
Semi-Supervised Medical Image Classification Based on Attention and Intrinsic Features of Samples


Abstract
:1. Introduction
- We fully learn the features of unlabeled data by introducing a sample intrinsic feature consistency loss similar to unsupervised consistency loss inside the network which is effective for both single-label and multi-label classification tasks;
- Based on focal loss, a new loss function is introduced to supervision loss which can effectively notice samples with wrong classifications and pay more attention to the characteristics of samples that easily lead to wrong classification;
- We conduct experiments on two large medical datasets for skin lesion classification and chest diseases and the experimental results show that our model is effective and superior to the current semi-supervised learning method.
2. Related Work
2.1. Semi-Supervised Learning Based on Consistency Regularization
2.2. Self-Attention Mechanism
2.3. Consistency Paradigm of Sample Relationship
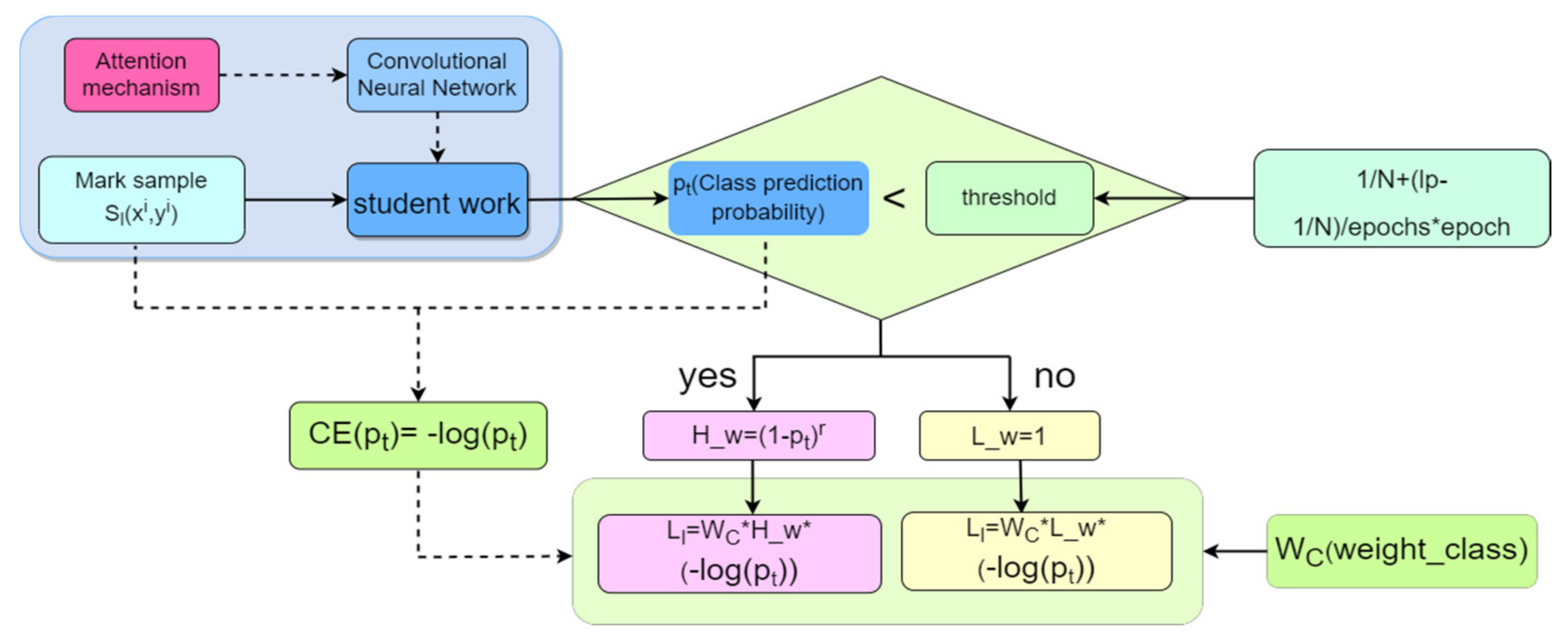
2.4. Supervision Loss
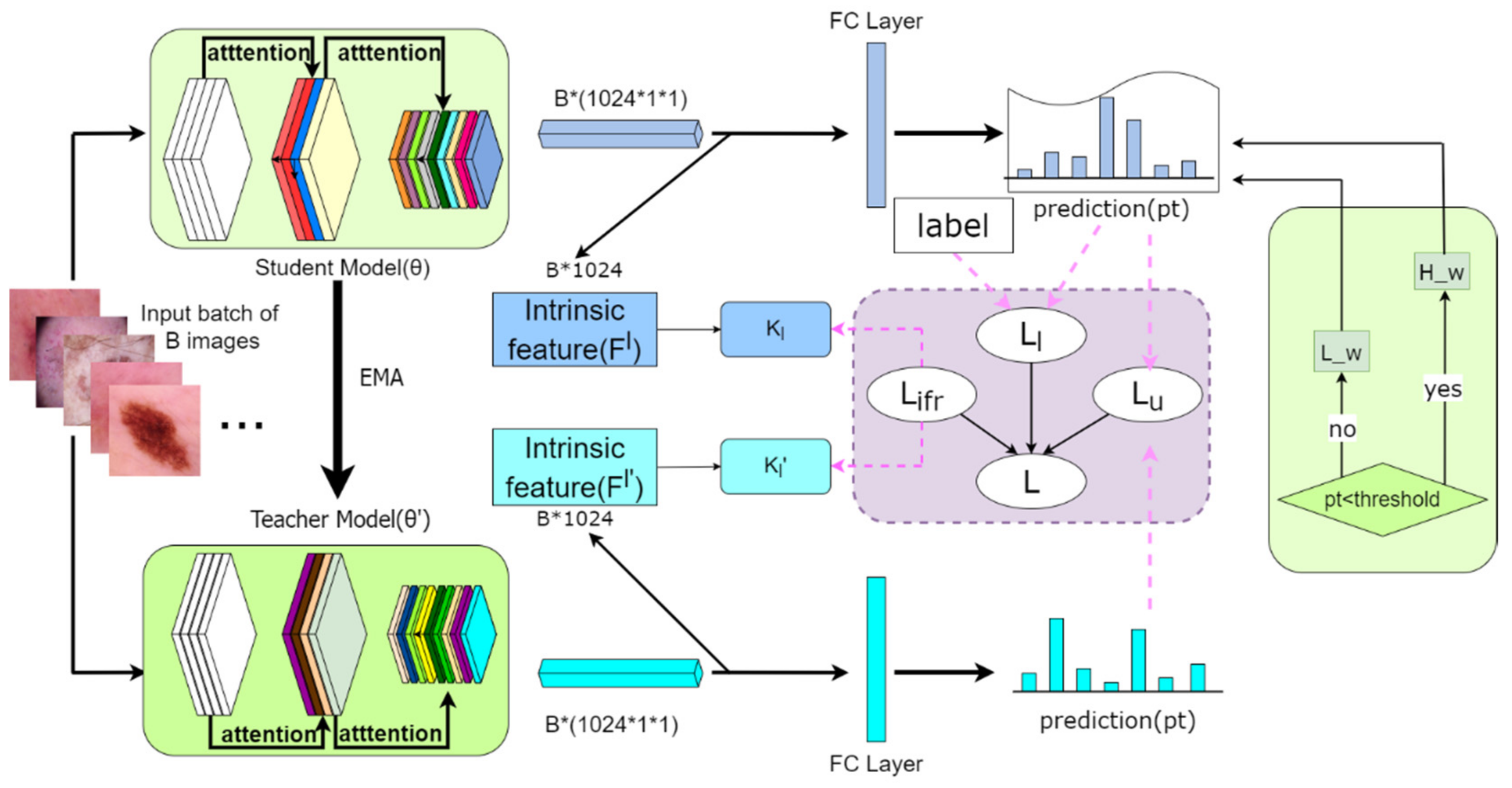
3. Method
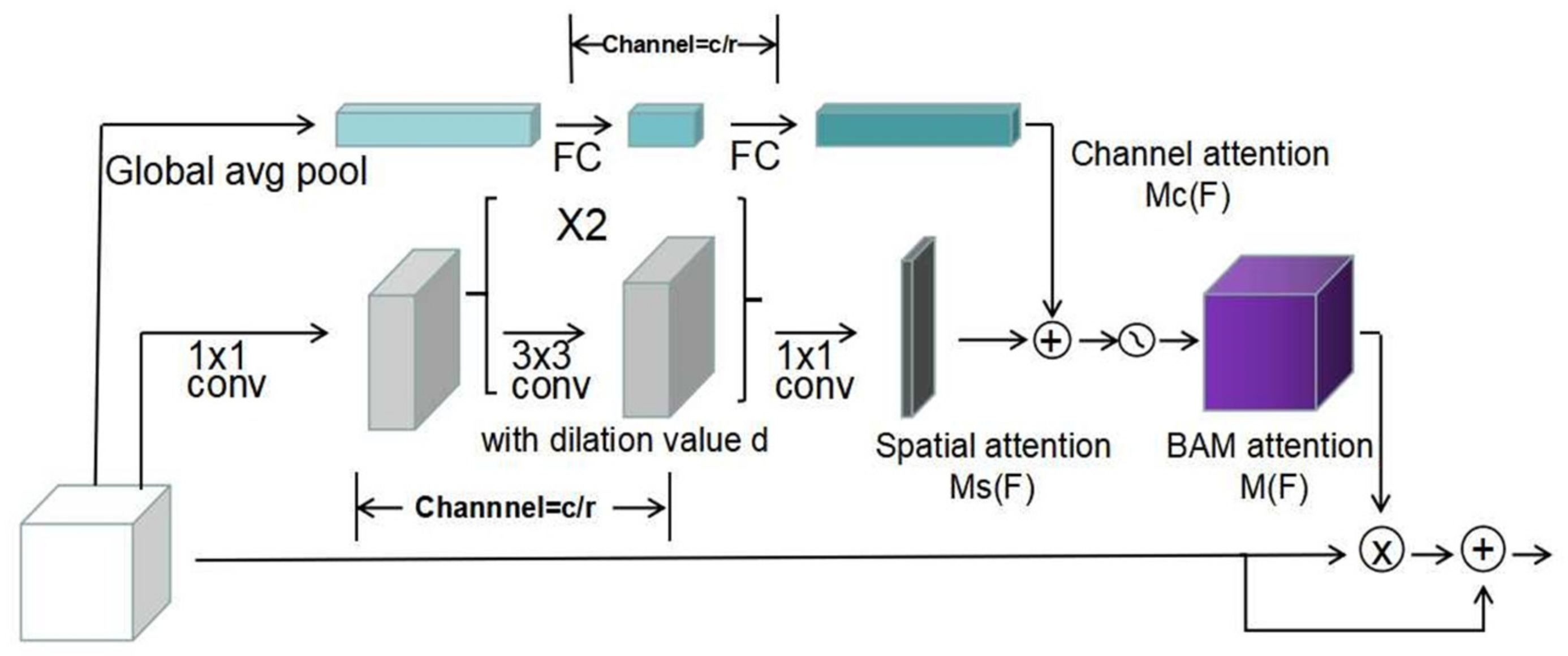
3.1. Channel and Spatial Attention Mechanisms
3.2. Loss of Consistency of Intrinsic Characteristics
3.3. Semi-Supervised Learning Framework
3.4. Total Loss Function and Details
4. Experiments
4.1. Parameter Setting
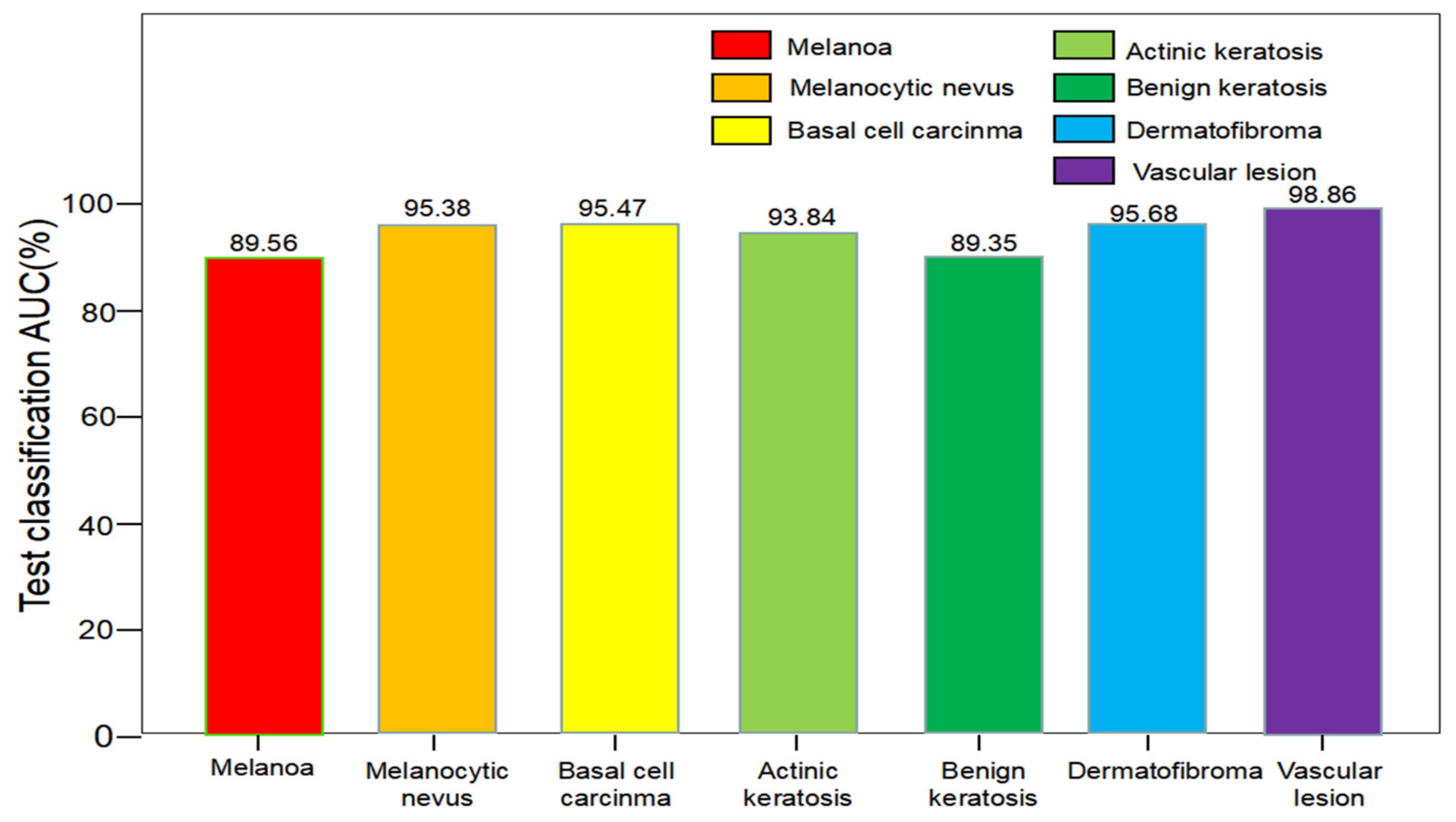
4.2. ISIC 2018 Dataset
4.3. ChestX-ray14 Dataset
4.4. Discussion of Parameters (lp)
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [Green Version]
- Sedai, S.; Mahapatra, D.; Hewavitharanage, S.; Maetschke, S.; Garnavi, R. Semi-supervised segmentation of optic cup in retinal fundus images using variational autoencoder. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; Springer: Cham, Switzerland, 2017; pp. 75–82. [Google Scholar]
