
Recognition and Positioning of Fresh Tea Buds Using YOLOv4-lighted + ICBAM Model and RGB-D Sensing
 , ,
, ,
Abstract
:1. Introduction
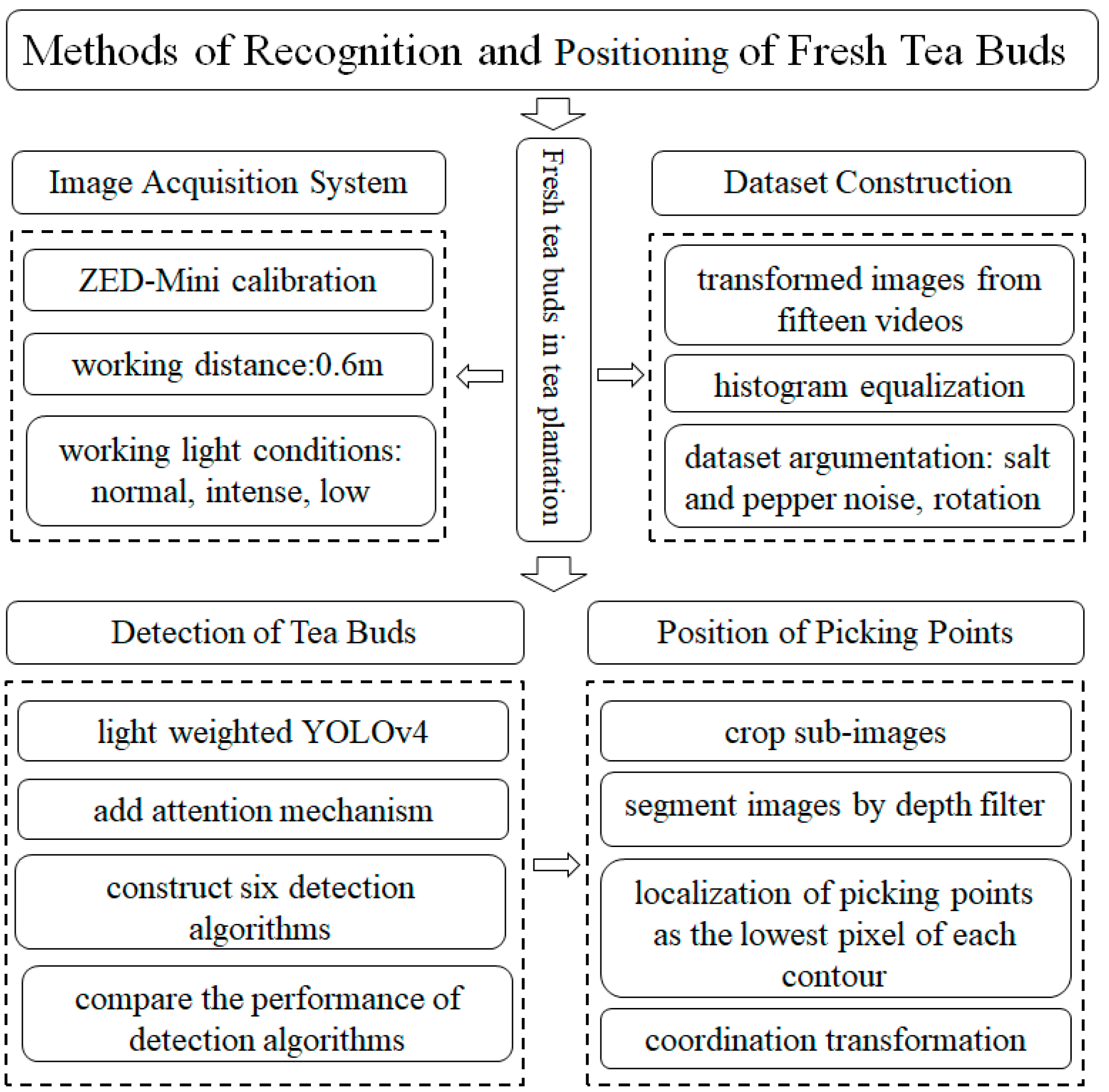
2. Materials and Methods
2.1. Image Acquisition and Dataset Construction
2.1.1. Tea Plants
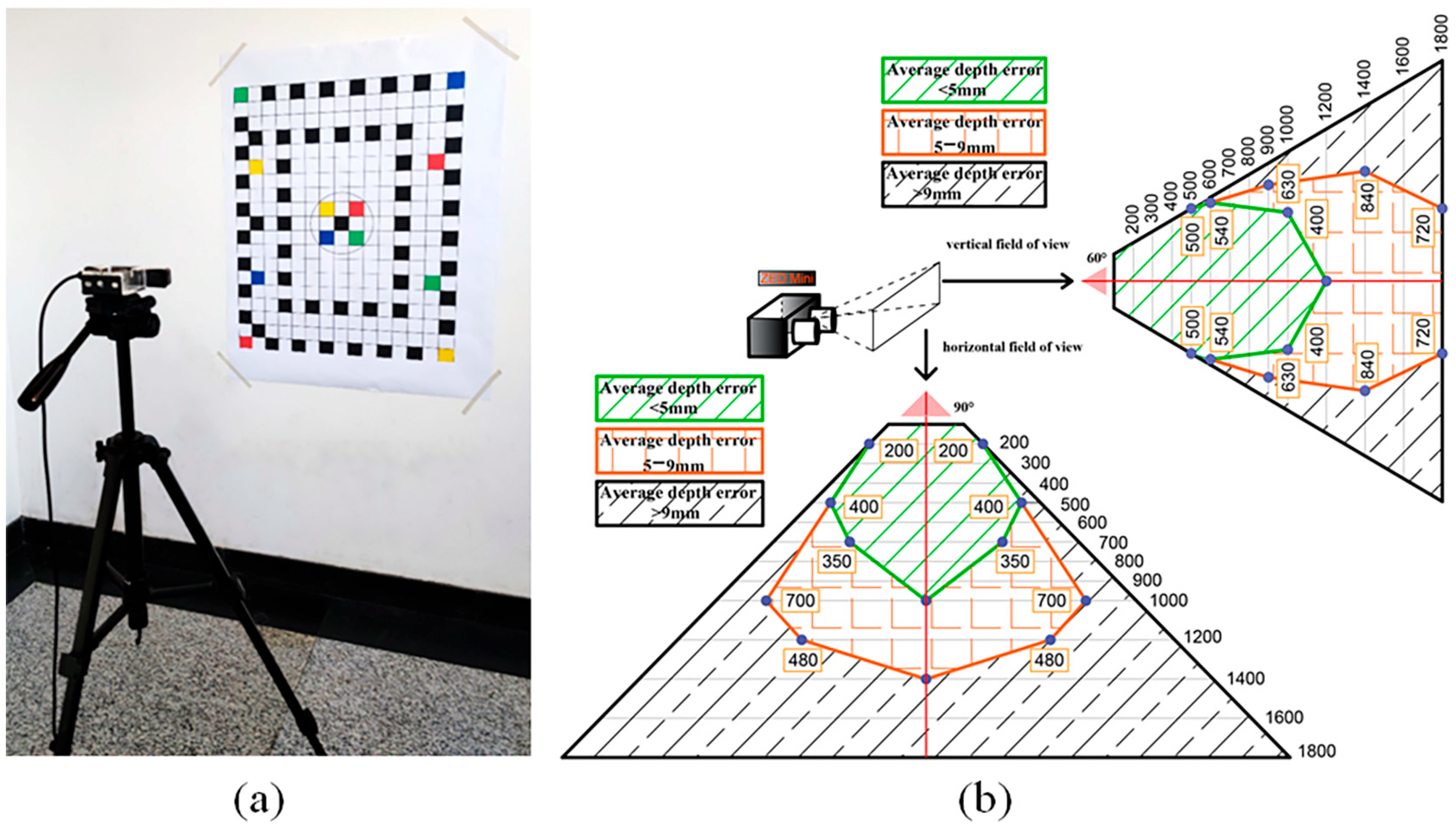
2.1.2. Image Acquisition System
2.1.3. Dataset Construction
2.2. Detection of Tea Buds
2.2.1. Baseline YOLOv4 Network
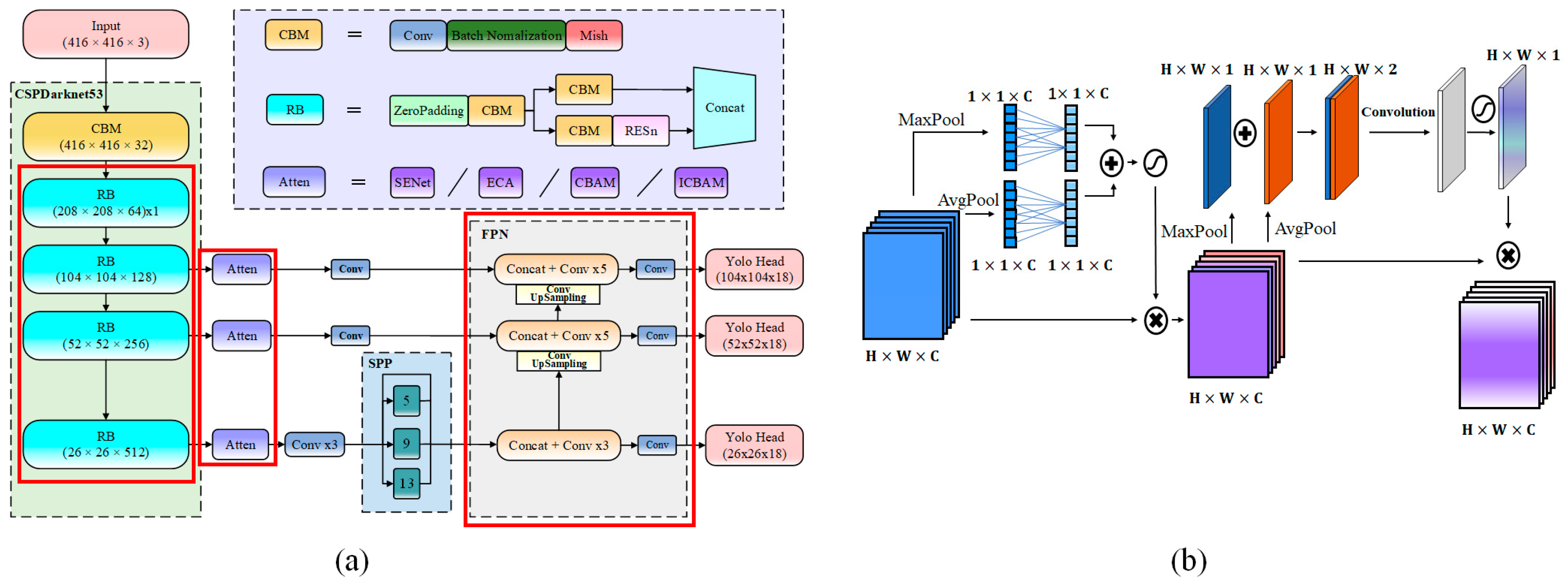
2.2.2. Lightweight YOLOv4 Network
2.2.3. Multi-Scale Fusion Pyramid with Attention Mechanism
2.2.4. Construction Strategy of Tea Buds Detection Algorithm
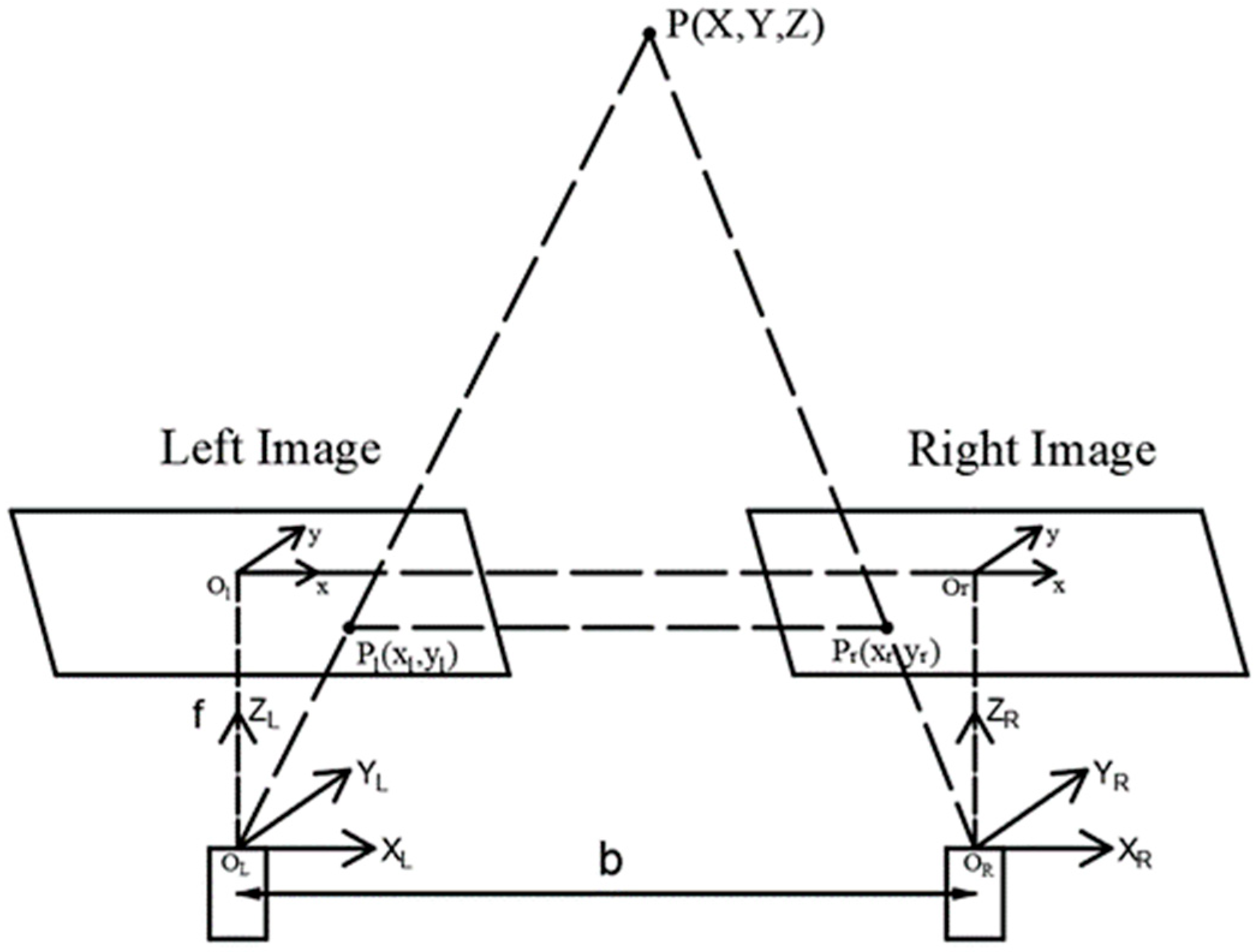
2.3. Position of Picking Points
3. Results
3.1. Detection of Tea Buds
3.1.1. Preprocessing
3.1.2. Model Training
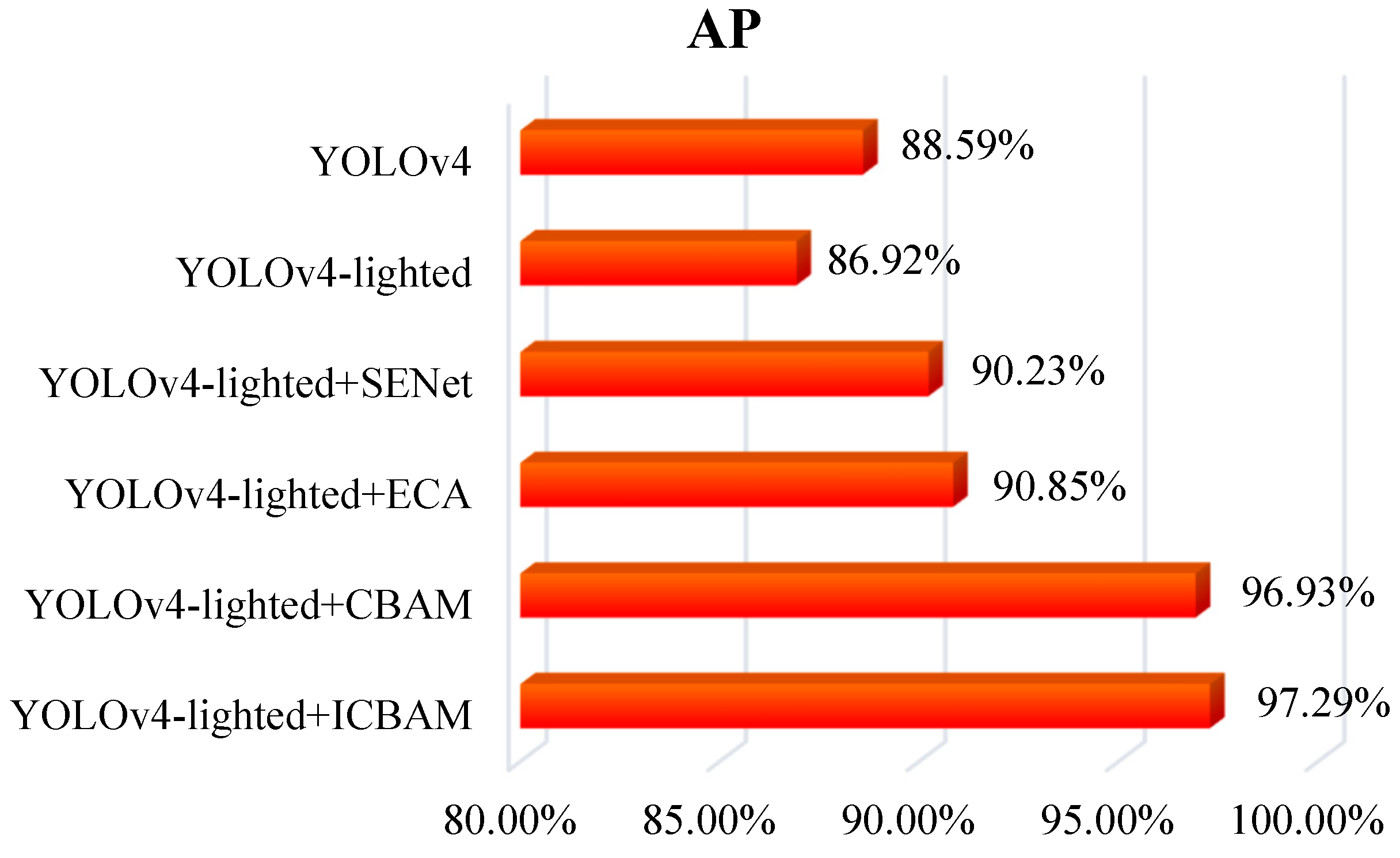
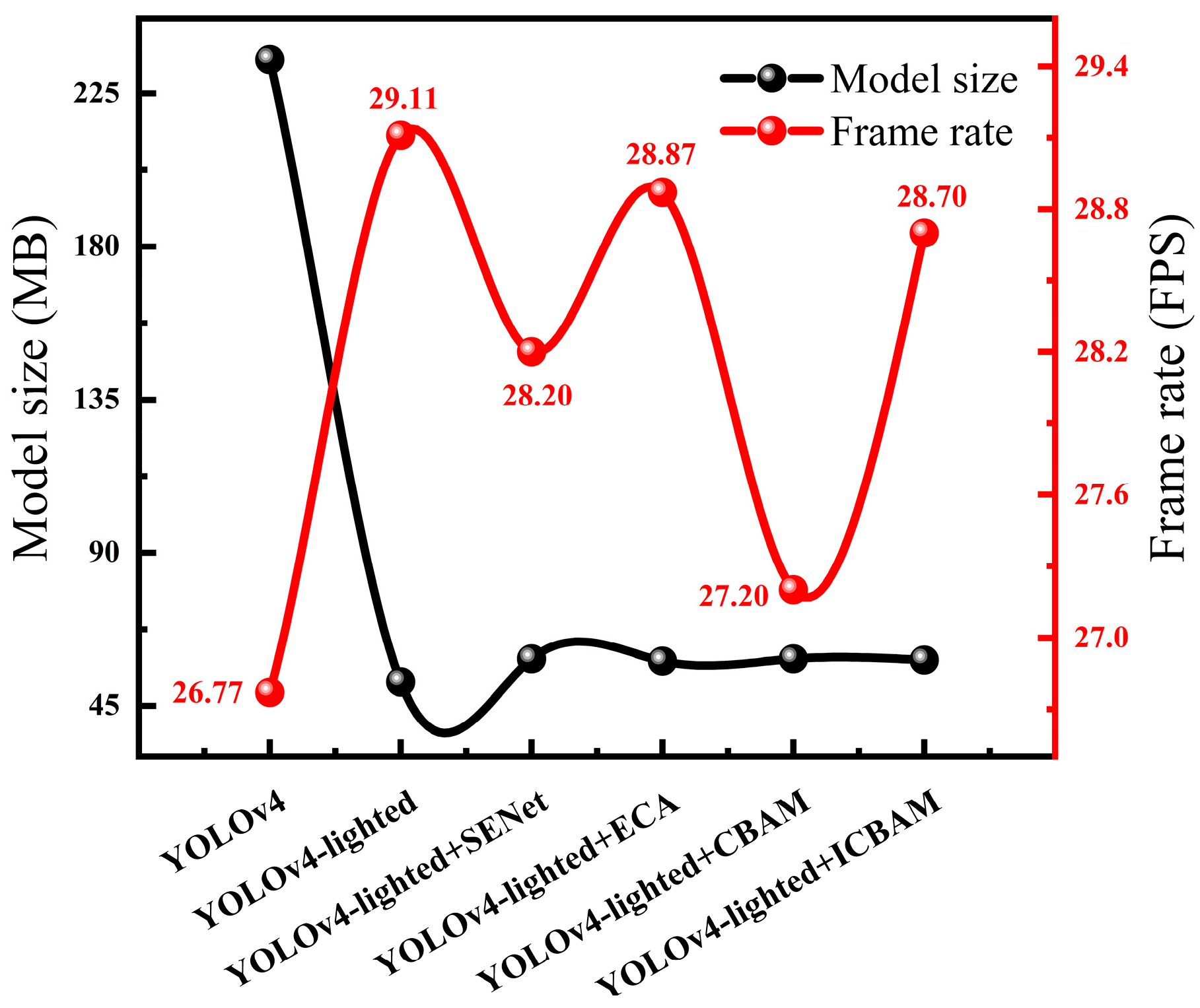
3.1.3. Performance Comparison of Six Tea Bud Detection Models
3.2. Position of Picking Points
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Diniz, P.; Pistonesi, M.; Alvarez, M.; Band, B.; Araujo, M. Simplified tea classification based on a reduced chemical composition profile via successive projections algorithm linear discriminant analysis (SPA-LDA). J. Food Compos. Anal. 2015, 39, 103–110. