
MBTI Personality Prediction Using Machine Learning and SMOTE for Balancing Data Based on Statement Sentences

Abstract
:1. Introduction
- Introvert (I)–Extrovert (E): This dimension measures how individuals react to their environment, whether they are oriented towards the outside (extrovert) or the inside (introvert).
- Intuition (N)–Sensing (S): This dimension measures how individuals process information, whether they rely more on information received through direct experience (sensing) or trust their instincts and imagination (intuition) more.
- Thinking (T)–Feeling (F): This dimension measures how individuals make decisions, whether they rely more on logic and analysis (thinking) or emotions and feelings (feeling).
- Judgment (J)–Perception (P): This dimension measures how individuals manage their environment, whether they are more inclined to make plans and stick to their tasks (judging) or are more flexible and accepting of change (perceiving).
2. Related Works
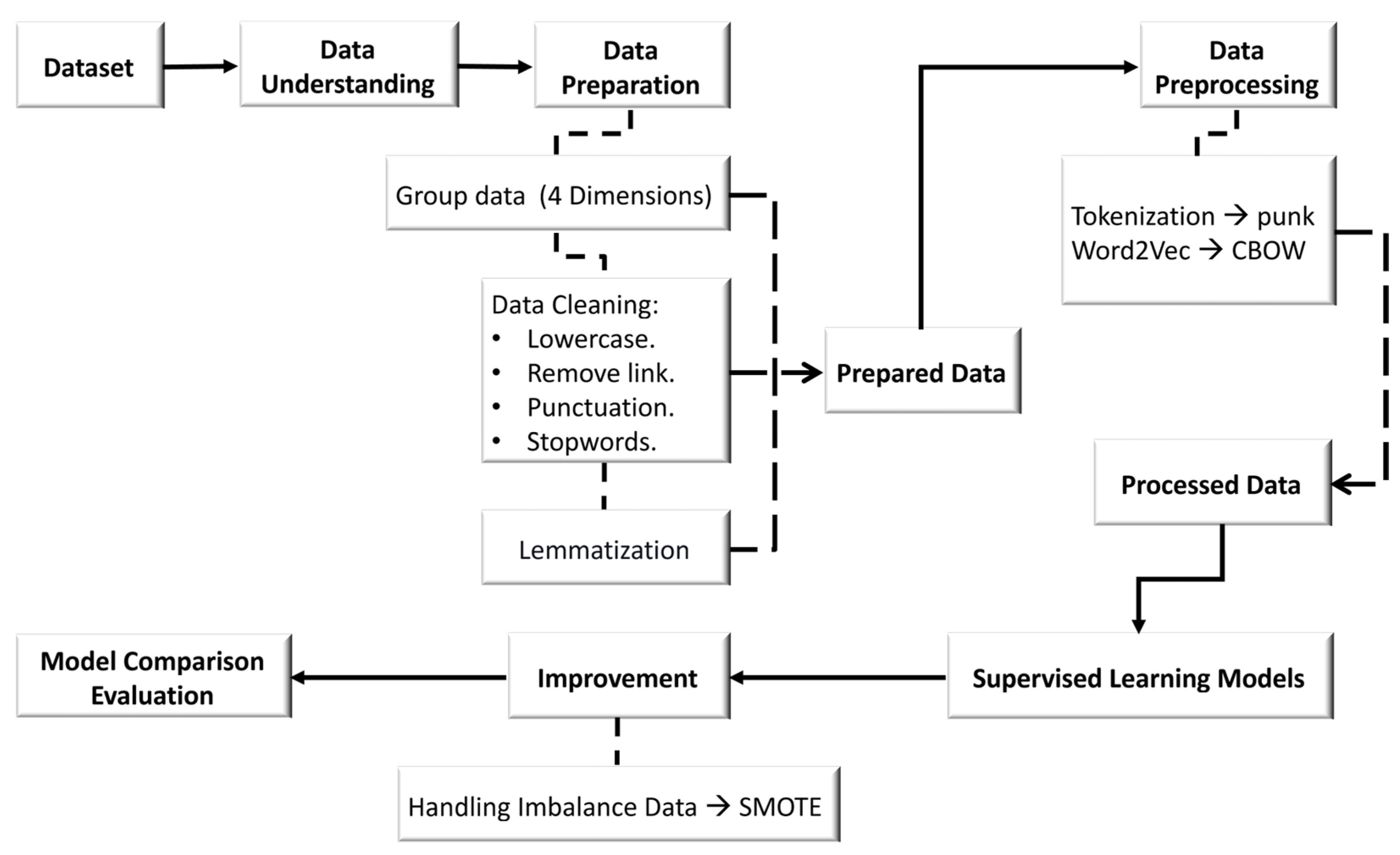
3. Methodology
3.1. Dataset
3.1.1. Data Understanding
3.1.2. Data Preparation
Four Dimensions
Data Cleaning
- Converting letters to lowercase.
