HBRNet: Boundary Enhancement Segmentation Network for Cropland Extraction in High-Resolution Remote Sensing Images

 , , , , , and
, , , , , and
Abstract
:1. Introduction
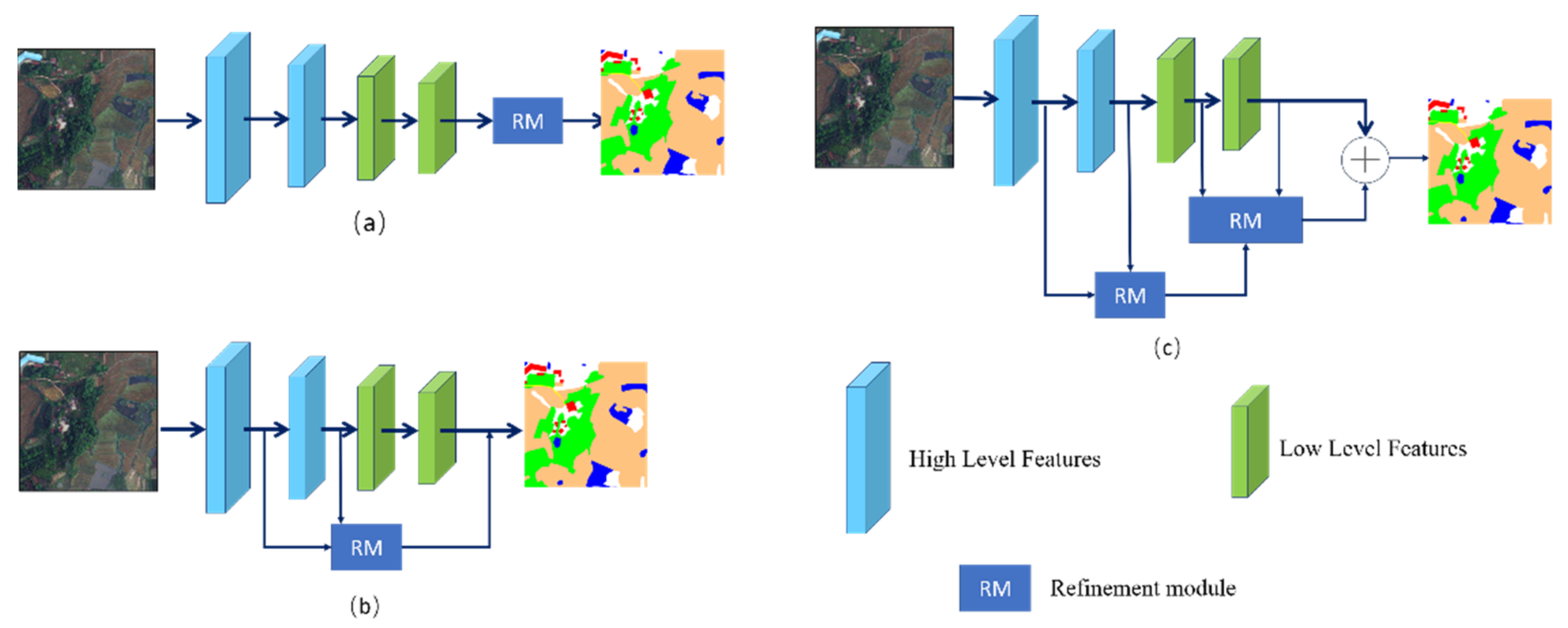
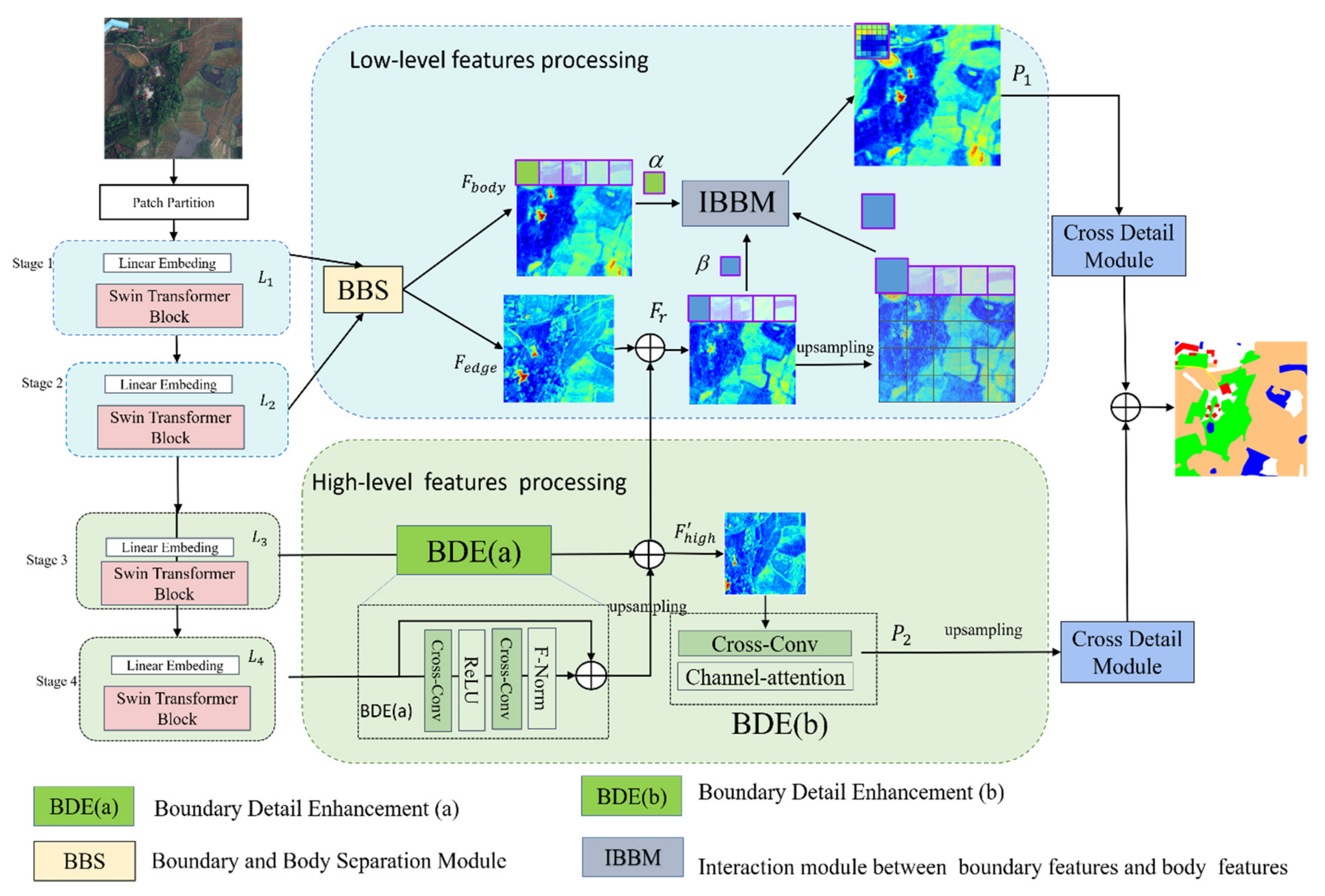
- In order to better distinguish between cropland features non-cropland features, we hierarchically refined the boundary information for multi-level network structures. For high-level features, we implemented the enhancement of boundary features while obtaining contextual information as much as possible. For low-level features with higher resolution, we used boundary-body separation module to extract boundary information and body information.
