
Transformers in the Real World: A Survey on NLP Applications


Abstract
:1. Introduction
2. Related Work
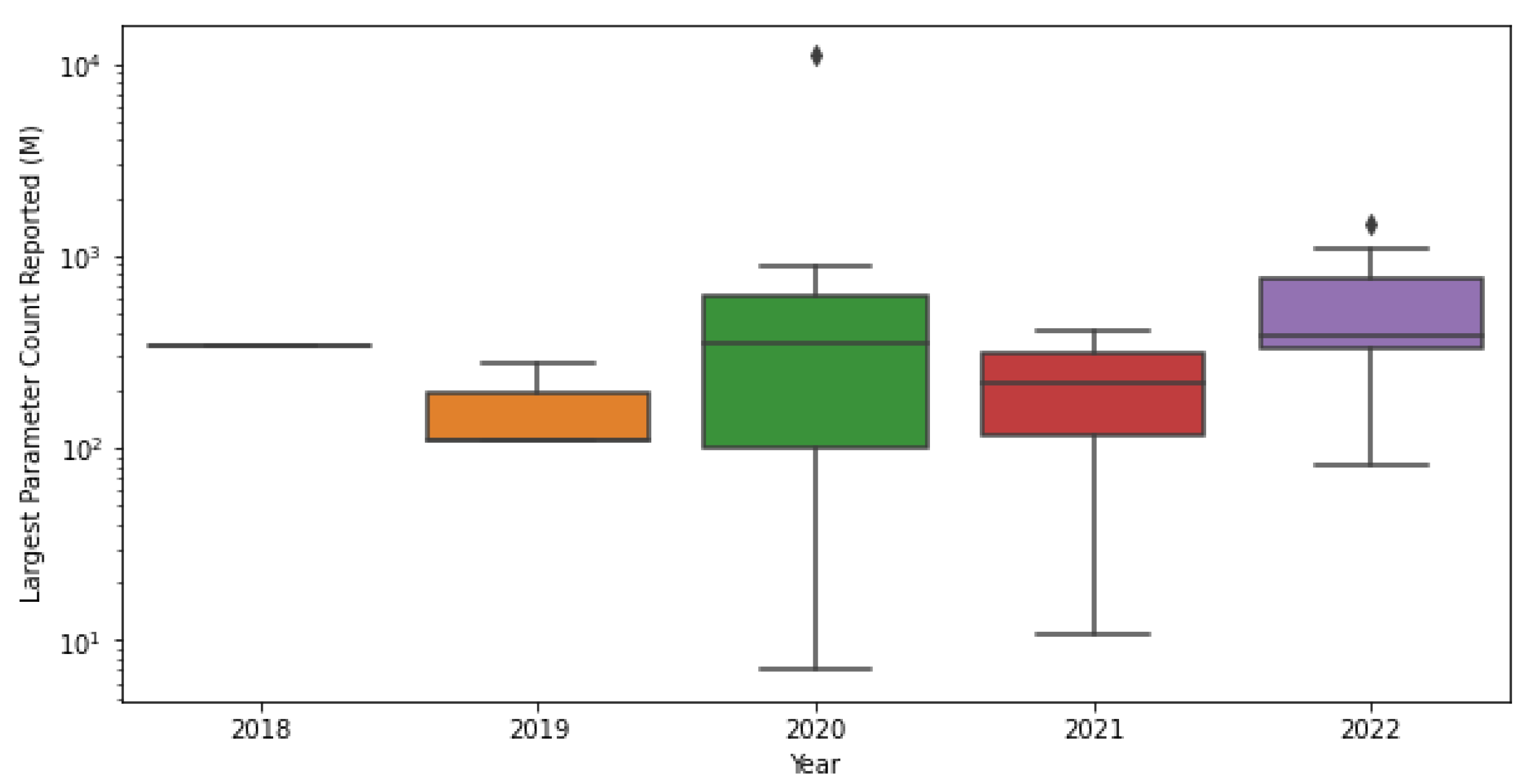
3. Methodology
- We first eliminated entries with a high degree of similarity, which we defined as a fuzzy similarity ratio greater than 95 compared to other entries in the list. We calculated the fuzzy similarity ratio using the FuzzyWuzzy library, which measures the similarity between two strings based on the Levenshtein distance which represents the minimum number of single-character edits (insertions, deletions, or substitutions) required to transform one string into another. The formula used to compute the fuzzy similarity ratio is presented in Equation (1). This step targeted “shorter” entries, i.e., those with fewer characters, in order to maximize information content in cases of high overlap.
