
Prediction of Greenhouse Tomato Crop Evapotranspiration Using XGBoost Machine Learning Model

 , and
, and
Abstract
:1. Introduction
2. Research Results
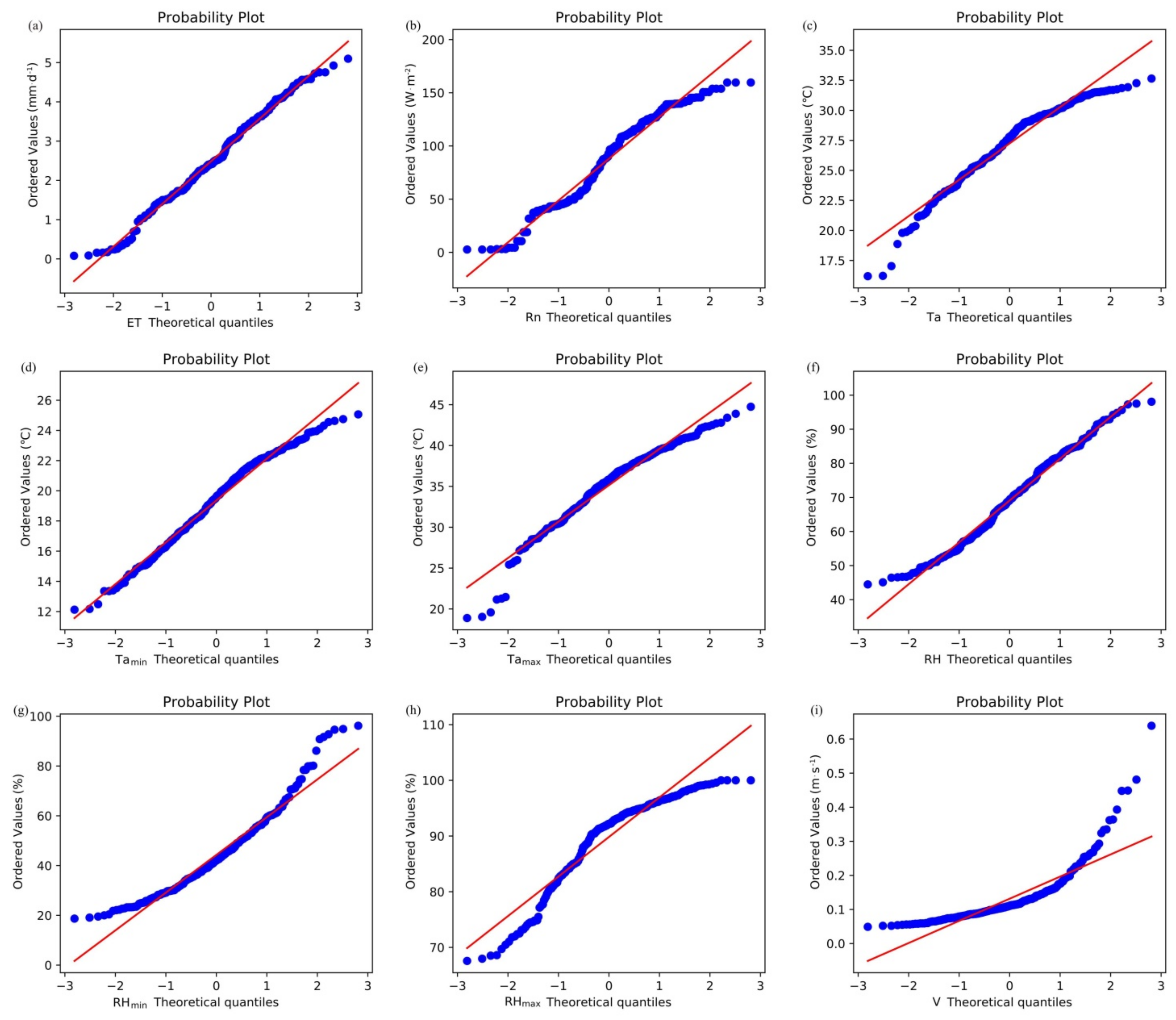
2.1. Analysis of the Normal Distribution