

Non-Contact Measurement of Pregnant Sows’ Backfat Thickness Based on a Hybrid CNN-ViT Model
Abstract
:1. Introduction
2. Materials and Methods
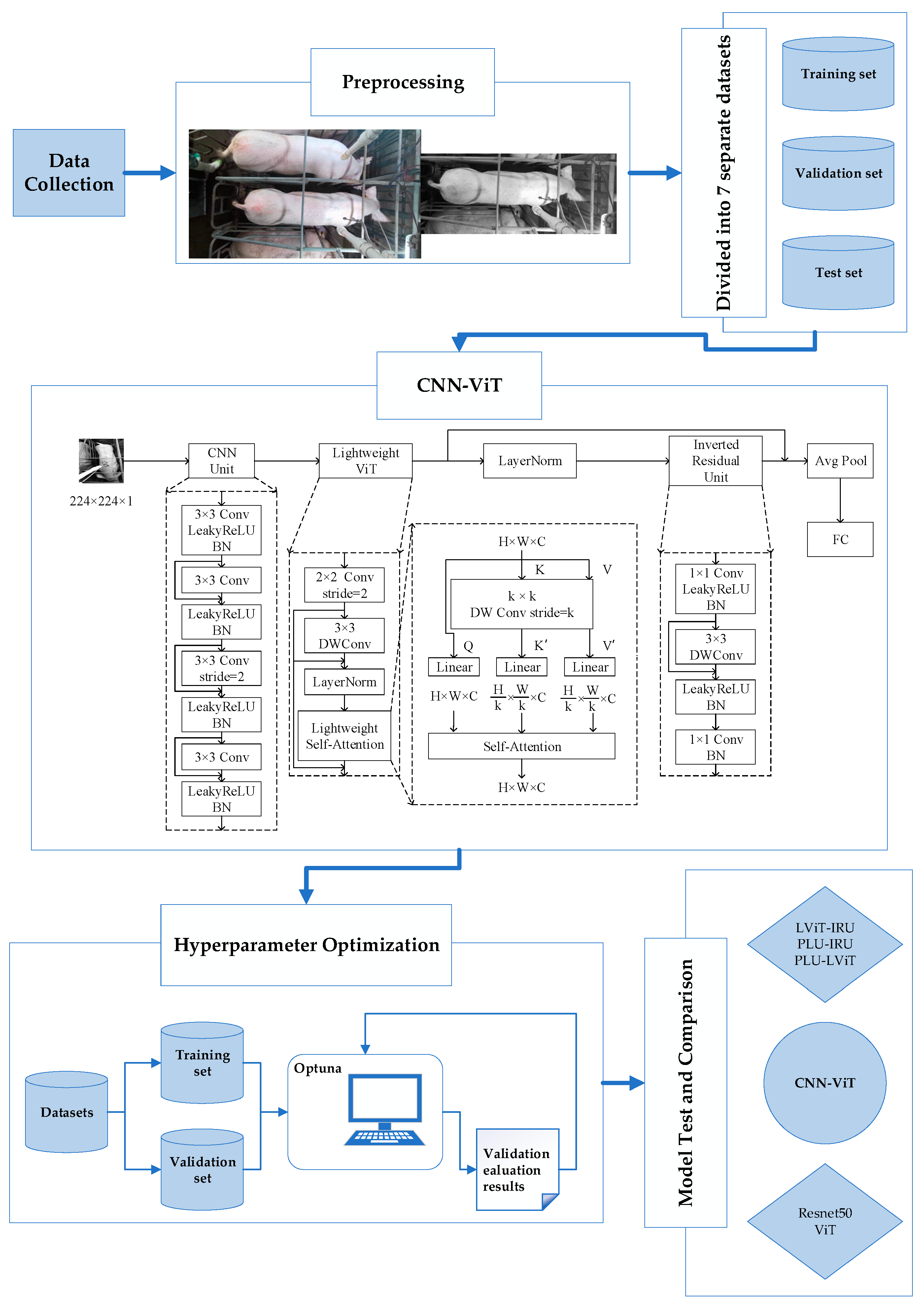
2.1. Data Collection
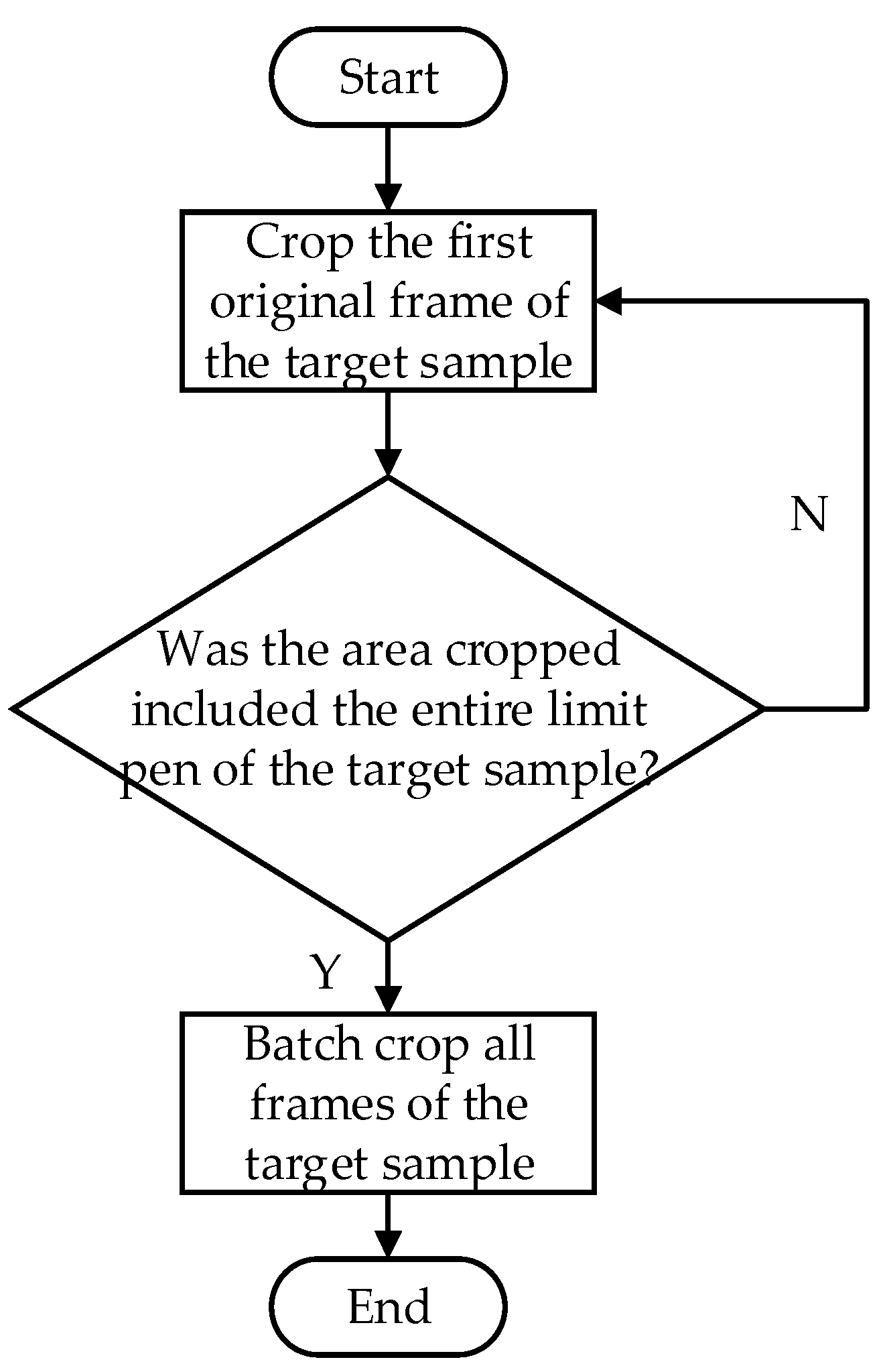
