



Algorithms 2024, 17(1), 45; https://doi.org/10.3390/a17010045 - 19 Jan 2024
Viewed by 1331
Abstract
►
Show Figures
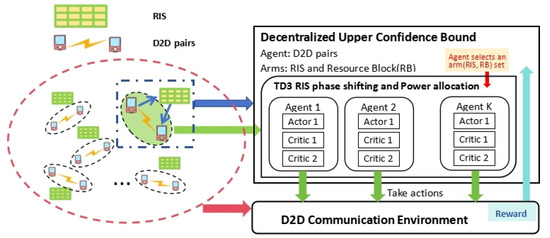
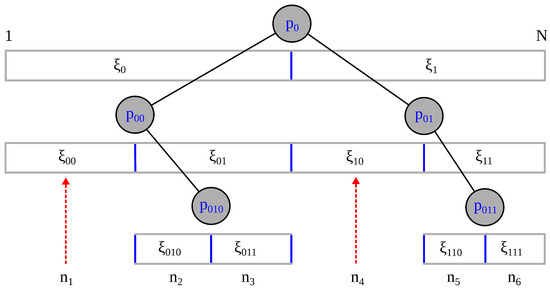
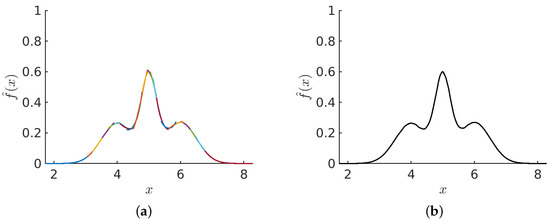
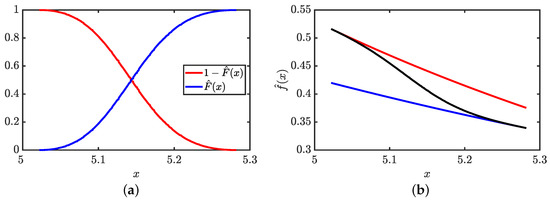
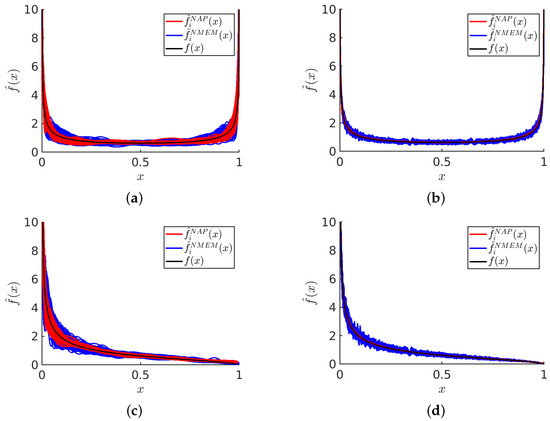
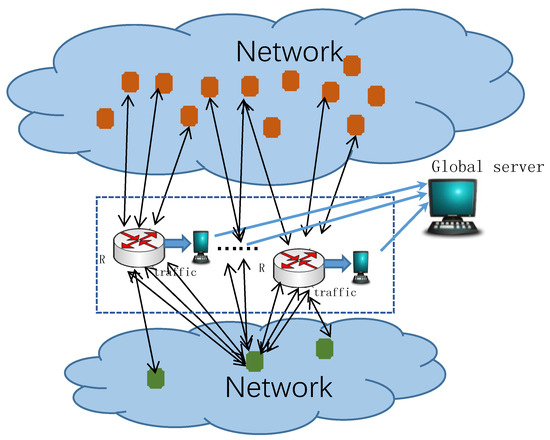
This study investigates the problem of decentralized dynamic resource allocation optimization for ad-hoc network communication with the support of reconfigurable intelligent surfaces (RIS), leveraging a reinforcement learning framework. In the present context of cellular networks, device-to-device (D2D) communication stands out as a promising
[...] Read more.