- Su, H.; Shi, X.; Cai, J.; Yang, L. Local and global consistency regularized mean teacher for semi-supervised nuclei classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 559–567. [Google Scholar]
- Feng, X.; Yang, J.; Laine, A.F.; Angelini, E.D. Discriminative localization in CNNs for weakly-supervised segmentation of pulmonary nodules. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; Springer: Cham, Switzerland, 2017; pp. 568–576. [Google Scholar]
- Kamnitsas, K.; Baumgartner, C.; Ledig, C.; Newcombe, V.; Simpson, J.; Kane, A.; Menon, D.; Nori, A.; Criminisi, A.; Rueckert, D.; et al. Unsupervised domain adaptation in brain lesion segmentation with adversarial networks. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; Springer: Cham, Switzerland, 2017; pp. 597–609. [Google Scholar]
- Bai, W.; Oktay, O.; Sinclair, M.; Suzuki, H.; Rajchl, M.; Tarroni, G.; Glocker, B.; King, A.; Matthews, P.M.; Rueckert, D. Semi-supervised learning for network-based cardiac MR image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; Springer: Cham, Switzerland, 2017; pp. 253–260. [Google Scholar]
- Jin, Y.; Cheng, K.; Dou, Q.; Heng, P.A. Incorporating temporal prior from motion flow for instrument segmentation in minimally invasive surgery video. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 440–448. [Google Scholar]
- Miyato, T.; Maeda, S.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef] [Green Version]
- Chartsias, A.; Joyce, T.; Papanastasiou, G.; Semple, S.; Williams, M.; Newby, D.; Dharmakumar, R.; Tsaftaris, S.A. Factorised spatial representation learning: Application in semi-supervised myocardial segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 490–498. [Google Scholar]
