
Multilingual Text Summarization for German Texts Using Transformer Models


Abstract
:1. Introduction
1.1. Problem Statement
1.2. Thesis Statement and Research Questions
- RQ1: What is the current body of knowledge regarding automatic text summarization for languages such as German?
- RQ2: What language models can be used for automatic text summarization in German?
- RQ3: How could the language models be used to conduct experiments on automatic text summarization in German?
- RQ4: How should the data be processed?
- RQ5: What is the quality of the automatic text summarization for the particular dataset?
2. Literature Review
2.1. Automated Text Summarization
“Text summarization approaches can be typically split into two groups: extractive summarization and abstractive summarization. Extractive summarization takes out the important sentences or phrases from the original documents and groups them to produce a text summary without any modification in the original text. Normally the sentences are in the same sequence as in the original text document. Nevertheless, abstractive summarization performs summarization by understanding the original text with the help of linguistic methods to understand and examine the text. The objective of abstractive summarization is to produce a generalized summary, which conveys information in a precise way that generally requires advanced language generation and compression techniques”.[5] (p. 1)
2.2. Multilingual Text Summarization
2.3. ROUGE Metrics
2.4. Research Gap
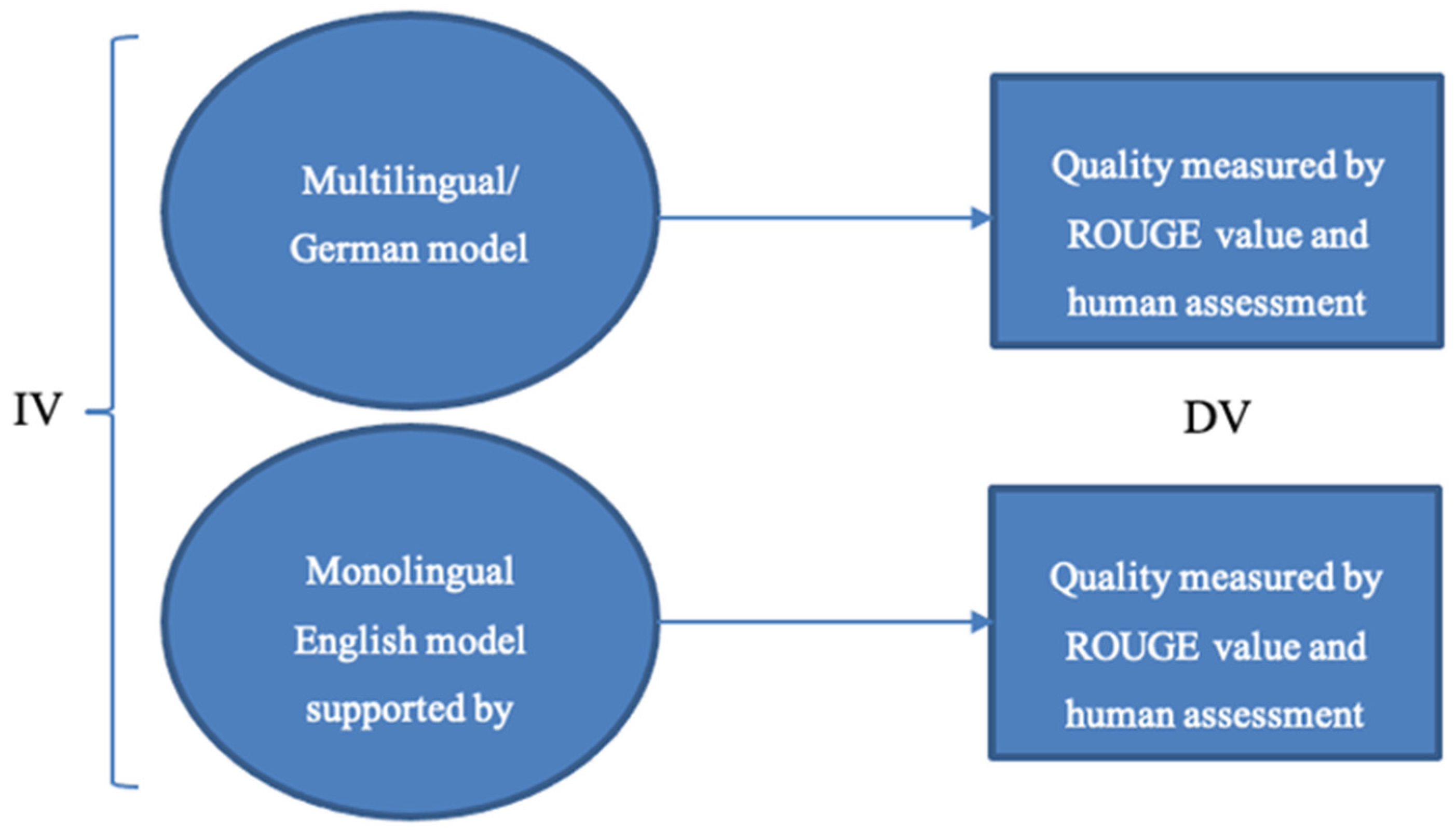
3. Research Design
- Use machine translation to translate German text into English, summarize the English text with a monolingual model and translate the summary back into German.
