

Learning Trajectory Tracking for an Autonomous Surface Vehicle in Urban Waterways
Abstract
:
1. Introduction
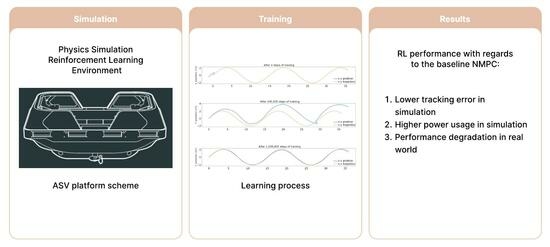
- Development of a comprehensive physical simulation for an ASV in urban waterways, including the modeling of the various disturbances and uncertainties affecting the platform based on a review of the relevant literature.
- Development of a deep reinforcement learning wrapper of the physical simulation in a standard learning environment and an end-to-end learning procedure modeled specifically with the task of trajectory tracking in urban waterways in mind.
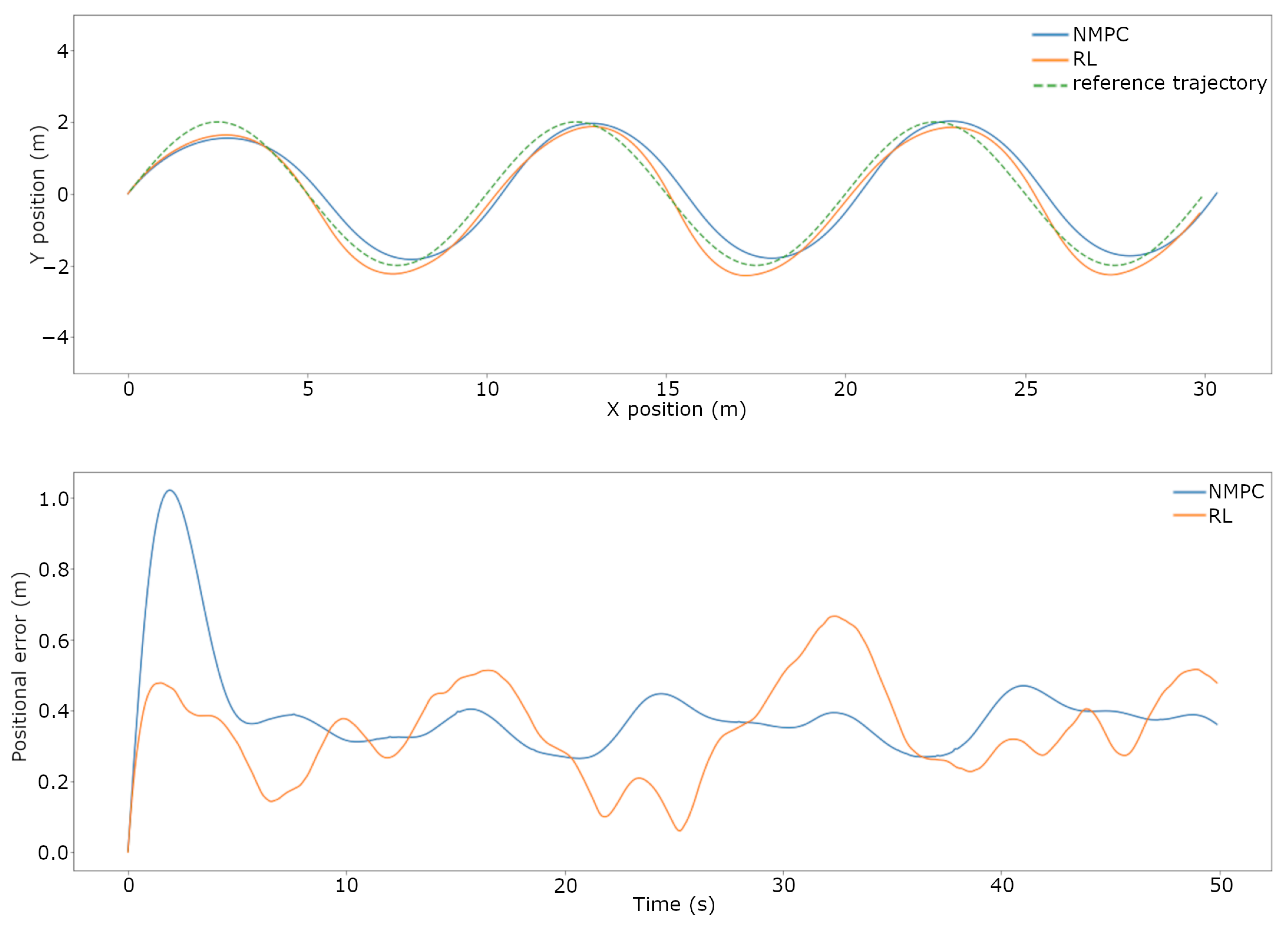
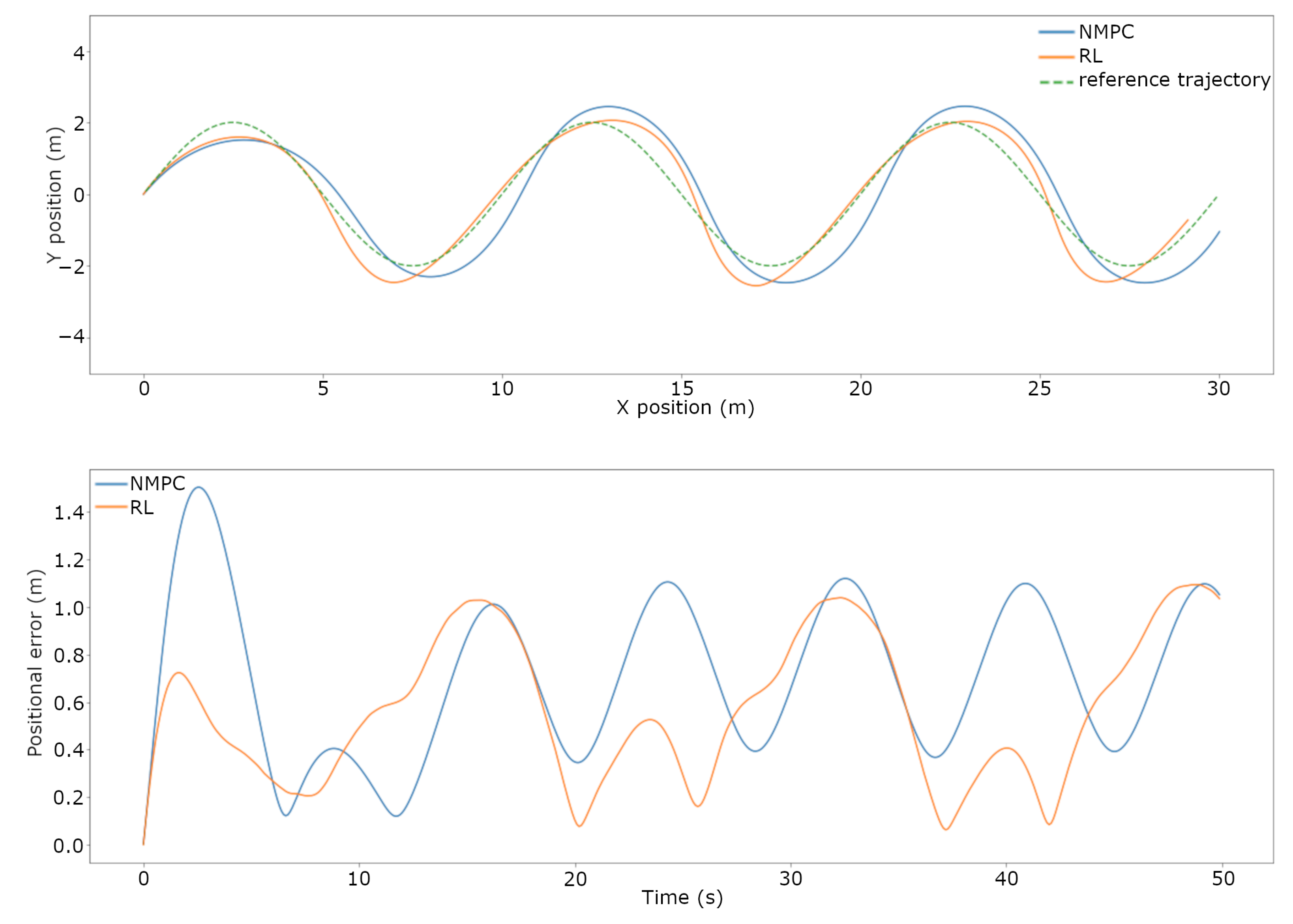
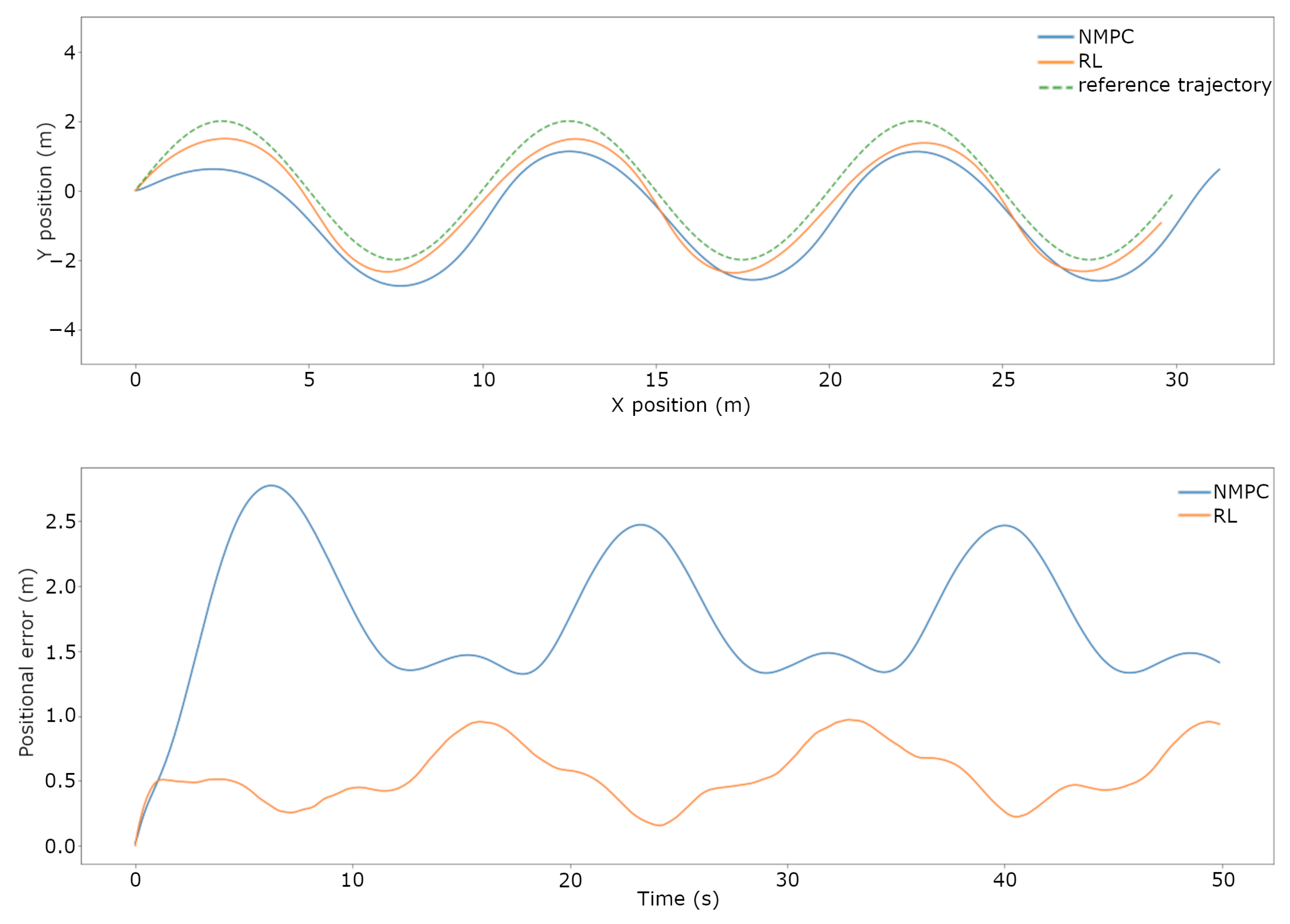
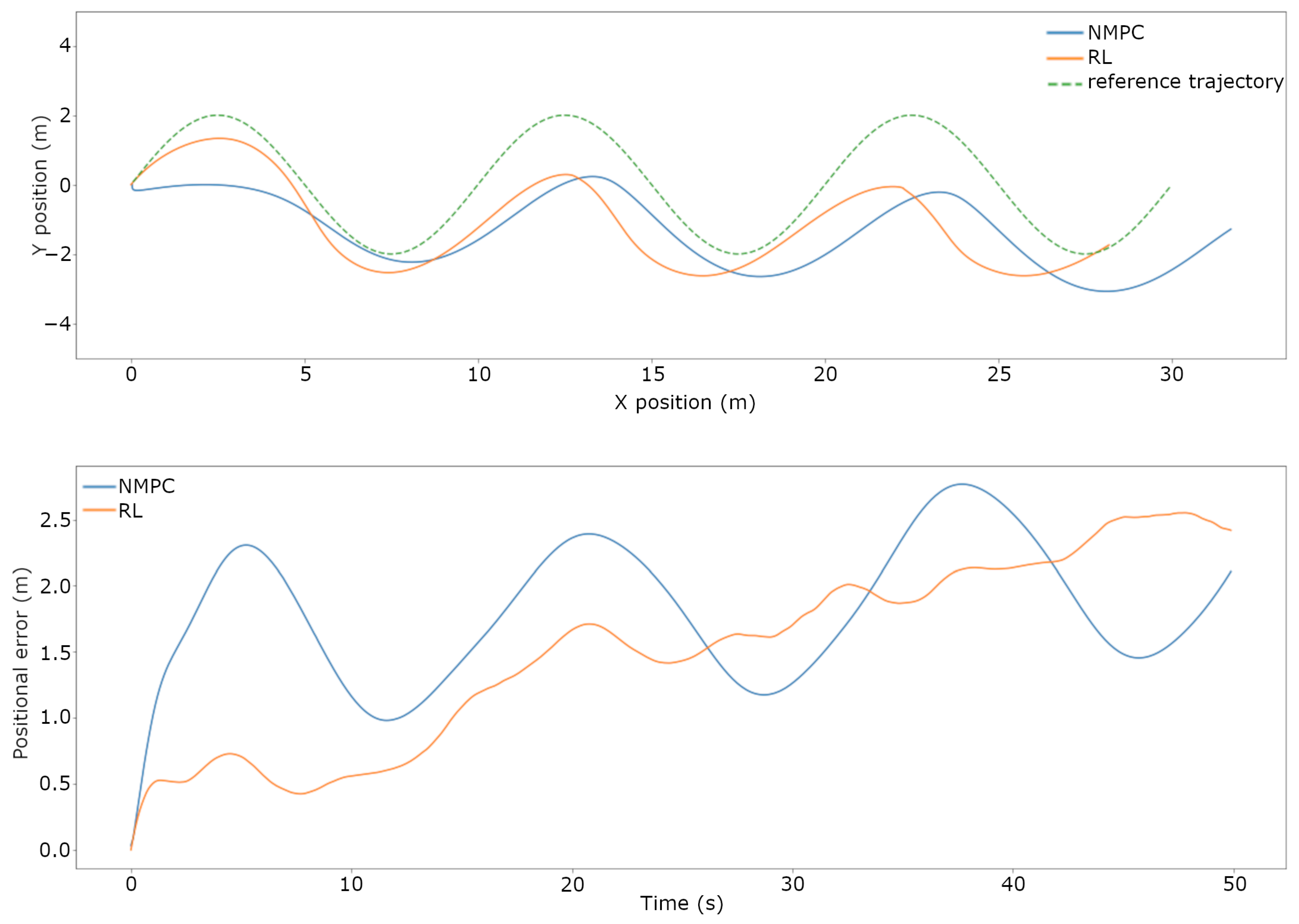
