1. Introduction
When endeavoring to develop a data analytics system, one of the foremost and daunting hurdles is acquiring a suitable dataset for the task at hand. It is not only imperative that the dataset encompasses relevant data pertaining to your objective, but it must also be abundant in quantity. Additionally, in numerous cases, these data must be appropriately labeled. This is especially crucial for data analytics systems like anomaly detection, where the dataset needs to distinctly differentiate between normal and anomalous data.
In cases where obtaining real-world data of adequate size to fulfill the requirements of the desired anomaly-detection task proves challenging and there are no feasible means to gather additional data, the only option left is to artificially generate the required data by accurately emulating the target conditions [
1].
Due to the immense scale of these datasets with specific characteristics, including a predefined rate of anomalies, it is not feasible to create them using any other methods besides algorithmic generation. If successfully accomplished, the potential for executing a significantly larger number of anomaly detection tasks should considerably expand as well.
Consequently, the goal of this paper is to construct a diverse set of algorithms (ADG Engine) that have the ability to generate high-quality labelled data that can be readily accessed and utilized by projects focused on anomaly detection.
The objective of the ADG Engine is to achieve this goal by examining five prevalent data platforms employed in data analytics endeavors. For each data platform, ADG Engine will develop an algorithm with the ability to analyze the data and ascertain attributes such as the proportion of abnormal behavior. This will enable us to generate additional data that aligns with the existing dataset. The ADG Engine does not propose or describe anomaly detection techniques, but the data generated by the Engine is used to build anomaly detection techniques. Moreover, the ADG Engine generates a rational database with eight different features compared to the other related work: Unlimited Data Size, Feature Number Flexibility, Anomaly Features, Rational Datasets, Real Data Aspects, User Behavior, No Initial Data Required, and Number of Applications Variety. The ADG Engine does not cover all platforms, but we focus on the most common platforms, and other platforms can be derived from our platform. For example, any financial data can be driven from our credit card data platform, such as debit card data, retail transaction data, and online transaction data.