- We designed a boundary detail enhancement module (BDE), which is applied to high-level features that obtain more global information. This enhancement highlights the information on the boundaries of the cropland more conducive to cropland extraction. After completing the boundary feature enhancement, we proposed an information interaction module (IBBM) for feature interaction between boundary features and body features to obtain a more precise feature map.
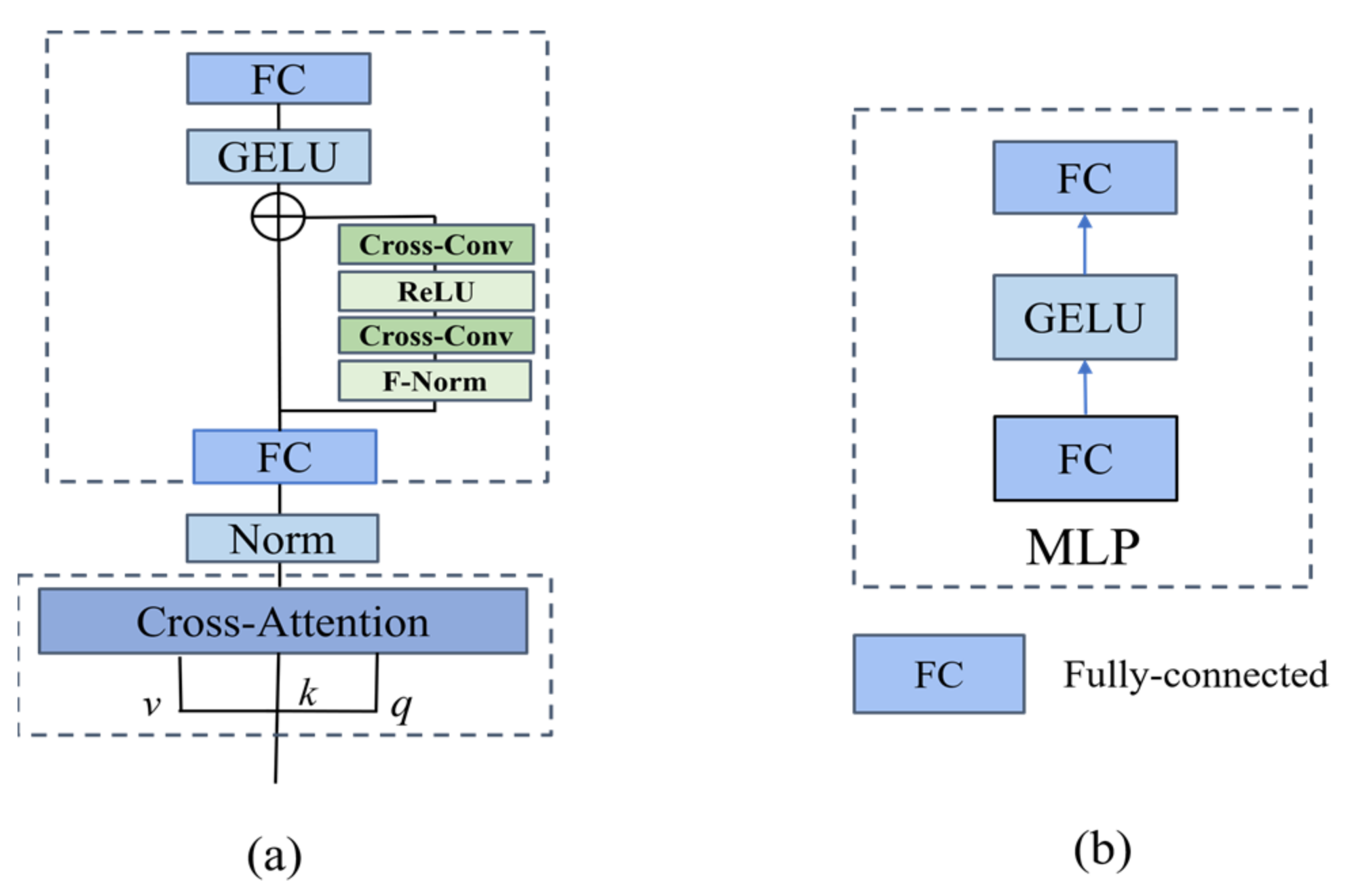
- We propose a cross-detail module by combining the cross-attention mechanism with an improved multi-layer perceptron (MLP). We set up the detail branch to the MLP layer, which makes it possible to enhance the detail information of the extracted features.
2. Materials and Methods
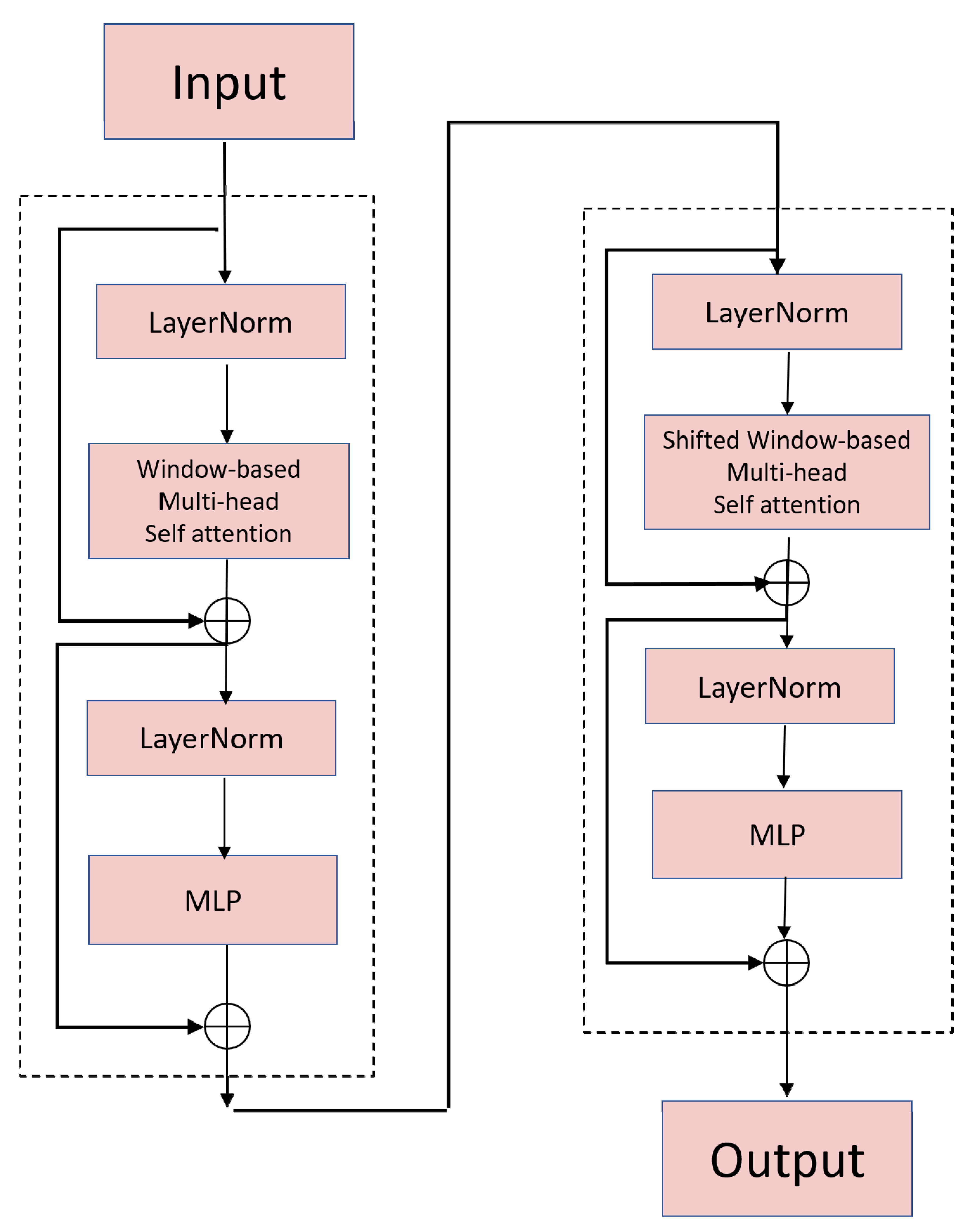
2.1. Network Architecture
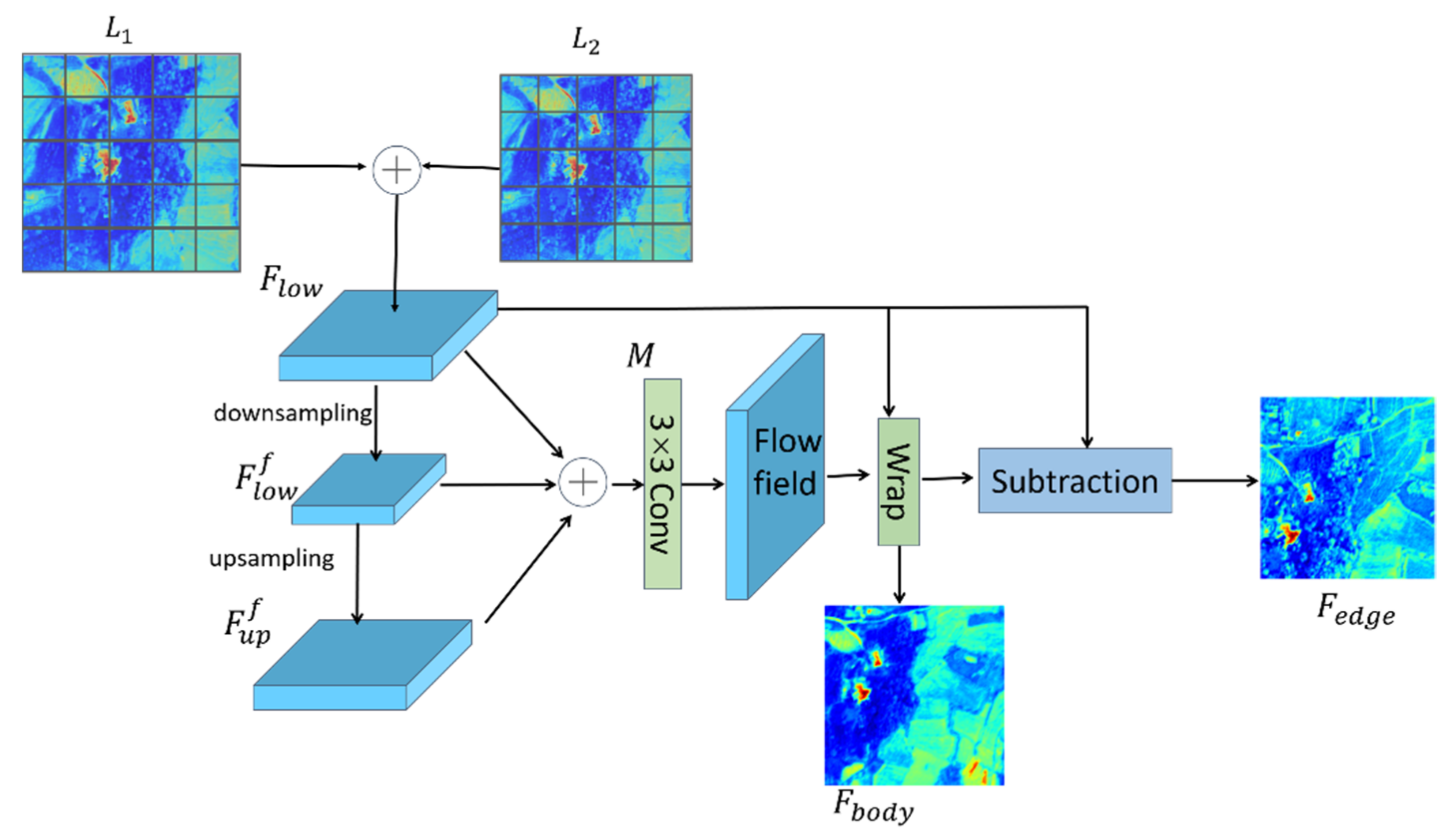
2.2. Boundary and Body Separation Module (BBS)
2.3. Boundary Detail Enhancement Module (BDE)
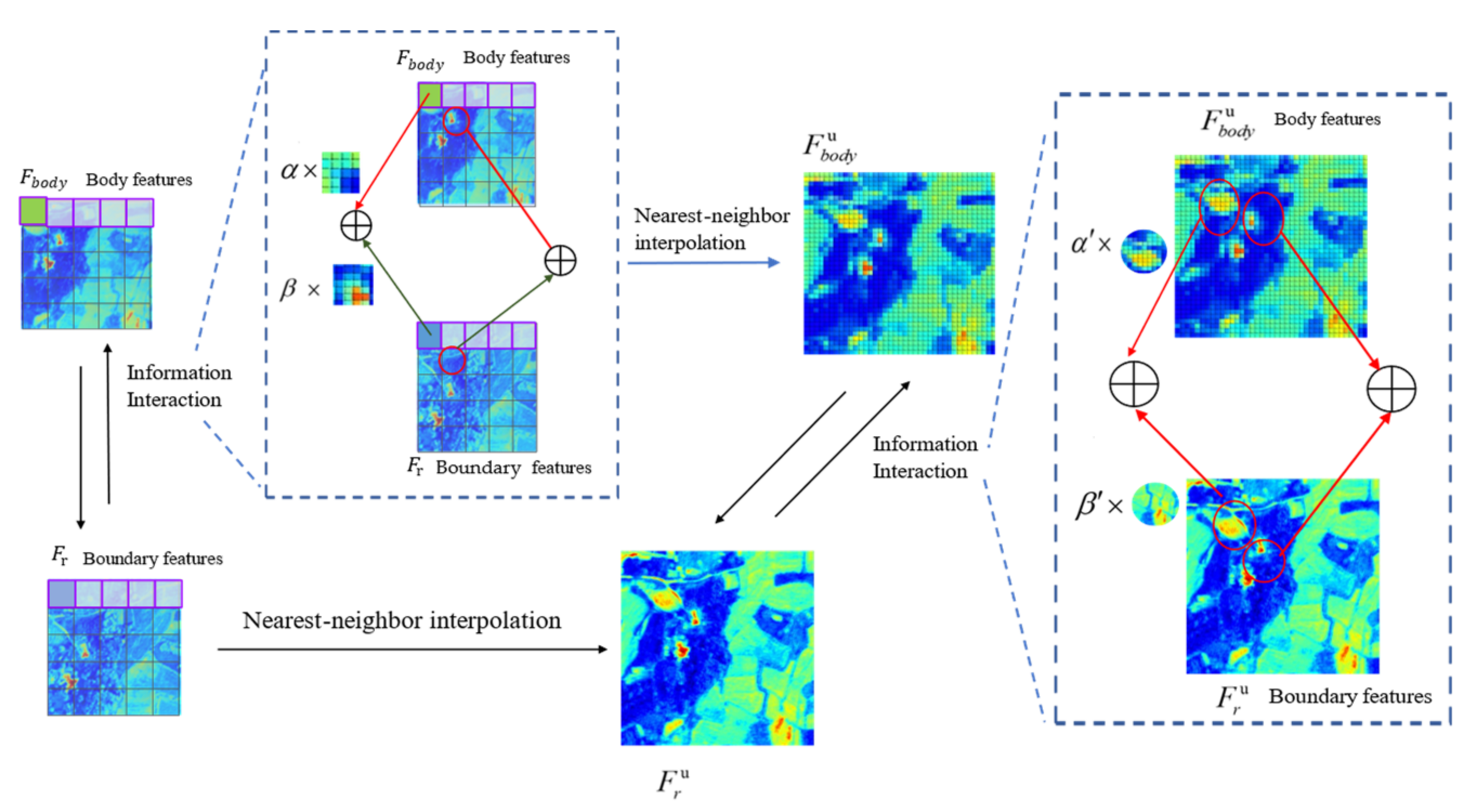
2.4. The Module for Interaction between Boundary Information and Body Information (IBBM)
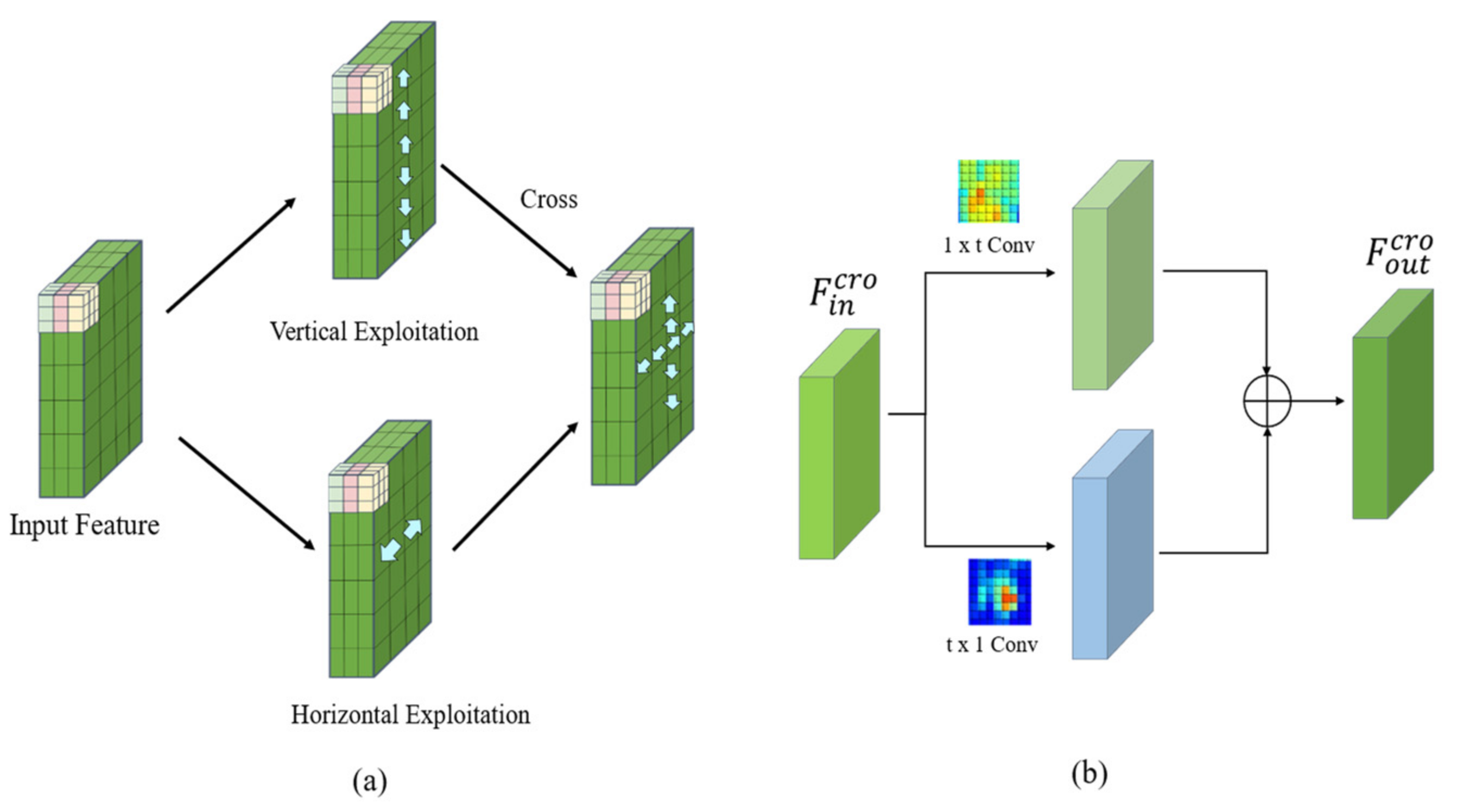
2.5. Cross-Detail Module
3. Results and Discussion
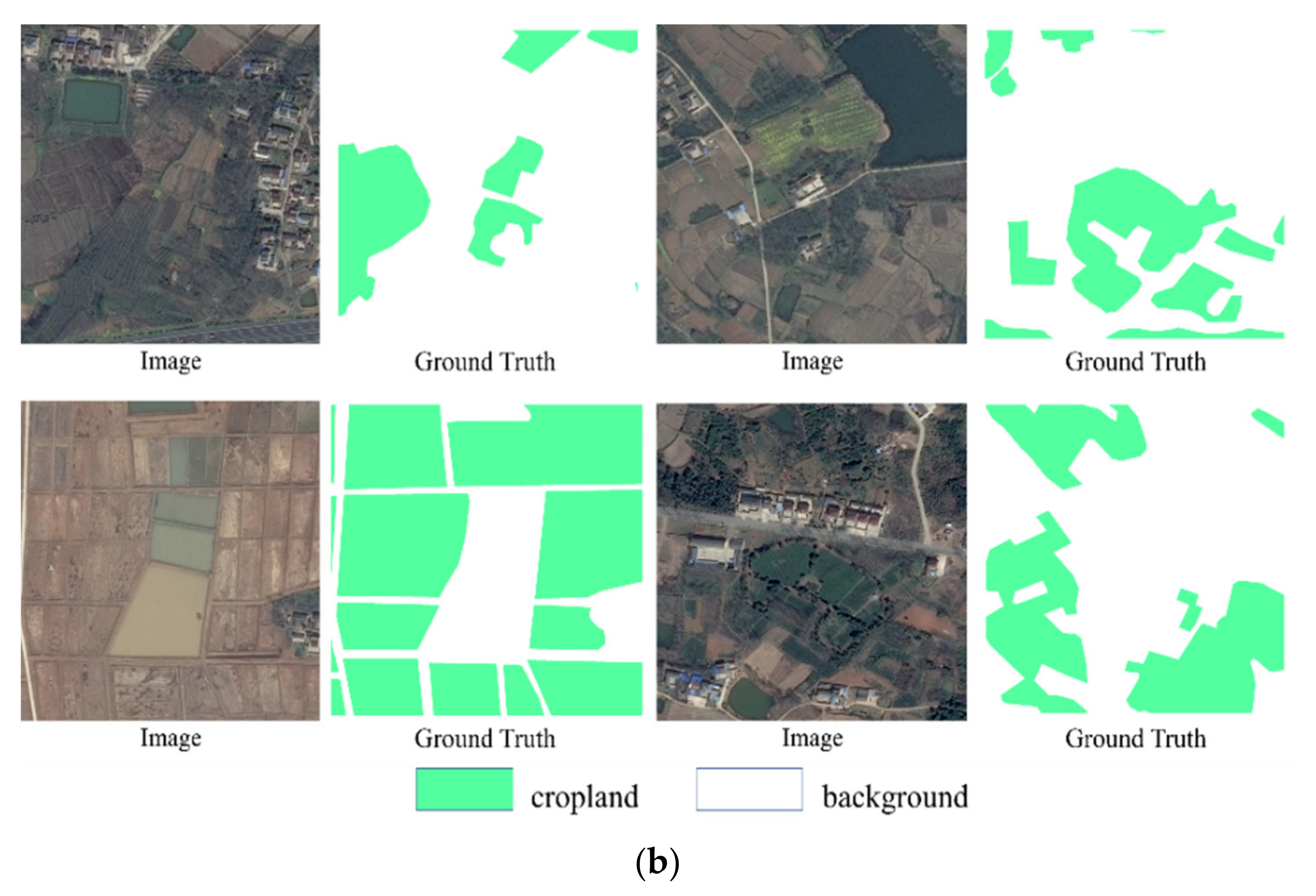
3.1. Datasets
3.1.1. Agriculture Dataset
3.1.2. DeepGlobe Dataset
3.2. Implementation Details
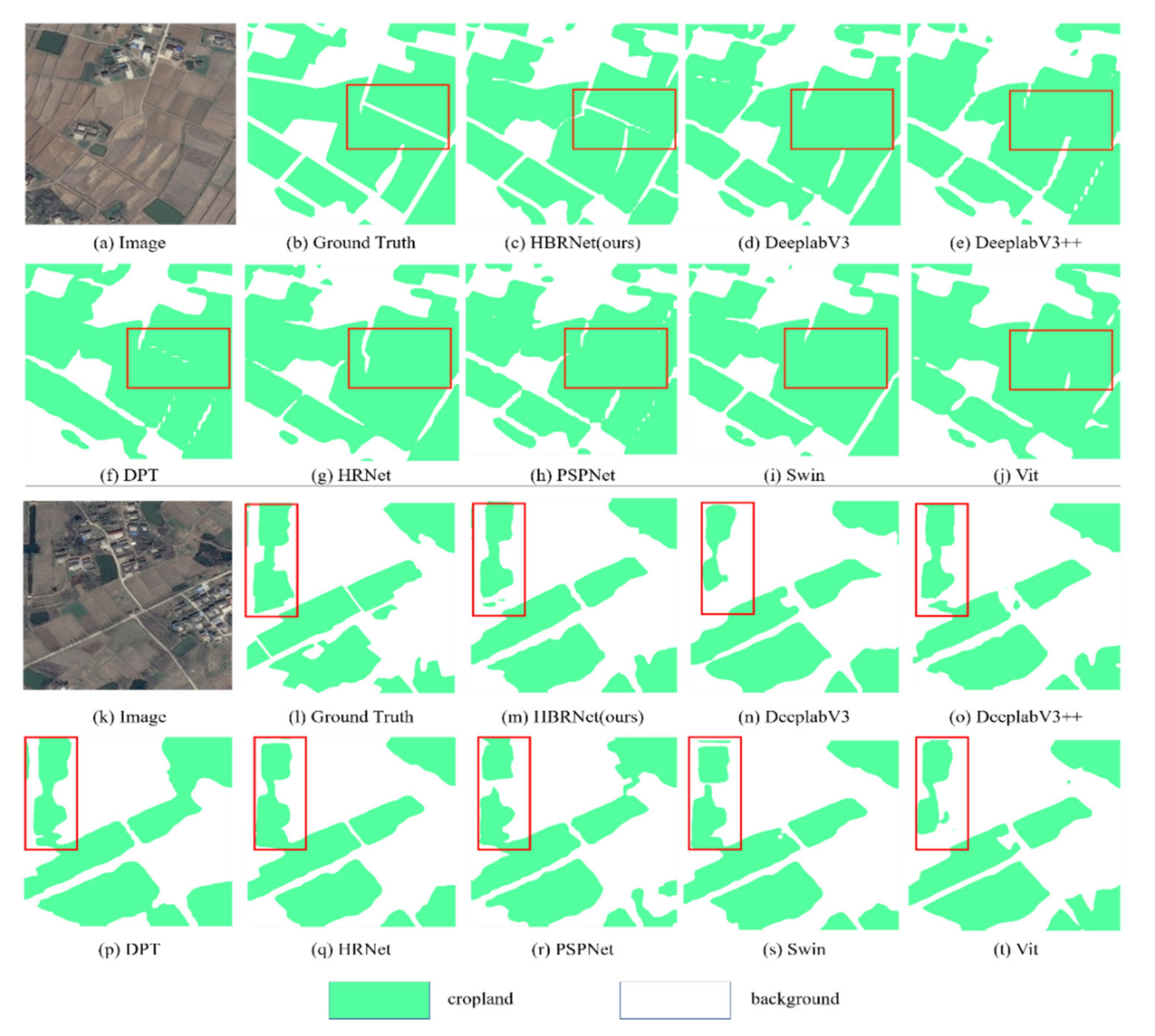
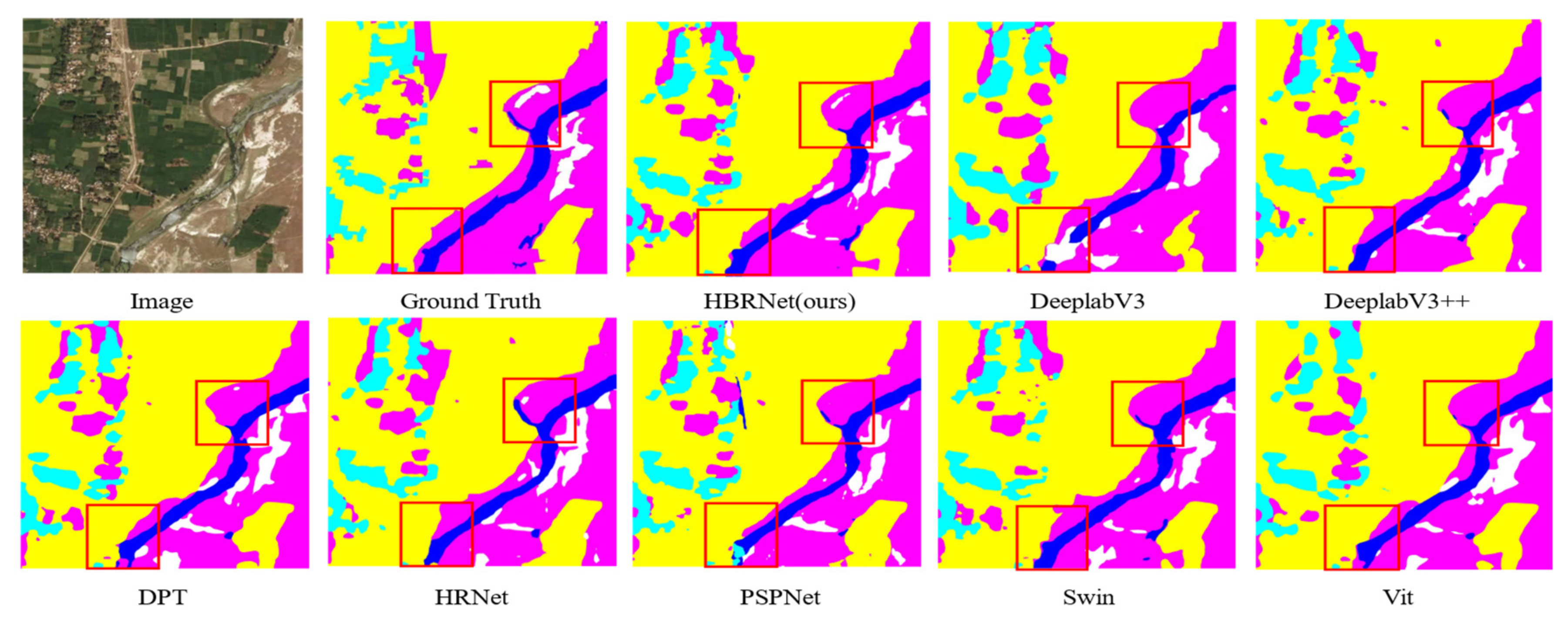
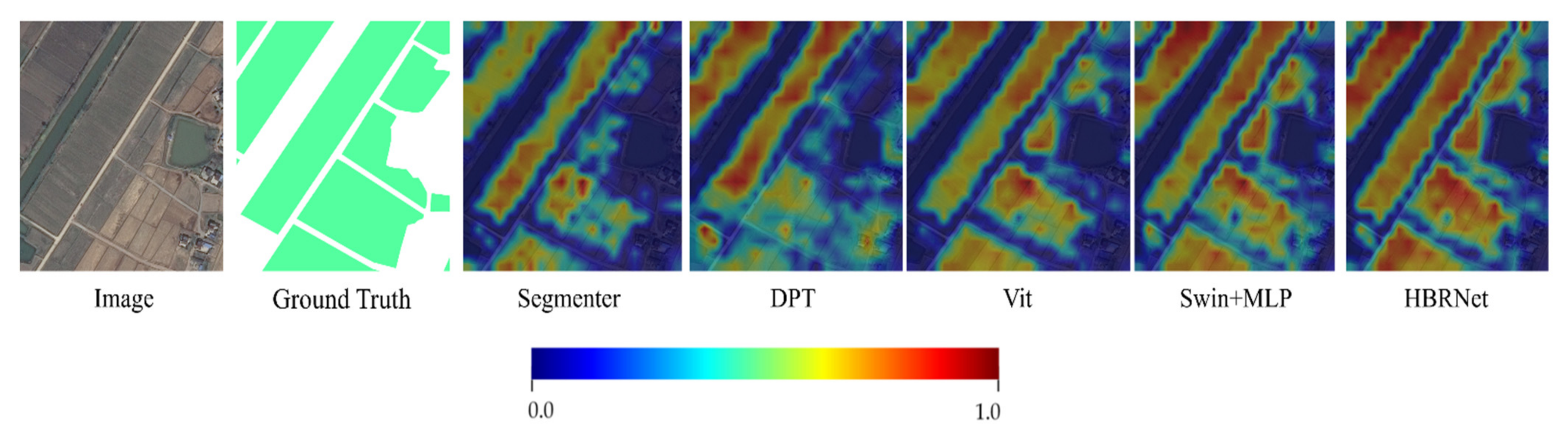
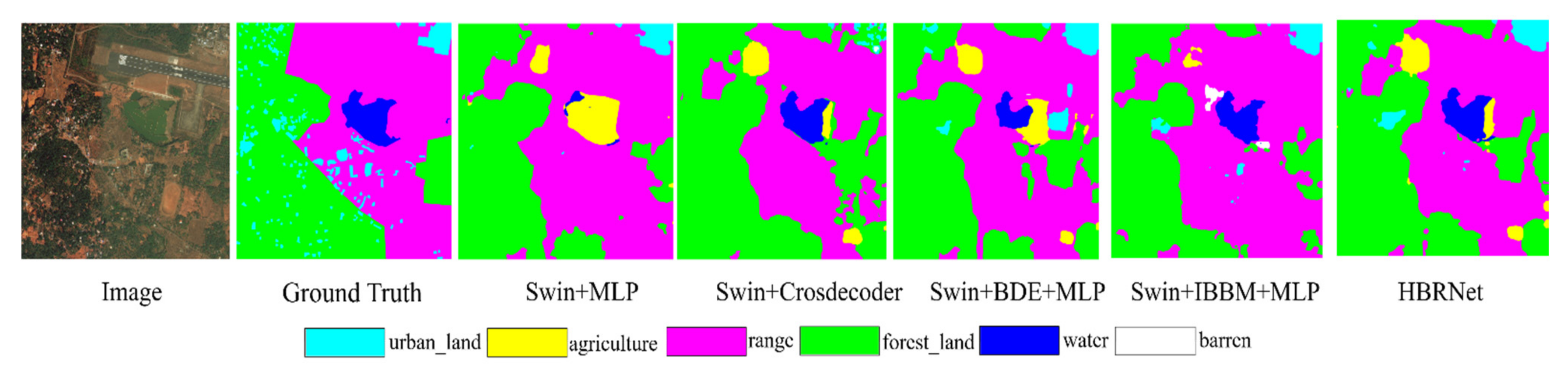
3.3. Semantic Segmentation Results and Analysis
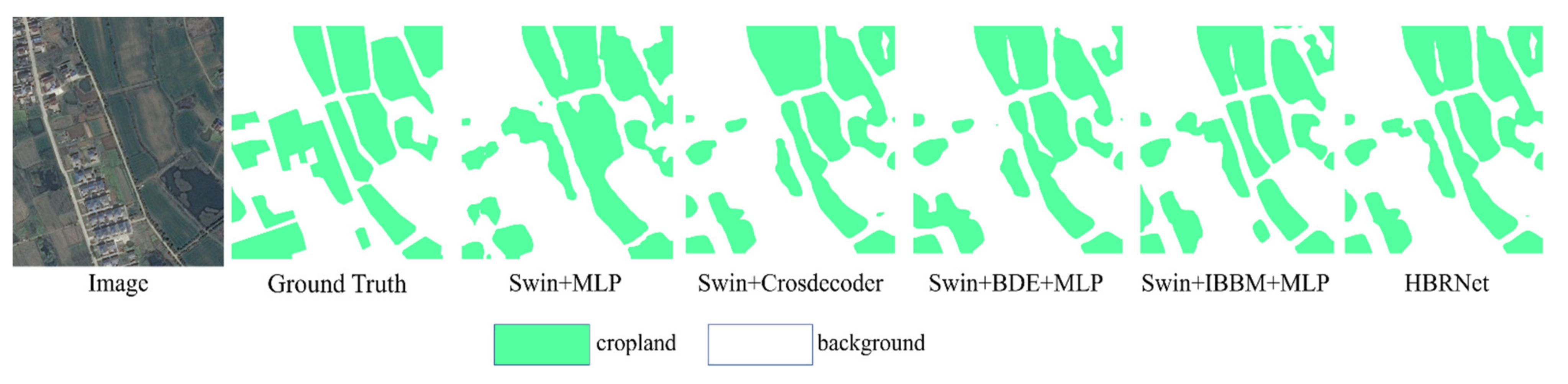
3.4. Ablation Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, J.; Weng, L.; Chen, B.; Xia, M. DFFAN: Dual Function Feature Aggregation Network for Semantic Segmentation of Land Cover. ISPRS Int. J. Geo-Inf. 2021, 10, 125. [Google Scholar] [CrossRef]