- A presentation of the rigorous testing procedure and the comparison between the current NMPC and the trained RL-based controller’s performance both in simulation and real-world scenarios. When subjected to disturbances and uncertainties, the RL-based controller was capable of performing trajectory tracking with a lower error than the current NMPC in a simulation, falling short in the real-world scenario.
2. Materials and Methods
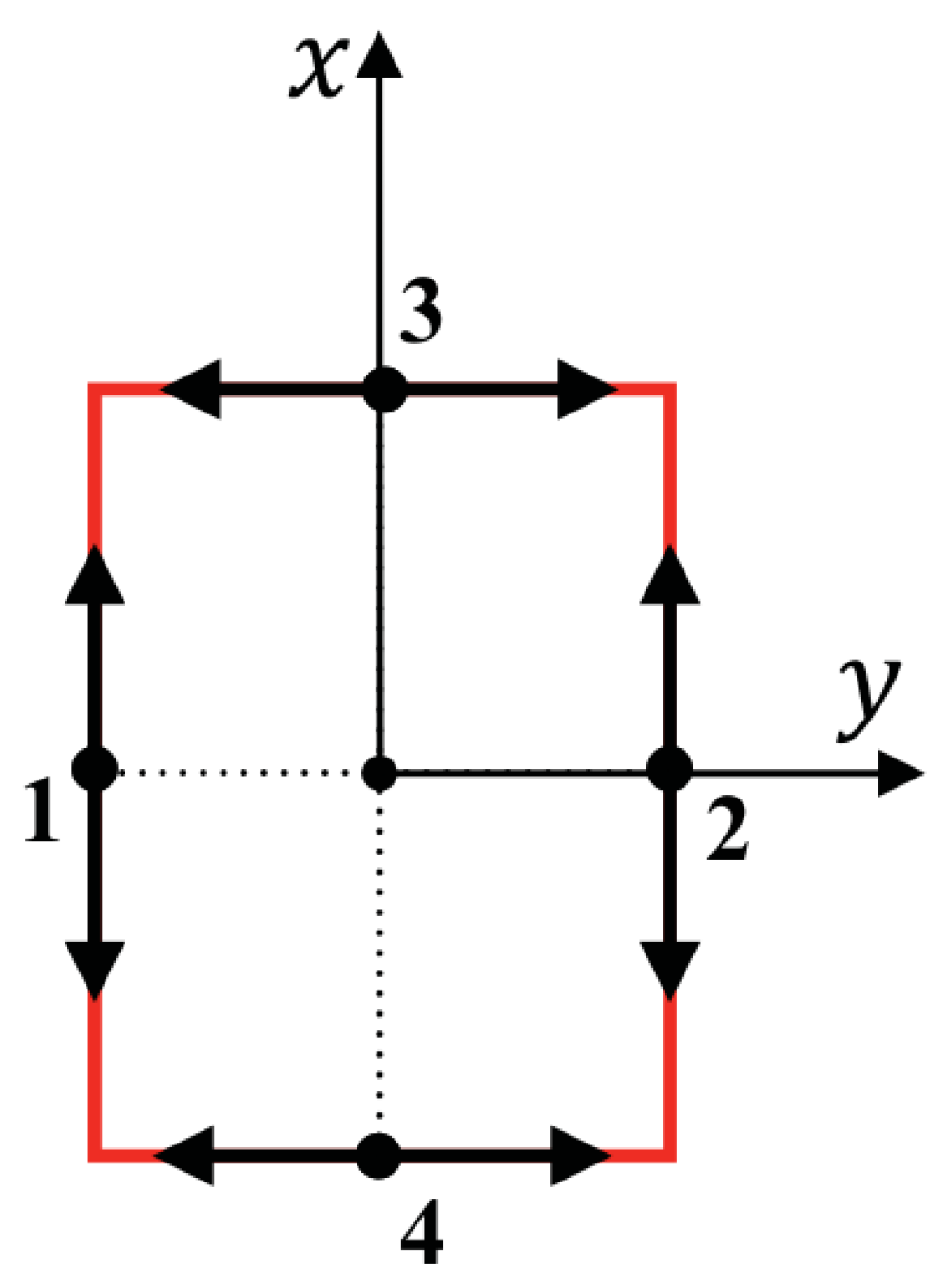
2.1. ASV Kinematics and Dynamics
2.2. Reinforcement Learning
- S is the set of possible states called the state space;
- A is the set of possible actions called the action space;
- is the probability of action a taken in state s leading to state ;
- is the immediate reward for taking action a in state s.
