
Uncertainty-Aware Deep Learning Classification of Adamantinomatous Craniopharyngioma from Preoperative MRI

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Acquisition
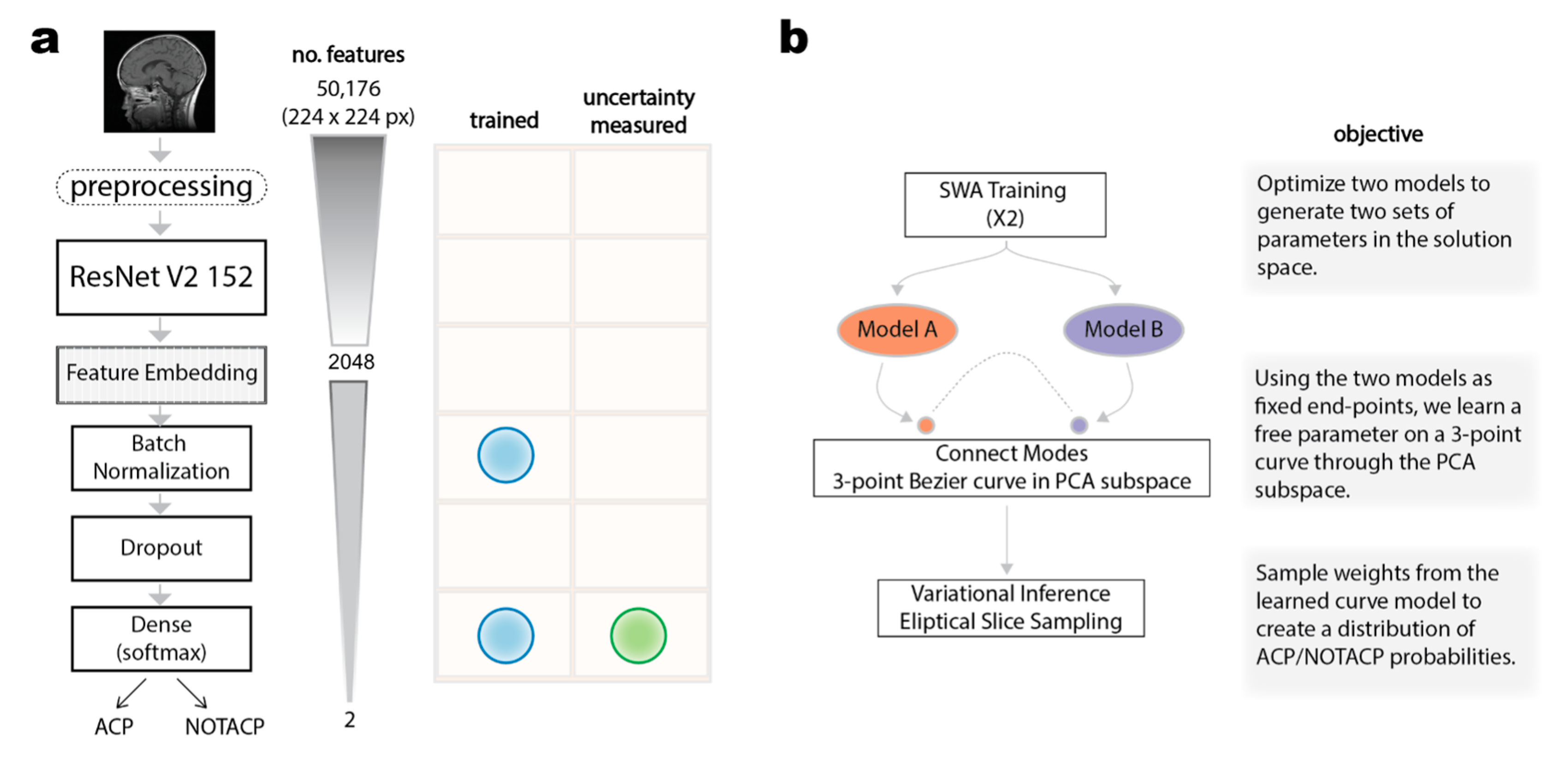
2.2. Deep Learning Classification of Preoperative MRI Images and Benchmarking
2.3. Bayesian Subspace Inference
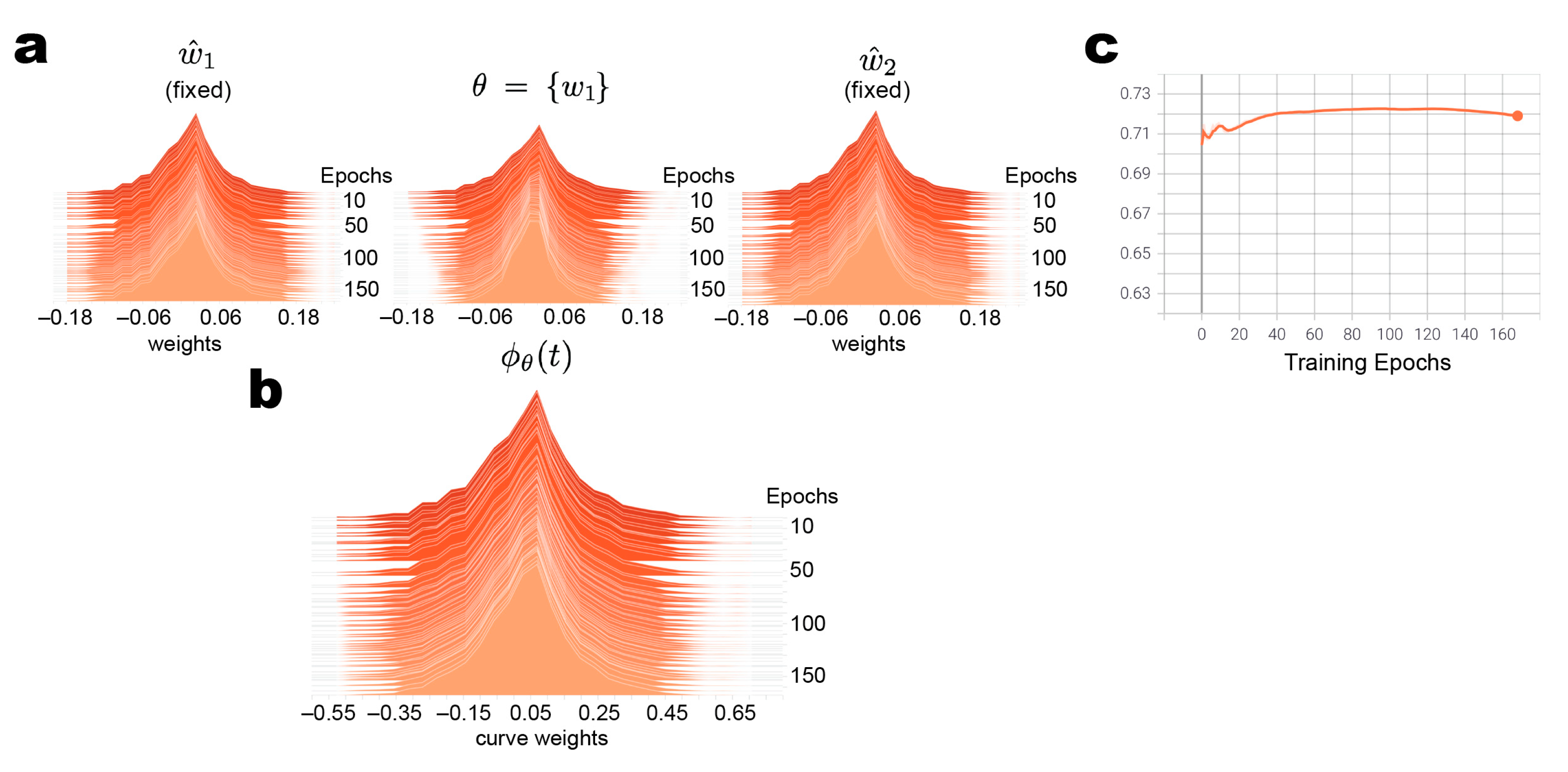
2.3.1. Construct PCA Subspace Curve End-Point Parameters through SWA Training
2.3.2. Connecting Loss Modes by Bezier Curves in PCA Subspace
2.3.3. Variational Inference by Elliptical Slice Sampling
2.4. Computational Infrastructure
3. Results
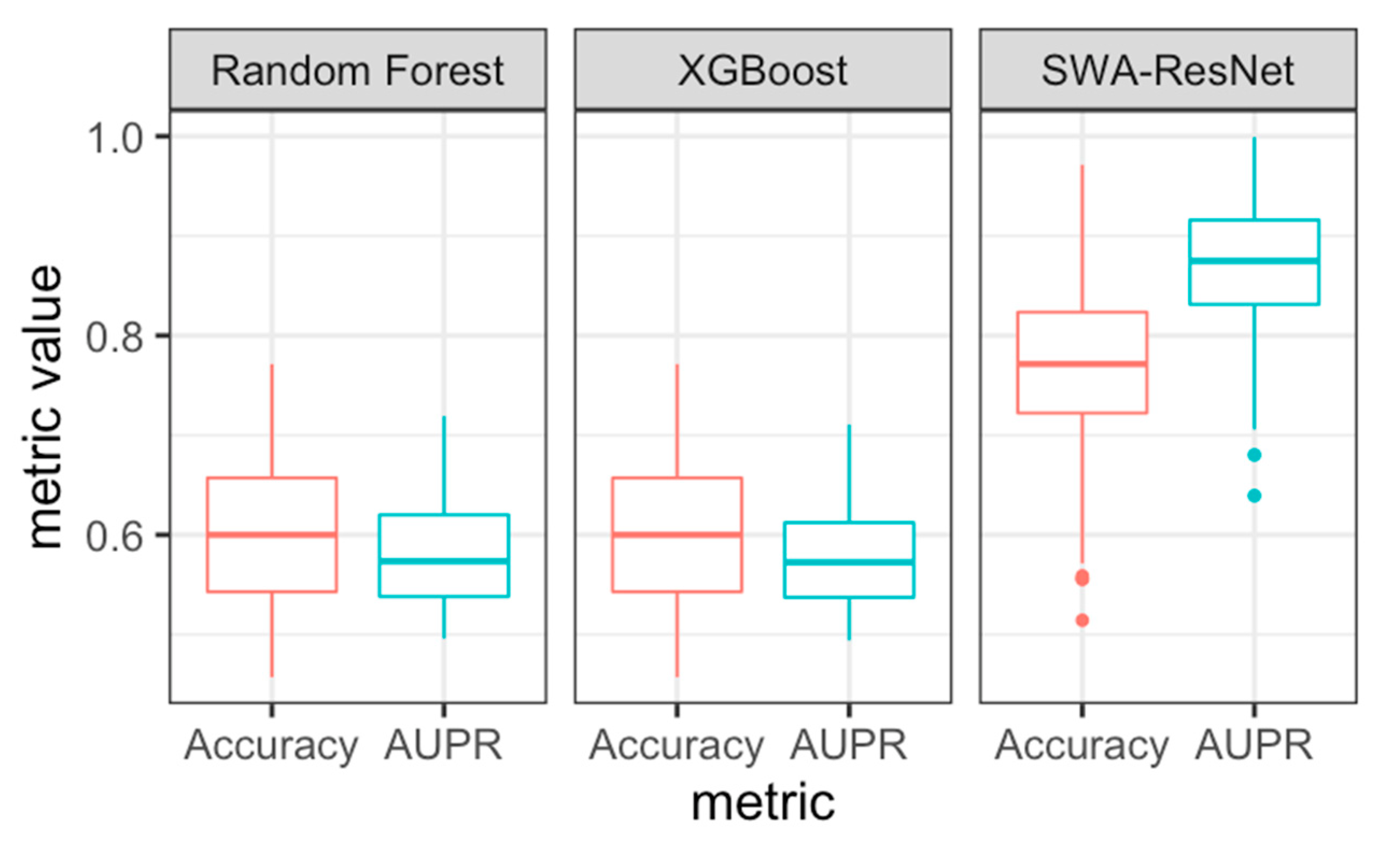
3.1. SWA-Tuned Model Outperforms Benchmarks
3.2. PCA Subspace Model Results in Stable but Reduced Test Performance
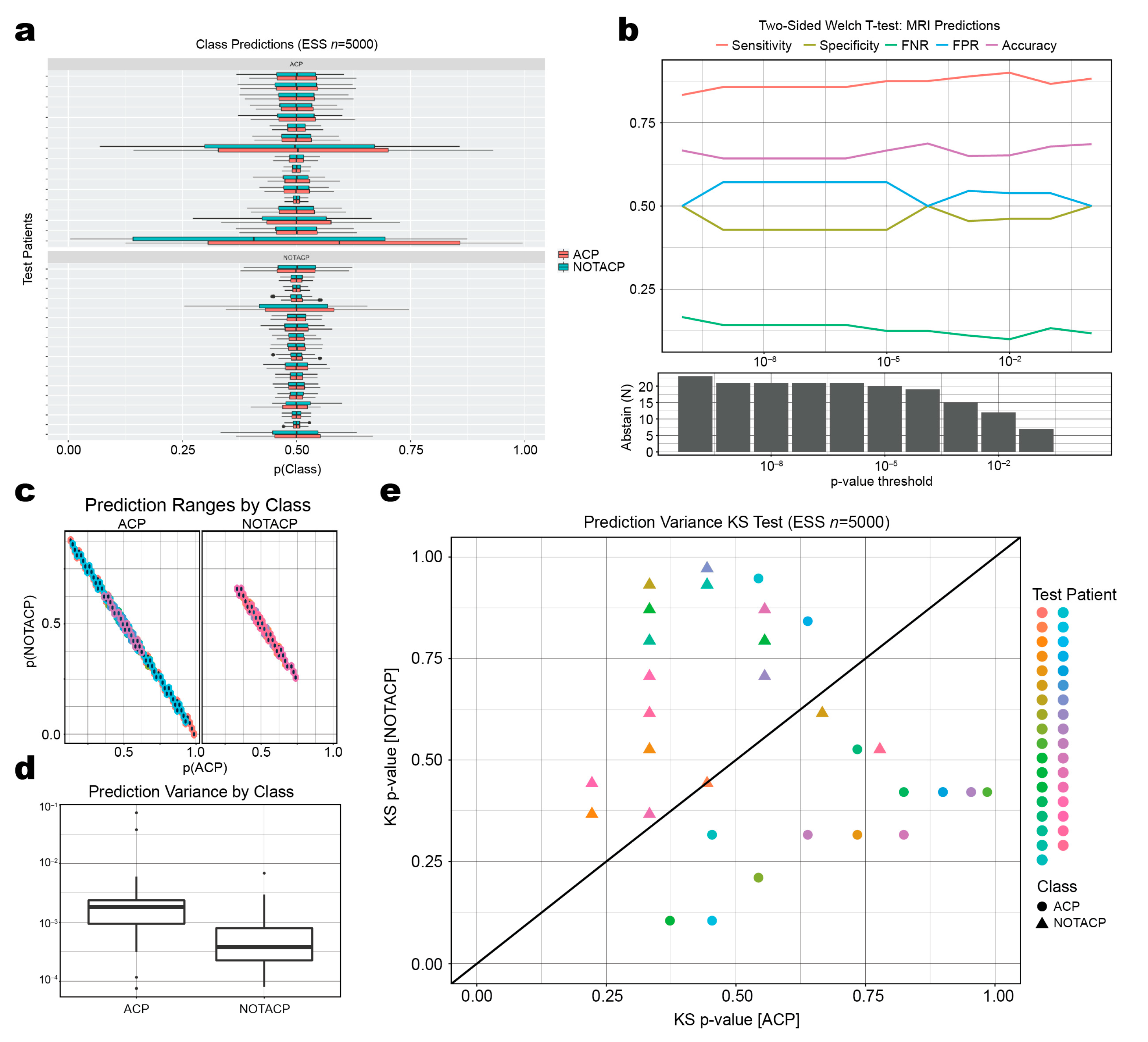
3.3. Mean Prediction Values Are Ambiguous, but Variance of Prediction Distributions Is Informative
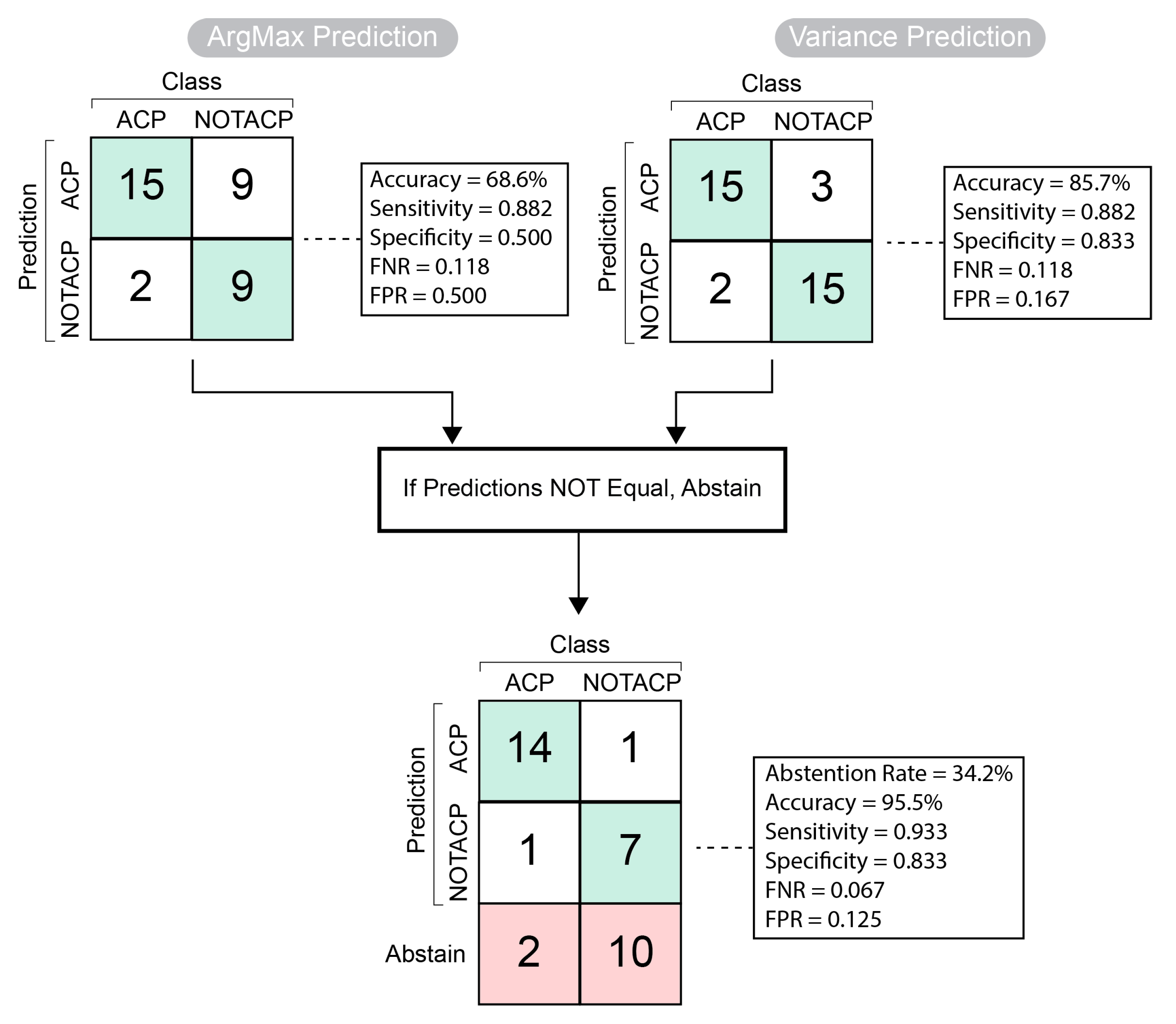
3.4. Classification Algorithm with Abstention Mechanism Improves Test Performance
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xue, J.; Wang, B.; Ming, Y.; Liu, X.; Jiang, Z.; Wang, C.; Liu, X.; Chen, L.; Qu, J.; Xu, S.; et al. Deep Learning–Based Detection and Segmentation-Assisted Management of Brain Metastases. Neuro-Oncology 2020, 22, 505–514. [Google Scholar] [CrossRef] [PubMed]
