
Singing Voice Detection in Electronic Music with a Long-Term Recurrent Convolutional Network



Abstract
:1. Introduction
2. Materials and Methods
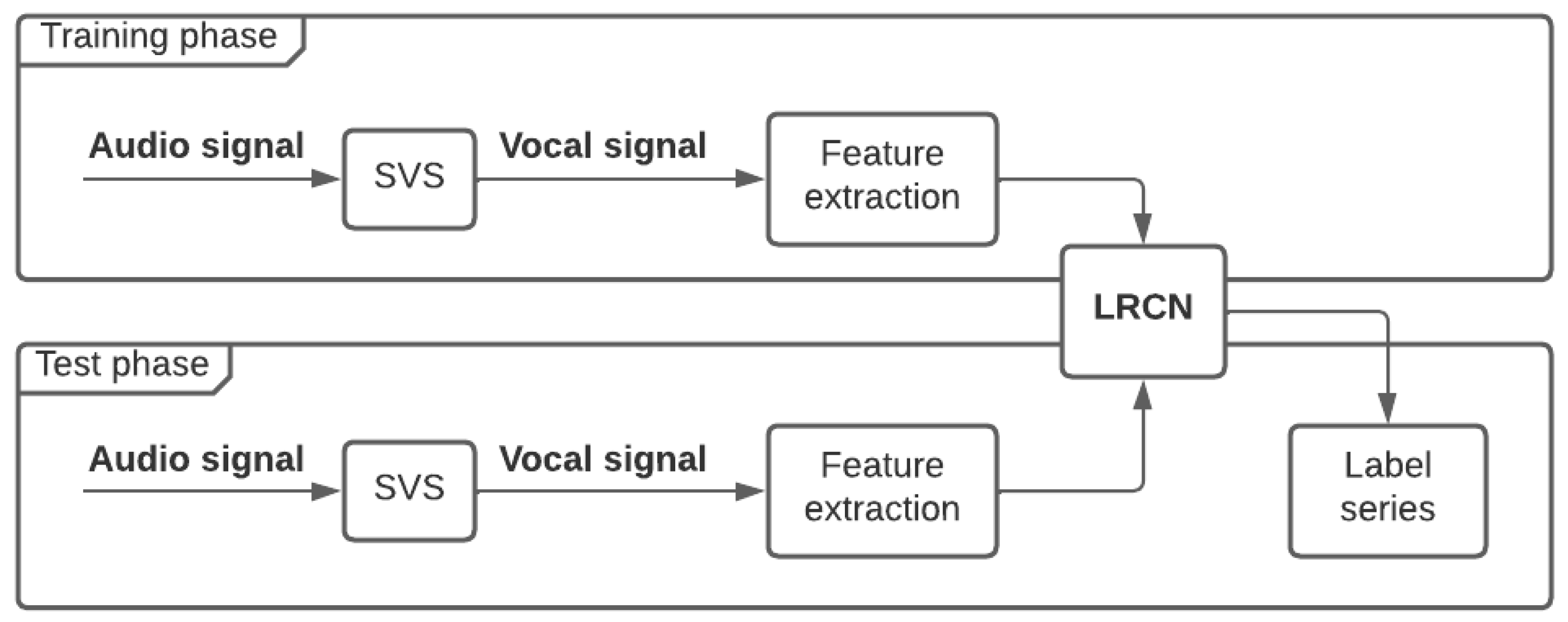
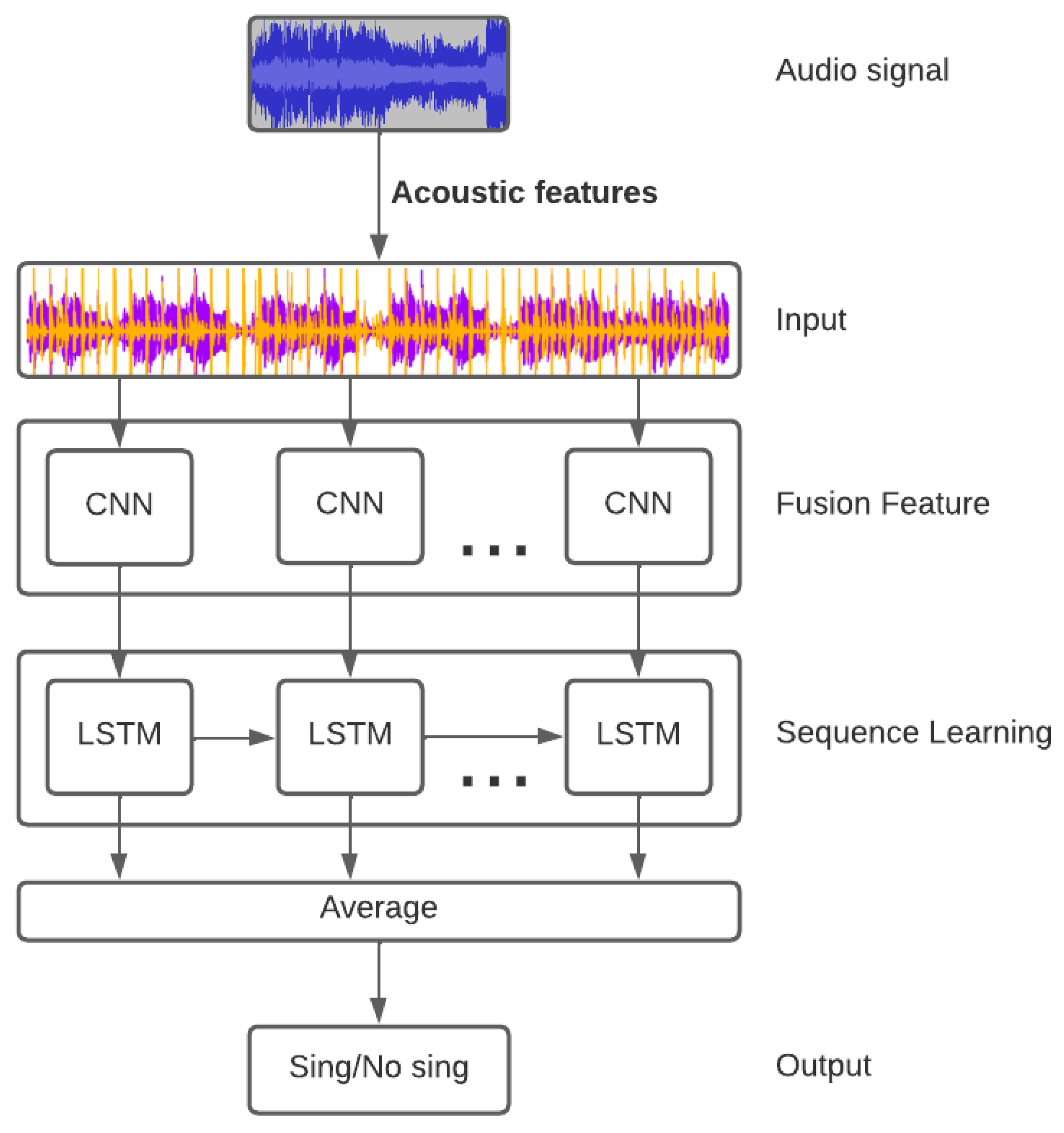
2.1. Architecture Layout
2.2. Singing Voice Separation
2.3. Feature Extraction
- ZCR (Zero-Crossing Rate): How many times a signal value changes sign (negative or positive) in a time framE.
