1. Introduction
Communication and information technologies have made tremendous growth in the recent past. At the same time, many scientific and non-scientific applications are putting complex demands on these networks. Grid and Cloud computation technologies offer many useful applications that are based on high-speed computation and communication [
1]. Some of these applications require data transmission to be completed within certain time bounds while others demand certain QoS to be maintained throughout its service [
2,
3,
4]. The network resources are often shared among various users and they may be assigned priorities over one another (preemptive and non-preemptive) [
5,
6]. Moreover, network resource dimensioning and capacity planning needs to be done efficiently, depending on the arriving traffic rate and pattern. In short, complex user demands and growing technologies offer too many challenges for the researchers to find a match between the two and they have attracted a lot of research attention. Mathematical and analytical modeling techniques have proven to be an effective and ideal tool for capturing these system behaviors and undertaking performance evaluations under varying conditions.
Grid/Cloud computing environment provides an abstract view of the underlying resources and seamless representation as a single entity to end-user [
7]. The users just need to focus on their tasks without worrying about the underlying architecture. The resources may include supercomputing devices, large storage capacities, and high-speed communication links, etc. In cases where the resource’s placement is geographically distributed, we can only estimate the capacity of bottleneck link along the path of data transfer, but no control over the traffic and its allocation. For capacity planning and network dimensioning, we consider such a Grid/Cloud computing environment, where all of the resources are under the control of a single, centralized entity, e.g., Grid’5000 [
8].
Any new system or proposed technique can be evaluated for correctness and effectiveness in three different ways.
Real Implementation: this is done by performing a real experiment on designated tools and devices. Although this approach will give us the exact results but it involves too much labor and cost (in terms of time and money). Moreover, the design may often require slight modification and tuning, but this approach is not flexible enough to accommodate these minor adjustments, and it will result in an increase in cost and delay. Therefore, this is not the best way to start with.
Simulation: this is done by performing simulations using simulators that closely reflect real-world intended scenarios. Although, the simulator may not capture exactly all real-world parameters and, hence, its results may be slightly different than the true results, but still gives nice insight into the system behavior. The simulation models are easy to be developed and used to have a quick initial glance of system behavior with proposed modifications. The parameters can be easily fine-tuned to achieve optimal results at zero cost. Simulators can be used as an effective start-up tool, but their results cannot be fully trusted, as they may not capture the exact real world.
Analytical Modeling: this is done by developing a mathematical model of the intended system and then the model can be used to evaluate the performance of a system under varying conditions to analyze its behavior. These models are often based on certain assumptions regarding some of the system parameters that are often criticized and considered as a flaw. In reality, anything other than real implementation is based on some assumptions in one way or the other. The assumptions are not just made blindly, rather they are supported by strong and valid arguments. Assumptions are based on a closed approximation of the real-world conditions.
Simulation modeling and analytical modeling are both considered to be the most efficient way of doing initial performance analysis and are often used in conjunction to validate each other. They are useful where the real system is not existing and yet to be developed. Once a technique is proven working through modeling and simulation, then its success is also more likely in real implementations.
Modeling and performance evaluation of multi-class queuing networks has gained a lot of research attention [
9,
10,
11,
12]. Typically, network system models are mostly based on Markov Chains. The bottleneck link can be viewed as a Single Server Queue and solved using Continuous Time Markov Chain (CTMC). Laplace and Fourier’s transformations are also frequently used in the solution of these queues. Some researchers have used the concept of Linear Programming by mapping this bottleneck link utilization problem to an optimization problem. Petri-nets are used in modeling scientific workflows that enable scientists to describe their work as a series of tasks without worrying about resource allocation and coordination. Several solution techniques can be found in [
13,
14,
15,
16].
This research is mainly aimed at developing a novel analytical model that is flexible enough to capture network behavior under multi-class flows with strict QoS requirements, such as deadline and priority constraints in Grid/Cloud networks. This work is an extension of our previous study [
17] in which, we have presented an analytical model for multi-class deadline constrained data transfer without considering preemption priorities. To the best of our knowledge, no such model has been developed until the write-up of this document, which can capture multi-class queuing system behavior with strict QoS demands and priority constraints. The proposed model is a representation of a system with multi-class users; each having certain priority and QoS constraints. An example of such a system can easily be found in several daily life queuing systems. For the sake of demonstration, we restrict our study to Grid/Cloud computing environment and the same can be extended/applicable to any queuing system with stated characteristics. Furthermore, we consider the Grid/Cloud computing environment with dedicated communication lines, because the model is only applicable where the notion of QoS is valid, while the traditional Internet is known for its best-effort services. Our goal is to design an integrated and unified model that can be used for performance evaluation of the system with multi-class users having a deadline and priority constraints. The proposed model will be useful in high-speed network dimensioning, QoS provisioning, and capacity planning.
The rest of the text is organized, as follows:
Section 2 presents a brief review of related work.
Section 3 presents a brief description of the network systems and their corresponding characteristics.
Section 5 depicts our proposed model.
Section 6 presents the performance analysis. The paper is concluded in
Section 7, with an outlook to our future work.
2. Related Work
With the advancement in communication and information technology, users and organization QoS demands are also growing and becoming more challenging. This section presents a brief review of various related models proposed in the literature. Each model captures network behavior under different conditions and user requirements. Bonald et al. conducted performance modeling and analysis of elastic flows in [
18]; however, deadline constraints are not included in their proposed model. They have modeled the bottleneck link as an M/G/1-PS queue for fairness analysis and onward mean throughput approximation of TCP protocol. Bandwidth dimensioning model was developed by Berger et al. in [
19] to estimate bandwidth share of individual connection in high-speed networks. They have considered a single bottleneck link in the network. Operations in semiconductor manufacturing are modeled as M/M(a,b)/c/PR priority queue by the authors of [
20]. They have considered two priority classes without modeling deadline constraints. AlQahtani et al. developed an analytical model for 3G wireless networks for performance analysis of various control schemes in [
21]. They have analyzed four different traffic classes, i.e., two non-real-time and two real-time.
Fodor G. et al. developed a model to estimate throughput guarantees and compute blocking probabilities for three kinds of flows in [
22] i.e., (a) Rigid/Non-adaptive streaming flows with strict throughput requirement, e.g., voice calls, (b) adaptive streaming flows has a peak bandwidth requirement
, but they can be squeezed down to
to accommodate other flows. Their holding time is independent of allocated
e.g., an adaptive video flow with codec enabled, and (c) elastic flows have lower and upper throughput bounds. The model is based on the extension of the classical loss model that was originally designed for ATM and circuit-switched networks. The concept of Partial Overlap (POL) is used in this model to divide the available capacity into two (1)
reserved for rigid flows (2)
reserved for Elastic and Adaptive flows. According to [
22], the acceptable blocking probability threshold for each class is assumed as
,
and
and
,
and
are the max no. of jobs of each class that can be accommodated, respectively. Because
is dependent upon
and it can be calculated easily using the Erlang-B formula. After fixing
, we can calculate the max. no. of jobs of rigid flows
as
where
is the peak bandwidth requirement of individual rigid flow.
The values of
and
are iteratively calculated using an algorithm, called the Iterative Link Allocation procedure. The algorithm starts with some large values of
and
, and it calculates their respective blocking probabilities
and
using CTMC. The values of
and
are decremented after every iteration until it results in such values for which
and
. It aims at establishing a trade-off between
and throughput as larger values of
and
will certainly reduce their respective
, but it will result in their throughput degradation. In [
23], the authors proposed an Autonomic Distributed Streaming Service (ADSS) model for the application that involves data streaming between remote systems with/without in-transit data processing. The proposed ADSS model enables the intermediate node to change their behavior in response to the environmental conditions, i.e., network congestion or destination receiving rate. In such cases, ADSS can opportunistically exploit intermediate processing nodes in order to perform partial/complete in-transit processing on data, or it can temporarily store the data into the hard disk to avoid buffer overflow and data loss. Provided that data arrival rate at an intermediate node is
, now, depending upon the reception rate of next-hop node and network congestion level, ADSS will automatically exploit perform in-transit processing on data at rate
or temporarily store the data onto a hard disk with the rate
. The model takes current values
,
, and
as input and calculates future values for
,
, and the number of processing units to use for the next interval of time. ADSS is implemented using Reference Net (a kind of Petri-Nets) that helps in achieving required synchronization between associating processing nodes. The model applies to applications with end-to-end QoS requirements and can combine in-transit processing with data transmission.
Network slicing and software-defined networking (SDN) are the two most commonly used solutions for provisioning QoS in 5G networks. However, the efficient utilization of the network resources requires precise modeling of the traffic. Santhosha et al. developed a multi-class network model using SDN and network slicing to quantify network performance [
24]. Heterogeneous flows are assumed from customers with different varying intensities without considering the deadline or priority constraints. A simulation-based model is presented in [
25] in order to study the stability region in multi-class queuing networks. The requests are processed based on the first-come-first-serve policy without having priorities. Baris et al. studied the abandonment behavior of multi-class customers due to network congestion in [
26]. Each class customer request receives different reward and cost rates, and their proposed model attempts to maximize their expected utilities. Likewise, many other studies can be found in the literature with emphasis on multi-class traffic modeling [
27,
28,
29]. However, none of these studies consider deadline constrained bulk data transfers with preemptive priorities. Rami et al. studied the multi-class queuing system with dynamic priorities that are dependent upon the workload without considering the deadline constraints [
30]. An improved scheduling policy is presented in [
31] for a real-time queuing system with rewards and deadlines while ignoring the priorities.
In [
32], the authors considered a multi-server queuing system with three priority classes and two servers. Each class of customers has its arrivals and service rates. They have used numerical analysis methods to solve the system of linear equations and calculate each class blocking probability and average queue length using system steady-state probabilities. Kannan et al. worked on scheduling bulk file transfers with deadline constraints by dividing the time scale into uniform time slices [
33]. Bandwidth adjustments are made at the start of every time slice. They have also explored file transfer over multi-paths and found significant improvement in throughput as compared to a single path. In [
34], Bin et al. studied the problem of scheduling bulk data transfer with a deadline constrained to find the optimal bandwidth allocation scheme, resulting in minimizing the overall network congestion. They have solved this problem for optimality using the maximum concurrent flow problem. In [
35], the authors presented a novel model for multi-class deadline constrained network flows with equal sharing of residual link capacity. They have modeled the underlying shared bottleneck link as an M/M/1/K-PS Queue and solved it while using multi-dimensional Continuous Time Markov Chain (CTMC). The model can be easily extended to any number of classes with varying arrival and service rates. The model is being validated using NS-2 and offline simulation, and used for the calculation of Blocking Probability (BP) of individual classes as well as the overall system. The authors also presented an algorithm for network dimensioning and capacity planning based on their model.
