1. Introduction
When machinery is rotated to achieve motion conversion, the bearing is the most critical component, and the most prone to fault, in the entire transmission system. According to statistics, 30% of machinery faults are caused by bearings [
1]. Fault prognosis is gaining traction because of the potential value in reducing loss to property by predicting the future performance of components.
At present, fault prognosis methods are mainly divided into two major directions: model-based fault prognosis and data-driven fault prognosis [
2]. The model-based fault prognosis method assumes that an accurate mathematical model of the object system can be constructed [
3]. The performance of the part is evaluated by calculation of functional damage, and the remaining life of the part is evaluated by building physical and simulation models [
4]. Janjarasjitt et al. constructed a mathematical model that characterizes the operating state of a bearing by using partially correlated integrals [
5]. Lei et al. used algebraic equations to construct a planetary gearbox vibration signal model for gearbox failure prediction [
6]. Huang et al. extracted fault feature information from the system’s operating state and built a fault state model using the Kalman rate and an expert system for fault prognosis [
7]. Du et al. combined the advantages of strong tracking square root Kalman filters and autoregressive models to build a future measurement state prediction model [
8]. Lin et al. combined the concept of fuzzy posted progress in fuzzy mathematics with particle filtering to realize the fault prognosis of a three-tank water tank system and a planetary gear system [
9]. Although the model-based method can achieve fault prognosis, it has two disadvantages that cannot be ignored: (1) There is a strong dependence on the model. The model built will directly affect the effect of fault prognosis, and it is often difficult to build accurate mathematical models for complex dynamic systems. (2) The model generalization is poor. The built model needs to consider various working conditions and operating states of the predicted object. The generality of the physical model is usually poor, causing unnecessary waste of human and financial resources.
The data-driven fault prognosis method is based on historical data and uses data mining to find the performance change characteristics of the model to achieve fault prognosis [
10]. Marco et al. extensively reviewed the latest developments in non-destructive techniques [
11]. Zhang et al. established a chaotic time series of oil chromatography data by introducing chaos theory, and used the Lyapunov exponent method to predict the gas volume trend in oil [
12]. Peng et al. used the moving average model to predict the dissolved gas content in transformer oil [
13]. Yan et al. established a system performance degradation model and used the auto-regression and moving average model to predict the remaining useful life of the system [
14]. Rigamonti et al. used an integrated echo state network for fault prognosis of industrial components [
15]. Xu et al. used a long short-term memory model and principal component analysis to realize shield fault prognosis [
16]. Li et al. used kernel principal component analysis and the hierarchically gated recursive unit network to predict the health status of bearings [
17]. Cecilia Surace et al. proposed an instantaneous spectral entropy and continuous wavelet transform for anomaly detection and fault diagnosis using gearbox vibration time histories [
18]. Zhou et al. combined the advantages of principal component analysis and automatic encoders to successfully implement early monitoring and prognosis of slowly varying fault signals [
19].
Although the data-driven fault prognosis method removes the dependence on models, there are still three shortcomings: (1) The health index that characterizes the changes in model performance directly affects the effectiveness of fault prediction. Machine learning methods such as principal component analysis (PCA) and locally linear embedding (LLE) have limited feature learning capabilities and cannot fully learn model performance change information. (2) The disturbance of the vibration signal noise collected by the sensor will cause random disturbances in the constructed health index, which will affect the fault prognosis effect. (3) The constructed health index is a continuous time series. Traditional intelligent prediction methods have limited ability to learn continuous data features.