- Nie, D.; Gao, Y.; Wang, L.; Shen, D. ASDNet: Attention based semi-supervised deep networks for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 370–378. [Google Scholar]
- Dong, N.; Kampffmeyer, M.; Liang, X.; Wang, Z.; Dai, W.; Xing, E. Unsupervised domain adaptation for automatic estimation of cardiothoracic ratio. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 544–552. [Google Scholar]
- Diaz-Pinto, A.; Colomer, A.; Naranjo, V.; Morales, S.; Xu, Y.; Frangi, A.F. Retinal image synthesis and semi-supervised learning for glaucoma assessment. IEEE Trans. Med. Imaging 2019, 38, 2211–2218. [Google Scholar] [CrossRef]
- Aviles-Rivero, A.I.; Papadakis, N.; Li, R.; Sellars, P.; Fan, Q.; Tan, R.T.; Schönlieb, C.B. GraphXNET—Chest X-Ray Classification under Extreme Minimal Supervision. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 504–512. [Google Scholar]
- Li, X.; Yu, L.; Chen, H.; Fu, C.-W.; Xing, L.; Heng, P.-A. Transformation-consistent self-ensembling model for semisupervised medical image segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 523–534. [Google Scholar] [CrossRef]
- Li, X.; Yu, L.; Chen, H.; Fu, C.W.; Heng, P.A. Semi-supervised skin lesion segmentation via transformation consistent self-ensembling model. arXiv 2018, arXiv:1808.03887. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Cui, W.; Liu, Y.; Li, Y.; Guo, M.; Li, Y.; Li, X.; Wang, T.; Zeng, X.; Ye, C. Semi-supervised brain lesion segmentation with an adapted mean teacher model. In Proceedings of the International Conference on Information Processing in Medical Imaging, Hong Kong, China, 2–7 June 2019; Springer: Cham, Switzerland, 2019; pp. 554–565. [Google Scholar]