In the Grid/Cloud computing environment, resources are often reserved in advance to perform certain tasks. Therefore, designated data must be made available at those resources within certain time bounds, and this is usually known as the deadline constraint of the data transfers. Moreover, data transfer requests may be categorized into various classes, depending upon their minimum bandwidth requirement. A system of multi-class deadline constrained bulk data transfers is modeled in [
35], where the classes are differentiated based on their minimum bandwidth requirement. Here, we are interested in extending this work by assigning each class a relative priority with preemption. This may reflect a system with multi-users, each having its priority, e.g., In Grids/Clouds, we may have two simple classes of users, as follows: (a) paid users/scientists whose request will be given the highest priority. (b) free users/students, whose request will be given the least priority. The same may be extended to any number of classes assigned with relative priorities with preemption.
Multi-class flow models with preemptive priorities have previously been explored in the literature, but none of them consider the deadline constraint. Our work is mainly focused on developing an analytical model for multi-class deadline-constrained data transfer requests with preemptive priorities. To the best of our knowledge, no such model exists in the literature by the write up of this document.
4. Problem Formulation
We are interested in the investigation and performance evaluation of a multi-class queuing system with strict QoS (deadline) and priority constraints. For the sake of demonstration, we apply our model to Grid/Cloud computing environment with two simple classes of users, as follows: (a) paid users/scientists, whose request will be given the highest priority, (b) free users/students, whose request will be given the least priority. This model can be extended/applicable to any queuing system with stated characteristics and any number of classes.
The Grid/Cloud computing network can be represented by a connected graph , where V is the set of all nodes (storage/computing resources) in the network and E is a set of edges (communication links) between nodes. Often, data transfer requests require multi-hop data transmission between source and destination located at remote stations. Let us say that is the path between source and destination . Network performance and throughput of the flows sharing the same path depend upon the efficient utilization of bottleneck link on the path with capacity C.
Definitions:
Data Transfer Request: a data transfer request is a tuple, where is the volume of r, is the active window (from arrival time to deadline ) and is the path connecting source and destination of the request r.
: Minimum Required Rate
of the request
r is calculated on the basis of its volume and active window, as follows:
: blocking Probability () is the ratio of total rejected requests and the total number of submitted requests.
Residual capacity
is the remaining capacity of the link and it can be calculated, as follows:
where
R is the total number of classes and
is the number of requests of
class.
Active request is the term used for all the accepted requests that are currently in the flow.
Consider a shared bottleneck link having capacity C. Data transfer requests are categorized into R classes that are based on their minimum required rates. Each class is assigned a priority i.e., is the priority of class request. A request is accepted if
It is
can be fulfilled. At any time instant
t, a request of an
class is accepted if
In cases where
and there are enough active request of lower classes, such that
where
Q is the list of accepted lower class requests. In this case, sufficient requests of lower classes will be ejected in order to accommodate the incoming request of the higher class.
The state of the system
S at any time instant
t can be represented as:
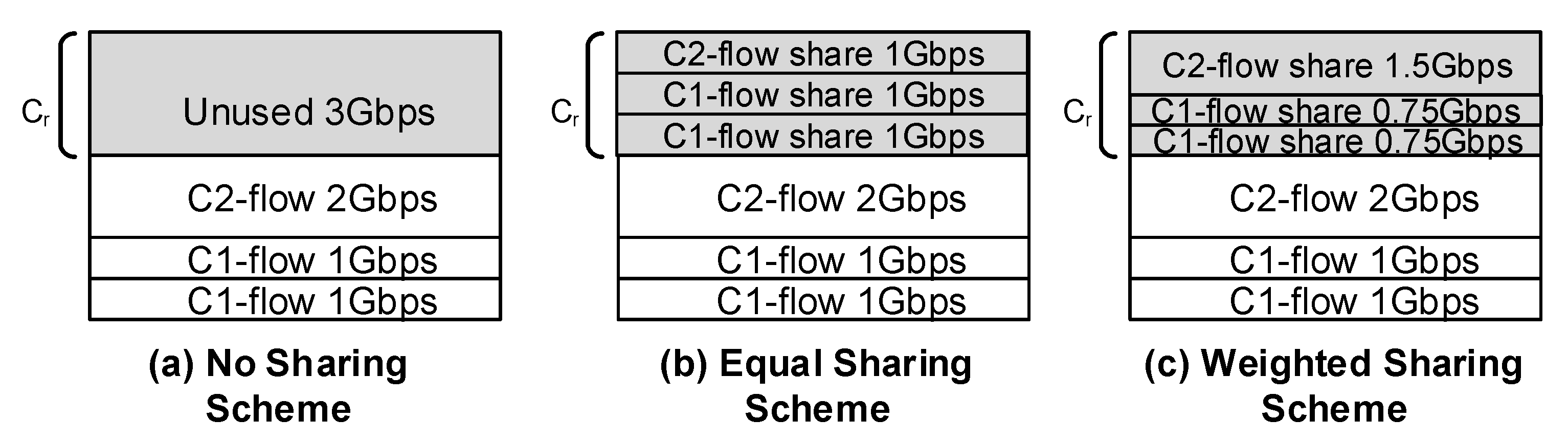
There are three possibilities to share the available residual capacity when .
The sharing of residual capacity
as per the above schemes is explained with an example in
Figure 1 with
Gbps, where the current state of the system is
i.e., two active flows of class 1 and one active flow of class 2. We can easily compute that
Gbps and the
Figure 1 explains how it is shared among the active flows, as per the three schemes. In this study, experiments are conducted with an equal sharing scheme only.
5. Proposed Model
Markov chains are successfully used for performance evaluation of many different types of queuing systems. For given system parameters, we can easily find performance measures, like BP, link utilization, mean flow time, etc. These performance measures are helpful in system dimensioning and capacity planning for provisioning better QoS.
In a queuing system, the users are often classified into multiple classes, depending upon their service requirement and paying capacity. In such a multi-class environment, priority is often also assigned to each class signifying their level of importance. Various models are proposed for the analysis of multi-class priority queuing systems. These models are based on varying system parameters, as per the nature of the application, different arrival and services distribution, queuing mechanism, and priority handling (preemptive or non-preemptive, resume or restart). In the queuing system, lower class requests are blocked for two reasons: (a) blocked due to non-availability of capacity in the system and (b) ejected by the higher class. Aggregating these two types of probabilities, we will obtain the overall BP of the corresponding lower class. Most of the models proposed in the literature can help in finding the overall BP of the lower class. To the best of our knowledge, there is no such model that can provide us with insight into the two components of the BP of lower classes stated above.
The proposed model presents a novel and more intuitive approach for treating Markov chains to find the BP of individual classes. By using this novel approach, we can obtain the detailed BP of a particular class from which we can easily obtain blocking due to higher classes ejection and blocking due to system capacity. Typically, by solving Markov chains, we get the steady-state probability (SSP) vector from initial one-step transition probabilities, but, here, we are interested in finding steady transition probabilities (STP), i.e., long-term probabilities of the system taking each transition. Next, we explain this concept with a simple example.
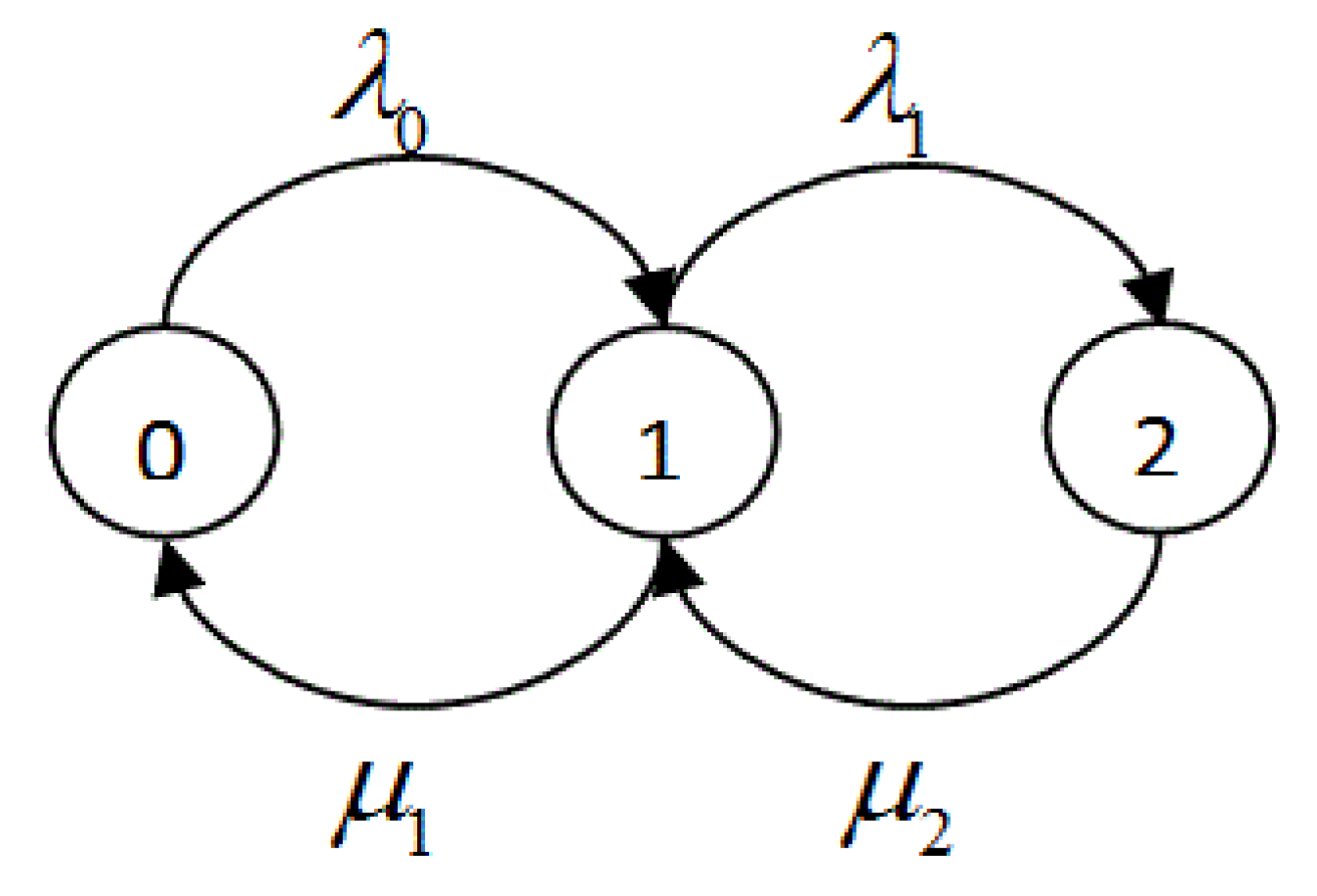
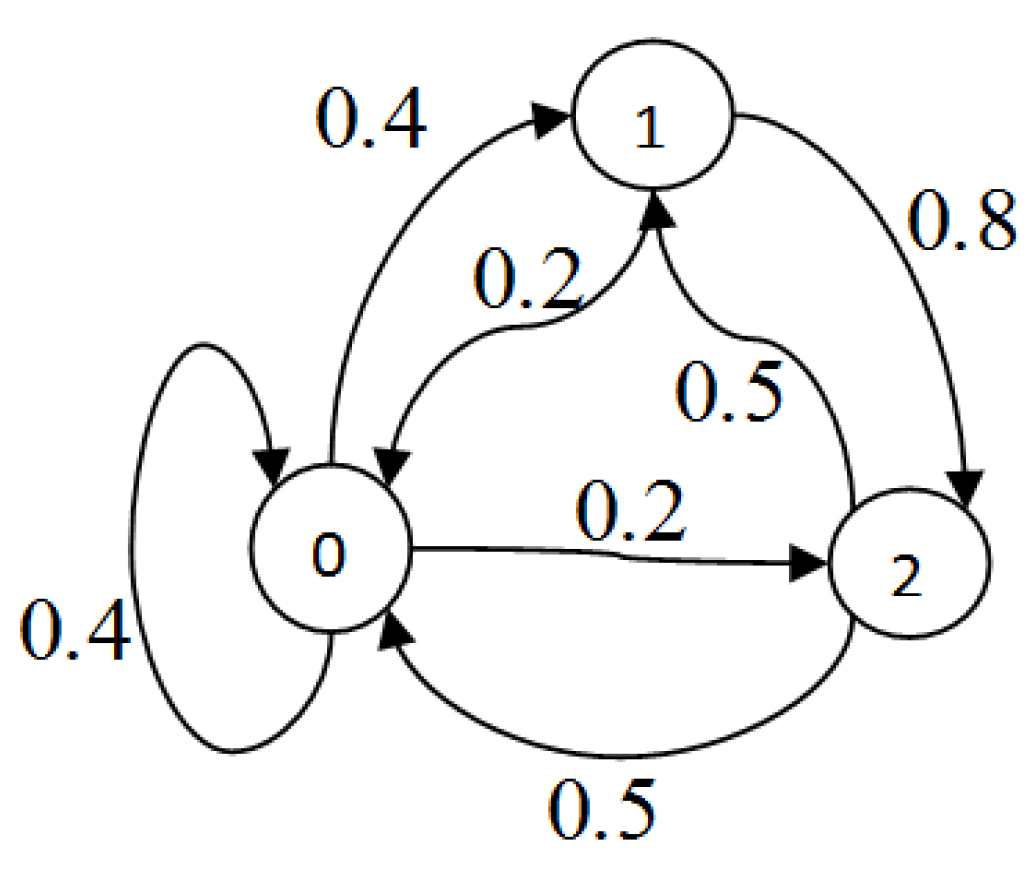
Consider a simple CTMC
having three states, as shown in
Figure 2, and the similarity rate matrix Q for this simple chain is given below
We can find one-step transition probability matrix
P from the above matrix Q using the following formula
The Markov chain that is given in
Figure 2 will look like that shown in
Figure 3 in terms of one-step transition probabilities.