- Second, we removed entries composed solely of uppercase letters, as they were likely abbreviations or acronyms unrelated to our target applications.
- Third, entries with fewer than five characters were excluded, as they were potentially incomplete or illegible.
- Fourth, we discarded entries containing numbers, as these were more likely to represent numerical codes or identifiers than descriptive labels.
- Finally, we removed entries with more than five words in order to exclude overly specific tasks not pertinent to the broader application themes that we aimed to investigate.
3.1. Categorization
4. Applications
4.1. Unimodal Applications
4.1.1. Language Modeling
4.1.2. Question Answering
- Open-Domain Question Answering (ODQA): This task involves finding an answer to a question from an open domain, such as the entire internet or a large corpus of text. The goal is to find the most relevant information to answer the question, even if it requires synthesizing information from multiple sources. Reformer, introduced by Kitaev et al. [18], has been shown to excel at ODQA, with its success attributed to the use of locality-sensitive hashing which enables far larger context windows than ordinary transformers.
- Conversational Question Answering (CQA): This task involves answering questions in a conversational setting, where the model must understand the context of the conversation and generate an answer that is relevant and appropriate for the current conversational context. SDNet [19] utilizes both inter-attention and self-attention mechanisms to effectively process context and questions separately and fuse them at multiple intervals.
- Answer Selection: This task involves ranking a set of candidate answers for a given question, where the goal is to select the most accurate answer from the candidate set. Fine-tuning pre-trained transformers has been shown to be an effective method within answer selection [20].
- Machine Reading Comprehension (MRC): This task involves understanding and answering questions about a given passage of text. The model must be able to comprehend the text, extract relevant information, and generate an answer that is accurate and relevant to the question. XLNet [21] uses a permutation-based training procedure that allows it to take into account all possible combinations of input tokens, rather than just the left-to-right order as in traditional transformer models. XLNet’s ability to capture long-range dependencies and its strong pre-training make it a highly competitive model for the MRC task.
4.1.3. Machine Translation
- Transliteration: This task involves translating text from one script to another, such as translating between the Latin and Cyrillic scripts. Transliteration is different from traditional MT in that it typically involves preserving the meaning of words, rather than translating the meaning of words to another language. Because transliteration requires support for non-Latin or often arbitrary characters, models developed for it often use character-level or byte-level encoding. For instance, a model by Wu et al. [22] based on the same principles has shown strong performance on transliteration, outperforming established recurrent baselines with large batch sizes.
- Unsupervised Machine Translation (UMT): This task involves translating between two languages without any parallel training data, meaning that there is no corresponding text in the target language for the source language text. UMT models are typically trained on monolingual data in each language and use various unsupervised techniques to learn the relationship between the languages. Zhu et al. [23] show strong performance on English–French and English–Romanian pairs without any fine-tuning. The idea behind the BERT-fused approach is to leverage pre-training with BERT to better understand the relationships between languages and to use the sequence-to-sequence architecture to generate translations;
- Bilingual Lexicon Induction (BLI): This task involves inducing a bilingual lexicon, which is a mapping between words in two languages. BLI is a critical component of MT, and is often used as a pre-processing step to generate initial alignments between words in the source and target languages.
4.1.4. Text Classification
- Document Classification: This task involves assigning a label or category to a full document, such as a news article, blog post, or scientific paper. Document classification is typically accomplished by first representing the document as a numerical vector and then using a machine learning model to make a prediction based on the document’s representation. LinkBERT [24] extends the pre-training objective of BERT to incorporate links between documents, which results in better classification quality.
- Cause and Effect Classification: This task involves identifying the cause and effect relationship between two events described in a sentence or paragraph. An approach by Hosseini et al. [25] has shown the efficacy of the language modeling paradigm by verbalizing knowledge graphs and using them as a pre-training corpus for a language model. The model obtains acceptable performance without any further fine-tuning or prompting.