- MFCC (Mel-Spectogram Cepstral Coefficients) [25]: Coefficients that represent the power spectrum speech based on human audition perception. First-order and second-order difference of MFCC are also computed.
- LPCC (Linear Prediction Cepstral Coefficients) [26]: Cepstrum coefficients in Linear Predicitive Coding (LPC) parameters that represent the nature of the sound based on the vocal tract shape.
- Chroma [27]: Descriptor that represents the tonal content of an audio signal.
- SSF (Spectral Statistical Features) [28]: Frequency information of the audio signal (RMSE, centroid, roll-off, flatness, bandwidth, contrast, polly).
- PLP (Perceptual Linear Prediction) [29]: Alternative to MFCC that wraps the spectra to maintain the content of speech.
- Spectrum: Representation of sound in terms of frequency vibration. It is calculated to verify the performance of the LRCN and its feature fusion capabilities.
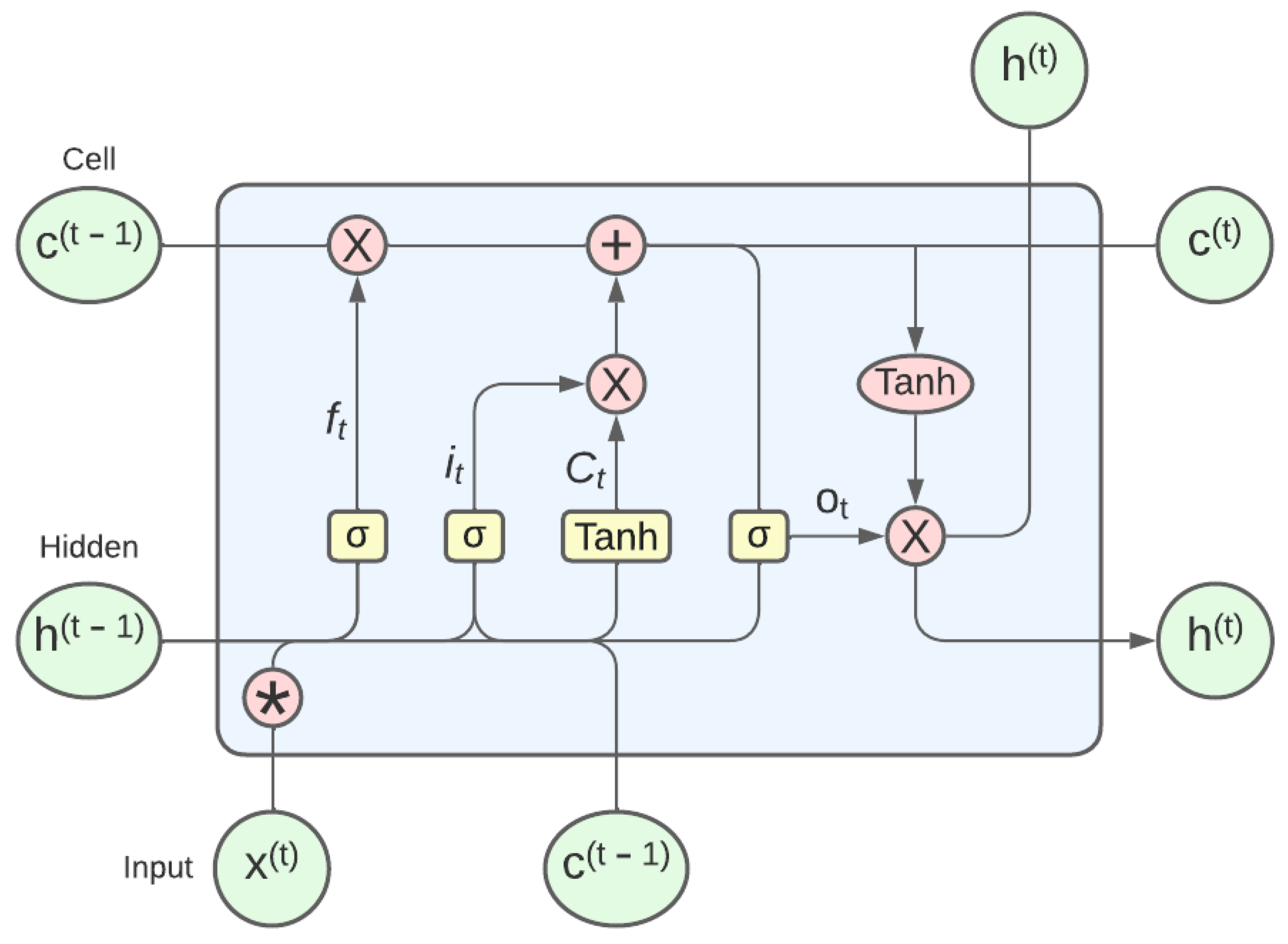
2.4. LRCN Components
- = Input gate;
- = Output gate;
- = Forget gate;
- = Input LRCN cell;
- = Output LRCN cell;
- W = Matrix of weights;
- b = Vector of bias;
- = Sigmoid function;
- * = Element-wise product;
- conv. = Convolution operator.
2.5. Existing Dataset—Jamendo Corpus
2.6. Proposed Dataset—Electrobyte
- All songs are stored in .mp3 format;
- Voice activation annotations were manually performed and stored for each song in a .lab file;
- The dataset is divided into a training set of 60 songs, validation set of 15 songs, and test set of 15 songs, which were all randomly selected for each set.
2.7. Evaluation Metrics
- = Total of true positive matches;
- = Total of false positive matches;
- = Total of true negative matches;
- = Total of false negative matches;
- = F1-measure.
