
Review of Energy-Efficient Embedded System Acceleration of Convolution Neural Networks for Organic Weeding Robots

Abstract
:1. Introduction
2. Basics of Artificial Neural Networks
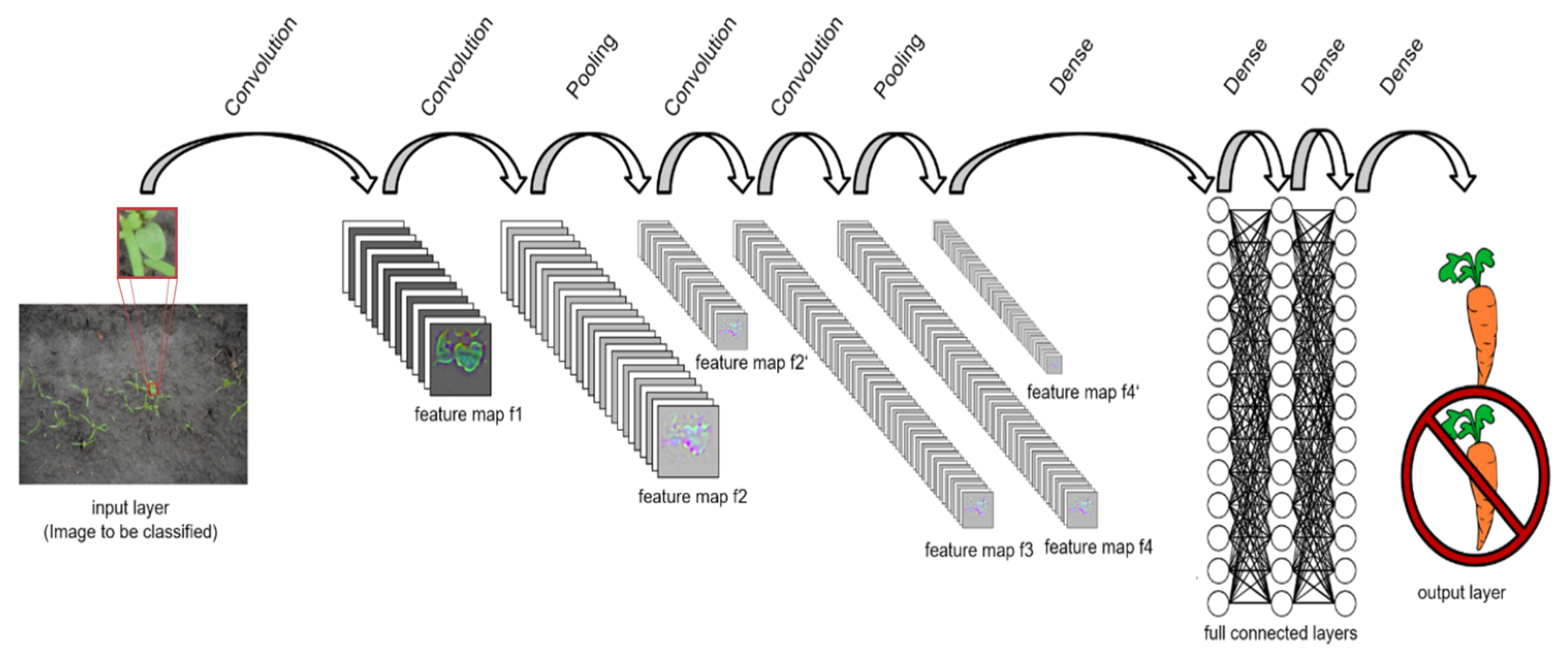
2.1. CNN Structure
2.2. Training and Inference Phase
2.3. CNN Architectures
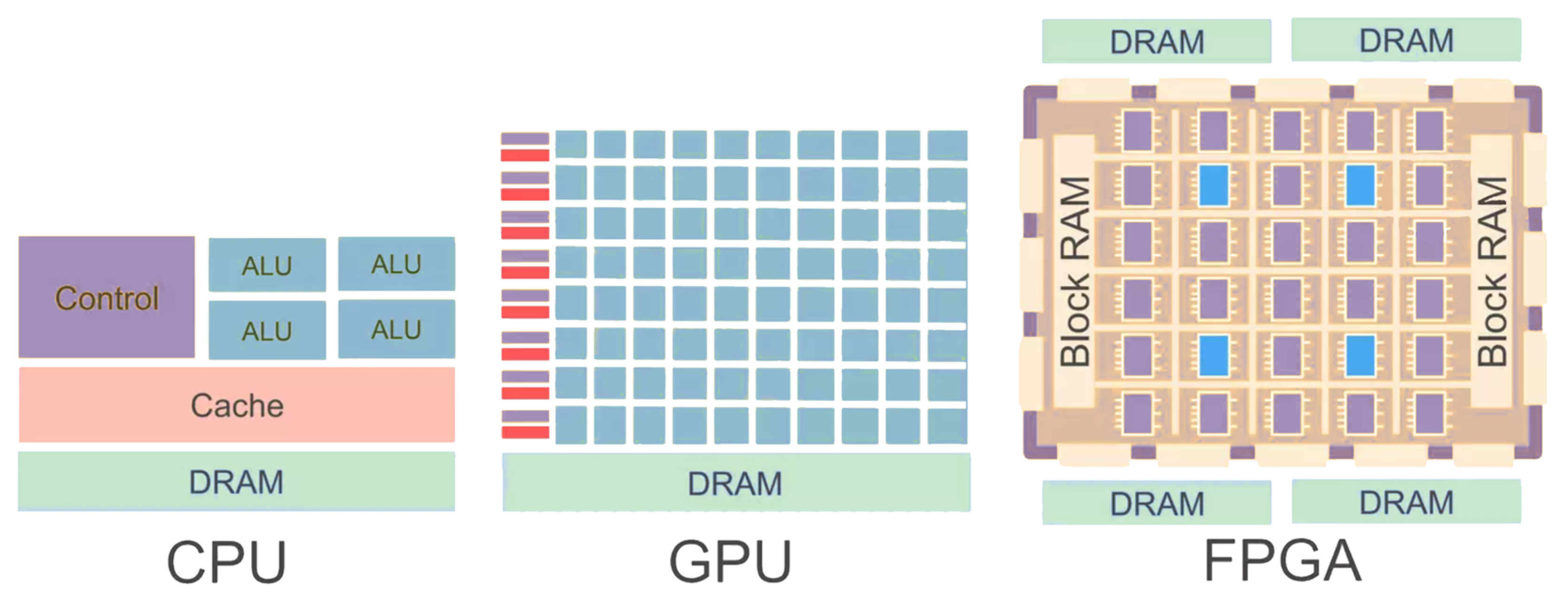
3. Hardware Accelerator Based on FPGAs
3.1. Comparison of Hardware Accelerators
3.2. FPGA Features
3.3. State-of-the-Art FPGA Accelerators
4. CNN Optimizations for Implementation in FPGAs
4.1. Optimization Approaches Related to Approximations of the CNN Network
4.2. Memory Optimization Approaches in the Context of Implementation on FPGAs
5. Proposed Energy Efficient Embedded System for Organic Weeding Robots and Discussion
5.1. Current Soft- and Hardware Configuration of the Developed Weeding Robot
5.2. FPGA Implementation of the YOLO Network
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Czymmek, V.; Harders, L.O.; Knoll, F.J.; Hussmann, S. Vision-Based Deep Learning Approach for Real-Time Detection of Weeds in Organic Farming. In Proceedings of the 2019 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Auckland, New Zealand, 20–23 May 2019; pp. 585–589. [Google Scholar] [CrossRef]
- Miron, R. Maschinell lernende, neuronale Netzwerke als Intelligenzgeber. Special Feature Digi-Key. 2016, pp. 54–56. Available online: https://blog.iao.fraunhofer.de/spielarten-der-kuenstlichen-intelligenz-maschinelles-lernen-und-kuenstliche-neuronale-netze (accessed on 4 October 2023).
