
A Multi-Pedestrian Tracking Algorithm for Dense Scenes Based on an Attention Mechanism and Dual Data Association
Abstract
:1. Introduction
- (1)
- The two branches of pedestrian detection and apparent feature extraction are integrated and trained by multi-task learning, so that they can output pedestrian detection results and corresponding pedestrian apparent feature vectors at the same time, reducing redundant computations and improving the overall speed of the tracking algorithm.
- (2)
- CenterNet uses multiple deformable convolutional and deconvolutional u-sampling of only one-quarter the size of the input image for prediction and does not fuse multi-layer pedestrian features, so the tracking network has a poor tracking effect for obscured pedestrians. Therefore, the FPN is introduced, and the obtained feature maps are up-sampled to obtain high-resolution feature maps after multi-layer features are fused, which effectively improves the stability of the network for tracking obscured pedestrians.
- (3)
- An improved attention mechanism module is introduced in the backbone network of CenterNet to enhance its ability to extract spatial location information and apparent features of pedestrians, improve the tracking algorithm accuracy, and reduce the incidence of IDs.
- (4)
- For pedestrian tracking in videos, the data association part is improved, and low-scoring detection boxes are associated with pedestrian trajectories for dual data association, which reduces the frequency of trajectory interruption when pedestrians are obscured and improves the robustness of the tracking module.
2. Materials and Methods
2.1. Dataset
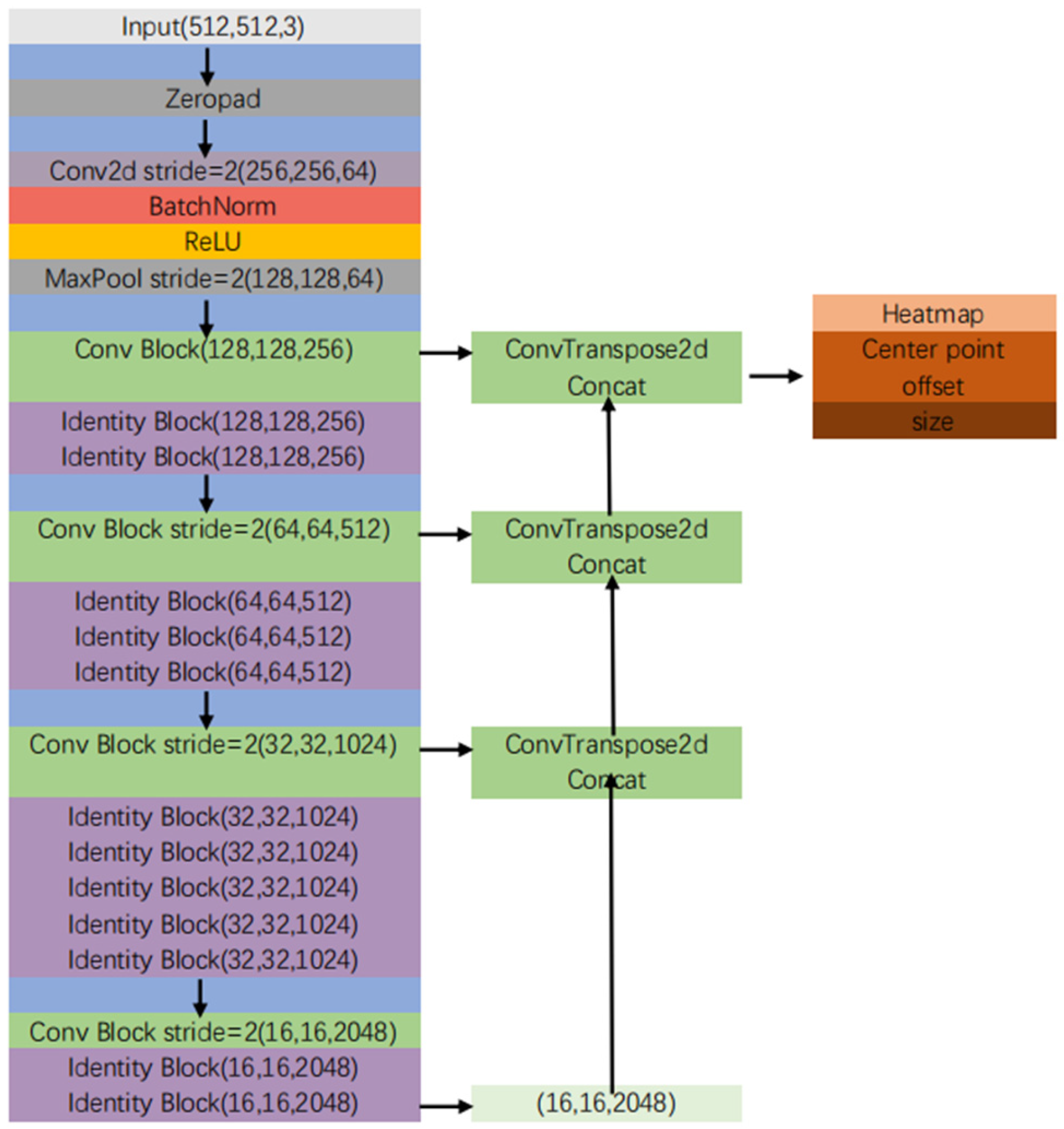
2.2. Structure of CenterNet
2.3. Improved CenterNet
2.3.1. Multi-Layer Feature Aggregation
2.3.2. High-Resolution Feature Maps
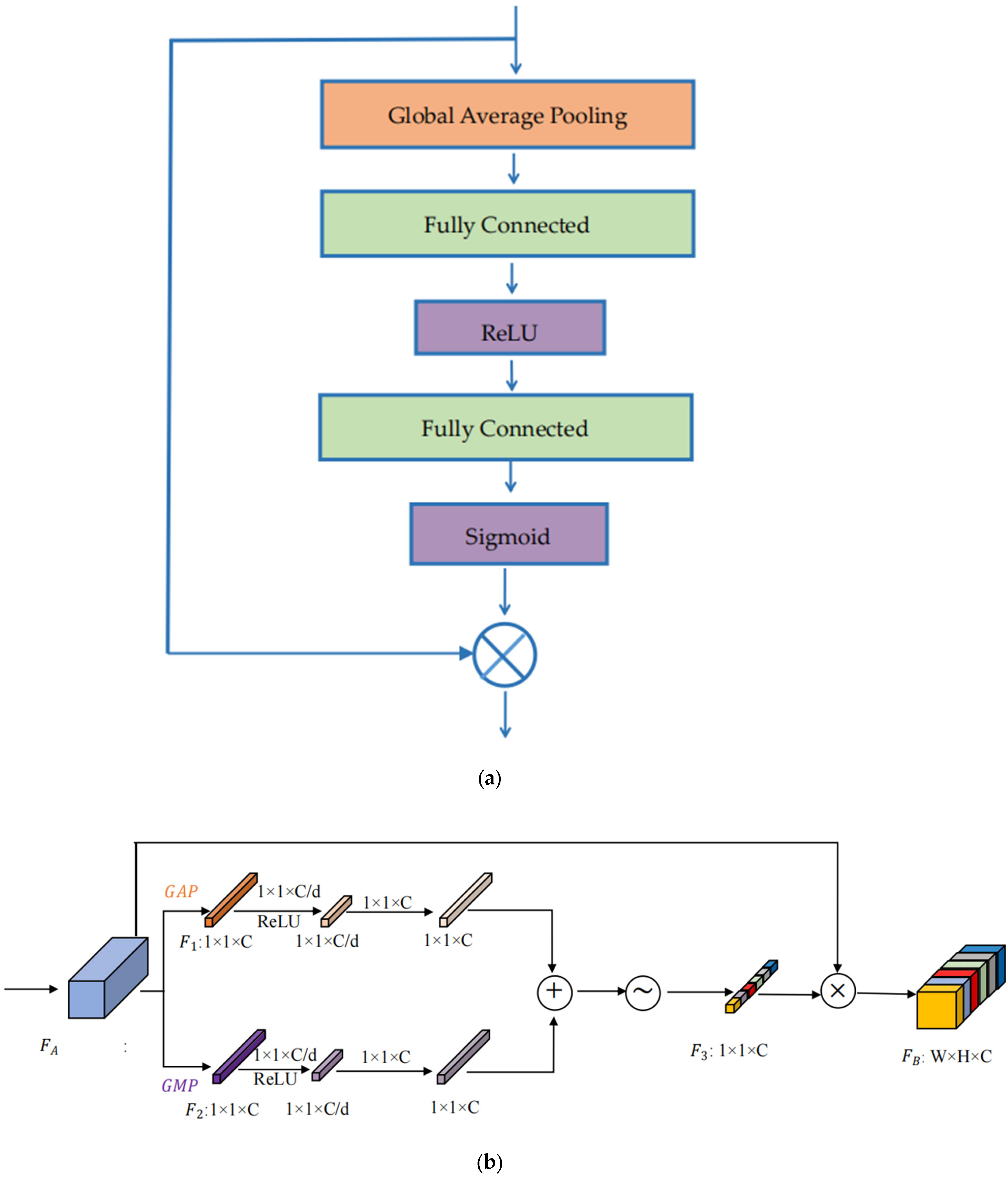
2.4. Improved Channel Attention Mechanism Module
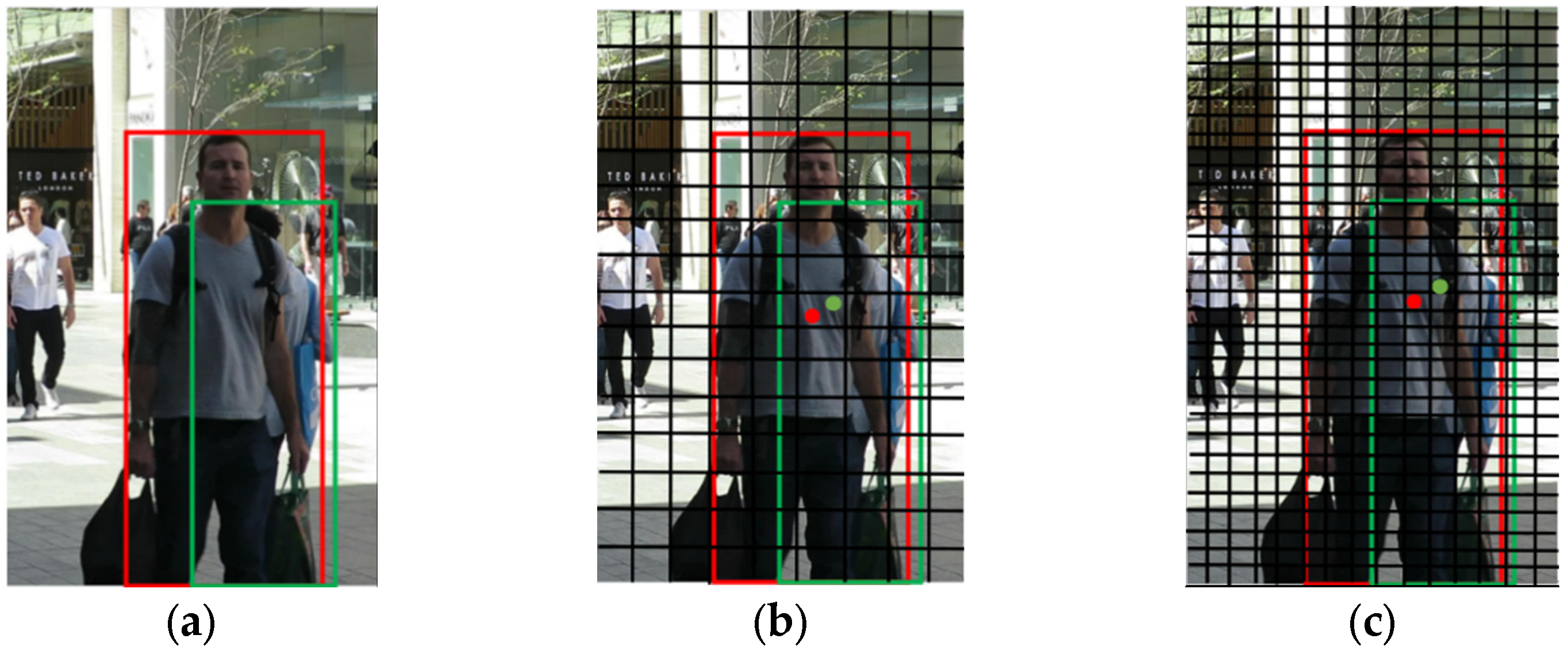
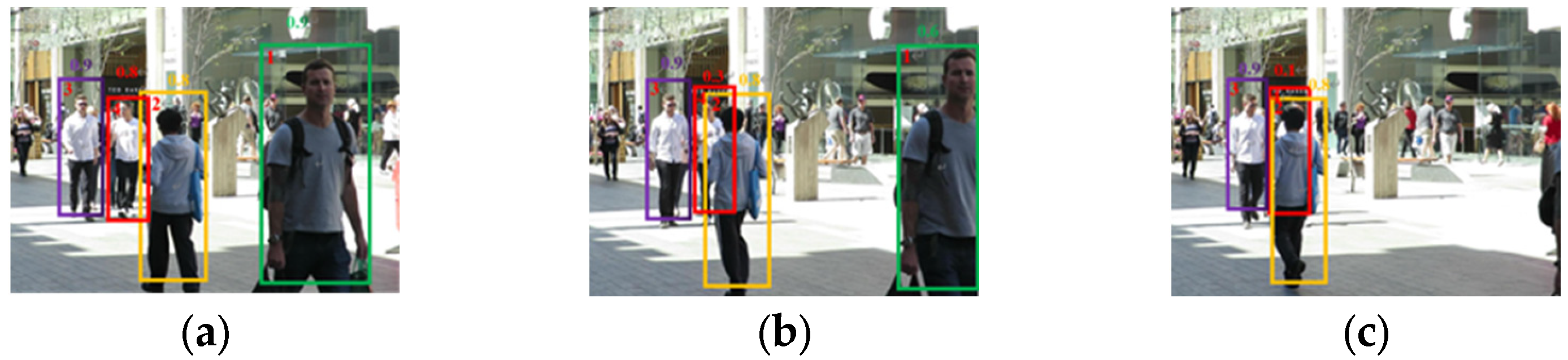
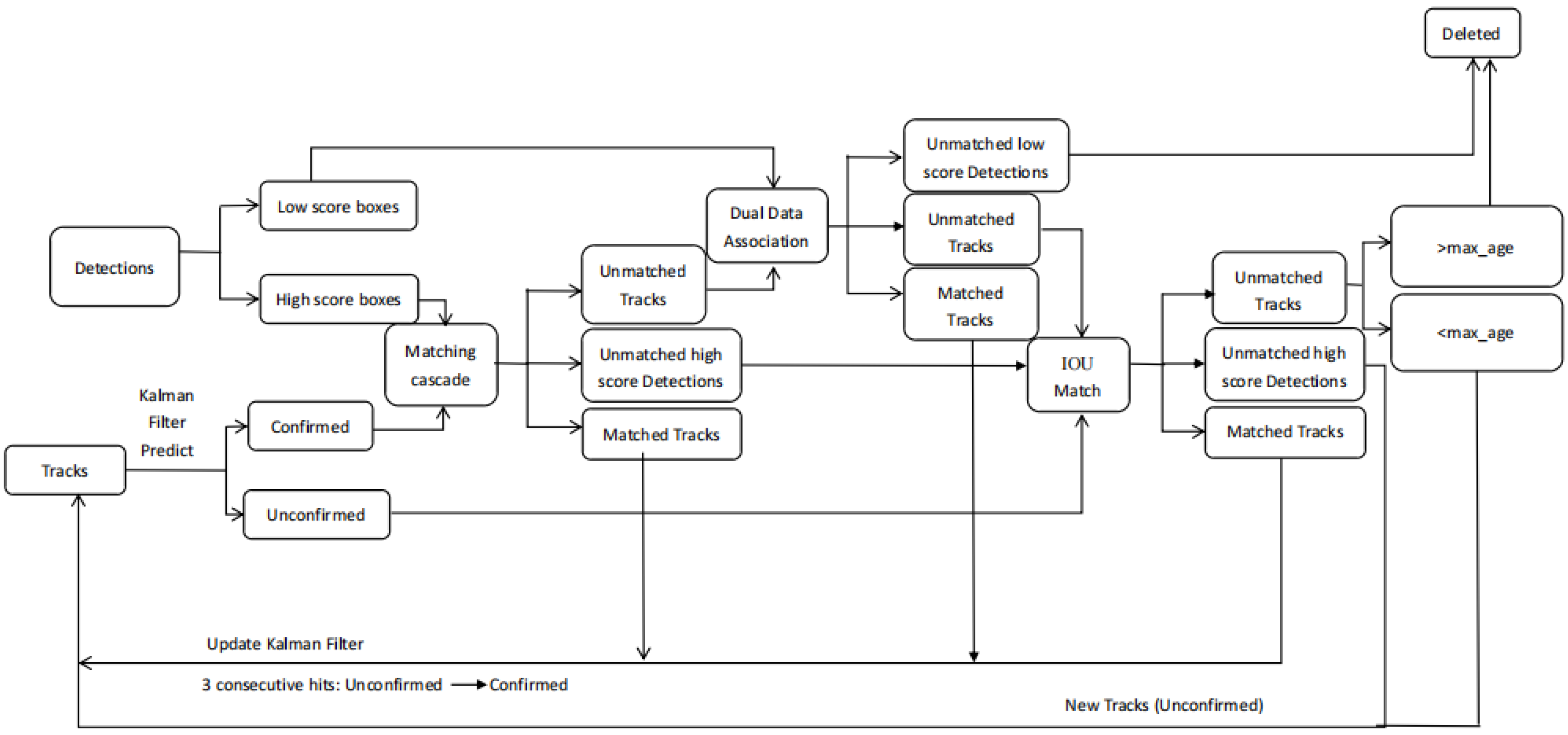
2.5. Dual Data Association
3. Experimental Results and Analysis
3.1. Experimental Environment
3.2. Experimental Evaluation Criteria
3.3. Ablation Experiments
3.3.1. Detection Performance
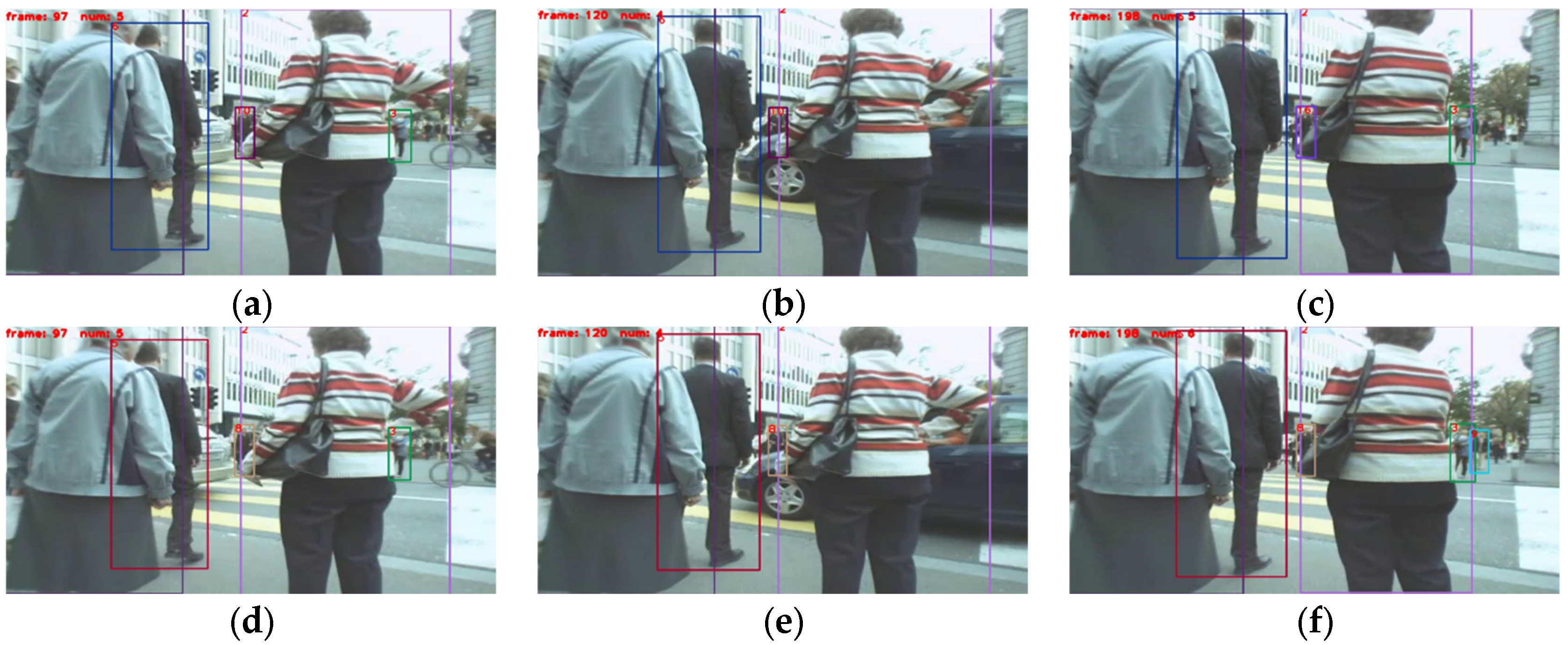
3.3.2. Tracking Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nama, M.K.; Nath, A.; Bechra., J. Machine learning-based traffic scheduling techniques for intelligent transportation system: Opportunities and challenges. Int. J. Commun. Syst. 2021, 34, e4814. [Google Scholar] [CrossRef]
- Blome, D.S.; Beveridge, J.R.; Draper, B.A.; Liu, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Coccoli, M.; De Francesco, V.; Fusco, A.; Maresca, P. A cloud-based cognitive computing solution with interoperable applications to counteract illegal dumping in smart cities. Multimed. Tools Appl. 2022, 81, 95–113. [Google Scholar] [CrossRef]