- the log probability of the output of the policy in state ;
- the estimator of the relative value taking the selected action at time t with regard to the old policy, called the advantage function;
- the learning rate.
- the new and old policy functions;
- the estimator of the relative value of a selected action at time t, called the advantage function.
- a hyperparameter, for example, 0.2;
- modifies the surrogate objective by clipping the probability ratio;
- immediate reward at time t.
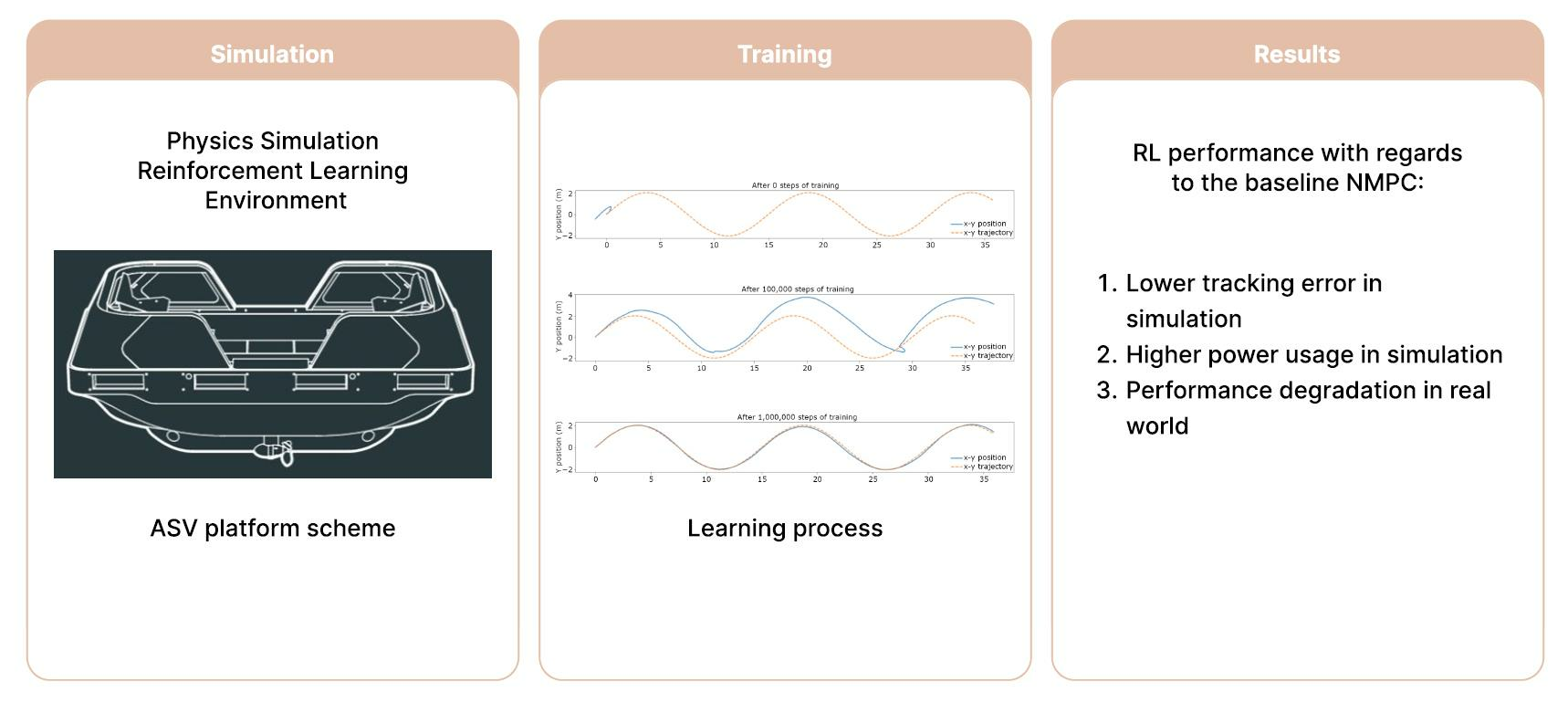
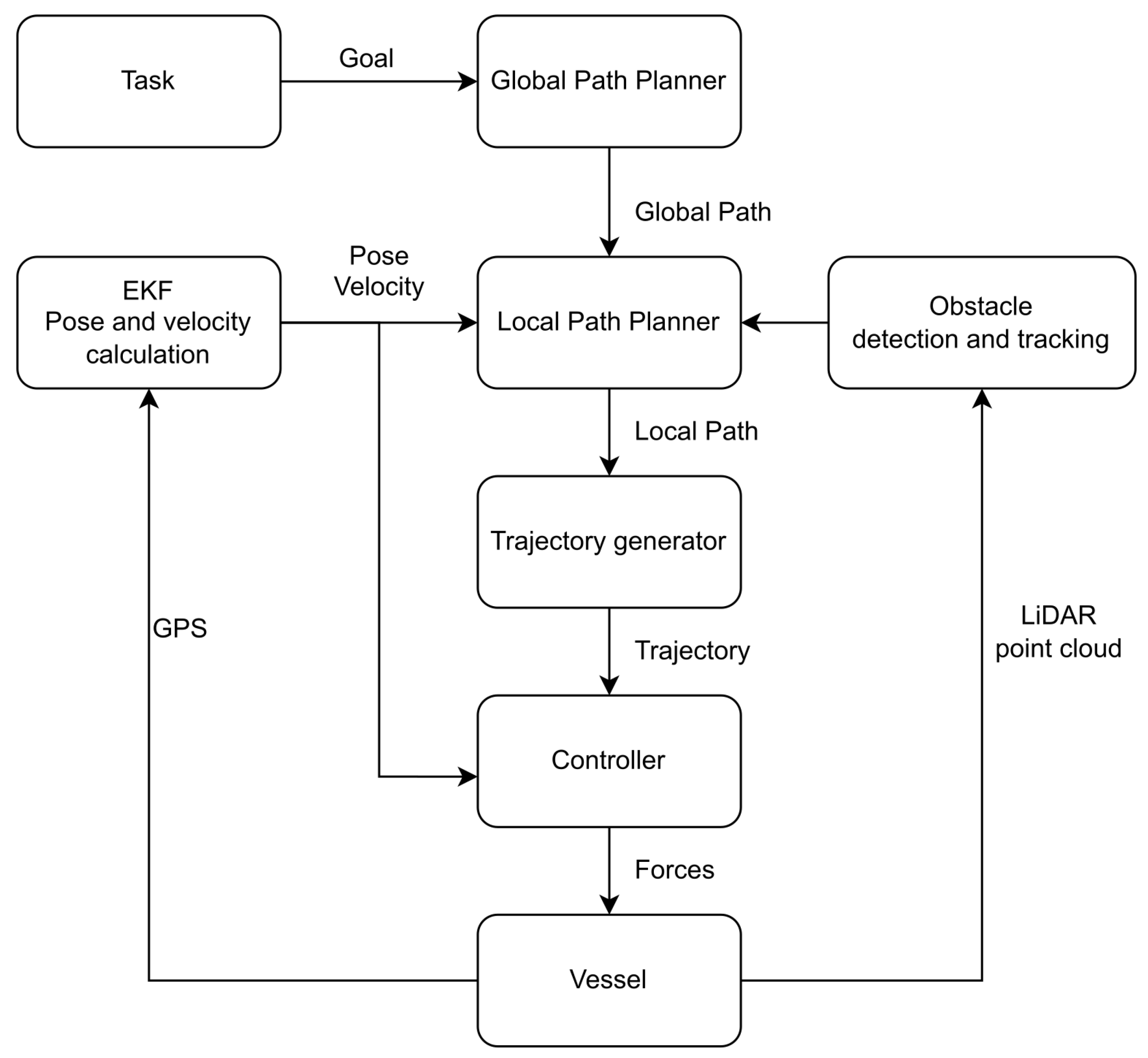
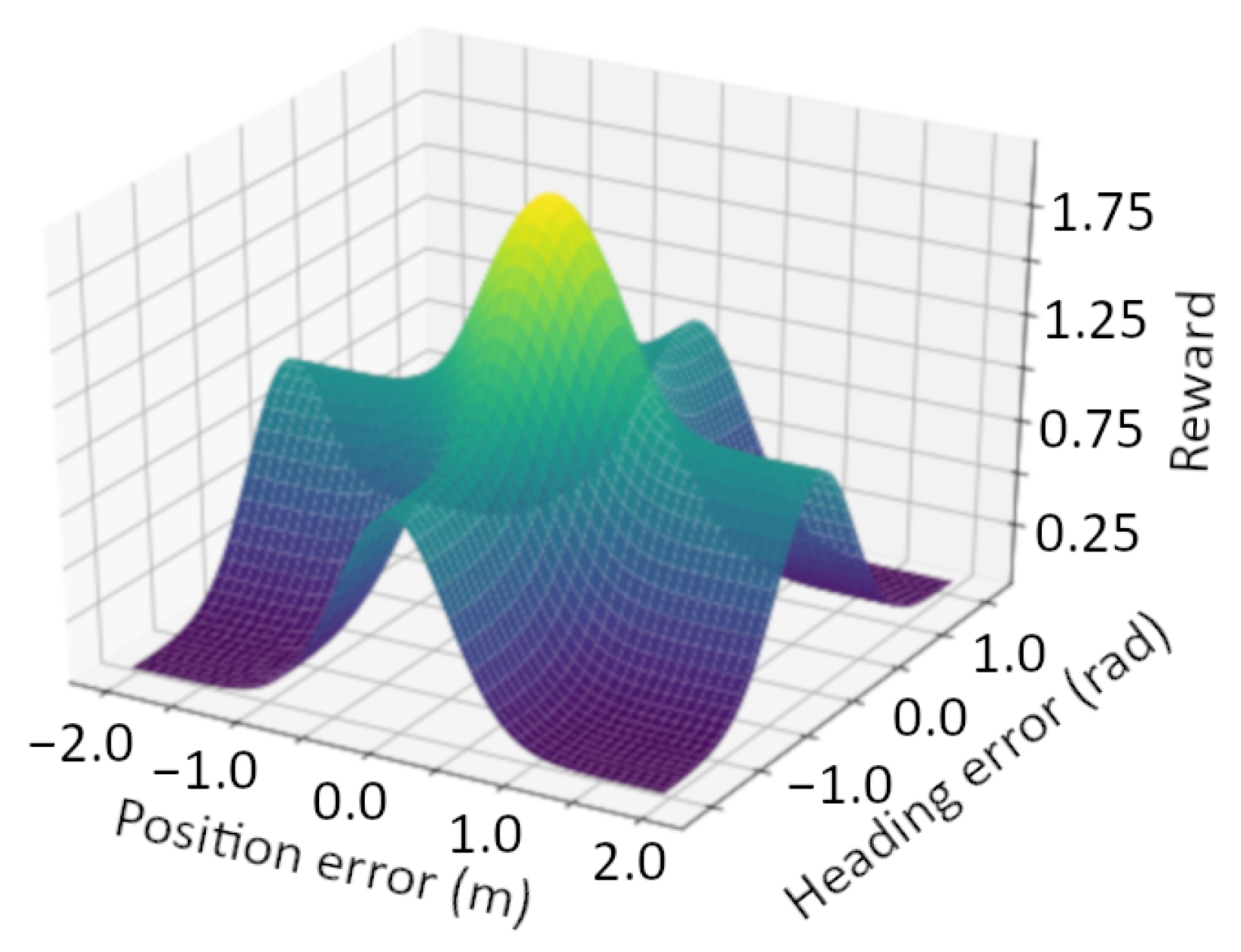
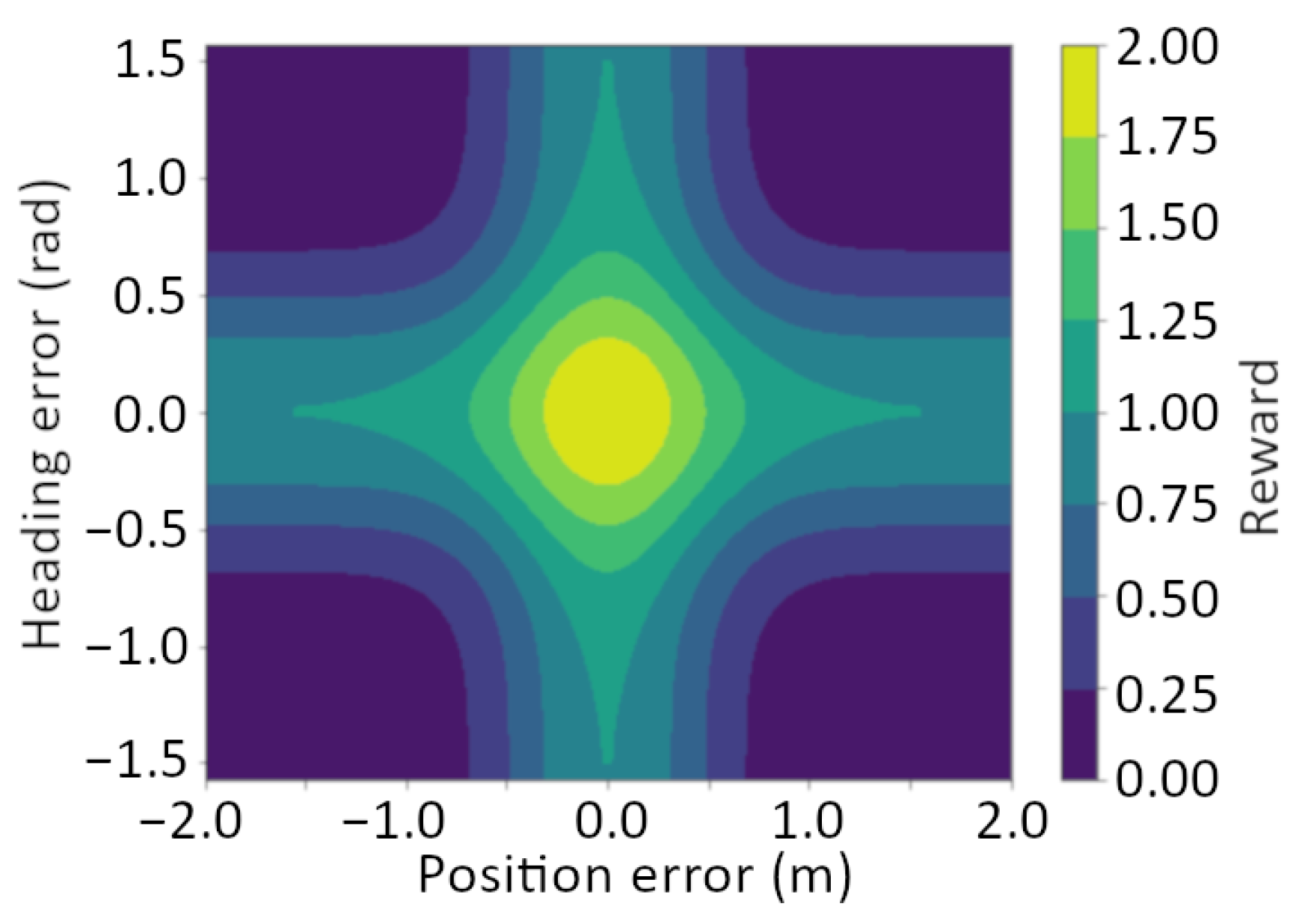
2.3. Simulation of the Roboat and Design of the RL Controller
3. Results
- Scenario 1—Baseline: without uncertainties and disturbances;
- Scenario 2—Payload: with a significant payload;
- Scenario 3—Current: facing a current disturbance;
- Scenario 4—Wind: facing a wind disturbance;
- Scenario 5—Real World: testing the controller on the real platform.
