
Investigating the Difference of Fake News Source Credibility Recognition between ANN and BERT Algorithms in Artificial Intelligence


Abstract
:1. Introduction
1.1. Research Background and Motivation
1.2. Research Objective and Problem
- (1)
- To discuss the recognition rate of the word-frequency-based ANN system on news source credibility.
- (2)
- To discuss the recognition rate of the semantics-based BERT system on news source credibility.
- (3)
- To compare the difference in the recognition rate of news source credibility between the word-frequency-based ANN system and the semantics-based BERT system.
2. Literacy Review
2.1. Fake News
2.2. Artificial Neural Network (ANN)
2.3. Bidirectional Encoder Representations from Transformers (BERT)
3. Research Method
3.1. Dataset Selection
3.2. System Design and Research Process
3.2.1. ANN
- (1)
- Data cleaning: Capture required fields from the database and check the null field in each record; if present, the record is excluded. Export the selected data with the CSV format of UTF-8 BOM as the raw data for the program.
- (2)
- Feature extraction: Regard the article title and article text in the source file as the string, apply CKIP Word Segmentation and Named Entity Recognition developed by CKIP Chinese Lexical Knowledge Base for word segmentation and analysis, execute part-of-speech tagging (POS tagging) and name entity recognition (NER), and term frequency (TF) after each word segmentation is calculated as the feature parameter of the training model.
- (3)
- Modeling: Apply the Keras Sequential model (a linear stack model with multiple network layers) and designate the size parameters of the input layer, hidden layer, and output layer for the compilation model. The parameter details used for the model.add function are shown below.Input layer: Characteristic dimension dim (130), nodes units (12), and activation function activation (ReLU).Hidden layer: Nodes units (12), number of layers (10), and activation function activation (ReLU).Output layer: Nodes units (1) and activation function activation (sigmoid).
- (4)
- Compilation model: The parameter details used for the model.compile function are shown below.loss function binary_crossentropy, optimal algorithm RMSprop, learning rate (0.0005), and measurement index metrics (accuracy).
- (5)
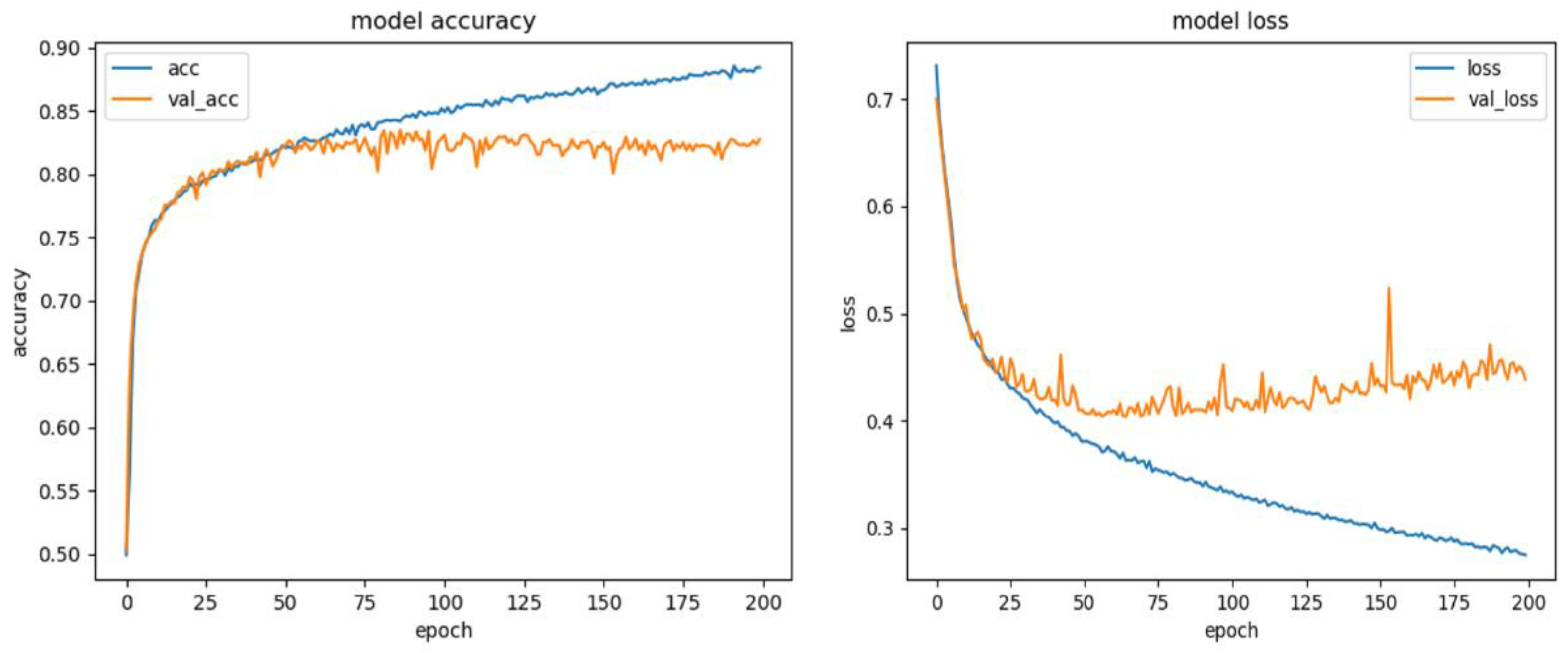
- Training and validation model: The parameters used for the model.fit function are shown below.batch size batch_size (250), number of training rounds epochs (200), and validation set splite ratio validation_split (0.2).
