
Dual-Modal Transformer with Enhanced Inter- and Intra-Modality Interactions for Image Captioning



Abstract
:
1. Introduction
2. Background
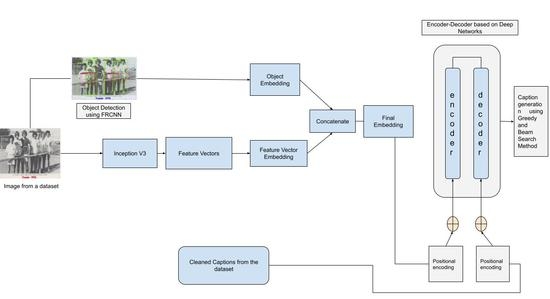
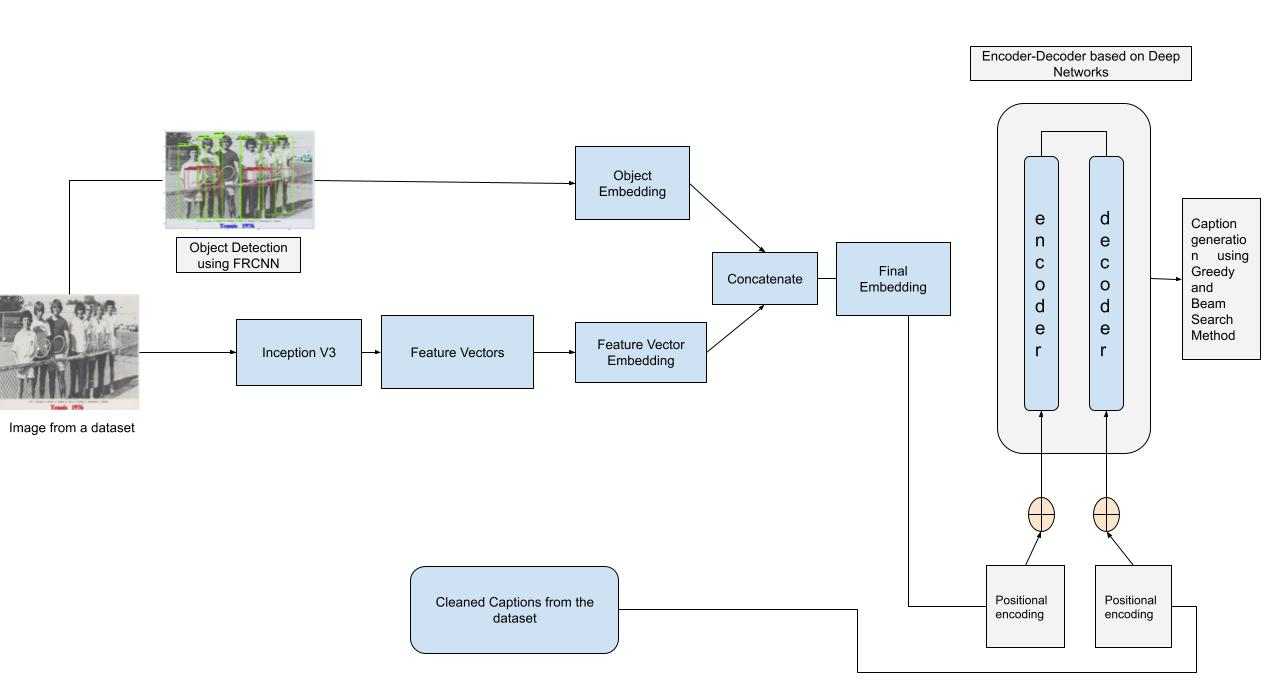
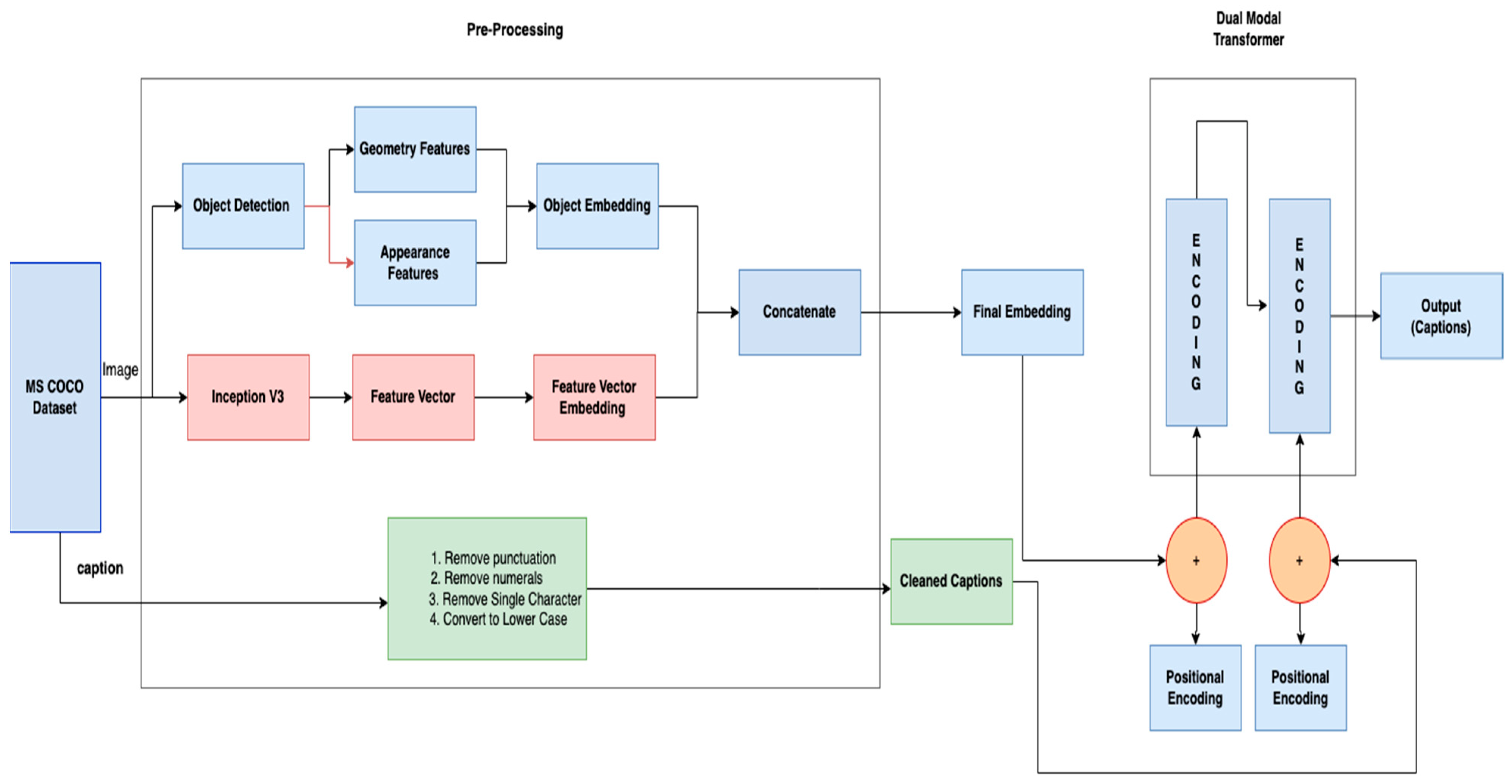
3. Proposed Methodology
3.1. Dataset Description
3.2. Pre-Processing
3.2.1. Feature Vector Based on Convolutional Neural Network (CNN)
3.2.2. Object Detection
3.2.3. Data Cleaning
3.3. Positional Encoding
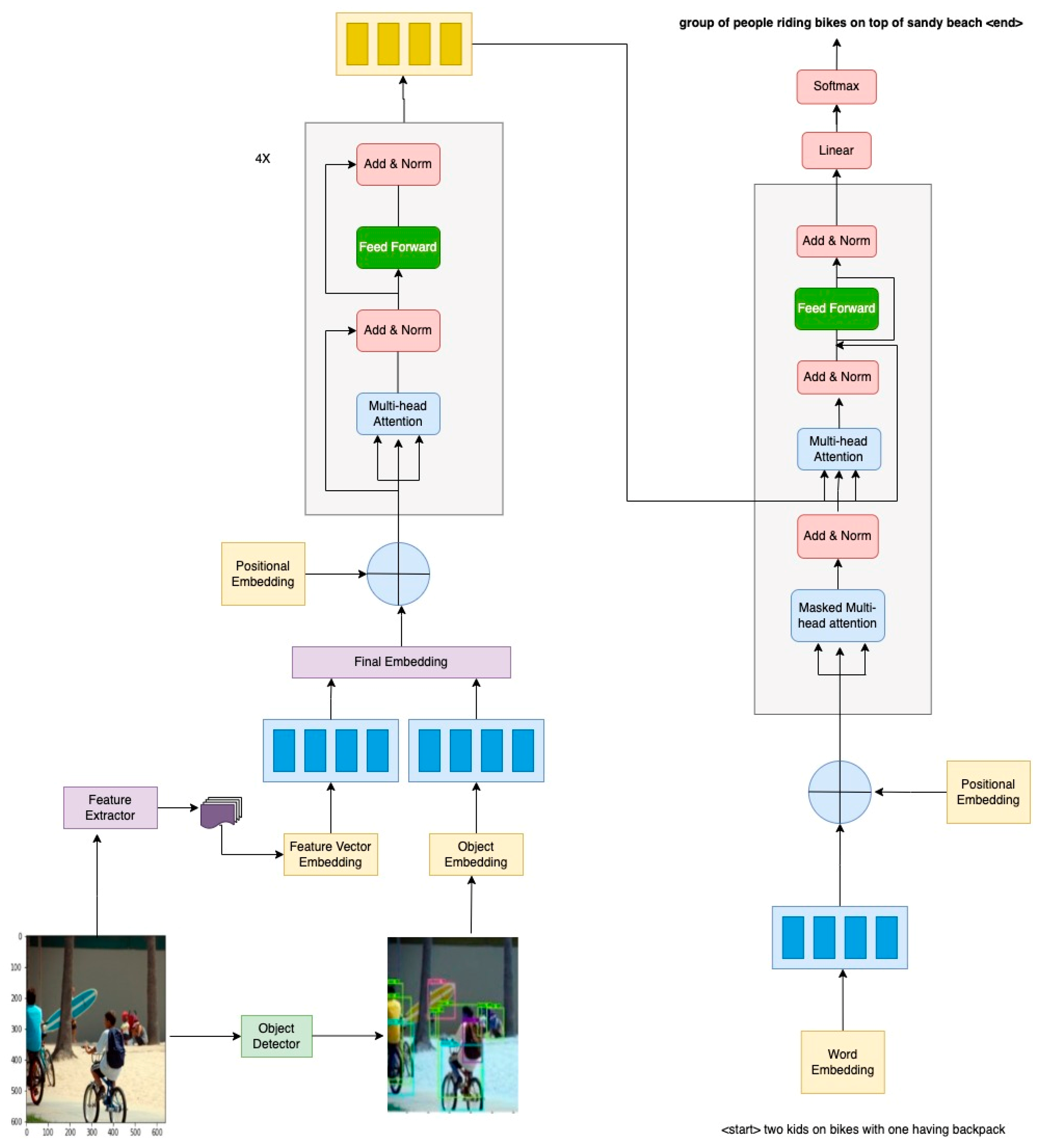
3.4. Dual-Modal Transformer
3.4.1. Multi-head Attention Layer
3.4.2. Encoder
3.4.3. Decoder
4. Results and Analysis
4.1. Greedy Search
4.2. Beam Search
4.3. Comparative Analysis
4.3.1. Attention Model
4.3.2. Encoder–Decoder Model
4.3.3. Analysis using State-of-the-Art Methods
4.3.4. Ablation Study
5. Conclusions and Future Scope
Author Contributions
Funding
Conflicts of Interest
References
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CsUR) 2019, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Universal image-text representation learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 104–120. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Yang, J.; Sun, Y.; Liang, J.; Ren, B.; Lai, S.H. Image captioning by incorporating affective concepts learned from both visual and textual components. Neurocomputing 2019, 328, 56–68. [Google Scholar] [CrossRef]
- Yu, J.; Li, J.; Yu, Z.; Huang, Q. Multimodal transformer with multi-view visual representation for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4467–4480. [Google Scholar] [CrossRef] [Green Version]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Karpathy, A.; Joulin, A.; Fei-Fei, L.F. Deep fragment embeddings for bidirectional image sentence mapping. Adv. Neural Inf. Processing Syst. 2014, 27, 1–9. [Google Scholar]
- Li, G.; Zhu, L.; Liu, P.; Yang, Y. Entangled transformer for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8928–8937. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2692–2700. [Google Scholar]
