 images belonging to 102 flower categories. For each class, we can find a total number of
n images, with 40 ≤
n ≤ 258, resulting in an unbalanced dataset. One of the main advantages of Oxford Flower 102 is a high variation with respect to flowers pose and light conditions in images, even within the same class.
The
Birds and Flowers Captions [
62] dataset describing the images contained in CUB-200 and in Oxford Flowers 102, is provided by Reed et al. [
12]. It consists of 10 short text captions for each image, together with their 1024 vector embeddings, retrieved via
Amazon Mechanical Turk. The text descriptions provide attributes such as appearances and colors of birds and flowers.
The choice to employ the aforementioned datasets is due to the visual chromatic variance which can be found in their images, a consequence of brightness, saturation and high contrast provided by colors in nature. Other types of datasets, even among the most common in this field such as COCO [
63], ADE20K [
64] or Cityscapes [
65], characterized by urban environments, display less variance. Moreover, the amount and high quality of the human-made captions provided by [
12] makes a strong contribution for the dataset choice.
4.2. Input Preparation
We discuss here the RGB input image preparation, the sketch generation process and the text embedding. Unless specifically reported, all the image data are resized to 256 × 256 pixels, which is the standard aRTIC GAN working resolution.
4.2.1. Background Generation
Background images are obtained directly from the CUB-200 dataset, upscaling the bird images and isolating the four
external edge squares, as suggested in [
11].
4.2.2. Sketch Mask and Input Generation
One of the two aRTIC GAN inputs is a merging of a sketch and an RGB background, which is either a random background image (in case of the first generated object) or the output of the previous generation step. The sketch is inpainted into the background image by replacing the corresponding pixels and the area within the sketch. At training time, the objects’ binary masks are taken from CUB-200 and Oxford Flowers 102 datasets. On the other hand, if a sketch is provided at test time, the binary mask is generated through
closure morphological operator and
Fill algorithms. The binary masks are resized to
,
and
to feed the corresponding upsampling block in the TMG (see
Figure 3).
4.2.3. Sketch Generation
In order to automatically reproduce plausible human-made sketches for the images in CUB-200 and Oxford Flowers 102 datasets, we apply an edge detection strategy on the ground truth images. The Canny algorithm [
66] is chosen as the baseline method for this purpose taking into account two separate thresholds to regulate the sensitiveness of the resulting sketch with respect to the amount of details. The choice of the sensitivity threshold level is particularly tricky in the case of the CUB-200 dataset because low values lead to noisy details while high values can remove contours and structural details (e.g., birds’ eyes). Two different Canny edge detectors are then employed, one working on the elements inside the object and one working on the segmentation mask to obtain the contours. Finally, the outcomes are summed up and normalized in
. Examples of the sketch generation procedure are displayed in
Figure 7.
4.2.4. Char CNN-RNN Text Embedding
Char CNN-RNN is employed to extract the visually discriminative text embedding of a given description, the second input of aRTIC GAN. This method was proposed by Reed et al. [
12] to pretrain a text encoder and it is largely used in Text-to-Image Synthesis tasks. It maps text descriptions to the common images feature space by learning a correspondence function between text and images. The choice to employ the aforementioned model in the evaluation phase is to pursue a fair comparison of aRTIC GAN with other generative models.
4.3. Network Setup
aRTIC GAN inputs have dimensions of 256 × 256 × 3 for the RGB image and 1 × 1 × 1024 for the text embedding. The text embedding feature vector is fed to the TMG, resulting in a 256 × 256 × 1 features map, which is concatenated to the RGB tensor as an additional channel.
The encoder-decoder structure is composed of eight convolutional blocks for the downsampling stage and seven transposed convolutional blocks for the upsampling. The encoder is equipped with batch normalization (BN) [
67] and the tanh activation function, with an exception for the first layer. The decoder is equipped with BN and ReLU activation functions. A dropout strategy is used in the first three blocks to improve the robustness of the model. We employed two AGBs and two DEBs with filters of dimension 8 × 8 and 4 × 4, respectively (see
Figure 2).
