


Predicting COVID-19 Hospital Stays with Kolmogorov–Gabor Polynomials: Charting the Future of Care

 , , , , ,
, , , , , 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Source
2.2. Data Description and Pre-Processing
2.3. Statistical Data Analysis
2.4. Predictive Modeling
2.5. Model Validation
- TP (True Positives) = The number of accurately identified prolonged LOS
- TN (True Negatives) = The number of accurately identified normal LOS
- FP (True Positives) = The number of inaccurately identified prolonged LOS
- FN (True Positives) = The number of inaccurately identified normal LOS
2.6. Ethical Considerations
3. Results
4. Discussion
4.1. Implications
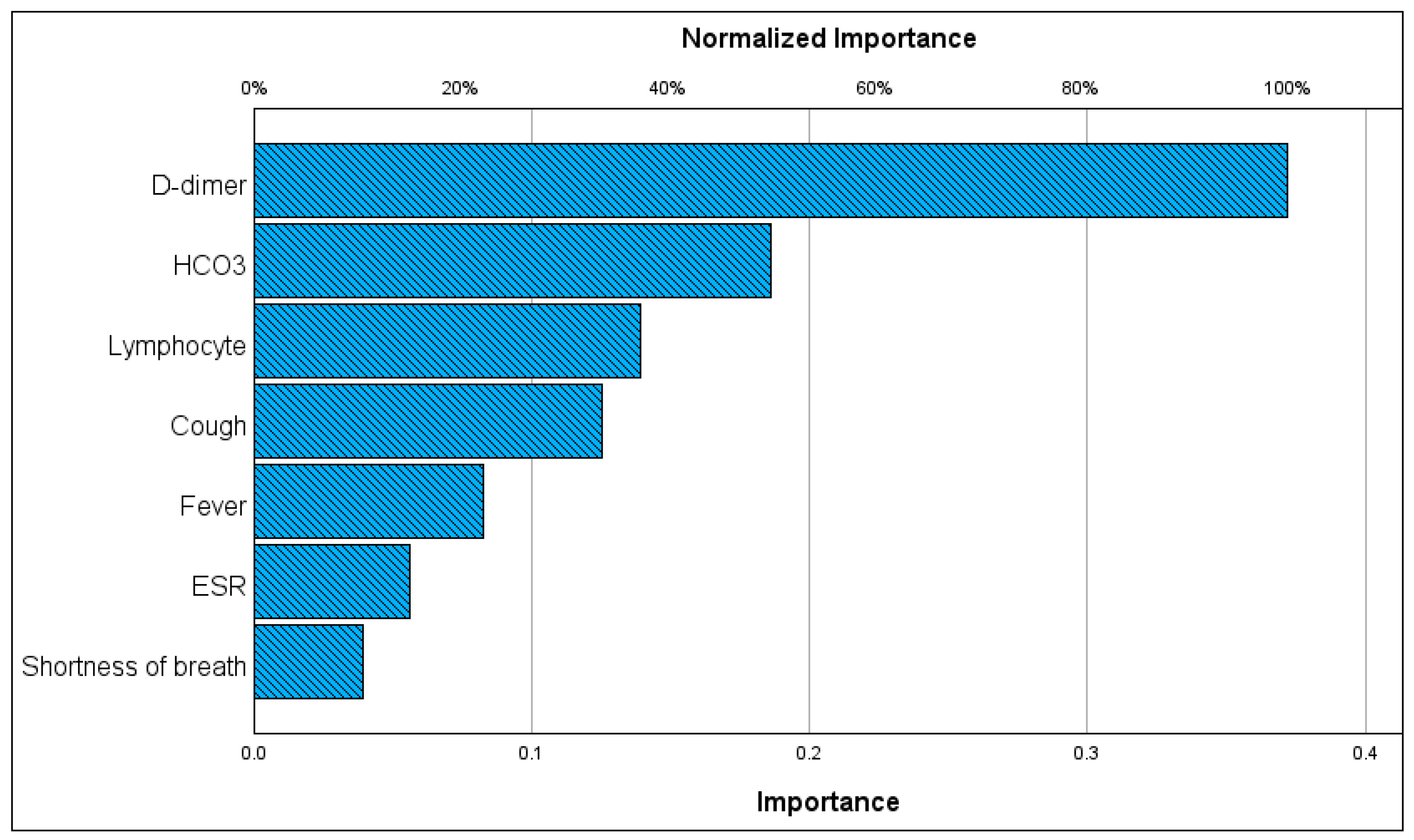
4.2. Risk Factors
4.3. The Properties of Kolmogorov–Gabor Polynomials
4.4. Performance Indices
4.5. Comparison with the State-of-the-Art
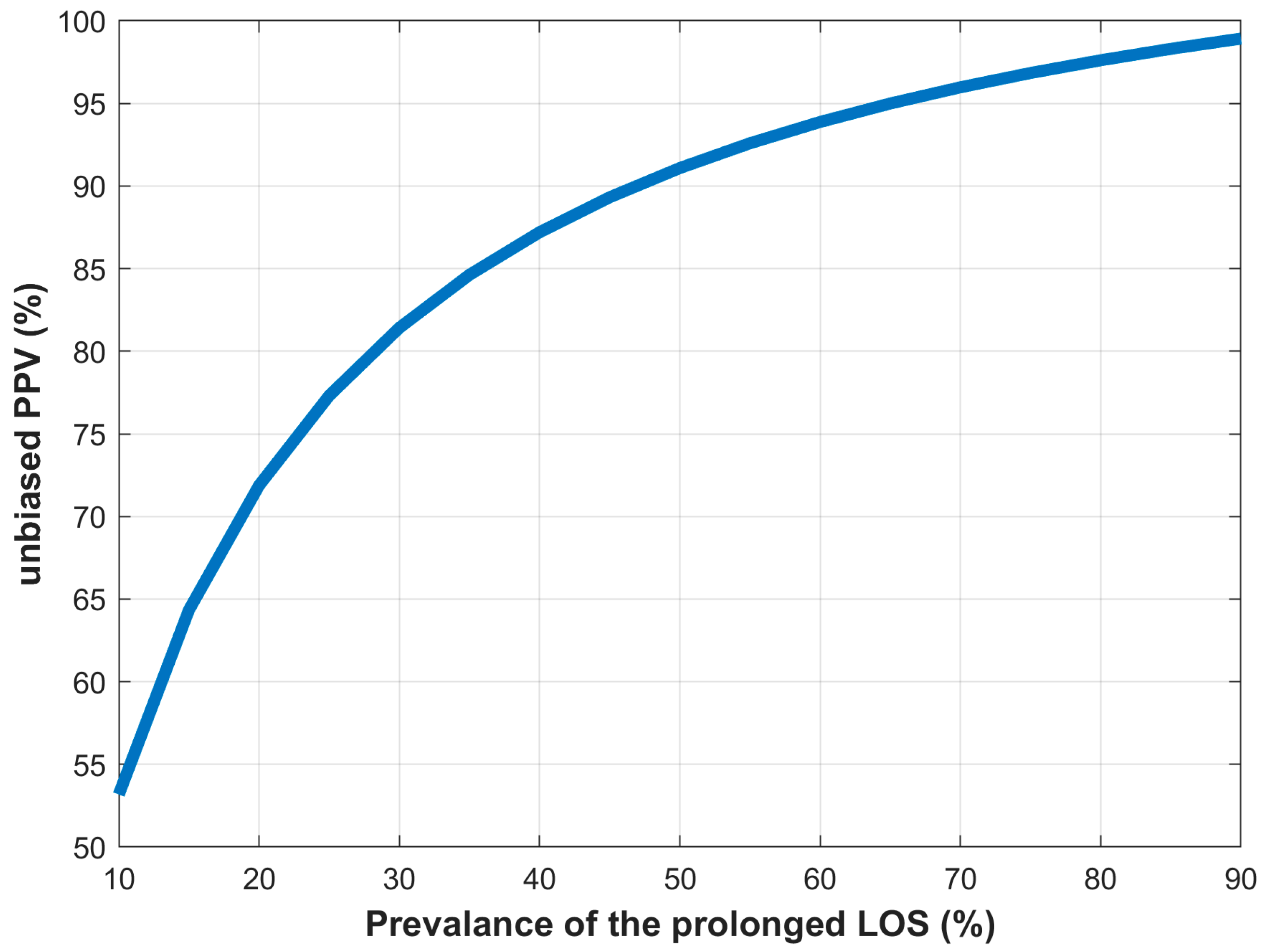
4.6. Dichotomous LOS Definition
4.7. Limitations and Future Research
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhuang, Z.; Cao, P.; Zhao, S.; Han, L.; He, D.; Yang, L. The shortage of hospital beds for COVID-19 and non-COVID-19 patients during the lockdown of Wuhan, China. Ann. Transl. Med. 2021, 9, 200. [Google Scholar] [CrossRef] [PubMed]
- Sen-Crowe, B.; Sutherland, M.; McKenney, M.; Elkbuli, A. A Closer Look into Global Hospital Beds Capacity and Resource Shortages During the COVID-19 Pandemic. J. Surg. Res. 2021, 260, 56–63. [Google Scholar] [CrossRef] [PubMed]
- Jaziri, R.; Alnahdi, S. Choosing which COVID-19 patient to save? The ethical triage and rationing dilemma. Ethics Med. Public Health 2020, 15, 100570. [Google Scholar] [CrossRef] [PubMed]
- Remuzzi, A.; Remuzzi, G. COVID-19 and Italy: What next? Lancet 2020, 395, 1225–1228. [Google Scholar] [CrossRef]
- Deschepper, M.; Eeckloo, K.; Malfait, S.; Benoit, D.; Callens, S.; Vansteelandt, S. Prediction of hospital bed capacity during the COVID-19 pandemic. BMC Health Serv. Res. 2021, 21, 468. [Google Scholar] [CrossRef]
- Pasquale, S.; Gregorio, G.L.; Caterina, A.; Francesco, C.; Beatrice, P.M.; Vincenzo, P.; Caterina, P.M. COVID-19 in Low- and Middle-Income Countries (LMICs): A Narrative Review from Prevention to Vaccination Strategy. Vaccines 2021, 9, 1477. [Google Scholar] [CrossRef]
- Sasangohar, F.; Jones, S.L.; Masud, F.N.; Vahidy, F.S.; Kash, B.A. Provider Burnout and Fatigue During the COVID-19 Pandemic: Lessons Learned from a High-Volume Intensive Care Unit. Anesth. Analg. 2020, 131, 106–111. [Google Scholar] [CrossRef]
- Sikaras, C.; Ilias, I.; Tselebis, A.; Pachi, A.; Zyga, S.; Tsironi, M.; Gil, A.P.R.; Panagiotou, A. Nursing staff fatigue and burnout during the COVID-19 pandemic in Greece. AIMS Public Health 2022, 9, 94–105. [Google Scholar] [CrossRef]
- Sagherian, K.; Steege, L.M.; Cobb, S.J.; Cho, H. Insomnia, fatigue and psychosocial well-being during COVID-19 pandemic: A cross-sectional survey of hospital nursing staff in the United States. J. Clin. Nurs. 2023, 32, 5382–5395. [Google Scholar] [CrossRef]
- Alsunaidi, S.J.; Almuhaideb, A.M.; Ibrahim, N.M.; Shaikh, F.S.; Alqudaihi, K.S.; Alhaidari, F.A.; Khan, I.U.; Aslam, N.; Alshahrani, M.S. Applications of Big Data Analytics to Control COVID-19 Pandemic. Sensors 2021, 21, 2282. [Google Scholar] [CrossRef]
- Marateb, H.R.; Mohebbian, M.R.; Shirzadi, M.; Mirshamsi, A.; Zamani, S.; Abrisham chi, A.; Bafande, F.; Mañanas, M.Á. Reliability of machine learning methods for diagnosis and prognosis during the COVID-19 pandemic: A comprehensive critical review. In High Performance Computing for Intelligent Medical Systems; IOP Publishing: Bristol, UK, 2021; pp. 5-1–5-25. [Google Scholar] [CrossRef]
- Steele, A.J.; Denaxas, S.C.; Shah, A.D.; Hemingway, H.; Luscombe, N.M. Machine learning models in electronic health records can outperform conventional survival models for predicting patient mortality in coronary artery disease. PLoS ONE 2018, 13, e0202344. [Google Scholar] [CrossRef] [PubMed]
- Alimadadi, A.; Aryal, S.; Manandhar, I.; Munroe, P.B.; Joe, B.; Cheng, X. Artificial intelligence and machine learning to fight COVID-19. Physiol. Genom. 2020, 52, 200–202. [Google Scholar] [CrossRef] [PubMed]
