Natural Language Processing and Applications: Challenges and Perspectives
Share This Topical Collection
Editor
 Prof. Dr. Diego Reforgiato Recupero
Prof. Dr. Diego Reforgiato Recupero
Prof. Dr. Diego Reforgiato Recupero
E-Mail
Website
Guest Editor
Department of Mathematics and Computer Science, Università degli Studi di Cagliari, 09124 Cagliari, Spain
Interests: machine learning; semantic web; sentiment analysis; text mining; knowledge graphs
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
The 2nd International Conference on Natural Language Processing and Applications (NLPA 2021) will be held in Copenhagen, Denmark, from 24 to 25 April 2021. NLPA 2021 will provide an excellent international forum for sharing knowledge and results concerning the theory, methodology, and applications of natural language computing. This Special Issue intends to contain a selection of the best papers presented at NLPA 2021, carefully revised and extended. Paper acceptance for NLPA 2021 will be based on quality, relevance to the conference theme, and originality.
The authors of a number of selected full papers of high quality will be invited after the conference to submit revised and extended versions of their originally accepted conference papers to this Special Issue of Information, published by MDPI in open access. The selection of these best papers will be based on their ratings in the conference review process, quality of presentation during the conference, and expected impact on the research community. For each submission to this Special Issue, at least 50% of the content should be new material, e.g., in the form of technical extensions, more in-depth evaluations, or additional use cases, and there should be a change of title, abstract, and keywords. These extended submissions will undergo a peer-review process according to the journal’s rules of action. At least two technical committees will act as reviewers for each extended article submitted to this Special Issue; if needed, additional external reviewers will be invited to guarantee a high-quality reviewing process.
Prof. Dr. Diego Reforgiato Recupero
Guest Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Information is an international peer-reviewed open access monthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1600 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- Phonology and morphology
- Chunking/shallow parsing
- Parsing/grammatical formalisms
- Semantic processing
- Lexical semantics
- Ontology
- Linguistic resources
- Statistical and knowledge-based methods
- POS tagging
- Discourse
- Paraphrasing/entailment/generation
- Machine translation
- Information retrieval
- Text mining
- Information extraction
- Question answering
- Dialog systems
- Spoken language processing
- Speech recognition and synthesis
- Computational linguistics and NLP Information retrieval and AI
- Semantics and NLP
Published Papers (36 papers)
Open AccessArticle
Robust Chinese Short Text Entity Disambiguation Method Based on Feature Fusion and Contrastive Learning
by
Qishun Mei and Xuhui Li
Viewed by 848
Abstract
To address the limitations of existing methods of short-text entity disambiguation, specifically in terms of their insufficient feature extraction and reliance on massive training samples, we propose an entity disambiguation model called COLBERT, which fuses LDA-based topic features and BERT-based semantic features, as
[...] Read more.
To address the limitations of existing methods of short-text entity disambiguation, specifically in terms of their insufficient feature extraction and reliance on massive training samples, we propose an entity disambiguation model called COLBERT, which fuses LDA-based topic features and BERT-based semantic features, as well as using contrastive learning, to enhance the disambiguation process. Experiments on a publicly available Chinese short-text entity disambiguation dataset show that the proposed model achieves an F1-score of 84.0%, which outperforms the benchmark method by 0.6%. Moreover, our model achieves an F1-score of 74.5% with a limited number of training samples, which is 2.8% higher than the benchmark method. These results demonstrate that our model achieves better effectiveness and robustness and can reduce the burden of data annotation as well as training costs.
Full article
►▼
Show Figures
Open AccessArticle
SRBerta—A Transformer Language Model for Serbian Cyrillic Legal Texts
by
Miloš Bogdanović, Jelena Kocić and Leonid Stoimenov
Viewed by 1546
Abstract
Language is a unique ability of human beings. Although relatively simple for humans, the ability to understand human language is a highly complex task for machines. For a machine to learn a particular language, it must understand not only the words and rules
[...] Read more.
Language is a unique ability of human beings. Although relatively simple for humans, the ability to understand human language is a highly complex task for machines. For a machine to learn a particular language, it must understand not only the words and rules used in a particular language, but also the context of sentences and the meaning that words take on in a particular context. In the experimental development we present in this paper, the goal was the development of the language model SRBerta—a language model designed to understand the formal language of Serbian legal documents. SRBerta is the first of its kind since it has been trained using Cyrillic legal texts contained within a dataset created specifically for this purpose. The main goal of SRBerta network development was to understand the formal language of Serbian legislation. The training process was carried out using minimal resources (single NVIDIA Quadro RTX 5000 GPU) and performed in two phases—base model training and fine-tuning. We will present the structure of the model, the structure of the training datasets, the training process, and the evaluation results. Further, we will explain the accuracy metric used in our case and demonstrate that SRBerta achieves a high level of accuracy for the task of masked language modeling in Serbian Cyrillic legal texts. Finally, SRBerta model and training datasets are publicly available for scientific and commercial purposes.
Full article
►▼
Show Figures
Open AccessArticle
Offensive Text Span Detection in Romanian Comments Using Large Language Models
by
Andrei Paraschiv, Teodora Andreea Ion and Mihai Dascalu
Viewed by 1392
Abstract
The advent of online platforms and services has revolutionized communication, enabling users to share opinions and ideas seamlessly. However, this convenience has also brought about a surge in offensive and harmful language across various communication mediums. In response, social platforms have turned to
[...] Read more.
The advent of online platforms and services has revolutionized communication, enabling users to share opinions and ideas seamlessly. However, this convenience has also brought about a surge in offensive and harmful language across various communication mediums. In response, social platforms have turned to automated methods to identify offensive content. A critical research question emerges when investigating the role of specific text spans within comments in conveying offensive characteristics. This paper conducted a comprehensive investigation into detecting offensive text spans in Romanian language comments using Transformer encoders and Large Language Models (LLMs). We introduced an extensive dataset of 4800 Romanian comments annotated with offensive text spans. Moreover, we explored the impact of varying model sizes, architectures, and training data volumes on the performance of offensive text span detection, providing valuable insights for determining the optimal configuration. The results argue for the effectiveness of BERT pre-trained models for this span-detection task, showcasing their superior performance. We further investigated the impact of different sample-retrieval strategies for few-shot learning using LLMs based on vector text representations. The analysis highlights important insights and trade-offs in leveraging LLMs for offensive-language-detection tasks.
Full article
►▼
Show Figures
Open AccessArticle
Weakly Supervised Learning Approach for Implicit Aspect Extraction
by
Aye Aye Mar, Kiyoaki Shirai and Natthawut Kertkeidkachorn
Viewed by 1247
Abstract
Aspect-based sentiment analysis (ABSA) is a process to extract an aspect of a product from a customer review and identify its polarity. Most previous studies of ABSA focused on explicit aspects, but implicit aspects have not yet been the subject of much attention.
[...] Read more.
Aspect-based sentiment analysis (ABSA) is a process to extract an aspect of a product from a customer review and identify its polarity. Most previous studies of ABSA focused on explicit aspects, but implicit aspects have not yet been the subject of much attention. This paper proposes a novel weakly supervised method for implicit aspect extraction, which is a task to classify a sentence into a pre-defined implicit aspect category. A dataset labeled with implicit aspects is automatically constructed from unlabeled sentences as follows. First, explicit sentences are obtained by extracting explicit aspects from unlabeled sentences, while sentences that do not contain explicit aspects are preserved as candidates of implicit sentences. Second, clustering is performed to merge the explicit and implicit sentences that share the same aspect. Third, the aspect of the explicit sentence is assigned to the implicit sentences in the same cluster as the implicit aspect label. Then, the BERT model is fine-tuned for implicit aspect extraction using the constructed dataset. The results of the experiments show that our method achieves 82% and 84% accuracy for mobile phone and PC reviews, respectively, which are 20 and 21 percentage points higher than the baseline.
Full article
►▼
Show Figures
Open AccessArticle
Multiple Information-Aware Recurrent Reasoning Network for Joint Dialogue Act Recognition and Sentiment Classification
by
Shi Li and Xiaoting Chen
Viewed by 1021
Abstract
The task of joint dialogue act recognition (DAR) and sentiment classification (DSC) aims to predict both the act and sentiment labels of each utterance in a dialogue. Existing methods mainly focus on local or global semantic features of the dialogue from a single
[...] Read more.
The task of joint dialogue act recognition (DAR) and sentiment classification (DSC) aims to predict both the act and sentiment labels of each utterance in a dialogue. Existing methods mainly focus on local or global semantic features of the dialogue from a single perspective, disregarding the impact of the other part. Therefore, we propose a multiple information-aware recurrent reasoning network (MIRER). Firstly, the sequence information is smoothly sent to multiple local information layers for fine-grained feature extraction through a BiLSTM-connected hybrid CNN group method. Secondly, to obtain global semantic features that are speaker-, context-, and temporal-sensitive, we design a speaker-aware temporal reasoning heterogeneous graph to characterize interactions between utterances spoken by different speakers, incorporating different types of nodes and meta-relations with node-edge-type-dependent parameters. We also design a dual-task temporal reasoning heterogeneous graph to realize the semantic-level and prediction-level self-interaction and interaction, and we constantly revise and improve the label in the process of dual-task recurrent reasoning. MIRER fully integrates context-level features, fine-grained features, and global semantic features, including speaker, context, and temporal sensitivity, to better simulate conversation scenarios. We validated the method on two public dialogue datasets, Mastodon and DailyDialog, and the experimental results show that MIRER outperforms various existing baseline models.
Full article
►▼
Show Figures
Open AccessReview
Thematic Analysis of Big Data in Financial Institutions Using NLP Techniques with a Cloud Computing Perspective: A Systematic Literature Review
by
Ratnesh Kumar Sharma, Gnana Bharathy, Faezeh Karimi, Anil V. Mishra and Mukesh Prasad
Viewed by 1841
Abstract
This literature review explores the existing work and practices in applying thematic analysis natural language processing techniques to financial data in cloud environments. This work aims to improve two of the five Vs of the big data system. We used the PRISMA approach
[...] Read more.
This literature review explores the existing work and practices in applying thematic analysis natural language processing techniques to financial data in cloud environments. This work aims to improve two of the five Vs of the big data system. We used the PRISMA approach (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) for the review. We analyzed the research papers published over the last 10 years about the topic in question using a keyword-based search and bibliometric analysis. The systematic literature review was conducted in multiple phases, and filters were applied to exclude papers based on the title and abstract initially, then based on the methodology/conclusion, and, finally, after reading the full text. The remaining papers were then considered and are discussed here. We found that automated data discovery methods can be augmented by applying an NLP-based thematic analysis on the financial data in cloud environments. This can help identify the correct classification/categorization and measure data quality for a sentiment analysis.
Full article
►▼
Show Figures
Open AccessArticle
Automated Assessment of Comprehension Strategies from Self-Explanations Using LLMs
by
Bogdan Nicula, Mihai Dascalu, Tracy Arner, Renu Balyan and Danielle S. McNamara
Cited by 1 | Viewed by 1693
Abstract
Text comprehension is an essential skill in today’s information-rich world, and self-explanation practice helps students improve their understanding of complex texts. This study was centered on leveraging open-source Large Language Models (LLMs), specifically FLAN-T5, to automatically assess the comprehension strategies employed by readers
[...] Read more.
Text comprehension is an essential skill in today’s information-rich world, and self-explanation practice helps students improve their understanding of complex texts. This study was centered on leveraging open-source Large Language Models (LLMs), specifically FLAN-T5, to automatically assess the comprehension strategies employed by readers while understanding Science, Technology, Engineering, and Mathematics (STEM) texts. The experiments relied on a corpus of three datasets (N = 11,833) with self-explanations annotated on 4 dimensions: 3 comprehension strategies (i.e., bridging, elaboration, and paraphrasing) and overall quality. Besides FLAN-T5, we also considered GPT3.5-turbo to establish a stronger baseline. Our experiments indicated that the performance improved with fine-tuning, having a larger LLM model, and providing examples via the prompt. Our best model considered a pretrained FLAN-T5 XXL model and obtained a weighted F1-score of 0.721, surpassing the 0.699 F1-score previously obtained using smaller models (i.e., RoBERTa).
Full article
►▼
Show Figures
Open AccessArticle
Social Media Analytics on Russia–Ukraine Cyber War with Natural Language Processing: Perspectives and Challenges
by
Fahim Sufi
Cited by 3 | Viewed by 4518
Abstract
Utilizing social media data is imperative in comprehending critical insights on the Russia–Ukraine cyber conflict due to their unparalleled capacity to provide real-time information dissemination, thereby enabling the timely tracking and analysis of cyber incidents. The vast array of user-generated content on these
[...] Read more.
Utilizing social media data is imperative in comprehending critical insights on the Russia–Ukraine cyber conflict due to their unparalleled capacity to provide real-time information dissemination, thereby enabling the timely tracking and analysis of cyber incidents. The vast array of user-generated content on these platforms, ranging from eyewitness accounts to multimedia evidence, serves as invaluable resources for corroborating and contextualizing cyber attacks, facilitating the attribution of malicious actors. Furthermore, social media data afford unique access to public sentiment, the propagation of propaganda, and emerging narratives, offering profound insights into the effectiveness of information operations and shaping counter-messaging strategies. However, there have been hardly any studies reported on the Russia–Ukraine cyber war harnessing social media analytics. This paper presents a comprehensive analysis of the crucial role of social-media-based cyber intelligence in understanding Russia’s cyber threats during the ongoing Russo–Ukrainian conflict. This paper introduces an innovative multidimensional cyber intelligence framework and utilizes Twitter data to generate cyber intelligence reports. By leveraging advanced monitoring tools and NLP algorithms, like language detection, translation, sentiment analysis, term frequency–inverse document frequency (TF-IDF), latent Dirichlet allocation (LDA), Porter stemming, n-grams, and others, this study automatically generated cyber intelligence for Russia and Ukraine. Using 37,386 tweets originating from 30,706 users in 54 languages from 13 October 2022 to 6 April 2023, this paper reported the first detailed multilingual analysis on the Russia–Ukraine cyber crisis in four cyber dimensions (geopolitical and socioeconomic; targeted victim; psychological and societal; and national priority and concerns). It also highlights challenges faced in harnessing reliable social-media-based cyber intelligence.
Full article
►▼
Show Figures
Open AccessArticle
Auditory Models for Formant Frequency Discrimination of Vowel Sounds
by
Can Xu and Chang Liu
Viewed by 1105
Abstract
As formant frequencies of vowel sounds are critical acoustic cues for vowel perception, human listeners need to be sensitive to formant frequency change. Numerous studies have found that formant frequency discrimination is affected by many factors like formant frequency, speech level, and fundamental
[...] Read more.
As formant frequencies of vowel sounds are critical acoustic cues for vowel perception, human listeners need to be sensitive to formant frequency change. Numerous studies have found that formant frequency discrimination is affected by many factors like formant frequency, speech level, and fundamental frequency. Theoretically, to perceive a formant frequency change, human listeners with normal hearing may need a relatively constant change in the excitation and loudness pattern, and this internal change in auditory processing is independent of vowel category. Thus, the present study examined whether such metrics could explain the effects of formant frequency and speech level on formant frequency discrimination thresholds. Moreover, a simulation model based on the auditory excitation-pattern and loudness-pattern models was developed to simulate the auditory processing of vowel signals and predict thresholds of vowel formant discrimination. The results showed that predicted thresholds based on auditory metrics incorporating auditory excitation or loudness patterns near the target formant showed high correlations and low root-mean-square errors with human behavioral thresholds in terms of the effects of formant frequency and speech level). In addition, the simulation model, which particularly simulates the spectral processing of acoustic signals in the human auditory system, may be used to evaluate the auditory perception of speech signals for listeners with hearing impairments and/or different language backgrounds.
Full article
►▼
Show Figures
Open AccessArticle
Natural Syntax, Artificial Intelligence and Language Acquisition
by
William O’Grady and Miseon Lee
Viewed by 1914
Abstract
In recent work, various scholars have suggested that large language models can be construed as input-driven theories of language acquisition. In this paper, we propose a way to test this idea. As we will document, there is good reason to think that processing
[...] Read more.
In recent work, various scholars have suggested that large language models can be construed as input-driven theories of language acquisition. In this paper, we propose a way to test this idea. As we will document, there is good reason to think that processing pressures override input at an early point in linguistic development, creating a temporary but sophisticated system of negation with no counterpart in caregiver speech. We go on to outline a (for now) thought experiment involving this phenomenon that could contribute to a deeper understanding both of human language and of the language models that seek to simulate it.
