
A Head/Tail Breaks-Based Approach to Characterizing Space-Time Risks of COVID-19 Epidemic in China’s Cities

Abstract
:1. Introduction
2. Data and Methodology
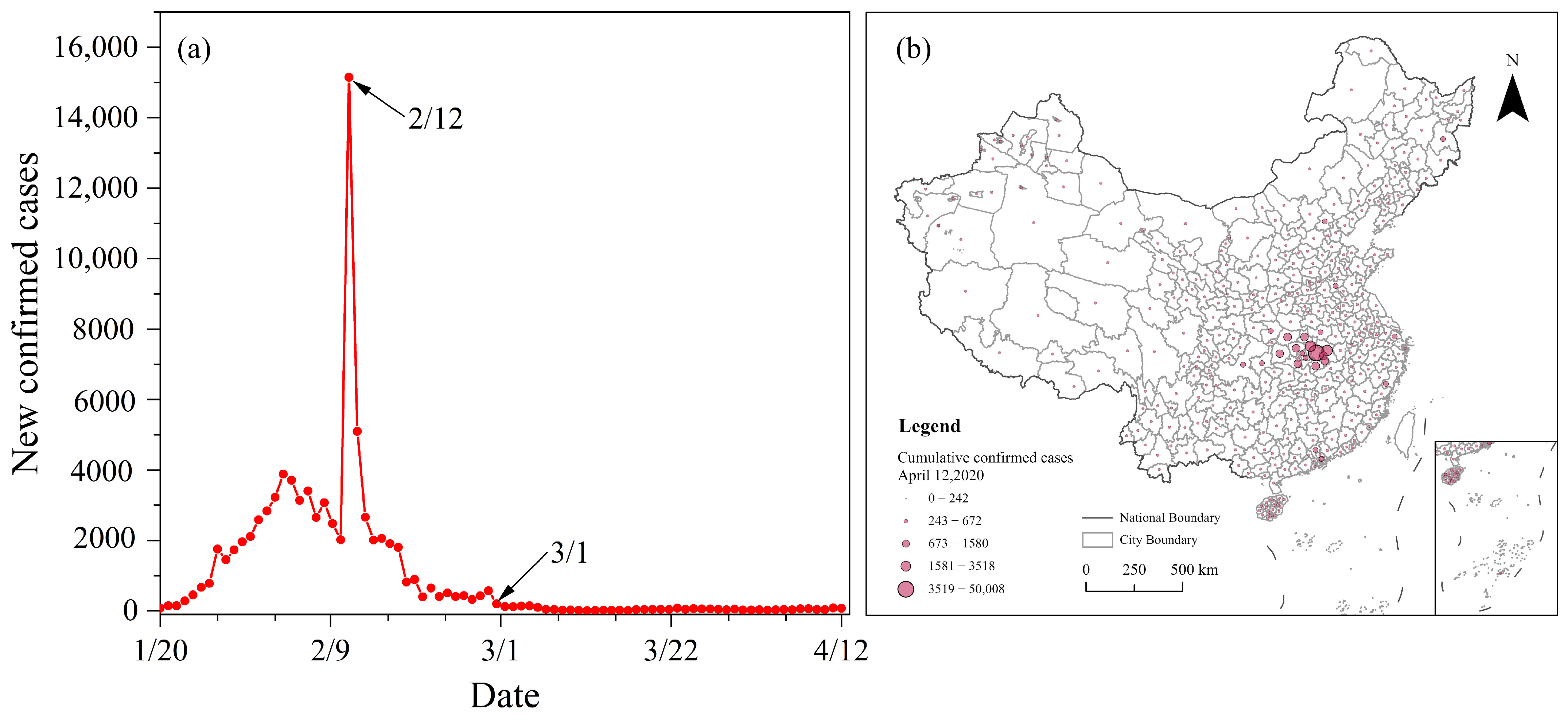
2.1. Study Area and Data Sources
2.2. Methodology
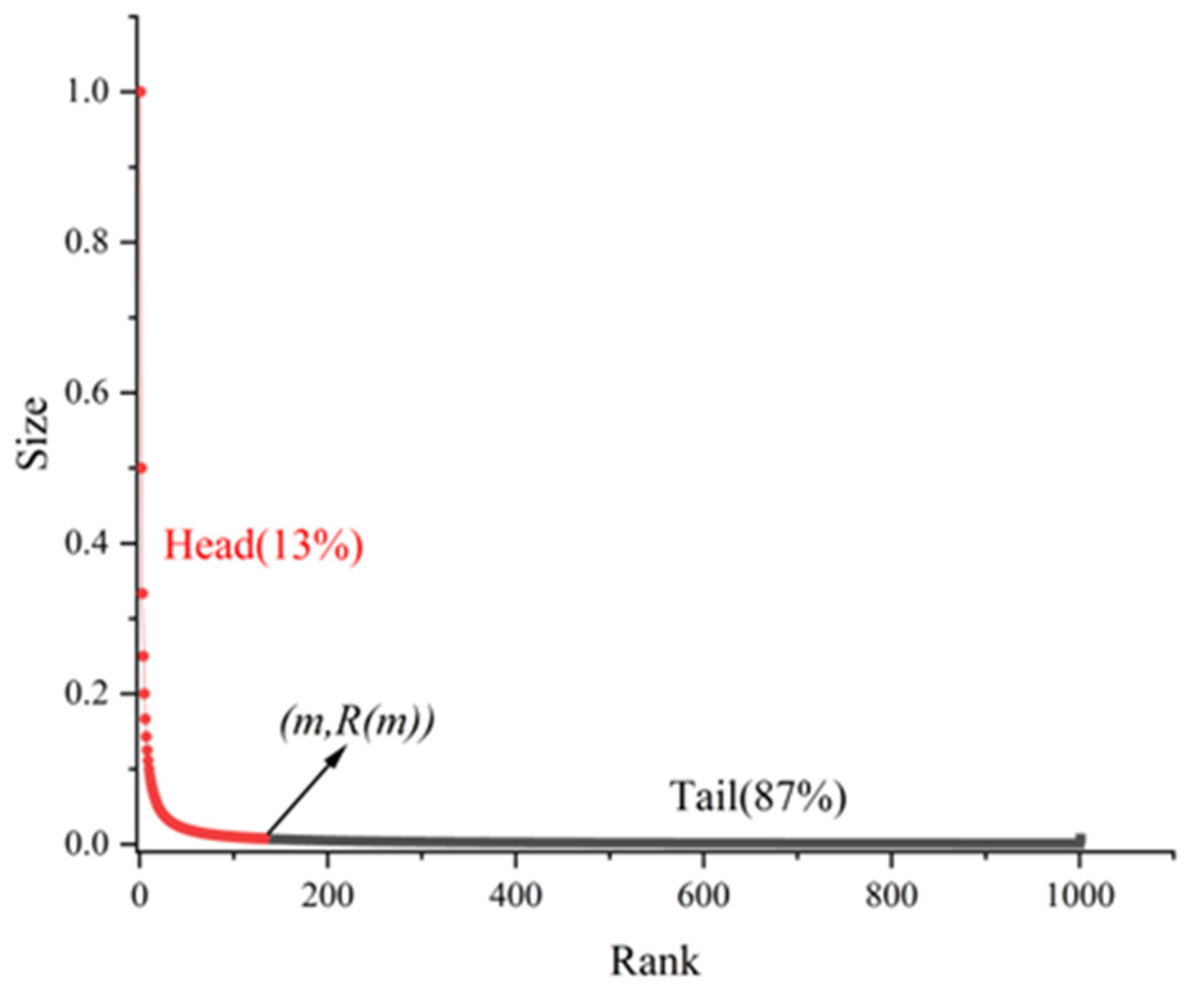
2.2.1. Heavy-Tailed Distributions
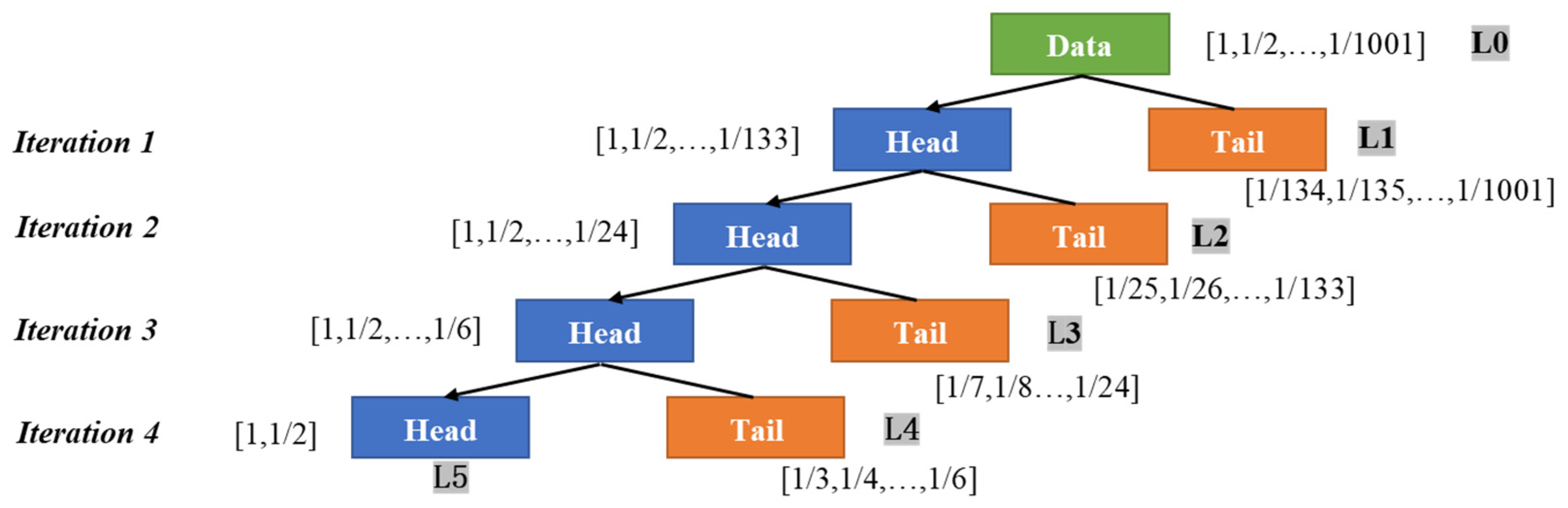
2.2.2. Head/Tail Breaks and ht Index
2.2.3. Epidemic Risk Measurement
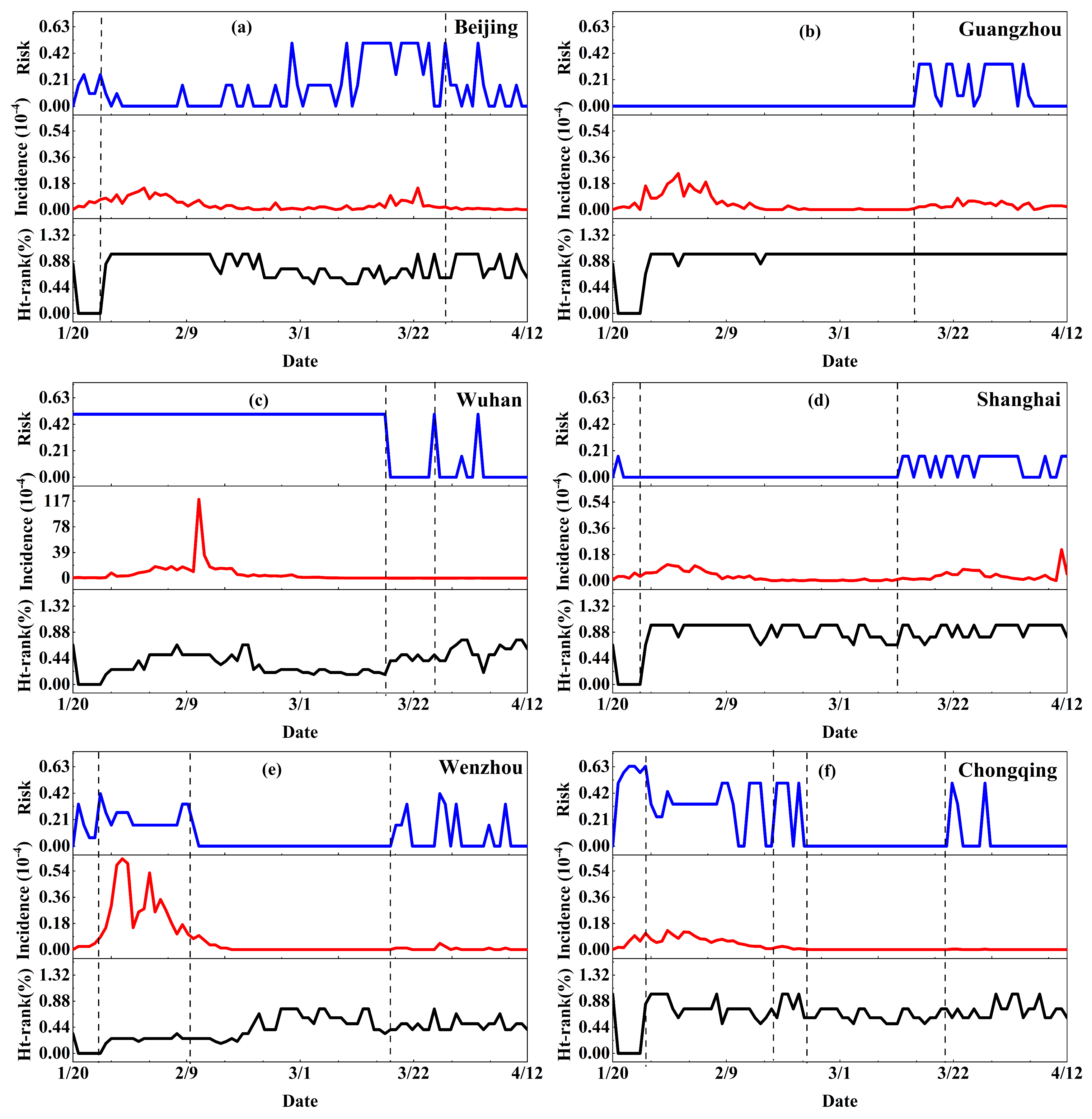
3. Results
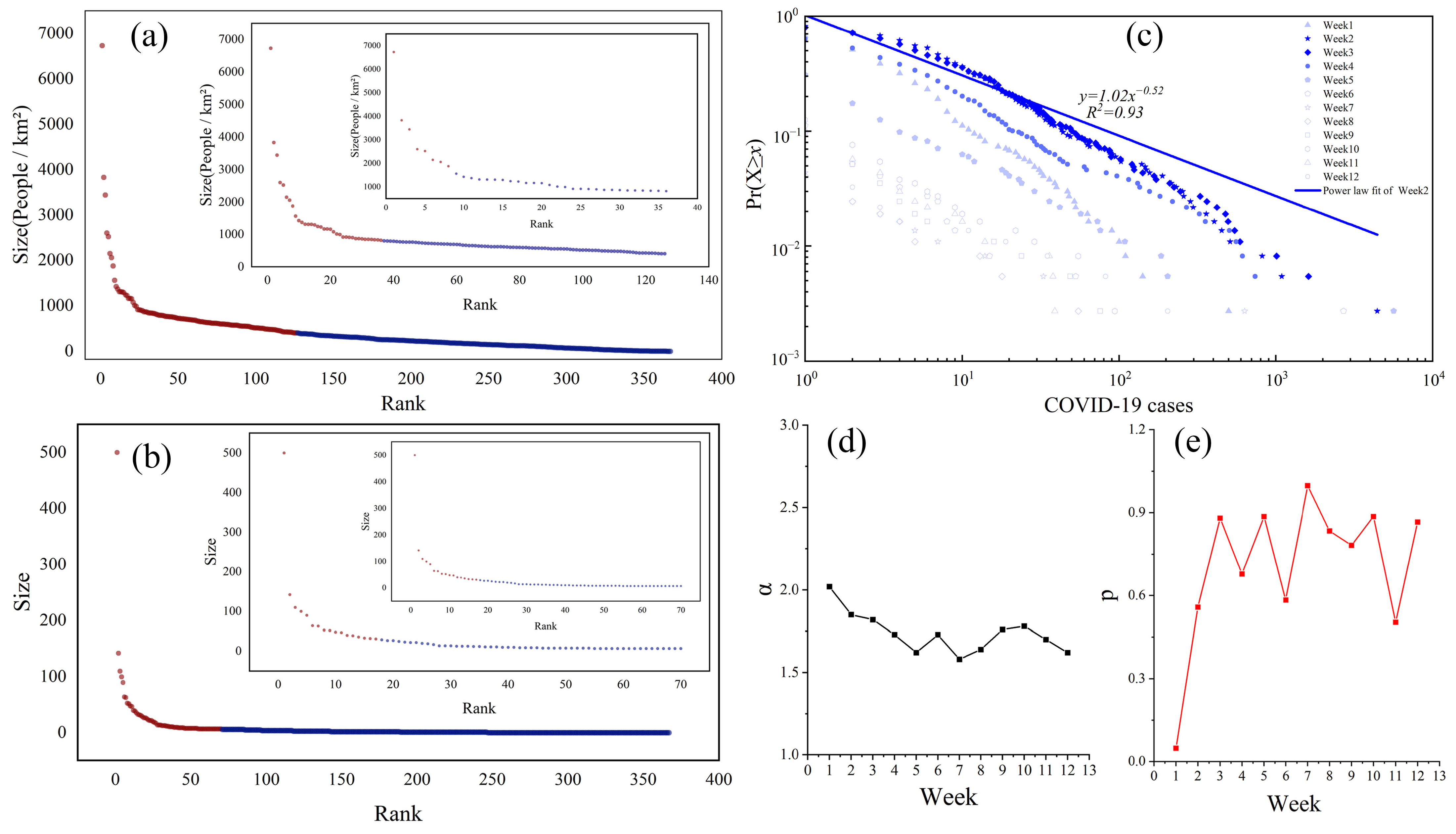
3.1. Exploration of Heavy-Tailed Distribution
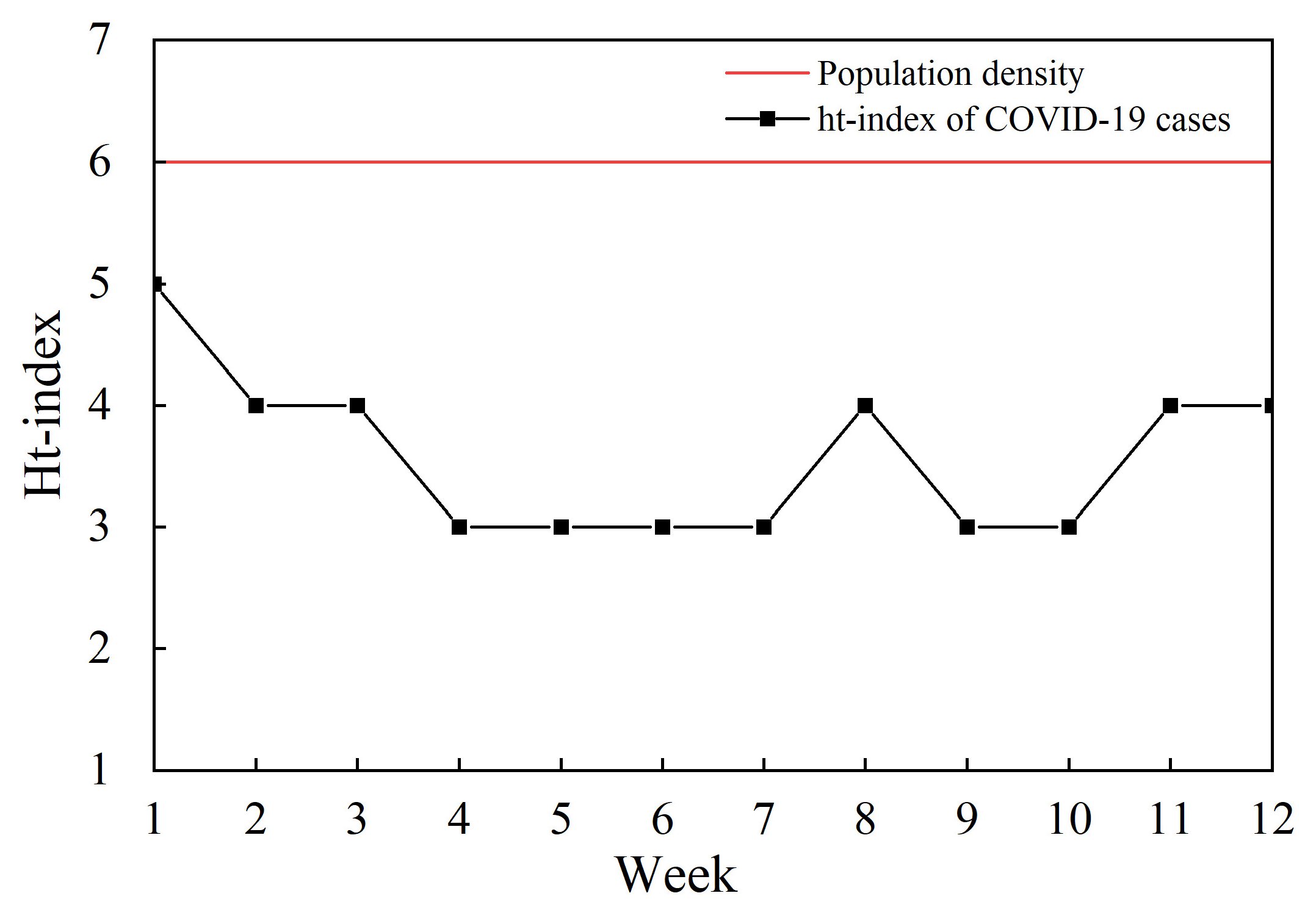
3.2. The ht Index and Spatial Hierarchy of COVID-19 Confirmed Cases and Population Density
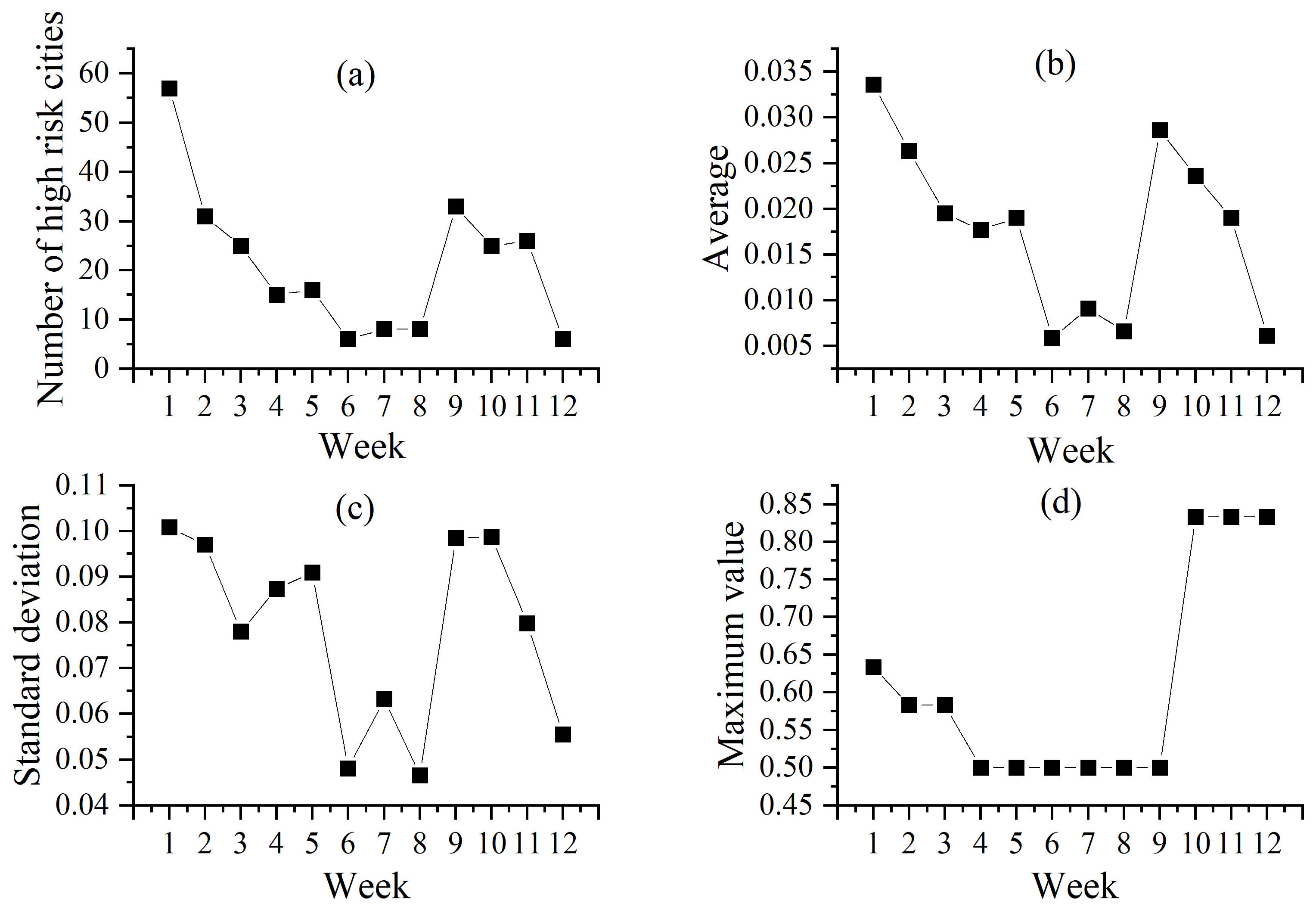
3.3. Assessment of the Risk of Transmission of COVID-19 Cases in China
3.4. Application of Outbreak Risk Assessment Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | City | Mean | Head | Tail | %Head |
|---|---|---|---|---|---|
| Week1 | 367 | 6.96 | 70 | 297 | 19% |
| 70 | 29.99 | 17 | 53 | 24% | |
| 17 | 87.06 | 5 | 12 | 29% | |
| 5 | 188.40 | 1 | 4 | 20% | |
| Week2 | 367 | 39.31 | 38 | 329 | 10% |
| 38 | 312.71 | 7 | 31 | 18% | |
| 7 | 1155 | 1 | 6 | 14% | |
| Week3 | 367 | 62.88 | 30 | 337 | 8% |
| 30 | 669.23 | 3 | 27 | 10% | |
| 3 | 4798 | 1 | 2 | 33% | |
| Week4 | 367 | 85.75 | 15 | 352 | 4% |
| 15 | 1971.33 | 1 | 14 | 6% | |
| Week5 | 367 | 18.73 | 16 | 351 | 4% |
| 16 | 412.63 | 1 | 15 | 6% | |
| Week6 | 367 | 7.84 | 6 | 361 | 2% |
| 6 | 467 | 1 | 5 | 17% | |
| Week7 | 367 | 1.93 | 9 | 358 | 2% |
| 9 | 78 | 1 | 8 | 11% | |
| Week8 | 367 | 0.31 | 15 | 352 | 4% |
| 15 | 7.47 | 3 | 12 | 20% | |
| 3 | 28.67 | 1 | 2 | 33% | |
| Week9 | 367 | 0.63 | 36 | 331 | 10% |
| 36 | 6.42 | 4 | 32 | 11% | |
| Week10 | 367 | 1.02 | 28 | 339 | 8% |
| 28 | 12.68 | 6 | 22 | 21% | |
| Week11 | 367 | 0.59 | 37 | 330 | 10% |
| 37 | 5.84 | 8 | 29 | 22% | |
| 8 | 20.25 | 3 | 5 | 38% | |
| Week12 | 367 | 1.04 | 12 | 355 | 3% |
| 12 | 30.83 | 3 | 9 | 25% | |
| 3 | 107.33 | 1 | 2 | 33% |
References
- Boldog, P.; Tekeli, T.; Vizi, Z.; Dénes, A.; Bartha, F.A.; Röst, G. Risk Assessment of Novel Coronavirus COVID-19 Outbreaks Outside China. J. Clin. Med. 2020, 9, 571. [Google Scholar] [CrossRef] [PubMed]
- Carballada, A.M.; Balsa-Barreiro, J. Geospatial Analysis and Mapping Strategies for Fine-Grained and Detailed COVID-19 Data with GIS. ISPRS Int. J. Geo-Inf. 2021, 10, 602. [Google Scholar] [CrossRef]
