
Attention-Gate-Based Model with Inception-like Block for Single-Image Dehazing


Abstract
:1. Introduction
- It provides a real-time and lightweight end-to-end image-dehazing CNN model that restores the blur caused by the haze environment without intermediate component computation for ASM and knowledge of the physical model.
- Before feeding hazy images to the CNN, an image pre-processing block was used to map normalized RGB images to different color spaces. The image pre-processing block increases the number of layers of feature maps such that the image-dehazing CNN can extract features effectively.
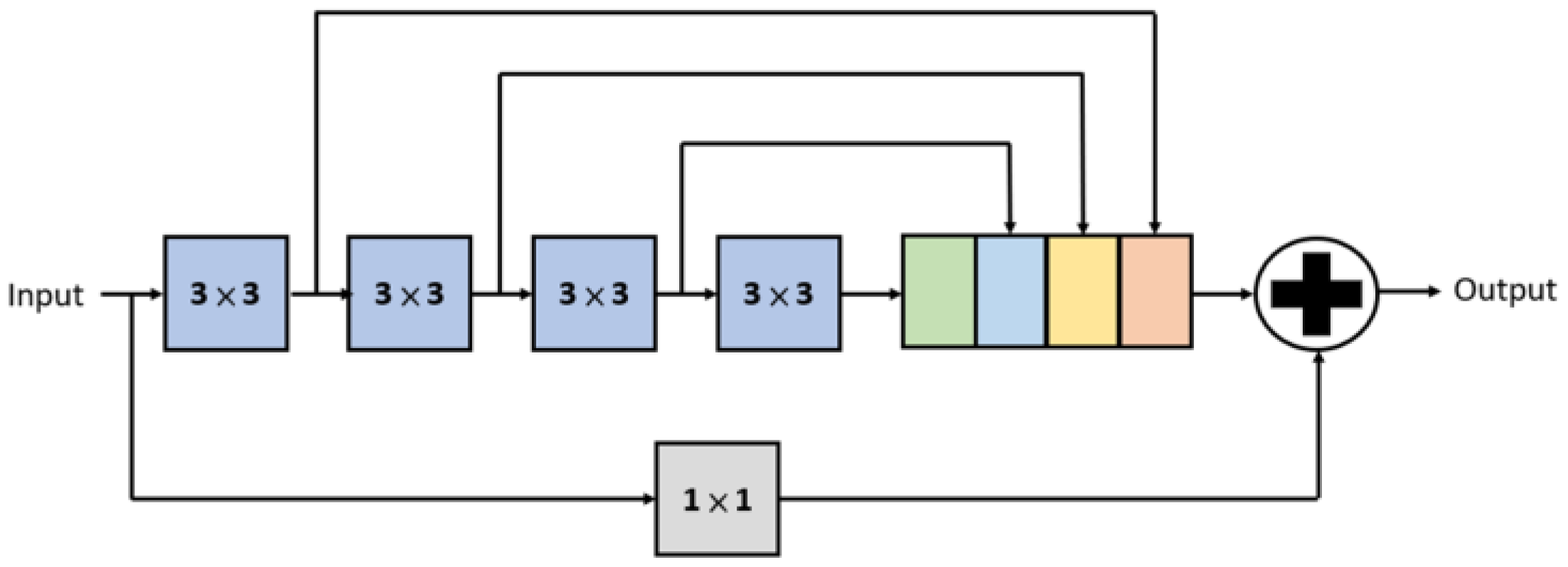
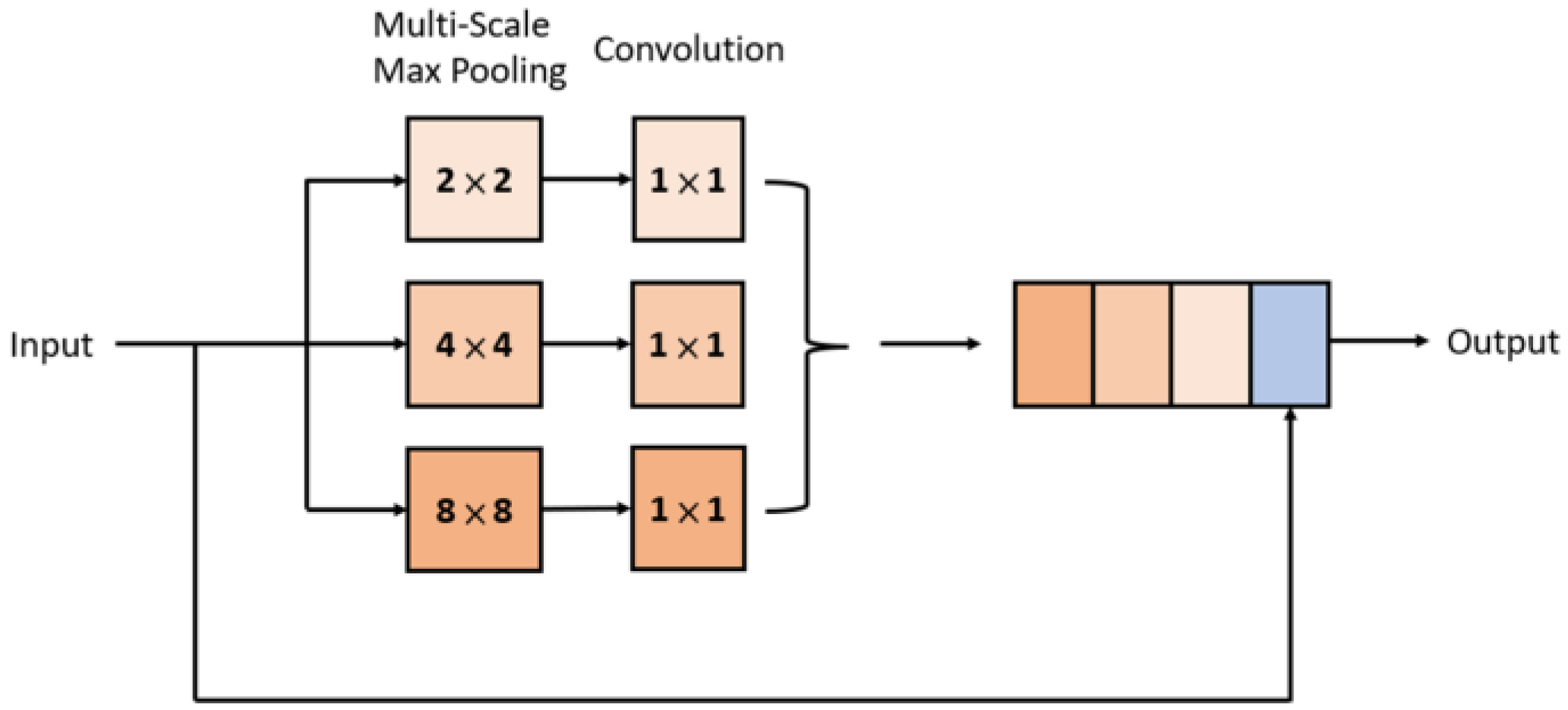
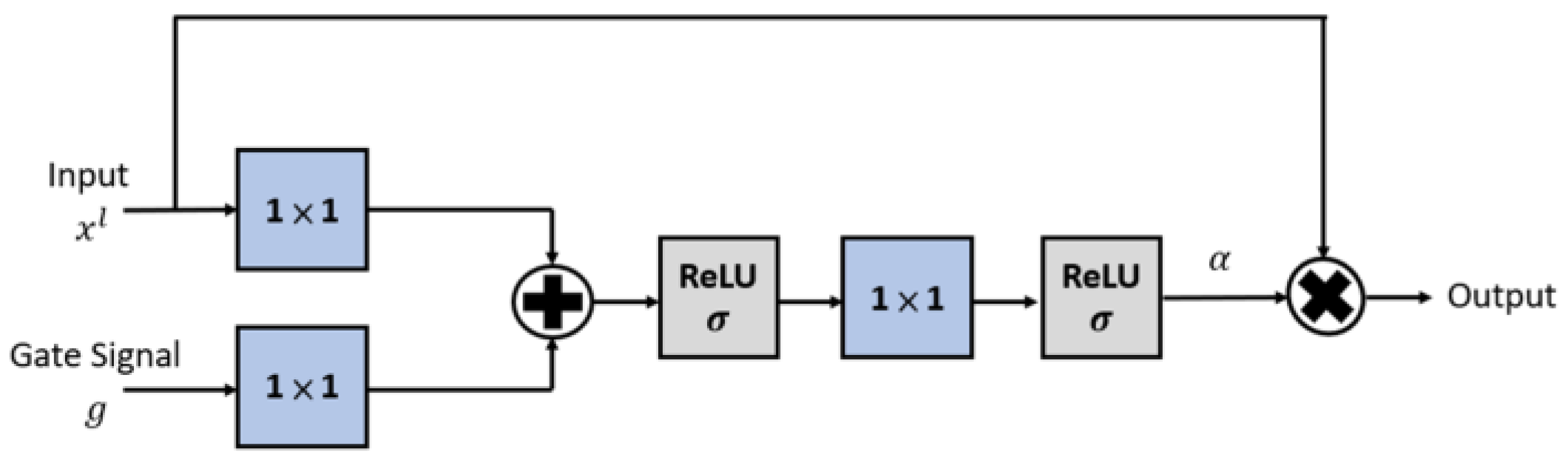
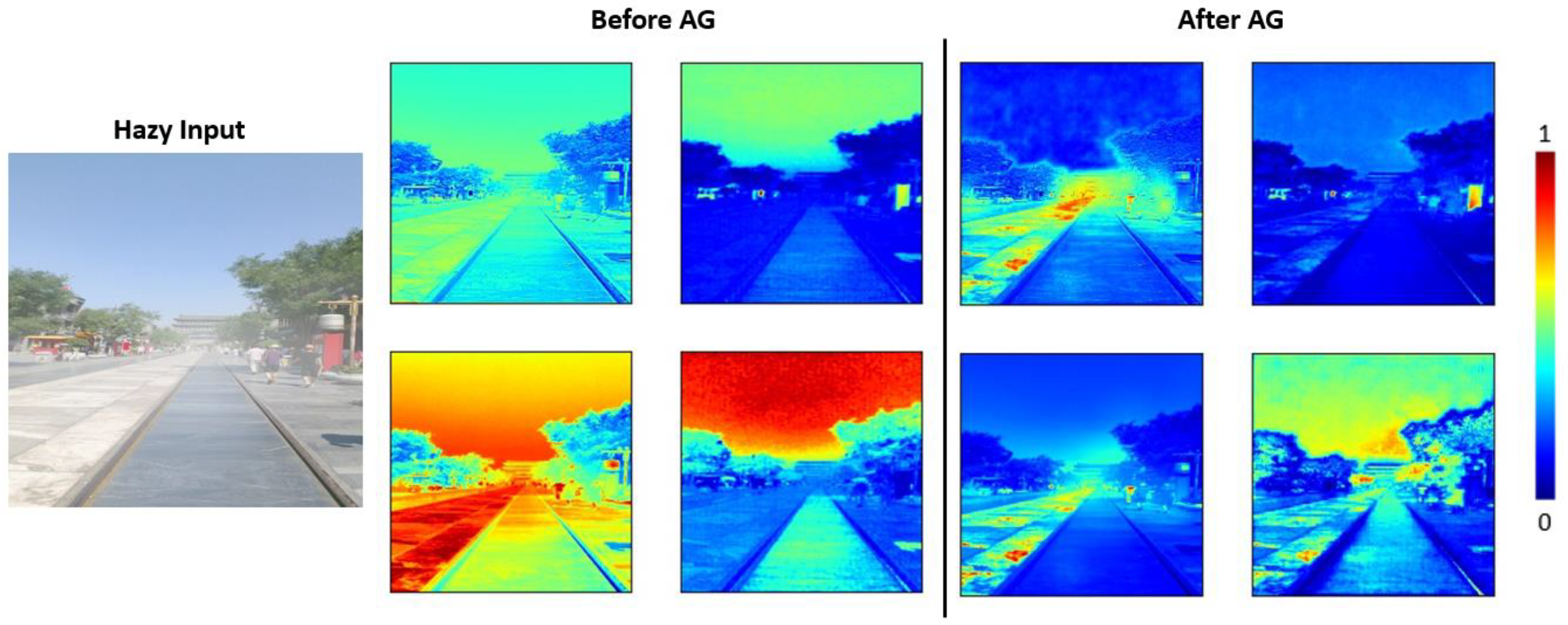
- The inception-like block uses two convolutions to replace one convolution, which effectively increases the receptive field. The SPP block utilizes different pooling kernel sizes to extract feature values and to generate more feature maps. The proposed attention gate can smartly pay more attention to unclear structures, such as buildings and pedestrians.
- Through an ablation study and a quantitative evaluation, this study demonstrates the advantages of using the image pre-processing block, the inception-like block, the spatial pooling blocks, and the proposed attention gate.