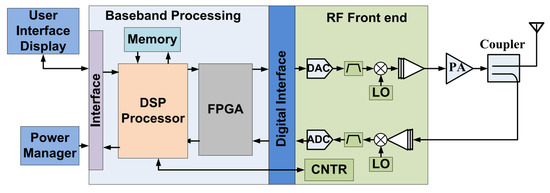
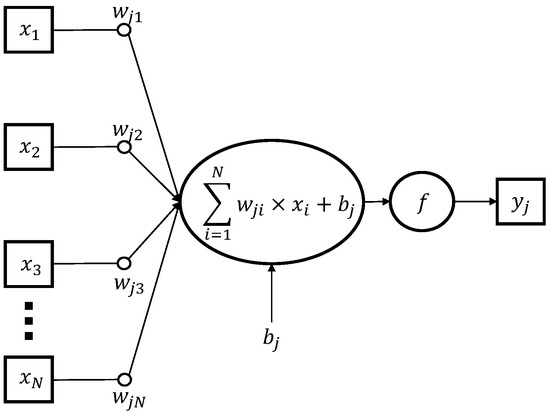
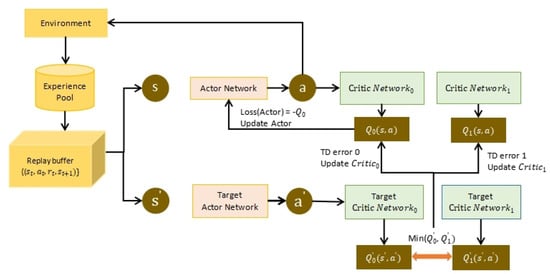
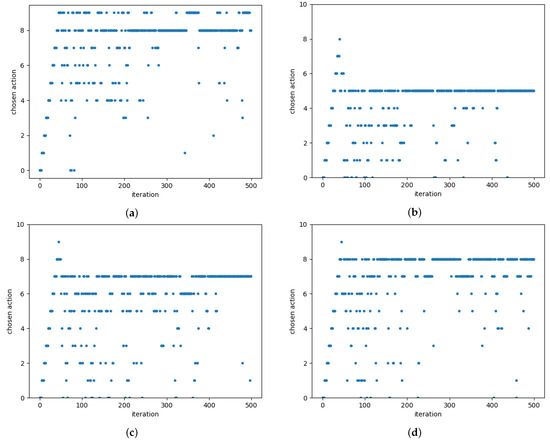
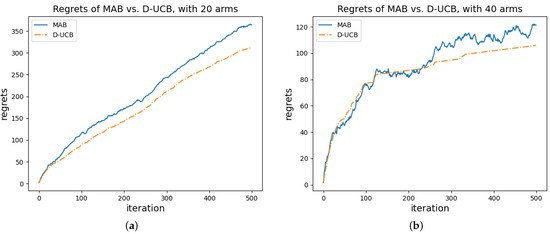
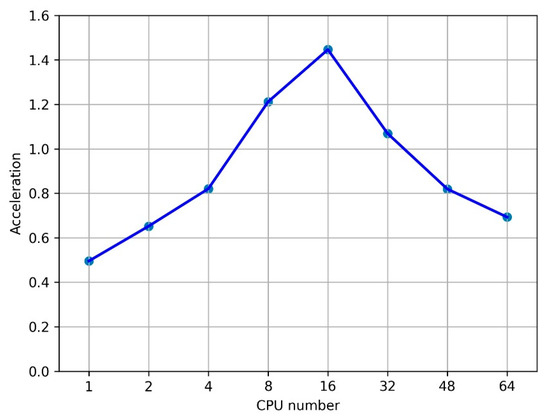
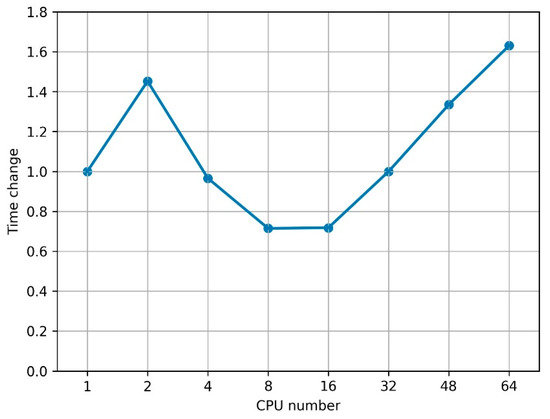
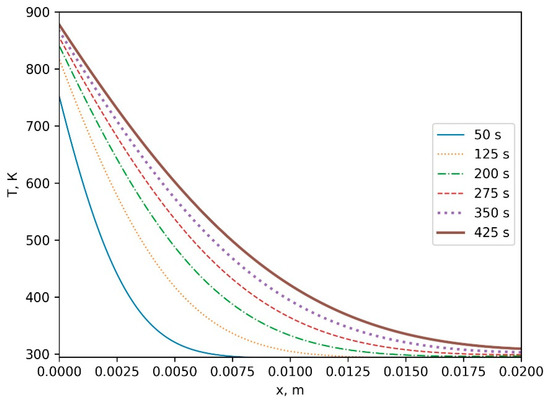
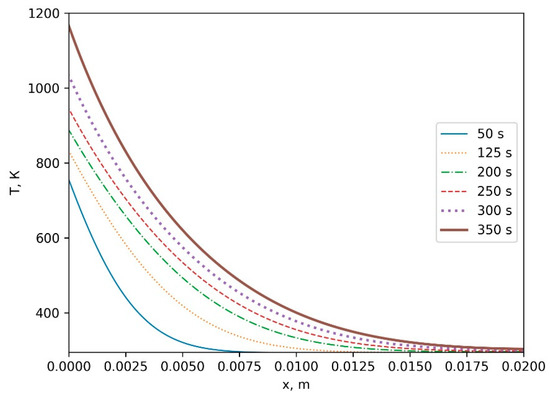
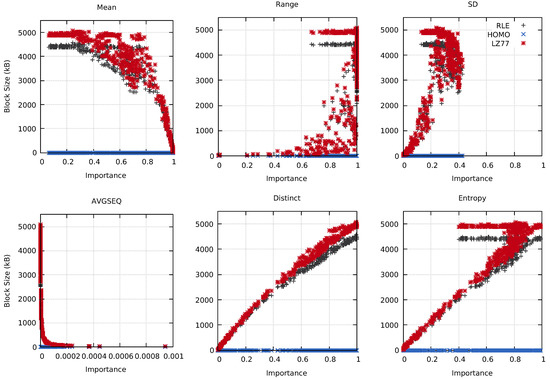
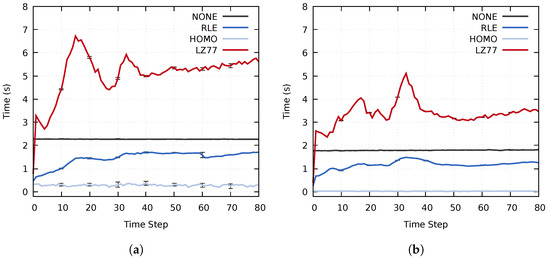
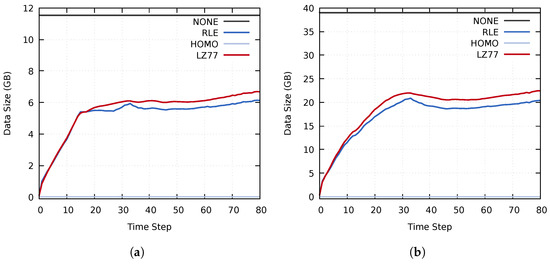
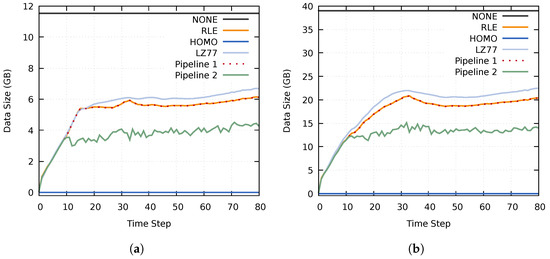
This study investigates the problem of decentralized dynamic resource allocation optimization for ad-hoc network communication with the support of reconfigurable