
Constrained Motion Planning of 7-DOF Space Manipulator via Deep Reinforcement Learning Combined with Artificial Potential Field


Abstract
:1. Introduction
2. Preliminary
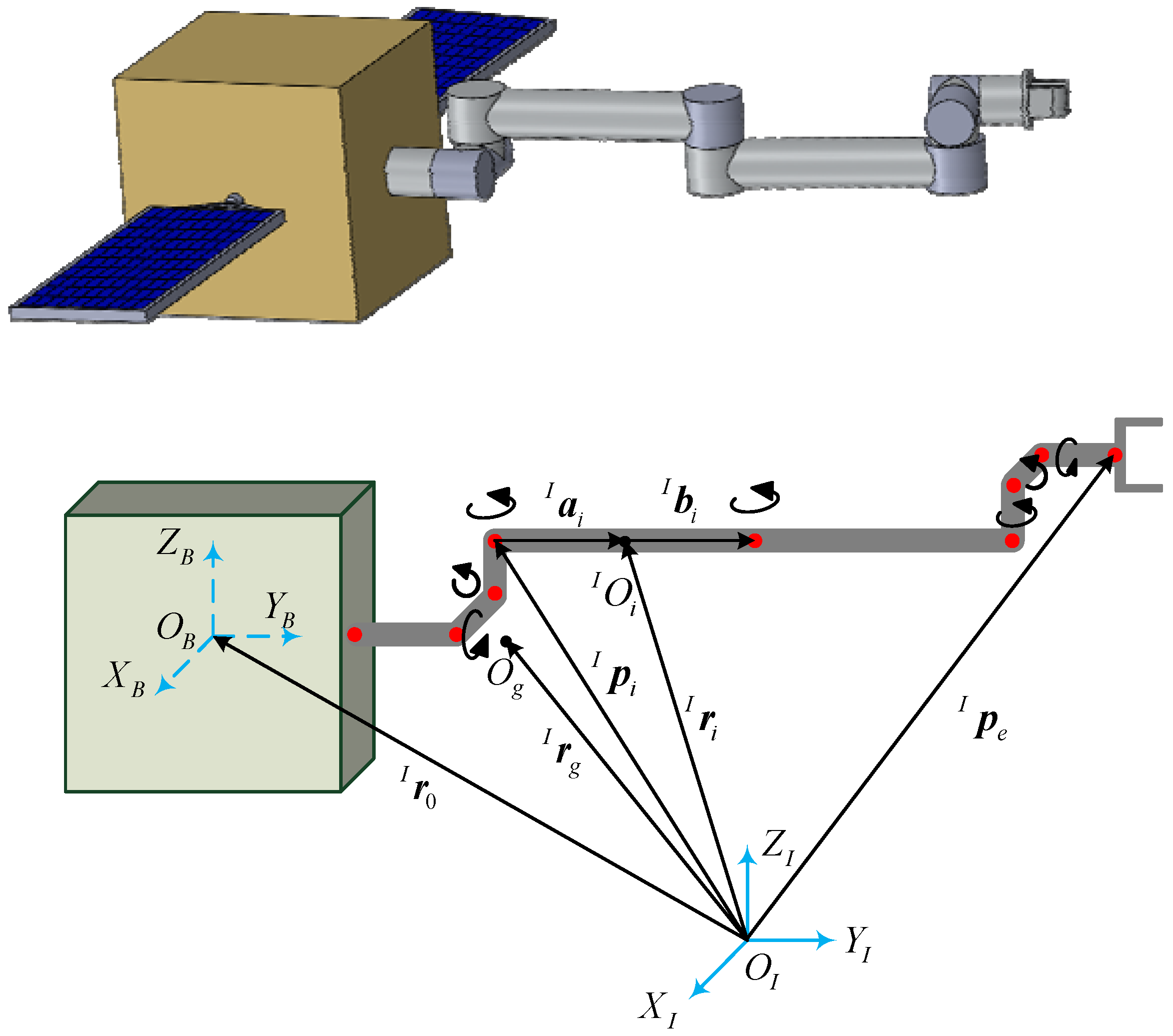
2.1. Kinematic Modeling of 7-DOF Free-Floating Space Manipulator
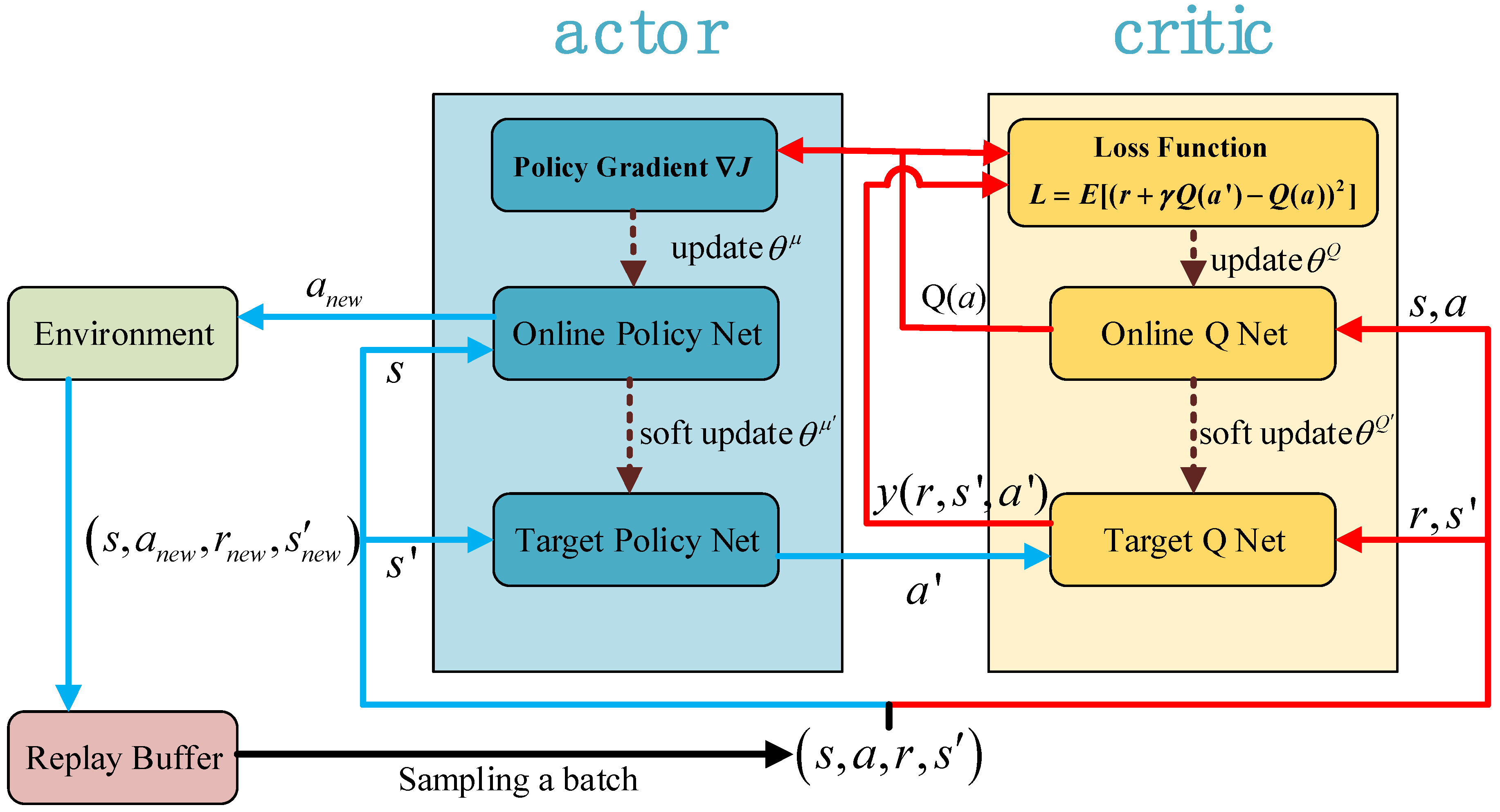
2.2. Deep Deterministic Policy Gradient Algorithm
- (1)
- Firstly, a set of state s is obtained from the environment, and the actor generates a set of action a according to s;
- (2)
- After the action a is applied to the environment, a set of new state s′ and the reward r of the current step are fed back from the environment;
- (3)
- According to the reward r, the action evaluation function of critic is updated, and then the actor will update its policy function in the direction suggested by the critic. The above steps are one-step training of the actor-critic learning framework, and then continue the loop above until the training succeed.