- The number of trainable parameters of the image-dehazing CNN is 207.3 K, the model size is 0.86 MB, and the average execution time per frame under GPU acceleration is 0.018 s, which is equivalent to 55.56 fps.
- RESIDE-SOTS and RESIDE-HSTS were used as the testing image-dehazing-quality datasets, which improved the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) compared to other state-of-the-art image-dehazing methods.
2. Preliminaries
2.1. Atmospheric Scattering Model
2.2. Deep-Learning-Based Method
2.3. Downsampling and Upsampling
2.4. Multiple Input Channel
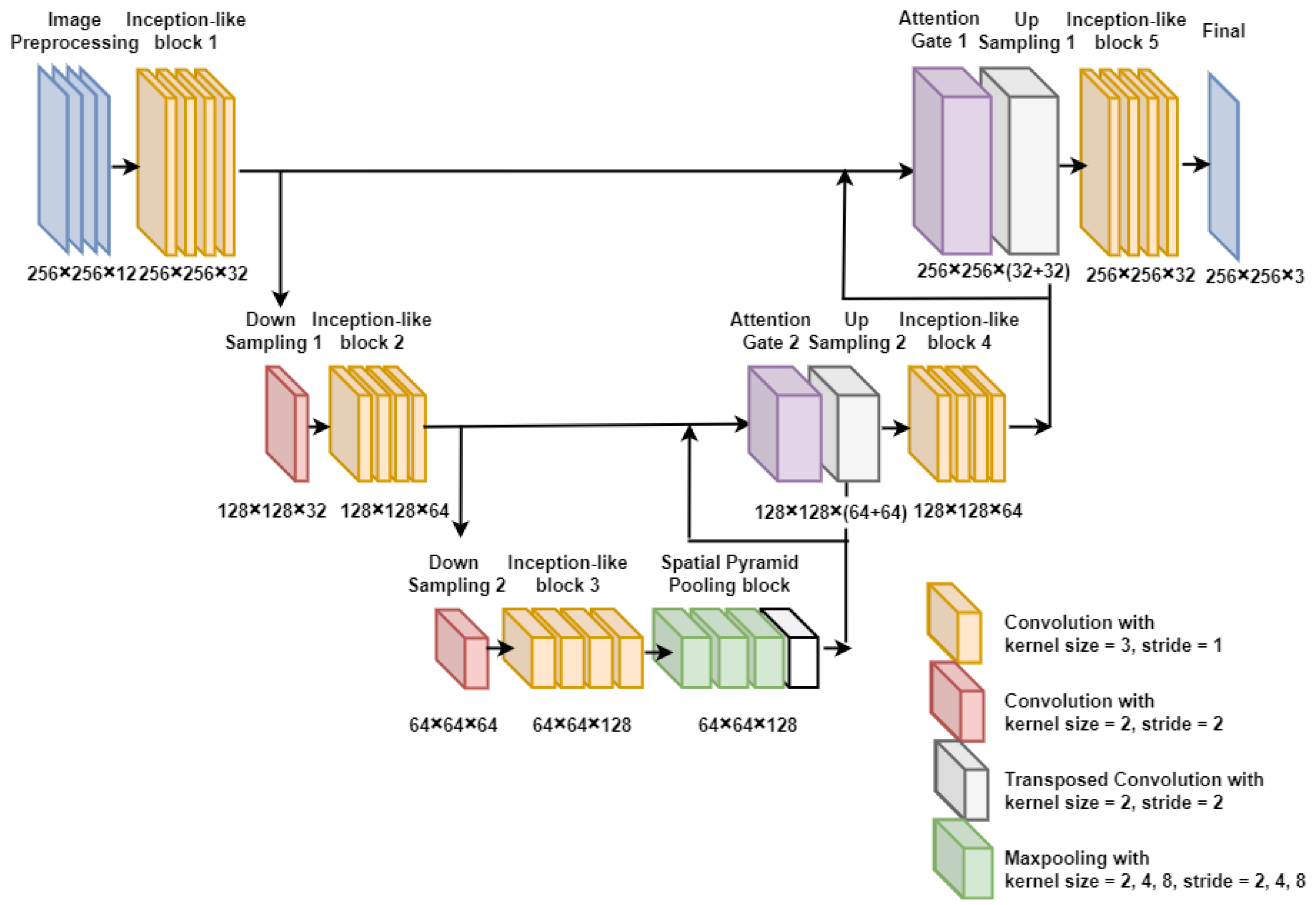
3. Proposed Method
3.1. Image Pre-Processing Block
3.2. Inception-like Block
3.3. SPP Block
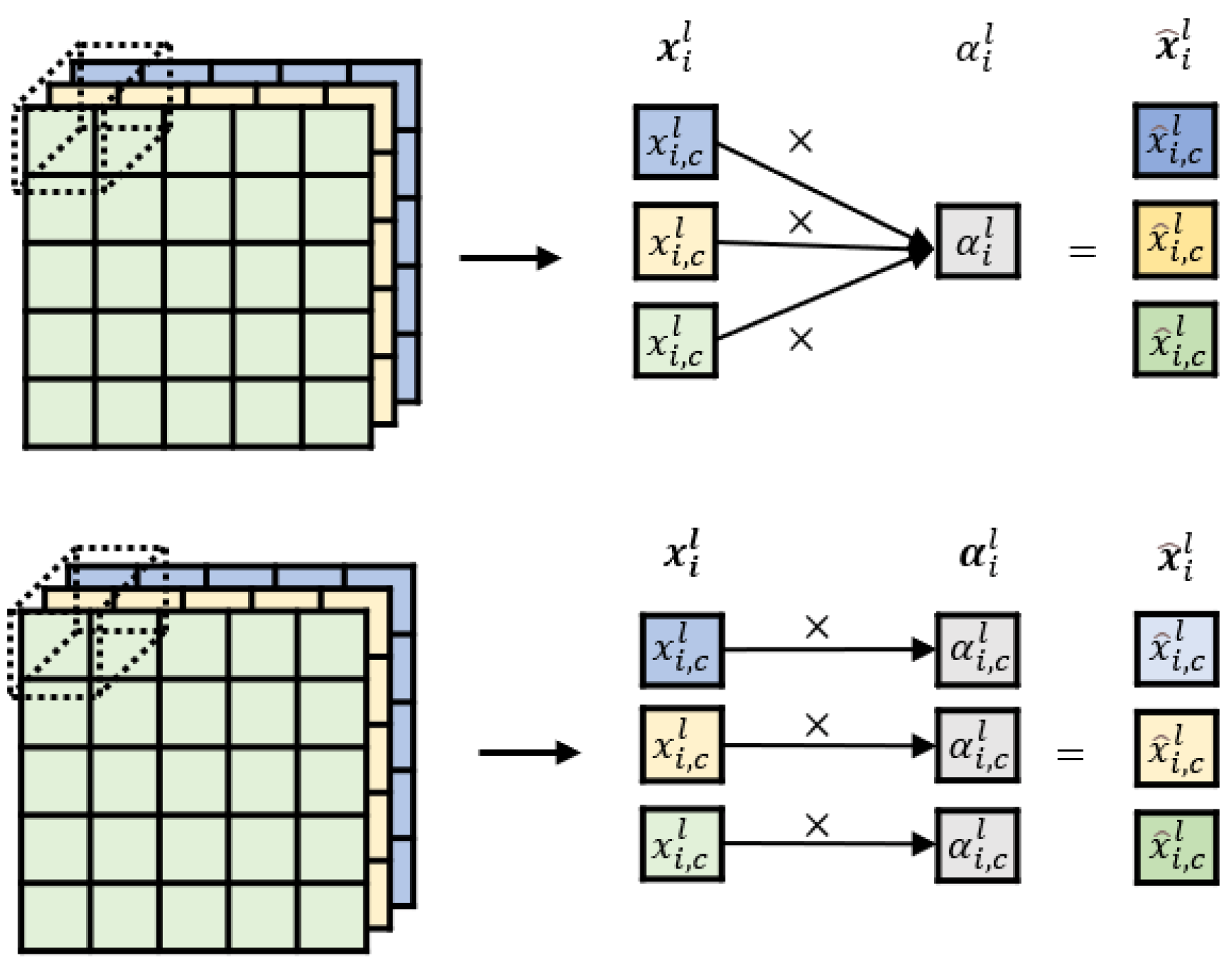
3.4. Attention Gate
3.5. Loss Function
4. Experiments and Analysis
4.1. Parameters of Neural Network
4.2. Image-Dehazing Datasets
4.3. Ablation Study
4.4. Performance and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gui, J.; Cong, X.; Cao, Y.; Ren, W.; Zhang, J.; Zhang, J.; Tao, D. A Comprehensive Survey on Image Dehazing Based on Deep Learning. arXiv 2021, arXiv:2106.03323. [Google Scholar]
- Cozman, F.; Krotkov, E. Depth from scattering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997. [Google Scholar]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local Image Dehazing. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ju, M.; Ding, C.; Ren, W.; Yang, Y.; Zhang, D.; Guo, Y.J. IDE: Image Dehazing and Exposure Using an Enhanced Atmospheric Scattering Model. IEEE Trans. Image Process. 2021, 30, 2180–2192. [Google Scholar] [CrossRef]
- Yang, G.; Evans, A.N. Improved single image dehazing methods for resource-constrained platforms. J. Real-Time Image Process. 2021, 18, 2511–2525. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-One Dehazing Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, J.; Tao, D. FAMED-Net: A fast and accurate multi-scale end-to-end dehazing network. IEEE Trans. Image Process. 2019, 29, 72–84. [Google Scholar] [CrossRef] [Green Version]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NJ, USA, 7–12 February 2020. [Google Scholar]