- Yogananda, C.G.B.; Shah, B.R.; Yu, F.F.; Pinho, M.C.; Nalawade, S.S.; Murugesan, G.K.; Wagner, B.C.; Mickey, B.; Patel, T.R.; Fei, B.; et al. A Novel Fully Automated MRI-Based Deep-Learning Method for Classification of 1p/19q Co-Deletion Status in Brain Gliomas. Neuro-Oncol. Adv. 2020, 2, iv42–iv48. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.; Kim, D.D.; Patel, J.B.; Zeng, X.; Huang, J.; Chang, K.; Xun, X.; Zhang, C.; Sollee, J.; Wu, J.; et al. Deep Learning-Based Automatic Tumor Burden Assessment of Pediatric High-Grade Gliomas, Medulloblastomas, and Other Leptomeningeal Seeding Tumors. Neuro-Oncology 2022, 24, 289–299. [Google Scholar] [CrossRef] [PubMed]
- Bae, S.; An, C.; Ahn, S.S.; Kim, H.; Han, K.; Kim, S.W.; Park, J.E.; Kim, H.S.; Lee, S.-K. Robust Performance of Deep Learning for Distinguishing Glioblastoma from Single Brain Metastasis Using Radiomic Features: Model Development and Validation. Sci. Rep. 2020, 10, 12110. [Google Scholar] [CrossRef] [PubMed]
- Matsui, Y.; Maruyama, T.; Nitta, M.; Saito, T.; Tsuzuki, S.; Tamura, M.; Kusuda, K.; Fukuya, Y.; Asano, H.; Kawamata, T.; et al. Prediction of Lower-Grade Glioma Molecular Subtypes Using Deep Learning. J. Neurooncol. 2020, 146, 321–327. [Google Scholar] [CrossRef]
- Ermiş, E.; Jungo, A.; Poel, R.; Blatti-Moreno, M.; Meier, R.; Knecht, U.; Aebersold, D.M.; Fix, M.K.; Manser, P.; Reyes, M.; et al. Fully Automated Brain Resection Cavity Delineation for Radiation Target Volume Definition in Glioblastoma Patients Using Deep Learning. Radiat. Oncol. 2020, 15, 100. [Google Scholar] [CrossRef]
