
Detection and Correction of Abnormal IoT Data from Tea Plantations Based on Deep Learning
 ,
,
Abstract
:1. Introduction
- (1)
- This paper proposes a general tea plantation IoT abnormal data detection model to detect abnormal data.
- (2)
- This paper proposes a combination algorithm of CNN, SVM, and LSTM for correcting abnormal data of the tea plantation IoT system and improving the authenticity and availability of datasets.
- (3)
- This paper uses the dataset of a tea plantation in the Huangshan area of Anhui Province to verify the algorithm. Compared with the traditional SVM or CNN/RNN models in other anomaly detection methods, our proposed algorithm can improve the accuracy by 3–4% and the specificity by 20–30%.
2. Materials and Methods
2.1. Dataset
2.2. Data Pre-Processing
2.2.1. Standardization
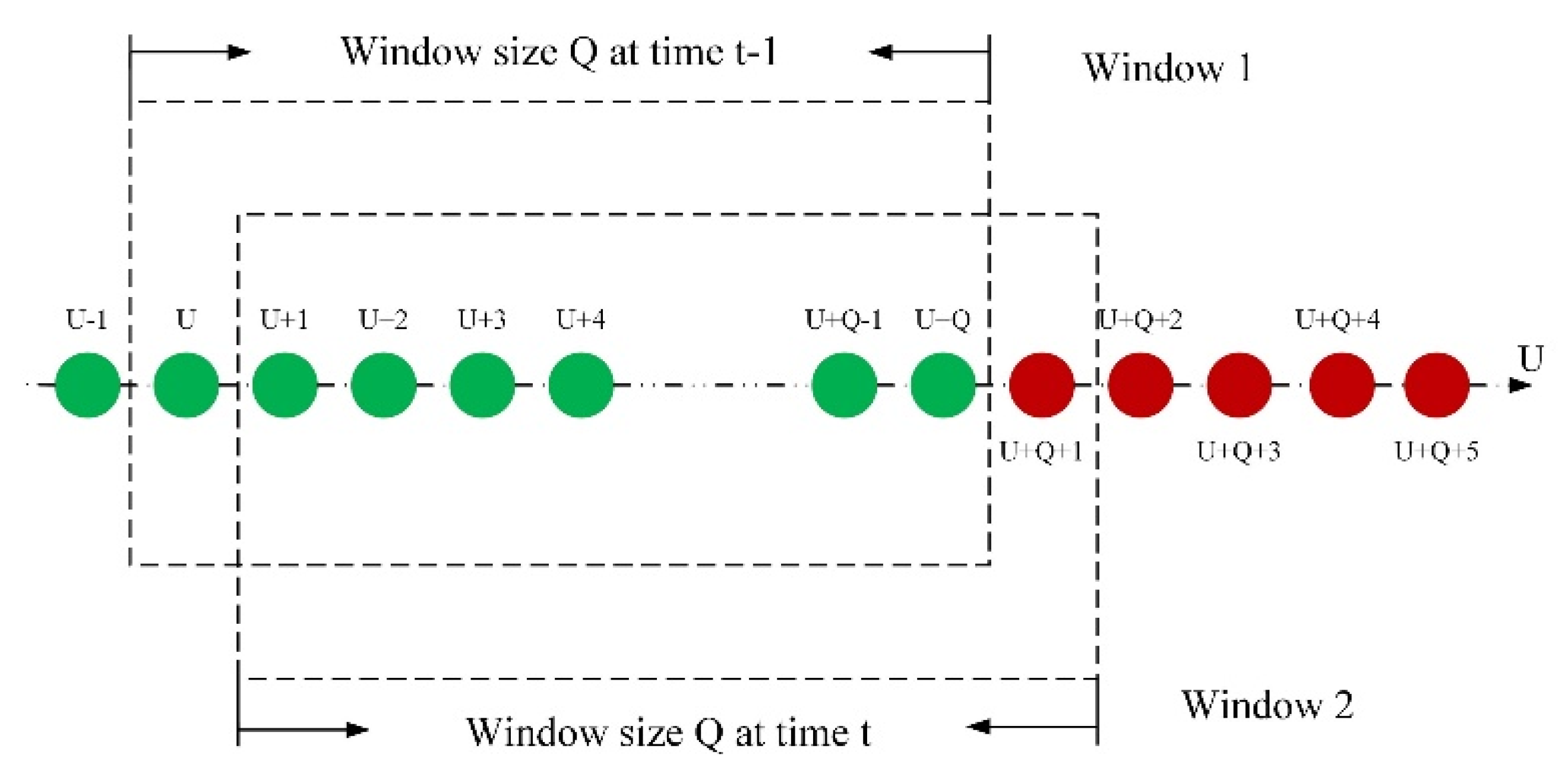
2.2.2. Sliding Window
2.3. Abnormal Data Detection Model
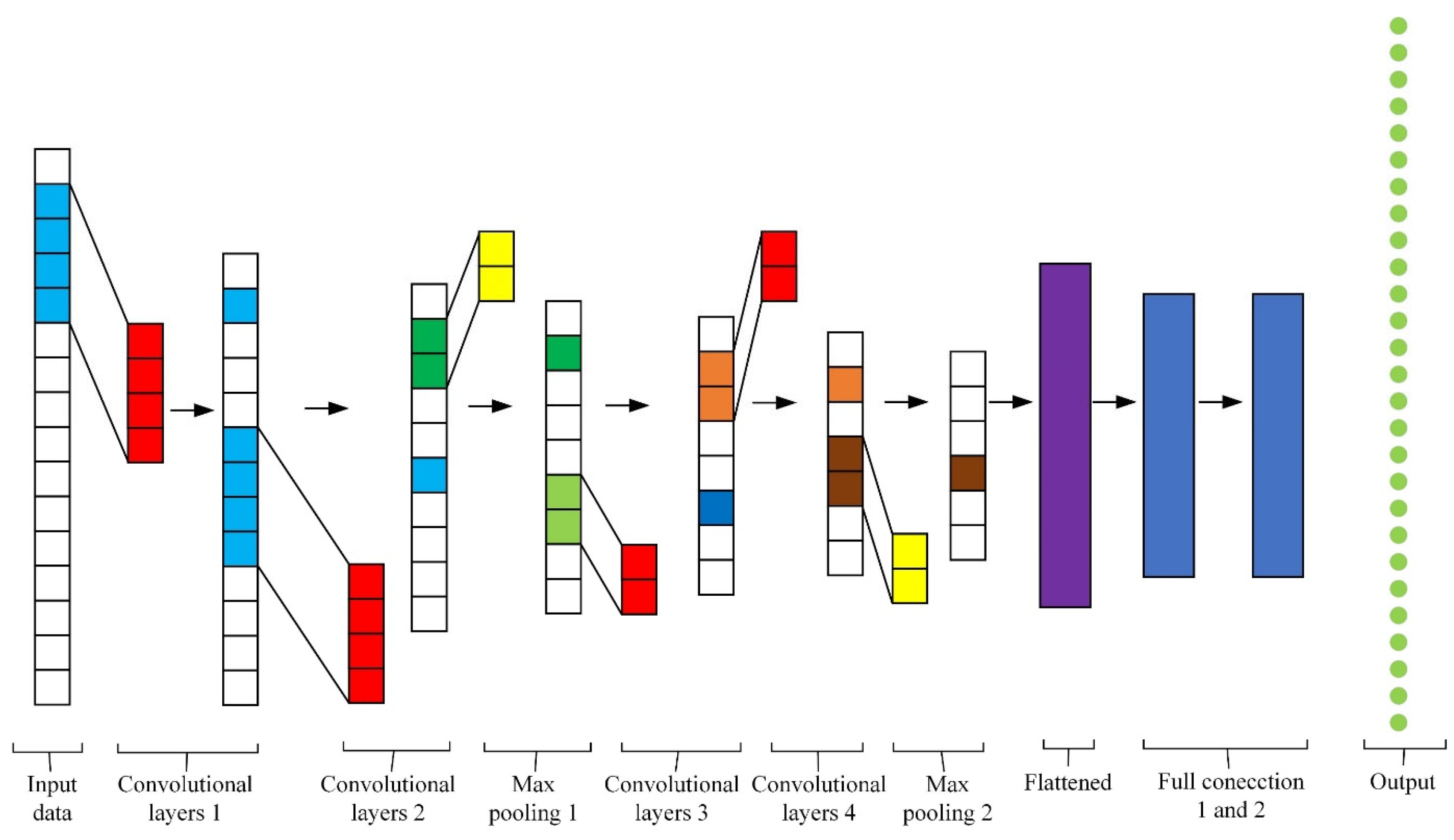
