
A Review and Comparative Study of Explainable Deep Learning Models Applied on Action Recognition in Real Time
 , , , and
, , , and
Abstract
:1. Introduction
2. Related Work
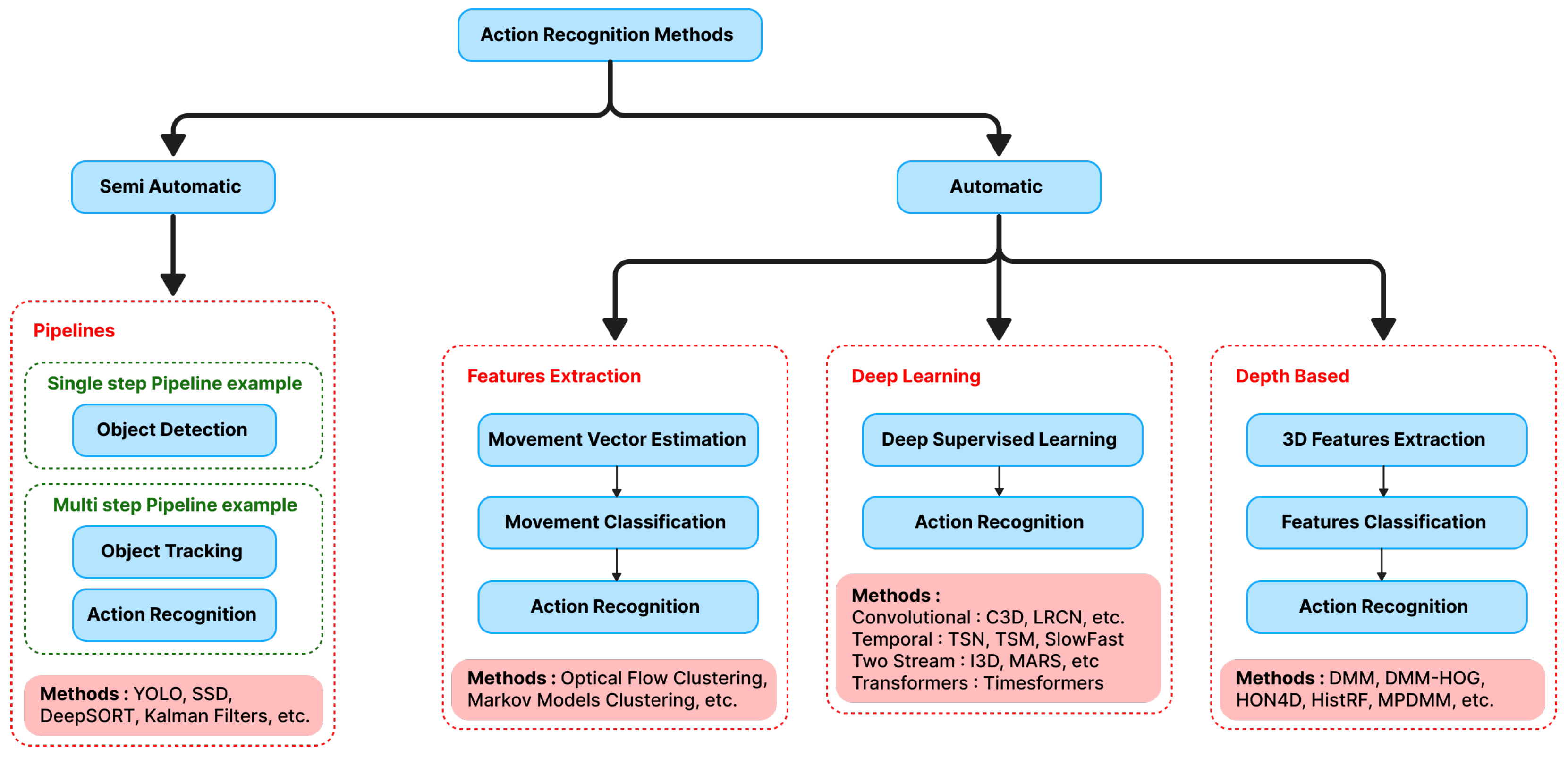
2.1. Semi-Automatic and Generic Action Recognition Approaches
- Object Detection: Advanced pipelines use some deep-based object detection methods [9] as an initial phase in a multi-phase approach. These object detection methods can be categorized into either one-stage methods such as YOLO [10] and SSD [11], or a two-stage region of interest proposal based methods such as Mask RCNN [12]. Other studies propose a much simpler pipeline by relying solely on single-frame object detection for action recognition through labeling objects with both identity and state information. For example, SW Pienaar et al. [13] used a dataset of toy soldiers, where bounding box annotations specified the state of each soldier who is either standing or lying down, to train an SSD MobileNet model [14] for action recognition through object detection. Improving this approach is carried out through multi-frame information fusion [15], which consists of applying object detection on multiple frames. Then, a majority vote system is applied, where the most detected action including a high number of frames represents the correct action to recognize.