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Brübach, A. Complement and alternative to established machine vision—Deep Learning at Vision. IEEE Ind. Eng. Effic. 2018, 9, 28–30. [Google Scholar]
- Wang, E.; Davis, J.J.; Zhao, R.; Ng, H.; Niu, H.; Cheung, P.; Constantinides, G.A. Deep Neural Network Approximation for Custom Hardware: Where We´ve Been, Where We´re Going. ACM Comput. Surv. 2019, 52, 1–39. [Google Scholar] [CrossRef]
- Abdelouahab, K.; Pelcat, M.; Sérot, J.; Berry, F. Accelerating CNN inference on FPGAs: A Survey. arXiv 2018, arXiv:1806.01683. [Google Scholar] [CrossRef]
- Shawahna, A.; Sait, S.M.; El-Maleh, A. FPGA-Based Accelerators of Deep Learning Networks for Learning and Classification: A Review. IEEE Access 2019, 7, 7823–7859. [Google Scholar] [CrossRef]
- Phu, H.V.; Tan, T.M.; Van Men, P.; Van Hieu, N.; Van Cuong, T. Design and Implementation of Configurable Convolutional Neural Network on FPGA. In Proceedings of the IEEE 6th NAFOSTED Conference on Information and Computer Science (NICS), Hanoi, Vietnam, 12–13 December 2019; pp. 298–302. [Google Scholar] [CrossRef]
- Nurvitadhi, E.; Sheffield, D.; Sim, J.; Mishra, A.; Venkatesh, G.; Marr, D. Accelerating Binarized Neural Networks: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 77–84. [Google Scholar] [CrossRef]
- Wang, T.; Wang, C.; Zhou, X.; Chen, H. An Overview of FPGA Based Deep Learning Accelerators: Challenges and Opportunities. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; pp. 1674–1681. [Google Scholar] [CrossRef]
- Hareth, S.; Mostafa, H.; Shehata, K.A. Low power CNN hardware FPGA implementation. In Proceedings of the 2019 31st International Conference on Microelectronics (ICM), Cairo, Egypt, 15–18 December 2019; pp. 162–165. [Google Scholar] [CrossRef]
- He, D.; Wang, Z.; Liu, J. A Survey to Predict the Trend of AI-able Server Evolution in the Cloud. IEEE Access 2018, 6, 10591–10602. [Google Scholar] [CrossRef]
- Wei, G.; Hou, Y.; Cui, Q.; Deng, G.; Tao, X.; Yao, Y. YOLO Acceleration using FPGA Architecture. In Proceedings of the 2018 IEEE/CIC International Conference on Communications in China (ICCC), Beijing, China, 16–18 August 2018; pp. 734–735. [Google Scholar] [CrossRef]
- Shahshahani, M.; Goswami, P.; Bhatia, D. Memory Optimization Techniques for FPGA based CNN Implementations. In Proceedings of the 2018 IEEE 13th Dallas Circuits and Systems Conference (DCAS), Dallas, TX, USA, 12 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Nurvitadhi, E.; Venkatesh, G.; Sim, J.; Marr, D.; Huang, R.; Ong Gee Hock, J.; Liew, Y.T.; Srivatsan, K.; Moss, D.; Subhaschandra, S.; et al. Can FPGAs Beat GPUs in Accelerating Next-Generation Deep Neural Networks? In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterrey, CA, USA, 22 February 2017; pp. 5–14. [Google Scholar] [CrossRef]
- Müller, P. KI offline und am Edge—Künstliche Intelligenz mit FPGAs: So gelingt der Einstieg. Elektron. Ind. 2020, 12, 18–19. [Google Scholar]