- Use a multilingual model (supporting the German language) to generate a summary of a German text.
4. Implementation
- German BERT2BERT fine-tuned on MLSUM DE for summarization (https://huggingface.co/mrm8488/bert2bert_shared-german-finetuned-summarization, accessed on 16 January 2023): This model is based on the German BERT Model and was fine-tuned on the MLSUM DE dataset for summarization. The German BERT Base Model was trained on German Wikipedia, OpenLegalData, and news articles.
- BART (large-sized model), fine-tuned on CNN Daily Mail (https://huggingface.co/facebook/bart-large-cnn, accessed on 16 January 2023): This model is pre-trained on the English language and fine-tuned on CNN Daily Mail articles. It was introduced by Lewis et al. [18] and matches the performance of RoBERTa, as well as achieving state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks.
5. Experiments and Evaluation Results
5.1. Dataset
5.2. Text Summarization Quality (ROUGE)
5.3. Evaluation Results
6. Discussion
6.1. BERT and BART Summarization
6.2. ROUGE Metric Evaluation
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Patel, A.; Siddiqui, T.J.; Tiwary, U.S. A language independent approach to multilingual text summarization. In Proceedings of the Conference RIAO 2007, Pittsburgh, PA, USA, 30 May–1 June 2007. [Google Scholar]
- Parida, S.; Motlicek, P. Abstract Text Summarization: A Low Resource Challenge. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5993–5997. [Google Scholar] [CrossRef]
- Bornea, M.; Pan, L.; Rosenthal, S.; Florian, R.; Sil, A. Multilingual transfer learning for QA using translation as data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 12583–12591. [Google Scholar]
- Widyassari, A.P.; Rustad, S.; Shidik, G.F.; Noersasongko, E.; Syukur, A.; Affandy, A.; Setiadi, D.R.I.M. Review of automatic text summarization techniques & methods. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 1029–1046. [Google Scholar] [CrossRef]
- Moratanch, N.; Chitrakala, S. A survey on abstractive text summarization. In Proceedings of the 2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 18–19 March 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, X.; Li, B.; Ge, B.; Tang, D. Integrating extractive and abstractive models for long text summarization. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; IEEE: Toulouse, France; pp. 305–312. [Google Scholar]
- Mahajani, A.; Pandya, V.; Maria, I.; Sharma, D. A comprehensive survey on extractive and abstractive techniques for text summarization. In Ambient Communications and Computer Systems: RACCCS-2018; Springer: Singapore, 2019; pp. 339–351. [Google Scholar]
- Kanapala, A.; Pal, S.; Pamula, R. Text summarization from legal documents: A survey. Artif. Intell. Rev. 2019, 51, 371–402. [Google Scholar] [CrossRef]
- Prudhvi, K.; Bharath Chowdary, A.; Subba Rami Reddy, P.; Lakshmi Prasanna, P. Text summarization using natural language processing. In Intelligent System Design—Proceedings of Intelligent System Design: INDIA 2019; Springer: Singapore, 2020; pp. 535–547. [Google Scholar]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Lin, H.; Ng, V. Abstractive summarization: A survey of the state of the art. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9815–9822. [Google Scholar]
- Suleiman, D.; Awajan, A. Deep learning based abstractive text summarization: Approaches, datasets, evaluation measures, and challenges. Math. Probl. Eng. 2020, 2020, 9365340. [Google Scholar] [CrossRef]
- Shi, T.; Keneshloo, Y.; Ramakrishnan, N.; Reddy, C.K. Neural abstractive text summarization with sequence-to-sequence models. ACM Trans. Data Sci. 2021, 2, 1–37. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Peters, M.E.; Neumann, M.; Zettlemoyer, L.; Yih, W. Dissecting Contextual Word Embeddings: Architecture and Representation. arXiv 2018, arXiv:1808.08949. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. Preprint. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 28 March 2023).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 16 January 2023).