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Fan, Y.; Fu, H.; Chen, F.; Ni, C.; Wang, J.; Yin, Q.; Mu, Q.; Yang, T.; She, Y. “Turn-off” fluorescent sensor for highly sensitive and specific simultaneous recognition of 29 famous green teas based on quantum dots combined with chemometrics. Anal. Chim. Acta 2017, 963, 119–128. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Xiao, H.; Qin, G.; Song, Z.; Ding, W.; Mei, S. Developing Situations of Tea Plucking Machine. Engineering 2014, 6, 268–273. [Google Scholar] [CrossRef] [Green Version]
- Du, Z.; Hu, Y.; Wang, S. Simulation and Experiment of Reciprocating Cutter Kinematic of Portable Tea Picking Machine. Trans. J. CSAM 2018, s1, 221–226. [Google Scholar]
- Motokura, K.; Takahashi, M.; Ewerton, M.; Peters, J. Plucking Motions for Tea Harvesting Robots Using Probabilistic Movement Primitives. IEEE Robot. Autom. Lett. 2020, 5, 3275–3282. [Google Scholar] [CrossRef]
- Madamombe, G.; Tesfamariam, E.; Taylor, N. Yield decline in mechanically harvested clonal tea (Camellia sinensis (L) O. Kuntze) as influenced by changes in source/sink and radiation interception dynamics in the canopy. Sci. Hortic.-Amst. 2015, 194, 286–294. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Han, W.; Anguo, H.; Wang, W. Design and Experiment of Intelligentized Tea-Plucking Machine for Human Riding Based on Machine Vision. Trans. J. CSAM 2016, 7, 15–20. [Google Scholar]
- Chen, J.; Yong, C.; Jin, X.; Che, J.; Gao, F.; Li, N. Research on a Parallel Robot for Tea Flushes Plucking. Engineering 2015, 22, 2352–5428. [Google Scholar]
- Yang, H.; Chen, L.; Ma, Z.; Chen, M.; Zhong, Y.; Deng, F.; Li, M. Computer vision-based high-quality tea automatic plucking robot using Delta parallel manipulator. Comput. Electron. Agric. 2021, 181, 105946. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. A review of key techniques of vision-based control for harvesting robot. Comput. Electron. Agric. 2016, 127, 311–323. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Kataoka, T. Fruit detection system and an end effector for robotic harvesting of Fuji apples. J. CIGR 2010, 12, 203–210. [Google Scholar]
