

Detection and Recognition of the Underwater Object with Designated Features Using the Technical Stereo Vision System

Abstract
:1. Introduction
2. Methods Problem Statement
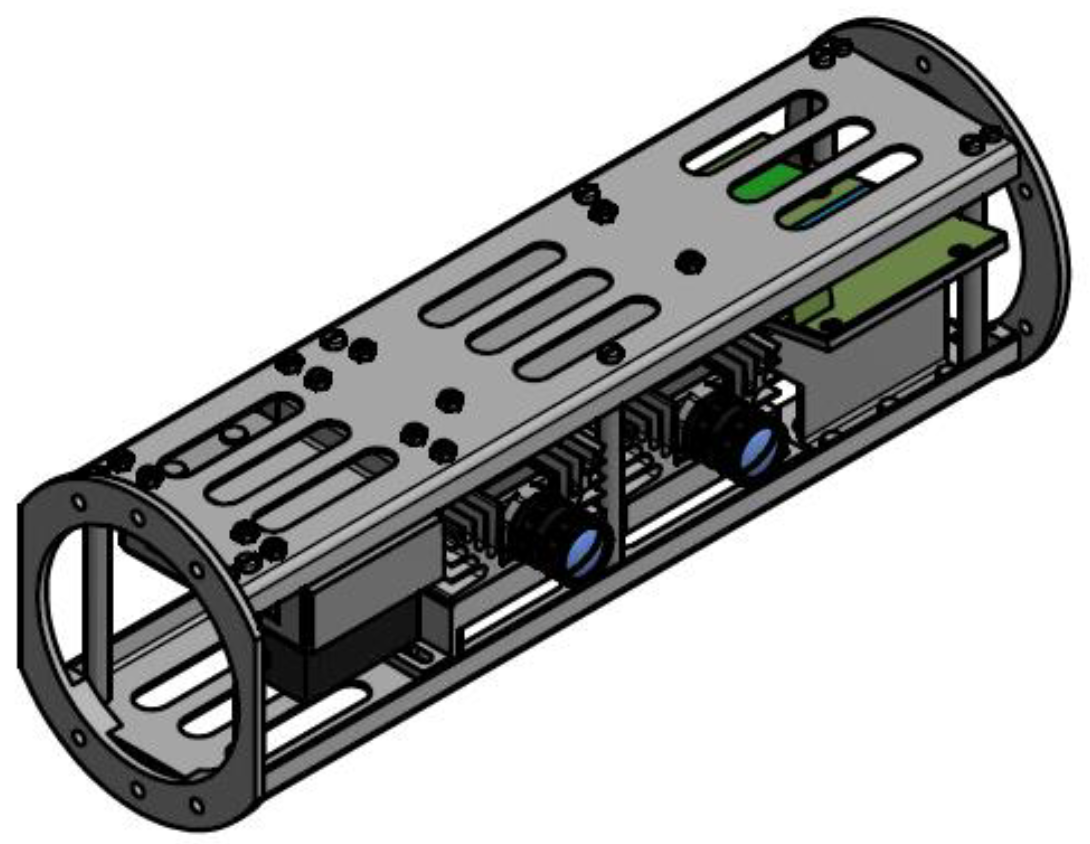
2.1. Equipment Description for the TSS System Deployment
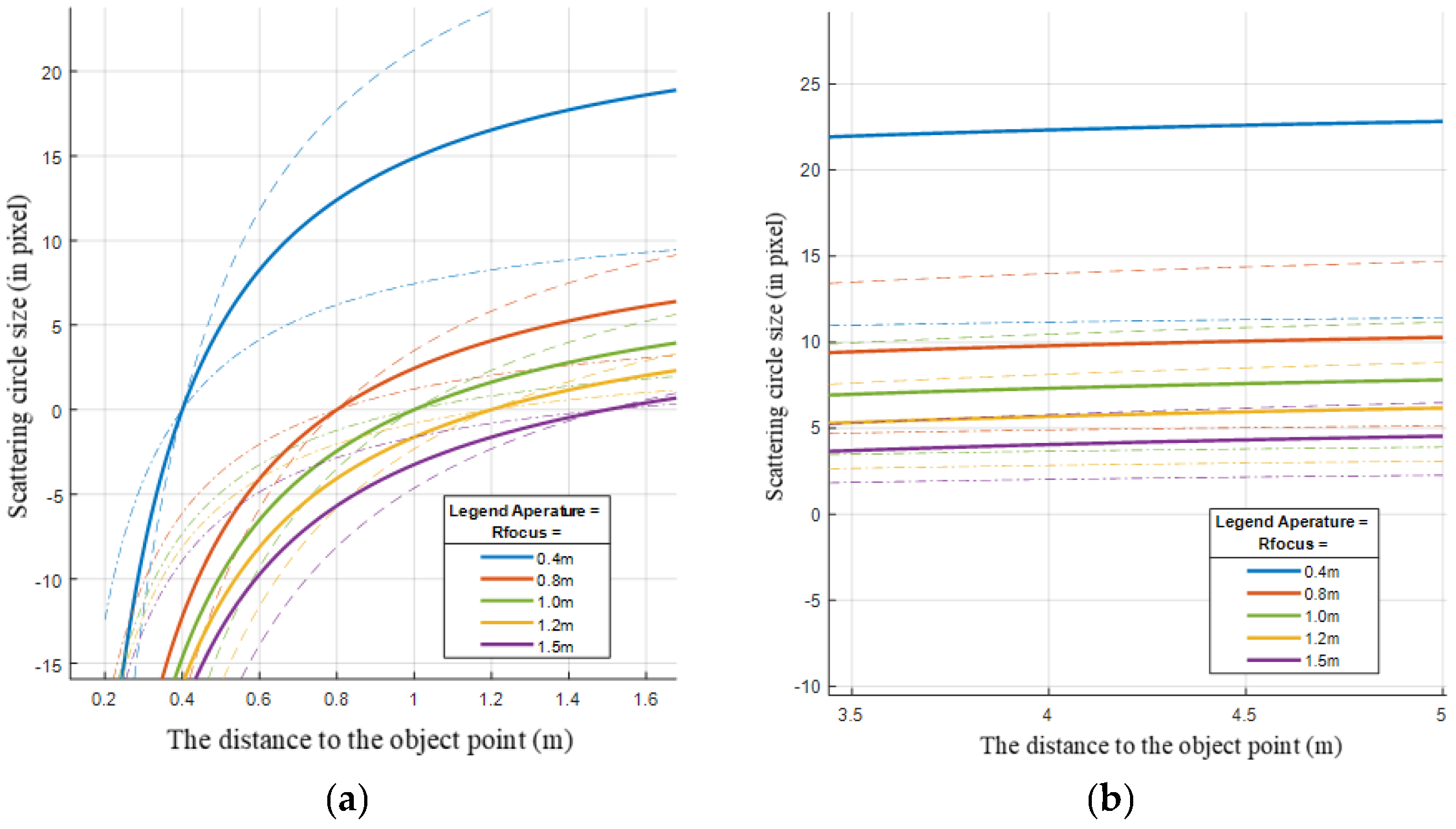
2.2. Camera Lens Issues
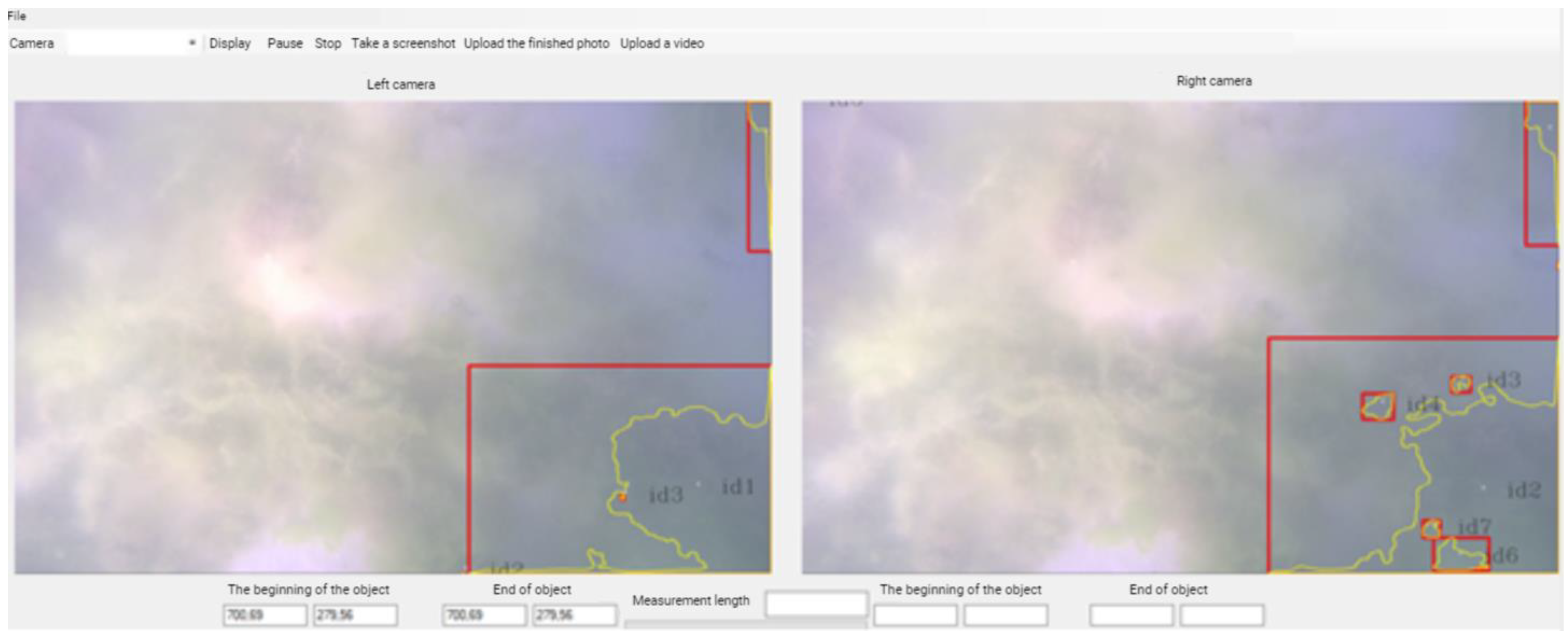
2.3. Software
- Mat preprocessing (Mat frame, Scalar LowScalar, Scalar HScalar)—the input parameter of the function is the image obtained from the cameras and the search criteria for the desired object by color. As output parameters, the function returns the processed image, which will be used for further object searches.
- void FindContrur (Mat frame, Mat src, Mat& drawing, Point2f[]& rect_points)—the input parameter of the function is the processed image obtained from the preprocessing function. The output parameter of the function is an array that contains the coordinates of the rectangle in which the found object is inscribed. In addition, the function returns an image with a contour applied to the found object.