- Object Tracking: Numerous approaches exist for multi-object tracking [16], with some building on object detection methods [17]. JK Tsai et al. [18] proposed to detect objects on multiple frames, which are then passed to the DeepSORT [19] object-tracking algorithm coupled with FaceNet [20] for subject identification. This information is fed to an I3D CNN [21] deep neural architecture that is able to take into account this mix of spatiotemporal information to recognize actions in a certain range of frames [22]. Other tracking solutions are not dependent on object detection, such as Siamese-based tracking [23] or correlation filter-based tracking [24]. These methods do not focused on objects in the scene. Thus, they are more abstract in the way they process scene information. They output different information such as pixel flow or shift as well as latent spatiotemporal features that can be used to perform other tasks.
- Action Recognition: This phase of the pipeline consists of feeding the acquired information through object tracking to a model that can relate these features to actions or events. In addition to the above-mentioned example, and in the case of subject-dependent object tracking, a trajectory can be used as in [25] where the authors applied action recognition from temporal trajectory data through Long Short-Term Memory (LSTM) and Temporal CNNs.

2.2. Automatic Approaches for Action Recognition
2.2.1. Features Extraction Methods for Action Recognition
2.2.2. Deep Learning Methods for Action Recognition
- Convolutional networks: generally, two-dimensional CNNs are used for 2D image classification and object detection. In contrast, 3D convolutional networks (3D ConvNet) can be used to incorporate the third dimension, which, in the context of action recognition, represents a brief temporal sequence of frames that compose the actions and movements, such as those proposed in [22]. Authors of [38] proposed to combine a 2D convolutional (CNN) with recurrent networks (RNNs) in order to take into account, respectively, spatial and temporal information. The recurrent connection within RNNs, and more particularly LSTMs, facilitates taking into account the previous image features within actions and thus detecting more accurately the type of action. Another method is proposed in [39] that applied spatial 2D convolutions followed, separately, by temporal convolution (1D) providing a specific convolution called (2+1D). This factorization offers significant gains in terms of precision thanks to the extraction of fine features.
- Two-Stream networks: the two-Stream reference method [40] is based on the operating principle of the human visual cortex, which is represented by two parts: the ventral part is involved to recognize objects, while the dorsal part is involved to recognize movements. Similarly, the two-Stream neural network architecture is composed of two parts: spatial and temporal where each one consists of a convolutional neural network. The spatial part allows the detection of actions based on the extracted images and object features while the temporal part allows improving the precision of action recognition by considering the order and frame succession in time. This evolution in time is calculated within motion vectors, estimated by the optical flow method [41]. The merging of the two parts’ features can be performed at the first layers “Early fusion”, the last layers “Late fusion” or in a progressive way “Slow fusion”. Authors in [42] found that the late fusion yields the best results. The two-Stream architecture has been improved by several works such as [43] that integrated the trajectory features. The authors of [44] proposed a novel spatiotemporal pyramid network for combining the spatial and temporal features in a pyramid structure in order to improve their reinforcement. In [45], the authors proposed to connect static and optical flow channel streams in order to increase the interactions between the streams. In [46], a new video representation was proposed for action detection by the aggregation of local convolutional features across the complete spatiotemporal extent of the video. The authors of [21] proposed to replace 2D convolutions (in a two-Stream network) with 3D convolutions in order to take into account the frames’ succession within the actions. Alternatively, the authors of [47] proposed a 3D CNN network that operates on RGB images and generates motion in order to avoid the computation of optical flow vectors, which are computationally intensive. During training, this method consists of minimizing the difference between the produced motion stream and motion features from the optical flow vectors. This allowed providing accurate results without the computation of optical flow offering real-time inference.