- Chen, S.; Yang, J.; Yang, W.; Wang, C.; Bärnighausen, T. COVID-19 Control in China during Mass Population Movements at New Year. Lancet 2020, 395, 764–766. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Zhao, S.; Yu, B.; Chen, Y.-M.; Wang, W.; Song, Z.-G.; Hu, Y.; Tao, Z.-W.; Tian, J.-H.; Pei, Y.-Y. A New Coronavirus Associated with Human Respiratory Disease in China. Nature 2020, 579, 265–269. [Google Scholar] [CrossRef] [PubMed]
- Navinya, C.; Patidar, G.; Phuleria, H.C. Examining Effects of the COVID-19 National Lockdown on Ambient Air Quality across Urban India. Aerosol Air Qual. Res. 2020, 20, 1759–1771. [Google Scholar] [CrossRef]
- Leung, K.; Wu, J.T.; Liu, D.; Leung, G.M. First-Wave COVID-19 Transmissibility and Severity in China Outside Hubei after Control Measures, and Second-Wave Scenario Planning: A Modelling Impact Assessment. Lancet 2020, 395, 1382–1393. [Google Scholar] [CrossRef]
- Zhang, C.; Pei, Y.; Li, J.; Qin, Q.; Yue, J. Application of Luojia 1-01 Nighttime Images for Detecting the Light Changes for the 2019 Spring Festival in Western Cities, China. Remote Sens. 2020, 12, 1416. [Google Scholar] [CrossRef]
- Wei, Y.; Lu, Y.; Xia, L.; Yuan, X.; Li, G.; Li, X.; Liu, L.; Liu, W.; Zhou, P.; Wang, C.-Y. Analysis of 2019 Novel Coronavirus Infection and Clinical Characteristics of Outpatients: An Epidemiological Study from a Fever Clinic in Wuhan, China. J. Med. Virol. 2020, 92, 2758–2767. [Google Scholar] [CrossRef]
- Chan, J.F.-W.; Yuan, S.; Kok, K.-H.; To, K.K.-W.; Chu, H.; Yang, J.; Xing, F.; Liu, J.; Yip, C.C.-Y.; Poon, R.W.-S. A Familial Cluster of Pneumonia Associated with the 2019 Novel Coronavirus Indicating Person-to-Person Transmission: A Study of a Family Cluster. Lancet 2020, 395, 514–523. [Google Scholar] [CrossRef]
- Backer, J.A.; Klinkenberg, D.; Wallinga, J. Incubation Period of 2019 Novel Coronavirus (2019-nCoV) Infections among Travellers from Wuhan, China, 20–28 January 2020. Eurosurveillance 2020, 25, 2000062. [Google Scholar] [CrossRef]
- Wu, J.T.; Leung, K.; Leung, G.M. Nowcasting and Forecasting the Potential Domestic and International Spread of the 2019-nCoV Outbreak Originating in Wuhan, China: A Modelling Study. Lancet 2020, 395, 689–697. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Yang, D.Y.; Dong, G.P.; Zhang, H.; Miao, C.H. The Spatio-Temporal Spread Characteristics of COVID-19 and Risk Assessment Based on Population Movement in Henan Province: Analysis Based on 1243 Case Reports. Econ. Geogr. 2020, 40, 24–32. [Google Scholar] [CrossRef]