- Aharoni, R.; Johnson, M.; Firat, O. Massively Multilingual Neural Machine Translation. arXiv 2019, arXiv:1903.00089. [Google Scholar] [CrossRef]
- GitHub, 2022. Available online: https://github.com/google-research/bert/ (accessed on 16 January 2023).
- Scheible, R.; Thomczyk, F.; Tippmann, P.; Jaravine, V.; Boeker, M. GottBERT: A pure German Language Model. arXiv 2020, arXiv:2012.02110. [Google Scholar] [CrossRef]
- Chan, B.; Schweter, S.; Möller, T. German’s Next Language Model. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6788–6796. [Google Scholar] [CrossRef]
- Scialom, T.; Dray, P.-A.; Lamprier, S.; Piwowarski, B.; Staiano, J. MLSUM: The Multilingual Summarization Corpus. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 16–20 November 2020; pp. 8051–8067. [Google Scholar] [CrossRef]
- Lin, C.-Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. Available online: https://aclanthology.org/W04-1013 (accessed on 16 January 2023).
- Eyal, M.; Baumel, T.; Elhadad, M. Question Answering as an Automatic Evaluation Metric for News Article Summarization. arXiv 2019, arXiv:1906.00318. [Google Scholar] [CrossRef]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating text generation with BERT. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Fabbri, A.R.; Kryściński, W.; McCann, B.; Xiong, C.; Socher, R.; Radev, D. Summeval: Re-evaluating summarization evaluation. Trans. Assoc. Comput. Linguist. 2021, 9, 391–409. [Google Scholar] [CrossRef]
- Park, J.; Song, C.; Han, J. A study of evaluation metrics and datasets for video captioning. In Proceedings of the 2017 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 24–26 November 2017; pp. 172–175. [Google Scholar] [CrossRef]
- Giannakopoulos, G.; Karkaletsis, V.; Vouros, G.; Stamatopoulos, P. Summarization system evaluation revisited: N-gram graphs. ACM Trans. Speech Lang. Process. 2008, 5, 5. [Google Scholar] [CrossRef]
- Tran, H.N.; Kruschwitz, U. Ur-iw-hnt at CheckThat! 2022: Cross-lingual Text Summarization for Fake News Detection. In Proceedings of the CLEF 2022: Conference and Labs of the Evaluation Forum, Bologna, Italy, 5–8 September 2022; p. 9. [Google Scholar]
- Vom Brocke, J.; Hevner, A.; Maedche, A. (Eds.) Design Science Research. In Cases; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Pythonorg General Python, F.A.Q. Python Documentation. 2023. Available online: https://docs.python.org/3/faq/general.html (accessed on 16 January 2023).
- Hugging Face. In Wikipedia. 2022. Available online: https://en.wikipedia.org/w/index.php?title=Hugging_Face&oldid=1118178422 (accessed on 16 January 2023).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2020, arXiv:1910.03771. [Google Scholar] [CrossRef]
- Fikri, F.B.; Oflazer, K.; Yanikoglu, B. Semantic similarity based evaluation for abstractive news summarization. In Proceedings of the 1st Workshop on Natural Language Generation, Evaluation, and Metrics (GEM 2021), Bangkok, Thailand, 5–6 August 2021; pp. 24–33. [Google Scholar]
- Campos Macias, N.; Düggelin, W.; Ruf, Y.; Hanne, T. Building a Technology Recommender System Using Web Crawling and Natural Language Processing Technology. Algorithms 2022, 15, 272. [Google Scholar] [CrossRef]


{kind=link}
| Attribute | Description |
|---|---|
| Source Text | Contains the text of the full German Wikipedia article. |
| Reference Summary | Contains the human-produced summary of the German Wikipedia article. |
| Computed Summary BERT | Contains the summary produced by the German BERT2BERT fine-tuned model. |
| F1 Score BERT | Contains the ROUGE-1 F1 value of the computed summary. |