- void FindPointADS (int limit_points, int metod_Disparity, vector <bool> metod_ImagePerProcessing)—the following function was written to build a depth map, where limit_points are restrictions on the number of points, metod_Disparity is a method for constructing a depth map, and metod_ImagePerProcessing is a method for preprocessing images.
- -
- Pylon (pylon SDK) is a library for Basler cameras, which contains a set of tools for working with any Basler camera for programming languages C, C++ on a PC with Windows operating system, Linux.
- -
- OpenCV (Open Source Computer Vision Library) is an open source library of computer vision algorithms, image processing, and general purpose numerical algorithms. It is implemented in C/C++.
- -
- Armadillo is a linear algebra library for the C++ programming language, which aims to provide efficient and optimized basic computing while at the same time having a simple and user-friendly interface.
3. Detecting an Object in the Aquatic Environment
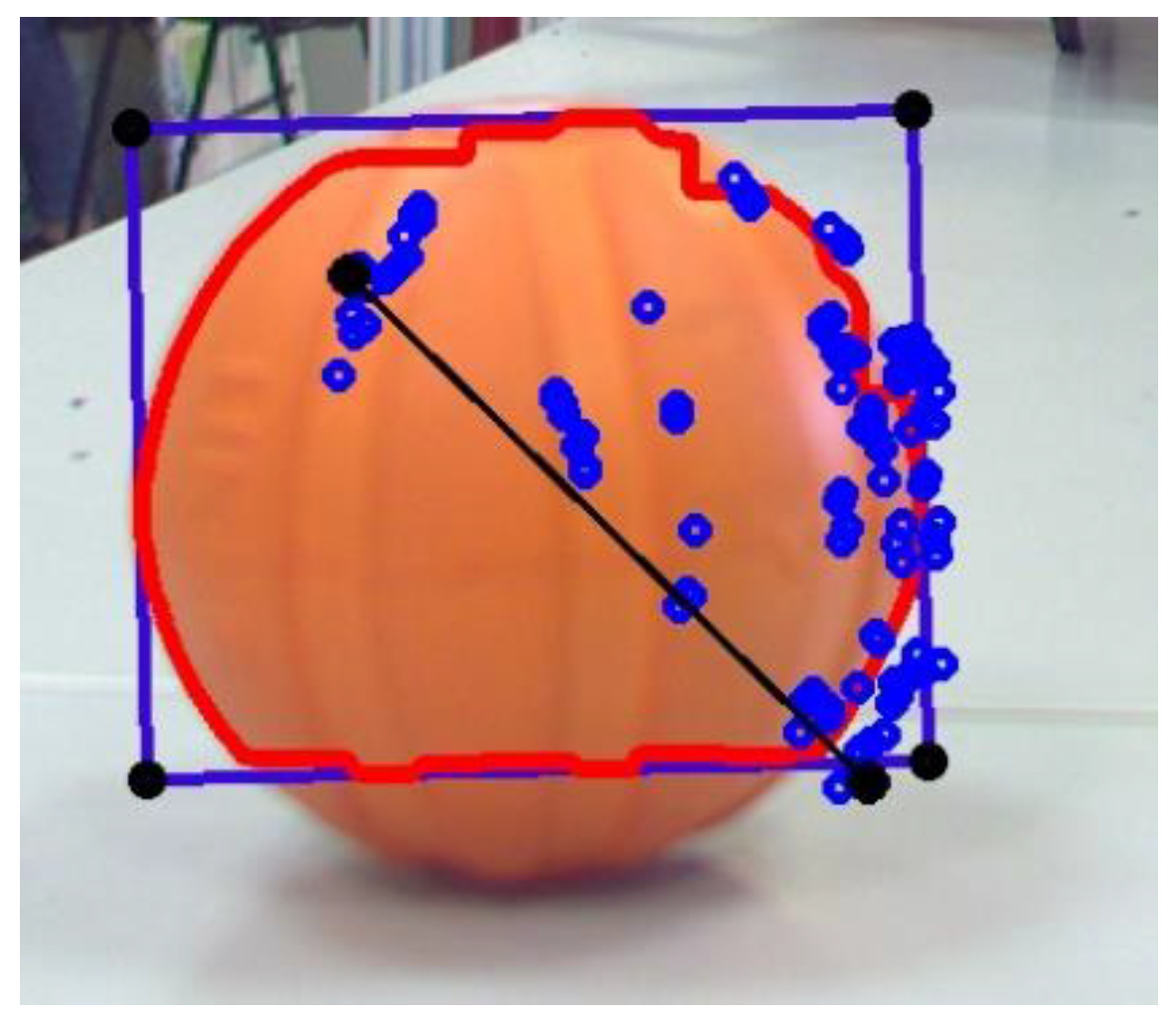
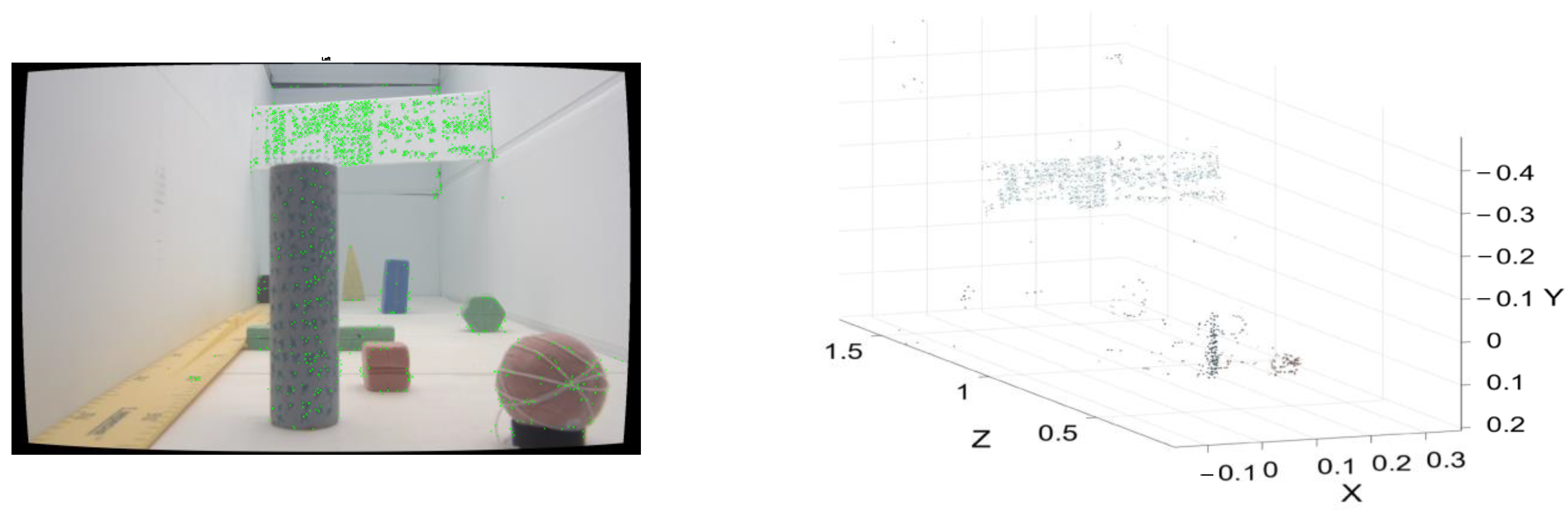
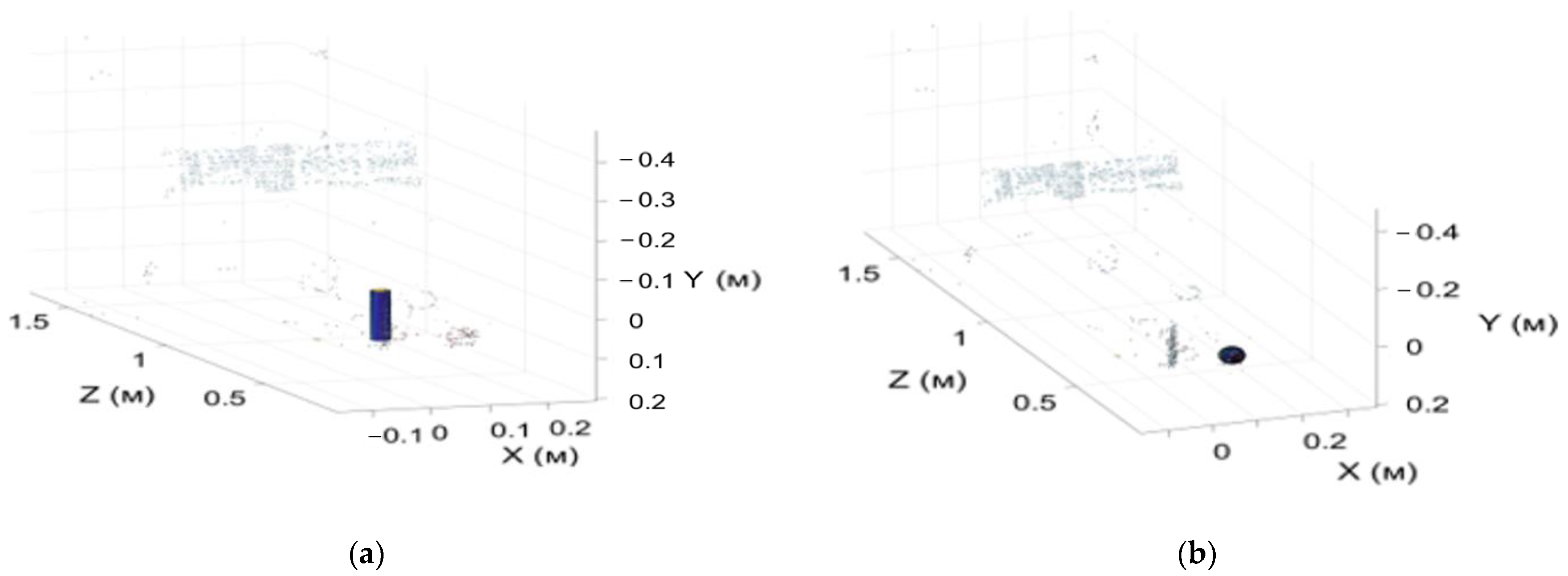
3.1. The 3D Point Cloud Method for Object Extraction
3.1.1. The 3D Search Algorithm for Stereo Images
3.1.2. D Point Cloud Clustering Algorithms
3.2. Contour Method
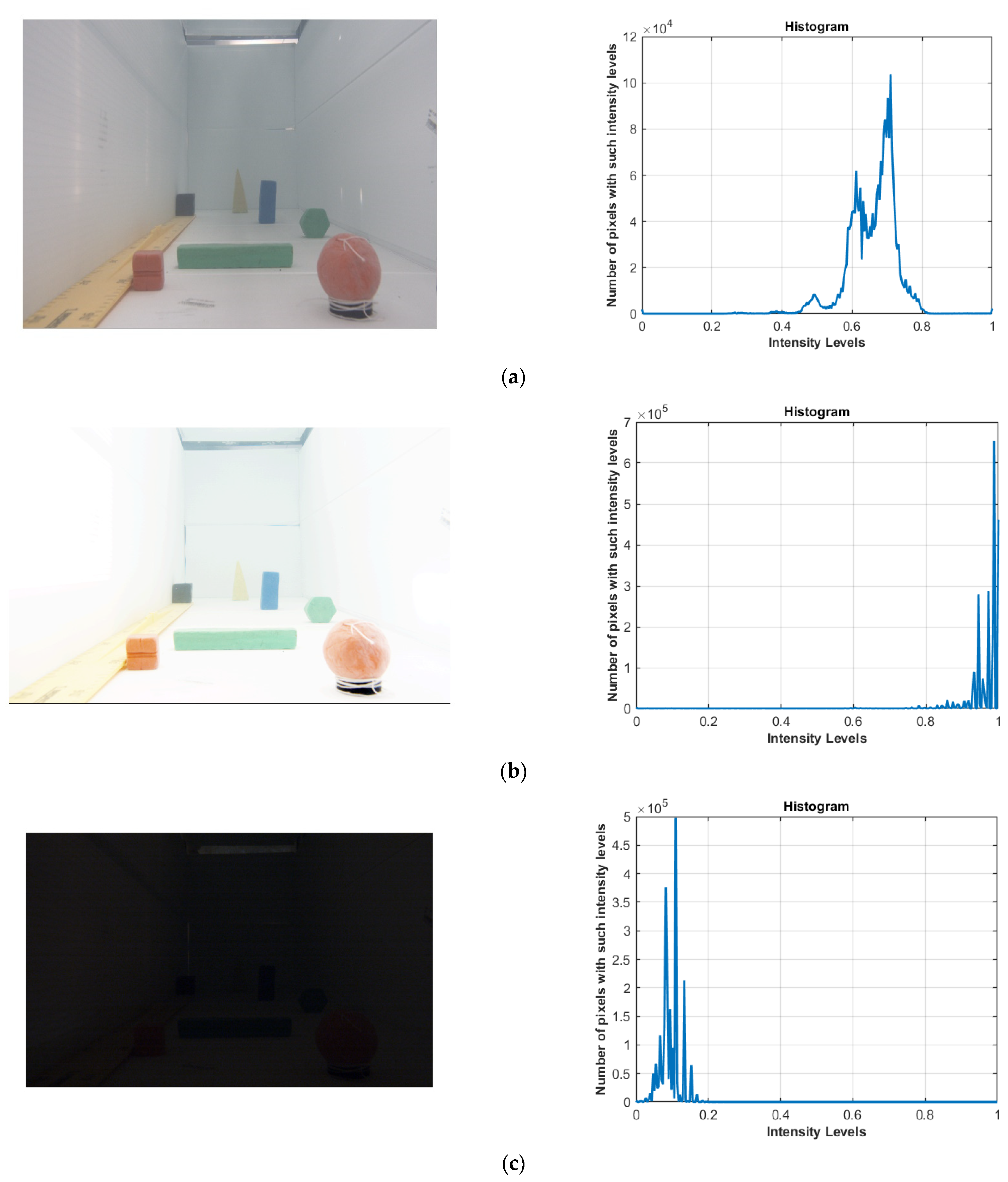
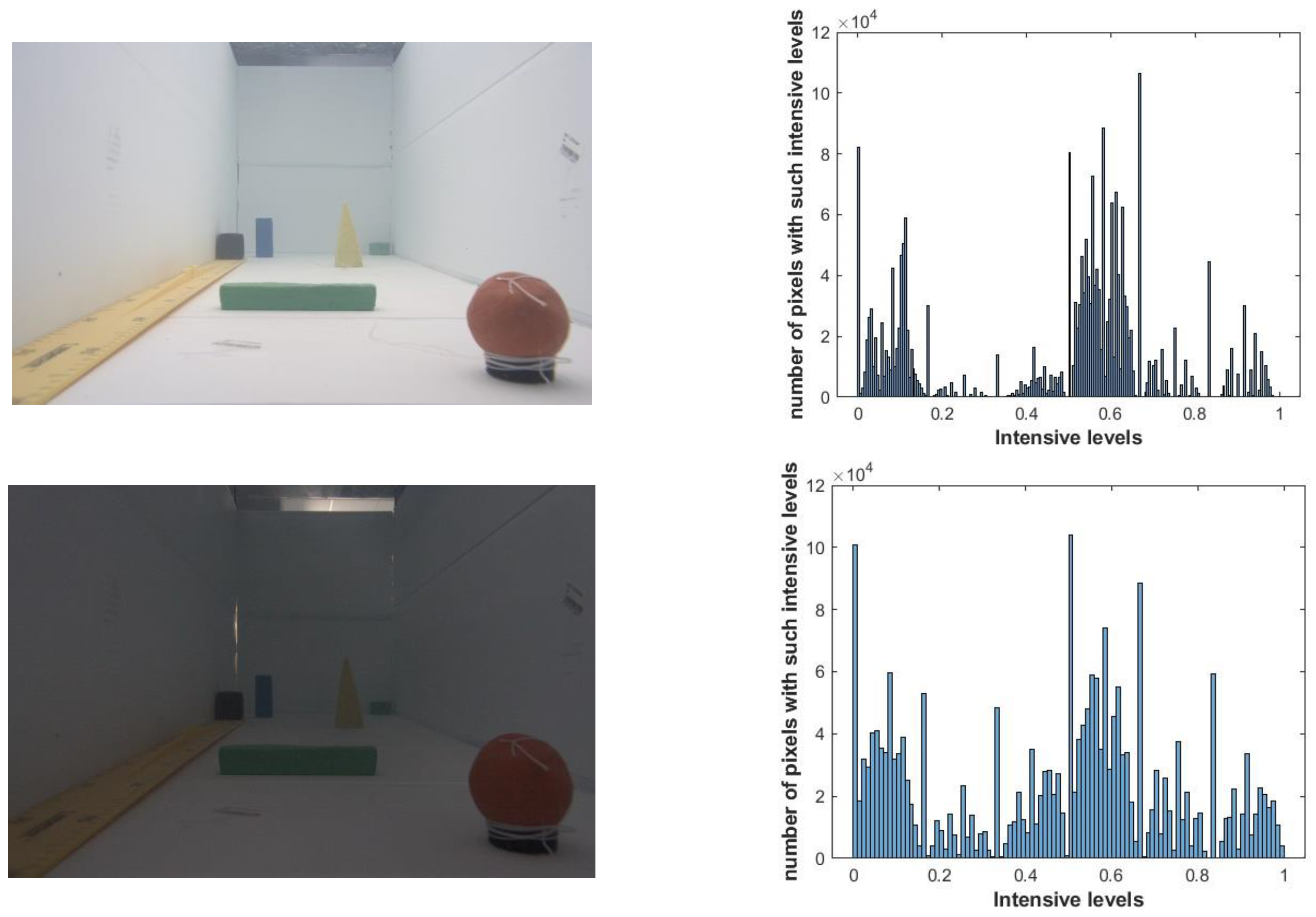
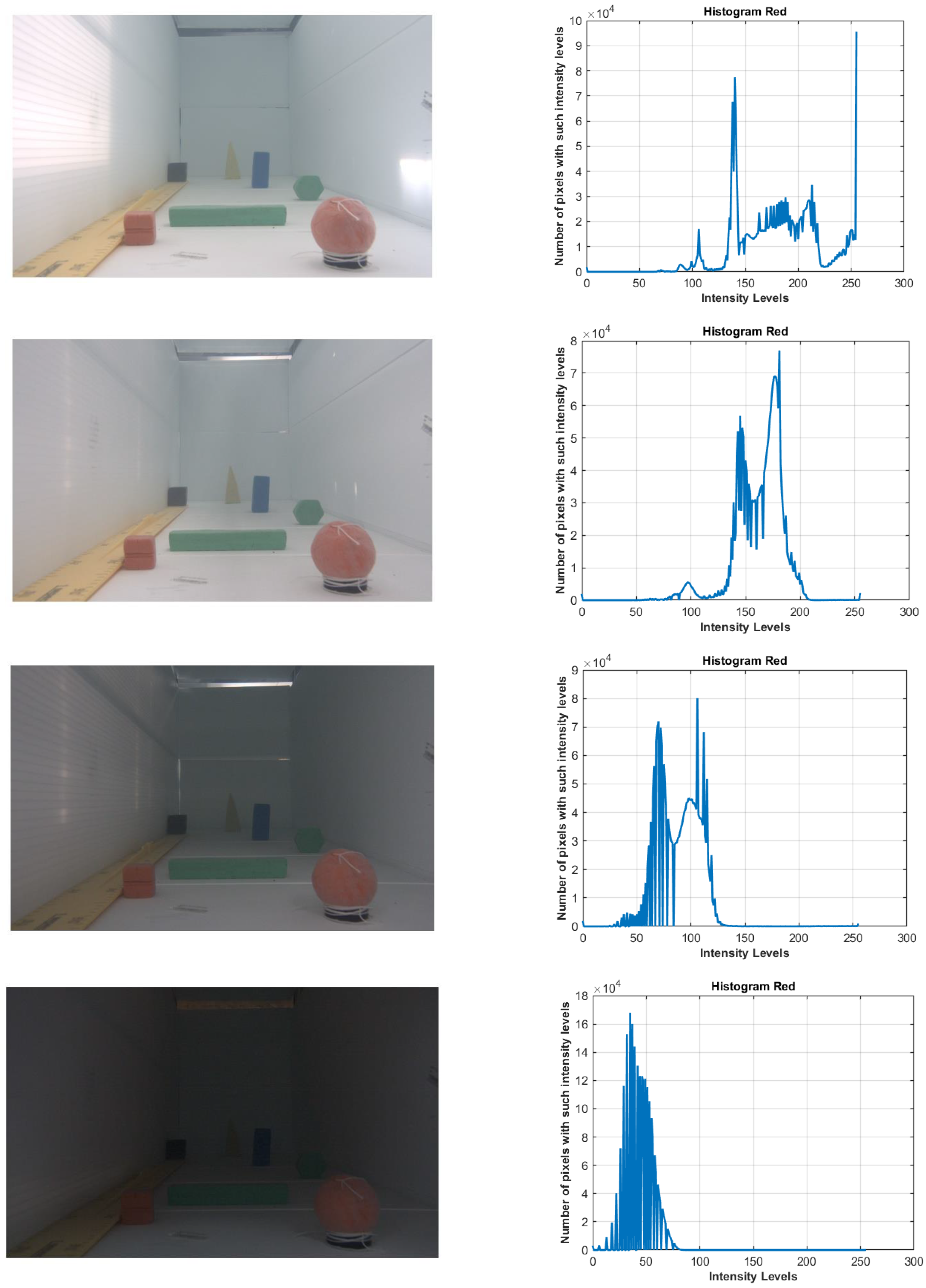
3.2.1. Image Quality Analysis
