1. Introduction
Glaucoma, which can cause irreversible visual impairment, is a widespread eye disease known as the “Invisible Vision Killer” due to its lack of noticeable symptoms in the early and middle stages, making it difficult to detect [
1]. Glaucoma is anticipated to impact an increasing number of individuals globally because of an aging population [
2,
3,
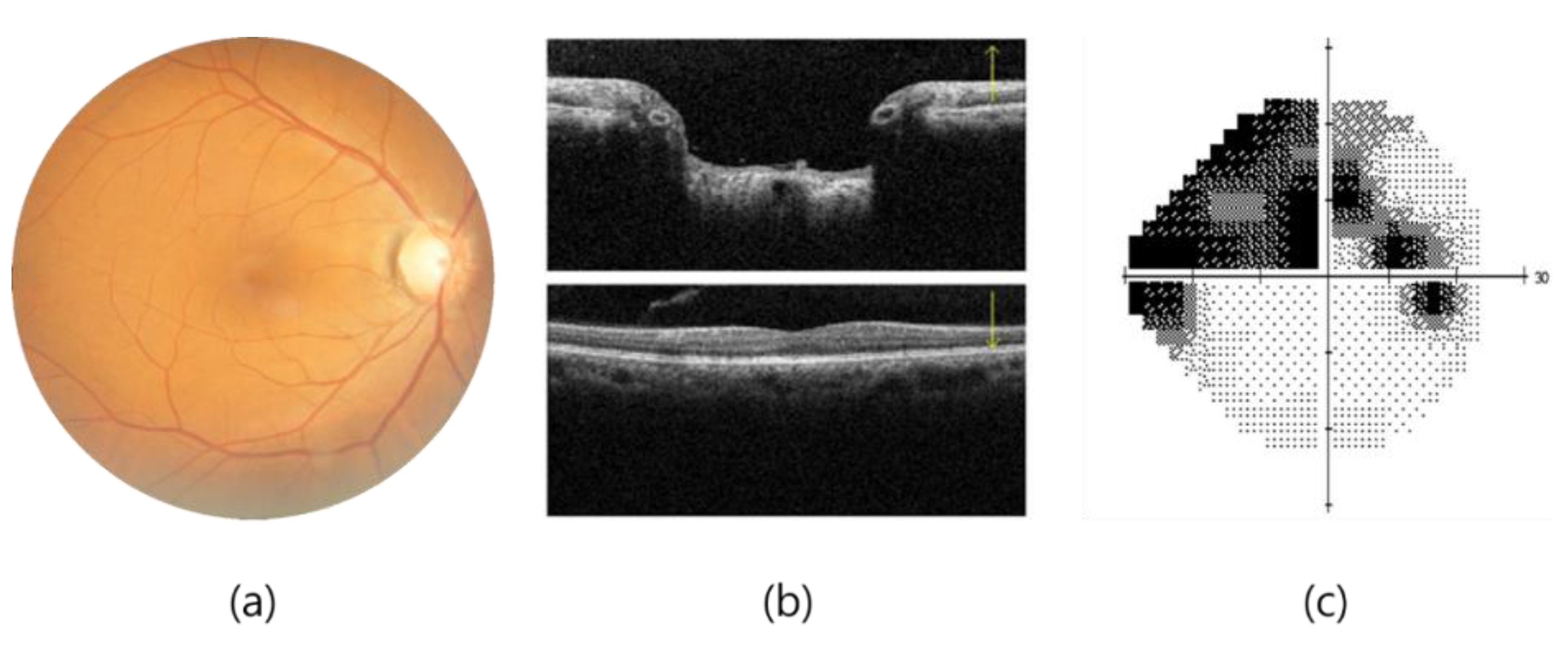
4]. The clinical diagnosis of glaucoma is achieved through various methods, such as fundoscopy, optical coherence tomography (OCT), and visual field examination, as shown in
Figure 1. OCT offers high-resolution information on the thickness of the cornea, retina, and optic nerve, but the importance of the thickness of the ganglion cell complex (GCC) in diagnosing glaucoma remains a matter of debate [
5]. A visual field examination can detect glaucoma when more than 40% of the optic nerve is damaged, resulting in changes in the visual field that threaten vision as they develop from the periphery, invade the center of the visual field, and advance. POAG, more prevalent in Westerners, leads to a gradual loss of vision, while PACG, more common in Easterners, causes rapid intraocular pressure increases, resulting in symptoms such as halo, blurred vision, severe eye pain, and nausea. Early screening is essential to prevent irreversible visual impairment.
Due to the superior image recognition capabilities of deep learning models, the medical field is increasingly using them to improve diagnosis accuracy and enhance human-machine collaboration. However, the lack of interpretability of early studies treating deep learning models as black boxes poses challenges in validating their effectiveness in clinical applications. To overcome this issue, researchers are using feature visualization methods to analyze deep learning models’ features and propose interpretable AI research that aligns with domain knowledge. The goal is to improve the reliability and acceptance of deep learning models for clinical applications.
The objective of this study is to train deep learning models on the NTUH Dataset fundus image dataset using four distinct approaches in order to analyze their impact on the model’s performance in measuring glaucoma. These approaches include:
- (a)
obtaining two versions of fundus images using different fundoscopic angles, namely disc-centered (CD) on the optic disc (CD Fundus) and macular as the center (CM), termed CM Fundus,
- (b)
using different cropping ratios to focus on smaller areas centered on the optic nerve disc (CD Crop) or macula (CM Crop) compared to the entire optic nerve disc-centered image,
- (c)
applying various dataset splitting methods to divide patients into training, verification, and testing sets using different ratios, and
- (d)
integrating the macular ganglion cell complex (GCC) thickness information with the fundus image for training the model.