We are interested in finding steady transition probabilities (STP)
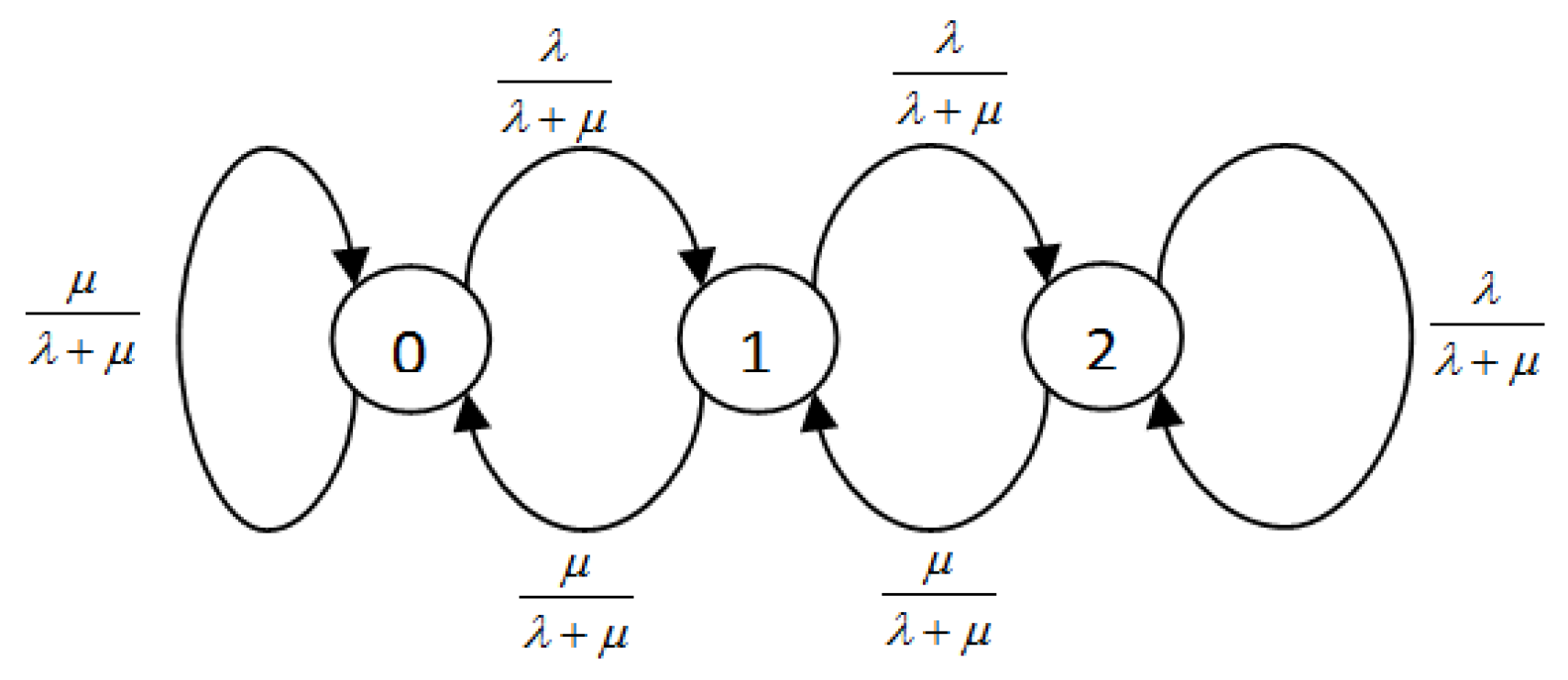
, i.e., the long term probability of the system taking each transition. In the next section, first, we will explain STP and how it can help provision the deep insight of blocking of the lower class in multi-service priority queuing system. Afterward, the concept of normalized arrival probabilities (NAP) is presented, i.e., another way of computing the blocking probability with proof of its correction while using a simple M/M/1/N queue as shown in
Figure 4.
5.1. Steady Transition Probabilities (STP)
The concept of steady transition probabilities (STP) is just a detailed view of the Markov chain, and we can obtain steady-state probabilities from steady transition probabilities and vice versa. As stated earlier, STP is the long-term probabilities of the system taking each transition, and these can be calculated in two ways.
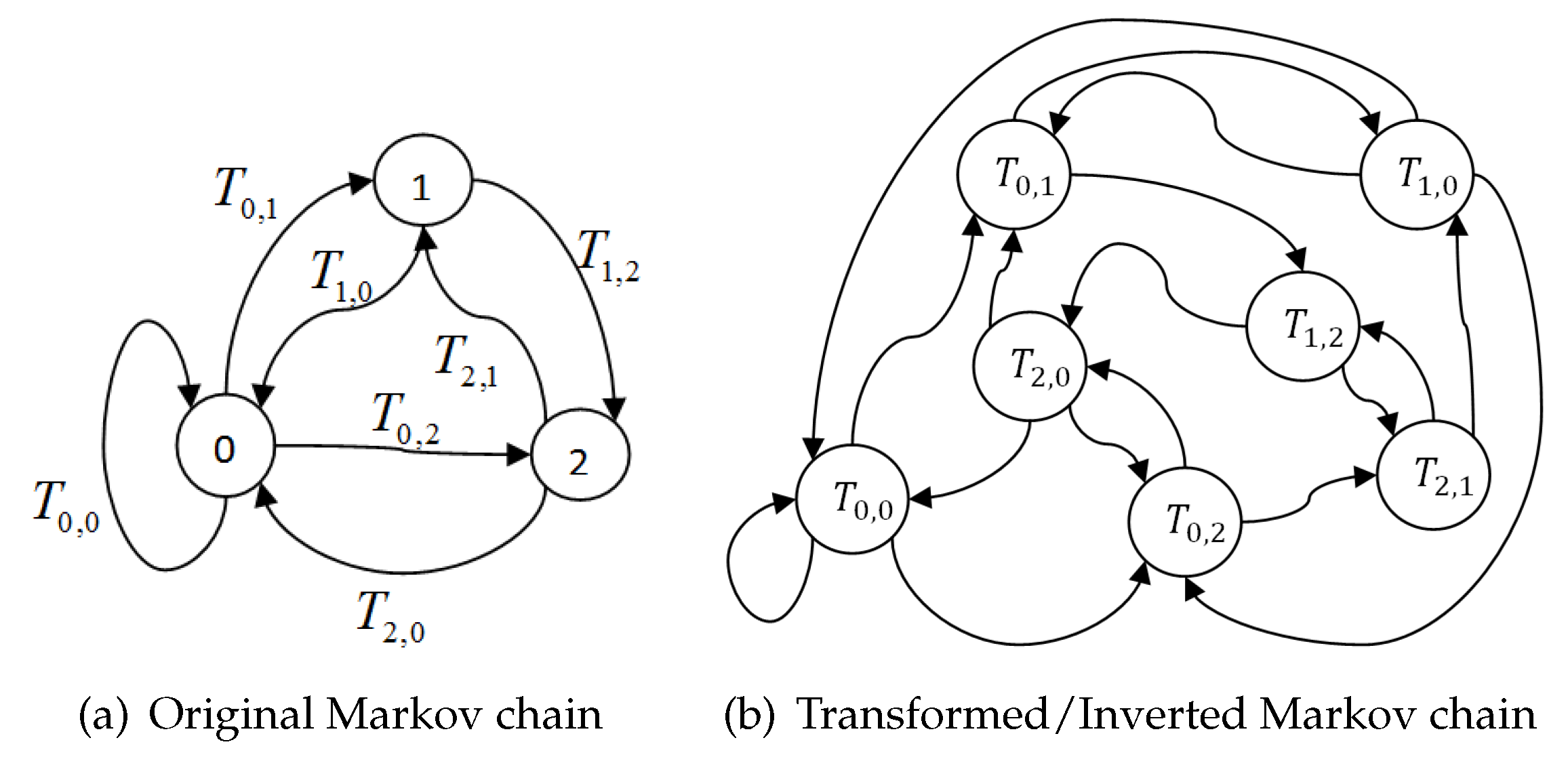
5.1.1. Inverted Markov Chains
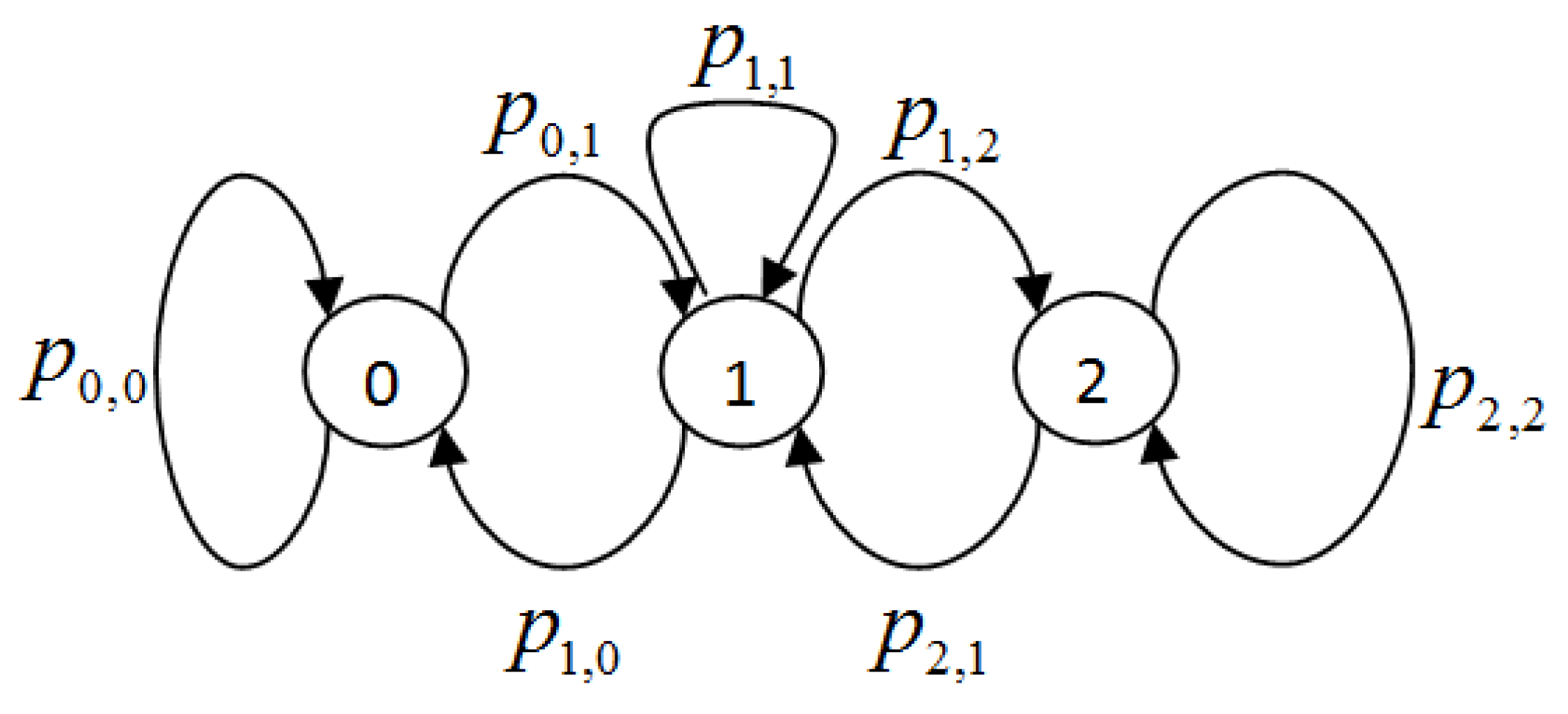
By solving the Markov chain, we obtain steady-state probabilities, i.e., the long-term probability of the system being in every state. Using Inverted Markov Chains, we simply consider transitions as the states of the Markov chain and we need one step transition-to-transition probabilities in order to calculate STP. Consider the simple Markov chain with three states and inter-state transition probabilities, as given in
Figure 5.
It is easy to get its one step probability matrix
P, as below.
Once, we obtain the one step transition probability matrix
P, the Iterative (Power) method [
36] can be used to calculate the steady state probability vector
, as follows:
where
is initial (random) probability distribution vector with condition
. After solving for above chain (
Figure 5), we get
i.e.,
We now redraw
Figure 5 by relabeling each transition as
, as shown in
Figure 6a, which shows the original Markov chain for sample M/M/1/2 queue along with the corresponding inverted Markov chain given in
Figure 6b.
The one step transition to transition probability matrix is given below
As it follows the Markov property, we can now find the steady transition probability vector
in the same way and, after solving, we get
i.e.,
We can easily see that for any state
si.e., the sum of all transition probabilities into state
s is equal to the sum of transition probabilities out of state
s and that is equal to the probability of being in state
s e.g., for
, we can easily see that,
The same can be observed for all other states. This shows that STP gives us a more detailed view of the system long term probabilities.
5.1.2. Alternative Approach Based on and P
From the previous results, we can easily deduce that
For example,
⇒
As
therefore we get
This method gives us a simple way to calculate STP, and this is more convenient in terms of computation as for large size CTMC, the size of one-step transition-to-transition probability matrix will grow enormously and it will require greater computations. In other words, we can simply calculate the steady transition probability of any transition
using Equation (
3).
5.2. Normalized Arrival Probabilities ()
STP gives us the long term probabilities of the system taking any transition. Mainly, we have two types of transitions in CTMC, i.e., arrivals and departures. For capacity planning, we are often interested in system BP, which is only related to arrivals only. Let
T be the set of all transition probabilities, then we can express it as
where
and
are the set of arrival and departure probabilities, respectively.
