
Traditional Chinese Medicine Word Representation Model Augmented with Semantic and Grammatical Information


Abstract
:1. Introduction
- We construct a lightweight representation model incorporating a three-layer network structure. The model is divided into two cases: verb-central words and non-verb-central words.
- For verb-central words, this paper extracts the basic syntactic information from the TCM text by formulating nine kinds of sentence meaning characterization rules with verbs as the core. For non-verb-central words, the POS weight coefficient is introduced to generate the POS weight vectors, reflecting the different contributions of words with different POS to sentence meaning understanding in TCM text.
- The model uses convolutional networks to extract word order features from context windows and introduces synonyms, antonyms, and analogous word lists to further improve the representation effect of word vectors on the related semantic information.
2. Related Work
2.1. Verb-Core Structure Theory
2.2. Word Embedding Methods Based on Part-of-Speech
3. Model Introduction
3.1. Semantic Model Construction of TCM Text
- Words themselves commonly used as verbs.
- Words commonly used as nouns, and there are more cases of nouns being used as verbs in TCM text.
3.2. VCPC-WE Model Construction
3.2.1. Model Solution Based on Verb-Central Word
3.2.2. Model Solution Based on a Non-Verb-Central Word
3.2.3. Word Order Feature Extraction
3.2.4. Synonymy, Antonymy, and Analogy Information
4. Experiment and Evaluation
4.1. Data Pre-Processing
4.2. Experimental Environment Configuration
- Operating system: Ubuntu 18.04.
- GPU: RTX2080ti, 32G RAM.
- Running framework: Pytorch 1.6.0.
4.3. Experimental Parameter Settings
4.4. Evaluation
4.4.1. Model Scale Comparison
4.4.2. Qualitative Analysis
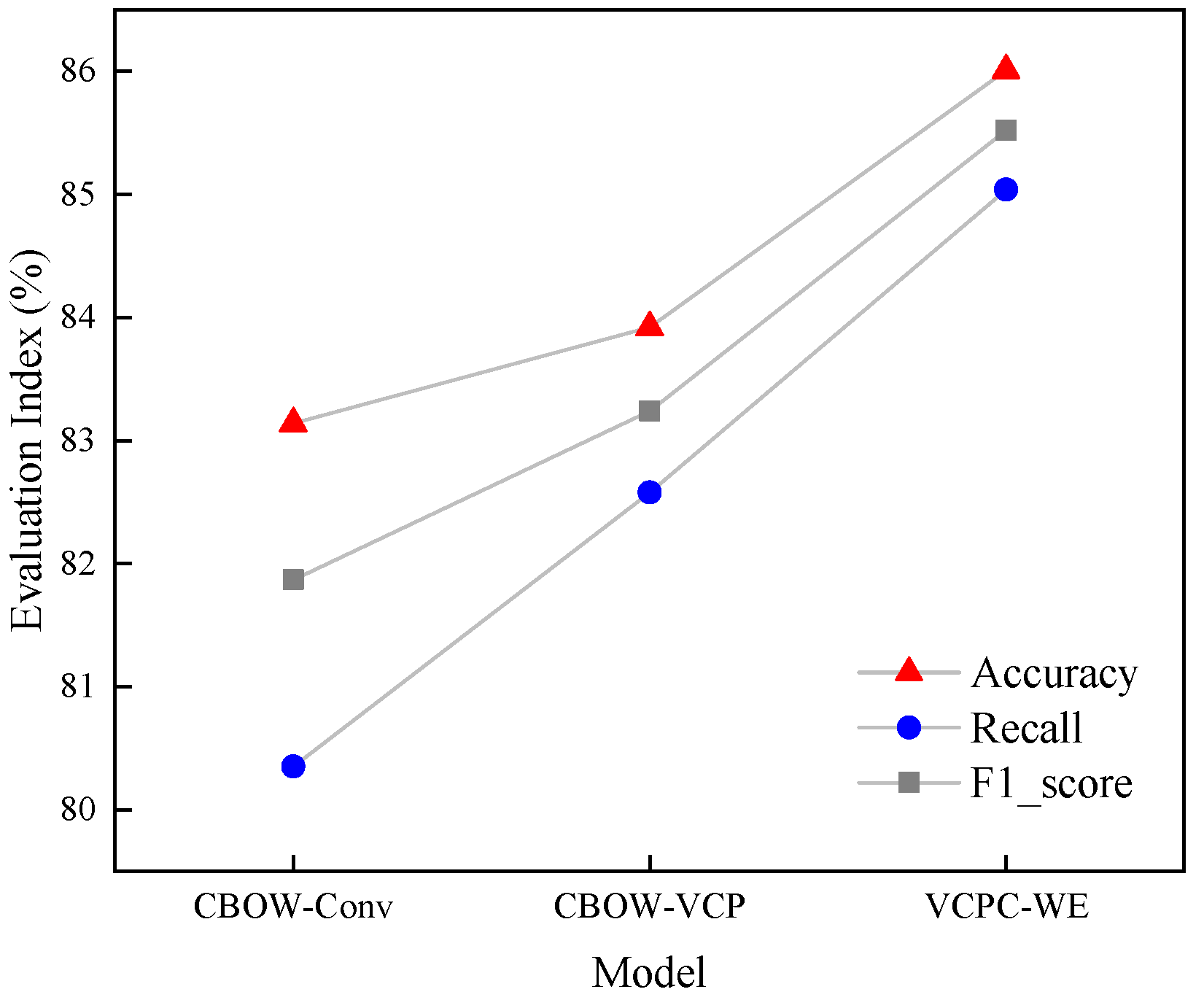
4.4.3. Entity Identification Experiments
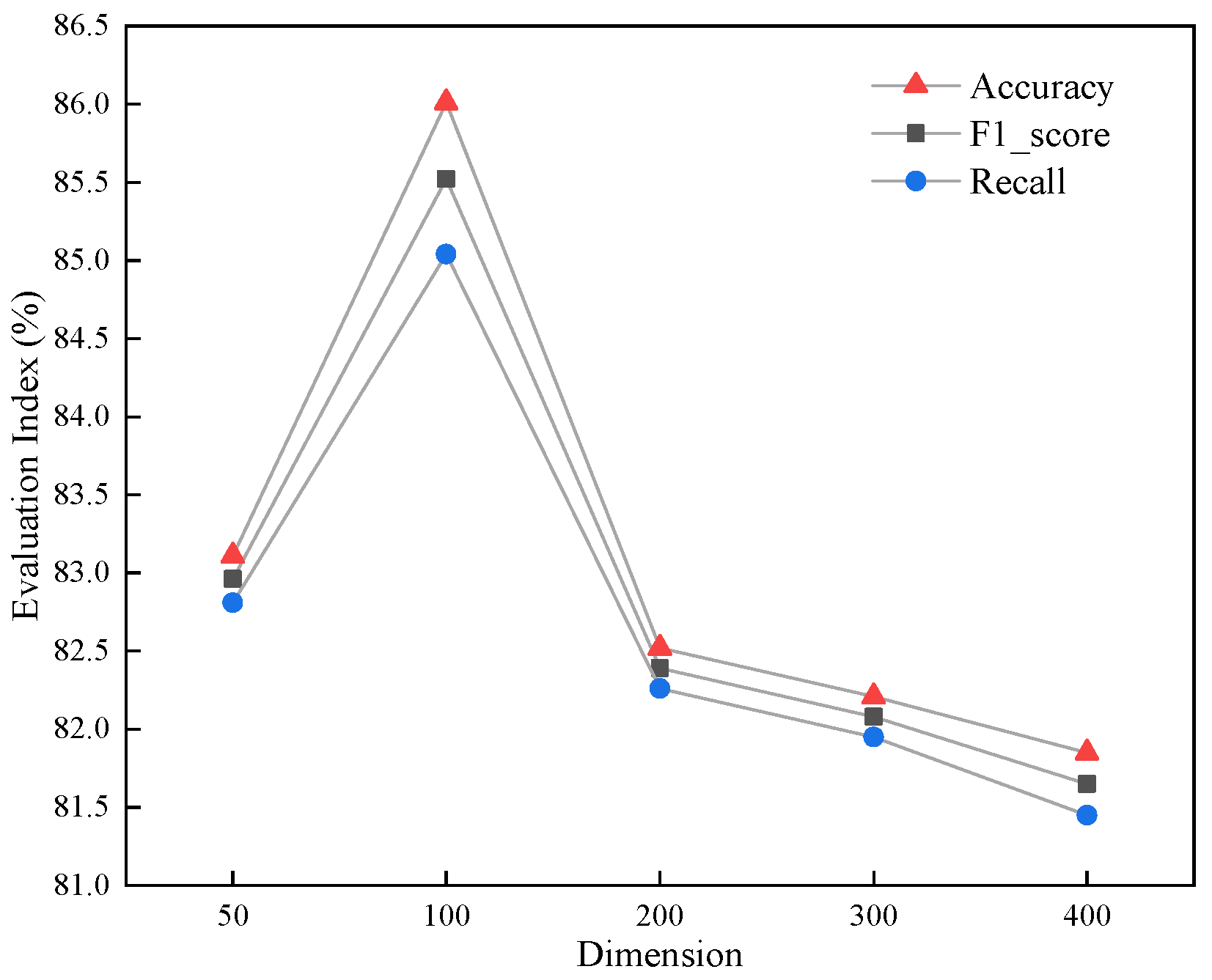
4.4.4. Effect of Different Dimensional Word Vectors on the Results
4.4.5. Effect of Different Window Sizes in the Context on the Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 2014 Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Lin, Y.; Tan, Y.; Frank, R. Open Sesame: Getting inside BERT’s Linguistic Knowledge. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; pp. 241–253. [Google Scholar]