After evaluating the impact of various network training methods on glaucoma diagnosis, this experiment will be repeated using the optimal method for both complete and cropped images of CD and CM. Moreover, two different visualization techniques, namely model-dependent CAM and model-independent LIME, will be utilized in this study to assess the areas of interest detected by the network models and verify their consistency with clinical diagnostic expertise.
This manuscript proposes three hypotheses, which will be tested through the following methods:
- (a)
Investigating whether the deep learning model can detect subtle differences in the shape of the macular area, which are difficult to observe with the naked eye, in addition to the differences in the optic disc area observed in general clinical diagnosis, to test the ability of the model in interpreting glaucoma through fundoscopy.
- (b)
Verifying whether the deep learning model reflects the changes in GCC cell layer thickness in the macula corresponding to glaucoma-induced optic nerve atrophy in fundoscopic image interpretation and determining whether the features learned from the model in the dataset have clinical reference value and testing whether the model reflects these changes.
- (c)
Identifying the factors responsible for the high accuracy of deep learning models on fundoscopic images and ensuring the validity of AI models for clinical applications.
2. AI Interpretable and Visualization Techniques
Artificial intelligence has become an integral part of various industries, including finance, justice, and healthcare. While some AI applications, such as advertising recommendation systems, do not require transparency in decision-making, others, such as clinical diagnosis, demand interpretability. In healthcare, the results of an AI model can heavily influence important decisions, such as identifying the nature of a patient’s tumor. In such cases, if the model operates as a “black box,” i.e., lacking transparency, it becomes challenging to validate its effectiveness in clinical diagnosis. Focusing solely on achieving high accuracy without an explanation to justify the model’s decision-making process could undermine its clinical acceptance and reliability, leaving professional physicians hesitant to replace their diagnosis with an unverifiable AI system.
Explainable AI (XAI) is crucial in enhancing the transparency and efficacy of AI models and establishing trust in their use by domain experts. The focus of XAI research is primarily on developing methods that enable humans to comprehend the decision-making processes of AI systems.
Samek et al. [
6] identified four key aspects of verifying, improving, learning from, and ensuring compliance with legislation to enhance the effectiveness and trustworthiness of AI systems. Christoph Molnar [
7] classified model interpretation methods based on their local or global interpretability. Local interpretability pertains to understanding the behavior of an individual sample or a group of samples. As models become more accurate, they also become more complex, making it challenging for humans to comprehend the relationship between features and outcomes. In the following sections, we will discuss two methods for interpretability: the model-independent LIME method [
8] and the model-dependent feature visualization CAM method [
9].
2.1. Local Interpretable Model-Agnostic Explanation (LIME)
LIME, proposed by M. T. Ribeiro et al. in 2015 [
8], is a model-independent technique for regional interpretability. By perturbing the input data of a network model, LIME identifies the input features that have the most influence on the model’s output. For instance, in the case of the Titanic passengers, numerical fields can be perturbed to comprehend which input features had a significant impact on whether the passengers survived the shipwreck. Today’s deep learning models offer high accuracy but have complex structures that make it challenging to explain their decision-making process. LIME is designed to address this problem by training a simple linear model that approximates the complex model and provides regional interpretability.
Figure 2 illustrates an interpretable area in the form of a concept map. The blue and red regions represent two categories of a complex classification model. Samples predicted within the red region are classified as “+”, while those in the blue region are classified as “●”. It is difficult to use a linear model to explain the behavior of the entire area of a complex model. However, if we focus on a specific area, a linear model can be used to fit the regional behavior of the complex model in that area. For instance, the thick red cross sample in
Figure 2 can be utilized to interpret the deep learning model regionally by taking perturbation samples around it, classifying these samples using the original complex model, and training a simple linear model, such as the black dashed line. This enables the use of locally interpretable models for regional interpretation of deep learning models.