- Temporal networks: these methods allow the consideration of temporal information without using recurrent cells or motion vectors. Indeed, the methods try to extract the short, medium, and long temporal changes between successive frames. In this context, authors in [48] proposed a flexible solution that models long-range temporal structures where the video is divided into segments having the same duration. A short video extract is randomly selected from each segment and passed to two-Stream networks composed of two CNNs, one for spatial characteristics and the other for temporal characteristics. In [49], the authors exploit 2D CNNs for action recognition by adding the particularity of moving the learned features between neighboring images. It is a very simple approach that considers the time dimension by keeping the use of 2D CNNs, less intensive in computation, compared to 3D CNNs or two-Stream networks. Another method called “SlowFast” [50] is inspired by biological studies, considering a video as a sequence of slow and fast movements. SlowFast is designed to combine two different paths in the network: one with a low rate (slow), and the other with a high rate (fast) of images from the video. The slow rate path enables the capturing of spatial information of slow movements, while the fast part is devoted to detect spatial information of fast movements.
- Transformers: a transformer is a deep learning architecture, introduced in 2017, based on the consideration of attention and self-attention mechanisms, which allow quantifying (weight) the importance of each part of the input data. Transformers were initially proposed for natural language processing (NLP) [51], and due to their promising results, their usage was extended for computer vision (CV) applications such as proposed within Vision transformers Vit [35]. As proposed within recurrent neural networks, Transformers can take into account temporal information. The main difference is that transformers can process the complete input at once thanks to the attention mechanism. Several transformer architectures have been proposed such as BERT [52] and GPT [53], which have provided excellent results for natural language processing and interpretation such as provided within ChatGPT tool [54]. Furthermore, transformers represent a powerful solution for video understanding. The authors of [55] proposed an improvement of R2+1D architecture [39] by replacing the Temporal Global Average Pooling (TGAP) layer present at the end of R(2+1)D network by the BERT attention mechanism. In fact, the TGAP does not consider the order or the importance of the temporal features learned by the network. With BERT and its “multi-headed” attention mechanism, we can learn this importance in addition to the R(2+1)D method. This permitted the improvement of the accuracy of action recognition within several public databases. In [56], authors proposed an extension of the vision transformer architecture (Vit) by integrating a temporal dimension. The TimeSformer takes as input a video clip, which is represented as a four-dimensional tensor of dimension: , where h and w are the height and width of each frame, c is the number of channels, and f the number of frames in the video. Then, the Timesformer divides each frame into n patches where each one is flattened into a vector representing spatial information within the patch.
2.2.3. Depth-Based Methods for Actions Detection
2.2.4. Explainability of Deep Neural Networks
2.2.5. Contribution
3. Comparative Analysis of Existing Solutions
- Precision: we analyzed the precision (top-1 accuracy) of the above-mentioned methods and noticed several observations:
- The use of 2D convolution networks is not sufficient for action recognition. They are generally replaced by 3D convolutional neural networks or combined with other networks that consider the temporal information of movements.
- The use of RNNs is designed to deal with temporal information, but they are hampered by the Vanishing gradient problem during the training process. As a solution, Transformer architectures are employed.
- By considering slow and fast movements during the training process, precision can be improved with a more generalized solution.
- The incorporation of depth information helps to enhance the results, but it cannot benefit from a deep learning process since there are few annotated databases including the depth information.
- Computation time: the two-Stream networks are very intensive in computation due to the calculation of optical flow and the application of two parts of the neural network. The recurrent neural networks are also very intensive since they need to consider long-term memory in the case of action recognition. On the other side, the use of transformers provided fast training and inference phases thanks to their use of a fast attention mechanism.
- Explainability: as shown in Section 2.2.3, several methods have been proposed recently to identify the responsible parameters (pixels) of each deep learning model and mainly those based on convolutional layers such as proposed within convolution networks, two-Stream, and some temporal networks (Section 2.2.1). However, the explainability of transformer architecture is more complex due to the use of the mechanism of attention. The depth-based approaches are better in terms of explainability since they are mainly based on classical models.