- Prince, E.W.; Whelan, R.; Mirsky, D.M.; Stence, N.; Staulcup, S.; Klimo, P.; Anderson, R.C.E.; Niazi, T.N.; Grant, G.; Souweidane, M.; et al. Robust Deep Learning Classification of Adamantinomatous Craniopharyngioma from Limited Preoperative Radiographic Images. Sci. Rep. 2020, 10, 16885. [Google Scholar] [CrossRef]
- Guo, J.; Li, B. The Application of Medical Artificial Intelligence Technology in Rural Areas of Developing Countries. Health Equity 2018, 2, 174–181. [Google Scholar] [CrossRef] [Green Version]
- Meskó, B.; Hetényi, G.; Győrffy, Z. Will Artificial Intelligence Solve the Human Resource Crisis in Healthcare? BMC Health Serv. Res. 2018, 18, 545. [Google Scholar] [CrossRef] [Green Version]
- Ardizzone, E.; Bonadonna, F.; Gaglio, S.; Marcenò, R.; Nicolini, C.; Ruggiero, C.; Sorbello, F. Artificial Intelligence Techniques for Cancer Treatment Planning. Med. Inform. 1988, 13, 199–210. [Google Scholar] [CrossRef]
- Shaban-Nejad, A.; Michalowski, M.; Buckeridge, D.L. Health Intelligence: How Artificial Intelligence Transforms Population and Personalized Health. NPJ Digit. Med. 2018, 1, 53. [Google Scholar] [CrossRef] [Green Version]
- Myers, T.G.; Ramkumar, P.N.; Ricciardi, B.F.; Urish, K.L.; Kipper, J.; Ketonis, C. Artificial Intelligence and Orthopaedics. J. Bone Jt. Surg. Am. 2020, 102, 830–840. [Google Scholar] [CrossRef]
- Fazal, M.I.; Patel, M.E.; Tye, J.; Gupta, Y. The Past, Present and Future Role of Artificial Intelligence in Imaging. Eur. J. Radiol. 2018, 105, 246–250. [Google Scholar] [CrossRef] [PubMed]