- Pickering, B.W.; Dong, Y.; Ahmed, A.; Giri, J.; Kilickaya, O.; Gupta, A.; Gajic, O.; Herasevich, V. The implementation of clinician designed, human-centered electronic medical record viewer in the intensive care unit: A pilot step-wedge cluster randomized trial. Int. J. Med. Inf. Inform. 2015, 84, 299–307. [Google Scholar] [CrossRef]
- Nemati, M.; Ansary, J.; Nemati, N. Machine-Learning Approaches in COVID-19 Survival Analysis and Discharge-Time Likelihood Prediction Using Clinical Data. Patterns 2020, 1, 100074. [Google Scholar] [CrossRef] [PubMed]
- Hong, Y.; Wu, X.; Qu, J.; Gao, Y.; Chen, H.; Zhang, Z. Clinical characteristics of Coronavirus Disease 2019 and development of a prediction model for prolonged hospital length of stay. Ann. Transl. Med. 2020, 8, 443. [Google Scholar] [CrossRef]
- Ebinger, J.; Wells, M.; Ouyang, D.; Davis, T.; Kaufman, N.; Cheng, S.; Chugh, S. A Machine Learning Algorithm Predicts Duration of hospitalization in COVID-19 patients. Intell. Based Med. 2021, 5, 100035. [Google Scholar] [CrossRef]
- Usher, M.G.; Tourani, R.; Simon, G.; Tignanelli, C.; Jarabek, B.; Strauss, C.E.; Waring, S.C.; Klyn, N.A.M.; Kealey, B.T.; Tambyraja, R.; et al. Overcoming gaps: Regional collaborative to optimize capacity management and predict length of stay of patients admitted with COVID-19. JAMIA Open 2021, 4, ooab055. [Google Scholar] [CrossRef]
- Mahboub, B.; Bataineh, M.T.A.; Alshraideh, H.; Hamoudi, R.; Salameh, L.; Shamayleh, A. Prediction of COVID-19 Hospital Length of Stay and Risk of Death Using Artificial Intelligence-Based Modeling. Front. Med. 2021, 8, 592336. [Google Scholar] [CrossRef]
- Liuzzi, P.; Campagnini, S.; Fanciullacci, C.; Arienti, C.; Patrini, M.; Carrozza, M.C.; Mannini, A. Predicting SARS-CoV-2 infection duration at hospital admission:a deep learning solution. Med. Biol. Eng. Comput. 2022, 60, 459–470. [Google Scholar] [CrossRef]
- Orooji, A.; Shanbehzadeh, M.; Mirbagheri, E.; Kazemi-Arpanahi, H. Comparing artificial neural network training algorithms to predict length of stay in hospitalized patients with COVID-19. BMC Infect. Dis. 2022, 22, 923. [Google Scholar] [CrossRef]
- Alabbad, D.A.; Almuhaideb, A.M.; Alsunaidi, S.J.; Alqudaihi, K.S.; Alamoudi, F.A.; Alhobaishi, M.K.; Alaqeel, N.A.; Alshahrani, M.S. Machine learning model for predicting the length of stay in the intensive care unit for COVID-19 patients in the eastern province of Saudi Arabia. Inf. Inform. Med. Unlocked 2022, 30, 100937. [Google Scholar] [CrossRef]
- Alam, F.; Ananbeh, O.; Malik, K.M.; Odayani, A.A.; Hussain, I.B.; Kaabia, N.; Aidaroos, A.A.; Saudagar, A.K.J. Towards Predicting Length of Stay and Identification of Cohort Risk Factors Using Self-Attention-Based Transformers and Association Mining: COVID-19 as a Phenotype. Diagnostics 2023, 13, 1760. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Li, L.; Hu, X.; Cui, G.; Sun, R.; Zhang, D.; Li, J.; Li, Y.; Shen, S.; He, P.; et al. Development of a model by LASSO to predict hospital length of stay (LOS) in patients with the SARS-CoV-2 omicron variant. Virulence 2023, 14, 2196177. [Google Scholar] [CrossRef] [PubMed]
- Wolkewitz, M.; Allignol, A.; Harbarth, S.; de Angelis, G.; Schumacher, M.; Beyersmann, J. Time-dependent study entries and exposures in cohort studies can easily be sources of different and avoidable types of bias. J. Clin. Epidemiol. 2012, 65, 1171–1180. [Google Scholar] [CrossRef] [PubMed]
- Pepe, M.S. The Statistical Evaluation of Medical Tests for Classification and Prediction; Oxford University Press: Oxford, UK; New York, NY, USA, 2003; 302p. [Google Scholar]
- Steyerberg, E.W. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating; Springer: New York, NY, USA, 2019; p. 558. [Google Scholar]
- Sami, R.; Soltaninejad, F.; Amra, B.; Naderi, Z.; Haghjooy Javanmard, S.; Iraj, B.; Haji Ahmadi, S.; Shayganfar, A.; Dehghan, M.; Khademi, N.; et al. A one-year hospital-based prospective COVID-19 open-cohort in the Eastern Mediterranean region: The Khorshid COVID Cohort (KCC) study. PLoS ONE 2020, 15, e0241537. [Google Scholar] [CrossRef]
- Charlson, M.E.; Pompei, P.; Ales, K.L.; MacKenzie, C.R. A new method of classifying prognostic comorbidity in longitudinal studies: Development and validation. J. Chronic Dis. 1987, 40, 373–383. [Google Scholar] [CrossRef]
