
Ensemble Tree Model for Long-Term Rockburst Prediction in Incomplete Datasets

Abstract
:1. Introduction
2. Methodology
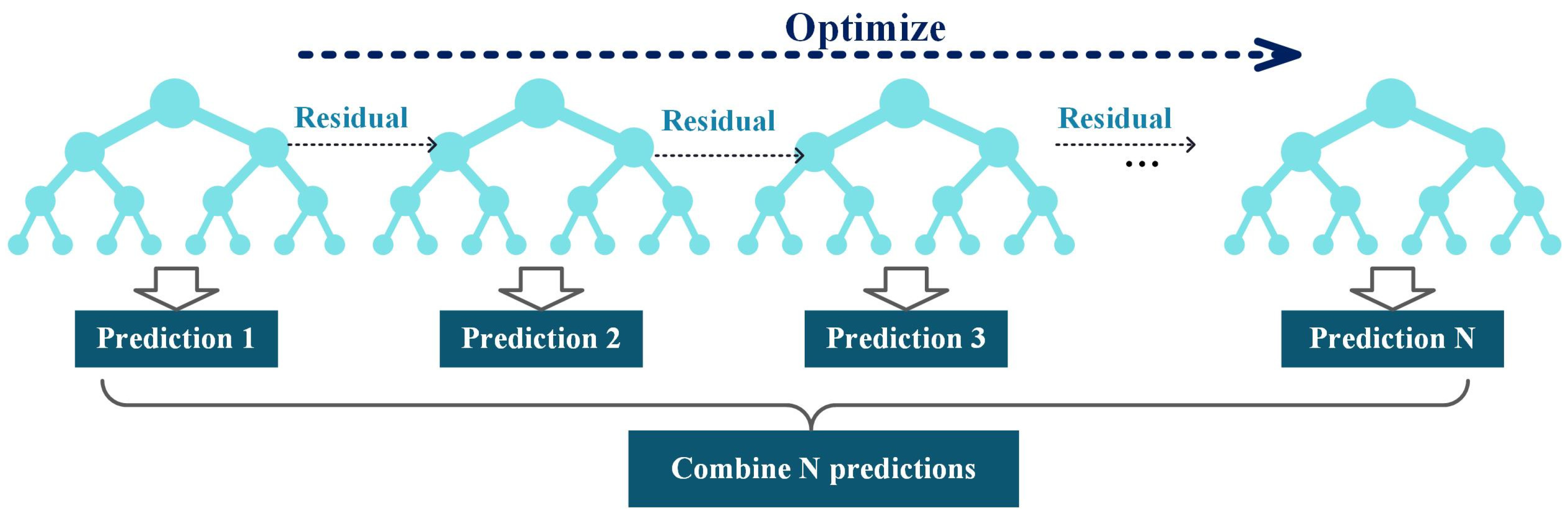
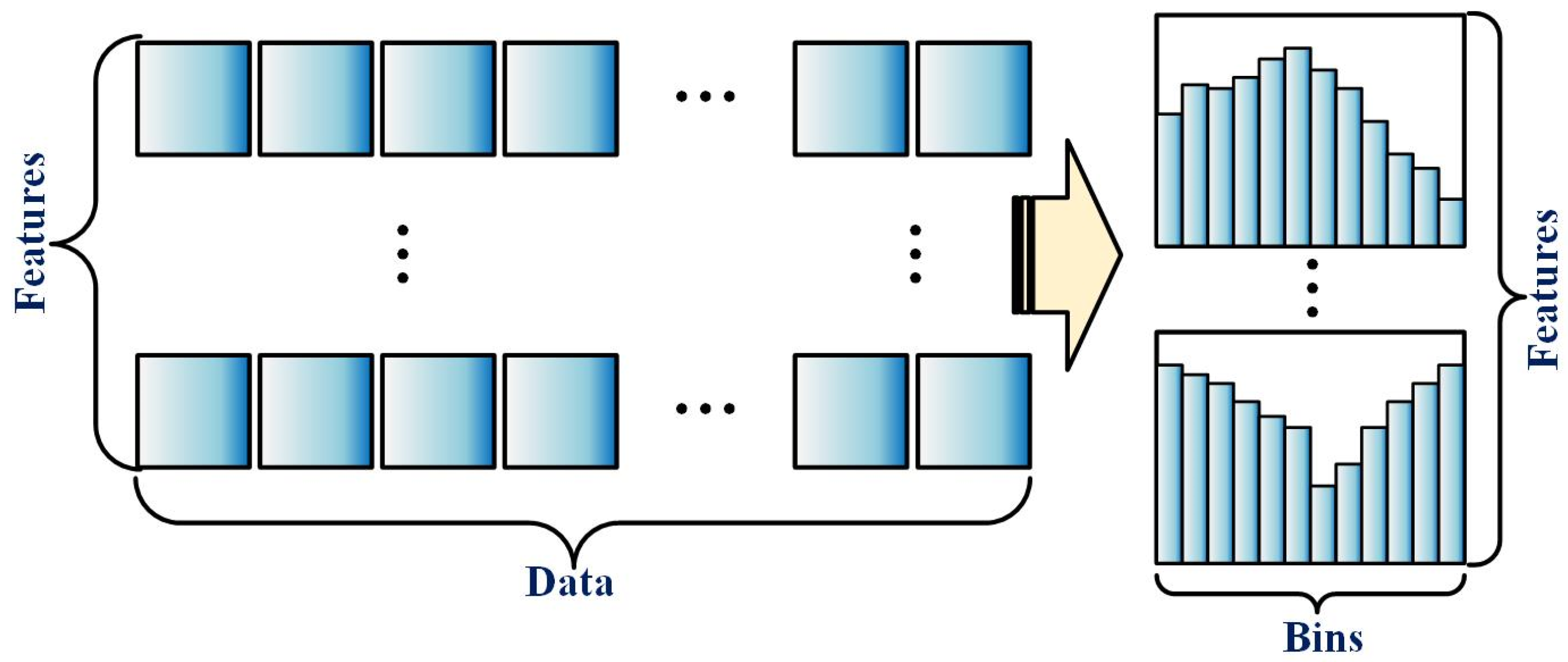
2.1. Histogram Gradient Boosting Tree
2.2. Hunger Games Search
- (1)
- Approach food
- (2)
- Hunger role
3. Database
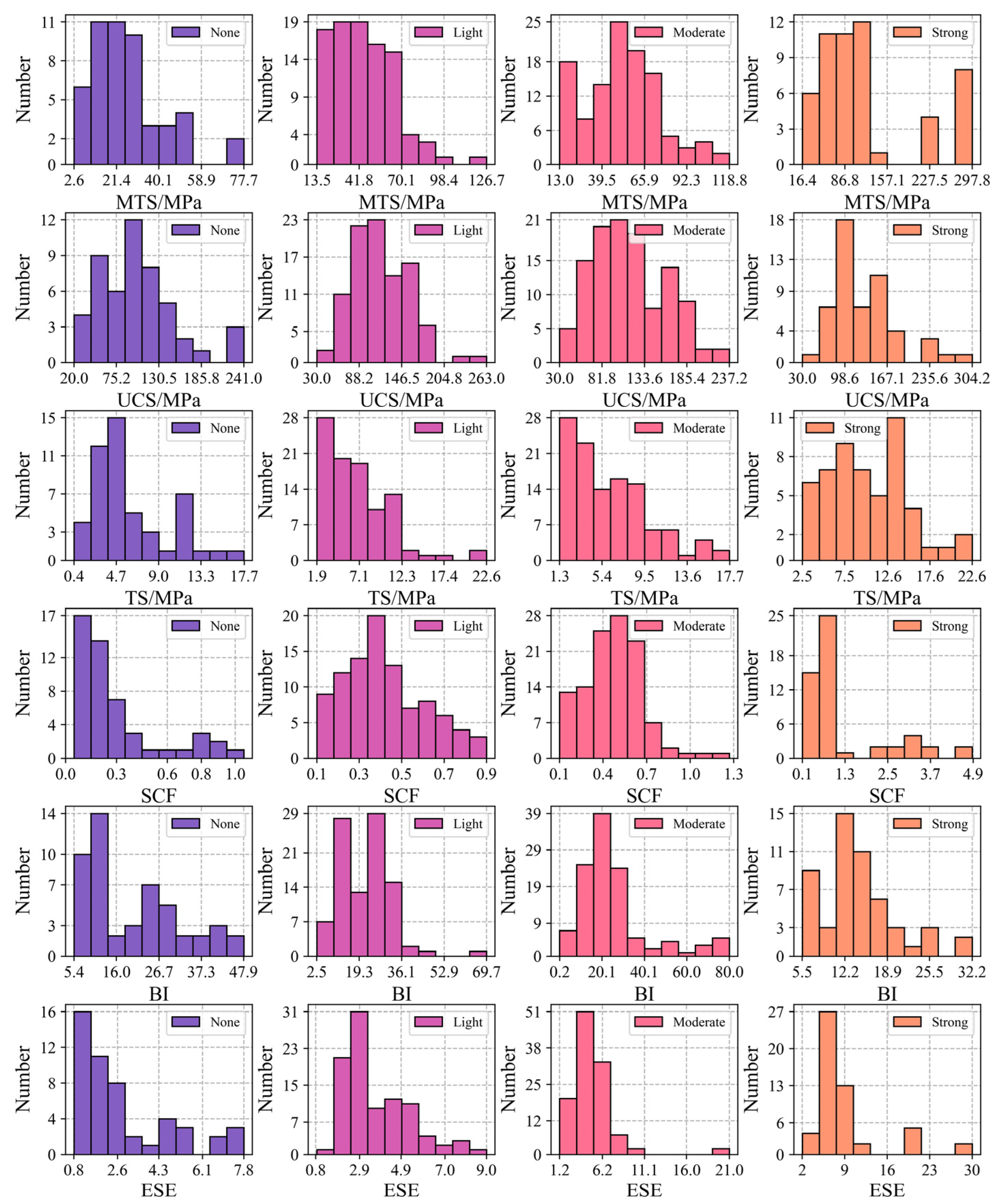
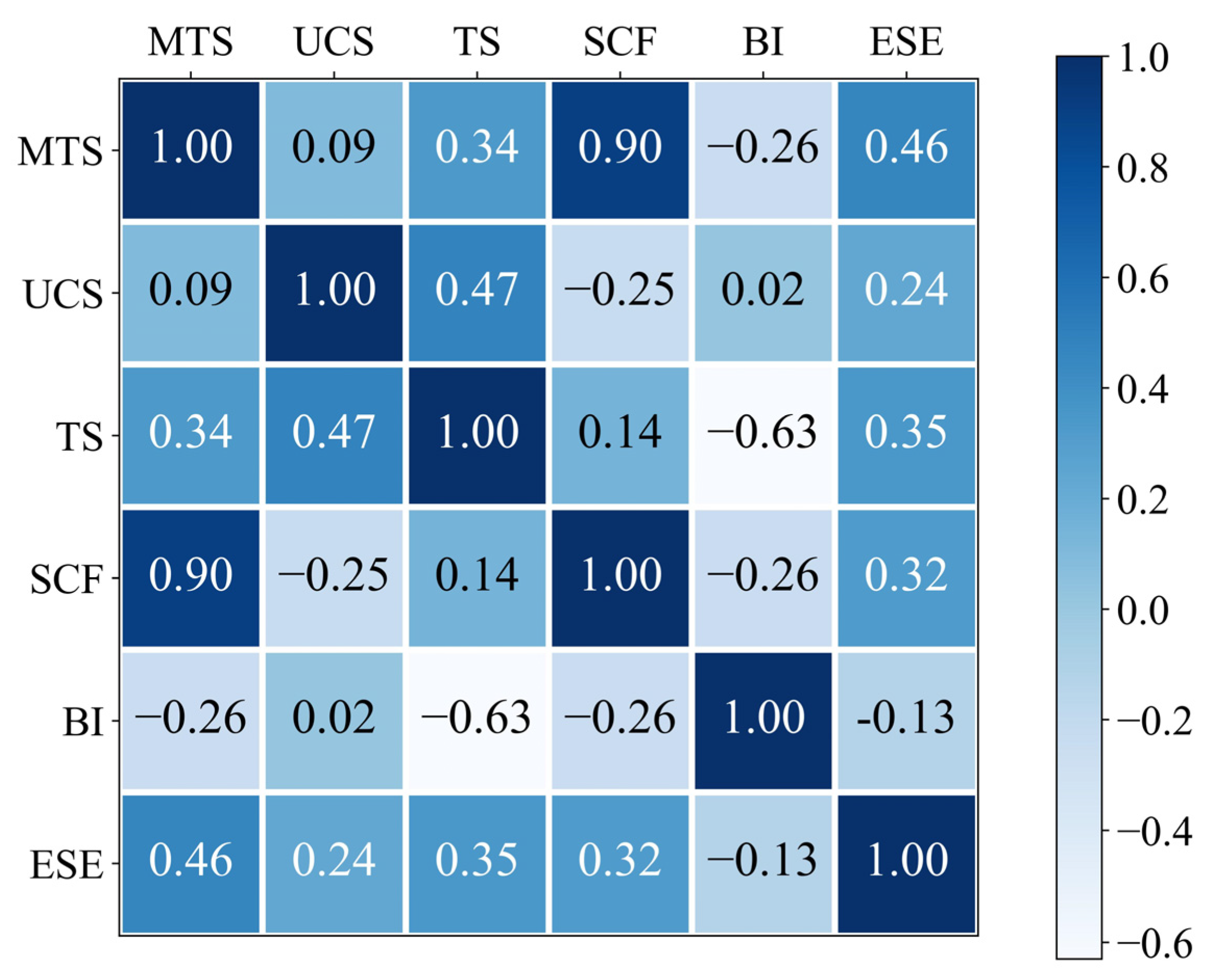
3.1. Data Collection and Description
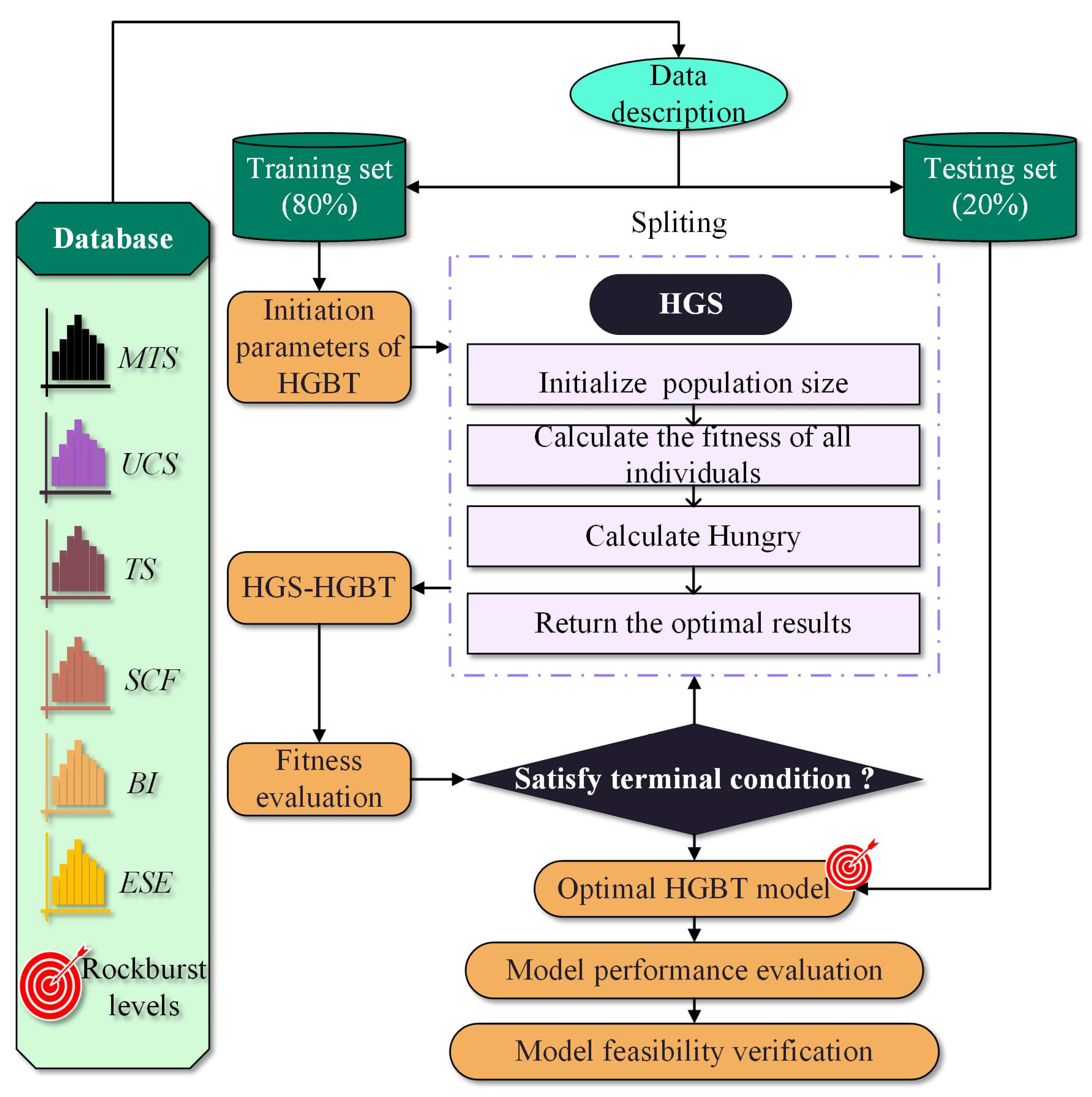
3.2. Step-by-Step Study Flowchart
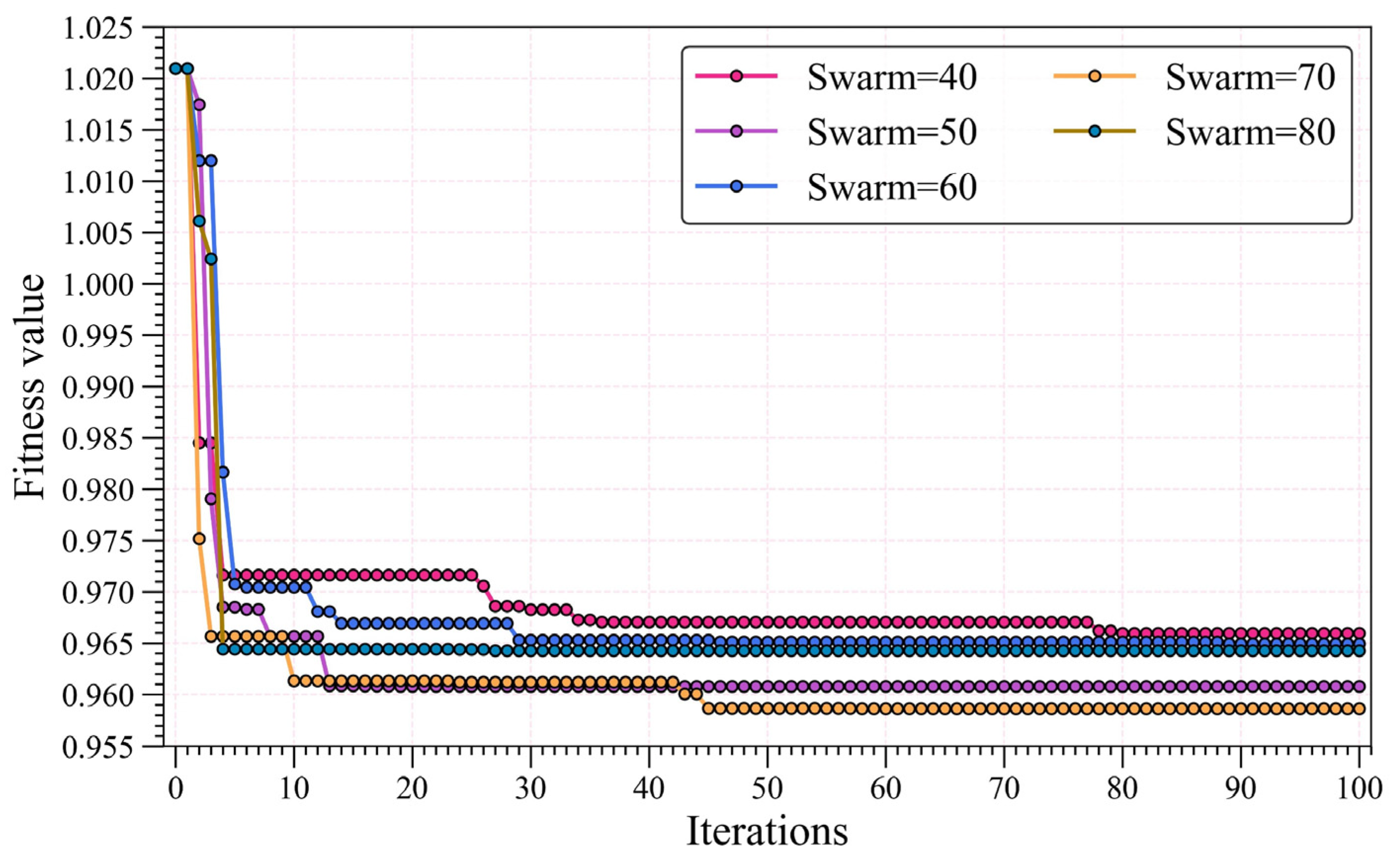
4. Modeling
5. Discussion
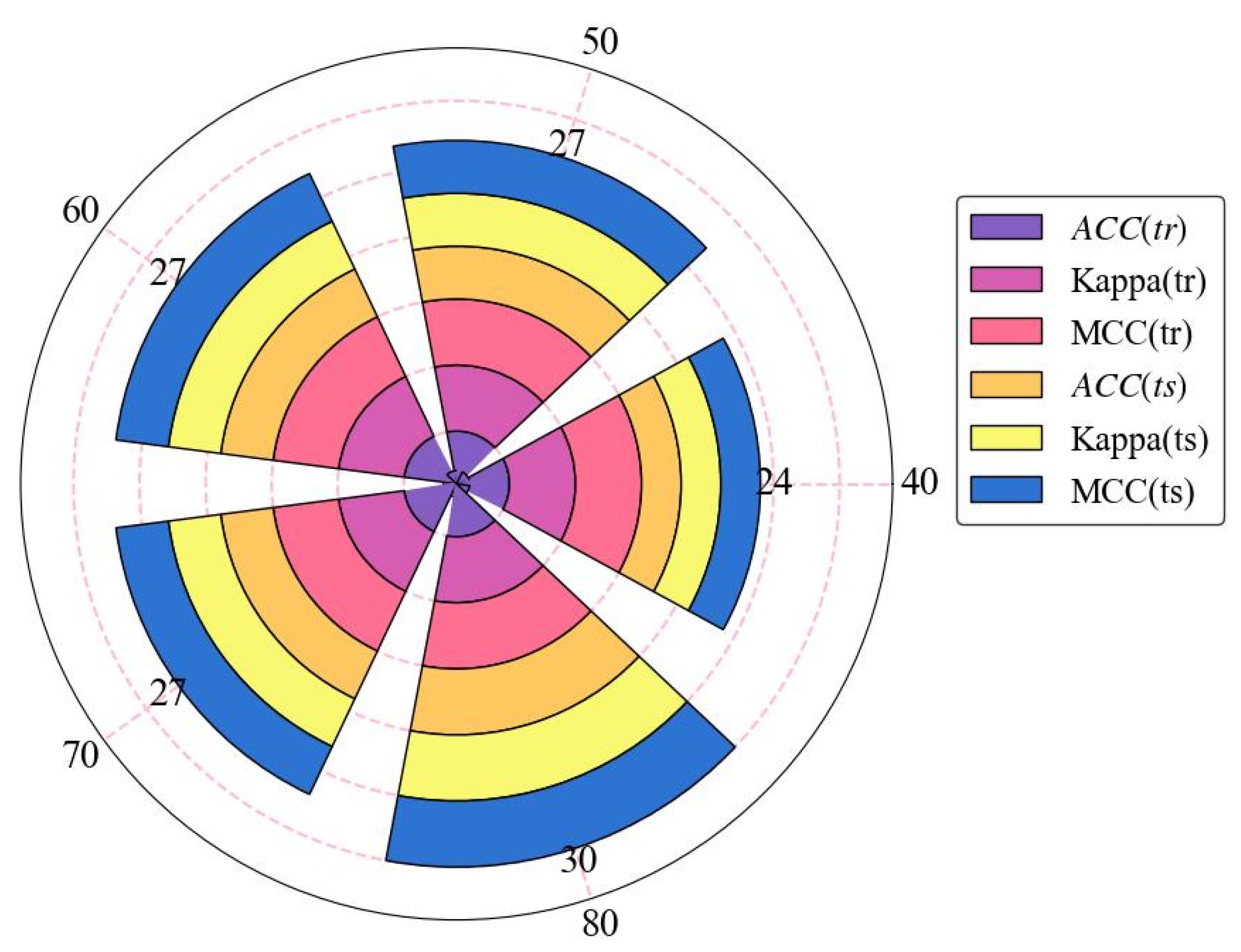
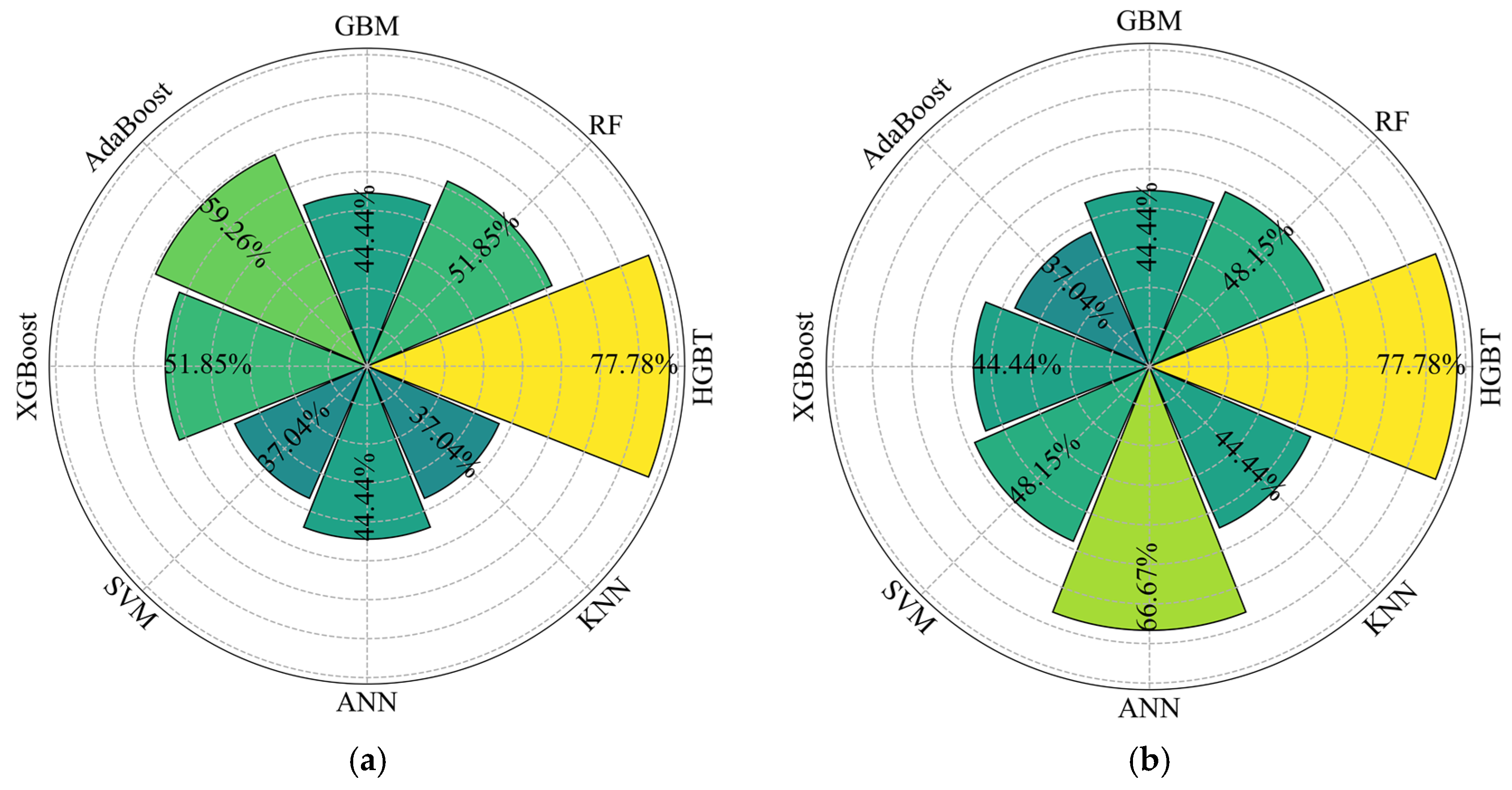
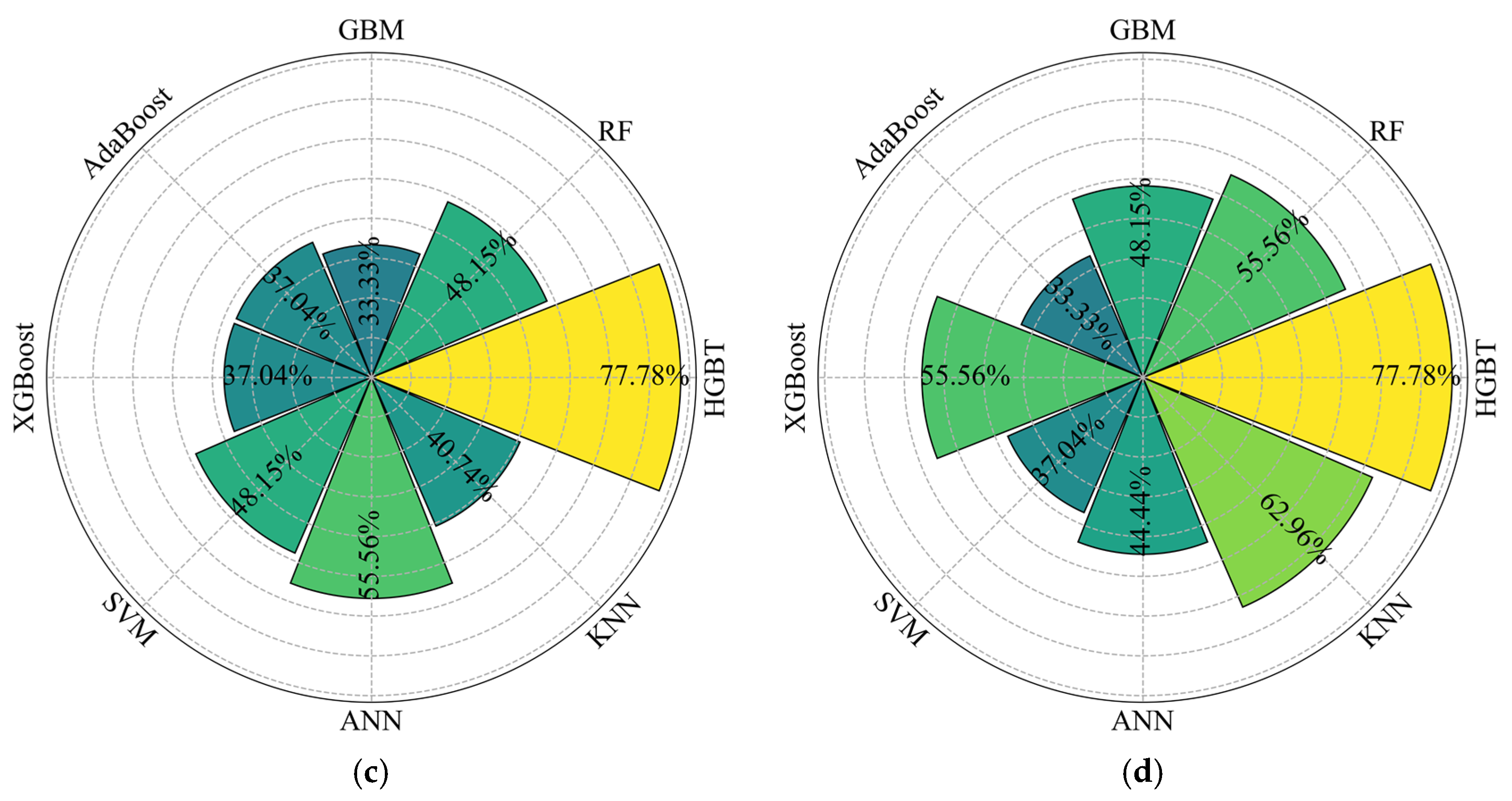
5.1. Performance Evaluation of HGBT in Incomplete Datasets
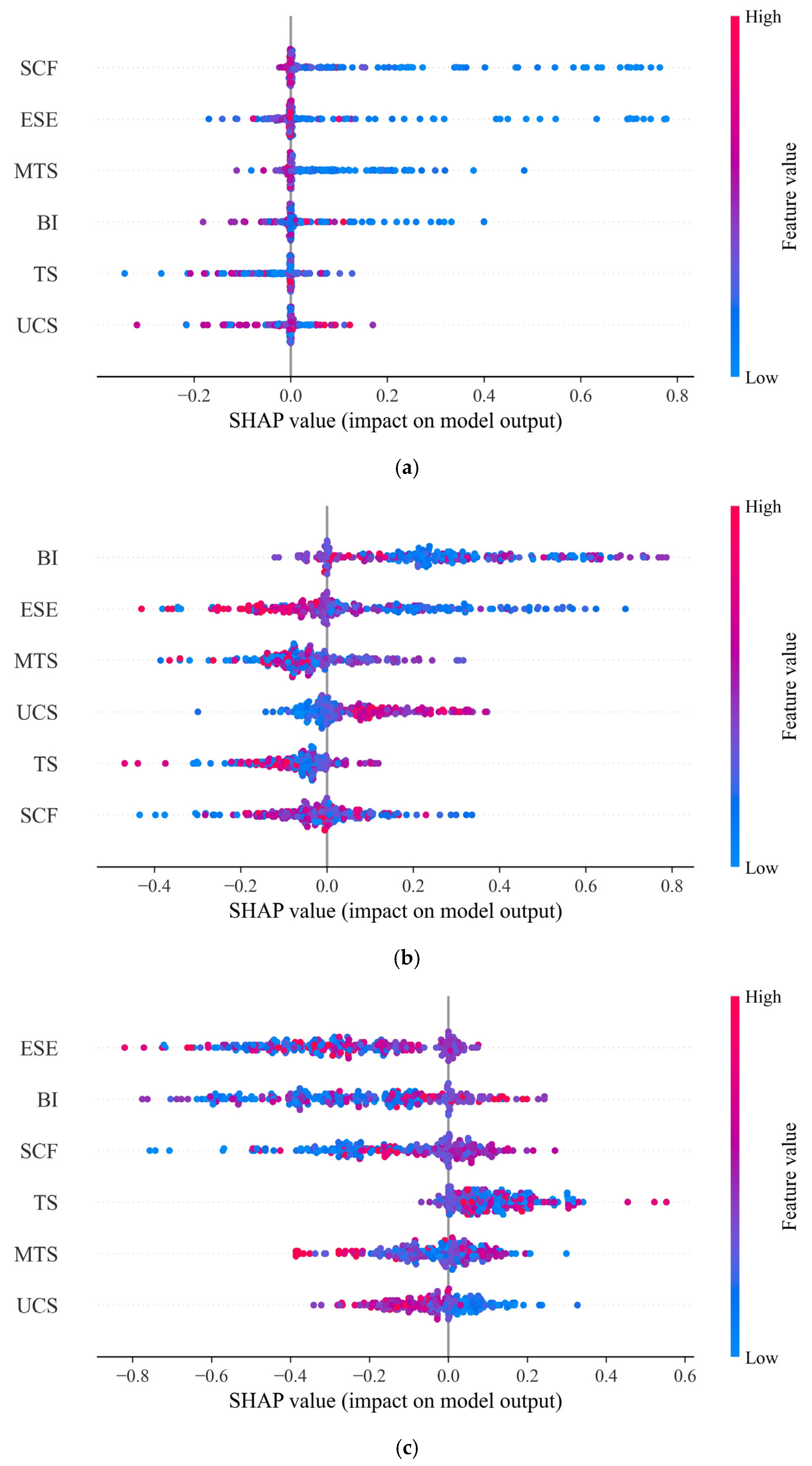
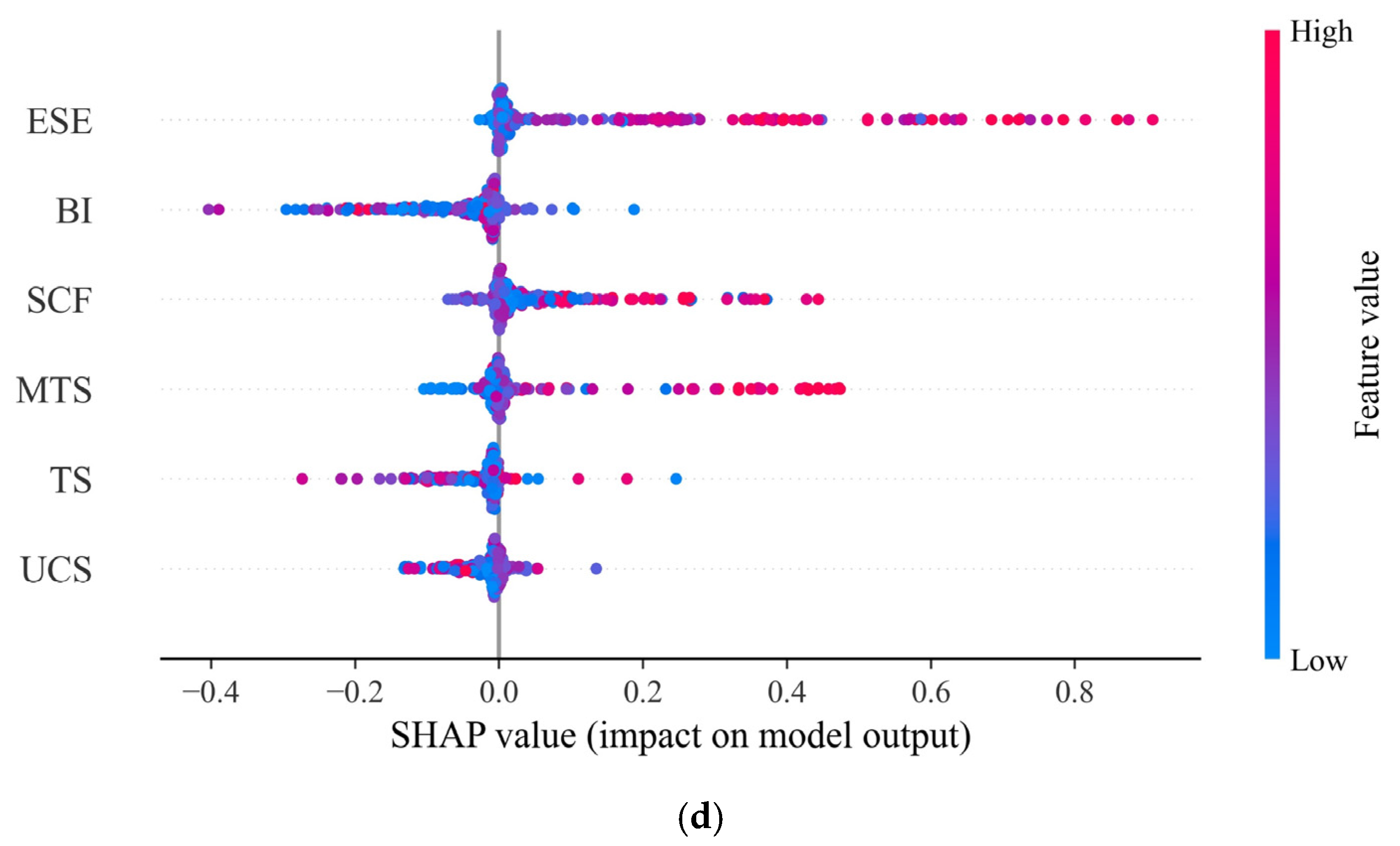
5.2. Model Interpretation
5.3. Model Feasibility Verification