intelligent surfaces (RIS), leveraging a reinforcement learning framework. In the present context of cellular networks, device-to-device (D2D) communication stands out as a promising technique to enhance the spectrum efficiency. Simultaneously, RIS have gained considerable attention due to their ability to enhance the quality of dynamic wireless networks by maximizing the spectrum efficiency without increasing the power consumption. However, prevalent centralized D2D transmission schemes require global information, leading to a significant signaling overhead. Conversely, existing distributed schemes, while avoiding the need for global information, often demand frequent information exchange among D2D users, falling short of achieving global optimization. This paper introduces a framework comprising an outer loop and inner loop. In the outer loop, decentralized dynamic resource allocation optimization has been developed for self-organizing network communication aided by RIS. This is accomplished through the application of a multi-player multi-armed bandit approach, completing strategies for RIS and resource block selection. Notably, these strategies operate without requiring signal interaction during execution. Meanwhile, in the inner loop, the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm has been adopted for cooperative learning with neural networks (NNs) to obtain optimal transmit power control and RIS phase shift control for multiple users, with a specified RIS and resource block selection policy from the outer loop. Through the utilization of optimization theory, distributed optimal resource allocation can be attained as the outer and inner reinforcement learning algorithms converge over time. Finally, a series of numerical simulations are presented to validate and illustrate the effectiveness of the proposed scheme.
Full article
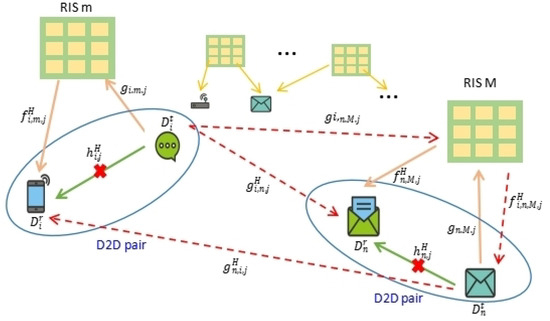
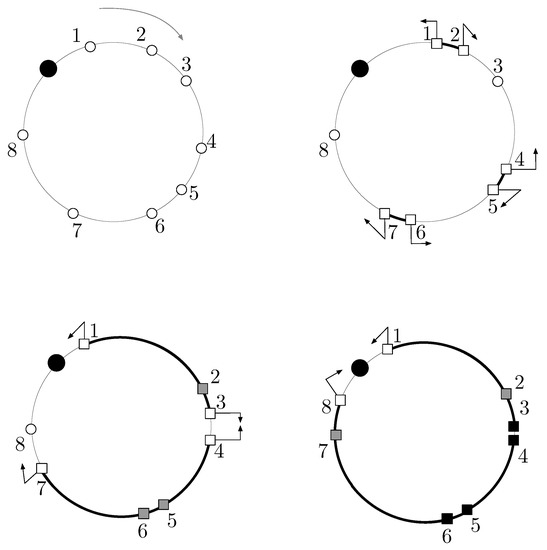
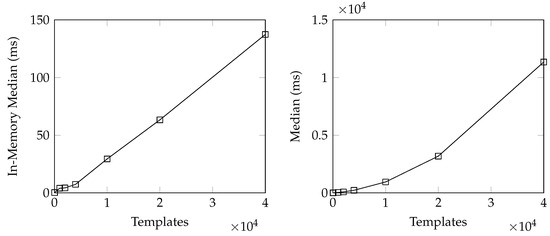
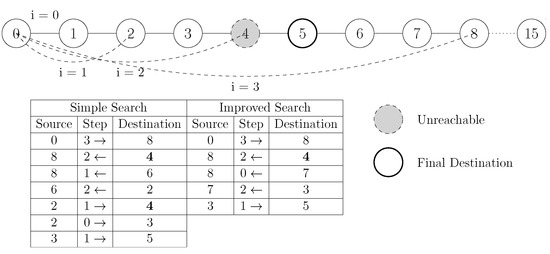
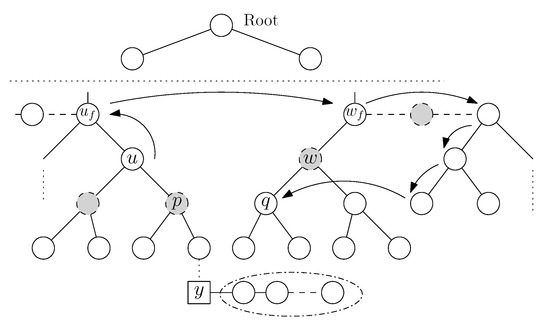