- Glasheen, W.P.; Cordier, T.; Gumpina, R.; Haugh, G.; Davis, J.; Renda, A. Charlson Comorbidity Index: ICD-9 Update and ICD-10 Translation. Am. Health Drug Benefits 2019, 12, 188–197. [Google Scholar]
- Comoglu, S.; Kant, A. Does the Charlson comorbidity index help predict the risk of death in COVID-19 patients? North. Clin. Istanb. 2022, 9, 117–121. [Google Scholar] [CrossRef]
- Walker, H.; Hall, W.; Hurst, J. Clinical Methods: The History, Physical, and Laboratory Examinations, 3rd ed.; Butterworths: Boston, MA, USA, 1990. [Google Scholar]
- Guan, W.J.; Ni, Z.Y.; Hu, Y.; Liang, W.H.; Ou, C.Q.; He, J.X.; Liu, L.; Shan, H.; Lei, C.L.; Hui, D.S.C.; et al. Clinical Characteristics of Coronavirus Disease 2019 in China. N. Engl. J. Med. 2020, 382, 1708–1720. [Google Scholar] [CrossRef]
- Mansourian, M.; Marateb, H.R.; Mansourian, M.; Mohebbian, M.R.; Binder, H.; Mañanas, M.Á. Rigorous performance assessment of computer-aided medical diagnosis and prognosis systems: A biostatistical perspective on data mining. Model. Anal. Act. Biopotential Signals Healthc. 2020, 2, 17-11–17-24. [Google Scholar] [CrossRef]
- Giavarina, D. Understanding Bland Altman analysis. Biochem. Med. 2015, 25, 141–151. [Google Scholar] [CrossRef] [PubMed]
- Ofori-Asenso, R.; Liew, D.; Mårtensson, J.; Jones, D. The Frequency of, and Factors Associated with Prolonged Hospitalization: A Multicentre Study in Victoria, Australia. J. Clin. Med. 2020, 9, 3055. [Google Scholar] [CrossRef]
- Madala, H.R.; Ivakhnenko, A.G.e. Inductive Learning Algorithms for Complex Systems Modeling; CRC Press: Boca Raton, FL, USA, 1994; p. 368. [Google Scholar]
- Hancock, J.T.; Khoshgoftaar, T.M. Survey on categorical data for neural networks. J. Big Data 2020, 7, 28. [Google Scholar] [CrossRef]
- Yoo, W.; Mayberry, R.; Bae, S.; Singh, K.; Peter He, Q.; Lillard, J.W., Jr. A Study of Effects of MultiCollinearity in the Multivariable Analysis. Int. J. Appl. Sci. Technol. 2014, 4, 9–19. [Google Scholar] [PubMed]
- Beck, A. Introduction to Nonlinear Optimization: Theory, Algorithms, and Applications with MATLAB; Society for Industrial and Applied Mathematics, Mathematical Optimization Society: Philadelphia, PA, USA, 2014; p. 282. [Google Scholar]
- Jain, R.K. Ridge regression and its application to medical data. Comput. Biomed. Res. 1985, 18, 363–368. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Lawrence, I.K.L. A Concordance Correlation Coefficient to Evaluate Reproducibility. Biometrics 1989, 45, 255–268. [Google Scholar] [CrossRef]
- Rees, E.M.; Nightingale, E.S.; Jafari, Y.; Waterlow, N.R.; Clifford, S.; Pearson, C.A.B.; Group, C.W.; Jombart, T.; Procter, S.R.; Knight, G.M. COVID-19 length of hospital stay: A systematic review and data synthesis. BMC Med. 2020, 18, 270. [Google Scholar] [CrossRef]
- Chicco, D.; Tötsch, N.; Jurman, G. The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min. 2021, 14, 13. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Collins, G.S.; Reitsma, J.B.; Altman, D.G.; Moons, K.G.M. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD Statement. BMC Med. 2015, 13, 1. [Google Scholar] [CrossRef] [PubMed]
- Yanez, N.D.; Weiss, N.S.; Romand, J.-A.; Treggiari, M.M. COVID-19 mortality risk for older men and women. BMC Public Health 2020, 20, 1742. [Google Scholar] [CrossRef]
- Uchiyama, S.; Sakata, T.; Tharakan, S.; Ishikawa, K. Body temperature as a predictor of mortality in COVID-19. Sci. Rep. 2023, 13, 13354. [Google Scholar] [CrossRef] [PubMed]
- Jin, H.; Yang, S.; Yang, F.; Zhang, L.; Weng, H.; Liu, S.; Fan, F.; Li, H.; Zheng, X.; Yang, H.; et al. Elevated resting heart rates are a risk factor for mortality among patients with coronavirus disease 2019 in Wuhan, China. J. Transl. Int. Med. 2021, 9, 285–293. [Google Scholar] [CrossRef] [PubMed]
- Devgun, J.M.; Zhang, R.; Brent, J.; Wax, P.; Burkhart, K.; Meyn, A.; Campleman, S.; Abston, S.; Aldy, K.; Group, T.I.C.F.S. Identification of Bradycardia Following Remdesivir Administration Through the US Food and Drug Administration American College of Medical Toxicology COVID-19 Toxic Pharmacovigilance Project. JAMA Netw. Open 2023, 6, e2255815. [Google Scholar] [CrossRef]