The significance of the ADG Engine stems from its robust design, which incorporates a synthetic data generation engine based on dual-mode user behavioral data that includes both normal and abnormal instances. Notably, the engine does not necessitate an initial dataset or data distribution. Instead, researchers can provide a normal/abnormal distribution that aids in simulating real-world data aspects. Furthermore, researchers have the flexibility to select relevant features that reflect the interrelationships observed in their research problem. This engine enables the creation of rational datasets for various data applications, and researchers can choose from five different applications. The availability of these features and options sets this engine apart from existing studies, offering researchers the ability to detect anomalies more effectively in future research endeavors [
1]. Given the high likelihood of users utilizing multiple platforms, the ADG Engine considers this factor by generating data from the same user across multiple datasets from different platforms. This approach enables the ADG Engine to better capture real-world data collection scenarios, where individuals rely on various platforms to meet their everyday needs. To accommodate diverse use cases, we aim to make key parameters of the ADG Engine adjustable. For instance, the proportion of generated events that are considered anomalous can be tailored to specific requirements. Additionally, user attributes like marital status and employment status can impact specific dataset features, allowing us to control the generated data by adjusting these attributes. The combination of connecting multiple datasets through individual users and the ability to control the ratio of normal and abnormal behavior provides the ADG Engine with remarkable flexibility and broad applicability. Successful implementation of the engine’s algorithms will enable the creation of effective anomaly detection systems, even when obtaining a large amount of training data is challenging. Furthermore, the principles embedded within the ADG Engine’s algorithms have general applicability to platforms beyond those covered in this study, making them adaptable for generating data for various platforms. The ADG Engine has the following contribution list:
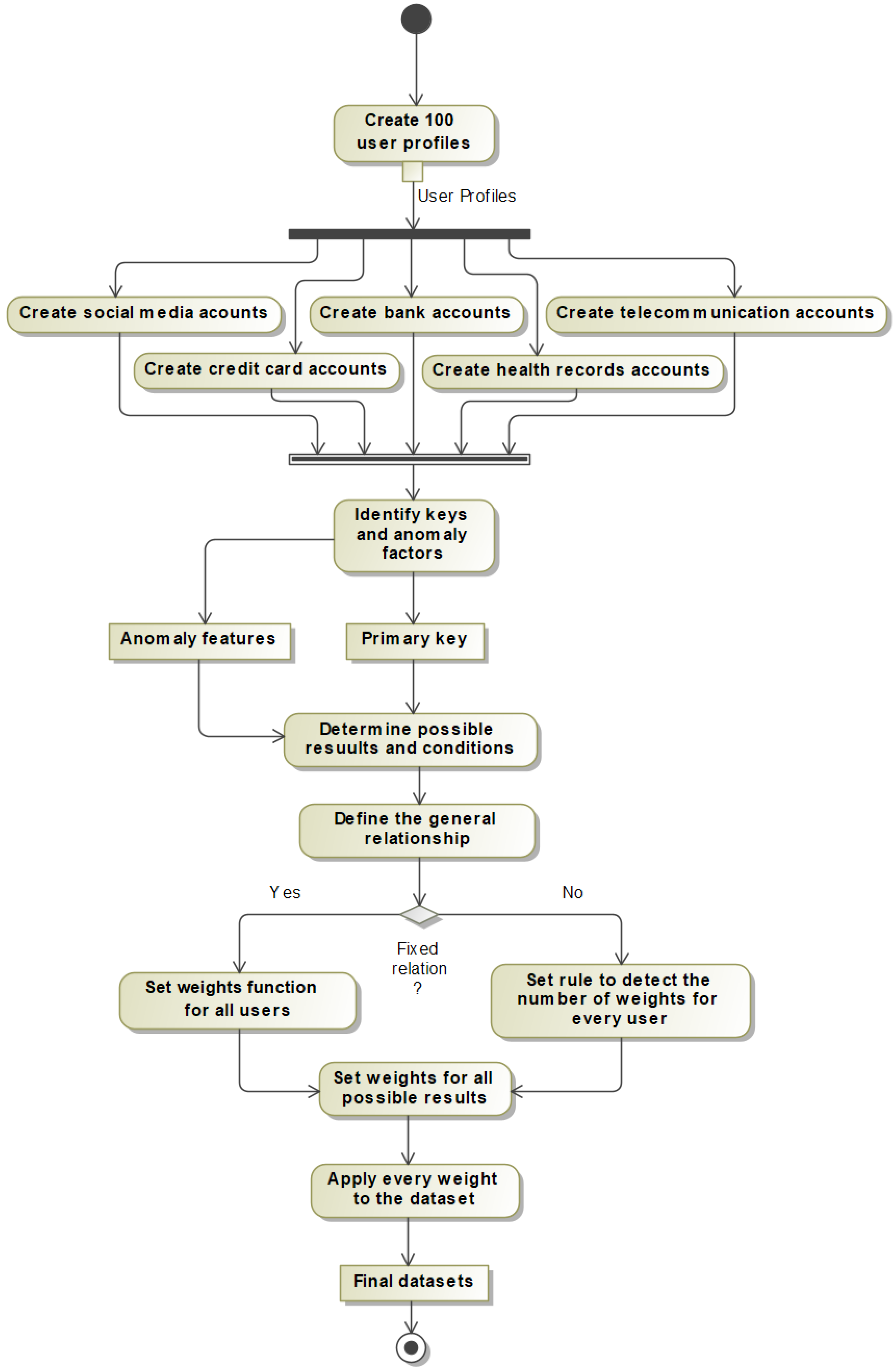
The ADG Engine generated a user dataset holding user general information. Initially it has 100 records that can be increased if needed.
The ADG Engine generated the above dataset for five common data platforms: credit cards, bank accounts, telecommunications, health records, and social media.
Each data platform has attributes that are related to user information or to user behaviors. The ADG Engine classified both types of attributes and used different analyses.
The ADG Engine imported user information from the user dataset and iterated over all users in each data platform.
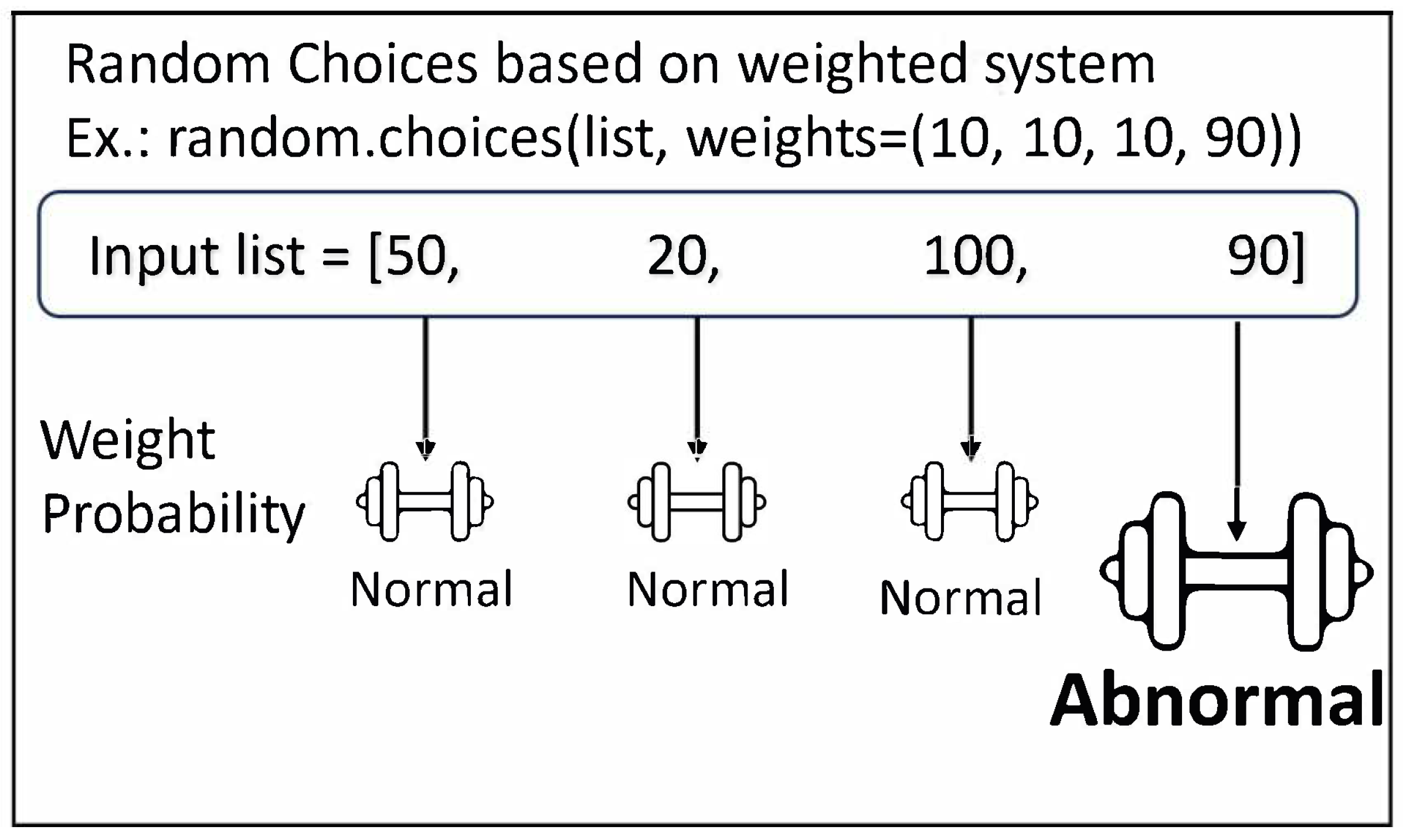
The ADG Engine set up a generation ratio system that can provide the normal/ abnormal ratio for user behavior attributes using weight systems that assign weights to each attribute option.
