3.1. Foundation
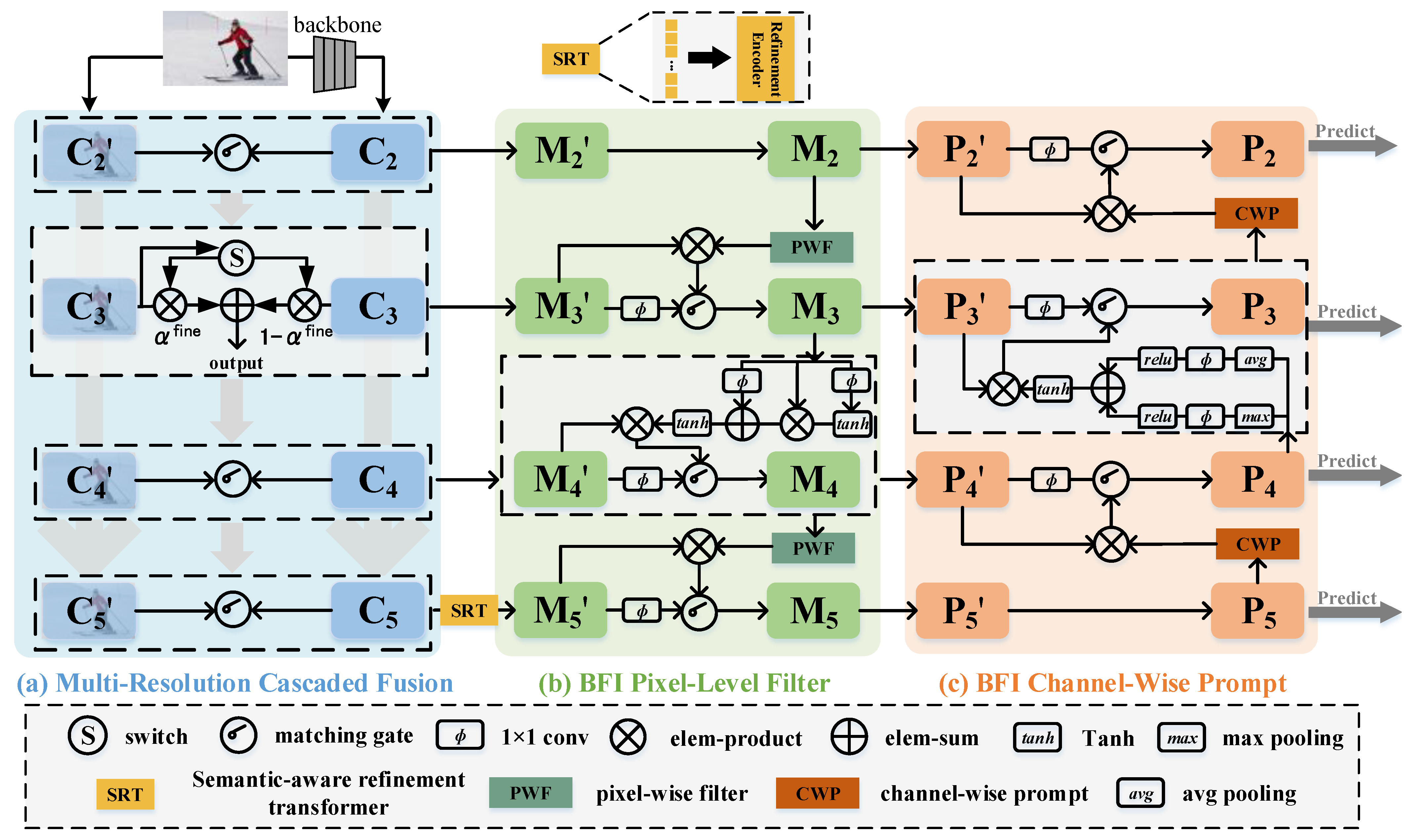
The overview of the proposed MSBA is illustrated in
Figure 2. As depicted in
Figure 2a, MCF comprises two feature information streams. The
indicate the features derived from the multi-resolution input image, processed through multiple convolutions to capture sufficient coarse-grained information.
represent features from distinct stages of the single-resolution image undergone by the backbone network. In
Figure 2b, to ensure consistent notation within the same module, we employ
in BFI to denote features derived from MCF’s output. SRT concentrates on enhancing the multi-scale semantic representation in the high-level feature, specifically targeting
. Besides, Additionally, BFI encompasses pixel-level filter interaction (PLI) and channel-wise prompt interaction (CWI). The output of PLI is denoted as
, where
remains unchanged (
) without any further operations. Similarly,
mirrors
and represents features resulting from PLI’s output. Additionally,
signify features enriched with meticulous semantic prompt information, primed for predictions.
