A Multi-Branch DQN-Based Transponder Resource Allocation Approach for Satellite Communications


Abstract
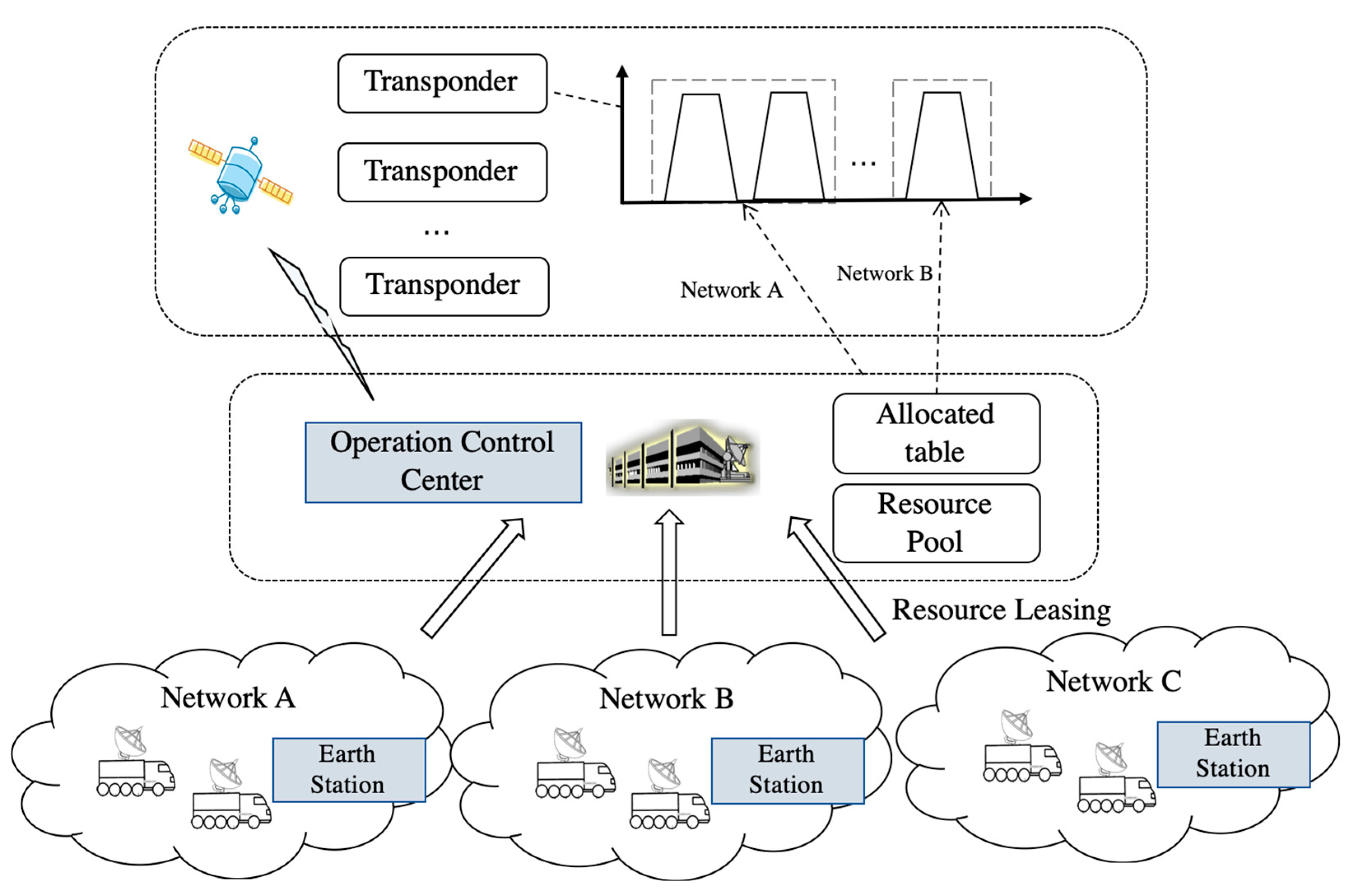
:1. Introduction
2. Related Work
3. Proposed Method
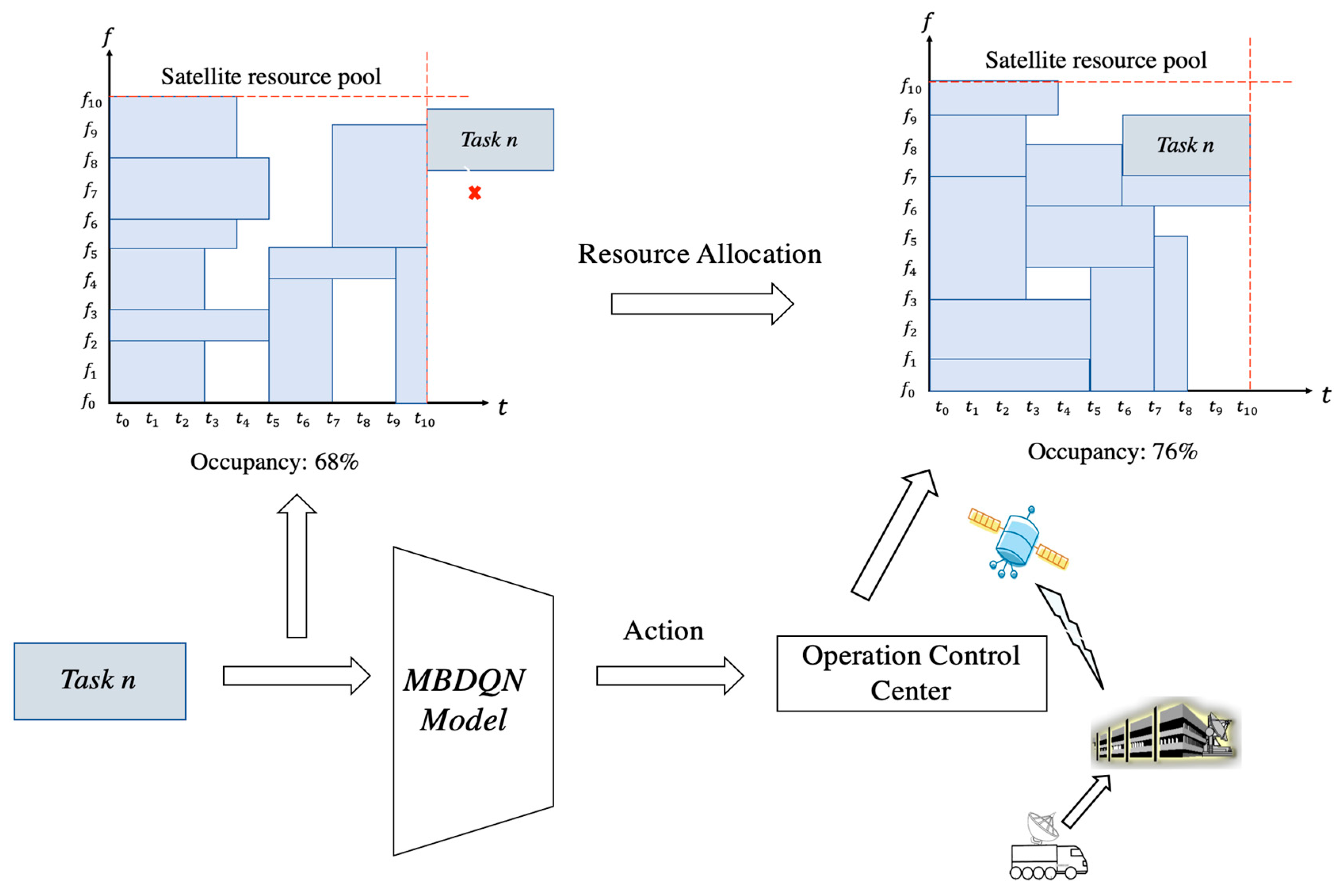
3.1. Problem Formulation
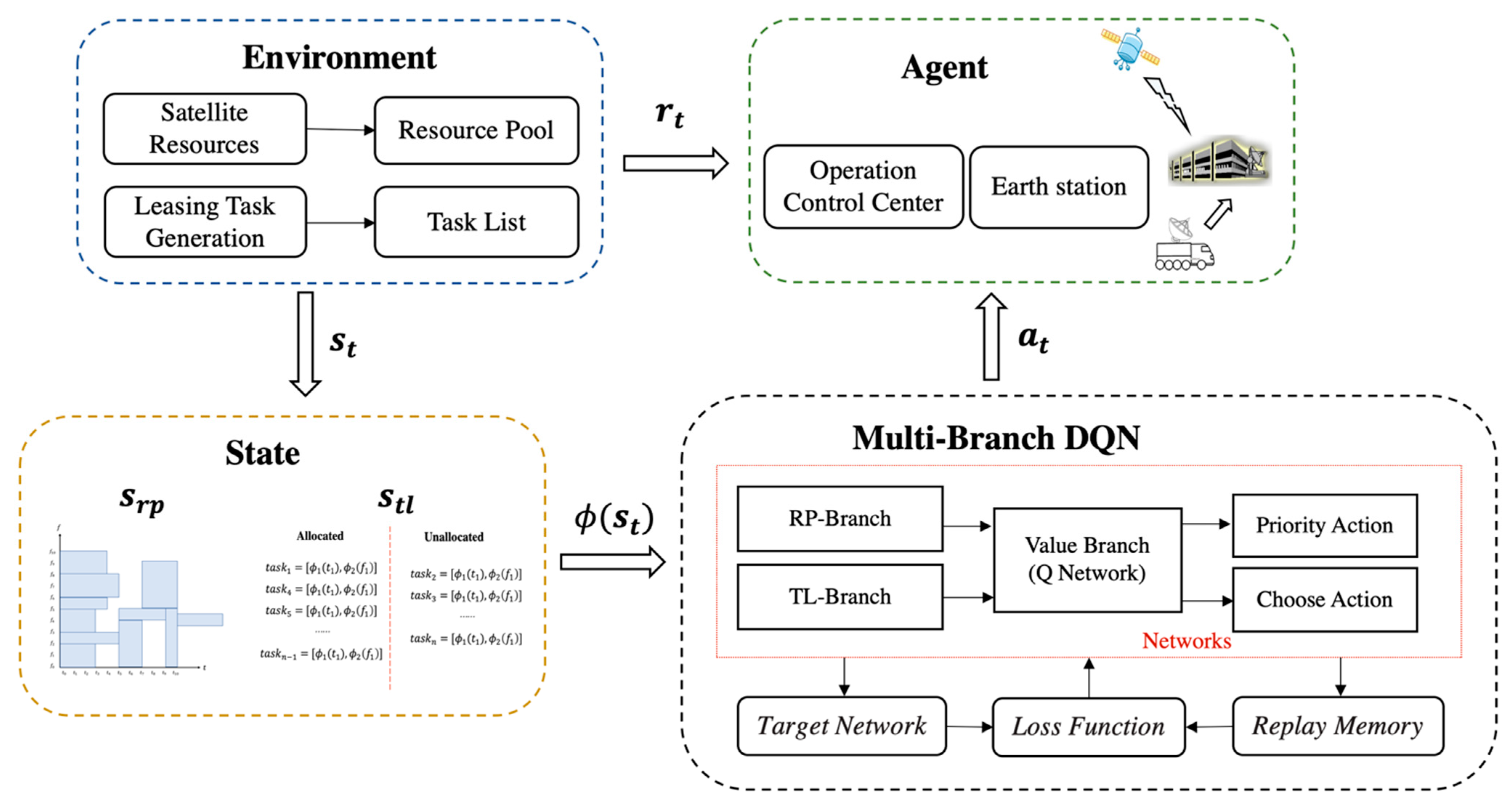
3.2. Modeling of MBDQN
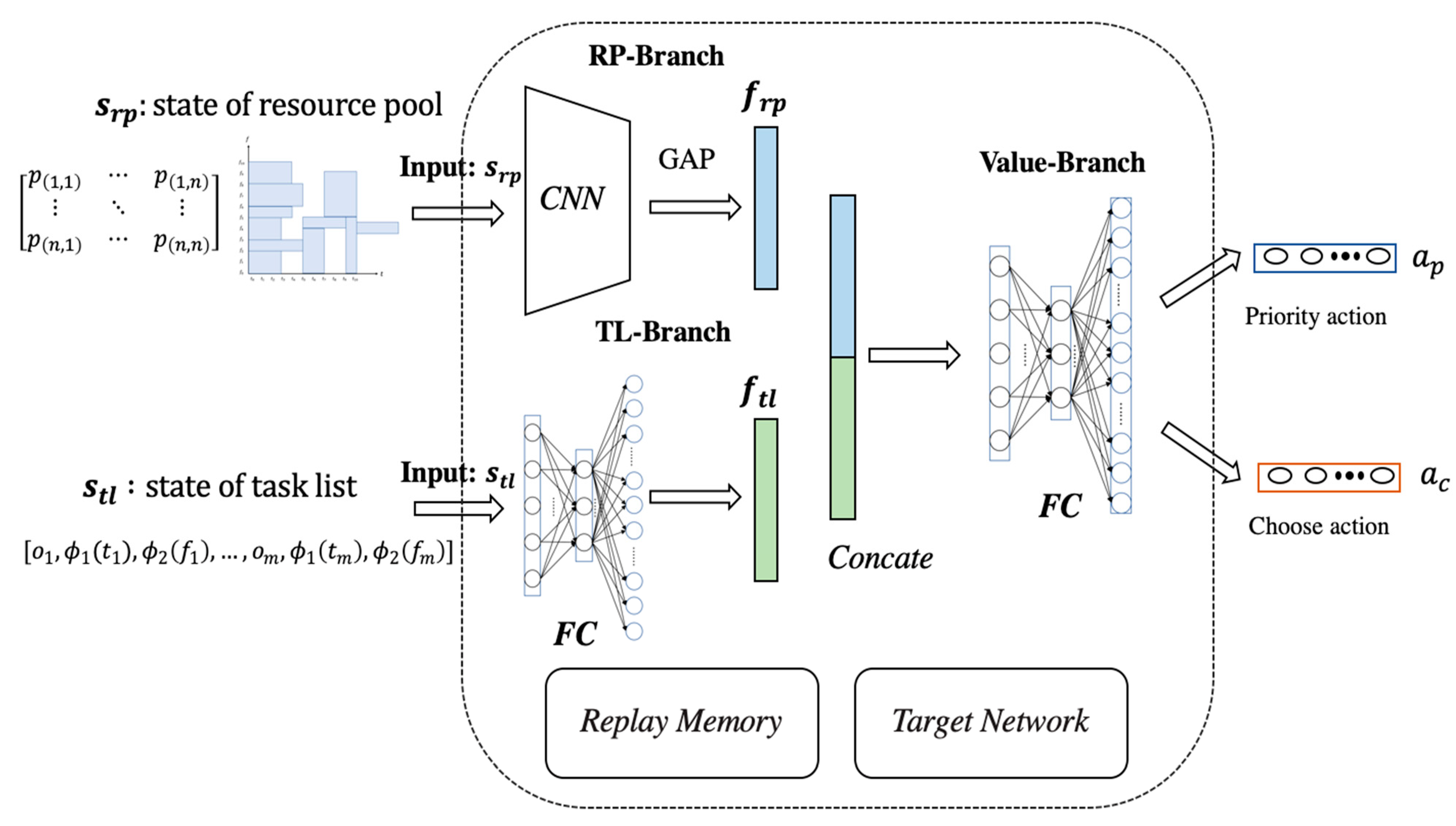
3.3. Structure of MBDQN
4. Experiments
4.1. Datasets and Implementation
4.1.1. Generation of Datasets
4.1.2. Implementation Details
4.2. Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, M.; Zhang, X.; Sun, J.; Gu, X.; Guo, Q. Intelligent resource management for satellite and terrestrial spectrum shared networking toward B5G. IEEE Wirel. Commun. 2020, 27, 54–61. [Google Scholar] [CrossRef]
- Yanlei, D.; Chunting, W.; Chenhua, S.; Yusheng, L.; Qing, X. Performance Evaluation for Satellite Communication Networks Based on AHP-BP Algorithm. In Proceedings of the 2018 10th International Conference on Communication Software and Networks (ICCSN), Chengdu, China, 6–9 July 2018; pp. 311–316. [Google Scholar]
- Bai, Y.; Liang, C.; Chen, Q. Network Slice Admission Control and Resource Allocation in LEO Satellite Networks: A Robust Optimization Approach. In Proceedings of the 2022 27th Asia Pacific Conference on Communications (APCC), Jeju Island, Republic of Korea, 19–21 October 2022; pp. 1–6. [Google Scholar]
- Guo, B.; Wang, H.; Wu, P. Application of constraint-based satellite mission planning model in forest fire monitoring. AIP Conf. Proc. 2017, 1890, 030012. [Google Scholar]