In order to solve the above problems, this paper proposes an intelligent fault prognosis method based on stacked autoencoders and continuous deep belief networks. Our work is summarized as follows:
- (1)
In order to construct a health index that can accurately represent the change in model performance, this paper makes full use of the powerful feature learning capabilities and information fusion capabilities of stacked autoencoders.
- (2)
In order to solve the problem of local random interference in the health index, this paper uses the exponential weighted moving average method to smooth the health index. It can integrate historical information with current information to reduce the impact of noise.
- (3)
In order to capture the feature information of the continuous time series, this paper makes full use of the continuous deep belief network’s powerful feature learning ability and fault prognosis ability for continuous data.
- (4)
In order to verify the prediction effect of the fault prognosis method in this paper, a comparative experiment on fault prognosis is carried out using intelligent maintenance systems (IMS) bearing data as an example.
The rest of the paper is arranged as follows: in
Section 2, we briefly introduce the stacked autoencoder and deep belief network; in
Section 3, we introduce the proposed fault prognosis method in detail; in
Section 4, we conduct experiments to verify the effectiveness of the proposed method; and
Section 5 is the conclusion.
3. Proposed Method
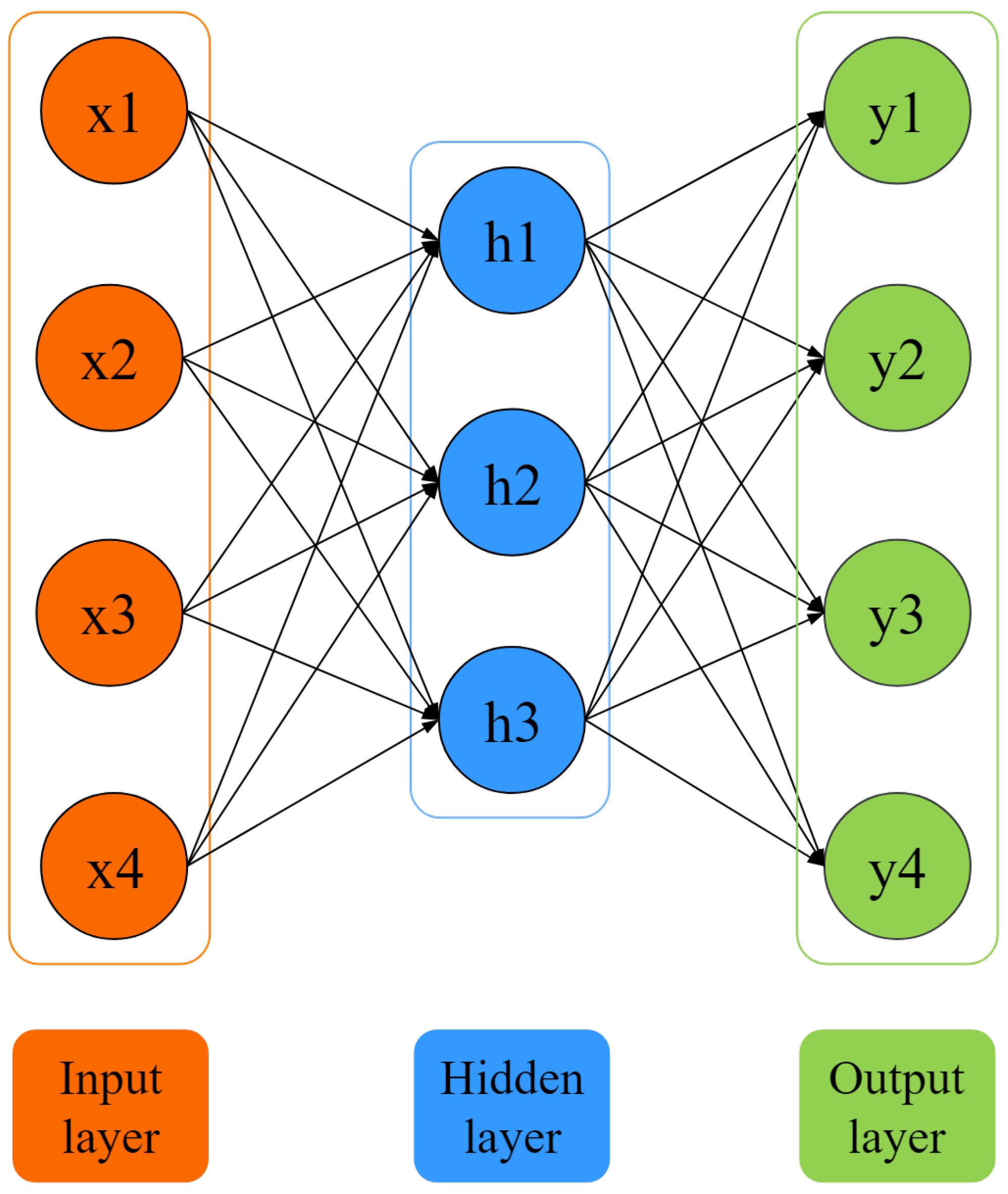
Constructing health indices that characterize model performance changes based on information collected by sensors. And predicting future model performance through feature learning and information mining of health indices are two of the most popular problems in the field of fault prognosis. This paper makes full use of the automatic information fusion capability of the stacked autoencoder and the continuous deep belief network’s excellent feature learning ability for continuous data. Taking bearing data as an example, an intelligent fault prognosis method based on stacked autoencoders and continuous deep belief networks is proposed to solve this problem. This method mainly includes two parts: The first part constructs health indices that accurately represent the change in model performance. A stacked autoencoder is used to perform feature learning and information fusion on bearing lifecycle vibration data to construct health indices that characterize the changes in bearing performance. Aiming at the local disturbance in health indices, the exponential weighted moving average method is used to smooth the data to reduce the impact of noise. The second part is the continuous deep belief network feature learning and information mining of health indices. Firstly, a continuous deep belief network suitable for processing continuous data is constructed on the basis of a standard deep belief network. Then, the continuous deep belief network is used to predict the future health status of the bearing by capturing the non-linear feature information of the health indices.
3.1. Construction of Health Index
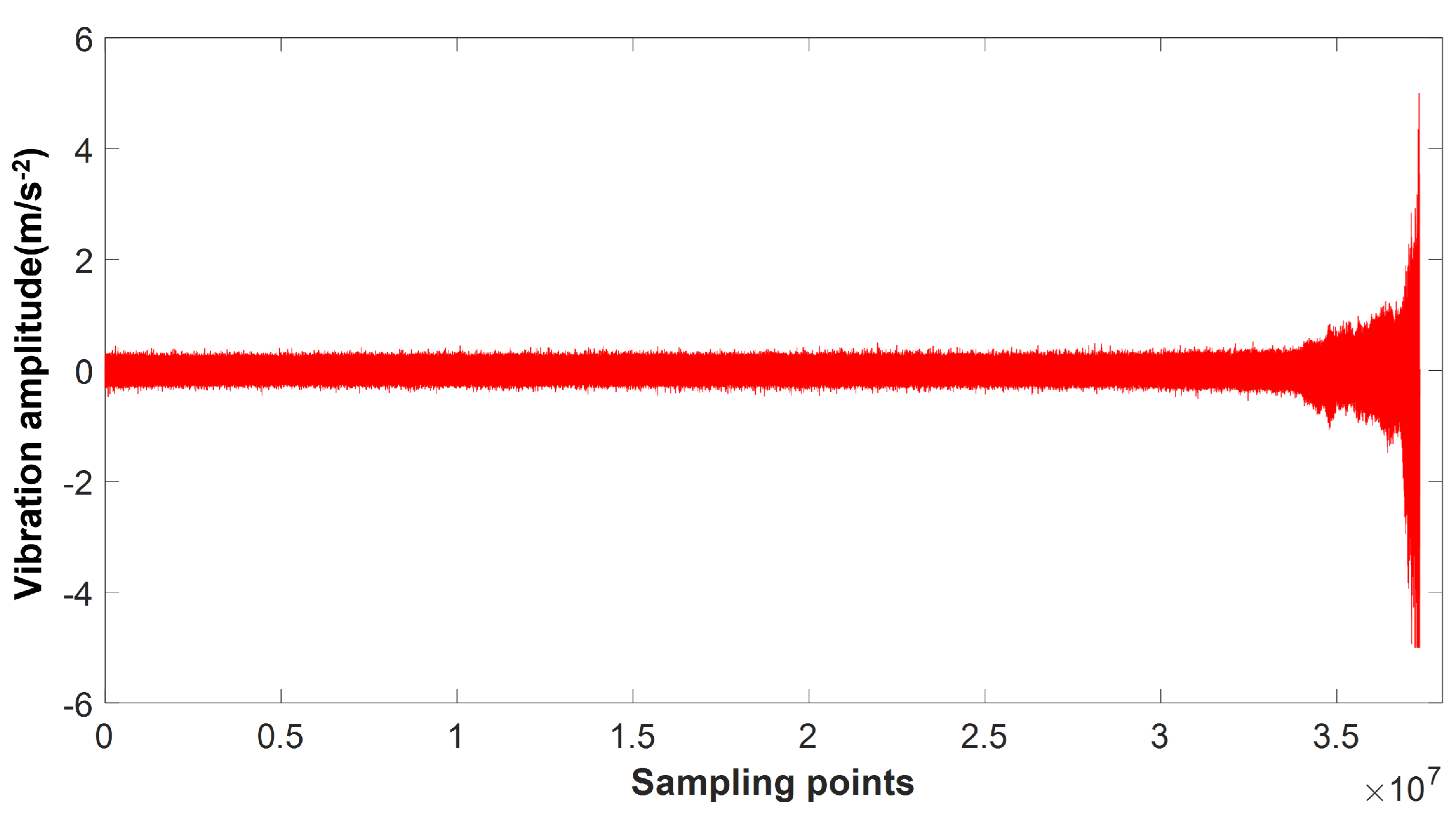
The premise of fault prognosis is to construct health indices that characterize the performance changes in the model based on the data collected by the sensors. Since the characteristic parameters of the vibration signal contain the significant information on model performance changes, in order to construct suitable health indices, it is necessary to extract the characteristic parameters of the model from the original bearing vibration signal. As shown in
Table 1, this paper extracts time domain parameters such as the average, variance, root mean square, peak-to-peak value, and kurtosis from time domain signals, and frequency domain parameters such as averages, variances, and root mean squares from frequency domain signals. This paper selects the feature data commonly used in signal processing, but proves that compared with single feature information, the feature information obtained after feature learning of multiple feature information by SAE and EWMA can better reflect the change in bearing health status with time.