The matching gate functions as a controller, aiming to mitigate inconsistencies and redundancy arising from rigorous interaction between two features. It dynamically modulates the fusion process in response to the present input. In detail, when provided with input features
as input, the matching gate
can be described as:
in which
represents the control matrix of
X and
means the Hadamard product.
can be obtained from the switch (
) in the matching gate as:
where
represents the operations such as 3 × 3 convolution and pooling.
signifies a nonlinear activation function, executed as
within our method. The matching gate adeptly fosters complementarity between the two features.
3.2. Multi-Resolution Cascaded Fusion
FPN employs a single-resolution image as its input to create a feature pyramid. It can partially mitigate the challenge of scale variation. However, this approach is limited since a single-resolution image can only offer a restricted amount of object information within a specific scale. Using high-resolution images as input can be advantageous for detecting small objects, yet it might lead to relatively lower performance in detecting larger objects. Conversely, utilizing low-resolution images as input may lead to subpar performance in detecting small objects. Consequently, employing a single-resolution image as input might not suffice for effectively detecting objects across various scales.
Hence, the inclusion of a multi-scale image input is crucial for detectors to gather a broader spectrum of object information across different resolutions. This observation motivates our introduction of the multi-resolution cascaded fusion, which integrates multi-resolution data into the network architecture, as illustrated in
Figure 2a. Initially, the input image undergoes both backbone processing and direct downsampling to align with the size of
from the backbone as
. Following this, the downsampled multi-resolution images undergo a sequence of convolution, batch normalization, and activation operations, culminating in the creation of corresponding features imbued with both coarse-grained spatial details and semantic insights. Furthermore, we employ a matching gate to adaptively manage the fusion process between the generated multi-resolution features and the multi-stage features derived from the backbone. This procedure can be described as:
Here,
refers to the input image that has been downsampled to align with the suitable spatial dimensions of
, with
i representing the feature level index from the backbone.
represents a sequence of operations, including a 3 × 3 Conv, BN, and ReLU to produce semantic features. Subsequently, we leverage
to merge with the corresponding
using a matching gate, thereby generating a feature that is more effective. Additionally, we formulate a multi-receptive-field cascaded fusion strategy to extract multi-scale spatial information from the lower-level features. The entire procedure can be expressed as follows:
where
signifies the convolution operator applied with different dilation rates.
corresponds to the input for the subsequent stage, enriched with ample coarse-grained and multi-scale spatial information. Notably,
is derived from the matching gate without the incorporation of dilated convolution.
Generally, our multi-resolution cascaded fusion supplies diverse resolution information. The proposed MCF is advantageous for object instances of varying scales. Additionally, we employ a matching gate as a controller to dynamically regulate the interaction process between multi-resolution images and the multi-stage features of the backbone. This adaptively controlled process aids in avoiding the inclusion of unnecessary information. Furthermore, the proposed multi-receptive-field cascaded fusion strategy contributes to the extraction of ample multi-scale spatial information for the high-level features. The resulting features consequently achieve a more comprehensive representation of different scales.