2.3.1. Convolution and Pooling Layer
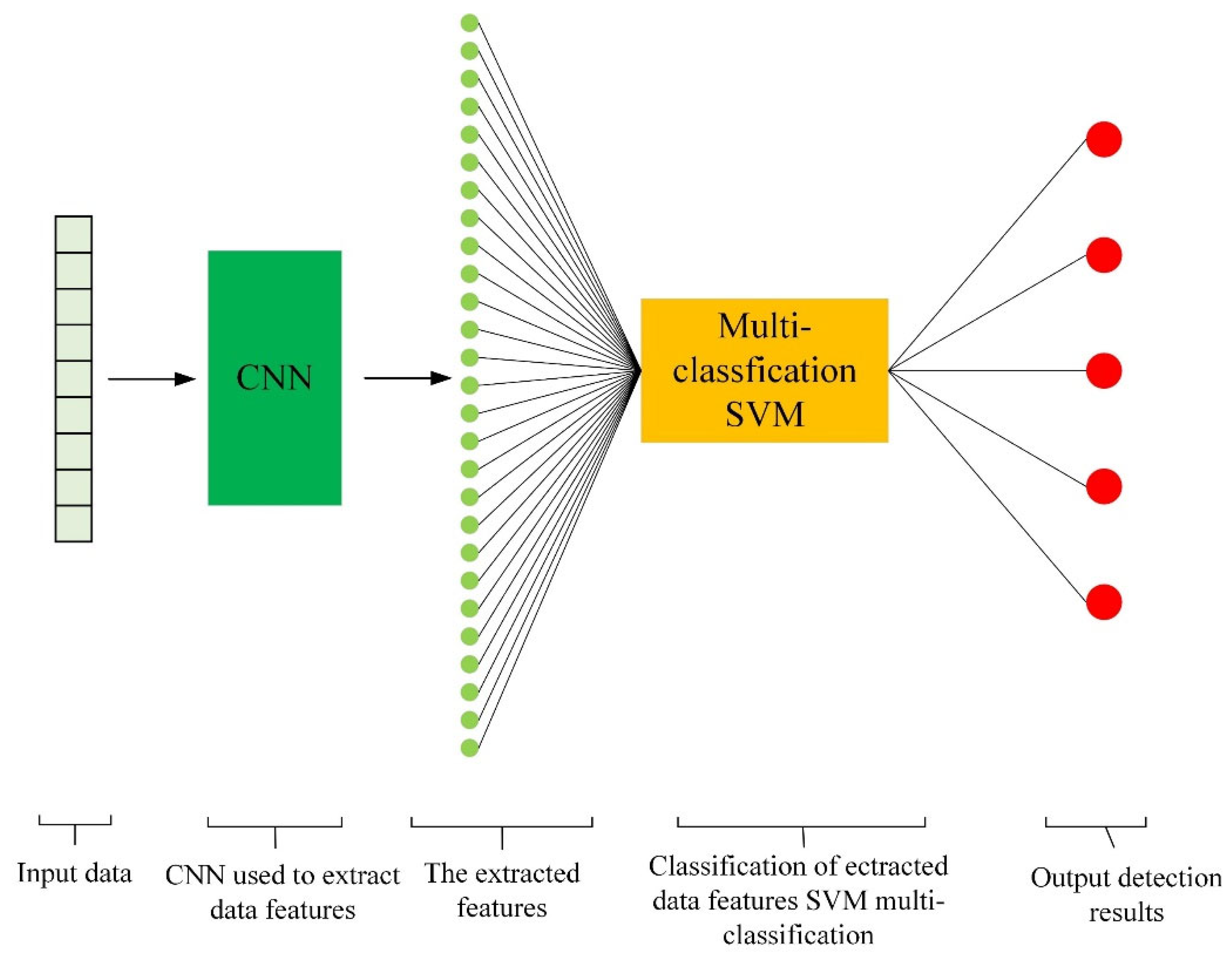
2.3.2. Fully Connected Layer and Support Vector Machine
2.3.3. Construction of Exception Data Detection Model
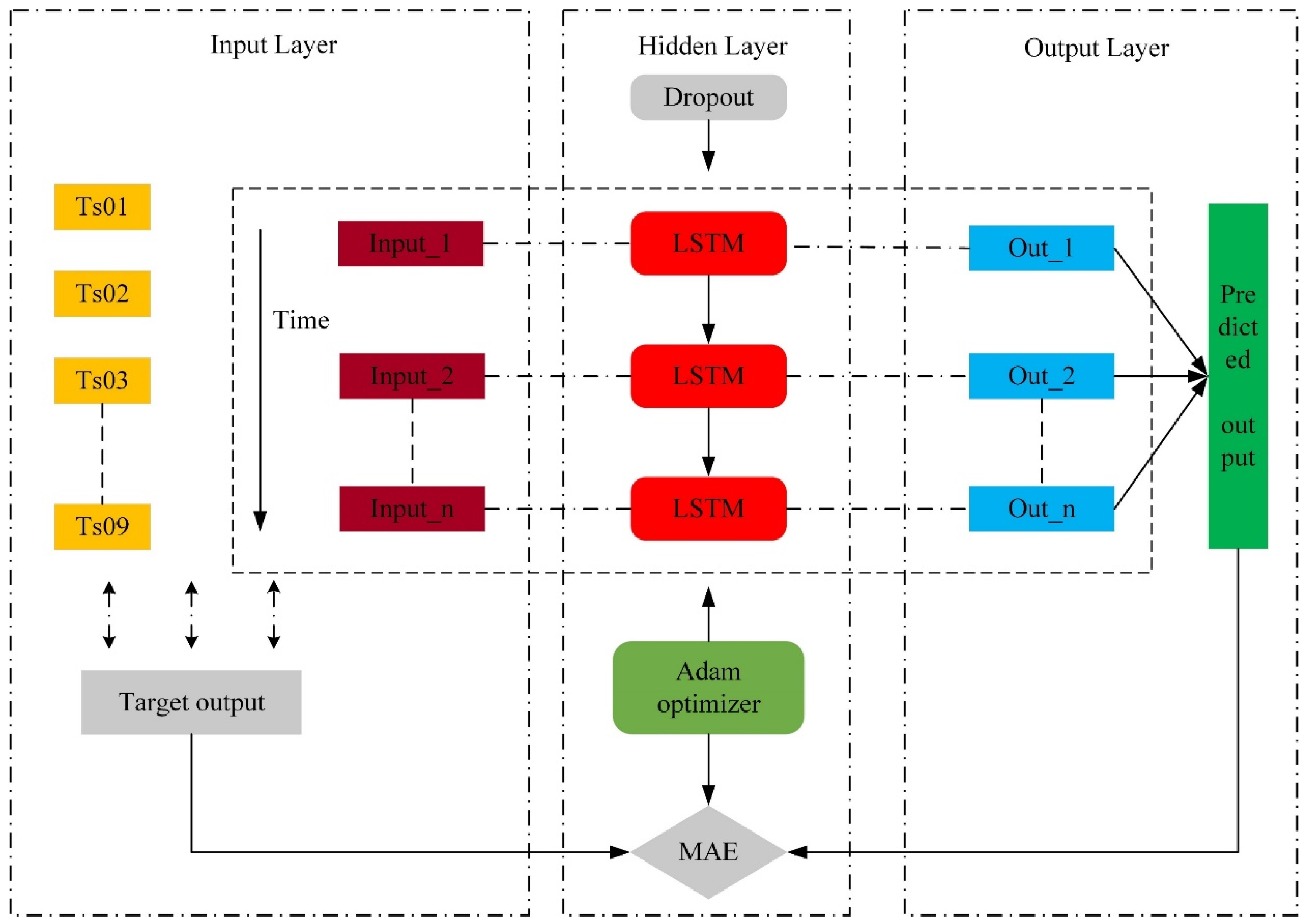
2.4. Tea Plantation Data Prediction Model
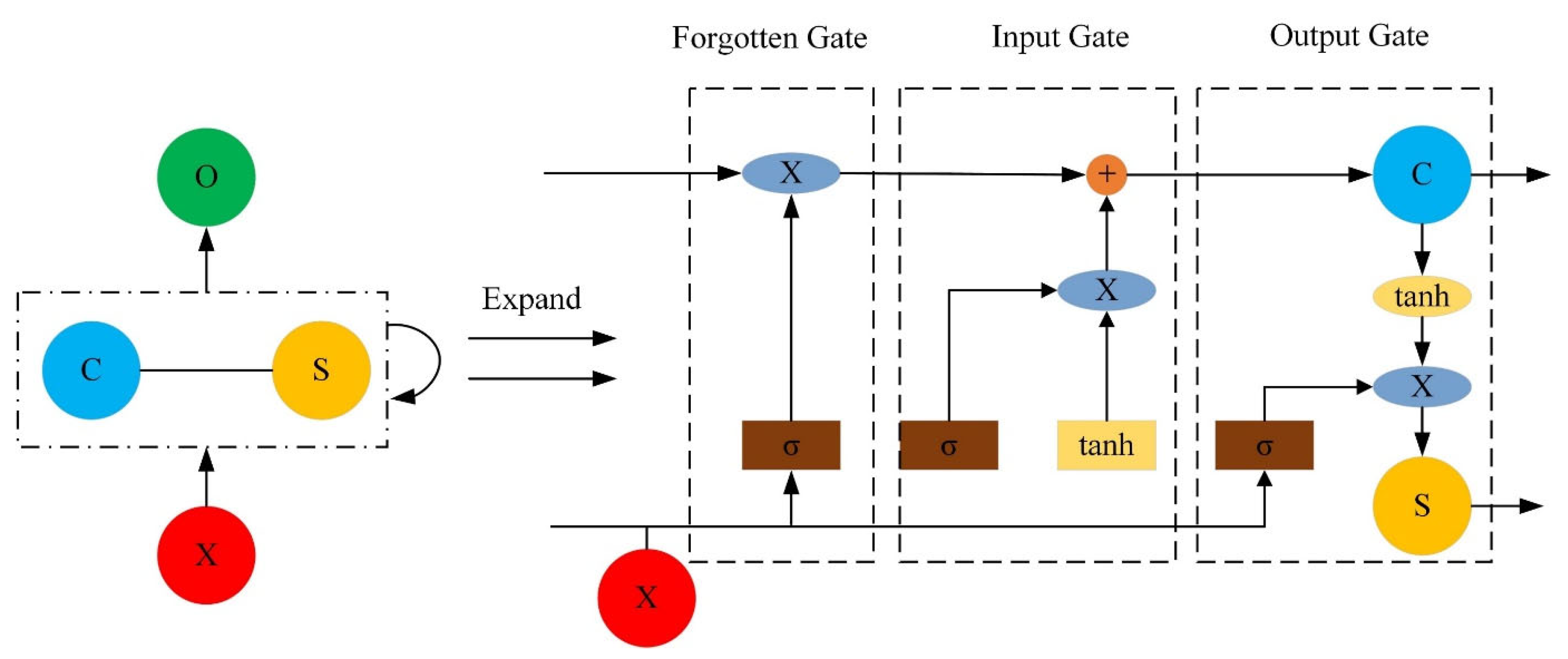
2.4.1. LSTM
2.4.2. Construction of the Tea Plantation Data Prediction Model
2.5. Evaluation Index of Abnormal Data Detection Algorithm
2.6. Evaluation Index of Tea Plantation Data Prediction Algorithm