- (6)
- Data visualization: The data generated after completing the model training are presented as a graph with matplotlib and saved in the Result folder, as shown in Figure 1.
3.2.2. BERT
- (1)
- Data preprocessing: Load tensorflow, tensorflow_dataset, transformers, and BertTokenizer from the library and apply vocab.txt corpus offered by Google, including encode_words and bert_encode, to transform the content word group in the training set into serial form and further transform it into a tensor.
- (2)
- Modeling: The applied model bert_model_chinese_wwm_ext is classified with TBbertForSequenceClassification, and bert_config.json is loaded and the checkpoint is set.
- (3)
- Compilation model: The used parameter details are shown below.loss function SparseCategoricalCrossentropy, optimal algorithm Adam, learning rate (0.000001), measurement index SparseCategoricalAccuracy.
- (4)
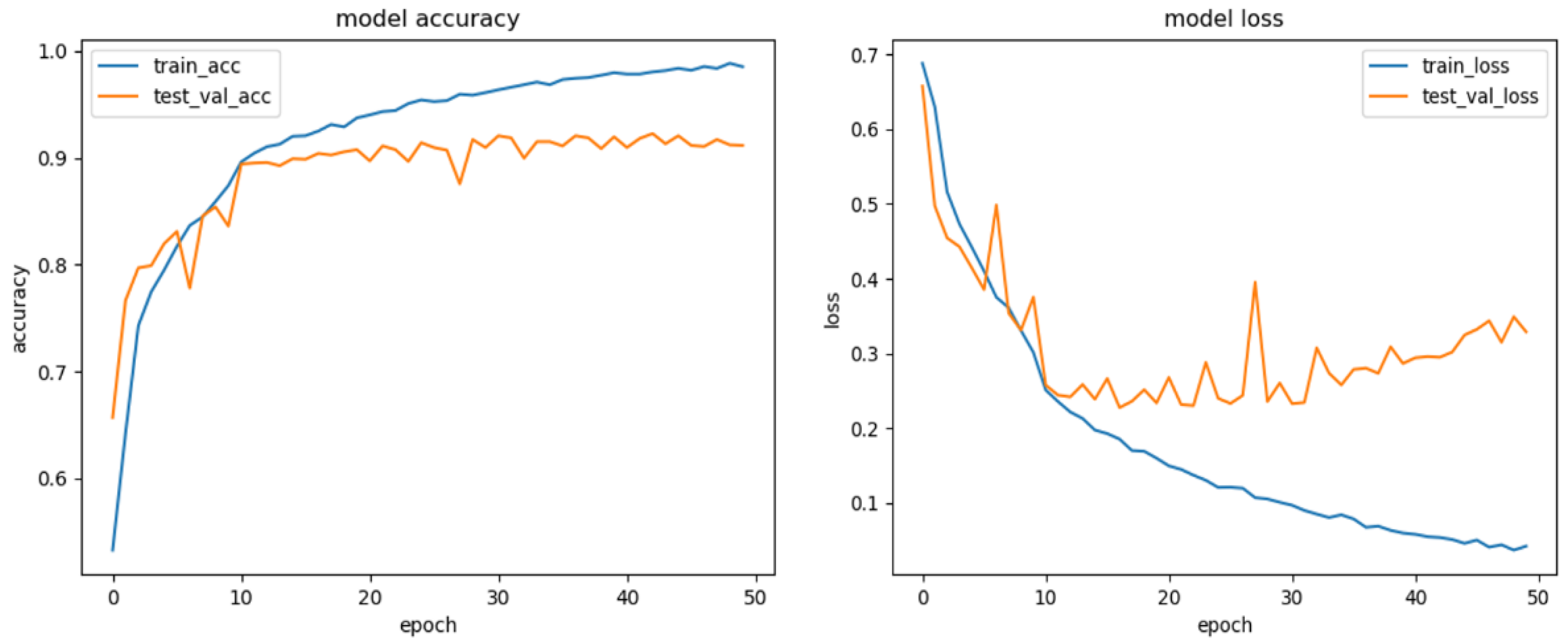
- Training and validation model: The used parameter details contain the batch size batch_size (5), number of training rounds epochs (50), and validation set split ratio validation_split (0.1).
