
Detection of Unripe Kernels and Foreign Materials in Chickpea Mixtures Using Image Processing

Abstract
:1. Introduction
2. Materials and Methods
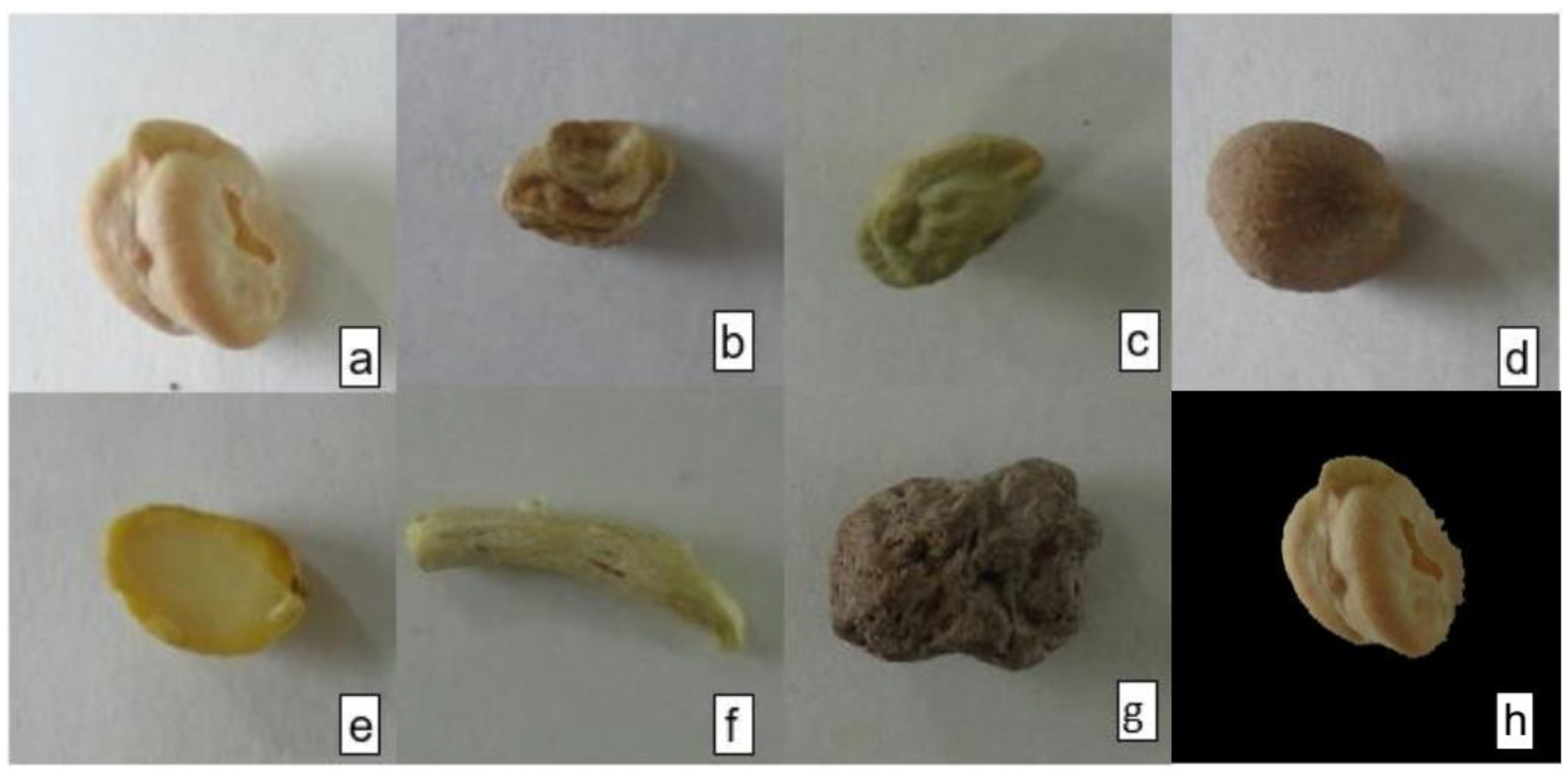
2.1. Image Acquisition
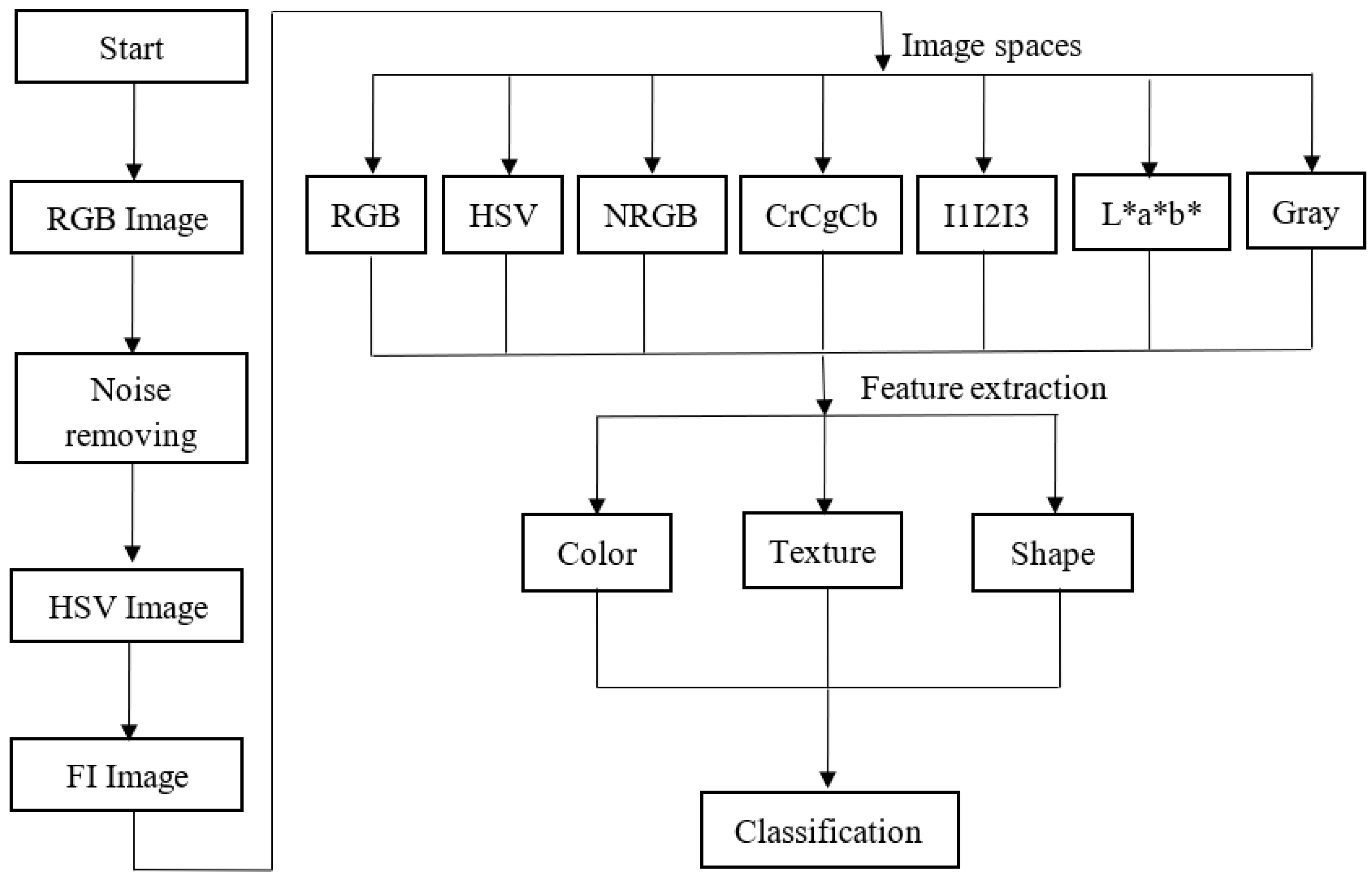
2.2. Image Preprocessing
2.3. Classification
3. Results
3.1. Efficient Features
3.2. Classification
3.2.1. Linear Discriminant Analysis
3.2.2. Support Vector Machine
3.2.3. Artificial Neural Network
3.3. Overall Accuracy
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Czuchajowska, Z.; Pomeranz, Y. Process for Fractionating Legumes to Obtain Pure Starch and a Protein Concentrate. Washington State University Research Fundation. U.S. Patent 5,364,471, 15 November 1993. [Google Scholar]
- Muehlbauer, F.I. Description and Culture of Chickpeas; Extension Bulletin 1112 Cooperative Extension Service Washington State University: Pullman, WA, USA, 1982. [Google Scholar]
- Sabaghpour, S.H. Major diseases of chickpea in Iran. In Proceedings of the Symposium on Grain Legumes in the Mediterranean. Agriculture, (LEGUMED), Rabat, Morocco, 25–27 October 2001. [Google Scholar]
- Jian, F.; Narendran, R.B.; Jayas, D.S. Segregation in stored grain bulks: Kinematics, dynamics, mechanisms, and minimization—A review. J. Stored Prod. Res. 2019, 81, 11–21. [Google Scholar] [CrossRef]
- Pandey, N.; Krishna, S.; Sharma, S. Automatic Seed Classification by Shape and Color Features using Machine Vision Technology. Int. J. Comput. Appl. Technol. 2013, 2, 208–213. [Google Scholar] [CrossRef]
- Mahajan, S.; Mittal, S.K.; Das, A. Machine vision based alternative testing approach for physical purity, viability and vigour testing of soybean seeds (Glycine max). J. Food Sci. Technol. 2018, 55, 3949–3959. [Google Scholar] [CrossRef]
- Kheiralipour, K.; Khazaee, Y.; Hosainpour, A.; Javadikia, H. Development of an algorithm based on image processing technique and sport vector machine to distinct potato from clod and stone. J. Res. Mech. Agric. Mach. 2019, 8, 1–11. [Google Scholar]
- Concha-Meyer, A.; Eifert, J.; Wang, H.; Sanglay, G. Volume estimation of strawberries, mushrooms, and tomatoes with a machine vision system. Int. J. Food Prop. 2018, 21, 1867–1874. [Google Scholar] [CrossRef]