Patterns of ET and Meteorological Factors
2.2. Correlations of ET and Meteorological Factors
2.3. Analysis of Model Accuracy
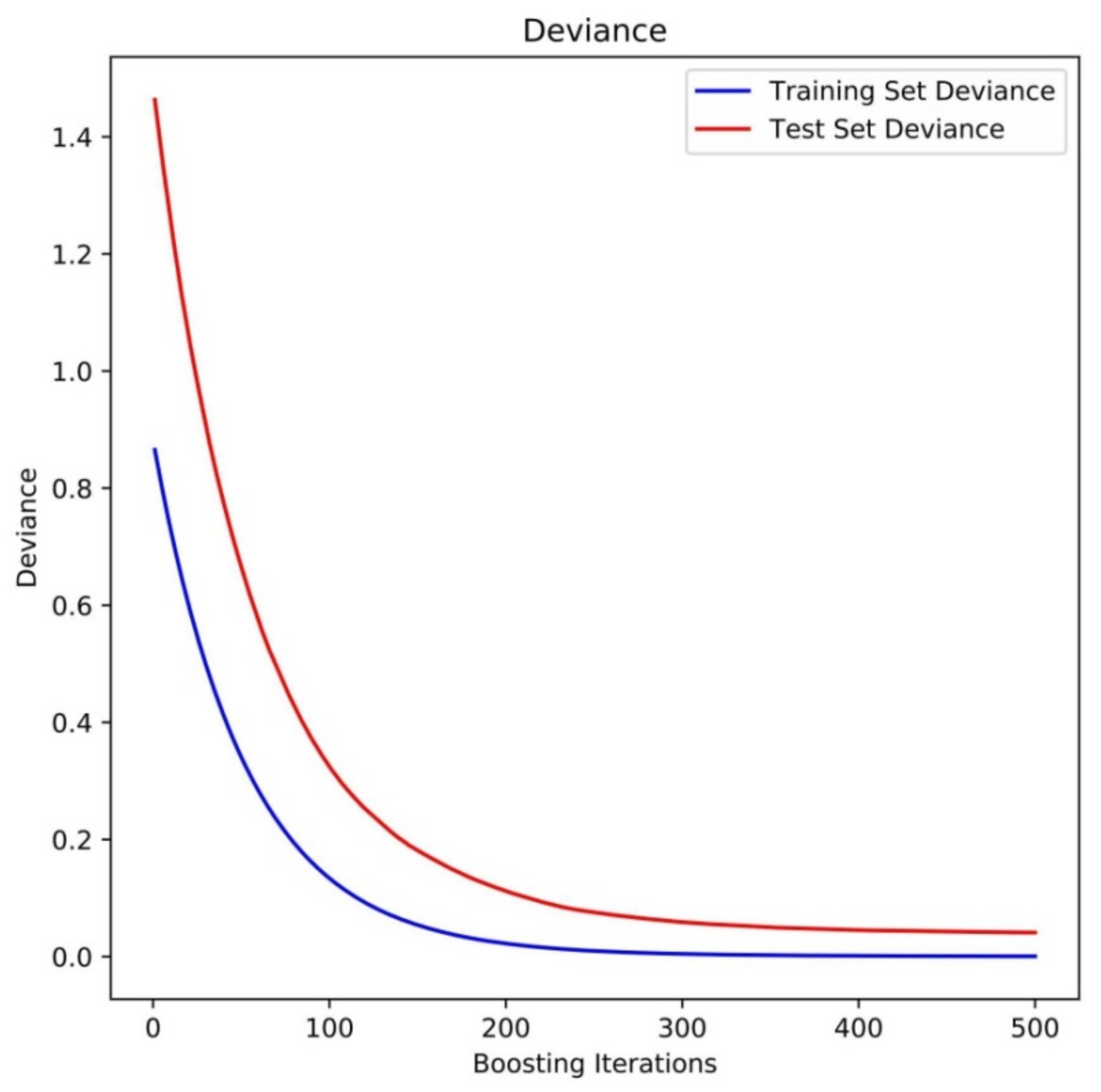
2.3.1. XGBR-ET Model Training and Testing
2.3.2. Analysis of the Predictions of Different Models
