

A Bottom-Up Methodology for the Fast Assessment of CNN Mappings on Energy-Efficient Accelerators

Abstract
:1. Introduction
- How can a flexible and energy-efficient MAC unit be designed that can handle wide bit-width data representations, ranging from 2 to 32 bits?
- How can we easily integrate candidate MAC units into typical CNN accelerator architectures to quickly evaluate their impact on their energy efficiency, when mapping and executing CNNs?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MobileNet | AlexNet | GoogleNet | ResNet-50 | VGGNet-16 | |
|---|---|---|---|---|---|
| 2017 [5] | 2012 [6] | 2014 [7] | 2015 [8] | 2014 [9] | |
| Input size | 224 × 224 | 227 × 227 | 224 × 224 | 224 × 224 | 224 × 224 |
| Num. of convolution layers | 22 | 5 | 57 | 53 | 13 |
| Num. weights | 3.17 M | 2.3 M | 6 M | 23.5 M | 14,7 M |
| Num. of MAC operations | 564 M | 666 M | 1,43 B | 3,86 B | 15.3 B |
| Num. of fully-connected layers | 1 | 3 | 1 | 1 | 3 |
| Num. of weights | 1 M | 58.6 M | 1 M | 2 M | 124 M |
| Num. of MAC operations | 1 M | 58.6 M | 1 M | 2 M | 124 M |
| Total weights | 4.2 M | 61 M | 7 M | 25.5 M | 138 M |
| Total MAC operations | 564 M | 724 M | 1.43 B | 3.9 B | 15.5 B |
1.1. Our Contribution
1.2. Outline
2. Related Work
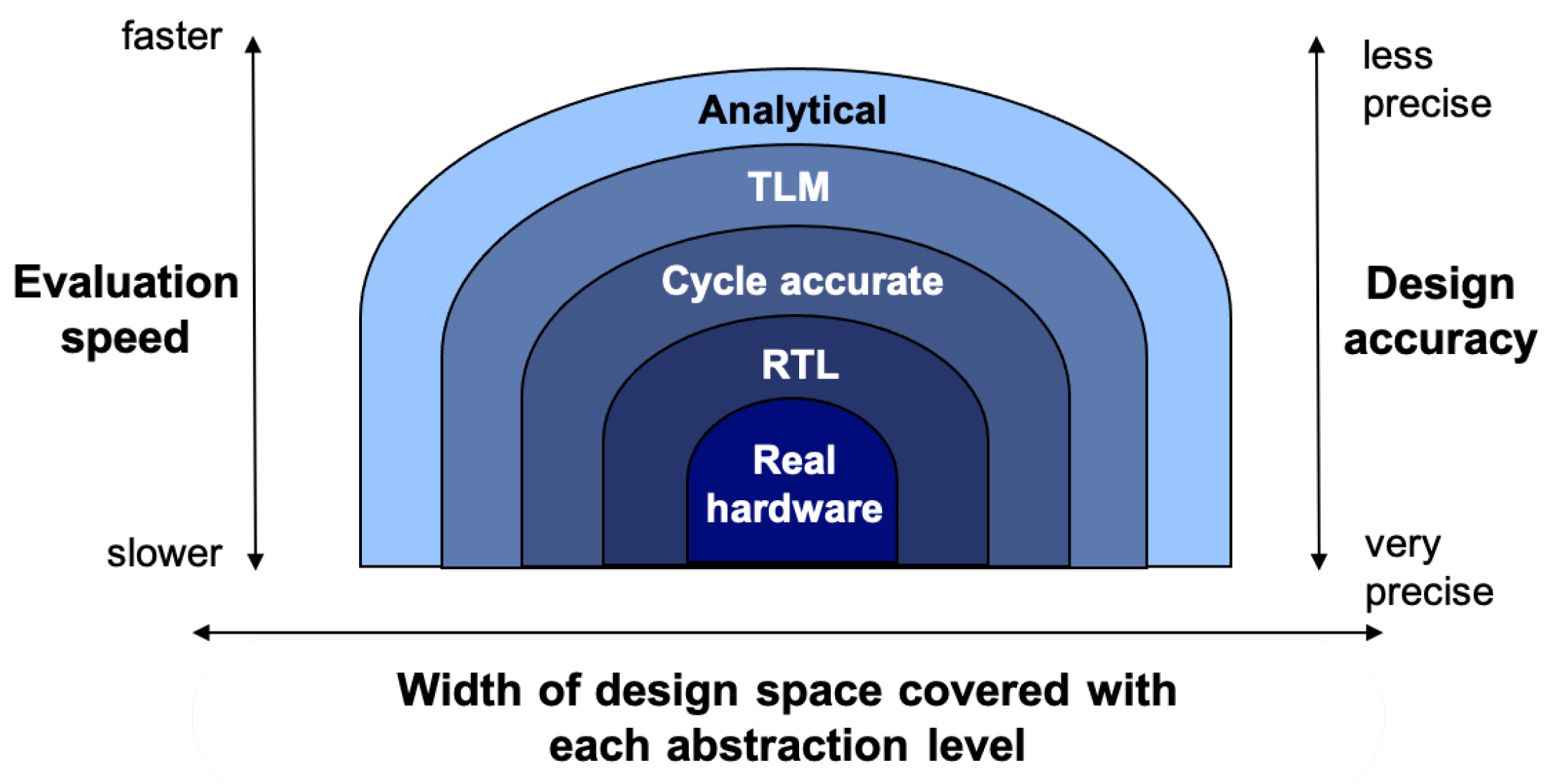
3. Overview of the Proposed Design Methodology
- (1)
- Accurate RTL design [32]. First, we present an efficient MAC unit and assess its energy gain in comparison to the current RISC-V GAP8 MAC unit.
