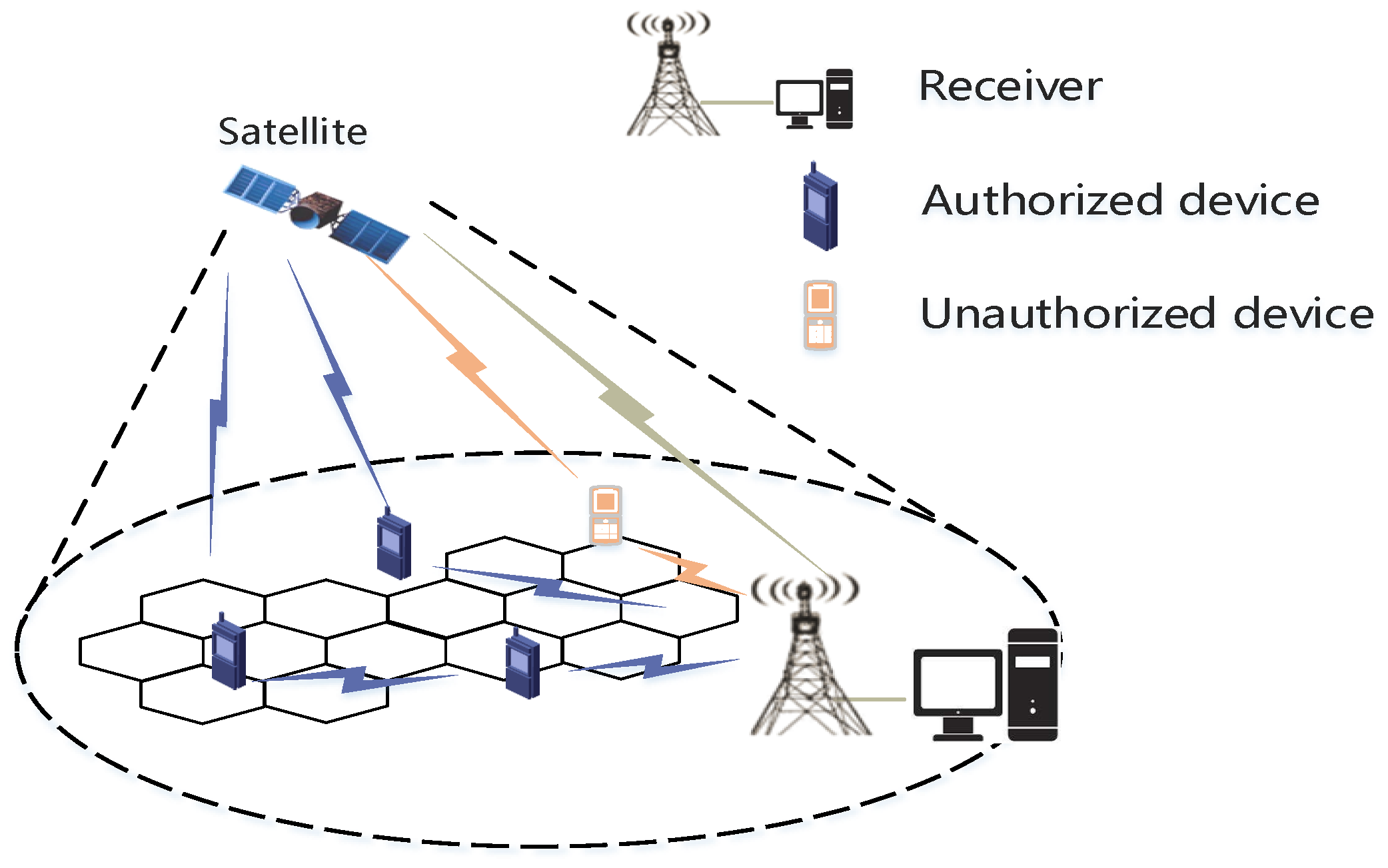
In this paper, we propose a knowledge inference and sharing-based OSR approach to solve the IoT device recognition problem of satellite-terrestrial-integrate IoT. It should perform well in the following scenario: given a fixed number of authorized devices, the recognition model can accurately identify authorized device signals and effectively detect unauthorized device signals. In this section, we need to verify the rationality of knowledge inference and knowledge sharing in solving the OSR problem for IoT devices. As a result, we first show the feature similarity between real unauthorized device signals and synthetic substitutes generated by the virtual knowledge inference module. Then, we demonstrate the performance improvement of the above two modules by ablation study. Furthermore, we evaluate that whether our approach has superior open-set recognition ability. Two experiments are designed to compare our approach and other four state-of-the-art OSR methods in terms of recognition performance and runtime. All simulation experiments use the ORACLE dataset [
35]. The following describes the implementation process and the analysis of experimental results.