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Keneti, A.; Sainsbury, B.-A. Review of published rockburst events and their contributing factors. Eng. Geol. 2018, 246, 361–373. [Google Scholar] [CrossRef]
- Skrzypkowski, K. A new design of support for burst-prone rock mass in underground ore mining. E3S Web Conf. 2018, 71, 00006. [Google Scholar] [CrossRef]
- Shirani Faradonbeh, R.; Taheri, A.; Karakus, M. The propensity of the over-stressed rock masses to different failure mechanisms based on a hybrid probabilistic approach. Tunn. Undergr. Space Technol. 2022, 119, 104214. [Google Scholar] [CrossRef]
- Wang, J.-A.; Park, H. Comprehensive prediction of rockburst based on analysis of strain energy in rocks. Tunn. Undergr. Space Technol. 2001, 16, 49–57. [Google Scholar] [CrossRef]
- Chen, B.-R.; Feng, X.-T.; Li, Q.-P.; Luo, R.-Z.; Li, S. Rock Burst Intensity Classification Based on the Radiated Energy with Damage Intensity at Jinping II Hydropower Station, China. Rock Mech. Rock Eng. 2015, 48, 289–303. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Shi, X. Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf. Sci. 2012, 50, 629–644. [Google Scholar] [CrossRef]
- Lee, S.M.; Park, B.S.; Lee, S.W. Analysis of rockbursts that have occurred in a waterway tunnel in Korea. Int. J. Rock Mech. Min. Sci. 2004, 41, 911–916. [Google Scholar] [CrossRef]
- Manouchehrian, A.; Cai, M. Numerical modeling of rockburst near fault zones in deep tunnels. Tunn. Undergr. Space Technol. 2018, 80, 164–180. [Google Scholar] [CrossRef]
- Afraei, S.; Shahriar, K.; Madani, S.H. Developing intelligent classification models for rock burst prediction after recognizing significant predictor variables, Section 1: Literature review and data preprocessing procedure. Tunn. Undergr. Space Technol. 2019, 83, 324–353. [Google Scholar] [CrossRef]