- Guzmán, E.; Baeten, V.; Fernández Pierna, J.A.; García-Mesa, J.A. Determination of the olive maturity index of intact fruits using image analysis. J. Food Sci. Technol. 2015, 52, 1462–1470. [Google Scholar] [CrossRef] [Green Version]
- Kaur, H.; Sawhney, B.K.; Jawandha, S.K. Evaluation of plum fruit maturity by image processing techniques. J. Food Sci. Technol. 2018, 55, 3008–3015. [Google Scholar] [CrossRef]
- Kheiralipour, K.; Kazemi, A. A new method to determine morphological properties of fruits and vegetables by image processing technique and nonlinear multivariate modeling. Int. J. Food Prop. 2020, 23, 368–374. [Google Scholar] [CrossRef] [Green Version]
- Kheiralipour, K.; Pormah, A. Introducing new shape features for classification of cucumber fruit based on image processing technique and artificial neural networks. J. Food Process Eng. 2017, 40, e12558. [Google Scholar] [CrossRef]
- Linker, R.; Cohen, O.; Naor, A. Determination of the number of green apples in RGB images recorded in orchards. Comput. Electron. Agric. 2012, 81, 45–57. [Google Scholar] [CrossRef]
- Patel, K.K.; Kar, A.; Jha, S.N.; Khan, M.A. Machine vision system: A tool for quality inspection of food and agricultural products. J. Food Sci. Technol. 2012, 49, 123–141. [Google Scholar] [CrossRef] [Green Version]
- Surya Prabha, D.; Satheesh Kumar, J. Assessment of banana fruit maturity by image processing technique. J. Food Sci. Technol. 2015, 52, 1316–1327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeMasurier, L.S.; Panozzo, J.F.; Walker, C.K. A digital image analysis method for assessment of lentil size traits. J. Food Eng. 2014, 128, 72–78. [Google Scholar] [CrossRef]
- Shahin, M.A.; Symons, S.J. Seed sizing from images of non-singulated grain samples. Can. Biosyst. Eng. 2005, 47, 49–55. [Google Scholar]
- Kheiralipour, K.; Ahmadi, H.; Rajabipour, A.; Rafiee, S. Thermal Imaging, Principles, Methods and Applications, 1st ed.; Ilam University Publication: Ilam, Iran, 2018. [Google Scholar]
