

Information, Volume 14, Issue 11 (November 2023) – 42 articles
Cover Story (view full-size image):
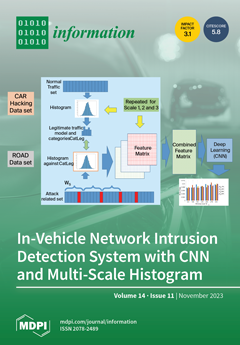
This paper proposes an Intrusion Detection System (IDS) for in-vehicle security networks based on the multi-scale histograms of CAN-ID message identifiers of the CAN-bus protocol. The proposed approach uses sequences of two and three CAN-bus messages to create multi-scale dictionaries from windows of in-vehicle network traffic. A preliminary multi-scale histogram model and dictionaries are created using only legitimate traffic. Against this model, the IDS creates and combines the feature spaces for the different scales. The created feature space is given in input to a Convolutional Neural Network (CNN) to identify the traffic windows where the attack is present. The proposed approach has been evaluated in two different public data sets. View this paper
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue