

Modeling Different Deployment Variants of a Composite Application in a Single Declarative Deployment Model

Abstract
:1. Introduction
- (i)
- Variable Deployment Models: We present a modeling approach to describe different deployment variants of a composite application in a single deployment model, which we call the Variable Deployment Model.
- (ii)
- Preprocessing: We introduce algorithms to preprocess such a Variable Deployment Model to derive a deployment model based on current context parameters, such as costs or scalability requirements.
- (iii)
- Prototype: We implement an open-source prototype called OpenTOSCA Vintner, which applies our approach to the TOSCA standard [4].
2. Fundamentals and Motivation
2.1. Fundamentals of Deployment Automation
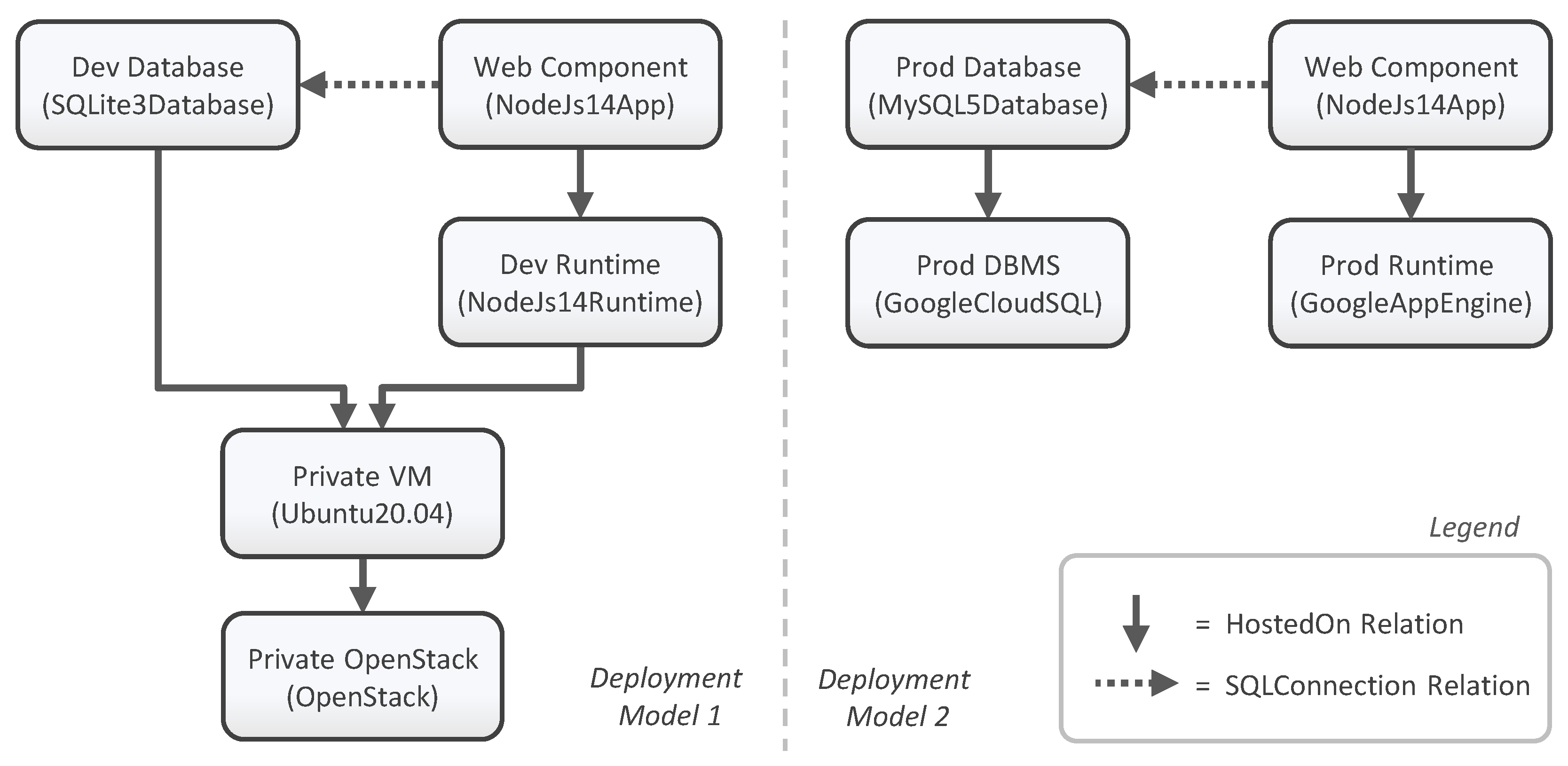
2.2. Motivating Scenario
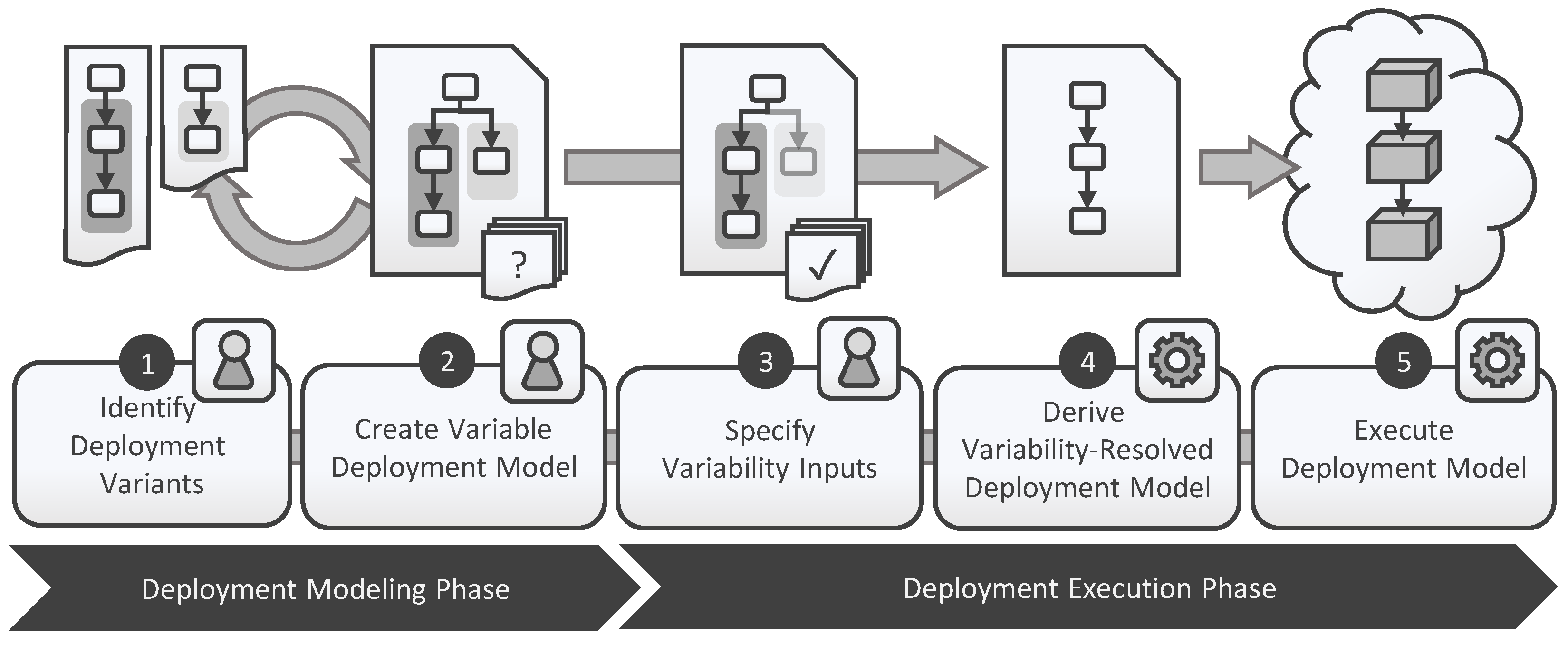
3. Variable Deployment Modeling Method
3.1. Step ➊: Identify Deployment Variants
3.2. Step ➋: Create Variable Deployment Model
3.3. Step ➌: Specify Variability Inputs
3.4. Step ➍: Derive Variability-Resolved Deployment Model
3.5. Step ➎: Execute Deployment Model
4. Variable Deployment Models
4.1. Variable Deployment Metamodel
- is the set of Components in . Each represents a component of the application. Considering our motivating scenario, the components “Web Component”, “Dev Runtime”, and “Private VM”, for example, belong to this set.
- is the set of Relations between two components in . Each represents a relationship between two components of the application, whereby is the Source and the Target Component. Considering our motivating scenario, the hosting relation between the (source) component “Web Component” and (target) component “Dev Runtime”, for example, is such a relationship.
- is the set of Component Types in . Each describes the semantics of a component having this type. Considering our motivating scenario, the component “Web Component”, for example, has the type “NodeJs14App” which describes, for example, that a hosting relation is required.
- is the set of Relation Types in . Each describes the semantics for each relation having this type. Considering our motivating scenario, the relation between the components “Web Component” and “Dev Runtime”, for example, is of type “hostedOn” and describes that the component “Web Component” is running on the component “Dev Runtime”.
- The set of Typed Elements is the union set of components and relations in . Considering our motivating scenario, the components “Web Component” and “Dev Runtime”, for example, along with their hosting relation belong to this set.