- (1)
- Online policy network: The online policy network is mainly used to interact with the environment, generate action a according to the current state s, and update the parameter θμ in the policy network.
- (2)
- Target policy network: The target strategy network uses the data extracted from the replay buffer for training, and completes the task of selecting the next action a′ according to the next state s′. The network parameters θμ′ are copied and soft updated from the online policy network.
- (3)
- Online Q network: The task of the online Q network is to calculate the value of the current state s and action a, and update the parameter θQ in the Q network.
- (4)
- Target Q network: The target Q network is mainly used to calculate the “label” , and the network parameters θQ′ are copied and soft updated from the online Q network
2.3. Artificial Potential Field
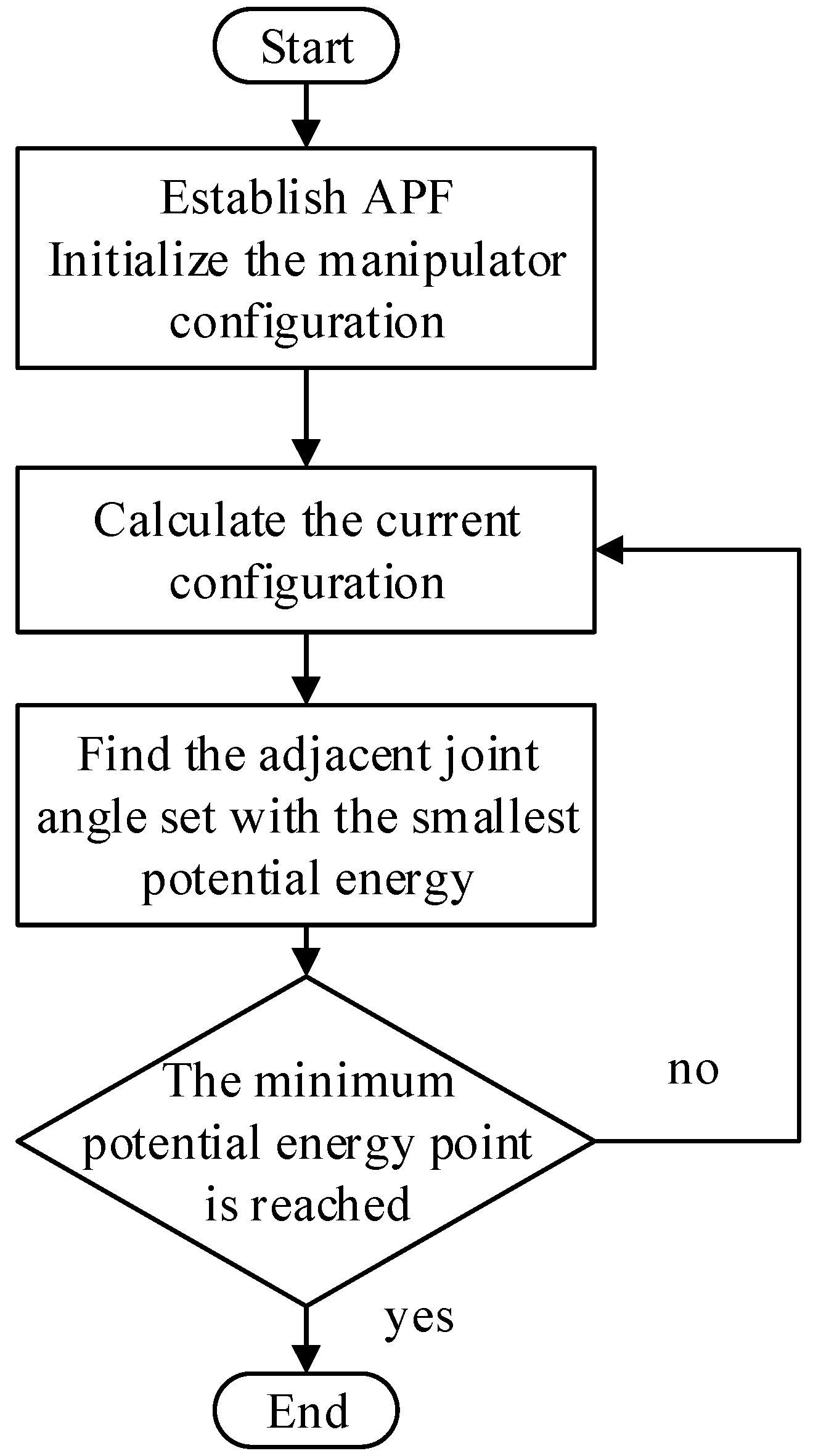
3. Motion Planning Algorithm Design
- (1)
- Establish artificial potential field according to the planning goal;
- (2)
- Calculate the configuration of the manipulator at the current step;
- (3)
- Traverse all the possible set of adjacent joint angles of the current configuration, find the set with the smallest total potential energy, and then proceed to (step 2).
- (1)
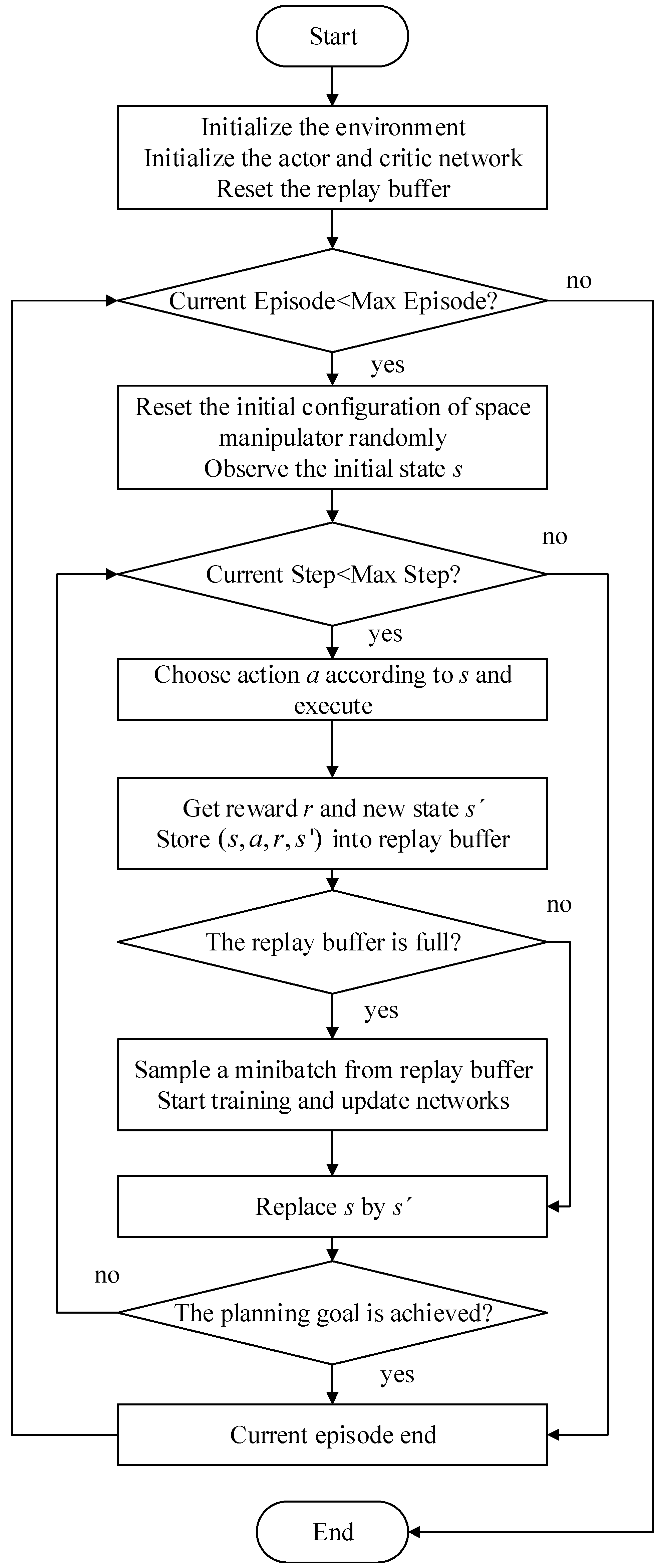
- Establish the model of space manipulator and artificial potential field in the environment;
- (2)
- Observe current state s from environment and choose action a;
- (3)
- Execute action a, obtain the new state s′, and calculate reward r of current step based on the potential energy difference between state s and s′;
- (4)
- Store (s, a, r, s′) into the replay buffer, and start training when the replay buffer is full;
- (5)
- Replace s by s′ and go to step 2.