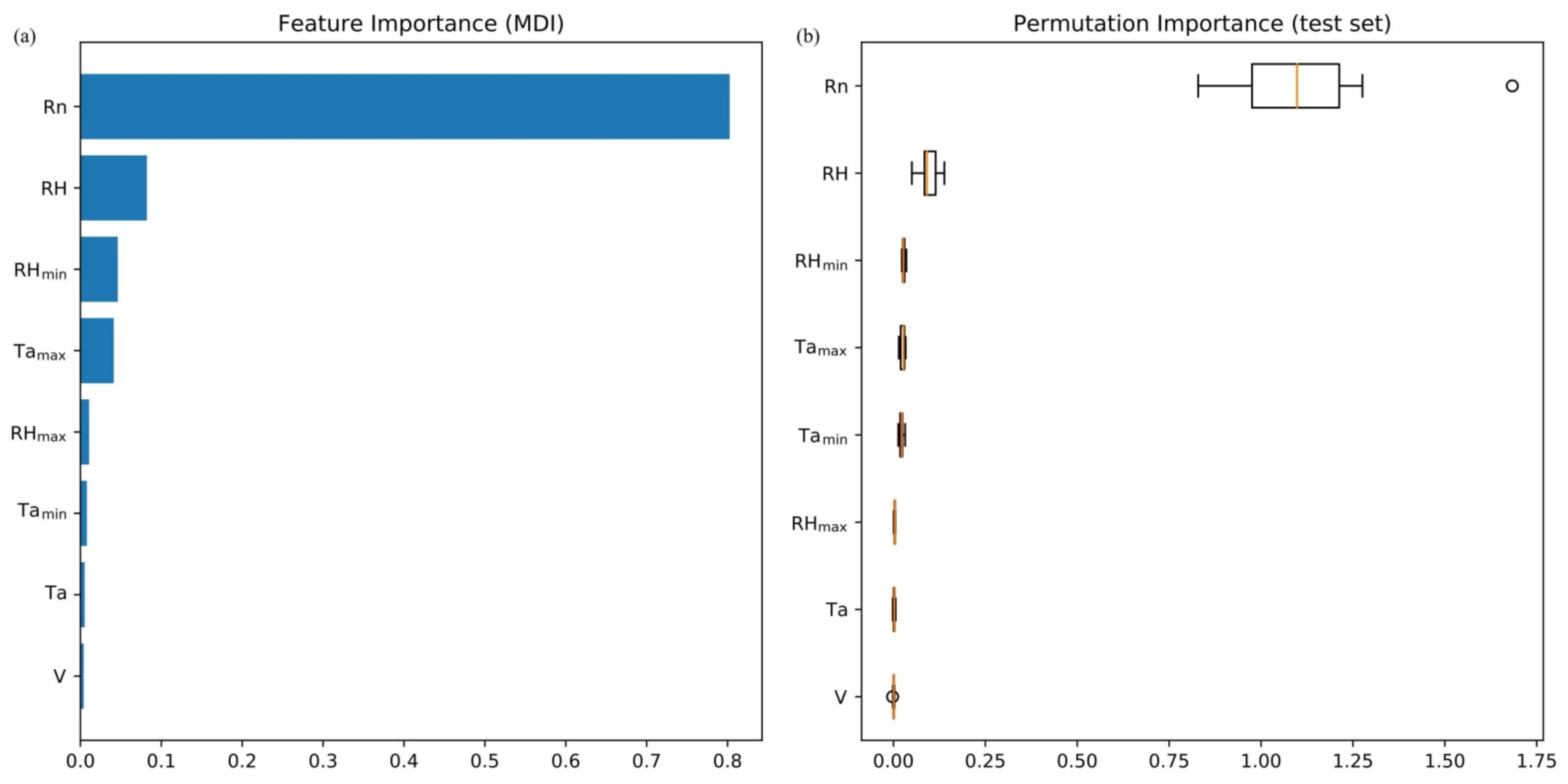
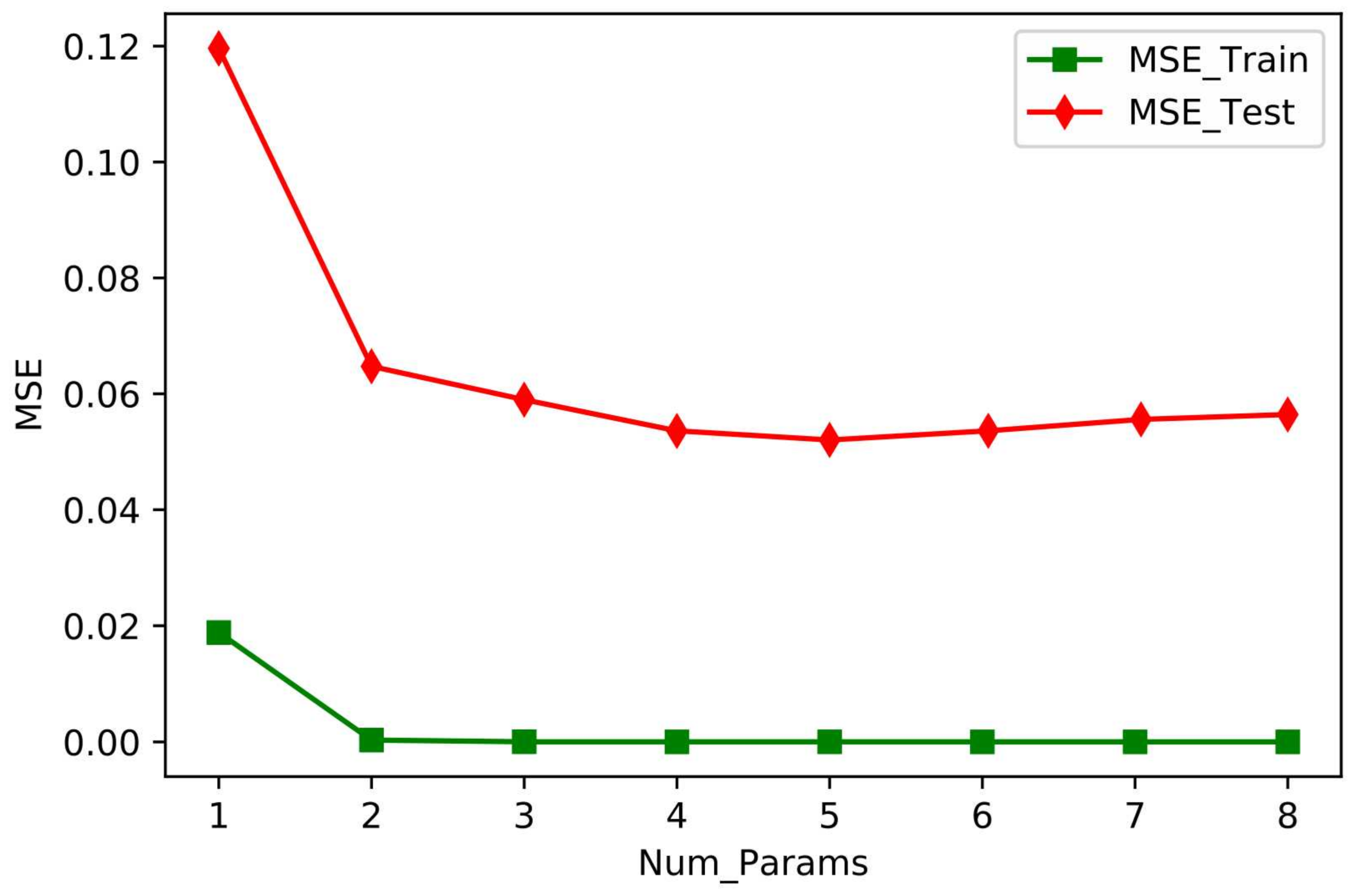
2.4. Weather Factor Ablation Experiment
3. Discussion
4. Materials and Methods
4.1. Experimental Site Overview and Design
4.2. Experimental Data Observation Content and Methods
4.2.1. Meteorological Data
4.2.2. Soil Water Content
4.2.3. Estimation of Tomato Evapotranspiration
4.3. The Eight Regression Algorithms
4.3.1. XGBoost Regression
- XGBoost basic function
- 2.