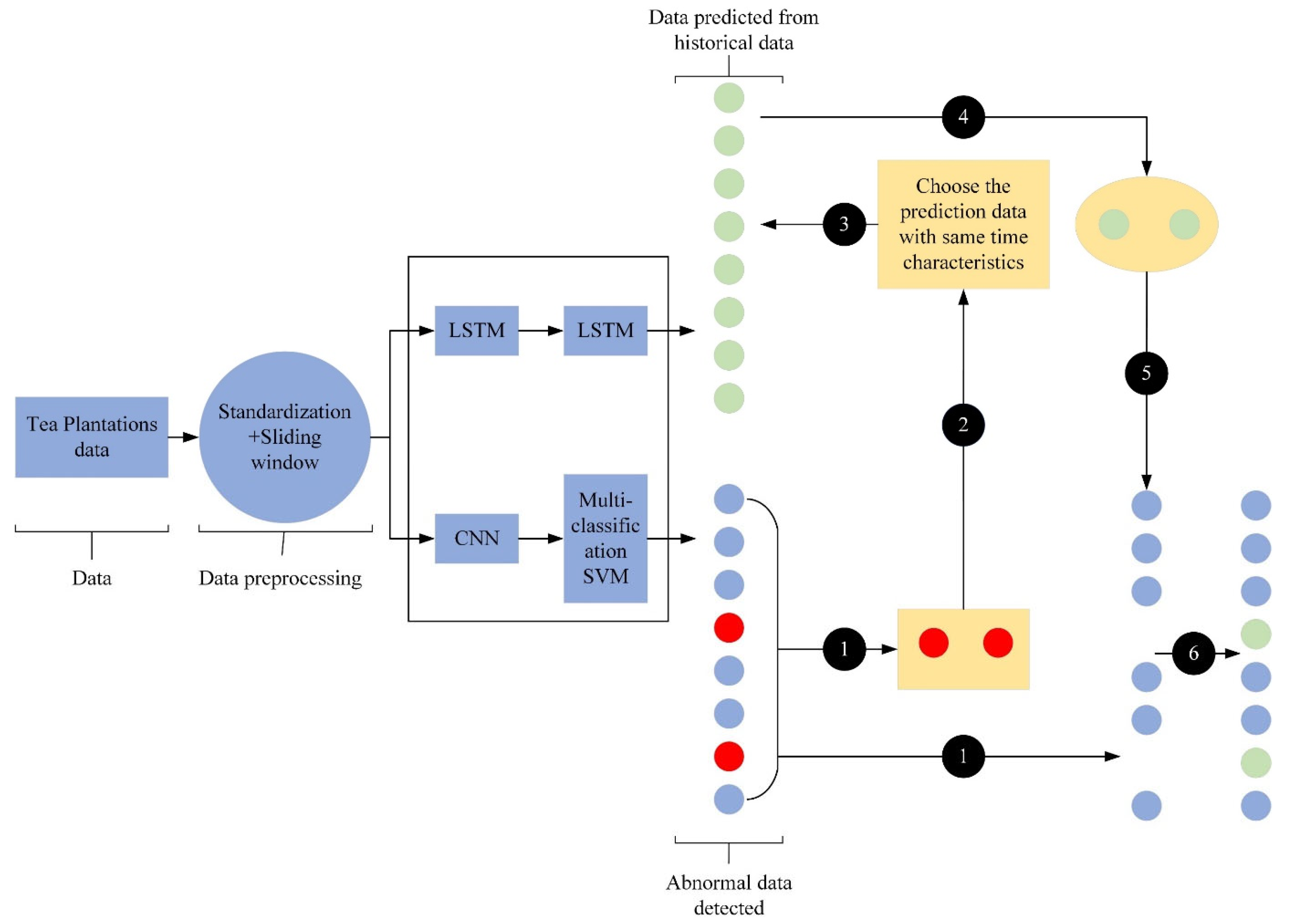
2.7. Correction Model of Abnormal Data in Tea Plantations
3. Results and Discussion
3.1. Results
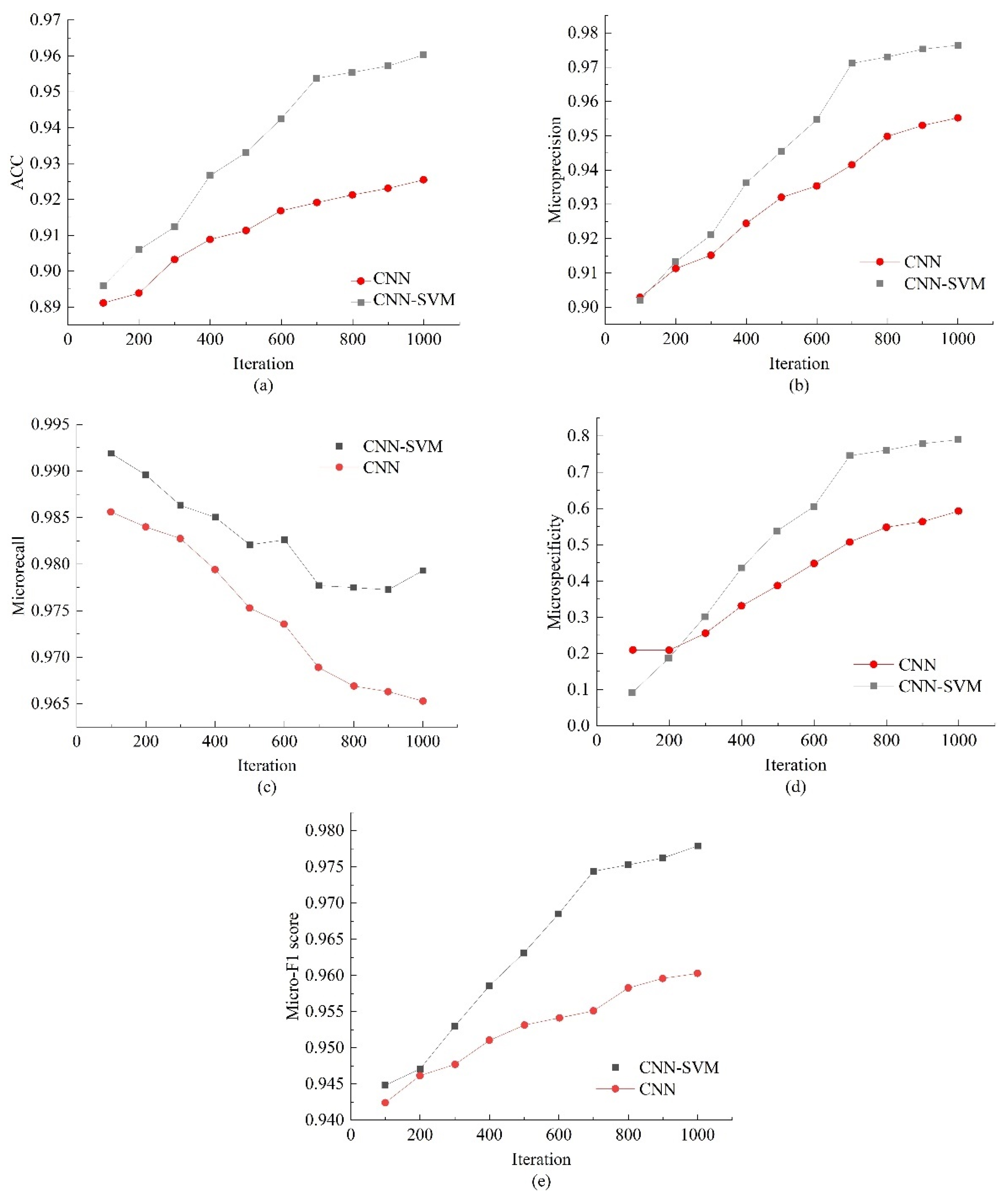
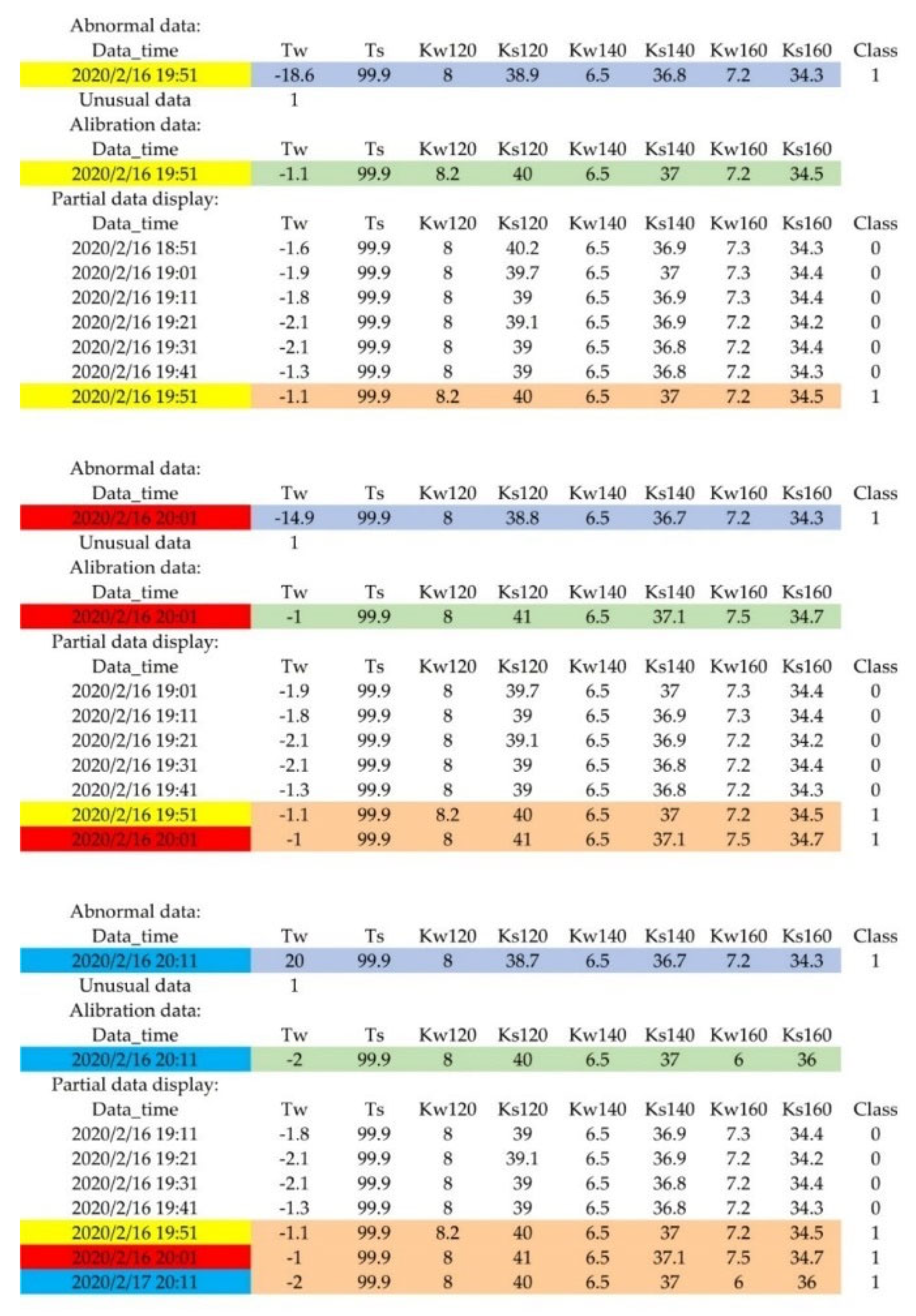
3.1.1. Results of the Abnormal Data Detection Algorithm
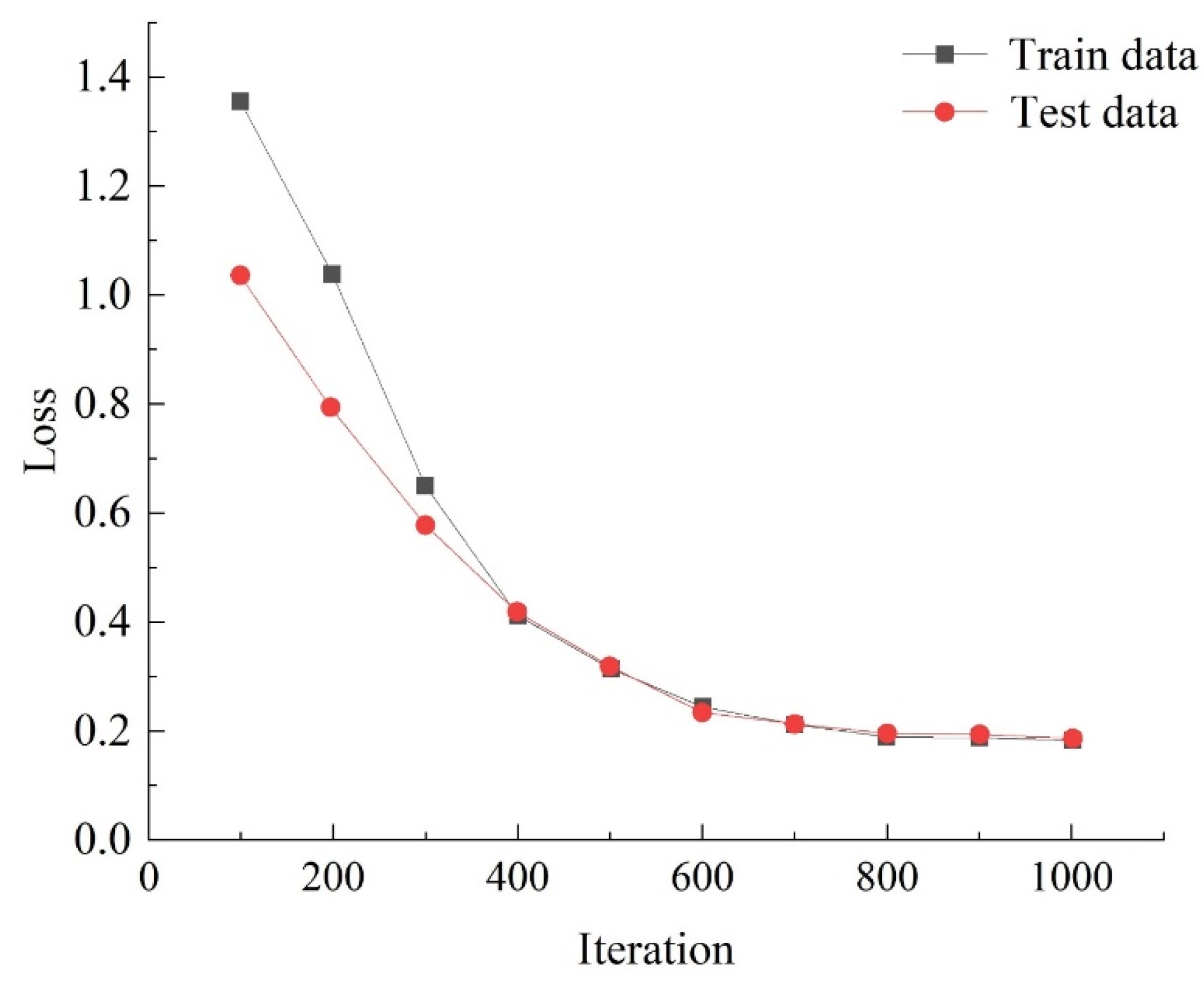
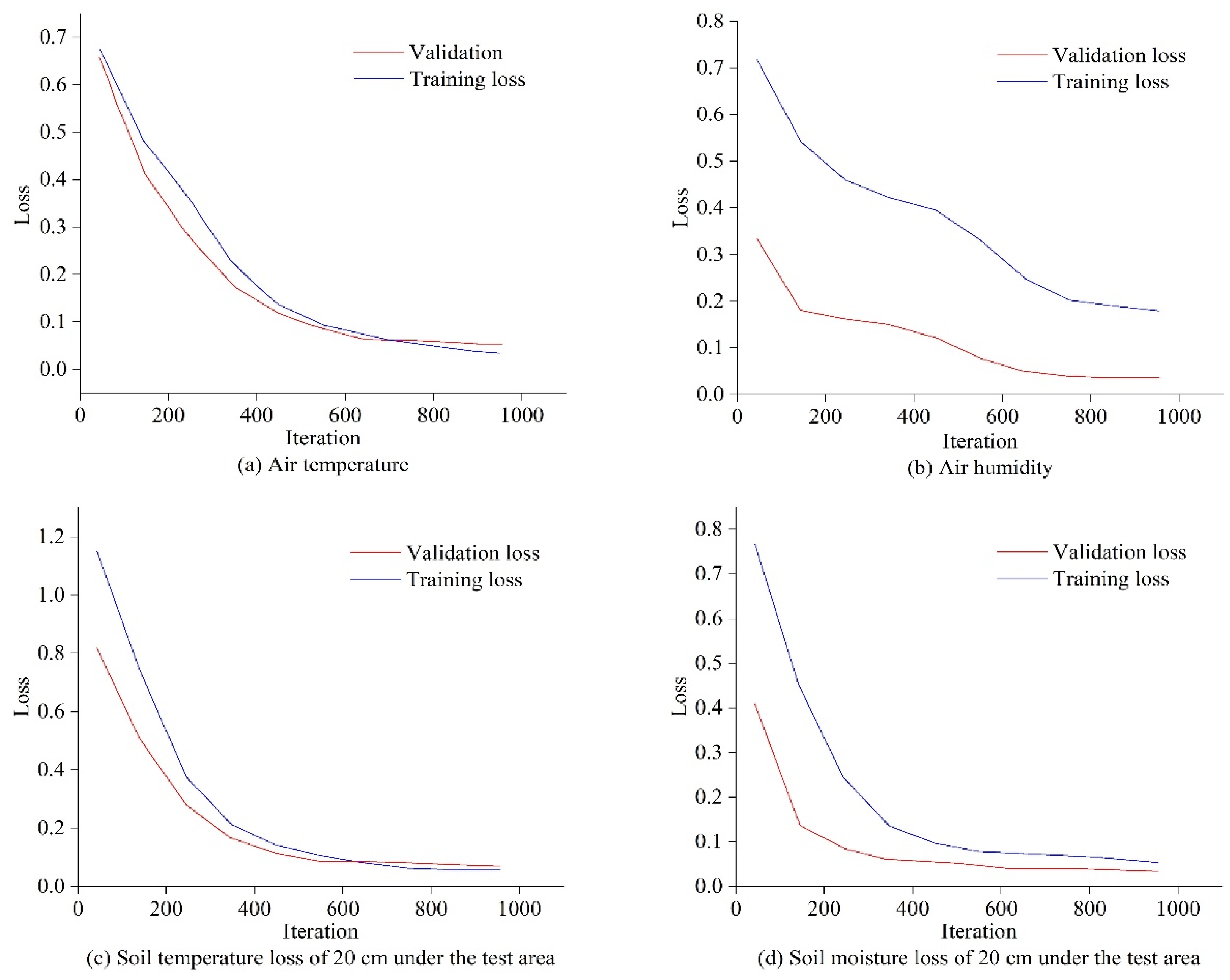
3.1.2. Results of Data Prediction Algorithm of Tea Plantations
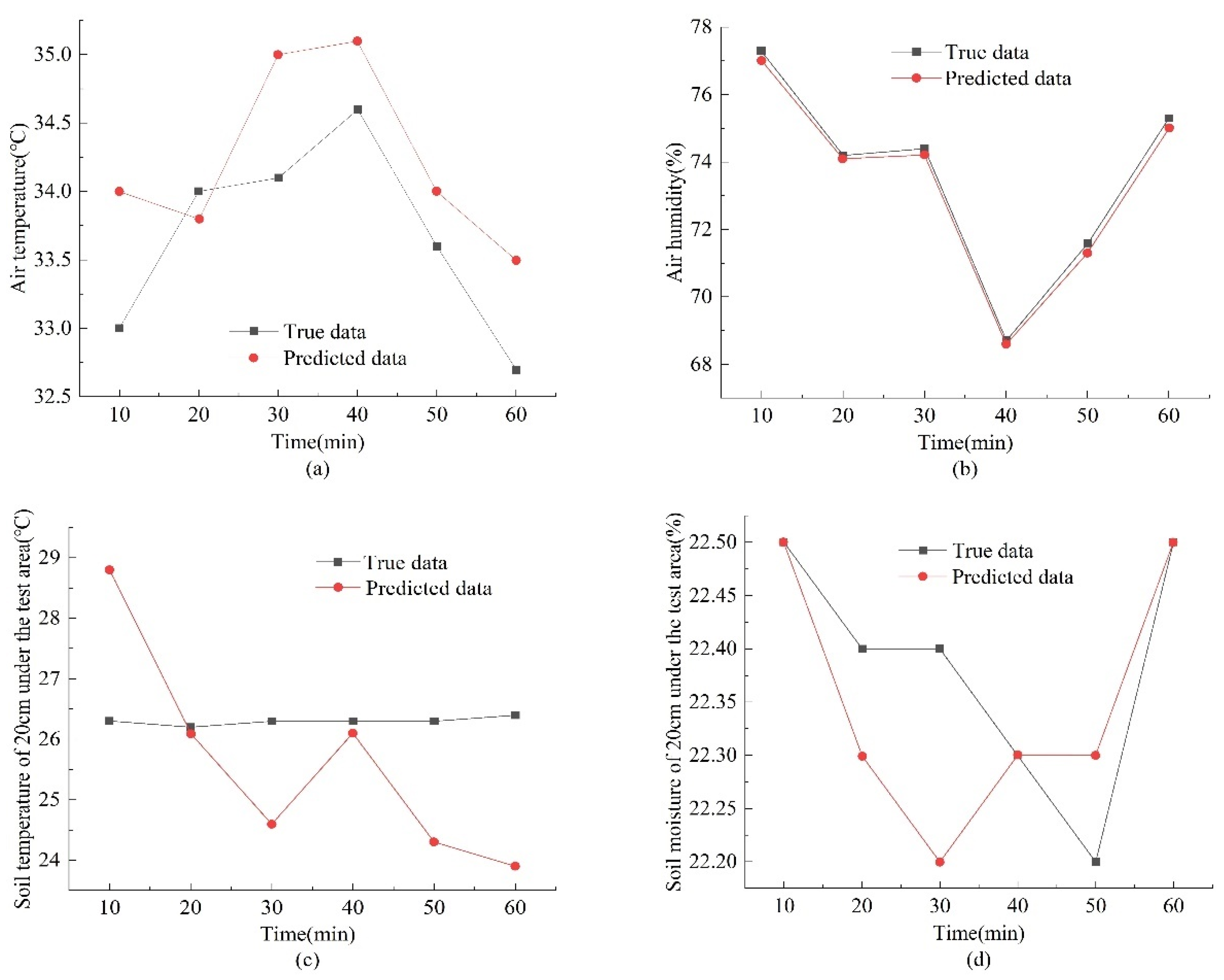
3.1.3. Results of Abnormal Data Correction
3.2. Discussion
4. Conclusions and Future Work
- Based on standardized data processing, the algorithm uses a CNN-SVM model with a sliding window to monitor the processed data online. The results show that compared with the traditional CNN model for anomaly detection algorithm, the proposed algorithm can obtain better detection results, with accuracy and micro-specificity improvements of 3–4% and 20–30%, respectively.
- An abnormal data correction method based on an LSTM model is proposed. This algorithm predicts the trends in abnormal data based on multifactor historical data, which effectively improves the detection accuracy of the model for time series of data. When the anomaly detection algorithm detects abnormal data, the time points of the anomalous data are extracted, normal data are predicted with the LSTM model, and the abnormal data are corrected and added to the tea plantation data set.