The characteristic parameters are the external information of the vibration signal, and different characteristic values reflect the internal information of different aspects of the signal [
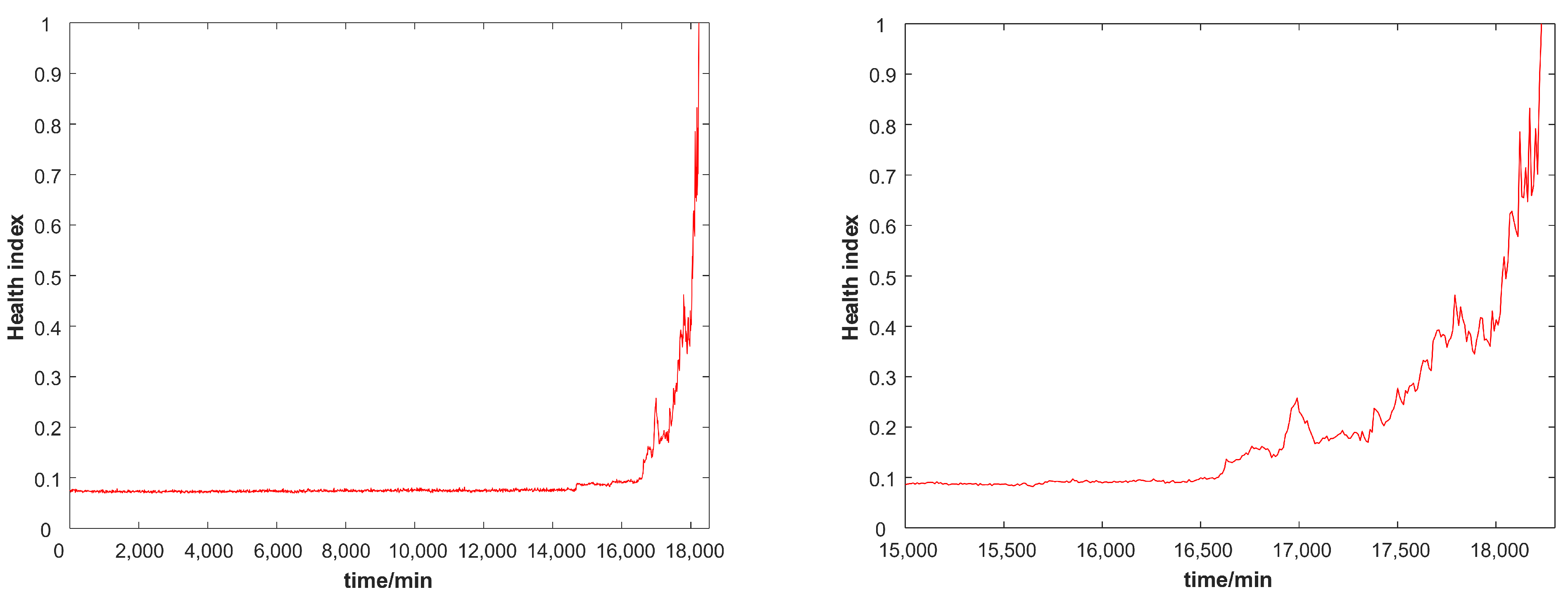
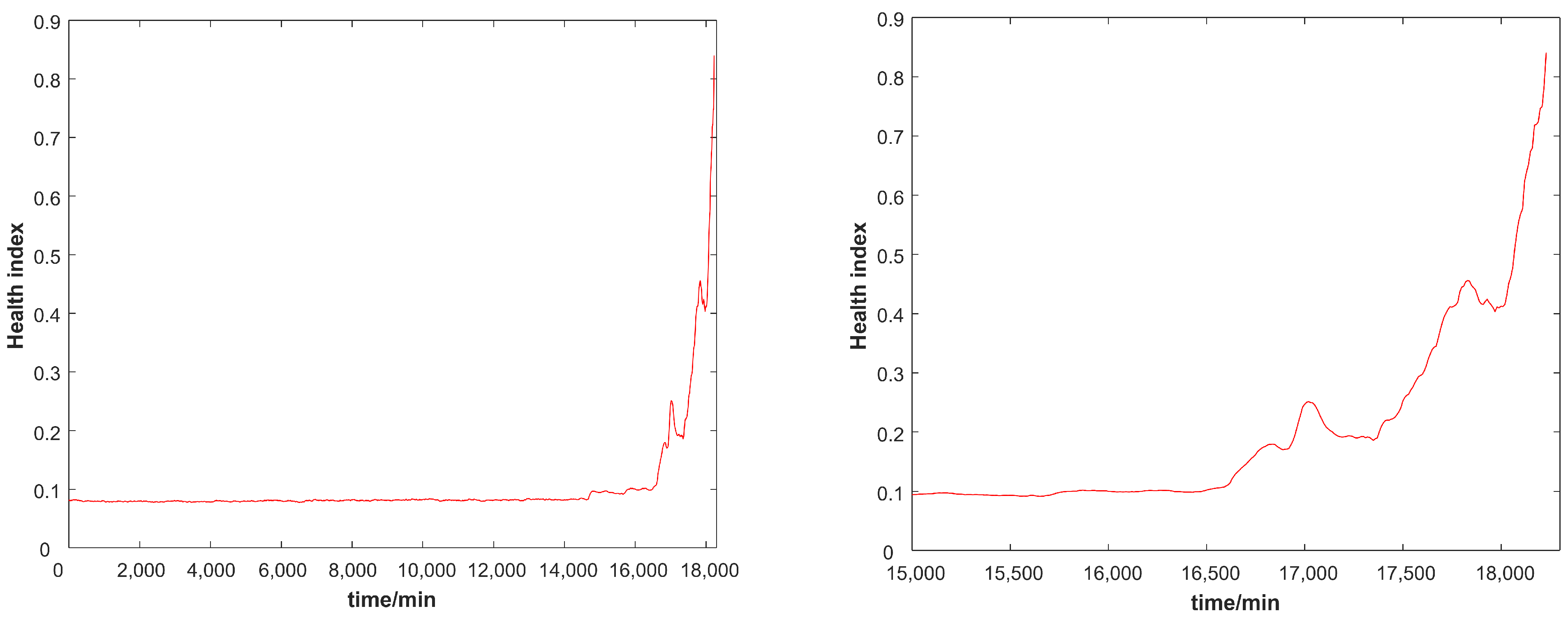
21]. In order to better construct the model’s health indices, it is necessary to perform feature learning and information fusion on information of all aspects of the vibration signal. Traditional methods for constructing health indices often use machine learning methods such as PCA and LLE to perform component analysis and data dimensionality reduction on feature parameters. In this paper, stacked autoencoders are used to perform feature learning and information mining on model feature parameters. By capturing the inherent information hidden in the feature parameters, the health indices that can characterize the performance changes in the model are constructed. Compared with the traditional health index construction method, the stacked autoencoder has three obvious advantages: (1) The stacked autoencoder is a deep learning model composed of multiple autoencoders. It can rely on the deep structure of the model to autonomously mine information about the model’s characteristic parameters and obtain information about the performance changes in the model hidden under the characteristic parameters. (2) The traditional health index construction method is a machine learning method. Compared with the stacked autoencoder, the feature learning ability and nonlinear data fitting ability are very limited. The stacked autoencoder can perform feature learning and information fusion on feature parameters more comprehensively and accurately, and the constructed health indices can more accurately track the performance changes in the model. (3) The stacked autoencoder model uses self-supervised training, which is very suitable for the construction of model health indices.