- Fowers, J.; Brown, G.; Wernsing, J.; Stitt, G. A performance and energy comparison of convolution on GPUs, FPGAs, and multicore processors. ACM Trans. Archit. Code Optim. 2013, 9, 25. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, Y.; Jia, X.; Tian, L.; Li, T.; Sui, L.; Xie, D.; Shan, Y. A High-Performance CNN Processor Based on FPGA for MobileNets. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 136–143. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, L.; Liu, H.; Tian, S.; Deng, Q.; Li, J. An Efficient Task Assignment Framework to Accelerate DPU-Based Convolutional Neural Network Inference on FPGAs. IEEE Access 2020, 8, 83224–83237. [Google Scholar] [CrossRef]
- Khabbazan, B.; Mirzakuchaki, S. Design and Implementation of a Low-Power, Embedded CNN Accelerator on a Low-end FPGA. In Proceedings of the 2019 22nd Euromicro Conference on Digital System Design (DSD), Kallithea, Greece, 28–30 August 2019; pp. 647–650. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H.-J. A High-Throughput and Power-Efficient FPGA Implementation of YOLO CNN for Object Detection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1861–1873. [Google Scholar] [CrossRef]
- Kljucaric, L.; George, A.D. Deep-Learning Inferencing with High-Performance Hardware Accelerators. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 24–26 September 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Nurvitadhi, E.; Sim, J.; Sheffield, D.; Mishra, A.; Krishnan, S.; Marr, D. Accelerating recurrent neural networks in analytics servers: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August 2016–2 September 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Werner, H. Intelligentere Edge-Endgeräte durch KI-Einsatz in FPGAs. Elektronikpraxis 2019, 7, 30–32. [Google Scholar]
- Vineetha, K.V.; Mohit, M.; Reddy, S.K.; Ramesh, C.; Kurup, G.D. An efficient design methodology to speed up the FPGA implementation of artificial neural networks. Eng. Sci. Technol. Int. J. 2023, 47, 101542. [Google Scholar] [CrossRef]
- Wu, R.; Guo, X.; Du, J.; Li, J. Accelerating Neural Network Inference on FPGA-Based Platforms—A Survey. Electronics 2021, 10, 1025. [Google Scholar] [CrossRef]
- Gupta, N. Tiefe neuronale Netze auf FPGAs. Markt&Technik 2015, 4, 32–34. [Google Scholar]
- Alawad, M.; Lin, M. Scalable FPGA Accelerator for Deep Convolutional Neural Networks with Stochastic Streaming. IEEE Trans. Multi-Scale Comput. Syst. 2018, 4, 888–899. [Google Scholar] [CrossRef]
- Yang, T.-J.; Chen, Y.-H.; Sze, V. Designing Energy-Efficient Convolutional Neural Networks Using Energy-Aware Pruning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6071–6079. [Google Scholar] [CrossRef]