- This paper’s CNN-SVM model and LSTM model are versatile and easy to combine with other algorithms. Although this research focuses on a tea plantation, the proposed method provides an important reference for detecting and processing sensor data.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ma, J.; Sun, L.; Wang, H.; Zhang, Y.; Aickelin, U. Supervised anomaly detection in uncertain pseudoperiodic data streams. ACM Trans. Internet Technol. 2016, 16, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Ou, E.; Loh, P.L.; Allen, T.; Agasie, R.; Liu, K. RNN-Based online anomaly detection in nuclear reactors for highly imbalanced datasets with uncertainty. Nucl. Eng. Des. 2020, 364, 110699. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Islam, M.R. A survey of anomaly detection techniques in financial domain. Futur. Gener. Comput. Syst. 2016, 55, 278–288. [Google Scholar] [CrossRef]
- Chen, Q.; Lam, K.Y.; Fan, P. Comments on “Distributed Bayesian algorithms for fault-tolerant event region detection in wireless sensor networks”. IEEE Trans. Comput. 2005, 54, 1182–1183. [Google Scholar] [CrossRef]
- Limthong, K.; Fukuda, K.; Ji, Y.; Yamada, S. Unsupervised learning model for real-time anomaly detection in computer networks. IEICE Trans. Inf. Syst. 2014, E97-D, 2084–2094. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Gryllias, K. A semi-supervised Support Vector Data Description-based fault detection method for rolling element bearings based on cyclic spectral analysis. Mech. Syst. Signal Process. 2020, 140, 106682. [Google Scholar] [CrossRef]
- Ghorbel, O.; Ayedi, W.; Snoussi, H.; Abid, M. Fast and efficient outlier detection method in wireless sensor networks. IEEE. Sens. J. 2015, 15, 3403–3411. [Google Scholar] [CrossRef]
- Samparthi VS, K.; Verma, H.K. Outlier detection of data in wireless sensor networks using kernel density estimation. Int. J. Comput. Appl. 2010, 5, 28–32. [Google Scholar] [CrossRef]
- Passalis, N.; Tsantekidis, A.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Time-series classification using neural bag-of-features. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 301–305. [Google Scholar]
- Jin, C.-B.; Li, S.; Do, T.D.; Kim, H. Real-time human action recognition using CNN over temporal images for static video surveillance cameras. In Pacific Rim Conference on Multimedia; Springer: Cham, Switzerland, 2015; pp. 330–339. [Google Scholar]
- Jiang, Z.; Li, T.; Min, W.; Qi, Z.; Rao, Y. Fuzzy c-means clustering based on weights and gene expression programming. Pattern Recognit. Lett. 2017, 90, 1–7. [Google Scholar] [CrossRef]
- Xu, R.; Cheng, Y.; Liu, Z.; Xie, Y.; Yang, Y. Improved Long Short-Term Memory based anomaly detection with concept drift adaptive method for supporting IoT services. Futur. Gener. Comput. Syst. 2020, 112, 228–242. [Google Scholar] [CrossRef]
- Xu, C.; Chen, H. A hybrid data mining approach for anomaly detection and evaluation in residential buildings energy data. Energy Build. 2020, 215, 109864. [Google Scholar] [CrossRef]
- Androulidakis, G.; Chatzigiannakis, V.; Papavassiliou, S. Network anomaly detection and classification via opportunistic sampling. IEEE Netw. 2009, 23, 6–12. [Google Scholar] [CrossRef]
- Xu, X. Sequential anomaly detection based on temporal-difference learning: Principles, models and case studies. Appl. Soft Comput. J. 2010, 10, 859–867. [Google Scholar] [CrossRef]
- Janke, J.; Castelli, M.; Popovič, A. Analysis of the proficiency of fully connected neural networks in the process of classifying digital images: Benchmark of different classification algorithms on high-level image features from convolutional layers. Expert Syst. Appl. 2019, 135, 12–38. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Gandhi, C.P.; Zhou, Y.; Kumar, R.; Xiang, J. Improved deep convolution neural network (CNN) for the identification of defects in the centrifugal pump using acoustic images. Appl. Acoust. 2020, 167, 107399. [Google Scholar] [CrossRef]
- Eapen, J.; Bein, D.; Verma, A. Novel deep learning model with CNN and bi-directional LSTM for improved stock market index prediction. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 264–270. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Rehman, A.; Saba, T.; Kashif, M.; Fati, S.M.; Bahaj, S.A.; Chaudhry, H. A revisit of internet of things technologies for monitoring and control strategies in smart agriculture. Agronomy 2022, 12, 127. [Google Scholar] [CrossRef]
- Khan, M.A.; Akram, T.; Sharif, M.; Awais, M.; Javed, K.; Ali, H.; Saba, T. CCDF: Automatic system for segmentation and recognition of fruit crops diseases based on correlation coefficient and deep CNN features. Comput. Electron. Agric. 2018, 155, 220–236. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, W.; Ding, J.; Xia, M.; Wang, M.; Rao, Y.; Jiang, Z. Deep Neural Network Compression for Plant Disease Recognition. Symmetry 2021, 13, 1769. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Ma, W. Analysis of anomaly detection method for Internet of things based on deep learning. Trans. Emerg. Telecommun. Technol. 2020, 31, e3893. [Google Scholar] [CrossRef]
- Ji, C.; Lu, S. Exploration of marine ship anomaly real-time monitoring system based on deep learning. J. Intell. Fuzzy Syst. 2020, 38, 1235–1240. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X.; Jin, L.; Wang, X.; Guo, D. Network intrusion detection: Based on deep hierarchical network and original flow data. IEEE Access 2019, 7, 37004–37016. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, Y.; Jun, Z.; Li, X. Deep learning in the information service system of agricultural Internet of Things for innovation enterprise. J. Supercomput. 2022, 78, 5010–5028. [Google Scholar] [CrossRef]
- Jin, X.B.; Yu, X.H.; Wang, X.Y.; Bai, Y.T.; Su, T.L.; Kong, J.L. Deep learning predictor for sustainable precision agriculture based on internet of things system. Sustainability 2020, 12, 1433. [Google Scholar] [CrossRef] [Green Version]
- Jin, X.B.; Yang, N.X.; Wang, X.Y.; Bai, Y.T.; Su, T.L.; Kong, J.L. Hybrid deep learning predictor for smart agriculture sensing based on empirical mode decomposition and gated recurrent unit group model. Sensors 2020, 20, 1334. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, P.; Xia, X.; Qiao, Y.; Cui, X. High-dimensional data anomaly detection for wsns based on deep belief network. Chin. J Sens. Actuators 2019, 32, 892–901. [Google Scholar] [CrossRef]