- Lin, Z.; An, K.; Niu, H.; Hu, Y.; Chatzinotas, S.; Zheng, G.; Wang, J. SLNR-based secure energy efficient beamforming in Multibeam Satellite Systems. IEEE Trans. Aerosp. Electron. Syst. 2022; early access. [Google Scholar] [CrossRef]
- Daoden, K.; Thaiupathump, T. Applying shuffled frog leaping algorithm and bottom left fill algorithm in rectangular packing problem. In Proceedings of the 2017 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC), Macau, China, 21–23 July 2017; pp. 136–139. [Google Scholar]
- Karaboga, D.; Gorkemli, B.; Ozturk, C.; Karaboga, N. A comprehensive survey: Artificial bee colony (ABC) algorithm and applications. Artif. Intell. Rev. 2014, 42, 21–57. [Google Scholar] [CrossRef]
- Chen, H.; Zhong, Z.; Wu, J.; Jing, N. Multi-satellite data downlink resource scheduling algorithm for incremental observation tasks based on evolutionary computation. In Proceedings of the 2015 Seventh International Conference on Advanced Computational Intelligence (ICACI), Wuyi, China, 27–29 March 2015; pp. 251–256. [Google Scholar]
- Zhang, Z.; Hu, F.; Zhang, N. Ant colony algorithm for satellite control resource scheduling problem. Appl. Intell. 2018, 48, 3295–3305. [Google Scholar] [CrossRef]
- Sarkheyli, A.; Bagheri, A.; Ghorbani-Vaghei, B.; Askari-Moghadam, R. Using an effective tabu search in interactive resources scheduling problem for LEO satellites missions. Aerosp. Sci. Technol. 2013, 29, 287–295. [Google Scholar] [CrossRef]