| Algorithm 1: The image quality estimation algorithm. |
| Mat src = imread(“picture.jpg”); |
| cvtColor(src, frame_HSV, COLOR_BGR2HSV); |
| split(frame_HSV, splitedHsv); |
| int VRez = 0; |
| for (int i = 0; i < frame_HSV.rows; i++) |
| { |
| for (int j = 0; j < frame_HSV.cols; j++) |
| { |
| int V = static_cast<int>(splitedHsv [2].at<uchar>(i, j)); |
| VRez = VRez + V; |
| } |
| } |
| cout << VRez/(frame_HSV2.rows*frame_HSV2.cols) << endl; |
3.2.2. Detecting a Specific Colored Object
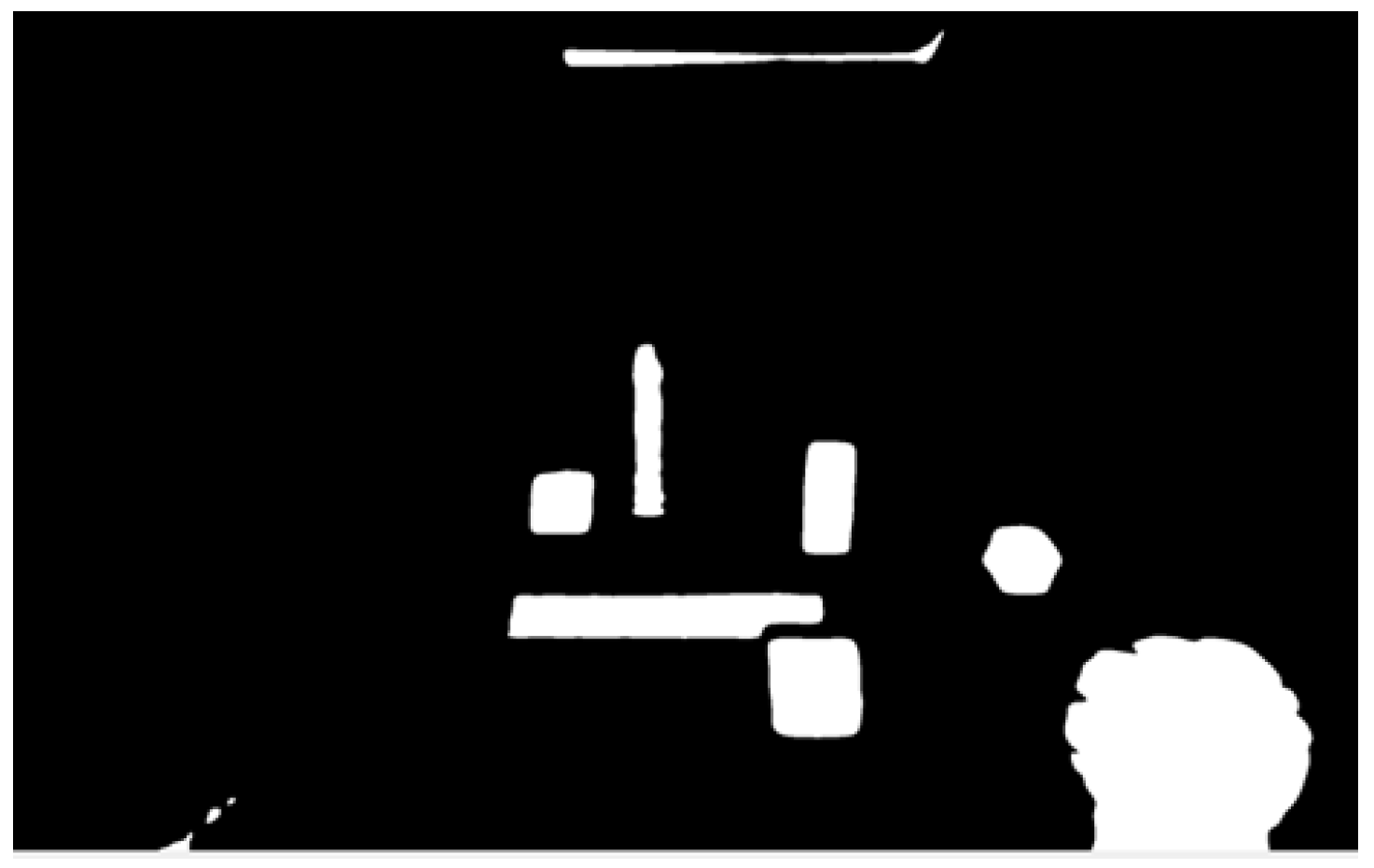
3.2.3. Defining the Image Outline
- Grayscale the image. It is necessary to simplify the image as much as possible. Color increases the signal-to-noise ratio, so there is no need to save colors to find contours.
- Gaussian blur algorithm. It is used to remove noise. The algorithm removes high-frequency content (e.g., noise, edges) from the image.
- Using a fixed-level threshold function. The threshold function is used to obtain a binary image from a grayscale image.