- Çakmak, Y.S.; Boyac, I.H. Quality evaluation of chickpeas using an artificial neural network integrated computer vision system. Int. J. Food Sci. Technol. 2011, 46, 194–200. [Google Scholar] [CrossRef]
- Ghamari, S. Classification of chickpea seeds using supervised and unsupervised artificial neural networks. Afr. J. Agric. Res. 2012, 7, 3193–3201. [Google Scholar]
- Sabzi, S.; Abbaspour Gilandeh, Y.; Razavi, M. Detection five varieties of Chickpea using image processing and hybrid artificial neural network particle swarm optimization classifier. In Proceedings of the 1st International and 5th National Conference on Organic vs. Conventional Agriculture, Ardabil, Iran, 16–17 August 2017. [Google Scholar]
- Pourdarbani, R.; Sabzi, S.; Kalantari, D.; Hernández-Hernández, J.L.; Ignacio Arribas, J. A computer vision system based on majority-voting ensemble neural network for the automatic classification of three chickpea varieties. Foods 2020, 9, 113. [Google Scholar] [CrossRef] [Green Version]
- Pourdarbani, R.; Sabzi, S.; García-Amicis, V.M.; García-Mateos, G.; Molina-Martínez, J.M.; Ruiz-Canales, A. Automatic classification of chickpea varieties using computer vision techniques. Agronomy 2019, 9, 672. [Google Scholar] [CrossRef] [Green Version]
- Sankaran, S.; Wang, M.; Vandemark, G.J. Image-based rapid phenotyping of chickpeas seed size. Eng. Agric. Environ. Food 2016, 9, 50–55. [Google Scholar] [CrossRef]
- Venora, G.; Grillo, O.; Shahin, M.A.; Symons, S.J. Identification of Sicilian landraces and Canadian cultivars of lentil using an image analysis system. Food Res. Int. 2007, 40, 161–166. [Google Scholar] [CrossRef]
- He, W.; Song, H.; Guo, Y.; Wang, X.; Bian, G.; Yuan, K. A Trajectory-based Attention Model for Sequential Impurity Detection. Neurocomputing 2020, 410, 271–283. [Google Scholar] [CrossRef]
- Chen, J.; Lian, Y.; Li, Y. Real-time grain impurity sensing for rice combine harvesters using image processing and decision-tree algorithm. Comput. Electron. Agric. 2020, 175, 105591. [Google Scholar] [CrossRef]
- Rong, D.; Wang, H.; Xie, L.; Ying, Y.; Zhang, Y. Impurity detection of juglans using deep learning and machine vision. Comput. Electron. Agric. 2020, 178, 105764. [Google Scholar] [CrossRef]
