
Metaheuristics Optimization with Deep Learning Enabled Automated Image Captioning System

 ,
,
Abstract
:1. Introduction
2. Prior Image Captioning Techniques
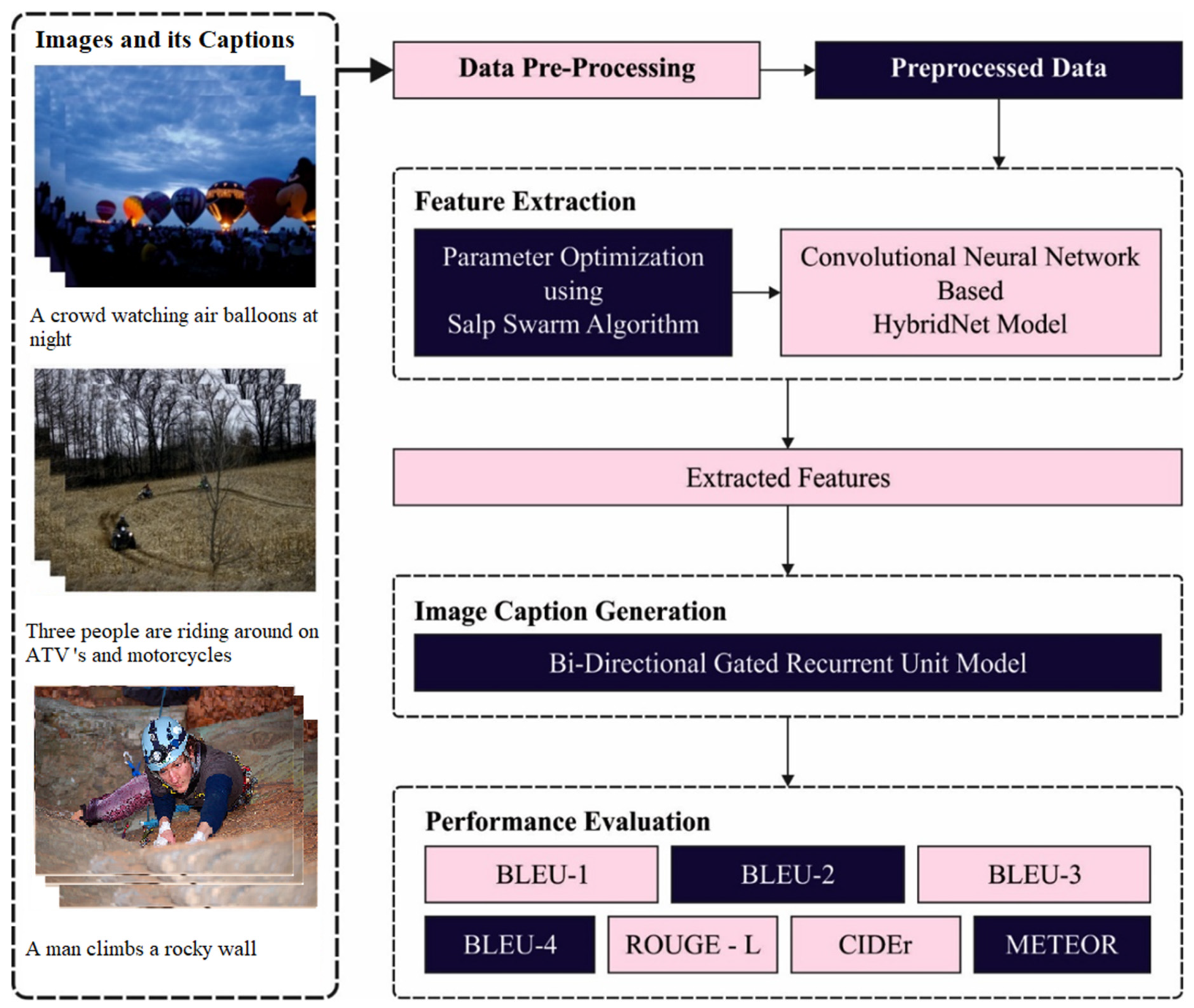
3. The Proposed Model
3.1. Data Pre-Processing
- Lower case conversion;
- Removal of punctuation marks to decrease complexity;
- Removal of numeric values;
- Tokenization;
- Vectorization (to turn the original strings into integer sequences where each integer represents the index of a word in a vocabulary).