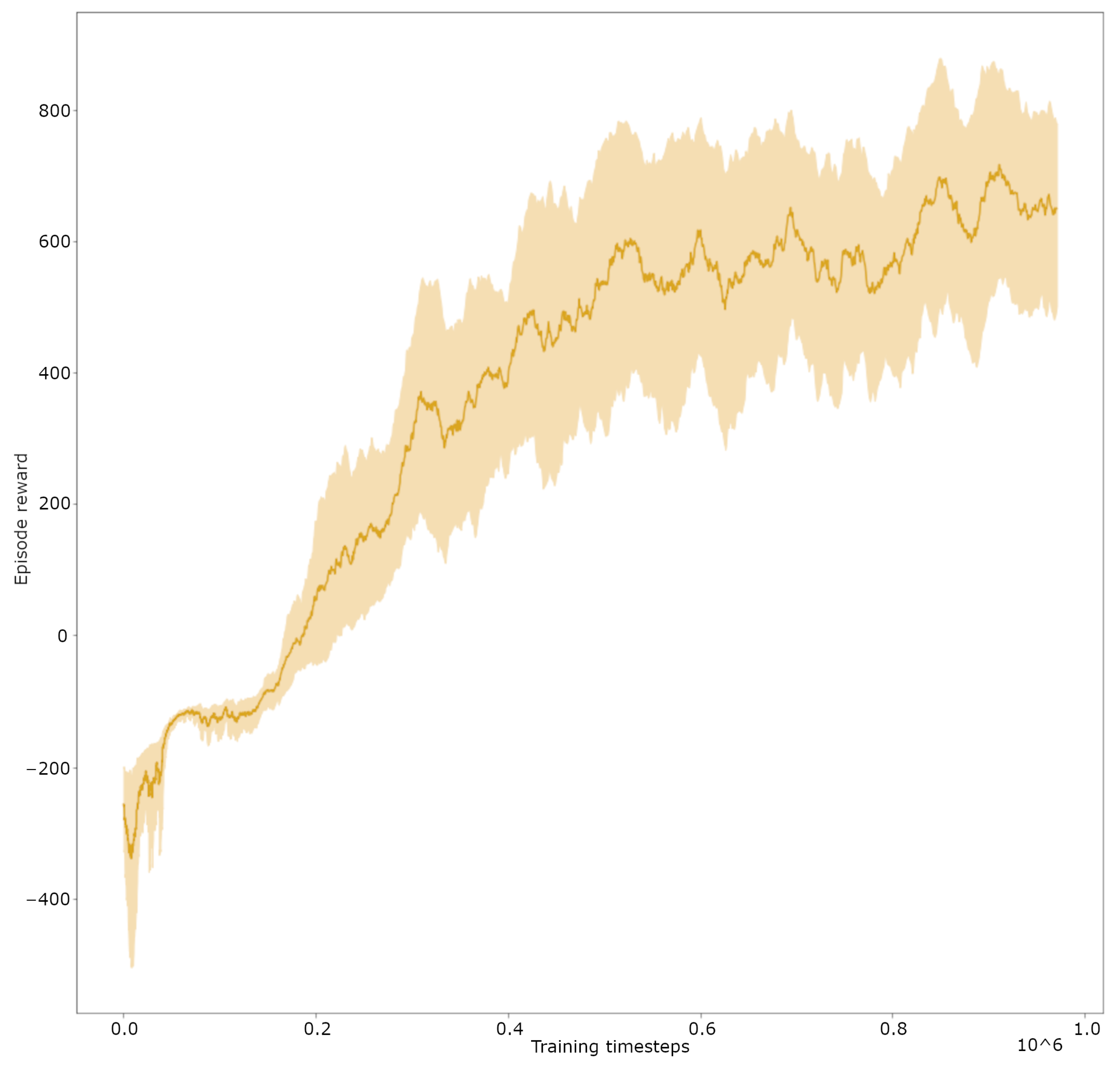
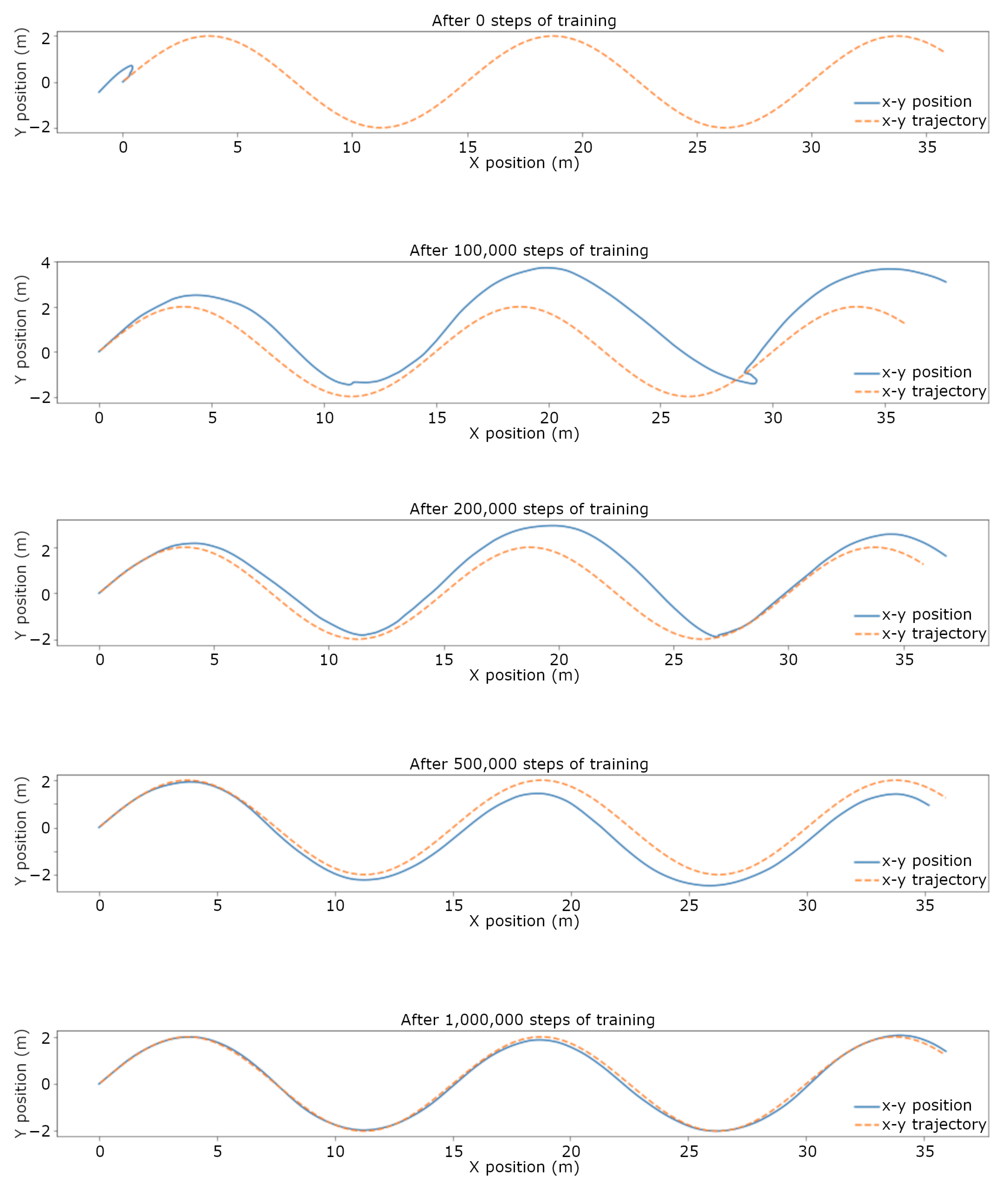
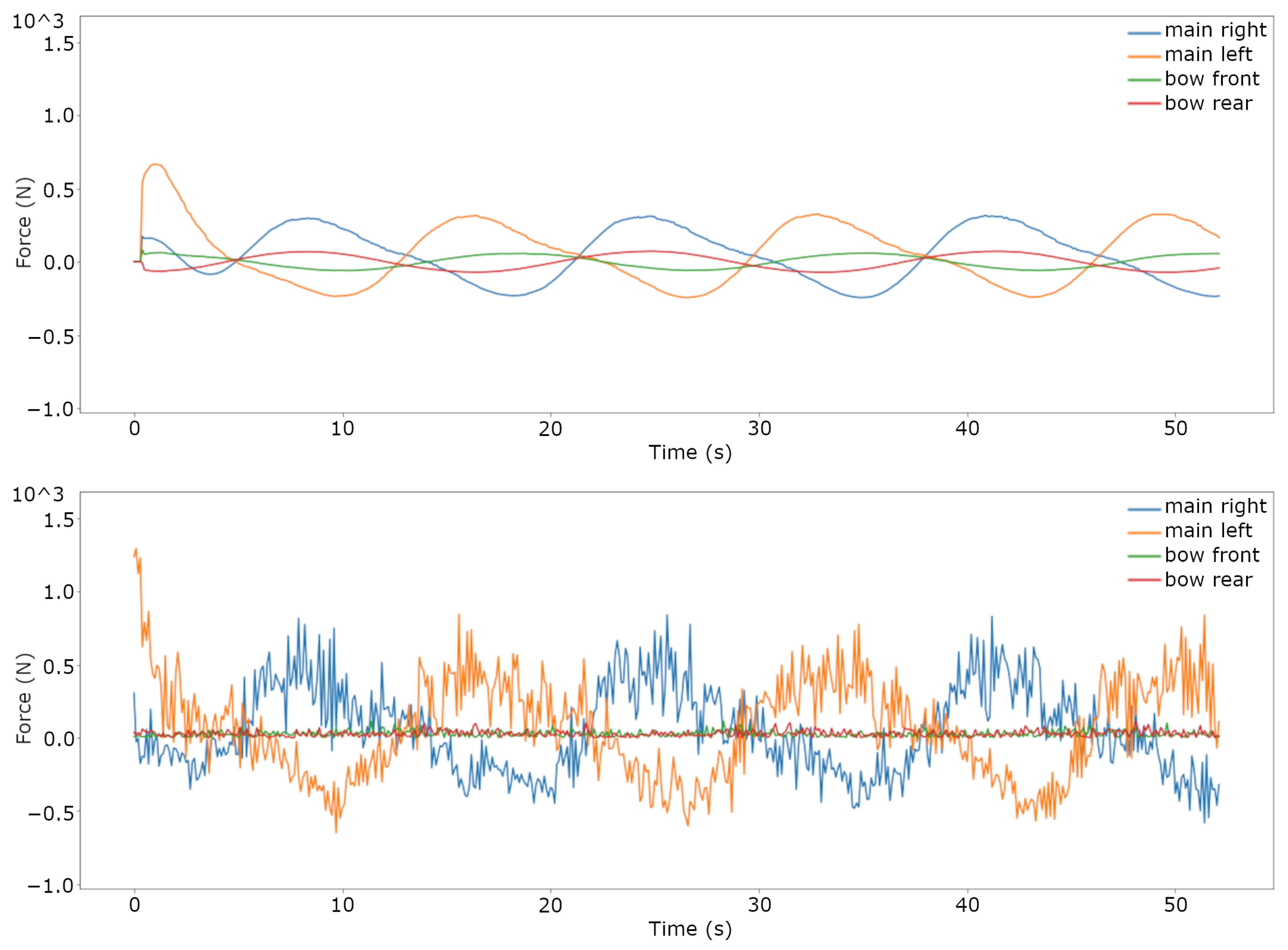
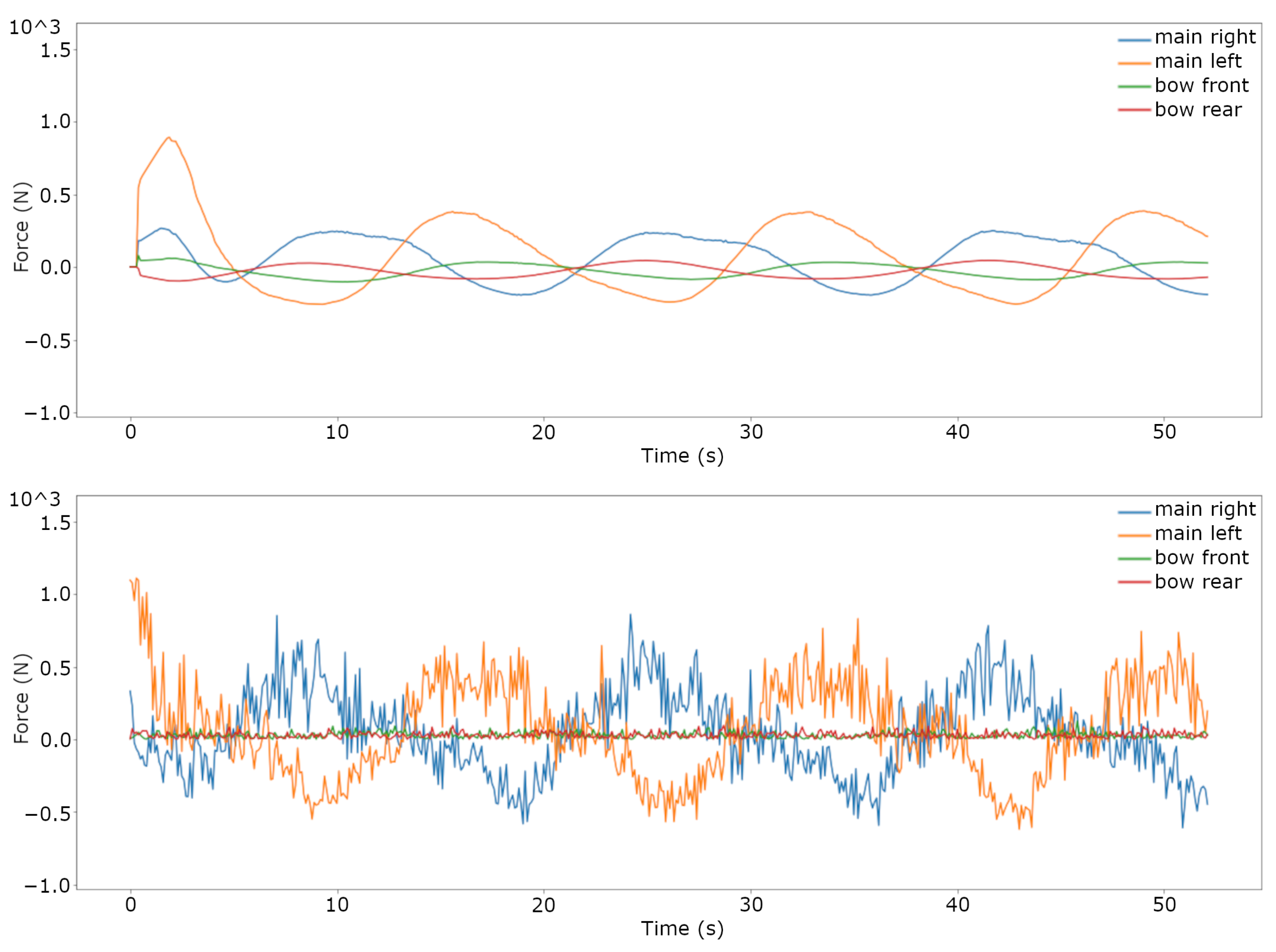
3.1. Trajectory Tracking Comparison in Simulation
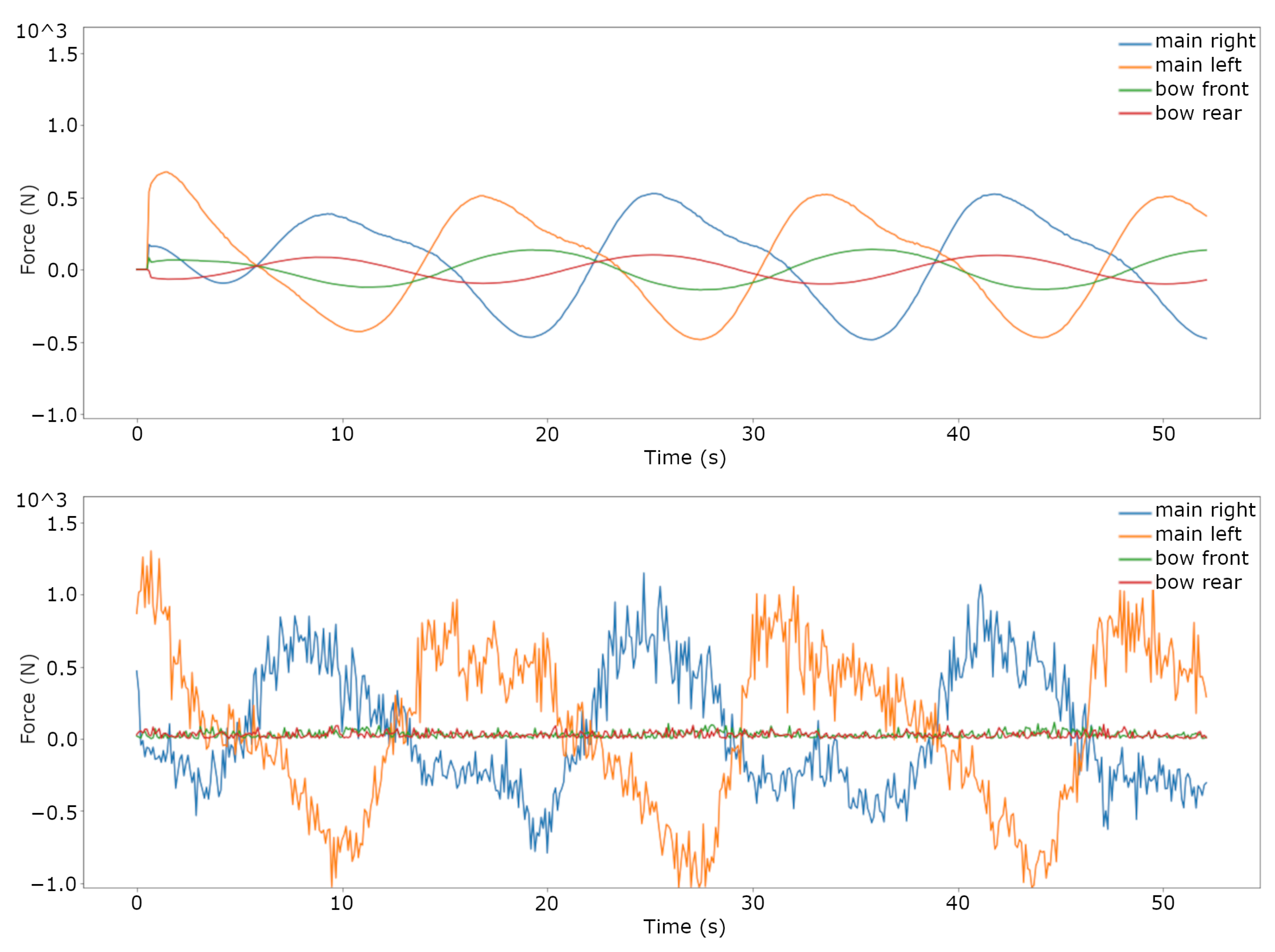
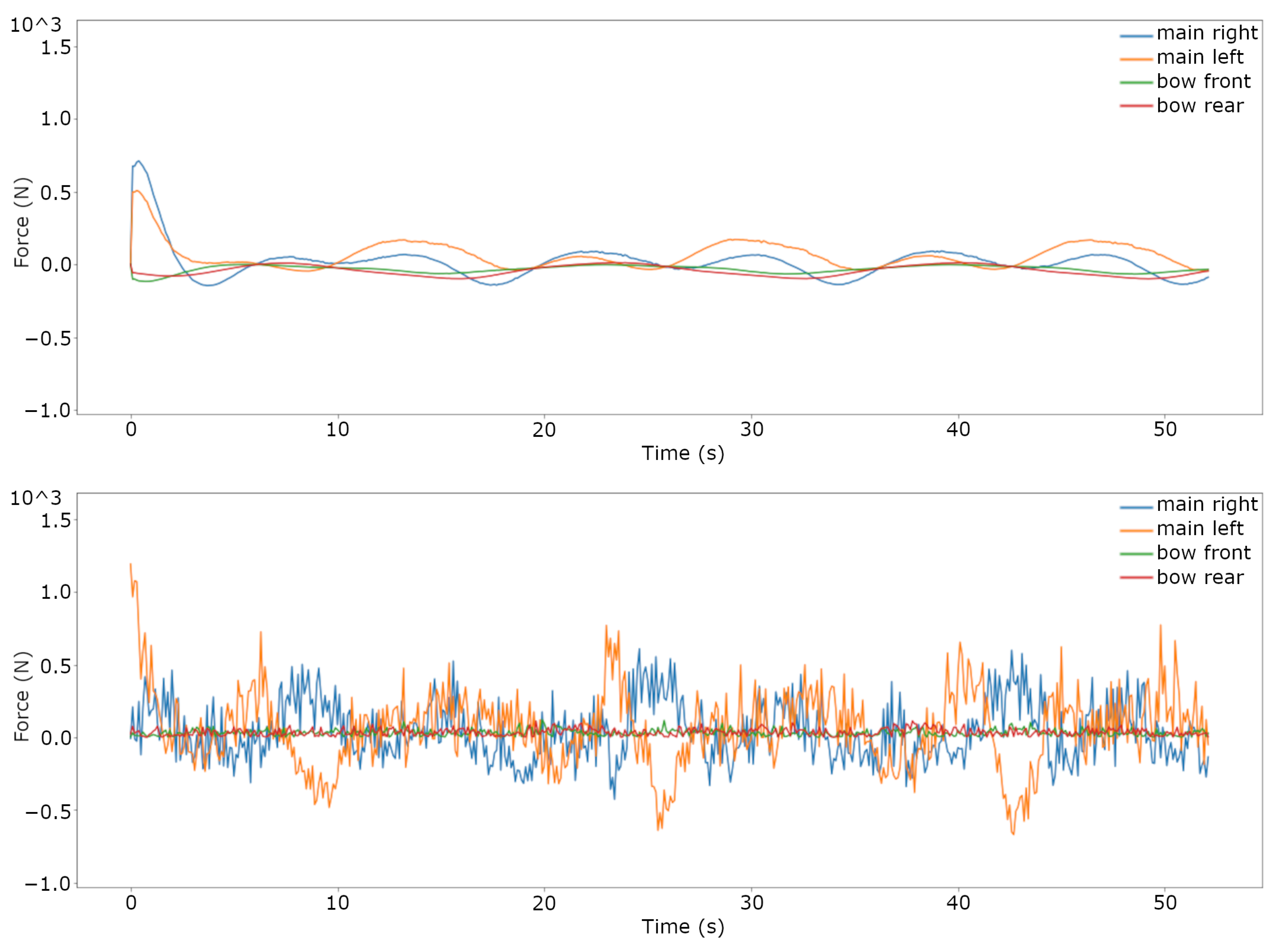
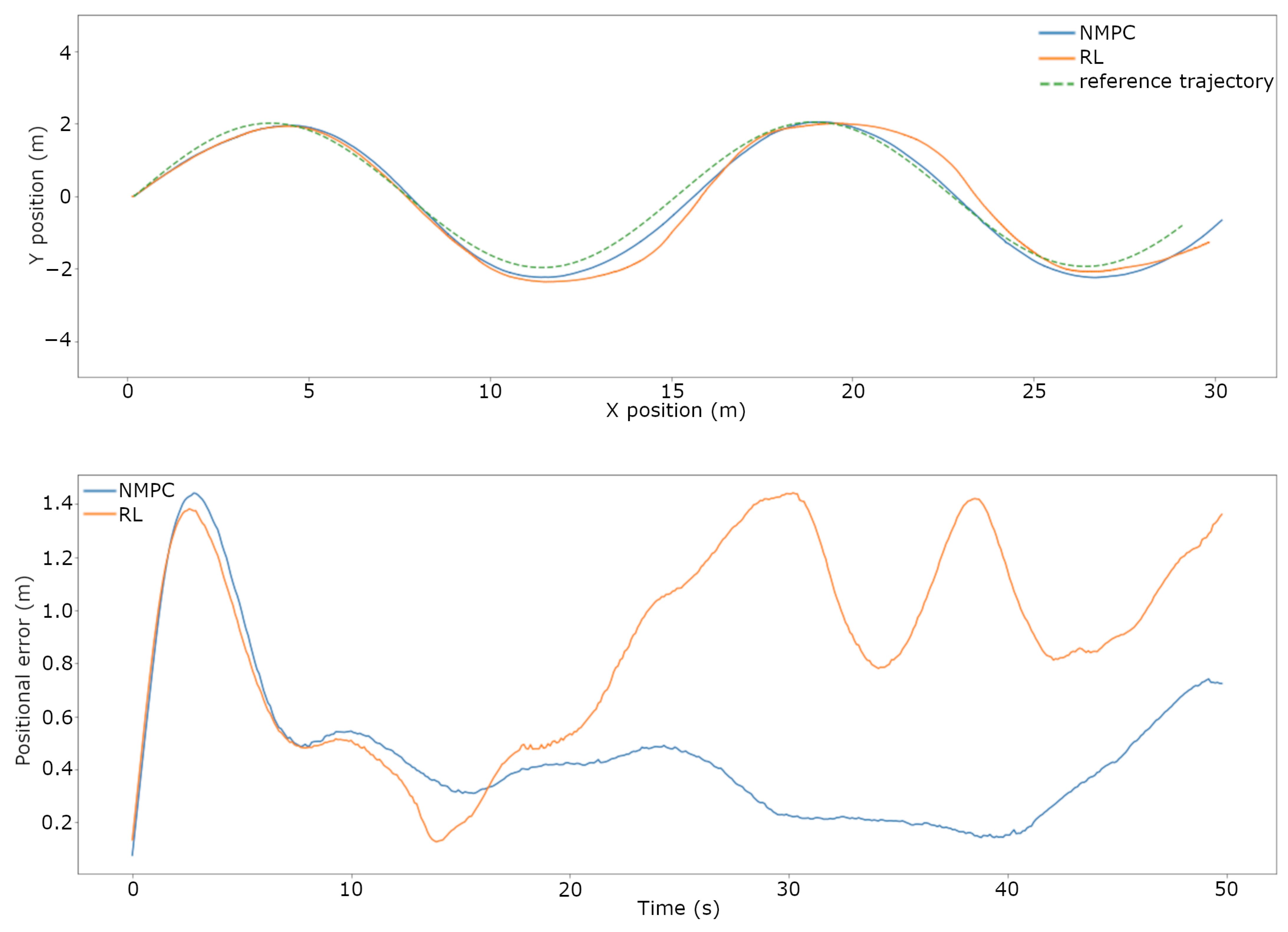
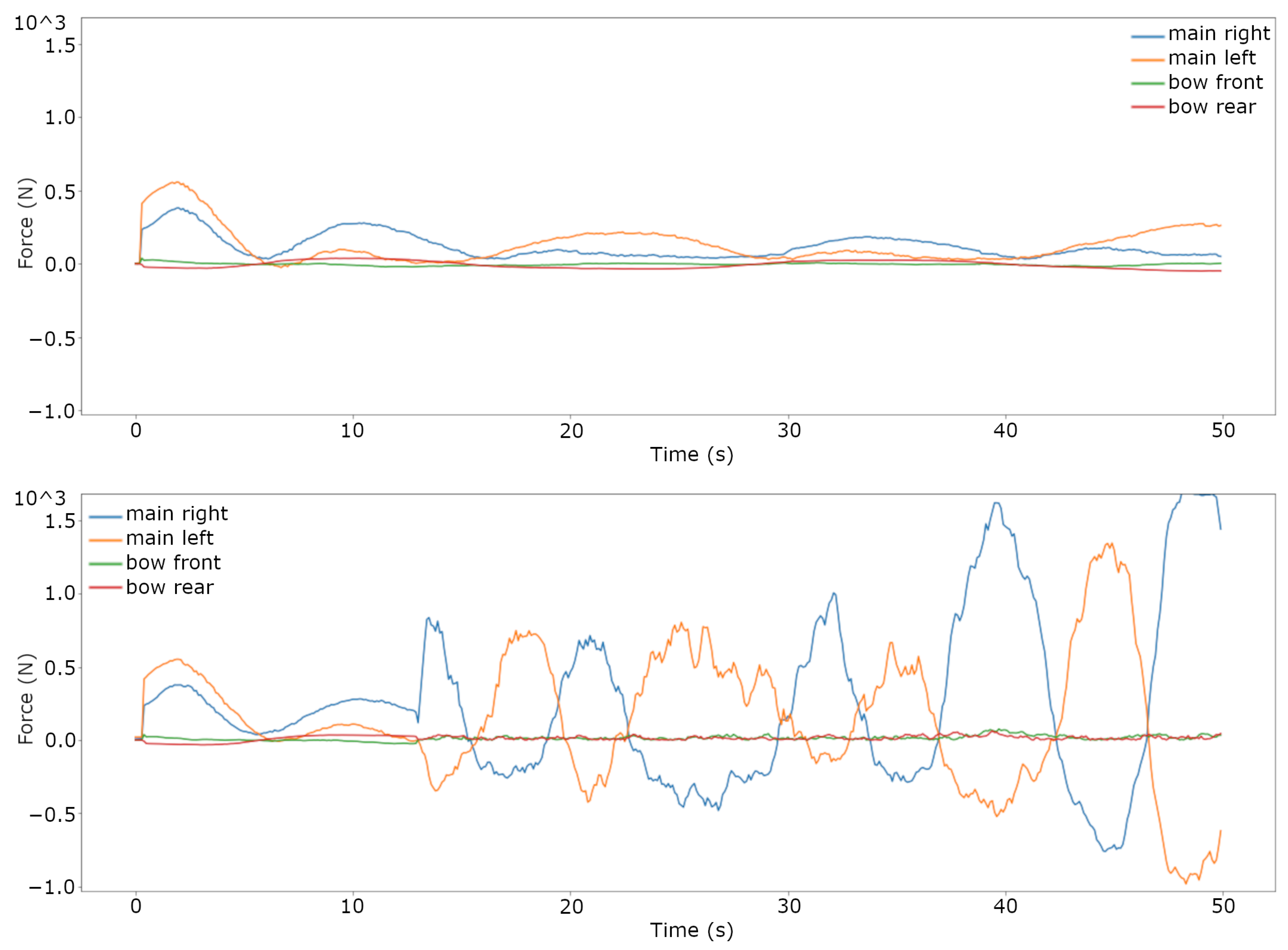
3.2. Trajectory Tracking Comparison on the Real System
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ASV | Autonomous surface vehicle |
| PPO | Proximal policy optimization |
| TRPO | Trust region policy optimization |
| ACER | Actor–critic experience replay |
| NMPC | Nonlinear model predictive control |
| USV | Unmanned surface vehicle |
| DDPG | Deep deterministic policy gradient |
| DOF | Degree of freedom |
| MDP | Markov decision process |
| RL | Reinforcement learning |
| gSDE | Generalized state-dependent exploration |
| RMSE | Root mean squared error |
References
- Curcio, J.; Leonard, J.; Patrikalakis, A. SCOUT—A low cost autonomous surface platform for research in cooperative autonomy. In Proceedings of the MTS/IEEE Oceans, Washington, DC, USA, 17–23 September 2005. [Google Scholar]
- Paull, L.; Saeedi, S.; Seto, M.; Li, H. AUV navigation and localization: A review. IEEE J. Ocean. Eng. 2014, 39, 131–149. [Google Scholar] [CrossRef]
- Dhariwal, A.; Sukhatme, G.S. Experiments in robotic boat localization. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007. [Google Scholar]
- Azzeria, M.N.; Adnanb, F.A.; Zaina, M.Z.M. Review of course keeping control system for unmanned surface vehicle. J. Teknologi 2015, 5, 11–20. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Annu. Rev. Control 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Wang, W.; Gheneti, B.; Mateos, L.A.; Duarte, F.; Ratti, C.; Rus, D. Roboat: An Autonomous Surface Vehicle for Urban Waterways. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 6340–6347. [Google Scholar]
- Wang, W.; Shan, T.; Leoni, P.; Fernandez-Gutierrez, D.; Meyers, D.; Ratti, C.; Rus, D. Roboat II: A Novel Autonomous Surface Vessel for Urban Environments. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021. [Google Scholar]