- Pachler, N.; Luis, J.J.G.; Guerster, M.; Crawley, E.; Cameron, B. Allocating power and bandwidth in multibeam satellite systems using particle swarm optimization. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–11. [Google Scholar]
- Hu, X.; Liu, S.; Chen, R.; Wang, W.; Wang, C. A deep reinforcement learning-based framework for dynamic resource allocation in multibeam satellite systems. IEEE Commun. Lett. 2018, 22, 1612–1615. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Cai, Q.; Hang, W.; Mirhoseini, A.; Tucker, G.; Wang, J.; Wei, W. Reinforcement learning driven heuristic optimization. arXiv 2019, arXiv:1906.06639. [Google Scholar]
- Deng, B.; Jiang, C.; Yao, H.; Guo, S.; Zhao, S. The next generation heterogeneous satellite communication networks: Integration of resource management and deep reinforcement learning. IEEE Wirel. Commun. 2019, 27, 105–111. [Google Scholar] [CrossRef]
- Huang, Y.; Mu, Z.; Wu, S.; Cui, B.; Duan, Y. Revising the observation satellite scheduling problem based on deep reinforcement learning. Remote Sens. 2021, 13, 2377. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Bortfeldt, A.; Gehring, H. New Large benchmark instances for the two-dimensional strip packing problem with rectangular pieces. In Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS’06), Kauai, HI, USA, 4–7 January 2006; p. 30b. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| N | Number of patches |
| M | Number of task lists |
| State of environment at time t | |
| State of resource pool | |