2.2. Class Activation Mapping (CAM)
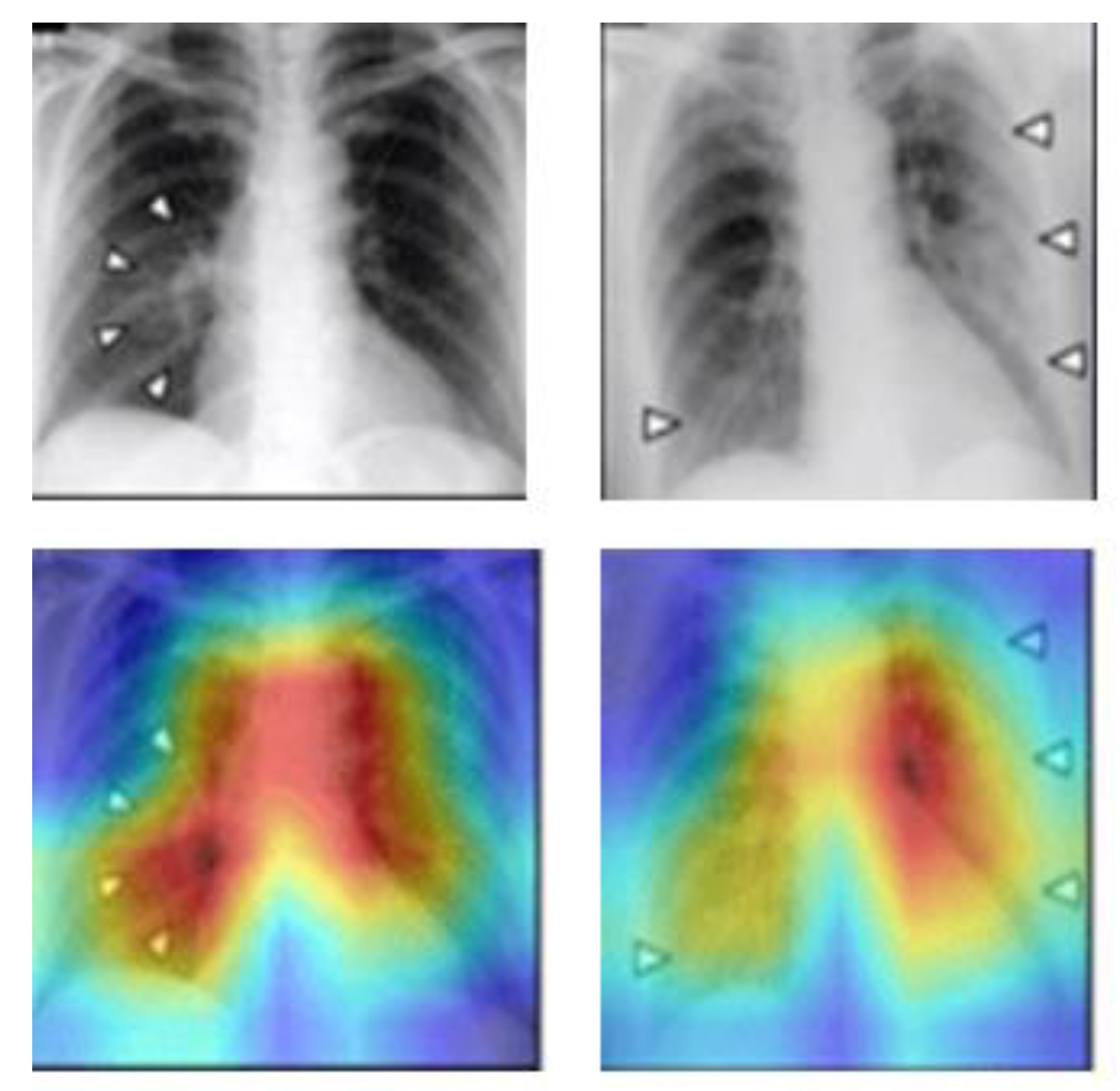
CAM is a CNN visualization technique introduced by B. Zhou et al. at the CVPR 2016 conference [
9]. It was originally proposed to solve the problem of weakly supervised learning, where CNNs are capable of detecting and localizing objects even if they lack labeled location information during training. This ability is lost when the network uses the Fully Connected Layer, but replacing it with the Global Average Pooling (GAP) layer preserves the localization ability and reduces the overall network parameters. The CAM method can visualize the CNN network’s position of interest in classification and generate a heatmap for the overall object localization of the network. By combining CAM and GAP, the CNN can classify the image and locate specific areas related to the classification. For example,
Figure 3 demonstrates the CAM schematic, where the CAM helps to identify the critical regions that need to be detected to diagnose COVID in the chest X-ray images.
3. Glaucoma Detection Based on Deep Learning
A. Diaz-Pinto et al. in 2019 used five different CNN architectures to evaluate the performance of glaucoma detection [
10], in which the authors concluded that previous automated detection algorithms were highly dependent on the use of optic nerve disc and optic nerve cup segmentation for subsequent glaucoma determination, including focusing only on the segmented optic nerve cup or optic nerve disc. In their study on glaucoma detection, the authors compared the performance of five CNN [
11] architectures, namely VGG16, VGG19, InceptionV3 [
12], ResNet50 [
13], and Xception [
14], without relying on the cup-to-disc ratio (CDR) calculation or optic nerve disc and cup segmentation. The authors argued that as CNNs can learn discriminative features from images, it is not necessary to use CDR or optic nerve segmentation for glaucoma determination. The authors utilized pre-trained ImageNet weights for transfer learning, and the experimental results indicated that Xception outperformed VGG16 and VGG19 in terms of computational cost and accuracy. However, the incorrect judgment could be due to the absence of a larger bright area in the glaucoma image or the poor quality of the input image.
When testing CNNs on various public datasets, it was discovered that they did not perform well in terms of generalization to different datasets. This may be due to varying annotation standards across different datasets, such as experts making decisions based on different factors, including the patient’s medical history and fundus image, versus solely using the fundus image, resulting in less strict decisions and potentially leading to more false annotations.
In 2019, S. Phene et al. [
15] proposed a CNN-based system for glaucoma detection and observation of optic nerve papillae features. They used an InceptionV3-based CNN architecture to train and evaluate color fundus images for glaucoma detection [
14]. Their system provided good performance with higher sensitivity than ophthalmologists and comparable specificity to ophthalmologists. The authors emphasized the importance of fundus imaging, which is still the most commonly used low-cost medical imaging modality for evaluating ONH structures worldwide, especially in economically disadvantaged or medically underfunded areas. They also noted that there is no specific standard for deep learning to detect glaucoma on fundus images, and the clinical value of these systems is limited by differences in standards. To address this issue, the authors developed a system that could observe the features of interest to the model in detecting glaucoma as a way to assess the similarity between the features of interest to the ophthalmologist and the system. The results showed that the system mainly observes features such as a cup-to-disc ratio greater than 0.7 and RNFL impairment, which are the same decision areas of interest to ophthalmologists. By examining a single ONH feature, it is also possible to better understand which features the model’s predictions depend on.