- Rauschecker, A.M.; Rudie, J.D.; Xie, L.; Wang, J.; Duong, M.T.; Botzolakis, E.J.; Kovalovich, A.M.; Egan, J.; Cook, T.C.; Bryan, R.N.; et al. Artificial Intelligence System Approaching Neuroradiologist-Level Differential Diagnosis Accuracy at Brain MRI. Radiology 2020, 295, 626–637. [Google Scholar] [CrossRef]
- Jaju, A.; Yeom, K.W.; Ryan, M.E. MR Imaging of Pediatric Brain Tumors. Diagnostics 2022, 12, 961. [Google Scholar] [CrossRef]
- Xie, Y.; Zaccagna, F.; Rundo, L.; Testa, C.; Agati, R.; Lodi, R.; Manners, D.N.; Tonon, C. Convolutional Neural Network Techniques for Brain Tumor Classification (from 2015 to 2022): Review, Challenges, and Future Perspectives. Diagnostics 2022, 12, 1850. [Google Scholar] [CrossRef]
- Benjamens, S.; Dhunnoo, P.; Meskó, B. The State of Artificial Intelligence-Based FDA-Approved Medical Devices and Algorithms: An Online Database. NPJ Digit. Med. 2020, 3, 118. [Google Scholar] [CrossRef]
- He, J.; Baxter, S.L.; Xu, J.; Xu, J.; Zhou, X.; Zhang, K. The Practical Implementation of Artificial Intelligence Technologies in Medicine. Nat. Med. 2019, 25, 30–36. [Google Scholar] [CrossRef]
- Begoli, E.; Bhattacharya, T.; Kusnezov, D. The Need for Uncertainty Quantification in Machine-Assisted Medical Decision Making. Nat. Mach. Intell. 2019, 1, 20–23. [Google Scholar] [CrossRef]
- Bhinder, B.; Gilvary, C.; Madhukar, N.S.; Elemento, O. Artificial Intelligence in Cancer Research and Precision Medicine. Cancer Discov. 2021, 11, 900–915. [Google Scholar] [CrossRef]