- Removing links.
- Removing punctuation.
- Removing stopwords.
3.1.3. Data Preprocessing
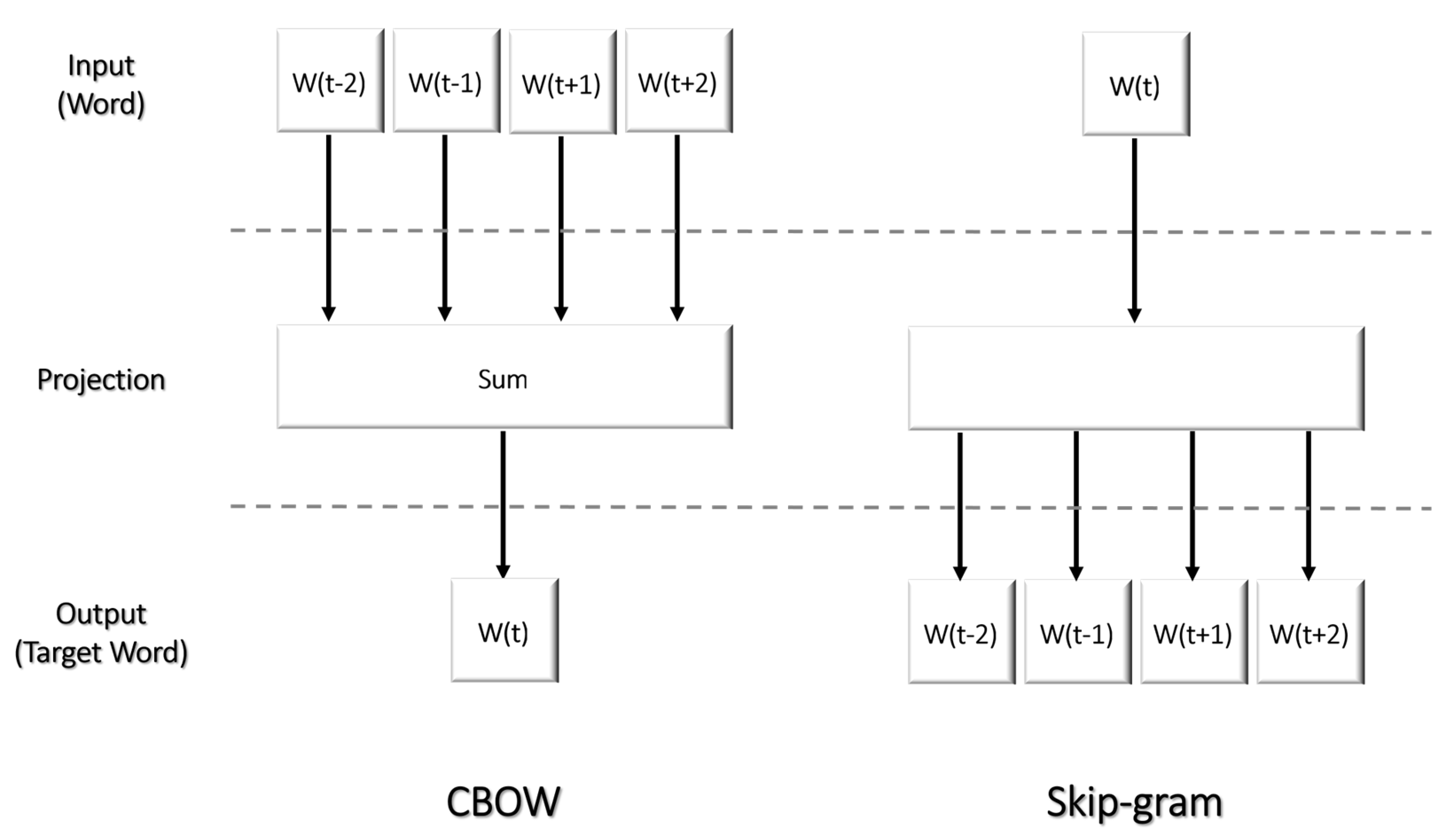
Tokenization
Word Embedding (Word2Vec)
Splitting of Data into Training Set and Testing Set
3.2. Modeling
3.2.1. Logistic Regression
3.2.2. Linear Support Vector Classification
3.2.3. Stochastic Gradient Descent
3.2.4. Random Forest
3.2.5. Extreme Gradient Boosting
3.2.6. CatBoost
- It utilizes a permutation-driven ordered boosting method instead of the conventional approach.