- Afraei, S.; Shahriar, K.; Madani, S.H. Developing intelligent classification models for rock burst prediction after recognizing significant predictor variables, Section 2: Designing classifiers. Tunn. Undergr. Space Technol. 2019, 84, 522–537. [Google Scholar] [CrossRef]
- Shirani Faradonbeh, R.; Taheri, A.; Ribeiro e Sousa, L.; Karakus, M. Rockburst assessment in deep geotechnical conditions using true-triaxial tests and data-driven approaches. Int. J. Rock Mech. Min. Sci. 2020, 128, 104279. [Google Scholar] [CrossRef]
- Dowding, C.H.; Andersson, C.-A. Potential for rock bursting and slabbing in deep caverns. Eng. Geol. 1986, 22, 265–279. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Liu, V.; Mitri, H. Machine learning methods for rockburst prediction-state-of-the-art review. Int. J. Min. Sci. Technol. 2019, 29, 565–570. [Google Scholar] [CrossRef]
- Shirani Faradonbeh, R.; Taheri, A. Long-term prediction of rockburst hazard in deep underground openings using three robust data mining techniques. Eng. Comput. 2018, 35, 659–675. [Google Scholar] [CrossRef]
- Liang, W.; Zhao, G. A review of long-term and short-term rockburst risk evaluations in deep hard rock. Yanshilixue Yu Gongcheng Xuebao/Chin. J. Rock Mech. Eng. 2022, 41, 19–39. [Google Scholar] [CrossRef]
- Liang, W.; Sari, Y.A.; Zhao, G.; McKinnon, S.D.; Wu, H. Probability Estimates of Short-Term Rockburst Risk with Ensemble Classifiers. Rock Mech. Rock Eng. 2021, 54, 1799–1814. [Google Scholar] [CrossRef]
- Ullah, B.; Kamran, M.; Rui, Y. Predictive Modeling of Short-Term Rockburst for the Stability of Subsurface Structures Using Machine Learning Approaches: T-SNE, K-Means Clustering and XGBoost. Mathematics 2022, 10, 449. [Google Scholar] [CrossRef]
- He, M.; Cheng, T.; Qiao, Y.; Li, H. A review of rockburst: Experiments, theories, and simulations. J. Rock Mech. Geotech. Eng. 2022. [Google Scholar] [CrossRef]