- Nakahara, H.; Fujii, T.; Sato, S. A fully connected layer elimination for a binarized convolutional neural network on an FPGA. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Kyriakos, A.; Kitsakis, V.; Louropoulos, A.; Papatheofanous, E.-A.; Patronas, I.; Reisis, D. High Performance Accelerator for CNN Applications. In Proceedings of the 2019 29th International Symposium on Power and Timing Modeling, Optimization and Simulation (PATMOS), Rhodes, Greece, 1–3 July 2019; pp. 135–140. [Google Scholar] [CrossRef]
- Chiu, G.R.; Ling, A.C.; Capalija, D.; Bitar, A.; Abdelfattah, M.S. Flexibility: FPGAs and CAD in Deep Learning Acceleration. In Proceedings of the ISPD 2018 International Symposium on Physical Design, Monterey, CA, USA, 25–28 March 2018; pp. 34–41. [Google Scholar] [CrossRef]
- Chang, X.; Pan, H.; Zhang, D.; Sun, Q.; Lin, W. A Memory-Optimized and Energy-Efficient CNN Acceleration Architecture Based on FPGA. In Proceedings of the 2019 IEEE 28th International Symposium on Industrial Electronics (ISIE), Vancouver, BC, Canada, 12–14 June 2019; pp. 2137–2141. [Google Scholar] [CrossRef]
- Lu, L.; Xie, J.; Huang, R.; Zhang, J.; Lin, W.; Liang, Y. An Efficient Hardware Accelerator for Sparse Convolutional Neural Networks on FPGAs. In Proceedings of the 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019; pp. 17–25. [Google Scholar] [CrossRef]
- Huang, C.; Ni, S.; Chen, G. A layer-based structured design of CNN on FPGA. In Proceedings of the 2017 IEEE 12th International Conference on ASIC (ASICON), Guiyang, China, 25–28 October 2017; pp. 1037–1040. [Google Scholar] [CrossRef]
- Czymmek, V.; Möller, C.; Harders, L.O.; Hussmann, S. Deep Learning Approach for high Energy efficient Real-Time Detection of Weeds in Organic Farming. In Proceedings of the 2021 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Glasgow, UK, 17–20 May 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Li, S.; Luo, Y.; Sun, K.; Yadav, N.; Choi, K.K. A Novel FPGA Accelerator Design for Real-Time and Ultra-Low Power Deep Convolutional Neural Networks Compared with Titan X GPU. IEEE Access 2020, 8, 105455–105471. [Google Scholar] [CrossRef]
- Bao, C.; Xie, T.; Feng, W.; Chang, L.; Yu, C. A Power-Efficient Optimizing Framework FPGA Accelerator Based on Winograd for YOLO. IEEE Access 2020, 8, 94307–94317. [Google Scholar] [CrossRef]
- Zhang, S.; Cao, J.; Zhang, Q.; Zhang, Q.; Zhang, Y.; Wang, Y. An FPGA-Based Reconfigurable CNN Accelerator for YOLO. In Proceedings of the 2020 IEEE 3rd International Conference on Electronics Technology (ICET), Chengdu, China, 8–12 May 2020; pp. 74–78. [Google Scholar] [CrossRef]
- Yang, A.; Li, Y.; Shu, H.; Deng, J.; Ma, C.; Li, Z.; Wang, Q. An OpenCL-Based FPGA Accelerator for Compressed YOLOv2. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019; pp. 235–238. [Google Scholar] [CrossRef]
- Ding, C.; Wang, S.; Liu, N.; Xu, K.; Wang, Y.; Liang, Y. REQ-YOLO: A Resource-Aware, Efficient Quantization Framework for Object Detection on FPGAs. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; pp. 33–42. [Google Scholar] [CrossRef]