| Computed Summary BART | Contains the German translated summary produced by the BART (large-sized) fine-tuned model. |
| F1 Score BART | Contains the ROUGE-1 F1 value of the computed summary. |
| # | Reference Summary | Computed Summary German BERT | F1 Score BERT | Computed Summary BART | F1 Score BART |
|---|---|---|---|---|---|
| 1 | Das Ehrenmal für die Seckbacher Gefallenen der Weltkriege steht innerhalb der Grünanlagen des Lohrparks auf dem Lohrberg in dem zu Frankfurt am Main gehörenden Stadtteil Seckbach. | Ein Krieger–Ehrenmal die Seckbacher, die der deutschen Einigungskriege 1864, 1866/71/71 gefallen sind, steht vor dem Kirchhof der Marienkirche. | 0.1168 | Vor dem Kirchhof der Marienkirche steht ein Kriegerdenkmal für die in den deutschen Einigungskriegen 1864, 1866 und 1870/71 gefallenen Seckbacher. Das Denkmal ist Teil der Anlage des 1924 angelegten Lohrer Parks und wird von einem 5 Meter hohen Kreuz dominiert. | 0.2055 |
| … | … | … | … | … | … |
| 50 | Klaus Draeger ist ein deutscher Ingenieur und Manager. Er war als Mitglied des Vorstands der BMW AG für die Bereiche Einkauf und Lieferantennetzwerk zuständig. | Draeger legte 1975 das Abitur ab und studierte danach von 1975 bis 1985 Maschinenbau an der Karlsruhe. Von 1982 bis 1985 war er Chef der BMW AG. | 0.3143 | Draeger legte 1975 sein Abitur am Alexander-von-Humboldt-Gymnasium Konstanz ab. Von 1975 bis 1981 studierte er Maschinenbau an der Universität Karlsruhe. Am 1. September 1985 trat er als Trainee in die BMW AG ein und war später in verschiedenen Führungspositionen tätig. Im Jahr 2006 wurde Draeger in den Vorstand des Unternehmens berufen. | 0.4663 |
| Measure | German BERT | BART |
|---|---|---|
| Average | 0.1820 | 0.1971 |
| Median | 0.1649 | 0.1952 |
| Standard Deviation | 0.0889 | 0.0607 |
| Variance | 0.0079 | 0.0036 |
| Minimum | 0.0000 | 0.1010 |
| Maximum | 0.4444 | 0.3181 |
| # | Source Article | Reference Summary | Computed Summary German BERT |
|---|---|---|---|
| 8 | Nach dem Schulbesuch studierte Berger zuerst an der Cornell University, schloss dieses Studium 1967 mit einem Bachelor of Arts ab und wurde auch Mitglied der Ehemaligenvereinigung “Quill and Dagger”. Ein anschliessendes postgraduales Studium der Rechtswissenschaften an der Law School der Harvard University beendete er 1971 mit einem Juris Doctor cum laude. Im Anschluss wurde er Redenschreiber von George McGovern während dessen Kandidatur für die Demokratische Partei bei der Praäsidentschaftswahl 1972 und lernte während dieser Zeit auch Bill Clinton kennen. […] | Samuel “Sandy” R. Berger war ein US-amerikanischer Rechtsanwalt, der zwischen 1997 und 2001 während der zweiten Amtszeit von US-Präsident Bill Clinton auch Nationaler Sicherheitsberater der USA war und der 2005 von einem Gericht wegen Entwendung geheimer Dokumente verurteilt wurde. | Nach dem Schulbesuch studierte Berger zuerst an der Cornell University, schloss dieses Studium 1967 mit einem Bachelor of Arts ab und wurde auch Mitglied der Ehemaligenvereinigung “Quill and Dagger“. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alcantara, T.H.M.; Krütli, D.; Ravada, R.; Hanne, T. Multilingual Text Summarization for German Texts Using Transformer Models. Information 2023, 14, 303. https://doi.org/10.3390/info14060303
Alcantara THM, Krütli D, Ravada R, Hanne T. Multilingual Text Summarization for German Texts Using Transformer Models. Information. 2023; 14(6):303. https://doi.org/10.3390/info14060303
Chicago/Turabian StyleAlcantara, Tomas Humberto Montiel, David Krütli, Revathi Ravada, and Thomas Hanne. 2023. "Multilingual Text Summarization for German Texts Using Transformer Models" Information 14, no. 6: 303. https://doi.org/10.3390/info14060303