- Flexibility: the presented deep learning approaches methods can be generalized but require regular retraining of the model with the consideration of a significant variation of actions, which is not so easy. However, the depth-based approaches are more suitable for generalization since they are based on texture, shape, and color features extraction before applying a classifier which makes them more independent from the learning data.
- They have been tested/pre-trained with one database only.
- They have been pre-trained/tested with different databases but high variation is noted in terms of accuracy.
4. Proposed Approach for Dangerous Action Recognition
4.1. Experimental Setup
- CPU Processor: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz with 32 cores, 48 GB of RAM.
- GPU Processor: GTX 1080ti, 3584 CUDA cores with 12 GB of RAM.
4.2. Data Generation and Preparation
4.3. Deep Learning Model Selection and Optimization
- Selected convolutional network: R(2+1D)
- Selected two-Stream network: I3D
- Selected Temporal networks: TSN and SlowFast
- Selected transformer networks: R(2+1D) and Timesformer
- Define the most convenient model for dangerous action recognition within railway construction sites. This selection is performed based on several metrics: precision, explainability, computation time, model memory size, and flexibility.
- Define the appropriate database needed for the training of these models among real, simulated, and mixed databases.
- Define the convenient ratio of real and simulated databases in case of using a mixed database.
- Propose an approach of action recognition based on users’ requirements in terms of precision, explainability, computation time, memory size, and flexibility.
4.4. Experimental Results
- Top-1 accuracy: provided by the models using the same parameters (simulated dataset, epochs, loss function = cross-entropy, learning rate decay for weights optimization, etc.). This top-1 accuracy is calculated for both the UCF-101 dataset and our simulated database in order to analyze the flexibility of the selected models.
- Explainability “XAI”: represented by two factors: XAI_Acc and XAI_Bias.
- XAI_Acc: calculated by comparing human explanation (responsible regions and pixels of each detected action) with the results obtained by one of the best XAI methods. This metric allows assessment of whether the model is focused on the correct regions during the decision phase, as presented in Figure 7.
- XAI_Bias: defined by the percentage of situation where the model detects accurately an action where the responsible regions of this decision are not correct, which represent a bias. As an example, Figure 8 illustrates an example of accurate detection of “Bucket-worker” action, where the responsible region detected by GradCAM is represented by the good collision region but accompanied by another region “Cloud”, which has no relation with this kind of action (this bias is due the quality of our simulated database). Low values of XAI_Bias correspond to a good model having a low level of bias and vice versa.
- Time: represented by the computation time of the training process and the test process (248 short videos).
- Model size: enables the definition of the suitable models for deployment on embedded resources that dispose of low capacity of memory and calculation.
4.4.1. Action Recognition within Simulated Videos
4.4.2. Action Recognition within Mixed Videos
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mahmoudi, S.A.; Sharif, H.; Ihaddadene, N.; Djeraba, C. Abnormal event detection in real time video. In Proceedings of the 1st International Workshop on Multimodal Interactions Analysis of Users in a Controlled Environment, ICMI, Chania, Greece, 20–22 October 2008. [Google Scholar]
- Benabbas, Y.; Lablack, A.; Ihaddadene, N.; Djeraba, C. Action Recognition Using Direction Models of Motion. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 4295–4298. [Google Scholar] [CrossRef]
- Mahmoudi, S.A.; Kierzynka, M.; Manneback, P. Real-time GPU-based motion detection and tracking using full HD videos. In Proceedings of the Intelligent Technologies for Interactive Entertainment: 5th International ICST Conference, INTETAIN 2013, Mons, Belgium, 3–5 July 2013; pp. 12–21. [Google Scholar]
- Benabbas, Y.; Ihaddadene, N.; Djeraba, C. Motion Pattern Extraction and Event Detection for Automatic Visual Surveillance. Eurasip Jbenabbas2 Video Process. 2011, 2011, 163682. [Google Scholar] [CrossRef]
- Mahmoudi, S.A.; Kierzynka, M.; Manneback, P.; Kurowski, K. Real-time motion tracking using optical flow on multiple GPUs. Bull. Pol. Acad. Sci. Tech. Sci. 2014, 62, 139–150. [Google Scholar] [CrossRef]