- The set of Typed Element Types is the union of component and relation types in . Considering our motivating scenario, the component type “NodeJs14App” and relation type “hostedOn”, for example, belong to this set.
- is the mapping function that assigns all components and relations in their respective component or relation type and, therefore, provides the semantics of typed elements. Considering our motivating scenario, the component “Web Component”, for example, is of type “NodeJs14App”.
- is the set of Properties in . Each describes a property of a component (type) or relation (type). Considering our motivating scenario, such properties are, for example, database credentials such as a username and password. However, properties are not shown in the figures for brevity.
- is the mapping function that assigns each typed element and typed element type its properties in . Considering our motivating scenario, the database connection between the “Web Component” and “Prod Database”, for example, is assigned its respective properties, such as a username and password. However, properties are not shown in the figures for brevity.
- is the set of Variability Inputs in . Each is used inside Variability Conditions. Considering our motivating scenario, a Variability Input “mode”, for example, states if the desired deployment is for development or for production. Other Variability Inputs could ask for enabled features such as elasticity or for the legal location to select a compliant hosting offering.
- is the set of Variability Conditions in . Each describes a Variability Condition under which a component, relation, or group is present in the deployment variant. Considering our motivating scenario, a Variability Condition “Dev”, for example, is assigned to the component “Dev Runtime” which evaluates that the Variability Input “mode” has the value “dev”. Other Variability Conditions could consider cloud offering prices.
- is the mapping function that assigns each Variability Condition the required set of Variability Inputs in that are required to evaluate . Considering our motivating scenario, the Variability Input “mode”, for example, is assigned to the Variability Condition “Dev”.
- is the set of all Groups in . Hereby, a is a group that consists of components and relations in that are grouped to associate one or more Variability Conditions to all elements contained in this group. Considering our motivating scenario, the components “Dev Runtime”, “Dev Database”, and “Private VM”, for example, along with their relations could have been added to the same group to manage all conditional elements which are present during the development variant.
- is a mapping function in that assigns each component , relation , and group the Variability Conditions under which it is present in the deployment variant. If a component, relation, or group have no Variability Conditions, the mapping function assigns them the empty set. Considering our motivating scenario, the Variability Condition “Dev”, for example, belongs to this set.
- is the function in that assigns under the Variability Inputs a Variability Condition either or . Considering our motivating scenario, this function evaluates, for example, regarding the Variability Condition “Dev” if the Variability Input “mode” has the value “dev”.
4.2. Algorithms for Resolving Variability
4.2.1. Variability Resolving Algorithm
| Algorithm 1 resolveVariability (): |
| 1: // Calculate all present components and relations |
| 2: |
| 3: |
| 4: |
| 5: // Return Deployment Model |
| 6: return |
4.2.2. Element Presence Check Algorithm
| Algorithm 2 checkElementPresence(, ): |
| 1: // Capture all conditions which are assigned to e |
| 2: |
| 3: |
| 4: // Add all conditions which are assigned to the groups of e |
| 5: for all ( do |
| 6: |
| 7: end for |
| 8: |
| 9: // Check that all conditions evaluate to true |
| 10: return |
4.2.3. Consistency Check Algorithm
| Algorithm 3 checkConsistency(, ): |
| 1: // Ensure that each relation source exists |
| 2: if then |
| 3: return |
| 4: end if |
| 5: |
| 6: // Ensure that each relation target exists |
| 7: if then |
| 8: return |
| 9: end if |
| 10: |
| 11: // Ensure that every component has at maximum one hosting relation |
| 12: if |
| 13: return |
| 14: end if |
| 15: |
| 16: // Ensure that every component that had a hosting relation previously still has one |
| 17: if |
| 18: return |
| 19: end if |
| 20: |
| 21: // All checks passed |
| 22: return |
5. Prototypical Validation and Case Study
5.1. Variability4TOSCA: An Extension of the TOSCA Standard
5.1.1. Mapping EDMM to TOSCA
5.1.2. Extending TOSCA for VDMM
| Listing 1. Excerpt of the Topology Template of our motivating scenario showing modeled Variability Conditions for the runtime of the web component as well as hosting relations to them. |
|
5.2. System Architecture for a Variability4TOSCA Deployment System
5.3. OpenTOSCA Vintner
5.4. Case Study Based on the Prototype
5.5. Benchmark Evaluation of the Variability Resolver Prototype
6. Related Work
6.1. Software Product Line Engineering
6.2. Variable Composite Applications
6.3. Context-Aware Deployments
6.4. Incomplete Deployment Models
6.5. Templating Engines
7. Threats to Validity
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wurster, M.; Breitenbücher, U.; Falkenthal, M.; Krieger, C.; Leymann, F.; Saatkamp, K.; Soldani, J. The Essential Deployment Metamodel: A Systematic Review of Deployment Automation Technologies. SICS Softw.-Intensive Cyber-Phys. Syst. 2019, 35, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Endres, C.; Breitenbücher, U.; Falkenthal, M.; Kopp, O.; Leymann, F.; Wettinger, J. Declarative vs. Imperative: Two Modeling Patterns for the Automated Deployment of Applications. In Proceedings of the 9th International Conference on Pervasive Patterns and Applications (PATTERNS 2017), Athens, Greece, 19–23 February 2017; pp. 22–27. [Google Scholar]
- Google Cloud Functions. Available online: https://cloud.google.com/functions (accessed on 16 October 2022).