- XGBoost objective function
- 3.
- XGBoost training
4.3.2. Linear Regression
4.3.3. Support Vector Regression
4.3.4. K Neighbors Regression
4.3.5. Random Forest Regression
4.3.6. AdaBoost Regression
4.3.7. Bagging Regression
4.3.8. Gradient Boosted Regression
4.4. Data Processing and Model Evaluation
- The data for 2019–2021 were combined and randomized and then divided into two datasets for training and testing in the ratio 4:1. The XGBoost regression algorithm was called using Python for model training and testing.
- The data were standardized before modeling in order to eliminate the influence of the magnitude between indicators on the prediction using the equation:
- 3.
- Mean square error (MSE), root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE) [44,45,46], and coefficient of determination (R2) were used to evaluate the accuracy of the model [47]. Lower values of MSE, RMSE, MAE, and MAPE indicate greater prediction accuracy. R2 indicates the degree of fit between predicted and measured values of the model; if R2 is close to 1, the model is a good fit. The equations are:
5. Conclusions
- Rn, Ta, and Tamax were positively correlated with ET, and Tamin, RH, RHmin, RHmax, and V were negatively correlated with ET. Rn had the greatest correlation with ET (r = 0.89), and V had the least correlation with ET (r = 0.43).
- Prediction accuracy of the models was, in descending order, XGBR-ET > GBR-ET > SVR-ET > ABR-ET > BR-ET > LR-ET > KNR-ET > RFR-ET. The respective values of MSE, RMSE, MAE, MAPE, and R2 for XGBR-ET were 0.032, 0.163, 0.132, 4.47%, and 0.981. XGBR-ET was more accurate in predicting ET than the other seven models. Thus, the XGBR-ET model better predicts daily evapotranspiration of the greenhouse tomato crop during the entire growth period.
- The results of the ablation experiments showed that the feature importance of the input variables of XGBR-ET was, in descending order, Rn > RH > RHmin > Tamax > RHmax > Tamin > Ta > V. When predicting ET of drip irrigated greenhouse tomato using XGBR, the selection of Rn, RH, RHmin, Tamax, and Tamin as model input variables will ensure maximum accuracy (MSE = 0.047).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Gong, X.W.; Liu, H.; Sun, J.S.; Ma, X.J.; Wang, W.N.; Cui, Y.S. Estimation of greenhouse tomato evapotranspiration under different water Conditions based on double crop Coefficient Method. J. Appl. Ecol. 2017, 28, 1255–1264. [Google Scholar]
- Balmat, J.F.; Lafont, F.; Ali, A.M.; Pessel, N.; Fernández, J.C.R. Evaluation of the reference evapotranspiration for a greenhouse crop using an Adaptive-Network-Based Fuzzy Inference System (ANFIS). In Proceedings of the 3rd International Conference on Machine Learning and Soft Computing (ICMLSC 2019), Da Lat, Vietnam, 25–27 January 2019; pp. 211–213. [Google Scholar]
- Yan, Z.H.; Li, M. A Stochastic Optimization Model for Agricultural Irrigation Water Allocation Based on the Field Water Cycle. Water 2018, 10, 1031. [Google Scholar] [CrossRef] [Green Version]
- Stephan, S.; Rike, B.; Carlos, R.C.J.; Muhammad, U.; Tim, A.D.B.; Ralf, M.; Chriscoph, S. Estimating water balance components in irrigated agriculture using a combined approach of soil moisture and energy balance monitoring, and numerical modelling. Hydrol. Process. 2021, 35, 14077. [Google Scholar]