- Mehta, S.S.; Burks, T.F. Vision-based control of robotic manipulator for citrus harvesting. Comput. Electron. Agric. 2014, 102, 146–158. [Google Scholar] [CrossRef]
- Edan, Y.; Rogozin, D. Robotic melon harvesting. IEEE J. Mag. 2000, 16, 831–835. [Google Scholar] [CrossRef]
- Hayashi, S.; Shigematsu, K.; Yamamoto, S.; Kobayashi, K.; Kohno, Y.; Kamata, J.; Kurite, M. Evaluation of a strawberry-harvesting robot in a field test. Biosyst. Eng. 2010, 105, 160–171. [Google Scholar] [CrossRef]
- Scarfe, A.J.; Flemmer, R.C.; Bakker, H.; Flemmer, C.L. Development of an autonomous kiwifruit picking robot. In Proceedings of the 4th International Conference on Autonomous Robots and Agents, Wellington, New Zealand, 10–12 February 2009; pp. 10–12. [Google Scholar]
- Ji, C.; Zhang, J.; Yuan, T.; Li, W. Research on Key Technology of Truss Tomato Harvesting Robot in Greenhouse. In Proceedings of the 2013 International Conference on Materials Engineering and Mechanical Automation (MEMA), Shanghai, China, 1–2 October 2013; pp. 480–486. [Google Scholar]
- Henten, E.; Hemming, J.; Tuijl, B.; Kornet, J.; Bontsema, J. Collision-Free Motion Planning for a Cucumber Picking Robot. Biosyst. Eng. 2003, 86, 135–144. [Google Scholar] [CrossRef]