- (2)
- Fast analytical design. Secondly, we explore the impact of the above MAC on energy efficiency at the chip or system level, and we develop an abstract model of the above MAC and integrate it into multiple ML accelerator architectures, besides GAP8.
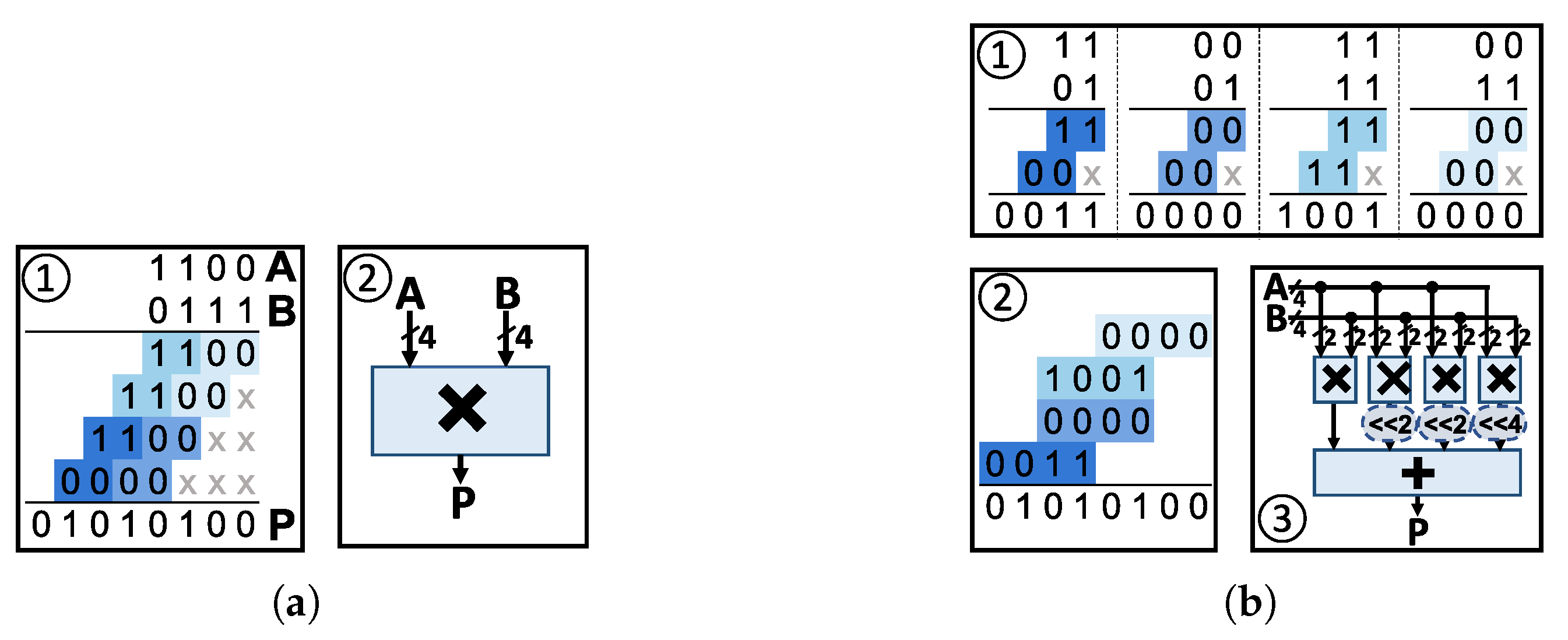
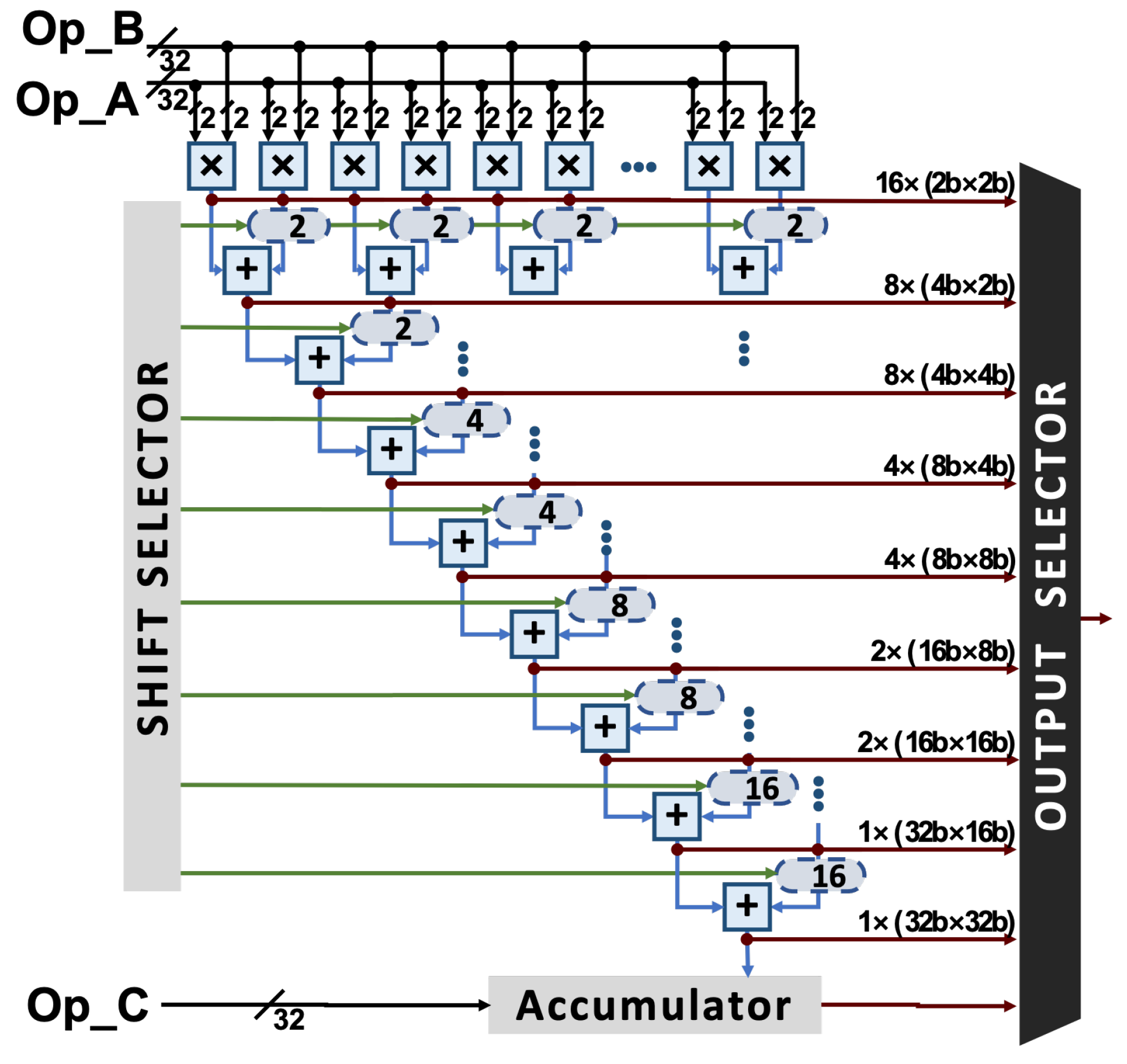
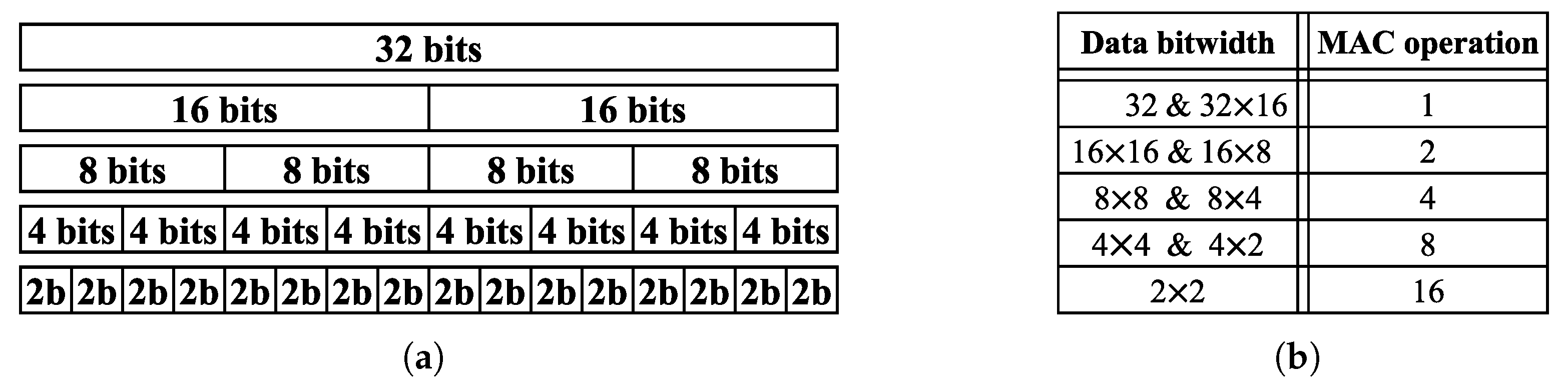
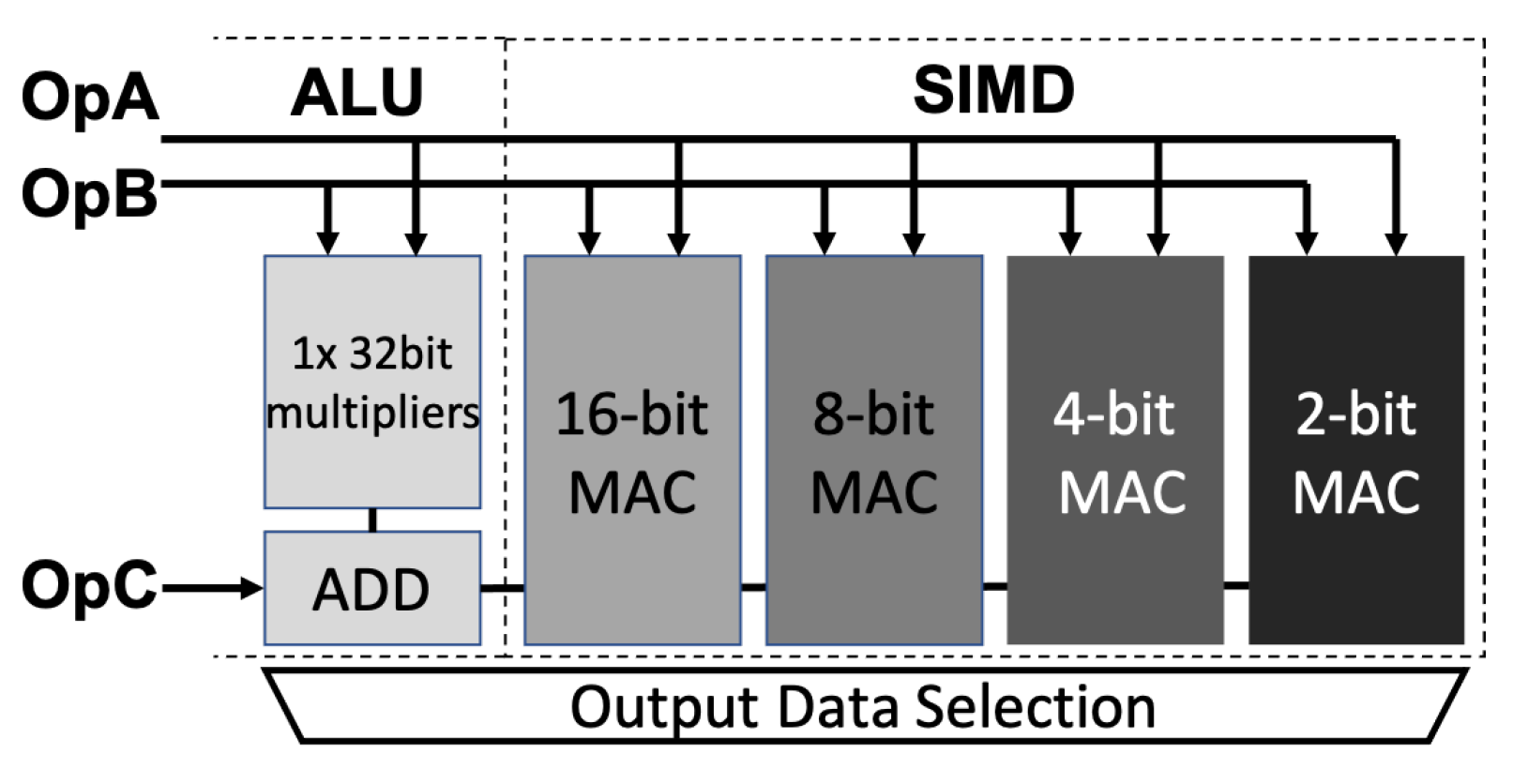
4. A Flexible MAC Unit Design at RTL Level
4.1. Proposed MAC Architecture
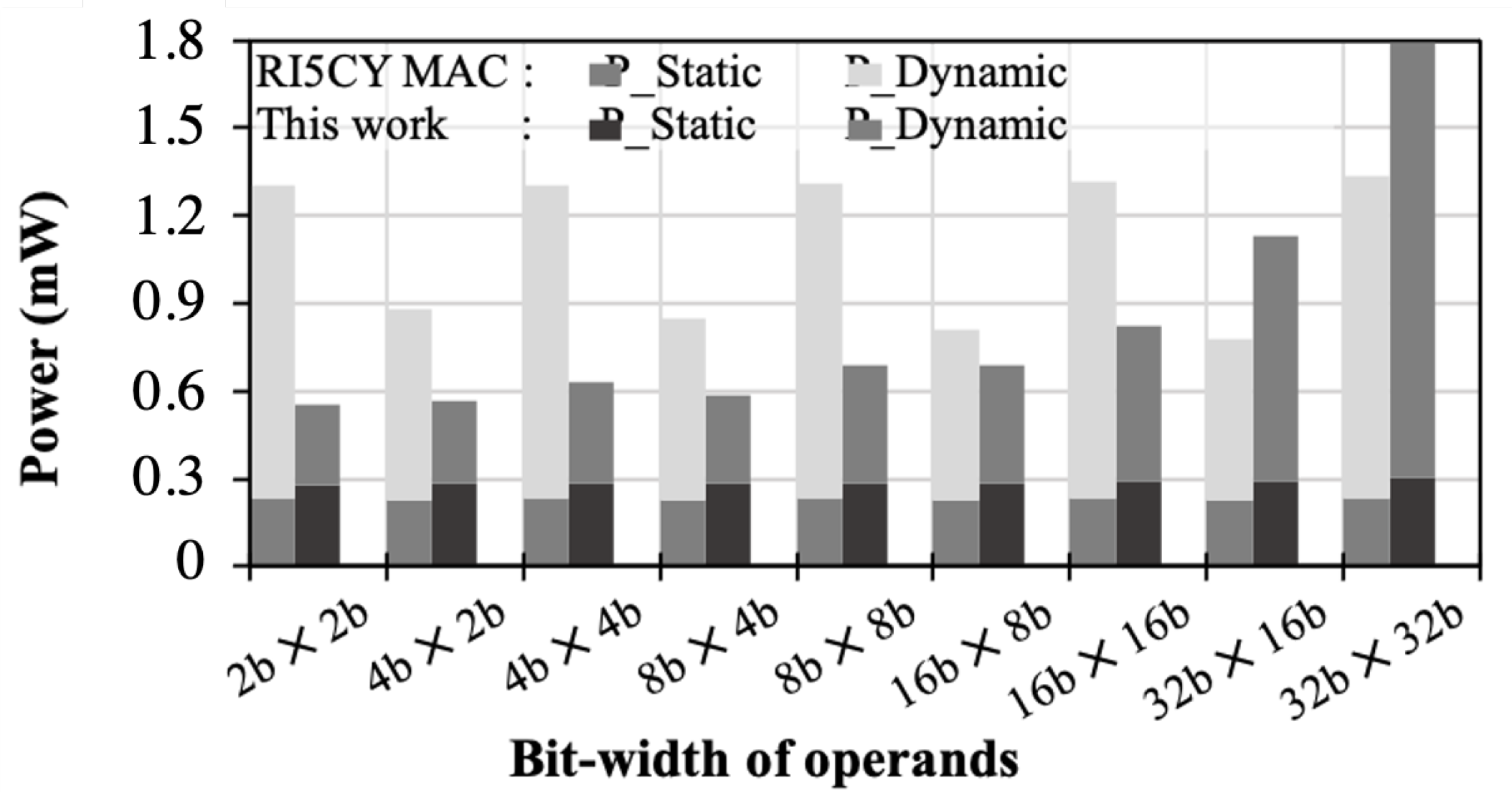
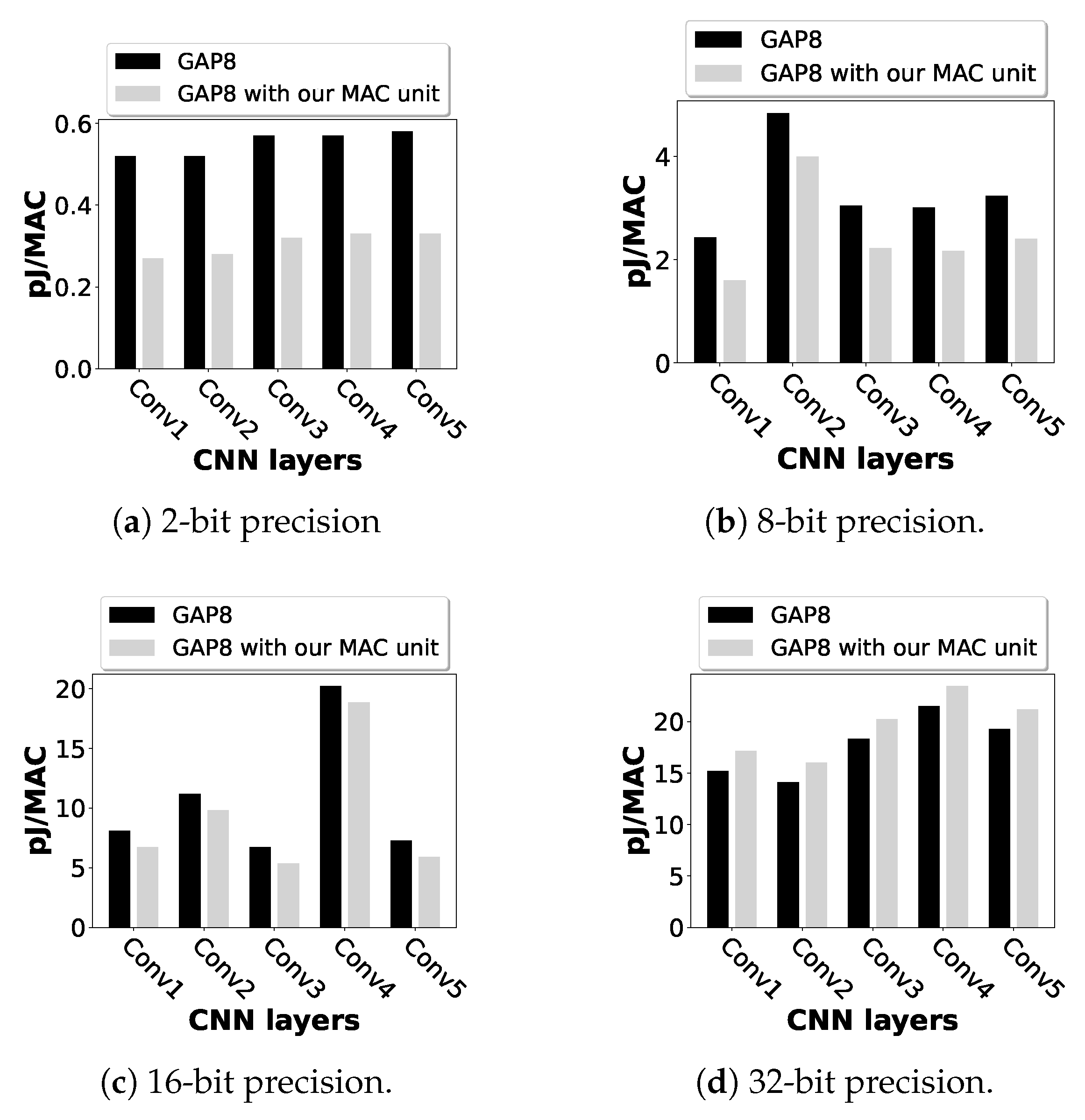
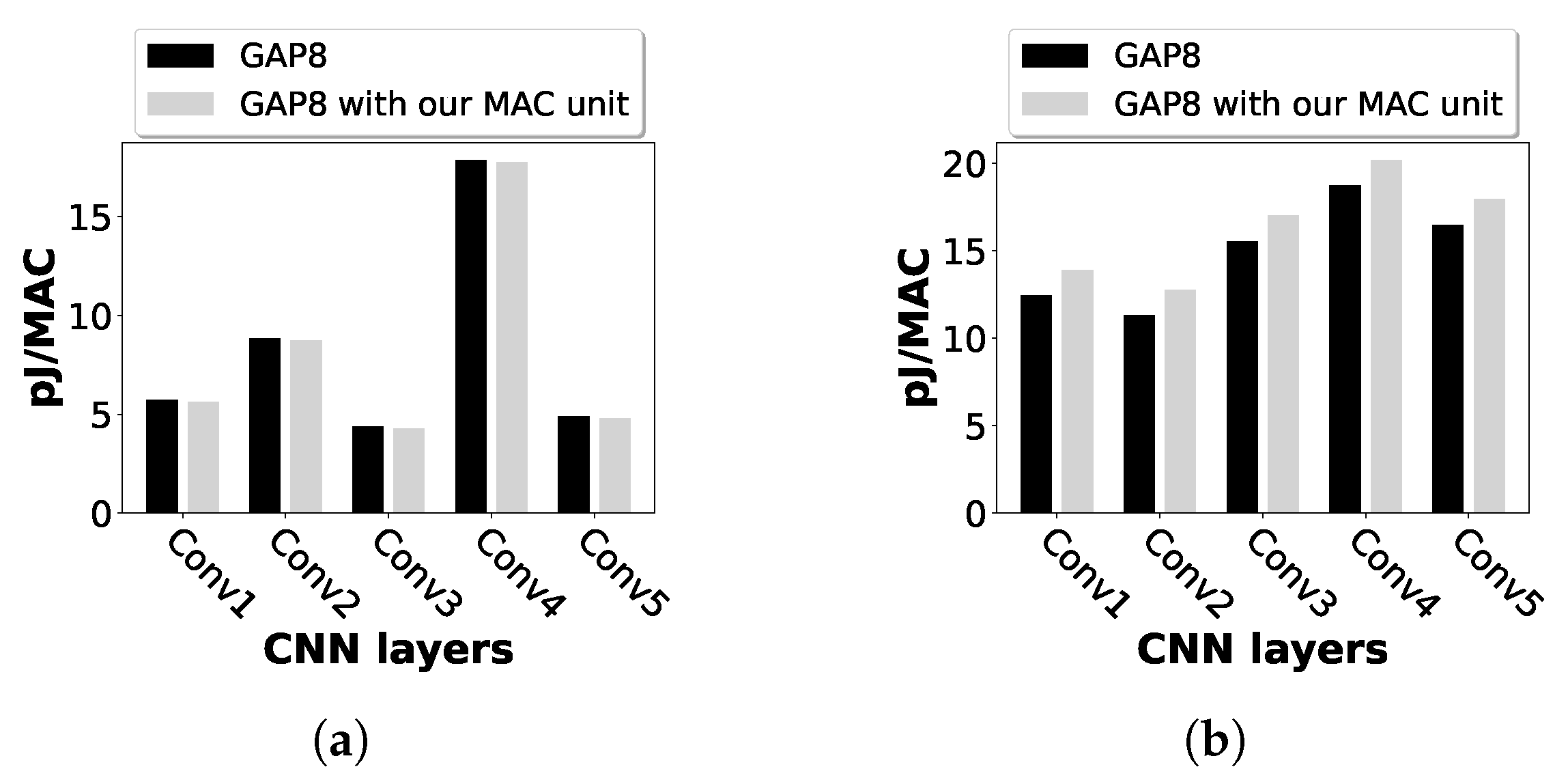
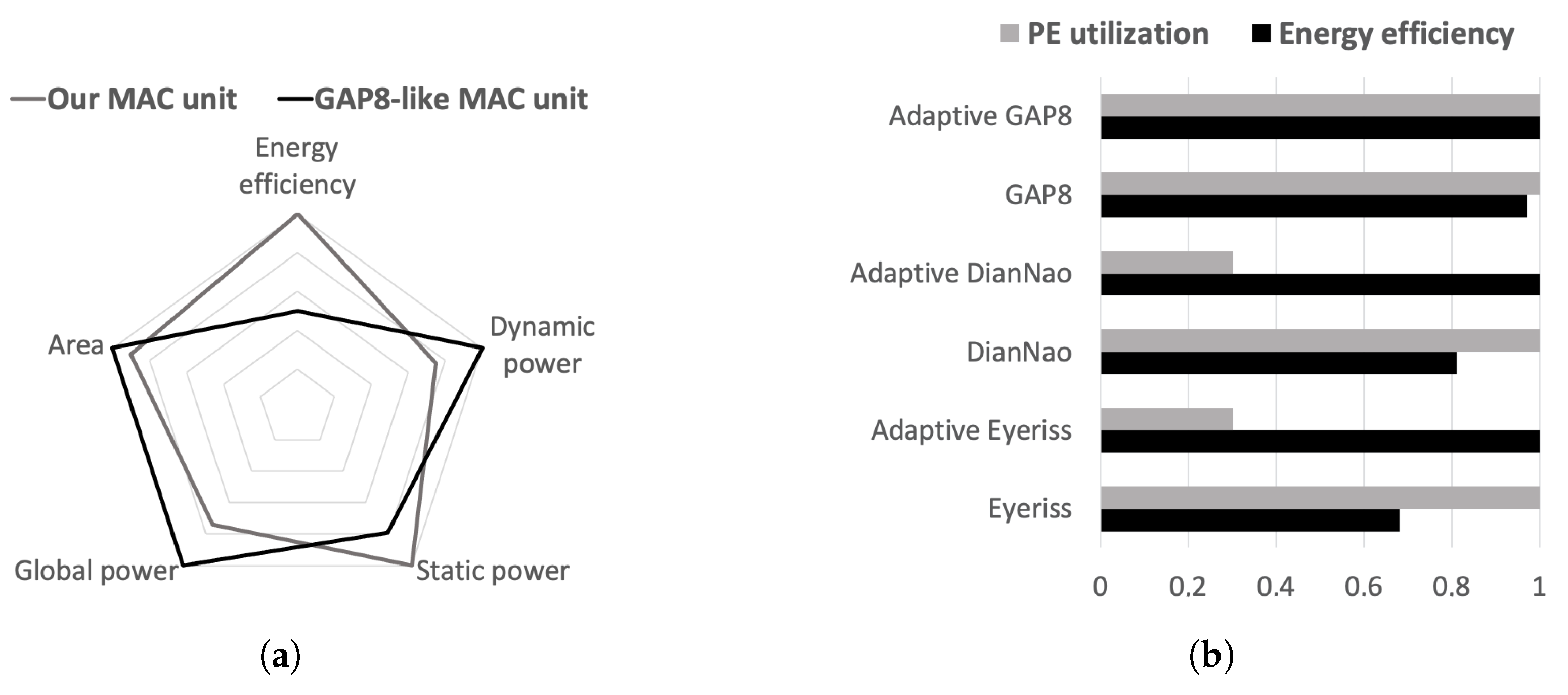
4.2. Design Evaluation