- Li, J.; Xia, S.T.; Ding, Q. Multi-level recognition on falls from activities of daily living. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 464–471. [Google Scholar]
- Tufek, N.; Yalcin, M.; Altintas, M.; Kalaoglu, F.; Li, Y.; Bahadir, S.K. Human Action Recognition Using Deep Learning Methods on Limited Sensory Data. IEEE Sensors J. 2020, 20, 3101–3112. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Xiang, X.; Xia, S.T.; Dong, S.; Cai, Y. TNT: An Interpretable Tree-Network-Tree Learning Framework using Knowledge Distillation. Entropy 2020, 22, 1203. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.e.a. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN, 2017. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pienaar, S.W.; Malekian, R. Human Activity Recognition using Visual Object Detection. In Proceedings of the 2019 IEEE 2nd Wireless Africa Conference (WAC), Pretoria, South Africa, 18–20 August 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Shinde, S.; Kothari, A.; Gupta, V. YOLO based Human Action Recognition and Localization. Procedia Comput. Sci. 2018, 133, 831–838. [Google Scholar] [CrossRef]
- Guo, S.; Wang, S.; Yang, Z.; Wang, L.; Zhang, H.; Guo, P.; Gao, Y.; Guo, J. A Review of Deep Learning-Based Visual Multi-Object Tracking Algorithms for Autonomous Driving. Appl. Sci. 2022, 12, 10741. [Google Scholar] [CrossRef]
- Zhang, Y.; Tokmakov, P.; Hebert, M.; Schmid, C. A structured model for action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9975–9984. [Google Scholar]
- Tsai, J.K.; Hsu, C.C.; Wang, W.Y.; Huang, S.K. Deep Learning-Based Real-Time Multiple-Person Action Recognition System. Sensors 2020, 20, 4758. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3645–3649. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, B.; Ye, Z.; Kuang, L.D.; Ning, X. Siamese anchor-free object tracking with multiscale spatial attentions. Sci. Rep. 2021, 11, 22908. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Liu, D.; Srivastava, G.; Połap, D.; Woźniak, M. Overview and methods of correlation filter algorithms in object tracking. Complex Intell. Syst. 2021, 7, 1895–1917. [Google Scholar] [CrossRef]
- Luo, F.; Poslad, S.; Bodanese, E. Temporal convolutional networks for multiperson activity recognition using a 2-d lidar. IEEE Internet Things J. 2020, 7, 7432–7442. [Google Scholar] [CrossRef]
- He, Z.; He, H. Unsupervised Multi-Object Detection for Video Surveillance Using Memory-Based Recurrent Attention Networks. Symmetry 2018, 10, 375. [Google Scholar] [CrossRef]
- Meng, L.; Zhao, B.; Chang, B.; Huang, G.; Sun, W.; Tung, F.; Sigal, L. Interpretable spatiotemporal Attention for Video Action Recognition. arxiv 2018, arXiv:1810.04511. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Sun, L.; Jia, K.; Yeung, D.Y.; Shi, B.E. Human action recognition using factorized spatiotemporal convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4597–4605. [Google Scholar]
- An, J.; Cheng, X.; Wang, Q.; Chen, H.; Li, J.; Li, S. Summary of continuous action recognition. J. Physics: Conf. Ser. 2020, 1607, 012116. [Google Scholar] [CrossRef]
- Wang, J.; Wen, X. A Spatiotemporal Attention Convolution Block for Action Recognition. J. Physics: Conf. Ser. 2020, 1651, 012193. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Medsker, L.; Jain, L.C. Recurrent Neural Networks: Design and Applications; CRC press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint 2020, arXiv:2010.11929. [Google Scholar]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertainty, Fuzziness -Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the International Conference on Machine Learning. PMLR, Lille, France, 7–9 July 2015; pp. 2342–2350. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Beauchemin, S.S.; Barron, J.L. The computation of optical flow. ACM Comput. Surv. 1995, 27, 433–466. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Yu, P.S. Spatiotemporal Pyramid Network for Video Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Christoph, R.; Pinz, F.A. Spatiotemporal residual networks for video action recognition. arXiv 2016, arXiv:1611.02155. [Google Scholar]
- Girdhar, R.; Ramanan, D.; Gupta, A.; Sivic, J.; Russell, B. ActionVLAD: Learning Spatiotemporal Aggregation for Action Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Crasto, N.; Weinzaepfel, P.; Alahari, K.; Schmid, C. Mars: Motion-augmented rgb stream for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7882–7891. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv preprint 2019, arXiv:1905.05950. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI. 2018. Available online: https://openai.com/research/language-unsupervised (accessed on 25 April 2023).