In 2020, M. A. Zapata et al. [
16] proposed a CNN-based glaucoma detection system that utilized five CNN models for various functional classifications. These included differentiating fundus images from other unrelated images in the dataset, selecting good-quality fundus images, distinguishing right eye (OD) and left eye (OS) in fundus images, detecting age-related macular degeneration (AMD), and detecting glaucomatous optic neuropathy. The model for detecting glaucoma was based on ResNet50 and mainly focused on observing the cup-to-disc ratio in the optic nerve disc region, along with some typical changes of glaucoma, such as RNFL defects. The authors also noted that non-mydriatic cameras (NMC) have become more popular for screening ophthalmic diseases using fundus imaging, which makes it a cost-effective approach. Incorporating AI into complementary diagnostic systems can also significantly reduce labor and time costs associated with image analysis. Furthermore, CNN can also be applied to other ophthalmic diseases, including AMD. Additionally, AI has the potential to observe information on fundus images that cannot be detected by the human eye, such as gender, age, and smoking status.
In 2019, S. Phan et al. [
17] presented a glaucoma detection system for fundus imaging that utilized three different CNN architectures, namely VGG19 [
11], ResNet152 [
13], and DenseNet201 [
18], to evaluate its performance and identify the region of interest for glaucoma diagnosis. The authors also employed a visualization technique called CAM to observe the identified region. The results demonstrated that the optic nerve disc was the primary area of observation for glaucoma diagnosis.
Similarly, in 2019, H. Liu et al. [
19] proposed a CNN-based fundus imaging glaucoma detection system that utilized a ResNet lite version of GD-CNN [
13]. The study not only evaluated the model’s performance but also incorporated visualization of the output heat map for observation purposes. The findings showed that the model correctly identified ONH lesions, RNFL defects, and localized defects.
In 2020, R. Hemelings et al. developed a CNN-based glaucoma detection system for fundus imaging that employed an active learning strategy and utilized ResNet50 for migratory learning. The model utilized uncertainty sampling as an active learning strategy, and the authors generated a significant map of the output model to observe the regions of concern and decisions made by the model. The authors found that the upper and lower edges of the optic nerve head (ONH) and the regions outside the ONH (the S and I regions in the ISNT principle) were relevant to the retinal nerve fiber layer (RNFL).
Also in 2020, F. Li et al. [
20] proposed a CNN-based glaucoma detection system that used ResNet101 architecture and incorporated patient history information in the final fully connected layer. The model’s main concerns were identified using heatmaps generated by blocking tests, which revealed that the model focused on the edge of the ONH in non-glaucoma cases and on the area of RNFL defects above and below the ONH in glaucoma cases.
In 2021, R. Hemelings et al. [
21] proposed another CNN-based glaucoma detection system using ResNet50 architecture, which aimed to address the lack of interpretability and decision transparency in deep learning glaucoma detection studies. The authors employed different cropping strategies to select 10–60% of the area centered on the ONH for cropping and removal, and the schematic for this cropping strategy is shown in
Figure 4. Although most deep learning glaucoma detection studies exhibit high sensitivity and specificity, their lack of interpretability limits their clinical contribution.
The interpretability of CNNs is crucial for medical diagnosis [
22,
23] and building trust among experts. The authors note that it is unclear to what extent the information provided outside the ONH region on fundus images is relevant to glaucoma at this stage of research. To better analyze the feature information provided by the ONH and outside the ONH region, the cropping strategy excludes both the ONH region and the area outside it. The experimental results demonstrate that the deep learning model can identify the presence of glaucoma in areas outside the ONH of the fundus image. Additionally, a significant map experiment was conducted with various cutting strategies. The results, depicted in
Figure 5, indicate that the model’s attention is mainly on the ONH region for glaucoma detection. As the area removed by cutting increased, the model’s attention was mainly on the upper (S) and lower (I) regions in the ISNT principle outside the ONH, which is the thickest area of RNFL in the retina. The final experimental results also demonstrate that the trained glaucoma model can detect and use the subtle changes in the RNFL that are not visible to the human eye.
8. Experimental Results
In this section, comprehensive experiments are conducted to understand the impact of different disc portions, crop sizes, and GCC thickness information, along with detailed ablation studies. A CAM visualization is also performed to understand the significance of the proposed model.