Here, we are only interested in arrival probabilities and let the summation of all arrival probabilities be
D, i.e.,
It can be observed that, for constant arrival and service rates,
We divide each arrival transition by
D to obtain the Normalized Arrival Probability (NAP), i.e.,
This
gives us the distribution of arrivals, e.g., if the total no. of arrival into the system is
A, then the arrival count along with each arrival transition
is given by
Thus, we obtain the approximate no. of arrivals on each arrival transition.
5.3. Using NAP to compute BP of queuing system
In this section, we will show how to use NAP to find the BP of the system. We will also prove that its result is the same as the BP calculated using traditional SSP. For instance, see
Figure 4, in which the blocking probability of the system is the probability of the system being in state N i.e.,
, and the same result can be obtained using
.
This is very intuitive to choose
only because all other arrivals are accommodated by the system and they cause a transition from one state to another.
is the only looping transition in
, i.e., arrivals along with this transition cause no change in the system’s state (loopback). In other words, all of the arrivals along
are blocked by the system. That is why we say that the BP of the system in NAP is the looping transitions in the case of
i.e.,
and this is more intuitive. Next, we will try to prove the following
For sake of illustration, we limit our queue size to
i.e.,
with arrival
and service rate
, as shown in
Figure 2.
Similarity, the Rate Matrix
Q of above
queue is given below.
We can find steady-state probabilities of this simple
by solving the following birth–death equation.
we know that
and the BP of the system is
We now try to find the same result using NAP, which is calculated by using SSP and one-step transition probabilities. To obtain one-step transition probabilities, we use the following formula
Redraw
Figure 2 using one-step transition probabilities, we get the picture that is shown in
Figure 7 (transition probability with zero value are ignored)
We can see that, among these six transitions, three are arrivals, i.e.,
. We can find
, as below
where
We can now compute that normalized arrival probability
, as below
Thus, we have proved that
This can be easily be extended to
. Moreover, for constant arrival rate
and service rate
, we can easily find out that sum of all services transitions
and the probability of the system being in an idle state is as below
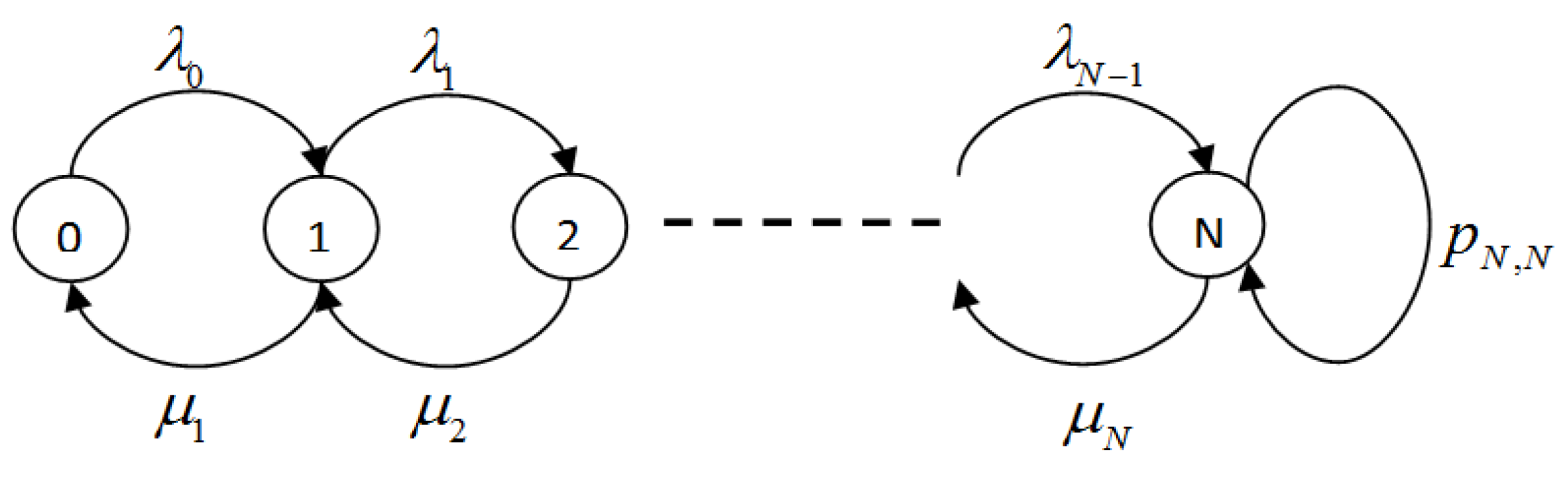
5.4. Model Implementation
We have modeled the bottleneck link of the network as a constant capacity
C server. Arrivals of multi-class requests are assumed to follow Poisson and the services are exponentially distributed with mean volume
V. Thus, the system is modeled as a multi-dimensional Continuous Time Markov Chain (CTMC), as shown in
Figure 8. Given the system is in state
, then the arrival of
request will result in a transition to state
and completion of a
class job will result in a transition to state
.
As arrival of all classes is equally likely and they are generated using Poisson distribution, therefore the transition rate from state
to
uponthe arrival of a
class request will become:
Upon the completion of a request of class
c, the system will make a transition from state
i to state
k. As in this study, the experiments are only conducted with an equal sharing scheme, and the service rate for this scheme is calculated, as follows:
where
V is the mean size of the requests and
are the total number of active flows of class
c in-state
i.