- Wang, J.; Xu, W.; Wang, Q.; Chan, A.B. Compare and reweight: Distinctive image captioning using similar images sets. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 370–386. [Google Scholar]
- Yeh, R.; Xiong, J.; Hwu, W.M.; Do, M.; Schwing, A. Interpretable and globally optimal prediction for textual grounding using image concepts. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Amirian, S.; Rasheed, K.; Taha, T.R.; Arabnia, H.R. A short review on image caption generation with deep learning. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV), Las Vegas, NV, USA, 29 July–1 August 2019; pp. 10–18. [Google Scholar]
- Chohan, M.; Khan, A.; Mahar, M.S.; Hassan, S.; Ghafoor, A.; Khan, M. Image Captioning using Deep Learning: A Systematic. Image 2020, 278–286. [Google Scholar]
- Nithya, K.C.; Kumar, V.V. A Review on Automatic Image Captioning Techniques. In Proceedings of the 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 28–30 July 2020; pp. 0432–0437. [Google Scholar]
- Aggarwal, A.; Chauhan, A.; Kumar, D.; Mittal, M.; Roy, S.; Kim, T.H. Video caption based searching using end-to-end dense captioning and sentence embeddings. Symmetry 2020, 12, 992. [Google Scholar] [CrossRef]
- Al-Muzaini, H.A.; Al-Yahya, T.N.; Benhidour, H. Automatic arabic image captioning using RNN-LSTM-based language model and CNN. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 67–73. [Google Scholar] [CrossRef]
- Herdade, S.; Kappeler, A.; Boakye, K.; Soares, J. Image captioning: Transforming objects into words. Adv. Neural Inf. Process. Syst. 2019, 1–11. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10578–10587. [Google Scholar]
- Fei, Z. Attention-Aligned Transformer for Image Captioning. In Proceedings of the Association for the advancements of Artificial Intelligence, Virtual, 22 Februrary–1 March 2022. [Google Scholar]
- Yan, S.; Xie, Y.; Wu, F.; Smith, J.S.; Lu, W.; Zhang, B. Image captioning via hierarchical attention mechanism and policy gradient optimization. Signal Process. 2020, 167, 107329. [Google Scholar] [CrossRef]
