

Evaluation of Dynamic Triple Modular Redundancy in an Interleaved-Multi-Threading RISC-V Core
 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
- To demonstrate that thanks to the inherent behavior of an Interleaved-Multi-Threading structure, the use of restoring mechanisms through checkpointing routines is unnecessary and can be replaced by a Dynamic TMR mechanism;
- To demonstrate the concept of Dynamic TMR and how it can be applied to an existing RISC-V IMT core;
- To report the evaluation of the effectiveness of the proposed technique in a RISC-V IMT core through an extensive fault-injection (FI) simulation.
2. Related Works
3. Proposed Approach
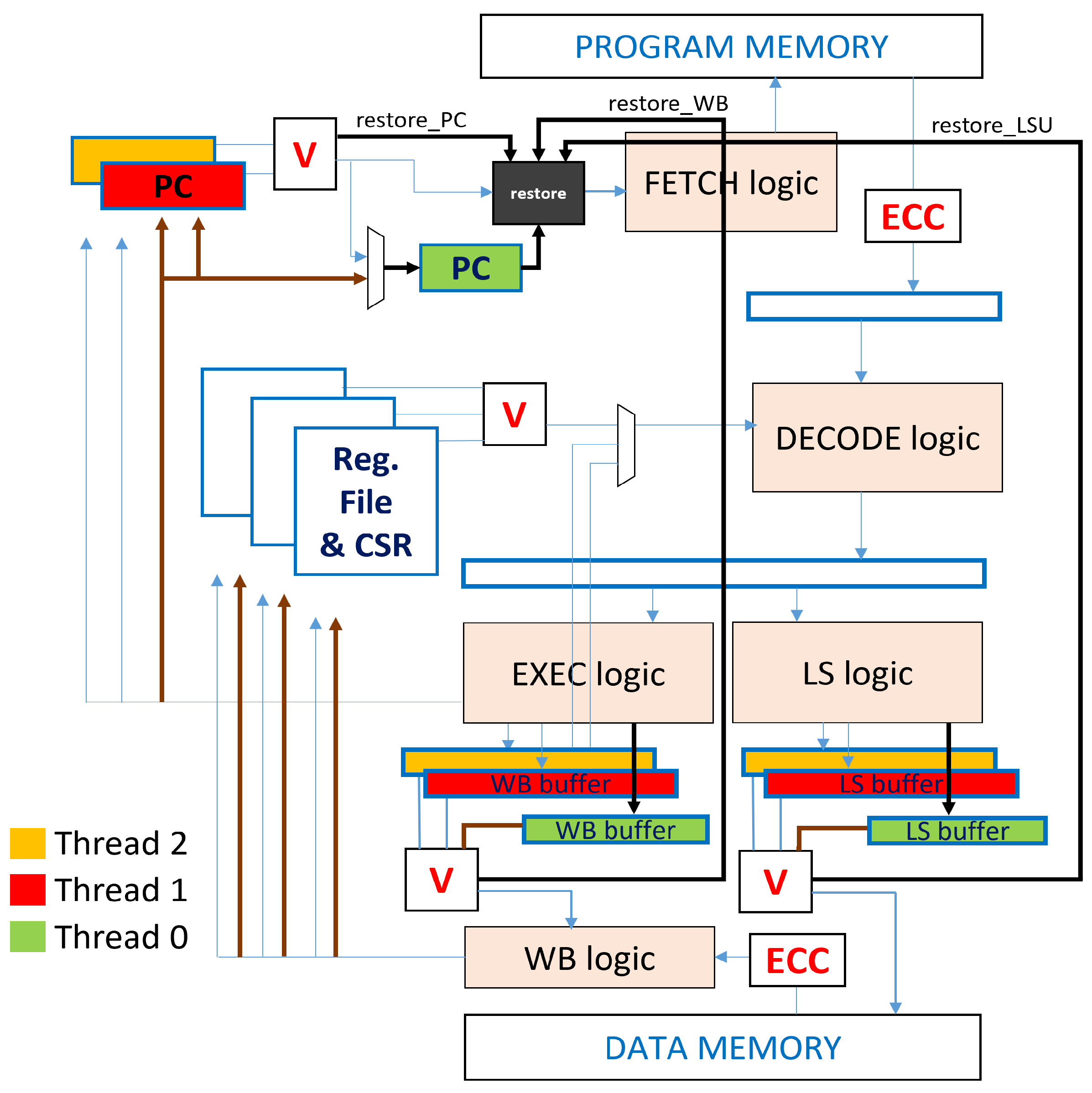
3.1. Klessydra-fT03 Microarchitecture
3.2. The Dynamic TMR Principle
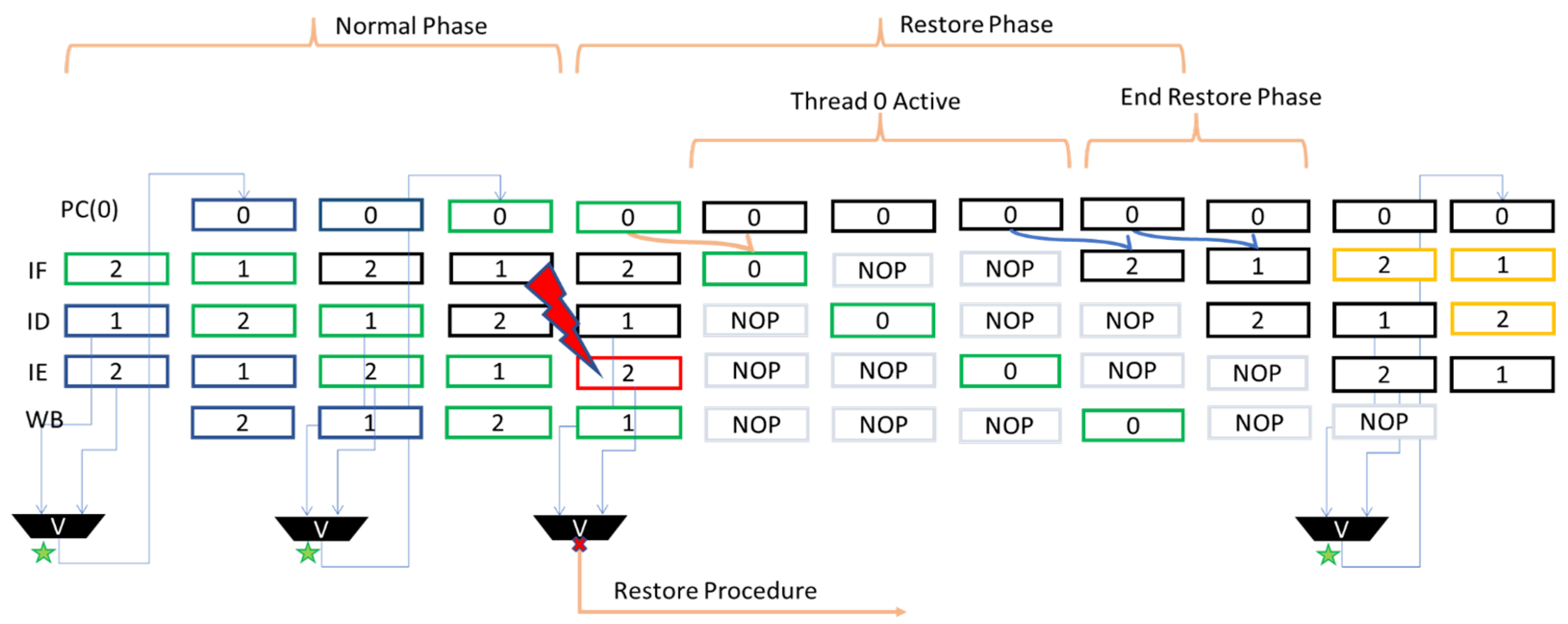
- Normal or “Buffered DMR” mode: Threads 2 and 1 work in interleaved mode (blue arrows in Figure 1), executing the same instructions and thus implementing spatial and temporal redundancy, with a buffered voting mechanism implemented in the critical units PC, Register File, Write Back unit, and Load Store Unit, that check for the correctness of the program execution.