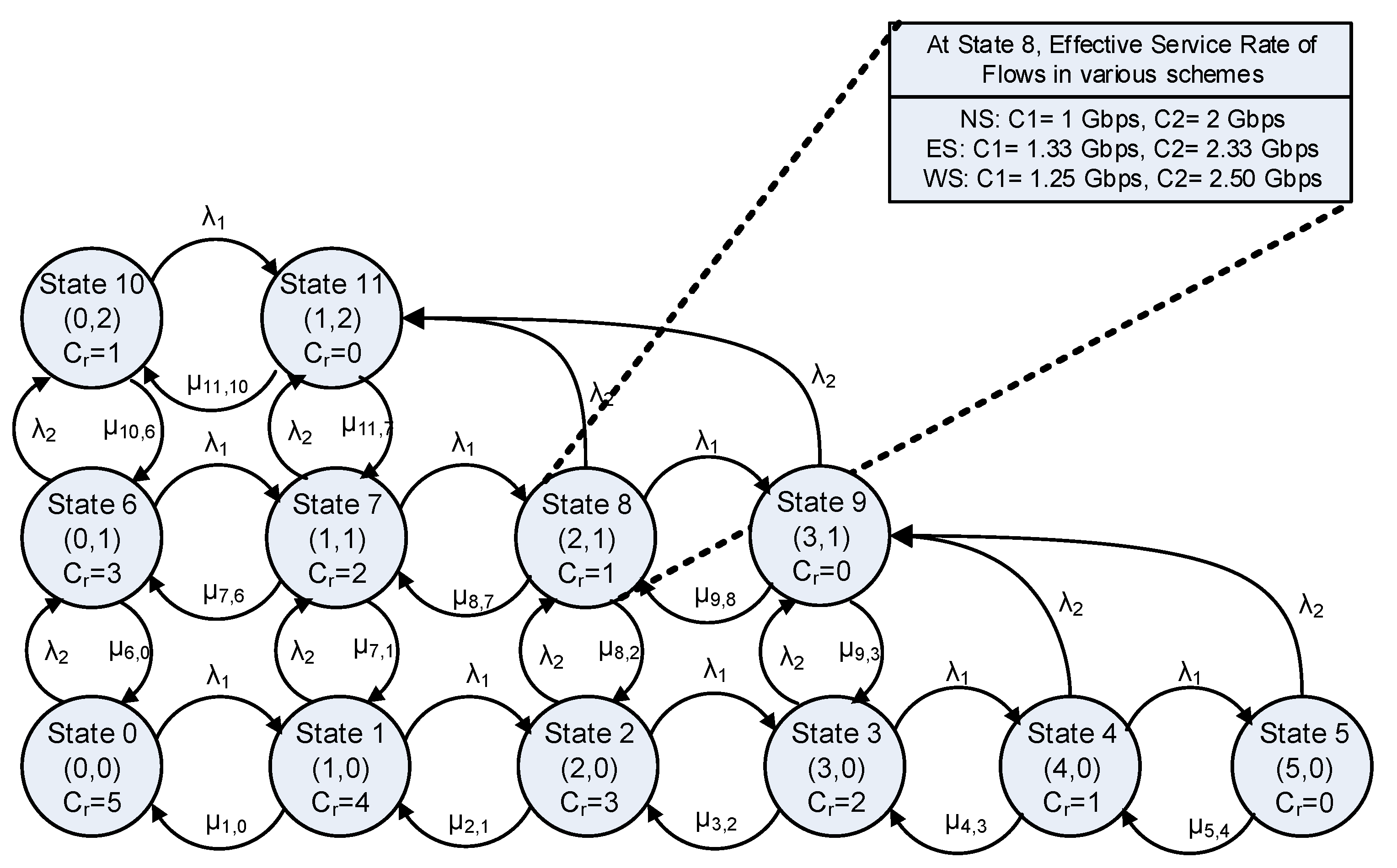
Figure 8 presents a sample CTMC for two classes with
Gbps. Class 2 jobs have preemption priority over class 1. It can be noted that, un states 4 and 5, there is no room for newly arriving requests of class 2, therefore transition is made to state 9, which results in the ejection of 1 and 2 requests of class 1, respectively. Likewise, the transition from states 8 and 9 to state 11 also results in the ejection of class 1 jobs.
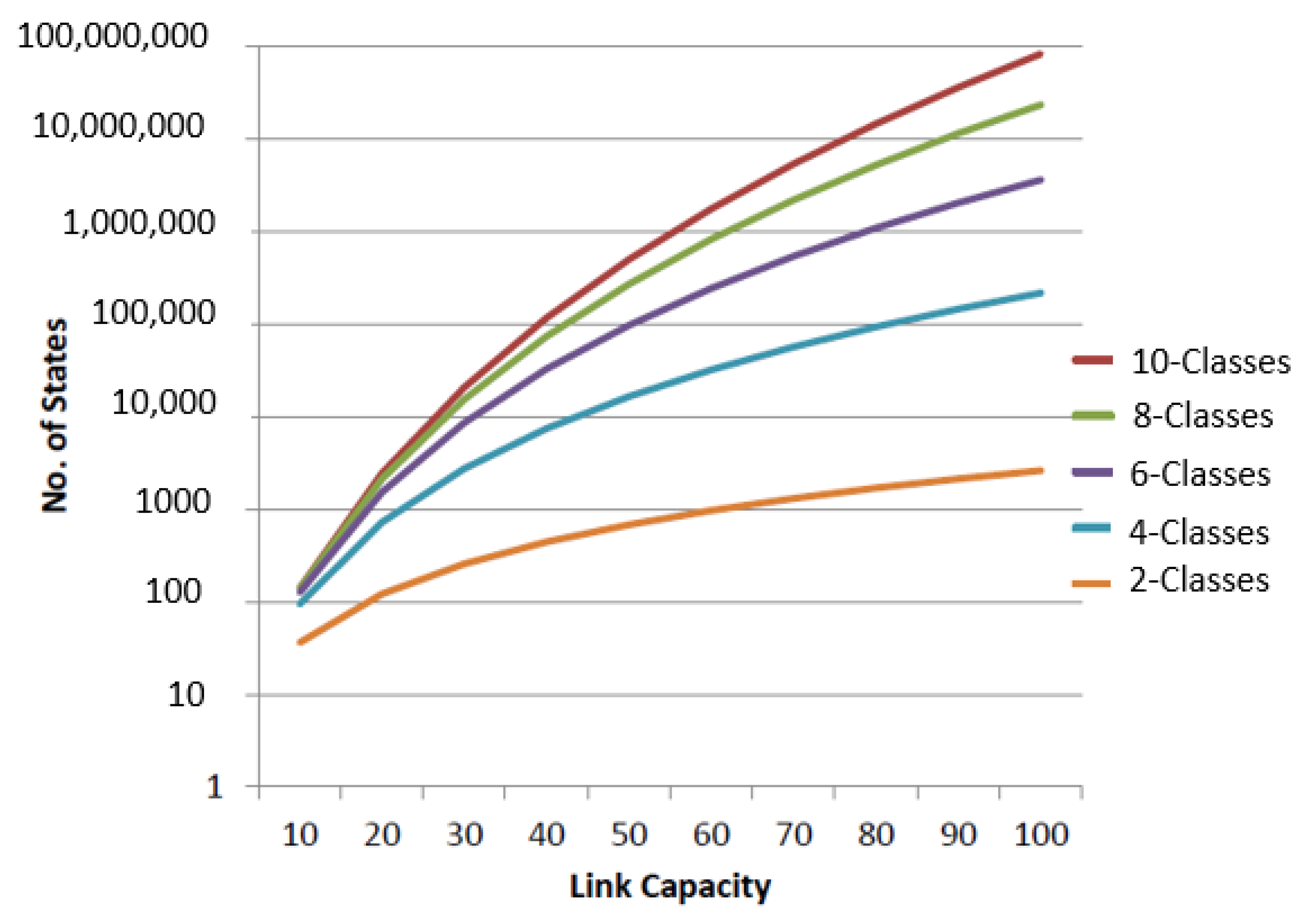
The total number of states in the CTMC grows exponentially with the increase in the link capacity
C and total number of classes, as shown in
Figure 9. A state
S in CTMC is valid if:
where
is the total number of active flows of
class having a minimum flow rate
.
After generating all of the possible states and corresponding transition probabilities, CTMC is solved using the iterative method, and we get steady-state probability vector of the system, which is then used to compute blocking probabilities of the overall system and individual classes and subsequent performance analysis.
5.4.1. Computation of BP
The blocking probabilities of the overall system and individual classes are computed while using the steady-state probability vector
. To compute
of class
x, set
of all those states in CTMC is required where a new request of class
x cannot be accommodated. Thus, the blocking probability of high priority class
x can be computed, as below:
where
is the long term probability of the system being in state
s.
The blocking probability of lower priority class
y can be computed, as below:
where
is a subset of normalized arrival probabilities, which results in the ejection of lower-class requests.
Blocking probability of the overall system can be computed as below:
5.4.2. Computation of Link Utilization
Percentage link utilization
of the system having link capacity
C is computed from state probability vector
, as follows:
where
is the link residual capacity in state
s.
6. Performance Evaluation
The objectives of performance evaluation are:
To validate the proposed model results.
To highlight effect on overall system blocking probability, due to preemptive priority as compared to the non-preemptive model.
To conduct a class-wise comparative analysis of blocking probabilities for preemptive and non-preemptive models.
To present a detailed analysis of lower-class blocking probabilities.
To perform analysis of link capacity utilization with varying traffic intensities.
The proposed model validation is conducted through simulation using an ad-hoc simulator that was developed in Microsoft Visual Studio 2017 using Visual Basic .NET (VB.NET). The simulation model considers an ideal network environment and it does not capture the network/packet-level details such as losses and overheads. In every simulation experiment, 100,000 requests/flows are generated using Poisson distribution. The flow volumes are exponentially distributed with mean a value of
V.
Table 1 presents the summary of configuration for different parameters that are related to models and simulations. The reported results are the average values for 10 different simulation runs for each experimental setup.
For the sake of simplicity and without losing any generality, the arrival rate of all classes is considered to be the same, i.e.,
where
R is the total number of classes and
is the arrival rate of all requests.