3.2. Feature Extraction: HybridNet Model
3.3. Hyperparameter Optimization
| Algorithm 1 Pseudocode of SSA |
| 1: Input: maximum iterations , population size 2: Initialization of salp position 3: While (stopping criteria is not fulfilled) 4: Determine fitness of all salps 5: Arrange salp position based on fitness value 6: Define as optimal place for present population 7: Upgrade Cl 8: For every salp position () 9: If upgrades the position of leading salps 10: Else upgrade the position of follower salp 11: end 12: end 13: Change the salp which crosses higher and lower limits 14: end 15: Display optimum output |
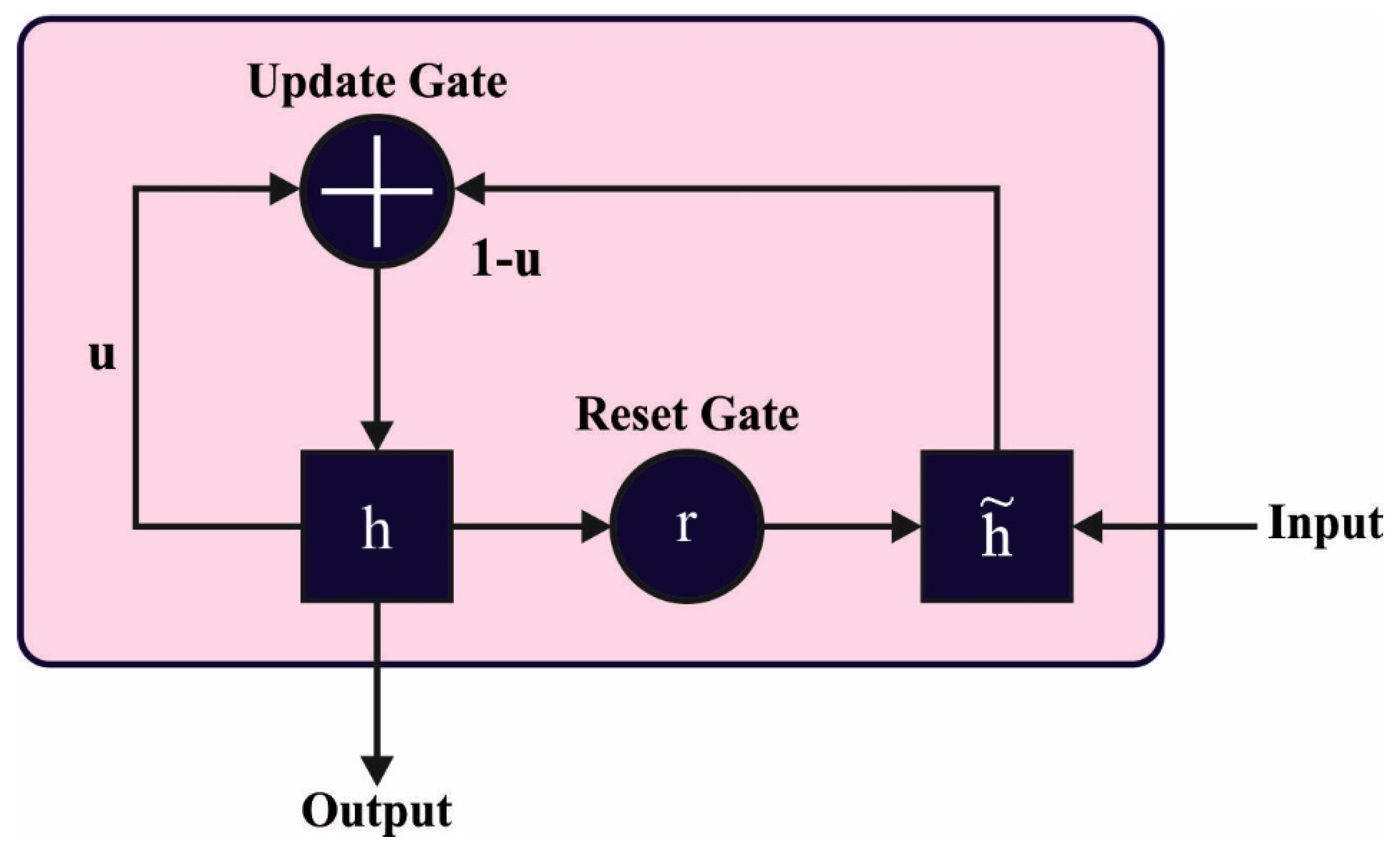
3.4. Image Captioning
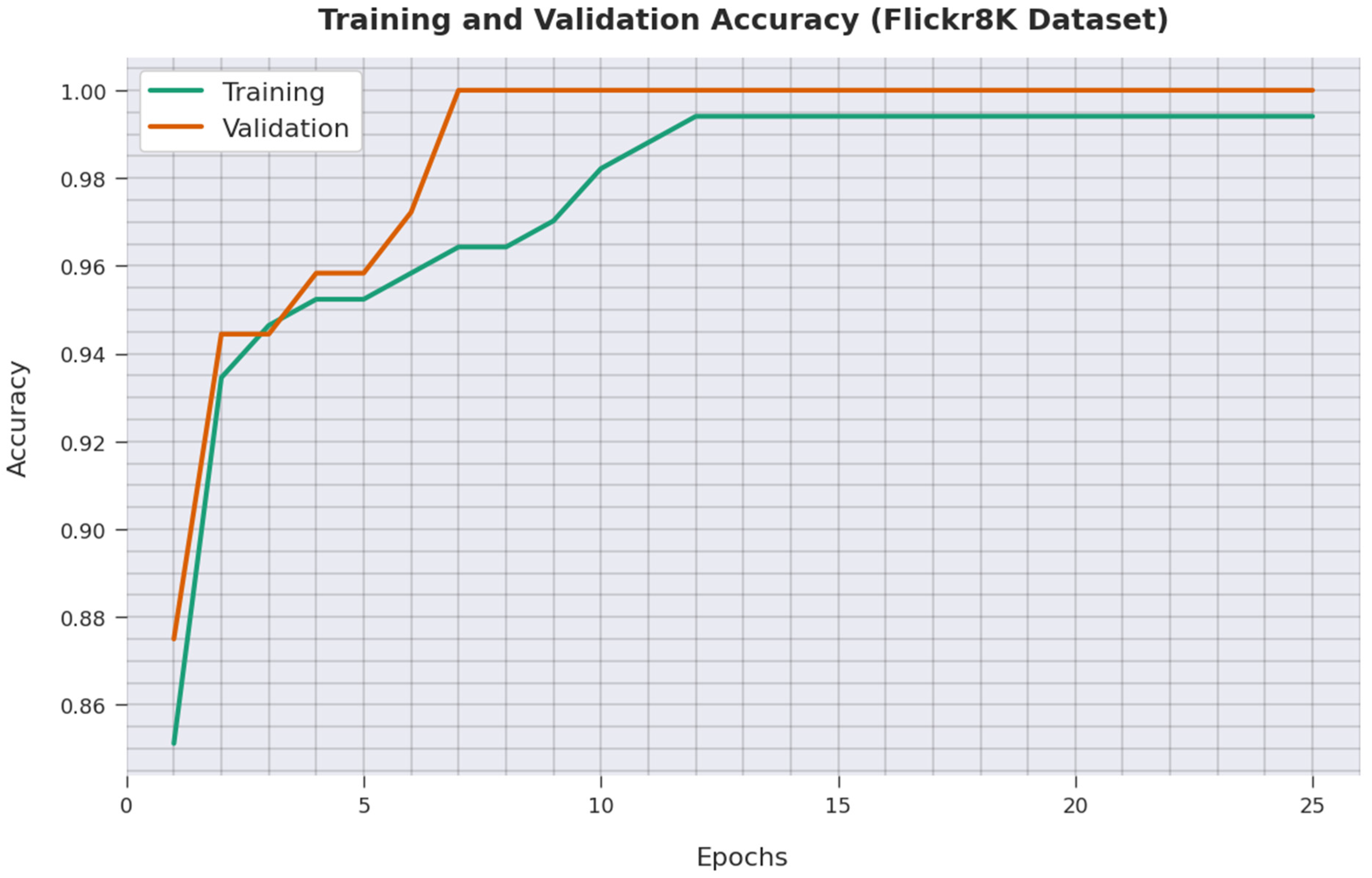
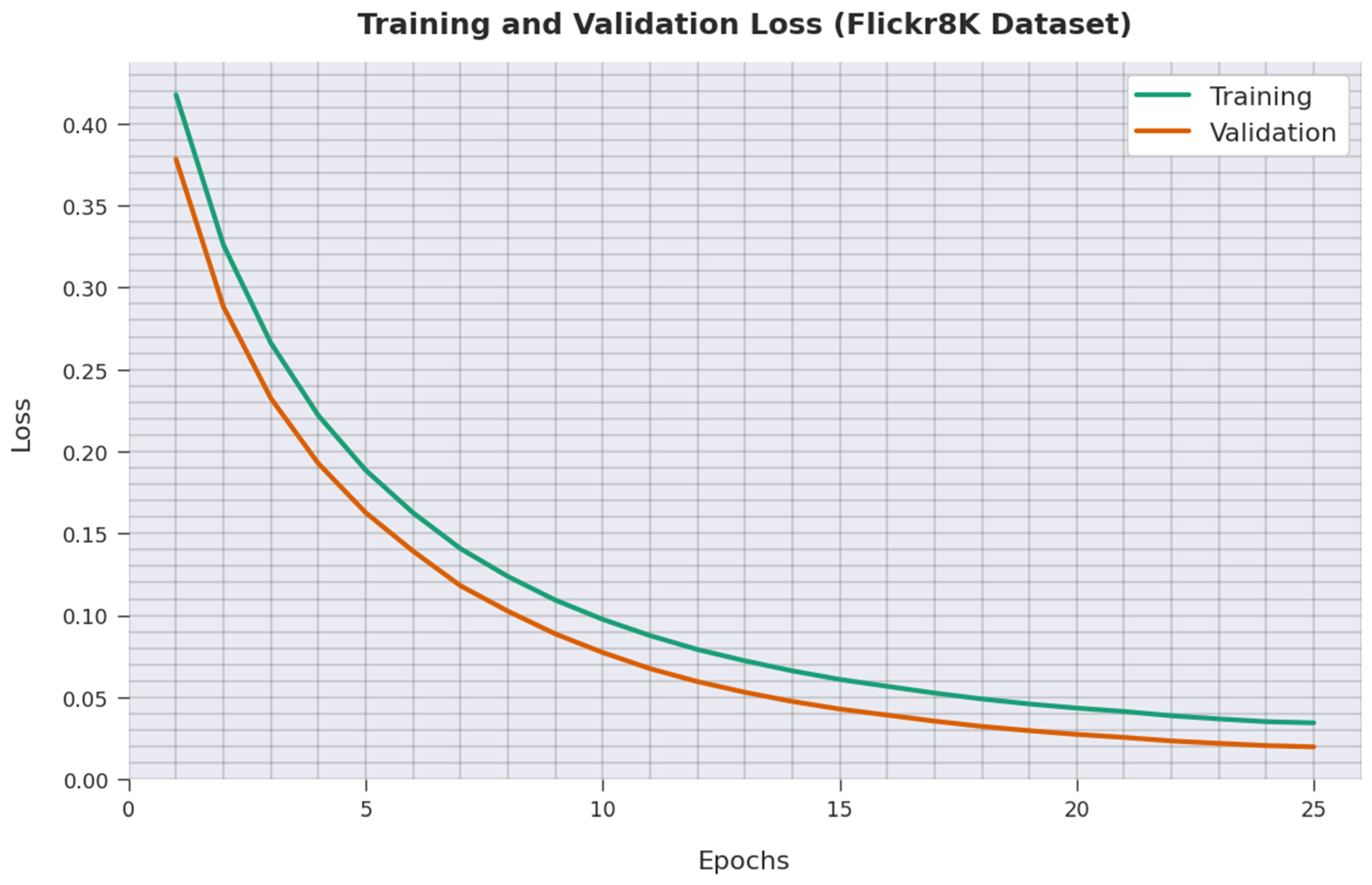
4. Performance Validation
4.1. Performance Measures
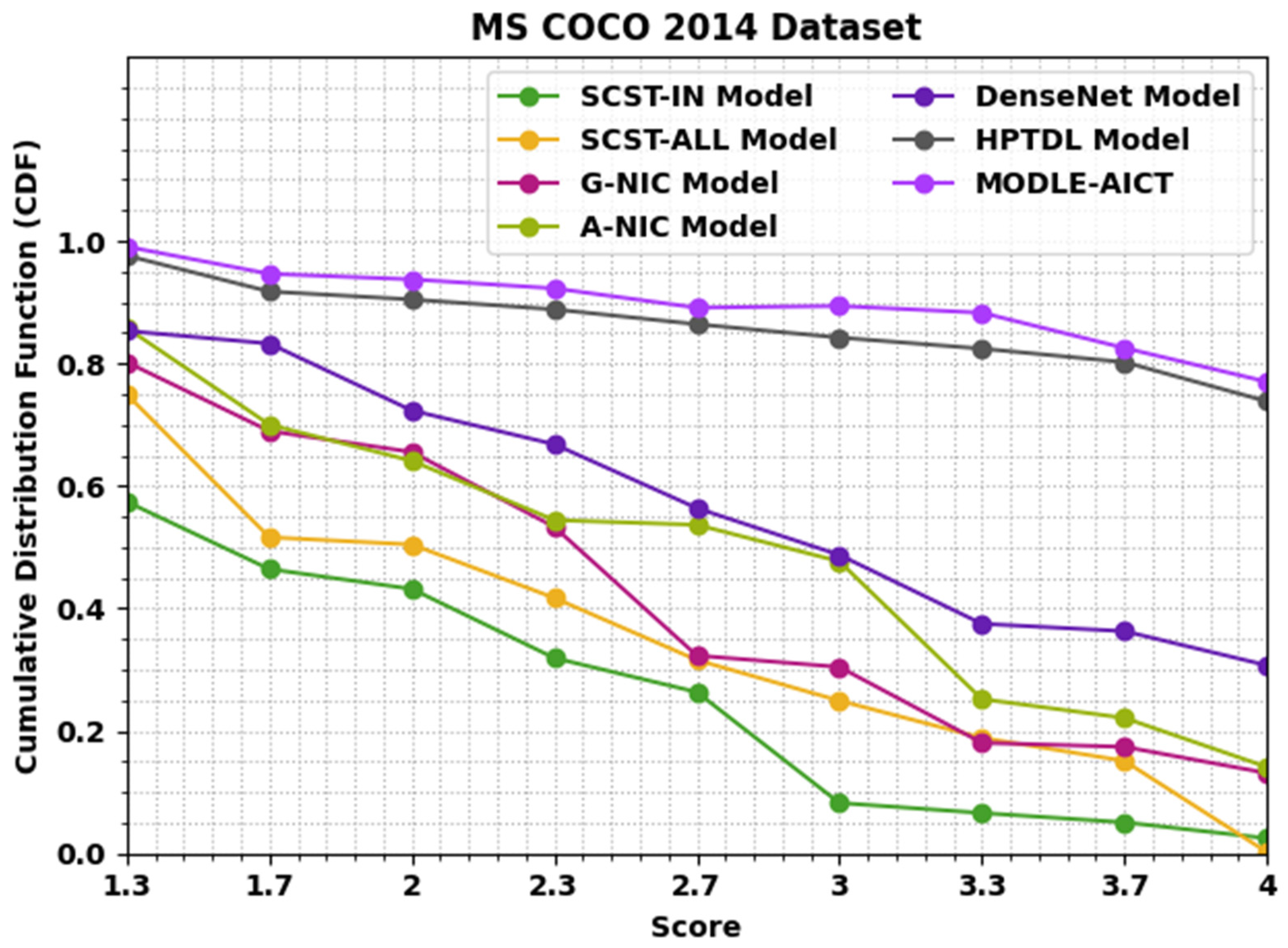
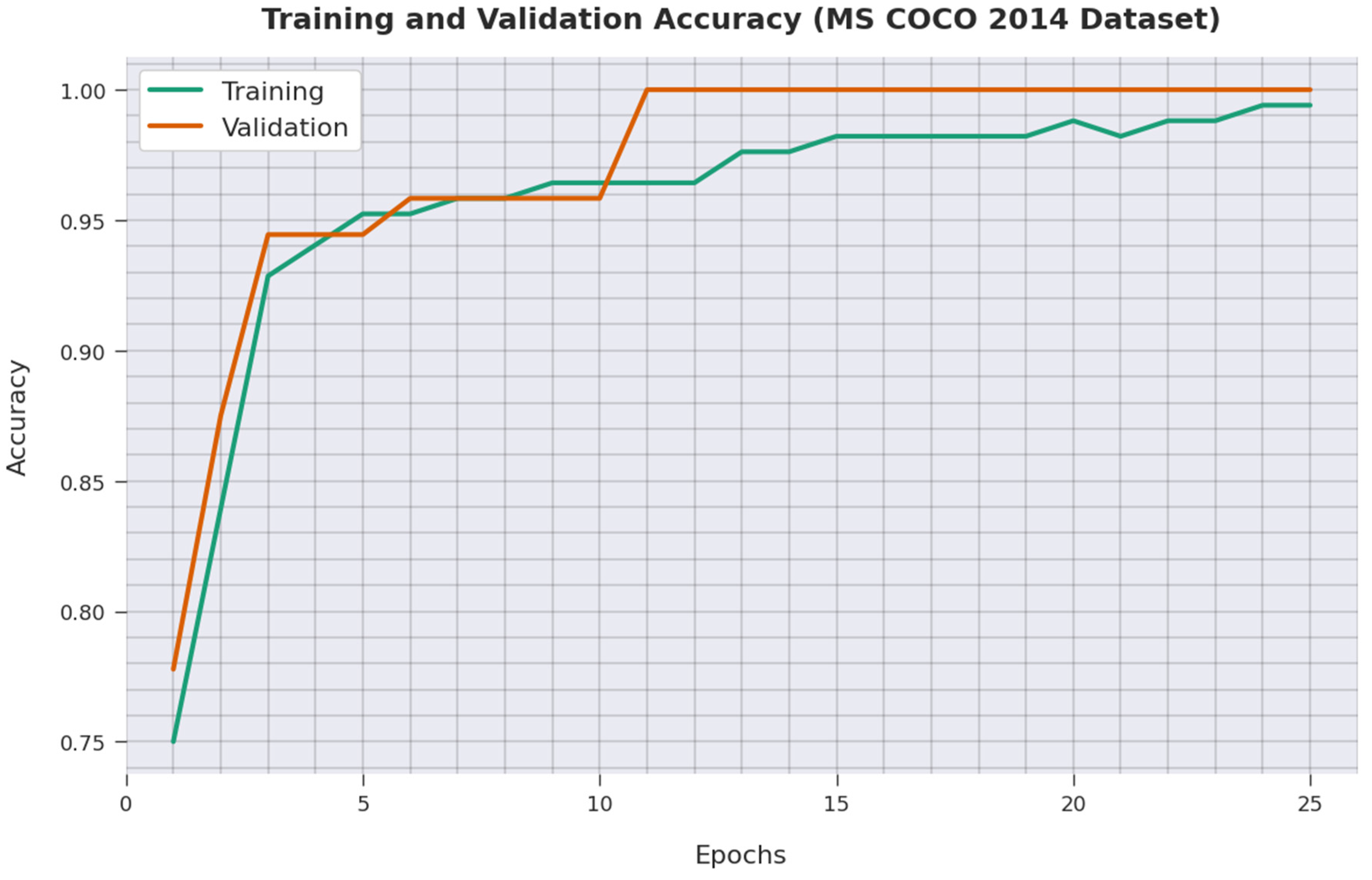