Full article
Open AccessArticle
MSGAT-Based Sentiment Analysis for E-Commerce
by
Tingyao Jiang, Wei Sun and Min Wang
Cited by 1 | Viewed by 1193
Abstract
Sentence-level sentiment analysis, as a research direction in natural language processing, has been widely used in various fields. In order to address the problem that syntactic features were neglected in previous studies on sentence-level sentiment analysis, a multiscale graph attention network (MSGAT) sentiment
[...] Read more.
Sentence-level sentiment analysis, as a research direction in natural language processing, has been widely used in various fields. In order to address the problem that syntactic features were neglected in previous studies on sentence-level sentiment analysis, a multiscale graph attention network (MSGAT) sentiment analysis model based on dependent syntax is proposed. The model adopts RoBERTa_WWM as the text encoding layer, generates graphs on the basis of syntactic dependency trees, and obtains sentence sentiment features at different scales for text classification through multilevel graph attention network. Compared with the existing mainstream text sentiment analysis models, the proposed model achieves better performance on both a hotel review dataset and a takeaway review dataset, with 94.8% and 93.7% accuracy and 96.2% and 90.4% F1 score, respectively. The results demonstrate the superiority and effectiveness of the model in Chinese sentence sentiment analysis.
Full article
►▼
Show Figures
Open AccessArticle
Arabic Mispronunciation Recognition System Using LSTM Network
by
Abdelfatah Ahmed, Mohamed Bader, Ismail Shahin, Ali Bou Nassif, Naoufel Werghi and Mohammad Basel
Cited by 2 | Viewed by 1182
Abstract
The Arabic language has always been an immense source of attraction to various people from different ethnicities by virtue of the significant linguistic legacy that it possesses. Consequently, a multitude of people from all over the world are yearning to learn it. However,
[...] Read more.
The Arabic language has always been an immense source of attraction to various people from different ethnicities by virtue of the significant linguistic legacy that it possesses. Consequently, a multitude of people from all over the world are yearning to learn it. However, people from different mother tongues and cultural backgrounds might experience some hardships regarding articulation due to the absence of some particular letters only available in the Arabic language, which could hinder the learning process. As a result, a speaker-independent and text-dependent efficient system that aims to detect articulation disorders was implemented. In the proposed system, we emphasize the prominence of “speech signal processing” in diagnosing Arabic mispronunciation using the Mel-frequency cepstral coefficients (MFCCs) as the optimum extracted features. In addition, long short-term memory (LSTM) was also utilized for the classification process. Furthermore, the analytical framework was incorporated with a gender recognition model to perform two-level classification. Our results show that the LSTM network significantly enhances mispronunciation detection along with gender recognition. The LSTM models attained an average accuracy of 81.52% in the proposed system, reflecting a high performance compared to previous mispronunciation detection systems.
Full article
►▼
Show Figures
Open AccessArticle
Text to Causal Knowledge Graph: A Framework to Synthesize Knowledge from Unstructured Business Texts into Causal Graphs
by
Seethalakshmi Gopalakrishnan, Victor Zitian Chen, Wenwen Dou, Gus Hahn-Powell, Sreekar Nedunuri and Wlodek Zadrozny
Cited by 1 | Viewed by 2833
Abstract
This article presents a state-of-the-art system to extract and synthesize causal statements from company reports into a directed causal graph. The extracted information is organized by its relevance to different stakeholder group benefits (customers, employees, investors, and the community/environment). The presented method of
[...] Read more.
This article presents a state-of-the-art system to extract and synthesize causal statements from company reports into a directed causal graph. The extracted information is organized by its relevance to different stakeholder group benefits (customers, employees, investors, and the community/environment). The presented method of synthesizing extracted data into a knowledge graph comprises a framework that can be used for similar tasks in other domains, e.g., medical information. The current work addresses the problem of finding, organizing, and synthesizing a view of the cause-and-effect relationships based on textual data in order to inform and even prescribe the best actions that may affect target business outcomes related to the benefits for different stakeholders (customers, employees, investors, and the community/environment).
Full article
►▼
Show Figures
Open AccessArticle
Authorship Identification of Binary and Disassembled Codes Using NLP Methods
by
Aleksandr Romanov, Anna Kurtukova, Anastasia Fedotova and Alexander Shelupanov
Viewed by 1329
Abstract
This article is part of a series aimed at determining the authorship of source codes. Analyzing binary code is a crucial aspect of cybersecurity, software development, and computer forensics, particularly in identifying malware authors. Any program is machine code, which can be disassembled
[...] Read more.
This article is part of a series aimed at determining the authorship of source codes. Analyzing binary code is a crucial aspect of cybersecurity, software development, and computer forensics, particularly in identifying malware authors. Any program is machine code, which can be disassembled using specialized tools and analyzed for authorship identification, similar to natural language text using Natural Language Processing methods. We propose an ensemble of fastText, support vector machine (SVM), and the authors’ hybrid neural network developed in previous works in this research. The improved methodology was evaluated using a dataset of source codes written in C and C++ languages collected from GitHub and Google Code Jam. The collected source codes were compiled into executable programs and then disassembled using reverse engineering tools. The average accuracy of author identification for disassembled codes using the improved methodology exceeds 0.90. Additionally, the methodology was tested on the source codes, achieving an average accuracy of 0.96 in simple cases and over 0.85 in complex cases. These results validate the effectiveness of the developed methodology and its applicability to solving cybersecurity challenges.
Full article
►▼
Show Figures
Open AccessArticle
An Intelligent Conversational Agent for the Legal Domain
by
Flora Amato, Mattia Fonisto, Marco Giacalone and Carlo Sansone
Viewed by 2500
Abstract
An intelligent conversational agent for the legal domain is an AI-powered system that can communicate with users in natural language and provide legal advice or assistance. In this paper, we present CREA2, an agent designed to process legal concepts and be able to
[...] Read more.
An intelligent conversational agent for the legal domain is an AI-powered system that can communicate with users in natural language and provide legal advice or assistance. In this paper, we present CREA2, an agent designed to process legal concepts and be able to guide users on legal matters. The conversational agent can help users navigate legal procedures, understand legal jargon, and provide recommendations for legal action. The agent can also give suggestions helpful in drafting legal documents, such as contracts, leases, and notices. Additionally, conversational agents can help reduce the workload of legal professionals by handling routine legal tasks. CREA2, in particular, will guide the user in resolving disputes between people residing within the European Union, proposing solutions in controversies between two or more people who are contending over assets in a divorce, an inheritance, or the division of a company. The conversational agent can later be accessed through various channels, including messaging platforms, websites, and mobile applications. This paper presents a retrieval system that evaluates the similarity between a user’s query and a given question. The system uses natural language processing (NLP) algorithms to interpret user input and associate responses by addressing the problem as a semantic search similar question retrieval. Although a common approach to question and answer (Q&A) retrieval is to create labelled Q&A pairs for training, we exploit an unsupervised information retrieval system in order to evaluate the similarity degree between a given query and a set of questions contained in the knowledge base. We used the recently proposed SBERT model for the evaluation of relevance. In the paper, we illustrate the effective design principles, the implemented details and the results of the conversational system and describe the experimental campaign carried out on it.
Full article
►▼
Show Figures
Open AccessArticle
Multilingual Text Summarization for German Texts Using Transformer Models
by
Tomas Humberto Montiel Alcantara, David Krütli, Revathi Ravada and Thomas Hanne
Cited by 1 | Viewed by 2875
Abstract
The tremendous increase in documents available on the Web has turned finding the relevant pieces of information into a challenging, tedious, and time-consuming activity. Text summarization is an important natural language processing (NLP) task used to reduce the reading requirements of text. Automatic
[...] Read more.
The tremendous increase in documents available on the Web has turned finding the relevant pieces of information into a challenging, tedious, and time-consuming activity. Text summarization is an important natural language processing (NLP) task used to reduce the reading requirements of text. Automatic text summarization is an NLP task that consists of creating a shorter version of a text document which is coherent and maintains the most relevant information of the original text. In recent years, automatic text summarization has received significant attention, as it can be applied to a wide range of applications such as the extraction of highlights from scientific papers or the generation of summaries of news articles. In this research project, we are focused mainly on abstractive text summarization that extracts the most important contents from a text in a rephrased form. The main purpose of this project is to summarize texts in German. Unfortunately, most pretrained models are only available for English. We therefore focused on the German BERT multilingual model and the BART monolingual model for English, with a consideration of translation possibilities. As the source of the experiment setup, took the German Wikipedia article dataset and compared how well the multilingual model performed for German text summarization when compared to using machine-translated text summaries from monolingual English language models. We used the ROUGE-1 metric to analyze the quality of the text summarization.
Full article
►▼
Show Figures
Open AccessArticle
Distilling Knowledge with a Teacher’s Multitask Model for Biomedical Named Entity Recognition
by
Tahir Mehmood, Alfonso E. Gerevini, Alberto Lavelli, Matteo Olivato and Ivan Serina
Viewed by 1248
Abstract
Single-task models (STMs) struggle to learn sophisticated representations from a finite set of annotated data. Multitask learning approaches overcome these constraints by simultaneously training various associated tasks, thereby learning generic representations among various tasks by sharing some layers of the neural network architecture.
[...] Read more.
Single-task models (STMs) struggle to learn sophisticated representations from a finite set of annotated data. Multitask learning approaches overcome these constraints by simultaneously training various associated tasks, thereby learning generic representations among various tasks by sharing some layers of the neural network architecture. Because of this, multitask models (MTMs) have better generalization properties than those of single-task learning. Multitask model generalizations can be used to improve the results of other models. STMs can learn more sophisticated representations in the training phase by utilizing the extracted knowledge of an MTM through the knowledge distillation technique where one model supervises another model during training by using its learned generalizations. This paper proposes a knowledge distillation technique in which different MTMs are used as the teacher model to supervise different student models. Knowledge distillation is applied with different representations of the teacher model. We also investigated the effect of the conditional random field (CRF) and softmax function for the token-level knowledge distillation approach, and found that the softmax function leveraged the performance of the student model compared to CRF. The result analysis was also extended with statistical analysis by using the Friedman test.
Full article
►▼
Show Figures
Open AccessReview
Transformers in the Real World: A Survey on NLP Applications
by
Narendra Patwardhan, Stefano Marrone and Carlo Sansone
Cited by 10 | Viewed by 8659
Abstract
The field of Natural Language Processing (NLP) has undergone a significant transformation with the introduction of Transformers. From the first introduction of this technology in 2017, the use of transformers has become widespread and has had a profound impact on the field of
[...] Read more.
The field of Natural Language Processing (NLP) has undergone a significant transformation with the introduction of Transformers. From the first introduction of this technology in 2017, the use of transformers has become widespread and has had a profound impact on the field of NLP. In this survey, we review the open-access and real-world applications of transformers in NLP, specifically focusing on those where text is the primary modality. Our goal is to provide a comprehensive overview of the current state-of-the-art in the use of transformers in NLP, highlight their strengths and limitations, and identify future directions for research. In this way, we aim to provide valuable insights for both researchers and practitioners in the field of NLP. In addition, we provide a detailed analysis of the various challenges faced in the implementation of transformers in real-world applications, including computational efficiency, interpretability, and ethical considerations. Moreover, we highlight the impact of transformers on the NLP community, including their influence on research and the development of new NLP models.
Full article
►▼
Show Figures
Open AccessArticle
Novel Task-Based Unification and Adaptation (TUA) Transfer Learning Approach for Bilingual Emotional Speech Data
by
Ismail Shahin, Ali Bou Nassif, Rameena Thomas and Shibani Hamsa
Viewed by 1496
Abstract
Modern developments in machine learning methodology have produced effective approaches to speech emotion recognition. The field of data mining is widely employed in numerous situations where it is possible to predict future outcomes by using the input sequence from previous training data. Since
[...] Read more.
Modern developments in machine learning methodology have produced effective approaches to speech emotion recognition. The field of data mining is widely employed in numerous situations where it is possible to predict future outcomes by using the input sequence from previous training data. Since the input feature space and data distribution are the same for both training and testing data in conventional machine learning approaches, they are drawn from the same pool. However, because so many applications require a difference in the distribution of training and testing data, the gathering of training data is becoming more and more expensive. High performance learners that have been trained using similar, already-existing data are needed in these situations. To increase a model’s capacity for learning, transfer learning involves transferring knowledge from one domain to another related domain. To address this scenario, we have extracted ten multi-dimensional features from speech signals using OpenSmile and a transfer learning method to classify the features of various datasets. In this paper, we emphasize the importance of a novel transfer learning system called Task-based Unification and Adaptation (TUA), which bridges the disparity between extensive upstream training and downstream customization. We take advantage of the two components of the TUA, task-challenging unification and task-specific adaptation. Our algorithm is studied using the following speech datasets: the Arabic Emirati-accented speech dataset (ESD), the English Speech Under Simulated and Actual Stress (SUSAS) dataset and the Ryerson Audio-Visual Database of Emotional Speech and Song dataset (RAVDESS). Using the multidimensional features and transfer learning method on the given datasets, we were able to achieve an average speech emotion recognition rate of 91.2% on the ESD, 84.7% on the RAVDESS and 88.5% on the SUSAS datasets, respectively.
Full article
►▼
Show Figures
Open AccessArticle
MBTI Personality Prediction Using Machine Learning and SMOTE for Balancing Data Based on Statement Sentences
by
Gregorius Ryan, Pricillia Katarina and Derwin Suhartono
Cited by 5 | Viewed by 10043
Abstract
The rise of social media as a platform for self-expression and self-understanding has led to increased interest in using the Myers–Briggs Type Indicator (MBTI) to explore human personalities. Despite this, there needs to be more research on how other word-embedding techniques, machine learning
[...] Read more.
The rise of social media as a platform for self-expression and self-understanding has led to increased interest in using the Myers–Briggs Type Indicator (MBTI) to explore human personalities. Despite this, there needs to be more research on how other word-embedding techniques, machine learning algorithms, and imbalanced data-handling techniques can improve the results of MBTI personality-type predictions. Our research aimed to investigate the efficacy of these techniques by utilizing the Word2Vec model to obtain a vector representation of words in the corpus data. We implemented several machine learning approaches, including logistic regression, linear support vector classification, stochastic gradient descent, random forest, the extreme gradient boosting classifier, and the cat boosting classifier. In addition, we used the synthetic minority oversampling technique (SMOTE) to address the issue of imbalanced data. The results showed that our approach could achieve a relatively high F1 score (between 0.7383 and 0.8282), depending on the chosen model for predicting and classifying MBTI personality. Furthermore, we found that using SMOTE could improve the selected models’ performance (F1 score between 0.7553 and 0.8337), proving that the machine learning approach integrated with Word2Vec and SMOTE could predict and classify MBTI personality well, thus enhancing the understanding of MBTI.
Full article
►▼
Show Figures
Open AccessReview
Applications of Text Mining in the Transportation Infrastructure Sector: A Review
by
Sudipta Chowdhury and Ammar Alzarrad
Cited by 3 | Viewed by 2816
Abstract
Transportation infrastructure is vital to the well-functioning of economic activities in a region. Due to the digitalization of data storage, ease of access to large databases, and advancement of social media, large volumes of text data that relate to different aspects of transportation
[...] Read more.
Transportation infrastructure is vital to the well-functioning of economic activities in a region. Due to the digitalization of data storage, ease of access to large databases, and advancement of social media, large volumes of text data that relate to different aspects of transportation infrastructure are generated. Text mining techniques can explore any large amount of textual data within a limited time and with limited resource allocation for generating easy-to-understand knowledge. This study aims to provide a comprehensive review of the various applications of text mining techniques in transportation infrastructure research. The scope of this research ranges across all forms of transportation infrastructure-related problems or issues that were investigated by different text mining techniques. These transportation infrastructure-related problems or issues may involve issues such as crashes or accidents investigation, driving behavior analysis, and construction activities. A Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA)-based structured methodology was used to identify relevant studies that implemented different text mining techniques across different transportation infrastructure-related problems or issues. A total of 59 studies from both the U.S. and other parts of the world (e.g., China, and Bangladesh) were ultimately selected for review after a rigorous quality check. The results show that apart from simple text mining techniques for data pre-processing, the majority of the studies used topic modeling techniques for a detailed evaluation of the text data. Other techniques such as classification algorithms were also later used to predict and/or project future scenarios/states based on the identified topics. The findings from this study will hopefully provide researchers and practitioners with a better understanding of the potential of text mining techniques under different circumstances to solve different types of transportation infrastructure-related problems. They will also provide a blueprint to better understand the ever-evolving area of transportation engineering and infrastructure-focused studies.
Full article
►▼
Show Figures
Open AccessReview
A Systematic Review of Transformer-Based Pre-Trained Language Models through Self-Supervised Learning
by
Evans Kotei and Ramkumar Thirunavukarasu
Cited by 11 | Viewed by 7745
Abstract
Transfer learning is a technique utilized in deep learning applications to transmit learned inference to a different target domain. The approach is mainly to solve the problem of a few training datasets resulting in model overfitting, which affects model performance. The study was
[...] Read more.