3.1. Setting of the State and Action in DDPG
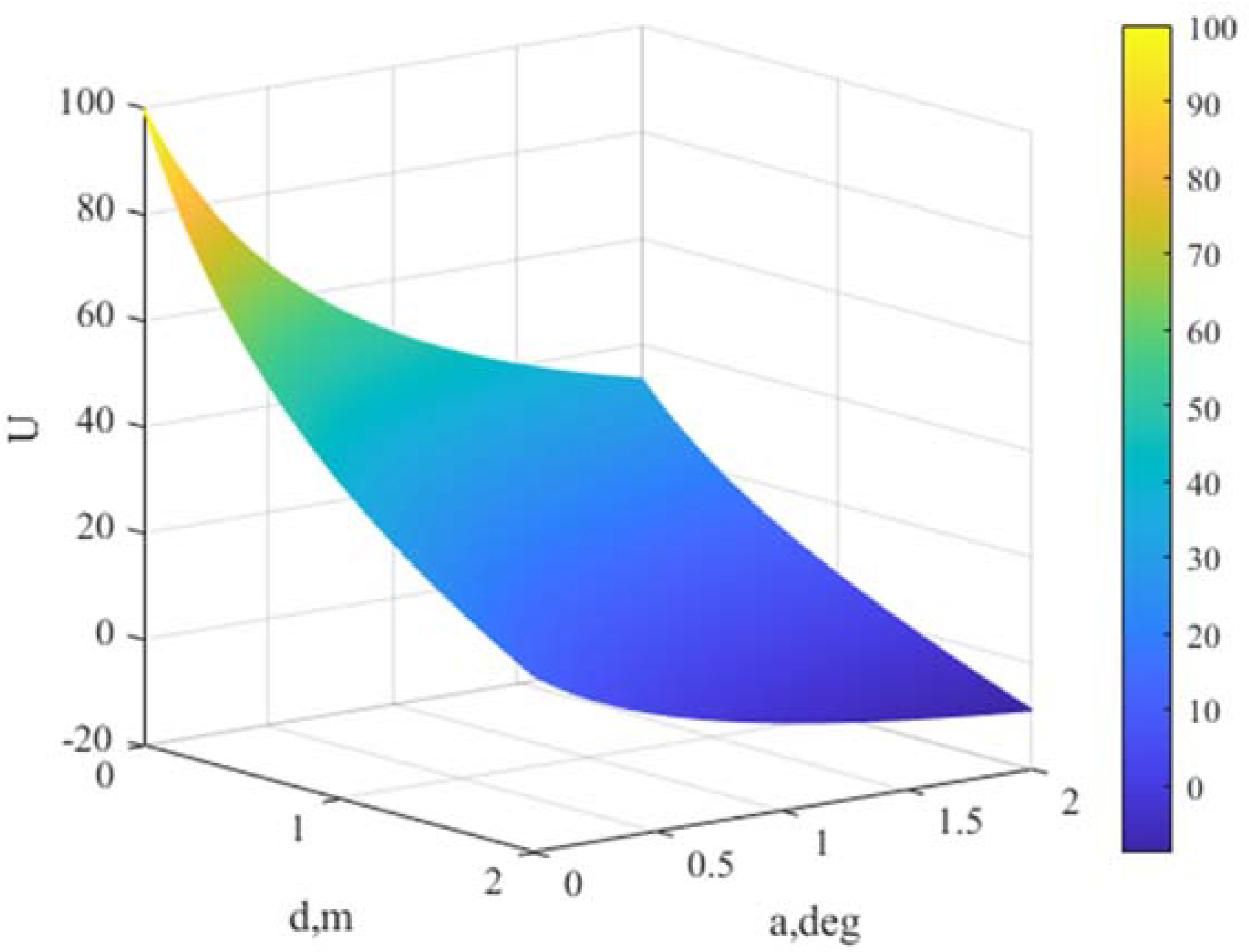
3.2. Reward Function Design
3.2.1. The Main Planning Goal
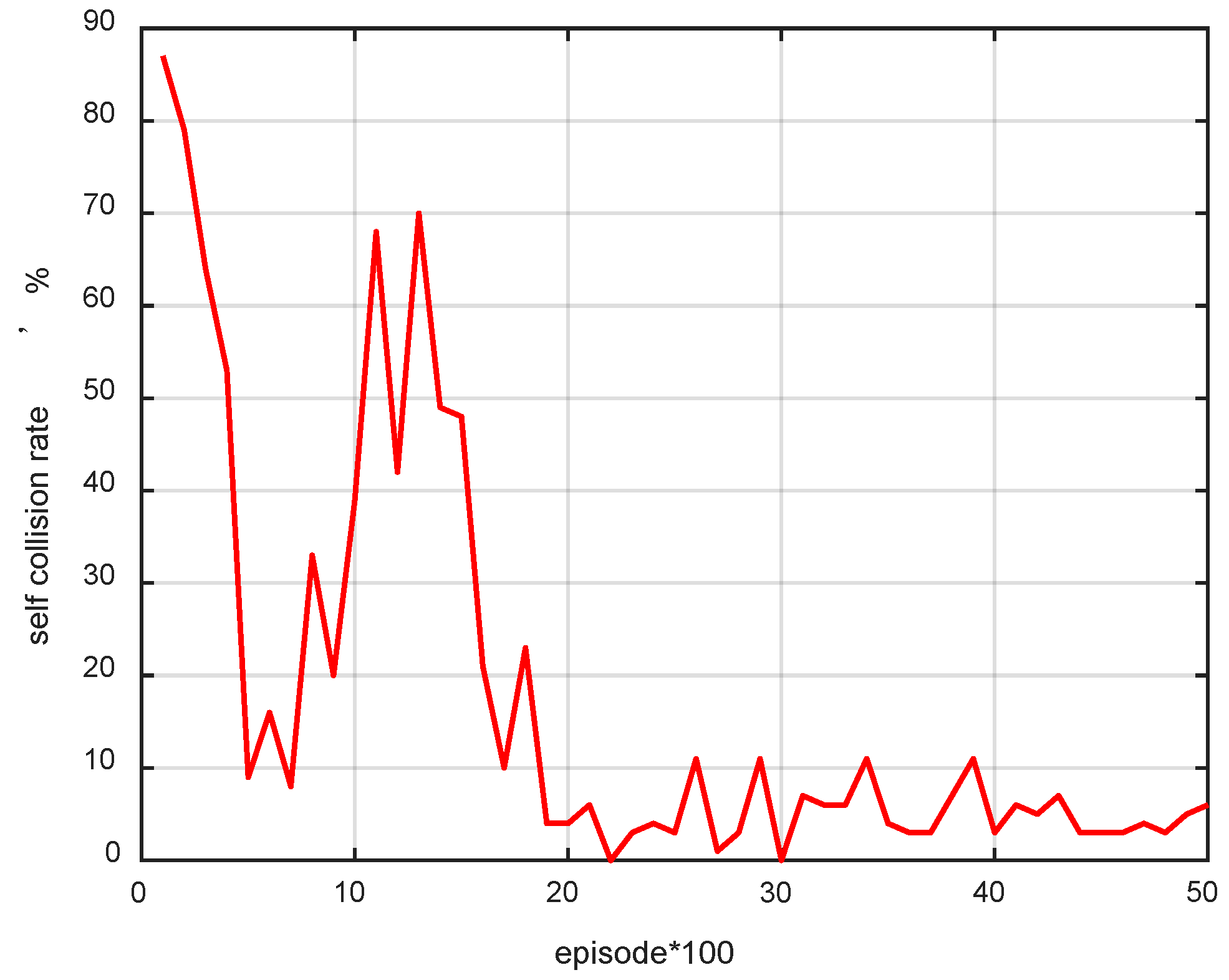
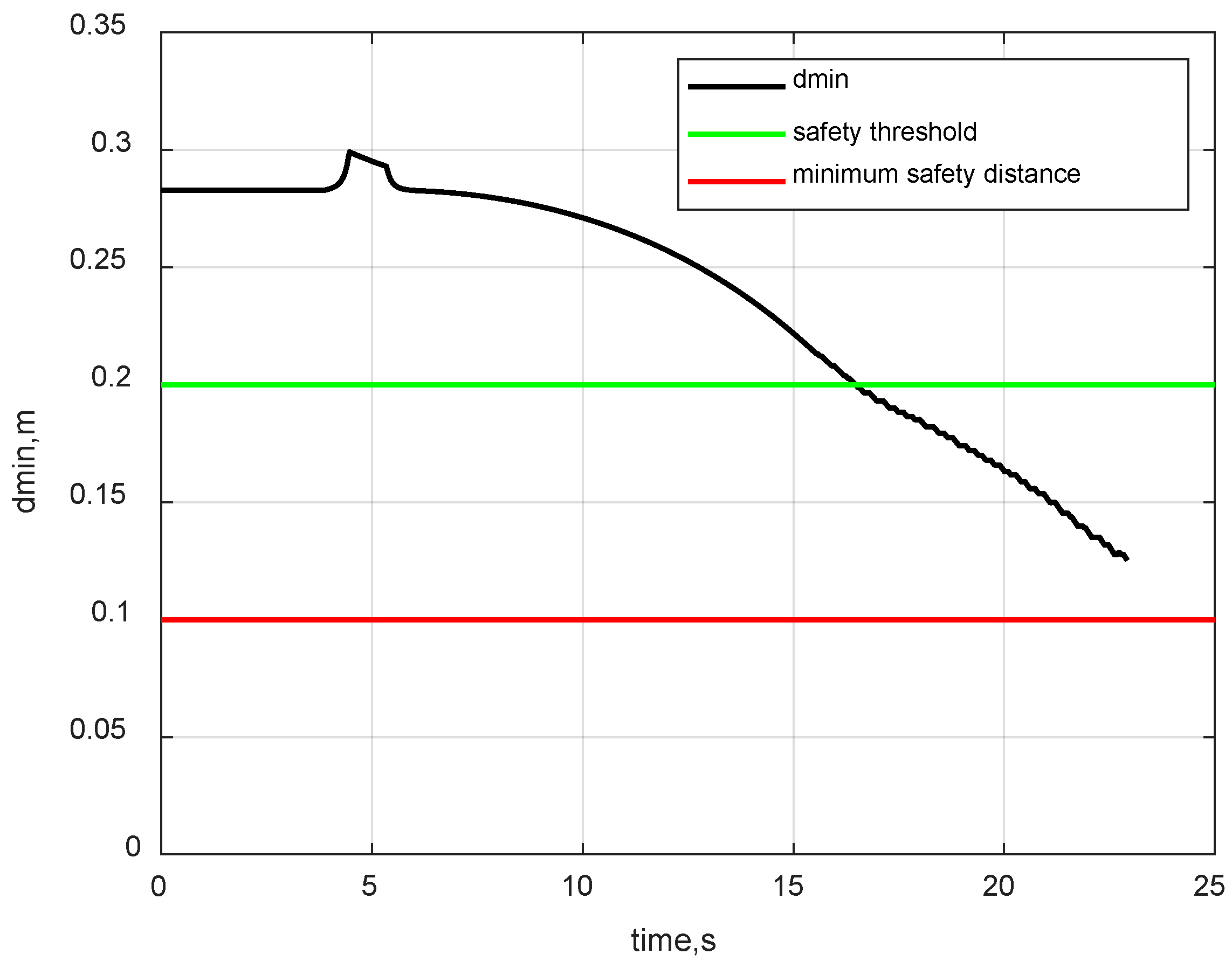
3.2.2. Self-Collision Avoidance Constraint
4. Simulation and Analysis
4.1. Simulation Setup
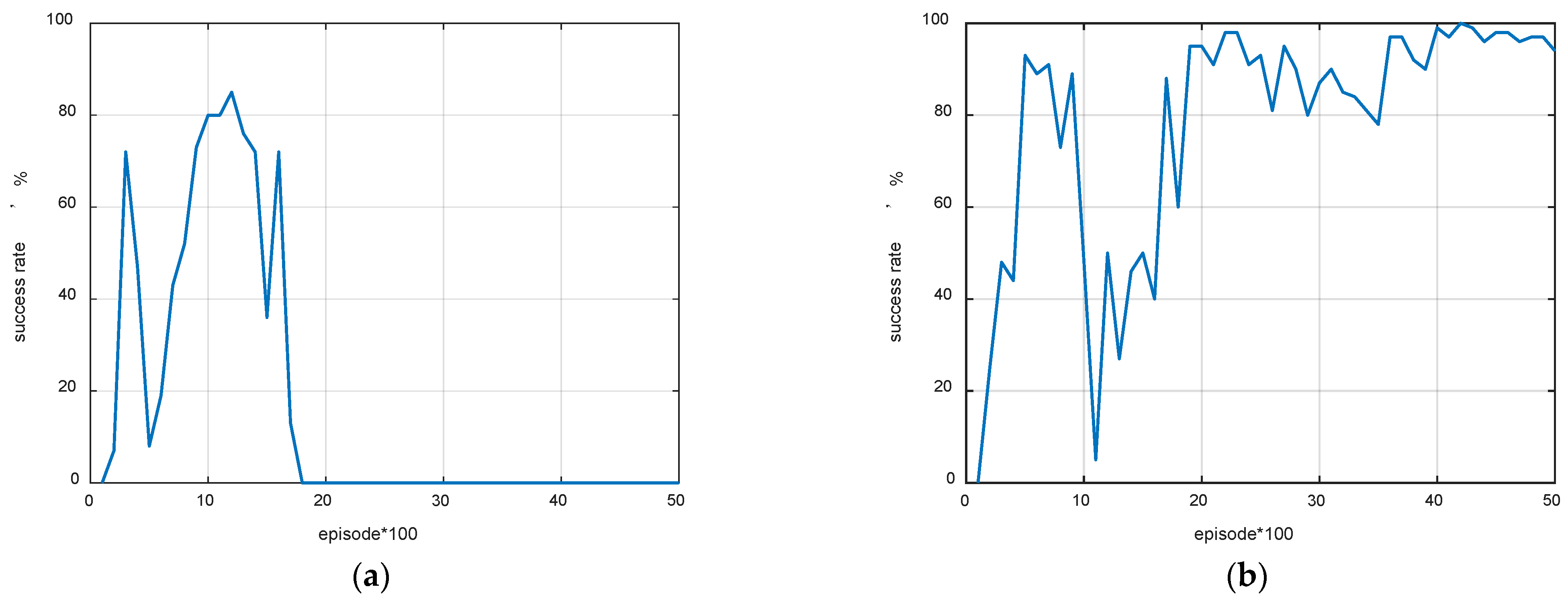
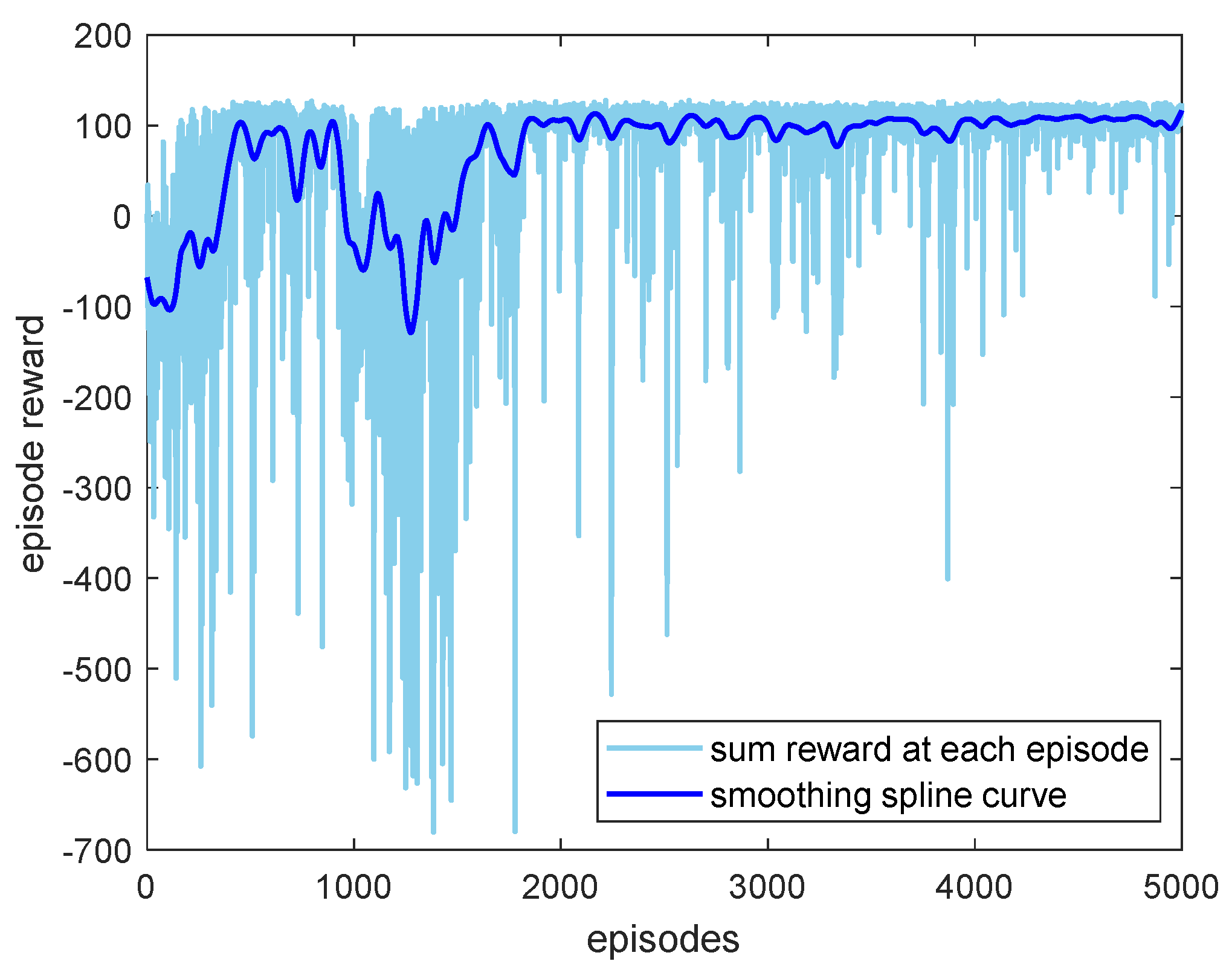
4.2. DDPG Training
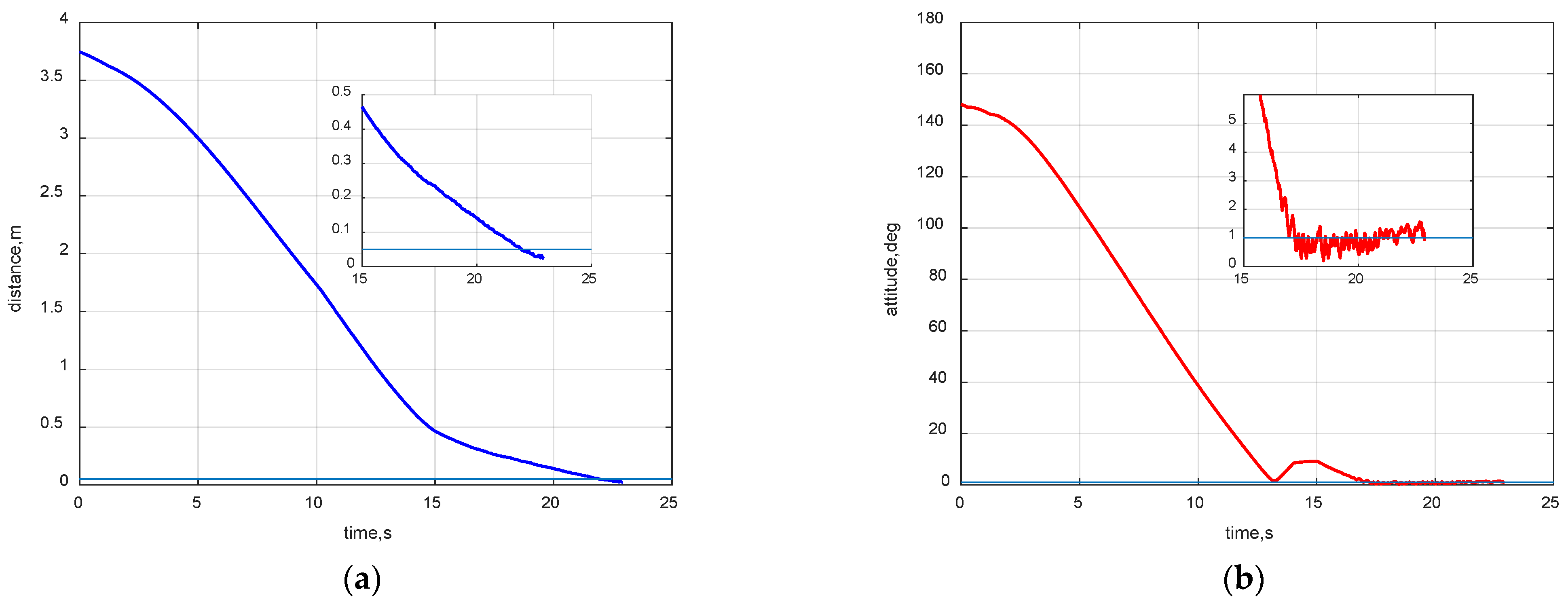
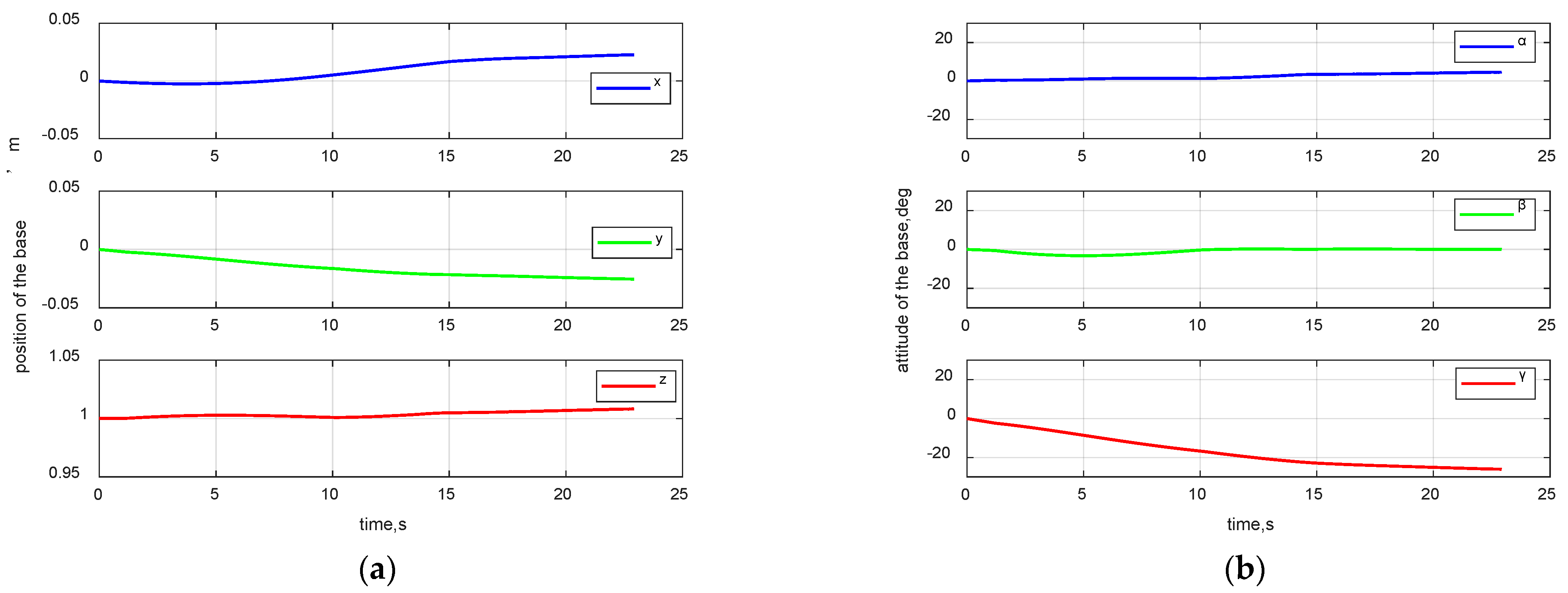
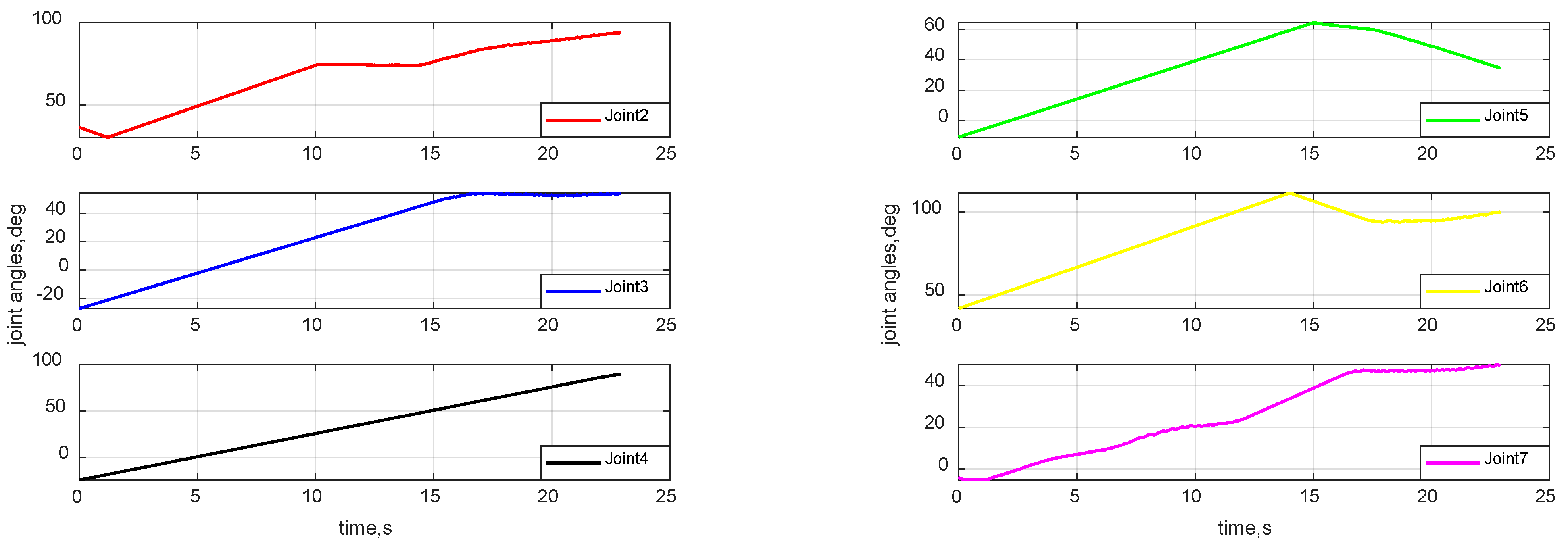
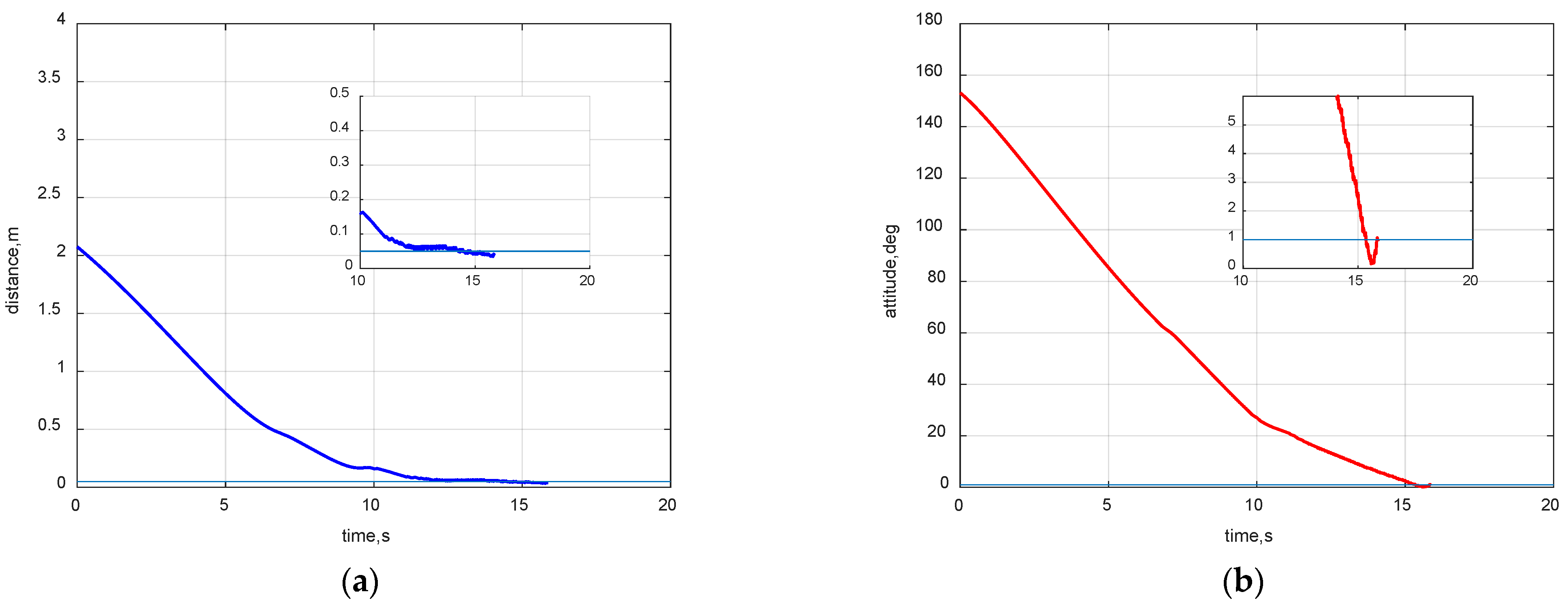
4.3. Space Mission Application Case
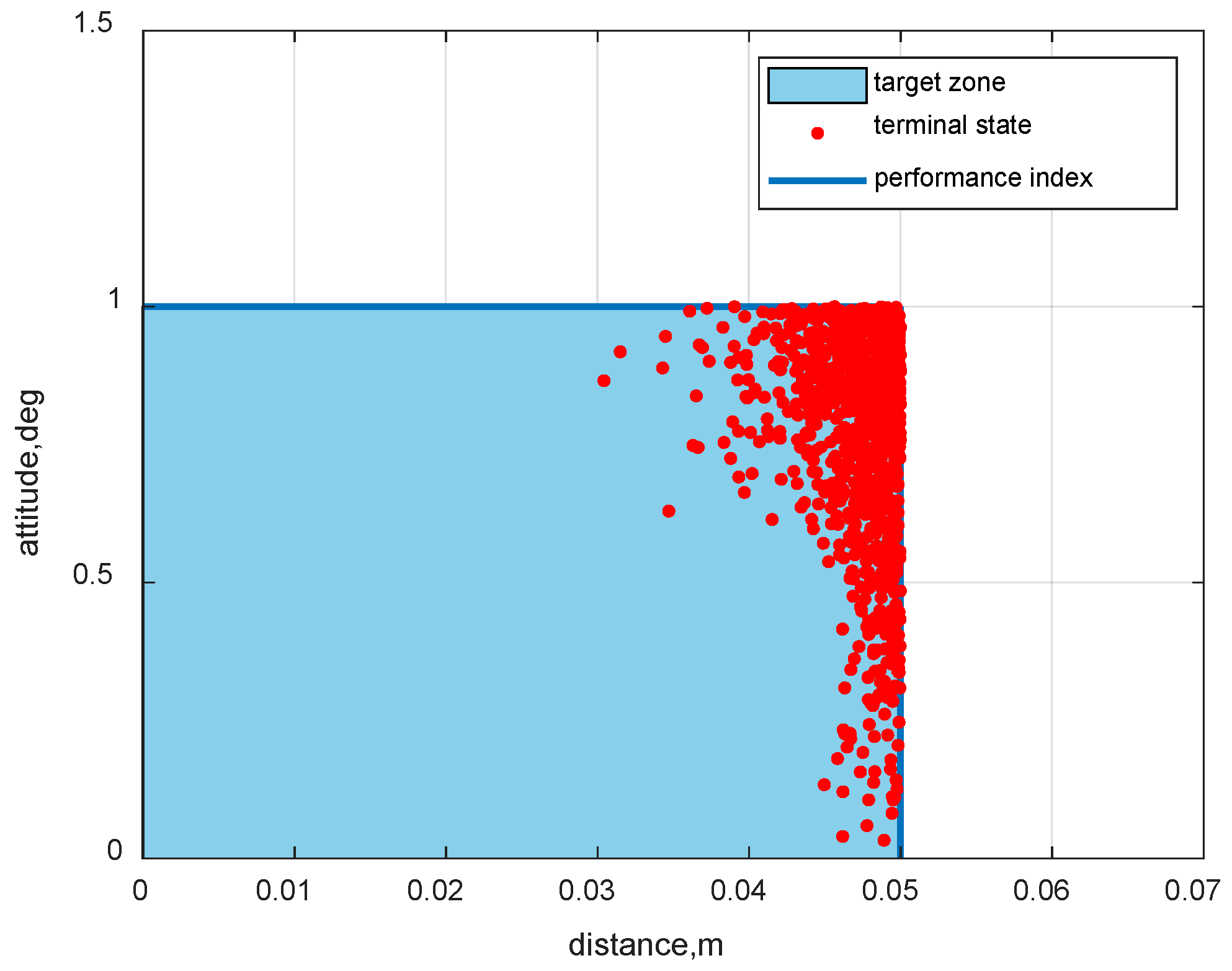
4.4. Robustness Verification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, F.; Jin, D. A high-efficient finite difference method for flexible manipulator with boundary feedback control. Space Sci. Technol. 2021, 2021, 9874563. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, Y.; Xu, W. A light space manipulator with high load-to-weight ratio: System development and compliance control. Space Sci. Technol. 2021, 2021, 9760520. [Google Scholar] [CrossRef]
- Li, S.; She, Y.; Sun, J. Inertial parameter estimation and control of non-cooperative target with unilateral contact constraint. Chin. J. Aeronaut. 2021, 34, 225–240. [Google Scholar] [CrossRef]
- Li, S.; She, Y. Recent advances in contact dynamics and post-capture control for combined spacecraft. Prog. Aerosp. Sci. 2021, 120, 100678. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; Liu, Z.; Jing, X.; Hu, C. A new recursive composite adaptive controller for robot manipulators. Space Sci. Technol. 2021, 2021, 9801421. [Google Scholar] [CrossRef]