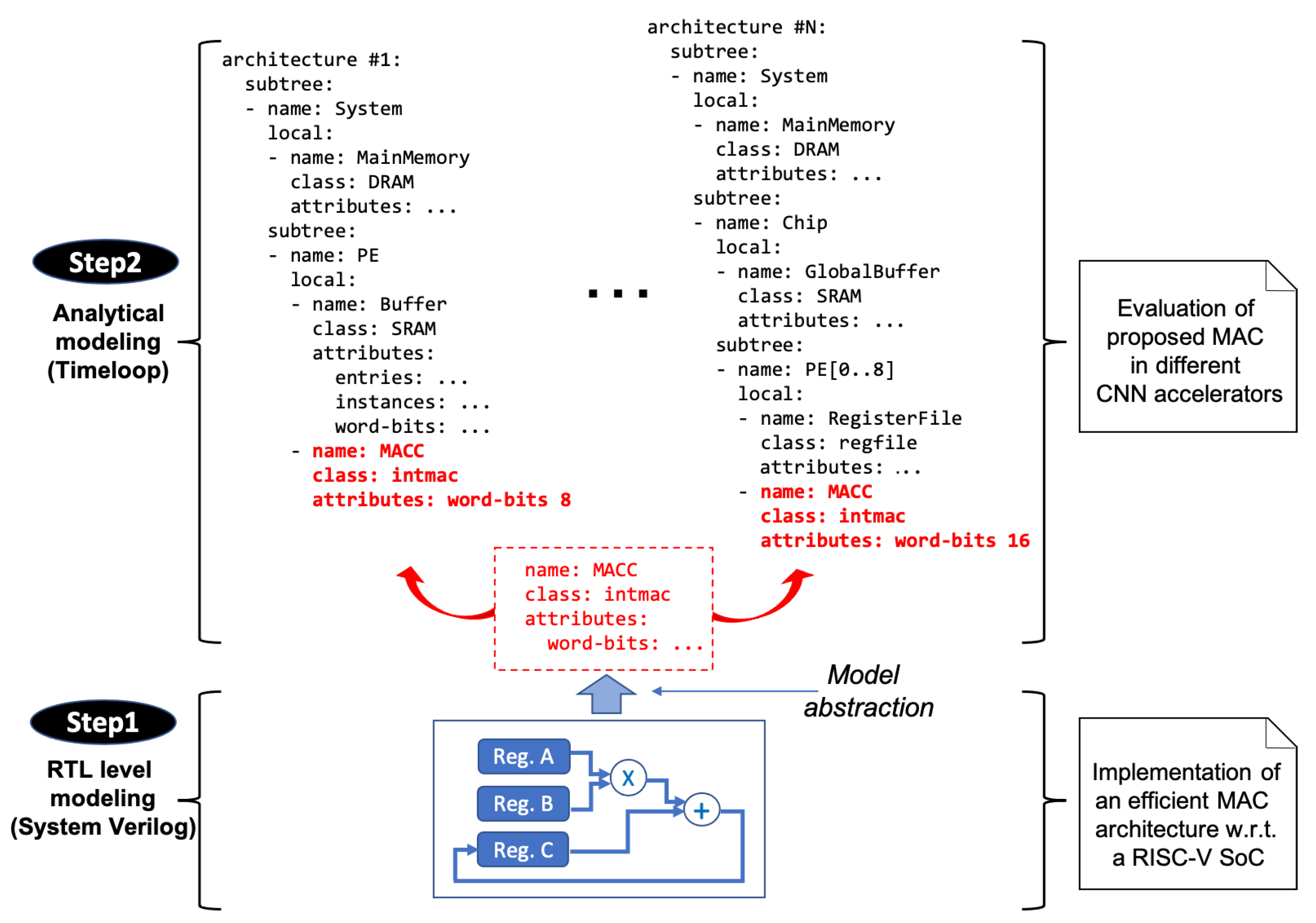
5. Abstraction toward Analytical Modeling of Our MAC Unit
5.1. Timeloop-Based Modeling
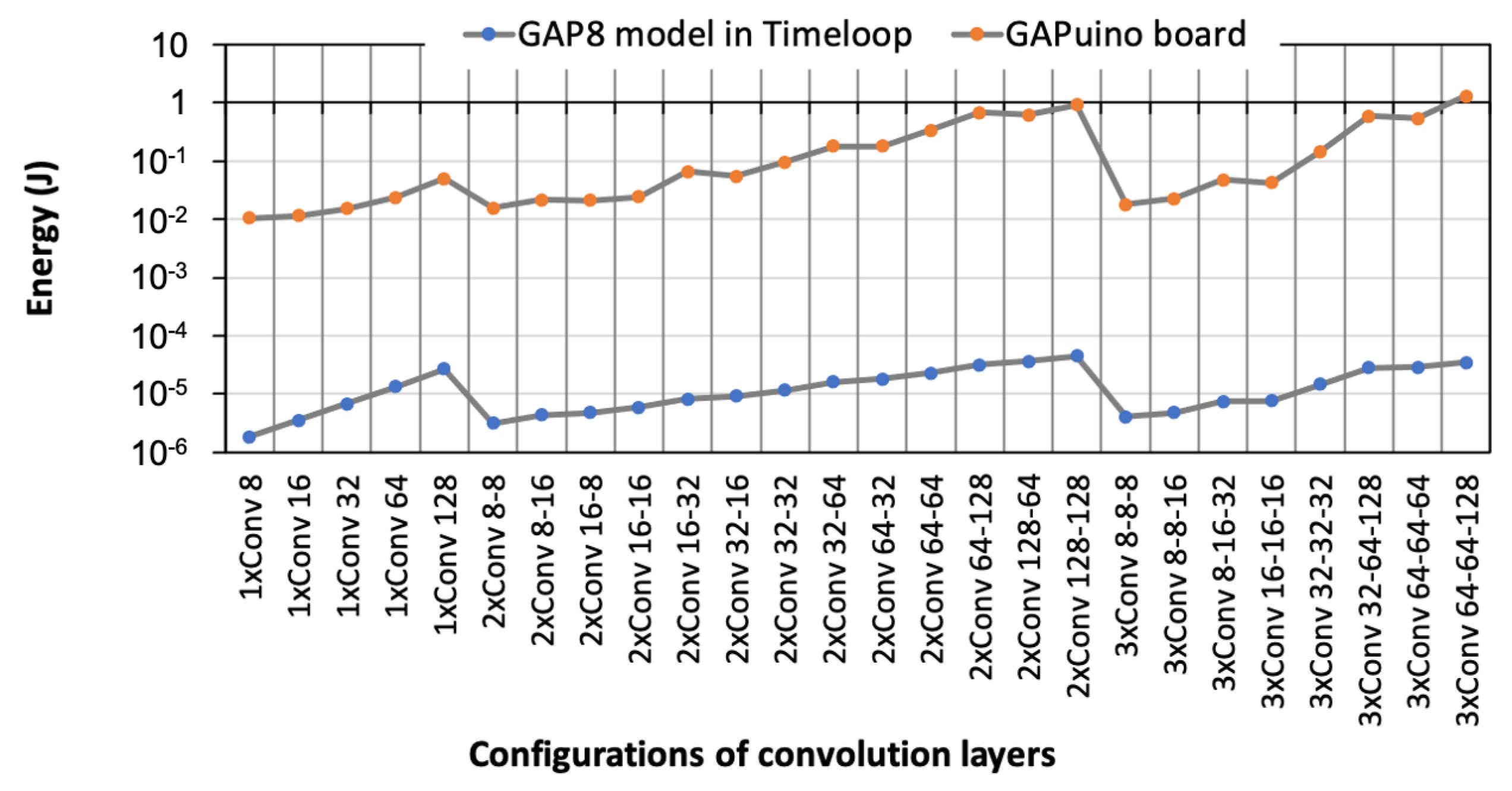
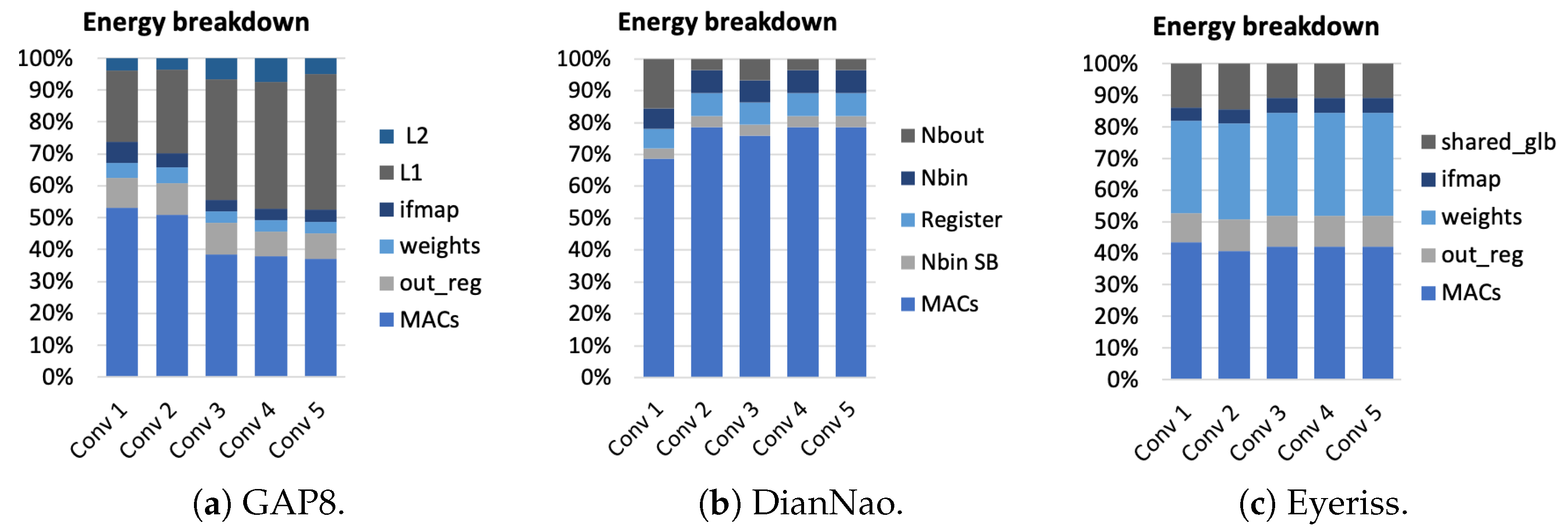
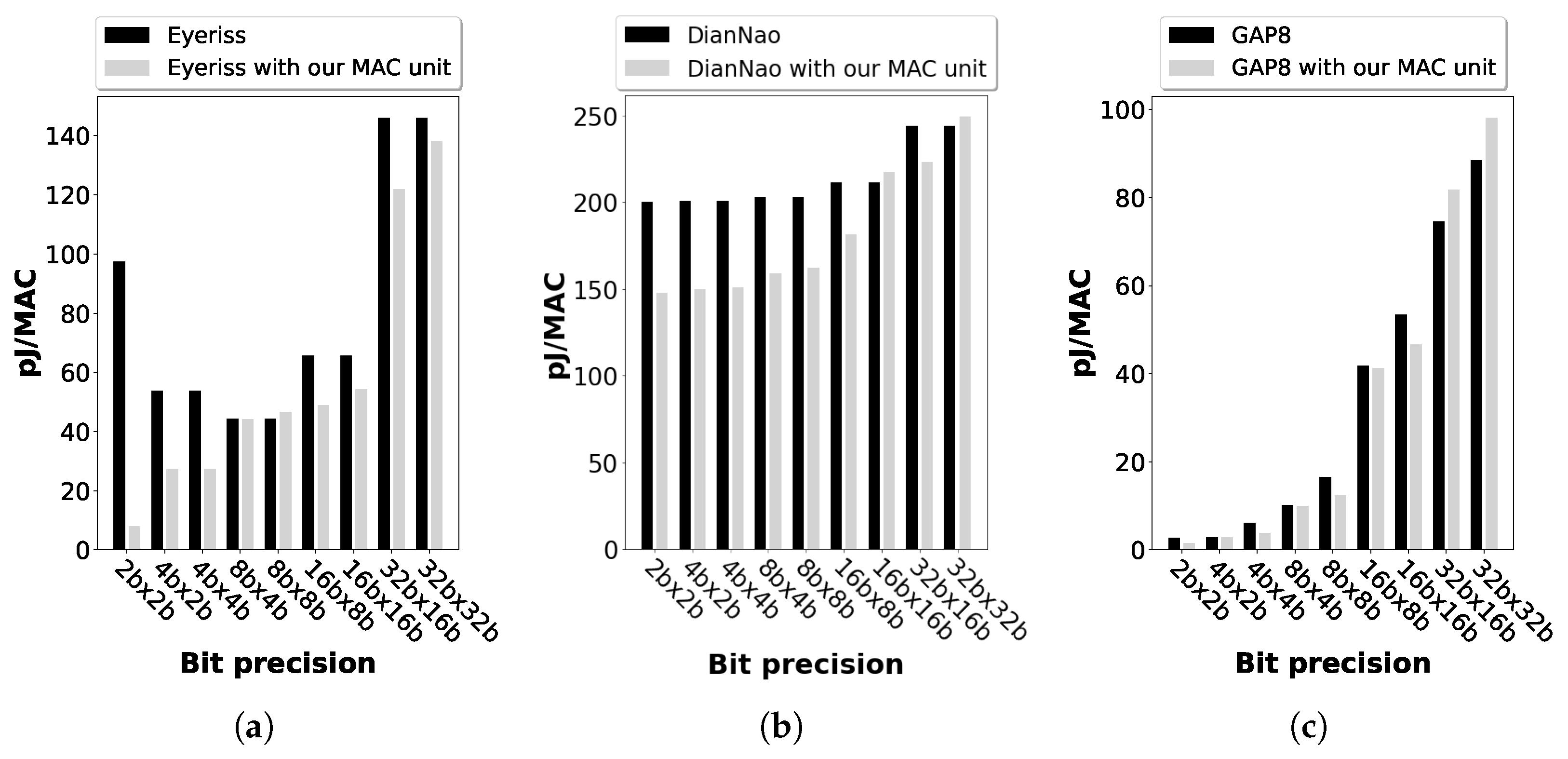
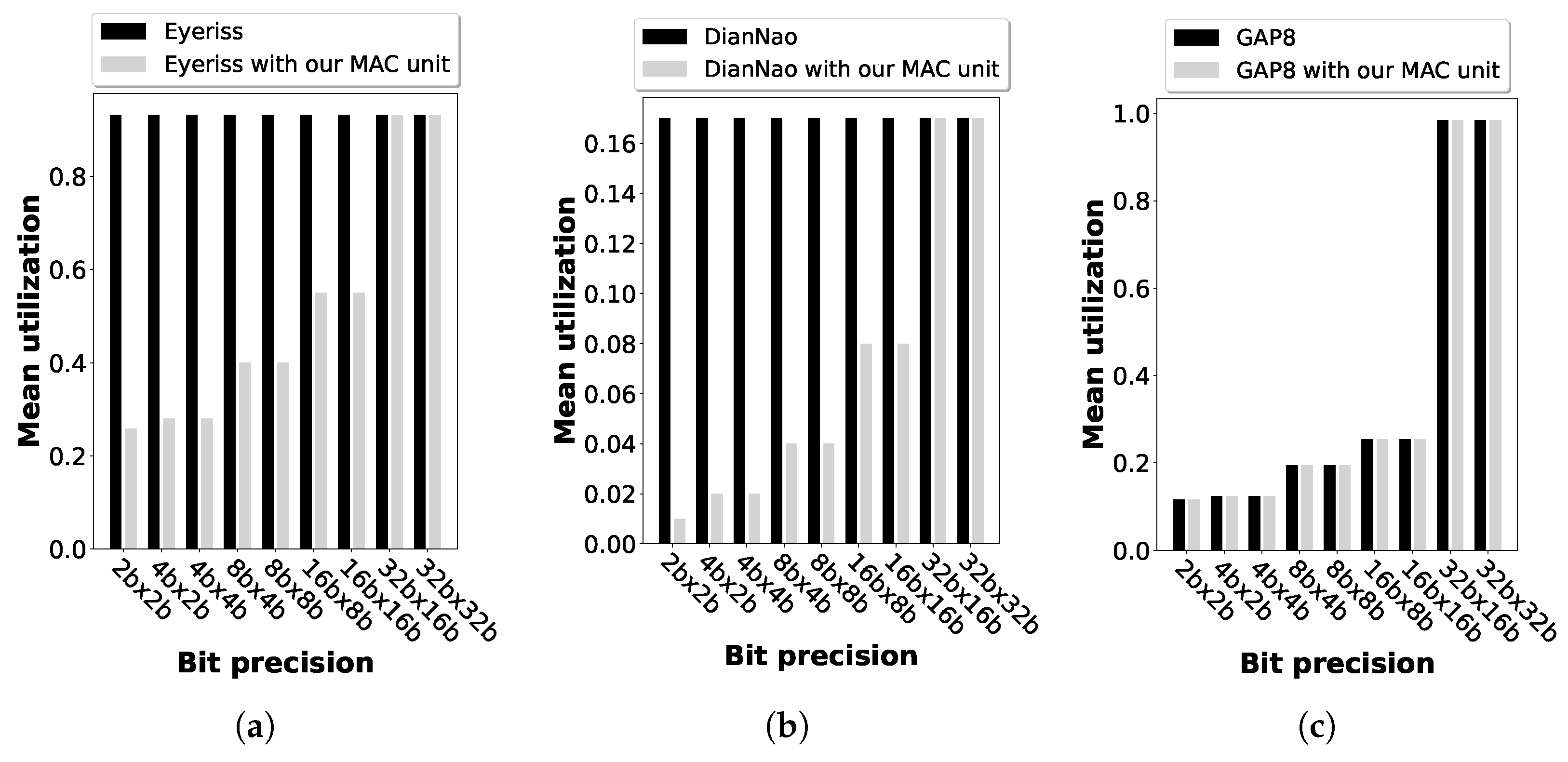
5.2. Evaluation with Regard to GAP8 RISC-V Architecture
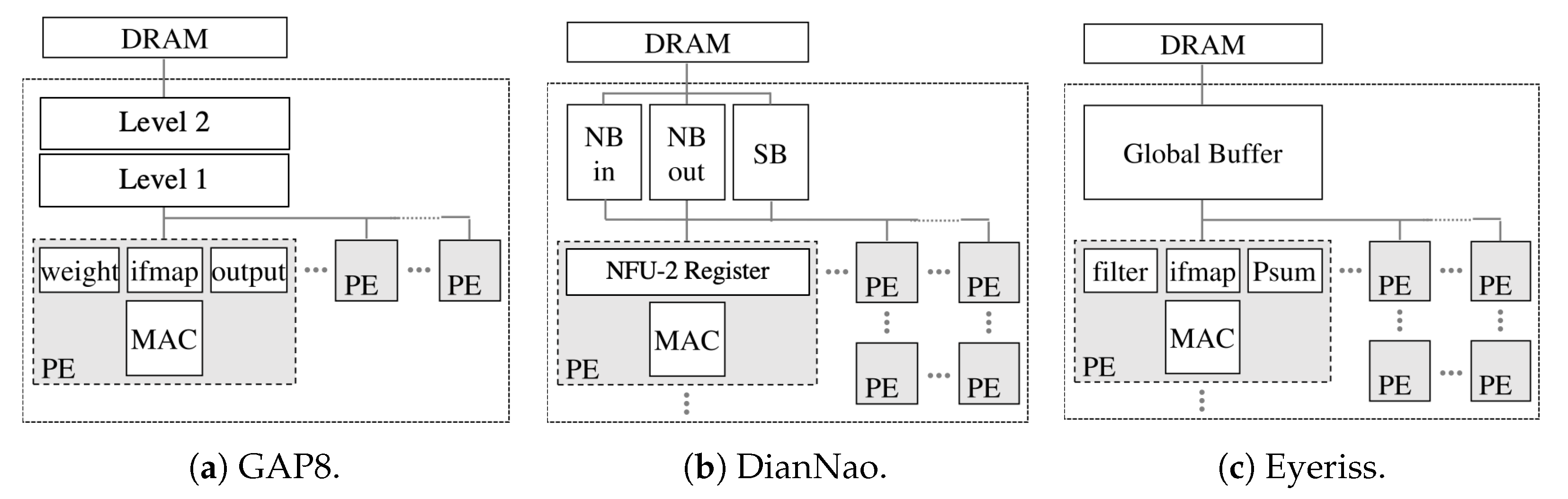
5.3. Evaluation with Regard to Further Architectures
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MAC | Multiply-and-Accumulate |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| RTL | Register Transfer Level |
| TLM | Transaction Level Modeling |
| ISA | Instruction Set Architecture |
| ASIC | Application-Specific Integrated Circuit |