- He, X.; Hong, Y.; Zheng, X.; Zhang, Y. What Are the Users’ Needs? Design of a User-Centered Explainable Artificial Intelligence Diagnostic System. Int. J. Hum.–Comput. Interact. 2022, 1–24. [Google Scholar] [CrossRef]
- Cai, C.J.; Winter, S.; Steiner, D.; Wilcox, L.; Terry, M. “Hello AI”: Uncovering the Onboarding Needs of Medical Practitioners for Human-AI Collaborative Decision-Making. Proc. ACM Hum.-Comput. Interact. 2019, 3, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Kompa, B.; Snoek, J.; Beam, A.L. Second Opinion Needed: Communicating Uncertainty in Medical Machine Learning. NPJ Digit. Med. 2021, 4, 4. [Google Scholar] [CrossRef]
- Shamsi, A.; Asgharnezhad, H.; Jokandan, S.S.; Khosravi, A.; Kebria, P.M.; Nahavandi, D.; Nahavandi, S.; Srinivasan, D. An Uncertainty-Aware Transfer Learning-Based Framework for COVID-19 Diagnosis. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1408–1417. [Google Scholar] [CrossRef] [PubMed]
- Abdar, M.; Fahami, M.A.; Rundo, L.; Radeva, P.; Frangi, A.F.; Acharya, U.R.; Khosravi, A.; Lam, H.-K.; Jung, A.; Nahavandi, S. Hercules: Deep Hierarchical Attentive Multilevel Fusion Model with Uncertainty Quantification for Medical Image Classification. IEEE Trans. Ind. Inform. 2023, 19, 274–285. [Google Scholar] [CrossRef]
- Momin, A.A.; Recinos, M.A.; Cioffi, G.; Patil, N.; Soni, P.; Almeida, J.P.; Kruchko, C.; Barnholtz-Sloan, J.S.; Recinos, P.F.; Kshettry, V.R. Descriptive Epidemiology of Craniopharyngiomas in the United States. Pituitary 2021, 24, 517–522. [Google Scholar] [CrossRef]