- Sun, Z.; Yang, H.; Dong, Q.; Mo, Y.; Li, H.; Jiang, Z. Autonomous Assembly Method of 3-Arm Robot to Fix the Multipin and Hole Load Plate on a Space Station. Space Sci. Technol. 2021, 2021, 9815389. [Google Scholar] [CrossRef]
- Jiang, Z.; Cao, X.; Huang, X.; Li, H.; Ceccarelli, M. Progress and Development Trend of Space Intelligent Robot Technology. Space Sci. Technol. 2022, 2022, 9832053. [Google Scholar] [CrossRef]
- Wang, R.; Liang, C.; Pan, D.; Zhang, X.; Xin, P.; Du, X. Research on a Visual Servo Method of a Manipulator Based on Velocity Feedforward. Space Sci. Technol. 2021, 2021, 9763179. [Google Scholar] [CrossRef]
- Wang, M.; Luo, J.; Fang, J.; Yuan, J. Optimal trajectory planning of free-floating space manipulator using differential evolution algorithm. Adv. Space Res. 2018, 61, 1525–1536. [Google Scholar] [CrossRef]
- Liu, X.; Baoyin, H.; Ma, X. Optimal path planning of redundant free-floating revolute-jointed space manipulators with seven links. Multibody Syst. Dyn. 2013, 29, 41–56. [Google Scholar] [CrossRef]
- Rybus, T.; Wojtunik, M.; Basmadji, F.L. Optimal collision-free path planning of a free-floating space robot using spline-based trajectories. Acta Astronaut. 2022, 190, 395–408. [Google Scholar] [CrossRef]
- Jin, R.; Rocco, P.; Geng, Y. Cartesian trajectory planning of space robots using a multi-objective optimization. Aerosp. Sci. Technol. 2021, 108, 106360. [Google Scholar] [CrossRef]
- Zhang, Q.; Kang, G.; Wu, J.; Zhang, H. Pre-impact Trajectory Planning of Nonredundant Free-Floating Space Manipulator. In Proceedings of the 2020 5th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 19–20 September 2020; pp. 58–65. [Google Scholar]
- Lu, X.; Jia, Y. Trajectory planning of free-floating space manipulators with spacecraft attitude stabilization and manipulability optimization. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 7346–7362. [Google Scholar] [CrossRef]