- Yu, L.; Wang, S.; Li, X.; Fu, C.W.; Heng, P.A. Uncertainty-aware self-ensembling model for semi-supervised 3D left atrium segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 605–613. [Google Scholar]
- Codella NC, F.; Nguyen, Q.B.; Pankanti, S.; Gutman, D.A.; Helba, B.; Halpern, A.C.; Smith, J.R. Deep learning ensembles for melanoma recognition in dermoscopy images. IBM J. Res. Dev. 2017, 61, 5:1–5:15. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Chen, H.; Dou, Q.; Qin, J.; Heng, P.-A. Automated melanoma recognition in dermoscopy images via very deep residual networks. IEEE Trans. Med. Imaging 2016, 36, 994–1004. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Y.; Xia, Y.; Shen, C. Attention residual learning for skin lesion classification. IEEE Trans. Med. Imaging 2019, 38, 2092–2103. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Ganster, H.; Pinz, P.; Rohrer, R.; Wildling, E.; Binder, M.; Kittler, H. Automated melanoma recognition. IEEE Trans. Med. Imaging 2001, 20, 233–239. [Google Scholar] [CrossRef]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 590–597. [Google Scholar]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Aviles-Rivero, A.I.; Papadakis, N.; Li, R.; Sellars, P.; Alsaleh, S.M.; Tan, R.T.; Schönlieb, C.-B. Energy Models for Better Pseudo-Labels: Improving Semi-Supervised Classification with the 1-Laplacian Graph Energy. arXiv 2019, arXiv:1906.08635. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Xie, Y.; Zhang, J.; Xia, Y. Semi-supervised adversarial model for benign–malignant lung nodule classification on chest CT. Med. Image Anal. 2019, 57, 237–248. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- French, G.; Oliver, A.; Salimans, T. Milking cowmask for semi-supervised image classification. arXiv 2020, arXiv:2003.12022. [Google Scholar]
