Towards Reduced CNNs for De-Noising Phase Images Corrupted with Speckle Noise


Abstract
:1. Introduction
2. Databases
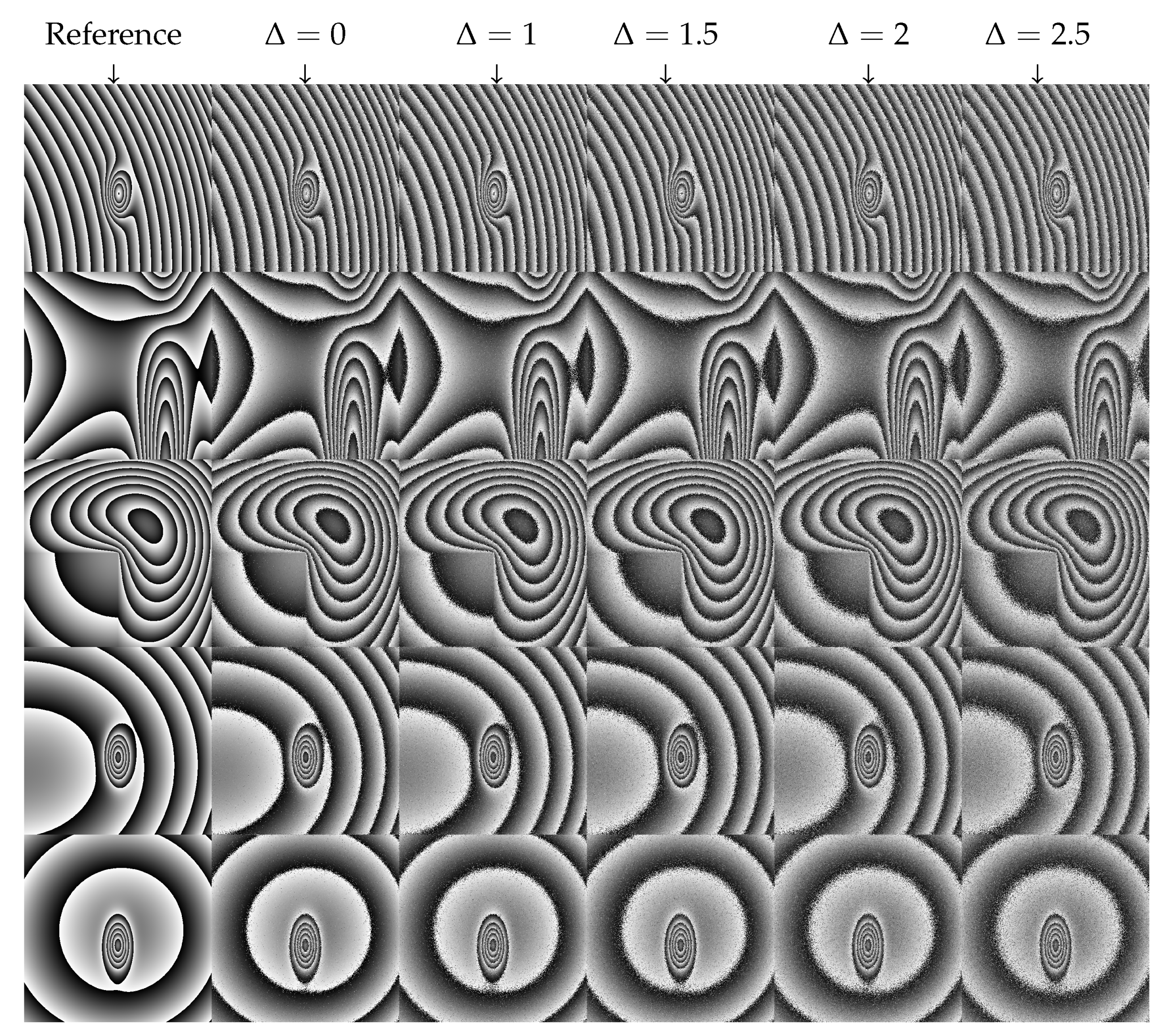
2.1. HOLODEEP Database
2.2. DATAEVAL Database
2.3. NATURAL Database
3. Baseline Approaches
3.1. Signal Processing Approaches for Speckle De-Noising
3.2. Deep Learning Approach for Speckle De-Noising
3.2.1. Data Augmentation
3.2.2. Baseline Implementation
3.2.3. Baseline Results
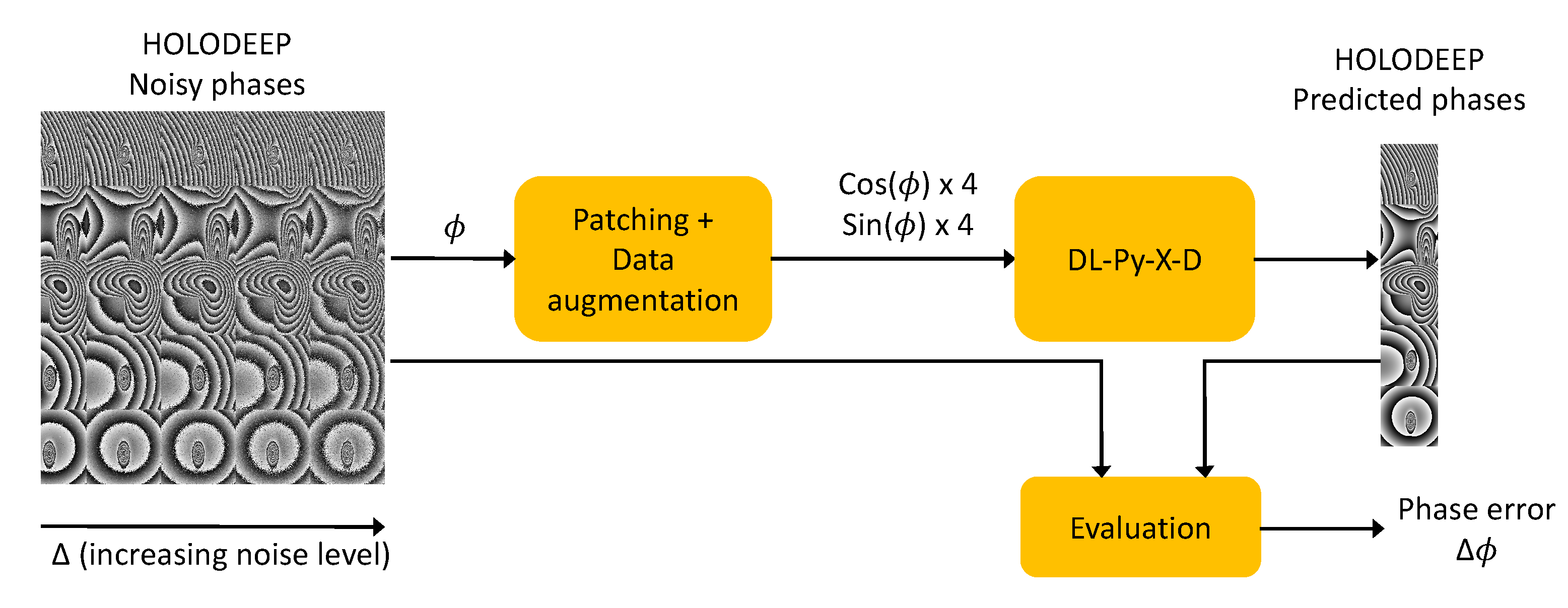
4. Experimental Protocols
4.1. Data Pre-Processing and Implementation
4.2. Evaluation Network Depth and Architecture
4.3. Evaluation of a Pre-Trained Network
5. Results and Discussion
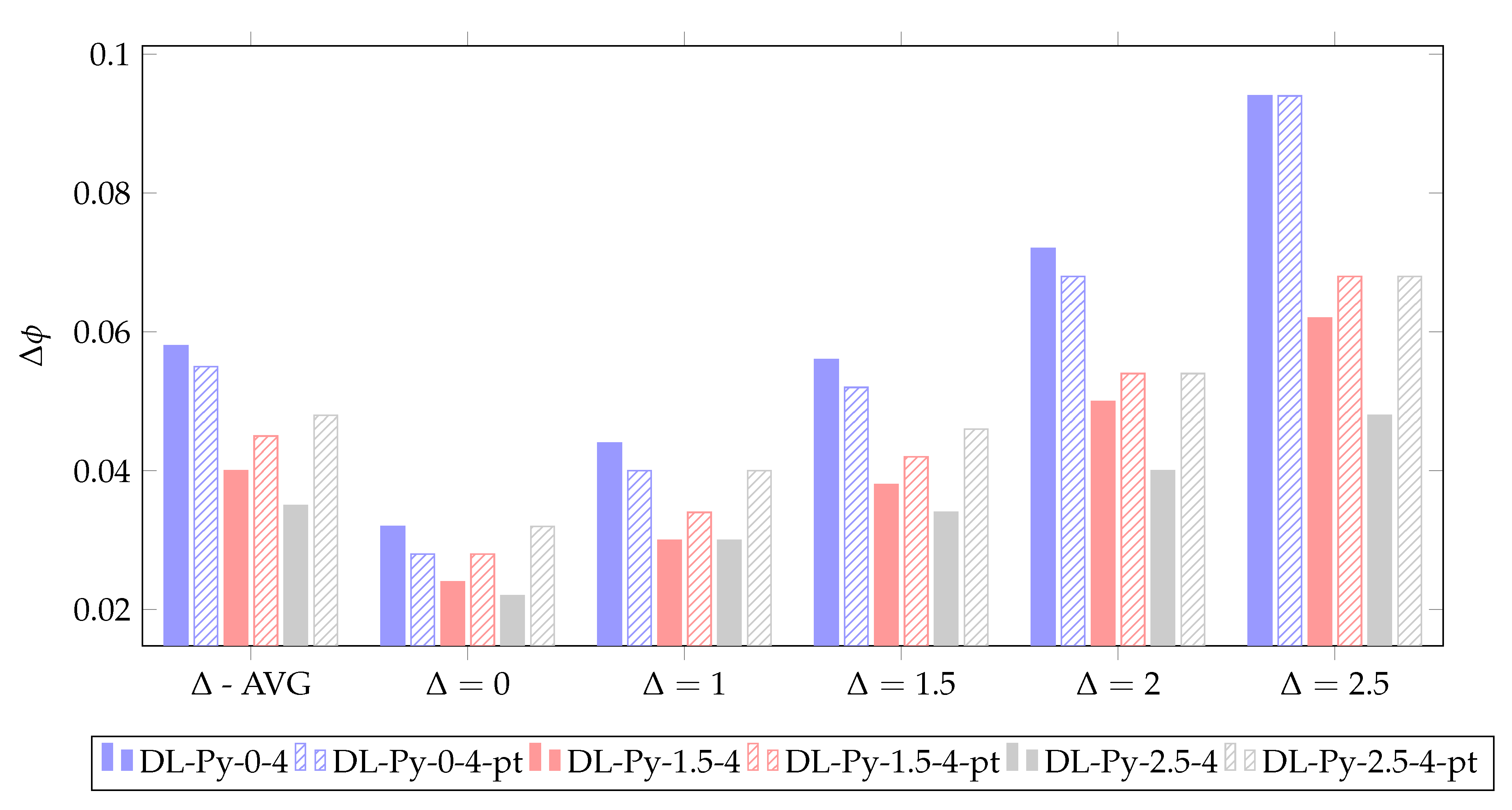
5.1. Network Depth and Architecture
5.2. Pre-Training
5.3. Evaluation on Target Images
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Picart, P.; Li, J. Digital Holography; John Wiley & Sons, Ltd.: London, UK, 2012. [Google Scholar]