- Shen, Y.; Yin, Y.; Li, B.; Zhao, C.; Li, G. Detection of impurities in wheat using terahertz spectral imaging and convolutional neural networks. Comput. Electron. Agric. 2021, 181, 105931. [Google Scholar] [CrossRef]
- Mohd Ali, M.; Hashim, N.; Abdul Hamid, A.S. Combination of laser-light backscattering imaging and computer vision for rapid determination of oil palm fresh fruit bunches maturity. Comput. Electron. Agric. 2020, 169, 105235. [Google Scholar] [CrossRef]
- Khazaee, Y.; Kheiralipour, K.; Hosainpour, A.; Javadikia, H.; Paliwal, J. Development of a novel image analysis and classification algorithms to separate tubers from clods and stones. Potato Res. 2022, 65, 1–22. [Google Scholar] [CrossRef]
- Jahanbakhshi, A.; Kheiralipour, K. Evaluation of image processing technique and discriminant analysis methods in postharvest processing of carrot fruit. Food Sci. Nutr. 2020, 8, 3346–3352. [Google Scholar] [CrossRef]
- Azadnia, R.; Kheiralipour, K. Recognition of leaves of different medicinal plant species using a robust image processing algorithm and artificial neural networks classifier. J. Appl. Res. Med. Aromat. Plants 2021, 25, 100327. [Google Scholar] [CrossRef]
- Mohammadi, V.; Kheiralipour, K.; Ghasemi-Varnamkhasti, M. Detecting maturity of persimmon fruit based on image processing technique. Sci. Hortic. 2015, 184, 123–128. [Google Scholar] [CrossRef]
- Jahanbakhshi, A.; Kheiralipour, K. Carrot sorting based on shape using image processing, artificial neural network, and support vector machine. J. Agric. Mach. 2019, 9, 295–307. [Google Scholar]
- Kheiralipour, K.; Ahmadi, H.; Rajabipour, A.; Rafiee, S.; Javan-Nikkhah, M. Classifying Healthy and Fungal Infected-Pistachio Kernel by Thermal Imaging Technology. Int. J. Food Prop. 2015, 18, 93–99. [Google Scholar] [CrossRef]
- Kheiralipour, K.; Ahmadi, H.; Rajabipour, A.; Rafiee, S.; Javan Nikkhah, M.; Digvir, S.J.; Siliveru, K.; Malihipour, A. Processing the Hyperspectral Images for Detecting Infection of Pistachio Kernel by R5 and KK11 Isolates of Aspergillus flavus Fungus. Iran. J. Biosyst. Eng. 2021, 52, 13–25. [Google Scholar]