- Kool, D.; Agam, N.; Lazarovitch, N.; Heitman, J.L.; Sauer, T.J.; Ben-Gal, A. A review of approaches for evapotranspiration partitioning. Agric. For. Meteorol. 2014, 184, 56–70. [Google Scholar] [CrossRef]
- Hu, H.J.; Li, J. Research on Reference Crop Evapotranspiration Forecast Based on FOA-GRNN. Int. J. Eng. Sci. 2021, 7, 108–116. [Google Scholar]
- Montibeller, B.; Jaagus, J.; Mander, Ü.; Uuemaa, E. Evapotranspiration Intensification Over Unchanged Temperate Vegetation in the Baltic Countries Is Being Driven by Climate Shifts. Front. For. Glob. Change 2021, 4, 663327. [Google Scholar] [CrossRef]
- Monteith, J.L. Evaporation and Environment. In Symposia of the Society for Experimental Biology; Cambridge University Press (CUP): Cambridge, UK, 1965; pp. 205–234. [Google Scholar]
- Shuttleworth, W.J.; Wallace, J.S. Evaporation from sparse crops-an energy combination theory. Q. J. R. Meteor. Soc. 1985, 111, 839–855. [Google Scholar] [CrossRef]
- Priestley, C.H.B.; Taylor, R.J. On the assessment of surface heat flux and evaporation using large-scale parameters. Mon. Weather Rev. 1972, 100, 81–92. [Google Scholar] [CrossRef]
- Allen, R.G.; Pereira, L.S.; Raes, D.; Smith, M. Crop Evapotranspiration: Guidelines for Computing Crop Water Requirements. Irrig. Drain. 1998, 56, 300. [Google Scholar]
- Gong, X.W.; Wang, S.S.; Xu, C.D.; Zhang, H.; Ge, J.K. Valuation of Several Reference Evapotranspiration Models and Determination of Crop Water Requirement for Tomato in a Solar Greenhouse. HortScience 2020, 55, 244–250. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Chen, S.W.; Yang, C.F.; Meng, F.J.; Nick, S. Prediction of plant transpiration from environmental parameters and relative leaf area index using the random forest regression algorithm. J. Clean. Prod. 2020, 261, 121–136. [Google Scholar] [CrossRef]
- Ahmed, E.; Attila, N.; Safwan, M.; Pande, C.B.; Kumar, M.; Ahmad, B.S.; József, Z.; László, H.; János, T.; Elza, K.; et al. Combination of Limited Meteorological Data for Predicting Reference Crop Evapotranspiration Using Artificial Neural Network Method. Agron. J. 2022, 12, 516. [Google Scholar]
- Jiang, X.Q.; Chen, W.F. Comparison between BP neural network and GA-BP prediction model of crop water demand. J. Irrig. Drain. Eng. 2018, 36, 762–766. [Google Scholar]
- Darouich, H.; Karfoul, R.; Ramos, T.B.; Moustafa, A.; Shaheen, B.; Pereira, L.S. Crop water requirements and crop coefficients for jute mallow (Corchorus olitorius L.) using the SIMDualKc model and assessing irrigation strategies for the Syrian Akkar region. Agric. Water Manag. 2021, 255, 107038. [Google Scholar] [CrossRef]
- Wang, X.H.; Zhang, L.; Li, J.Q.; Sun, Y.C.; Tian, J.; Han, R.Y. Research on improved XGBoost method based on genetic algorithm and random forest. Comput. Sci. 2020, 47, 454458+463. [Google Scholar]
- Song, L.L.; Wang, S.H.; Yang, C.; Sheng, X. Application research of improved XGBoost in unbalanced data processing. Comput. Sci. 2020, 47, 98–103. [Google Scholar]