- Ghiglia, D.C.; Pritt, M.D. Two-Dimensional Phase Unwrapping: Theory, Algorithms, and Software; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Poittevin, J.; Gautier, F.; Pézerat, C.; Picart, P. High-speed holographic metrology: Principle, limitations, and application to vibroacoustics of structures. Opt. Eng. 2016, 55, 121717–121729. [Google Scholar] [CrossRef]
- Lagny, L.; Secail-Geraud, M.; Le Meur, J.; Montresor, S.; Heggarty, K.; Pezerat, C.; Picart, P. Visualization of travelling waves propagating in a plate equipped with 2D ABH using wide-field holographic vibrometry. J. Sound Vib. 2019, 461, 114925. [Google Scholar] [CrossRef]
- Meteyer, E.; Montresor, S.; Foucart, F.; Le Meur, J.; Heggarty, K.; Pezerat, C.; Picart, P. Lock-in vibration retrieval based on high-speed full-field coherent imaging. Sci. Rep. 2021, 11, 1–15. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising with block-matching and 3D filtering. In Proceedings of the SPIE, Image Processing: Algorithms and Systems, Neural Networks, and Machine Learning, San Jose, CA, USA, 16–18 January 2006; Volume 6064, p. 606414. [Google Scholar]
- Selesnick, I.W.; Baraniuk, R.G.; Kingsbury, N.C. The dual-tree complex wavelet transform. IEEE Signal Process. Mag. 2005, 22, 123–151. [Google Scholar] [CrossRef] [Green Version]
- Kemao, Q.; Wang, H.; Gao, W. Windowed Fourier transform for fringe pattern analysis: Theoretical analyses. Appl. Opt. 2008, 47, 5408–5419. [Google Scholar] [CrossRef]
- Jain, V.; Seung, S. Natural image denoising with convolutional networks. In Advances in Neural Information Processing Systems; Koller, D., Schuurmans, D., Bengio, Y., Bottou, L., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2009; Volume 21, pp. 769–776. Available online: https://www.researchgate.net/publication/221620211_Natural_Image_Denoising_with_Convolutional_Networks (accessed on 2 June 2021).