Transfer learning is a technique utilized in deep learning applications to transmit learned inference to a different target domain. The approach is mainly to solve the problem of a few training datasets resulting in model overfitting, which affects model performance. The study was carried out on publications retrieved from various digital libraries such as SCOPUS, ScienceDirect, IEEE Xplore, ACM Digital Library, and Google Scholar, which formed the Primary studies. Secondary studies were retrieved from Primary articles using the backward and forward snowballing approach. Based on set inclusion and exclusion parameters, relevant publications were selected for review. The study focused on transfer learning pretrained NLP models based on the deep transformer network. BERT and GPT were the two elite pretrained models trained to classify global and local representations based on larger unlabeled text datasets through self-supervised learning. Pretrained transformer models offer numerous advantages to natural language processing models, such as knowledge transfer to downstream tasks that deal with drawbacks associated with training a model from scratch. This review gives a comprehensive view of transformer architecture, self-supervised learning and pretraining concepts in language models, and their adaptation to downstream tasks. Finally, we present future directions to further improvement in pretrained transformer-based language models.
Full article
►▼
Show Figures
Open AccessArticle
Adapting Off-the-Shelf Speech Recognition Systems for Novel Words
by
Wiam Fadel, Toumi Bouchentouf, Pierre-André Buvet and Omar Bourja
Viewed by 1942
Abstract
Current speech recognition systems with fixed vocabularies have difficulties recognizing Out-of-Vocabulary words (OOVs) such as proper nouns and new words. This leads to misunderstandings or even failures in dialog systems. Ensuring effective speech recognition is crucial for the proper functioning of robot assistants.
[...] Read more.
Current speech recognition systems with fixed vocabularies have difficulties recognizing Out-of-Vocabulary words (OOVs) such as proper nouns and new words. This leads to misunderstandings or even failures in dialog systems. Ensuring effective speech recognition is crucial for the proper functioning of robot assistants. Non-native accents, new vocabulary, and aging voices can cause malfunctions in a speech recognition system. If this task is not executed correctly, the assistant robot will inevitably produce false or random responses. In this paper, we used a statistical approach based on distance algorithms to improve OOV correction. We developed a post-processing algorithm to be combined with a speech recognition model. In this sense, we compared two distance algorithms: Damerau–Levenshtein and Levenshtein distance. We validated the performance of the two distance algorithms in conjunction with five off-the-shelf speech recognition models. Damerau–Levenshtein, as compared to the Levenshtein distance algorithm, succeeded in minimizing the Word Error Rate (WER) when using the MoroccanFrench test set with five speech recognition systems, namely VOSK API, Google API, Wav2vec2.0, SpeechBrain, and Quartznet pre-trained models. Our post-processing method works regardless of the architecture of the speech recognizer, and its results on our MoroccanFrench test set outperformed the five chosen off-the-shelf speech recognizer systems.
Full article
►▼
Show Figures
Open AccessReview
Reconsidering Read and Spontaneous Speech: Causal Perspectives on the Generation of Training Data for Automatic Speech Recognition
by
Philipp Gabler, Bernhard C. Geiger, Barbara Schuppler and Roman Kern
Cited by 2 | Viewed by 2696
Abstract
Superficially, read and spontaneous speech—the two main kinds of training data for automatic speech recognition—appear as complementary, but are equal: pairs of texts and acoustic signals. Yet, spontaneous speech is typically harder for recognition. This is usually explained by different kinds of variation
[...] Read more.
Superficially, read and spontaneous speech—the two main kinds of training data for automatic speech recognition—appear as complementary, but are equal: pairs of texts and acoustic signals. Yet, spontaneous speech is typically harder for recognition. This is usually explained by different kinds of variation and noise, but there is a more fundamental deviation at play: for read speech, the audio signal is produced by recitation of the given text, whereas in spontaneous speech, the text is transcribed from a given signal. In this review, we embrace this difference by presenting a first introduction of causal reasoning into automatic speech recognition, and describing causality as a tool to study speaking styles and training data. After breaking down the data generation processes of read and spontaneous speech and analysing the domain from a causal perspective, we highlight how data generation by annotation must affect the interpretation of inference and performance. Our work discusses how various results from the causality literature regarding the impact of the direction of data generation mechanisms on learning and prediction apply to speech data. Finally, we argue how a causal perspective can support the understanding of models in speech processing regarding their behaviour, capabilities, and limitations.
Full article
►▼
Show Figures
Open AccessArticle
Multilingual Speech Recognition for Turkic Languages
by
Saida Mussakhojayeva, Kaisar Dauletbek, Rustem Yeshpanov and Huseyin Atakan Varol
Cited by 4 | Viewed by 3363
Abstract
The primary aim of this study was to contribute to the development of multilingual automatic speech recognition for lower-resourced Turkic languages. Ten languages—Azerbaijani, Bashkir, Chuvash, Kazakh, Kyrgyz, Sakha, Tatar, Turkish, Uyghur, and Uzbek—were considered. A total of 22 models were developed (13 monolingual
[...] Read more.
The primary aim of this study was to contribute to the development of multilingual automatic speech recognition for lower-resourced Turkic languages. Ten languages—Azerbaijani, Bashkir, Chuvash, Kazakh, Kyrgyz, Sakha, Tatar, Turkish, Uyghur, and Uzbek—were considered. A total of 22 models were developed (13 monolingual and 9 multilingual). The multilingual models that were trained using joint speech data performed more robustly than the baseline monolingual models, with the best model achieving an average character and word error rate reduction of 56.7%/54.3%, respectively. The results of the experiment showed that character and word error rate reduction was more likely when multilingual models were trained with data from related Turkic languages than when they were developed using data from unrelated, non-Turkic languages, such as English and Russian. The study also presented an open-source Turkish speech corpus. The corpus contains 218.2 h of transcribed speech with 186,171 utterances and is the largest publicly available Turkish dataset of its kind. The datasets and codes used to train the models are available for download from our GitHub page.
Full article
Open AccessReview
Automatic Sarcasm Detection: Systematic Literature Review
by
Alexandru-Costin Băroiu and Ștefan Trăușan-Matu
Cited by 11 | Viewed by 3940
Abstract
Sarcasm is an integral part of human language and culture. Naturally, it has garnered great interest from researchers from varied fields of study, including Artificial Intelligence, especially Natural Language Processing. Automatic sarcasm detection has become an increasingly popular topic in the past decade.
[...] Read more.
Sarcasm is an integral part of human language and culture. Naturally, it has garnered great interest from researchers from varied fields of study, including Artificial Intelligence, especially Natural Language Processing. Automatic sarcasm detection has become an increasingly popular topic in the past decade. The research conducted in this paper presents, through a systematic literature review, the evolution of the automatic sarcasm detection task from its inception in 2010 to the present day. No such work has been conducted thus far and it is essential to establish the progress that researchers have made when tackling this task and, moving forward, what the trends are. This study finds that multi-modal approaches and transformer-based architectures have become increasingly popular in recent years. Additionally, this paper presents a critique of the work carried out so far and proposes future directions of research in the field.
Full article
►▼
Show Figures
Open AccessSystematic Review
Automatic Text Summarization of Biomedical Text Data: A Systematic Review
by
Andrea Chaves, Cyrille Kesiku and Begonya Garcia-Zapirain
Cited by 12 | Viewed by 4937
Abstract
In recent years, the evolution of technology has led to an increase in text data obtained from many sources. In the biomedical domain, text information has also evidenced this accelerated growth, and automatic text summarization systems play an essential role in optimizing physicians’
[...] Read more.
In recent years, the evolution of technology has led to an increase in text data obtained from many sources. In the biomedical domain, text information has also evidenced this accelerated growth, and automatic text summarization systems play an essential role in optimizing physicians’ time resources and identifying relevant information. In this paper, we present a systematic review in recent research of text summarization for biomedical textual data, focusing mainly on the methods employed, type of input data text, areas of application, and evaluation metrics used to assess systems. The survey was limited to the period between 1st January 2014 and 15th March 2022. The data collected was obtained from WoS, IEEE, and ACM digital libraries, while the search strategies were developed with the help of experts in NLP techniques and previous systematic reviews. The four phases of a systematic review by PRISMA methodology were conducted, and five summarization factors were determined to assess the studies included:
Input,
Purpose,
Output,
Method, and
Evaluation metric. Results showed that
of 801 studies met the inclusion criteria. Moreover,
Single-document,
Biomedical Literature,
Generic, and
Extractive summarization proved to be the most common approaches employed, while techniques based on
Machine Learning were performed in 16 studies and
Rouge (Recall-Oriented Understudy for Gisting Evaluation) was reported as the evaluation metric in 26 studies. This review found that in recent years, more transformer-based methodologies for summarization purposes have been implemented compared to a previous survey. Additionally, there are still some challenges in text summarization in different domains, especially in the biomedical field in terms of demand for further research.
Full article
►▼
Show Figures
Open AccessArticle
Traditional Chinese Medicine Word Representation Model Augmented with Semantic and Grammatical Information
by
Yuekun Ma, Zhongyan Sun, Dezheng Zhang and Yechen Feng
Cited by 2 | Viewed by 2008
Abstract
Text vectorization is the basic work of natural language processing tasks. High-quality vector representation with rich feature information can guarantee the quality of entity recognition and other downstream tasks in the field of traditional Chinese medicine (TCM). The existing word representation models mainly
[...] Read more.
Text vectorization is the basic work of natural language processing tasks. High-quality vector representation with rich feature information can guarantee the quality of entity recognition and other downstream tasks in the field of traditional Chinese medicine (TCM). The existing word representation models mainly include the shallow models with relatively independent word vectors and the deep pre-training models with strong contextual correlation. Shallow models have simple structures but insufficient extraction of semantic and syntactic information, and deep pre-training models have strong feature extraction ability, but the models have complex structures and large parameter scales. In order to construct a lightweight word representation model with rich contextual semantic information, this paper enhances the shallow word representation model with weak contextual relevance at three levels: the part-of-speech (POS) of the predicted target words, the word order of the text, and the synonymy, antonymy and analogy semantics. In this study, we conducted several experiments in both intrinsic similarity analysis and extrinsic quantitative comparison. The results show that the proposed model achieves state-of-the-art performance compared to the baseline models. In the entity recognition task, the F1 value improved by 4.66% compared to the traditional continuous bag-of-words model (CBOW). The model is a lightweight word representation model, which reduces the training time by 51% compared to the pre-training language model BERT and reduces 89% in terms of memory usage.
Full article
►▼
Show Figures
Open AccessArticle
Contextualizer: Connecting the Dots of Context with Second-Order Attention
by
Diego Maupomé and Marie-Jean Meurs
Cited by 1 | Viewed by 1757
Abstract
Composing the representation of a sentence from the tokens that it comprises is difficult, because such a representation needs to account for how the words present relate to each other. The Transformer architecture does this by iteratively changing token representations with respect to
[...] Read more.
Composing the representation of a sentence from the tokens that it comprises is difficult, because such a representation needs to account for how the words present relate to each other. The Transformer architecture does this by iteratively changing token representations with respect to one another. This has the drawback of requiring computation that grows quadratically with respect to the number of tokens. Furthermore, the scalar attention mechanism used by Transformers requires multiple sets of parameters to operate over different features. The present paper proposes a lighter algorithm for sentence representation with complexity linear in sequence length. This algorithm begins with a presumably erroneous value of a context vector and adjusts this value with respect to the tokens at hand. In order to achieve this, representations of words are built combining their symbolic embedding with a positional encoding into single vectors. The algorithm then iteratively weighs and aggregates these vectors using a second-order attention mechanism, which allows different feature pairs to interact with each other separately. Our models report strong results in several well-known text classification tasks.
Full article
►▼
Show Figures
Open AccessArticle
Robust Complaint Processing in Portuguese
by
Henrique Lopes-Cardoso, Tomás Freitas Osório, Luís Vilar Barbosa, Gil Rocha, Luís Paulo Reis, João Pedro Machado and Ana Maria Oliveira
Cited by 1 | Viewed by 2803
Abstract
The Natural Language Processing (NLP) community has witnessed huge improvements in the last years. However, most achievements are evaluated on benchmarked curated corpora, with little attention devoted to user-generated content and less-resourced languages. Despite the fact that recent approaches target the development of
[...] Read more.
The Natural Language Processing (NLP) community has witnessed huge improvements in the last years. However, most achievements are evaluated on benchmarked curated corpora, with little attention devoted to user-generated content and less-resourced languages. Despite the fact that recent approaches target the development of multi-lingual tools and models, they still underperform in languages such as Portuguese, for which linguistic resources do not abound. This paper exposes a set of challenges encountered when dealing with a real-world complex NLP problem, based on user-generated complaint data in Portuguese. This case study meets the needs of a country-wide governmental institution responsible for food safety and economic surveillance, and its responsibilities in handling a high number of citizen complaints. Beyond looking at the problem from an exclusively academic point of view, we adopt application-level concerns when analyzing the progress obtained through different techniques, including the need to obtain explainable decision support. We discuss modeling choices and provide useful insights for researchers working on similar problems or data.
Full article
►▼
Show Figures
Open AccessArticle
A Comparative Study of Arabic Part of Speech Taggers Using Literary Text Samples from Saudi Novels
by
Reyadh Alluhaibi, Tareq Alfraidi, Mohammad A. R. Abdeen and Ahmed Yatimi
Cited by 3 | Viewed by 2729
Abstract
Part of Speech (POS) tagging is one of the most common techniques used in natural language processing (NLP) applications and corpus linguistics. Various POS tagging tools have been developed for Arabic. These taggers differ in several aspects, such as in their modeling techniques,
[...] Read more.
Part of Speech (POS) tagging is one of the most common techniques used in natural language processing (NLP) applications and corpus linguistics. Various POS tagging tools have been developed for Arabic. These taggers differ in several aspects, such as in their modeling techniques, tag sets and training and testing data. In this paper we conduct a comparative study of five Arabic POS taggers, namely: Stanford Arabic, CAMeL Tools, Farasa, MADAMIRA and Arabic Linguistic Pipeline (ALP) which examine their performance using text samples from Saudi novels. The testing data has been extracted from different novels that represent different types of narrations. The main result we have obtained indicates that the ALP tagger performs better than others in this particular case, and that Adjective is the most frequent mistagged POS type as compared to Noun and Verb.
Full article
►▼
Show Figures
Open AccessArticle
Developing Core Technologies for Resource-Scarce Nguni Languages
by
Jakobus S. du Toit and Martin J. Puttkammer
Cited by 2 | Viewed by 2328
Abstract
The creation of linguistic resources is crucial to the continued growth of research and development efforts in the field of natural language processing, especially for resource-scarce languages. In this paper, we describe the curation and annotation of corpora and the development of multiple
[...] Read more.
The creation of linguistic resources is crucial to the continued growth of research and development efforts in the field of natural language processing, especially for resource-scarce languages. In this paper, we describe the curation and annotation of corpora and the development of multiple linguistic technologies for four official South African languages, namely isiNdebele, Siswati, isiXhosa, and isiZulu. Development efforts included sourcing parallel data for these languages and annotating each on token, orthographic, morphological, and morphosyntactic levels. These sets were in turn used to create and evaluate three core technologies, viz. a lemmatizer, part-of-speech tagger, morphological analyzer for each of the languages. We report on the quality of these technologies which improve on previously developed rule-based technologies as part of a similar initiative in 2013. These resources are made publicly accessible through a local resource agency with the intention of fostering further development of both resources and technologies that may benefit the NLP industry in South Africa.
Full article
Open AccessArticle
A Knowledge-Based Sense Disambiguation Method to Semantically Enhanced NL Question for Restricted Domain
by
Ammar Arbaaeen and Asadullah Shah
Cited by 1 | Viewed by 2037
Abstract
Within the space of question answering (QA) systems, the most critical module to improve overall performance is question analysis processing. Extracting the lexical semantic of a Natural Language (NL) question presents challenges at syntactic and semantic levels for most QA systems. This is
[...] Read more.
Within the space of question answering (QA) systems, the most critical module to improve overall performance is question analysis processing. Extracting the lexical semantic of a Natural Language (NL) question presents challenges at syntactic and semantic levels for most QA systems. This is due to the difference between the words posed by a user and the terms presently stored in the knowledge bases. Many studies have achieved encouraging results in lexical semantic resolution on the topic of word sense disambiguation (WSD), and several other works consider these challenges in the context of QA applications. Additionally, few scholars have examined the role of WSD in returning potential answers corresponding to particular questions. However, natural language processing (NLP) is still facing several challenges to determine the precise meaning of various ambiguities. Therefore, the motivation of this work is to propose a novel knowledge-based sense disambiguation (KSD) method for resolving the problem of lexical ambiguity associated with questions posed in QA systems. The major contribution is the proposed innovative method, which incorporates multiple knowledge sources. This includes the question’s metadata (date/GPS), context knowledge, and domain ontology into a shallow NLP. The proposed KSD method is developed into a unique tool for a mobile QA application that aims to determine the intended meaning of questions expressed by pilgrims. The experimental results reveal that our method obtained comparable and better accuracy performance than the baselines in the context of the pilgrimage domain.