| FPGA | Field-Programmable Gate Array |
| SIMD | Single Instruction Multiple Data |
| ML | Machine Learning |
| SoC | System-on-Chip |
| PE | Processing Element |
References
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for internet of things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Li, H.; Ota, K.; Dong, M. Learning IoT in Edge: Deep Learning for the Internet of Things with Edge Computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef] [Green Version]
- Moons, B.; Goetschalckx, K.; Van Berckelaer, N.; Verhelst, M. Minimum energy quantized neural networks. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 1921–1925. [Google Scholar] [CrossRef] [Green Version]
- Pimentel, A.D. Exploring Exploration: A Tutorial Introduction to Embedded Systems Design Space Exploration. IEEE Des. Test 2017, 34, 77–90. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. CoRR 2017, abs/1704.04861. Available online: https://arxiv.org/abs/1704.04861 (accessed on 4 January 2023).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. CoRR 2014, abs/1409.4842. Available online: https://arxiv.org/abs/1409.4842 (accessed on 4 January 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. CoRR 2015, abs/1512.03385. Available online: https://arxiv.org/abs/1512.03385 (accessed on 4 January 2023).
- Karen Simonyan, A.Z. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; Available online: http://arxiv.org/abs/1409.1556 (accessed on 4 January 2023).