- Hemming, J.; Bac, C.W.; Tuijl, J.V.; Barth, R. A robot for harvesting sweet-pepper in greenhouses. Comput. Sci. 2014, 1, 13–18. [Google Scholar]
- Wu, X.; Tang, X.; Zhang, F.; Gu, J. Tea buds image identification based on lab color model and K-means clustering. J. CSAM 2015, 36, 161–164. [Google Scholar]
- Zhang, L.; Zhang, H.; Chen, Y.; Dai, S. Real-time monitoring of optimum timing for harvesting fresh tea leaves based on machine vision. Int. J. Agric. Biol. Eng. 2019, 12, 6–9. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldu, F. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Gao, P.; Xu, W.; Yan, T.; Zhang, C.; Lv, X.; He, Y. Application of Near-Infrared Hyperspectral Imaging with Machine Learning Methods to Identify Geographical Origins of Dry Narrow-Leaved Oleaster (Elaeagnus angustifolia) Fruits. Foods 2019, 8, 620. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qian, C.; Li, M.; Ren, Y. Tea Sprouts Segmentation via Improved Deep Convolutional Encoder-Decoder Network. IEICE Trans. Inf. Syst. 2020, 103, 476–479. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Zhao, L.; Li, J.; Shang, S.; Ding, X.; Wang, T. Detection and classification of tea buds based on deep learning. Comput. Electron. Agric. 2022, 192, 106547. [Google Scholar] [CrossRef]