- Hopkins Tanne, J. US guidelines say blood pressure of 120/80 mm Hg is not “normal”. BMJ 2003, 326, 1104. [Google Scholar] [CrossRef]
- Mejía, F.; Medina, C.; Cornejo, E.; Morello, E.; Vásquez, S.; Alave, J.; Schwalb, A.; Málaga, G. Oxygen saturation as a predictor of mortality in hospitalized adult patients with COVID-19 in a public hospital in Lima, Peru. PLoS ONE 2020, 15, e0244171. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, R.; He, G. Hematological findings in coronavirus disease 2019: Indications of progression of disease. Ann. Hematol. 2020, 99, 1421–1428. [Google Scholar] [CrossRef]
- Cheng, L.; Li, H.; Li, L.; Liu, C.; Yan, S.; Chen, H.; Li, Y. Ferritin in the coronavirus disease 2019 (COVID-19): A systematic review and meta-analysis. J. Clin. Lab. Anal. 2020, 34, e23618. [Google Scholar] [CrossRef]
- Stringer, D.; Braude, P.; Myint, P.K.; Evans, L.; Collins, J.T.; Verduri, A.; Quinn, T.J.; Vilches-Moraga, A.; Stechman, M.J.; Pearce, L.; et al. The role of C-reactive protein as a prognostic marker in COVID-19. Int. J. Epidemiol. 2021, 50, 420–429. [Google Scholar] [CrossRef]
- Maradit-Kremers, H.; Nicola, P.J.; Crowson, C.S.; Ballman, K.V.; Jacobsen, S.J.; Roger, V.L.; Gabriel, S.E. Raised erythrocyte sedimentation rate signals heart failure in patients with rheumatoid arthritis. Ann. Rheum. Dis. 2007, 66, 76–80. [Google Scholar] [CrossRef] [PubMed]
- Nakakubo, S.; Unoki, Y.; Kitajima, K.; Terada, M.; Gatanaga, H.; Ohmagari, N.; Yokota, I.; Konno, S. Serum Lactate Dehydrogenase Level One Week after Admission Is the Strongest Predictor of Prognosis of COVID-19: A Large Observational Study Using the COVID-19 Registry Japan. Viruses 2023, 15, 671. [Google Scholar] [CrossRef] [PubMed]
- Krishnasamy, N.; Rajendran, K.; Barua, P.; Ramachandran, A.; Panneerselvam, P.; Rajaram, M. Elevated Liver Enzymes along with Comorbidity Is a High Risk Factor for COVID-19 Mortality: A South Indian Study on 1512 Patients. J. Clin. Transl. Hepatol. 2022, 10, 120–127. [Google Scholar] [CrossRef] [PubMed]
- Yin, L.K.; Tong, K.S. Elevated Alt and Ast in an Asymptomatic Person: What the primary care doctor should do? Malays. Fam. Physician 2009, 4, 98–99. [Google Scholar]
- Hosten, A.O. BUN and Creatinine. In Clinical Methods: The History, Physical, and Laboratory Examinations; Walker, H.K., Hall, W.D., Hurst, J.W., Eds.; Butterworth Publishers: Boston, MA, USA, 1990. [Google Scholar]
- Fine, M.J.; Pratt, H.M.; Obrosky, D.S.; Lave, J.R.; McIntosh, L.J.; Singer, D.E.; Coley, C.M.; Kapoor, W.N. Relation between length of hospital stay and costs of care for patients with community-acquired pneumonia. Am. J. Med. 2000, 109, 378–385. [Google Scholar] [CrossRef]
- White, B.A.; Biddinger, P.D.; Chang, Y.; Grabowski, B.; Carignan, S.; Brown, D.F. Boarding inpatients in the emergency department increases discharged patient length of stay. J. Emerg. Med. 2013, 44, 230–235. [Google Scholar] [CrossRef]
- Chang, R.; Elhusseiny, K.M.; Yeh, Y.-C.; Sun, W.-Z. COVID-19 ICU and mechanical ventilation patient characteristics and outcomes—A systematic review and meta-analysis. PLoS ONE 2021, 16, e0246318. [Google Scholar] [CrossRef]
- Group, I.C.C.; Baillie, J.K.; Joaquin, B.; Abigail, B.; Lucille, B.; Fernando Augusto, B.; Tessa, B.; Aidan, B.; Gail, C.; Barbara Wanjiru, C.; et al. ISARIC COVID-19 Clinical Data Report issued: 27 March 2022. medRxiv 2022. [Google Scholar] [CrossRef]
- Alwafi, H.; Naser, A.Y.; Qanash, S.; Brinji, A.S.; Ghazawi, M.A.; Alotaibi, B.; Alghamdi, A.; Alrhmani, A.; Fatehaldin, R.; Alelyani, A.; et al. Predictors of Length of Hospital Stay, Mortality, and Outcomes Among Hospitalised COVID-19 Patients in Saudi Arabia: A Cross-Sectional Study. J. Multidiscip. Healthc. 2021, 14, 839–852. [Google Scholar] [CrossRef]
- Garbacz, S. Average COVID-19 Hospital Stay Greater than Three Weeks. Available online: https://www.kpcnews.com/covid-19/article_8ab408ad-8fb0-5f74-8d57-11e586bd8a4f.html (accessed on 26 August 2023).
- Nguyen, N.T.; Chinn, J.; De Ferrante, M.; Kirby, K.A.; Hohmann, S.F.; Amin, A. Male gender is a predictor of higher mortality in hospitalized adults with COVID-19. PLoS ONE 2021, 16, e0254066. [Google Scholar] [CrossRef]