3. Experiments
3.1. Technical Requirements
- For the training of the LRCN, the following parameters were used across all experiments, based on the model proposed by Zhang et al. [11]:
- –
- Batch size = 32;
- –
- Drop-out rate = 0.2;
- –
- Learning rate = 0.0001;
- –
- Number of epochs = 10,000;
- –
- Early stopping = true.
- Feature vectors are calculated by dividing the audio signal into overlapping frames and calculating the FFT (Fast Fourier Transform) of each frame in a Hamming window. After computing and combining the coefficients of MFCC, LPCC, PLP, chroma, and SSF, each feature vector contains 288 coefficients, which then are used to classify the vocal or nonvocal segments with the LRCN model. The frame parameters are based on the values proposed by Zhang et al. [11]:
- –
- Sampling rate = 16,000 Hz;
- –
- Low-frequency limit = 0 Hz;
- –
- High-frequency limit = 800 Hz;
- –
- Overlap size = 1536 samples (0.96 s);
- –
- Frame size = 2048 samples (1.28 s).
- For the hardware requirements, the system was operated and trained on a laptop with an Intel(R) Core(TM) i7-9750H CPU @2.60GHz and 16GB of RAM.
- For the software requirements, Python 3.9.5 was used to develop the SVD system. Additionally, the following Python libraries were installed:
- –
- audioread—2.1.9;