- Norris, G.A.; Garcia, J.; Hankinson, T.C.; Handler, M.; Foreman, N.; Mirsky, D.; Stence, N.; Dorris, K.; Green, A.L. Diagnostic Accuracy of Neuroimaging in Pediatric Optic Chiasm/Sellar/Suprasellar Tumors. Pediatr. Blood Cancer 2019, 66, e27680. [Google Scholar] [CrossRef]
- Hipp, J.D.; Fernandez, A.; Compton, C.C.; Balis, U.J. Why a Pathology Image Should Not Be Considered as a Radiology Image. J. Pathol. Inform. 2011, 2, 26. [Google Scholar] [CrossRef]
- Kayo, A.; Yogi, A.; Hamada, S.; Nakanishi, K.; Kinjo, S.; Sugawara, K.; Ishiuchi, S.; Nishie, A. Primary Diffuse Leptomeningeal Atypical Teratoid Rhabdoid Tumor (AT/RT) Demonstrating Atypical Imaging Findings in an Adolescent Patient. Radiol. Case Rep. 2022, 17, 485–488. [Google Scholar] [CrossRef]
- Oren, O.; Gersh, B.J.; Bhatt, D.L. Artificial Intelligence in Medical Imaging: Switching from Radiographic Pathological Data to Clinically Meaningful Endpoints. Lancet Digit. Health 2020, 2, e486–e488. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Izmailov, P.; Podoprikhin, D.; Garipov, T.; Vetrov, D.; Wilson, A.G. Averaging Weights Leads to Wider Optima and Better Generalization. arXiv 2019, arXiv:1803.05407v3. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980v9. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101v3. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. arXiv 2017, arXiv:1506.01186v6. [Google Scholar]
- Swiler, L.P.; Paez, T.L.; Mayes, R.L. Epistemic Uncertainty Quantification Tutorial. In Proceedings of the IMAC XXVII Conference and Exposition on Structural Dynamics, Society for Experimental Mechanics, Orlando, FL, USA, 9–12 February 2009. [Google Scholar]