- Wai, Y.J.; Yussof, Z.B.M.; Salim, S.I.B.; Chuan, L.K. Fixed Point Implementation of Tiny-Yolo-v2 using OpenCL on FPGA. IJACSA Int. J. Adv. Comput. Sci. Appl. 2018, 9, 506–512. [Google Scholar] [CrossRef]
- Yang, X.; Zhuang, C.; Feng, W.; Yang, Z.; Wang, Q. FPGA Implementation of a Deep Learning Acceleration Core Architecture for Image Target Detection. Appl. Sci. 2023, 13, 4144. [Google Scholar] [CrossRef]
- Zhang, Z.; Mahmud, M.A.P. Resource-constrained FPGA implementation of YOLOv2. Neural Comput. Appl. 2022, 34, 16989–17006. [Google Scholar] [CrossRef]
- Farrukh, F.U.D.; Xie, T.; Zhang, C.; Wang, Z. Optimization for Efficient Hardware Implementation of CNN on FPGA. In Proceedings of the 2018 IEEE International Conference on Integrated Circuits, Technologies and Applications (ICTA), Beijing, China, 21–23 November 2018; pp. 88–89. [Google Scholar] [CrossRef]
- Yoshimoto, Y.; Shuto, D.; Tamukoh, H. FPGA-enabled Binarized Convolutional Neural Networks toward Real-time Embedded Object Recognition System for Service Robots. In Proceedings of the 2019 IEEE International Circuits and Systems Symposium (ICSyS), Kuantan, Malaysia, 18–19 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Kim, H.; Choi, K. Low Power FPGA-SoC Design Techniques for CNN-based Object Detection Accelerator. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 1130–1134. [Google Scholar] [CrossRef]
- Farrukh, F.U.D.; Zhang, C.; Jiang, Y.; Zhang, Z.; Wang, Z.; Wang, Z.; Jiang, H. Power Efficient Tiny Yolo CNN Using Reduced Hardware Resources Based on Booth Multiplier and WALLACE Tree Adders. IEEE Open J. Circuits Syst. 2020, 1, 76–87. [Google Scholar] [CrossRef]
- Czymmek, V.; Schramm, R.; Hussmann, S. Vision Based Crop Row Detection for Low Cost UAV Imagery in Organic Agriculture. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Dubrovnik, Croatia, 25–28 May 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Harders, L.O.; Czymmek, V.; Wrede, A.; Ufer, T.; Hussmann, S. Deep learning approach for UAV-based weed detection in horticulture using edge processing. Appl. Mach. Learn. 2022, 12227, 122270R. [Google Scholar] [CrossRef]
- Harders, L.O.; Czymmek, V.; Wrede, A.; Ufer, T.; Hussmann, S. UAV-based real-time weed detection in horticulture using edge processing. SPIE J. Electron. Imaging 2023, 32, 052405. [Google Scholar] [CrossRef]
- Hussmann, S.; Clausen, K.; Harders, L.O. Vision-based crop row detection system for UAV-based weed detection in arboriculture. In Proceedings of the Optical Technology and Measurement for Industrial Applications Conference, Yokohama, Japan, 17–21 April 2023; p. 1260707. [Google Scholar] [CrossRef]
- Czymmek, V.; Moeller, C.; Schacht, E.; Harders, L.O.; Hussmann, S. Autonomous fawn tracking system based on drone images and CNNs. In Proceedings of the Optical Technology and Measurement for Industrial Applications Conference, Yokohama, Japan, 17–21 April 2023. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | CPU | GPU | FPGA | ASIC |