- –
- chainer—7.8.1;
- –
- ffmpeg—1.4;
- –
- h5py—3.6.0;
- –
- joblib—1.1.0;
- –
- keras—2.8.0;
- –
- librosa—0.9.1;
- –
- matplotlib—3.4.2;
- –
- numba—0.55.1;
- –
- numpy—1.20.3;
- –
- pandas—1.4.1;
- –
- playsound—1.2.2;
- –
- pydub—0.25.1;
- –
- reportlab—3.6.9;
- –
- scikit-learn—1.0.2;
- –
- scipy—1.8.0;
- –
- SoundFile—0.10.3;
- –
- spectrum—0.8.1;
- –
- tensorflow—2.8.0;
- –
- tqdm—4.64.0;
- –
- wavfile—3.1.1.
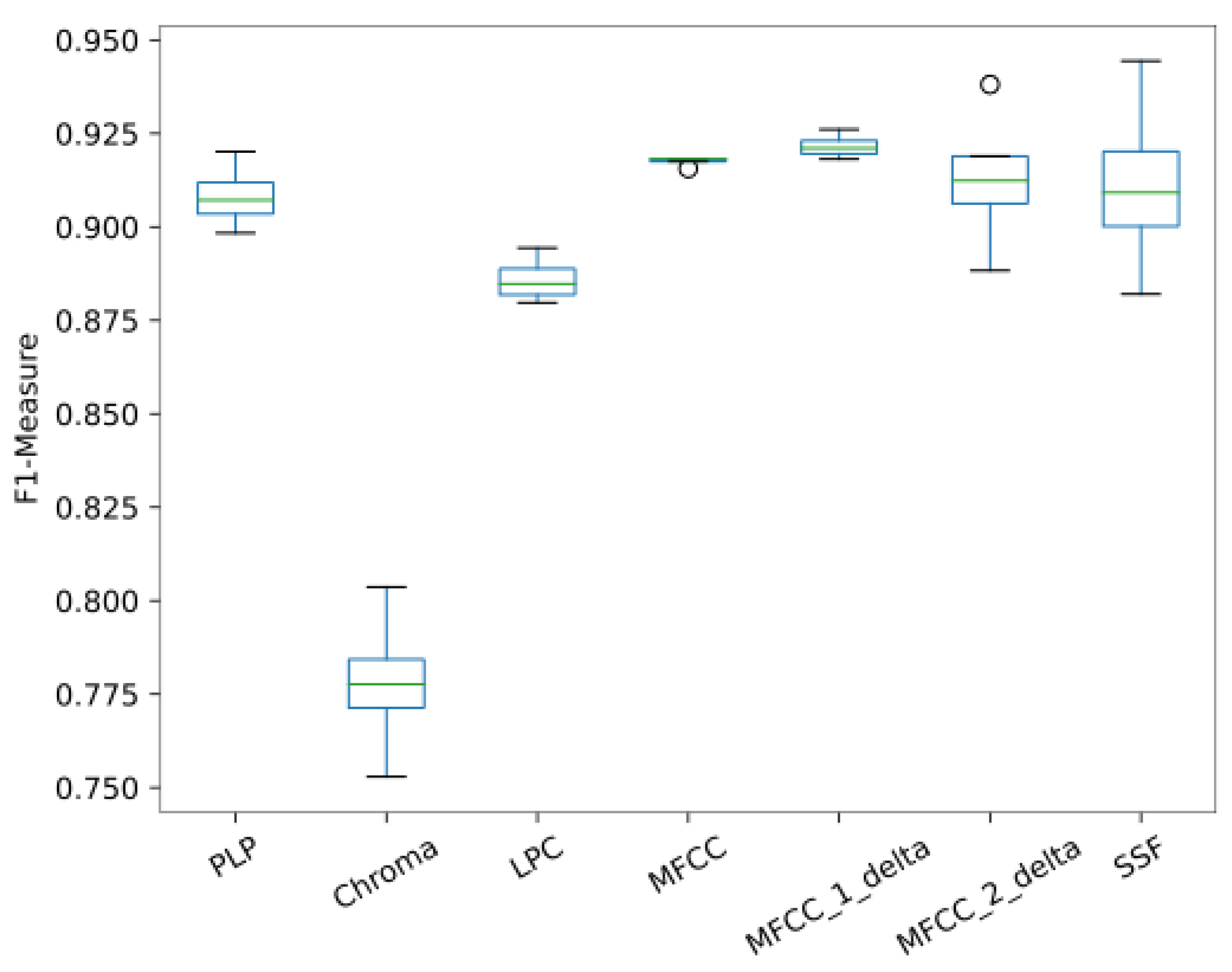
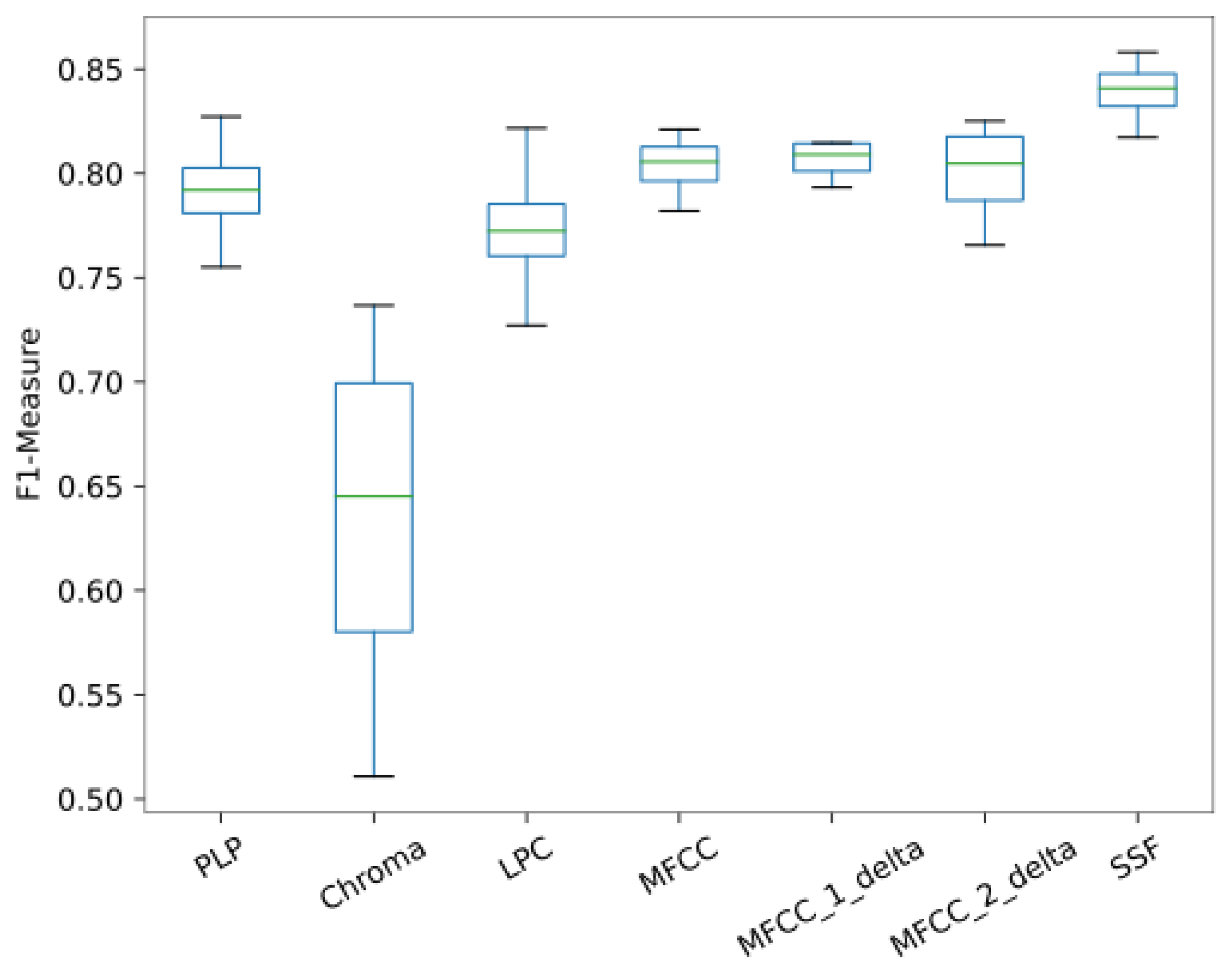
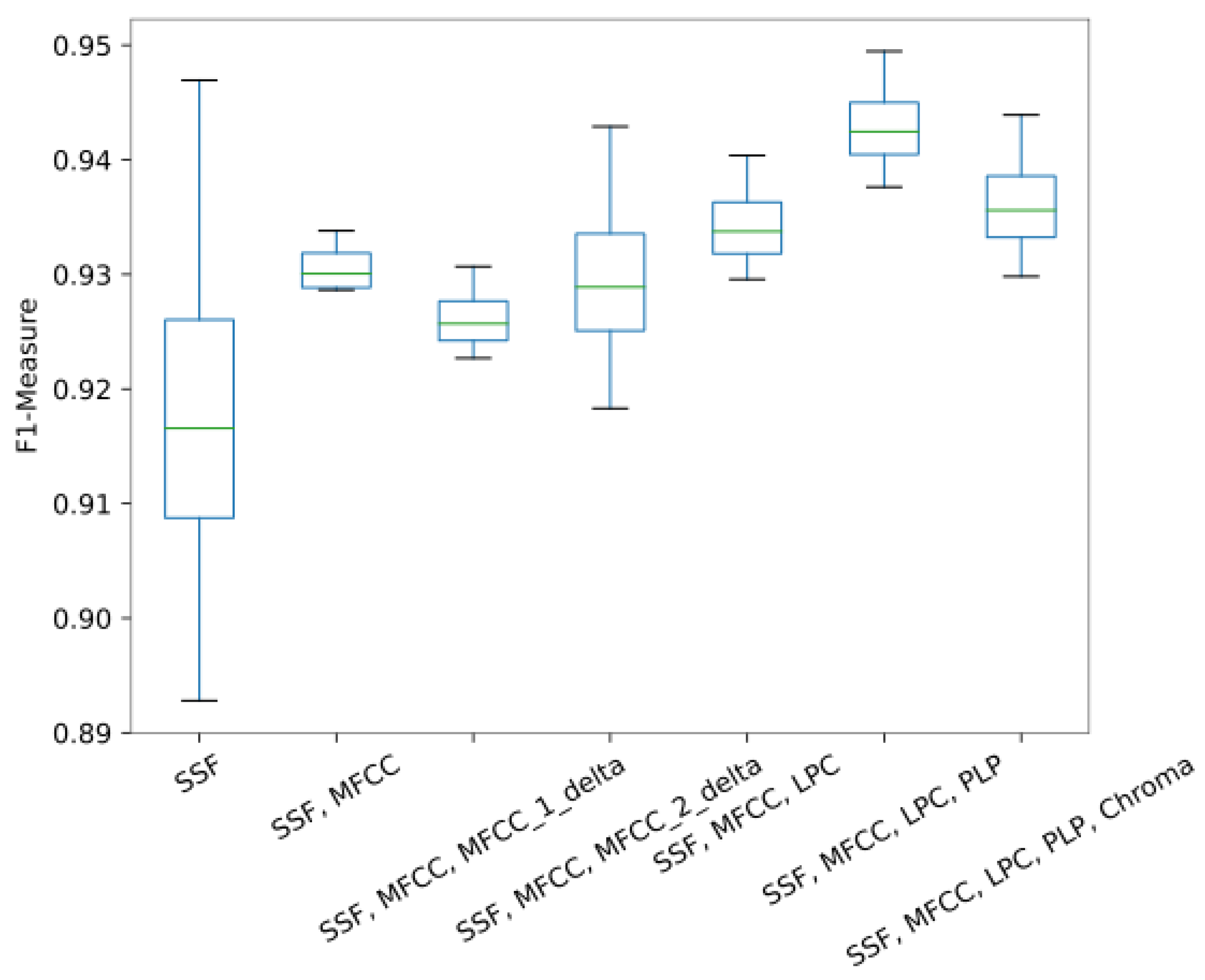
3.2. Performance across Features
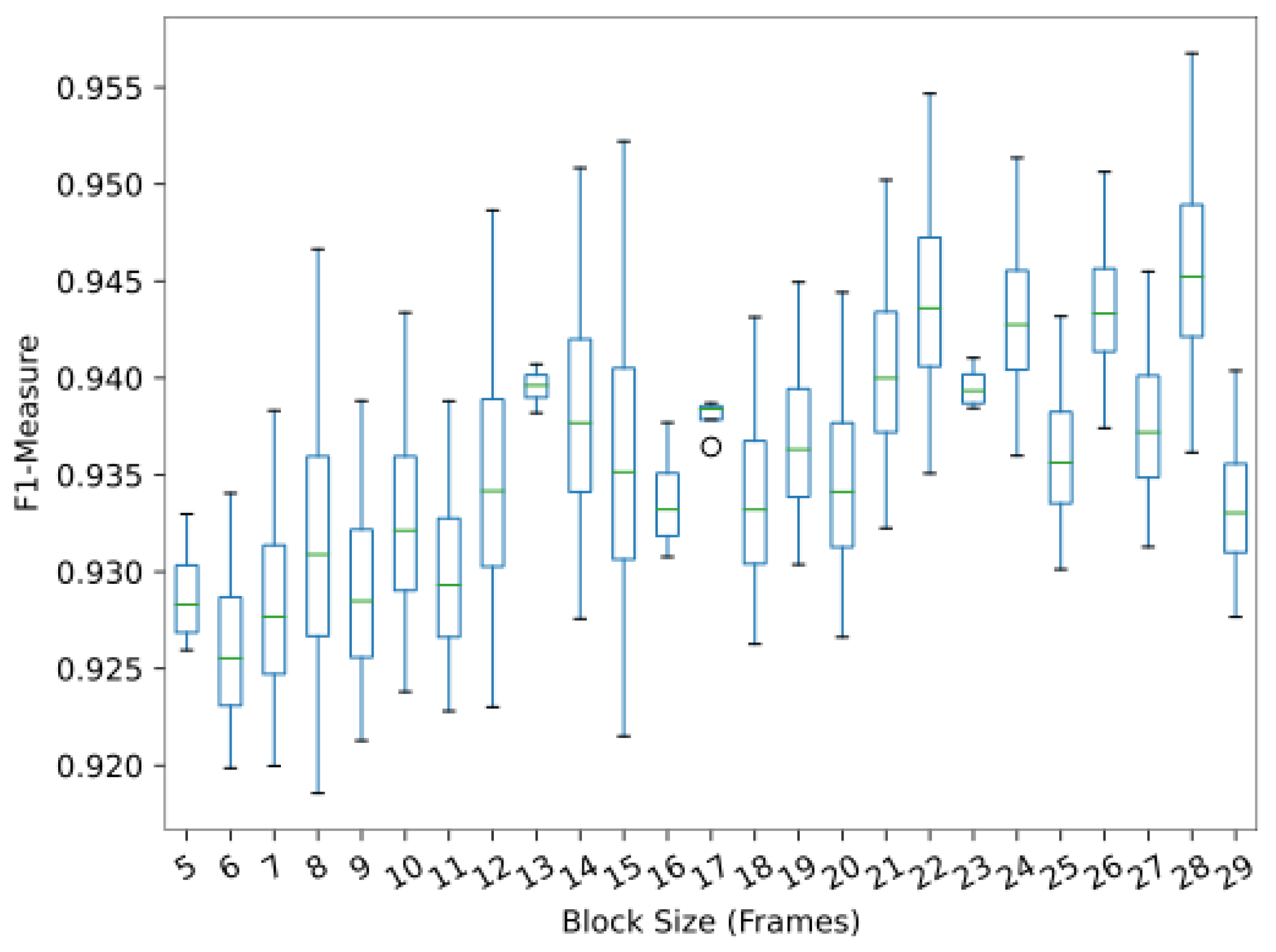
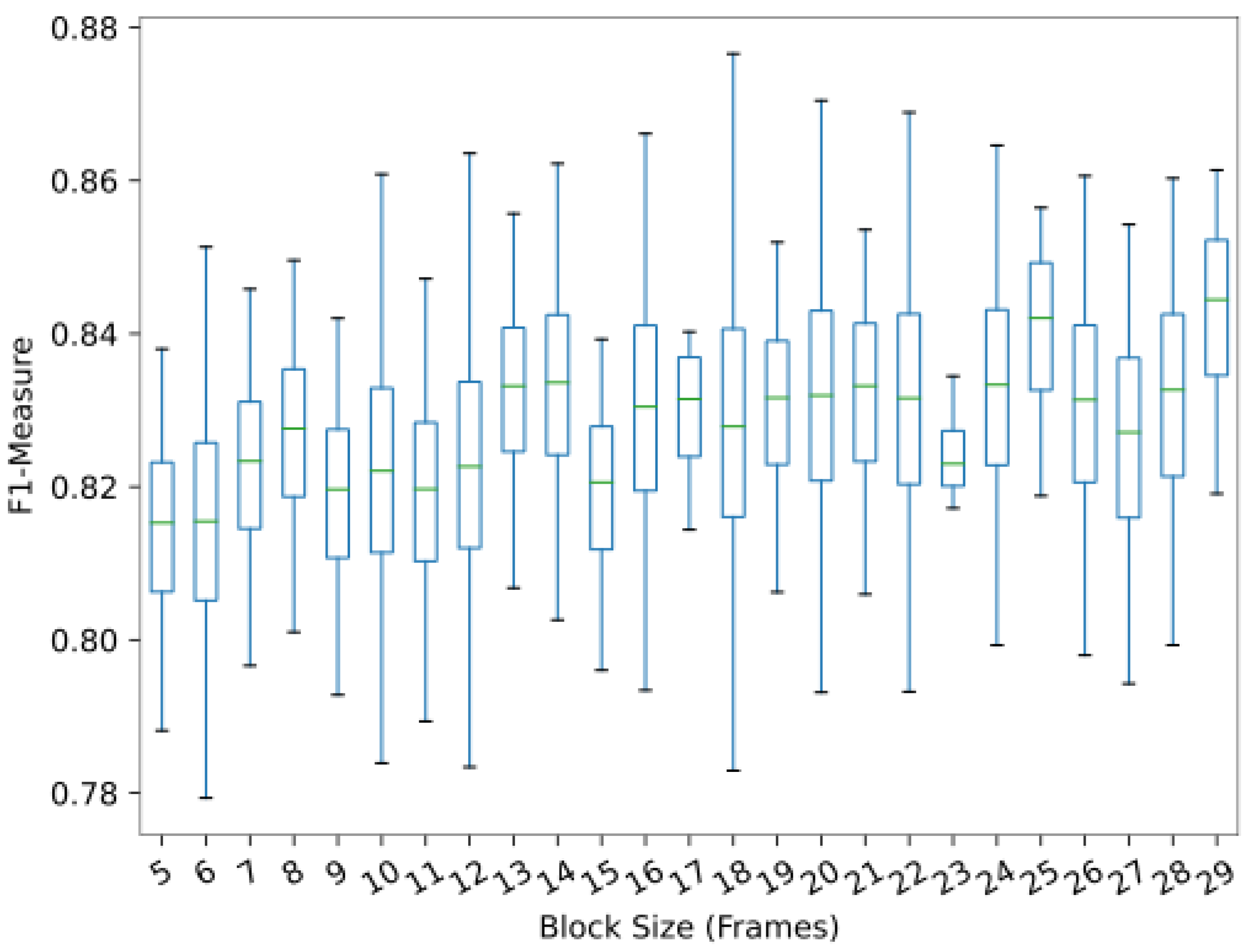
3.3. Block Size Setting
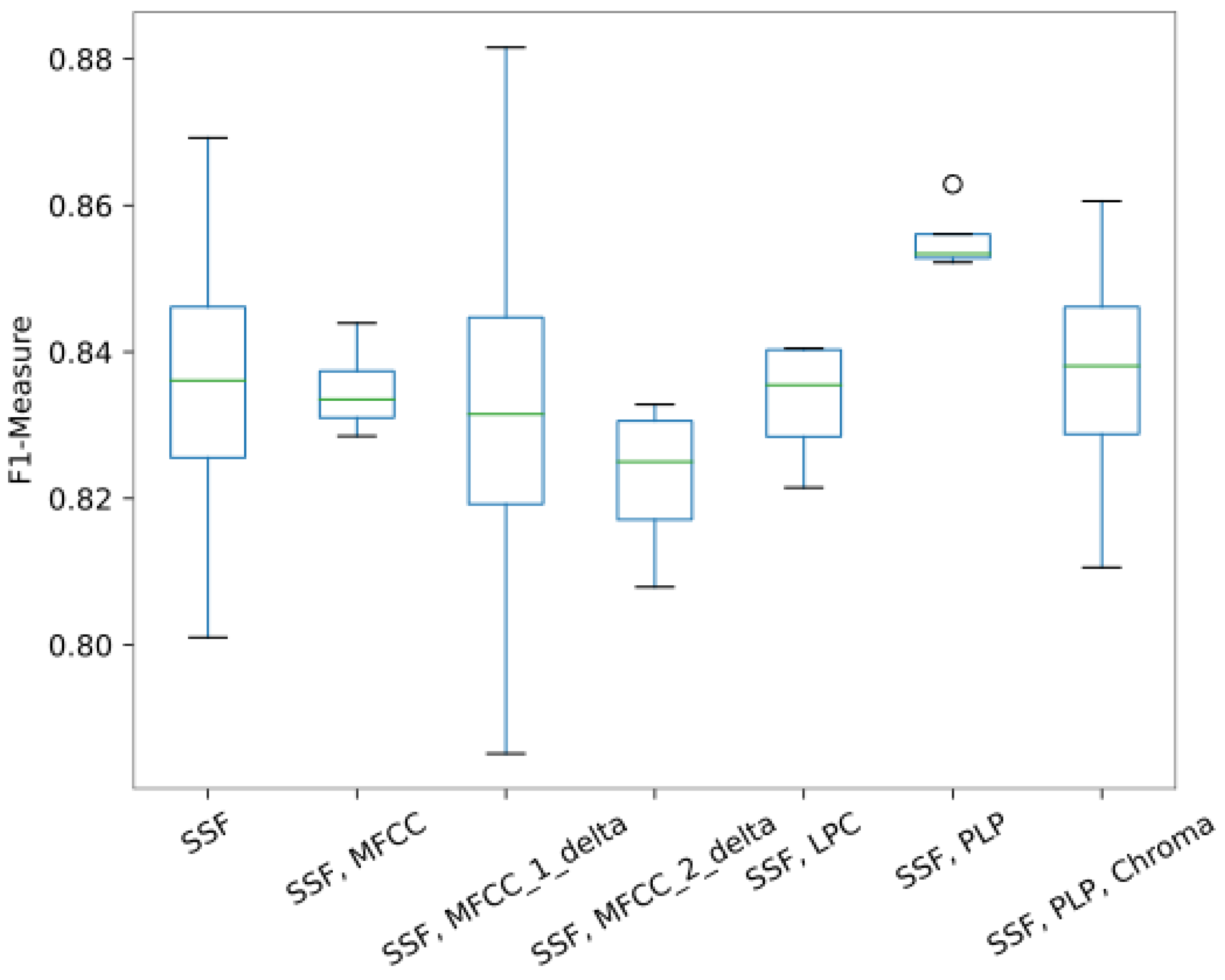
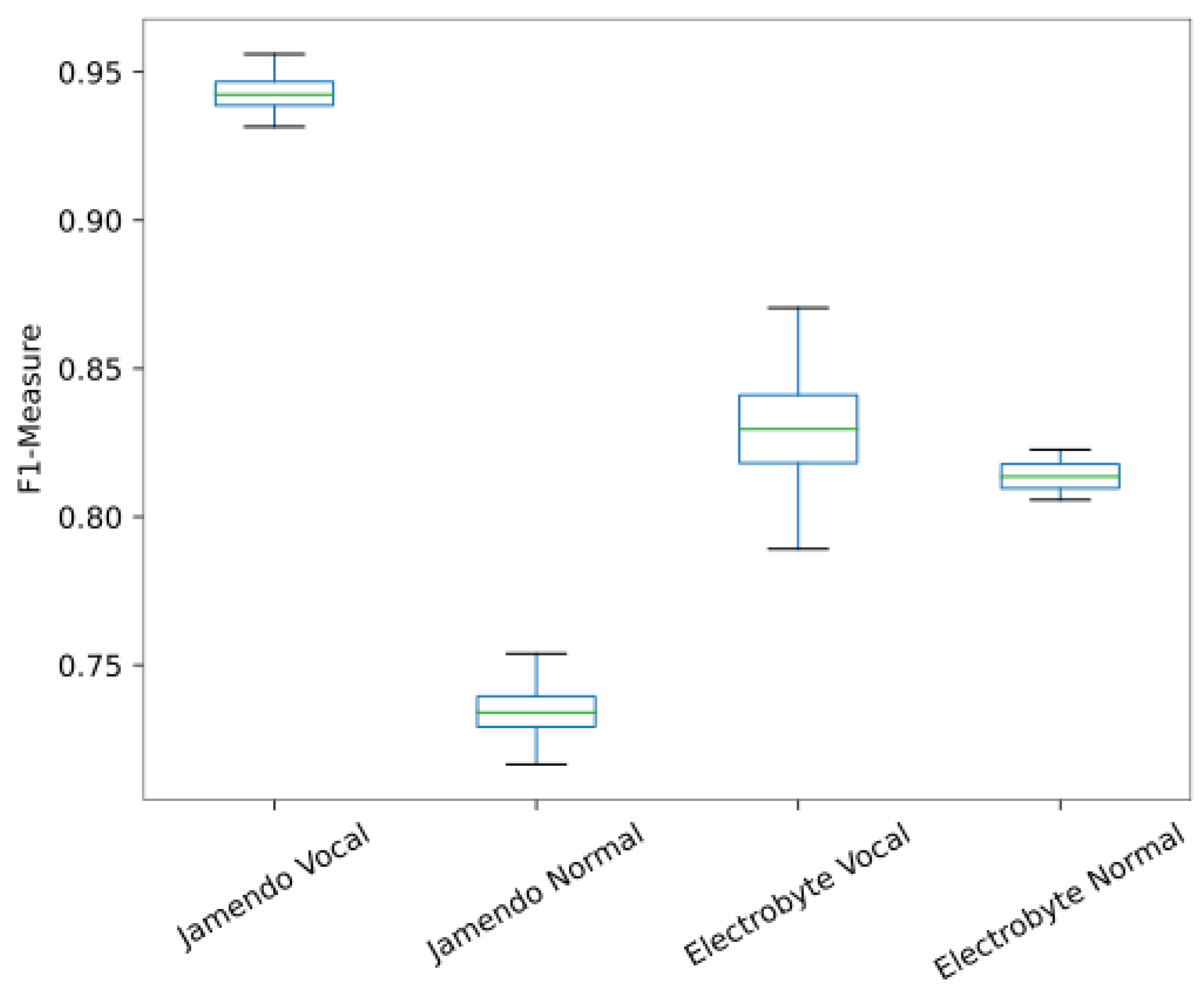
3.4. Effects of Singing Voice Separation
3.5. Comparison with Related Works on Existing Datasets
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MIR | Music Information Retrieval |
| SVD | Singing Voice Detection |
| SVS | Singing Voice Separation |
| DL | Deep Learning |
| MFCC | Mel-Frequency Cepstral Coefficients |
| LPCC | Linear Prediction Cepstral Coefficients |
| ZCR | Zero-Crossing Rate |
| PLP | Perceptual Linear Prediction |
| SSF | Spectral Statistical Features |
| LRCN | Long-Term Recurrent Convolutional Network |