2.2. Dataset Production
2.3. Construction of BF Measurement Model for Pregnant Sows
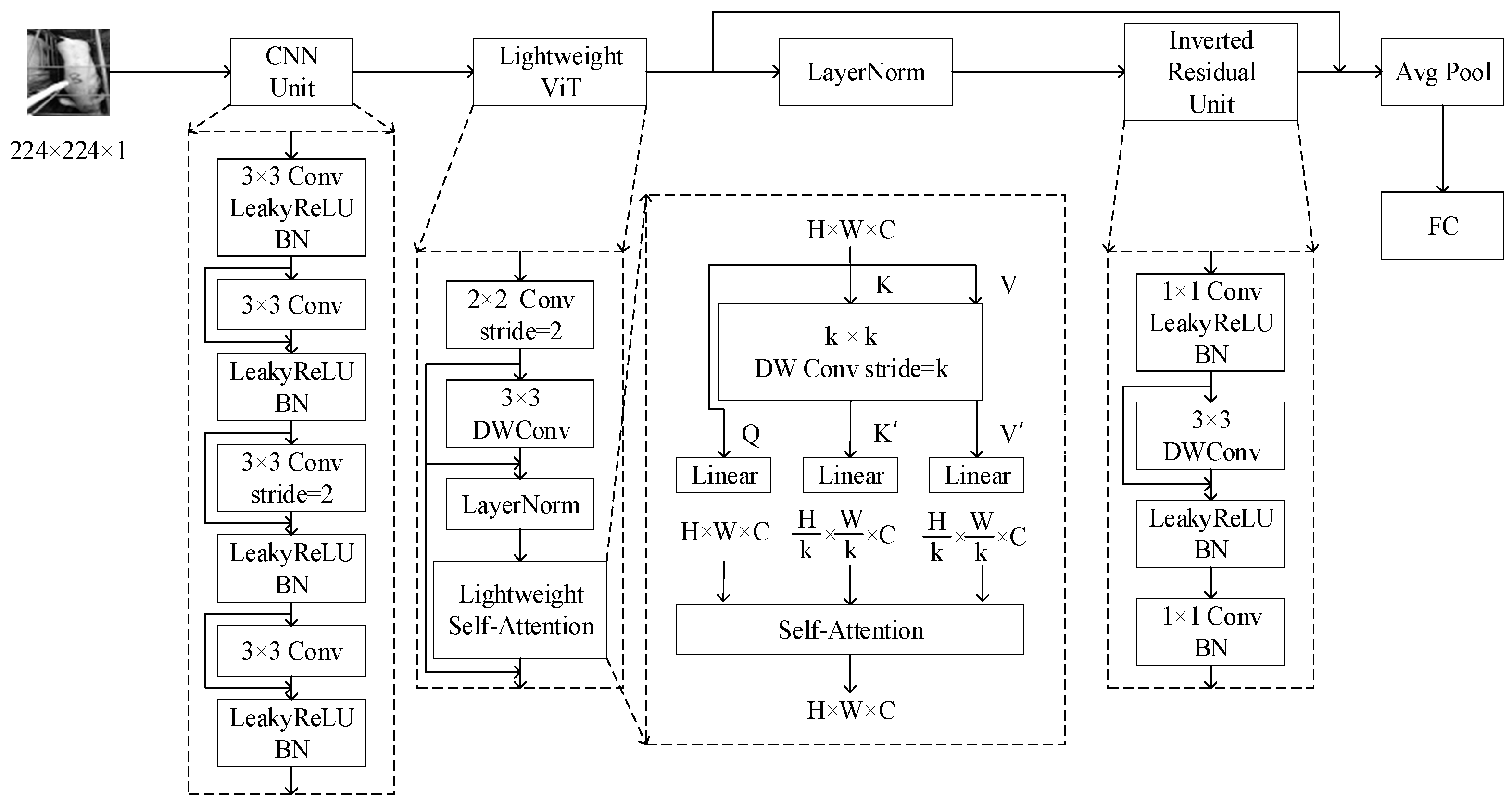
2.3.1. Pre-Local Unit
2.3.2. Lightweight ViT
2.3.3. Inverted Residual Unit
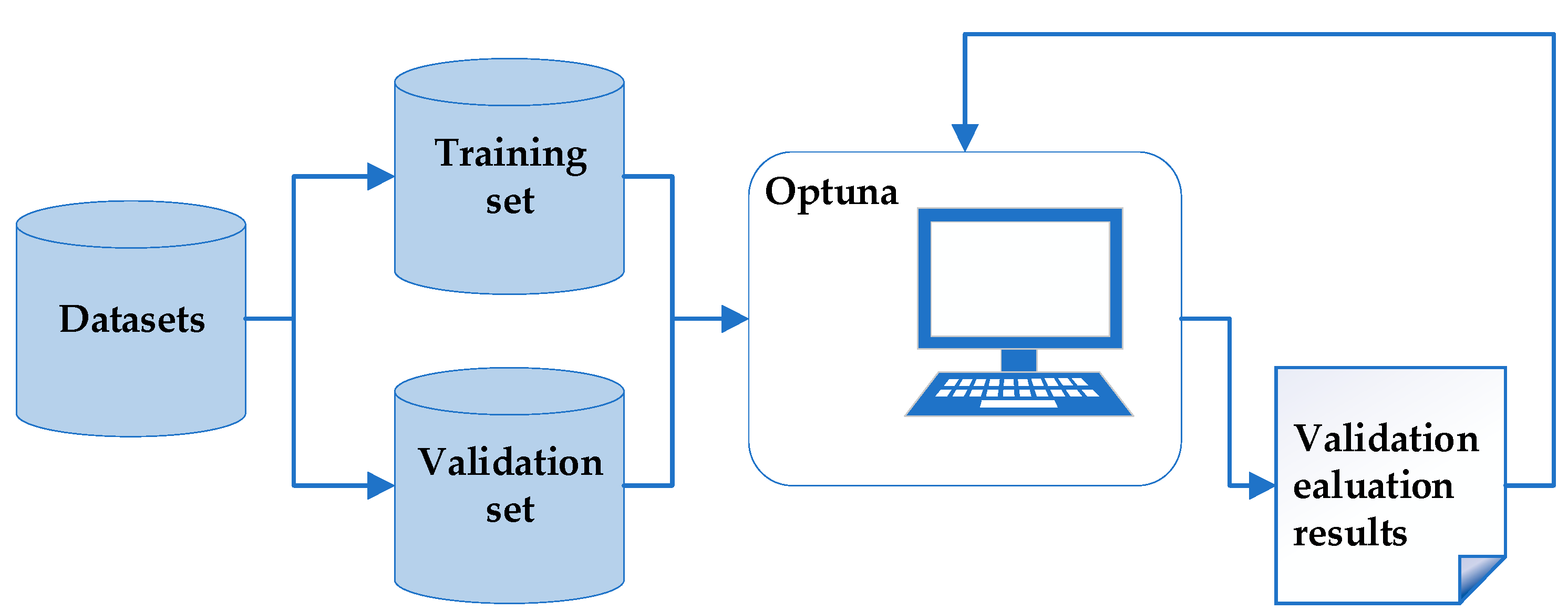