- Tenney, I.; Xia, P.; Chen, B.; Wang, A.; Poliak, A.; McCoy, R.; Kim, N.; Das, B. What do you learn from context? Probing for sentence structure in contextualized word representations. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; pp. 6–9. [Google Scholar]
- Ettinger, T. What BERT is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models. Trans. Assoc. Comput. Linguist. 2020, 8, 34–48. [Google Scholar] [CrossRef]
- Zhang, C.; Lin, D.; Cao, D.; Li, S. Grammar guided embedding based Chinese long text sentiment classification. Concurr. Comput. Pract. Exp. 2021, 33, e6439. [Google Scholar] [CrossRef]
- Chang, Y.; Kong, L.; Jia, K.; Meng, Q. Chinese named entity recognition method based on BERT. In Proceedings of the 2021 IEEE International Conference on Data Science and Computer Application, Dalian, China, 29–31 October 2021; pp. 294–299. [Google Scholar]
- Sun, M.; Yang, Q.; Wang, H.; Pasquine, M.; Hameed, I.A. Learning the Morphological and Syntactic Grammars for Named Entity Recognition. Information 2022, 13, 49. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Liu, J.; Huang, Y.; Xie, X. Sentiment lexicon enhanced neural sentiment classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1091–1100. [Google Scholar]
- Mao, X.; Chang, S.; Shi, J.; Li, F.; Shi, R. Sentiment-aware word embedding for emotion classification. Appl. Sci. 2019, 9, 1334. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Wu, F.; Katiyar, A.; Weinberger, K.Q.; Artzi, Y. Revisiting Few-sample BERT Fine-tuning. In Proceedings of the 9th International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021; pp. 1484–1506. [Google Scholar]
- Gao, Q. Fundamentals of Unified Linguistics; Science Press: Beijing, China, 2009. [Google Scholar]
- Fan, X. A Grammatical View of the Three Planes; Beijing Language and Culture University Press: Beijing, China, 1996. [Google Scholar]
- Fan, X. Research on verb–core structure. Bull. Linguist. Stud. 2011, 1, 1–34. [Google Scholar]