- Zhang, H.; Peng, Q. PSO and K-means-based semantic segmentation toward agricultural products. Future Gener. Comput. Syst. 2022, 126, 82–87. [Google Scholar] [CrossRef]
- Nzabarinda, V.; Bao, A.; Xu, W.; Uwamahoro, S.; Huang, X.; Gao, Z.; Umugwaneza, A.; Kayumba, P.M.; Maniraho, A.P.; Jiang, Z. Impact of cropland development intensity and expansion on natural vegetation in different African countries. Ecol. Inform. 2021, 64, 101359. [Google Scholar] [CrossRef]
- Liu, J.; Wang, D.; Maeda, E.E.; Pellikka, P.K.E.; Heiskanen, J. Mapping Cropland Burned Area in Northeastern China by Integrating Landsat Time Series and Multi-Harmonic Model. Remote Sens. 2021, 13, 5131. [Google Scholar] [CrossRef]
- Copenhaver, K.; Hamada, Y.; Mueller, S.; Dunn, J.B. Examining the Characteristics of the Cropland Data Layer in the Context of Estimating Land Cover Change. ISPRS Int. J. Geo-Inf. 2021, 10, 281. [Google Scholar] [CrossRef]
- Chen, Q.; Cao, W.; Shang, J.; Liu, J.; Liu, X. Superpixel-Based Cropland Classification of SAR Image with Statistical Texture and Polarization Features. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Sun, Y.; Qin, Q.; Ren, H.; Zhang, Y. Decameter Cropland LAI/FPAR Estimation From Sentinel-2 Imagery Using Google Earth Engine. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Chen, J.; Wang, H.; Guo, Y.; Sun, G.; Zhang, Y.; Deng, M. Strengthen the Feature Distinguishability of Geo-Object Details in the Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2327–2340. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, M.; Yao, R.; Liu, B.; Li, H. Semantic Segmentation of Remote-Sensing Images Based on Multiscale Feature Fusion and Attention Refinement. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wei, H.; Xu, X.; Ou, N.; Zhang, X.; Dai, Y. DEANet: Dual Encoder with Attention Network for Semantic Segmentation of Remote Sensing Imagery. Remote. Sens. 2021, 13, 3900. