
Machine Learning for Early Parkinson’s Disease Identification within SWEDD Group Using Clinical and DaTSCAN SPECT Imaging Features

Abstract
:1. Introduction
1.1. Related Works
1.2. Contributions
- A diagnostic tool based on ML methods is proposed to improve the performance of early PD diagnosis within SWEDD groups, as the regular SWEDD subjects are likely to have PD at follow-up;
- The PPMI dataset was used as an input (548 samples with nine features) for the proposed method, as it is a large database that includes healthy and unhealthy subjects from different locations, which adds diversity in the dataset and makes the proposed method robust. Those heterogeneous features are divided into four features derived from DaTSCAN SPECT images (SBR values of left and right caudate and putamen), and five scores were derived from computer clinical assessments (Unified Parkinson’s Disease Rating Scale (UPDRS III), Montreal Cognitive Assessment (MoCA), University of Pennsylvania Identification Test (UPSIT) State-Trait Anxiety Inventory (STAI) and Geriatric Depression Scale (GDS));
- The optimum features were chosen from the nine features of the three groups (PD, HC and SWEDD) through PCA and LDA feature reduction algorithms to keep relevant information. This resulted in a reduction in the computational cost and improvement of the proposed method’s performance;
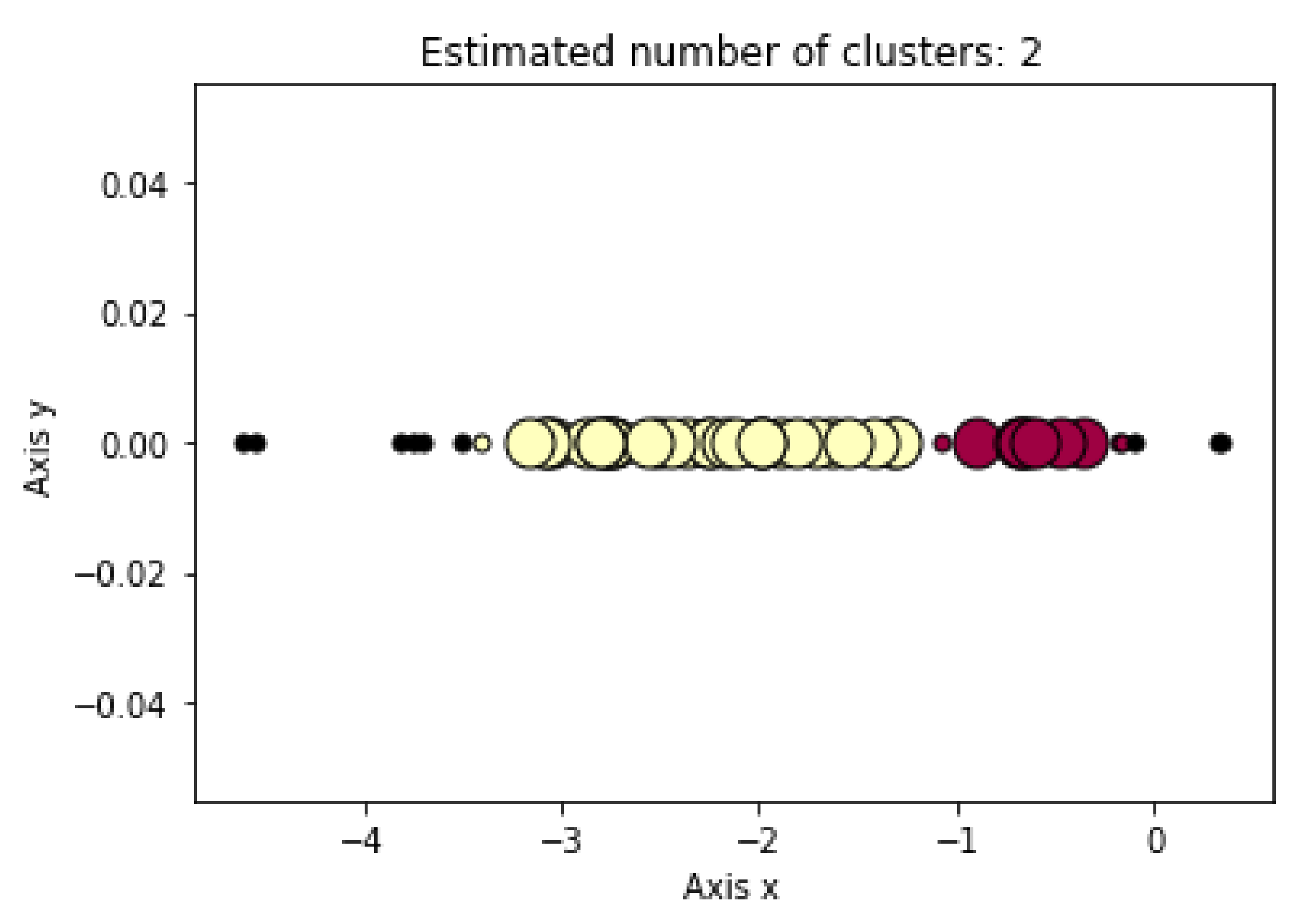
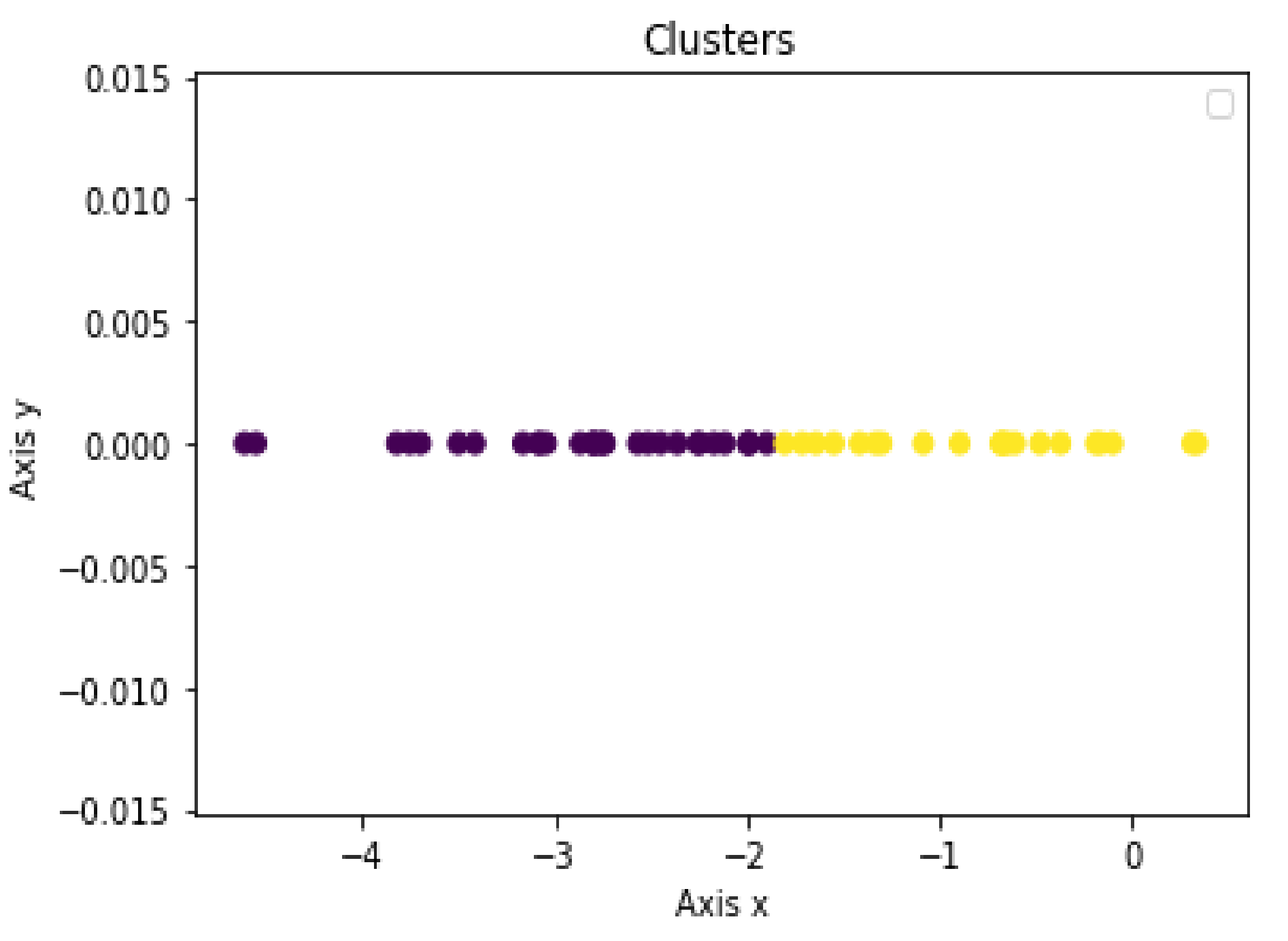
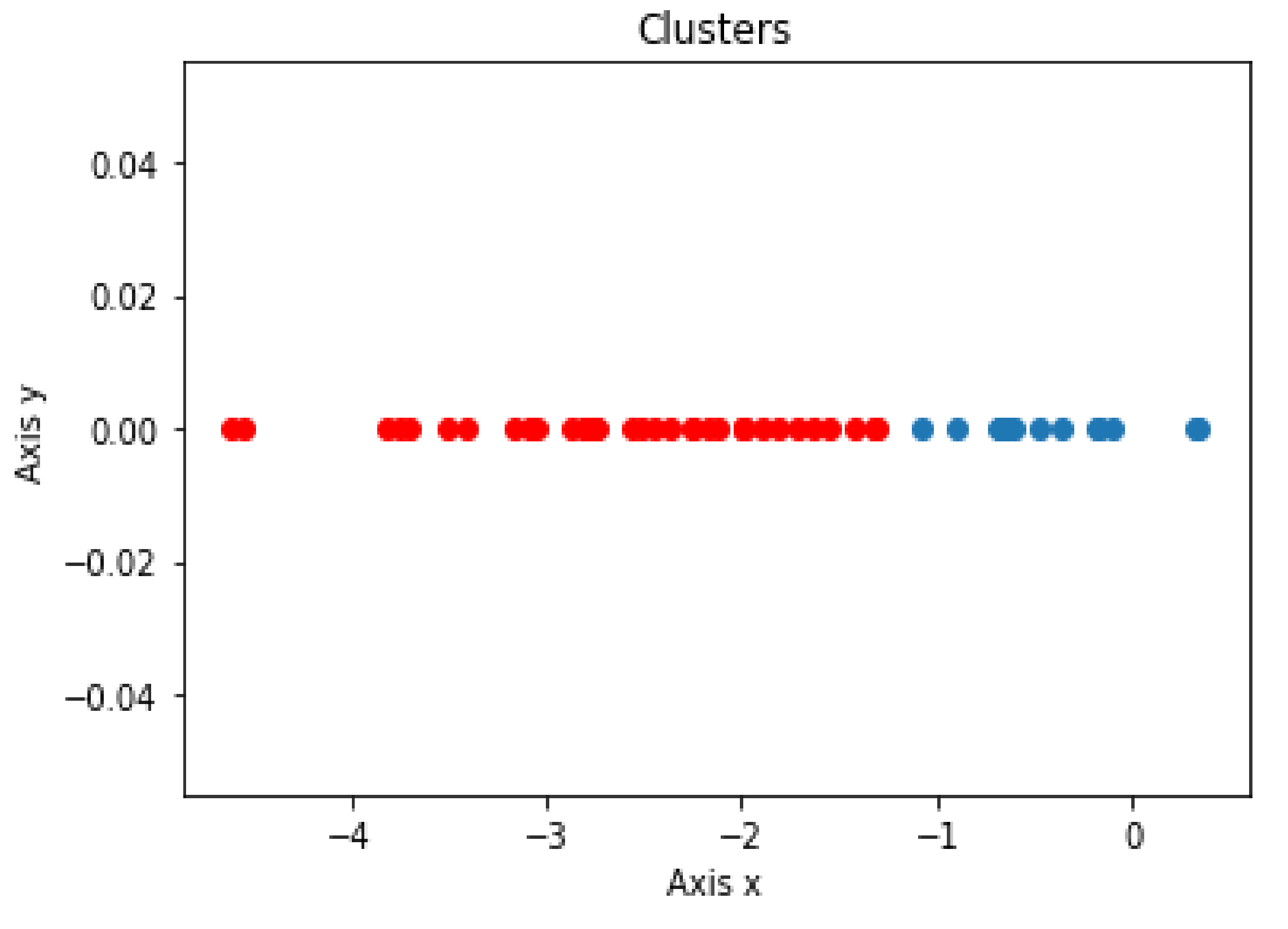
- Clustering assessments were used to distinguish PD patients from HC subjects within SWEDD using DBSCAN, K-means and Hierarchical Clustering (the reduction technique result of the SWEDD group was used as input for these ML clustering algorithms);
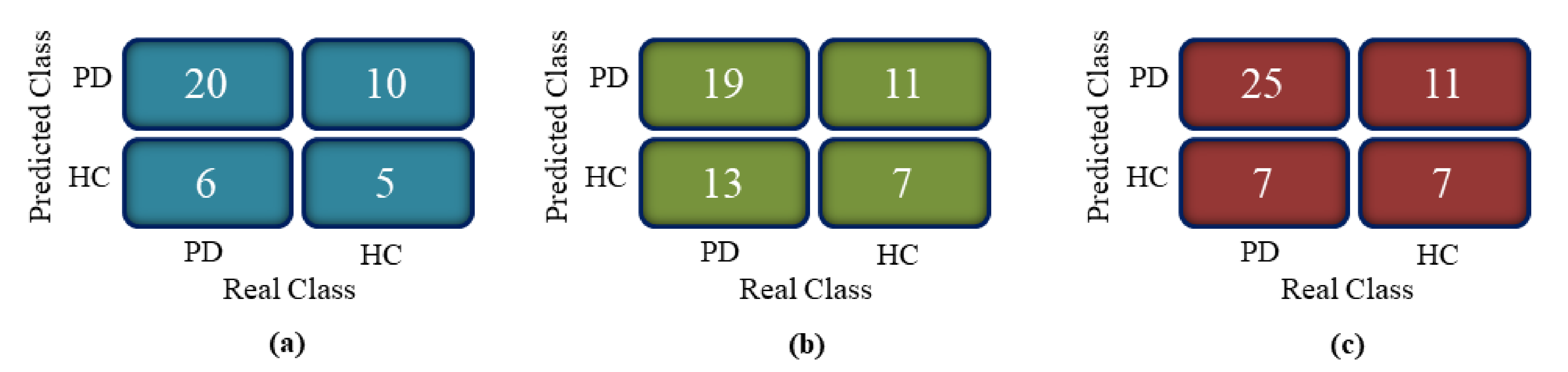
- The proposed model was evaluated for accuracy, specificity, sensitivity and F1 score by comparing clustering outcomes with the SWEDD ground truth (after follow-up, some SWEDD subjects developed PD, whereas other subjects continued to have normal dopaminergic imaging (HC)).