We know that traffic intensity
can be computed, as below:
For a given/desired traffic intensity, the mean flow size
V can be obtained as
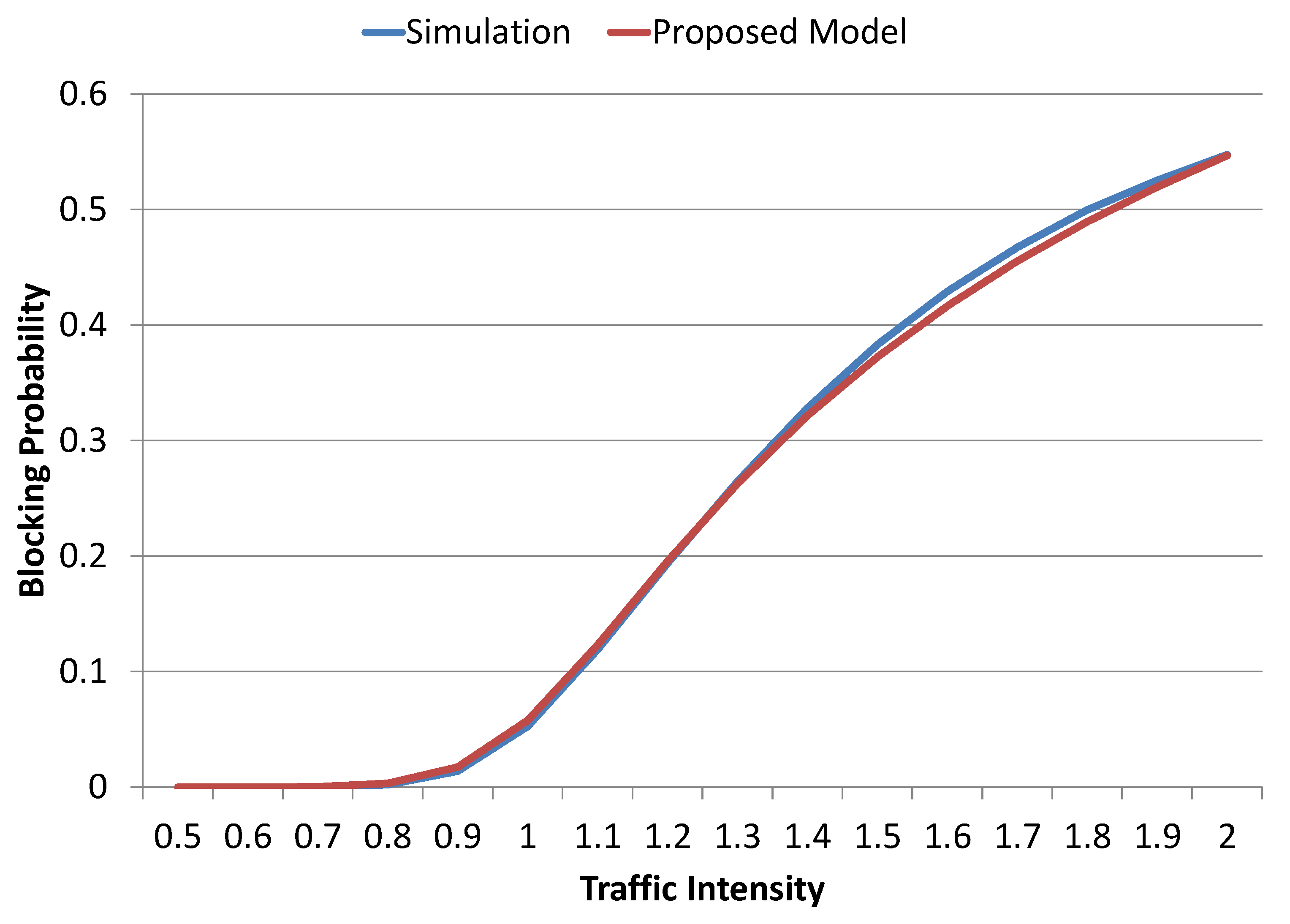
Figure 10 shows the blocking probabilities that were calculated for various traffic intensities using analytical model and simulation while considering the link capacity of
Gbps. Model and simulation results are both nicely aligned for all traffic intensities varying from 0.5 to 2.0. These results clearly show that the simulations validate the model. For traffic intensities that are below 1.0, the overall system blocking probability is very low (acceptable). However, a significant increase in the blocking probabilities can be observed as traffic intensity approaches 2.0, where more than
of requests are blocked by the system. Furthermore, these results also confirmed that the system blocking probability is not linearly increasing with the increase in traffic intensity.
Next, we study the effect on the overall system blocking probability due to preemptive priority as compared to the non-preemptive model [
17].
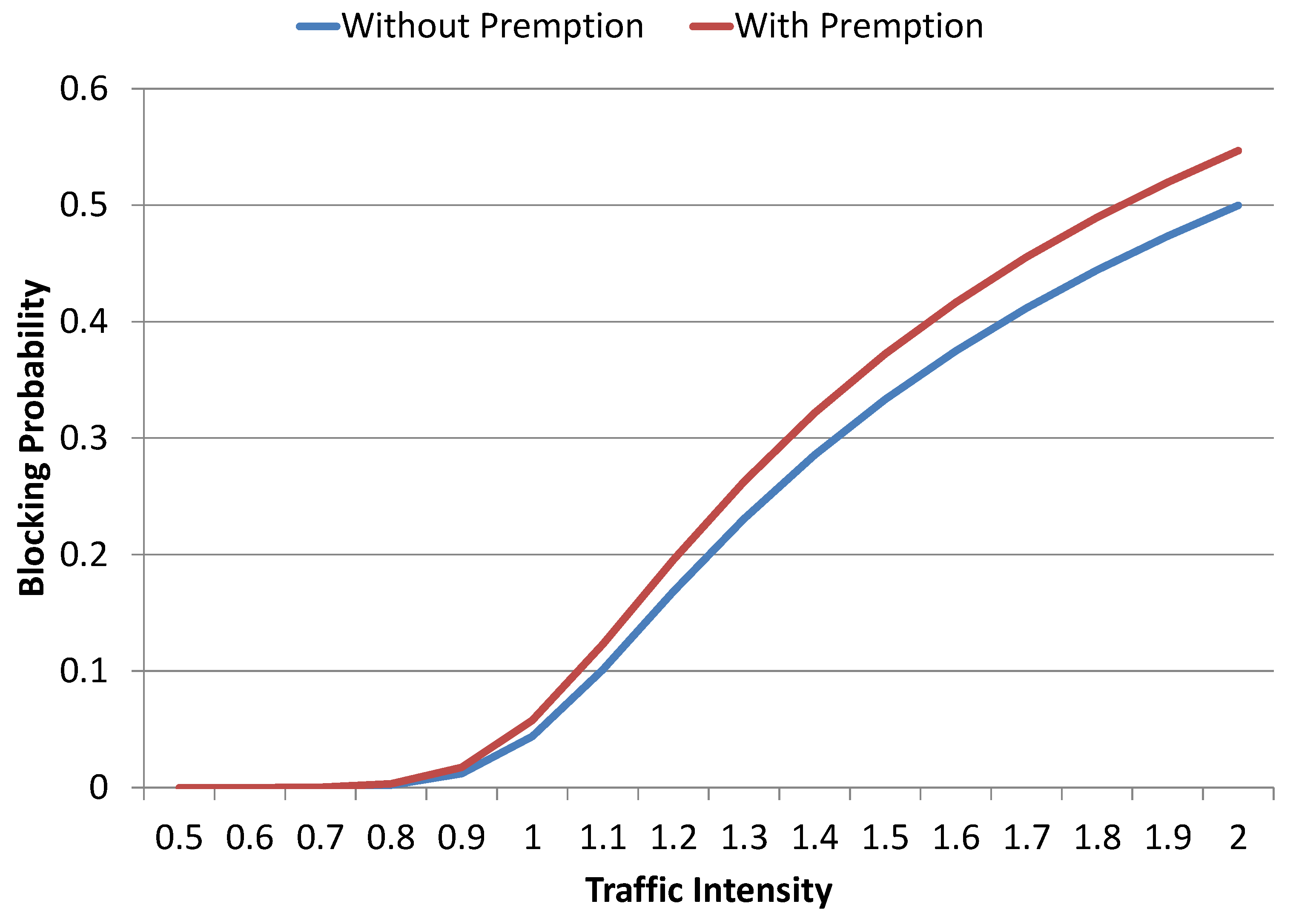
Figure 11 presents the comparative analysis of blocking probabilities for preemptive and non-preemptive models results with
Gbps. For traffic intensities that are below 1.0, there is no significant difference in blocking probabilities of the two models, and this is due to the underutilization of link capacity. However, a gradual increase in difference among the blocking probabilities of the two models can be observed as traffic intensity approaches 2.0 where approx.
and
of requests are blocked by the system in case of the non-preemptive and preemptive model, respectively. These results show that the preemptive model results in less than a
(absolute) increase in the system overall blocking probability when compared to its counterpart non-preemptive model.
An increase in the system overall blocking probability by the preemptive model is not particularly significant, i.e., less than
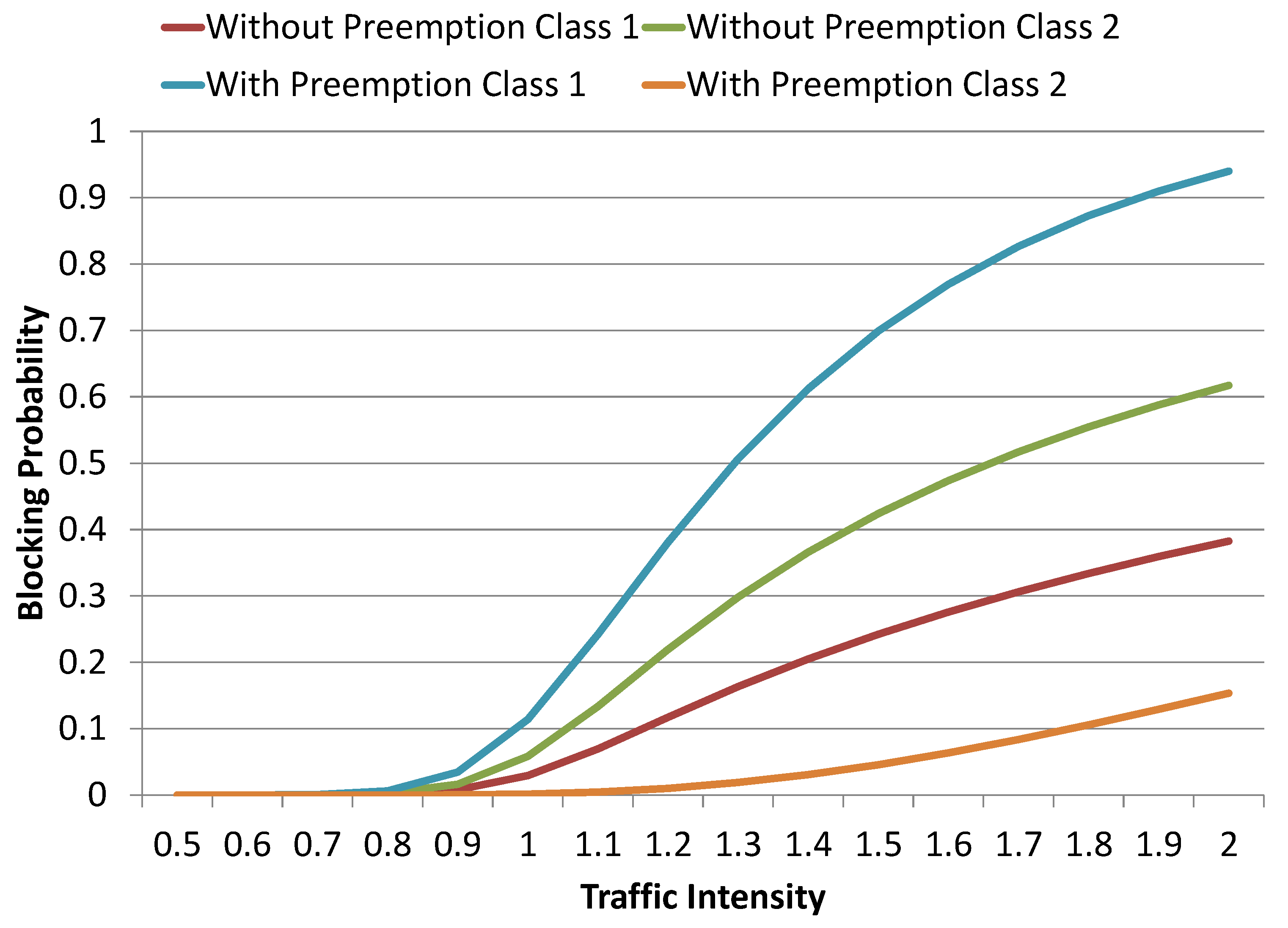
(absolute) when compared to its counterpart non-preemptive model. However, a detailed investigation of individual class probabilities revealed a significant increase in the lower-class (class 1) probabilities, as shown in
Figure 12. Once again, for traffic intensities that are below 1.0, the difference in individual class blocking probabilities of the two models is very low, which is due to the underutilization of link capacity. However, a significant increase in difference among the individual class blocking probabilities of the two models can be observed with an increase in traffic intensity. In the case of the non-preemptive model, for a traffic intensity of 2.0, the blocking probabilities of class 1 and class 2 are
and
, respectively. When both of the classes are treated equally by the system, then class requests are experiencing high blocking probability due to their high QoS requirement i.e.,
. Whereas, in the case of the preemptive model, the same blocking probabilities changed to
and
, for class 1 and class 2, respectively. The significantly high blocking probabilities of class 1 (
) is due to two reasons: (a) being blocked by the system due to unavailability of required QoS (
) as a result of high utilization of system capacity and (b) ejected by the system to make room for high priority jobs. The whole link capacity is available for class 2 requests, as if class 1 requests do not exist (virtually) and, therefore, the blocking probability of class 2 is reduced from
to
, for traffic intensity of 2.0.