- Liu, L.; Tan, R.T. Certainty driven consistency loss on multi-teacher networks for semi-supervised learning. Pattern Recognit. 2021, 120, 108140. [Google Scholar] [CrossRef]
- Liu, Q.; Yu, L.; Luo, L.; Dou, Q.; Heng, P.A. Semi-supervised medical image classification with relation-driven self-ensembling model. IEEE Trans. Med. Imaging 2020, 39, 3429–3440. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Sergievskiy, N.; Ponamarev, A. Reduced focal loss: 1st place solution to xview object detection in satellite imagery. arXiv 2019, arXiv:1903.01347. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Metrics | |||
|---|---|---|---|---|
| AUC | Sensitivity | Accuracy | Specificity | |
| Self-training [8] | 90.58 | 67.63 | 92.37 | 93.31 |
| SS-DCGAN [14] | 91.28 | 67.72 | 92.27 | 92.56 |
| TCSE [17] | 92.24 | 68.17 | 92.35 | 92.51 |
| TE [30] | 92.70 | 69.81 | 92.26 | 92.55 |
| MT [18] | 92.96 | 69.75 | 92.48 | 92.20 |
| SRC-MT [39] | 93.58 | 71.47 | 92.54 | 92.72 |
| Ours | 94.02 | 72.03 | 92.61 | 91.78 |
| Method | Percentage | Metrics | ||||
|---|---|---|---|---|---|---|
| Labeled | Unlabeled | AUC | Sensitivity | Accuracy | Specificity | |
| Upper bound | 100% | 0 | 95.43 | 75.20 | 95.10 | 94.94 |
| SRC-MT | 5% | 95% | 87.61 | 62.04 | 88.77 | 89.36 |
| Ours | 5% | 95% | 89.56 | 64.32 | 88.56 | 88.96 |
| SRC-MT | 10% | 90% | 90.31 | 66.29 | 89.30 | 90.47 |
| Ours | 10% | 90% | 91.24 | 67.56 | 89.56 | 90.16 |
| SRC-MT | 20% | 80% | 93.58 | 71.47 | 92.54 | 92.72 |
| Ours | 20% | 80% | 94.02 | 72.03 | 92.61 | 91.78 |
| Label Percentage | 2% | 5% | 10% | 15% | 20% |
|---|---|---|---|---|---|
| GraphXNET [15] | 53 | 58 | 63 | 68 | 78 |
| SRC-MT | 66.95 | 72.29 | 75.28 | 77.76 | 79.23 |
| Ours | 68.24 | 73.65 | 77.62 | 78.35 | 79.74 |
| Method | Fully Supervised | MT | SRC-MT | Ours |
|---|---|---|---|---|