References
- Bryan Pardo, Z.R.; Duan, Z. Audio Source Separation in a Musical Context. In Handbook of Systematic Musicology; Springer Handbooks; Springer: Berlin/Heidelberg, Germany, 2018; pp. 285–298. [Google Scholar]
- Li, Y.; Wang, D. Separation of Singing Voice from Music Accompaniment for Monaural Recordings. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1475–1487. [Google Scholar] [CrossRef] [Green Version]
- Rao, V.; Rao, P. Vocal Melody Extraction in the Presence of Pitched Accompaniment in Polyphonic Music. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 2145–2154. [Google Scholar] [CrossRef]
- Kan, M.Y.; Wang, Y.; Iskandar, D.; Nwe, T.L.; Shenoy, A. LyricAlly: Automatic Synchronization of Textual Lyrics to Acoustic Music Signals. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 338–349. [Google Scholar] [CrossRef]
- Fujihara, H.; Goto, M. Lyrics-to-Audio Alignment and its Application. In Multimodal Music Processing; Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2012. [Google Scholar]
- Hosoya, T.; Suzuki, M.; Ito, A.; Makino, S. Lyrics Recognition from a Singing Voice Based on Finite State Automaton for Music Information Retrieval. In Proceedings of the 6th International Conference on Music Information Retrieval, London, UK, 11–15 September 2005. [Google Scholar]