4.1.5. Text Generation
- Dialogue Generation: This category focuses on generating text in the form of a conversation between two or more agents. Dialogue generation systems are used in various applications, such as chatbots, virtual assistants, and conversational AI systems. These systems use dialogue history, user input, and context to generate appropriate and coherent responses. P2-BOT [27] is a transmitter–receiver-based framework that aims to explicitly model understanding in chat dialogue systems through mutual persona perception, resulting in improved personalized dialogue generation based on both automated metrics and human evaluation.
- Code Generation: This category focuses on generating code based on a given input, such as a natural language description of a software problem. Code generation systems are used in software development to automate repetitive tasks, improve productivity, and reduce errors. These systems can be trained to use expert knowledge, and can be specialized for a single programming language, such as SQL [28], or trained on a large corpus to support various programming languages and different programming paradigms [29];
- Data-to-Text Generation: This category focuses on generating natural language text from structured data such as tables, databases, or graphs. Data-to-text generation systems are used in various applications, such as news reporting, data visualization, and technical writing. These systems use natural language generation techniques to convert data into human-readable text, taking into account the context, target audience, and purpose of the text. Control Prefixes [30] extend prefix tuning by incorporating input-dependent information into a pre-trained transformer through attribute-level learnable representations, resulting in a parameter-efficient data-to-text model.
4.1.6. Text Summarization
- Extractive Summarization: This is the most straightforward subtask of text summarization, where the goal is to extract the most important sentences or phrases from a document and present them as a summary. Extractive summarization methods typically use a combination of information retrieval and natural language processing techniques to identify the most informative sentences or phrases in a document.
- The attention mechanism of Longformer [32] is a substitute for standard self-attention, and merges localized windowed attention with globally focused attention. The encoder–decoder version of the longformer (called LED) has demonstrated its effectiveness on the arXiv summarization dataset, and is used often for processing long contexts in real-world applications.
- Abstractive Summarization: This subtask aims to generate a summary by synthesizing new information based on the input document. Abstractive summarization methods typically use deep learning models, such as recurrent neural networks or transformers, to generate a summary. These models are trained on large amounts of data and can generate summaries that are more concise and coherent than extractive summaries. mBart is a sequence-to-sequence transformer [33] trained on multiple large-scale monolingual corpora with the objective of denoising. Due to its rich pretraining dataset and ability to process multiple languages using the same network, it excels at abstractive summarization.
- Multi-Document Summarization: This subtask addresses the problem of summarizing multiple related documents into a single summary. Multi-document summarization methods typically use information retrieval techniques to identify the most important documents and natural language processing techniques to generate a summary from the selected documents. While prior state-of-the-art methods relied on GNNs to take advantage of inherent connectivity, Primer by Xiao et al. [34] has shown better performance in zero-shot, few-shot, and fine-tuned paradigms by introducing a new pretraining objective in the form of predicting masked salient sentences.
- Query-Focused Summarization: This subtask focuses on summarizing a document based on a specific query or topic. Query-focused summarization methods typically use information retrieval techniques to identify the most relevant sentences or phrases in a document and present them as a summary. Baumel et al. [35] introduced a pre-inference step involving computing the relevance between the query and each sentence of the document. The quality of summarization has been shown to improve when incorporating this form of relevance as an additional input. Support for multiple documents is achieved using a simple iterative scheme that uses maximum word count as a budget.
- Sentence Compression: This subtask focuses on reducing the length of a sentence while preserving its meaning. Sentence compression methods typically use natural language processing techniques to identify redundant or unnecessary words or phrases in a sentence and remove them to create a more concise sentence. Ghalandari et al. [36] trained six-layer model called DistilRoBERTa with reinforcement learning to predict a binary classifier that keeps or discards words to reduce the sentence length.