Class-wise comparative analysis of blocking probabilities, as given in
Figure 12, indicate a significant increase (
) in the blocking probabilities of class 1 for the preemptive model when compared to the non-preemptive model. This is due to two reasons: (a) being blocked by the system due to unavailability of required QoS (b) ejected by the system to make room for high-priority jobs.
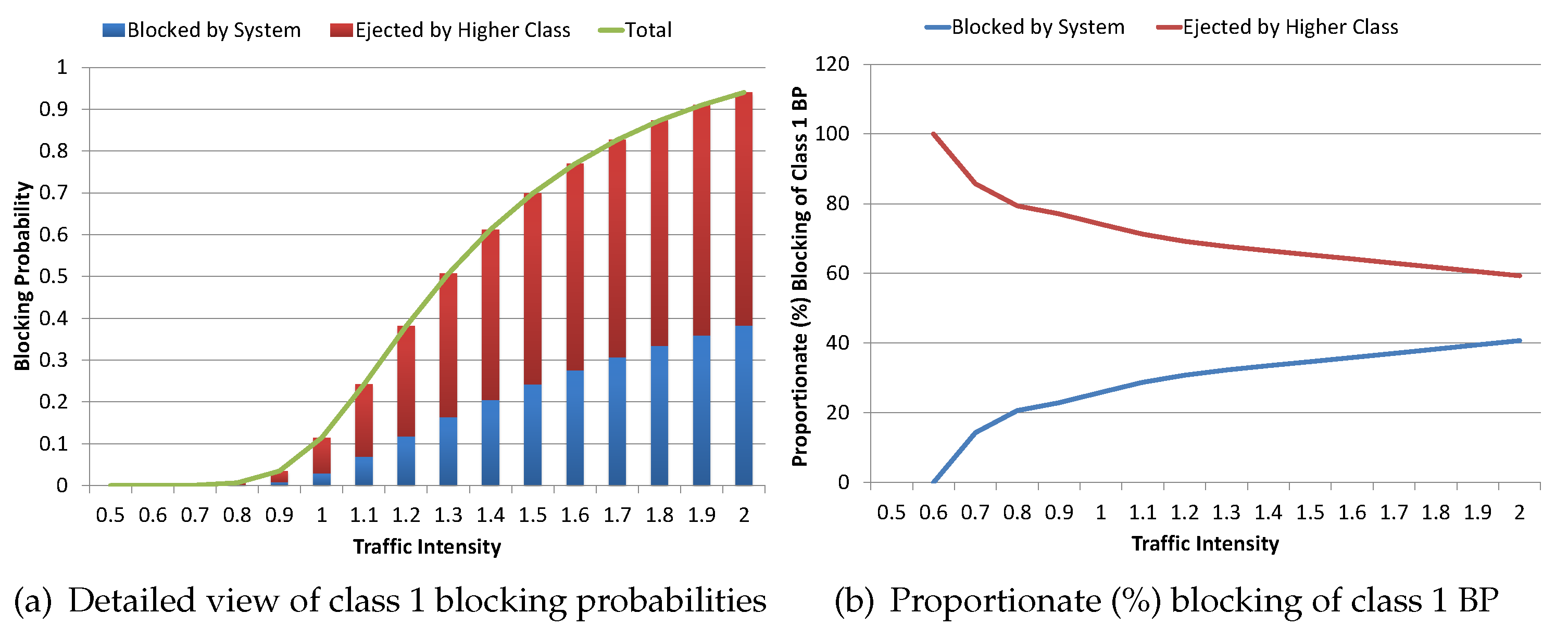
Figure 13 shows the detailed analysis of blocking probabilities components for class 1 while using preemptive model results with
Gbps, No. of classes
and
.
Figure 13a provided detailed insight regarding class 1 blocking probabilities, along with the contribution of each component, in total, the blocking probabilities. We can observe that a major portion of the class 1 requests are blocked due to ejection by the arrival of higher class jobs as compared to blocking by the system due to the unavailability of the required QoS. This is due to the relatively higher QoS requirement of class 2 jobs i.e., having
Gbps. In other words, when the residual capacity is zero, the arrival of the class 2 job will cause an ejection of two requests (in progress) of class 1 if available. This is also evident from
Figure 13b, which provides proportionate (%) blocking of class 1 blocking probability. For lower traffic intensities, a relatively low percentage of class 1 requests are blocked by the system as compared to the ones ejected by higher classes. For instance, with a traffic intensity of 1.0, around
requests of class 1 are blocked and, out of these
blocked requests, around
are blocked by the system, and
are ejected due to the arrival of higher class requests. Whereas, with a traffic intensity of 2.0, a total of around
requests of class 1 are blocked and, out of these
blocked requests, around
are blocked by the system whereas
are ejected due to the arrival of higher class requests. In other words, more requests of class 1 are blocked by the system with an increase in traffic intensity due to high link utilization.
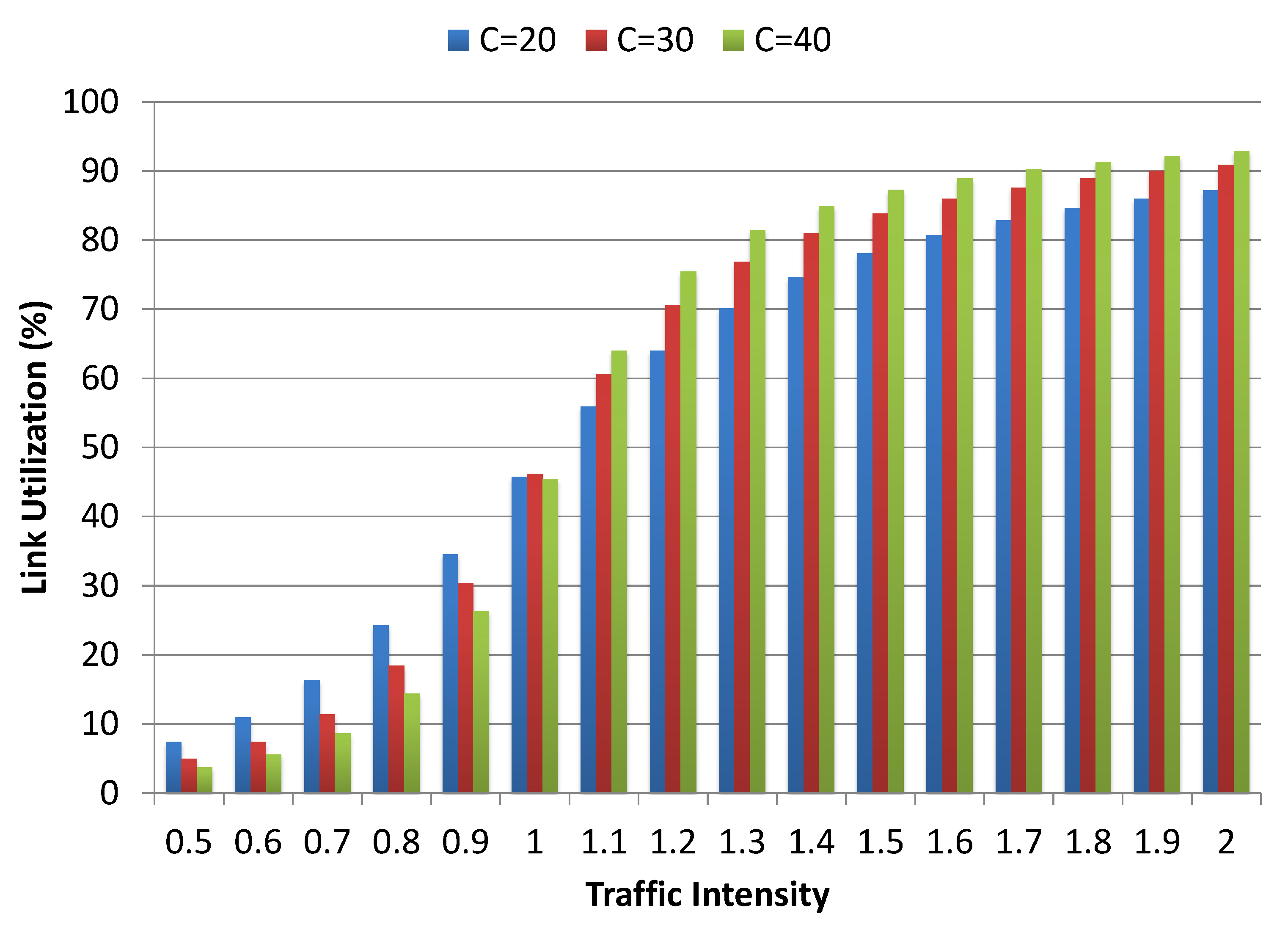
Figure 14 shows the percentage link capacity utilization by proposed model with varying traffic intensities for
Gbps. For traffic intensities that are below 1.0, the link capacity utilization is below
, i.e., significant link capacity is available most of the time, which is the main reason for having significantly low blocking probabilities for traffic intensities that are below 1.0. A gradual increase in the link capacity utilization can be observed as the traffic intensity increases beyond 1.0 up to 1.5, but, afterward, there is no significant improvement in link capacity utilization. This shows that, as we approach towards the maximum achievable link utilization, an increase in traffic intensity contributes less in maximizing link utilization and, in contrast, it results in a drastic increase in the system blocking probability, which is evident from earlier results.