- Kheiralipour, K.; Ahmadi, H.; Rajabipour, A.; Rafiee, S.; Javan-Nikkhah, M.; Jayas, D.S.; Siliveru, K. Detection of fungal infection in pistachio kernel by long-wave near infrared hyperspectral imaging technique. Qual. Assur. Saf. Crops Foods 2016, 8, 129–135. [Google Scholar] [CrossRef]
- Chelladurai, V.; Jayas, D.S.; White, N.D.G. Thermal imaging for determining fungal infection in stored wheat. J. Stored Prod. Res. 2010, 46, 174–179. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2021, 17, 168–192. [Google Scholar] [CrossRef]
- Ting, K.M. Confusion Matrix. In Encyclopedia of Machine Learning, 1st ed.; Sammut, C., Webb, G.I., Eds.; Springer: New York, NY, USA, 2010. [Google Scholar]



{kind=link}
{kind=link}
| Feature | Ch Ș | Chickpea Kernel | Foreign Material | |||||
|---|---|---|---|---|---|---|---|---|
| Sound | Wrinkle | Unripe | Brownish | Split | Stone | Stalk | ||
| Correlation (pix ȘȘ) | R | 0.99 ± 0.00 | 0.99 ± 0.01 | 0.97 ± 0.02 | 0.98 ± 0.01 | 0.99 ± 0.00 | 0.97 ± 0.01 | 0.98 ± 0.01 |
| Energy (pix) | R | 0.79 ± 0.05 | 0.89 ± 0.04 | 0.91 ± 0.05 | 0.90 ± 0.04 | 0.85 ± 0.02 | 0.83 ± 0.10 | 0.89 ± 0.06 |
| Energy (pix) | B | 0.79 ± 0.06 | 0.91 ± 0.32 | 0.92 ± 0.05 | 0.94 ± 0.03 | 0.88 ± 0.02 | 0.85 ± 0.09 | 0.90 ± 0.06 |
| Energy (pix) | a * | 0.82 ± 0.53 | 0.93 ± 0.37 | 0.97 ± 0.03 | 0.90 ± 0.04 | 0.91 ± 0.03 | 0.89 ± 0.07 | 0.93 ± 0.054 |
| Mean (pix) | I2 | 0.10 ± 0.01 | 0.10 ± 0.02 | 0.08 ± 0.01 | 0.08 ± 0.01 | 0.14 ± 0.01 | 0.04 ± 0.01 | 0.09 ± 0.01 |
| Mean (pix) | Cb | −0.14 ± 0.13 | −0.14 ± 0.03 | −0.13 ± 0.01 | −0.09 ± 0.02 | −0.21 ± 0.02 | −0.06 ± 0.01 | −0.14 ± 0.02 |
| Homogeneity (pix) | H | 1.00 ± 0.00 | 1.00 ± 00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| Correlation (pix) | V | 0.99 ± 0.00 | 0.98 ± 0.01 | 0.97 ± 0.15 | 0.98 ± 0.01 | 0.99 ± 0.00 | 0.97 ± 0.01 | 0.98 ± 0.01 |
| Homogeneity (pix) | V | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| Area (Kpix) | 82.28 ± 16.12 | 51.86 ± 16.45 | 29.51 ± 21.99 | 43.71 ± 21.079 | 81.61 ± 12.58 | 67.50 ± 48.08 | 53.30 ± 37.54 | |
| Centroid (pix) | 483.68 ± 77.35 | 561.08 ± 70.31 | 486.37 ± 100.64 | 496.81 ± 93.48 | 552.47 ± 84.54 | 468.10 ± 100.34 | 629.67 ± 138.65 | |