- Commission, E. Hospital Discharges and Length of Stay Statistics. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Hospital_discharges_and_length_of_stay_statistics&oldid=561104#Average_length_of_hospital_stay_for_in-patients (accessed on 26 August 2023).
- Garibaldi, B.T.; Fiksel, J.; Muschelli, J.; Robinson, M.L.; Rouhizadeh, M.; Perin, J.; Schumock, G.; Nagy, P.; Gray, J.H.; Malapati, H.; et al. Patient Trajectories Among Persons Hospitalized for COVID-19: A Cohort Study. Ann. Intern. Med. 2021, 174, 33–41. [Google Scholar] [CrossRef]
- Karagiannidis, C.; Mostert, C.; Hentschker, C.; Voshaar, T.; Malzahn, J.; Schillinger, G.; Klauber, J.; Janssens, U.; Marx, G.; Weber-Carstens, S.; et al. Case characteristics, resource use, and outcomes of 10 021 patients with COVID-19 admitted to 920 German hospitals: An observational study. Lancet Respir. Med. 2020, 8, 853–862. [Google Scholar] [CrossRef]
- Alimohamadi, Y.; Sepandi, M.; Taghdir, M.; Hosamirudsari, H. Determine the most common clinical symptoms in COVID-19 patients: A systematic review and meta-analysis. J. Prev. Med. Hyg. 2020, 61, E304–E312. [Google Scholar] [CrossRef]
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef]
- Tan, L.; Wang, Q.; Zhang, D.; Ding, J.; Huang, Q.; Tang, Y.-Q.; Wang, Q.; Miao, H. Lymphopenia predicts disease severity of COVID-19: A descriptive and predictive study. Signal Transduct. Target. Ther. 2020, 5, 33. [Google Scholar] [CrossRef]
- Henry, B.; Cheruiyot, I.; Vikse, J.; Mutua, V.; Kipkorir, V.; Benoit, J.; Plebani, M.; Bragazzi, N.; Lippi, G. Lymphopenia and neutrophilia at admission predicts severity and mortality in patients with COVID-19: A meta-analysis. Acta Biomed. 2020, 91, e2020008. [Google Scholar] [CrossRef]
- Chen, R.; Sang, L.; Jiang, M.; Yang, Z.; Jia, N.; Fu, W.; Xie, J.; Guan, W.; Liang, W.; Ni, Z.; et al. Longitudinal hematologic and immunologic variations associated with the progression of COVID-19 patients in China. J. Allergy Clin. Immunol. 2020, 146, 89–100. [Google Scholar] [CrossRef]
- Liang, J.; Nong, S.; Jiang, L.; Chi, X.; Bi, D.; Cao, J.; Mo, L.; Luo, X.; Huang, H. Correlations of disease severity and age with hematology parameter variations in patients with COVID-19 pre- and post-treatment. J. Clin. Lab. Anal. 2021, 35, e23609. [Google Scholar] [CrossRef]
- Gelzo, M.; Cacciapuoti, S.; Pinchera, B.; De Rosa, A.; Cernera, G.; Scialò, F.; Mormile, M.; Fabbrocini, G.; Parrella, R.; Gentile, I.; et al. Prognostic Role of Neutrophil to Lymphocyte Ratio in COVID-19 Patients: Still Valid in Patients That Had Started Therapy? Front. Public Health 2021, 9, 664108. [Google Scholar] [CrossRef]
- Rubio-Rivas, M.; Mora-Luján, J.M.; Formiga, F.; Corrales González, M.; García Andreu, M.D.M.; Moreno-Torres, V.; García García, G.M.; Alcalá Pedrajas, J.N.; Boixeda, R.; Pérez-Lluna, L.; et al. Clusters of inflammation in COVID-19: Descriptive analysis and prognosis on more than 15,000 patients from the Spanish SEMI-COVID-19 Registry. Intern. Emerg. Med. 2022, 17, 1115–1127. [Google Scholar] [CrossRef]
- Coccheri, S. COVID-19: The crucial role of blood coagulation and fibrinolysis. Intern. Emerg. Med. 2020, 15, 1369–1373. [Google Scholar] [CrossRef]
- Martín-Rojas, R.M.; Pérez-Rus, G.; Delgado-Pinos, V.E.; Domingo-González, A.; Regalado-Artamendi, I.; Alba-Urdiales, N.; Demelo-Rodríguez, P.; Monsalvo, S.; Rodríguez-Macías, G.; Ballesteros, M.; et al. COVID-19 coagulopathy: An in-depth analysis of the coagulation system. Eur. J. Haematol. 2020, 105, 741–750. [Google Scholar] [CrossRef]
- Rodriguez-Morales, A.J.; Cardona-Ospina, J.A.; Gutiérrez-Ocampo, E.; Villamizar-Peña, R.; Holguin-Rivera, Y.; Escalera-Antezana, J.P.; Alvarado-Arnez, L.E.; Bonilla-Aldana, D.K.; Franco-Paredes, C.; Henao-Martinez, A.F.; et al. Clinical, laboratory and imaging features of COVID-19: A systematic review and meta-analysis. Travel Med. Infect. Dis. 2020, 34, 101623. [Google Scholar] [CrossRef]
- Lu, R.; Qin, J.; Wu, Y.; Wang, J.; Huang, S.; Tian, L.; Zhang, T.; Wu, X.; Huang, S.; Jin, X.; et al. Epidemiological and clinical characteristics of COVID-19 patients in Nantong, China. J. Infect. Dev. Ctries. 2020, 14, 440–446. [Google Scholar] [CrossRef]