4.1.7. Sentiment Analysis
4.1.8. Named Entity Recognition
4.1.9. Information Retrieval
4.2. Multimodal Applications
4.2.1. Generative Control
4.2.2. Description Generation
4.2.3. Multimodal Question Answering
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| API | Application Programming Interface |
| BERT | Bidirectional Encoder Representations from Transformers |
| GPT | Generative Pretrained Transformers |
| NER | Named Entity Recognition |
| SQL | Structured Query Language |
| TTS | Text-to-Speech |
| MT | Machine Translation |
| UMT | Unsupervised Machine Translation |
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 3058. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. OpenAI 2018. [Google Scholar]
- Chowdhary, K.; Chowdhary, K. Natural language processing. Fundam. Artif. Intell. 2020, 1, 603–649. [Google Scholar]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual Event, 3–10 March 2021; pp. 610–623. [Google Scholar]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment analysis based on deep learning: A comparative study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Danilevsky, M.; Qian, K.; Aharonov, R.; Katsis, Y.; Kawas, B.; Sen, P. A survey of the state of explainable AI for natural language processing. arXiv 2020, arXiv:2010.0071. [Google Scholar]
- Alyafeai, Z.; AlShaibani, M.S.; Ahmad, I. A survey on transfer learning in natural language processing. arXiv 2020, arXiv:2007.04239. [Google Scholar]
- Wu, L.; Chen, Y.; Shen, K.; Guo, X.; Gao, H.; Li, S.; Pei, J.; Long, B. Graph neural networks for natural language processing: A survey. Found. Trends® Mach. Learn. 2023, 16, 119–328. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Shin, T.; Razeghi, Y.; Logan IV, R.L.; Wallace, E.; Singh, S. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. arXiv 2020, arXiv:2010.15980. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Krause, B.; Kahembwe, E.; Murray, I.; Renals, S. Dynamic evaluation of transformer language models. arXiv 2019, arXiv:1904.08378. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-tuning language models from human preferences. arXiv 2019, arXiv:1909.08593. [Google Scholar]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Zhu, C.; Zeng, M.; Huang, X. Sdnet: Contextualized attention-based deep network for conversational question answering. arXiv 2018, arXiv:1812.03593. [Google Scholar]
- Garg, S.; Vu, T.; Moschitti, A. Tanda: Transfer and adapt pre-trained transformer models for answer sentence selection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7780–7788. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 3088. [Google Scholar]
- Wu, S.; Cotterell, R.; Hulden, M. Applying the transformer to character-level transduction. arXiv 2020, arXiv:2005.10213. [Google Scholar]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T.Y. Incorporating bert into neural machine translation. arXiv 2020, arXiv:2002.06823. [Google Scholar]
- Yasunaga, M.; Leskovec, J.; Liang, P. Linkbert: Pretraining language models with document links. arXiv 2022, arXiv:2203.15827. [Google Scholar]
- Hosseini, P.; Broniatowski, D.A.; Diab, M. Knowledge-augmented language models for cause-effect relation classification. In Proceedings of the First Workshop on Commonsense Representation and Reasoning (CSRR 2022), Dublin, UK, 27 May 2022; pp. 43–48. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Liu, Q.; Chen, Y.; Chen, B.; Lou, J.G.; Chen, Z.; Zhou, B.; Zhang, D. You impress me: Dialogue generation via mutual persona perception. arXiv 2020, arXiv:2004.05388. [Google Scholar]
- Guo, T.; Gao, H. Content enhanced bert-based text-to-sql generation. arXiv 2019, arXiv:1910.07179. [Google Scholar]
- Wang, Y.; Wang, W.; Joty, S.; Hoi, S.C. Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. arXiv 2021, arXiv:2109.00859. [Google Scholar]
- Clive, J.; Cao, K.; Rei, M. Control prefixes for parameter-efficient text generation. In Proceedings of the 2nd Workshop on Natural Language Generation, Evaluation, and Metrics (GEM), Online, 7–11 December 2022; pp. 363–382. [Google Scholar]