Due to the influence of noise in the vibration signal collected by the sensor, although the constructed health indices can reflect the performance change in the model as a whole, random disturbances appear locally. This not only cannot accurately represent the actual changes in the model, but also directly affects the result of fault prognosis. Therefore, in order to reduce the influence of noise, this paper uses the exponential weighted moving average method to perform further data smoothing of health indices. The exponentially weighted moving average method is a method to determine the estimated value by referring to the current data and historical data simultaneously. The mechanism of the exponential moving average algorithm is described as follows:
where
represents the estimated value;
is a parameter to control the data smoothing effect;
is the current data; and
represents the historical data. Equation (
7) is a recursive formula. If it is expanded, the mechanism can be described as:
The change in configuration should be a continuous change. The exponential weighted moving average method refers to both current data and historical information to evaluate the actual value of the health indices. It can greatly reduce the impact of noise interference and capture mutation information while accurately maintaining the changes in health indices, which is very suitable for the construction of model health indices.
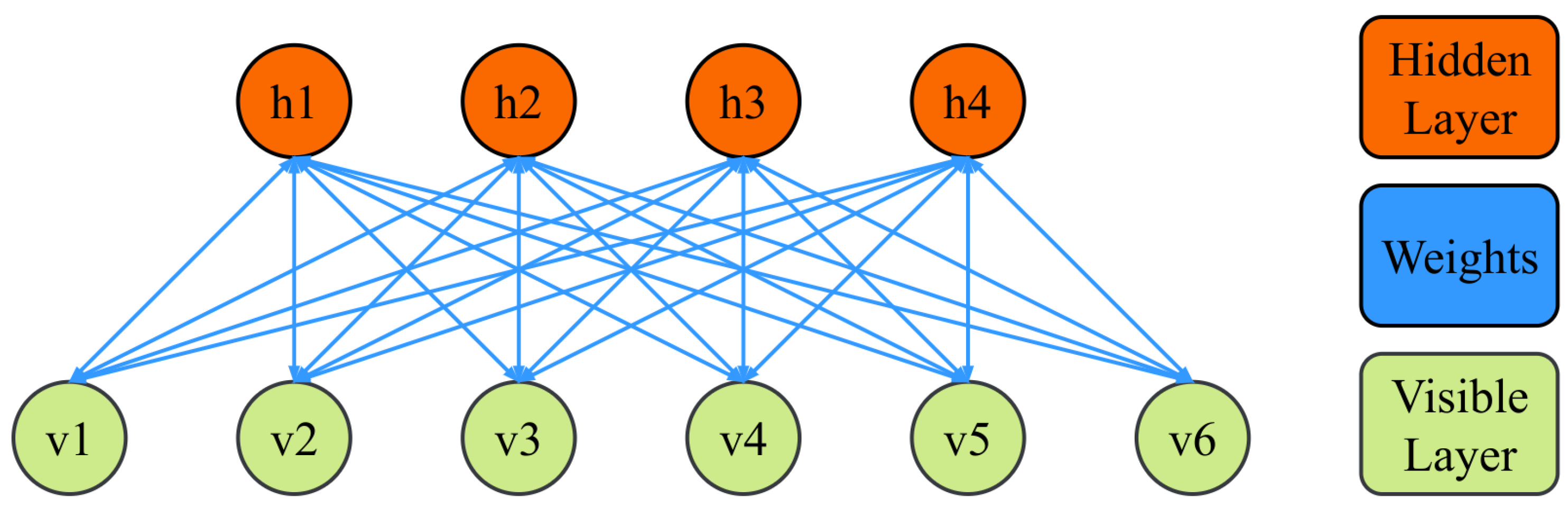
3.2. The Continuous Deep Belief Network
The feature learning effect of health indices directly determines the failure prognosis result. Deep belief networks can quickly and efficiently perform feature learning of health indices by simulating the deep structure of the human brain. Deep belief networks perform feature learning through data discretization, improving the efficiency of feature learning based on sacrificing data continuity. However, the model’s health index is a continuous time series. It is difficult for a standard deep belief network to obtain high-precision fault prognosis results [
22]. Through in-depth research on RBMs, Chen et al. proved that RBMs theoretically have the ability to process continuity data, and designed a continuity restricted Boltzmann machine (CRBM) [
23]. Based on the research into CRBMs, this paper designs a continuous deep belief network (CDBN) for fault prognosis of health indices.
CRBMs are the most basic component and function realization unit of CDBNs, so the CRBM was constructed first. The CRBM is a variant of a standard RBM, created in order to better handle continuous data, so a CRBM model was built on the basis of RBMs. (1) Gaussian noise was added with an average of 0 and a variance of 1 to each unit of the visible layer and the hidden layer to build a continuous random unit. (2) Continuous activation was used to activate the state of each neuron while retaining the sigmoid transfer function, and upper and lower asymptotes were added along with parameters that control the slope of the activation function. (3) The probability discrete binary process was cancelled in a standard RBM. The status of each unit in the CRBM model is as follows:
where
W represents the weight between the visible layer and the hidden layer in the CRBM model;
is the activation function of the CRBM;
is Gaussian noise with an average of 0 and a variance of 1;
is a constant;
and
are the lower and upper asymptotes, respectively; and
is used to control the slope of the continuity activation function.