- Henry, B.M.; de Oliveira, M.H.S.; Benoit, S.; Plebani, M.; Lippi, G. Hematologic, biochemical and immune biomarker abnormalities associated with severe illness and mortality in coronavirus disease 2019 (COVID-19): A meta-analysis. Clin. Chem. Lab. Med. 2020, 58, 1021–1028. [Google Scholar] [CrossRef]
- Zhang, Z.L.; Hou, Y.L.; Li, D.T.; Li, F.Z. Laboratory findings of COVID-19: A systematic review and meta-analysis. Scand. J. Clin. Lab. Investig. 2020, 80, 441–447. [Google Scholar] [CrossRef]
- Tan, L.; Xu, Q.; Li, C.; Chen, X.; Bai, H. Association Between the Admission Serum Bicarbonate and Short-Term and Long-Term Mortality in Acute Aortic Dissection Patients Admitted to the Intensive Care Unit. Int. J. Gen. Med. 2021, 14, 4183–4195. [Google Scholar] [CrossRef]
- Erbel, R. Hypotensive Systolic Blood Pressure Predicts Severe Complications and In-Hospital Mortality in Acute Aortic Dissection. J. Am. Coll. Cardiol. 2018, 71, 1441–1443. [Google Scholar] [CrossRef]
- Al-Kindi, S.G.; Sarode, A.; Zullo, M.; Rajagopalan, S.; Rahman, M.; Hostetter, T.; Dobre, M. Serum Bicarbonate Concentration and Cause-Specific Mortality: The National Health and Nutrition Examination Survey 1999-2010. Mayo Clin. Proc. 2020, 95, 113–123. [Google Scholar] [CrossRef]
- GMDH-Methodology and Implementation in MATLAB; Imperial College Press: London, UK, 2014; p. 284.
- Sterne, J.A.C.; White, I.R.; Carlin, J.B.; Spratt, M.; Royston, P.; Kenward, M.G.; Wood, A.M.; Carpenter, J.R. Multiple imputation for missing data in epidemiological and clinical research: Potential and pitfalls. BMJ 2009, 338, b2393. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R. Improvements on Cross-Validation: The 632+ Bootstrap Method. J. Am. Stat. Assoc. 1997, 92, 548–560. [Google Scholar] [CrossRef]
- Soda, P.; D’Amico, N.C.; Tessadori, J.; Valbusa, G.; Guarrasi, V.; Bortolotto, C.; Akbar, M.U.; Sicilia, R.; Cordelli, E.; Fazzini, D.; et al. AIforCOVID: Predicting the clinical outcomes in patients with COVID-19 applying AI to chest-X-rays. An Italian multicentre study. Med. Image Anal. 2021, 74, 102216. [Google Scholar] [CrossRef]
- Rani, G.; Misra, A.; Dhaka, V.S.; Buddhi, D.; Sharma, R.K.; Zumpano, E.; Vocaturo, E. A multi-modal bone suppression, lung segmentation, and classification approach for accurate COVID-19 detection using chest radiographs. Intell. Syst. Appl. 2022, 16, 200148. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
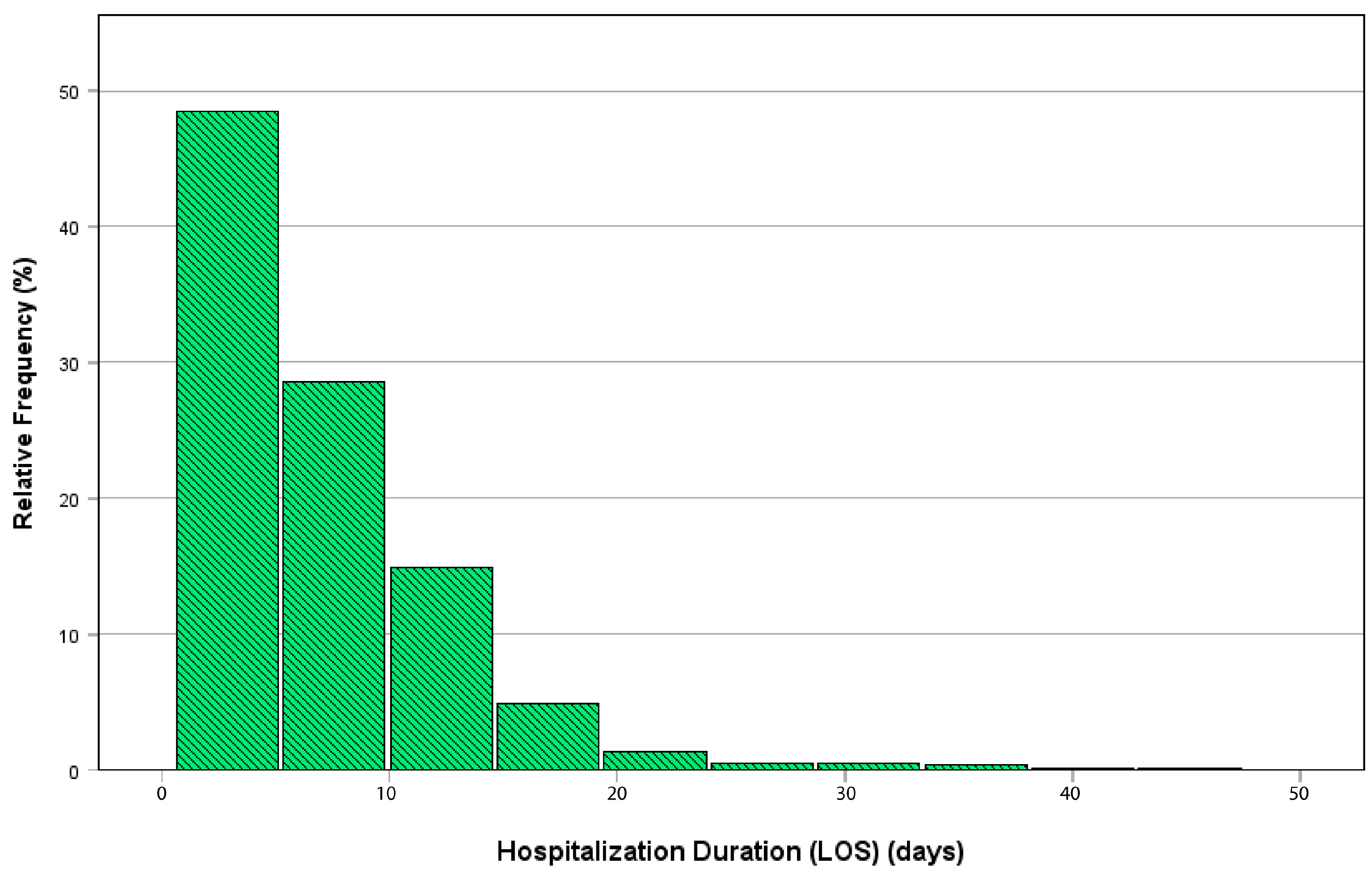
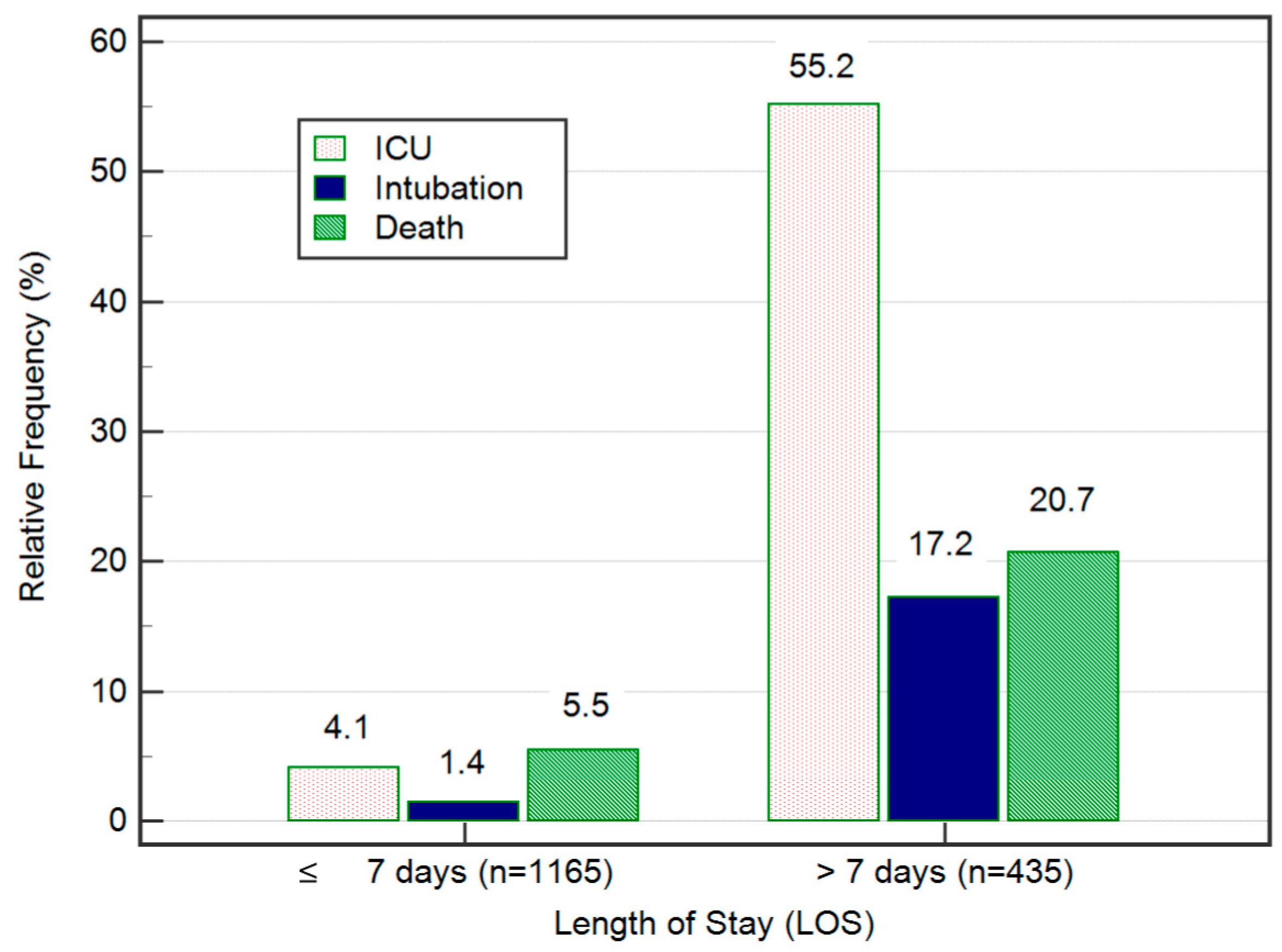
| Parameters | Total (n = 1600) | Length of Stay (LOS) | p-Value b | |
|---|---|---|---|---|
| ≤7 Days “Normal” (n = 1165) | >7 Days “Prolonged” (n = 435) | |||
| LOS, days a | 6.01 (4.85) | 3.76 (1.94) | 12.11 (5.09) | <0.001 |
| Age (>65 years) | 562 (56.10%) | 507 (43.50%) | 55 (12.60%) | <0.001 |
| Gender (% Female) | 670 (48.80%) | 464 (39.80%) | 206 (47.30%) | 0.001 |
| Charlson Comorbidity Index (CCI) a | 2.67 (2.13) | 2.49 (2.11) | 3.13 (2.13) | <0.001 |
| Temperature maximum (≥38 degrees Celsius) | 412 (25.75%) | 322 (23.64%) | 90 (20.68%) | 0.745 |
| Heart rate, beats per minute (<60 or >100) | 478 (53.98%) | 388 (33.3%) | 90 (20.68%) | 0.028 |
| Respiratory rate, breaths per minute a | 22.41 (5.67) | 22.02 (5.27) | 23.49 (6.56) | 0.006 |
| Systolic blood pressure (≥120 mmHg) | 574 (35.80%) | 247 (21.01%) | 277 (63.70%) | <0.001 |
| Diastolic blood pressure (≥90 mmHg) | 218 (13.60%) | 113 (9.60%) | 105 (24.10%) | 0.046 |
| % O2 saturation minimum (<90) | 754 (47.10%) | 606 (52.01%) | 148 (34.02%) | 0.001 |
| Neutrophils (<4 × 109/L) | 956 (59.75%) | 620 (53.22%) | 336 (77.20%) | 0.028 |
| Lymphocytes (<1 × 109/L) | 900 (96.40%) | 621 (53.30%) | 279 (64.10%) | 0.028 |
| Hemoglobin (<12 g/dL) | 356 (22.30%) | 293 (20.50%) | 63 (14.40%) | 0.085 |
| Platelets (<150 × 109/L) | 678 (59.75%) | 480 (41.20%) | 198 (45.51%) | 0.142 |
| Ferritin (>500 ng/mL) | 94 (5.80%) | 72 (6.01%) | 22 (5.05%) | 0.298 |
| CRP (>30 mg/L) | 685 (42.80%) | 542 (46.52%) | 143 (32.87%) | 0.017 |
| ESR (>60 mm/h) | 420 (26.30%) | 245 (21.03%) | 175 (40.20%) | 0.027 |
| LDH (>222 U/L) | 672 (42.00%) | 416 (35.70%) | 256 (58.80%) | 0.046 |
| D-dimer (>0.5 mg/L) | 381 (23.80%) | 95 (8.20%) | 286 (65.70%) | 0.036 |
| AST (>35 IU/L) | 1156 (72.30%) | 749 (64.30%) | 407 (93.50%) | 0.330 |