4.2. Implementation Details
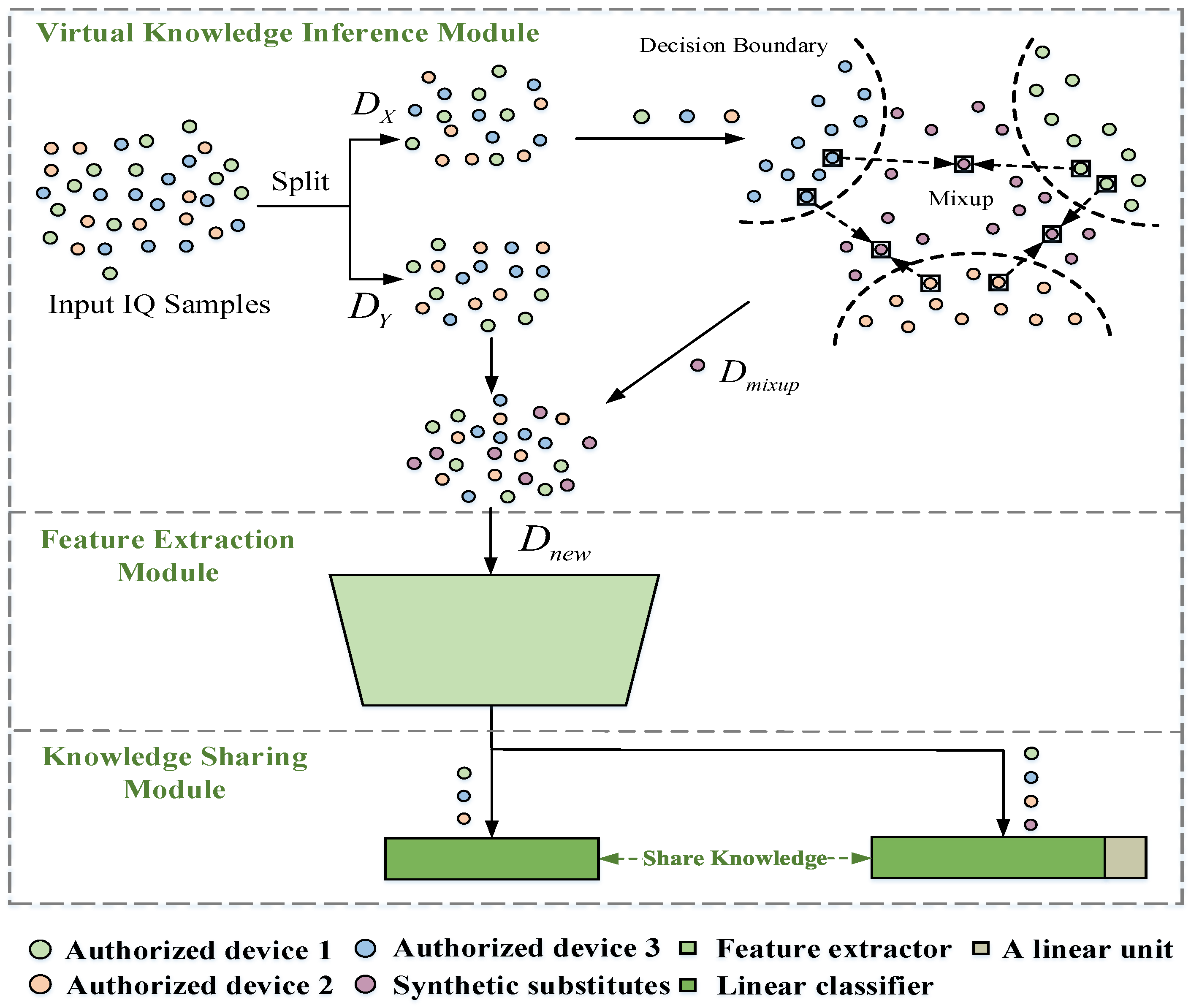
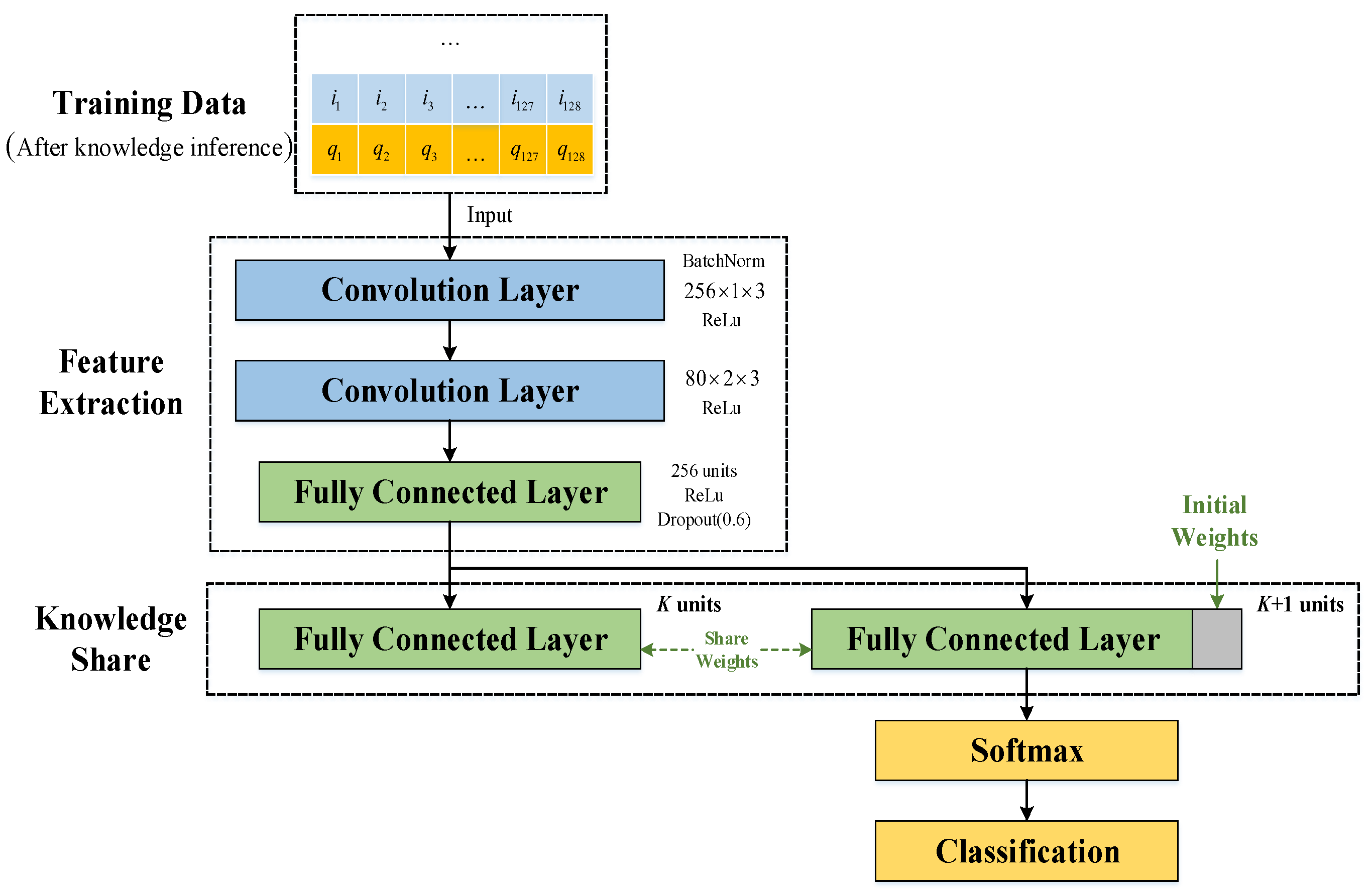
Our approach’s training process is divided into four stages to achieve stable results: (1) closed-set model pre-training, (2) synthetic substitutes construction based on existing knowledge inference, (3) training set augmentation and model architecture expansion, and (4) model open-set fine-tuning based on knowledge sharing. More specifically, in the first stage, the closed-set model (includes
and
) is pre-trained on the training set consisting of signals from
K authorized devices. We do for 350 epochs utilizing the Adam optimizer with a learning rate of
, the size of each minibatch is set to 64, and the penalty coefficient of center loss is
. In the second stage, the virtual knowledge is constructed as substitutes for unauthorized device signals after making reasonable inferences on the training set, which can compensate for the model’s missing information of unauthorized classes. In the third stage, these synthetic substitutes are used to augment the training set, and the model architecture is expanded by sharing
K output units and adding an additional unit (