- Wang, X.F.; Sun, X.M.; Fang, Y. Genetic algorithm solution for multi-period two-echelon integrated competitive/uncompetitive facility location problem. Asia-Pac. J. Oper. Res. 2008, 25, 33–56. [Google Scholar] [CrossRef]
- Pittino, F.; Puggl, M.; Moldaschl, T.; Hirschl, C. Automatic anomaly detection on in-production manufacturing machines using statistical learning methods. Sensors 2020, 20, 2344. [Google Scholar] [CrossRef] [Green Version]
- Munir, M.; Siddiqui, S.A.; Dengel, A.; Ahmed, S. DeepAnT: A Deep Learning Approach for Unsupervised Anomaly Detection in Time Series. IEEE Access 2019, 7, 1991–2005. [Google Scholar] [CrossRef]
- Canizo, M.; Triguero, I.; Conde, A.; Onieva, E. Multi-head CNN–RNN for multi-time series anomaly detection: An industrial case study. Neurocomputing 2019, 363, 246–260. [Google Scholar] [CrossRef]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A practical guide to support vector classification. 2003. [Google Scholar]
- Ravanbakhsh, M.; Nabi, M.; Mousavi, H.; Sangineto, E.; Sebe, N. Plug-and-play cnn for crowd motion analysis: An application in abnormal event detection. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1689–1698. [Google Scholar]
- Zheng, Q.; Tasian, G.; Fan, Y. Transfer learning for diagnosis of congenital abnormalities of the kidney and urinary tract in children based on ultrasound imaging data. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018. [Google Scholar]
- Fang, W.; Tan, X.; Wilbur, D. Application of intrusion detection technology in network safety based on machine learning. Saf. Sci. 2020, 124, 104604. [Google Scholar] [CrossRef]
- Sun, S.; Li, G.; Chen, H.; Guo, Y.; Wang, J.; Huang, Q.; Hu, W. Optimization of support vector regression model based on outlier detection methods for predicting electricity consumption of a public building WSHP system. Energy Build. 2017, 151, 35–44. [Google Scholar] [CrossRef]
- Xing, G.; Chen, J.; Hou, R.; Zhou, L.; Dong, M.; Zeng, D.; Luo, J.; Ma, M. Isolation Forest-Based Mechanism to Defend against Interest Flooding Attacks in Named Data Networking. IEEE Commun. Mag. 2021, 59, 98–103. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sliding Window Size | Correct Rate for 100 Rounds of Training (Accuracy) | Correct Rate for 500 Rounds of Training (Accuracy) |
|---|---|---|
| 89.350% | 96.002% | |
| 89.450% | 95.996% | |
| 89.470% | 96.101% | |
| 89.330% | 95.990% | |
| 89.310% | 95.938% |
| Title 1 | Title 2 |
|---|---|
| Filter | 64 |
| Kernel_size 1 | 4 |
| 0.6 | |
| Filter 2 | 64 |
| Pool_size | 2 |
| Units | 128 |
| Learning rate | 0.001 |
| Filter 3 | 32 |
| Filter 4 | 32 |
| Kernel_size 2 | 2 |
| Parameter Name | Value |
|---|---|
| Unit 1 | 128 |
| Unit 2 | 64 |
| Unit 3 | 8 |
| Bias_initializer | zeros |
| Dropout | 0.5 |
| Use_bias | True |
| Unit_forget_bias | Ture |
| Kernel_initializer | glorot_unfiprm |
| Learning rate | 0.001 |
| Formula | |
|---|---|
| Accuracy | |
| Micro-precision | |
| Micro-recall | |
| Micro-specificity | |
| Micro-F1 score |
| Formula | |
|---|---|
| Mean absolute error (MAE) | |
| Root mean square error (RMSE) | |
| squared value ) |
| Iterations | MAE | RMSE | R2 |
|---|---|---|---|
| 200 | 0.3442 | 0.5867 | 0.7562 |
| 400 | 0.0973 | 0.0386 | 0.8614 |
| 600 | 0.0061 | 0.0200 | 0.9090 |
| 800 | 0.0039 | 0.0198 | 0.9413 |
| 1000 | 0.0022 | 0.0148 | 0.9669 |
| Model | ACC | Class | Microprecision | Microrecall | Micro-F1 Score |
|---|---|---|---|---|---|
| CNN-SVM | 93.35% | Class 0 | 99.02% | 92.48% | 95.64% |
| Class 1 | 99.34% | 97.43% | 98.38% | ||
| Class 2 | 48.69% | 78.15% | 59.99% | ||
| Class 3 | 74.15% | 90.83% | 81.65% | ||
| Class 4 | 92.11% | 87.50% | 89.75% | ||
| Class 5 | 73.76% | 86.67% | 79.70% | ||
| SVM | 86.42% | Class 0 | 93.06% | 91.38% | 92.21% |
| Class 1 | 35.53% | 68.07% | 46.69% | ||
| Class 2 | 45.78% | 63.87% | 53.33% | ||
| Class 3 | 98.46% | 53.33% | 69.19% | ||
| Class 4 | 62.73% | 57.50% | 60.00% | ||
| Class 5 | 71.08% | 49.17% | 63.86% | ||
| Iforest | 92.51% | Class 0 | 98.55% | 94.03% | 96.24% |
| Class 1 | 61.67% | 93.28% | 74.25% | ||
| Class 2 | 74.31% | 89.92% | 81.37% | ||
| Class 3 | 59.39% | 81.67% | 68.77% | ||
| Class 4 | 84.07% | 79.17% | 81.55% | ||
| Class 5 | 66.23% | 83.33% | 73.80% | ||
| LOF | 82.34% | Class 0 | 93.25% | 85.60% | 89.26% |
| Class 1 | 55.08% | 53.33% | 54.19% | ||
| Class 2 | 58.00% | 48.74% | 52.97% | ||
| Class 3 | 58.67% | 73.33% | 65.19% | ||
| Class 4 | 70.25% | 70.83% | 70.54% | ||
| Class 5 | 64.46% | 65.00% | 64.73% |
| Model | Prediction Category 2 | MAE | MSE | R2 |
|---|---|---|---|---|
| LSTM | air temperature | 0.4859 | 0.9499 | 0.9639 |
| air humidity | 0.6386 | 1.0828 | 0.9680 | |
| soil temperature (20 cm) | 0.3347 | 0.3030 | 0.9695 | |
| soil temperature (40 cm) | 0.3625 | 0.3070 | 0.9681 | |
| soil temperature (60 cm) | 0.3557 | 0.3049 | 0.9680 | |
| RNN | air temperature | 1.0539 | 1.0741 | 0.9284 |
| air humidity | 1.6497 | 2.2547 | 0.9259 | |
| soil temperature (20 cm) | 0.7149 | 0.6231 | 0.9467 | |
| soil temperature (40 cm) | 0.6941 | 0.6150 | 0.9461 | |
| soil temperature (60 cm) | 0.6807 | 0.7098 | 0.9462 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Feng, J.; Zhang, W.; Liu, B.; Wang, T.; Zhang, C.; Xu, S.; Zhang, L.; Zuo, G.; Lv, Y.; et al. Detection and Correction of Abnormal IoT Data from Tea Plantations Based on Deep Learning. Agriculture 2023, 13, 480. https://doi.org/10.3390/agriculture13020480
Wang R, Feng J, Zhang W, Liu B, Wang T, Zhang C, Xu S, Zhang L, Zuo G, Lv Y, et al. Detection and Correction of Abnormal IoT Data from Tea Plantations Based on Deep Learning. Agriculture. 2023; 13(2):480. https://doi.org/10.3390/agriculture13020480
Chicago/Turabian StyleWang, Ruiqing, Jinlei Feng, Wu Zhang, Bo Liu, Tao Wang, Chenlu Zhang, Shaoxiang Xu, Lifu Zhang, Guanpeng Zuo, Yixi Lv, and et al. 2023. "Detection and Correction of Abnormal IoT Data from Tea Plantations Based on Deep Learning" Agriculture 13, no. 2: 480. https://doi.org/10.3390/agriculture13020480