Full article
►▼
Show Figures
Open AccessArticle
Optimizing Small BERTs Trained for German NER
by
Jochen Zöllner, Konrad Sperfeld, Christoph Wick and Roger Labahn
Cited by 2 | Viewed by 2495
Abstract
Currently, the most widespread neural network architecture for training language models is the so-called BERT, which led to improvements in various Natural Language Processing (NLP) tasks. In general, the larger the number of parameters in a BERT model, the better the results obtained
[...] Read more.
Currently, the most widespread neural network architecture for training language models is the so-called BERT, which led to improvements in various Natural Language Processing (NLP) tasks. In general, the larger the number of parameters in a BERT model, the better the results obtained in these NLP tasks. Unfortunately, the memory consumption and the training duration drastically increases with the size of these models. In this article, we investigate various training techniques of smaller BERT models: We combine different methods from other BERT variants, such as ALBERT, RoBERTa, and relative positional encoding. In addition, we propose two new fine-tuning modifications leading to better performance: Class-Start-End tagging and a modified form of Linear Chain Conditional Random Fields. Furthermore, we introduce Whole-Word Attention, which reduces BERTs memory usage and leads to a small increase in performance compared to classical Multi-Head-Attention. We evaluate these techniques on five public German Named Entity Recognition (NER) tasks, of which two are introduced by this article.
Full article
►▼
Show Figures
Open AccessArticle
Multi-Task Learning for Sentiment Analysis with Hard-Sharing and Task Recognition Mechanisms
by
Jian Zhang, Ke Yan and Yuchang Mo
Cited by 13 | Viewed by 3161
Abstract
In the era of big data, multi-task learning has become one of the crucial technologies for sentiment analysis and classification. Most of the existing multi-task learning models for sentiment analysis are developed based on the soft-sharing mechanism that has less interference between different
[...] Read more.
In the era of big data, multi-task learning has become one of the crucial technologies for sentiment analysis and classification. Most of the existing multi-task learning models for sentiment analysis are developed based on the soft-sharing mechanism that has less interference between different tasks than the hard-sharing mechanism. However, there are also fewer essential features that the model can extract with the soft-sharing method, resulting in unsatisfactory classification performance. In this paper, we propose a multi-task learning framework based on a hard-sharing mechanism for sentiment analysis in various fields. The hard-sharing mechanism is achieved by a shared layer to build the interrelationship among multiple tasks. Then, we design a task recognition mechanism to reduce the interference of the hard-shared feature space and also to enhance the correlation between multiple tasks. Experiments on two real-world sentiment classification datasets show that our approach achieves the best results and improves the classification accuracy over the existing methods significantly. The task recognition training process enables a unique representation of the features of different tasks in the shared feature space, providing a new solution reducing interference in the shared feature space for sentiment analysis.
Full article
►▼
Show Figures
Open AccessReview