- Zeng, T.; So, H.K.H.; Lam, E.Y. Computational image speckle suppression using block matching and machine learning. Appl. Opt. 2019, 58, B39–B45. [Google Scholar] [CrossRef]
- Krishnan, J.P.; Bioucas-Dias, J.M.; Katkovnik, V. Dictionary learning phase retrieval from noisy diffraction patterns. Sensors 2018, 18, 4006. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS)-Volume 2, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Barbastathis, G.; Ozcan, A.; Situ, G. On the use of deep learning for computational imaging. Optica 2019, 6, 921–943. [Google Scholar] [CrossRef]
- Rivenson, Y.; Zhang, Y.; Günaydın, H.; Teng, D.; Ozcan, A. Phase recovery and holographic image reconstruction using deep learning in neural networks. Light Sci. Appl. 2018, 23, 17141. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Wang, H.; Li, G.; Situ, G. Learning from simulation: An end-to-end deep-learning approach for computational ghost imaging. Opt. Express 2019, 27, 25560–25572. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of Deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Jiang, F.; Zhang, S.; Wang, R.; Zhao, D.; Zhou, H. Hierarchical residual learning for image denoising. Signal Process. Image Commun. 2019, 76, 243–251. [Google Scholar] [CrossRef]
- Choi, G.; Ryu, D.; Jo, Y.; Kim, Y.S.; Park, W.; Min, H.S.; Park, Y. Cycle-consistent deep learning approach to coherent noise reduction in optical diffraction tomography. Opt. Express 2019, 27, 4927–4943. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral image denoising employing a spatial spectral deep residual convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1205–1218. [Google Scholar] [CrossRef] [Green Version]
- Jeon, W.; Jeong, W.; Son, K.; Yang, H. Speckle noise reduction for digital holographic images using multi-scale convolutional neural networks. Opt. Lett. 2018, 43, 4240–4243. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Chen, X.; Zhu, W.; Cheng, X.; Xiang, D.; Shi, F. Speckle noise reduction in optical coherence tomography images based on edge-sensitive cGAN. Biomed. Opt. Express 2018, 9, 5129–5146. [Google Scholar] [CrossRef] [PubMed]
- Montrésor, S.; Picart, P. Quantitative appraisal for noise reduction in digital holographic phase imaging. Opt. Express 2016, 24, 14322–14343. [Google Scholar] [CrossRef]
- Montrésor, S.; Picart, P.; Sakharuk, O.; Muravsky, L. Error analysis for noise reduction in 3D deformation measurement with digital color holography. J. Opt. Soc. Am. B 2017, 34, B9–B15. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Han, Z.; Yu, S.; Lin, S.B.; Zhou, D.X. Depth selection for deep ReLU nets in feature extraction and generalization. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Montresor, S.; Tahon, M.; Laurent, A.; Picart, P. Computational de-noising based on deep learning for phase data in digital holographic interferometry. APL Photonics 2020, 5, 030802. [Google Scholar] [CrossRef] [Green Version]
- Picart, P.; Montresor, S.; Sakharuk, O.; Muravsky, L. Refocus criterion based on maximization of the coherence factor in digital three-wavelength holographic interferometry. Opt. Lett. 2017, 42, 275–278. [Google Scholar] [CrossRef] [PubMed]
- Picart, P.; Tankam, P.; Song, Q. Experimental and theoretical investigation of the pixel saturation effect in digital holography. J. Opt. Soc. Am. A 2011, 28, 1262–1275. [Google Scholar] [CrossRef] [PubMed]