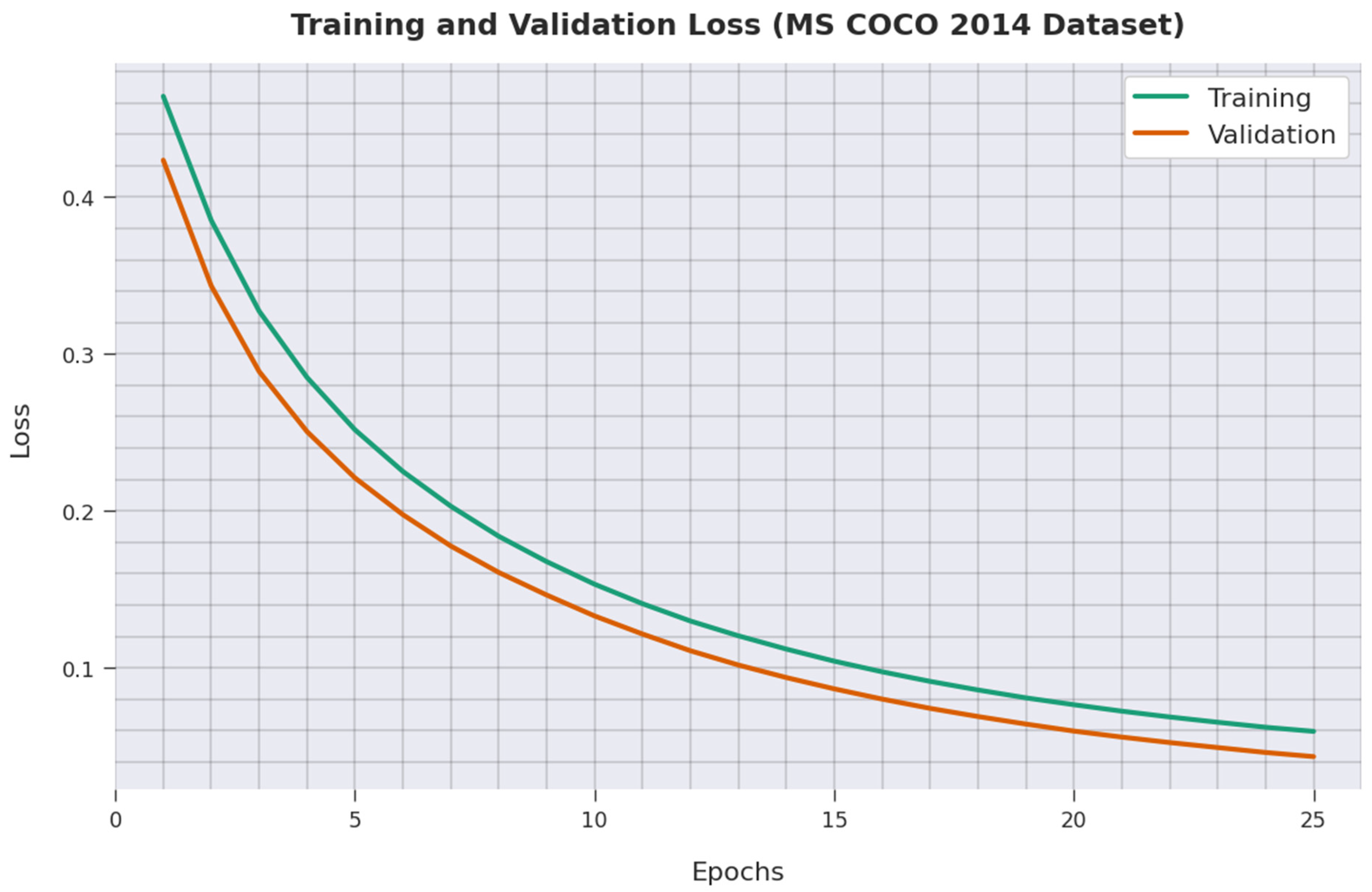
4.2. Result Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CsUR) 2019, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Sharma, H.; Agrahari, M.; Singh, S.K.; Firoj, M.; Mishra, R.K. Image captioning: A comprehensive survey. In Proceedings of the 2020 International Conference on Power Electronics & IoT Applications in Renewable Energy and its Control (PARC), Mathura, India, 28–29 February 2020; pp. 325–328.