- Monir, R.; Kostrzewa, D.; Mrozek, D. Singing Voice Detection: A Survey. Entropy 2022, 24, 114. [Google Scholar] [CrossRef] [PubMed]
- Regnier, L.; Peeters, G. Singing voice detection in music tracks using direct voice vibrato detection. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 1685–1688. [Google Scholar]
- Rocamora, M.; Herrera, P. Comparing audio descriptors for singing voice detection in music audio files. In Proceedings of the 11th Brazilian Symposium on Computer Music (SBCM 2007), São Paulo, Brazil, 1–3 September 2007. [Google Scholar]
- Vijayan, K.; Li, H.; Toda, T. Speech-to-Singing Voice Conversion: The Challenges and Strategies for Improving Vocal Conversion Processes. IEEE Signal Process. Mag. 2019, 36, 95–102. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, Y.; Gao, Y.; Chen, X.; Li, W. Research on Singing Voice Detection Based on a Long-Term Recurrent Convolutional Network with Vocal Separation and Temporal Smoothing. Electronics 2020, 9, 1458. [Google Scholar] [CrossRef]
- Schlüter, J.; Grill, T. Exploring Data Augmentation for Improved Singing Voice Detection with Neural Networks. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Málaga, Spain, 26–30 October 2015. [Google Scholar]
- You, S.; Liu, C.H.; Chen, W.K. Comparative study of singing voice detection based on deep neural networks and ensemble learning. Hum.-Centric Comput. Inf. Sci. 2018, 8, 34. [Google Scholar] [CrossRef]
- Huang, H.M.; Chen, W.K.; Liu, C.H.; You, S.D. Singing voice detection based on convolutional neural networks. In Proceedings of the 2018 7th International Symposium on Next Generation Electronics (ISNE), Taipei, Taiwan, 7–9 May 2018; pp. 1–4. [Google Scholar]
- Hughes, T.; Mierle, K. Recurrent neural networks for voice activity detection. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7378–7382. [Google Scholar]
- Lehner, B.; Widmer, G.; Böck, S. A low-latency, real-time-capable singing voice detection method with LSTM recurrent neural networks. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 21–25. [Google Scholar]
- Leglaive, S.; Hennequin, R.; Badeau, R. Singing voice detection with deep recurrent neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 121–125. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014. [Google Scholar]
- Scholz, F.; Vatolkin, I.; Rudolph, G. Singing Voice Detection across Different Music Genres. Semantic Audio. 2017. Available online: https://www.aes.org/e-lib/browse.cfm?elib=18771 (accessed on 25 February 2022).