|---|---|---|---|---|
| Processing Peak Power | moderate | high | very high | highest |
| Power Consumption | high | very high | low | very low |
| Flexibility | highest | moderate | high | lowest |
| Training | poor | best yet | not efficient | not available |
| Inference | poor | good | best | potentially best |
| FPGA | Processing Power | Power Efficiency |
|---|---|---|
| Xilinx Zynq-7000 | moderate | moderate |
| Intel Arria 10 | high | moderate |
| Intel Stratix 10 | very high | low |
| Xilinx Artix 7 | low | high |
| Efinix Trion T120 | moderate | moderate |
| Optimization Approach | Advantages | Disadvantages |
|---|---|---|
| Parallelism | Efficient utilization of concurrent processing | Complex design and synchronization challenges |
| Customization | Tailored hardware for specific architectures and data types | Requires specialized skills and extensive development time |
| Memory Hierarchy | Reduced latency and increased throughput | Challenging memory access patterns and design complexities |
| Quantization | Reduced memory and computation complexity | Potential accuracy degradation with aggressive quantization |
| Dataflow Optimization | Improved throughput and efficiency | Complexity for dynamic workloads and complex network structures |
| Resource Utilization | Efficient hardware usage and cost reduction | Constraints for accommodating changes and updates |
| Power Efficiency | Suitable for energy-constrained applications | Trade-offs with performance and design constraints |
| Flexibility and Reconfigurability | Adaptability to changing requirements and network variations | Overhead and complexity for reconfiguration |
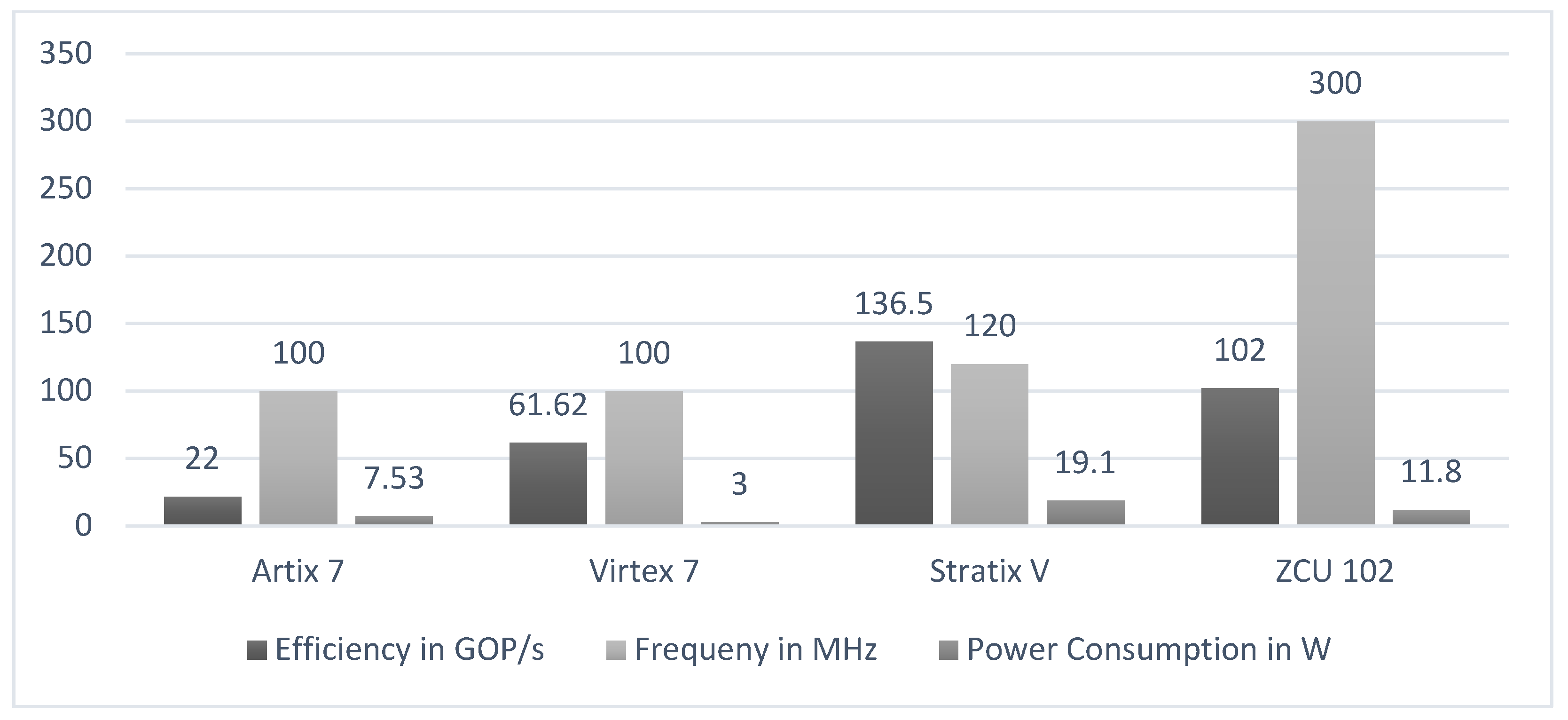
| FPGA Implementation | Inference Time (ms) | Energy Efficiency (W) | Accuracy (%) |
|---|---|---|---|
| YOLOv2 with Configurable CNN Accelerator and Winograd Algorithm | 10 | 2.7 | 78.25 |
| YOLOv2 with BNN Pynq Implementation | 15 | 5.1 | 72.3 |
| YOLOv2 on Artix 7 FPGA | 18 | 7.53 | 68.9 |
| YOLOv2 on Stratix V FPGA | 20 | 19.1 | - |
| Tiny YOLOv2 with Wallace Adder Trees on Zynq 706 FPGA | 16 | 6.2 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Czymmek, V.; Köhn, C.; Harders, L.O.; Hussmann, S. Review of Energy-Efficient Embedded System Acceleration of Convolution Neural Networks for Organic Weeding Robots. Agriculture 2023, 13, 2103. https://doi.org/10.3390/agriculture13112103
Czymmek V, Köhn C, Harders LO, Hussmann S. Review of Energy-Efficient Embedded System Acceleration of Convolution Neural Networks for Organic Weeding Robots. Agriculture. 2023; 13(11):2103. https://doi.org/10.3390/agriculture13112103
Chicago/Turabian StyleCzymmek, Vitali, Carolin Köhn, Leif Ole Harders, and Stephan Hussmann. 2023. "Review of Energy-Efficient Embedded System Acceleration of Convolution Neural Networks for Organic Weeding Robots" Agriculture 13, no. 11: 2103. https://doi.org/10.3390/agriculture13112103