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Virtual, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision(ECCV), Glasgow, UK, 23–28 August 2020; pp. 173–190. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. HRFormer: High-Resolution Transformer for Dense Prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Ganesan, R.; Raajini, X.M.; Nayyar, A.; Padmanaban, S.; Hossain, E.; Ertas, A.H. BOLD: Bio-Inspired Optimized Leader Election for Multiple Drones. Sensors 2020, 20, 3134. [Google Scholar] [CrossRef]
- Wei, Z.; Youqiang, S.; He, H.; Haotian, P.; Jiajia, S.; Po, Y. Pest Region Detection in Complex Backgrounds via Contextual Information and Multi-Scale Mixed Attention Mechanism. Agriculture 2022, 12, 1104. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Liu, M.; Yin, H. Efficient pyramid context encoding and feature embedding for semantic segmentation. Image Vis. Comput. 2021, 111, 104195. [Google Scholar] [CrossRef]
- Bousselham, W.; Thibault, G.; Pagano, L.; Machireddy, A.; Gray, J.; Chang, Y.H.; Song, X. Efficient Self-Ensemble Framework for Semantic Segmentation. arXiv 2021, arXiv:2111.13280. [Google Scholar]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A Novel Transformer based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Peng, C.; Ma, J. Semantic segmentation using stride spatial pyramid pooling and dual attention decoder. Pattern Recognit. 2020, 107, 107498. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision(ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Chong, Y.; Chen, X.; Pan, S. Context Union Edge Network for Semantic Segmentation of Small-Scale Objects in Very High Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 10–14. [Google Scholar] [CrossRef]
- Pan, S.; Tao, Y.; Nie, C.; Chong, Y. PEGNet: Progressive Edge Guidance Network for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 637–641. [Google Scholar] [CrossRef]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 905–909. [Google Scholar] [CrossRef]