- It employs a unique categorical feature-processing algorithm.
3.3. Data Balancing Using SMOTE and F1 Score Metric
3.3.1. SMOTE
3.3.2. F1 Score
4. Result and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BERT | Bidirectional encoder representations from transformers |
| BI-LSTM | Bidirectional long short-term memory |
| CatBoost | Cat boosting classifier |
| CBOW | Continuous bag of words |
| CNN | Convolutional neural network |
| CRISP-DM | Cross-industry standard process for data mining |
| Dim | Dimension |
| DISC | Dominance, influence, steadiness, and conscientiousness |
| E | Extrovert |
| F | Feeling |
| FDD | Fault detection and diagnosis |
| GDBT | Gradient boosting decision tree model |
| GloVe | Global vectors for word representation |
| I | Introvert |
| J | Judgment |
| LR | Logistic regression |
| LSVC | Linear support vector classification |
| MBTI | Myers–briggs type indicator |
| N | Intuition |
| NLP | Natural language processing |
| NLTK | Natural language toolkit |
| OCEAN | Openness, conscientiousness, extraversion, agreeableness, and neuroticism |
| P | Perception |
| RF | Random forest |
| RNN | Recurrent neural network |
| S | Sensing |
| SGD | Stochastic gradient descent |
| SMOTE | Synthetic minority oversampling technique |
| SVM | Support vector machine |
| T | Thinking |
| TF-IDF | Term frequency-inverse document frequency |
| XGBoost | Extreme gradient boosting classifier |
References
- Petrosyan, A. Worldwide Digital Population July 2022. Statista. Available online: https://www.statista.com/statistics/617136/digital-population-worldwide/ (accessed on 6 January 2023).
- Dixon, S. Number of Social Media Users Worldwide 2017–2027. Statista. 2022. Available online: https://www.statista.com/statistics/278414/number-of-worldwide-social-network-users/ (accessed on 6 January 2023).
- Dixon, S. Global Social Networks Ranked by Number of Users 2022. Statista. 2022. Available online: https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ (accessed on 6 January 2023).
- Myers, I.B.; Mccaulley, M.H. Manual, a Guide to the Development and Use of the Myers-Briggs Type Indicator; Consulting Psychologists Press: Palo Alto, CA, USA, 1992. [Google Scholar]
- The Myers & Briggs Foundation—MBTI® Basics. Available online: https://www.myersbriggs.org/my-mbti-personality-type/mbti-basics/home.htm (accessed on 8 January 2023).
- Varvel, T.; Adams, S.G. A Study of the Effect of the Myers Briggs Type Indicator. In Proceedings of the 2003 Annual Conference Proceedings, Nashville, TN, USA, 22–25 June 2003. [Google Scholar] [CrossRef]
- Amirhosseini, M.H.; Kazemian, H. Machine Learning Approach to Personality Type Prediction Based on the Myers–Briggs Type Indicator®. Multimodal Technol. Interact. 2020, 4, 9. [Google Scholar] [CrossRef] [Green Version]
- Ong, V.; Rahmanto, A.D.; Suhartono, D.; Nugroho, A.E.; Andangsari, E.W.; Suprayogi, M.N. Personality Prediction Based on Twitter Information in Bahasa Indonesia. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems, Prague, Czech Republic, 3–6 September 2017. [Google Scholar] [CrossRef] [Green Version]
- DISC Profile. What Is DiSC®. Discprofile.com. 2021. Available online: https://www.discprofile.com/what-is-dis (accessed on 9 January 2023).