- Yang, K.; Qiao, G.; Li, J.; Chen, H.; Xin, X.; Zhu, Y. Epidemic of Coronavirus Disease 2019 in Zhejiang Province, China: Characteristics of Spatial Diffusion and Impact Factors. Chin. J. Virol. 2021, 37, 9. [Google Scholar] [CrossRef]
- Wang, J.; Du, D.; Wei, Y.; Yang, H.H. The Development of COVID-19 in China: Spatial Diffusion and Geographical Pattern. Geogr. Res. 2020, 39, 1450–1462. [Google Scholar] [CrossRef]
- Yang, D.; Shi, W.; Yu, Y.; Chen, L.; Chen, R. Analysis of the Spatial Distribution and Associated Factors of the Transmission Locations of COVID-19 in the First Four Waves in Hong Kong. ISPRS Int. J. Geo-Inf. 2023, 12, 111. [Google Scholar] [CrossRef]
- Hu, J.X.; Liu, T.; Xiao, J.P.; He, G.H.; Rong, Z.H.; Yin, L.H.; Wan, D.H.; Zeng, W.L.; Gong, D.X.; Guo, L.C. Risk Assessment and Early Warning of Imported COVID-19 in Guangdong Province. Chin. J. Epidemiol. 2020, 41, 657–661. [Google Scholar] [CrossRef]
- Pang, S.; Xiao, J.; Fang, Y. Risk Assessment Model and Application of COVID-19 Virus Transmission in Closed Environments at Sea. Sustain. Cities Soc. 2021, 74, 103245. [Google Scholar] [CrossRef]
- Ranjan, A.K.; Patra, A.K.; Gorai, A.K. Effect of Lockdown Due to SARS COVID-19 on Aerosol Optical Depth (AOD) over Urban and Mining Regions in India. Sci. Total Environ. 2020, 745, 141024. [Google Scholar] [CrossRef]
- Chirisa, I.; Mutambisi, T.; Chivenge, M.; Mabaso, E.; Matamanda, A.R.; Ncube, R. The Urban Penalty of COVID-19 Lockdowns across the Globe: Manifestations and Lessons for Anglophone Sub-Saharan Africa. GeoJournal 2022, 87, 815–828. [Google Scholar] [CrossRef]
- He, X.; Zhou, C.; Wang, Y.; Yuan, X. Risk Assessment and Prediction of COVID-19 Based on Epidemiological Data from Spatiotemporal Geography. Front. Environ. Sci. 2021, 9, 634156. [Google Scholar] [CrossRef]
- Luo, M.; Qin, S.; Tan, B.; Cai, M.; Yue, Y.; Xiong, Q. Population Mobility and the Transmission Risk of the COVID-19 in Wuhan, China. ISPRS Int. J. Geo-Inf. 2021, 10, 395. [Google Scholar] [CrossRef]
- Gomes, D.S.; Andrade, L.A.; Ribeiro, C.J.N.; Peixoto, M.V.S.; Lima, S.V.M.A.; Duque, A.M.; Cirilo, T.M.; Góes, M.A.O.; Lima, A.G.C.F.; Santos, M.B.; et al. Risk Clusters of COVID-19 Transmission in Northeastern Brazil: Prospective Space–Time Modelling. Epidemiol. Infect. 2020, 148, e188. [Google Scholar] [CrossRef] [PubMed]
- Coccia, M. An Index to Quantify Environmental Risk of Exposure to Future Epidemics of the COVID-19 and Similar Viral Agents: Theory and Practice. Environ. Res. 2020, 191, 110155. [Google Scholar] [CrossRef] [PubMed]