8.1. Different Disc Positions and Crop Sizes
The experiments using different fundoscopic angles, as listed in
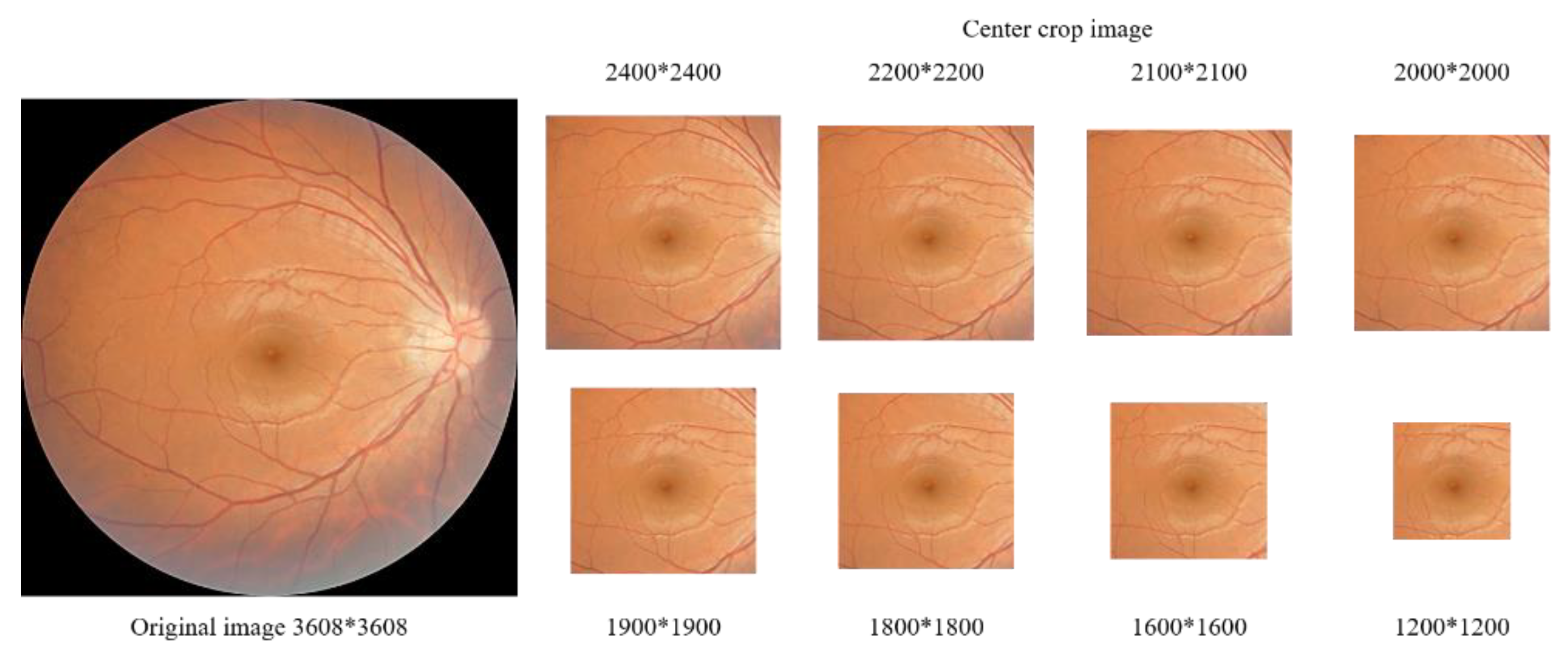
Table 3, showed that CM alone had an accuracy of 85.7% and focused more on learning non-glaucoma features based on specificity results. Further observation of features provided by CD and CM through fundus images with different cropping scales was deemed necessary. Experiments with different crop sizes, as listed in
Table 4, revealed that the macular area alone had an accuracy of 79%, and the accuracy of different cuts of the optic disc area alone was also higher than that of the macular area alone, which aligns with clinical diagnosis. CM cuts, which excluded the optic disc area, achieved an accuracy of 76.4% or better, indicating that the macular region provides sufficient non-robust features for representing the presence or absence of glaucoma.
8.2. GCC Thickness Information
Table 5 shows the experimental results of using the GCC thickness information method, which improved the accuracy to 90.8%. This suggests that the model can more easily learn about the characteristics of glaucoma by avoiding errors or other complications in the OCT instrument output. However, since Type II and III images were excluded from the test, the results may be less rigorous and more biased. To address this issue, the network model was further tested using a set of CM images without GCC thickness information.
Table 6 shows that the model with GCC thickness information had about 4% higher accuracy than the model without it. Fundus images can provide information on GCC layer damage in addition to glaucoma characteristics, and the model was found to be affected by the presence or absence of GCC layer damage.
8.3. GCC Partitioned by Patients
The results of the experiments using GCC partitioned by patients are shown in
Table 7. From the experimental results, it can be seen that patient-based data set slicing can avoid bias in the determination and thus obtain a more rigorous performance evaluation.
8.4. Different Ratios
Table 8 presents the results of experiments with different data set slice ratios. When using a ratio of 6:2:2 for training, validation, and test sets, as compared to a ratio of 7:2:1, the results were more rigorous, with an accuracy of 89.3% and a more balanced sensitivity and specificity. This is because the number of validation and test sets was equal, leading to a more reliable evaluation of the model’s performance.
8.5. Ablation Test
Based on the experimental results of various experiments in the previous sections, the aim of this study is to evaluate the effect of adding different methods on the network model’s performance and accuracy, so the ablation test was planned. The test set used in this experiment is fixed to the original CM test set without any further processing. The results of the ablation experiment are shown in
Table 9.
8.6. Complete Experiments with CD Fundus Images
The complete experimental results for CD are shown in
Table 10. The accuracy of the trained network model for determining the presence of glaucoma was almost the same for both the full image and the optic nerve disc-centered fundus image at various crop scales. Whether or not the model pays more attention to the optic disc area makes little difference to the final result.
8.7. Complete Experiments with CM Fundus Images
The complete experimental results for CM are shown in
Table 11. The accuracy of the trained network model in determining the presence of glaucoma decreases as the cropping area becomes smaller and more attention is paid to the macula and its surrounding area, using either the full image or a fundus image centered on the visual macula at various cropping scales. However, the minimum is more than 80.6%, and after the crop size range is below 2000, the fundus image almost only includes the macula and its surrounding area, which can exclude the influence of the optic disc. The results of the sensitivity and specificity experiments showed that the model at this time focused more on the health characteristics of non-glaucoma patients in determining whether glaucoma was present.