- Stefanini, M.; Cornia, M.; Baraldi, L.; Cascianelli, S.; Fiameni, G.; Cucchiara, R. From show to tell: A survey on deep learning-based image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef] [PubMed]
- Oluwasammi, A.; Aftab, M.U.; Qin, Z.; Ngo, S.T.; Doan, T.V.; Nguyen, S.B.; Nguyen, S.H.; Nguyen, G.H. Features to text: A comprehensive survey of deep learning on semantic segmentation and image captioning. Complexity 2021, 2021, 5538927. [Google Scholar] [CrossRef]
- Wan, B.; Jiang, W.; Fang, Y.M.; Zhu, M.; Li, Q.; Liu, Y. Revisiting image captioning via maximum discrepancy competition. Pattern Recognit. 2022, 122, 108358. [Google Scholar] [CrossRef]
- Anwer, H.; Hadeel, A.; Fahd, N.; Mohamed, K.; Abdelwahed, M.; Ani, K.; Ishfaq, Y.; Abu Sarwar, Z. Fuzzy cognitive maps with bird swarm intelligence optimization-based remote sensing image classification. Comput. Intell. Neurosci. 2022, 2022, 4063354. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Abunadi, I.; Althobaiti, M.M.; Al-Wesabi, F.N.; Hilal, A.M.; Medani, M.; Hamza, M.A.; Rizwanullah, M.; Zamani, A.S. Federated learning with blockchain assisted image classification for clustered UAV networks. Comput. Mater. Contin. 2022, 72, 1195–1212. [Google Scholar] [CrossRef]
- Huang, W.; Wang, Q.; Li, X. Denoising-based multiscale feature fusion for remote sensing image captioning. IEEE Geosci. Remote Sens. Lett. 2020, 18, 436–440. [Google Scholar] [CrossRef]
- Chohan, M.; Khan, A.; Mahar, M.S.; Hassan, S.; Ghafoor, A.; Khan, M. Image captioning using deep learning: A systematic literature review. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- Xu, N.; Zhang, H.; Liu, A.A.; Nie, W.; Su, Y.; Nie, J.; Zhang, Y. Multi-level policy and reward-based deep reinforcement learning framework for image captioning. IEEE Trans. Multimed. 2019, 22, 1372–1383. [Google Scholar] [CrossRef]
- Lakshminarasimhan Srinivasan, D.S.; Amutha, A.L. Image captioning—A deep learning approach. Int. J. Appl. Eng. Res. 2018, 13, 7239–7242. [Google Scholar]
- Zhao, R.; Shi, Z.; Zou, Z. High-resolution remote sensing image captioning based on structured attention. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Hoxha, G.; Melgani, F.; Demir, B. Toward remote sensing image retrieval under a deep image captioning perspective. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4462–4475. [Google Scholar] [CrossRef]