- Du, Z.; Wang, L.; Cauchemez, S.; Xu, X.; Wang, X.; Cowling, B.J.; Meyers, L.A. Risk for Transportation of Coronavirus Disease from Wuhan to Other Cities in China. Emerg. Infect. Dis. 2020, 26, 1049. [Google Scholar] [CrossRef] [PubMed]
- Hâncean, M.-G.; Perc, M.; Lerner, J. Early Spread of COVID-19 in Romania: Imported Cases from Italy and Human-to-Human Transmission Networks. R. Soc. Open Sci. 2020, 7, 200780. [Google Scholar] [CrossRef] [PubMed]
- Bontempi, E.; Vergalli, S.; Squazzoni, F. Understanding COVID-19 Diffusion Requires an Interdisciplinary, Multi-Dimensional Approach. Environ. Res. 2020, 188, 109814. [Google Scholar] [CrossRef]
- Chen, Y.-C.; Lu, P.-E.; Chang, C.-S.; Liu, T.-H. A Time-Dependent SIR Model for COVID-19 with Undetectable Infected Persons. IEEE Trans. Netw. Sci. Eng. 2020, 7, 3279–3294. [Google Scholar] [CrossRef]
- Cooper, I.; Mondal, A.; Antonopoulos, C.G. A SIR Model Assumption for the Spread of COVID-19 in Different Communities. Chaos Solitons Fractals 2020, 139, 110057. [Google Scholar] [CrossRef]
- Lai, S.; Ruktanonchai, N.W.; Zhou, L.; Prosper, O.; Luo, W.; Floyd, J.R.; Wesolowski, A.; Santillana, M.; Zhang, C.; Du, X. Effect of Non-Pharmaceutical Interventions to Contain COVID-19 in China. Nature 2020, 585, 410–413. [Google Scholar] [CrossRef]
- Chang, S.; Pierson, E.; Koh, P.W.; Gerardin, J.; Redbird, B.; Grusky, D.; Leskovec, J. Mobility Network Models of COVID-19 Explain Inequities and Inform Reopening. Nature 2021, 589, 82–87. [Google Scholar] [CrossRef]
- Annas, S.; Pratama, M.I.; Rifandi, M.; Sanusi, W.; Side, S. Stability Analysis and Numerical Simulation of SEIR Model for Pandemic COVID-19 Spread in Indonesia. Chaos Solitons Fractals 2020, 139, 110072. [Google Scholar] [CrossRef] [PubMed]
- Basnarkov, L. SEAIR Epidemic Spreading Model of COVID-19. Chaos Solitons Fractals 2021, 142, 110394. [Google Scholar] [CrossRef] [PubMed]
- Chan, T.-L.; Yuan, H.-Y.; Lo, W.-C. Modeling Covid-19 Transmission Dynamics with Self-Learning Population Behavioral Change. Front. Public Health 2021, 9, 2136. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.; Ning, P.; Qiu, J.; Tao, V.; Devlin, A.T.; Chen, H.; Wang, J.; Lin, H. Modeling the Complete Spatiotemporal Spread of the COVID-19 Epidemic in Mainland China. Int. J. Infect. Dis. 2021, 110, 247–257. [Google Scholar] [CrossRef] [PubMed]
- Mandal, M.; Jana, S.; Nandi, S.K.; Khatua, A.; Adak, S.; Kar, T.K. A Model Based Study on the Dynamics of COVID-19: Prediction and Control. Chaos Solitons Fractals 2020, 136, 109889. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Yi, C.; Vajdi, A.; Cohnstaedt, L.W.; Wu, H.; Guo, X.; Scoglio, C.M. Short-Term Forecasts and Long-Term Mitigation Evaluations for the COVID-19 Epidemic in Hubei Province, China. Infect. Dis. Model. 2020, 5, 563–574. [Google Scholar] [CrossRef]