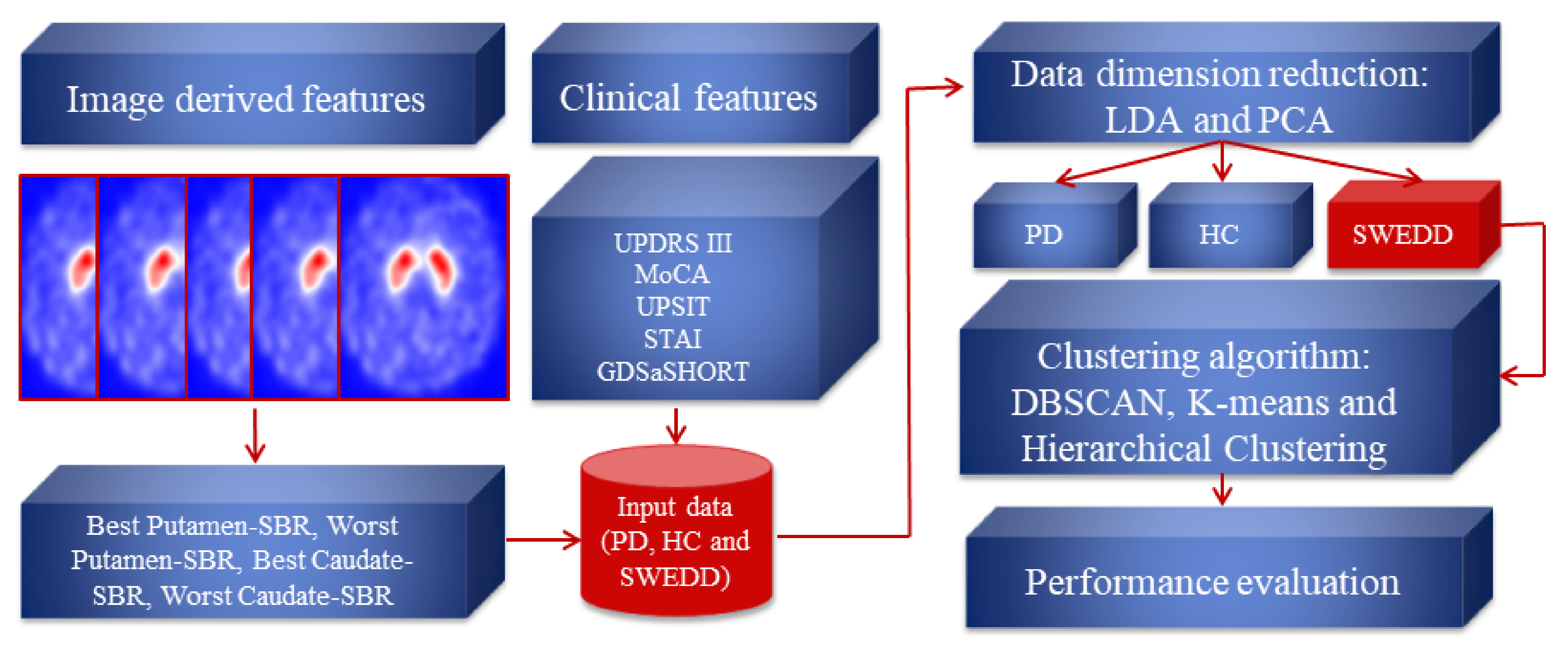
2. Materials and Methods
2.1. Dataset Description
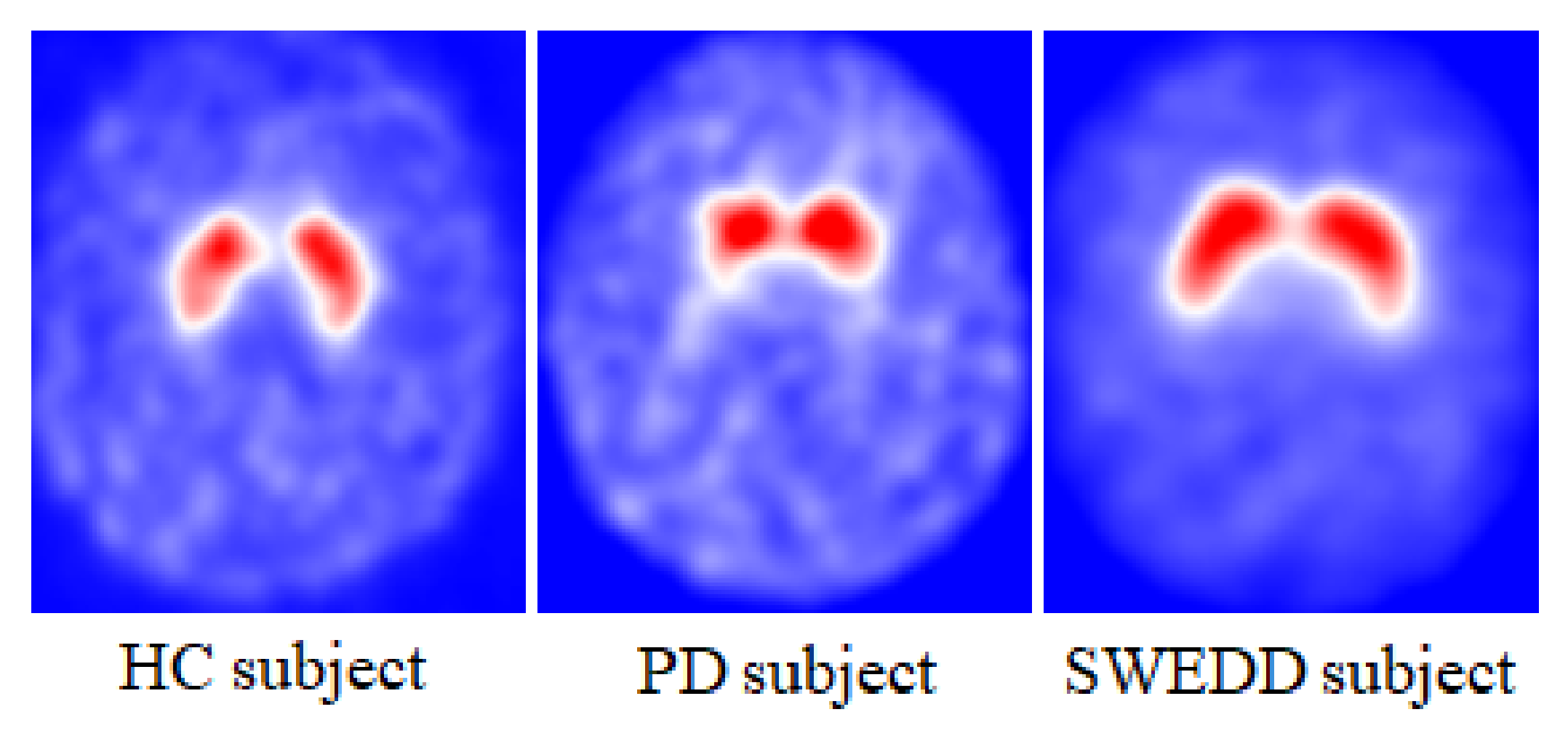
2.1.1. SPECT Imaging Features: Striatal Binding Ratio (SBR)
2.1.2. Clinical Features
- Unified Parkinson’s Disease Rating Scale (UPDRS III): covers the motor evaluation of disability;
- Montreal Cognitive Assessment (MoCA): assesses different types of cognitive abilities;
- University of Pennsylvania Identification Test (UPSIT): determines an individual’s olfactory ability;
- State-Trait Anxiety Inventory (STAI); diagnoses anxiety and distinguishes it from depressive syndromes;
- Geriatric Depression Scale (short form, GDS): identifies depression symptoms.