2.3.4. Hyperparameter Optimization
2.4. Model Training and Performance Evaluation
2.4.1. Training Environment
2.4.2. Evaluation Indicators
3. Results and Discussion
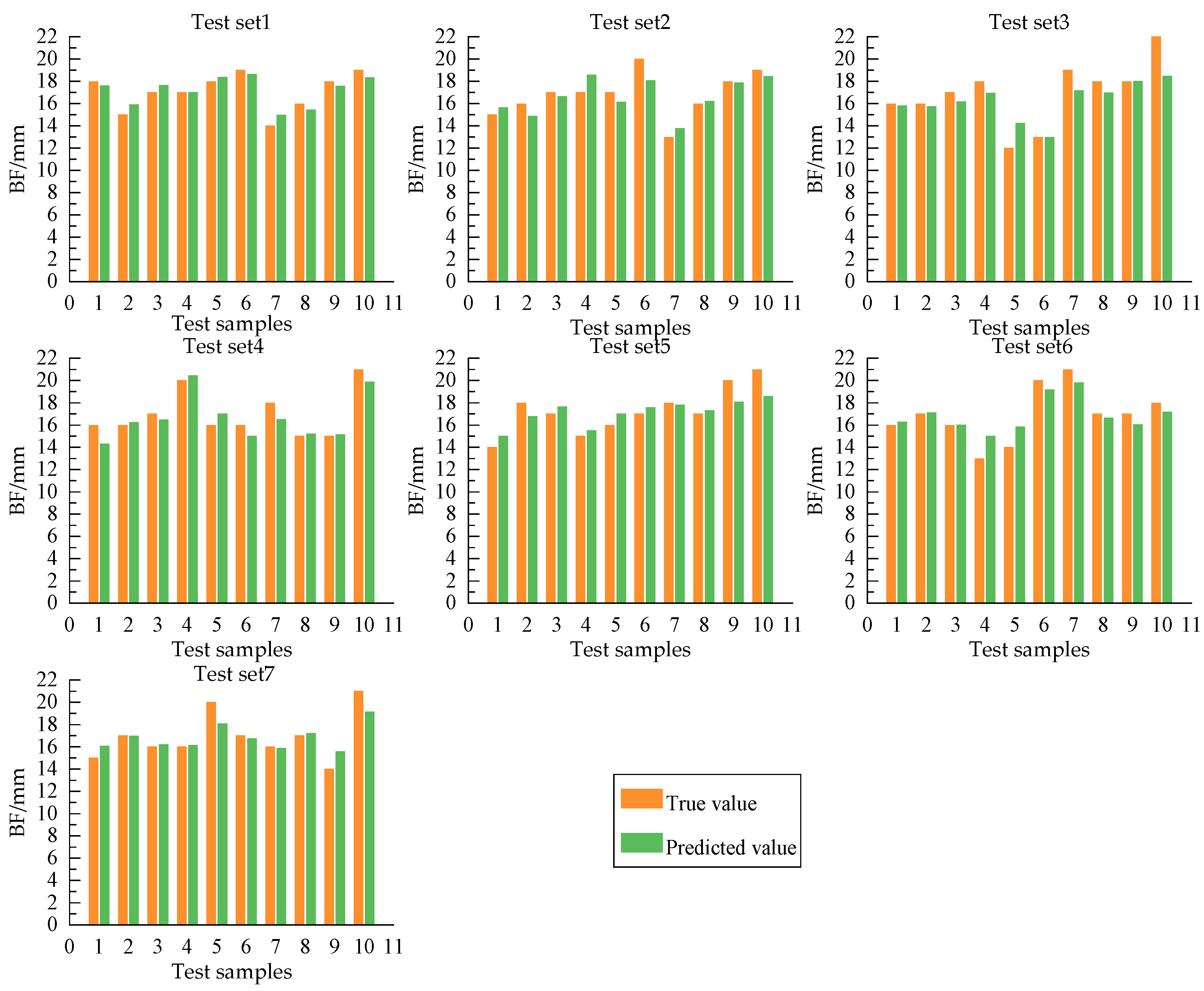
3.1. Test Results of CNN-ViT