| Labeled | 100% | 20% | 20% | 20% |
| Unlabeled | 0 | 80% | 80% | 80% |
| Atelectasis | 77.32 | 75.12 | 75.38 | 76.12 |
| Cardiomegaly | 88.85 | 87.37 | 87.70 | 88.06 |
| Effusion | 82.11 | 80.81 | 81.58 | 81.77 |
| Infiltration | 70.95 | 70.67 | 70.40 | 70.57 |
| Mass | 82.92 | 77.72 | 78.03 | 78.86 |
| Nodule | 77.00 | 73.27 | 73.64 | 74.23 |
| Pneumonia | 71.28 | 69.17 | 69.27 | 69.56 |
| Pneumothorax | 86.87 | 85.63 | 86.12 | 86.32 |
| Consolidation | 74.88 | 72.51 | 73.11 | 73.84 |
| Edema | 84.74 | 82.72 | 82.94 | 83.13 |
| Emphysema | 93.35 | 88.16 | 88.98 | 90.02 |
| Fibrosis | 84.46 | 78.24 | 79.22 | 80.43 |
| Pleural Thickening | 77.34 | 74.43 | 75.63 | 75.61 |
| Hernia | 92.51 | 87.74 | 87.27 | 87.86 |
| Average AUC | 81.75 | 78.83 | 79.23 | 79.74 |
| Parameter (lp) | Metrics | |||
|---|---|---|---|---|
| AUC | Sensitivity | Accuracy | Specificity | |
| 0.6 | 92.24 | 68.34 | 91.06 | 89.65 |
| 0.7 | 92.70 | 69.75 | 91.54 | 90.86 |
| 0.8 | 93.55 | 71.54 | 91.98 | 91.24 |
| 0.9 | 93.86 | 71.87 | 92.24 | 91.66 |
| 1.0 | 94.02 | 72.03 | 92.61 | 91.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Lu, C.; Wang, W.; Dang, W.; Gong, K. Semi-Supervised Medical Image Classification Based on Attention and Intrinsic Features of Samples. Appl. Sci. 2022, 12, 6726. https://doi.org/10.3390/app12136726
Zhou Z, Lu C, Wang W, Dang W, Gong K. Semi-Supervised Medical Image Classification Based on Attention and Intrinsic Features of Samples. Applied Sciences. 2022; 12(13):6726. https://doi.org/10.3390/app12136726
Chicago/Turabian StyleZhou, Zhuohao, Chunyue Lu, Wenchao Wang, Wenhao Dang, and Ke Gong. 2022. "Semi-Supervised Medical Image Classification Based on Attention and Intrinsic Features of Samples" Applied Sciences 12, no. 13: 6726. https://doi.org/10.3390/app12136726