| HCO3 (mEq/L) | 23.65 (3.67) | 17.25 (3.76) | 20.45 (2.78) | 0.0123 |
| ALT (>45 IU/L) | 401 (25.10%) | 305 (26.18%) | 96 (22.06%) | 0.204 |
| Creatinine (>1 mg/dL) | 822 (51.40%) | 591 (45.40%) | 231 (53.10%) | <0.001 |
| Phosphorus (mg/dL) a | 3.06 (0.85) | 2.97 (0.85) | 3.24 (0.81) | <0.001 |
| Magnesium (mg/dL) a | 1.96 (0.51) | 1.95 (0.27) | 1.99 (0.74) | 0.335 |
| Sodium (mEq/L) a | 136.30 (4.13) | 136.42 (3.94) | 136.09 (4.46) | 0.054 |
| Potassium (mEq/L) a | 4.02 (0.56) | 3.99 (0.54) | 4.08 (0.60) | 0.055 |
| BUN (mg/dL) a | 19.79 (13.47) | 18.67 (12.37) | 21.92 (15.13) | <0.001 |
| Total bilirubin (mg/dL) a | 1.03 (2.17) | 1.06 (2.61) | 0.98 (0.61) | 0.361 |
| Symptoms | Total | Length of Stay | p-Value a | |
|---|---|---|---|---|
| ≤7 Days “Normal” (n = 1165) | >7 Days “Prolonged” (n = 435) | |||
| Fever | 1118 (69.9%) | 721 (61.9%) | 397 (91.3%) | < 0.001 |
| Cough | 1125 (70.3%) | 990 (85.0%) | 135 (31.0%) | < 0.001 |
| Myalgia | 838 (52.4%) | 562 (48.2%) | 276 (63.4%) | < 0.001 |
| Throat pain | 255 (15.9%) | 168 (14.4%) | 87 (20.0%) | 0.058 |
| Weight Loss | 259 (16.2%) | 164 (14.1%) | 95 (21.8%) | 0.018 |
| Chest pain | 394 (24.6%) | 279 (23.9%) | 115 (26.4%) | 0.365 |
| Dizziness | 97 (6.1%) | 64 (5.5%) | 33 (7.6%) | 0.540 |
| Headache | 515 (32.2%) | 372 (31.9%) | 143 (32.9%) | 0.112 |
| Loss of smell and taste | 186 (11.6%) | 134 (11.5%) | 52 (12.0%) | 0.260 |
| Diarrhea | 377 (23.6%) | 247 (21.2%) | 130 (29.9%) | 0.113 |
| Vomiting | 352 (22.0%) | 233 (20.0%) | 119 (27.4%) | 0.478 |
| Nausea | 543 (33.9%) | 373 (32.0%) | 170 (39.1%) | 0.518 |
| Shortness of breath | 995 (62.2%) | 646 (55.5%) | 349 (80.2%) | 0.032 |
| Stomachache | 243 (15.2%) | 166 (14.2%) | 77 (17.7%) | 0.393 |
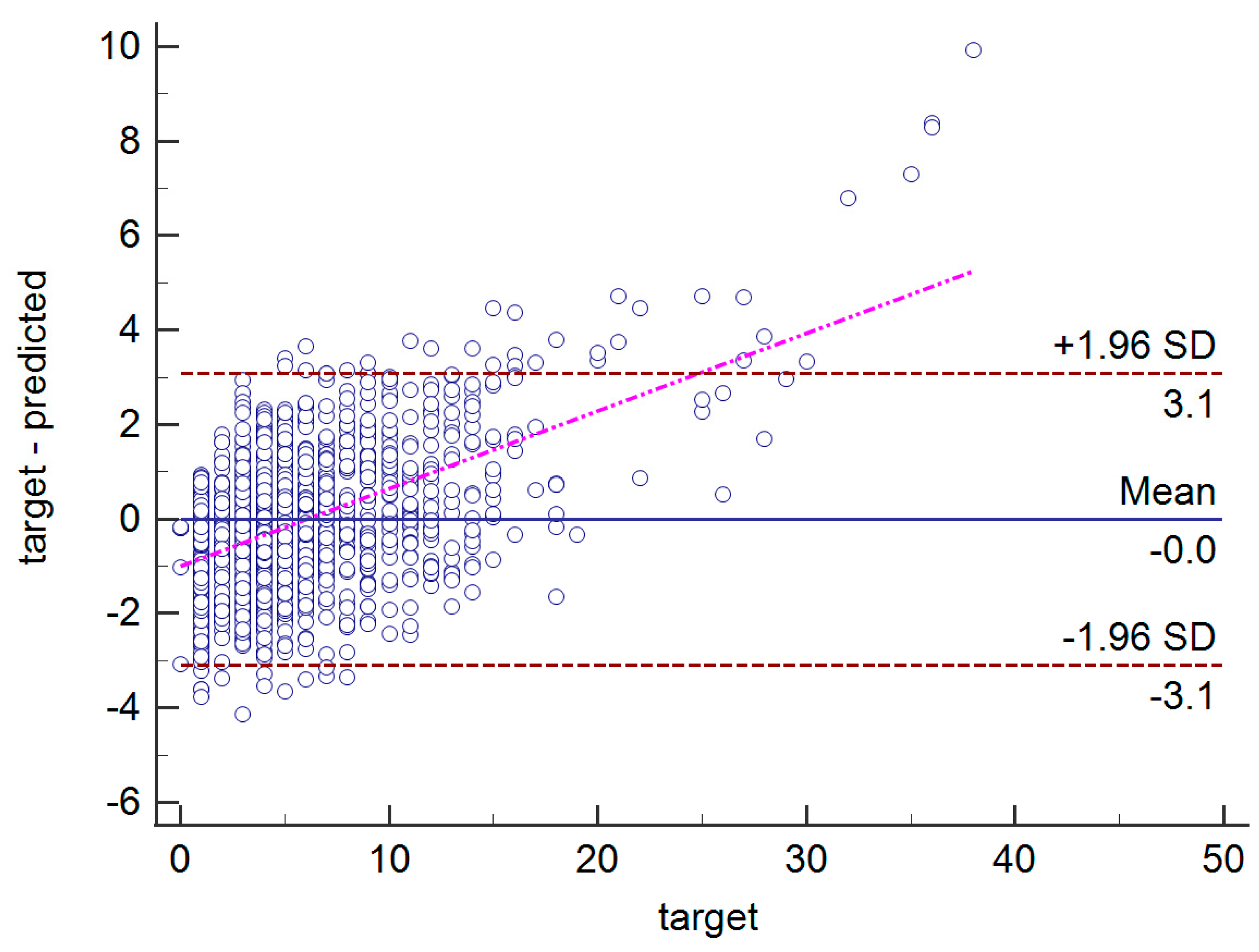
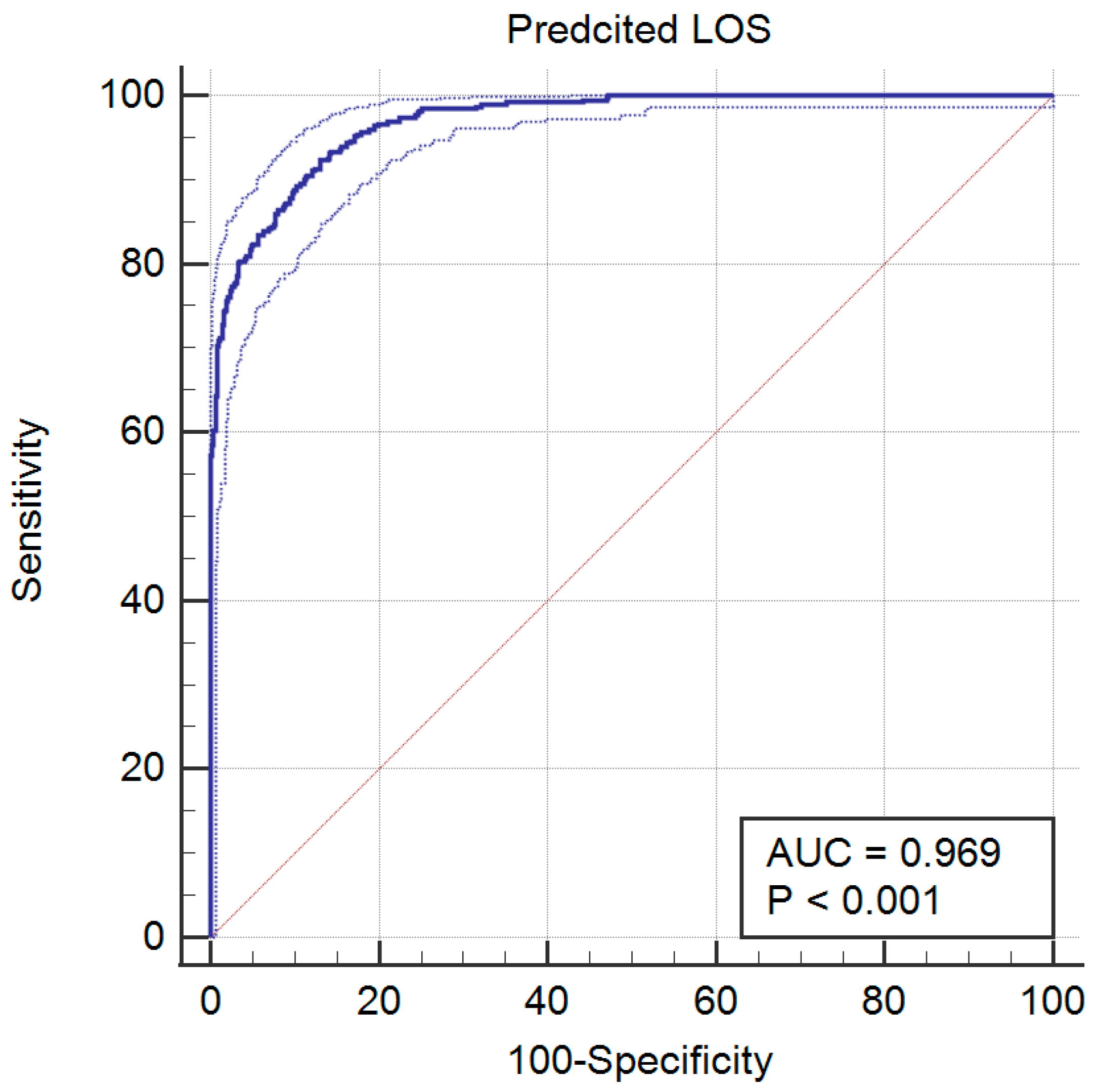
| Indices | RMSE | MAE1 | MAE2 | R2 | adj. R2 | Se | Sp | PPV | DOR | AUC | F1 | MCC | K(C) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1.58 | 1.22 | 0.98 | 89 | 81 | 94 | 92 | 91 | 79 | 112 | 91 | 80 | 79 | 79 |
| 95% CI-Lower | 1.51 | 1.16 | 0.92 | 88 | 79 | 93 | 89 | 89 | 75 | 71 | 89 | 76 | 77 | 75 |
| 95% CI-Upper | 1.64 | 1.28 | 1.05 | 91 | 84 | 95 | 95 | 93 | 83 | 179 | 94 | 85 | 81 | 83 |
| Reference | Center/Region | Sample Size | Inputs | Important Features | Outputs | Models | Validation | Indices (the Best Method) | Important Characteristics |
|---|---|---|---|---|---|---|---|---|---|
| Ebinger et al., 2021 [17] | Cedars-Sinai Medical Center (Los Angeles), USA | 966 | 353 variables | Age, respiratory rate, oxygen flow rate | LOS > 8 days vs. LOS ≤ 8 days | 42 models | 20% Hold-out | Se = 93% Sp = 63% F1 = 78% PPV = 67% AUC = 0.82 | Missing imputation; cumulative day three information was used. |
| Hong et al., 2020 [16] | A tertiary care hospital in Zhejiang province, China | 75 | 37 variables | Lymphocyte count, heart rate, cough, Epidermis, procalcitonin; | LOS > 14 days vs. LOS ≤ 14 days | Stepwise multivariable regression | No internal or external validation | AUC = 0.85 [CI 95: 0.75–0.94] | Missing imputation; |
| Orooji et al., 2022 [21] | Ayatollah Taleghani Hospital, Abadan, Iran | 1225 | 53 variables | 20 variables: Age, creatinine, WBC, lymphocyte/neutrophil count, BUN, ASP, ALT, LDH, activated PTT, coughing, hypertension, CVD, diabetes, dyspnea, oxygen therapy, pneumonia, GI complications, ESR, and CRP. | LOS | Statistical feature selection (correlation coefficient)+ MLP+ 12 training algorithms | 10% Hold-out | RMSE = 1.6213 (days) | Patients who died within three days of admission were excluded (n = 128); selection bias. Missing data imputation. |
| Zhang et al., 2023 [24] | Zhengzhou University Hospital (Henan), China | 384 | 83 variables | Immunotherapy, heparin, familial cluster, rhinorrhea (runny nose), and APTT | LOS | LASSO+ linear regression | Bootstrap validation (N = 2000) | R2 = 0.30 | Missing data imputation (10 imputations); |
| Alabbad et al., 2022 [22] | King Fahad University hospital, Saudi Arabia | 895 | 43 variables | Age, C-reactive protein (CRP), nasal oxygen support days | 9-class ICU LOS | Random forest (RF) (the best classifier), gradient boosting (GB), extreme gradient boosting (XGBoost), and ensemble models | 3-fold cross-validation | PPV = 94% Se = 94% F1 = 94% | Missing data imputation; SMOTE was used to balance nine classes to have 144 records each, biased performance indices. The original samples ranged from 12 to 144 for the classes; no admission date was provided. |