- John, O.P.; Srivastava, S. The Big-Five Trait Taxonomy: History, Measurement, and Theoretical Perspectives; University of California: Berkeley, CA, USA, 1999; pp. 102–138. [Google Scholar]
- Tandera, T.; Suhartono, D.; Wongso, R.; Prasetio, Y.L. Personality Prediction System from Facebook Users. Procedia Comput. Sci. 2017, 116, 604–611. [Google Scholar] [CrossRef]
- Santos, V.G.D.; Paraboni, I. Myers-Briggs Personality Classification from Social Media Text Using Pre-Trained Language Models. JUCS—J. Univers. Comput. Sci. 2022, 28, 378–395. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar] [CrossRef]
- Aizawa, A. An Information-Theoretic Perspective of Tf–Idf Measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Ashraf, S.; Sabahat, N. Predicting MBTI Personality Type with K-Means Clustering and Gradient Boosting. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020. [Google Scholar] [CrossRef]
- Ontoum, S.; Chan, J.H. Personality Type Based on Myers-Briggs Type Indicator with Text Posting Style by Using Traditional and Deep Learning. arXiv 2022, arXiv:2201.08717. [Google Scholar] [CrossRef]
- (MBTI) Myers-Briggs Personality Type Dataset. Available online: https://www.kaggle.com/datasets/datasnaek/mbti-type (accessed on 20 November 2022).
- Jalayer, M.; Kaboli, A.; Orsenigo, C.; Vercellis, C. Fault Detection and Diagnosis with Imbalanced and Noisy Data: A Hybrid Framework for Rotating Machinery. Machines 2022, 10, 237. [Google Scholar] [CrossRef]
- Loper, E.; Steven, B. NLTK: The Natural Language Toolkit. arXiv 2019, arXiv:cs/0205028. [Google Scholar] [CrossRef]
- Sklearn.model_selection.train_test_split–Scikit-Learn 0.20.3 Documentation. 2018. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html (accessed on 10 January 2023).
- Nick, T.G.; Campbell, K.M. Logistic Regression. In Topics in Biostatistics; Springer: Berlin/Heidelberg, Germany, 2007; pp. 273–301. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2001. [Google Scholar]
- Binary Logistic Regression—A Tutorial. 2021. Available online: https://digitaschools.com/binary-logistic-regression-introduction/ (accessed on 10 January 2023).
- Wong, G.Y.; Mason, W.M. The Hierarchical Logistic Regression Model for Multilevel Analysis. J. Am. Stat. Assoc. 1985, 80, 513–524. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Zhang, W.; Yoshida, T.; Tang, X. Text Classification Based on Multi-Word with Support Vector Machine. Knowl. Based Syst. 2008, 21, 879–886. [Google Scholar] [CrossRef]
- Suthaharan, S. Support Vector Machine. Mach. Learn. Model. Algorithms Big Data Classif. 2016, 36, 207–235. [Google Scholar] [CrossRef]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Microsoft: Washington, DC, USA, 1998. [Google Scholar]
- Stochastic Gradient Descent—Scikit-Learn 0.23.2 Documentation. Available online: https://scikit-learn.org/stable/modules/sgd.html (accessed on 11 January 2023).
- Gaye, B.; Zhang, D.; Wulamu, A. Sentiment Classification for Employees Reviews Using Regression Vector- Stochastic Gradient Descent Classifier (RV-SGDC). PeerJ Comput. Sci. 2021, 7, e712. [Google Scholar] [CrossRef]
- Bottou, L. Stochastic Gradient Descent Tricks. In Neural Networks: Tricks of the Trade, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar] [CrossRef] [Green Version]
- IBM. What Is Random Forest?|IBM. Available online: https://www.ibm.com/topics/random-forest (accessed on 11 January 2023).