8.8. Comparison of CD and CM Complete Experiments
The accuracy of the complete experimental results of CD and CM was further organized into a table for direct comparison and evaluation, and the comparison table of experimental results is shown in
Table 12. The CM part of the results is shown in red, which means that the fundus images used in the training of the model contain almost only the macula and its surrounding area, which can exclude the effect of the optic disc.
In the comparison of the experimental results, it can be found that whether the training images are used in full or in part, the final judgment result is not affected by the use of the visual plexus area. This part is also consistent with the clinical diagnostic experience, and it means that the models are learning whether robustness features represent glaucoma or not. In the case of the macular region only, although the accuracy of the results is reduced due to the exclusion of the optic disc and its region during training, it is not so reduced that the results are not credible or have no reference value for determining whether glaucoma is present. However, it is not easy to focus on specific features in the macular region on the fundus image with the naked eye clinically, indicating that the model can actually learn through the macula and its surrounding area what the human naked eye cannot detect and observe enough non-robust features to represent glaucoma.
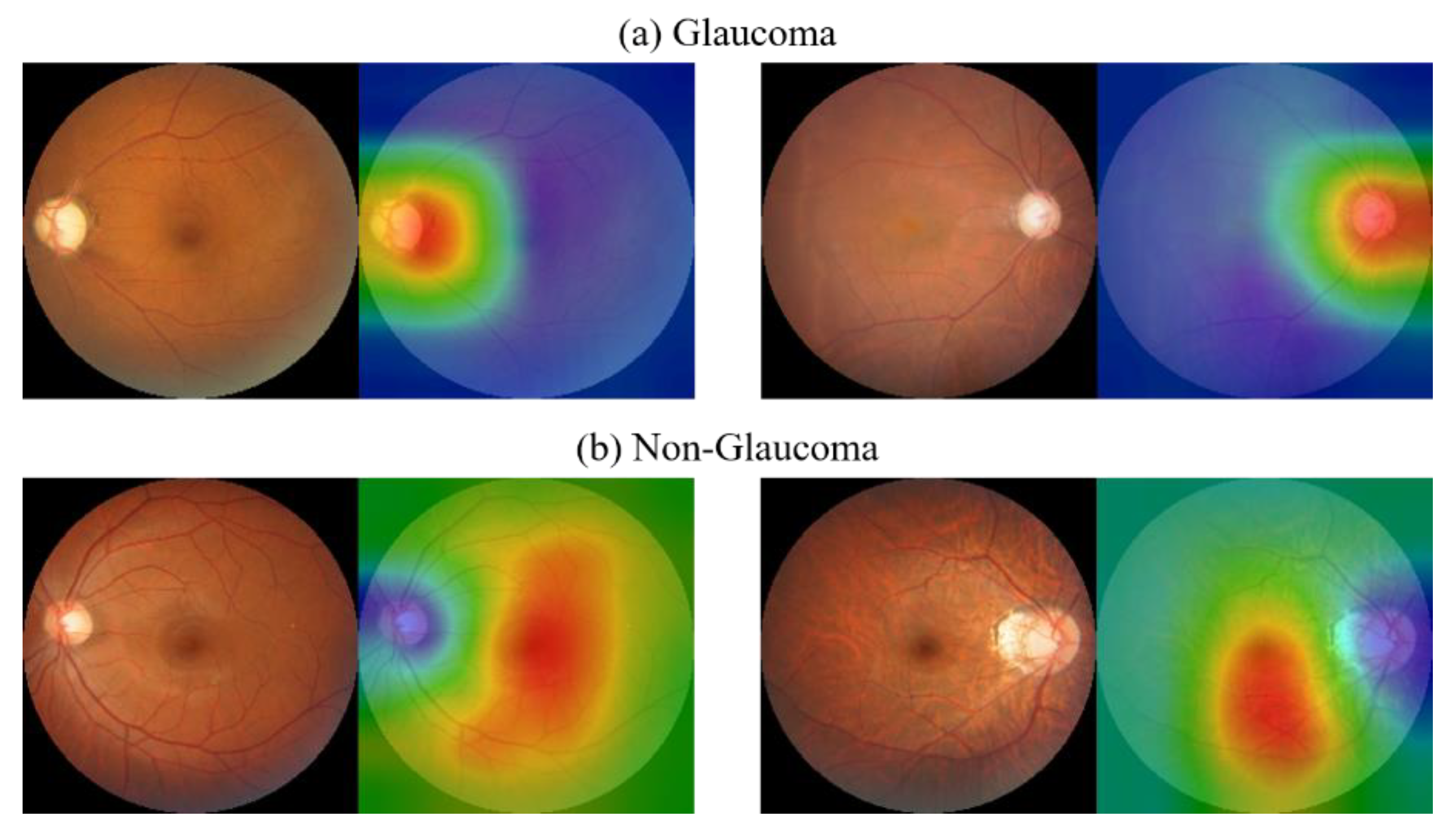
8.9. CAM Visualization
The results of the CAM analysis for two categories are shown in
Figure 17. From the results of the CAM experiment of CM images, it can be found that when the images are judged as glaucoma, the area of greatest concern for the model is the optic disc area, and this part is also consistent with the clinical diagnosis experience. In non-glaucoma cases, the opposite result was found as in glaucoma cases, where the model focused on all areas except the optic disc, with emphasis on the macula and its surrounding areas.