- Xiong, W.; Gupta, A.; Toshniwal, S.; Mehdad, Y.; Yih, W.T. Adapting Pretrained Text-to-Text Models for Long Text Sequences. arXiv 2022, arXiv:2209.10052. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual denoising pre-training for neural machine translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Xiao, W.; Beltagy, I.; Carenini, G.; Cohan, A. Primer: Pyramid-based masked sentence pre-training for multi-document summarization. arXiv 2021, arXiv:2110.08499. [Google Scholar]
- Baumel, T.; Eyal, M.; Elhadad, M. Query focused abstractive summarization: Incorporating query relevance, multi-document coverage, and summary length constraints into seq2seq models. arXiv 2018, arXiv:1801.07704. [Google Scholar]
- Ghalandari, D.G.; Hokamp, C.; Ifrim, G. Efficient Unsupervised Sentence Compression by Fine-tuning Transformers with Reinforcement Learning. arXiv 2022, arXiv:2205.08221. [Google Scholar]
- Wang, X.; Jiang, Y.; Bach, N.; Wang, T.; Huang, Z.; Huang, F.; Tu, K. Automated concatenation of embeddings for structured prediction. arXiv 2020, arXiv:2010.05006. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 24–28 June 2022; pp. 10684–10695. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Wang, C.; Chen, S.; Wu, Y.; Zhang, Z.; Zhou, L.; Liu, S.; Chen, Z.; Liu, Y.; Wang, H.; Li, J.; et al. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. arXiv 2023, arXiv:2301.02111. [Google Scholar]
- Li, C.; Xu, H.; Tian, J.; Wang, W.; Yan, M.; Bi, B.; Ye, J.; Chen, H.; Xu, G.; Cao, Z.; et al. mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections. arXiv 2022, arXiv:2205.12005. [Google Scholar]
- Plepi, J.; Kacupaj, E.; Singh, K.; Thakkar, H.; Lehmann, J. Context transformer with stacked pointer networks for conversational question answering over knowledge graphs. In Proceedings of the The Semantic Web: 18th International Conference, ESWC 2021, Online, 6–10 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 356–371. [Google Scholar]
- Oguz, B.; Chen, X.; Karpukhin, V.; Peshterliev, S.; Okhonko, D.; Schlichtkrull, M.; Gupta, S.; Mehdad, Y.; Yih, S. Unik-qa: Unified representations of structured and unstructured knowledge for open-domain question answering. arXiv 2020, arXiv:2012.14610. [Google Scholar]
- Wang, W.; Bao, H.; Dong, L.; Bjorck, J.; Peng, Z.; Liu, Q.; Aggarwal, K.; Mohammed, O.K.; Singhal, S.; Som, S.; et al. Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv 2022, arXiv:2208.10442. [Google Scholar]


{kind=link}
| Paper Title | Link to Source |
|---|---|
| Autoprompt: Eliciting knowledge from language models with automatically generated prompts | https://github.com/ucinlp/autoprompt, accessed on 1 April 2023. |
| Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context | https://github.com/kimiyoung/transformer-xl, accessed on 1 April 2023. |
| Dynamic Evaluation of Transformer Language Models | https://github.com/benkrause/dynamiceval-transformer, accessed on 1 April 2023. |
| Paper Title | Link to Source |
|---|---|
| Reformer: The efficient transformer | https://github.com/google/trax/tree/master/trax/models/reformer, accessed on 20 March 2023. |
| Sdnet: Contextualized attention-based deep network for conversational question answering | https://github.com/Microsoft/SDNet, accessed on 20 March 2023. |
| Tanda: Transfer and adapt pre-trained transformer models for answer sentence selection | https://github.com/alexa/wqa_tanda, accessed on 20 March 2023. |
| Xlnet: Generalized autoregressive pretraining for language understanding | https://github.com/zihangdai/xlnet, accessed on 20 March 2023. |
| Paper Title | Link to Source |
|---|---|
| Applying the transformer to character-level transduction | https://github.com/shijie-wu/neural-transducer, assessed on 1 April 2023. |
| Incorporating BERT into neural machine translation | https://github.com/bert-nmt/bert-nmt, assessed on 1 April 2023. |
| Paper Title | Link to Source |
|---|---|
| Linkbert: Pretraining language models with document links | https://github.com/michiyasunaga/LinkBERT, accessed on 20 March 2023. |
| Knowledge-augmented language models for cause-effect relation classification | https://github.com/phosseini/causal-reasoning, accessed on 20 March 2023. |
| Paper Title | Link to Source |
|---|---|