- OASIS. TOSCA Simple Profile in YAML Version 1.3; Organization for the Advancement of Structured Information Standards (OASIS): 2020. Available online: https://docs.oasis-open.org/tosca/TOSCA-Simple-Profile-YAML/v1.3/os/TOSCA-Simple-Profile-YAML-v1.3-os.html (accessed on 16 October 2022).
- Google Cloud App Engine. Available online: https://cloud.google.com/appengine (accessed on 16 October 2022).
- Google Cloud SQL. Available online: https://cloud.google.com/sql (accessed on 16 October 2022).
- Terraform. Available online: https://terraform.io (accessed on 16 October 2022).
- Puppet. Available online: https://puppet.com (accessed on 16 October 2022).
- Kubernetes. Available online: https://kubernetes.io (accessed on 16 October 2022).
- Ansible. Available online: https://ansible.com (accessed on 16 October 2022).
- Wurster, M.; Breitenbücher, U.; Brogi, A.; Falazi, G.; Harzenetter, L.; Leymann, F.; Soldani, J.; Yussupov, V. The EDMM Modeling and Transformation System. In Proceedings of the Service-Oriented Computing—ICSOC 2019 Workshops, Toulouse, France, 28–31 October 2019; Springer: Cham, Switzerland, 2019. [Google Scholar]
- OpenTOSCA Vintner. Available online: https://github.com/opentosca/opentosca-vintner (accessed on 16 October 2022).
- xOpera. Available online: https://github.com/xlab-si/xopera-opera (accessed on 16 October 2022).
- Unfurl. Available online: https://github.com/onecommons/unfurl (accessed on 16 October 2022).
- Wurster, M.; Breitenbücher, U.; Harzenetter, L.; Leymann, F.; Soldani, J.; Yussupov, V. TOSCA Light: Bridging the Gap between the TOSCA Specification and Production-ready Deployment Technologies. In Proceedings of the 10th International Conference on Cloud Computing and Services Science (CLOSER 2020), Prague, Czech Republic, 7–9 May 2020; pp. 216–226. [Google Scholar]
- Binz, T.; Breitenbücher, U.; Kopp, O.; Leymann, F. TOSCA: Portable Automated Deployment and Management of Cloud Applications. In Advanced Web Services; Springer: New York, NY, USA, 2014; pp. 527–549. [Google Scholar]
- Binz, T.; Breiter, G.; Leymann, F.; Spatzier, T. Portable Cloud Services Using TOSCA. IEEE Internet Comput. 2012, 16, 80–85. [Google Scholar] [CrossRef]
- Windows-Subsystem for Linux. Available online: https://learn.microsoft.com/en-us/windows/wsl (accessed on 16 October 2022).
- Pohl, K.; Böckle, G.; van der Linden, F. Software Product Line Engineering; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Pohl, K.; Metzger, A. Variability Management in Software Product Line Engineering. In Proceedings of the 28th International Conference on Software Engineering, ICSE ’06, Shanghai, China, 20–28 May 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 1049–1050. [Google Scholar]
- Pohl, K.; Metzger, A. Software Product Lines. In The Essence of Software Engineering; Springer International Publishing: Cham, Switzerland, 2018; pp. 185–201. [Google Scholar]
- Beuche, D.; Dalgarno, M. Software product line engineering with feature models. Overload J. 2007, 78, 5–8. [Google Scholar]
- Kang, K.C.; Cohen, S.G.; Hess, J.A.; Novak, W.E.; Peterson, A.S. Feature-Oriented Domain Analysis (FODA) Feasibility Study; Technical Report; Carnegie Mellon University, Software Engineering Institute: Pittsburgh, PA, USA, 1990. [Google Scholar]
- Groher, I.; Voelter, M. Expressing feature-based variability in structural models. In Proceedings of the Workshop on Managing Variability for Software Product Lines, Kyoto, Japan, 4–10 September 2007. [Google Scholar]
- Czarnecki, K.; Antkiewicz, M.; Kim, C.H.P.; Lau, S.; Pietroszek, K. Model-Driven Software Product Lines. In Proceedings of the Companion to the 20th Annual ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA ’05, San Diego, CA, USA, 16–20 October 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 126–127. [Google Scholar]
- Czarnecki, K.; Antkiewicz, M. Mapping Features to Models: A Template Approach Based on Superimposed Variants. In Generative Programming and Component Engineering; Glück, R., Lowry, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 422–437. [Google Scholar]