Based on the user general information dataset, the ADG Engine generated five data platforms with different sizes. The dataset size for each platform is chosen at random from 500,000 to 1 million, and it can be made bigger if needed.
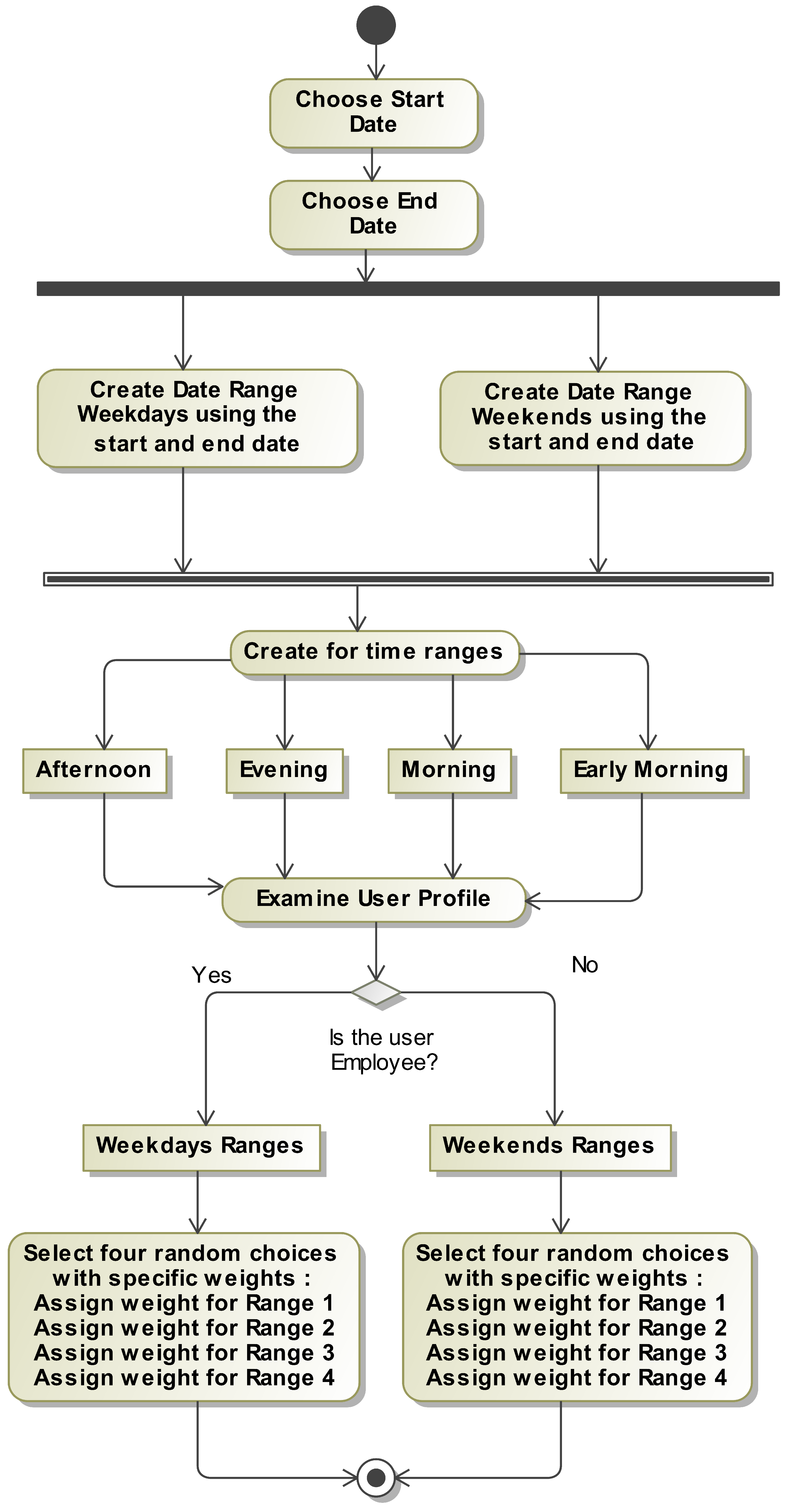
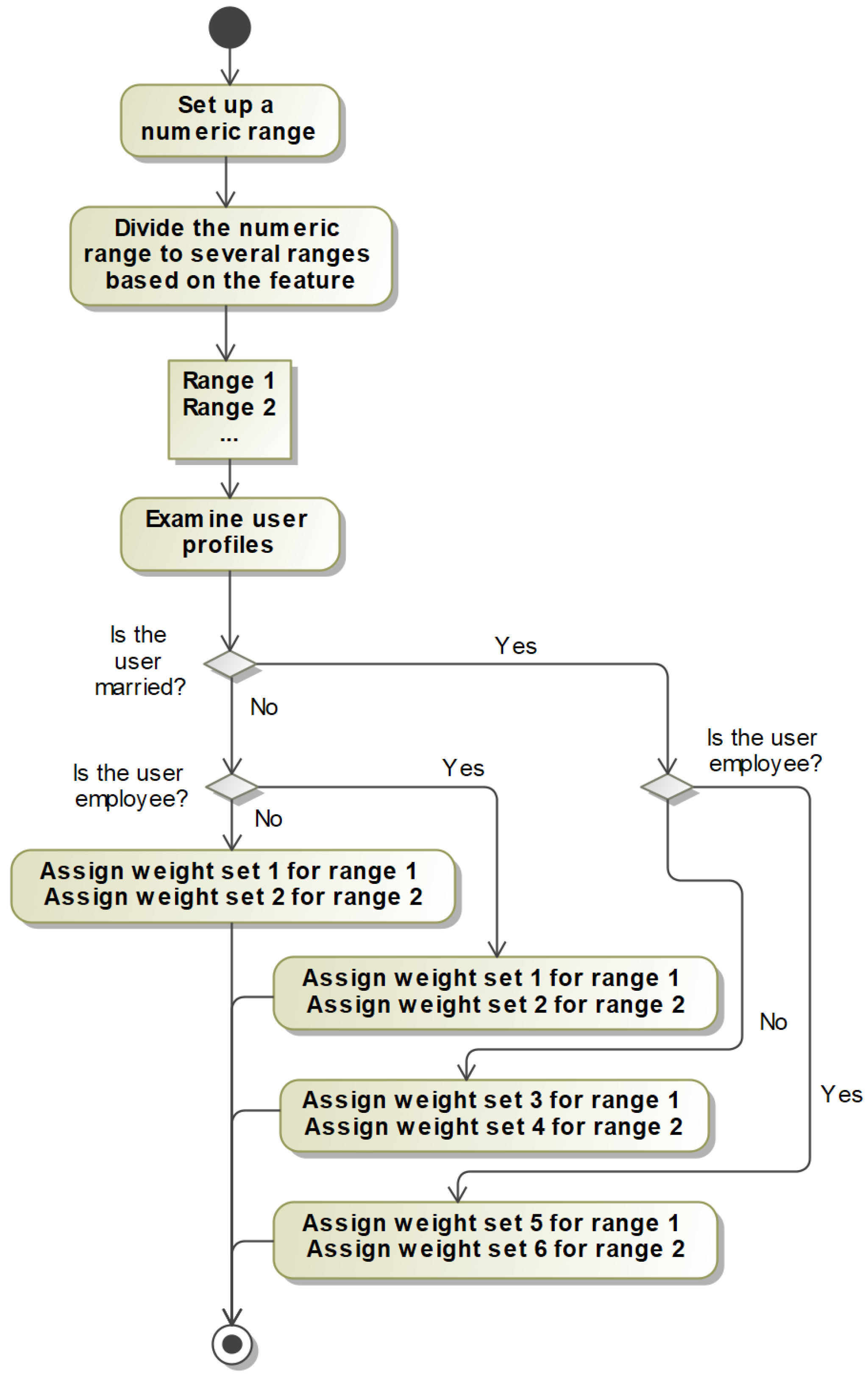
The ADG Engine created two algorithms: the Time-Based Anomaly Generation Process and the Numeric-Based Anomaly Generation Process. These algorithms divided time, dates, and amounts into normal and abnormal instances.
The rest of the paper is structured as follows:
Section 2 centers around the most pertinent research in the field of dataset generation;
Section 3 describes the method we use to generate data.
Section 4 and
Section 5 explore the details and configuration of the model; and, in
Section 6, we test our model and discuss the results.
2. Related Work
There are several papers that use data generation engines or data expansion. In [
2], Patki et al. introduced the Synthetic Data Vault (SDV), a system designed to generate synthetic data for relational databases. Their research focuses on developing generative models that can sample from the model to create synthetic data. The SDV algorithm computes statistics by considering the relationships between different database tables. It utilizes a state-of-the-art multivariate modeling technique to capture the underlying patterns in the data. By iterating through all possible relations, the SDV builds a comprehensive model of the entire database. Once the model is established, the SDV can synthesize data by sampling from any section of the database using the available relational information. This paper accomplishes most of the requirements needed to match the ADG Engine. However, there are still two differences between this paper and the ADG Engine, which are the need for an initial data distribution and anomaly features. The ADG Engine creates the data from scratch and has anomaly features included at user-specified ratios.