- Wang, W.; Fernández-Gutiérrez, D.; Doornbusch, R.; Jordan, J.; Shan, T.; Leoni, P.; Hagemann, N.; Schiphorst, J.K.; Duarte, F.; Ratti, C.; et al. Roboat III: An Autonomous Surface Vessel for Urban Transportation. J. Field Robot. 2023, 1–14. [Google Scholar] [CrossRef]
- Wang, W.; Mateos, L.A.; Park, S.; Leoni, P. Design, Modeling, and Nonlinear Model Predictive Tracking Control of a Novel Autonomous Surface Vehicle. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning quadrupedal locomotion over challenging terrain. Sci. Robot. 2020, 5, 47. [Google Scholar] [CrossRef] [PubMed]
- Balchen, J.; Jenssen, N.; Mathisen, E.; Saelid, S. Dynamic Positioning of Floating Vessels Based on Kalman Filtering and Optimal Control. In Proceedings of the 19th IEEE Conference on Decision and Control including the Symposium on Adaptive Processes, Albuquerque, NM, USA, 10–12 December 1980; pp. 852–864. [Google Scholar]
- Holzhüter, T. Lqg approach for the high-precision track control of ships. IEE Proc. Control Theory Appl. 1997, 144, 121–127. [Google Scholar] [CrossRef]
- Fossen, T.; Paulsen, M. Adaptive feedback linearization applied to steering of ships. Model. Identif. Control Nor. Res. Bull. 1995, 14, 229–237. [Google Scholar] [CrossRef]
- Fossen, T.I. Guidance and Control of Ocean Vehicles; Wiley: Hoboken, NJ, USA, 1994. [Google Scholar]
- Fossen, T.I. A Survey on Nonlinear Ship Control: From Theory to Practice; IFAC: Aalborg, Denmark, 2000. [Google Scholar]
- Zhang, L.; Qiao, L.; Chen, J.; Zhang, W. Neural-network-based reinforcement learning control for path following of underactuated ships. In Proceedings of the 5th Chinese Control Conference, Chengdu, China, 27–29 July 2016. [Google Scholar]
- Woo, J.; Yu, C.; Kim, N. Deep reinforcement learning-based controller for path following of an unmanned surface vehicle. Ocean. Eng. 2019, 183, 155–166. [Google Scholar] [CrossRef]