- Gamatié, A.; Devic, G.; Sassatelli, G.; Bernabovi, S.; Naudin, P.; Chapman, M. Towards Energy-Efficient Heterogeneous Multicore Architectures for Edge Computing. IEEE Access 2019, 7, 49474–49491. [Google Scholar] [CrossRef]
- Apvrille, L.; Bécoulet, A. Prototyping an Embedded Automotive System from its UML/SysML Models. In Proceedings of the Embedded Real Time Software and Systems (ERTS’2012), Toulouse, France, 29 January–1 February 2012. [Google Scholar]
- Dekeyser, J.L.; Gamatié, A.; Etien, A.; Ben Atitallah, R.; Boulet, P. Using the UML Profile for MARTE to MPSoC Co-Design. In Proceedings of the First International Conference on Embedded Systems Critical Applications (ICESCA’08), Tunis, Tunisia, 28 May 2008. [Google Scholar]
- Quadri, I.R.; Gamatié, A.; Boulet, P.; Dekeyser, J.L. Modeling of Configurations for Embedded System Implementations in MARTE. In Proceedings of the 1st workshop on Model Based Engineering for Embedded Systems Design-Design, Automation and Test in Europe (DATE 2010), Dresden, Germany, 8–12 March 2010. [Google Scholar]
- Yu, H.; Gamatié, A.; Rutten, É.; Dekeyser, J. Safe design of high-performance embedded systems in an MDE framework. Innov. Syst. Softw. Eng. 2008, 4, 215–222. [Google Scholar] [CrossRef]
- Breuer, M.; Friedman, A.; Iosupovicz, A. A Survey of the State of the Art of Design Automation. Computer 1981, 14, 58–75. [Google Scholar] [CrossRef]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The Gem5 Simulator. SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Butko, A.; Gamatié, A.; Sassatelli, G.; Torres, L.; Robert, M. Design Exploration for next Generation High-Performance Manycore On-chip Systems: Application to big. LITTLE Architectures. In In Proceedings of the ISVLSI: International Symposium on Very Large Scale Integration; IEEE: Montpellier, France, 2015; pp. 551–556. [Google Scholar] [CrossRef] [Green Version]
- Nocua, A.; Bruguier, F.; Sassatelli, G.; Gamatié, A. ElasticSimMATE: A fast and accurate gem5 trace-driven simulator for multicore systems. In Proceedings of the 12th International Symposium on Reconfigurable Communication-centric Systems-on-Chip, ReCoSoC 2017, Madrid, Spain, 12–14 July 2017; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Ghenassia, F. Transaction-Level Modeling with SystemC: TLM Concepts and Applications for Embedded Systems; Springer: New York, NY, USA, 2006. [Google Scholar]
- Latif, K.; Selva, M.; Effiong, C.; Ursu, R.; Gamatie, A.; Sassatelli, G.; Zordan, L.; Ost, L.; Dziurzanski, P.; Indrusiak, L.S. Design Space Exploration for Complex Automotive Applications: An Engine Control System Case Study. In Proceedings of the 2016 Workshop on Rapid Simulation and Performance Evaluation: Methods and Tools, Prague, Czech Republic, 18 January 2016; RAPIDO ’16. Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Mello, A.; Maia, I.; Greiner, A.; Pecheux, F. Parallel simulation of systemC TLM 2.0 compliant MPSoC on SMP workstations. In Proceedings of the 2010 Design, Automation Test in Europe Conference Exhibition (DATE 2010), Dresden, Germany, 8–12 March 2010; pp. 606–609. [Google Scholar] [CrossRef] [Green Version]
- Schirner, G.; Dömer, R. Quantitative Analysis of the Speed/Accuracy Trade-off in Transaction Level Modeling. ACM Trans. Embed. Comput. Syst. 2009, 8, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Russo, E.; Palesi, M.; Monteleone, S.; Patti, D.; Lahdhiri, H.; Ascia, G.; Catania, V. Exploiting the Approximate Computing Paradigm with DNN Hardware Accelerators. In Proceedings of the 2022 11th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 7–10 June 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Corvino, R.; Gamatié, A.; Geilen, M.; Józwiak, L. Design space exploration in application-specific hardware synthesis for multiple communicating nested loops. In Proceedings of the 2012 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation, SAMOS XII, Samos, Greece, 16–19 July 2012; pp. 128–135. [Google Scholar] [CrossRef] [Green Version]
- An, X.; Boumedien, S.; Gamatié, A.; Rutten, E. CLASSY: A Clock Analysis System for Rapid Prototyping of Embedded Applications on MPSoCs. In Proceedings of the 15th International Workshop on Software and Compilers for Embedded Systems, St. Goar, Germany, 27–28 June 2011; SCOPES ’12. Association for Computing Machinery: New York, NY, USA, 2012; pp. 3–12. [Google Scholar] [CrossRef]
- Caliri, G.V. Introduction to analytical modeling. In Proceedings of the 26th International Computer Measurement Group Conference, Orlando, FL, USA, 10–15 December 2000; pp. 31–36. [Google Scholar]
- Garofalo, A.; Tagliavini, G.; Conti, F.; Rossi, D.; Benini, L. XpulpNN: Accelerating Quantized Neural Networks on RISC-V Processors Through ISA Extensions. In Proceedings of the 2020 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 186–191. [Google Scholar] [CrossRef]
- Gautschi, M.; Schiavone, P.D.; Traber, A.; Loi, I.; Pullini, A.; Rossi, D.; Flamand, E.; Gürkaynak, F.K.; Benini, L. Near-Threshold RISC-V Core With DSP Extensions for Scalable IoT Endpoint Devices. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 2700–2713. [Google Scholar] [CrossRef] [Green Version]
- Parashar, A.; Raina, P.; Shao, Y.S.; Chen, Y.H.; Ying, V.A.; Mukkara, A.; Venkatesan, R.; Khailany, B.; Keckler, S.W.; Emer, J. Timeloop: A Systematic Approach to DNN Accelerator Evaluation. In Proceedings of the 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Madison, WI, USA, 24–26 March 2019; pp. 304–315. [Google Scholar] [CrossRef]
- Wu, Y.N.; Emer, J.S.; Sze, V. Accelergy: An Architecture-Level Energy Estimation Methodology for Accelerator Designs. In Proceedings of the 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Delobelle, T.; Péneau, P.Y.; Gamatié, A.; Bruguier, F.; Senni, S.; Sassatelli, G.; Torres, L. MAGPIE: System-level Evaluation of Manycore Systems with Emerging Memory Technologies. In Proceedings of the 2nd International Workshop on Emerging Memory Solutions-Technology, Manufacturing, Architectures, Design and Test at Design Automation and Test in Europe (DATE’2017), Lausanne, Switzerland, 27–31 March 2017. [Google Scholar]
- Devic, G.; France-Pillois, M.; Salles, J.; Sassatelli, G.; Gamatié, A. Highly-Adaptive Mixed-Precision MAC Unit for Smart and Low-Power Edge Computing. In Proceedings of the 2021 19th IEEE International New Circuits and Systems Conference (NEWCAS), Toulon, France, 13–16 June 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Dally, W.J.; Turakhia, Y.; Han, S. Domain-Specific Hardware Accelerators. Commun. ACM 2020, 63, 48–57. [Google Scholar] [CrossRef]
- Peccerillo, B.; Mannino, M.; Mondelli, A.; Bartolini, S. A survey on hardware accelerators: Taxonomy, trends, challenges, and perspectives. J. Syst. Archit. 2022, 129, 102561. [Google Scholar] [CrossRef]
- Gwennap, L. Esperanto maxes out RISC-V: High-End Maxion CPU Raises RISC-V Performance Bar. Microprocess. Rep. Tech. Rep. 2018. Available online: https://www.esperanto.ai/wp-content/uploads/2018/12/Esperanto-Maxes-Out-RISC-V.pdf (accessed on 4 January 2023).
- Conti, F.; Benini, L. A ultra-low-energy convolution engine for fast brain-inspired vision in multicore clusters. In Proceedings of the 2015 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 683–688. [Google Scholar] [CrossRef]
- DSP for Cortex-M. Available online: https://developer.arm.com/architectures/instruction-sets/dsp-extensions/dsp-for-cortex-m (accessed on 28 January 2012).
- Venieris, S.I.; Bouganis, C.S. fpgaConvNet: A Framework for Mapping Convolutional Neural Networks on FPGAs. In Proceedings of the 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Washington, DC, USA, 1–3 May 2016; pp. 40–47. [Google Scholar] [CrossRef] [Green Version]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; FPGA ’17. Association for Computing Machinery: New York, NY, USA, 2017; pp. 65–74. [Google Scholar] [CrossRef] [Green Version]
- Dundar, A.; Jin, J.; Martini, B.; Culurciello, E. Embedded Streaming Deep Neural Networks Accelerator With Applications. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1572–1583. [Google Scholar] [CrossRef] [PubMed]
- Dundar, A.; Jin, J.; Gokhale, V.; Martini, B.; Culurciello, E. Memory access optimized routing scheme for deep networks on a mobile coprocessor. In Proceedings of the 2014 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 9–11 September 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, Y.; Emer, J.S.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. In Proceedings of the ISCA. IEEE Computer Society, Seoul, Republic of Korea, 18–22 June 2016; pp. 367–379. [Google Scholar]
- Chen, Y.H.; Yang, T.J.; Emer, J.; Sze, V. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning. In Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems, Salt Lake City, UT, USA, 1–5 March 2014; ASPLOS ’14. Association for Computing Machinery: New York, NY, USA, 2014; pp. 269–284. [Google Scholar] [CrossRef]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient Inference Engine on Compressed Deep Neural Network. CoRR 2016, abs/1602.01528. Available online: https://arxiv.org/abs/1602.01528 (accessed on 4 January 2023).