- (5)
- Data visualization: The data generated after completing model training are drawn as a curve with matplotlib and saved as an image in Results, as shown in Figure 2.
4. Results
4.1. ANN
4.2. BERT
5. Discussion and Conclusions
5.1. ANN Prediction Results
- (1)
- The ANN system presents a better source credibility recognition rate for mainstream news than content farms.
- (2)
- The ANN system found the lowest source credibility recognition rate for nooho.net.
5.2. BERT Prediction Results
- (1)
- The experimental results of the BERT system are almost identical to the test results of the saved model.
- (2)
- The BERT system has a better true news hit rate for mainstream news platforms than the fake news hit rate for content farms.
5.3. Comparison of System Prediction Results
- (1)
- The ANN and BERT systems show high similarity in their hit rates.
- (2)
- In comparison with the ANN system, the BERT system presents a higher and more stable source credibility recognition rate.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- The Consumer Foundation’s Top 10 Consumer News of 2018: The Toilet Paper Chaos Wins the Championship (Photo). Available online: https://newtalk.tw/news/view/2019-01-10/192829 (accessed on 14 March 2019).
- Malicious Dissemination Endangers Democracy, NCC Calls Out the Media and Fines 2 Million for Failing to Verify Fake News. Available online: https://tw.appledaily.com/headline/20180918/E6OY7CEMWNWDL4I4WWT7XI4UFU/ (accessed on 14 March 2019).
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef] [Green Version]
- Reuters Institute Digital News Report. 2017. Available online: https://reutersinstitute.politics.ox.ac.uk/sites/default/files/Digital%20News%20Report%202017%20web_0.pdf (accessed on 20 May 2020).
- Did Facebook’s Mark Zuckerberg Coin The Phrase ‘Fake News’? Available online: https://www.forbes.com/sites/kalevleetaru/2017/02/17/did-facebooks-mark-zuckerberg-coin-the-phrase-fake-news/?sh=5f77d38b6bc4 (accessed on 17 February 2019).
- What Is Fake News? Its Origins and How It Grew in 2016. Available online: https://grassrootjournalist.org/2017/06/17/what-is-fake-news-its-origins-and-how-it-grew-in-2016/ (accessed on 29 December 2017).
- Why People Post Fake News. Vice: The Truth and Lies Issue. Available online: https://www.vice.com/en/article/9kpz3v/why-people-post-fake-news-v26n1 (accessed on 20 June 2019).
- Journalism, ‘Fake News’ & Disinformation. Available online: https://en.unesco.org/sites/default/files/journalism_fake_news_disinformation_print_friendly_0.pdf (accessed on 27 July 2021).
- Information Disorder: Toward an Interdisciplinary Framework for Research and Policy Making. Available online: https://rm.coe.int/information-disorder-toward-an-interdisciplinary-framework-for-researc/168076277c (accessed on 27 July 2021).
- Guess, A.; Nagler, J.; Tucker, J. Less than you think: Prevalence and predictors of fake news dissemination on Facebook. Sci. Adv. 2019, 5, eaau4586. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leeder, C. How college students evaluate and share “fake news” stories. Libr. Inf. Sci. Res. 2019, 41, 100967. [Google Scholar] [CrossRef]
- Cooke, N.A. Posttruth, truthiness, and alternative facts: Information behavior and critical information consumption for a new age. Libr. Q. 2017, 87, 211–221. [Google Scholar] [CrossRef]
- What Is Fake News? How to Spot It and What You Can Do to Stop It. Available online: https://www.theguardian.com/media/2016/dec/18/what-is-fake-news-pizzagate (accessed on 28 December 2019).
- Reuters Institute Digital News Report. 2018. Available online: https://reutersinstitute.politics.ox.ac.uk/sites/default/files/digital-news-report-2018.pdf (accessed on 20 May 2020).