2.2. Data Dimension Reduction: Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) Techniques
| Algorithm 1: PCA steps |
| 1: Ignore the dataset (consists of d-dimensional sample) class labels. |
| 2: Calculate the d-dimensional mean vectors: the mean for every dimension of the whole dataset. The mean vector is computed by the following equation: |
| (1) |
| 3: Calculate the scatter matrix or the covariance matrix of the dataset. The mean vector is computed by the following equation: |
| (2) |
| 4: Calculate the eigenvectors and corresponding eigenvalues of the covariance matrix. |
| 5: Sort the eigenvalues by decreasing eigenvalues and pick k eigenvectors with the largest eigenvalues to form a d × k dimensional matrix W of eigenvectors. |
| 6: Use the W eigenvector matrix to transform the sample (original matrix) into the new subspace via the equation: |
| (3) |
| where x is a d × 1-dimensional vector representing one sample and y is the transformed k × 1-dimensional sample in the new subspace. |
| Algorithm 2: LDA steps |
| 1: Compute the d-dimensional mean vectors of the dataset classes: |
| (4) |
| 2: Compute the scatter matricesbetween-class and within-class scatter matrix. |
| The within-class scatter matrix is computed by the following equation: |
| (5) |
| (6) |
| The between-class scatter matrix is computed by the following equation: |
| (7) |
| where m is the overall mean, and and are the sample mean and the size of the respective classes. |
| 3: Compute the eigenvectors and associated eigenvalues for the scatter matrices. |
| 4: Sort the eigenvectors by decreasing eigenvalues and select k eigenvectors with the highest eigenvalues to form a d x k dimensional matrix W. |
| 5: Use the W eigenvector matrix to transform the original matrix onto the new subspace via the equation: |
| (8) |
| where X is an n × d-dimensional matrix representing the n samples, and Y is the transformed n × k-dimensional sample in the new subspace. |
2.3. Clustering Algorithms: K-means, DBSCAN and Hierarchical Clustering
2.3.1. K-means Algorithm
| Algorithm 3: K-means steps |
| 1: Select the required number of clusters, k. |
| 2: Select k starting points to be used as initial estimates of the cluster centroids. |
| 3: Attribute each point in the database to the cluster whose centroid is the nearest. |
| 4: Recalculate the new k centroids. |
| 5: Repeat steps 3 and 4 until no data point changes its cluster assignment or until the centroids no longer move (until the clusters stop changing). |
2.3.2. Density-Based Spatial (DBSCAN) Algorithm
| Algorithm 4: DBSCAN steps |
| 1: The algorithm begins with a random sample in which neighborhood information is taken from the ϵ parameter. |
| 2: If this sample contains Nmin within ϵ neighborhood, cluster formation starts. Otherwise, the pattern is marked as noise or may later be found in the ϵ neighborhood of a different pattern and, hence, can be incorporated into the cluster. If a sample is found to be a core point, then the samples within the ϵ neighborhood are also part of the cluster. So, all the samples found within ϵ neighborhood are added, along with their own ϵ neighborhood, if they are also core points. |
| 3: The process (step 2) restarts with a new point, which can be a part of a new cluster or labeled as noise, skipping every sample already assigned to a cluster by the preceding iterations. After DBSCAN completes the data processing, each sample is assigned to a particular cluster or it is an outlier. |
2.3.3. Hierarchical Clustering
3. Results
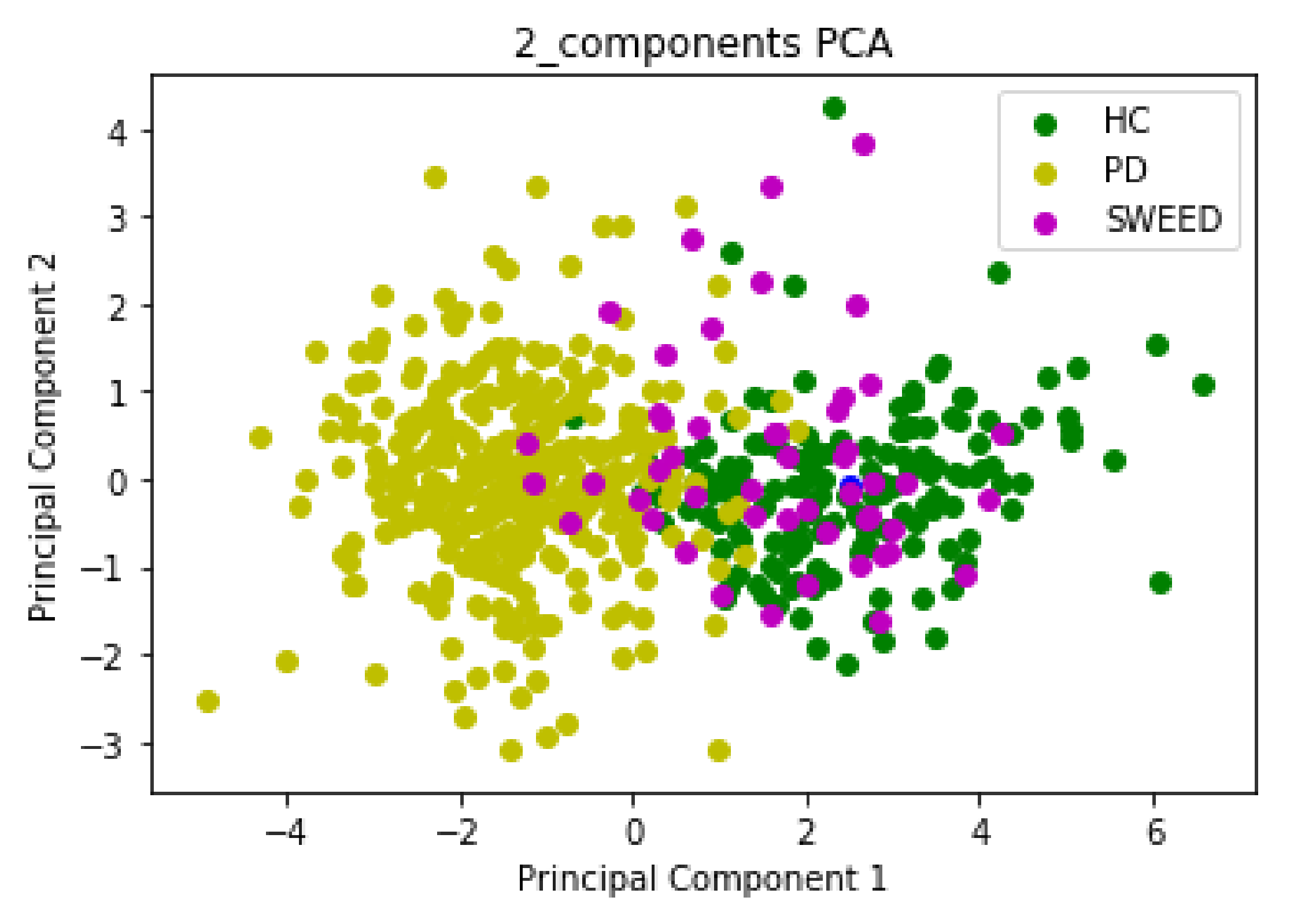
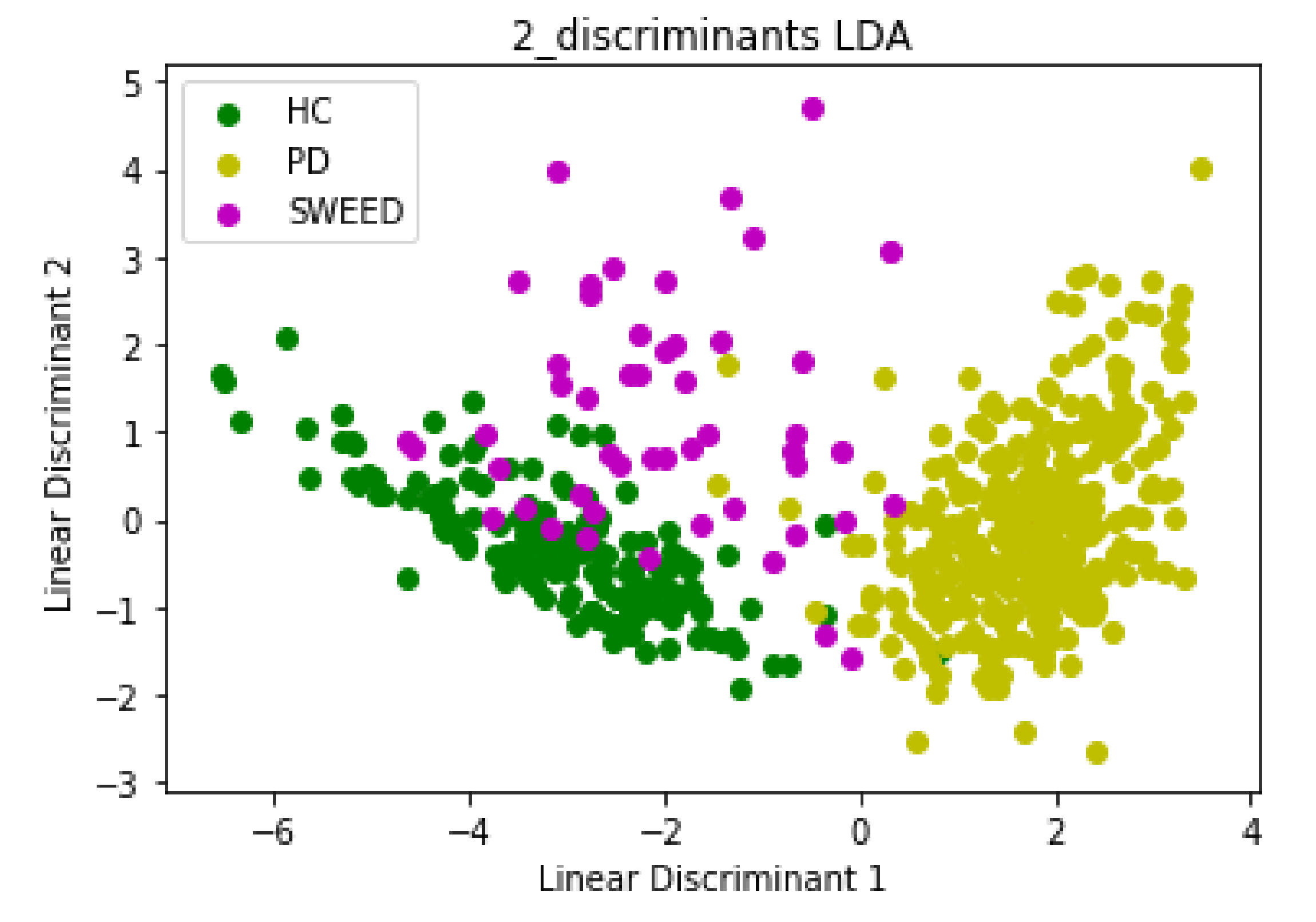
3.1. Data Dimension Reduction: Feature Extraction Based on PCA and LDA Techniques
3.2. Clustering Algorithm: K-means, DBSCAN and Hierarchical Clustering
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tolosa, E.; Wenning, G.; Poewe, W. The diagnosis of Parkinson’s disease. Lancet Neurol. 2006, 5, 75–86. [Google Scholar] [CrossRef]