- Hasan, A.; Putri, E.R.; Susanto, H.; Nuraini, N. Data-Driven Modeling and Forecasting of COVID-19 Outbreak for Public Policy Making. ISA Trans. 2022, 124, 135–143. [Google Scholar] [CrossRef]
- Song, J.; Xie, H.; Gao, B.; Zhong, Y.; Gu, C.; Choi, K.-S. Maximum Likelihood-Based Extended Kalman Filter for COVID-19 Prediction. Chaos Solitons Fractals 2021, 146, 110922. [Google Scholar] [CrossRef]
- Alotaibi, N.; Elbatal, I.; Almetwally, E.M.; Alyami, S.A.; Al-Moisheer, A.S.; Elgarhy, M. Truncated Cauchy Power Weibull-G Class of Distributions: Bayesian and Non-Bayesian Inference Modelling for COVID-19 and Carbon Fiber Data. Mathematics 2022, 10, 1565. [Google Scholar] [CrossRef]
- Jiang, B.; de Rijke, C. A Power-Law-Based Approach to Mapping COVID-19 Cases in the United States. Geo-Spat. Inf. Sci. 2021, 24, 333–339. [Google Scholar] [CrossRef]
- Ren, H.; Zhao, L.; Zhang, A.; Song, L.; Liao, Y.; Lu, W.; Cui, C. Early Forecasting of the Potential Risk Zones of COVID-19 in China’s Megacities. Sci. Total Environ. 2020, 729, 138995. [Google Scholar] [CrossRef] [PubMed]
- Pang, S.; Wu, J.; Lu, Y. Thermodynamic Imaging Calculation Model on COVID-19 Transmission and Epidemic Cities Risk Level Assessment—Data from Hubei in China. Pers. Ubiquitous Comput. 2023, 27, 715–731. [Google Scholar] [CrossRef] [PubMed]
- Oh, Y.; Park, S.; Ye, J.C. Deep Learning COVID-19 Features on CXR Using Limited Training Data Sets. IEEE Trans. Med. Imaging 2020, 39, 2688–2700. [Google Scholar] [CrossRef] [PubMed]
- Lalmuanawma, S.; Hussain, J.; Chhakchhuak, L. Applications of Machine Learning and Artificial Intelligence for Covid-19 (SARS-CoV-2) Pandemic: A Review. Chaos Solitons Fractals 2020, 139, 110059. [Google Scholar] [CrossRef] [PubMed]
- Dandekar, R.; Rackauckas, C.; Barbastathis, G. A Machine Learning-Aided Global Diagnostic and Comparative Tool to Assess Effect of Quarantine Control in COVID-19 Spread. Patterns 2020, 1, 100145. [Google Scholar] [CrossRef] [PubMed]
- Kraemer, M.U.; Yang, C.-H.; Gutierrez, B.; Wu, C.-H.; Klein, B.; Pigott, D.M.; Open COVID-19 Data Working Group; Du Plessis, L.; Faria, N.R.; Li, R.; et al. The Effect of Human Mobility and Control Measures on the COVID-19 Epidemic in China. Science 2020, 368, 493–497. [Google Scholar] [CrossRef]