- Sun, X.; Mu, S.; Xu, Y.; Cao, Z.H.; Su, T. Detection algorithm of tea tender buds under complex background based on deep learning. J. Hebei Univ. 2019, 39, 211–216. [Google Scholar]
- Chen, B.; Yan, J.; Wang, K. Fresh Tea Sprouts Detection via Image Enhancement and Fusion SSD. J. Control Sci. Eng. 2021, 26, 13–24. [Google Scholar] [CrossRef]
- Li, Y.; He, L.; Jia, J.; Chen, J.; Lyu, L.; Wu, C. High-efficiency tea shoot detection method via a compressed deep learning model. Int. J. Agric. Biol. Eng. 2022, 3, 159–166. [Google Scholar] [CrossRef]
- Yang, H.; Chen, L.; Chen, M.; Ma, Z.; Deng, F.; Li, M. Tender Tea Shoots Recognition and Positioning for Picking Robot Using Improved YOLO-V3 Model. IEEE Access 2019, 7, 180998–181011. [Google Scholar] [CrossRef]
- Tao, W.; Zhang, K.; Zhang, W.; Wang, R.; Wan, S.; Rao, Y.; Jiang, Z.; Gu, L. Tea Picking Point Detection and Location Based on Mask-RCNN. Inf. Process. Agric. 2021. Available online: https://www.sciencedirect.com/science/article/pii/S2214317321000962 (accessed on 25 December 2022).