- Song, K.; Yan, F.; Ding, T.; Gao, L.; Lu, S.B. A steel property optimization model based on the XGBoost algorithm and improved PSO. Comp. Mater. Sci. 2020, 174, 109472. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Hu, L.Y.; Wang, C.; Ye, Z.R.; Wang, S. Estimating gaseous pollutants from bus emissions: A hybrid model based on GRU and XGBoost. Sci. Total Environ. 2021, 783, 146870. [Google Scholar] [CrossRef]
- Li, W.; Yin, Y.B.; Quan, X.W.; Zhang, H. Gene Expression Value Prediction Based on XGBoost Algorithm. Front. Genet. 2019, 10, 1077. [Google Scholar] [CrossRef] [Green Version]
- Alves, D.J.D.; Batista, D.C.L.; Otávio, B.D.J.; Lucca, F.D.S.J.; Braz, J.G.; Corrêa, S.A.; Cardoso, D.P.A.; Acatauassú, N.R.; Marcelo, G. Automatic method for classifying COVID-19 patients based on chest X-ray images, using deep features and PSO-optimized XGBoost. Expert Syst. Appl. 2021, 183, 115452. [Google Scholar]
- Li, Y.; Huang, Y.X.; Zhao, L.J.; Liu, C.L. Tool Wear Evaluation under Multiple Conditions Based on T-Distributed Neighborhood Embedding and XGBoost. Chin. J. Mech. Eng. 2020, 56, 132–140. [Google Scholar]
- Nikita, P.; Ivan, S. BagMeLiF: Stable boosting-based hybrid-ensemble feature selection algorithm for high-dimensional data. In Proceedings of the 2020 International Conference on Control, Robotics and Intelligent System, Xiamen, China, 27–29 October 2020; pp. 204–209. [Google Scholar]
- Zhang, Y.Z.; Liu, Y.W.; Chen, C.H. Review on Deep Learning in Feature Selection. In Proceedings of the 10th International Conference on Computer Engineering and Networks, Xi’an, China, 16–18 October 2020; pp. 459–467. [Google Scholar]
- Preethi, D.; Neelu, K. EFS-LSTM (Ensemble-Based Feature Selection With LSTM) Classifier for Intrusion Detection System. Int. J. e-Collab. 2020, 16, 72–86. [Google Scholar] [CrossRef]
- Luo, Z.F.; Zheng, Y.; Ma, Y.L.; She, Q.S.; Sun, M.X.; Shen, T. A New Feature Selection Method for Driving Fatigue Detection Using EEG Signals. In Proceedings of the 11th International Conference on Computer Engineering and Networks, Part I, Hechi, China, 21–25 October 2021; pp. 545–552. [Google Scholar]
- Li, T.Q.; Chen, J.; Liu, J.Y.; Lian, Z.; Li, J. Recognition of Autumn Crop Based on Polsar Data and Feature Selection. In Proceedings of the 5th International Conference on Environmental and Energy Engineering, Yangzhou, China, 19–21 March 2021; pp. 182–187. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An Analysis of Variance Test for Normality (Complete Samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Gong, X.W.; Qiu, R.J.; Zhang, B.Z.; Wang, S.S.; Ge, J.K.; Gao, S.K.; Yang, Z.Q. Energy budget for tomato plants grown in a greenhouse in northern China. Agric. Water Manag. 2021, 255, 107039. [Google Scholar] [CrossRef]
- Su, Y.Y.; Fan, X.K. Research and analysis of main meteorological factors affecting evapotranspiration based on weighing method. Agric. Res. Arid Area 2020, 38, 40–48. [Google Scholar]
- Cheng, W.J.; Xi, H.Y.; Celestin, S. Application of geodetector in sensitivity analysis of reference crop evapotranspiration spatial changes in Northwest China. Sci. Cold Arid Reg. 2021, 13, 314–325. [Google Scholar]
- Wang, S.; Fu, Z.Y.; Chen, H.S.; Ding, Y.L.; Wu, L.P.; Wang, K.L. Simulation of reference evapotranspiration based on stochastic forest algorithm. Chin. Soc. Agric. Mach. 2017, 48, 302–309. [Google Scholar]