| Roundness (pix) | 0.60 ± 0.15 | 0.49 ± 0.23 | 0.23 ± 0.11 | 0.31 ± 0.20 | 0.68 ± 0.08 | 0.20 ± 0.11 | 0.29 ± 0.16 | |
| Major diameter (pix) | 359.55 ± 38.65 | 299.62 ± 53.04 | 242.92 ± 100.12 | 288.820 ± 63.66 | 362.66 ± 35.33 | 346.36 ± 128.08 | 518.65 ± 275.79 | |
| Elongation (pix) | 1.22 ± 0.11 | 1.41 ± 0.45 | 1.67 ± 0.49 | 1.49 ± 0.36 | 1.26 ± 0.15 | 1.68 ± 0.58 | 3.82 ± 1.94 | |
| Classifier | Step | D a | U b | F c | GA d | SA e | TA f | |
|---|---|---|---|---|---|---|---|---|
| Linear discriminant analysis | Training | D a | 36 | 5 | 0 | 87.8 | 91.3 | 91.9 |
| U b | 5 | 101 | 2 | 93.5 | ||||
| F c | 0 | 6 | 48 | 88.9 | ||||
| Testing | D a | 13 | 0 | 0 | 100.0 | 94.0 | ||
| U b | 0 | 36 | 0 | 100.0 | ||||
| F c | 0 | 4 | 14 | 77.8 | ||||
| Support vector machine | Training | D a | 41 | 0 | 0 | 100.0 | 100.0 | 88.5 |
| U b | 0 | 108 | 0 | 100.0 | ||||
| F c | 0 | 0 | 54 | 100.0 | ||||
| Testing | D a | 0 | 13 | 0 | 0.0 | 53.8 | ||
| U b | 0 | 36 | 0 | 100.0 | ||||
| F c | 0 | 18 | 0 | 0.0 | ||||
| Optimal artificial neural network | Training | D a | 33 | 0 | 1 | 97.1 | 98.8 | 94.4 |
| U b | 0 | 86 | 0 | 100.0 | ||||
| F c | 0 | 1 | 42 | 97.7 | ||||
| Validating | D a | 9 | 1 | 0 | 90.0 | 81.5 | ||
| U b | 1 | 24 | 4 | 82.8 | ||||
| F c | 1 | 3 | 11 | 73.3 | ||||
| Testing | D a | 11 | 0 | 0 | 100.0 | 92.6 | ||
| U b | 2 | 27 | 0 | 0.0 | ||||
| F c | 0 | 2 | 12 | 85.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salam, S.; Kheiralipour, K.; Jian, F. Detection of Unripe Kernels and Foreign Materials in Chickpea Mixtures Using Image Processing. Agriculture 2022, 12, 995. https://doi.org/10.3390/agriculture12070995
Salam S, Kheiralipour K, Jian F. Detection of Unripe Kernels and Foreign Materials in Chickpea Mixtures Using Image Processing. Agriculture. 2022; 12(7):995. https://doi.org/10.3390/agriculture12070995
Chicago/Turabian StyleSalam, Somayeh, Kamran Kheiralipour, and Fuji Jian. 2022. "Detection of Unripe Kernels and Foreign Materials in Chickpea Mixtures Using Image Processing" Agriculture 12, no. 7: 995. https://doi.org/10.3390/agriculture12070995