- Yan, C.; Chen, Z.; Li, Z.; Liu, R.; Li, Y.; Xiao, H.; Lu, P.; Xie, B. Tea Sprout Picking Point Identification Based on Improved DeepLabV3+. Agriculture 2022, 12, 1594. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, S. Localizing plucking points of tea leaves using deep convolutional neural networks—ScienceDirect. Comput. Electron. Agric. 2020, 171, 105298. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. IEEE Conf. Comput. Vis. Pattern Recognit. 2016, 27, 779–788. [Google Scholar]
- Fu, L.; Feng, Y.; Wu, J.; Liu, Z.; Gao, F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model. Precis. Agric. 2021, 22, 754–776. [Google Scholar] [CrossRef]
- Magalhães, S.A.; Castro, L.; Moreira, G.; Santos, F.; Cunha, M.; Dias, J.; Moreira, A. Evaluating the Single-Shot MultiBox Detector and YOLO Deep Learning Models for the Detection of Tomatoes in a Greenhouse. Sensors 2021, 21, 3569. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; Fang, W.; Sun, X.; Wu, Z.; Zhao, G.; Li, G.; Li, R.; Fu, L.; Zhang, Q. A novel apple fruit detection and counting methodology based on deep learning and trunk tracking in modern orchard. Comput. Electron. Agric. 2022, 197, 107000–107005. [Google Scholar] [CrossRef]
- Li, D.; Sun, X.; Elkhouchlaa, H.; Jia, Y.; Yao, Z.; Lin, P.; Li, J.; Lu, H. Fast detection and location of longan fruits using UAV images. Comput. Electron. Agric. 2021, 190, 106–109. [Google Scholar] [CrossRef]
- Xu, Z.F.; Jia, R.S.; Liu, Y.B.; Zhao, C.Y.; Sun, H.M. Fast Method of Detecting Tomatoes in a Complex Scene for Picking Robots. IEEE Access 2020, 8, 55289–55299. [Google Scholar] [CrossRef]
- Cao, Z.; Yuan, R. Real-Time Detection of Mango Based on Improved YOLOv4. Electronics 2022, 11, 3853. [Google Scholar] [CrossRef]
- Fan, R.; Pei, M. Lightweight Forest Fire Detection Based on Deep Learning. IEEE Access 2021, 1, 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. Comput. Sci. 2020, 2004, 10934. [Google Scholar]
- Lee, J.; Lee, B.; Hwang, J.; Ko, K.; Chung, J.; Kim, E.; Lee, S.; Hong, Y. Metabolic Dependence of Green Tea on Plucking Positions Revisited: A Metabolomic Study. J. Agric. Food Chem. 2011, 59, 79–85. [Google Scholar] [CrossRef]
- Gall, G.; Colquhoun, I.; Defernez, M. Metabolite Profiling Using 1H NMR Spectroscopy for Quality Assessment of Green Tea, Camellia sinensis. J. Agric. Food Chem. 2004, 52, 692–700. [Google Scholar] [CrossRef]
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. Comput. Sci. 2019, 8, 681–684. [Google Scholar]
- Wang, C.; Liao, H.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. CVF Conf. Comput. Vis. Pattern Recognit. Work. 2020, 28, 1571–1580. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. IEEE CVF Conf. Comput. Vis. Pattern Recognit. 2018, 18, 8759–8768. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 1, 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. IEEE CVF Conf. Comput. Vis. Pattern Recognit. 2020, 1, 11531–11539. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. CBAM: Convolutional Block Attention Module. Comput. Vis. 2018, 11211, 3–19. [Google Scholar]
- Yang, F.; Yang, L.; Tian, Y.; Yang, Q. Recognition of the tea sprout based on color and shape features. Trans. J. CSAM 2009, 40, 119–123. [Google Scholar]