- Liu, Z.; Xiao, B.; Alrabeiah, M.; Wang, K.; Chen, J. Single Image Dehazing with a Generic Model-Agnostic Convolutional Neural Network. IEEE Signal Process. Lett. 2019, 26, 833–837. [Google Scholar] [CrossRef]
- Engin, D.; Genç, A.; Ekenel, H.K. Cycle-dehaze: Enhanced cyclegan for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced Pix2pix Dehazing Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Mehta, A.; Sinha, H.; Narang, P.; Mandal, M. HIDeGan: A Hyperspectral-guided Image Dehazing GAN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 5–9 October 2015. [Google Scholar]
- Mehra, A.; Narang, P.; Mandal, M. TheiaNet: Towards fast and inexpensive CNN design choices for image dehazing. J. Vis. Commun. Image Represent. 2021, 77, 103137. [Google Scholar] [CrossRef]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.-H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wan, Y.; Chen, Q. Joint image dehazing and contrast enhancement using the HSV color space. In Proceedings of the 2015 Visual Communications and Image Processing (VCIP), Singapore, 13–16 December 2015. [Google Scholar]
- Tufail, Z.; Khurshid, K.; Salman, A.; Nizami, I.F.; Khurshid, K.; Jeon, B. Improved Dark Channel Prior for Image Defogging Using RGB and YCbCr Color Space. IEEE Access 2018, 6, 32576–32587. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Mehra, A.; Mandal, M.; Narang, P.; Chamola, V. ReViewNet: A Fast and Resource Optimized Network for Enabling Safe Autonomous Driving in Hazy Weather Conditions. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4256–4266. [Google Scholar] [CrossRef]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. RESIDE: A Benchmark for Single Image Dehazing. arXiv 2017, arXiv:1712.04143. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Blocks | Layers | Num |