- Chen, Z.; Huang, S.; Tao, D. Context refinement for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 71–86. [Google Scholar]
- Ng, E.G.; Pang, B.; Sharma, P.; Soricut, R. Understanding Guided Image Captioning Performance across Domains. arXiv 2020, arXiv:2012.02339. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Atliha, V.; Šešok, D. Comparison of VGG and ResNet used as Encoders for Image Captioning. In Proceedings of the 2020 IEEE Open Conference of Electrical, Electronic and Information Sciences (ESTREAM), Vilnius, Lithuania, 30 April 2020; pp. 1–4. [Google Scholar]
- Zhou, L.; Xu, C.; Koch, P.; Corso, J.J. Watch what you just said: Image captioning with text-conditional attention. In Proceedings of the on Thematic Workshops of ACM Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 305–313. [Google Scholar]
- Iwamura, K.; Louhi Kasahara, J.Y.; Moro, A.; Yamashita, A.; Asama, H. Image Captioning Using Motion-CNN with Object Detection. Sensors 2021, 21, 1270. [Google Scholar] [CrossRef] [PubMed]
- Aneja, J.; Deshpande, A.; Schwing, A.G. Convolutional image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5561–5570. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Ji, J.; Luo, Y.; Sun, X.; Chen, F.; Luo, G.; Wu, Y.; Gao, Y.; Ji, R. Improving image captioning by leveraging intra-and inter-layer global representation in transformer network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1655–1663. [Google Scholar]
- Deshpande, A.; Aneja, J.; Wang, L.; Schwing, A.G.; Forsyth, D. Fast, diverse and accurate image captioning guided by part-of-speech. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10695–10704. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Guided open vocabulary image captioning with constrained beam search. arXiv 2016, arXiv:1612.00576. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Chintala, S. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Shukla, N.; Fricklas, K. Machine Learning with TensorFlow; Manning: Greenwich, UK, 2018. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Gao, Y.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Yang, Z.; Zhang, Y.J.; Huang, Y. Image captioning with object detection and localization. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; Springer: Cham, Switzerland, 2017; pp. 109–118. [Google Scholar]