- Misra, G.; Bai, X. Optimal path planning for free-flying space manipulators via sequential convex programming. J. Guid. Control. Dyn. 2017, 40, 3019–3026. [Google Scholar] [CrossRef]
- Misra, G.; Bai, X. Task-Constrained Trajectory Planning of Free-Floating Space-Robotic Systems Using Convex Optimization. J. Guid. Control. Dyn. 2017, 40, 2857–2870. [Google Scholar] [CrossRef]
- Lu, J.; Yang, H. Trajectory Planning of Satellite Base Attitude Disturbance Optimization for Space Robot. In Proceedings of the 2020 3rd International Conference on Control and Robots (ICCR), Tokyo, Japan, 26–29 December 2020; pp. 85–89. [Google Scholar]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. In Autonomous Robot Vehicles; Springer: Berlin/Heidelberg, Germany, 1986. [Google Scholar]
- Liu, S.; Zhang, Q.; Zhou, D. Obstacle avoidance path planning of space manipulator based on improved artificial potential field method. J. Inst. Eng. Ser. C 2014, 95, 31–39. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, M.; Wang, X.; He, S.; He, J.; Xu, Z. An improved artificial potential field method of trajectory planning and obstacle avoidance for redundant manipulators. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418799562. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Wang, Z.; Ou, Y. Obstacle avoidance of manipulators based on improved artificial potential field method. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 564–569. [Google Scholar]
- Zhang, N.; Zhang, Y.; Ma, C.; Wang, B. Path planning of six-DOF serial robots based on improved artificial potential field method. In Proceedings of the 2017 IEEE International Conference on Robotics and Biomimetics (ROBIO), Macau, China, 5–8 December 2017; pp. 617–621. [Google Scholar]