- Thorp, H.H. ChatGPT is Fun, but not an Author. 2023. Available online: https://openai.com/blog/chatgpt (accessed on 25 April 2023).
- Kalfaoglu, M.E.; Kalkan, S.; Alatan, A.A. Late temporal modeling in 3d cnn architectures with bert for action recognition. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; pp. 731–747. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the ICML, Virtual, 18–24 July 2021; Volume 2, p. 4. [Google Scholar]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing actions using depth motion maps-based histograms of oriented gradients. In Proceedings of the 20th ACM International Conference on Multimedia, New York, NY, USA, 29 October–2 November 2012; pp. 1057–1060. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time human action recognition based on depth motion maps. J. -Real-Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Lee, H.; Battle, A.; Raina, R.; Ng, A. Efficient sparse coding algorithms. Adv. Neural Inf. Process. Syst. 2006, 19, 801–808. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Rahmani, H.; Mahmood, A.; Huynh, D.Q.; Mian, A. Real time action recognition using histograms of depth gradients and random decision forests. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; IEEE: Piscataway, NJ, USA; pp. 626–633. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Satyamurthi, S.; Tian, J.; Chua, M.C.H. Action recognition using multi-directional projected depth motion maps. J. Ambient. Intell. Humaniz. Comput. 2018, 1–7. [Google Scholar] [CrossRef]
- He, D.C.; Wang, L. Texture unit, texture spectrum, and texture analysis. IEEE Trans. Geosci. Remote. Sens. 1990, 28, 509–512. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2014, arXiv:1312.6034. [Google Scholar]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. Smoothgrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the ICML, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Petsiuk, V.; Das, A.; Saenko, K. RISE: Randomized Input Sampling for Explanation of Black-box Models. arXiv 2018, arXiv:1806.07421. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Jiang, P.T.; Zhang, C.B.; Hou, Q.; Cheng, M.M.; Wei, Y. LayerCAM: Exploring hierarchical class activation maps for localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef]
- Englebert, A.; Cornu, O.; Vleeschouwer, C.D. Poly-CAM: High resolution class activation map for convolutional neural networks. arXiv 2022, arXiv:2204.13359v2. [Google Scholar]
- Jalwana, M.A.; Akhtar, N.; Bennamoun, M.; Mian, A. CAMERAS: Enhanced resolution and sanity preserving class activation mapping for image saliency. In Proceedings of the CVPR, Virtual, 19–25 June 2021. [Google Scholar]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the CVPR Worshop on TCV, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint 2012, arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, IEEE, Barcelona, Spain, 6–13 June 2011; pp. 2556–2563. [Google Scholar]
- Contributors, M. OpenMMLab’s Next Generation Video Understanding Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmaction2 (accessed on 25 April 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Reed, R. Pruning algorithms-a survey. IEEE Trans. Neural Networks 1993, 4, 740–747. [Google Scholar] [CrossRef]
- Gray, R.M.; Neuhoff, D.L. Quantization. IEEE Trans. Inf. Theory 1998, 44, 2325–2383. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acc | XAI | Time | Mem | Flexibility | |||
|---|---|---|---|---|---|---|---|
| Deep Learning methods | Convolutional | C3D | 90.4% | + | - - - | - | - |