- Parameswaran, S.N.; Das, S. A Bottom-Up and Top-Down Approach for Image Captioning using Transformer. In Proceedings of the 11th Indian Conference on Computer Vision, Graphics and Image Processing, Hyderabad, India, 18–22 December 2018; pp. 1–9. [Google Scholar]
- Luo, Y.; Ji, J.; Sun, X.; Cao, L.; Wu, Y.; Huang, F.; Gao, Y.; Ji, R. Dual-level collaborative transformer for image captioning. arXiv 2021, arXiv:2101.06462. [Google Scholar]
- Jiang, W.; Ma, L.; Jiang, Y.G.; Liu, W.; Zhang, T. Recurrent fusion network for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 499–515. [Google Scholar]
- Melas-Kyriazi, L.; Rush, A.M.; Han, G. Training for diversity in image paragraph captioning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 757–761. [Google Scholar]
- Ranzato, M.A.; Chopra, S.; Auli, M.; Zaremba, W. Sequence level training with recurrent neural networks. arXiv 2015, arXiv:1511.06732. [Google Scholar]
- Biswas, R.; Barz, M.; Sonntag, D. Towards explanatory interactive image captioning using top-down and bottom-up features, beam search and re-ranking. KI-KünstlicheIntelligenz 2020, 34, 571–584. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Chen, H.; Ding, G.; Lin, Z.; Zhao, S.; Han, J. Show, Observe and Tell: Attribute-driven Attention Model for Image Captioning. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 606–612. [Google Scholar]
- Xiao, X.; Wang, L.; Ding, K.; Xiang, S.; Pan, C. Deep hierarchical encoder–decoder network for image captioning. IEEE Trans. Multimed. 2019, 21, 2942–2956. [Google Scholar] [CrossRef]
- Yang, Z.; Yuan, Y.; Wu, Y.; Cohen, W.W.; Salakhutdinov, R.R. Review networks for caption generation. Adv. Neural Inf. Processing Syst. 2016, 1–9. [Google Scholar]
- Liu, W.; Chen, S.; Guo, L.; Zhu, X.; Liu, J. Cptr: Full transformer network for image captioning. arXiv 2021, arXiv:2101.10804. [Google Scholar]