- Jankovic, J. Parkinson’s disease: Clinical features and diagnosis. J. Neurol. Neurosurg. Psychiatry 2008, 79, 368–376. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schrag, A.; Good, C.D.; Miszkiel, K.; Morris, H.R.; Mathias, C.J.; Lees, A.J.; Quinn, N.P. Differentiation of atypical parkinsonian syndromes with routine MRI. Neurology 2000, 54, 697–702. [Google Scholar] [CrossRef] [PubMed]
- Hayes, M.T. Parkinson’s Disease and Parkinsonism. Am. J. Med. 2019, 132, 802–807. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Trutoiu, L.; Murai, A.; Alcindor, D.; Oh, M.; De la Torre, F.; Hodgins, J. Quantitative Measurement of Motor Symptoms in Parkinson’s Disease: A Study with Full-body Motion Capture Data. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 6789–6792. [Google Scholar] [CrossRef]
- Thobois, S.; Prange, S.; Scheiber, C.; Broussolle, E. What a neurologist should know about PET and SPECT functional imaging for parkinsonism: A practical perspective. Parkinsonism Relat. Disord. 2019, 59, 93–100. [Google Scholar] [CrossRef]
- Marek, K.; Seibyl, J.; Eberly, S.; Oakes, D.; Shoulson, I.; Lang, A.E.; Hyson, C.; Jennings, D. Longitudinal follow-up of SWEDD subjects in the PRECEPT Study. Neurology 2014, 82, 1791–1797. [Google Scholar] [CrossRef] [Green Version]
- De Rosa, A.; Carducci, C.; Carducci, C.; Peluso, S.; Lieto, M.; Mazzella, A.; Saccà, F.; Brescia Morra, V.; Pappatà, S.; Leuzzi, V.; et al. Screening for dopa-responsive dystonia in patients with Scans Without Evidence of Dopaminergic Deficiency (SWEDD). J. Neurol. 2014, 261, 2204–2208. [Google Scholar] [CrossRef]
- Taylor, J.C.; Fenner, J.W. Comparison of machine learning and semi-quantification algorithms for (I123)FP-CIT classification: The beginning of the end for semi-quantification? EJNMMI Phys. 2017, 4, 29. [Google Scholar] [CrossRef] [Green Version]
- Jalalian, A.; Mashohor, S.B.; Mahmud, H.R.; Saripan, M.I.; Ramli, A.R.; Karasfi, B. Computer-aided detection/diagnosis of breast cancer in mammography and ultrasound: A review. J. Clin. Imaging 2013, 37, 420–426. [Google Scholar] [CrossRef] [Green Version]
- Roth, H.R.; Lu, L.; Liu, J.; Yao, J.; Seff, A.; Cherry, K.; Kim, L.; Summers, R.M. Improving Computer-aided Detection using Convolutional Neural Networks and Random View Aggregation. IEEE Trans. Med. Imaging 2016, 35, 1170–1181. [Google Scholar] [CrossRef] [Green Version]
- Jomaa, H.; Mabrouk, R.; Morain-Nicolier, F.; Khlifa, N. Multi-scale and Non Local Mean based filter for Positron Emission Tomography imaging denoising. In Proceedings of the 2nd International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Monastir, Tunisia, 21–23 March 2016; pp. 108–112. [Google Scholar] [CrossRef]
- Firmino, M.; Angelo, G.; Morais, H.; Dantas, M.R.; Valentim, R. Computer aided detection (CADe) and diagnosis (CADx) system for lung cancer with likelihood of malignancy. Biomed. Eng. Online 2016, 15, 1–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aboudi, N.; Guetari, R.; Khlifa, N. Multi-objectives optimisation of features selection for the classification of thyroid nodules in ultrasound images. IET Image Processing 2020, 14, 1901–1908. [Google Scholar] [CrossRef]
- Mastouri, R.; Khlifa, N.; Neji, H.; Hantous-Zannad, S. A bilinear convolutional neural network for lung nodules classification on CT images. Int. J. CARS 2021, 16, 91–101. [Google Scholar] [CrossRef] [PubMed]
- Prashanth, R.; Roy, S.D.; Mandal, P.K.; Ghosh, S. Automatic classification and prediction models for early Parkinson’s disease diagnosis from SPECT imaging. Expert Syst. Appl. 2014, 41, 3333–3342. [Google Scholar] [CrossRef]
- Mabrouk, R.; Chikhaoui, B.; Bentabet, L. Machine Learning Based Classification Using Clinical and DaTSCAN SPECT Imaging Features: A Study on Parkinson’s Disease and SWEDD. Trans. Radiat. Plasma Med. Sci. 2018, 3, 170–177. [Google Scholar] [CrossRef]