- Jia, J.S.; Lu, X.; Yuan, Y.; Xu, G.; Jia, J.; Christakis, N.A. Population Flow Drives Spatio-Temporal Distribution of COVID-19 in China. Nature 2020, 582, 389–394. [Google Scholar] [CrossRef]
- Habibi, R.; Alesheikh, A.A.; Bayat, S. An Event-Based Model and a Map Visualization Approach for Spatiotemporal Association Relations Discovery of Diseases Diffusion. Sustain. Cities Soc. 2022, 87, 104187. [Google Scholar] [CrossRef]
- Moftakhar, L.; Mozhgan, S.; Safe, M.S. Exponentially Increasing Trend of Infected Patients with COVID-19 in Iran: A Comparison of Neural Network and ARIMA Forecasting Models. Iran. J. Public Health 2020, 49, 92. [Google Scholar] [CrossRef]
- Xiong, Y.; Wang, Y.; Chen, F.; Zhu, M. Spatial Statistics and Influencing Factors of the COVID-19 Epidemic at Both Prefecture and County Levels in Hubei Province, China. Int. J. Environ. Res. Public Health 2020, 17, 3903. [Google Scholar] [CrossRef]
- Tang, W.; Liao, H.; Marley, G.; Wang, Z.; Cheng, W.; Wu, D.; Yu, R. The Changing Patterns of Coronavirus Disease 2019 (COVID-19) in China: A Tempogeographic Analysis of the Severe Acute Respiratory Syndrome Coronavirus 2 Epidemic. Clin. Infect. Dis. 2020, 71, 818–824. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Huang, X.; Li, Z. A Content Analysis of Chinese News Coverage on COVID-19 and Tourism. Curr. Issues Tour. 2022, 25, 198–205. [Google Scholar] [CrossRef]
- Liu, Q.; Sha, D.; Liu, W.; Houser, P.; Zhang, L.; Hou, R.; Lan, H.; Flynn, C.; Lu, M.; Hu, T. Spatiotemporal Patterns of COVID-19 Impact on Human Activities and Environment in Mainland China Using Nighttime Light and Air Quality Data. Remote Sens. 2020, 12, 1576. [Google Scholar] [CrossRef]
- Iqbal, N.; Fareed, Z.; Shahzad, F.; He, X.; Shahzad, U.; Lina, M. The Nexus between COVID-19, Temperature and Exchange Rate in Wuhan City: New Findings from Partial and Multiple Wavelet Coherence. Sci. Total Environ. 2020, 729, 138916. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Tang, J.; Wei, F. Updated Understanding of the Outbreak of 2019 Novel Coronavirus (2019-nCoV) in Wuhan, China. J. Med. Virol. 2020, 92, 441–447. [Google Scholar] [CrossRef] [PubMed]
- Lighter, J.; Phillips, M.; Hochman, S.; Sterling, S.; Johnson, D.; Francois, F.; Stachel, A. Obesity in Patients Younger than 60 Years is a Risk Factor for COVID-19 Hospital Admission. Clin. Infect. Dis. 2020, 71, 896–897. [Google Scholar] [CrossRef] [PubMed]
- Deng, X.; Yang, J.; Wang, W.; Wang, X.; Zhou, J.; Chen, Z.; Li, J.; Chen, Y.; Yan, H.; Zhang, J. Case Fatality Risk of the First Pandemic Wave of Coronavirus Disease 2019 (COVID-19) in China. Clin. Infect. Dis. 2021, 73, e79–e85. [Google Scholar] [CrossRef]