- He, S.; Liao, W.; Tavakoli, H.R.; Yang, M.; Rosenhahn, B.; Pugeault, N. Image captioning through image transformer. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Song, Z.; Zhou, X.; Mao, Z.; Tan, J. Image captioning with context-aware auxiliary guidance. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2584–2592. [Google Scholar]
- Osolo, R.I.; Yang, Z.; Long, J. An Attentive Fourier-Augmented Image-Captioning Transformer. Appl. Sci. 2021, 11, 8354. [Google Scholar] [CrossRef]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. Available online: https://aclanthology.org/W04-10 (accessed on 27 April 2022).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 | A giraffe standing next to a log in a fenced-in enclosure with people walking on the other side of the fence. A giraffe stretching its head over a log to eat weeds. A giraffe eating grasses in a wooded area. A giraffe in its zoo enclosure bending over to eat. A giraffe grazing in the grass next to rocks and trees. |
 | A couple of young men riding bikes down a street. A kid wearing a backpack rides his bike near a beach. A couple of people are riding bicycles on the beach. A young man riding his bike through the park. Two kids on bikes with one having a backpack. |
 | Porcelain sink with a white decorated bathroom and blue accents. A bathroom sink with flowers and soap on the counter. A clean bathroom is seen in this image. A clean bathroom vanity artistically displays flowers, soap and a hand towel. There is a white sink in the bathroom. |
 | Seven guys holding tennis rackets and standing on a tennis court. Seven guys are standing next to the net with their tennis rackets. Some guys line up at the net with their rackets. A picture of some tennis players playing tennis. Some guys holding the tennis racket. |
| Flickr 8k | Flickr 30k | MS COCO |
|---|---|---|
 |  |  |
| Real Caption: woman in blue tank top and shorts is jogging down an asphalt road. | Real Caption: football game in progress | Real Caption: two kids on bikes with one having backpack |