- Ziadi, T.; Hélouët, L.; Jézéquel, J.M. Towards a UML Profile for Software Product Lines. In Software Product-Family Engineering; van der Linden, F.J., Ed.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 129–139. [Google Scholar]
- Clauß, M.; Jena, I. Modeling variability with UML. In GCSE 2001 Young Researchers Workshop; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Razavian, M.; Khosravi, R. Modeling Variability in Business Process Models Using UML. In Proceedings of the Fifth International Conference on Information Technology: New Generations (ITNG 2008), Las Vegas, NV, USA, 7–8 April 2008; pp. 82–87. [Google Scholar]
- Junior, E.A.O.; de Souza Gimenes, I.M.; Maldonado, J.C. Systematic Management of Variability in UML-based Software Product Lines. J. Univers. Comput. Sci. 2010, 16, 2374–2393. [Google Scholar]
- Korherr, B.; List, B. A UML 2 Profile for Variability Models and their Dependency to Business Processes. In Proceedings of the 18th International Workshop on Database and Expert Systems Applications (DEXA 2007), Regensburg, Germany, 3–7 September 2007; pp. 829–834. [Google Scholar]
- Robak, S.; Franczyk, B.; Politowicz, K. Extending the UML for modeling variability for system families. Int. J. Appl. Math. Comput. Sci 2002, 12, 285–298. [Google Scholar]
- Ferko, E.; Bucaioni, A.; Carlson, J.; Haider, Z. Automatic Generation of Configuration Files: An Experience Report from the Railway Domain. J. Object Technol. 2021, 20, 1–15. [Google Scholar] [CrossRef]
- The C Preprocessor: ConditionalsExpress—Node.js Web Application Framework. Available online: https://gcc.gnu.org/onlinedocs/gcc-3.0.2/cpp_4.html (accessed on 16 October 2022).
- Munge—Simple Java Preprocessor. Available online: https://github.com/sonatype/munge-maven-plugin (accessed on 16 October 2022).
- Antenna—An Ant-to-End Solution For Wireless Java. Available online: http://antenna.sourceforge.net (accessed on 16 October 2022).
- Cavalcante, E.; Almeida, A.; Batista, T.; Cacho, N.; Lopes, F.; Delicato, F.C.; Sena, T.; Pires, P.F. Exploiting Software Product Lines to Develop Cloud Computing Applications. In Proceedings of the 16th International Software Product Line Conference, SPLC ’12, Salvador, Brazil, 2–7 September 2012; Association for Computing Machinery: New York, NY, USA, 2012; Volume 2, pp. 179–187. [Google Scholar]
- Lee, K.C.A.; Segarra, M.T.; Guelec, S. A deployment-oriented development process based on context variability modeling. In Proceedings of the 2014 2nd International Conference on Model-Driven Engineering and Software Development (MODELSWARD), Lisbon, Portugal, 7–9 January 2014; pp. 454–459. [Google Scholar]
- Tahri, A.; Duchien, L.; Pulou, J. Using Feature Models for Distributed Deployment in Extended Smart Home Architecture. In Software Architecture; Weyns, D., Mirandola, R., Crnkovic, I., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 285–293. [Google Scholar]
- Jamshidi, P.; Pahl, C. Orthogonal Variability Modeling to Support Multi-cloud Application Configuration. In Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2015; pp. 249–261. [Google Scholar]
- Kumara, I.P.; Ariz, M.; Baruwal Chhetri, M.; Mohammadi, M.; Heuvel, W.J.V.D.; Tamburri, D.A.A. FOCloud: Feature Model Guided Performance Prediction and Explanation for Deployment Configurable Cloud Applications. IEEE Trans. Serv. Comput. 2022. [Google Scholar] [CrossRef]
- Saller, K.; Lochau, M.; Reimund, I. Context-Aware DSPLs: Model-Based Runtime Adaptation for Resource-Constrained Systems. In Proceedings of the 17th International Software Product Line Conference Co-Located Workshops, SPLC ’13 Workshops, Tokyo, Japan, 26–30 August 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 106–113. [Google Scholar]
- Hochgeschwender, N.; Gherardi, L.; Shakhirmardanov, A.; Kraetzschmar, G.K.; Brugali, D.; Bruyninckx, H. A model-based approach to software deployment in robotics. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3907–3914. [Google Scholar]