- Paez, A.; Lopez, F.A.; Menezes, T.; Cavalcanti, R.; da Rocha Pitta, M.G. A Spatio-temporal Analysis of the Environmental Correlates of COVID-19 Incidence in Spain. Geogr. Anal. 2021, 53, 397–421. [Google Scholar] [CrossRef]
- Zhu, Y.; Xie, J.; Huang, F.; Cao, L. The Mediating Effect of Air Quality on the Association between Human Mobility and COVID-19 Infection in China. Environ. Res. 2020, 189, 109911. [Google Scholar] [CrossRef]
- Sinha, I.P.; Lee, A.R.; Bennett, D.; McGeehan, L.; Abrams, E.M.; Mayell, S.J.; Harwood, R.; Hawcutt, D.B.; Gilchrist, F.J.; Auth, M.K. Child Poverty, Food Insecurity, and Respiratory Health during the COVID-19 Pandemic. Lancet Respir. Med. 2020, 8, 762–763. [Google Scholar] [CrossRef]
- Oronce, C.I.A.; Scannell, C.A.; Kawachi, I.; Tsugawa, Y. Association between State-Level Income Inequality and COVID-19 Cases and Mortality in the USA. J. Gen. Intern. Med. 2020, 35, 2791–2793. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B. Head/Tail Breaks: A New Classification Scheme for Data with a Heavy-Tailed Distribution. Prof. Geogr. 2013, 65, 482–494. [Google Scholar] [CrossRef]
- Jiang, B.; Ren, Z. Geographic Space as a Living Structure for Predicting Human Activities Using Big Data. Int. J. Geogr. Inf. Sci. 2019, 33, 764–779. [Google Scholar] [CrossRef]
- Jiang, B. Head/Tail Breaks for Visualization of City Structure and Dynamics. Cities 2015, 43, 69–77. [Google Scholar] [CrossRef]
- Gao, P.; Liu, Z.; Liu, G.; Zhao, H.; Xie, X. Unified Metrics for Characterizing the Fractal Nature of Geographic Features. Ann. Am. Assoc. Geogr. 2017, 107, 1315–1331. [Google Scholar] [CrossRef]
- Ma, D.; Osaragi, T.; Oki, T.; Jiang, B. Exploring the Heterogeneity of Human Urban Movements Using Geo-Tagged Tweets. Int. J. Geogr. Inf. Sci. 2020, 34, 2475–2496. [Google Scholar] [CrossRef]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-Law Distributions in Empirical Data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Jiang, B.; Liu, X. Scaling of Geographic Space from the Perspective of City and Field Blocks and Using Volunteered Geographic Information. Int. J. Geogr. Inf. Sci. 2012, 26, 215–229. [Google Scholar] [CrossRef]
- Jiang, B.; Yin, J. Ht-Index for Quantifying the Fractal or Scaling Structure of Geographic Features. Ann. Assoc. Am. Geogr. 2014, 104, 530–540. [Google Scholar] [CrossRef]