The CDBN is a deep learning model made up of multiple CRBMs through the greedy algorithm. The training method of the CDBN is almost the same as the standard DBN, and it also includes two parts: supervised learning and unsupervised learning. The unsupervised learning part is mainly used by each CRBM to train its own model using the MCD algorithm. The greedy algorithm, that is, the hidden layer of the first CRBM, is used as the visible layer of the second CRBM to realize feature learning and information fusion of the input information.
where
m is momentum;
is the learning rate; and
and
represent the state of the neuron after a Gibbs sample.
The CDBN trains the parameters in the model to a more suitable range through unsupervised learning. During the supervised phase, the CDBN is regarded as an initialized BP neural network as a whole, and the gradient descent method is used for further fine-tuning based on the error of the prediction information and the actual information:
where
is the learning rate;
is the residual of the
i-th unit of the model; and
is the input value of the unit of each layer without passing through the activation function.
The above gradient is the gradient update method for a single sample in the dataset. When the entire dataset is trained, the individual gradients are usually added to obtain the average gradient. After obtaining the gradient value of each parameter, the gradient descent method is used to fine-tune the parameters of the model in the CDBN until the supervised learning is complete.
3.3. The Fault Prognosis Steps Based on the Proposed Method
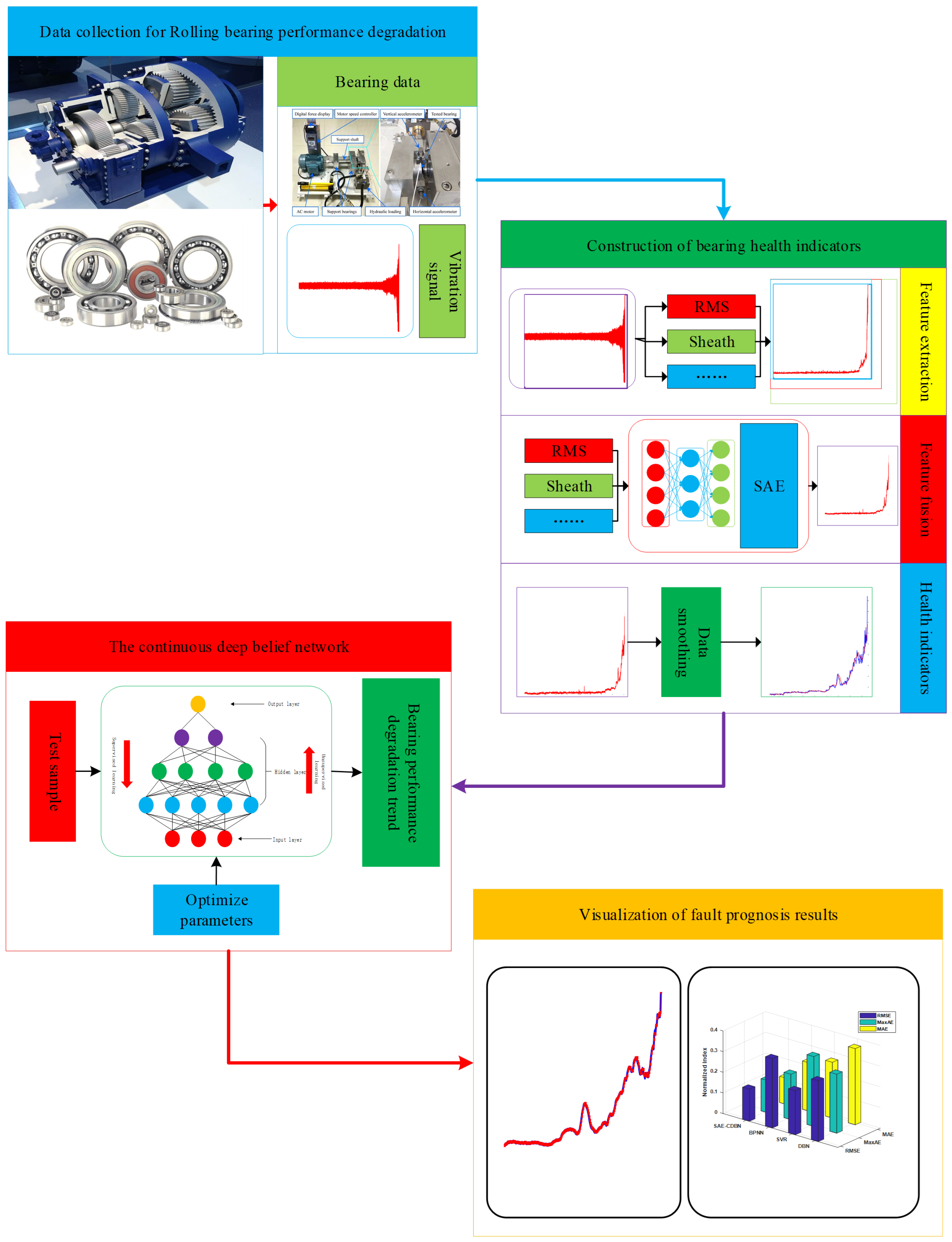
As shown in
Figure 4, the intelligent fault prognosis method based on a stacked autoencoder and a continuous deep belief network mainly includes four aspects: data collection, construction of health indices, feature learning of continuous deep belief network, and visualization of fault prediction results.