The first and second most discriminating features are further extracted from the heatmap and compared with the GCC thickness map. It can be found that the areas of interest and structure of the model are to some extent similar to the damaged areas of the GCC layer. Discriminative features are visualized as shown in
Figure 18. This again validates the model’s ability to observe subtle non-robust features on the macula and its surrounding areas, as well as providing information on GCC layer damage and the relevance of GCC layer damage to the development of glaucoma after incorporating GCC thickness information.
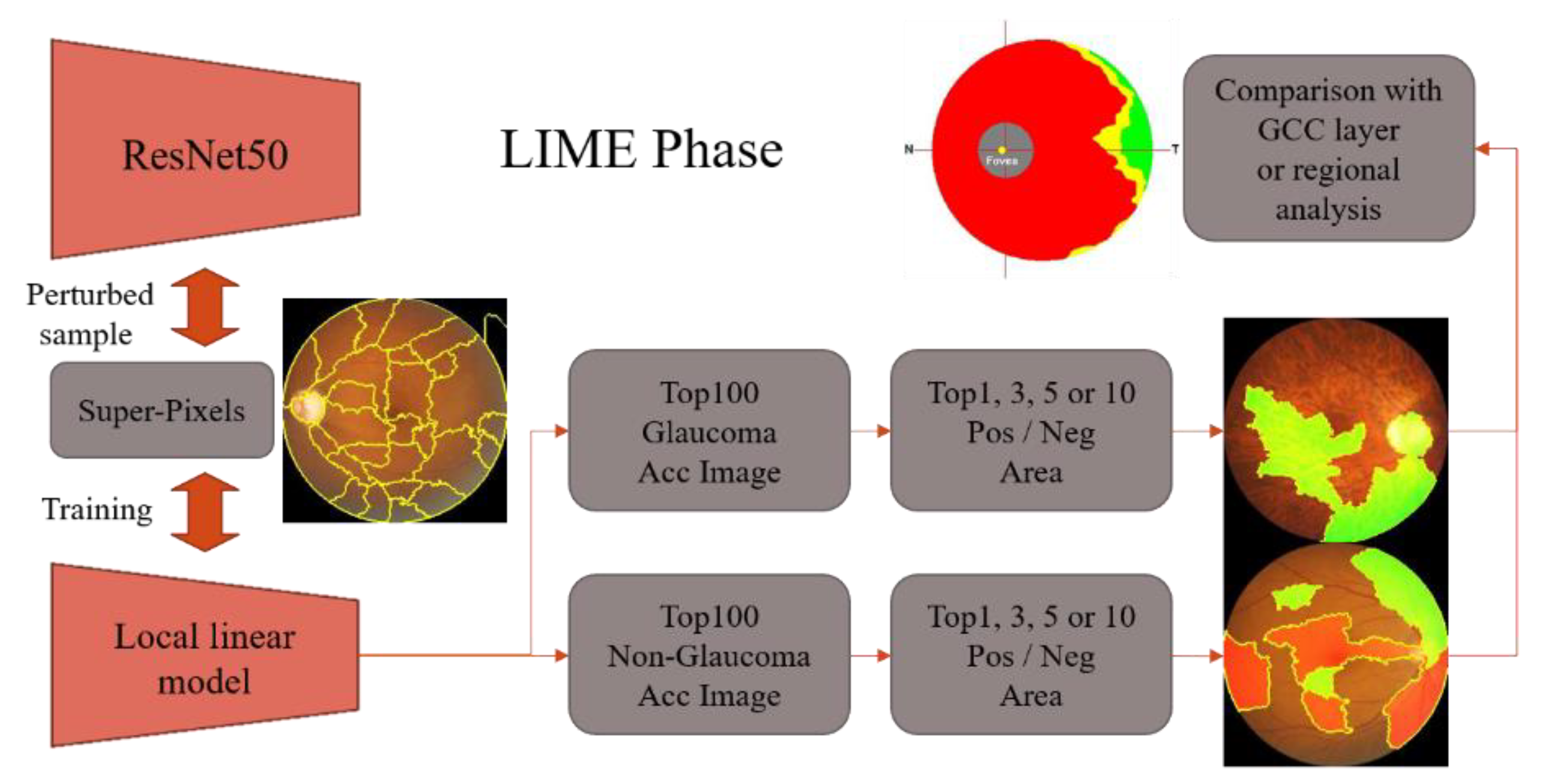
8.10. LIME Visualization
The results of the LIME analysis for two categories are shown in
Figure 19. When the image is determined to be glaucoma, the first 10 areas of the image are all green positive areas (glaucoma plus areas), and the positive areas all contain the optic disc itself. When the image is determined to be non-glaucoma, one or more red negative areas begin to appear in the top 10 areas of the image, and the red areas then contain the optic disc itself. Because of the Super-Pixel approach, the top 10 regions are a bit too extensive to be observed simultaneously. In order to arrive at a more precise explanation, the experiment further analyzes the positive and negative regions of the top 1 and top 3 in each case. The results of the LIME analysis for two categories are shown in
Figure 20.
Based on the LIME visualization outcomes for the top 1 and top 3, it is apparent that the areas of interest for glaucoma and non-glaucoma are contrasting. Moreover, it can be inferred that when identifying glaucoma, the optic disc area is the primary focus, while for non-glaucoma, the emphasis is not on the optic disc area but on the macula and its surrounding region.