| State of task lists | |
| Action selected at time t | |
| Priority action selected | |
| Choose action selected | |
| Action space of MBDQN | |
| Effective time resource range | |
| Effective frequency resource range | |
| Patch (i, j) of resource pool | |
| Reward at time t | |
| Parameters of MBDQN | |
| Parameters of target network | |
| Action-value function of MBDQN | |
| Action-value function of target network | |
| State reformulation on time | |
| State reformulation on frequency | |
| Discount factor reward | |
| TD target at time t | |
| Loss function of the model | |
| Feature embedding of RP-Branch | |
| Feature embedding of TL-Branch | |
| Status of the m-th task |
| 1. | Training Process: |
| 2. | Initialize params of MBDQN and target network |
| 3. | Initialize hyperparams for training |
| 4. | For step in episode do: |
| 5. | Observe states and from environment at time t |
| 6. | Format and , and obtain state |
| 7. | Evaluate MBDQN and obtain |
| 8. | Select action by Equation (4) |
| 9. | Execute action and observe state |
| 10. | Calculate the reward by Equation (5) |
| 11. | Save transition in replay memory |
| 12. | Sample a minibatch of from replay memory |
| 13. | Calculate TD target by Equation (6) |
| 14. | Calculate loss function by Equation (7) |
| 15. | Update params of MBDQN through SGD optimizer |
| 16. | For every T step, update params of target network |
| 17. | End For |
| 18. | Save and export params |
| After training | |
| 1. | Testing Process: |