Another research study, presented by E. Lopez-Rojas and S. Axelsson [
3], is a BankSim model. BankSim is a software simulation tool that replicates bank payment transactions using combined and summarized data obtained from a bank in Spain. The primary goal of BankSim is to create artificial data that can be effectively employed in studies related to detecting fraudulent activities. To develop and fine-tune the simulation model, statistical analysis and social network analysis (SNA) methods were applied to examine the connections between merchants and customers. The ultimate aim is for BankSim to accurately simulate different scenarios, encompassing both normal payment transactions and pre-defined fraudulent patterns. This work was designed for fraud detection, which is a bit closer to the ADG Engine. There are several differences between the ADG Engine and this model. In terms of data size, this study is limited because it has a fixed amount of observations. The study is not flexible enough to add or remove features based on user design. The research only uses one dataset for all users, which is incompatible with rational datasets. The paper only covers one application, which is the credit card application.
Zhao et al. [
4] developed a Data Generation Algorithm that utilizes complex event processing (CEP) techniques. CEP involves processing real-time data streams and extracting valuable information from events as they occur. The primary objective of complex event processing is to identify significant data patterns in real-time scenarios and promptly respond to them. The authors introduce the concepts of selective event flow, sequential event flow, and causal event flow. Experimental findings demonstrate the effectiveness of this method. This paper has two differences compared to the ADG Engine: anomaly features are not included in this paper, and a variety of applications such as social media and credit cards are not provided either.
Research paper [
5] represents a model of uncertain data and corresponding uncertain data generation algorithms with different types of uncertain data. The analysis and experiments show that the algorithm proposed in their work has practicality as a tool. In contrast to our ADG Engine, research [
5] only shares one feature, which is unlimited data generation quantity, but it does not incorporate any other features present in our Engine.
In their study, Kim et al. [
6] utilize a large-scale location-based social network (LBSN) simulation to establish a framework for simulating human behavior and generating synthetic, yet realistic, LBSN data based on typical human activity patterns. These data encompass not only the geographical locations of users over time but also their interactions within social networks. To simulate patterns of life, the researchers assign agents (representing individuals) a range of "needs" that they strive to fulfill. For instance, agents return home when they are tired, visit restaurants when they are hungry, go to work to meet their financial obligations, and visit recreational sites to socialize with friends and satisfy their social needs. This paper does not apply anomaly features and it doesn’t provide rational datasets. Initial data is required to the data generation process and it is limited to one application domain.
In their research article [
7], the authors introduce a synthetic dataset generator specifically designed for tabular data. This generator has the ability to identify and utilize nonlinear causal relationships among variables during the data generation process. Traditional approaches for discovering nonlinear causalities are often inefficient. To enhance efficiency, the authors limit the causal discovery process to features that appear in frequent patterns obtained through a pattern mining algorithm. To validate their approach, the authors develop a framework for generating synthetic datasets with known causal relationships. Extensive experiments conducted on various synthetic and real datasets with known causalities demonstrate the effectiveness of the proposed method. In this research, they have only two features that match the ADG Engine. The remaining features that are related to abnormal observations or user behavior are not included.
A. Kothare et al. [
8] used an open-source engine named Faker (v5.6.1) and Gaussian copula to create a platform that can generate datasets, based on user requirements as well as available resources. The user can also perform a variety of machine learning algorithms and differentiate their performance over either the generated dataset or a predefined dataset. This research uses a good tool to generate unlimited data observations with features that can be added or deleted, as no initial data are required. However, the real data aspects for abnormal user behavior are not included, which makes this research and the ADG Engine differ in five features.
In ref. [
9], the authors introduce the notion of a shadow database and present a framework for creating a shadow database that closely aligns with the distribution characteristics of a production database. Additionally, they develop and implement an integrated tool for generating synthetic data. This tool utilizes the data distribution profile, including histograms derived from the source data, as input to generate the corresponding shadow database. This research has several features, such as data size and related datasets, but does not include the abnormal data design based on user behavior for several applications.
In ref. [
10], the researchers conducted a study to explore the effectiveness of different synthetic data generation algorithms on various datasets. They examined the impact of SMOTE, Borderline-SMOTE, and random data generation algorithms on 33 datasets. To achieve a comprehensive evaluation, each dataset was fully balanced through synthetic data generation. The datasets were then categorized into three groups based on their balance status: balanced, partially balanced–unbalanced, and unbalanced, according to the unbalanced ratio. This research is more of a study of dataset generators, but the datasets are only applied to dataset size and real data aspects instead of abnormal features for datasets that are based on user behavior.
In their publication [
11], the authors introduced a generative adversarial network (GAN) combined with differential privacy mechanisms to generate a smart healthcare dataset that is both realistic and private. The proposed approach has the ability to generate synthetic data samples that closely resemble real data, while also ensuring privacy through differential privacy techniques. The approach accommodates different scenarios, such as learning from a noisy distribution or adding noise to the learned distribution. The research team validated and assessed the effectiveness of the proposed approach using a real-world Fitbit dataset. This research has real data aspects and a rational dataset structure with unlimited datasets. However, the other abnormal user aspects with several applications are not available in this research.