- Jin, G. Semantic Computation Theory of Verbs in Modern Chinese; Peking University Press: Beijing, China, 2001. [Google Scholar]
- Zhu, L.; Yu, T.; Yang, F. Study on semantic relations discovery based on key verbs in Chinese classical medical books. China Digit. Med. 2016, 11, 73–75. [Google Scholar]
- Babiniotis, G. Towards a Linguistic Theory of Specification Based on a Verb Grammar. Linguistics 2022, 10, 176–180. [Google Scholar]
- Qian, Z.; Lee, E.K.; Lu, D.H.Y.; Garnsey, S.M. Native and non-native (L1-Mandarin) speakers of English differ in online use of verb-based cues about sentence structure. Biling. Lang. Cogn. 2019, 22, 897–911. [Google Scholar] [CrossRef]
- Zhou, H.; Hou, M.; Teng, Y. Construction research on opinion verbs-opinion targets intelligent computing. J. Shanxi Univ. (Nat. Sci. Ed.) 2022, 45, 274–283. [Google Scholar]
- Liu, Q.; Ling, Z.; Jiang, H.; Hu, Y. Part-of-Speech Relevance Weights for Learning Word Embeddings. arXiv 2016, arXiv:1301.3781. [Google Scholar]
- Hu, B.; Tang, B.; Chen, Q.; Kang, L. A novel word embedding learning model using the dissociation between nouns and verbs. Neurocomputing 2016, 171, 1108–1117. [Google Scholar] [CrossRef]
- Pan, B.; Yu, C.; Zhang, Q.; Xu, S.; Cao, S. The improved model for word2vec based on part of speech and word order. Acta Electonica Sin. 2018, 46, 1976–1982. [Google Scholar]
- Wang, Z.; Liu, X.; Wang, L.; Qiao, Y.; Xie, X.; Fowlkes, C. Structured triplet learning with pos-tag guided attention for visual question answering. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1888–1896. [Google Scholar]
- Deng, C.; Lai, G.; Deng, H. Improving word vector model with part-of-speech and dependency grammar information. CAAI Trans. Intell. Technol. 2020, 5, 276–282. [Google Scholar] [CrossRef]
- Ren, X.; Zhang, L.; Ye, W.; Hua, H.; Zhang, S. Attention enhanced Chinese word embeddings. In Proceedings of the 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 154–165. [Google Scholar]
- Yang, Y.; Mao, H.; Zhang, C. The impact of Inner Canon’s language feature on its translation. J. Zhejiang Bus. Technol. Inst. 2015, 14, 80–88. [Google Scholar]
- Qian, C. Neijing Language Research; People’s Medical Publishing House: Beijing, China, 1990. [Google Scholar]