- “Fake News”, Disinformation, and Propaganda. Available online: https://guides.library.harvard.edu/fake (accessed on 29 May 2021).
- How To Spot Fake News, Misinformation, and Propaganda. Available online: https://www.ifla.org/resources/?oPubId=11174 (accessed on 21 June 2017).
- The Content Mill Empire Behind Online Disinformation in Taiwan. Available online: https://www.twreporter.org/a/information-warfare-business-disinformation-fake-news-behind-line-groups-english (accessed on 26 December 2020).
- Batchelor, O. Getting out the truth: The role of libraries in the fight against fake news. Ref. Serv. Rev. 2017, 45, 143–148. [Google Scholar] [CrossRef]
- Eva, N.; Shea, E. Amplify your impact: Marketing libraries in an era of “fake news”. Ref. User Serv. Q. 2018, 57, 168–171. [Google Scholar] [CrossRef] [Green Version]
- Andretta, S. Information Literacy: A Practitioner’s Guide, 1st ed.; Elsevier: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Dos Santos, C.N.; Gatti, M. Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In COLING 2014, Proceedings of the 25th International Conference on Computational Linguistics, Dublin, Ireland, 23–29 August 2014; Technical Papers; Dublin City University: Dublin, Ireland; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 69–78. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Lopez, M.M.; Kalita, J. Deep Learning applied to NLP. arXiv 2017, arXiv:1703.03091. [Google Scholar]
- Vajjala, S.; Majumder, B.; Gupta, A.; Surana, H. Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems, 1st ed.; O’Reilly Media: Sevastopol, CA, USA, 2020. [Google Scholar]
- The Unreasonable Effectiveness of Recurrent Neural Networks. Available online: http://karpathy.github.io/2015/05/21/rnn-effectiveness (accessed on 21 May 2016).
- Hochreiter, S.; Schmidhuber, J. Long Short-Term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Understanding LSTM Networks. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 27 August 2020).
- Sitaula, C.; Basnet, A.; Mainali, A.; Shahi, T.B. Deep learning-based methods for sentiment analysis on Nepali COVID-19-related tweets. Comput. Intell. Neurosci. 2021, 2021, 2158184. [Google Scholar] [CrossRef] [PubMed]
- Shahi, T.B.; Sitaula, C.; Paudel, N. A Hybrid Feature Extraction Method for Nepali COVID-19-Related Tweets Classification. Comput. Intell. Neurosci. 2022, 2022, 5681574 . [Google Scholar] [CrossRef]
- Gorbachev, V.; Nikitina, M.; Velina, D.; Mutallibzoda, S.; Nosov, V.; Korneva, G.; Terekhova, A.; Artemova, E.; Khashir, B.; Sokolov, I.; et al. Artificial Neural Networks for Predicting Food Antiradical Potential. Appl. Sci. 2022, 12, 6290. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kao, W.T.; Wu, T.H.; Chi, P.H.; Hsieh, C.C.; Lee, H.Y. Further boosting BERT-based models by duplicating existing layers: Some intriguing phenomena inside BERT. arXiv 2020, arXiv:2001.09309v1. [Google Scholar]
- Adhikari, A.; Ram, A.; Tang, R.; Lin, J. Docbert: Bert for document classification. arXiv 2019, arXiv:1904.08398. [Google Scholar]
- Liu, Y. Fine-tune BERT for extractive summarization. arXiv 2019, arXiv:1903.10318. [Google Scholar]
- Huang, W.; Cheng, X.; Chen, K.; Wang, T.; Chu, W. Toward fast and accurate neural chinese word segmentation with multi-criteria learning. arXiv 2019, arXiv:1903.04190. [Google Scholar]
- Yang, W.; Xie, Y.; Tan, L.; Xiong, K.; Li, M.; Lin, J. Data augmentation for bert fine-tuning in open-domain question answering. arXiv 2019, arXiv:1904.06652. [Google Scholar]
- Yang, W.; Zhang, H.; Lin, J. Simple applications of BERT for ad hoc document retrieval. arXiv 2019, arXiv:1903.10972. [Google Scholar]