Ontology-Based Approach to Semantically Enhanced Question Answering for Closed Domain: A Review
by
Ammar Arbaaeen and Asadullah Shah
Cited by 8 | Viewed by 4974
Abstract
For many users of natural language processing (NLP), it can be challenging to obtain concise, accurate and precise answers to a question. Systems such as question answering (QA) enable users to ask questions and receive feedback in the form of quick answers to
[...] Read more.
For many users of natural language processing (NLP), it can be challenging to obtain concise, accurate and precise answers to a question. Systems such as question answering (QA) enable users to ask questions and receive feedback in the form of quick answers to questions posed in natural language, rather than in the form of lists of documents delivered by search engines. This task is challenging and involves complex semantic annotation and knowledge representation. This study reviews the literature detailing ontology-based methods that semantically enhance QA for a closed domain, by presenting a literature review of the relevant studies published between 2000 and 2020. The review reports that 83 of the 124 papers considered acknowledge the QA approach, and recommend its development and evaluation using different methods. These methods are evaluated according to accuracy, precision, and recall. An ontological approach to semantically enhancing QA is found to be adopted in a limited way, as many of the studies reviewed concentrated instead on NLP and information retrieval (IR) processing. While the majority of the studies reviewed focus on open domains, this study investigates the closed domain.
Full article
►▼
Show Figures
Planned Papers
The below list represents only planned manuscripts. Some of these
manuscripts have not been received by the Editorial Office yet. Papers
submitted to MDPI journals are subject to peer-review.
Title: An intelligent conversational agent for the legal domain
Authors: Flora Amato (1), Mattia Fonisto (1), Marco Giacalone (2), Carlo Sansone (1)
Affiliation: (1) DIETI, Universita' degli Studi di Napoli Federico II
(2) Vrije Universiteit, Brussel
Abstract: An intelligent conversational agent for the legal domain is an AI-powered system that can communicate with users in natural language and provide legal advice or assistance. In this paper, we present CREA2, an agent designed to process legal concepts and be able to provide guidance to users on legal matters.
The conversational agent can help users navigate legal procedures, understand the legal jargon, and provide recommendations for legal action. The agent can also assist in drafting legal documents, such as contracts, leases, and notices.
The system uses natural language processing (NLP) and machine learning (ML) algorithms to interpret user input and generate responses. The conversational agent can be accessed through various channels, including messaging platforms, websites, and mobile applications. In the legal domain, conversational agents can help bridge the gap between legal experts and the general public by providing access to legal information and advice. Additionally, conversational agents can help reduce the workload of legal professionals by handling routine legal tasks. CREA2, in particular, will guide the user in the resolution of disputes between people residing within the European Union, proposing solutions in controversies between two or more people who are contending over assets in a divorce, an inheritance, or the division of a company. The conversational interface will assist them in entering data and providing explanations regarding all the output suggestions, offering dedicated services to users with different levels of legal knowledge. The bot will have to narrow the gap for less knowledgeable users on the subject when required. In the paper, we illustrate the design principles and the implemented details of the conversational system and describe the experimental campaign carried out on it.