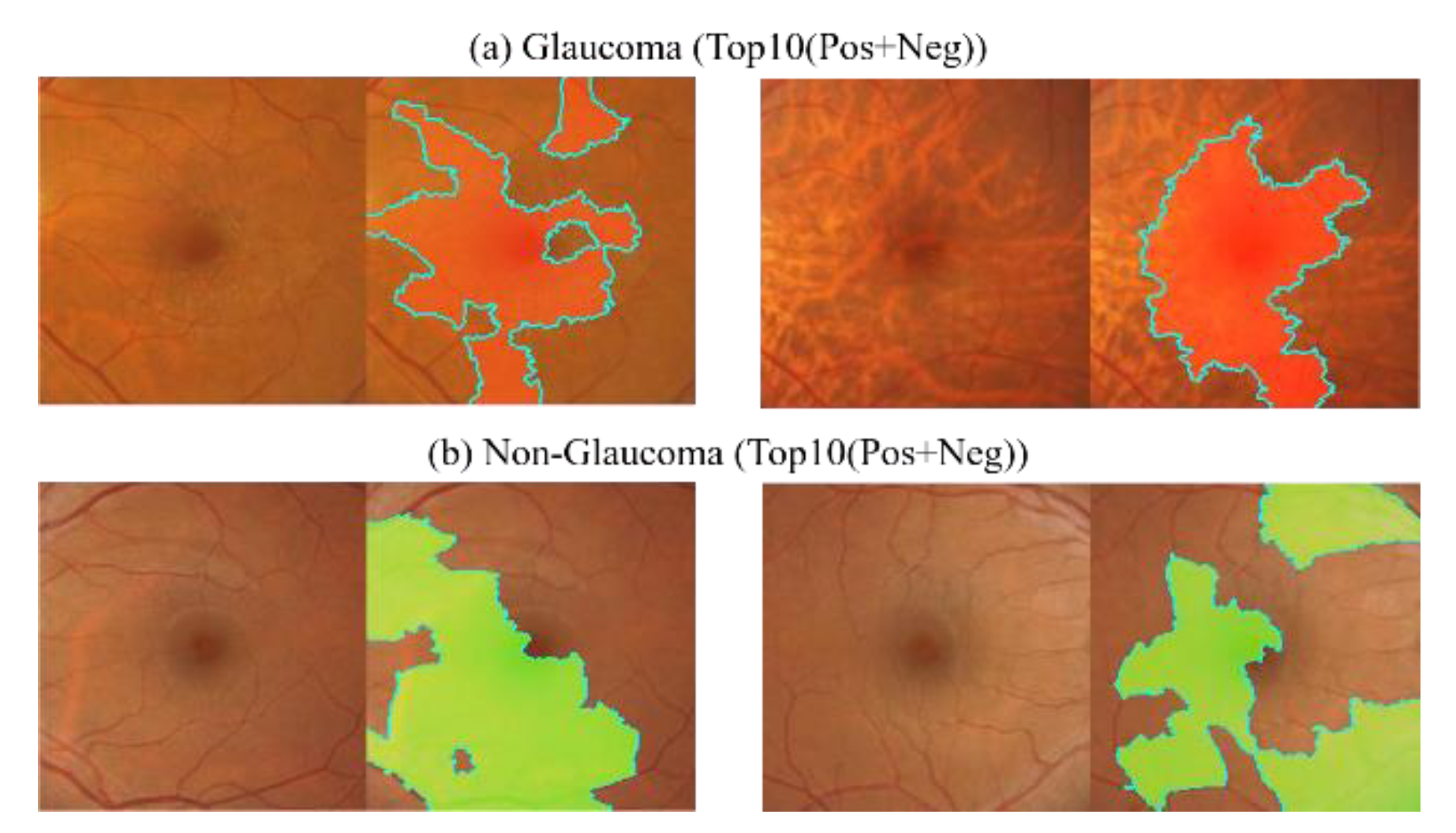
The experimental findings using the 1800 × 1800 size CM fundus images with LIME for the top 10 positive and negative decision areas differ from those obtained using full CM images, as shown in
Figure 21. This difference can be attributed to the exclusion of the effect caused by the optic disc area in the cropped images.
The top 10 areas identified by the deep learning model as having the most significant impact on determining glaucoma or non-glaucoma are primarily focused on the macula and its surrounding regions. However, a notable difference is observed in the top 10 glaucoma cases, where there are no positive areas of interest, indicating that negative areas are stronger features for glaucoma detection. On the other hand, the top 10 non-glaucoma cases are in the positive region, indicating that only fundus images of the macula can collapse into a pattern to determine non-glaucoma cases. However, the macula alone may not provide enough features to determine the presence of glaucoma, but it can help determine the absence of glaucoma. As both results are extreme, the study further analyzes the positive and negative regions for the top 1 and top 3 cases in each category, as shown in
Figure 22. The LIME analysis of the two categories is also presented in the figure.
The LIME visualization results for the top 1 and top 3 showed that the areas of interest for glaucoma and non-glaucoma were opposite to the results obtained using the entire CM image. However, when considering the top 10 glaucoma macular regions, LIME visualization was found to be stronger at identifying negative regions. Therefore, in glaucoma detection, more attention should be paid to the features that indicate non-glaucoma in the macular region, while in non-glaucoma detection, only the macular region should be considered without focusing on other surrounding areas.

 ,
, 























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}