- Shen, Y.; Lin, W.; Wang, Z.; Li, J.; Sun, X.; Wu, X.; Wang, S.; Huang, F. Rapid Detection of Camouflaged Artificial Target Based on Polarization Imaging and Deep Learning. IEEE Photonics J. 2021, 13, 1–9. [Google Scholar] [CrossRef]
- Hong, H.H.; Yi, X.; Yan, J.H.; Qian, Y.; Zhi, G.Z. Pedestrian Tracking by Learning Deep Features. J. Vis. Commun. Image Represent. 2022, 83, 103428. [Google Scholar] [CrossRef]
- Kim, S.J.; Nam, J.Y.; Ko, B.C. Online Tracker Optimization for Multi-Pedestrian Tracking Using a Moving Vehicle Camers. IEEE Access 2018, 6, 48675–48678. [Google Scholar] [CrossRef]
- Kalun, H.; Janis, K.; Margret, K. Unsupervised Multiple Person Tracking using AutoEncoder-Based Lifted Multicuts. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020. [Google Scholar]
- Yuan, G.; Jian, N.C.; Xiao, S.Y.; Cheng, D.W. A Modified Multi-Pedestrian Tracking System. In Proceedings of the Chinese Control Conference, Guangzhou, China, 27–30 July 2019. [Google Scholar]
- Kai, C.; Xiao, S.; Xiang, Z. An Integrated Deep Learning Framework for Occluded Pedestrian Tracking. IEEE Access 2019, 7, 26060–26072. [Google Scholar]
- Sungmin, Y.; Sungho, K. Recurrent YOLO and LSTM-based IR single pedestrian tracking. In Proceedings of the 19th International Conference on Control Automation and Systems (ICCAS), Jeju, Korea, 15–18 October 2019; pp. 94–96. [Google Scholar]