- Liu, X.; Huang, H.; Jiang, Y.; Wang, T.; Xu, Y.; Abbaszade, G.; Schnelle-Kreis, J.; Zimmermann, R. Assessment of German Population Exposure Levels to PM10 Based on Multiple Spatial-Temporal Data. Environ. Sci. Pollut. Res. 2020, 27, 6637–6648. [Google Scholar] [CrossRef]
- Sun, K.; Chen, J.; Viboud, C. Early Epidemiological Analysis of the Coronavirus Disease 2019 Outbreak Based on Crowdsourced Data: A Population-Level Observational Study. Lancet Digit. Health 2020, 2, e201–e208. [Google Scholar] [CrossRef] [PubMed]
- Hellewell, J.; Abbott, S.; Gimma, A.; Bosse, N.I.; Jarvis, C.I.; Russell, T.W.; Munday, J.D.; Kucharski, A.J.; Edmunds, W.J.; Sun, F.; et al. Feasibility of Controlling COVID-19 Outbreaks by Isolation of Cases and Contacts. Lancet Glob. Health 2020, 8, e488–e496. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Yao, M.; Meng, C.; Claramunt, C. Risk Assessment of the Overseas Imported COVID-19 of Ocean-Going Ships Based on AIS and Infection Data. ISPRS Int. J. Geo-Inf. 2020, 9, 351. [Google Scholar] [CrossRef]
- Phelan, A.L.; Katz, R.; Gostin, L.O. The Novel Coronavirus Originating in Wuhan, China: Challenges for Global Health Governance. JAMA 2020, 323, 709–710. [Google Scholar] [CrossRef]
- Anderson, R.M.; Heesterbeek, H.; Klinkenberg, D.; Hollingsworth, T.D. How Will Country-Based Mitigation Measures Influence the Course of the COVID-19 Epidemic? Lancet 2020, 395, 931–934. [Google Scholar] [CrossRef]









| City | Mean | Head | Tail | %Head | |
|---|---|---|---|---|---|
| Population density | 367 | 403.71 | 126 | 241 | 34% |
| 126 | 861.24 | 30 | 96 | 24% | |
| 30 | 1668.05 | 8 | 22 | 27% | |
| 8 | 3150.71 | 3 | 5 | 38% | |
| 3 | 4666.17 | 1 | 2 | 33% | |
| First week COVID-19 confirmed case | 367 | 6.96 | 70 | 297 | 19% |
| 70 | 29.99 | 17 | 53 | 24% | |
| 17 | 87.06 | 5 | 12 | 29% | |
| 5 | 188.4 | 1 | 4 | 20% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, T.; Hu, B.; Luo, J.; Qi, S. A Head/Tail Breaks-Based Approach to Characterizing Space-Time Risks of COVID-19 Epidemic in China’s Cities. ISPRS Int. J. Geo-Inf. 2023, 12, 485. https://doi.org/10.3390/ijgi12120485
Wu T, Hu B, Luo J, Qi S. A Head/Tail Breaks-Based Approach to Characterizing Space-Time Risks of COVID-19 Epidemic in China’s Cities. ISPRS International Journal of Geo-Information. 2023; 12(12):485. https://doi.org/10.3390/ijgi12120485
Chicago/Turabian StyleWu, Tingting, Bisong Hu, Jin Luo, and Shuhua Qi. 2023. "A Head/Tail Breaks-Based Approach to Characterizing Space-Time Risks of COVID-19 Epidemic in China’s Cities" ISPRS International Journal of Geo-Information 12, no. 12: 485. https://doi.org/10.3390/ijgi12120485