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pedro, J.S.; Pere, R.; Gabriel, O.; Giuseppe, C.; Yvan, P.; Carlos, S.; Claudio, M. Alessio Turetta TRIDENT: An European Project Targeted to Increase the Autonomy Levels for Underwater Intervention Missions. In Proceedings of the 2013 OCEANS, San Diego, CA, USA, 23–27 September 2013. [Google Scholar]
- Drap, P.; Seinturier, J.; Scaradozzi, D. Photogrammetry for virtual exploration of underwater archeological sites. In Proceedings of the 21st International Symposium, CIPA 2007: AntiCIPAting the Future of the Cultural Past, Athens, Greece, 1–6 October 2007. [Google Scholar]
- Casalino, G.; Caccia, M.; Caiti, A.; Antonelli, G.; Indiveri, G.; Melchiorri, C.; Caselli, S. MARIS: A National Project on Marine Robotics for Interventions. In Proceedings of the 2014 22nd Mediterranean Conference on Control and Automation University of Palermo, Palermo, Italy, 16–19 June 2014; pp. 864–869. [Google Scholar] [CrossRef]
- Kabanov, A.; Kramar, V.; Ermakov, I. Design and modeling of an experimental rov with six degrees of freedom. Drones 2021, 5, 113. [Google Scholar] [CrossRef]
- Bazeille, S.; Quidu, I.; Jaulin, L.; Malkasse, J.P. Automatic underwater image pre-processing. In Proceedings of the CMM’06, Brest, France, 16–19 October 2006. [Google Scholar]
- Rizzini, D.L. Integration of a stereo vision system into an autonomous underwater vehicle for pipe manipulation tasks. Com-Puter. Electr. Eng. 2017, 58, 560–571. [Google Scholar] [CrossRef]
- Brandou, V.; Allais, A.-G.; Perrier, M.; Malis, E.; Rives, P.; Sarrazin, J.; Sarradin, P.-M. 3D reconstruction of natural underwater scenes using the stereovision system IRIS. In Proceedings of the OCEANS 2007-Europe, Aberdeen, UK, 18–21 June 2007; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Skorohod, B.A.; Statsenko, A.V.; Fateev, S.I.; Zhilyakov, P.V. Accuracy analysis of 3D points reconstructed from workspace of underwater robot. J. Phys. Conf. Ser. 2020, 1661, 012124. [Google Scholar] [CrossRef]
- Prabhakar, C.J.; Praveen, K.P.U. 3D Surface Reconstruction of Underwater Objects. J. Comput. Eng. Inf. Technol. 2015, 5, 31–37. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, Z.; Dai, F.; Bu, Y.; Wang, H. Monocular Vision-Based Underwater Object Detection. Sensors 2017, 17, 1784. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Lu, H.; Li, J.; Li, X.; Li, Y.; Serikawa, S. Underwater image de-scattering and classification by deep neural network. Comput. Electr. Eng. 2016, 54, 68–77. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, Z.; Bu, Y.; Dai, F.; Fan, T.; Wang, H. Underwater Object Segmentation Based on Optical Features. Sensors 2018, 18, 196. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Sys. Man. Cyber. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.; Kim, G.; Kim, D.; Myung, H.; Choi, H. Vision-based object detection and tracking for autonomous navigation of underwater robots. Ocean Eng. 2012, 48, 59–68. [Google Scholar] [CrossRef]
- Chen, B.; Li, R.; Bai, W.; Zhang, X.; Li, J.; Guo, R. Research on Recognition Method of Optical Detection Image of Underwater Robot for Submarine Cable. In Proceedings of the 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 11–13 October 2019; pp. 1973–1976. [Google Scholar] [CrossRef]
- Jordt, A.; Koch, R. Refractive calibration of underwater cameras. Computer Vision—ECCV 2012. ECCV 2012. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, 2012. [Google Scholar] [CrossRef]
- Skorohod, B.A.; Zhiljakov, P.V.; Stacenko, A.V.; Fateev, S.I. Analysis of the accuracy of constructing 3D coordinates of the working space of an underwater robot. Environ. Control. Syst. 2020, 3, 163–170. (In Russian) [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Recommendation ITU-R BT.601-7. Available online: https://www.itu.int/dms_pubrec/itu-r/rec/bt/R-REC-BT.601-7-201103-I!!PDF-E.pdf (accessed on 27 February 2023).
- Zhilyakov, P.V.; Fateev, S.I. Acceleration of the underwater system of technical stereo vision with the help of multithreaded organization of algorithms. Mar. Intellect. Technol. 2021, 4, 252–257. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Camera Settings | Lens Parameters | ||
|---|---|---|---|---|
| Photosensitivity | Exposure Time, s | Aperture, Aperture Number | Focus Distance, m | |
| Water | Auto | Auto (1⁄200) | F2 | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kramar, V.; Kabanov, A.; Kramar, O.; Fateev, S.; Karapetian, V. Detection and Recognition of the Underwater Object with Designated Features Using the Technical Stereo Vision System. Fluids 2023, 8, 92. https://doi.org/10.3390/fluids8030092
Kramar V, Kabanov A, Kramar O, Fateev S, Karapetian V. Detection and Recognition of the Underwater Object with Designated Features Using the Technical Stereo Vision System. Fluids. 2023; 8(3):92. https://doi.org/10.3390/fluids8030092
Chicago/Turabian StyleKramar, Vadim, Aleksey Kabanov, Oleg Kramar, Sergey Fateev, and Valerii Karapetian. 2023. "Detection and Recognition of the Underwater Object with Designated Features Using the Technical Stereo Vision System" Fluids 8, no. 3: 92. https://doi.org/10.3390/fluids8030092