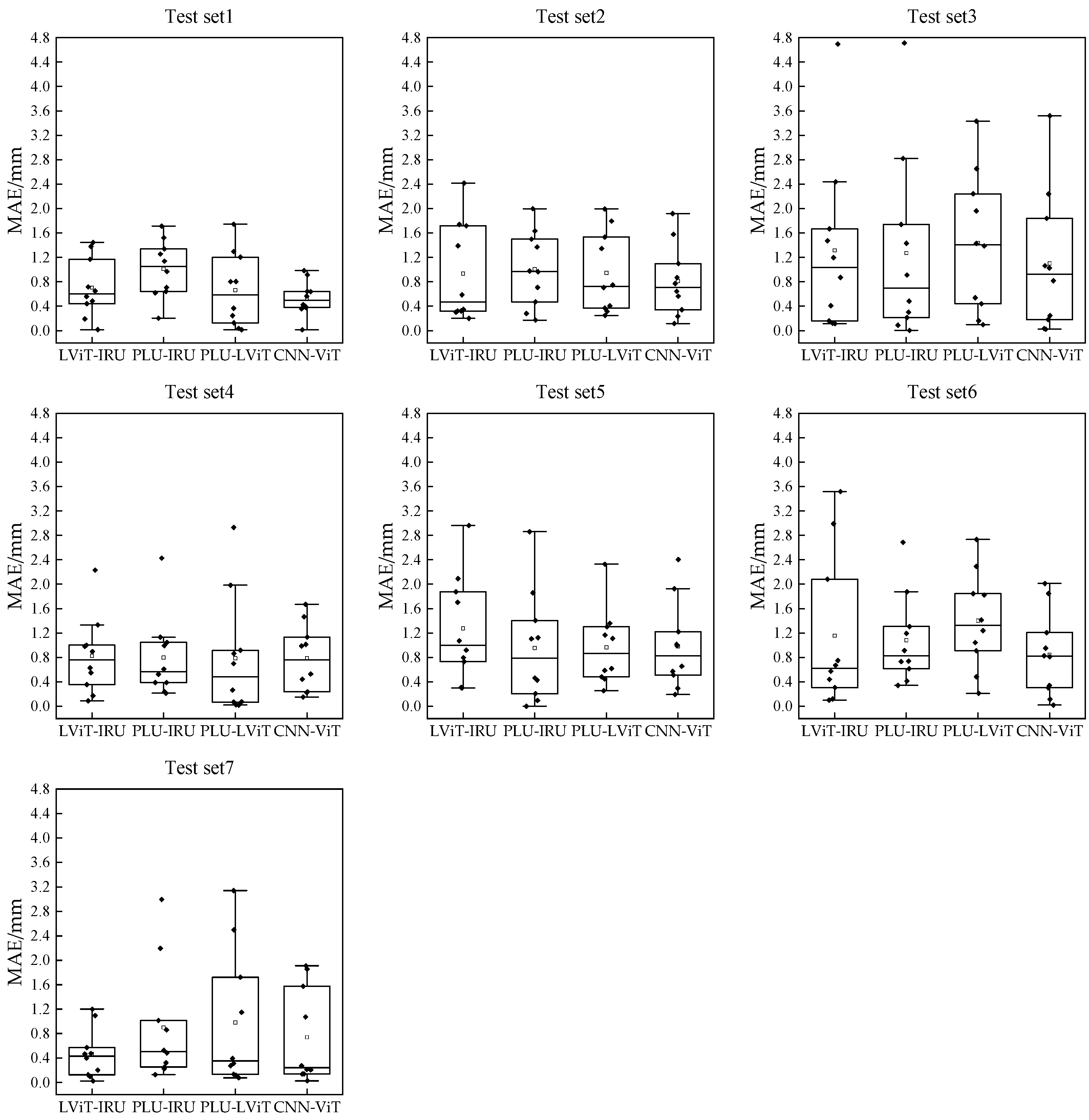
3.2. Comparative Analysis Based on Different Structural Models
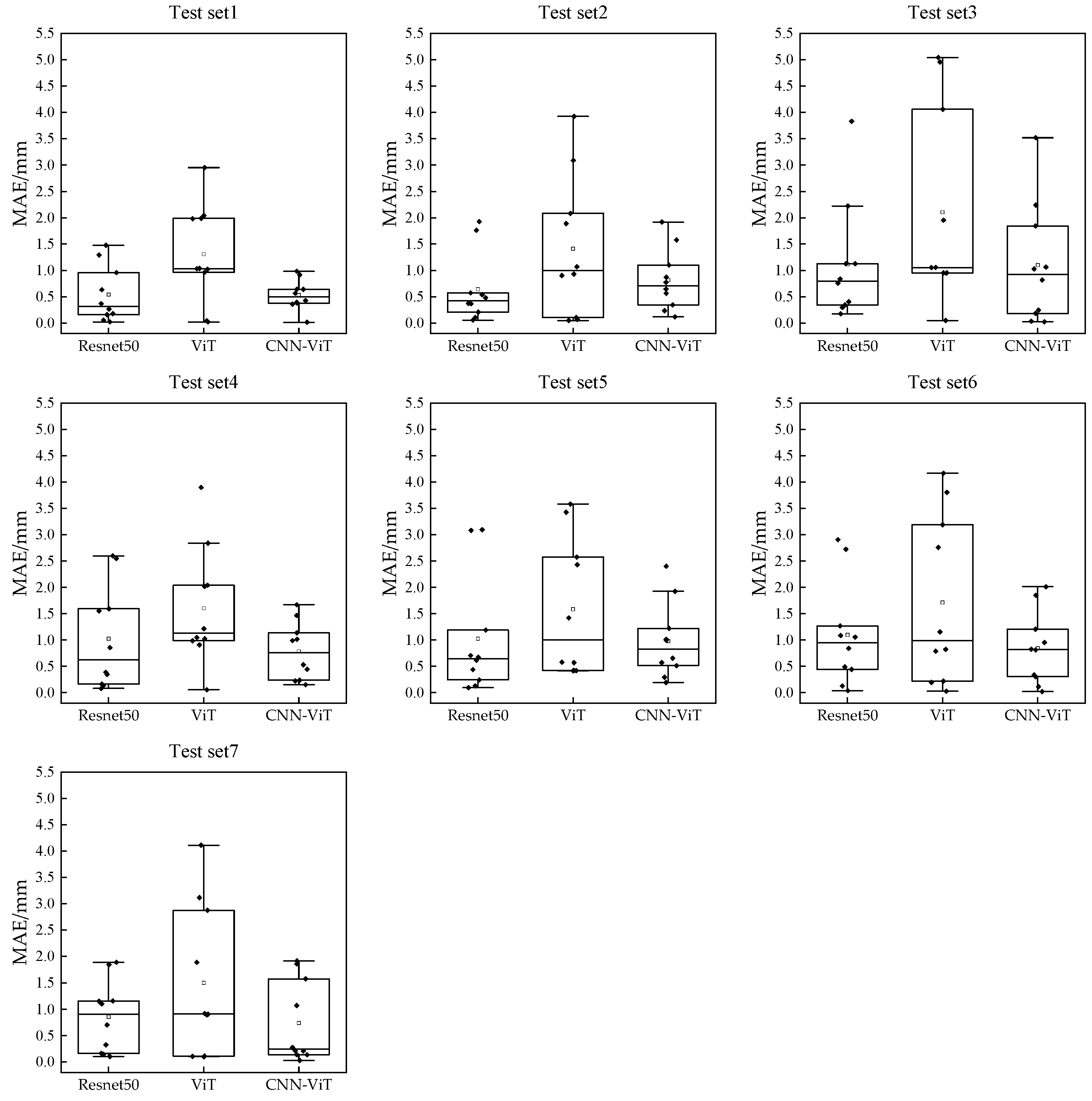
3.3. Comparative Analysis Based on Different Deep Learning Models
4. Conclusions and Future Work
- The MAE of CNN-ViT on the seven randomly divided test sets was 0.83 mm, the RMSE was 1.05 mm, the MAPE was 4.87%, and R2 was 0.74. The model could complete the non-contact measurement of sows’ BF with relatively high accuracy and generalization.