- Cavigelli, L.; Gschwend, D.; Mayer, C.; Willi, S.; Muheim, B.; Benini, L. Origami: A Convolutional Network Accelerator. CoRR 2015, abs/1512.04295. Available online: https://arxiv.org/pdf/1512.04295.pdf (accessed on 4 January 2023).
- Yin, S.; Ouyang, P.; Tang, S.; Tu, F.; Li, X.; Liu, L.; Wei, S. A 1.06-to-5.09 TOPS/W reconfigurable hybrid-neural-network processor for deep learning applications. In Proceedings of the 2017 Symposium on VLSI Circuits, Kyoto, Japan, 5–8 June 2017; pp. C26–C27. [Google Scholar] [CrossRef]
- Ando, K.; Ueyoshi, K.; Orimo, K.; Yonekawa, H.; Sato, S.; Nakahara, H.; Ikebe, M.; Asai, T.; Takamaeda-Yamazaki, S.; Kuroda, T.; et al. BRein memory: A 13-layer 4.2 K neuron/0.8 M synapse binary/ternary reconfigurable in-memory deep neural network accelerator in 65 nm CMOS. In Proceedings of the 2017 Symposium on VLSI Circuits, Kyoto, Japan, 5–8 June 2017; pp. C24–C25. [Google Scholar] [CrossRef]
- Sharma, H.; Park, J.; Suda, N.; Lai, L.; Chau, B.; Kim, J.K.; Chandra, V.; Esmaeilzadeh, H. Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks. CoRR 2017, abs/1712.01507. Available online: https://arxiv.org/pdf/1712.01507.pdf (accessed on 4 January 2023).
- Sharify, S.; Lascorz, A.D.; Judd, P.; Moshovos, A. Loom: Exploiting Weight and Activation Precisions to Accelerate Convolutional Neural Networks. CoRR 2017, abs/1706.07853. Available online: https://arxiv.org/abs/1706.07853 (accessed on 4 January 2023).
- Lee, J.; Kim, C.; Kang, S.; Shin, D.; Kim, S.; Yoo, H.J. UNPU: A 50.6TOPS/W unified deep neural network accelerator with 1b-to-16b fully-variable weight bit-precision. In Proceedings of the 2018 IEEE International Solid - State Circuits Conference-(ISSCC), San Francisco, CA, USA, 11–15 February 2018; pp. 218–220. [Google Scholar] [CrossRef]
- Ueyoshi, K.; Ando, K.; Hirose, K.; Takamaeda-Yamazaki, S.; Hamada, M.; Kuroda, T.; Motomura, M. QUEST: Multi-Purpose Log-Quantized DNN Inference Engine Stacked on 96-MB 3-D SRAM Using Inductive Coupling Technology in 40-nm CMOS. IEEE J. -Solid-State Circuits 2019, 54, 186–196. [Google Scholar] [CrossRef]
- Moons, B.; Uytterhoeven, R.; Dehaene, W.; Verhelst, M. 14.5 Envision: A0.26-to-10TOPS/W subword-parallel dynamic-voltage-accuracy-frequency-Convolutional Neural Network processor in 28nm FDSOI. In Proceedings of the 2017 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–9 February 2017; pp. 246–247. [Google Scholar] [CrossRef]
- Shin, D.; Lee, J.; Lee, J.; Yoo, H.J. 14.2 DNPU: An 8.1TOPS/W reconfigurable CNN-RNN processor for general-purpose deep neural networks. In Proceedings of the 2017 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–9 February 2017; pp. 240–241. [Google Scholar] [CrossRef]
- Yuan, Z.; Yang, Y.; Yue, J.; Liu, R.; Feng, X.; Lin, Z.; Wu, X.; Li, X.; Yang, H.; Liu, Y. 16284.2 A 65nm 24.7µJ/Frame 12.3mW Activation-Similarity-Aware Convolutional Neural Network Video Processor Using Hybrid Precision, Inter-Frame Data Reuse and Mixed-Bit-Width Difference-Frame Data Codec. In Proceedings of the 2020 IEEE International Solid- State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020; pp. 232–234. [Google Scholar] [CrossRef]
- Wang, J.; Lou, Q.; Zhang, X.; Zhu, C.; Lin, Y.; Chen, D. Design Flow of Accelerating Hybrid Extremely Low Bit-width Neural Network in Embedded FPGA. CoRR 2018, abs/1808.04311. Available online: https://arxiv.org/abs/1808.04311 (accessed on 4 January 2023).
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Yang, J.; Ye, D.; Hua, G. LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 373–390. [Google Scholar]
- Wang, K.; Liu, Z.; Lin, Y.; Lin, J.; Han, S. HAQ: Hardware-Aware Automated Quantization With Mixed Precision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jin, Q.; Yang, L.; Liao, Z. AdaBits: Neural Network Quantization with Adaptive Bit-Widths. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Soufleri, E.; Roy, K. Network Compression via Mixed Precision Quantization Using a Multi-Layer Perceptron for the Bit-Width Allocation. IEEE Access 2021, 9, 135059–135068. [Google Scholar] [CrossRef]
- Camus, V.; Mei, L.; Enz, C.; Verhelst, M. Review and Benchmarking of Precision-Scalable Multiply-Accumulate Unit Architectures for Embedded Neural-Network Processing. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 697–711. [Google Scholar] [CrossRef]
- Roelke, A.; Stan, M.R. Risc5: Implementing the RISC-V ISA in gem5. In Proceedings of the First Workshop on Computer Architecture Research with RISC-V (CARRV), Boston, MA, USA, 14 October 2017. [Google Scholar]
- RISC-V. Spike RISC-V ISA Simulator. 2021. Available online: https://github.com/riscv/riscv-isa-sim (accessed on 24 October 2022).
- Imperas. riscvOVPsim - Free Imperas RISC-V Instruction Set Simulator. Available online: https://www.imperas.com/riscvovpsim-free-imperas-risc-v-instruction-set-simulator (accessed on 24 October 2022).
- RISC-V. RARS – RISC-V Assembler and Runtime Simulator. Available online: https://github.com/TheThirdOne/rars (accessed on 24 October 2022).
- QEMU. RISC-V System Emulator. 2021. Available online: https://qemu.readthedocs.io/en/latest/system/target-riscv.html (accessed on 24 October 2022).
- GAPuino GAP8 Development Board. Available online: https://greenwaves-technologies.com/product/gapuino/ (accessed on 24 October 2022).
- Page Github du Coeur cv32e40p (RI5CY). [en Ligne] Consulté le. Available online: https://github.com/openhwgroup/cv32e40p (accessed on 20 August 2021).
- Ottavi, G.; Garofalo, A.; Tagliavini, G.; Conti, F.; Di Mauro, A.; Benini, L.; Rossi, D. Dustin: A 16-Cores Parallel Ultra-Low-Power Cluster with 2b-to-32b Fully Flexible Bit-Precision and Vector Lockstep Execution Mode. 2022. Available online: https://arxiv.org/abs/2201.08656 (accessed on 4 January 2023).

















| Name | Technology (nm) | Frequency (MHz) | Energy Eff. (TOPS/W) | MAC Adaptivity | Supported Bit Widths |
|---|---|---|---|---|---|
| Eyeriss [42] | 28 | 200 | 0.15–0.35 | no | 16 |
| Eyeriss V2 [43] | 65 | 200 | 0.96 | no | 8 |
| Envision [53] | 28 | 200 | 0.53–10 | yes | 2, 4, 8, 16 |
| UNPU [51] | 65 | 200 | 3.08–50 | yes | 1–16 |
| DNPU [54] | 65 | 200 | 2.1–8.1 | yes | 4, 8, 16 |
| Origami [46] | 65 | 500 | 0.44–0.80 | no | 12 |
| BRein memory [48] | 65 | 400 | 2.3–6.0 | no | 2, 3 |
| QUEST [52] | 40 | 330 | 0.88 | yes | 1, 4 |
| Zhe Yuan et al. [55] | 65 | 100 | 0.13–13.3 | - | 1, 2, 4, 8 |
| DianNao [44] | 65 | 980 | 0.93 | no | 16 |
| EIE [45] | 45 | 800 | 10.49 | no | 4 |
| Bit Fusion [49] | 45 | 500 | - | yes | 2, 4, 8, 16 |
| Loom [50] | 65 | 1000 | - | yes | 2, 4, 8, 16 |
| Yin et al. [47] | 65 | 200 | 1.27 | yes | 8–16 |
| Wang et al. [56] | FPGA | 200 | 10.3 | yes | 1–8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Devic, G.; Sassatelli, G.; Gamatié, A. A Bottom-Up Methodology for the Fast Assessment of CNN Mappings on Energy-Efficient Accelerators. J. Low Power Electron. Appl. 2023, 13, 5. https://doi.org/10.3390/jlpea13010005
Devic G, Sassatelli G, Gamatié A. A Bottom-Up Methodology for the Fast Assessment of CNN Mappings on Energy-Efficient Accelerators. Journal of Low Power Electronics and Applications. 2023; 13(1):5. https://doi.org/10.3390/jlpea13010005
Chicago/Turabian StyleDevic, Guillaume, Gilles Sassatelli, and Abdoulaye Gamatié. 2023. "A Bottom-Up Methodology for the Fast Assessment of CNN Mappings on Energy-Efficient Accelerators" Journal of Low Power Electronics and Applications 13, no. 1: 5. https://doi.org/10.3390/jlpea13010005