| Greedy Caption: woman jogging up hill | Greedy Caption: two men in white shirts try to tackle player of football players against the team | Greedy Caption: couple of people riding bikes on beach |
| Beam Search (k = 3) Caption: woman in purple shirt and blue shorts is jogging on the path near a mountain | Beam Search (k = 3) Caption: two football players are wearing red and white jerseys. | Beam Search (k = 3) Caption: a group of people riding bikes on top of beach |
| Beam Search (k = 5) Caption: the woman is wearing purple shirt and blue shorts and jogging on the road in the middle of the dry day | Beam Search (k = 5) Caption: two football players talk during a football game | Beam Search (k = 5) Caption: group of people riding bikes on a top of sandy beach |
 |  |  |
| Real Caption: snowboarder flies through the air | Real Caption: here is rod stewart in concert singing live with pat benatar | Real Caption: giraffe grazing in the grass next to rocks and trees |
| Greedy Caption: snowboarder is jumping in the air after a jump | Greedy Caption: two people are playing the guitars and other people are singing on stage | Greedy Caption: giraffe standing on a dirt road next to trees |
| Beam Search (k = 3) Caption: the snowboarder is jumping through the air after jumping of the snow-covered mountain jump | Beam Search (k = 3) Caption: a group of people are playing music on stage | Beam Search (k = 3) Caption: there are two giraffes that are standing in the grass |
| Beam Search (k = 5) Caption: the snowboarder is jumping through the air on their snowboard in front of the ski jump | Beam Search (k = 5) Caption: a group of people are playing musical instruments in what appears to be church | Beam Search (k = 5) Caption: close up view of very pretty giraffes in wooded area |
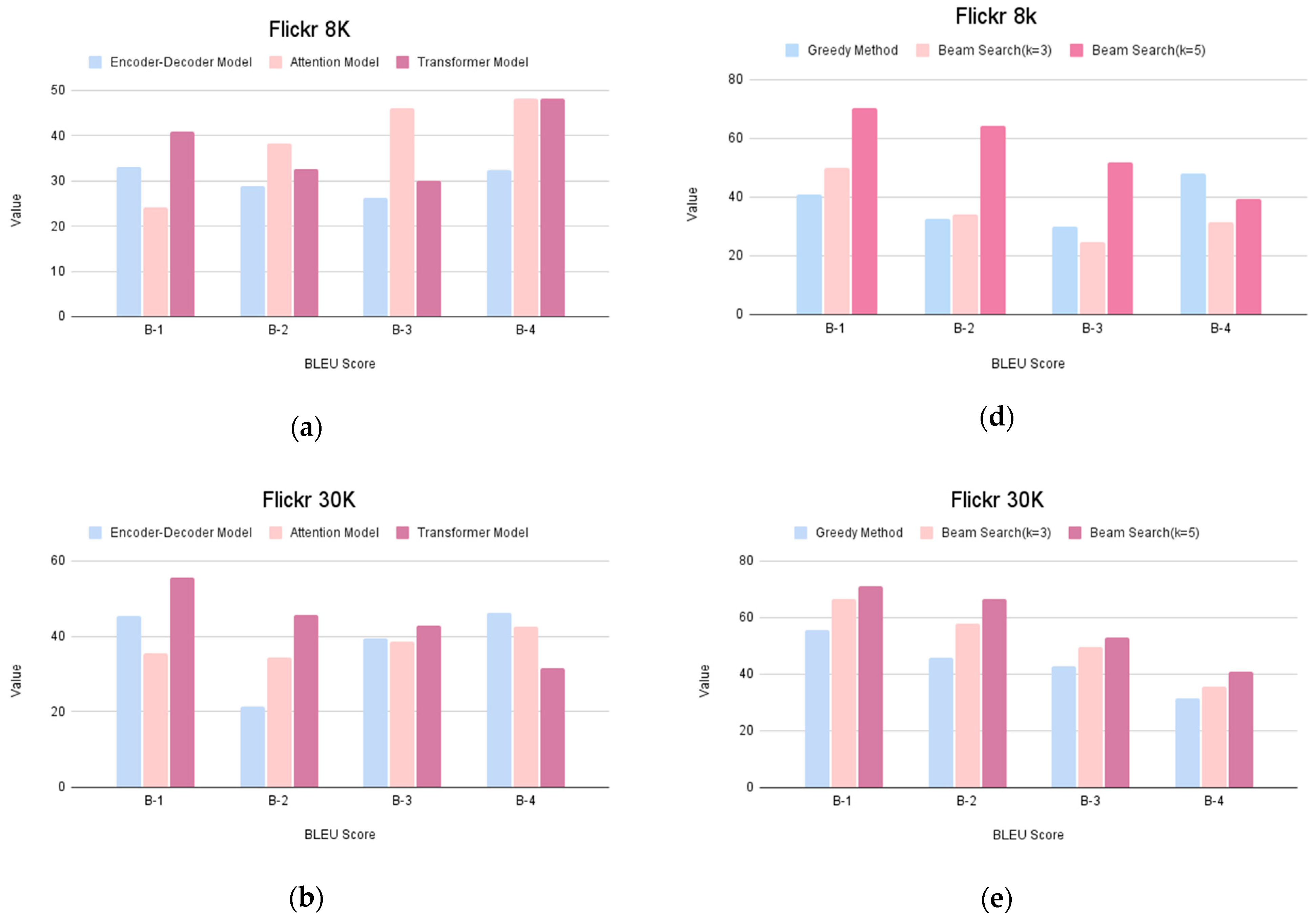
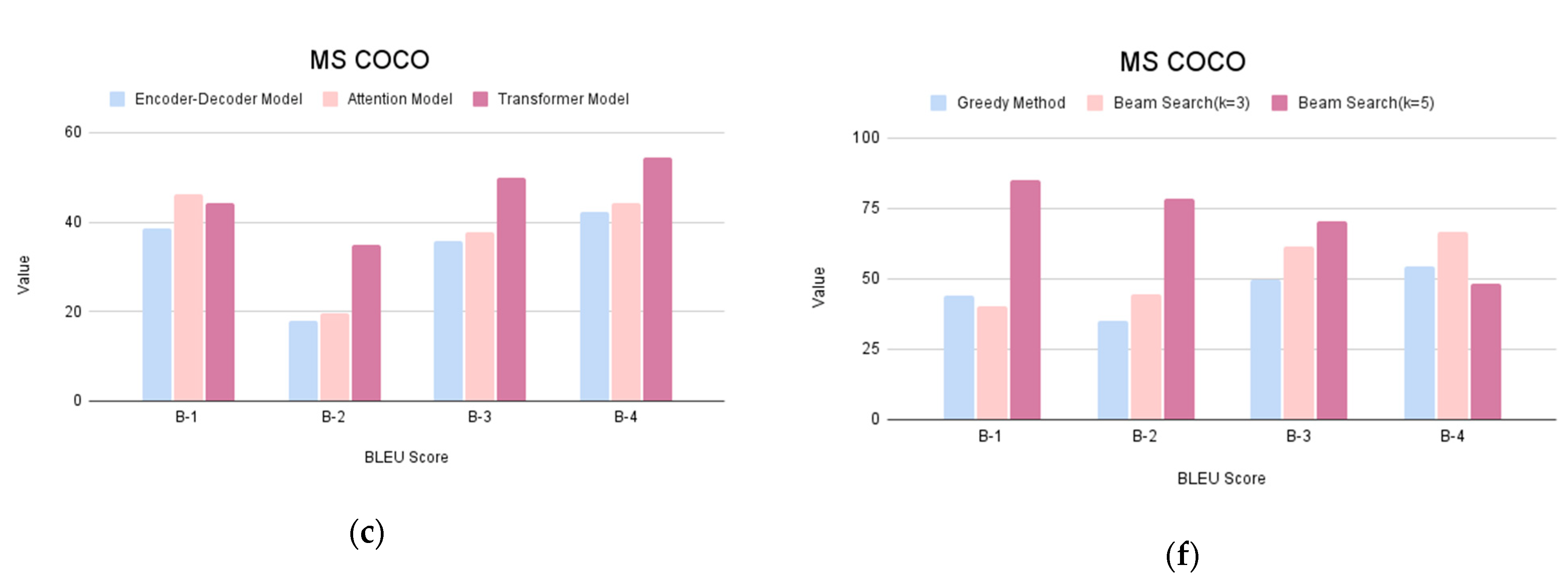
| Dataset | Greedy Caption | Beam Search (k = 3) | Beam Search (k = 5) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B-1 | B-2 | B-3 | B-4 | B-1 | B-2 | B-3 | B-4 | B-1 | B-2 | B-3 | B-4 | |