- Ghandorh, H.; Boulila, W.; Masood, S.; Koubaa, A.; Ahmed, F.; Ahmad, J. Semantic Segmentation and Edge Detection—Approach to Road Detection in Very High Resolution Satellite Images. Remote Sens. 2022, 14, 613. [Google Scholar] [CrossRef]
- Li, Q.; Yang, W.; Liu, W.; Yu, Y.; He, S. From Contexts to Locality: Ultra-high Resolution Image Segmentation via Locality-aware Contextual Correlation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 7232–7241. [Google Scholar]
- Huynh, C.; Tran, A.; Luu, K.; Hoai, M. Progressive Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Virtual, 19–25 June 2021; pp. 16755–16764. [Google Scholar]
- Zhu, L.; Ji, D.; Zhu, S.; Gan, W.; Wu, W.; Yan, J. Learning statistical texture for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 12532–12541. [Google Scholar]
- Chen, B.; Xia, M.; Huang, J. MFANet: A Multi-Level Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote. Sens. 2021, 13, 731. [Google Scholar] [CrossRef]
- Padmanaban, S.; Daya, F.J.L.; Blaabjerg, F.; Wheeler, P.W.; Szcześniak, P.; Oleschuk, V.; Ertas, A.H. Wavelet-fuzzy speed indirect field oriented controller for three-phase AC motor drive—Investigation and implementation. Eng. Sci. Technol. Int. J. 2016, 19, 1099–1107. [Google Scholar] [CrossRef] [Green Version]
- Padmanaban, S.; Daya, F.J.L.; Blaabjerg, F.; Mir-Nasiri, N.; Ertas, A.H. Numerical implementation of wavelet and fuzzy transform IFOC for three-phase induction motor. Eng. Sci. Technol. Int. J. 2016, 19, 96–100. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, Virtual, 6–14 December 2021; pp. 1–16. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raska, R. DeepGlobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving Semantic Segmentation via Decoupled Body and Edge Supervision. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 435–452. [Google Scholar]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4141–4150. [Google Scholar]