Title: Identification of the Assembly Code Author Using NLP Methods
Authors: Aleksandr Romanov, Anna Kurtukova, Alexander Shelupanov and Anastasia Fedotova
Affiliation: --
Abstract: The article is a continuation of a series devoted to determining the authorship of program source codes. The problem of assembly code analysis is one of the key issues in cybersecurity, software and computer forensics. Most malware is byte-code, which can be subsequently disassembled by specialized tools and analyzed for authorship identification, similarly to natural language text. In this article, we consider various NLP methods to improve the previously developed technique for determining the authorship of the source code of a program. That technique is based on a hybrid neural network combining Inception-V1 and BiGRU architectures. An experimental evaluation of the improved technique is provided on a dataset of source codes in C and C++ languages collected from GitHub. The collected source codes were compiled into executable software modules and then disassembled using reverse engineering tools. The average accuracy of identifying the author of the disassembled code by the improved technique is more than 90%. The results confirm the effectiveness of the developed technique and the possibility of its use for solving cybersecurity problems.
Title: Auditory models for formant frequency discrimination of vowel sounds
Authors: Can Xu and Chang Liu
Affiliation: The University of Texas at Austin, Austin, TX 78712, USA
Abstract: Based on Kewley-Port and Zheng’s findings (1998) that auditory metrics derived from auditory excitation and loudness patterns accounted well for discrimination of vowel formant frequencies, the present study examined whether such metrics could explain the effects of formant frequency and speech level on formant frequency discrimination thresholds. Moreover, a simulation model based on the auditory excitation-pattern and loudness-pattern models was developed to simulate the auditory processing of vowel signals and predict thresholds of vowel formant discrimination. Excitation and loudness patterns were calculated for standard vowels and vowels with formant shifts. A simulation model based on three excitation-pattern metrics and three loudness-pattern metrics (i.e., peak-to-valley contrast, 4-ERBN area, and 1-peak-1-valley area) was used to predict thresholds of vowel formant frequency discrimination for F1 and F2 frequency of four American English vowels at three speech levels. Results showed that predicted thresholds based on auditory metrics incorporating auditory excitation or loudness levels near the target formant showed high correlations and low root-mean-square errors with behavioral thresholds of human listeners reported in a previous study. These results indicated that normal-hearing listeners needed a relatively constant change in auditory excitation or loudness patterns near the target formant to discriminate changes in vowel formant frequency, independent of formant frequency and speech level. These results also suggest that the simulation model, which particularly simulates spectral processing of acoustic signals in the auditory system, may be used to evaluate the auditory perception of speech signals for listeners with hearing impairment and listeners with different language backgrounds.