- Jansen, S.; Brinkkemper, S. Modelling Deployment Using Feature Descriptions and State Models for Component-Based Software Product Families. In Component Deployment; Dearle, A., Eisenbach, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 119–133. [Google Scholar]
- Mietzner, R.; Leymann, F. A Self-Service Portal for Service-Based Applications. In Proceedings of the IEEE International Conference on Service-Oriented Computing and Applications (SOCA 2010), Perth, Australia, 13–15 December 2010. [Google Scholar]
- Mietzner, R. A Method and Implementation to Define and Provision Variable Composite Applications, and Its Usage in Cloud Computing. Ph.D. Thesis, Universität Stuttgart, Fakultät Informatik, Elektrotechnik und Informationstechnik, Stuttgart, Germany, 2010. [Google Scholar]
- Mietzner, R.; Unger, T.; Titze, R.; Leymann, F. Combining Different Multi-Tenancy Patterns in Service-Oriented Applications. In Proceedings of the 13th IEEE Enterprise Distributed Object Conference (EDOC 2009), Auckland, New Zealand, 1–4 September 2009; Society, I.C., Ed.; pp. 131–140. [Google Scholar]
- Mietzner, R.; Leymann, F.; Unger, T. Horizontal and Vertical Combination of Multi-Tenancy Patterns in Service-Oriented Applications. Enterp. Inf. Syst. 2010, 5, 59–77. [Google Scholar] [CrossRef]
- Mietzner, R.; Fehling, C.; Karastoyanova, D.; Leymann, F. Combining horizontal and vertical composition of services. In Proceedings of the IEEE International Conference on Service Oriented Computing and Applications (SOCA 2010), Perth, Australia, 13–15 December 2010. [Google Scholar]
- Koetter, F.; Kochanowski, M.; Renner, T.; Fehling, C.; Leymann, F. Unifying Compliance Management in Adaptive Environments through Variability Descriptors (Short Paper). In Proceedings of the 6th IEEE International Conference on Service Oriented Computing and Applications (SOCA), Koloa, HI, USA, 16–18 December 2013; pp. 1–8. [Google Scholar]
- Koetter, F.; Kintz, M.; Kochanowski, M.; Fehling, C.; Gildein, P.; Leymann, F.; Weisbecker, A. Unified Compliance Modeling and Management using Compliance Descriptors. In Proceedings of the 6th International Conference on Cloud Computing and Services Science—Volume 2: CLOSER, INSTICC, Rome, Italy, 23–25 April 2016; pp. 159–170. [Google Scholar]
- Mietzner, R.; Leymann, F. Generation of BPEL Customization Processes for SaaS Applications from Variability Descriptors. In Proceedings of the International Conference on Services Computing, Industry Track, SCC, Honolulu, HI, USA, 8–11 July 2008. [Google Scholar]
- Mietzner, R.; Unger, T.; Leymann, F. Cafe: A Generic Configurable Customizable Composite Cloud Application Framework. In Proceedings of the On the Move to Meaningful Internet Systems: OTM 2009 (CoopIS 2009), Vilamoura, Portugal, 1–6 November 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 357–364. [Google Scholar]
- Fehling, C.; Leymann, F.; Mietzner, R. A Framework for Optimized Distribution of Tenants in Cloud Applications. In Proceedings of the 2010 IEEE International Conference on Cloud Computing (CLOUD 2010), Miami, FL, USA, 5–10 July 2010; pp. 1–8. [Google Scholar]
- Mietzner, R.; Leymann, F. Towards Provisioning the Cloud: On the Usage of Multi-Granularity Flows and Services to Realize a Unified Provisioning Infrastructure for SaaS Applications. In Proceedings of the International Congress on Services (SERVICES 2008), Honolulu, HI, USA, 6–11 July 2008; pp. 3–10. [Google Scholar]
- Fehling, C.; Mietzner, R. Composite as a Service: Cloud Application Structures, Provisioning, and Management. It Inf. Technol. 2011, 53, 188–194. [Google Scholar] [CrossRef]
- Le Nhan, T.; Sunyé, G.; Jézéquel, J.M. A Model-Driven Approach for Virtual Machine Image Provisioning in Cloud Computing. In Service-Oriented and Cloud Computing; De Paoli, F., Pimentel, E., Zavattaro, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 107–121. [Google Scholar]