| LRCN | 82.92% | + | - - - | - - | - | ||
| R(2+1D) | 98.17% | ++ | ++ | - - - | - | ||
| Two-Stream | Two Stream | 86.9% | + | - - - | - - | - | |
| I3D | 98% | + | ++ | +++ | - | ||
| MARS | 97.8% | + | - - - | - | - | ||
| Temporal | TSN | 94% | + | - - | +++ | ++ | |
| TSM | 95.9% | + | ++ | ++ | ++ | ||
| SlowFast | 95.7% | ++ | ++ | + | + | ||
| Transformers | R(2+1)D BERT | 98.69% | - | ++ | - - - | - | |
| Timesformer | 95.43% | - | ++ | - - - | - | ||
| Depth based methods | With 3D | DMM-HOG | 85.52% | +++ | + | + | + |
| DMM | 90.5% | +++ | + | + | + | ||
| HON4D | 88.89% | +++ | + | + | + | ||
| HistRF | 88% | +++ | + | + | + | ||
| MPDMM | 94.8% | +++ | + | + | + |
| Classes | # Clips | Duration | Frames Number | ||||
|---|---|---|---|---|---|---|---|
| Min | Max | Avg | Min | Max | Avg | ||
| Other | 504 | 0.03 | 3.03 | 2.89 | 1 | 91 | 86.71 |
| Cabin-Worker | 320 | 0.23 | 14.33 | 3.07 | 7 | 430 | 92.12 |
| Bucket-Worker | 468 | 0.20 | 5.73 | 1.16 | 6 | 172 | 35.07 |
| Track-Excavator | 352 | 0.20 | 13.96 | 2.72 | 6 | 419 | 81.67 |
| Actions | Definition |
|---|---|
| Other | No dangerous actions to be notified |
| Cabin-Worker | Worker moving too close to the cabin while the excavator is being operated |
| Bucket-Worker | Worker moving under the bucket, In danger of getting hit, or materials may fall from the bucket |
| Track-Excavator | The excavator moving forward to the tracks (active railway line or electric wires) |
| Model Category | Model Name | UCF 101 | Simulated Videos (Railway Site) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Top-1 Acc | Top-1 Acc | XAI | Time | Model Size (MB) | ||||||
| Test | Train | Valid | Test | XAI_Acc | XAI Bias | Train | Test | |||
| Conv | R(2+1D) | 98.17% | 93.96% | 86.17% | 87.90% | 55% | 40% | 2 h | 25 s | 243 |
| Two stream | I3D | 98% | 93.79% | 85.38% | 85.48% | 55% | 90% | 2h25 | 60 s | 107 |
| Temp | TSM | 95.9% | 83.55% | 83.40% | 86.29% | 45% | 45% | 0h32 | 16 s | 123 |
| SlowFast | 95.7% | 96.24% | 90.91% | 91.53% | 85% | 55% | 2h01 | 33 s | 196 | |
| Trans- formers | R(2+1D) BERT | 98.69% | 94.60% | 88.62% | 89.83% | — | — | 1h02 | 17 s | 464 |
| Times- former | 95.43% | 83.62% | 82.21% | 81.60% | — | — | 1h45 | 20 s | 309 | |
| Training on Simulated Videos | Training on Real Videos | Training on Mixed Videos | |||
|---|---|---|---|---|---|
| 100% Simulated 0% Real | 0% Simulated 100% Real | 50% Simulated 50% Real | 60% Simulated 40% Real | 75% Simulated 25% Real | |
| Test on simulated videos | 91.53% | 91.53% | 87.88% | 91.78% | 96.81% |
| Test on real videos | 39.08% | 51.52% | 42.42% | 48.48% | 54.07% |
| Test on mixed videos | 66.28% | 72.99% | 70.08% | 73.29% | 78.44% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmoudi, S.A.; Amel, O.; Stassin, S.; Liagre, M.; Benkedadra, M.; Mancas, M. A Review and Comparative Study of Explainable Deep Learning Models Applied on Action Recognition in Real Time. Electronics 2023, 12, 2027. https://doi.org/10.3390/electronics12092027
Mahmoudi SA, Amel O, Stassin S, Liagre M, Benkedadra M, Mancas M. A Review and Comparative Study of Explainable Deep Learning Models Applied on Action Recognition in Real Time. Electronics. 2023; 12(9):2027. https://doi.org/10.3390/electronics12092027
Chicago/Turabian StyleMahmoudi, Sidi Ahmed, Otmane Amel, Sédrick Stassin, Margot Liagre, Mohamed Benkedadra, and Matei Mancas. 2023. "A Review and Comparative Study of Explainable Deep Learning Models Applied on Action Recognition in Real Time" Electronics 12, no. 9: 2027. https://doi.org/10.3390/electronics12092027