- Wang, H. Study on the Thought of Numerology in Huangdi Neijing. Ph.D. Thesis, Beijing University of Chinese Medicine, Beijing, China, 2017. [Google Scholar]
- Zhang, H. Discussion on the classification according to manifestation is the essence of Chinese medicine theory. China J. Tradit. Chin. Med. Pharm. 2016, 31, 4899–4901. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Value of Verbs | Verb Examples | Rules |
|---|---|---|
| Bivalent verb | 主 (govern) 伤 (impair) 发于 (occur in) 入通于 (related to) | Noun–Verb–Noun |
| Verb–Noun–Noun | ||
| Noun–Noun–Verb | ||
| Pronoun–Verb–Noun | ||
| Noun–Verb–Pronoun | ||
| Verb–Noun–Pronoun | ||
| Verb–Pronoun–Noun | ||
| Monovalent verbs | 至 (reach) 溢泻 (emit) | Noun–Verb |
| Verb–Noun |
| Category | Lexical Category | Description |
|---|---|---|
| Strong semantic words | Nouns (n) | Includes person nouns, place nouns, location nouns, and time nouns. |
| Verbs (v) | Verbalization of nouns exists after the inclusion of corpus correction. | |
| Adjectives (a) | ||
| Quantifier (q) | Includes number and measure words. | |
| Weak semantic words | Pronouns (r) | Includes personal pronouns, interrogative pronouns, etc. |
| Adverbs (d) | Includes general adverbs as well as negative adverbs. | |
| Conjunctive (c) | ||
| Other lexical (o) | Includes auxiliary words, onomatopoeia, and others. |
| Synonyms | Antonyms | ||
|---|---|---|---|
| 神–明 (God–Ming) | 征–兆 (Sign–Omen) | 本–末 (Begin–End) | 长–短 (Long–Short) |
| 肇–基 (Start–Base) | 变–化 (Change–Conversion) | 表–里 (Surface–Inside) | 白–黑 (White–Black) |
| 魂–魄 (Soul–Spirit) | 津–液 (Saliva–Fluid) | 春–秋 (Spring–Autumn) | 迟–数 (Late–Frequent) |
| 懈–惰 (Slack–Lazy) | 空–穴 (Empty–Cave) | 日–暮 (Sunrise–Sunset) | 丑–善 (Ugly–Good) |
| 移–易 (Shift–Change) | 分–别 (Divide–Leave) | 德–过 (Morality–Fault) | 粗–细 (Coarse–Thin) |
| Analogous Phrases | |||
|---|---|---|---|
| 五脏–五行 (Five Internal Organs–Five Elements) | 肺–金 (Lung–Gold) | 五脏–五味 (Five Internal Organs–Five Tastes) | 肺–辛 (Lung–Pungent) |
| 肝–木 (Liver–Wood) | 肝–酸 (Liver–Acid) | ||
| 肾–水 (Kidney–Water) | 肾–咸 (Kidney–Salty) | ||
| 心–火 (Heart–Fire) | 心–苦 (Heart–Bitter) | ||
| 脾–土 (Spleen–Earth) | 脾–甘 (Spleen–Sweet) | ||