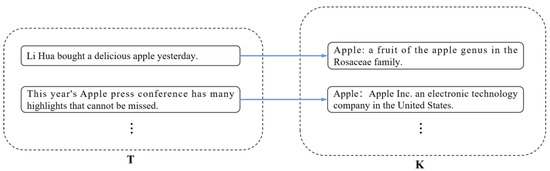

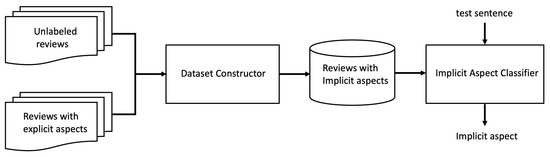

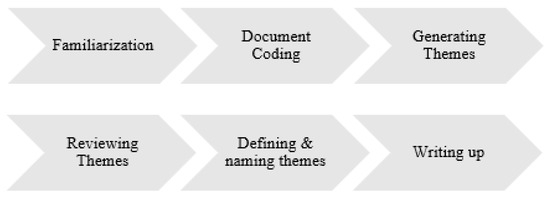
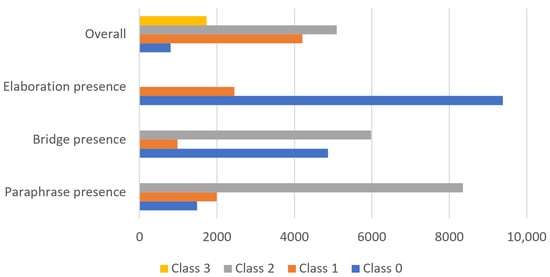
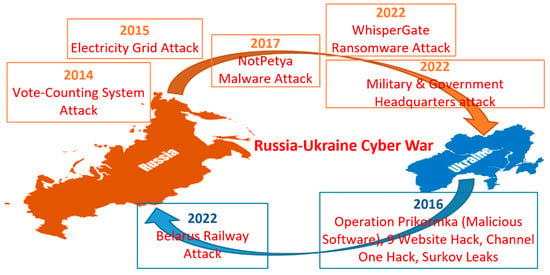
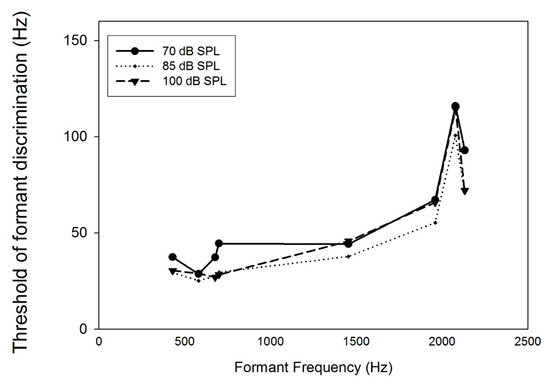
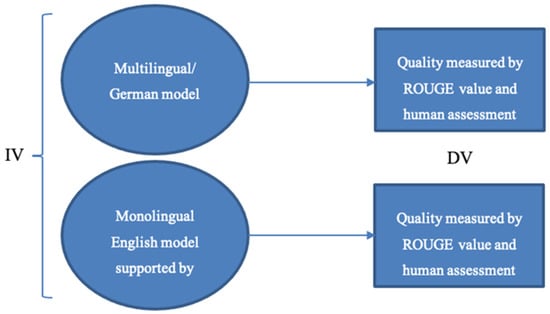
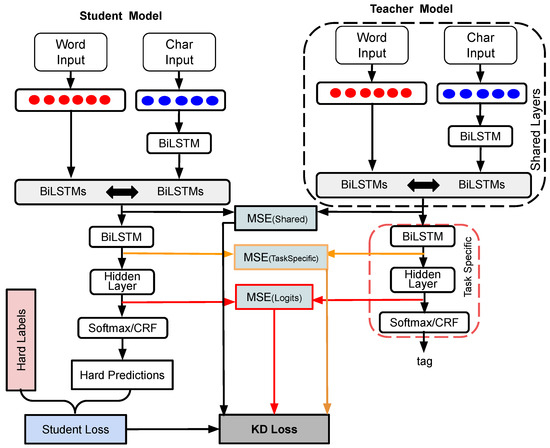
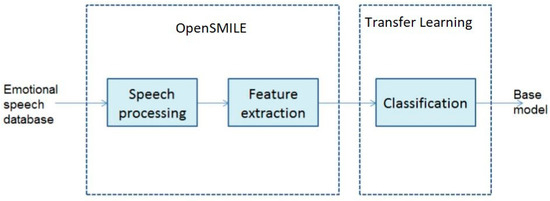


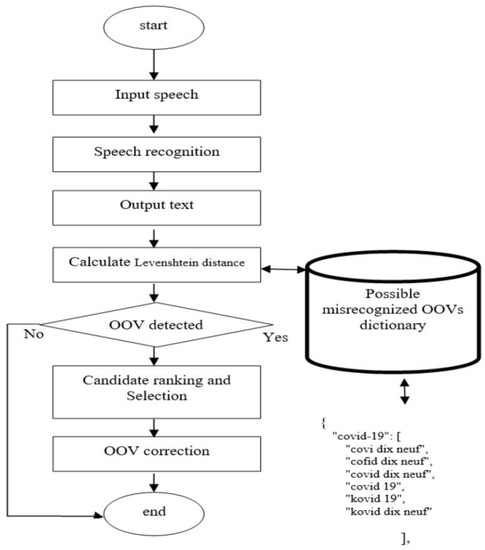

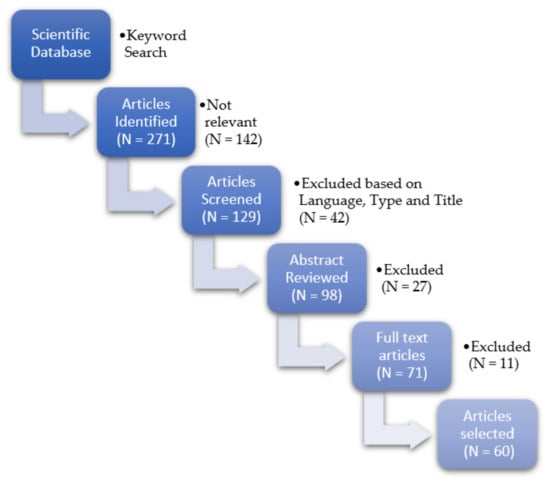
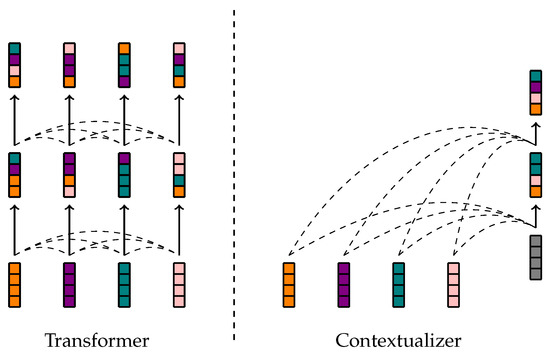

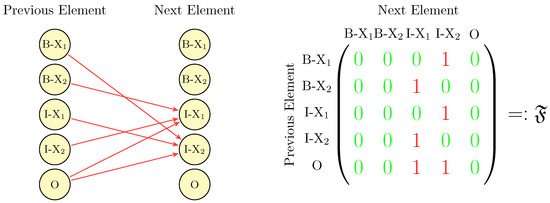
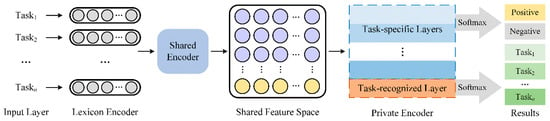
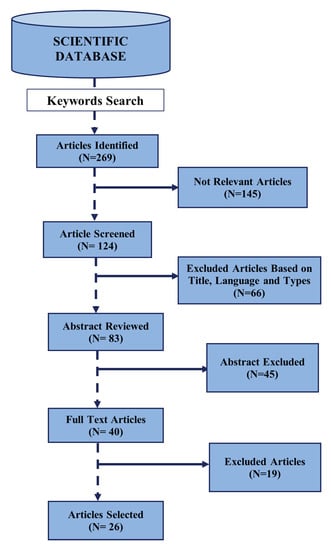
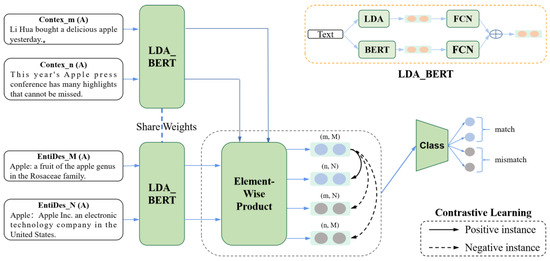{kind=link}
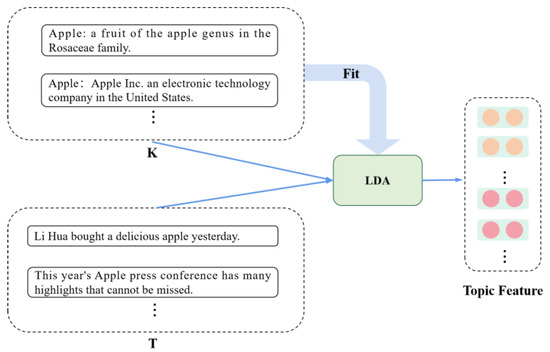{kind=link}
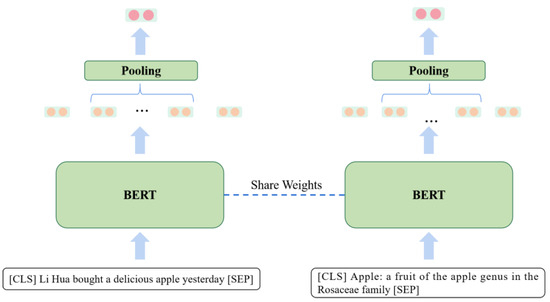{kind=link}
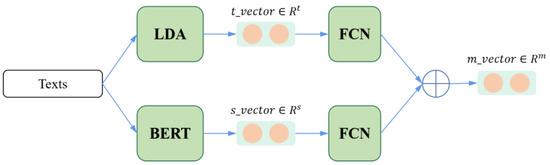{kind=link}
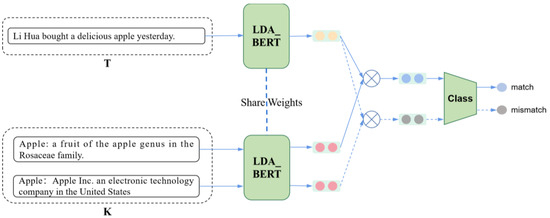{kind=link}
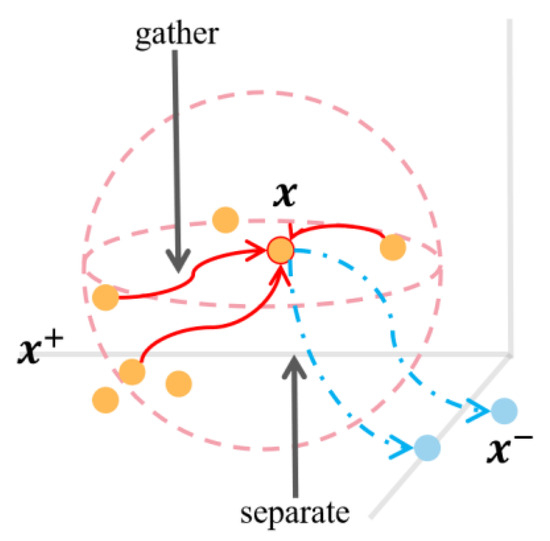{kind=link}
{kind=link}
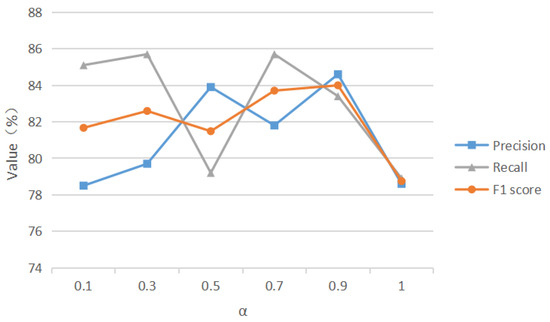{kind=link}
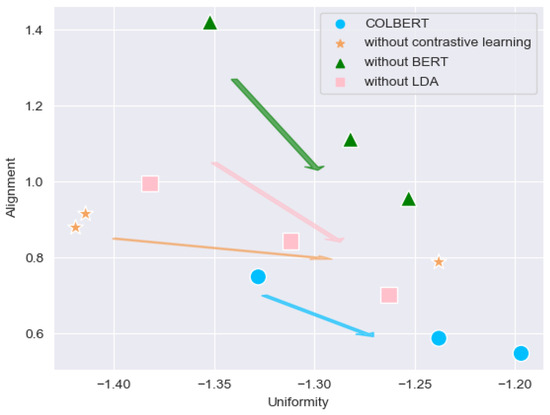{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
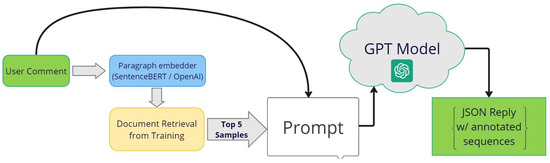{kind=link}
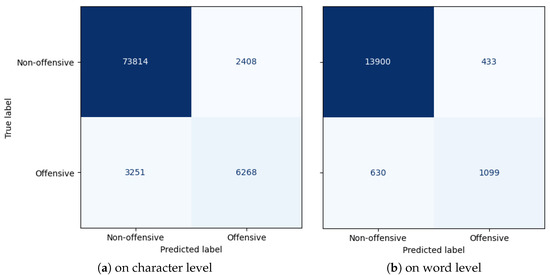{kind=link}
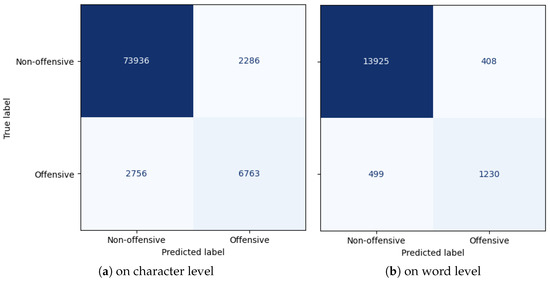{kind=link}
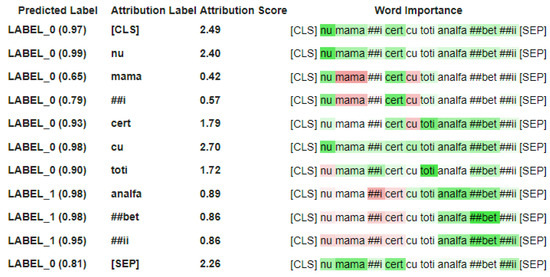{kind=link}
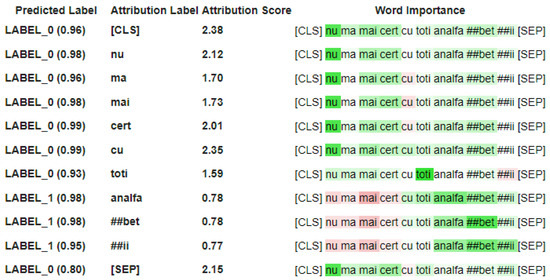{kind=link}
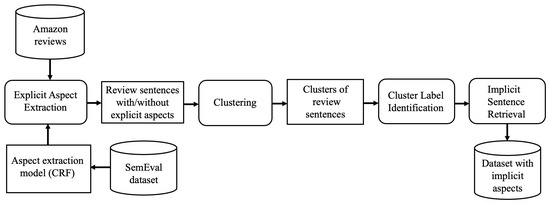{kind=link}
{kind=link}
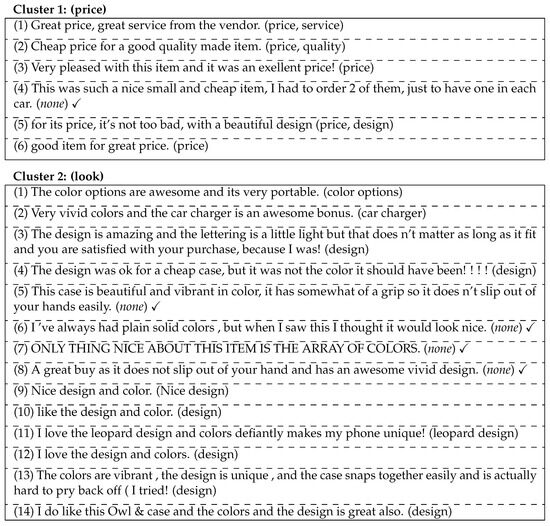{kind=link}
{kind=link}
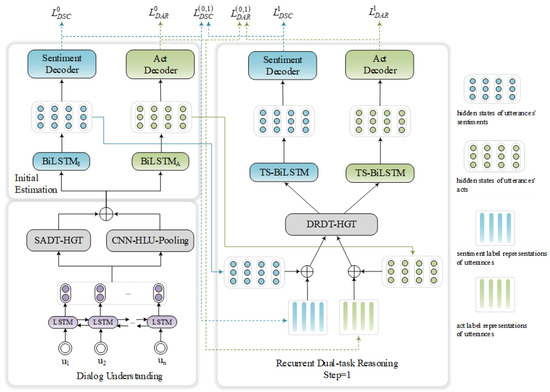{kind=link}
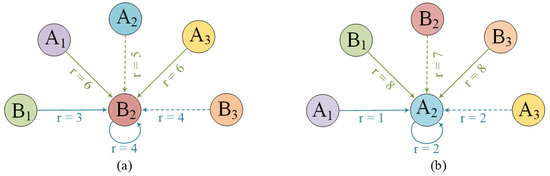{kind=link}
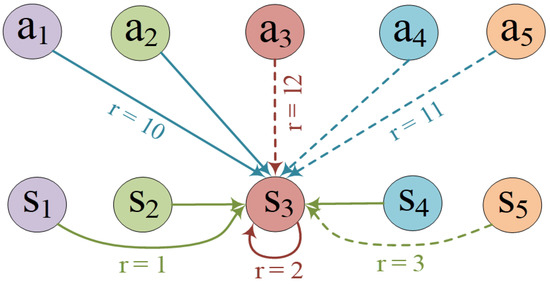{kind=link}
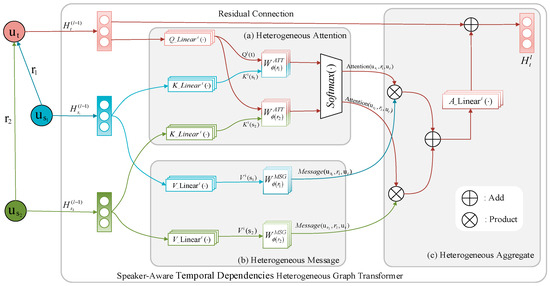{kind=link}
{kind=link}
{kind=link}
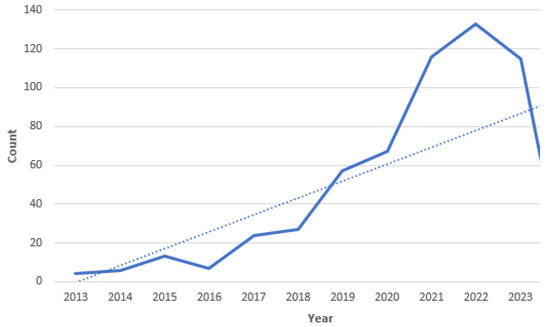{kind=link}
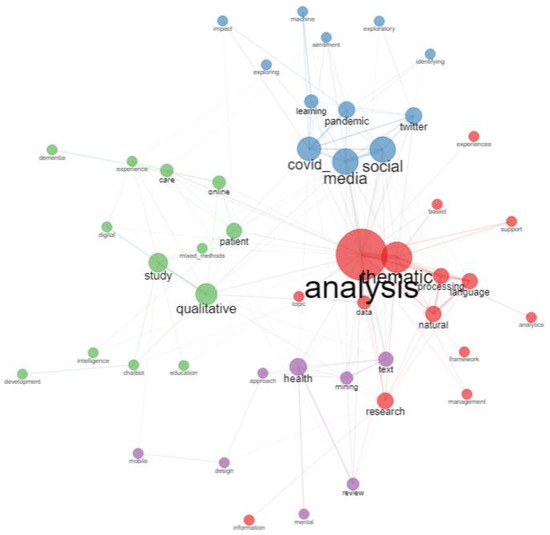{kind=link}
{kind=link}
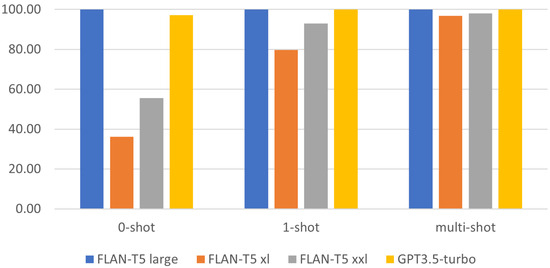{kind=link}
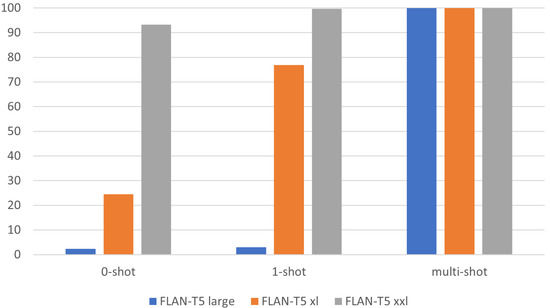{kind=link}
{kind=link}
{kind=link}
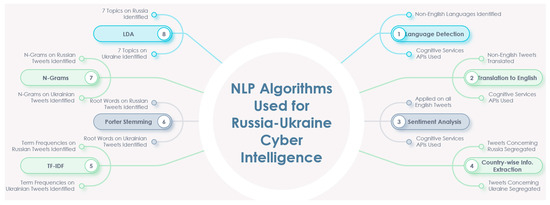{kind=link}
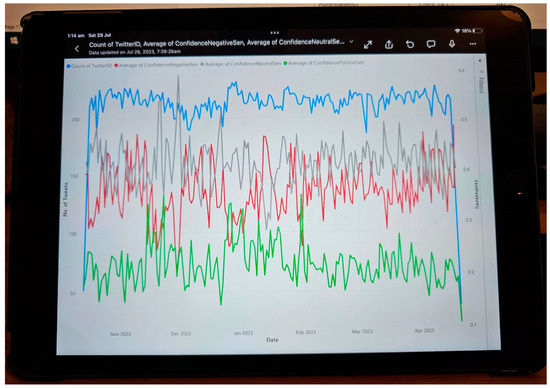{kind=link}
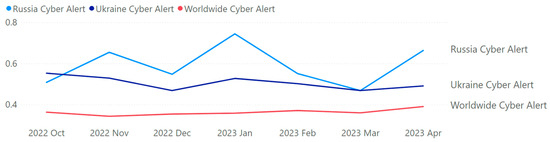{kind=link}
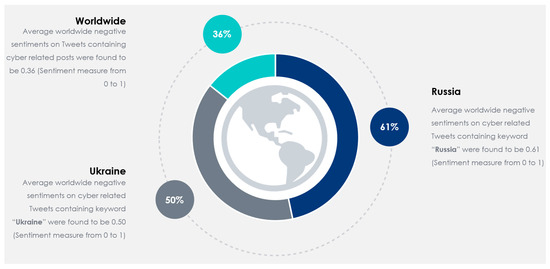{kind=link}
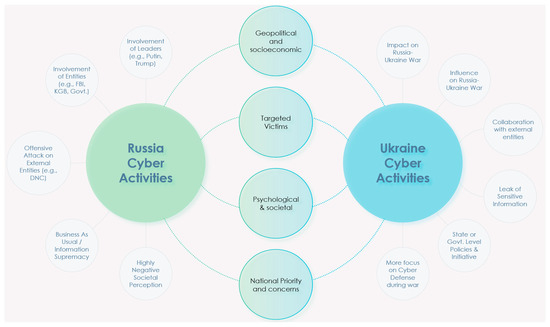{kind=link}
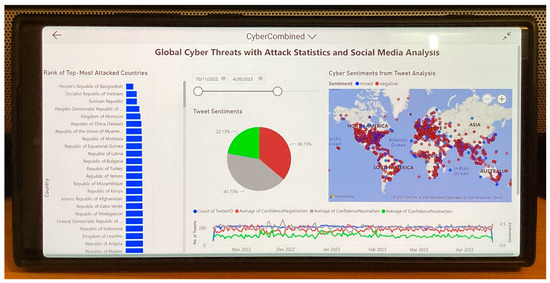{kind=link}
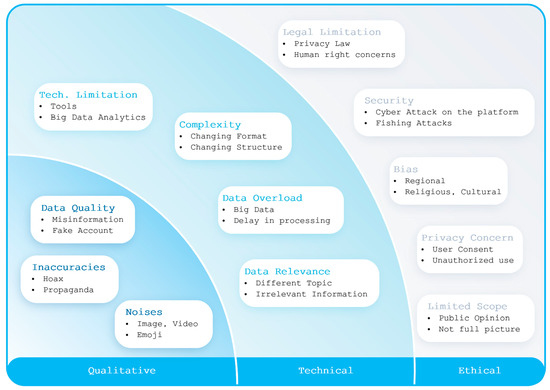{kind=link}
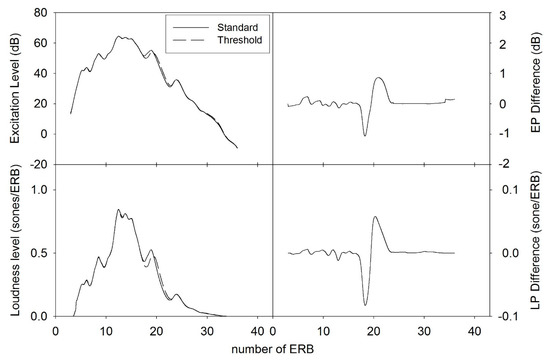{kind=link}
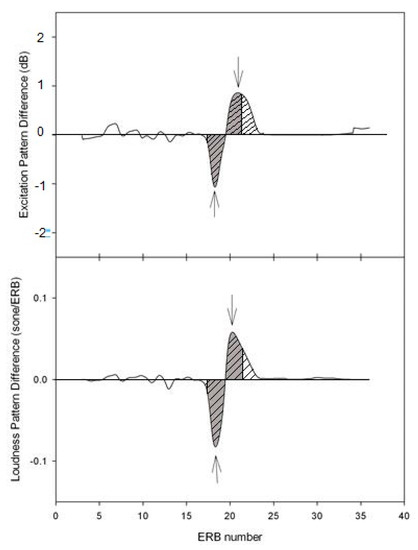{kind=link}
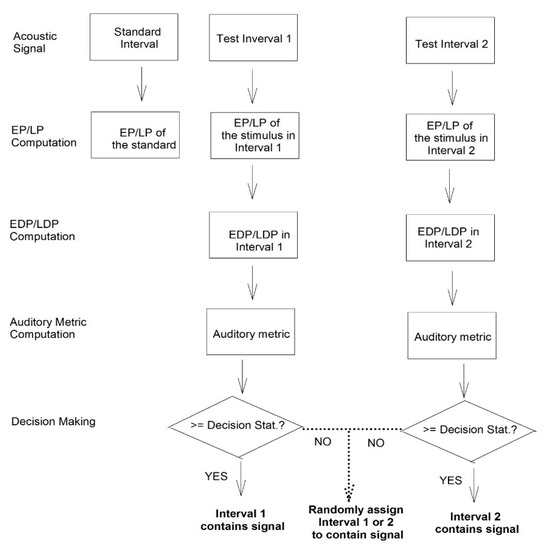{kind=link}
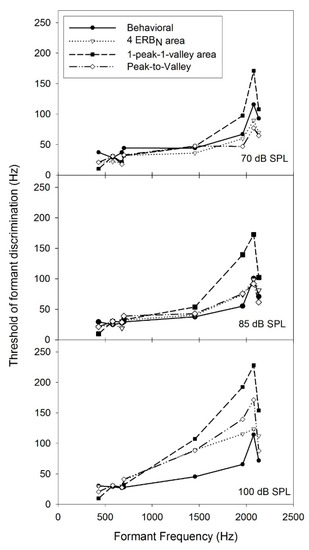{kind=link}
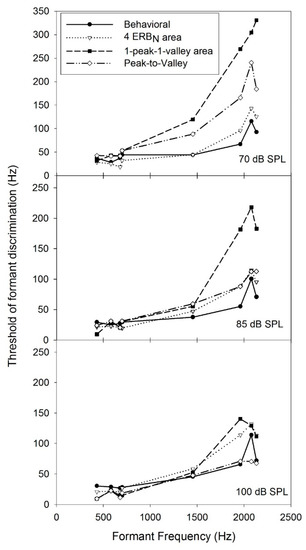{kind=link}
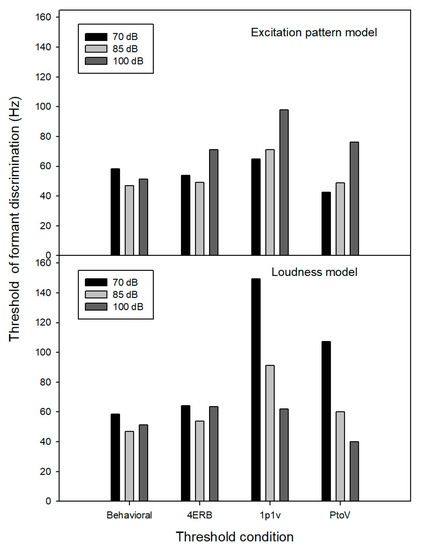{kind=link}
{kind=link}
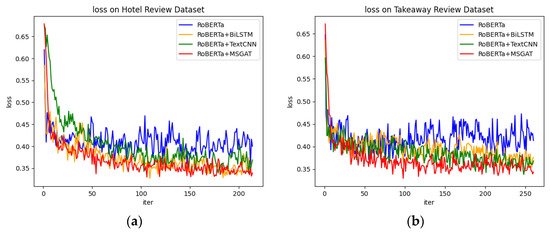{kind=link}
{kind=link}
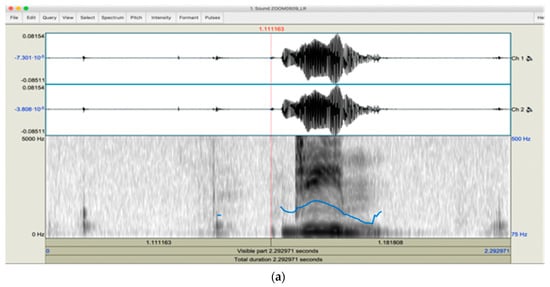{kind=link}
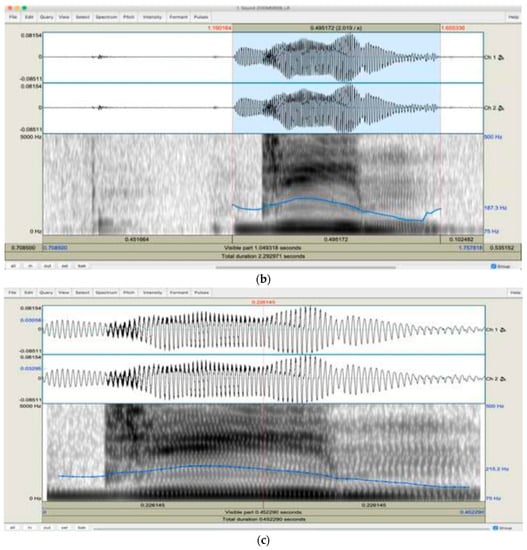{kind=link}
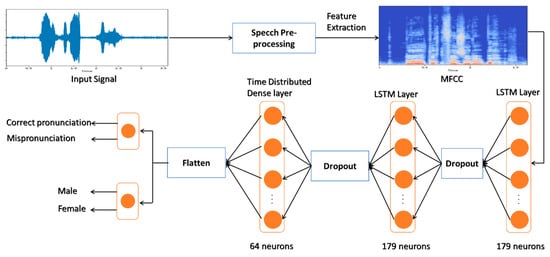{kind=link}
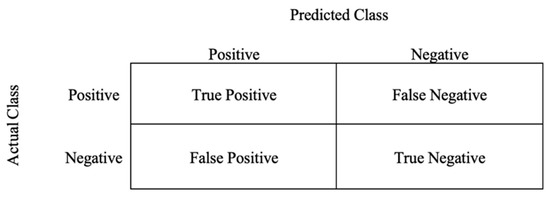{kind=link}
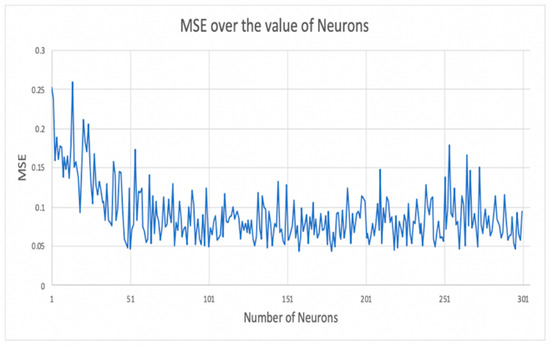{kind=link}
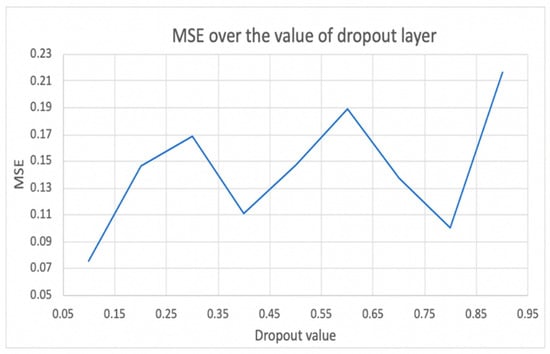{kind=link}
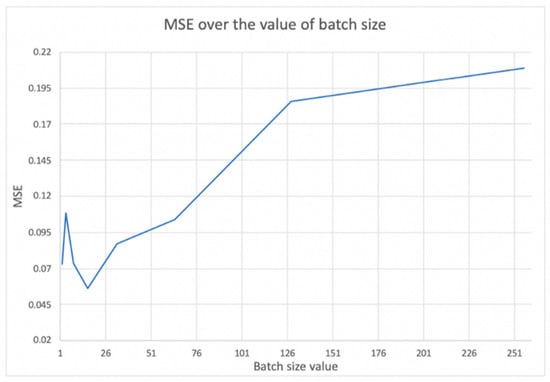{kind=link}
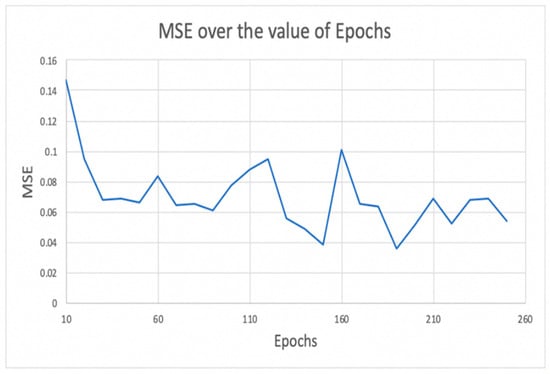{kind=link}
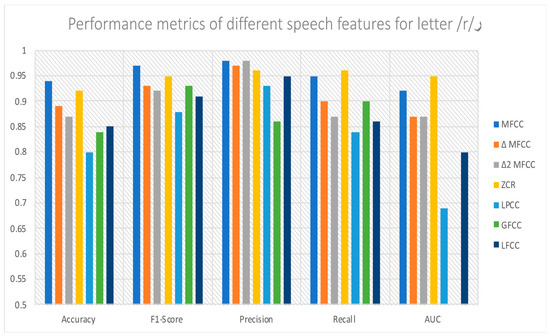{kind=link}
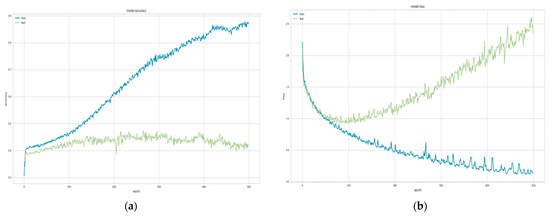{kind=link}