- Biau, G.; Erwan, S. A Random Forest Guided Tour. TEST 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Matthew, W. Classification and regression by randomForest. R New 2022, 2, 18–22. [Google Scholar]
- Jabeur, S.B.; Gharib, C.; Mefteh-Wali, S.; Arfi, W.B. CatBoost model and artificial intelligence techniques for corporate failure prediction. Technol. Forecast. Soc. Chang. 2021, 166, 120658. [Google Scholar] [CrossRef]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A Comparison of Random Forest Variable Selection Methods for Classification Prediction Modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ramraj, S.; Uzir, N.; Sunil, R.; Banerjee, S. Experimenting XGBoost algorithm for prediction and classification of different datasets. Int. J. Control. Theory Appl. 2016, 9, 651–662. [Google Scholar]
- Chen, T.; Carlos, G. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’16, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- CatBoost—Amazon SageMaker. Available online: https://docs.aws.amazon.com/id_id/sagemaker/latest/dg/catboost.html (accessed on 2 February 2023).
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. arXiv 2019, arXiv:1706.09516. [Google Scholar] [CrossRef]
- Hussain, S.; Mustafa, M.W.; Jumani, T.A.; Baloch, S.K.; Alotaibi, H.; Khan, I.; Khan, A. A Novel Feature Engineered-CatBoost-Based Supervised Machine Learning Framework for Electricity Theft Detection. Energy Rep. 2021, 7, 4425–4436. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. arXiv 2018, arXiv:1810.11363. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Dalianis, H. Evaluation Metrics and Evaluation. In Clinical Text Mining; Springer: Berlin/Heidelberg, Germany, 2018; pp. 45–53. [Google Scholar] [CrossRef] [Green Version]
- Sklearn.metrics.f1_score—Scikit-Learn 0.21.2 Documentation. 2019. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html (accessed on 11 January 2023).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Available online: https://aclanthology.org/D14-1162.pdf (accessed on 11 January 2023).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