The discriminator input has size 256 × 256 × 7, obtained by the concatenation of the inquired image, the Text Mask and the ground truth (GT) image. The two shared architectures are composed of three downsampling blocks (with a factor of 2). Every convolutional layer is followed by BN and ReLU activation functions. The final discriminator outputs representing the Binary, Patch and Text Reconstruction tensors, have dimensions of 1 × 1 × 1, 16 × 16 × 1 and 1 × 1 × 1024, respectively. The Binary and Patch Losses exploit a Mean Square Error (MSE) cost function, while Text Reconstruction utilizes the Cosine Similarity (CS). The weights chosen for the two final loss functions (Equations (
5) and (
6)) are:
,
,
,
and
. Our model is trained with a batch size of 3 for 200 epochs with image augmentation and for an additional 100 epochs with background augmentation (experiments described in
Section 5.2). Finally, aRTIC GAN is trained with single-object generation, as each generation is independent from the others.
4.4. Training Procedures
aRTIC GAN can generate an object in a scene while preserving the given background up to a plausible inpainting using only a single generator–discriminator pair. When generating multiple objects, this structure allows the model to handle each object generation as almost completely independent from the others. Indeed, occlusions and artifacts are processed separately at each step.
Accordingly, two training strategies have been developed for aRTIC GAN: independent steps learning and random consecutive steps training.
The
Independent steps learning strategy is based on the idea of training aRTIC GAN on a single object at a time. The whole procedure is summarized in Algorithm 1. The input background is either composed by random environment surroundings or a GT image belonging to one of the two datasets used, mimicking the context of multi-object images. The gradients for both the generator G and discriminator D are computed at each step as well as their weights update. This strategy allows us to provide the final image starting from any type of sketch, description and background, avoiding any dependency with respect to the position, patterns and relative occlusions from other inputs. This modality has been exploited for all the results shown in our work.
| Algorithm 1: Independent steps learning |
| Input: Inpainted sketch, text embedding and GT image |
| Output: Generated image and weights update step |
| 1 Generator Call over the inpainted sketch and text embedding
|
| 2 Discriminator Call over the generator output and the GT
|
| 3 Generator Losses: Binary, Patch and Double L1
|
| 4 Discriminator Losses: Binary, Patch and Text Reconstruction
|
| 5 Gradient Computation |
| 6 Weights Update; |
Random consecutive steps training is an alternative procedure based on a sequence of generation steps and a single-discriminator evaluation. The procedure is summarized in Algorithm 2, where the input is defined as a set of
m, with
, sketch-text embedding pairs. The final image is generated via consecutive calls of G, where the current sketch is inpainted in the output of the previous step (except for the first object, which is inpainted in the initial background input), while the Double L1 Loss is computed and stored at each step. After all the generations are completed, the discriminator is called and its loss is computed along with the Binary and Patch components of the Generator Loss in order to perform a single gradient descent step.
| Algorithm 2: Random consecutive steps training |
![Electronics 11 01737 i001]() |
5. Experiments and Results
Extensive experiments have been carried out to prove the validity of the proposed method. In
Section 5.1, we report the metrics used to measure aRTIC GAN performance. In
Section 5.2, we evaluate the generation of multiple elements, highlighting the behavior of aRTIC GAN with respect to different backgrounds. A comparative analysis is then provided in
Section 5.3. Finally, an ablation study of the main components is described in
Section 5.4.
5.1. Metrics
A quantitative evaluation has been performed using several metrics: the Inception Score (IS) [
17] (the higher the better) for the realism of the generated image, the Structure Similarity (SSIM) [
68] to quantify the similarity between the GT and the generated images (
), the Cosine Similarity (CS) to measure text descriptions’ variations and the Frèchet Inception Distance (FID) [
69] (the lower the better), which compares the distribution of the generated images with the distribution of the training images. The definitions of the cited metrics are shown below.
IS is a measure of the characteristics of a generative model:
where
is an image generator to be evaluated,
y is the label,
is the posterior probability of a label computed for an image
x,
is the marginal class distribution and
is the KL-divergence between two probability distributions
.