- Quinton, C.; Romero, D.; Duchien, L. Automated Selection and Configuration of Cloud Environments Using Software Product Lines Principles. In Proceedings of the 2014 IEEE 7th International Conference on Cloud Computing, Anchorage, AK, USA, 2–27 July 2014; pp. 144–151. [Google Scholar]
- Gui, N.; De Florio, V.; Sun, H.; Blondia, C. A Framework for Adaptive Real-Time Applications: The Declarative Real-Time OSGi Component Model. In Proceedings of the 7th Workshop on Reflective and Adaptive Middleware, ARM ’08, Leuven, Belgium, 1–5 December 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 35–40. [Google Scholar]
- Anthony, R.J.; Chen, D.; Pelc, M.; Persson, M.; Torngren, M. Context-aware adaptation in DySCAS. Electron. Commun. EASST 2009, 19. [Google Scholar] [CrossRef]
- Alkhabbas, F.; Murturi, I.; Spalazzese, R.; Davidsson, P.; Dustdar, S. A Goal-Driven Approach for Deploying Self-Adaptive IoT Systems. In Proceedings of the 2020 IEEE International Conference on Software Architecture (ICSA), Salvador, Brazil, 16–20 March 2020; pp. 146–156. [Google Scholar]
- Kephart, J.; Chess, D. The vision of autonomic computing. Computer 2003, 36, 41–50. [Google Scholar] [CrossRef]
- Ayed, D.; Taconet, C.; Bernard, G.; Berbers, Y. CADeComp: Context-aware deployment of component-based applications. J. Netw. Comput. Appl. 2008, 31, 224–257. [Google Scholar] [CrossRef]
- Ayed, D.; Taconet, C.; Bernard, G.; Berbers, Y. An Adaptation Methodology for the Deployment of Mobile Component-based Applications. In Proceedings of the 2006 ACS/IEEE International Conference on Pervasive Services, Lyon, France, 26–29 June 2006; pp. 193–202. [Google Scholar]
- Atoui, W.S.; Assy, N.; Gaaloul, W.; Yahia, I.G.B. Configurable Deployment Descriptor Model in NFV. J. Netw. Syst. Manag. 2020, 28, 693–718. [Google Scholar] [CrossRef]
- Sáez, S.G.; Andrikopoulos, V.; Bitsaki, M.; Leymann, F.; van Hoorn, A. Utility-Based Decision Making for Migrating Cloud-Based Applications. ACM Trans. Internet Technol. 2018, 18, 1–22. [Google Scholar] [CrossRef]
- Johnsen, E.B.; Schlatte, R.; Tapia Tarifa, S.L. Deployment Variability in Delta-Oriented Models. In Leveraging Applications of Formal Methods, Verification and Validation. Technologies for Mastering Change; Margaria, T., Steffen, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 304–319. [Google Scholar]
- The ABS Modeling Language. Available online: https://abs-models.org (accessed on 16 October 2022).
- Schaefer, I.; Bettini, L.; Bono, V.; Damiani, F.; Tanzarella, N. Delta-oriented programming of software product lines. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2010; Volume 6287, pp. 77–91. [Google Scholar]
- Schaefer, I.; Damiani, F. Pure Delta-Oriented Programming. In Proceedings of the 2nd International Workshop on Feature-Oriented Software Development, FOSD ’10, Eindhoven, The Netherlands, 10 October 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 49–56. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Kraetzschmar, G.K.; Shakhimardanov, A.; Paulus, J.; Hochgeschwender, N.; Reckhaus, M. Best Practice in Robotics. In Deliverable D-2.2: Specifications of Architectures, Modules, Modularity, and Interfaces for the BROCTE Software Platform and Robot Control Architecture Workbench; Bonn-Rhine-Sieg University: Sankt Augustin, Germany, 2010. [Google Scholar]
- Breitenbücher, U.; Binz, T.; Kopp, O.; Leymann, F.; Wieland, M. Context-Aware Provisioning and Management of Cloud Applications. In Cloud Computing and Services Science; Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2015; pp. 151–168. [Google Scholar]
- Terraform—The Count Meta-Argument. Available online: https://terraform.io/language/meta-arguments/count (accessed on 16 October 2022).
- Ansible—Conditionals. Available online: https://docs.ansible.com/ansible/6/user_guide/playbooks_conditionals.html (accessed on 16 October 2022).
- Jinja2. Available online: https://jinja.palletsprojects.com (accessed on 16 October 2022).