- Guojiang, S.; Linfeng, Z.; Jihan, L. Infrared Multi-Pedestrian Tracking in Vertical View via Siamese Convolution Network. IEEE Access 2019, 7, 42718–42725. [Google Scholar]
- Ge, Y.; Zihao, C. Pedestrian Tracking Algorithm for Dense Crowd based on Deep Learning. In Proceedings of the 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 568–572. [Google Scholar]
- Li, C.; Li, G. Learning Multiple Instance Deep Representation for Objects Tracking. J. Vis. Commun. Image Represent. 2022, 71, 102737. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and real-time tracking. In Proceedings of the International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Zhao, X.; Kim, T.-K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Mahmoudi, N.; Ahadi, S.M.; Rahmati, M. Multi-target tracking using CNN-based features. Multimed. Tools Appl. 2019, 78, 7077–7096. [Google Scholar] [CrossRef]
- Chen, L.; Ai, H.; Zhuang, Z. Real-time multiple people tracking with deeply learned candidate selection and person re-identification. In Proceedings of the 26th IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Xing, K.Z.; Shu, C.L.; Xu, W. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11 October 2021; pp. 2778–2788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ross, G. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tsung, Y.L.; Priya, G.; Ross, G. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and real-time tracking with a deep association metric. In Proceedings of the International Conference on Image Processing, Beijing, China, 17–20 September 2017. [Google Scholar]