The article [
12] introduces an original framework designed to create synthetic data. The framework reorganizes the data generation procedure into asynchronous stages, with the goal of enhancing autonomy through two distinct methods. Firstly, programmers are empowered to craft parameterized scripts, allowing for the independent generation of a wide array of datasets. Secondly, the integration of a user interface permits domain experts to exert influence over the generation process autonomously, eliminating the need for programmer intervention. This paper has several features that the ADG Engine has but it is also missing feature flexibility, a rational database, no initial data required, and number of applications.
In the study outlined in reference [
13], the researchers introduce an approach that employs an intrusion detection system (IDS) dataset for the purpose of producing synthetic tabular data representations from the original raw dataset. This approach also tackles the problem of class imbalance during the data generation process. The method involves a feature selection procedure that identifies crucial attributes contributing to precise data generation. Additionally, the study showcases similar performance results in comparison to well-known machine learning (ML) methods when applied to the task of anomaly detection. This study uses an approach to generate unlimited data observations with feature selection that can be added or deleted with real data aspects. However, rational datasets, no initial data required, and a number of applications are not included, which makes this research and the ADG Engine differ in three features.
As described in research paper [
14], the authors introduce a framework for simulating and generating attacks. This framework enables the training of the attack generator using either simulated or authentic attacks in the context of vehicular ad hoc networks (VANETs). The paper outlines the framework’s structure and elucidates the configuration of a compliant attack simulator. This simulator is designed to produce valid CAM and DENM messages adhering to the standardized specifications established by the European Telecommunications Standards Institute (ETSI) within the Cooperative Intelligent Transport Systems (C-ITS) standards. This paper does not apply the following features: feature number flexibility; rational datasets that include several datasets related to each other; initial data are required to generate this data in this paper; and these data are focused on only one application.
In the tutorial provided by Sanghi and Haritsa [
15], a comprehensive exploration of synthetic data generation is offered. The tutorial extensively discusses various classes of frameworks, elucidating both their advantages and constraints. Towards the conclusion, a collection of unresolved technical challenges and potential avenues for future research are outlined. In this research, they have only two features that match the ADG Engine: unlimited data generation and real data aspects.
The study conducted in reference [
16] delves into the examination of conditional tabular generative adversarial networks (CTGANs) for the purpose of generating data. Specifically, the authors employ these networks to synthesize mobile sensor data that encompass both continuous and discrete attributes—an endeavor that previous cutting-edge methods had not yet tackled. The authors demonstrate that the HAR-CTGANs, in particular, yield more realistic data, leading to improved performance in downstream human activity recognition (HAR) models. Moreover, when incorporating the characteristics of HAR-CTGANs into existing state-of-the-art models, the downstream performance is also enhanced. In this research, they have these features that match the ADG Engine: unlimited data generation, feature flexibility number, user behavior, and real data aspects. The other features are missing, such as several applications, no initial data required, and rational datasets.
In article [
17], the author undertook a comprehensive comparison of various Python data generation models and reached several significant conclusions. Firstly, for the task of expanding data from a limited dataset, the DataSynthesizer model emerged as the most effective tool. In scenarios requiring the generation of contact or date information, the Pydbgen and Mimesis models were deemed suitable choices. Similarly, when the objective was to generate relational data, the Synthetic Data Vault (SDV) model demonstrated remarkable suitability. For situations necessitating the creation of data from scratch with a defined data structure, Plaitpy was identified as the preferred model. When dealing with time series data generation, both the TimeSeriesGenerator and SDV models were found to be highly effective. In the realm of AI data generation, Gretel Synthetics and Scikit-learn were identified as the two most commonly used models. For tasks involving agent-based modeling to generate data for complex scenarios, Mesa emerged as the most suitable model. Finally, in the domain of image data generation, Zpy was determined to be the optimal choice.
Among the various approaches employed by synthetic data generation tools, one method involves describing the original dataset through a Bayesian network. This approach, utilized in the open-source tool DataSynthesizer, has shown effectiveness, especially for datasets containing a limited to moderate number of attributes. In study [
18], the authors replaced the conventional greedy algorithm, typically used for learning the Bayesian network, with a significantly faster genetic algorithm. Additionally, the aim is to safeguard highly sensitive attributes by minimizing specific correlations within the synthetic data that could potentially expose personal information.
In study [
19], the authors employed three Python-accessible synthetic data generation packages: the Synthetic Data Vault, DataSynthesizer, and Smartnoise-synth. Various data generation models within these packages were showcased using 13 tabular datasets as sample inputs for generating synthetic data. The authors proceeded to generate synthetic data from each dataset and generator combination, assessing the effectiveness of the generators through analysis of five hypothetical scenarios.
Table 1 shows a comparison of the differences between the ADG Engine and the existing data generation models. The first column is about generating a chosen number of observations in which you can enter any number you want. The second column is the flexibility of choosing a feature that is related to the research or generating more columns. The anomaly features column indicates that the data have injected some anomalous features or observations. The rational datasets feature is differentiated in whether the model is capable of generating multiple datasets related to one user or not. The real data aspect is a column that focuses on making conditions and relations between several features simulate real-world data. User behavior is studying the model that generates all the observations based on the users and has several scenarios to describe the user behavior (such as working scenario, holiday scenario, and weekend scenario). Some models require initial data observations or an initial data distribution to generate more data that are not generated from scratch or at least using libraries. The last column is classifying research papers based on the use of multiple data applications, such as credit card applications, telecommunication applications, and health care applications.