- Huang, X.; Li, S.; Yang, B.; Sun, P.; Liu, X.; Liu, X. Spacecraft guidance and control based on artificial intelligence: Review. Acta Aeronaut. Astronaut. Sin. 2021, 42, 524201. [Google Scholar]
- She, Y.; Li, S.; Xin, M. Quantum-interference Artificial Neural Network with Application to Space Manipulator Control. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 2167–2182. [Google Scholar] [CrossRef]
- Nguyen, H.; La, H. Review of deep reinforcement learning for robot manipulation. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 590–595. [Google Scholar]
- Yan, C.; Zhang, Q.; Liu, Z.; Wang, X.; Liang, B. Control of free-floating space robots to capture targets using soft q-learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 654–660. [Google Scholar]
- Liang, B.; Chen, Z.; Guo, M.; Wang, Y.; Wang, Y. Space robot target intelligent capture system based on deep reinforcement learning model. J. Phys. Conf. Ser. 2021, 1848, 012078. [Google Scholar] [CrossRef]
- Stan, L.; Nicolescu, A.F.; Pupăză, C. Reinforcement learning for assembly robots: A review. Proc. Manuf. Syst. 2020, 15, 135–146. [Google Scholar]
- Li, Z.; Ma, H.; Ding, Y.; Wang, C.; Jin, Y. Motion planning of six-dof arm robot based on improved DDPG algorithm. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 3954–3959. [Google Scholar]
- Zhou, J.; Zheng, H.; Zhao, D.; Chen, Y. Intelligent Control of Manipulator Based on Deep Reinforcement Learning. In Proceedings of the 2021 12th International Conference on Mechanical and Aerospace Engineering (ICMAE), Athens, Greece, 16–19 July 2021; pp. 275–279. [Google Scholar]
- Man, H.; Ge, N.; Xu, L. Intelligent Motion Control Method Based on Directional Drive for 3-DOF Robotic Arm. In Proceedings of the 2021 5th International Conference on Robotics and Automation Sciences (ICRAS), Wuhan, China, 11–13 June 2021; pp. 144–149. [Google Scholar]