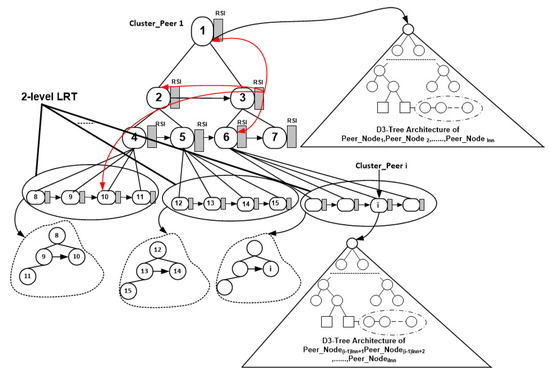
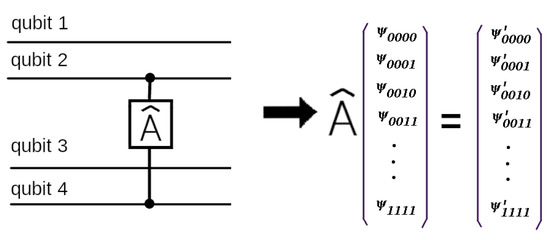
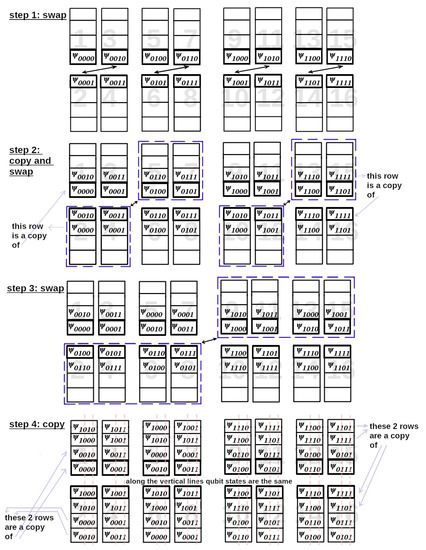
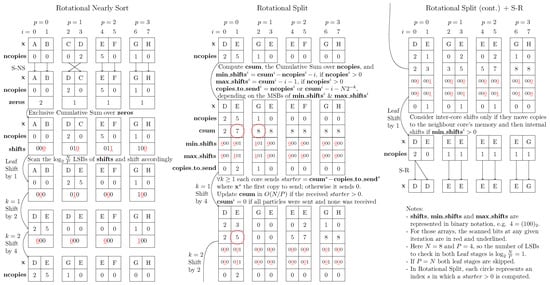
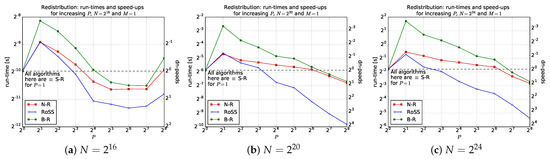
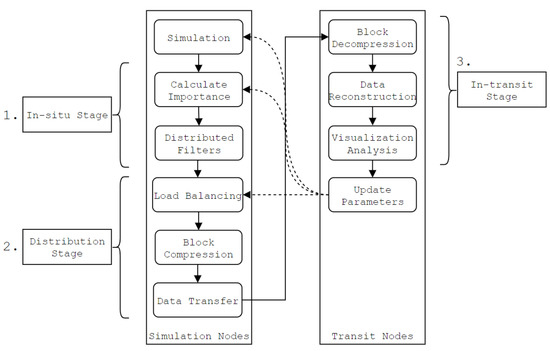
Figure 1


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
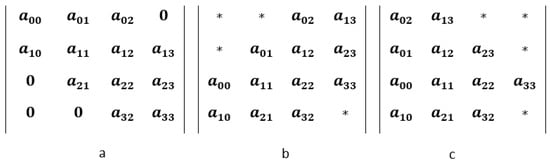{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
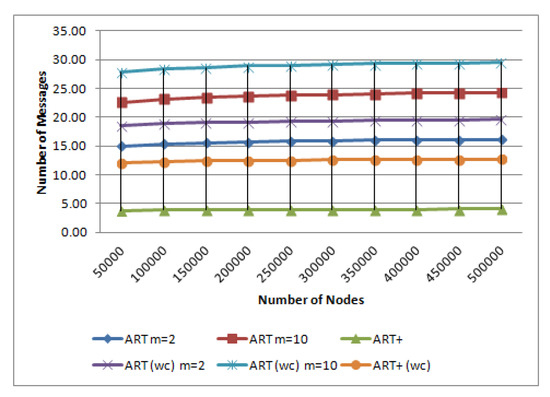{kind=link}
{kind=link}
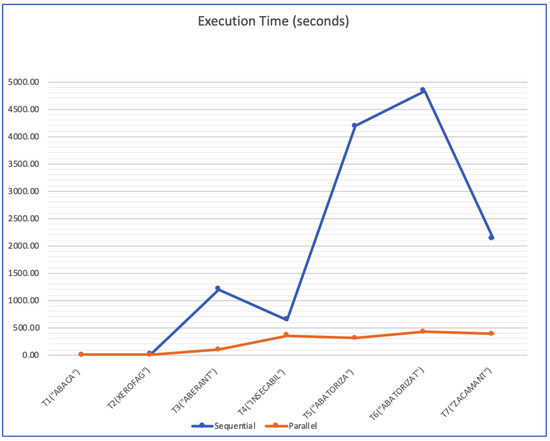{kind=link}
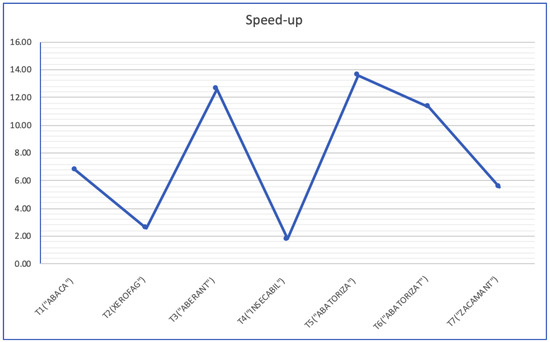{kind=link}
{kind=link}
{kind=link}
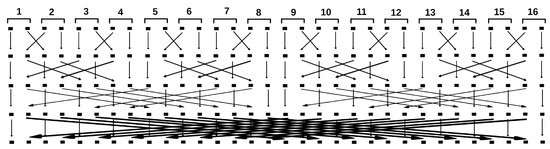{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}