| 2. | Load and initialize the trained params of MBDQN |
| 3. | For m in number M do: |
| 4. | Observe states and from environment at time t |
| 5. | Format and , and obtain state |
| 6. | Evaluate MBDQN and obtain |
| 7. | Select action |
| 8. | Execute action and observe state |
| 9. | End For |
| Block | Module | Module Structure | Tensor Size |
|---|---|---|---|
| RP-Branch | Conv1 | Conv(K = 3)-BN-ReLU- MaxPool | (1,N,N) (32,N/2,N/2) |
| Conv2 | Conv(K = 1,3,1)-BN-ReLU, | (32,N/2,N/2) (64,N/4,N/4) | |
| Conv3 | Conv(K = 1,3,1)-BN-ReLU, | (64,N/4,N/4) (128,N/4,N/4) | |
| GAP | Global Average Pooling | (128,N/4,N/4) (128,1) | |
| TL-Branch | FC1 | FC(128)-BN-Dropout(0.5)-FC(256) | (3 * M,1) (256,1) |
| FC2 | FC(256)-BN-Dropout(0.5)-FC(128) | (256,1) (128,1) | |
| Value-Branch | Concat | Concat(GAP, FC2) | [(128,1),(128,1)] (256,1) |
| FC3 | FC(256)-BN-Dropout(0.5)-FC(128) | (256,1) (128,1) | |
| FC4 | FC(128)-BN-Dropout(0.5)-FC(128) | (256,1) (128,1) | |
| Q-value | [FC(2),FC(M)] | (128,1) [(2,1),(M,1)] |
| 1. | Input: |
| 2. | Frequency range and time range |
| 3. | Number of tasks |
| 4. | Area ratio and aspect ratio |
| 5. | Initialize set |
| 6. | For in do: |
| 7. | Calculate max product in |
| 8. | Randomly select in , satisfying |
| 9. | Delete from |
| 10. | Randomly select slicing dimension, satisfying |
| 11. | Slice to subtasks |
| 12. | Add in |
| 13. | End For |
| 14. | Return |
| Task Number | Bottom Left [6] | Bee Colony [7] | GA-PSO [11] | MBDQN (Ours) | ||||
|---|---|---|---|---|---|---|---|---|