Figure 14 also shows that, with an increase in traffic intensity, link utilization exhibits a converse behavior with an increase in the link capacities. For instance, with lower link capacity (
Gbps), link utilization grows faster in the early stages and gets slower towards the end to reach the maximum. Conversely, with higher link capacity (
Gbps), the growth in link utilization is slower in the beginning and it gets faster towards the end to reach the maximum.
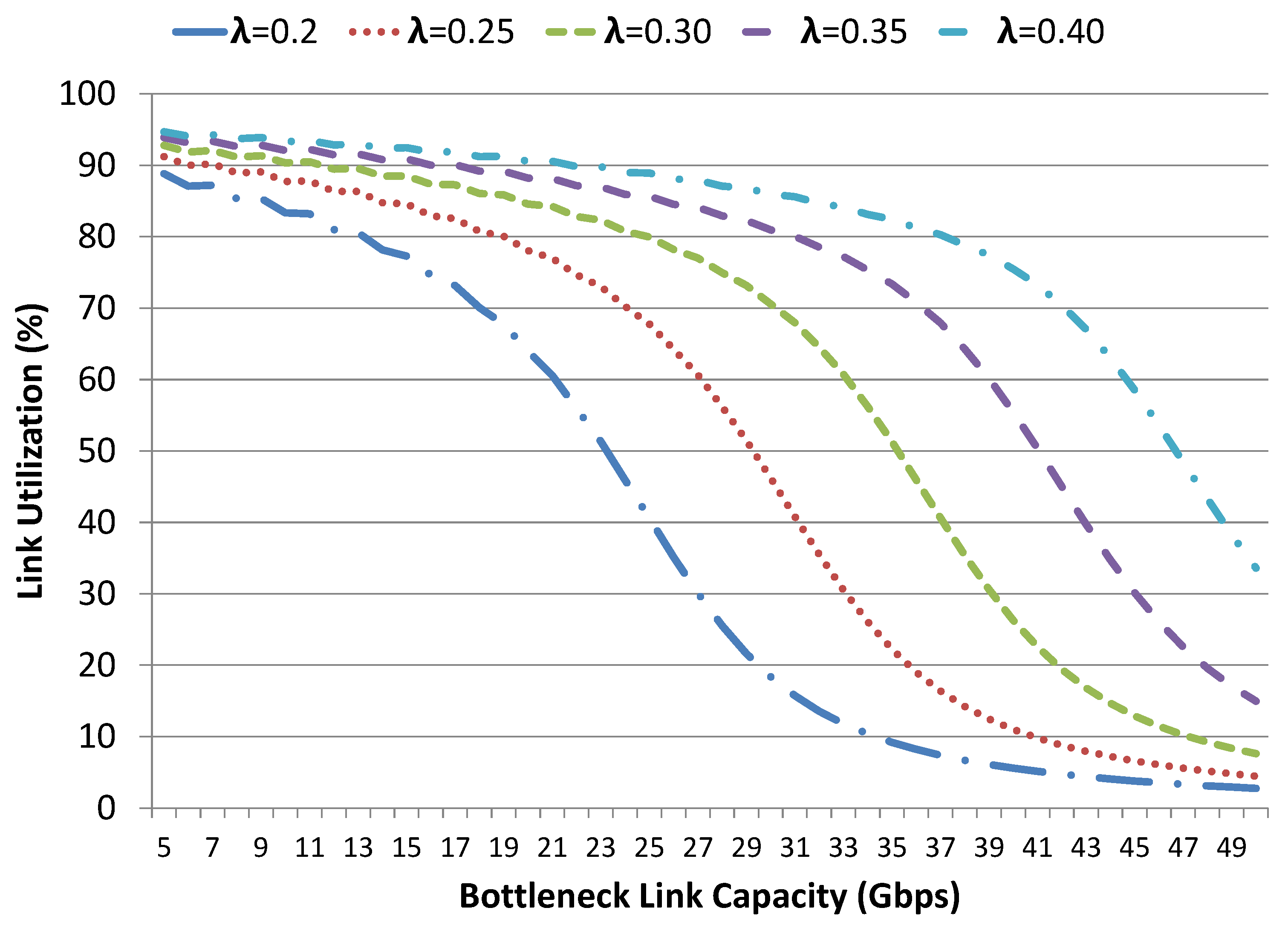
In order to further illustrate the bottleneck link capacity utilization, we have conducted another set of experiments with varying requests arrival rate
having a mean volume size of 120 Gbps and the results are shown in
Figure 15. It is evident from the results that, for low bottleneck link capacities, the link utilization is very high, i.e., around 90% for all arrival rates. As we increase the bottleneck link capacity, a gradual decrease in link utilization can be observed. For lower arrival rate
, the decrease in link utilization is faster when compared to the results of a higher arrival rate
. For instance, for
, when the bottleneck link capacity
C is increased from 20 Gbps to 40 Gbps, the link utilization is reduced from
to
. Whereas, for
, when the bottleneck link capacity
C is increased from 20 Gbps to 40 Gbps, the link utilization is reduced from
to
.
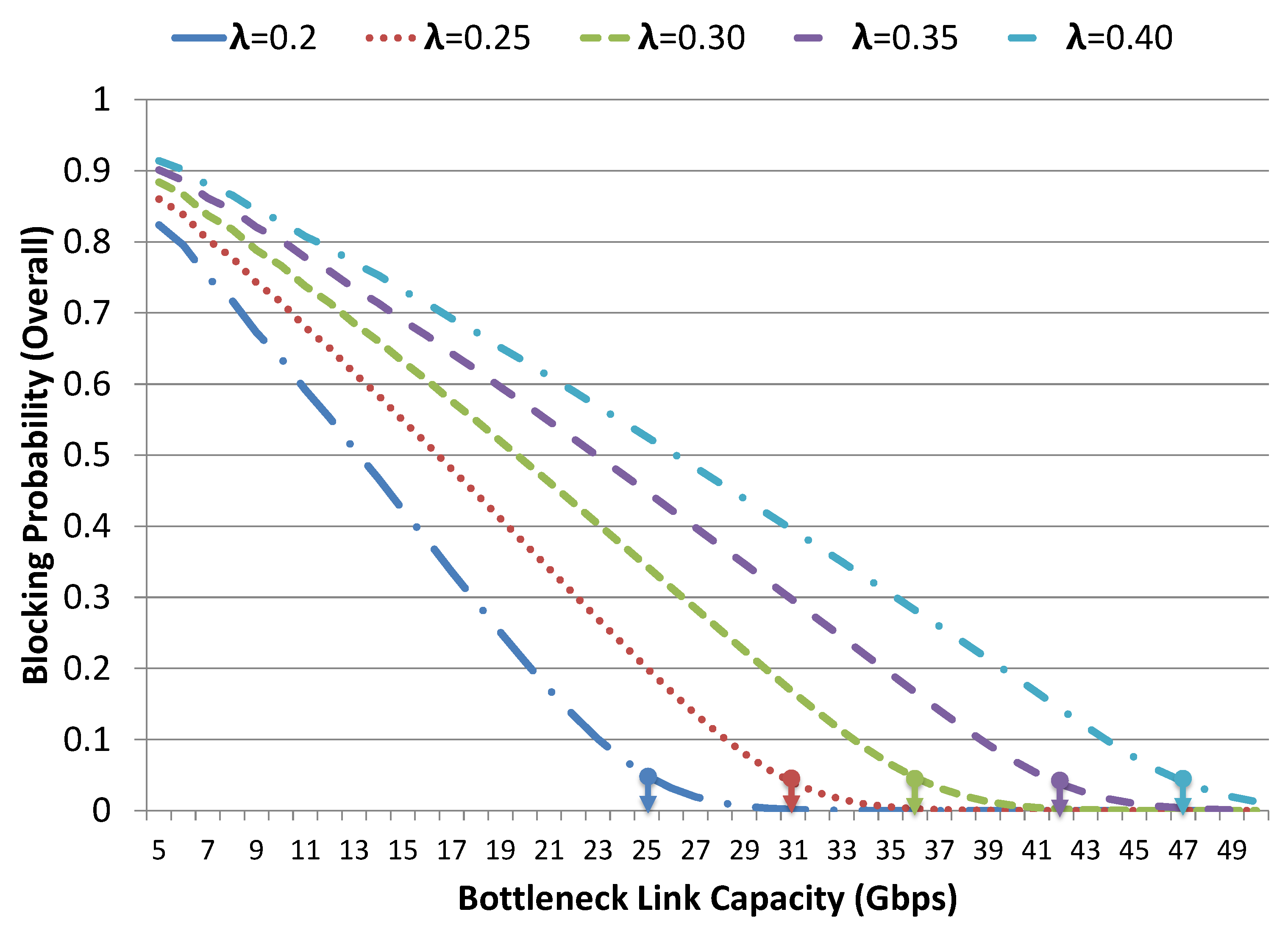
Algorithm 1 can be used for network capacity planning in order to compute optimal bottleneck link capacity for a given traffic intensity and requests an arrival rate, such that the overall network blocking probability remains within a certain acceptable range, i.e., .
The experiments are conducted for a certain case study with varying requests for arrival rate
having mean volume size of 120 Gbps. Here, we are interested in finding the optimal bottleneck link capacity, such that the overall network blocking probability remains with a certain acceptable range i.e.,
with
. There are two classes of user requests and
for class-1 and class-1 requests are 1 Gbps and 2 Gbps, respectively. Furthermore, class-2 requests have preemptive priority over class-1.
Figure 16 provides the proposed model results for the aforementioned case study. The results show that the overall blocking probability of the system gets decreased with the gradual increase in bottleneck link capacity and, finally, we obtain different optimal bottleneck link capacity for each arrival rate, as indicated in
Figure 16. With the increase in the arrival rate of incoming requests, we need to increase the bottleneck link capacity in order to have the overall blocking probability of the system below the desired range. For instance, the optimal bottleneck link capacity is 31 Gbps for the request arrival rate
in order to have the overall blocking probability around
. Whereas, for request arrival rate
, the optimal bottleneck link capacity results in 47 Gbps. This is just an example to illustrate the utility of the proposed model in the capacity planning of a network with given traffic conditions.
| Algorithm 1 Network Capacity Planning |
| Require: |
| Ensure: |
| |
| |
| |
| while do |
| |
| Generate system states S for |
| Compute states transition probabilities for S using and Equation (5) |
| Compute states-state probability vector |
| Update using Equation (6) |
| if then |
| |
| |
| end if |
| if then |
| |
| else |
| |
| end if |
| end while |
| return |




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}