- Chen, Y.; Wu, C.; Chen, S. Application of Deep Learning Algorithm on Tea Shoot Identification and Localization. Comput. Sci. 2018, 3, 159–169. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lighting Condition | Original Image | Contrast Enhanced | Added Salt and Pepper Noise | Rotated | Total |
|---|---|---|---|---|---|
| Normal light | 1300 | 0 | 1300 | 2600 | 5200 |
| Intense light | 0 | 1300 | 1300 | 2600 | 5200 |
| Low light | 0 | 1300 | 1300 | 2600 | 5200 |
| YOLOv4 | YOLOv4-lighted | SENet | ECA | CBAM | ICBAM | Number of Parameters |
|---|---|---|---|---|---|---|
| √ | 64,429,405 | |||||
| √ | 14,811,101 | |||||
| √ | √ | 14,984,253 | ||||
| √ | √ | 14,811,116 | ||||
| √ | √ | 14,984,550 | ||||
| √ | √ | 14,820,358 |
| Component | Description |
|---|---|
| CPU | Intel Core i5-10400F (2.9 GHz) |
| GPU hardware | NVIDIA GeForce GTX 1650 |
| GPU programming library | CUDA 11.0 and CUDNN 8.0 |
| Integrated development environment | PyCharm 2021.1.1 |
| Operating system | Windows 10 |
| Model | Precision (%) | Recall (%) | F1 Score |
|---|---|---|---|
| YOLOv4 | 85.94 | 86.21 | 0.84 |
| YOLOv4-lighted | 86.52 | 81.23 | 0.84 |
| YOLOv4-lighted + SENet | 87.13 | 84.93 | 0.86 |
| YOLOv4-lighted + ECA | 86.38 | 87.92 | 0.87 |
| YOLOv4-lighted + CBAM | 94.30 | 93.66 | 0.94 |
| YOLOv4-lighted + ICBAM | 94.19 | 93.50 | 0.94 |
| Experiment Number | Number of Tea Buds | Detected Tea Buds | Correct Picking Points | Correct Positioning Rate (%) | Average Positioning Time (s) |
|---|---|---|---|---|---|
| 1 | 24 | 22 | 19 | 86.36 | 0.12 |
| 2 | 30 | 27 | 24 | 88.88 | 0.15 |
| 3 | 47 | 43 | 38 | 88.37 | 0.10 |
| Average | 34 | 31 | 27 | 87.10 | 0.12 |
| Paper | Background | Method/Model | Picking Point | Precision | Recall | F1-Score | Accuracy | Time |
|---|---|---|---|---|---|---|---|---|
| Yang et al. [49] | Simple | Color and shape characteristics | — | — | — | — | 0.94 | 0.45 |
| Zhang et al. [20] | Complex | Bayesian discriminant principle | — | — | — | — | 0.90 | 1.21 |
| Wu et al. [19] | Complex | K-means clustering method | — | — | — | — | 0.94 | 8.79 |
| Xu et al. [24] | Complex | DenseNet201 | — | 0.99 | 0.89 | 0.95 | — | — |
| Yang et al. [28] | Simple | improved YOLO-V3 and K-means method | √ | 0.92 | 0.91 | 0.92 | — | — |
| Wang et al. [29] | Complex | Mask-RCNN | √ | 0.94 | 0.92 | — | — | — |
| Chen et al. [50] | Complex | Faster R-CNN | — | — | — | — | 0.86 | 0.13 |
| Chen et al. [31] | Complex | Faster R-CNN and FCN | √ | 0.79 | 0.90 | — | 0.85 | — |
| Our method | Complex | YOLOv4-lighted + ICBAM | √ | 0.94 | 0.94 | 0.94 | 0.98 | 0.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, S.; Yoon, S.-C.; Li, L.; Wang, W.; Zhuang, H.; Wei, C.; Liu, Y.; Li, Y. Recognition and Positioning of Fresh Tea Buds Using YOLOv4-lighted + ICBAM Model and RGB-D Sensing. Agriculture 2023, 13, 518. https://doi.org/10.3390/agriculture13030518
Guo S, Yoon S-C, Li L, Wang W, Zhuang H, Wei C, Liu Y, Li Y. Recognition and Positioning of Fresh Tea Buds Using YOLOv4-lighted + ICBAM Model and RGB-D Sensing. Agriculture. 2023; 13(3):518. https://doi.org/10.3390/agriculture13030518
Chicago/Turabian StyleGuo, Shudan, Seung-Chul Yoon, Lei Li, Wei Wang, Hong Zhuang, Chaojie Wei, Yang Liu, and Yuwen Li. 2023. "Recognition and Positioning of Fresh Tea Buds Using YOLOv4-lighted + ICBAM Model and RGB-D Sensing" Agriculture 13, no. 3: 518. https://doi.org/10.3390/agriculture13030518