- Compared with different structural models (LViT-IRU, PLU-IRU and PLU-LViT) and different deep learning models (Resnet50 and ViT), the CNN-ViT model performed better.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, J.; Yan, P. Effects of Backfat Thickness on Oxidative Stress and Inflammation of Placenta in Large White Pigs. Vet. Sci. 2022, 9, 302. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Xu, T.; Cai, A.; Wu, Y.; Wei, H.; Jiang, S.; Peng, J. Excessive backfat of sows at 109 d of gestation induces lipotoxic placental environment and is associated with declining reproductive performance. J. Animal Sci. 2018, 96, 250–257. [Google Scholar] [CrossRef] [PubMed]
- Li, J.-W.; Hu, J.; Wei, M.; Guo, Y.-Y.; Yan, P.-S. The Effects of Maternal Obesity on Porcine Placental Efficiency and Proteome. Animals 2019, 9, 546. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Superchi, P.; Saleri, R.; Menčik, S.; Dander, S.; Cavalli, V.; Izzi, C.; Ablondi, M.; Sabbioni, A. Relationships among maternal backfat depth, plasma adipokines and the birthweight of piglets. Livest. Sci. 2019, 223, 138–143. [Google Scholar] [CrossRef]
- Roongsitthichai, A.; Koonjaenak, S.; Tummaruk, P. Backfat Thickness at First Insemination Affects Litter Size at Birth of the First Parity Sows. Agric. Nat. Resour. 2010, 44, 1128–1136. [Google Scholar]
- Thongkhuy, S.; Chuaychu, S.B.; Burarnrak, P.; Ruangjoy, P.; Juthamanee, P.; Nuntapaitoon, M.; Tummaruk, P. Effect of backfat thickness during late gestation on farrowing duration, piglet birth weight, colostrum yield, milk yield and reproductive performance of sows. Livest. Sci. 2020, 234, 103983. [Google Scholar] [CrossRef]
- Koketsu, Y.; Takahashi, H.; Akachi, K. Longevity, Lifetime Pig Production and Productivity, and Age at First Conception in a Cohort of Gilts Observed over Six Years on Commercial Farms. J. Vet. Med. Sci. 1999, 61, 1001–1005. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Chen, Y.; Jiang, X.; Guo, Z.; Zhong, Z.; Zhang, S.; Zhu, L. Effect of backfat thickness on body condition score and reproductive performance of sows during pregnancy. Acta Agric. Zhejiangensis 2020, 32, 390–397. [Google Scholar]
- Zhao, Y.X.; Yang, W.P.; Tao, R.J.; Li, Z.Y.; Zhang, C.L.; Liu, X.H.; Chen, Y.S. Effect of backfat thickness during pregnancy on farrowing duration and reproductive performance of sows. China Anim. Husb. Vet. Med. 2019, 46, 1397–1404. [Google Scholar]
- Fisher, A.V. A review of the technique of estimating the composition of livestock using the velocity of ultrasound. Comput. Electron. Agric. 1997, 17, 217–231. [Google Scholar] [CrossRef]
- Ginat, D.T.; Gupta, R. Advances in Computed Tomography Imaging Technology. Annu. Rev. Biomed. Eng. 2014, 16, 431–453. [Google Scholar] [CrossRef] [PubMed]
- Sharma, S.; Mittal, R.; Goyal, N. An Assessment of Machine Learning and Deep Learning Techniques with Applications. ECS Trans. 2022, 1, 107. [Google Scholar] [CrossRef]
- Teng, G.; Shen, Z.; Zhang, J.; Shi, C.; Yu, J. Non-contact sow body condition scoring method based on Kinect sensor. Trans. Chin. Soc. Agric. Eng. 2018, 34, 211–217. [Google Scholar]
- Araujo Fernandes, A.F.; Dorea, J.; Valente, B.; Fitzgerald, R.; Herring, W.; Rosa, G. Comparison of data analytics strategies in computer vision systems to predict pig body composition traits from 3D images. J. Anim. Sci. 2020, 98, skaa250. [Google Scholar] [CrossRef]
- Zuo, C.; Zhang, X.; Hu, Y.; Yin, W.; Shen, D.; Zhong, J.; Zheng, J.; Chen, Q. Has 3D finally come of age?—An introduction to 3D structured-light sensor. Infrared Laser Eng. 2020, 49, 9–53. [Google Scholar]
- Xiao, Z.; Zhou, M.; Yuan, H.; Liu, Y.; Fan, C.; Cheng, M. Influence Analysis of Light Intensity on Kinect v2 depth measurement accuracy. Trans. Chin. Soc. Agric. Mach. 2021, 52, 108–117. [Google Scholar]