- Zeng, R.; Liu, M.; Zhang, J.; Li, X.; Zhou, Q.; Jiang, Y. Manipulator control method based on deep reinforcement learning. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 415–420. [Google Scholar]
- Du, D.; Zhou, Q.; Qi, N.; Wang, X.; Liu, Y. Learning to Control a Free-floating Space Robot using Deep Reinforcement Learning. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 17–19 October 2019; pp. 519–523. [Google Scholar]
- Hu, X.; Huang, X.; Hu, T.; Shi, Z.; Hui, J. MRDDPG Algorithms for Path Planning of Free-Floating Space Robot. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 1079–1082. [Google Scholar]
- Wu, Y.H.; Yu, Z.C.; Li, C.Y.; He, M.J.; Hua, B.; Chen, Z.M. Reinforcement learning in dual-arm trajectory planning for a free-floating space robot. Aerosp. Sci. Technol. 2020, 98, 105657. [Google Scholar] [CrossRef]
- Li, Y.; Hao, X.; She, Y.; Li, S.; Yu, M. Constrained motion planning of free-float dual-arm space manipulator via deep reinforcement learning. Aerosp. Sci. Technol. 2021, 109, 106446. [Google Scholar] [CrossRef]
- Umetani, Y.; Yoshida, K. Resolved motion rate control of space manipulators with generalized Jacobian matrix. IEEE Trans. Robot. Autom. 1989, 5, 303–314. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Body | Mass, kg | Shape | Length, m | |||
|---|---|---|---|---|---|---|
| Base | 3000 | Box | 835 | 835 | 835 | [1, 1, 1] |
| Link 1 | 5 | Cylinder | 0.04 | 0.04 | 0.00625 | 0.3 |
| Link 2 | 5 | Cylinder | 0.02 | 0.02 | 0.00625 | 0.2 |
| Link 3 | 5 | Cylinder | 0.02 | 0.02 | 0.00625 | 0.2 |
| Link 4 | 20 | Cylinder | 1.68 | 1.68 | 0.025 | 1 |
| Link 5 | 20 | Cylinder | 1.68 | 1.68 | 0.025 | 1 |