- (1)
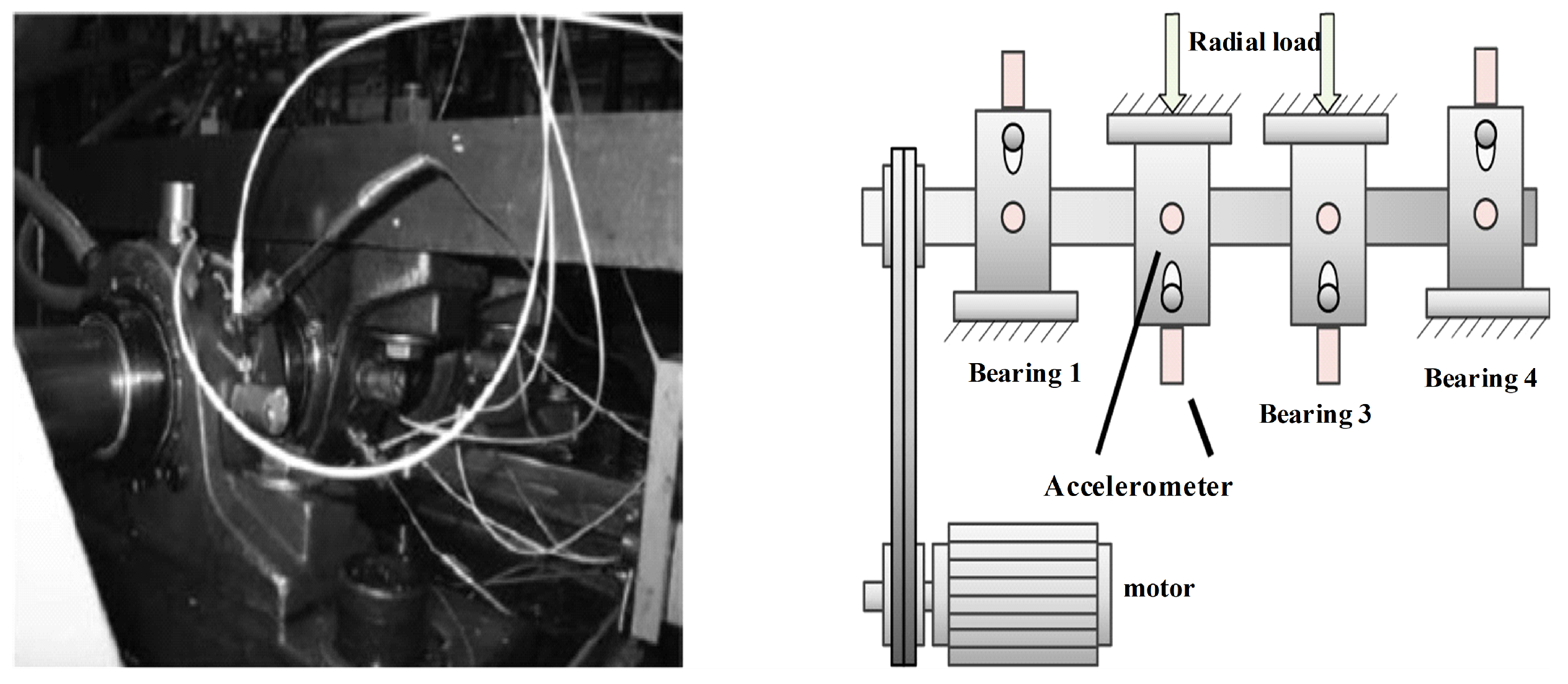
Data collection. A bearing performance test experiment is designed and sensors are used to collect bearing lifecycle vibration information.
- (2)
Establish health indices. Firstly, feature parameters containing information on bearing performance changes are extracted from the vibration signals collected by the sensors. Then, the stacked autoencoder is used to perform feature learning and information fusion on the extracted feature parameters to construct the health indices that characterize the performance change in the model. Aiming at the local fluctuations in health indices caused by noise, the data are smoothed using the exponentially weighted moving average method to reduce the impact of noise.
- (3)
Feature learning for continuous deep belief networks. The model performance change index is a continuous time series. Firstly, a CDBN model suitable for processing continuous data is constructed. Then, its own powerful feature learning ability and information mining ability is used to capture the performance change trends hidden in health indices, and model fault prognosis is performed.