- Yu, M.; Zheng, H.; Xu, D.; Shuai, Y.; Tian, S.; Cao, T.; Zhou, M.; Zhu, Y.; Zhao, S.; Li, X. Non-contact detection method of pregnant sows backfat thickness based on two-dimensional images. Anim. Genet. 2022, 53, 769–781. [Google Scholar] [CrossRef]
- Rodríguez Alvarez, J.; Arroqui, M.; Mangudo, P.; Toloza, J.; Jatip, D.; Rodríguez, J.M.; Teyseyre, A.; Sanz, C.; Zunino, A.; Machado, C. Body condition estimation on cows from depth images using Convolutional Neural Networks. Comput. Electron. Agric. 2018, 155, 12–22. [Google Scholar] [CrossRef] [Green Version]
- Yukun, S.; Pengju, H.; Yujie, W.; Ziqi, C.; Yang, L.; Baisheng, D.; Runze, L.; Yonggen, Z. Automatic monitoring system for individual dairy cows based on a deep learning framework that provides identification via body parts and estimation of body condition score. J. Dairy Sci. 2019, 102, 10140–10151. [Google Scholar] [CrossRef]
- Zhao, K.; Zhang, M.; Shen, W.; Liu, X.; Ji, J.; Dai, B.; Zhang, R. Automatic body condition scoring for dairy cows based on efficient net and convex hull features of point clouds. Comput. Electron. Agric. 2023, 205, 107588. [Google Scholar] [CrossRef]
- Shi, W.; Dai, B.; Shen, W.; Sun, Y.; Zhao, K.; Zhang, Y. Automatic estimation of dairy cow body condition score based on attention-guided 3D point cloud feature extraction. Comput. Electron. Agric. 2023, 206, 107666. [Google Scholar] [CrossRef]
- Lv, P.; Wu, W.; Zhong, Y.; Du, F.; Zhang, L. SCViT: A Spatial-Channel Feature Preserving Vision Transformer for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4409512. [Google Scholar] [CrossRef]
- Moutik, O.; Sekkat, H.; Tigani, S.; Chehri, A.; Rachid, S.; Ait Tchakoucht, T.; Paul, A. Convolutional Neural Networks or Vision Transformers: Who Will Win the Race for Action Recognitions in Visual Data? Sensors 2023, 23, 734. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations(ICLR), Vienna, Austria, 4 May 2021. [Google Scholar]
- Hou, R.; Chen, J.; Feng, Y.; Liu, S.; He, S.; Zhou, Z. Contrastive-weighted self-supervised model for long-tailed data classification with vision transformer augmented. Mech. Syst. Signal Process. 2022, 177, 109174. [Google Scholar] [CrossRef]
- Park, S.; Kim, G.; Oh, Y.; Seo, J.B.; Lee, S.M.; Kim, J.H.; Moon, S.; Lim, J.-K.; Park, C.M.; Ye, J.C. Self-evolving vision transformer for chest X-ray diagnosis through knowledge distillation. Nat. Commun. 2022, 13, 3848. [Google Scholar] [CrossRef]
- Dhanya, V.G.; Subeesh, A.; Kushwaha, N.L.; Vishwakarma, D.K.; Nagesh Kumar, T.; Ritika, G.; Singh, A.N. Deep learning based computer vision approaches for smart agricultural applications. Artif. Intell. Agric. 2022, 6, 211–229. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning (ICML), Electr Network, Online, 18–24 July 2021. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Verma, V.; Gupta, D.; Gupta, S.; Uppal, M.; Anand, D.; Ortega-Mansilla, A.; Alharithi, F.S.; Almotiri, J.; Goyal, N. A Deep Learning-Based Intelligent Garbage Detection System Using an Unmanned Aerial Vehicle. Symmetry 2022, 14, 960. [Google Scholar] [CrossRef]
- Mishra, A.; Harnal, S.; Mohiuddin, K.; Gautam, V.; Nasr, O.; Goyal, N.; Alwetaishi, M.; Singh, A. A Deep Learning-based Novel Approach for Weed Growth Estimation. Intell. Autom. Soft Comput. 2022, 2, 1157–1173. [Google Scholar] [CrossRef]
- Greer, E.; Mort, P.; Lowe, T.; Giles, L. Accuracy of ultrasonic backfat testers in predicting carcass P2 fat depth from live pig measurement and the effect on accuracy of mislocating the P2 site on the live pig. Aust. J. Exp. Agric. 1987, 27, 27. [Google Scholar] [CrossRef]
- Vakharia, V.; Shah, M.; Nair, P.; Borade, H.; Sahlot, P.; Wankhede, V. Estimation of Lithium-ion Battery Discharge Capacity by Integrating Optimized Explainable-AI and Stacked LSTM Model. Batteries 2023, 9, 125. [Google Scholar] [CrossRef]