- Gonzalez-Garcia, A.; Barragan-Alcantar, D.; Collado-Gonzalez, I.; Garrido, L. Adaptive dynamic programming and deep reinforcement learning for the control of an unmanned surface vehicle: Experimental results. Control Eng. Pract. 2021, 111, 104807. [Google Scholar] [CrossRef]
- Gonzalez-Garcia, A.; Castañeda, H.; Garrido, L. Usv Path-Following Control Based on Deep Reinforcement Learning and Adaptive Control; Global Oceans: Singapore; Gulf Coast, TX, USA, 2020. [Google Scholar]
- Martinsen, A.B.; Lekkas, A.M. Straight-path following for underactuated marine vessels using deep reinforcement learning. In Proceedings of the 11th IFAC Conference on Control Applications in Marine Systems, Robotics, and Vehicles, Opatija, Croatia, 10–12 September 2018. [Google Scholar]
- Martinsen, A.B.; Lekkas, A.M. Curved path following with deep reinforcement learning: Results from three vessel models. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018. [Google Scholar]
- Wang, Y.; Tong, J.; Song, T.-Y.; Wan, Z.-H. Unmanned surface vehicle course tracking control based on neural network and deep deterministic policy gradient algorithm. In Proceedings of the 2018 OCEANS—TS/IEEE Kobe Techno-Oceans, Kobe, Japan, 28–31 May 2018. [Google Scholar]
- Martinsen, A.B.; Lekkas, A.; Gros, S.; Glomsrud, J.; Pedersen, T. Reinforcement learning-based tracking control of usvs in varying operational conditions. Front. Robot. AI 2020, 7, 32. [Google Scholar] [CrossRef] [PubMed]
- Øvereng, S.S.; Nguyen, D.T.; Hamre, G. Dynamic positioning using deep reinforcement learning. Ocean. Eng. 2021, 235, 109433. [Google Scholar] [CrossRef]
- Chen, L.; Dai, S.-L.; Dong, C. Adaptive Optimal Tracking Control of an Underactuated Surface Vessel Using Actor–Critic Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Wei, Z.; Du, J. Reinforcement learning-based optimal trajectory tracking control of surface vessels under input saturations. Int. J. Robust Nonlinear Control 2023, 33, 3807–3825. [Google Scholar] [CrossRef]