- Harzenetter, L.; Breitenbücher, U.; Falkenthal, M.; Guth, J.; Krieger, C.; Leymann, F. Pattern-based Deployment Models and Their Automatic Execution. In Proceedings of the 11th IEEE/ACM International Conference on Utility and Cloud Computing (UCC 2018). IEEE Computer Society, Zurich, Switzerland, 17–20 December 2018; pp. 41–52. [Google Scholar]
- Harzenetter, L.; Breitenbücher, U.; Falkenthal, M.; Guth, J.; Leymann, F. Pattern-based Deployment Models Revisited: Automated Pattern-driven Deployment Configuration. In Proceedings of the Twelfth International Conference on Pervasive Patterns and Applications (PATTERNS 2020), Nice, France, 25–29 October 2020; pp. 40–49. [Google Scholar]
- Knape, S. Dynamic Automated Selection and Deployment of Software Components within a Heterogeneous Multi-Platform Environment. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2015. [Google Scholar]
- Hirmer, P.; Breitenbücher, U.; Binz, T.; Leymann, F. Automatic Topology Completion of TOSCA-based Cloud Applications. In Proceedings des CloudCycle14 Workshops auf der 44. Jahrestagung der Gesellschaft für Informatik e.V. (GI); Gesellschaft für Informatik e.V. (GI): Bonn, Germany, 2014; Volume 232, LNI; pp. 247–258. [Google Scholar]
- Saatkamp, K.; Breitenbücher, U.; Leymann, F.; Wurster, M. Generic Driver Injection for Automated IoT Application Deployments. In Proceedings of the 19th International Conference on Information Integration and Web-based Applications & Services, Salzburg, Austria, 4–6 December 2017; ACM: New York, NY, USA, 2017; pp. 320–329. [Google Scholar]
- Saatkamp, K.; Breitenbücher, U.; Kopp, O.; Leymann, F. Topology Splitting and Matching for Multi-Cloud Deployments. In Proceedings of the 7th International Conference on Cloud Computing and Services Science (CLOSER 2017), Porto, Portugal, 24–26 April 2017; pp. 247–258. [Google Scholar]
- Kuroda, T.; Kuwahara, T.; Maruyama, T.; Satoda, K.; Shimonishi, H.; Osaki, T.; Matsuda, K. Weaver: A Novel Configuration Designer for IT/NW Services in Heterogeneous Environments. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–14 December 2019; pp. 1–6. [Google Scholar]
- Inzinger, C.; Nastic, S.; Sehic, S.; Vögler, M.; Li, F.; Dustdar, S. MADCAT: A Methodology for Architecture and Deployment of Cloud Application Topologies. In Proceedings of the 2014 IEEE 8th International Symposium on Service Oriented System Engineering, Oxford, UK, 7–11 April 2014; pp. 13–22. [Google Scholar]
- Go Templating Engine. Available online: https://pkg.go.dev/text/template (accessed on 16 October 2022).
- Helm. Available online: https://helm.sh (accessed on 16 October 2022).
- Embedded JavaScript Templating. Available online: https://ejs.co (accessed on 16 October 2022).
- Pug. Available online: https://pugjs.org (accessed on 16 October 2022).
- Express. Available online: https://expressjs.com (accessed on 16 October 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test | Seed | Templates | Median | Median/Template | File Size | File Lines |
|---|---|---|---|---|---|---|
| 1 | 10 | 40 | 0.295 ms | 0.007 ms | n/a | n/a |
| 2 | 250 | 1000 | 4.045 ms | 0.004 ms | n/a | n/a |
| 3 | 500 | 2000 | 4.329 ms | 0.002 ms | n/a | n/a |
| 4 | 1000 | 4000 | 7.383 ms | 0.002 ms | n/a | n/a |
| 5 | 2500 | 10,000 | 29.436 ms | 0.003 ms | n/a | n/a |
| 6 | 5000 | 20,000 | 63.307 ms | 0.003 ms | n/a | n/a |
| 7 | 10,000 | 40,000 | 137.353 ms | 0.003 ms | n/a | n/a |
| 8 | 10 | 40 | 3.335 ms | 0.083 ms | 14 kB | 360 |
| 9 | 250 | 1000 | 39.033 ms | 0.039 ms | 351 kB | 8760 |
| 10 | 500 | 2000 | 88.504 ms | 0.044 ms | 704 kB | 17,510 |
| 11 | 1000 | 4000 | 225.444 ms | 0.056 ms | 1.409 MB | 35,010 |
| 12 | 2500 | 10,000 | 947.011 ms | 0.095 ms | 3.553 MB | 87,510 |
| 13 | 5000 | 20,000 | 3.185 s | 0.159 ms | 7.125 MB | 175,010 |
| 14 | 10,000 | 40,000 | 11.345 s | 0.284 ms | 14.270 MB | 350,010 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stötzner, M.; Becker, S.; Breitenbücher, U.; Képes, K.; Leymann, F. Modeling Different Deployment Variants of a Composite Application in a Single Declarative Deployment Model. Algorithms 2022, 15, 382. https://doi.org/10.3390/a15100382
Stötzner M, Becker S, Breitenbücher U, Képes K, Leymann F. Modeling Different Deployment Variants of a Composite Application in a Single Declarative Deployment Model. Algorithms. 2022; 15(10):382. https://doi.org/10.3390/a15100382
Chicago/Turabian StyleStötzner, Miles, Steffen Becker, Uwe Breitenbücher, Kálmán Képes, and Frank Leymann. 2022. "Modeling Different Deployment Variants of a Composite Application in a Single Declarative Deployment Model" Algorithms 15, no. 10: 382. https://doi.org/10.3390/a15100382