| Exploring the limits of transfer learning with a unified text-to-text transformer | https://github.com/google-research/text-to-text-transfer-transformer, accessed on 2 March 2023. |
| You impress me: Dialogue generation via mutual persona perception | https://github.com/SivilTaram/Persona-Dialogue-Generation, accessed on 2 March 2023. |
| Content Enhanced BERT-based Text-to-SQL Generation | https://github.com/guotong1988/NL2SQL-RULE, accessed on 2 March 2023. |
| Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation | https://github.com/salesforce/CodeT5, accessed on 2 March 2023. |
| Control prefixes for parameter-efficient text generation | https://github.com/jordiclive/ControlPrefixes, accessed on 2 March 2023. |
| Paper Title | Link to Source |
|---|---|
| Adapting Pretrained Text-to-Text Models for Long Text Sequences | https://github.com/facebookresearch/bart_ls, accessed on 10 March 2023. |
| Longformer: The long-document transformer | https://github.com/allenai/longformer, accessed on 10 March 2023. |
| Multilingual denoising pre-training for neural machine translation | https://github.com/facebookresearch/fairseq/tree/main/examples/mbart, accessed on 10 March 2023. |
| Primer: Pyramid-based masked sentence pre-training for multi-document summarization | https://github.com/allenai/PRIMER, accessed on 10 March 2023. |
| Query focused abstractive summarization: Incorporating query relevance, multi-document coverage, and summary length constraints into seq2seq models | https://github.com/talbaumel/RSAsummarization, accessed on 10 March 2023. |
| Efficient Unsupervised Sentence Compression by Fine-tuning Transformers with Reinforcement Learning | https://github.com/complementizer/rl-sentence-compression, accessed on 10 March 2023. |
| Paper Title | Link to Source |
|---|---|
| Exploring the limits of transfer learning with a unified text-to-text transformer | https://github.com/google-research/text-to-text-transfer-transformer, accessed on 1 March 2023. |
| Xlnet: Generalized autoregressive pretraining for language understanding | https://github.com/zihangdai/xlnet, accessed on 1 March 2023. |
| Paper Title | Link to Source |
|---|---|
| Automated concatenation of embeddings for structured prediction | https://github.com/Alibaba-NLP/AC, accessed on 1 March 2023. |
| Paper Title | Link to Source |
|---|---|
| RoBERTa: A Robustly Optimized BERT Pretraining Approach | https://github.com/facebookresearch/fairseq, accessed on 1 March 2023. |
| Paper Title | Link to Source |
|---|---|
| High-resolution image synthesis with latent diffusion models | https://github.com/CompVis/latent-diffusion, accessed on 1 March 2023. |
| Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers | https://github.com/microsoft/unilm/tree/master/valle, accessed on 1 March 2023. |
| Paper Title | Link to Source |
|---|---|
| mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections | https://github.com/alibaba/AliceMind/tree/main/mPLUG, accessed on 10 March 2023. |
| Paper Title | Link to Source |
|---|---|
| Context transformer with stacked pointer networks for conversational question answering over knowledge graphs | https://github.com/endrikacupaj/CARTON, accessed on 10 March 2023. |
| Unik-qa: Unified representations of structured and unstructured knowledge for open-domain question answering | https://github.com/facebookresearch/UniK-QA, accessed on 10 March 2023. |
| Image as a foreign language: Beit pretraining for all vision and vision-language tasks | https://github.com/microsoft/unilm/tree/master/beit, accessed on 10 March 2023. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patwardhan, N.; Marrone, S.; Sansone, C. Transformers in the Real World: A Survey on NLP Applications. Information 2023, 14, 242. https://doi.org/10.3390/info14040242
Patwardhan N, Marrone S, Sansone C. Transformers in the Real World: A Survey on NLP Applications. Information. 2023; 14(4):242. https://doi.org/10.3390/info14040242
Chicago/Turabian StylePatwardhan, Narendra, Stefano Marrone, and Carlo Sansone. 2023. "Transformers in the Real World: A Survey on NLP Applications" Information 14, no. 4: 242. https://doi.org/10.3390/info14040242