- Mayrose, H.; Bairy, G.M.; Sampathila, N.; Belurkar, S.; Saravu, K. Machine Learning-Based Detection of Dengue from Blood Smear Images Utilizing Platelet and Lymphocyte Characteristics. Diagnostics 2023, 13, 220. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. CMT: Convolutional Neural Networks Meet Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J.; He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Naseer, M.; Ranasinghe, K.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Intriguing Properties of Vision Transformers. In Proceedings of the Neural Information Processing Systems (NeurIPS), Electr Network, Virtual, 6–14 December 2021. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
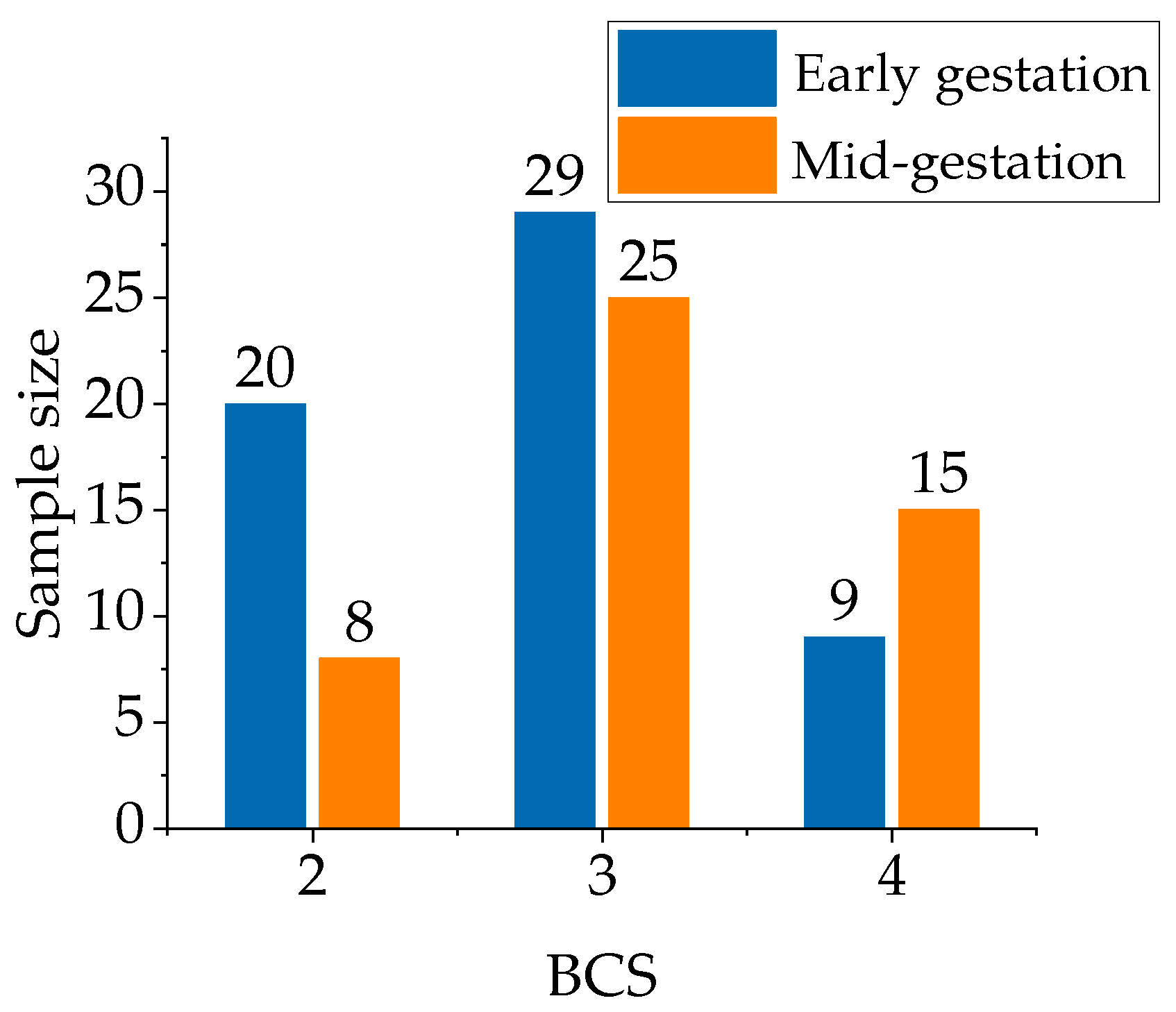{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BCS | BF/mm |
|---|---|
| 1 | <10 |
| 2 | ≥10~15 |
| 3 | >15~18 |
| 4 | >18~22 |
| 5 | >22 |
| Dataset | Gestation | BCS | Total | ||
|---|---|---|---|---|---|
| 2 | 3 | 4 | |||
| Train | Early | 16 | 23 | 8 | 86 |
| Mid | 7 | 20 | 12 | ||
| Validation | Early | 2 | 3 | 1 | 10 |
| Mid | 1 | 2 | 1 | ||
| Test | Early | 2 | 3 | 0 | 10 |
| Mid | 0 | 3 | 2 | ||
| Structure | Hyperparameters | Setting Ranges |
|---|---|---|
| PLU | Number of convolution kernels in layer 1 | 2 ^ 5~2 ^ 8 |
| Number of convolution kernels in layer 2 | ||
| Number of convolution kernels in layer 3 | ||
| Number of convolution kernels in layer 4 | ||
| FC | Number of features |
| Structure | Hyperparameters | Values |
|---|---|---|
| PLU | Number of convolution kernels in layer 1 | 128 |
| Number of convolution kernels in layer 2 | 32 | |
| Number of convolution kernels in layer 3 | 256 | |
| Number of convolution kernels in layer 4 | 256 | |
| LViT | Dimension of image block flattening | 46 |
| Number of heads of attention | 1 | |
| Lightweight dimension of attention k | 8 | |
| IRU | Proportion of dimensional raising | 3.6 |
| Proportion of dimensional reduction | 3.6 | |
| FC | Number of features | 128 |
| Test Set | MAE/mm | RMSE/mm | MAPE/% | R2 |
|---|---|---|---|---|
| 1 | 0.53 | 0.60 | 3.24 | 0.86 |
| 2 | 0.81 | 0.98 | 4.82 | 0.73 |
| 3 | 1.10 | 1.54 | 6.38 | 0.68 |
| 4 | 0.79 | 0.94 | 4.58 | 0.77 |
| 5 | 0.98 | 1.19 | 5.48 | 0.65 |
| 6 | 0.84 | 1.07 | 5.34 | 0.78 |
| 7 | 0.74 | 1.04 | 4.28 | 0.73 |
| AVG | 0.83 | 1.05 | 4.87 | 0.74 |
| Model | MAE ± SE/mm | RMSE ± SE/mm | MAPE ± SE/% | R2 ± SE | Params/M | FLOPs/G |
|---|---|---|---|---|---|---|
| LViT-IRU | 0.95 ± 0.11 | 1.24 ± 0.16 | 5.75 ± 0.69 | 0.63 ± 0.06 | 2.50 | 0.38 |
| PLU-IRU | 1.00 ± 0.05 | 1.29 ± 0.10 | 5.93 ± 0.38 | 0.61 ± 0.03 | 1.79 | 24.09 |
| PLU-LViT | 1.02 ± 0.10 | 1.31 ± 0.11 | 6.12 ± 0.67 | 0.60 ± 0.03 | 1.00 | 11.60 |
| PLU-LViT-IRU (CNN-ViT) | 0.83 ± 0.06 | 1.05 ± 0.10 | 4.87 ± 0.35 | 0.74 ± 0.02 | 0.39 | 3.85 |
| Model | MAE ± SE/mm | RMSE ± SE/mm | MAPE ± SE/% | R2 ± SE | Params/M | FLOPs/G |
|---|---|---|---|---|---|---|
| Resnet50 | 0.90 ± 0.08 | 1.22 ± 0.11 | 5.28 ± 0.44 | 0.64 ± 0.05 | 23.50 | 4.05 |
| ViT | 1.60 ± 0.09 | 2.06 ± 0.13 | 9.69 ± 0.65 | 0.01 ± 0.00 | 51.49 | 2.57 |
| CNN-ViT | 0.83 ± 0.06 | 1.05 ± 0.10 | 4.87 ± 0.35 | 0.74 ± 0.02 | 0.39 | 3.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Yu, M.; Xu, D.; Zhao, S.; Tan, H.; Liu, X. Non-Contact Measurement of Pregnant Sows’ Backfat Thickness Based on a Hybrid CNN-ViT Model. Agriculture 2023, 13, 1395. https://doi.org/10.3390/agriculture13071395
Li X, Yu M, Xu D, Zhao S, Tan H, Liu X. Non-Contact Measurement of Pregnant Sows’ Backfat Thickness Based on a Hybrid CNN-ViT Model. Agriculture. 2023; 13(7):1395. https://doi.org/10.3390/agriculture13071395
Chicago/Turabian StyleLi, Xuan, Mengyuan Yu, Dihong Xu, Shuhong Zhao, Hequn Tan, and Xiaolei Liu. 2023. "Non-Contact Measurement of Pregnant Sows’ Backfat Thickness Based on a Hybrid CNN-ViT Model" Agriculture 13, no. 7: 1395. https://doi.org/10.3390/agriculture13071395