| Nemati et al., 2020 [15] | Global dataset | 1182 | Five variables | Age, sex | LOS | Stagewise GB (the best method), IPCRidge, CoxPH, Coxnet, Componentwise GB, Fast SVM, Fast Kernel SVM | No internal or external validation | C-index = 0.71 | No comprehensive features except symptoms onset date, symptoms, and chronic disease binary variable |
| Usher et al., 2021 [18] | 36 hospitals (Minnesota, Wisconsin, and the Dakotas) | 2665 | 20 variables | Various variables, including age, critical illness, oxygen requirement, weight loss, and nursing home admission | LOS at >5, >10 and >15 days | GLM, RF (the best model) | 5-fold cross-validation | AUC = 0.89 | ICU admission, mechanical ventilation, and mortality risk are among the input features; selection and immortal-time bias. |
| Liuzzi et al., 2022 [20] | 28 centers (Fondazione Don Carlo Gnocchi (FDG) Living COVID-19 Registry), Italy | 222 | 829 | 55 variables: anagraphical data, admission clinical scales, admission signs and symptoms, admission supports, COVID-19 therapy, therapy prior to COVID-19, hematochemics | LOS | Sequential convolutional neural network | Repeated (N = 10) 5-fold cross-validation | MAE2 = 2.7 days (IQR = 3.0 days) | 17 COVID-19 therapies were included in the input data; selection and immortal-time bias. |
| Mahboub et al., 2021 [19] | Rashid Hospital (Dubai), UAE | 2017 | 22 variables | Urea, PLT, D-dimer, K+, anti-inflammatory medicine, antiviral medicine, mechanical ventilation, hemoglobin, azithromycin medicine, vitamin C medicine, painkiller medicine | LOS | Decision Tree | 25% Hold-out | R2 = 0.5 | In addition to mechanical ventilation, treatments were used as input features; selection and immortal-time bias. |
| Alam et al., 2023 [23] | Prince Sultan Hospital (Riyadh), Saudi Arabia | 308 | 89 variables | Laboratory, X-ray, clinical data, and treatments, including LDH and D-dimer levels, lymphocyte count, and comorbidities such as hypertension and diabetes | Seven-class LOS | Tab Transformer | 30% stratified hold-out | Pr = 83%, Se = 93%, F1 = 93% (discharged) Pr = 75%, Se = 98%, F1 = 84% (dead) | SMOTE-N oversampling technique was used to balance the classes and biased performance indices. Treatments, including anticoagulants, antibiotics, antivirals, an immunomodulators, were used as the inputs; selection and immortal-time bias. |
| This study | Khorshid Hospital (Isfahan), Iran | 1600 | 42 | Inflammatory markers (ESR, D-dimer, lymphocyte counts), HCO3, and fever | LOS and also LOS≤ 7 days vs. LOS > 7 days | The Kolmogorov–Gabor polynomial plus regularized least squares | Three-fold cross-validation | LOS: R2 = 0.89 [0.88–0.91], = 0.94 [0.93–0.95], RMSE = 1.58 [1.64–1.51] days MAE1 = 1.22 [1.28–1.16] days, MAE2 = 0.98 [0.92–1.05] days LOS categories: Se = 92% [89–95], Sp = 91% [89–93], PPV = 79% [75–83], AUC = 0.87 [84–89], F1 = 80% [76–85] | No class balancing was used. ICU admission, mechanical ventilation, and treatments were not used as the input features. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marateb, H.; Norouzirad, M.; Tavakolian, K.; Aminorroaya, F.; Mohebbian, M.; Mañanas, M.Á.; Lafuente, S.R.; Sami, R.; Mansourian, M. Predicting COVID-19 Hospital Stays with Kolmogorov–Gabor Polynomials: Charting the Future of Care. Information 2023, 14, 590. https://doi.org/10.3390/info14110590
Marateb H, Norouzirad M, Tavakolian K, Aminorroaya F, Mohebbian M, Mañanas MÁ, Lafuente SR, Sami R, Mansourian M. Predicting COVID-19 Hospital Stays with Kolmogorov–Gabor Polynomials: Charting the Future of Care. Information. 2023; 14(11):590. https://doi.org/10.3390/info14110590
Chicago/Turabian StyleMarateb, Hamidreza, Mina Norouzirad, Kouhyar Tavakolian, Faezeh Aminorroaya, Mohammadreza Mohebbian, Miguel Ángel Mañanas, Sergio Romero Lafuente, Ramin Sami, and Marjan Mansourian. 2023. "Predicting COVID-19 Hospital Stays with Kolmogorov–Gabor Polynomials: Charting the Future of Care" Information 14, no. 11: 590. https://doi.org/10.3390/info14110590