- Liu, Y.; Jia, Q.; Fan, X.; Wang, S.; Ma, S.; Gao, W. Cross-SRN: Structure-Preserving Super-Resolution Network with Cross Convolution. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4927–4939. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, S.; Zhang, J.; Wang, S.; Ma, S.; Gao, W. Iterative Network for Image Super-Resolution. IEEE Trans. Multimed. 2021, 24, 2259–2272. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.-F.R.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 347–356. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Kim, T.H.; Sajjadi, M.S.M.; Hirsch, M.; Sch, B. Encoder-Decoder with Atrous Separable Convolution for Semantic. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 111–127. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12159–12168. [Google Scholar]
- Huang, L.; Yuan, Y.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Interlaced Sparse Self-Attention for Semantic Segmentation. arXiv 2019, arXiv:1907.12273. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive Pyramid Context Network for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7519–7528. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the Annual Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021; pp. 12077–12090. [Google Scholar]
- Strudel, R.; Pinel, R.G.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 7242–7252. [Google Scholar]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking BiSeNet for Real-Time Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 9716–9725. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 432–448. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | IoU Per Category (%) | mIoU (%) | OA | |
|---|---|---|---|---|---|
| CropLand | Background | ||||
| HRNet | W32 | 81.99 | 70.92 | 76.46 | 87.49 |
| PSPNet | ResNet50 | 82.70 | 71.52 | 77.11 | 87.94 |
| IsaNet | ResNet50 | 82.66 | 71.40 | 77.03 | 87.90 |
| UNet + FCN | UNet-S5 | 79.08 | 69.00 | 74.08 | 85.74 |
| ApcNet | ResNet50 | 82.55 | 71.38 | 76.97 | 87.84 |
| DeeplabV3 | ResNet50 | 81.73 | 70.84 | 76.28 | 87.34 |
| Deeplab V3+ | ResNet50 | 82.58 | 71.60 | 76.87 | 87.82 |
| Swin-MLP | Swin-T | 83.70 | 73.20 | 78.45 | 88.72 |
| SegFormer | MIT-B0 | 82.89 | 72.86 | 77.92 | 88.32 |
| Segmenter-Mask | Vit-T_16 | 83.47 | 72.93 | 78.20 | 88.56 |
| DPT | Vit-b16 | 83.62 | 72.17 | 78.17 | 88.60 |
| Vit-upernet | Vit-b16 | 83.60 | 73.12 | 78.36 | 88.66 |
| HBRNet | Swin-T | 84.59 | 74.64 | 79.61 | 89.40 |
| Method | Backbone | IoU Per Category (%) | mIoU (%) | OA | |||||
|---|---|---|---|---|---|---|---|---|---|
| Urban | Agriculture | Range | Forest | Water | Barren | ||||
| HRNet | W32 | 72.57 | 88.08 | 36.02 | 80.64 | 82.57 | 62.59 | 70.41 | 88.03 |
| PSPNet | ResNet50 | 73.28 | 88.66 | 38.25 | 81.38 | 83.36 | 64.10 | 71.50 | 88.51 |
| IsaNet | ResNet50 | 78.05 | 88.09 | 34.30 | 78.55 | 78.28 | 68.39 | 70.94 | 88.47 |
| UNet + FCN | UNet-S5 | 72.73 | 86.97 | 33.15 | 79.99 | 81.64 | 57.46 | 68.66 | 86.94 |
| ApcNet | ResNet50 | 72.42 | 89.02 | 41.58 | 83.55 | 83.45 | 61.08 | 71.85 | 88.75 |
| DeeplabV3 | ResNet50 | 71.99 | 88.57 | 35.27 | 81.46 | 81.65 | 63.64 | 70.43 | 88.19 |
| Deeplab V3+ | ResNet50 | 72.93 | 88.55 | 34.98 | 81.27 | 84.05 | 61.99 | 70.63 | 88.24 |
| Swin- MLP | Swin-T | 75.00 | 89.85 | 44.32 | 83.74 | 85.44 | 66.35 | 74.12 | 89.60 |
| SegFormer | MIT-B0 | 74.66 | 89.22 | 42.99 | 84.16 | 83.47 | 63.84 | 73.06 | 89.25 |
| Segmenter | Vit-T16 | 74.68 | 89.41 | 43.11 | 83.16 | 84.10 | 66.50 | 73.49 | 89.32 |
| DPT | Vit-b16 | 73.22 | 88.80 | 40.91 | 82.98 | 82.60 | 65.96 | 72.29 | 88.73 |
| Vit- upernet | Vit-b16 | 72.55 | 89.19 | 44.48 | 83.02 | 80.10 | 66.96 | 72.72 | 88.92 |