| AOP (%) | RO (s) | AOP (%) | RO (s) | AOP (%) | RO (s) | AOP (%) | RO (s) | |
| M = 10 | 85.2 | 0.13 | 97.5 | 4.16 | 97.9 | 10.42 | 97.7 | 0.59 |
| M = 20 | 86.9 | 0.22 | 93.5 | 9.32 | 95.1 | 18.96 | 95.3 | 0.83 |
| M = 30 | 89.1 | 0.30 | 93.0 | 13.05 | 93.7 | 24.50 | 94.6 | 1.21 |
| M = 40 | 91.3 | 0.37 | 92.6 | 19.41 | 93.9 | 32.54 | 95.1 | 1.47 |
| Task Number | Bottom Left [6] | Bee Colony [7] | GA-PSO [11] | MBDQN (Ours) | ||||
|---|---|---|---|---|---|---|---|---|
| AOP (%) | RO (s) | AOP (%) | RO (s) | AOP (%) | RO (s) | AOP (%) | RO (s) | |
| M = 10 | 76.3 | 0.12 | 85.1 | 4.52 | 85.2 | 11.44 | 85.5 | 0.63 |
| M = 20 | 80.5 | 0.22 | 85.8 | 10.65 | 85.8 | 18.90 | 86.4 | 0.86 |
| M = 30 | 82.4 | 0.31 | 86.2 | 14.20 | 87.0 | 24.43 | 87.7 | 1.24 |
| M = 40 | 83.8 | 0.36 | 87.9 | 21.39 | 88.4 | 31.81 | 89.6 | 1.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, W.; Zhang, W.; Ma, N.; Jia, M. A Multi-Branch DQN-Based Transponder Resource Allocation Approach for Satellite Communications. Electronics 2023, 12, 916. https://doi.org/10.3390/electronics12040916
Sun W, Zhang W, Ma N, Jia M. A Multi-Branch DQN-Based Transponder Resource Allocation Approach for Satellite Communications. Electronics. 2023; 12(4):916. https://doi.org/10.3390/electronics12040916
Chicago/Turabian StyleSun, Wenyu, Weijia Zhang, Ning Ma, and Min Jia. 2023. "A Multi-Branch DQN-Based Transponder Resource Allocation Approach for Satellite Communications" Electronics 12, no. 4: 916. https://doi.org/10.3390/electronics12040916