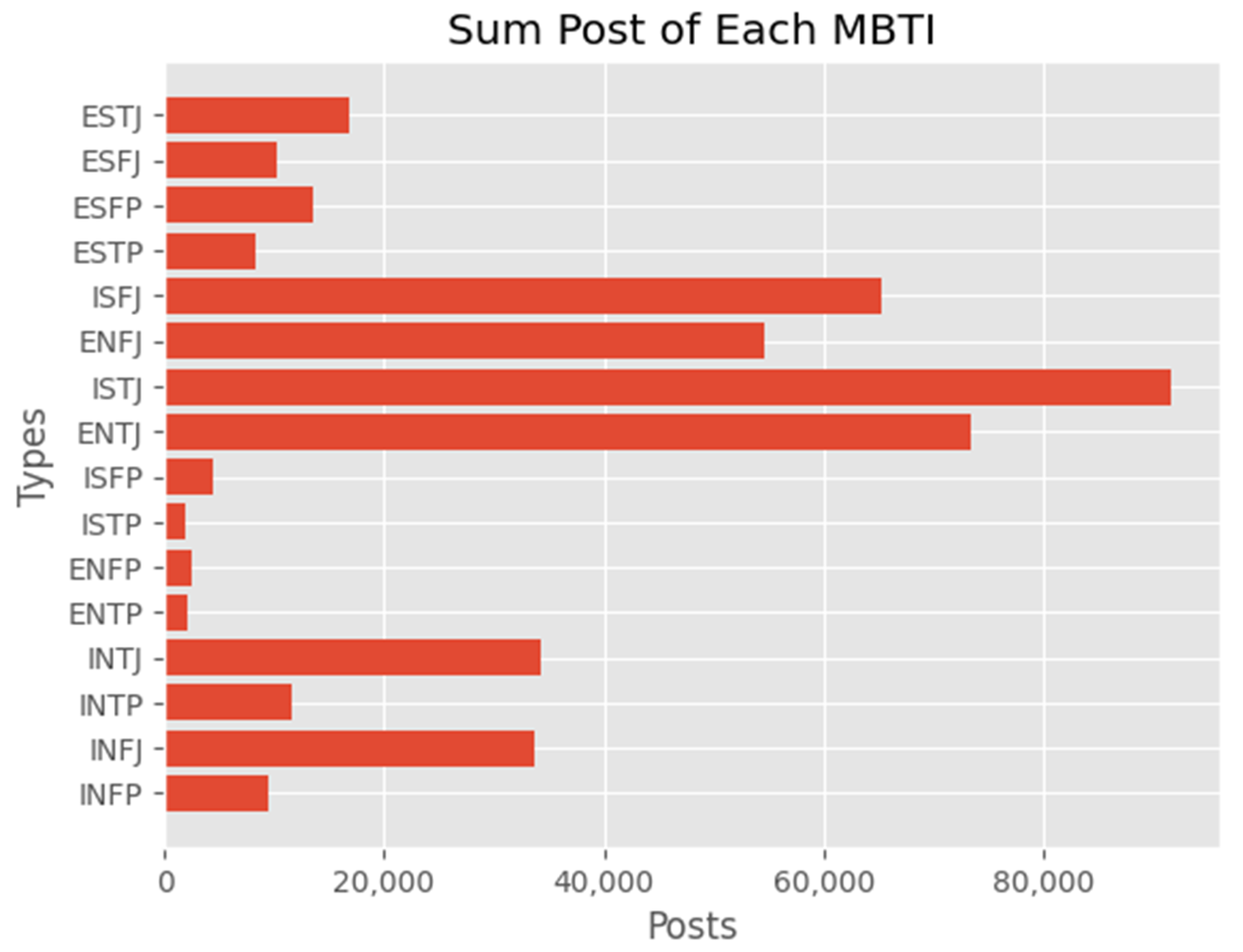
| MBTI Type Class | Distribution |
|---|---|
| Introvert (I) | 6676 |
| Extrovert (E) | 1999 |
| Intuition (N) | 7478 |
| Sensing (S) | 1197 |
| Thinking (T) | 4694 |
| Feeling (F) | 3981 |
| Judgment (J) | 3434 |
| Perception (P) | 5241 |
| Model | Dim 1 (I/E) | Dim 2 (F/T) | Dim 3 (N/S) | Dim 4 (J/P) | Average |
|---|---|---|---|---|---|
| LR | 0.8202 | 0.8559 | 0.8818 | 0.7548 | 0.8282 |
| LSVC | 0.8210 | 0.8563 | 0.8758 | 0.7533 | 0.8266 |
| SGD | 0.8299 | 0.8472 | 0.8242 | 0.7268 | 0.8070 |
| RF | 0.7149 | 0.8010 | 0.8022 | 0.6350 | 0.7383 |
| XGBoost | 0.7671 | 0.8213 | 0.8447 | 0.6885 | 0.7804 |
| CatBoost | 0.7890 | 0.8360 | 0.8470 | 0.7087 | 0.7952 |
| Model | Dim 1 (I/E) | Dim 2 (F/T) | Dim 3 (N/S) | Dim 4 (J/P) | Average |
|---|---|---|---|---|---|
| LR | 0.8389 | 0.8561 | 0.8821 | 0.7578 | 0.8337 |
| LSVC | 0.8322 | 0.8522 | 0.8808 | 0.7587 | 0.8310 |
| SGD | 0.8191 | 0.8476 | 0.8579 | 0.7523 | 0.8192 |
| RF | 0.7388 | 0.7951 | 0.8361 | 0.6510 | 0.7553 |
| XGBoost | 0.7864 | 0.8193 | 0.8528 | 0.6862 | 0.7862 |
| CatBoost | 0.7935 | 0.8365 | 0.8654 | 0.7054 | 0.8002 |
| Model | Without SMOTE (F1 Score (%)) | With SMOTE (F1 Score (%)) |
|---|---|---|
| LR | 0.8282 | 0.8337 |
| LSVC | 0.8266 | 0.8310 |
| SGD | 0.8070 | 0.8192 |
| RF | 0.7383 | 0.7553 |
| XGBoost | 0.7804 | 0.7862 |
| CatBoost | 0.7952 | 0.8002 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryan, G.; Katarina, P.; Suhartono, D. MBTI Personality Prediction Using Machine Learning and SMOTE for Balancing Data Based on Statement Sentences. Information 2023, 14, 217. https://doi.org/10.3390/info14040217
Ryan G, Katarina P, Suhartono D. MBTI Personality Prediction Using Machine Learning and SMOTE for Balancing Data Based on Statement Sentences. Information. 2023; 14(4):217. https://doi.org/10.3390/info14040217
Chicago/Turabian StyleRyan, Gregorius, Pricillia Katarina, and Derwin Suhartono. 2023. "MBTI Personality Prediction Using Machine Learning and SMOTE for Balancing Data Based on Statement Sentences" Information 14, no. 4: 217. https://doi.org/10.3390/info14040217