| Flickr 8k | 40.76 | 32.64 | 29.97 | 48.13 | 50.00 | 33.96 | 24.82 | 31.31 | 70.47 | 64.23 | 51.92 | 39.22 |
| Flickr 30k | 55.55 | 45.64 | 42.89 | 31.55 | 66.66 | 57.73 | 49.39 | 35.49 | 71.11 | 66.69 | 53.12 | 41.03 |
| MS COCO | 44.12 | 34.96 | 49.76 | 54.50 | 40.30 | 44.72 | 61.70 | 66.87 | 85.01 | 78.37 | 70.34 | 48.33 |
| Flickr 8k | Flickr 30k | MS COCO |
|---|---|---|
 |  |  |
| Real Caption: woman in black is sitting next to a man wearing glasses in the coffee shop | Real Caption: woman wearing the striped shirt is looking at mannequin holding up a necklace in a store window | Real Caption: porcelain sink with a white decorated bathroom and blue accents |
| Predicted Caption: man and woman are sitting down and having to drink | Predicted Caption: woman in a black tank top is holding the cup | Predicted Caption: a couple of a sink and a white towel under a stove |
| Flickr 8k | Flickr 30k | MS COCO |
|---|---|---|
 |  |  |
| Real Caption: dog chases ball that has dropped in the water | Real Caption: a young girl in a blue dress is walking on the beach. | Real Caption: a few people riding skissnow-covered snow covered slope |
| Predicted Caption: two dogs look at something in the water | Predicted Caption: a young boy in a blue shirt is walking on the beach | Predicted Caption: a man standing on top of a snow-covered slope |
| Model | Dataset | B-1 | B-2 | B-3 | B-4 |
|---|---|---|---|---|---|
| Encoder–Decoder Model | Flickr 8k | 33.09 | 28.88 | 26.37 | 32.36 |
| Flickr 30k | 45.45 | 21.32 | 39.56 | 46.17 | |
| MS COCO | 38.46 | 17.90 | 35.62 | 42.31 | |
| Attention Model | Flickr 8k | 24.26 | 38.36 | 46.07 | 48.23 |
| Flickr 30k | 35.52 | 34.24 | 38.51 | 42.66 | |
| MS COCO | 46.15 | 19.61 | 37.62 | 44.28 |
| Technique | B-1 | B2 | B-3 | B-4 | METEOR | ROUGE |
|---|---|---|---|---|---|---|
| Review Net [48] | 72.0 | 55.0 | 41.4 | 31.3 | 34.7 | 68.6 |
| Adaptive [49] | 74.8 | 58.4 | 44.4 | 33.6 | 26.4 | 55.0 |
| CNN + Attn [50] | 71.5 | 54.5 | 40.8 | 30.4 | 24.6 | 52.5 |