). Finally, the expanded model is trained on the new training set for model fine-tuning and knowledge sharing in order to achieve IoT device recognition. In this stage, we set the batch_size is 64 and do for 600 epochs and the Adam optimizer is used with a learning rate of
, then, saving optimal model parameters. In addition, we use the coefficient
of the KD loss to correct model decision boundaries, as shown in
Table 2.
4.3. Ablation Study
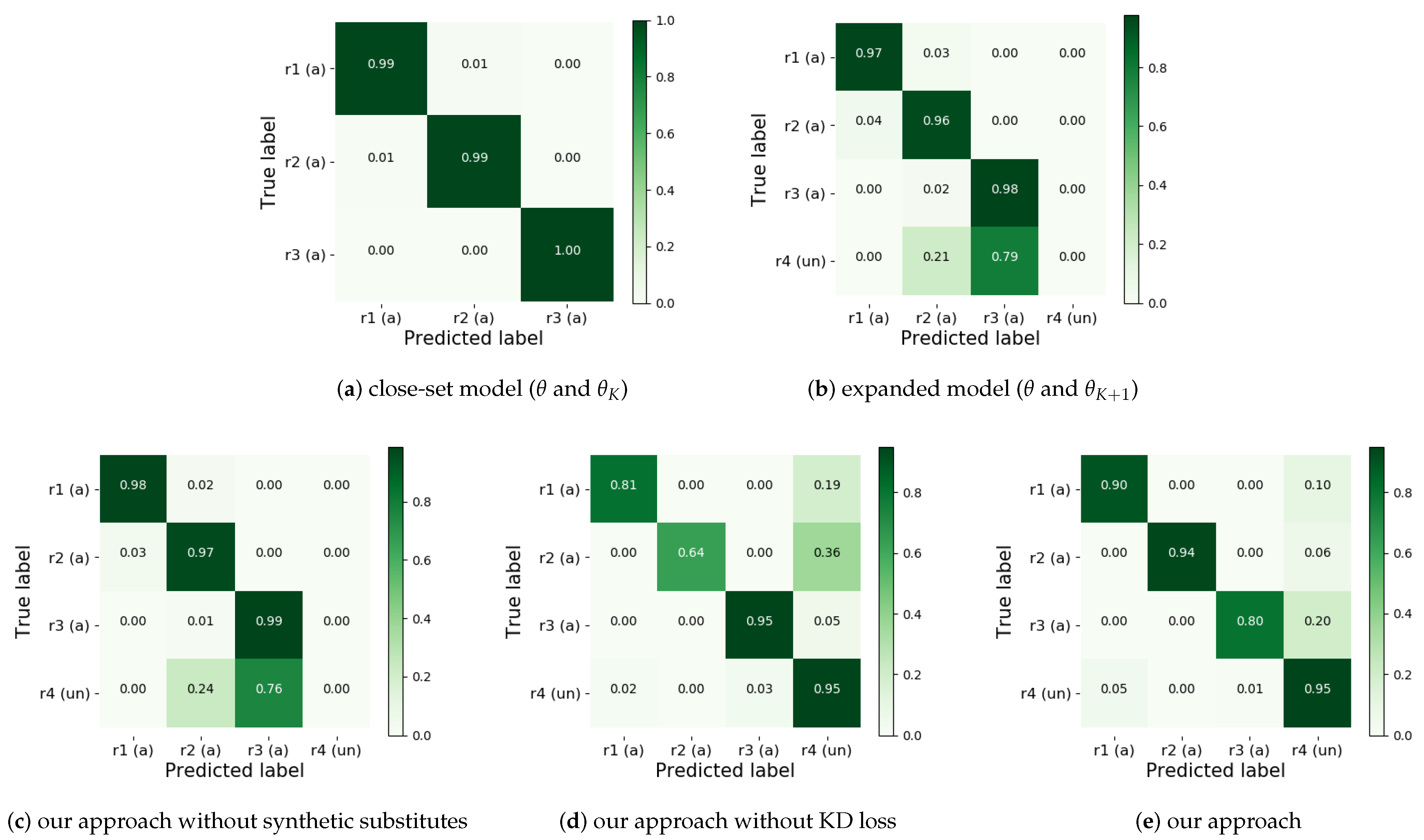
In this paper, our approach makes two efforts to enhance the recognition performance of the model. One is knowledge inference, which constructs substitutes for unauthorized device signals after inferring on the training set, providing the model with the missing decision information. The second is knowledge sharing, which expands the model by reserving an output unit for unauthorized classes and introduces knowledge distillation for decision boundary correction, so that the model inherits learned knowledge and discovers new knowledge. In the following, two experiments are performed to demonstrate the contribution of the above two improvements to the overall performance improvement. The first one shows the similarity between the constructed synthetic substitute and the real unauthorized device signals, as shown in