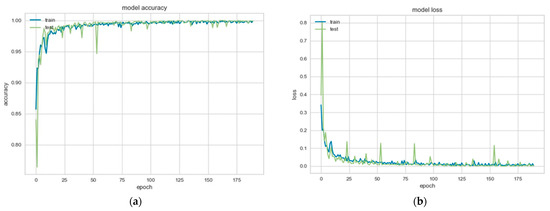{kind=link}
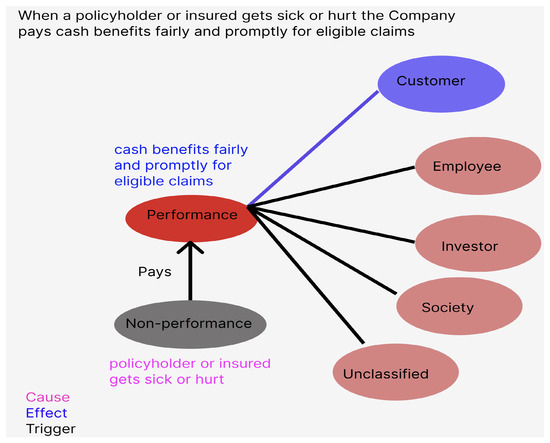{kind=link}
{kind=link}
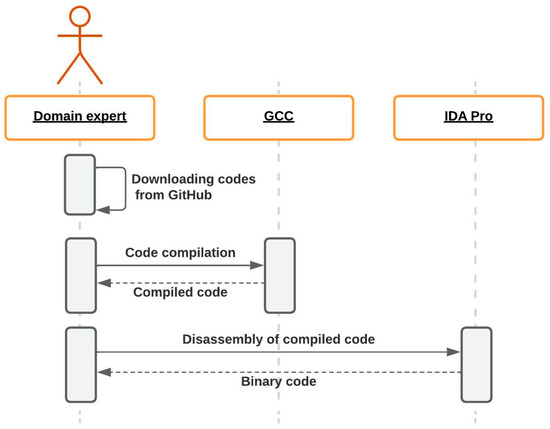{kind=link}
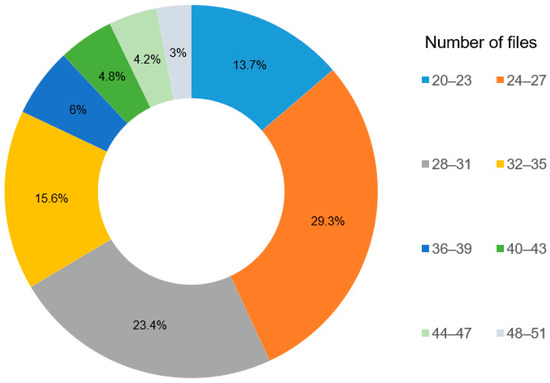{kind=link}
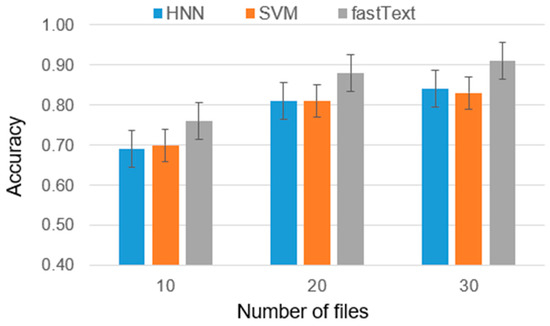{kind=link}
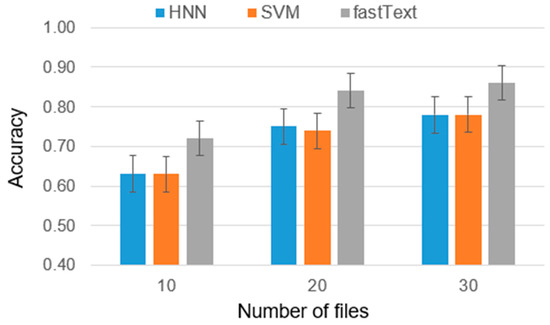{kind=link}
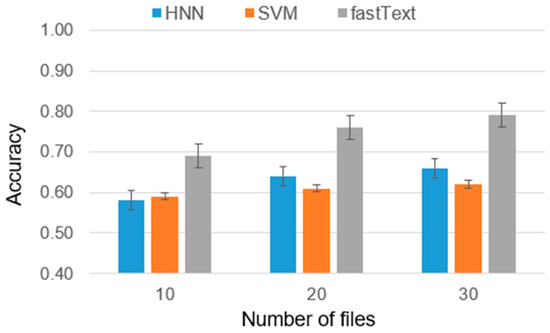{kind=link}
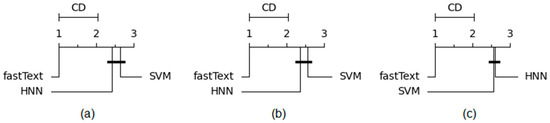{kind=link}
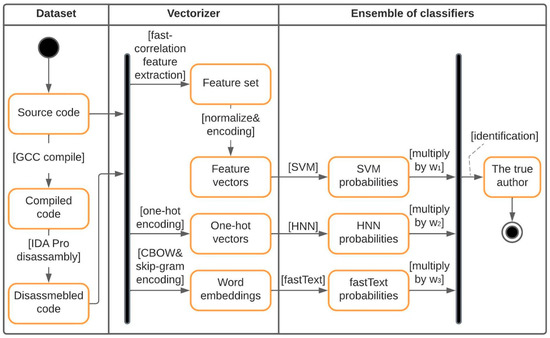{kind=link}
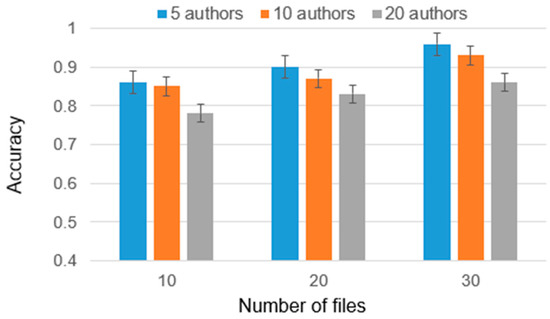{kind=link}
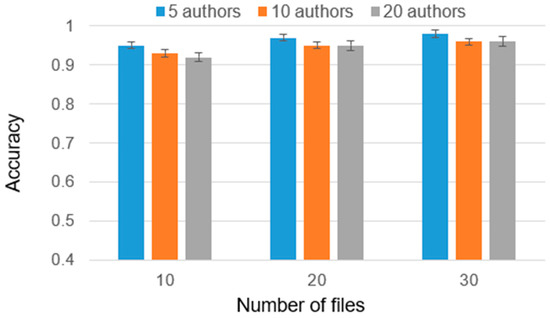{kind=link}
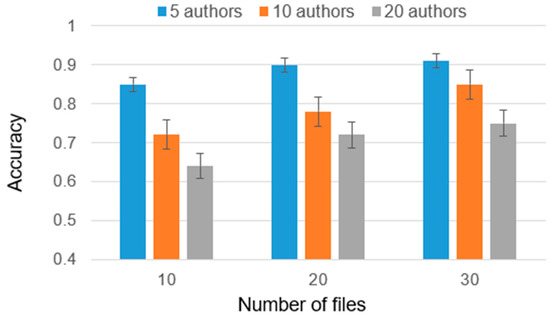{kind=link}
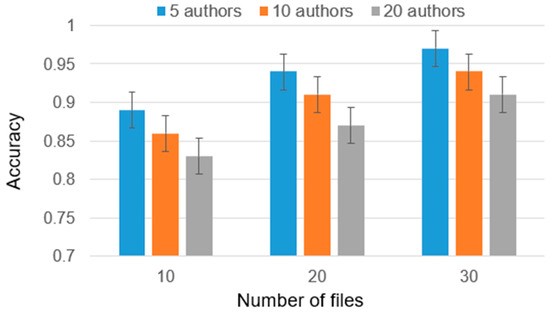{kind=link}
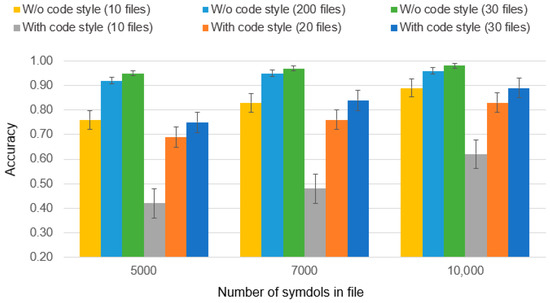{kind=link}
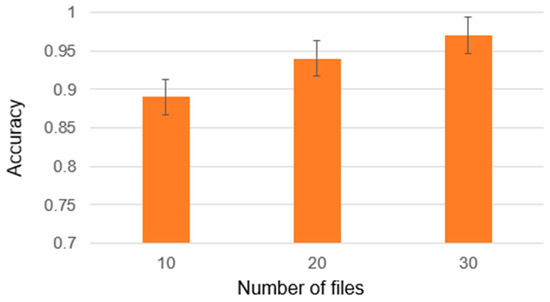{kind=link}
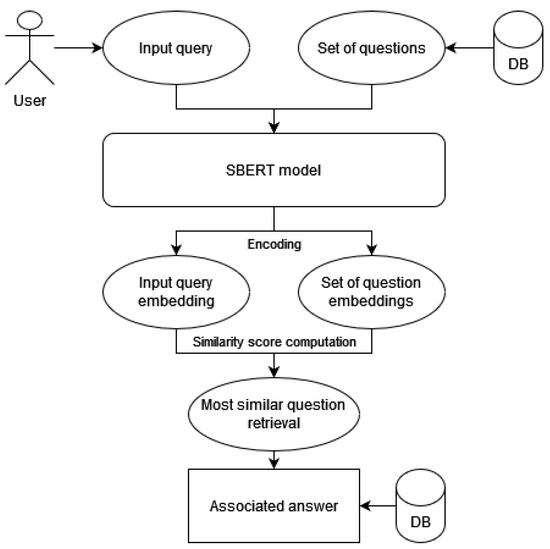{kind=link}
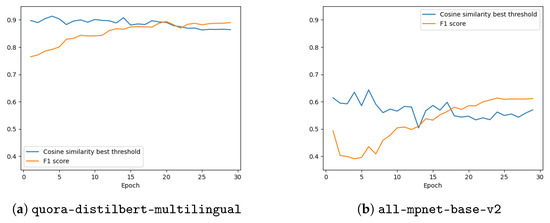{kind=link}
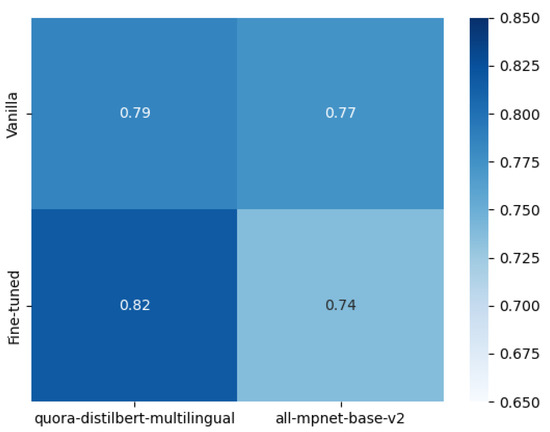{kind=link}
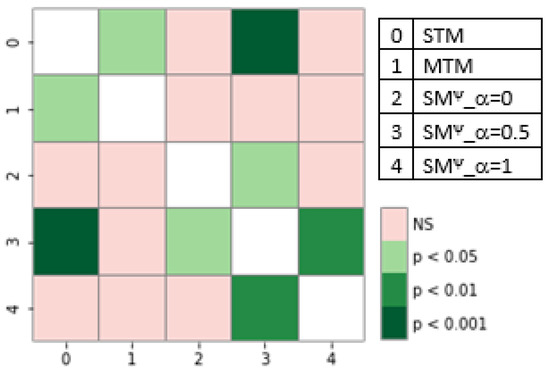{kind=link}
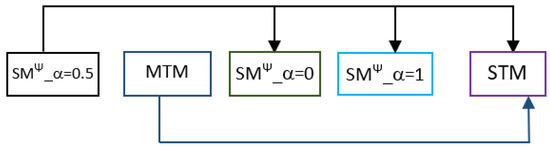{kind=link}
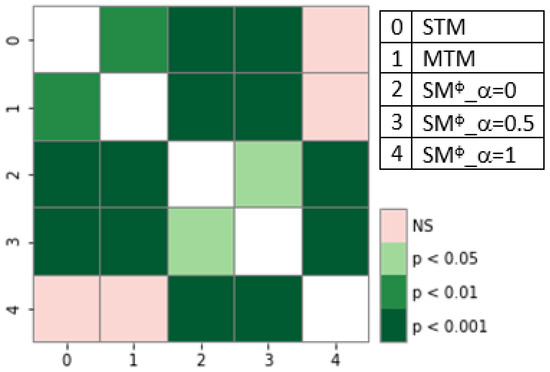{kind=link}
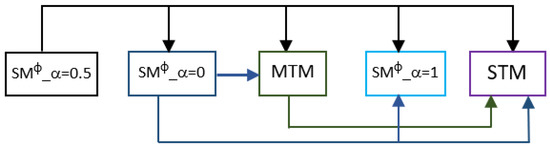{kind=link}
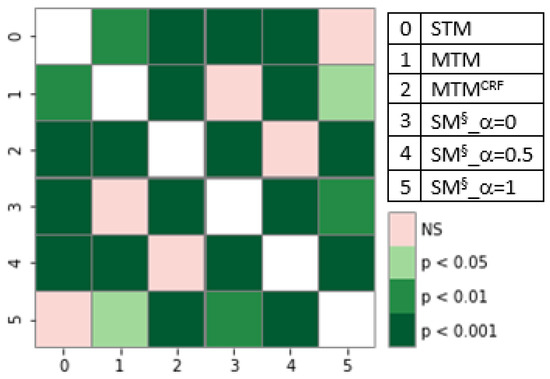{kind=link}
{kind=link}
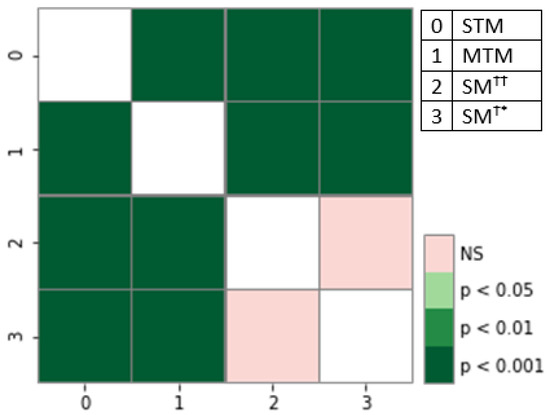{kind=link}
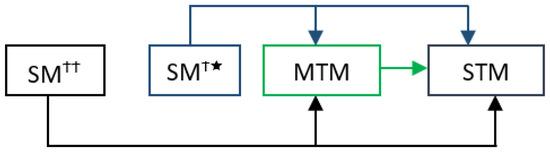{kind=link}
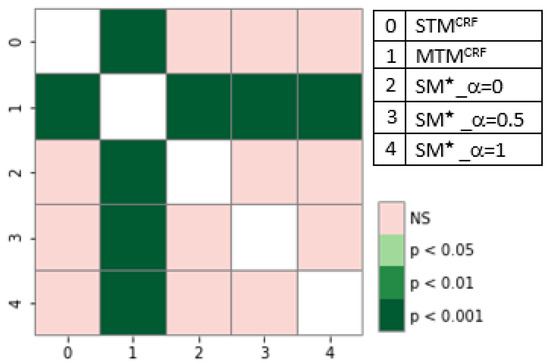{kind=link}
{kind=link}
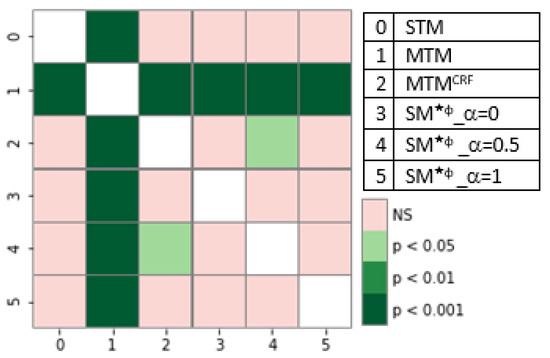{kind=link}
{kind=link}
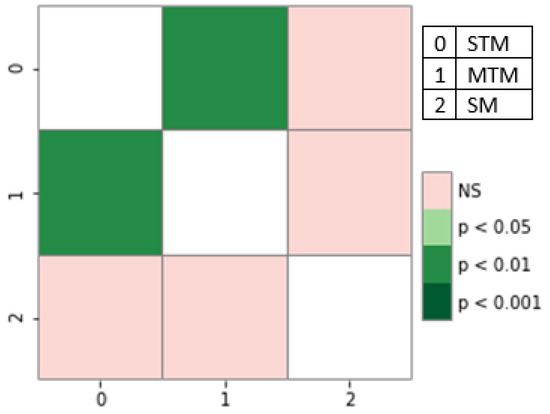{kind=link}
{kind=link}
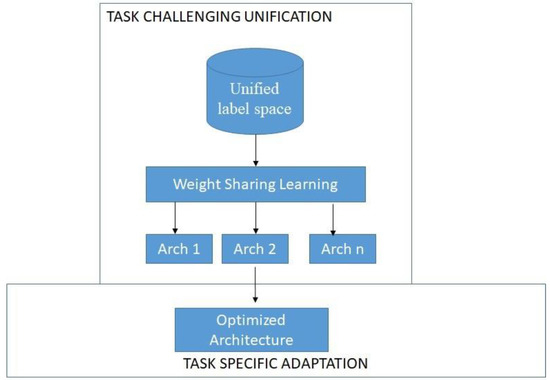{kind=link}
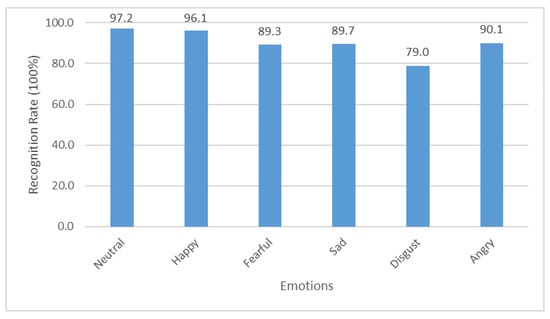{kind=link}
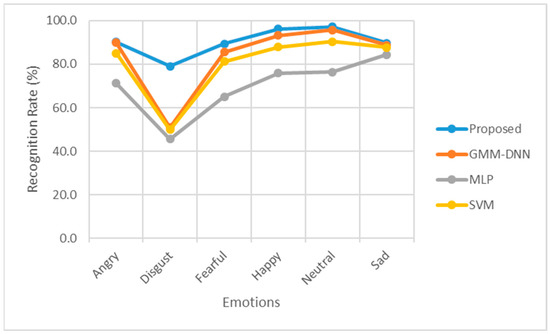{kind=link}
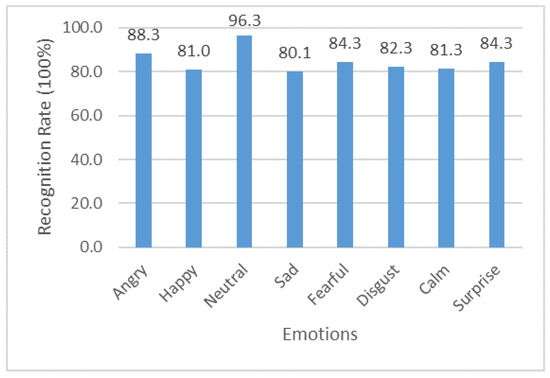{kind=link}
{kind=link}
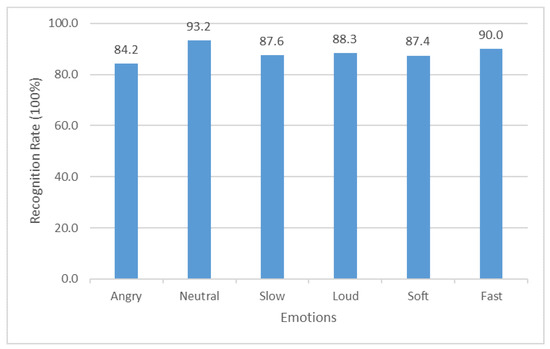{kind=link}
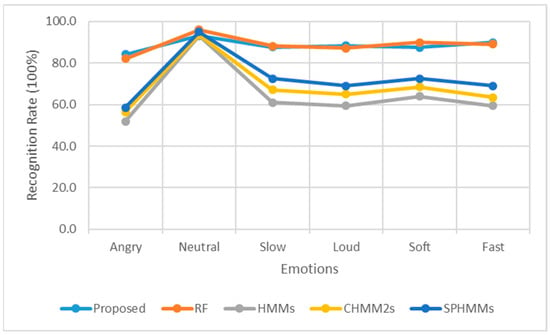{kind=link}
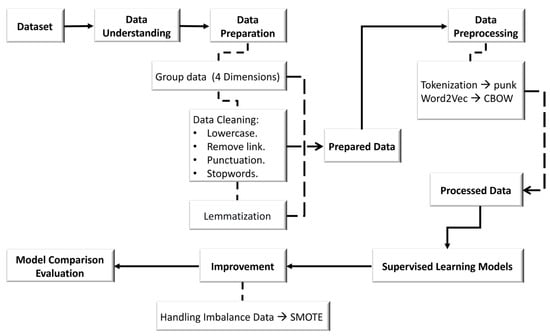{kind=link}
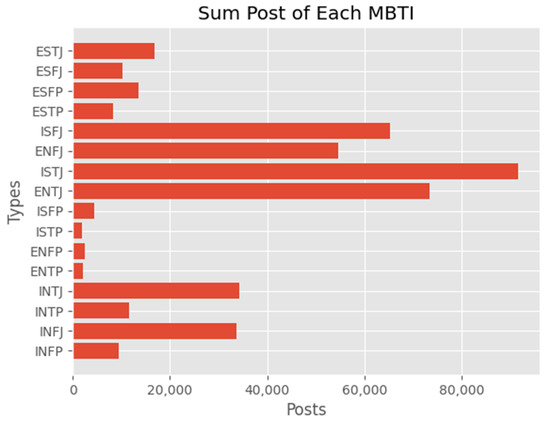{kind=link}
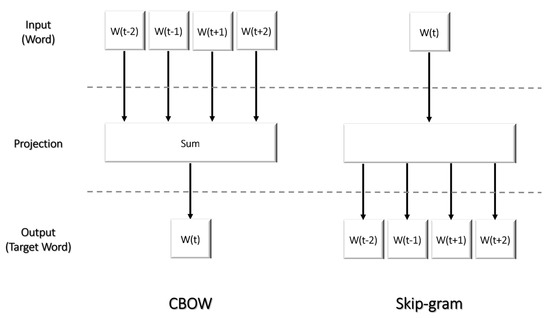{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
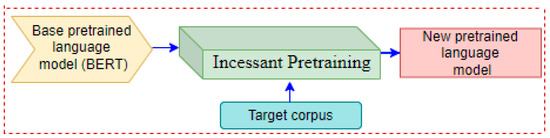{kind=link}
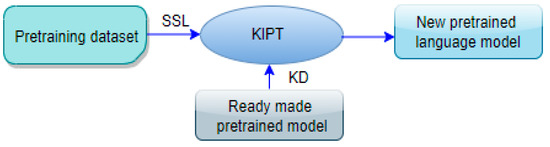{kind=link}
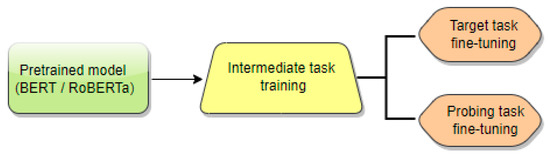{kind=link}
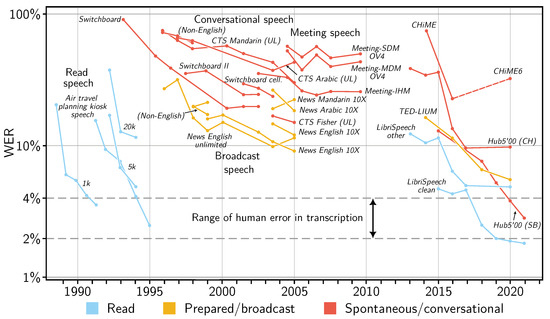{kind=link}
{kind=link}
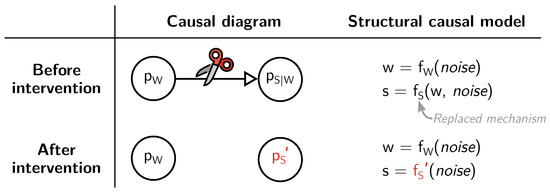{kind=link}
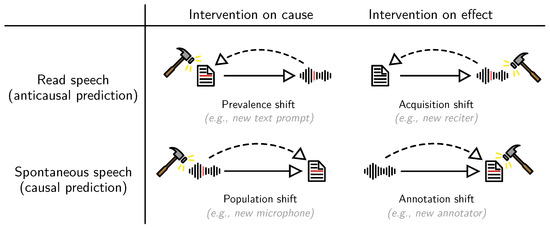{kind=link}
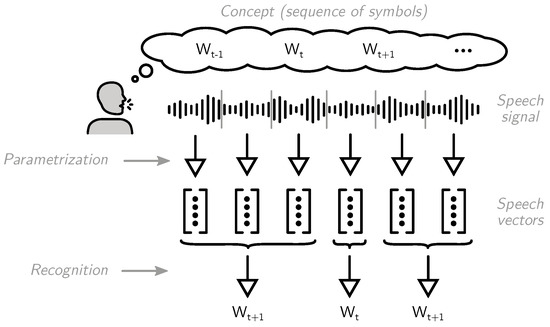{kind=link}
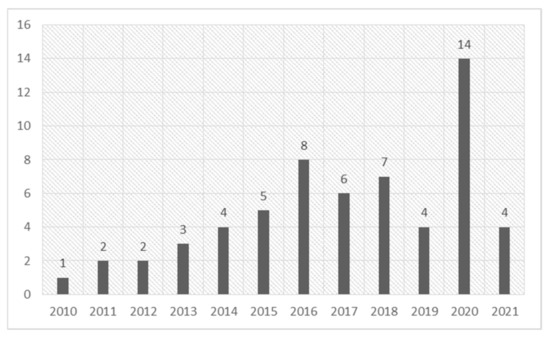{kind=link}
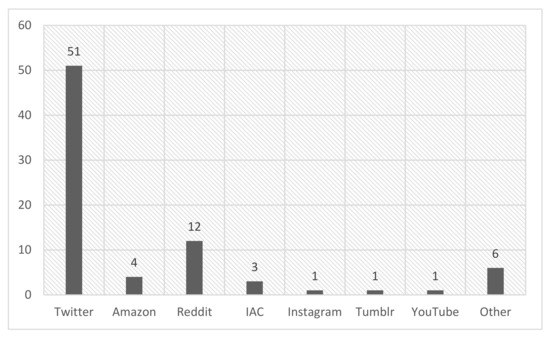{kind=link}
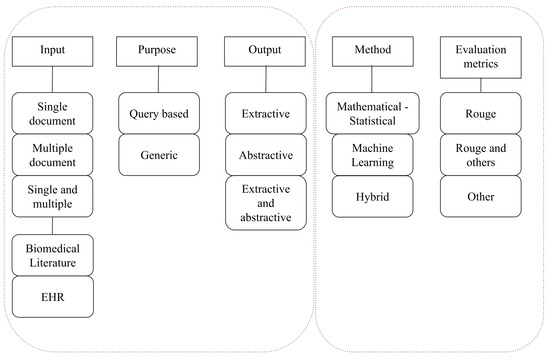{kind=link}
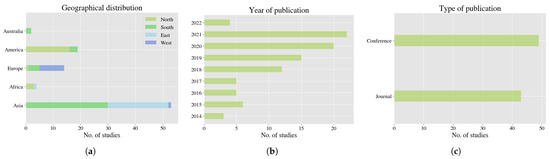{kind=link}
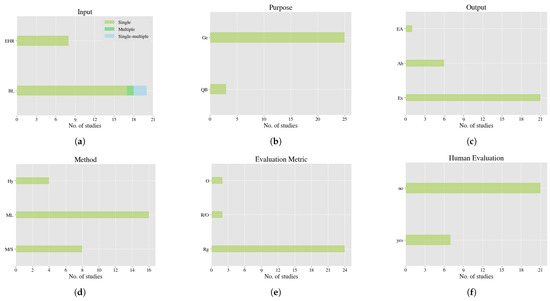{kind=link}
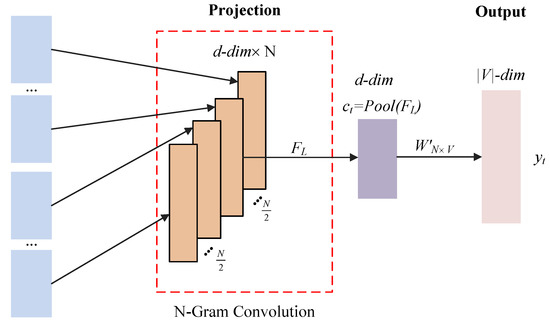{kind=link}
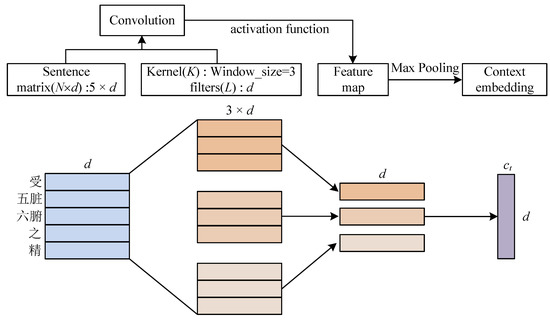{kind=link}
{kind=link}
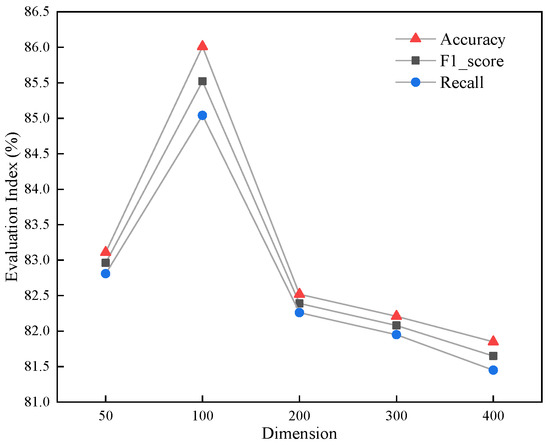{kind=link}
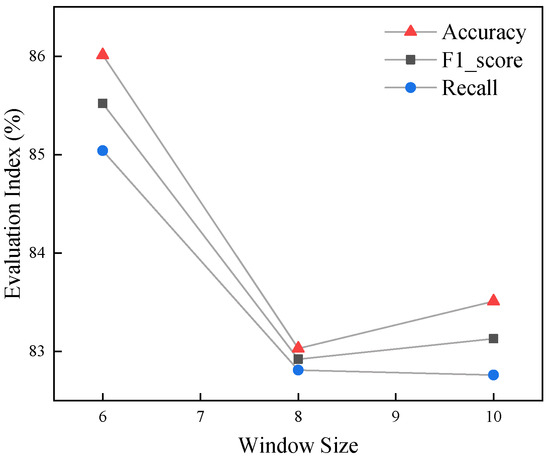{kind=link}
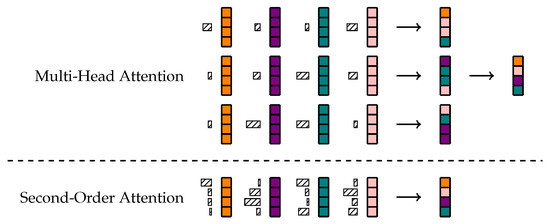{kind=link}
{kind=link}
{kind=link}
{kind=link}
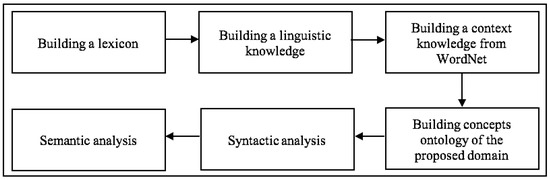{kind=link}
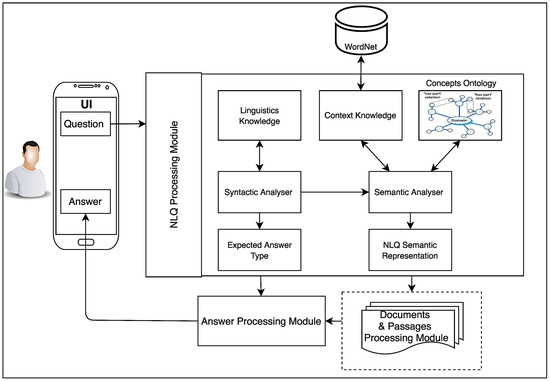{kind=link}
{kind=link}
{kind=link}
{kind=link}
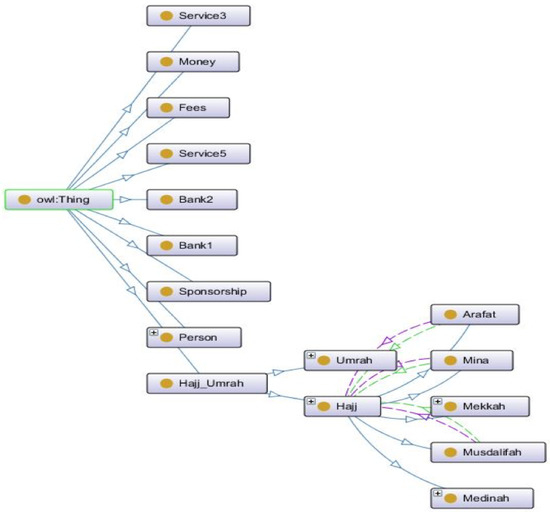{kind=link}
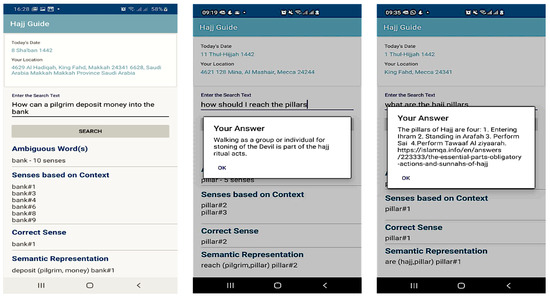{kind=link}
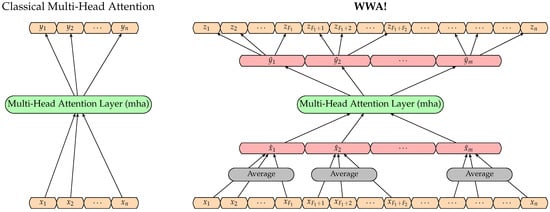{kind=link}
{kind=link}
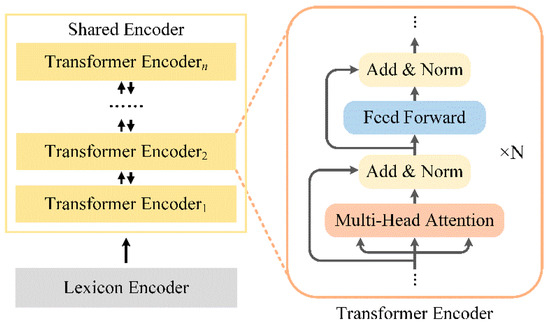{kind=link}
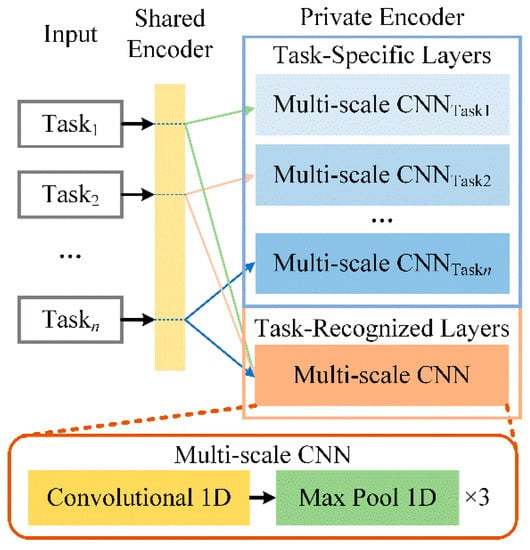{kind=link}
{kind=link}
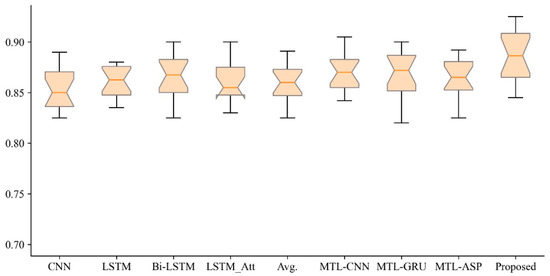{kind=link}
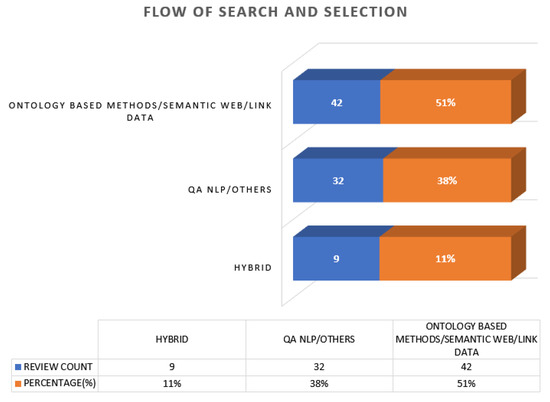{kind=link}