- Lin, J.Y.; Yu, C.F.; Ning, X. Video Instance Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5188–5197. [Google Scholar]
- Kaiming, H.; Georgia, G.; Piotr, D. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhong, D.W.; Liang, Z.; Yi, X.L. Towards Real-Time Multi-Objects Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 107–122. [Google Scholar]
- Yi, Y.Z.; Chun, Y.W.; Xing, G.W. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar]
- Kai, W.D.; Song, B.; Ling, X.X. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tsung, Y.L.; Piotr, D.; Ross., G. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Dendorfer, P.; Osep, A.; Milan, A.; Schindler, K.; Cremers, D.; Reid, I.; Roth, S.; Leal-Taixé, L. MOT Challenge: A Benchmark for Single-Camera Multiple Target Tracking. Int. J. Comput. Vis. 2021, 129, 845–881. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep Layer Aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the 14th International Conference on Artifical Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherland, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y. YOLOV4: Optimal Speed and Accuracy of Object Detection. In Proceedings of the Conference on Computer Vision and Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Processing Syst. 2015, 28, 28–32. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bo, P.; Yi, Z.L.; Yi, F.Z. Tubetk: Adopting tubes to tracks multi-object in a one-step training model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6308–6318. [Google Scholar]
- Chao, L.; Zhi, P.Z.; Xue, Z. Rethinking the competition between detection and reid in multi-object tracking. arXiv 2020, arXiv:2010.12138. [Google Scholar]
- Pei, Z.S.; Jin, K.C.; Yi, R. Transtrack: Multiple-object tracking with transformer. In Proceedings of the Conference on Computer Vision and Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Criteria | Meaning of Criteria |
|---|---|
| FP↓ | Rate of being misidentified as a positive sample, i.e., false detection rate |
| FN↓ | Rate of being mistaken for negative samples, i.e., missed detection rate |
| IDs↓ | Number of pedestrian ID switches, i.e., pedestrian identity changes |
| MOTA↑ | Tracking accuracy calculated by metrics, such as FP, FN, IDs |
| IDF1↑ | Accuracy and recall of tracking with constant ID |
| ML↓ | Tracking of failed pedestrians as a percentage of all pedestrians |
| MT↑ | Track of successful pedestrians as a percentage of all pedestrians |
| Algorithms | mAP(%) |
|---|---|
| CenterNet | 68.5 |
| CenterNet+FPN | 68.9 |
| CenterNet+HR | 68.6 |
| CenterNet+FPN+HR | 70.3 |
| Algorithms | mAP(%) |