|---|---|---|
| Inception-like block 1 and 5 | Conv2D(3,3) 1 Conv2D(3,3) | 8 8 |
| Conv2D(3,3) Conv2D(3,3) | 8 8 | |
| Conv2D(1,1) | 32 | |
| Inception-like block 2 and 4 | Conv2D(3,3) Conv2D(3,3) | 16 16 |
| Conv2D(3,3) Conv2D(3,3) | 16 16 | |
| Conv2D(1,1) | 64 | |
| Inception-like block 3 | Conv2D(3,3) Conv2D(3,3) | 32 32 |
| Conv2D(3,3) Conv2D(3,3) | 32 32 | |
| Conv2D(1,1) | 128 | |
| Pyramid pooling block | Conv2D(1,1) Conv2D(1,1) Conv2D(1,1) Conv2D(1,1) | 32 32 32 32 |
| Attention gate 1 | Conv2D(1,1) Conv2D(1,1) Conv2D(1,1) Conv2D(1,1) | 32 32 32 32 |
| Attention gate 2 | Conv2D(1,1) Conv2D(1,1) Conv2D(1,1) Conv2D(1,1) | 64 64 64 64 |
| Downsampling 1 | Conv2D(2,2) | 32 |
| Downsampling 2 | Conv2D(2,2) | 64 |
| Upsampling 1 | ConvT2D(2,2) 2 | 32 |
| Upsampling 2 | ConvT2D(2,2) | 64 |
| Final convolution | Conv2D(1,1) | 3 |
| Methods | Trainable Parameters | Model Size |
|---|---|---|
| DehazeNet [9] | 8.305 K | 0.035 MB |
| AOD-Net [10] | 1.76 K | 0.008 MB |
| ReViewNet [28] | 399.7 K | 5 MB |
| FFA-Net [12] | 4455.9 K | 21.3 MB |
| TheiaNet [20] | 157.9 K | 1.98 MB |
| Proposed Method | 207.3 K | 0.86 MB |
| Datasets | Training Dataset | Testing Dataset | ||
|---|---|---|---|---|
| Categories | Indoor | Outdoor | Indoor | Outdoor |
| RESIDE ITS | 13,990 | - | - | - |
| RESIDE OTS | - | 72,135 | - | - |
| RESIDE SOTS | - | - | 500 | 500 |
| RESIDE HSTS | - | - | - | 10 |
| Blocks | Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 (Proposed) |
|---|---|---|---|---|---|---|
| Image pre-processing block | - | - | - | - | O | O |
| Inception-like block | - | O | O | O | O | O |
| Pyramid pooling block | - | - | O | O | O | O |
| Original attention gate | - | - | - | O | O | - |
| Proposed attention gate | - | - | - | - | - | O |
| Methods | SSIM | PSNR | Trainable Parameters |
|---|---|---|---|
| Model 1 | 0.9587 | 25.04 | 123.539 K |
| Model 2 | 0.9602 | 26.01 | 175.107 K |
| Model 3 | 0.9644 | 26.50 | 191.619 K |