Figure 4. The second one compares the change in model recognition performance by adding the synthetic substitutes and the KD loss function, respectively, as shown in
Figure 5 and
Table 3.
In the following two experiments, we set the first three devices in the ORACLE WiFi signal dataset as authorized classes
, and the fourth and fifth devices as unauthorized classes
. The dataset is set as follows: firstly, we get subset
and subset
from each of the authorized classes
to form the training set and valication set, and pre-train the three class closed-set model in advance. Secondly, we use the training set for model open-set fine-tuning. Finally, we get the subset
from each of the authorized classes
the subset
from each of the unauthorized classes
to make up the valication set and the test set for performance evaluation of our model. Other details are set as described in
Section 4.1 and
Section 4.2.
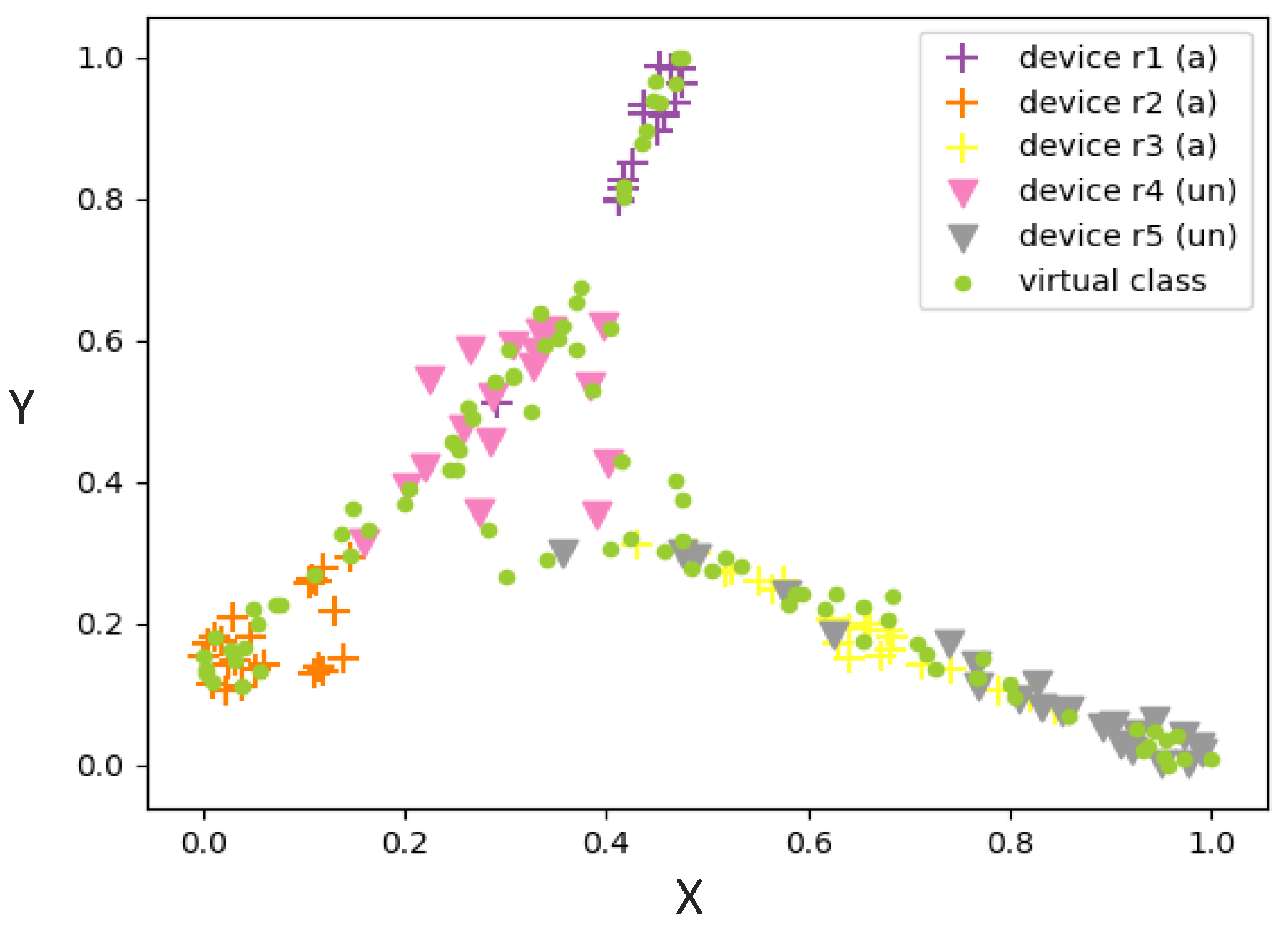
Most existing models are unable to solve the OSR problem since they lack the decision information of unauthorized devices. As a result, we propose the knowledge inference module to compensate for the lack of information. This module constructs virtual substitutes for