- Restore or Recovery mode: If the voting logic gives a negative result due to a fault, specific control signals named restore_ signals (Figure 1) are asserted, and the core enters the recovery mode. Notably, a fault is always detected before the Register File would be updated with a wrong result using the faulted instruction. Following the black arrows in Figure 1, the restore_ signals activate the restore block (black unit in Figure 1), which wakes up the sleeping auxiliary thread. As the new thread enters the IMT pipeline, it fetches the last successfully executed instruction indicated by the dummy PC register (see next section), while the other threads are stalled.
- End of Restore Phase: Once the recovered instruction is completed, the produced result is compared with the results previously produced by the other two mismatching threads (brown arrows in Figure 1), thus obtaining a majority voting similar to a TMR system, and writing back the correct value into the Register File. The recovery procedure ends with the suspension of the auxiliary Thread 0, and the loading of the address of the next instruction in the PCs of Threads 2 and 1, so that they restart from the instruction following the one that faulted.
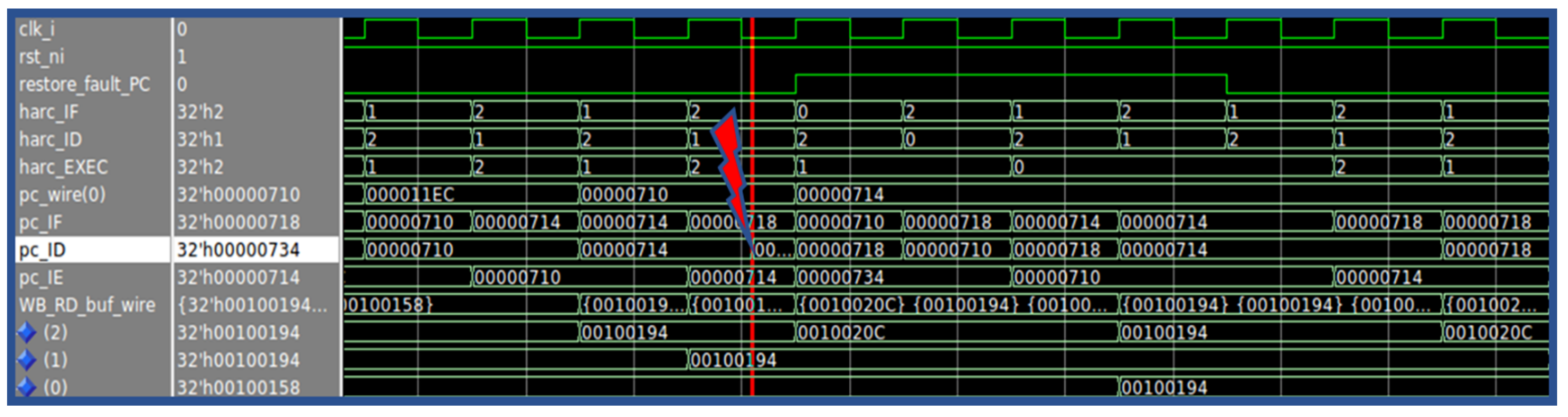
4. An Example of Implementation and Operation
5. Validation Setup
5.1. The Time Frame Span Approach
5.2. Test Programs
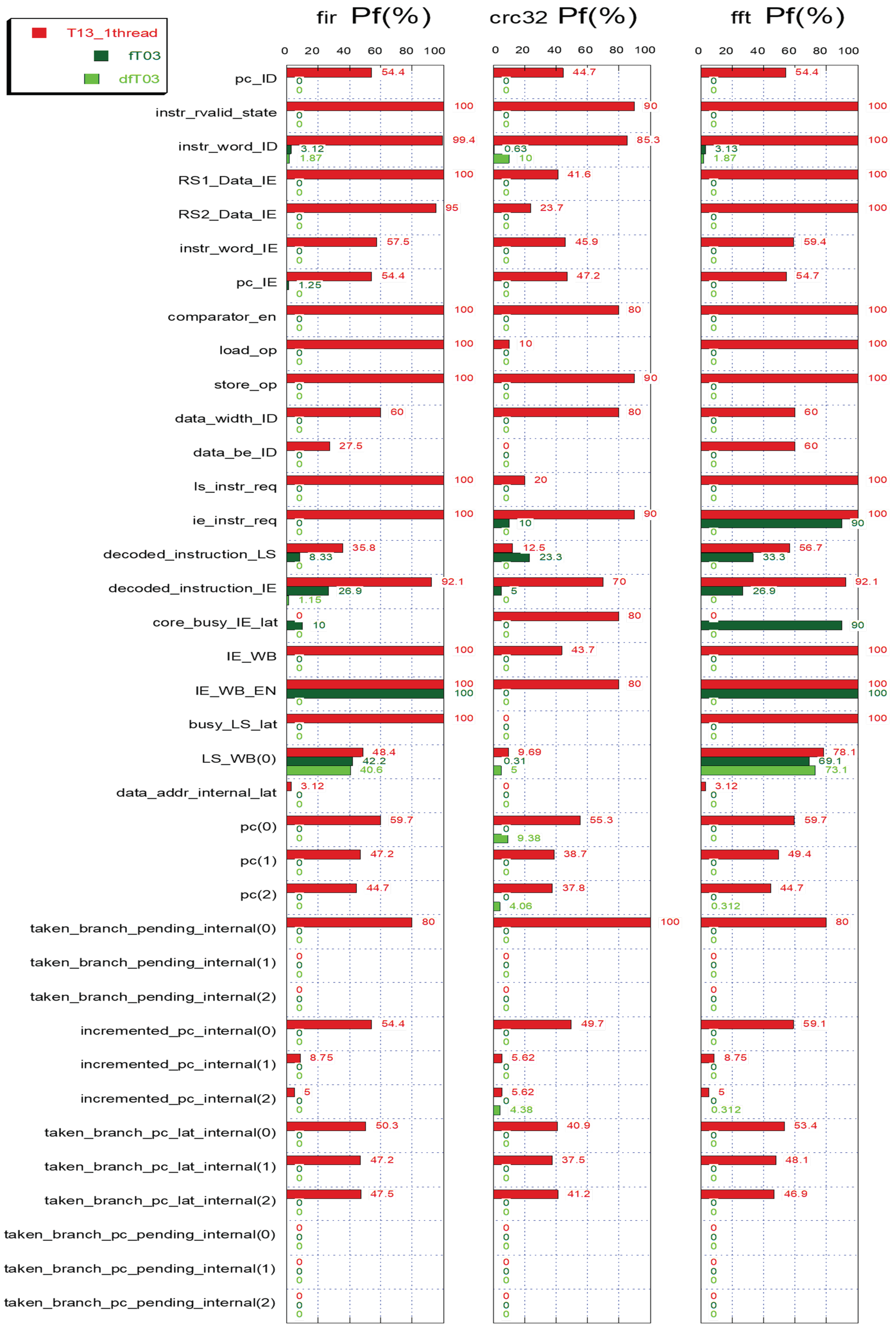
6. Experimental Results
7. Performance Comparison Analysis
8. Impact on Hardware Resources
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Azimi, S.; Sterpone, L. Digital design techniques for dependable high performance computing. In Proceedings of the 2020 IEEE International Test Conference (ITC), Washington, DC, USA, 1–6 November 2020; pp. 1–10. [Google Scholar]
- De Sio, C.; Azimi, S.; Sterpone, L.; Du, B. Analyzing Radiation-Induced Transient Errors on SRAM-Based FPGAs by Propagation of Broadening Effect. IEEE Access 2019, 7, 140182–140189. [Google Scholar] [CrossRef]
- Buzzin, A.; Rossi, A.; Giovine, E.; de Cesare, G.; Belfiore, N.P. Downsizing Effects on Micro and Nano Comb Drives. Actuators 2022, 11, 71. [Google Scholar] [CrossRef]
- De Sio, C.; Azimi, S.; Portaluri, A.; Sterpone, L. SEU evaluation of hardened-by-replication software in RISC-V soft processor. In Proceedings of the 2021 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Athens, Greece, 6–8 October 2021; pp. 1–6. [Google Scholar]
- Azimi, S.; De Sio, C.; Sterpone, L. In-Circuit Mitigation Approach of Single Event Transients for 45nm Flip-Flops. In Proceedings of the 2020 IEEE 26th International Symposium on On-Line Testing and Robust System Design (IOLTS), Napoli, Italy, 13–15 July 2020; pp. 1–6. [Google Scholar]