The Structure Similarity (SSIM) estimates the visual impact of shifts in image luminance, changes in image contrast and structural changes. The SSIM between two image windows
and
with the same dimension is defined as:
where
control the significance of each of the three terms. The luminance, contrast and structural components are defined as:
where
and
represent the means of the two images,
and
represent the standard deviations,
is the covariance of the two images and
.
The Frèchet Inception Distance (FID) is the Wasserstein distance between two multivariate normal distributions
and
:
Furthermore, an additional metric has been defined to evaluate the capability of the generator to reproduce the target domain distribution for the given conditional input. In particular, we compute
as the absolute difference between the similarity obtained on the ideal transformation (inputGT) and the one performed by aRTIC GAN (inputGen) as follows:
where
and
are the structural similarities computed over the input image with respect to the ground truth and the generated output.
Finally, we exploit the Cosine Similarity (CS) metric to understand text embeddings’ variations and similarities.
The CS between two vectors
and
is defined as:
The CS measures in fact the similarity between two vectors of an inner product space on the basis of their angle cosine. A CS value equal to zero means that the two vectors are orthogonal, while two vectors pointing up to the same direction correspond to a CS value equal to one. We refer to the CS value of a dataset as the mean value of all CSs calculated on different vector combinations among the dataset text embeddings. Furthermore, we refer to the CS value of a dataset pair as the mean value of all CSs calculated on pairs of vectors taken from the respective datasets. This value can be empirically used as the distance between the two datasets’ text embeddings.
5.2. aRTIC GAN Evaluation
Table 1 reports the performance of aRTIC GAN in terms of IS, SSIM and
over the two datasets and their combined usage. An interesting result is represented by the increasing performance in terms of IS when training aRTIC GAN over both domains (birds and flowers), keeping the same hyperparameters setting. This highlights the importance of using a multi-domain dataset to improve the quality of image generation.
The combined use of text embeddings and sketches is analyzed in
Table 2 in relation to the respective datasets (i.e., CUB-200 [
13] and Oxford Flower 102 [
14]).
The reported CS values in the case of single dataset show the coherence of text embeddings in the Oxford Flower and CUB-200 datasets, with the latter showing a smaller value because of the greater variety of text descriptions of birds with respect to flowers. The almost-zero CS value calculated between the two datasets suggests that the respective embeddings are almost orthogonal; thus, a multi-domain training will increase the model generalization.
A qualitative analysis is provided in
Figure 8, showing a large set of resulting images with respect to several conditions (e.g., single-object, multiple-object generation). The left block shows examples of aRTIC GAN outputs when trained on both the domains, while the middle and right blocks display results provided by single domain training procedure. By the combined use of the two domains (left block), aRTIC GAN is able to improve the realism of color-pattern textures, boosting the IS value of about ∼2 points (see
Table 1).
Finally, the possibility of generating objects out of their original environments has to be considered since random backgrounds can be provided as inputs to our model. In order to deal with this issue, we investigated a fine-tuning training strategy over an augmented dataset using the procedure introduced in [
11]. The GT object and relative sketch pair is inpainted both into the original background and into a randomly chosen one.
Table 3 reports the obtained IS, which slightly decreases in the more challenging setting of complete random backgrounds. In
Figure 9, some background images and original-augmented GT image pairs are presented in the first and second rows, respectively. The last two rows provide examples of the generation process employing or not the background augmentation technique. The not-augmented model, while trying to preserve the background, propagates black regions from the input image, resulting in unrealistic outputs.
5.3. Comparison with the State of the Art on Single Domain
A straightforward comparison between aRTIC GAN and other methods is not trivial. As already mentioned, T2IS and I2IT lack, respectively, spatial and color-pattern constraints, possibly leading to
Mode Collapse events. Even if the Inception Score (IS) outputs a lower score in the case of Mode Collapse [
70], the actual supervision is hard to be measured: neither text-based methods, e.g., DF-GAN [
34], DM-GAN [
32] and StackGAN [
5], nor sketch-based methods, e.g., Pix2PixHD [
8], CUT [
24] and CycleGAN [
10], have the expressive power required to enforce both the constraints (details and textures). On the other hand, multi-conditioned methods [
11] actually exploit the combined use of background images and text descriptions, but no actual control over the object’s shape or details is provided, resulting in a slight variation in the Text-to-Image Synthesis task.