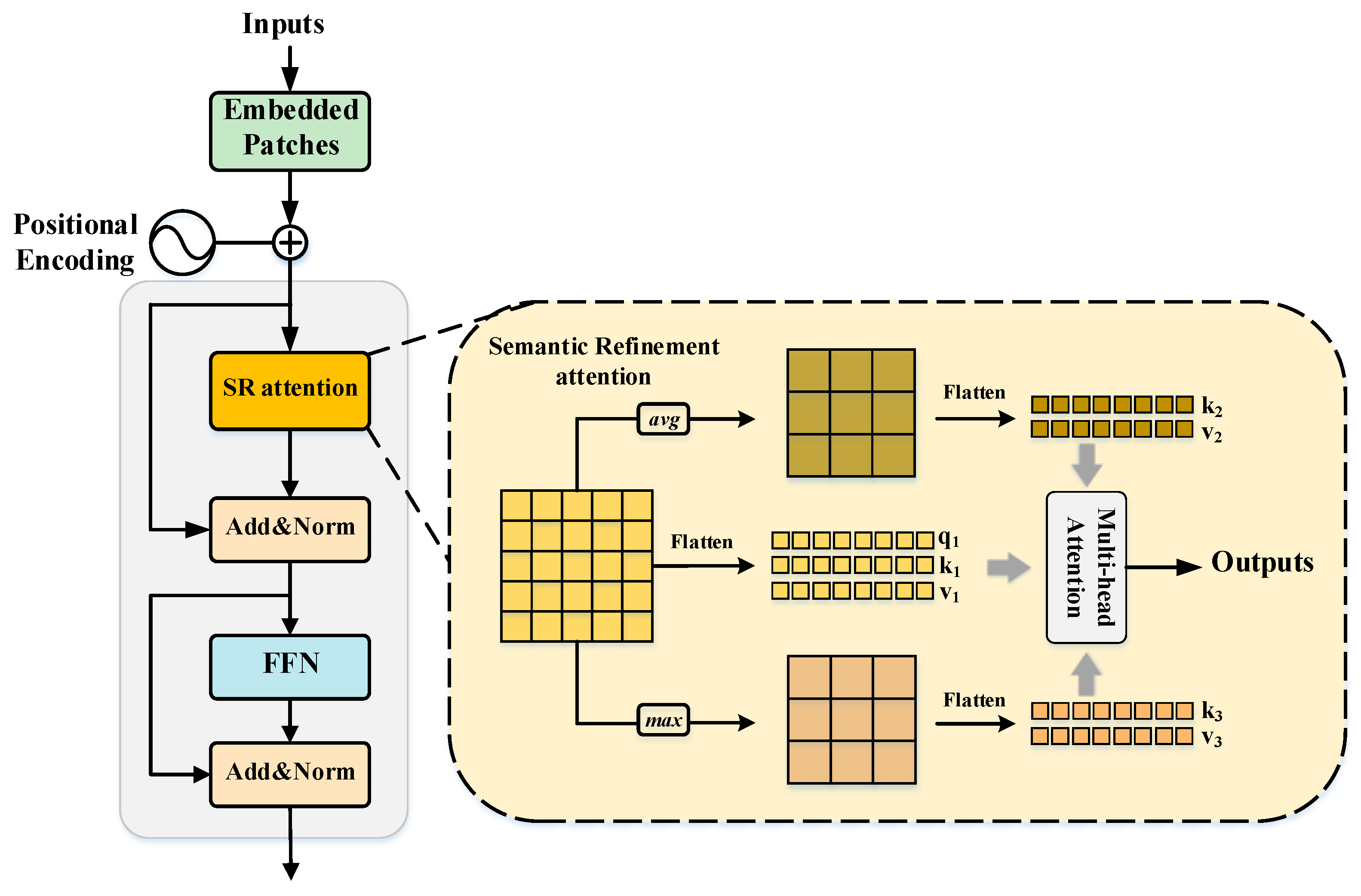
3.3. Semantic-Aware Refinement Transformer
Based on earlier investigations [
9,
55], it is evident that the semantic message contained in the high-level features significantly contributes to mitigating scale variations. However, in conventional approaches, there is a lack of distinction between different levels. Common methods merely employ high-level features to provide semantic information in their original states. Moreover, the transformer is designed to capture long-range semantic messages due to its self-attention mechanism. Nevertheless, directly applying the transformer to high-level features may disregard the variations in features across diverse representation situations. Thus, we propose the SRT transformer encoder to enhance the comprehensive semantic representation of high-level features across different feature states. This enhancement facilitates the acquisition of multi-scale semantic global information by high-level features.
As illustrated in
Figure 3, we employ SRT on
to augment the semantic information. The entire process of SRT can be elucidated as follows:
where
denotes the layer normailzation operation.
introduces the position embedding for the feature and the
serves to enhance the non-linearity of these features.
signifies the novel SRT attention mechanism, enabling the query of the original feature to probe long-range semantic relationships across various feature states. Furthermore, the sufficient semantic information can be integrated through the SRT attention mechanism effectively. The process can be delineated as:
The term
represents the query extracted from the original feature. The keys, namely
,
, along with the values
,
, signify the keys and values obtained through processing the corresponding features using average and max pooling operations. The processed features can achieve more expressive with tiny spatial size. The
h denotes the number of attention heads. Following this,
engages in interactions with the other keys to amplify the semantic representation of the high-level feature under various representation states. The mechanism
is employed to calculate token-wise correlations among the features. Details can be formulated as follows:
where
q,
k, and
v represent the query, key, and value, separately.
denotes the feature channels. Our proposed approach employs the initial query to compute correlations with other keys sourced from diverse sections of the feature. This process enables the sufficient extraction of semantic information from the high-level feature.