- Li, J.; Zhang, S.; Bao, C. DuckCore: A Fault-Tolerant Processor Core Architecture Based on the RISC-V ISA. Electronics 2021, 11, 122. [Google Scholar] [CrossRef]
- Santos, D.A.; Luza, L.M.; Dilillo, L.; Zeferino, C.A.; Melo, D.R. Reliability analysis of a fault-tolerant RISC-V system-on-chip. Microelectron. Reliab. 2021, 125, 114346. [Google Scholar] [CrossRef]
- Wilson, A.E.; Wirthlin, M. Neutron radiation testing of fault tolerant RISC-V soft processor on Xilinx SRAM-based FPGAs. In Proceedings of the 2019 IEEE Space Computing Conference (SCC), Pasadena, CA, USA, 30 July–1 August 2019; pp. 25–32. [Google Scholar]
- Carmichael, C.; Fuller, E.; Fabula, J.; Lima, F. Proton testing of SEU mitigation methods for the Virtex FPGA. In Proceedings of the Military and Aerospace Applications of Programmable Logic Devices MAPLD; 2001. [Google Scholar]
- Reis, G.A.; Chang, J.; August, D.I. Automatic instruction-level software-only recovery. IEEE Micro 2007, 27, 36–47. [Google Scholar] [CrossRef]
- Reis, G.A.; Chang, J.; Vachharajani, N.; Rangan, R.; August, D.I. SWIFT: Software implemented fault tolerance. In Proceedings of the International Symposium on Code Generation and Optimization, San Jose, CA, USA, 20–23 March 2005; pp. 243–254. [Google Scholar]
- Serrano-Cases, A.; Restrepo-Calle, F.; Cuenca-Asensi, S.; Martínez-Álvarez, A. Softerror mitigation for multi-core processors based on thread replication. In Proceedings of the 2019 IEEE Latin American Test Symposium (LATS), Santiago, Chile, 11–13 March 2019; pp. 1–5. [Google Scholar]
- Ma, Y.; Zhou, H. Efficient transient-fault tolerance for multithreaded processors using dual-thread execution. In Proceedings of the 2006 International Conference on Computer Design, San Jose, CA, USA, 1–4 October 2006; pp. 120–126. [Google Scholar]
- Sundaramoorthy, K.; Purser, Z.; Rotenberg, E. Slipstream processors: Improving both performance and fault tolerance. ACM SIGPLAN Not. 2000, 35, 257–268. [Google Scholar] [CrossRef]
- Osinski, L.; Langer, T.; Mottok, J. A survey of fault tolerance approaches on different architecture levels. In Proceedings of the ARCS 2017; 30th International Conference on Architecture of Computing Systems, VDE, Vienna, Austria, 3–6 April 2017; pp. 1–9. [Google Scholar]
- Shernta, S.A.; Tamtum, A.A. Using triple modular redundant (tmr) technique in critical systems operation. In Proceedings of the Proceedings of First Conference for Engineering Sciences and Technology (CEST-2018), Garaboulli, Libya, 25–27 September 2018; Volume 1, p. 53. [Google Scholar]