- Poittevin, J.; Picart, P.; Gautier, F.; Pezerat, C. Quality assessment of combined quantization-shot-noise-induced decorrelation noise in high-speed digital holographic metrology. Opt. Express 2015, 23, 30917–30932. [Google Scholar] [CrossRef]
- Baumbach, T.; Kolenovic, E.; Kebbel, V.; Jüptner, W. Improvement of accuracy in digital holography by use of multiple holograms. Appl. Opt. 2006, 45, 6077–6085. [Google Scholar] [CrossRef]
- Montresor, S.; Tahon, M.; Laurent, A.; Picart, P. An iterative scheme based on deep learning combined with input noise estimator for phase data processing in digital holographic interferometry. In Proceedings of the Imaging and Applied Optics Congress, Washington, DC, USA, 22–26 June 2020; p. HTu4B.4. [Google Scholar]
- Macary, M.; Tahon, M.; Estève, Y.; Rousseau, A. On the use of self-supervised pre-trained acoustic and linguistic features for continuous speech emotion recognition. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), IEEE, Shenzhen, China, 19–22 January 2021; pp. 373–380. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | # iter | HOLODEEP | DATAEVAL | ||
|---|---|---|---|---|---|
| 25 Images | Test1 | Test2 | Test3 | ||
| WFT2F | 1 | 0.026 | 0.044 | 0.164 | 0.105 |
| DtDWT | 1–3 | 0.046 | 0.078 | 0.519 | 0.214 |
| BM3D | 1–3 | 0.068 | 0.113 | 0.580 | 0.094 |
| ine DL-3 | 1 | 0.041 | 0.107 | 0.585 | 0.105 |
| DL-3 | 3 | 0.031 | 0.078 | 0.559 | 0.077 |
| DnCNN [17] | DL-3 [29] | DL-Py | |||
|---|---|---|---|---|---|
| original size | |||||
| patch size | |||||
| batch size | 128 | 128 | 128 | ||
| learning rate | 0.1 to 0.001 | 0.0006 | 0.001; 0.0005 | ||
| # epochs | 50 | 1920 | <200 | ||
| noise type | Gaussian | Gauss+speckle | speckle | ||
| noise | , | ||||
| SNR (dB) range | >13 | 7.32 − 11.46 | 7.32 − 11.46 | 5.08 − 11.46 | 3.10 − 11.46 |
| # train images | 400 | ||||
| # patches | k | k | k | k | k |
| Trained on HOLODEEP | Pre-Trained | |||
|---|---|---|---|---|
| (#patch) | D | 16 | 4 | 4 |
| 0 (15.3k) | model | DL-Py-0-16 | DL-Py-0-4 | DL-Py-0-4-pt |
| BestEpoch/Max | 195/200 | 200/200 | 190/200 | |
| 0.057 | 0.058 | 0.055 | ||
| ine 0–1.5 (46.1k) | model | DL-Py-1.5-16 | DL-Py-1.5-4 | DL-Py-1.5-4-pt |
| BestEpoch/Max | 70/70 | 140/150 | 85/95 | |
| 0.042 | 0.040 | 0.045 | ||
| ine 0–2.5 (76.8k) | model | DL-Py-2.5-16 | DL-Py-2.5-4 | DL-Py-2.5-4-pt |
| BestEpoch/Max | 40/50 | 90/95 | 50/55 | |
| 0.038 | 0.035 | 0.048 | ||
| Method | HOLODEEP | DATAEVAL | ||
|---|---|---|---|---|
| 25 Images | Test1 | Test2 | Test3 | |
| WFT2F | 0.026 | 0.044 | 0.163 | 0.105 |
| DL-3 | 0.041 | 0.107 | 0.585 | 0.105 |
| DL-Py-0-4 | 0.058 | 0.142 | 0.629 | 0.117 |
| DL-Py-0-4-pt | 0.055 | 0.146 | 0.629 | 0.105 |
| DL-Py-1.5-4 | 0.040 | 0.095 | 0.593 | 0.103 |
| DL-Py-1.5-4-pt | 0.045 | 0.112 | 0.609 | 0.111 |
| DL-Py-2.5-4 | 0.035 | 0.072 | 0.597 | 0.109 |
| DL-Py-2.5-4-pt | 0.048 | 0.097 | 0.660 | 0.134 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tahon, M.; Montresor, S.; Picart, P. Towards Reduced CNNs for De-Noising Phase Images Corrupted with Speckle Noise. Photonics 2021, 8, 255. https://doi.org/10.3390/photonics8070255
Tahon M, Montresor S, Picart P. Towards Reduced CNNs for De-Noising Phase Images Corrupted with Speckle Noise. Photonics. 2021; 8(7):255. https://doi.org/10.3390/photonics8070255
Chicago/Turabian StyleTahon, Marie, Silvio Montresor, and Pascal Picart. 2021. "Towards Reduced CNNs for De-Noising Phase Images Corrupted with Speckle Noise" Photonics 8, no. 7: 255. https://doi.org/10.3390/photonics8070255