- Martinsen, A.B.; Lekkas, A.M.; Gros, S. Reinforcement learning-based NMPC for tracking control of ASVs: Theory and experiments. Control Eng. Pract. 2022, 120, 105024. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347v2. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall Press: Saddle River, NJ, USA, 2009. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Proceedings, P.M. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Wang, Z.; Bapst, V.; Heess, N.; Mnih, V.; Munos, R.; Kavukcuoglu, K.; de Freitas, N. Sample Efficient Actor-Critic with Experience Replay. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Mysore, S.; Mabsout, B.; Mancuso, R.; Saenko, K. Regularizing Action Policies for Smooth Control with Reinforcement Learning. arXiv 2021, arXiv:2012.06644. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | ||||||
|---|---|---|---|---|---|---|
| Value | 3 | 3 | 1 | 0.5 | 0.1 | 0.7 |
| Parameter | Learning Rate | N Steps per Update | Batch Size | N Epochs | Discount Factor | Use gSDE |
|---|---|---|---|---|---|---|
| Value | 0.0003 | 2048 | 256 | 10 | 0.99 | False |
| Scenario | Undisturbed | Added Payload | Current | Wind | Real World |
|---|---|---|---|---|---|
| pos. NMPC (m) | 0.3018 | 0.6979 | 1.6810 | 1.8032 | 0.4587 |
| pos. RL (m) | 0.2836 | 0.5836 | 0.5803 | 1.701 | 0.8721 |
| Difference | −6.03% | −22.83% | −65.48% | −5.69% | 90.10% |
| P NMPC (W) | 323.7134 | 559.3913 | 412.3100 | 184.7790 | 161.4688 |
| P RL (W) | 491.3406 | 742.1449 | 460.2448 | 300.3304 | 543.6210 |
| Difference | 51.78% | 32.67% | 11.63% | 62.53% | 336.67% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sikora, T.; Schiphorst, J.K.; Scattolini, R. Learning Trajectory Tracking for an Autonomous Surface Vehicle in Urban Waterways. Computation 2023, 11, 216. https://doi.org/10.3390/computation11110216
Sikora T, Schiphorst JK, Scattolini R. Learning Trajectory Tracking for an Autonomous Surface Vehicle in Urban Waterways. Computation. 2023; 11(11):216. https://doi.org/10.3390/computation11110216
Chicago/Turabian StyleSikora, Toma, Jonathan Klein Schiphorst, and Riccardo Scattolini. 2023. "Learning Trajectory Tracking for an Autonomous Surface Vehicle in Urban Waterways" Computation 11, no. 11: 216. https://doi.org/10.3390/computation11110216