- Wang, C.; Yang, H.; Meinel, C. Image captioning with deep bidirectional LSTMs and multi-task learning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–20. [Google Scholar] [CrossRef]
- Chang, Y.H.; Chen, Y.J.; Huang, R.H.; Yu, Y.T. Enhanced Image Captioning with Color Recognition Using Deep Learning Methods. Appl. Sci. 2021, 12, 209. [Google Scholar] [CrossRef]
- Xiong, Y.; Du, B.; Yan, P. Reinforced transformer for medical image captioning. In International Workshop on Machine Learning in Medical Imaging; Springer: Cham, Switzerland, 2019; pp. 673–680. [Google Scholar]
- Chen, T.; Li, Z.; Wu, J.; Ma, H.; Su, B. Improving image captioning with Pyramid Attention and SC-GAN. Image Vis. Comput. 2022, 117, 104340. [Google Scholar] [CrossRef]
- Al-Malla, M.A.; Jafar, A.; Ghneim, N. Image captioning model using attention and object features to mimic human image understanding. J. Big Data 2022, 9, 1–16. [Google Scholar] [CrossRef]
- Wang, S.; Ye, X.; Gu, Y.; Wang, J.; Meng, Y.; Tian, J.; Hou, B.; Jiao, L. Multi-label semantic feature fusion for remote sensing image captioning. ISPRS J. Photogramm. Remote Sens. 2022, 184, 1–18. [Google Scholar] [CrossRef]
- Robert, T.; Thome, N.; Cord, M. Hybridnet: Classification and reconstruction cooperation for semi-supervised learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 153–169. [Google Scholar]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Liu, J.; Yang, Y.; Lv, S.; Wang, J.; Chen, H. Attention-based BiGRU-CNN for Chinese question classification. J. Ambient. Intell. Humaniz. Comput. 2019, 1–12. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 MSCOCO image captioning challenge. IEEE Trans. Pattern Anal. Mach. Int. 2017, 39, 652–663. [Google Scholar] [CrossRef] [Green Version]
- Chu, Y.; Yue, X.; Yu, L.; Sergei, M.; Wang, Z. Automatic image captioning based on ResNet50 and LSTM with soft attention. Wireless Communications and Mobile Computing. Wirel. Commun. Mob. Comput. 2020, 2020, 8909458. [Google Scholar] [CrossRef]
- Wang, E.K.; Zhang, X.; Wang, F.; Wu, T.Y.; Chen, C.M. Multilayer dense attention model for image caption. IEEE Access 2019, 7, 66358–66368. [Google Scholar] [CrossRef]