In summary, our proposed SRT comprehensively investigates the semantic information across different states of the high-level feature. This facilitates the refinement and enhancement of multi-scale semantic details through long-range relationship interactions. Moreover, the computational cost remains minimal due to the small spatial size of the high-level feature.
3.4. Bidirectional Fine-Grained Interaction
While acquiring the appropriate input for the merging process, a more effective interaction of features among various levels becomes essential. In a typical feature pyramid, a top-down pathway connects features from high to low levels in a progressive manner. Low-level features are enriched with semantic information from higher levels, which proves advantageous for classification tasks. Nevertheless, detection tasks demand sufficient information pertinent to both classification and regression tasks, which poses a challenge due to the differing information needs of these tasks. The regression task mandates precise object contours and detailed information from high-resolution levels. Additionally, the classification task necessitates ample semantic information from low-resolution levels. However, the FPN scheme is not fully harnessed, resulting in the underutilization of high-resolution information from lower levels. The integration of numerous object contours and detailed information does not occur as effectively as anticipated. Furthermore, the semantic information gradually diminishes along the top-down path.
Building upon the aforementioned knowledge, we introduce bidirectional fine-grained interaction to address the challenge of underutilizing multi-scale features and to foster interplay across distinct levels. Initially, we recognize that a straightforward bottom-up path could potentially introduce additional noise in lower levels. Therefore, we devise a pixel-level filter (PLF), depicted in
Figure 2b, which centers on salient locations and dynamically sieves out extraneous pixel-level information based on the current feature’s characteristics. Moreover, high-level features often lack location-specific information. As a solution, we introduce a bottom-up scheme where low-level features employ the pixel-level filter to guide high-level features towards object-specific locations.
The pixel-level filter comprises two primary components: the identification of salient locations and the removal of superfluous pixel-level information, as well as the provision of fine-grained location guidance. The initial component, referred to as the pixel-level filter, can be outlined as follows:
where
is tanh activation that transforms the operation into an encoded feature vector, ranging from (−1, 1);
refers to a 1 × 1 conv operation; and
ensures non-negativity.
is the output of PLF that denotes the filter result of
. The pixel-level filter effectively removes superfluous information by suppressing values below 0 and dynamically emphasizes the salient region. In the subsequent part, the adjacent layer
is guided by the filter results
from preceding layers, facilitating focus on the desired region:
is a convolution operator applied to
with the intention of obtaining a focused region through a learning strategy.
signifies the output of interaction. It is obtained by matching the
with the prominent information derived from preceding layers.
remains unchanged, equivalent to
.
Upon acquiring features enriched with accurate object contour and detailed information, we incorporate the concept of channel-wise prompt to facilitate the propagation of semantic information. As shown in
Figure 2c, channel-wise prompt is devoted to extracting the semantic prompt map of the feature at the channel level, adaptively. Then, we utilize the semantic prompt map of higher levels to instruct the adjacent layer, which can heighten the semantic perception ability of objects. The detailed process can be articulated as:
where
denotes the semantic prompt map of high-level features, and
and
represent the average pooling and max pooling operation block. Then,
learns the semantic knowledge according to the prompt map. The process can be written as:
The proposed bidirectional fine-grained interaction takes full advantage of multi-scale features. During the bidirectional interaction process, both semantic and spatial information can be effectively completed among different levels. The low-level layers, which possess high-resolution information, effectively capture salient location information via pixel-level filtering at the pixel level. This information is then utilized to establish a bottom-up information flow. This aids in enhancing the essential location information of objects within high-level layers. Conversely, the high-level layers, abundant in semantic information, contribute significant semantic prompts when subjected to channel-wise prompting at the channel level. The prominent semantic prompt can be effectively transmitted to the low-level layers with minimal loss. BGI promotes adequate interaction among different levels with abundant multi-scale information.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}