5. Experiment Setup
The primary data platform contains information about each user the ADG Engine tracks. Each row of the data platform represents an individual user. It includes the following features: Name, User ID Function, Phone Number Function, Marital Status Function, Employment Status Function, Job, Company, Social Security Number (SSN), Residence, Current Location, Blood Type, Website, Username, Sex, Address, Email, and Birth Date. Details for this data platform are shown in
Figure 6.
This data platform holds information that is common to all other data platforms in the ADG Engine. For all other tasks in the Engine, it is possible to refer to the qualities of the users listed here. Features like age or marital status will be quite valuable for generating accurate information about this user. There are no anomaly features in this data platform, as there are no user actions listed here, but instead, this data platform includes the information necessary to calibrate the anomaly features of the other data platforms.
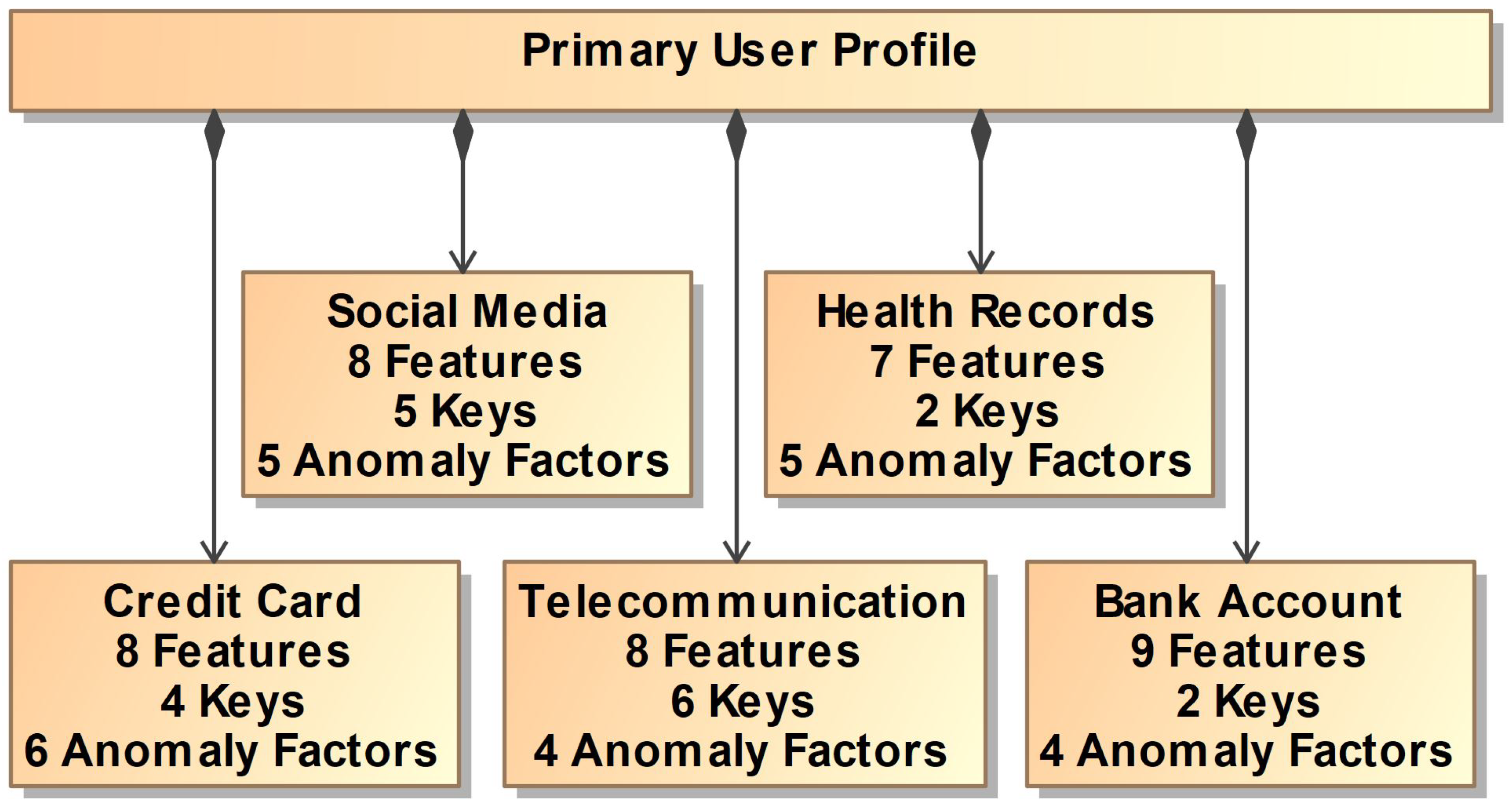
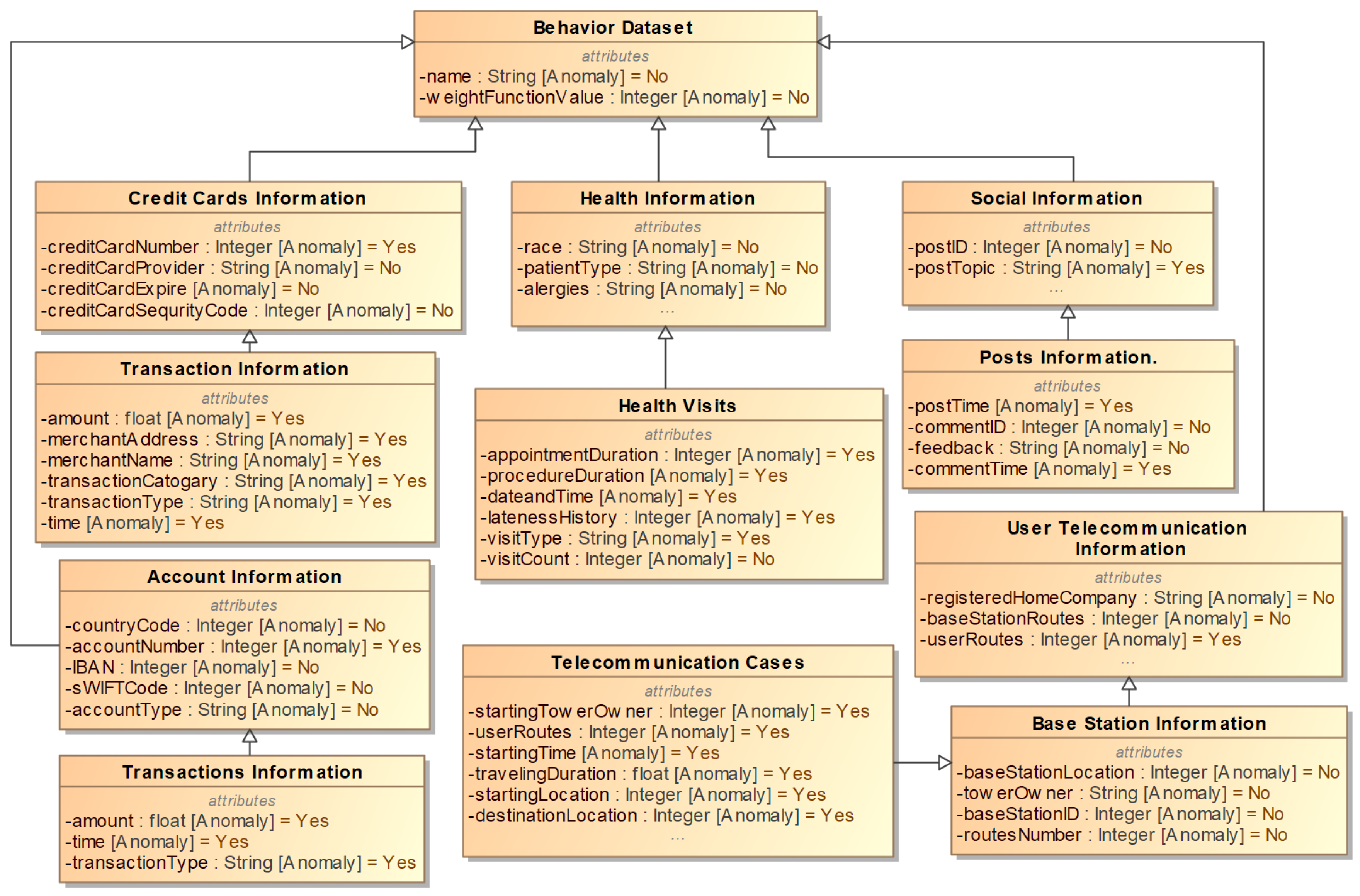
The first of our five data platforms is credit card activity. Each row of the data platform represents a single credit card transaction. This data platform includes the following features: name (string), credit card number (integer), transaction amount (float), merchant address (string), merchant name (string), transaction type (string), and time (date). The anomaly features in the credit card activity data platform are credit card number, transaction amount, merchant address, merchant name, transaction category, transaction type, and time. The relationship between this platform and the rest of the platforms can be seen in
Figure 7.
The second of our five platforms is bank account activity. Each row of the data platform represents a single bank account transaction. This data platform includes the following features: name (string), transaction amount (float), time (date), country code (integer), account number (integer), IBAN (integer), SWIFT code (integer), account type (string), and transaction type (string). The anomaly features in the bank account activity data platform are account number, transaction amount, transaction type, and time. The relationship between this platform and the rest of the platforms can be seen in
Figure 7.
The third of our five platforms is health records. Each row of the data platform represents a single appointment. This platform includes the following features: name (string), appointment duration (integer), procedure duration (integer), appointment date and time (date), lateness history (integer), visit type (string), and visit count (integer). The anomaly features in the health records platform are appointment duration, procedure duration, date and time, lateness history, and visit type. The relationship between this platform and the rest of the platforms can be seen in
Figure 7.
The fourth of our five platforms is telecommunication activity. Each row of the platform represents a single communication. This platform includes the following features: name (string), starting tower owner (integer), registered home company (string), user routes (integer), starting time (date), travel time (float), starting location (integer), and destination location (integer). The anomaly features in the telecommunications platform are user routes, starting tower owner, starting time, traveling duration, starting location, and destination location. The relationship between this platform and the rest of the platforms can be seen in
Figure 7.
The last of our five platforms is social media activity. Each row of the platform represents a single post on social media. This platform includes the following features: name (string), post ID (integer), topic of post (string), time of post (date), comment ID (integer), feedback (string), and time of comment (date). The anomaly features in the social media activity platform are: post topic, post time, and comment time. The relationship between this platform and the rest of the platforms can be seen in
Figure 7.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}