Moreover, the comparison with another multi-conditioned model, SPADE by Park et al. [
23], is not an easy task due to the different inputs used. Pairing style images to text descriptions is far from being a trivial task, and no assurance on providing the same amount of information can be given. If no style image is fed to the network, SPADE falls into the same category as Pix2Pix and Pix2PixHD.
Nonetheless, we compared aRTIC GAN with several baseline models in single-domain setting in order to provide a general indicator for the realism quality of the generated images; these include the aforementioned stacked approaches, more modern architectures and even a single-stage generation competitor model, due to their high reputations among the scientific community and the availability of common metric scores on CUB-200 and Oxford Flowers 102 datasets.
Table 4 reports the achieved results in terms of Inception Score and FID score, respectively: the competitors’ values have been taken directly from the original papers with the exception of Pix2Pix, which had to be trained specifically for the sake of comparison purposes. Even if our aRTIC GAN aims to tackle a more challenging objective with respect to I2IT and T2IS, due to the used inputs, the IS achieved on CUB is
and the FID score is
, while on Oxford Flowers the IS achieved is
, resulting in extremely competitive performances in both datasets: LeicaGAN* (which is LeicaGAN trained with a custom training-testing split) is the only one performing slightly better on CUB, even if it lacks the quality of controls of our proposed method, as it displays a mono-conditional I2T approach; aRTIC GAN performs better than all the presented competitors’ models on Oxford Flowers dataset.
For a qualitative analysis,
Figure 10 demonstrates how aRTIC GAN can control the output image, given the same background and text caption, through a change in the input sketch. In the provided examples, our method is able to generate the correct poses and species, as opposed to the methodologies that exploit random noise to generate different output images. The example in
Figure 11 shows how our method reacts to a fixed-input sketch and different captions: aRTIC GAN is able to produce different coloring on request, proving the avoidance of
Mode Collapses as opposed to other competitors’ I2IT methods.
5.4. Ablation Study
We perform an ablation study to highlight the effects of the Patch Loss, the Text Reconstruction Loss, the Anti-Grid Block and the Detail Enforcement Block. These elements are compared using a conditional discriminator baseline with the Binary Loss, where the Gaussian Smoothing and Sharpening techniques replace the proposed refinement blocks.
The Binary Loss alone produces globally consistent yet inaccurate images, failing to correct heavy image artifacts produced by the generator. We found that setting
to
in Equation (
6) improves detail generation while keeping a global coherence, as shown in
Figure 12. The combined use of the Binary and Patch Losses makes the discriminator focus on spatial constraints, while the generator tends to choose the median pixel color to minimize the two L1 losses [
7].
The TRL enforces the text description, as shown in
Figure 12, where the generation process is sensible to the input caption resulting in the correct color pattern. Moreover,
Table 5 reports several implementations of the TMG, as in
Section 3.1, and the corresponding number of parameters of the generator and the Inception Score. We empirically found that the best performance is obtained through the 32 × 32 implementation, which demonstrates the capability of this block to generalize the information provided by text.
Here we investigate the use of the
Gaussian Smoothing and
Sharpening techniques when replacing the Anti-Grid Block and the Detail Enforcement Block. As shown in
Figure 13, these filters affect the whole image neither preserving the background nor adapting to specific cases. Instead, the AGB removes the grid-pattern artifacts without influencing the contours and the surroundings. On the other hand, DEB contrasts the lack of details and sharp lines.
For a more holistic view of the ablation study,
Table 6 shows the effects, in terms of the FID metric, derived from the suppression of various components in the complete model, highlighting and quantifying their importance in the presented architecture.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}