unauthorized devices after making reasonable inference on the original training set. In the well-trained neural network, the feature representations of unauthorized classes are located in the low-confidence region near decision boundaries [
16], so that of constructed substitutes should also appear in these feature space. In this section, we use the feature extraction module to map the original signals of authorized devices, unauthorized devices and constructed virtual classes into latent features, and then apply the t-SNE algorithm [
39] to reduce the dimension of these features to two dimensions.
In
Figure 4, we show the latent feature distribution of virtual substitutes and real unauthorized device signals. These simulation results show that the constructed virtual substitutes appear in the target region where unauthorized device features are located, which matches our expectations. Furthermore, these virtual substitutes are generated in a simple manner that requires no additional computational or training effort. It proves that these virtual class data are ideal substitutes for unauthorized device signals, and our approach aims to use them to pre-occupy the feature space where the unauthorized classes may appear.
In addition, the model expansion of our approach is realized by sharing the
K linear output units of the pre-trained closed-set model and adding an additional output unit for unauthorized classes. Then, we hope to sovle the OSR problem of IoT devices by fine-tuning the expanded model on the augumented the original training set. However, the obtained results (as shown in
Figure 5a,b) are not consistent with our expectations. After model fine-tuning, the expanded model (includes
and
) forgets the knowledge learned from the original training set, resulting in the performance degradation of the model on the authorization class (the value of AKS decreased from 99.33% to 97.00% as shown in
Table 3). The reason is that the latent feature distribution of authorized classes has changed, and the original decision boundary is no longer optimal.
In this paper, we construct substitutes for unauthorized devices after inferring on the training set, providing the model with the missing decision information. Furthermore, drawing inspiration from Li et al. [
17], we introduce KD loss to alleviate the forgetting phenomenon by modifying the model’s decision boundary. The simulation results of the ablation study are shown in
Figure 5 and
Table 3.