| CPTR [51] | 81.7 | 66.6 | 52.2 | 40.0 | 29.1 | 59.2 |
| Multi-modal transformer [5] | 81.7 | 66.8 | 52.4 | 40.4 | 29.4 | 59.6 |
| Image Transformer [35] | 80.8 | - | - | 39.5 | 29.1 | 59.0 |
| DLCT [42] | 82.4 | 67.4 | 52.8 | 40.6 | 29.8 | 59.8 |
| CAAG [34] | 81.1 | 66.4 | 51.7 | 39.6 | 29.2 | 59.2 |
| GET [54] | 82.1 | - | - | 40.6 | 29.8 | 59.6 |
| AFCT [53] | 80.5 | - | - | 38.7 | 29.2 | 58.4 |
| Dual-Modal Transformer (proposed) | 85.0 | 78.4 | 70.3 | 48.3 | 35.4 | 69.2 |
| Model | B-1 | B2 | B-3 | B-4 | METEOR | ROUGE |
|---|---|---|---|---|---|---|
| Simple Word embeddings | 64.5 | 52.3 | 51.2 | 30.3 | 23.7 | 52.7 |
| Word Embeddings + Object Embeddings | 72.3 | 63.5 | 58.6 | 35.6 | 27.4 | 58.3 |
| Word Embeddings + Object Embeddings+ VGG 16 (Feature Embedding) | 82.1 | 72.7 | 66.7 | 40.4 | 30.2 | 62.6 |
| Word Embeddings + Object Embeddings+ VGG-19 (Feature Embedding) | 83.4 | 76.5 | 68.3 | 42.0 | 32.4 | 64.5 |
| Word Embeddings + Object Embeddings+ Res-Net (Feature Embedding) | 84.0 | 77.2 | 69.7 | 45.4 | 32.8 | 66.9 |
| Dual-Modal Transformer with Word Embeddings + Object Embeddings+ InceptionV3 (Feature Embedding) (proposed) | 85.0 | 78.4 | 70.3 | 48.3 | 35.4 | 69.2 |
| Dual-Modal Transformer with Word Embeddings + Object Embeddings+ InceptionV4 (Feature Embedding) | 85.0 | 78.4 | 70.3 | 48.2 | 35.3 | 69.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, D.; Srivastava, V.; Popescu, D.E.; Hemanth, J.D. Dual-Modal Transformer with Enhanced Inter- and Intra-Modality Interactions for Image Captioning. Appl. Sci. 2022, 12, 6733. https://doi.org/10.3390/app12136733
Kumar D, Srivastava V, Popescu DE, Hemanth JD. Dual-Modal Transformer with Enhanced Inter- and Intra-Modality Interactions for Image Captioning. Applied Sciences. 2022; 12(13):6733. https://doi.org/10.3390/app12136733
Chicago/Turabian StyleKumar, Deepika, Varun Srivastava, Daniela Elena Popescu, and Jude D. Hemanth. 2022. "Dual-Modal Transformer with Enhanced Inter- and Intra-Modality Interactions for Image Captioning" Applied Sciences 12, no. 13: 6733. https://doi.org/10.3390/app12136733