| Model 4 | 0.9673 | 27.31 | 196.885 K |
| Model 5 | 0.9718 | 28.64 | 196.885 K |
| Model 6 | 0.9736 | 29.15 | 207.267 K |
| Categories | Indoor | Outdoor | ||
|---|---|---|---|---|
| Method | SSIM (% inc) | PSNR (%inc) | SSIM (% inc) | PSNR (% inc) |
| DCP [4] | 0.8179 (17.75) | 16.62 (66.79) | 0.8148 (19.49) | 19.13 (52.38) |
| CAP [5] | 0.8364 (15.15) | 19.05 (45.51) | 0.8514 (14.35) | 22.46 (29.79) |
| DehazeNet [9] | 0.8472 (13.68) | 21.14 (31.13) | 0.8630 (12.82) | 22.57 (29.15) |
| AOD-Net [10] | 0.8504 (13.25) | 19.06 (45.44) | 0.8765 (11.07) | 20.29 (43.67) |
| HIDeGAN [17] | 0.8680 (10.96) | 24.71 (12.18) | 0.8780 (10.89) | 25.54 (14.13) |
| ReViewNet [28] | 0.8946 (7.66) | 23.61 (17.41) | 0.9137 (6.56) | 23.64 (23.31) |
| TheiaNet [20] | 0.9116 (5.65) | 25.73 (7.73) | 0.9468 (2.83) | 25.55 (14.09) |
| Proposed Method | 0.9631 (best) | 27.72 (best) | 0.9736 (best) | 29.15 (best) |
| Model | SSIM (% inc) | PSNR (% inc) |
|---|---|---|
| DCP [4] | 0.7609 (29.36) | 14.84 (120.69) |
| CAP [5] | 0.8726 (12.75) | 21.53 (52.11) |
| HIDeGAN [17] | 0.8940 (10.10) | 28.04 (16.80) |
| AOD-Net [10] | 0.8973 (9.70) | 20.55 (59.37) |
| DehazeNet [9] | 0.9153 (7.54) | 24.48 (33.78) |
| ReViewNet [28] | 0.9582 (2.72) | 27.50 (19.09) |
| TheiaNet [20] | 0.9606 (2.47) | 30.30 (8.09) |
| Proposed Method | 0.9843 (best) | 32.75 (best) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, C.-Y.; Chen, C.-L. Attention-Gate-Based Model with Inception-like Block for Single-Image Dehazing. Appl. Sci. 2022, 12, 6725. https://doi.org/10.3390/app12136725
Tsai C-Y, Chen C-L. Attention-Gate-Based Model with Inception-like Block for Single-Image Dehazing. Applied Sciences. 2022; 12(13):6725. https://doi.org/10.3390/app12136725
Chicago/Turabian StyleTsai, Cheng-Ying, and Chieh-Li Chen. 2022. "Attention-Gate-Based Model with Inception-like Block for Single-Image Dehazing" Applied Sciences 12, no. 13: 6725. https://doi.org/10.3390/app12136725