Two aspects of information are shown in the confusion matrix in
Figure 5b,c. First, the addition of the KD loss function improves the model’s average accuracy for authorized devices (AKS) by 1%. Second, only relying on KD loss without synthetic substitutes, our model cannot identify unauthorized devices since lacking the decision information about these unauthorized classes. Furthermore, the results show in
Figure 5c,e prove that the substitutes we constructed is useful, which improves recognition performance of the extended model by sharing the learned knowledge of the closed-set model. In addition,
Figure 5d,e show the effect of adding KD loss on our approach’s recognition accuracy. It can be seen that the KD loss in our approach not only rarely affects the model’s ability to discover unauthorized devices, but also improves the accuracy of authorized devices by 8% (the average accuracy of authorized devices (AKS) increased from 80.00% to 88.00% as shown in
Table 3). This indicates that the KD loss coordinates the identification and discovery capabilities of the model by correcting the decision boundary, and achieves an improvement in model recognition performance. Our approach is able to effectively discover unauthorized devices while improving the model forgetting on authorized ones. However, in contrast to our approach, most open-set models ignore the coordination between known and unknown classes, and they sacrifice the performance of known classes for the better performance of unknown classes.
4.4. Performance Comparison
The goal of open-set recognition is to effectively discover unauthorized device signals while recognizing authorized device signals. Therefore, experiments should demonstrate the ability of the proposed method to meet the above requirement. In this section, two experiments are contructed to compare the performance between our approach and other four state-of-the-art OSR methods in terms of recognition accuracy and running time. Softmax and Openmax [
3] are a typical type of OSR methods that identify unknown classes by setting decision thresholds, and DC_LSTM [
4] is a derivative of Openmax applied in the signal recognition field. DML (Deep Manifold Learning) [
40] is another type of OSR methods, which maps the unauthorized class signals to the learned authorized class manifold representations, and uses a clustering model DBSCAN to distinguish unauthorized devices and authorized devices. It can be used to achieve open-set recognition of IoT devices, but the device number (or category number) need to be known in advance.
In this section, we randomly select
K authorized devices and one unauthorized device in the ORACLE dataset for experiments with
K = 3, 4, 5, respectively. The training set, valication set, and test set are set up similarly to
Section 4.1. Each experiment is repeated 15 times, the value of mean and variance are taken in
Table 4 and
Table 5.
Table 4 gives the test accuracy of our approach and the other four state-of-the-art OSR methods. It can be found that our approach outperforms other OSR methods in different open-set scenarios, although when the authorized device number
K = 3, the test accuracy is improved by about 7.7% on average compared to the suboptimal DML method. Experimental results demonstrate that our approach is effective. Its effectiveness stems from the fact that our approach not only utilizes the knowledge inference module to construct ideal substitutes for unauthorized devices, but also uses the knowledge sharing module to correct the model’s decision boundaries. In contrast to other four OSR methods, our approach considers balancing the recognition performance of the model for authorized and unauthorized classes.
Table 5 shows the recognition performance of our approach through a variety of evaluation metrics. Here, we conducted three OSR experiments when the number of authorized classes
K is set to 3, 4, and 5. From
Table 5, we can draw the following two conclusions. First, given a fixed number of authorized devices, the model’s accuracy on different unauthorized devices (AUS) is stable. Second, when the number of authorized devices changes, the model’s accuracy on unauthorized devices (AUS) decrease with the crease of authorized device numbers. The major reason for this is that as the number of authorized devices grows, the source of synthetic substitutes becomes more complex, and thus the interference caused by these substitutes to the authorized devices in the feature space also increases.
Here, we discuss the computational complexity of our approach. As we all know that time complexity and space complexity are two important evaluation indexes of computational complexity [
41,
42]. Time complexity is generally represented by the number of floating-point operations (FLOPs), which can be understood as the amount of computation and is the approximate estimation of the computing speed of the model. The multiply–adds (MAdds) index serves a similar purpose. Space complexity refers to how many parameters (Params) the model contains, which can be understood as the size of the model. As shown in
Table 6, we provide the complexity evaluation results when the number of authorized classes
K = 3, 4, 5.