- Omri, M.; Abdel-Khalek, S.; Khalil, E.M.; Bouslimi, J.; Joshi, G.P. Modeling of Hyperparameter Tuned Deep Learning Model for Automated Image Captioning. Mathematics 2022, 10, 288. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2–7. [Google Scholar]
- Mnih, A.; Hinton, G. Three new graphical models for statistical language modelling. In Proceedings of the ICML ’07.: 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 641–648. [Google Scholar]
- Karpathy, A.; Li, F. Deep Visual-Semantic Alignments for Generating Image Descriptions; Stanford University: Palo Alto, CA, USA, 2015. [Google Scholar]
- Bujimalla, S.; Subedar, M.; Tickoo, O. B-SCST: Bayesian self-critical sequence training for image captioning. arXiv 2020, arXiv:2004.02435. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Image | Different Captions |
|---|---|
 | A crowd watching air balloons at night |
| A group of hot air balloons lit up at night | |
| People are watching hot air balloons in the park | |
| People watching hot air balloons | |
| Seven large balloons are lined up at night-time near a crowd | |
 | A man climbs a rocky wall |
| A climber wearing a blue helmet and headlamp is attached to a rope on the rock face | |
| A rock climber climbs a large rock | |
| A woman in purple snakeskin pants climbs a rock | |
| Person with blue helmet and purple pants is rock climbing | |
 | People on ATVs and dirt bikes are traveling along a worn path in a field surrounded by trees |
| Three people are riding around on ATVs and motorcycles | |
| Three people on motorbikes follow a trail through dry grass | |
| Three people on two dirt bikes and one four-wheeler are riding through brown grass | |
| Three people ride off-road bikes through a field surrounded by trees |
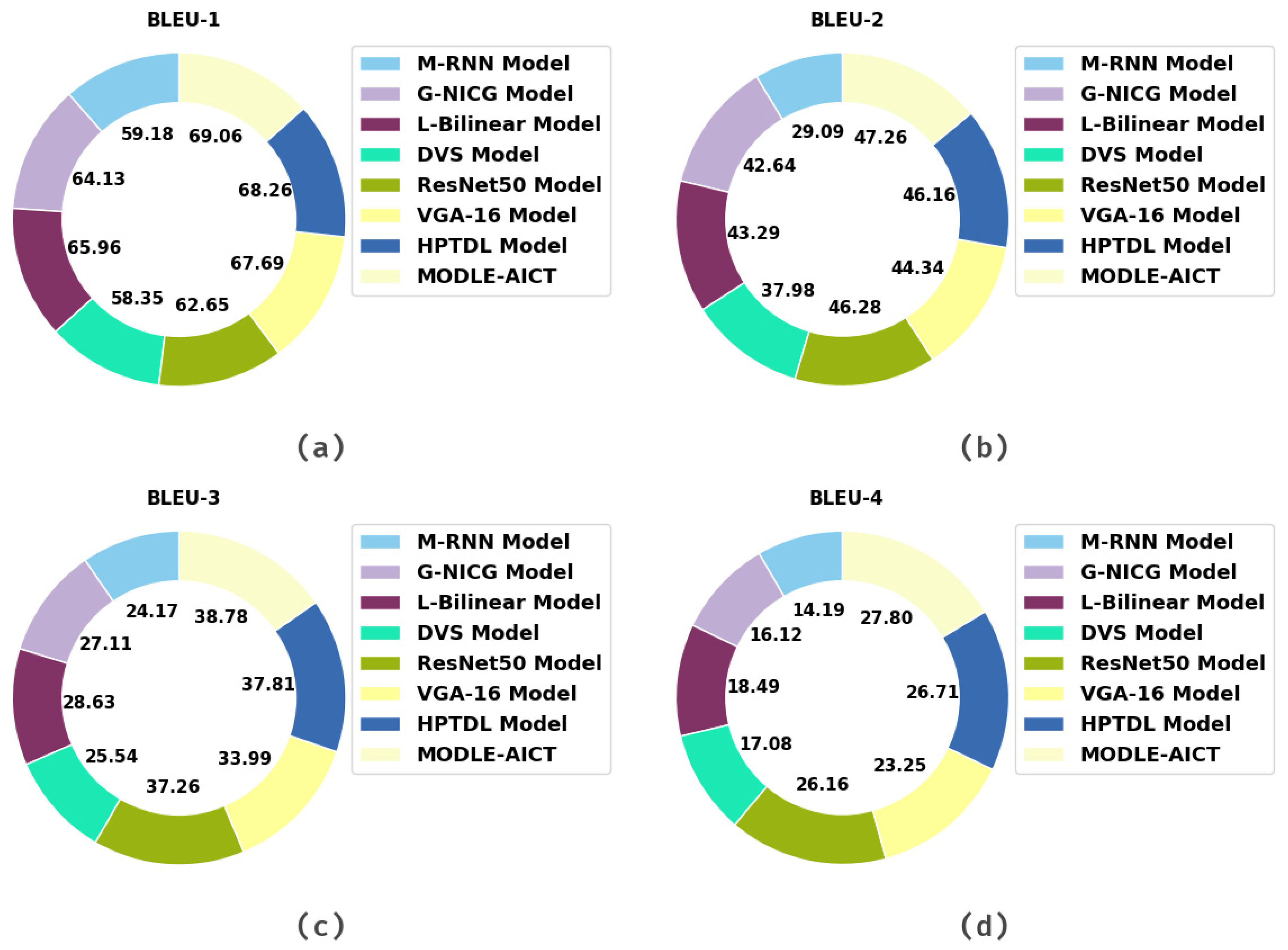
| Methods | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|---|
| M-RNN Model [24] | 59.18 | 29.09 | 24.17 | 14.19 |
| G-NICG Model [26] | 64.13 | 42.64 | 27.11 | 16.12 |
| L-Bilinear Model [27] | 65.96 | 43.29 | 28.63 | 18.49 |
| DVS Model [28] | 58.35 | 37.98 | 25.54 | 17.08 |
| ResNet50 Model [23] | 62.65 | 46.28 | 37.26 | 26.16 |
| VGA-16 Model [23] | 67.69 | 44.34 | 33.99 | 23.25 |
| HPTDL Model [25] | 68.26 | 46.16 | 37.81 | 26.71 |
| MODLE-AICT | 69.06 | 47.26 | 38.78 | 27.80 |