- Segovia, F.; Górriz, J.M.; Ramírez, J.; Levin, J.; Schuberth, M.; Brendel, M.; Rominger, A.; Garraux, G.; Phillips, C. Analysis of 18F-DMFP PET Data Using Multikernel Classification in Order to Assist the Diagnosis of Parkinsonism. In Proceedings of the Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), San Diego, CA, USA, 31 October–7 November 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Segovia, F.; Gorriz, J.M.; Ramírez, J.; Salas-Gonzalez, D. Multiclass classification of 18 F-DMFP-PET data to assist the diagnosis of parkinsonism. In Proceedings of the International Workshop on Pattern Recognition in Neuroimaging (PRNI), Trento, Italy, 22–24 June 2016; pp. 18–21. [Google Scholar] [CrossRef]
- Khachnaoui, H.; Mabrouk, R.; Khlifa, N. Machine learning and deep learning for clinical data and PET/SPECT imaging in Parkinson’s disease: A review. IET Image Processing 2020, 14, 4013–4026. [Google Scholar] [CrossRef]
- Castillo-Barnes, D.; Ramírez, J.; Segovia, F.; Martínez-Murcia, F.J.; Salas-Gonzalez, D.; Górriz, J.M. Robust Ensemble Classification Methodology for I123-Ioflupane SPECT Images and Multiple Heterogeneous Biomarkers in the Diagnosis of Parkinson’s Disease. Front. Neuroinform. 2018, 12, 53. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Wei, L.; Hu, Y.; Wu, Y.; Hu, L.; Nie, S. Classification of Parkinson’s disease based on Multi-modal Features and Stacking Ensemble Learning. J. Neurosci. Methods 2021, 350, 109019. [Google Scholar] [CrossRef]
- Dotinga, M.; van Dijk, J.D.; Vendel, B.N.; Slump, C.H.; Portman, A.T.; van Dalen, J.A. Clinical value of machine learning-based interpretation of I-123 FP-CIT scans to detect Parkinson’s disease: A two-center study. Ann. Nucl. Med. 2021, 35, 378–385. [Google Scholar] [CrossRef]
- Nicastro, N.; Wegrzyk, J.; Preti, M.G.; Fleury, V.; Van de Ville, D.; Garibotto, V.; Burkhard, P.R. Classification of degenerative parkinsonism subtypes by support-vector-machine analysis and striatal 123I-FP-CIT indices. J. Neurol. 2019, 266, 1771–1781. [Google Scholar] [CrossRef] [Green Version]
- Lavanya, M.B.; Kadambari, K.V. Fast and robust supervised machine learning approach for classification and prediction of Parkinson’s disease onset. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2021, 9, 1–17. [Google Scholar] [CrossRef]
- Lavanya, M.B.; Kadambari, K.V. A novel supervised machine learning algorithm to detect Parkinson’s disease on its early stages. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 5257–5276. [Google Scholar]
- Castillo-Barnes, D.; Martinez-Murcia, F.J.; Ortiz, A.; Salas-Gonzalez, D.; Ramirez, J.; Gorriz, J.M. Morphological Characterization of Functional Brain Imaging by Isosurface Analysis in Parkinson’s Disease. Int. J. Neural Syst. 2020, 30, 2050044. [Google Scholar] [CrossRef] [PubMed]
- Marek, K.; Jennings, D.; Lasch, S.; Siderowf, A.; Tanner, C.; Simuni, T.; Coffey, C.; Kieburtz, K.; Flagg, E.; Chowdhury, S.; et al. The Parkinson Progression Marker Initiative (PPMI). Prog. Neurobiol. 2011, 95, 629–635. [Google Scholar] [CrossRef] [PubMed]
- Hauser, R.A.; Grosset, D.G. [123I] FP-CIT (DaTscan) SPECT brain imaging in patients with suspected parkinsonian syndromes. J. Neuroimaging 2012, 22, 225–230. [Google Scholar] [CrossRef] [PubMed]
- Pagano, G.; Niccolini, F.; Politis, M. Imaging in Parkinson’s disease. Clin. Med. (Lond) 2016, 16, 371–375. [Google Scholar] [CrossRef]
- Sveinbjornsdottir, S. The clinical symptoms of Parkinson’s disease. J. Neurochem. 2016, 139, 318–324. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iddi, S.; Li, D.; Aisen, P.S.; Rafii, M.S.; Litvan, I.; Thompson, W.K.; Donohue, M.C. Estimating the Evolution of Disease in the Parkinson’s Progression Markers Initiative. Neurodegener. Dis. 2018, 18, 173–190. [Google Scholar] [CrossRef]
- Chen, W.S.; Chuan, C.A.; Shih, S.W.; Chang, S.H. Iris recognition using 2D-LDA + 2D-PCA. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 869–872. [Google Scholar] [CrossRef]