| 四经–四时 (Four Canons–Four Seasons) | 肝–春 (Liver–Spring) | 阳–天 (Yang–Sky) | 阴–地 (Yin–Earth) |
| 心–夏 (Heart–Summer) | 阳–日 (Yang–Day) | 阴–月 (Yin–Moon) | |
| 肺–秋 (Lung–Autumn) | 阳–火 (Yang–Fire) | 阴–水 (Yin–Water) | |
| 肾–冬 (Kidney–Winter) | 天气–雨 (Tianqi–Rain) | 地气–云 (Diqi–Clouds) | |
| Model | Training Time (Iter/s) | Parameters (MB) | Memory Usage (MB) |
|---|---|---|---|
| ELMo [4] | 17.68 | 93.6 | 10,141 |
| BERT [6] | 15.3 | 110 | 13,631 |
| VCPC-WE | 7.52 | 67.9 | 1430 |
| Models | 阳 (Yang) and 天 (Sky) | 阳 (Yang) and 日 (Day) | 阳 (Yang) and 火 (Fire) | 阳 (Yang) and 阴 (Yin) |
|---|---|---|---|---|
| CBOW [1] | 0.04227 | 0.02883 | 0.03077 | 0.17383 |
| Skip–gram [2] | 0.04093 | 0.03595 | 0.03356 | 0.19334 |
| Glove [3] | 0.04181 | 0.03082 | 0.03682 | 0.19267 |
| PWE [24] | 0.06341 | 0.04763 | 0.04965 | 0.17768 |
| CBOW+P+G [28] | 0.06840 | 0.06167 | 0.06475 | 0.17028 |
| AWE [29] | 0.07565 | 0.07203 | 0.07114 | 0.15031 |
| ELMo [4] | 0.09546 | 0.07043 | 0.07908 | 0.14108 |
| BERT [6] | 0.11756 | 0.15122 | 0.10916 | 0.07883 |
| VCPC–WE | 0.19083 | 0.22339 | 0.13990 | 0.04327 |
| Models | Accuracy Rate % | Recall Rate % | F1 Value % |
|---|---|---|---|
| Skip–gram [2] | 83.17 | 76.09 | 79.47 |
| Glove [3] | 82.07 | 76.58 | 79.22 |
| CBOW [1] | 83.61 | 78.30 | 80.86 |
| PWE [24] | 83.24 | 80.53 | 81.85 |
| CBOW+P+G [28] | 83.92 | 80.34 | 82.09 |
| AWE [29] | 84.56 | 81.94 | 83.23 |
| ELMo [4] | 85.24 | 80.80 | 82.95 |
| BERT [6] | 84.97 | 82.42 | 83.67 |
| VCPC–WE | 86.01 | 85.04 | 85.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Sun, Z.; Zhang, D.; Feng, Y. Traditional Chinese Medicine Word Representation Model Augmented with Semantic and Grammatical Information. Information 2022, 13, 296. https://doi.org/10.3390/info13060296
Ma Y, Sun Z, Zhang D, Feng Y. Traditional Chinese Medicine Word Representation Model Augmented with Semantic and Grammatical Information. Information. 2022; 13(6):296. https://doi.org/10.3390/info13060296
Chicago/Turabian StyleMa, Yuekun, Zhongyan Sun, Dezheng Zhang, and Yechen Feng. 2022. "Traditional Chinese Medicine Word Representation Model Augmented with Semantic and Grammatical Information" Information 13, no. 6: 296. https://doi.org/10.3390/info13060296