- Hüllermeier, E.; Waegeman, W. Aleatoric and Epistemic Uncertainty in Machine Learning: An Introduction to Concepts and Methods. Mach. Learn. 2021, 110, 457–506. [Google Scholar] [CrossRef]
- Wilson, A.G. The Case for Bayesian Deep Learning. arXiv 2020, arXiv:2001.10995. [Google Scholar]
- Garipov, T.; Izmailov, P.; Podoprikhin, D.; Vetrov, D.; Wilson, A.G. Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs. arXiv 2018, arXiv:1802.10026v4. [Google Scholar]
- Wenzel, F.; Roth, K.; Veeling, B.S.; Świątkowski, J.; Tran, L.; Mandt, S.; Snoek, J.; Salimans, T.; Jenatton, R.; Nowozin, S. How Good Is the Bayes Posterior in Deep Neural Networks Really? arXiv 2020, arXiv:2002.02405. [Google Scholar]
- Izmailov, P.; Maddox, W.J.; Kirichenko, P.; Garipov, T.; Vetrov, D.; Wilson, A.G. Subspace Inference for Bayesian Deep Learning. In Proceedings of the 35th Uncertainty in Artificial Intelligence Conference, Tel Aviv, Israel, 22–25 July 2019; 2020. PMLR. pp. 1169–1179. [Google Scholar]
- Murray, I.; Adams, R.; MacKay, D. Elliptical Slice Sampling. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; JMLR Workshop and Conference Proceedings. pp. 541–548. [Google Scholar]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the Tidyverse. JOSS 2019, 4, 1686. [Google Scholar] [CrossRef] [Green Version]