- Huang, Y.; Li, S.E. Contribution analysis of meteorological factors to reference crop evapotranspiration change in Minqin area. J. Chin. Agric. Univ. 2021, 26, 118–128. [Google Scholar]
- Yu, J.X.; Zheng, W.J.; Xu, L.L.; Zhang, L.L.; Zhang, G.; Shan, F.F. A PSO-XGBoost Model for Estimating Daily Reference Evapotranspiration in the Solar Greenhouse. Intell. Autom Soft Comput. 2020, 26, 989–1003. [Google Scholar] [CrossRef]
- Liu, W.H.; Zhang, B.Z.; Han, S.J. Quantitative Analysis of the Impact of Meteorological Factors on Reference Evapotranspiration Changes in Beijing, 1958–2017. Water 2020, 12, 2263. [Google Scholar] [CrossRef]
- Zhang, X.P.; Sheng, L.L.; Liu, H.Q.; Zhang, H.; Cai, H.J. Relationship between evapotranspiration of reference crops and meteorological factors under drip irrigation in solar greenhouse. Water Sav. Irrig. 2014, 9, 1–4. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Yoav, F.; Robert, E.S. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Benya, S.; Somrawee, A.; Manop, K.; Paskorn, C. Water Irrigation Decision Support System for Practical Weir Adjustment Using Artificial Intelligence and Machine Learning Techniques. Sustainability 2020, 12, 1763. [Google Scholar]
- Patryk, H.; Magdalena, P.; Gniewko, N. Selection of Independent Variables for Crop Yield Prediction Using Artificial Neural Network Models with Remote Sensing Data. Land 2021, 10, 609. [Google Scholar]
- Aston, C.; Zhang, Y.S.; Louis, K.; Nathaniel, N.; Andrew, D.; Harvey, H.; Richard, W.; Qian, B.D.; Bahram, D.; Frederic, B.; et al. Evaluation of the Integrated Canadian Crop Yield Forecaster (ICCYF) model for in-season prediction of crop yield across the Canadian Agricultural landscape. Agric. For. Meteorol. 2015, 206, 137–150. [Google Scholar]
- Mayer, D.G.; Butler, D.G. Statistical validation. Ecol. Model. 1993, 68, 21–31. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MSE | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|
| LR-ET | 0.067 | 0.257 | 0.172 | 8.36% | 0.812 |
| SVR-ET | 0.053 | 0.218 | 0.162 | 6.72% | 0.854 |
| KNR-ET | 0.115 | 0.303 | 0.237 | 10.83% | 0.807 |
| RFR-ET | 0.072 | 0.285 | 0.197 | 8.77% | 0.805 |
| ABR-ET | 0.071 | 0.282 | 0.216 | 9.95% | 0.834 |
| BR-ET | 0.042 | 0.207 | 0.159 | 6.59% | 0.823 |
| XGBR-ET | 0.032 | 0.163 | 0.132 | 4.47% | 0.981 |
| GBR-ET | 0.039 | 0.205 | 0.154 | 6.38% | 0.960 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, J.; Zhao, L.; Yu, Z.; Liu, H.; Zhang, L.; Gong, X.; Sun, H. Prediction of Greenhouse Tomato Crop Evapotranspiration Using XGBoost Machine Learning Model. Plants 2022, 11, 1923. https://doi.org/10.3390/plants11151923
Ge J, Zhao L, Yu Z, Liu H, Zhang L, Gong X, Sun H. Prediction of Greenhouse Tomato Crop Evapotranspiration Using XGBoost Machine Learning Model. Plants. 2022; 11(15):1923. https://doi.org/10.3390/plants11151923
Chicago/Turabian StyleGe, Jiankun, Linfeng Zhao, Zihui Yu, Huanhuan Liu, Lei Zhang, Xuewen Gong, and Huaiwei Sun. 2022. "Prediction of Greenhouse Tomato Crop Evapotranspiration Using XGBoost Machine Learning Model" Plants 11, no. 15: 1923. https://doi.org/10.3390/plants11151923