- Gomaa, M.; Scarbrough, C.; Vijaykumar, T.; Pomeranz, I. Transient-fault recovery for chip multiprocessors. In Proceedings of the 30th Annual International Symposium on Computer Architecture, San Diego, CA, USA, 9–11 June 2003; pp. 98–109. [Google Scholar]
- Oz, I.; Arslan, S. A survey on multithreading alternatives for soft error fault tolerance. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Vargas, V.; Ramos, P.; Méhaut, J.F.; Velazco, R. NMR-MPar: A fault-tolerance approach for multi-core and many-core processors. Appl. Sci. 2018, 8, 465. [Google Scholar] [CrossRef] [Green Version]
- Popov, G.; Nenova, M.; Raynova, K. Reliability Investigation of TMR and DMR Systems with Global and Partial Reservation. In Proceedings of the 2018 Seventh Balkan Conference on Lighting (BalkanLight), Varna, Bulgaria, 20–22 September 2018; pp. 1–4. [Google Scholar]
- Barbirotta, M.; Cheikh, A.; Mastrandrea, A.; Menichelli, F.; Vigli, F.; Olivieri, M. A Fault Tolerant soft-core obtained from an Interleaved-Multi-Threading RISC-V microprocessor design. In Proceedings of the 2021 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Athens, Greece, 6–8 October 2021; pp. 1–4. [Google Scholar]
- Barbirotta, M.; Cheikh, A.; Mastrandrea, A.; Menichelli, F.; Olivieri, M. Design and Evaluation of Buffered Triple Modular Redundancy in Interleaved-Multi-Threading Processors. IEEE Access 2022, 10, 126074–126088. [Google Scholar] [CrossRef]
- Barbirotta, M.; Cheikh, A.; Mastrandrea, A.; Menichelli, F.; Olivieri, M. Analysis of a Fault Tolerant Edge-Computing Microarchitecture Exploiting Vector Acceleration. In Proceedings of the 2022 17th Conference on Ph. D Research in Microelectronics and Electronics (PRIME), Villasimius, SU, Italy, 12–15 June 2022; pp. 237–240. [Google Scholar]
- Reviriego, P.; Bleakley, C.J.; Maestro, J.A. Diverse double modular redundancy: A new direction for soft error detection and correction. IEEE Des. Test Comput. 2013, 30, 87–95. [Google Scholar] [CrossRef]
- Nakagawa, S.; Fukumoto, S.; Ishii, N. Optimal checkpointing intervals of three error detection schemes by a double modular redundancy. Math. Comput. Model. 2003, 38, 1357–1363. [Google Scholar] [CrossRef]
- Li, Y.; Li, Y.; Jie, H.; Hu, J.; Yang, F.; Zeng, X.; Cockburn, B.; Chen, J. Feedback-based low-power soft-error-tolerant design for dual-modular redundancy. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1585–1589. [Google Scholar] [CrossRef]
- Nomura, S.; Sinclair, M.D.; Ho, C.H.; Govindaraju, V.; De Kruijf, M.; Sankaralingam, K. Sampling+ dmr: Practical and low-overhead permanent fault detection. ACM SIGARCH Comput. Archit. News 2011, 39, 201–212. [Google Scholar] [CrossRef]