- (4)
Visualization of failure results. The fault prognosis results are visualized.
5. Conclusions
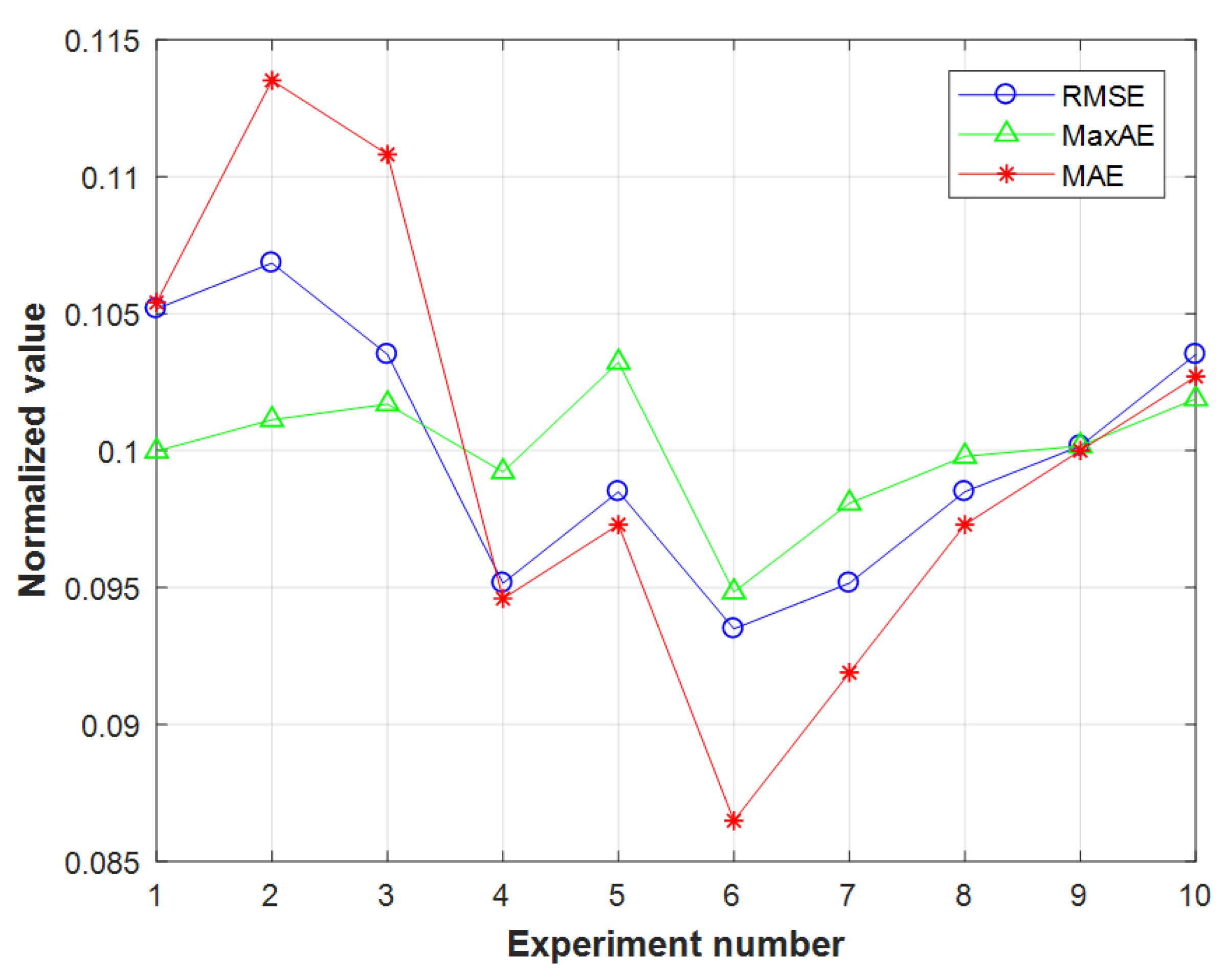
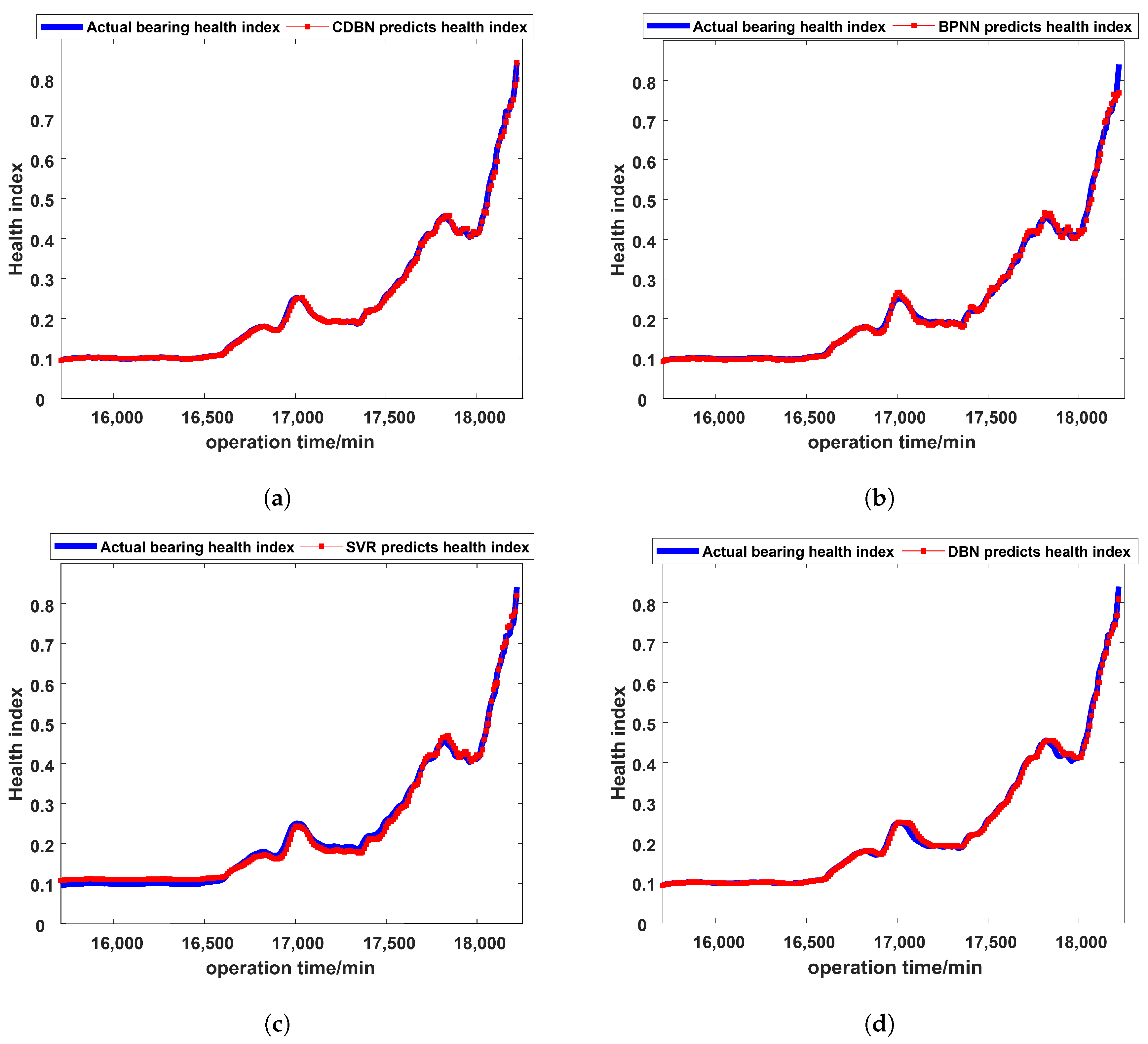
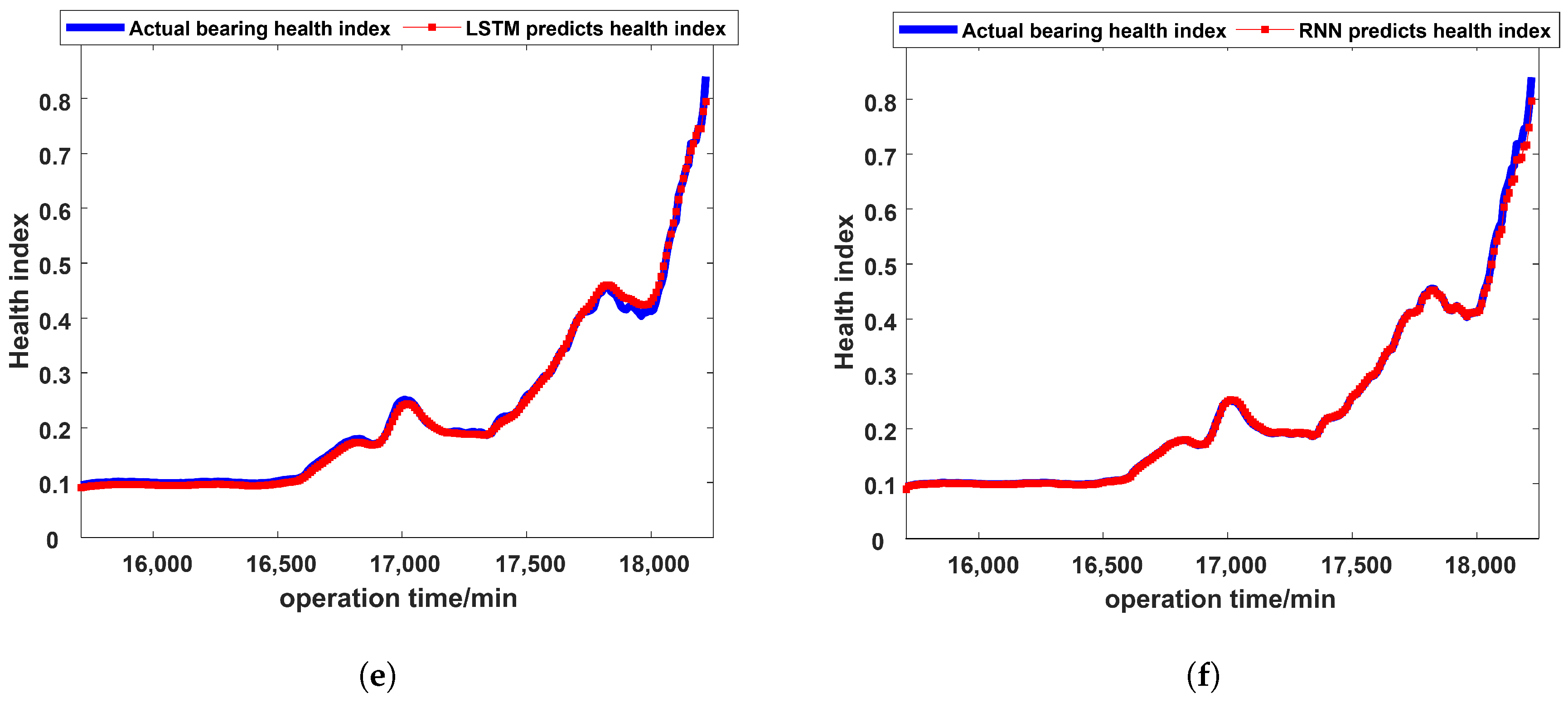
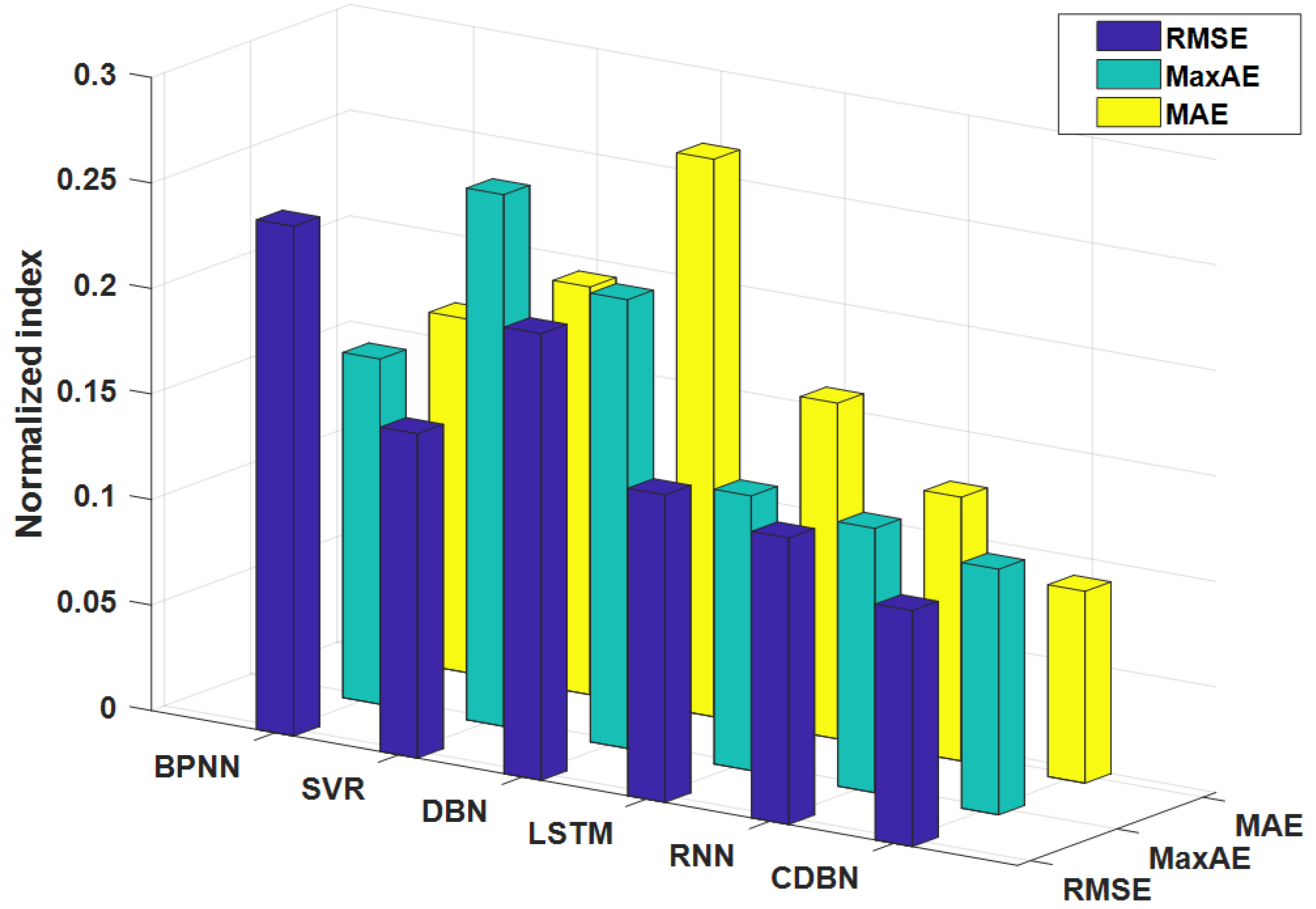
This paper is based on two aspects: the construction of health indices that characterize model performance changes and the fault prognosis of health indices. Combining the strong feature learning capabilities of stacked autoencoders and the continuous information fusion capabilities of continuous deep belief networks, a novel intelligent fault prognosis method based on a stacked autoencoder and a continuous deep belief network is proposed. This method consists of two parts: (1) The stacked autoencoder is used to perform feature learning and information fusion on the extracted feature parameters to build the health indices that characterize the performance change in the model. To solve the problem of local random fluctuations in health indices caused by noise, the exponential weighted moving average method is used to smooth the data, which greatly reduces the impact of noise on health indices. By comparing the performance of different health indices with the performance of actual models, it is proven that the proposed method can more accurately represent the changes in model performance. (2) Continuous deep belief networks are used to perform feature learning and fault prognosis on health indices. In order to verify the fault prognosis ability of the CDBN, a comparative experiment of intelligent prognosis methods was performed. The method in this paper evaluates the performance of the BPNN, SVR, DBN, LSTM, RNN, and the proposed method, CDBN. Furthermore, the normalized RMSE, MaxAE, and MAE indices are as low as 5.6 × 10, 4.98 × 10, and 3.2 × 10, respectively. The experimental results prove that compared with traditional intelligent prognosis methods, the CDBN model used in this paper has stronger feature learning capabilities, can determine the regularity of model performance changes in health indices, and can accurately predict changes in bearing performance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}