- Akbari, Z.; Unland, R. A Powerful Holonic and Multi-Agent-Based Front-End for Medical Diagnostics Systems. In Handbook of Artificial Intelligence in Healthcare: Vol. 1—Advances and Applications; Lim, C.-P., Vaidya, A., Jain, K., Mahorkar, V.U., Jain, L.C., Eds.; Intelligent Systems Reference Library; Springer International Publishing: Cham, Switzerland, 2022; pp. 313–352. ISBN 978-3-030-79161-2. [Google Scholar]
- Masegosa, A.R. Learning under Model Misspecification: Applications to Variational and Ensemble Methods. arXiv 2020, arXiv:1912.08335. [Google Scholar]
- Huang, Y.; Huang, W.; Li, L.; Li, Z. Meta-Learning PAC-Bayes Priors in Model Averaging. AAAI 2020, 34, 4198–4205. [Google Scholar] [CrossRef]
- Betancourt, M. A Conceptual Introduction to Hamiltonian Monte Carlo. arXiv 2018, arXiv:1701.02434v2. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prince, E.W.; Ghosh, D.; Görg, C.; Hankinson, T.C. Uncertainty-Aware Deep Learning Classification of Adamantinomatous Craniopharyngioma from Preoperative MRI. Diagnostics 2023, 13, 1132. https://doi.org/10.3390/diagnostics13061132
Prince EW, Ghosh D, Görg C, Hankinson TC. Uncertainty-Aware Deep Learning Classification of Adamantinomatous Craniopharyngioma from Preoperative MRI. Diagnostics. 2023; 13(6):1132. https://doi.org/10.3390/diagnostics13061132
Chicago/Turabian StylePrince, Eric W., Debashis Ghosh, Carsten Görg, and Todd C. Hankinson. 2023. "Uncertainty-Aware Deep Learning Classification of Adamantinomatous Craniopharyngioma from Preoperative MRI" Diagnostics 13, no. 6: 1132. https://doi.org/10.3390/diagnostics13061132