|---|---|
| CenterNet | 68.5 |
| CenterNet+FPN+HR | 70.3 |
| CenterNet+FPN+HR+CA_ours | 70.5 |
| Algorithms | AP(%) |
|---|---|
| SSD | 31.2 |
| YOLOV4 | 43.5 |
| Faster RCNN | 34.7 |
| Mask-RCNN | 39.8 |
| CenterNet | 47 |
| CenterNet_ours | 47.6 |
| Algorithms | MOTA | IDF | IDs | FN | FP |
|---|---|---|---|---|---|
| Tube_TK(one-shot) [41] | 63.0 | 58.6 | 413 | 177,483 | 27,060 |
| CSTrack(one-shot) [42] | 74.9 | 72.6 | 3567 | 114,303 | 23,847 |
| DeepSORT(two-stage) | 60.3 | 61.2 | 2442 | 185,301 | 36,111 |
| TransTrack(one-shot) [43] | 65.8 | 56.9 | 5355 | 163,683 | 24,000 |
| FairMOT(one-shot) | 73.7 | 72.3 | 3303 | 117,477 | 27,507 |
| AMDDATrack(one-shot) | 74.3 | 75.3 | 2056 | 84,932 | 26,773 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Wang, Y.; Liu, X. A Multi-Pedestrian Tracking Algorithm for Dense Scenes Based on an Attention Mechanism and Dual Data Association. Appl. Sci. 2022, 12, 9597. https://doi.org/10.3390/app12199597
Li C, Wang Y, Liu X. A Multi-Pedestrian Tracking Algorithm for Dense Scenes Based on an Attention Mechanism and Dual Data Association. Applied Sciences. 2022; 12(19):9597. https://doi.org/10.3390/app12199597
Chicago/Turabian StyleLi, Chang, Yiding Wang, and Xiaoming Liu. 2022. "A Multi-Pedestrian Tracking Algorithm for Dense Scenes Based on an Attention Mechanism and Dual Data Association" Applied Sciences 12, no. 19: 9597. https://doi.org/10.3390/app12199597