- Krause, M.; Müller, M.; Weiß, C. Singing Voice Detection in Opera Recordings: A Case Study on Robustness and Generalization. Electronics 2021, 10, 1214. [Google Scholar] [CrossRef]
- Conklin, D.W.W.; Gasser, M.; Oertl, S. Creative Chord Sequence Generation for Electronic Dance Music. Appl. Sci. 2018, 8, 1704. [Google Scholar] [CrossRef] [Green Version]
- Schlüter, J.; Lehner, B. Zero-Mean Convolutions for Level-Invariant Singing Voice Detection. In Proceedings of the 19th International Society for Music Information Retrieval Conference, Paris, France, 23–27 September 2018. [Google Scholar]
- Cohen-Hadria, A.; Röbel, A.; Peeters, G. Improving singing voice separation using Deep U-Net and Wave-U-Net with data augmentation. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Jansson, A.; Humphrey, E.J.; Montecchio, N.; Bittner, R.M.; Kumar, A.; Weyde, T. Singing Voice Separation with Deep U-Net Convolutional Networks. In Proceedings of the 18th International Society for Music Information Retrieval Conference, Suzhou, China, 23–27 October 2017. [Google Scholar]
- You, S.D.; Wu, Y.C.; Peng, S.H. Comparative Study of Singing Voice Detection Methods. Multimed. Tools Appl. 2016, 75, 15509–15524. [Google Scholar] [CrossRef]
- Gupta, H.; Gupta, D. LPC and LPCC method of feature extraction in Speech Recognition System. In Proceedings of the 2016 6th International Conference—Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 498–502. [Google Scholar]
- Ellis, D.P.W.; Poliner, G.E. Identifying ‘Cover Songs’ with Chroma Features and Dynamic Programming Beat Tracking. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV–1429–IV–1432. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.W.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and Music Signal Analysis in Python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015. [Google Scholar]
- Hermansky, H.; Morgan, N.; Bayya, A.; Kohn, P. RASTA-PLP speech analysis technique. In Proceedings of the ICASSP-92: 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, CA, USA, 23–26 March 1992; Volume 1, pp. 121–124. [Google Scholar]
- Ramona, M.; Richard, G.; David, B. Vocal detection in music with support vector machines. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 1885–1888. [Google Scholar]
- TheFatRat. The Arcadium. 2016. Available online: https://www.youtube.com/c/TheArcadium (accessed on 20 April 2022).
- Woodford, B. NCS (No Copytight Sounds)—Free Music for Content Creators. 2011. Available online: https://ncs.io (accessed on 27 April 2022).
- Lehner, B.; Widmer, G.; Sonnleitner, R. On the reduction of false positives in singing voice detection. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar] [CrossRef]
- Lehner, B.; Sonnleitner, R.; Widmer, G. Towards Light-Weight, Real-Time-Capable Singing Voice Detection. In Proceedings of the 14th International Conference on Music Information Retrieval (ISMIR 2013), Curitiba, Brazil, 4–8 November 2013. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape | Parameter |
|---|---|---|
| reshape-1 (Reshape) | (None,1,1,20,276) | 0 |
| conv_lstm_2d-1 (ConvLSTM2D) | (None,1,17,13) | 60,164 |
| dropout-1 (Dropout) | (None,1,17,13) | 0 |
| max_pooling_2d-1 (MaxPooling2D) | (None,1,8,13) | 0 |
| dropout-2 (Dropout) | (None,1,8,13) | 0 |
| flatten-1 (Flatten) | (None,104) | 0 |
| dense-1 (Dense) | (None,200) | 21,000 |
| dropout-3 (Dropout) | (None,200) | 0 |
| dense-2 (Dense) | (None,50) | 10,050 |
| dropout-4 (Dropout) | (None,50) | 0 |
| dense-3 (Dense) | (None,1) | 51 |
| Accuracy | Precision | Recall | F1-Measure | Deviation | |
|---|---|---|---|---|---|
| Jamendo | 0.939 | 0.937 | 0.945 | 0.942 | 0.004 |
| Electrobyte | 0.833 | 0.798 | 0.861 | 0.828 | 0.006 |
| Accuracy | Precision | Recall | F-Measure | Deviation | |
|---|---|---|---|---|---|
| Ramona [30] | 0.822 | - | - | 0.831 | - |
| Schlüter [12] | 0.923 | - | 0.903 | - | - |
| Lehner-1 [33] | 0.882 | 0.880 | 0.862 | 0.871 | - |
| Lehner-2 [34] | 0.848 | - | - | 0.846 | - |
| Lehner-3 [16] | 0.894 | 0.898 | 0.906 | 0.902 | - |
| Leglaive [17] | 0.915 | 0.895 | 0.926 | 0.910 | - |
| Zhang [11] | 0.924 | 0.926 | 0.924 | 0.927 | - |
| LRCN | 0.939 | 0.937 | 0.945 | 0.942 | 0.004 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romero-Arenas, R.; Gómez-Espinosa, A.; Valdés-Aguirre, B. Singing Voice Detection in Electronic Music with a Long-Term Recurrent Convolutional Network. Appl. Sci. 2022, 12, 7405. https://doi.org/10.3390/app12157405
Romero-Arenas R, Gómez-Espinosa A, Valdés-Aguirre B. Singing Voice Detection in Electronic Music with a Long-Term Recurrent Convolutional Network. Applied Sciences. 2022; 12(15):7405. https://doi.org/10.3390/app12157405
Chicago/Turabian StyleRomero-Arenas, Raymundo, Alfonso Gómez-Espinosa, and Benjamín Valdés-Aguirre. 2022. "Singing Voice Detection in Electronic Music with a Long-Term Recurrent Convolutional Network" Applied Sciences 12, no. 15: 7405. https://doi.org/10.3390/app12157405