- Neagoe, V.; Mugioiu, A.; Stanculescu, I. Face Recognition using PCA versus ICA versus LDA cascaded with the neural classifier of Concurrent Self-Organizing Maps. In Proceedings of the 2010 8th International Conference on Communications, Bucharest, Romania, 10–12 June 2010; pp. 225–228. [Google Scholar] [CrossRef]
- Ferizal, R.; Wibirama, S.; Setiawan, N.A. Gender recognition using PCA and LDA with improve preprocessing and classification technique. In Proceedings of the 2017 7th International Annual Engineering Seminar (InAES), Yogyakarta, Indonesia, 1–2 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Wittek, P. Unsupervised Learning. Quantum Mach. Learn. 2014, 1, 57–62. [Google Scholar]
- Marini, F.; Amigo, J.M. Unsupervised exploration of hyperspectral and multispectral images. Hyperspectral Imaging 2020, 32, 93–114. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Objectives | Sample Size | Features | Methods | Accuracy |
|---|---|---|---|---|---|
| Diego et al. (2018) [21] | Classify PD patients and HC subjects | 388 subjects obtained from PPMI database | Morphological features extracted from DaTSCAN images with biomedical tests | SVM classifier with LOO-CV method | 96% |
| Nicolas Nicastro et al. (2019) [24] | Distinguish PD patients from other parkinsonian syndromes and HC subjects | 578 subjects (local database) | Semi-quantitative 123-FP-CIT SPECT uptake values | SVM with five-fold CV method | 58.4% |
| Yang et al. (2020) [22] | Classify PD patients and HC subjects | 101 subjects taken from PPMI dataset | Multimodel neuroimaging features composed of MRI and DTI with clinical evaluation | SVM, Random Forests, K-nearest Neighbors, Artificial Neural Network and Logistic Regression with ten-fold CV method | 96.88% |
| Dotinga et al. (2021) [23] | Distinguish PD patients from non-PD subjects | 210 subjects | SBR values computed from I-123 FP-CIT SPECT, age and gender | SVM with ten-fold CV method | 95% |
| Lavanya Madhuri Bollipo et al. (2021) [25] | Classify early PD patients and HC subjects | 600 subjects obtained from PPMI dataset | Clinical scores, SBRs values and demographic information | Incremental SVM with LOO-CV method | 98.3% |
| Lavanya Madhuri Bollipo et al. (2021) [26] | Distinguish early PD patients from HC subjects | 634 subjects taken from PPMI dataset | Motor, cognitive symptom scores and SBR values computed from DaTSCAN | SVR | 96.73% |
| Diego Castillo-Barnes et al. (2021) [27] | Distinguish PD patients from HC subjects | 386 samples selected from PPMI database | Morphological features computed from 123I-FP-CIT SPECT | SVM, Naive Bayesian and MLP with ten-fold CV method | 97.04% |
| HC | SWEDD | PD | |
|---|---|---|---|
| Number | 156 | 51 | 341 |
| SBR (Best Putamen) | 2.26 | 2.17 | 0.97 |
| SBR (Worst Putamen) | 2.04 | 1.89 | 0.66 |
| SBR (Best Caudate) | 3.08 | 2.94 | 2.16 |
| SBR (Worst Caudate) | 2.85 | 2.72 | 1.79 |
| UPDRS III | 1.20 | 14 | 20.61 |
| MoCA | 28.20 | 27.16 | 26.59 |
| UPSIT | 34.03 | 31.37 | 22.12 |
| STAI | −0.24 | 0.04 | 0.09 |
| GDS | 5.15 | 5.71 | 5.26 |
| Measure | DBSCAN | K-means | Hierarchical Clusternig |
|---|---|---|---|
| Accuracy % | 60.98 | 61.29 | 64.00 |
| Sensitivity % | 76.92 | 59.38 | 78.13 |
| Specitivity % | 33.33 | 38.89 | 38.89 |
| F1 score % | 71.43 | 61.29 | 73.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khachnaoui, H.; Khlifa, N.; Mabrouk, R. Machine Learning for Early Parkinson’s Disease Identification within SWEDD Group Using Clinical and DaTSCAN SPECT Imaging Features. J. Imaging 2022, 8, 97. https://doi.org/10.3390/jimaging8040097
Khachnaoui H, Khlifa N, Mabrouk R. Machine Learning for Early Parkinson’s Disease Identification within SWEDD Group Using Clinical and DaTSCAN SPECT Imaging Features. Journal of Imaging. 2022; 8(4):97. https://doi.org/10.3390/jimaging8040097
Chicago/Turabian StyleKhachnaoui, Hajer, Nawres Khlifa, and Rostom Mabrouk. 2022. "Machine Learning for Early Parkinson’s Disease Identification within SWEDD Group Using Clinical and DaTSCAN SPECT Imaging Features" Journal of Imaging 8, no. 4: 97. https://doi.org/10.3390/jimaging8040097