| Link 6 | 5 | Cylinder | 0.02 | 0.02 | 0.00625 | 0.2 |
| Link 7 | 5 | Cylinder | 0.02 | 0.02 | 0.00625 | 0.2 |
| Link 8 | 5 | Cylinder | 0.04 | 0.04 | 0.00625 | 0.3 |
| Link 1 | Link 2 | Link 3 | Link 4 | Link 5 | Link 6 | Link 7 | Link 8 | |
|---|---|---|---|---|---|---|---|---|
| Link 1 | - | - | × | √ | √ | √ | √ | √ |
| Link 2 | - | - | - | × | × | × | × | √ |
| Link 3 | × | - | - | - | × | × | × | √ |
| Link 4 | √ | × | - | - | - | × | × | √ |
| Link 5 | √ | × | × | - | - | - | × | √ |
| Link 6 | √ | × | × | × | - | - | - | × |
| Link 7 | √ | × | × | × | × | - | - | - |
| Link 8 | √ | √ | √ | √ | √ | × | - | - |
| States | Initial Configuration for Training | Initial Configuration for Testing |
|---|---|---|
| (0, 0, 1) | (0, 0, 1) | |
| (0, 0, 0) | (0, 0, 0) | |
| (0, 0, 0) | (0, 0, 0) | |
| (0, 0, 0) | (0, 0, 0) | |
| Random selected within movable range of joints | (0.635, −0.474, −0.423, −0.190, 0.727, −0.072) (0.648, 0.232, 0.546, 0.321, −0.389, −0.382) | |
| 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, D.; Zhu, W.; Sun, J.; Zhang, X.; Li, S. Constrained Motion Planning of 7-DOF Space Manipulator via Deep Reinforcement Learning Combined with Artificial Potential Field. Aerospace 2022, 9, 163. https://doi.org/10.3390/aerospace9030163
Li Y, Li D, Zhu W, Sun J, Zhang X, Li S. Constrained Motion Planning of 7-DOF Space Manipulator via Deep Reinforcement Learning Combined with Artificial Potential Field. Aerospace. 2022; 9(3):163. https://doi.org/10.3390/aerospace9030163
Chicago/Turabian StyleLi, Yinkang, Danyi Li, Wenshan Zhu, Jun Sun, Xiaolong Zhang, and Shuang Li. 2022. "Constrained Motion Planning of 7-DOF Space Manipulator via Deep Reinforcement Learning Combined with Artificial Potential Field" Aerospace 9, no. 3: 163. https://doi.org/10.3390/aerospace9030163