- Vadlamani, R.; Zhao, J.; Burleson, W.; Tessier, R. Multicore soft error rate stabilization using adaptive dual modular redundancy. In Proceedings of the 2010 Design, Automation & Test in Europe Conference & Exhibition (DATE 2010), Dresden, Germany, 8–12 March 2010; pp. 27–32. [Google Scholar]
- Matsuo, I.B.M.; Zhao, L.; Lee, W.J. A dual modular redundancy scheme for CPU–FPGA platform-based systems. IEEE Trans. Ind. Appl. 2018, 54, 5621–5629. [Google Scholar] [CrossRef]
- Violante, M.; Meinhardt, C.; Reis, R.; Reorda, M.S. A low-cost solution for deploying processor cores in harsh environments. IEEE Trans. Ind. Electron. 2011, 58, 2617–2626. [Google Scholar] [CrossRef]
- de Oliveira, Á.B.; Rodrigues, G.S.; Kastensmidt, F.L. Analyzing lockstep dual-core ARM cortex-A9 soft error mitigation in FreeRTOS applications. In Proceedings of the Proceedings of the 30th Symposium on Integrated Circuits and Systems Design: Chip on the Sands, Fortaleza, Brazil, 28 August–1 September 2017; pp. 84–89. [Google Scholar]
- Rodrigues, C.; Marques, I.; Pinto, S.; Gomes, T.; Tavares, A. Towards a Heterogeneous Fault-Tolerance Architecture based on Arm and RISC-V Processors. In Proceedings of the IECON 2019-45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; Volume 1, pp. 3112–3117. [Google Scholar]
- Silva, I.; do Espírito Santo, O.; do Nascimento, D.; Xavier-de Souza, S. Cevero: A soft-error hardened soc for aerospace applications. In Proceedings of the Anais Estendidos do X Simpósio Brasileiro de Engenharia de Sistemas Computacionais; SBC: Porto Alegre, RS, Brasil, 2020; pp. 121–126. [Google Scholar]
- Rossi, D.; Conti, F.; Marongiu, A.; Pullini, A.; Loi, I.; Gautschi, M.; Tagliavini, G.; Capotondi, A.; Flatresse, P.; Benini, L. PULP: A parallel ultra low power platform for next generation IoT applications. In Proceedings of the 2015 IEEE Hot Chips 27 Symposium (HCS). IEEE Computer Society, Cupertino, CA, USA, 22–25 August 2015; pp. 1–39. [Google Scholar]
- Conti, F.; Rossi, D.; Pullini, A.; Loi, I.; Benini, L. Energy-efficient vision on the PULP platform for ultra-low power parallel computing. In Proceedings of the 2014 IEEE Workshop on Signal Processing Systems (SiPS), Belfast, UK, 20–22 October 2014; pp. 1–6. [Google Scholar]
- Rossi, D.; Loi, I.; Conti, F.; Tagliavini, G.; Pullini, A.; Marongiu, A. Energy efficient parallel computing on the PULP platform with support for OpenMP. In Proceedings of the 2014 IEEE 28th Convention of Electrical & Electronics Engineers in Israel (IEEEI), Eilat, Israel, 3–5 December 2014; pp. 1–5. [Google Scholar]