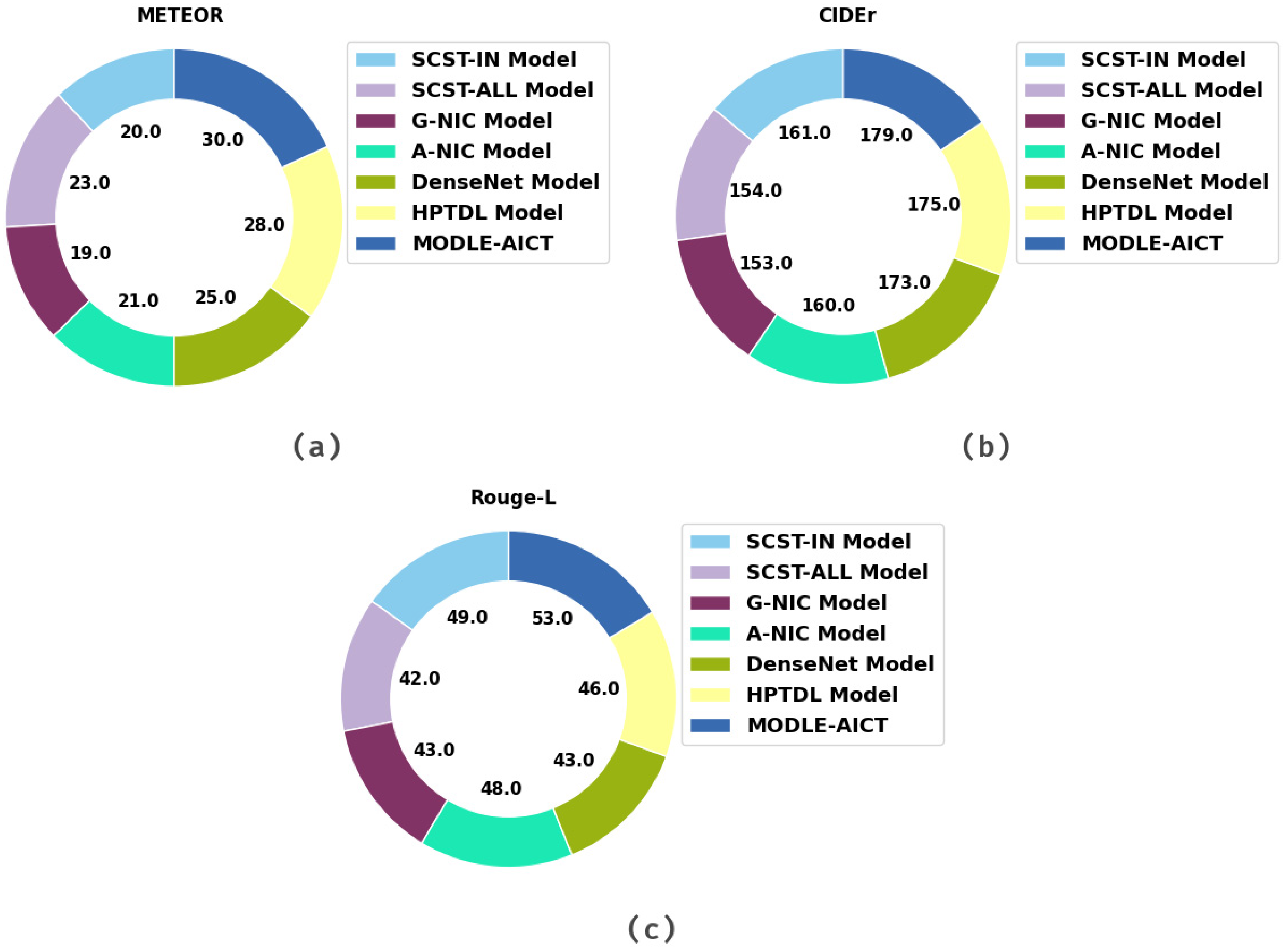
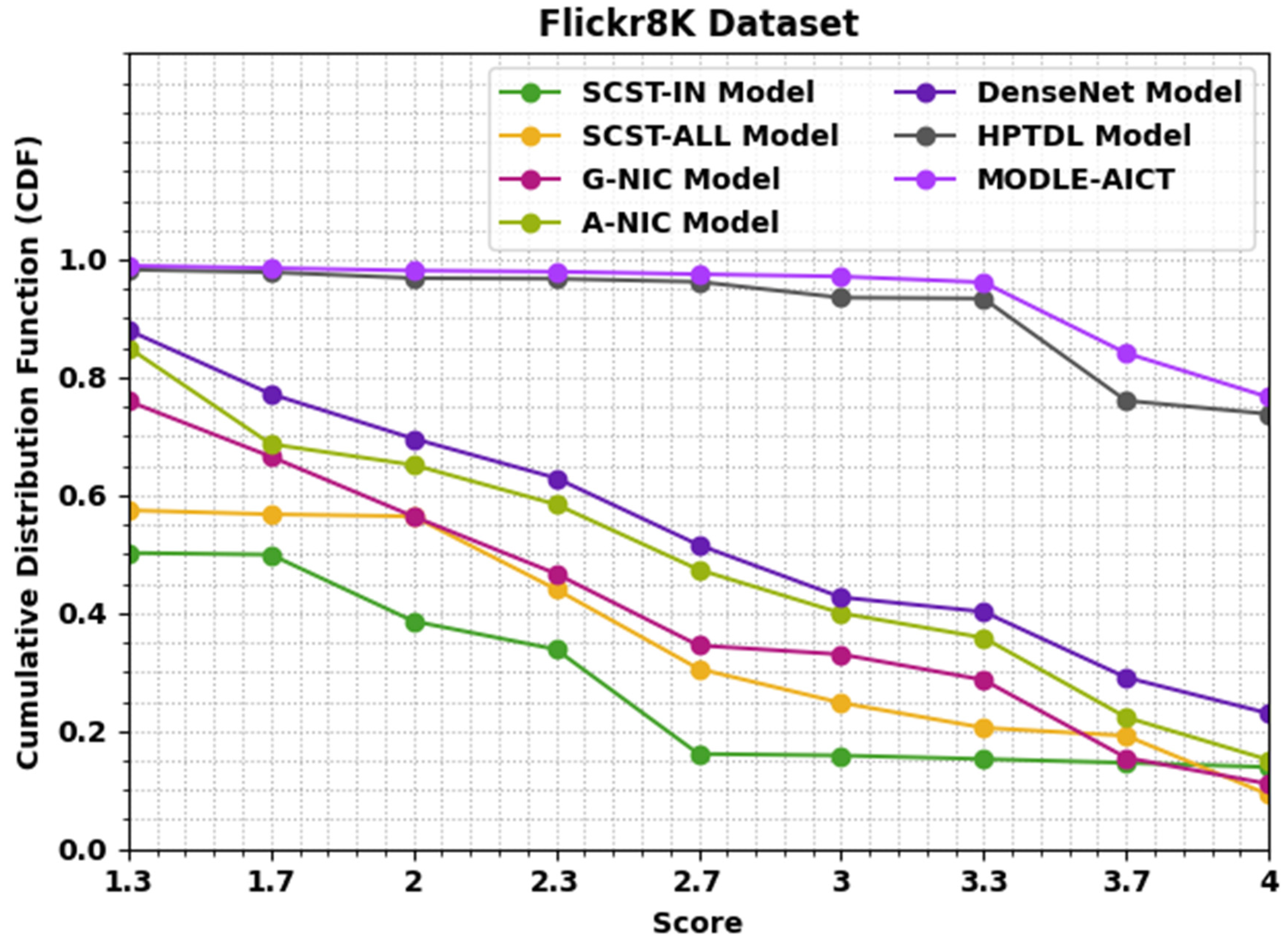
| Methods | METEOR | CIDEr | Rouge-L |
|---|---|---|---|
| SCST-IN Model [29] | 20.00 | 161.00 | 49.00 |
| SCST-ALL Model [29] | 23.00 | 154.00 | 42.00 |
| G-NIC Model [26] | 19.00 | 153.00 | 43.00 |
| A-NIC Model [26] | 21.00 | 160.00 | 48.00 |
| DenseNet Model [24] | 25.00 | 173.00 | 43.00 |
| HPTDL Model [25] | 28.00 | 175.00 | 46.00 |
| MODLE-AICT | 30.00 | 179.00 | 53.00 |
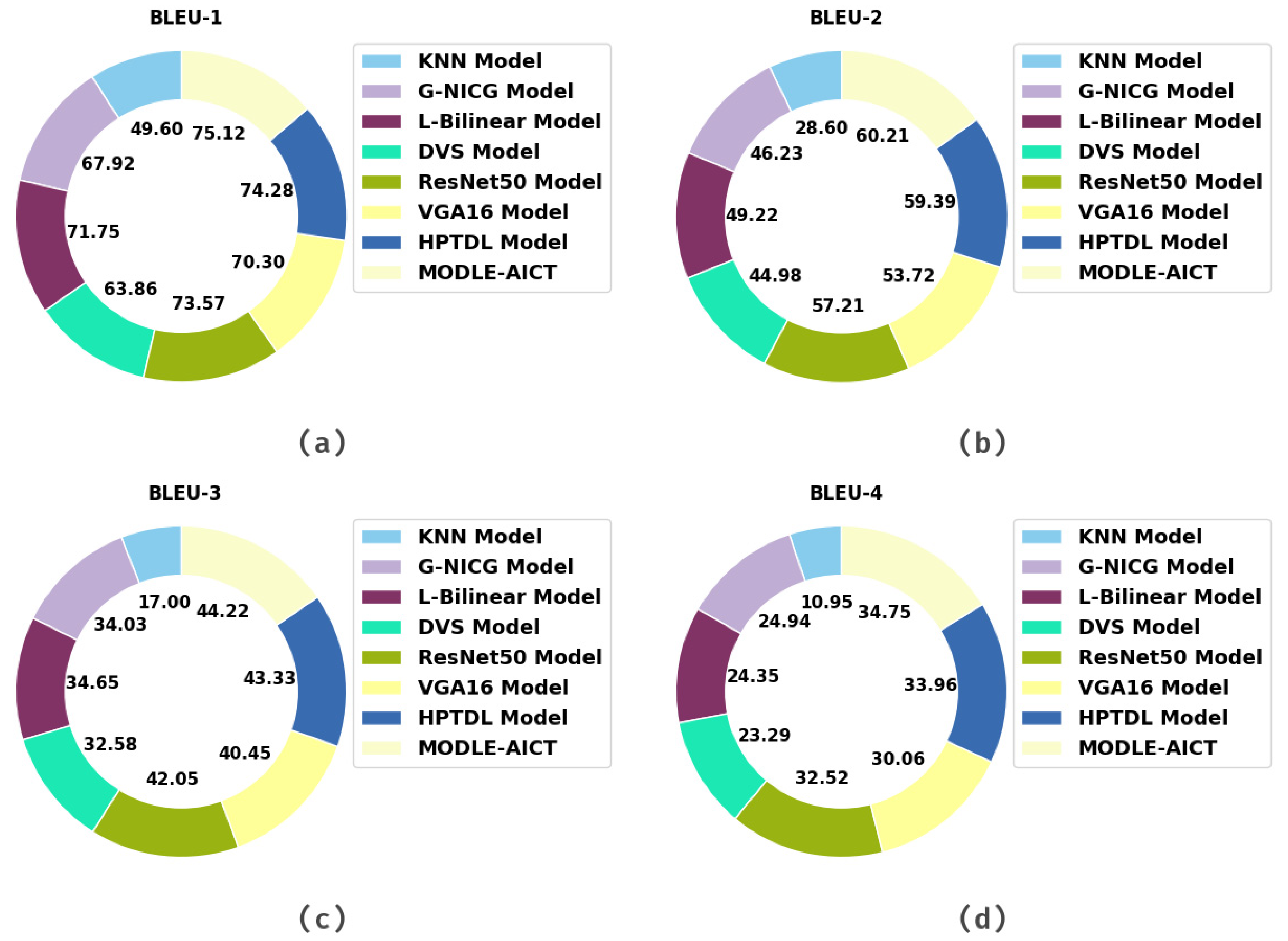
| Methods | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|---|
| KNN Model [25] | 49.60 | 28.60 | 17.00 | 10.95 |
| G-NICG Model [26] | 67.92 | 46.23 | 34.03 | 24.94 |
| L-Bilinear Model [27] | 71.75 | 49.22 | 34.65 | 24.35 |
| DVS Model [28] | 63.86 | 44.98 | 32.58 | 23.29 |
| ResNet50 Model [23] | 73.57 | 57.21 | 42.05 | 32.52 |
| VGA16 Model | 70.30 | 53.72 | 40.45 | 30.06 |
| VGA-16 Model [23] | 74.28 | 59.39 | 43.33 | 33.96 |
| HPTDL Model [25] | 75.12 | 60.21 | 44.22 | 34.75 |
| Methods | METEOR | CIDEr | Rouge-L |
|---|---|---|---|
| SCST-IN Model [29] | 22.00 | 109.00 | 51.00 |
| SCST-ALL Model [29] | 25.00 | 114.00 | 59.00 |
| G-NIC Model [26] | 21.00 | 111.00 | 51.00 |
| A-NIC Model [26] | 24.00 | 110.00 | 58.00 |
| DenseNet Model [24] | 24.00 | 122.00 | 57.00 |
| HPTDL Model [25] | 34.00 | 125.00 | 60.00 |
| MODLE-AICT | 37.00 | 129.00 | 63.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Duhayyim, M.; Alazwari, S.; Mengash, H.A.; Marzouk, R.; Alzahrani, J.S.; Mahgoub, H.; Althukair, F.; Salama, A.S. Metaheuristics Optimization with Deep Learning Enabled Automated Image Captioning System. Appl. Sci. 2022, 12, 7724. https://doi.org/10.3390/app12157724
Al Duhayyim M, Alazwari S, Mengash HA, Marzouk R, Alzahrani JS, Mahgoub H, Althukair F, Salama AS. Metaheuristics Optimization with Deep Learning Enabled Automated Image Captioning System. Applied Sciences. 2022; 12(15):7724. https://doi.org/10.3390/app12157724
Chicago/Turabian StyleAl Duhayyim, Mesfer, Sana Alazwari, Hanan Abdullah Mengash, Radwa Marzouk, Jaber S. Alzahrani, Hany Mahgoub, Fahd Althukair, and Ahmed S. Salama. 2022. "Metaheuristics Optimization with Deep Learning Enabled Automated Image Captioning System" Applied Sciences 12, no. 15: 7724. https://doi.org/10.3390/app12157724