| HBRNet | Swin-T | 76.28 | 90.37 | 47.93 | 84.36 | 84.67 | 67.37 | 75.15 | 90.16 |
| Method | IoU Per Category (%) | mIoU (%) | OA | |
|---|---|---|---|---|
| CropLand | Background | |||
| Swin + mlp | 83.7 | 73.2 | 78.45 | 88.72 |
| Swin + CDD | 83.78 | 73.67 | 78.73 | 88.85 |
| Swin + BDE + mlp | 84.03 | 73.85 | 78.94 | 88.99 |
| Swin + IBBM + mlp | 83.81 | 73.91 | 78.86 | 88.9 |
| Swin + BDE + IBBM + CDD | 84.59 | 74.64 | 79.61 | 89.4 |
| Method | IoU Per Category (%) | mIoU (%) | OA | |||||
|---|---|---|---|---|---|---|---|---|
| Urban | Agriculture | Range | Forest | Water | Barren | |||
| Swin + mlp | 75.00 | 89.85 | 44.32 | 83.74 | 85.44 | 66.35 | 74.12 | 89.60 |
| Swin + CDD | 74.54 | 90.18 | 47.24 | 84.18 | 85.62 | 67.84 | 74.93 | 89.95 |
| Swin + BDE + mlp | 75.45 | 90.27 | 45.30 | 82.72 | 86.96 | 67.73 | 74.74 | 89.76 |
| Swin + IBBM + mlp | 75.33 | 90.08 | 46.89 | 83.79 | 86.44 | 67.57 | 75.02 | 89.85 |
| Swin + BDE + IBBM + CDD | 76.18 | 90.37 | 47.93 | 84.36 | 84.67 | 67.37 | 75.15 | 90.16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, J.; Sun, Y.; Huang, H.; Xu, W.; Pei, H.; Zhang, W.; Wu, X. HBRNet: Boundary Enhancement Segmentation Network for Cropland Extraction in High-Resolution Remote Sensing Images. Agriculture 2022, 12, 1284. https://doi.org/10.3390/agriculture12081284
Sheng J, Sun Y, Huang H, Xu W, Pei H, Zhang W, Wu X. HBRNet: Boundary Enhancement Segmentation Network for Cropland Extraction in High-Resolution Remote Sensing Images. Agriculture. 2022; 12(8):1284. https://doi.org/10.3390/agriculture12081284
Chicago/Turabian StyleSheng, Jiajia, Youqiang Sun, He Huang, Wenyu Xu, Haotian Pei, Wei Zhang, and Xiaowei Wu. 2022. "HBRNet: Boundary Enhancement Segmentation Network for Cropland Extraction in High-Resolution Remote Sensing Images" Agriculture 12, no. 8: 1284. https://doi.org/10.3390/agriculture12081284