Table 6 shows that the value of the total Params, total FLOPs, and the total MAdds does not change much as the number of authorized classes increases, which indicates that our approach does not require many additional computing resources and model memory.
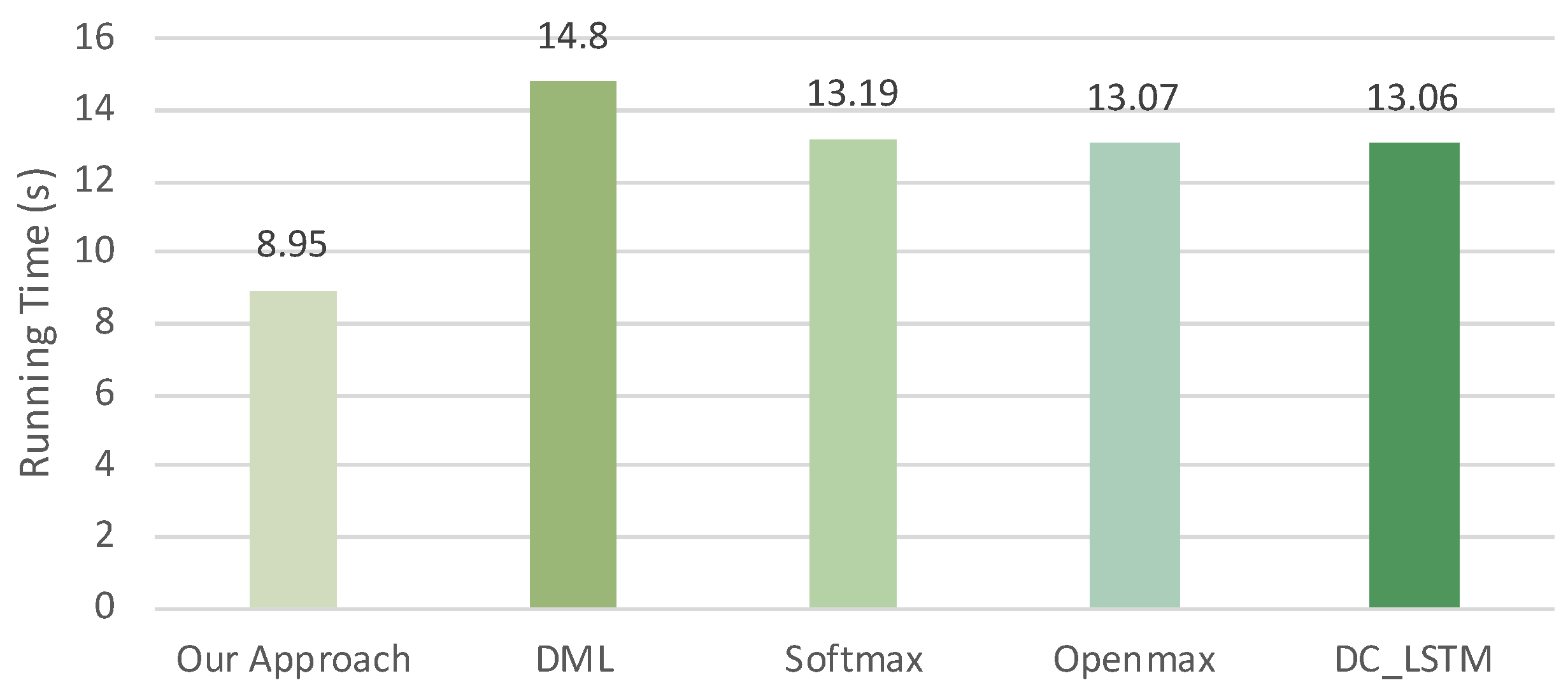
In addition, running time is an important factor to evaluate the complexity of OSR methods. The definition is the total time spent on one epoch model training and a corresponding test. We compared the running time spent by five OSR methods for the recognition model training on the ORACLE dataset. The running time results, as shown in
Figure 6, confirmed that our approach outperforms other four OSR methods. Combined with the results shown in
Table 4, our approach provides a significant performance advantage over than other four OSR methods. Therefore, we suggest that the OSR method proposed in this paper be used for wireless device recognition in open-set scenarios.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}