- Abate, F.; Sterpone, L.; Violante, M. A new mitigation approach for soft errors in embedded processors. IEEE Trans. Nucl. Sci. 2008, 55, 2063–2069. [Google Scholar] [CrossRef]
- Herdt, V.; Große, D.; Le, H.M.; Drechsler, R. Extensible and configurable RISC-V based virtual prototype. In Proceedings of the 2018 Forum on Specification & Design Languages (FDL), Garching, Germany, 10–12 September 2018; pp. 5–16. [Google Scholar]
- Barbirotta, M.; Mastrandrea, A.; Menichelli, F.; Vigli, F.; Blasi, L.; Cheikh, A.; Sordillo, S.; Di Gennaro, F.; Olivieri, M. Fault resilience analysis of a RISC-V microprocessor design through a dedicated UVM environment. In Proceedings of the 2020 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Frascati, Italy, 19–21 October 2020; pp. 1–6. [Google Scholar]
- George, N.J.; Elks, C.R.; Johnson, B.W.; Lach, J. Transient fault models and AVF estimation revisited. In Proceedings of the 2010 IEEE/IFIP International Conference on Dependable Systems & Networks (DSN), Chicago, IL, USA, 28 June–1 July 2010; pp. 477–486. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| fft | crc32 | fir | |||||||
|---|---|---|---|---|---|---|---|---|---|
| core | |||||||||
| Total clock cycles | 106,090 | 159,492 | 134,192 | 15,042 | 20,037 | 18,563 | 49,140 | 72,566 | 64,653 |
| # frames | 10 | 10 | 10 | ||||||
| faults / frame | 250 | 425 | 355 | 40 | 53 | 50 | 131 | 194 | 170 |
| Deterministic fault rate | 1 every 35 cycles | 1 every 35 cycles | 1 every 35 cycles | ||||||
| Core | LUTs | FFs | Energy [pJ/cycle] |
|---|---|---|---|
| T03 (non-hardened) | 5524 | 4489 | 380 |
| fT03 (hardened) | 6429 | 4905 | 390 |
| dfT03 (hardened) | 6923 | 5019 | 390 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barbirotta, M.; Cheikh, A.; Mastrandrea, A.; Menichelli, F.; Ottavi, M.; Olivieri, M. Evaluation of Dynamic Triple Modular Redundancy in an Interleaved-Multi-Threading RISC-V Core. J. Low Power Electron. Appl. 2023, 13, 2. https://doi.org/10.3390/jlpea13010002
Barbirotta M, Cheikh A, Mastrandrea A, Menichelli F, Ottavi M, Olivieri M. Evaluation of Dynamic Triple Modular Redundancy in an Interleaved-Multi-Threading RISC-V Core. Journal of Low Power Electronics and Applications. 2023; 13(1):2. https://doi.org/10.3390/jlpea13010002
Chicago/Turabian StyleBarbirotta, Marcello, Abdallah Cheikh, Antonio Mastrandrea, Francesco Menichelli, Marco Ottavi, and Mauro Olivieri. 2023. "Evaluation of Dynamic Triple Modular Redundancy in an Interleaved-Multi-Threading RISC-V Core" Journal of Low Power Electronics and Applications 13, no. 1: 2. https://doi.org/10.3390/jlpea13010002