- Vig, J.; Ramea, K. Comparison of transfer-learning approaches for response selection in multi-turn conversations. In Proceedings of the Workshop on Dialog System Technology Challenges 7 (DSTC7), Honolulu, HI, USA, 27 January 2019. [Google Scholar]
- Li, H.; Ma, Y.; Ma, Z.; Zhu, H. Weibo Text Sentiment Analysis Based on BERT and Deep Learning. Appl. Sci. 2021, 11, 10774. [Google Scholar] [CrossRef]
- Kang, M.; Lee, K.H.; Lee, Y. Filtered BERT: Similarity Filter-Based Augmentation with Bidirectional Transfer Learning for Protected Health Information Prediction in Clinical Documents. Appl. Sci. 2021, 11, 3668. [Google Scholar] [CrossRef]
- Zhuang, Y.; Kim, J. A BERT-Based Multi-Criteria Recommender System for Hotel Promotion Management. Sustainability 2021, 13, 8039. [Google Scholar] [CrossRef]
- Ireton, C.; Posetti, J. Journalism, Fake News & Disinformation: Handbook for Journalism Education and Training; United Nations Educational, Science, and Cultural Organization: Paris, France, 2018. [Google Scholar]



{kind=link}
{kind=link}
| Mainstream News | N | Content Farm News | N |
|---|---|---|---|
| Apple Daily | 93,715 | mission-tw.com | 12,960 |
| China Times | 144,107 | nooho.net | 1839 |
| Liberty Times | 79,078 | kknews.cc | 42,577 |
| United Daily News | 610,572 | buzzhand.com | 719 |
| ETtoday | 340,804 | qiqi.news | 32,916 |
| Central News Agency | 57,309 | Global Military | 6036 |
| Total | 1,325,585 | Total | 97,047 |
| Mainstream News | ||||||
| Test data source | Apple Daily | China Times | Liberty Times | United Daily News | ETtoday | Central News Agency |
| N | 200 | 200 | 200 | 200 | 200 | 200 |
| Hit rate | 82.0% | 71.0% | 96.5% | 93.0% | 66.0% | 88.5% |
| CI (95%) | 76.57~87.43% | 64.58~77.42% | 93.90~99.10% | 89.39~96.61% | 59.30~72.70% | 83.99~93.01% |
| Error | 5.43% | 6.42% | 2.60% | 3.61% | 6.70% | 4.51% |
| Content Farm News | ||||||
| Test data source | mission-tw.com | nooho.net | kknews.cc | buzzhand.com | qiqi.news | Global Military |
| N | 200 | 200 | 200 | 200 | 200 | 200 |
| Hit rate | 85.0% | 65.5% | 87.0% | 98.0% | 86.0% | 87.0% |
| CI (95%) | 79.95~90.05% | 58.78~72.22% | 82.24~91.76% | 96.02~99.18% | 81.09~90.91% | 82.24~91.76% |
| Error | 5.05% | 6.72% | 4.76% | 1.98% | 4.91% | 4.76% |
| Mainstream News | ||||||
| Test data source | Apple Daily | China Times | Liberty Times | United Daily News | ETtoday | Central News Agency |
| N | 200 | 200 | 200 | 200 | 200 | 200 |
| Hit rate | 90.5% | 90.5% | 100.0% | 96.5% | 89.0% | 100.0% |
| CI (95%) | 86.35~94.65% | 86.35~94.65% | 100.0% | 93.90~99.10% | 84.58~93.42% | 100.0% |
| Error | 4.15% | 4.15% | 0% | 2.60% | 4.42% | 0% |
| Content Farm News | ||||||
| Test data source | mission-tw.com | nooho.net | kknews.cc | buzzhand.com | qiqi.news | Global Military |
| N | 200 | 200 | 200 | 200 | 200 | 200 |
| Hit rate | 98.5% | 79.0% | 85.0% | 89.0% | 83.0% | 88.5% |
| CI (95%) | 100~96.78% | 73.24~84.76% | 79.95~90.05% | 84.58~93.42% | 77.69~88.31% | 93.01~83.99% |
| Error | 1.72% | 5.76% | 5.05% | 4.42% | 5.31% | 4.51% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chiang, T.H.C.; Liao, C.-S.; Wang, W.-C. Investigating the Difference of Fake News Source Credibility Recognition between ANN and BERT Algorithms in Artificial Intelligence. Appl. Sci. 2022, 12, 7725. https://doi.org/10.3390/app12157725
Chiang THC, Liao C-S, Wang W-C. Investigating the Difference of Fake News Source Credibility Recognition between ANN and BERT Algorithms in Artificial Intelligence. Applied Sciences. 2022; 12(15):7725. https://doi.org/10.3390/app12157725
Chicago/Turabian StyleChiang, Tosti H. C., Chih-Shan Liao, and Wei-Ching Wang. 2022. "Investigating the Difference of Fake News Source Credibility Recognition between ANN and BERT Algorithms in Artificial Intelligence" Applied Sciences 12, no. 15: 7725. https://doi.org/10.3390/app12157725