- Kabwe, E.; Wang, Y. Review on Rockburst Theory and Types of Rock Support in Rockburst Prone Mines. Open J. Saf. Sci. Technol. 2015, 5, 18. [Google Scholar] [CrossRef] [Green Version]
- Askaripour, M.; Saeidi, A.; Rouleau, A.; Mercier-Langevin, P. Rockburst in underground excavations: A review of mechanism, classification, and prediction methods. Undergr. Space 2022, 7, 577–607. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Evaluation method of rockburst: State-of-the-art literature review. Tunn. Undergr. Space Technol. 2018, 81, 632–659. [Google Scholar] [CrossRef]
- Xiao, P.; Li, D.; Zhao, G.; Liu, M. Experimental and Numerical Analysis of Mode I Fracture Process of Rock by Semi-Circular Bend Specimen. Mathematics 2021, 9, 1769. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, G.; Song, Y.; Hu, S.; Liu, M.; Li, J. Evaluation of rock burst intensity based on annular grey target decision-making model with variable weight. Arab. J. Geosci. 2019, 12, 43. [Google Scholar] [CrossRef]
- Xue, Y.; Li, Z.; Li, S.; Qiu, D.; Tao, Y.; Wang, L.; Yang, W.; Zhang, K. Prediction of rock burst in underground caverns based on rough set and extensible comprehensive evaluation. Bull. Eng. Geol. Environ. 2019, 78, 417–429. [Google Scholar] [CrossRef]
- Liang, W.; Zhao, G.; Wu, H.; Dai, B. Risk assessment of rockburst via an extended MABAC method under fuzzy environment. Tunn. Undergr. Space Technol. 2019, 83, 533–544. [Google Scholar] [CrossRef]
- Xue, Y.; Bai, C.; Kong, F.; Qiu, D.; Li, L.; Su, M.; Zhao, Y. A two-step comprehensive evaluation model for rockburst prediction based on multiple empirical criteria. Eng. Geol. 2020, 268, 105515. [Google Scholar] [CrossRef]
- Xue, Y.; Bai, C.; Qiu, D.; Kong, F.; Li, Z. Predicting rockburst with database using particle swarm optimization and extreme learning machine. Tunn. Undergr. Space Technol. 2020, 98, 103287. [Google Scholar] [CrossRef]
- Zhou, J.; Koopialipoor, M.; Li, E.; Armaghani, D.J. Prediction of rockburst risk in underground projects developing a neuro-bee intelligent system. Bull. Eng. Geol. Environ. 2020, 79, 4265–4279. [Google Scholar] [CrossRef]
- Ribeiro e Sousa, L.; Miranda, T.; Leal e Sousa, R.; Tinoco, J. The Use of Data Mining Techniques in Rockburst Risk Assessment. Engineering 2017, 3, 552–558. [Google Scholar] [CrossRef]
- Wang, J.; Apel, D.B.; Pu, Y.; Hall, R.; Wei, C.; Sepehri, M. Numerical modeling for rockbursts: A state-of-the-art review. J. Rock Mech. Geotech. Eng. 2021, 13, 457–478. [Google Scholar] [CrossRef]
- Zubelewicz, A.; Mróz, Z. Numerical simulation of rock burst processes treated as problems of dynamic instability. Rock Mech. Rock Eng. 1983, 16, 253–274. [Google Scholar] [CrossRef]
- Wang, S.Y.; Lam, K.C.; Au, S.K.; Tang, C.A.; Zhu, W.C.; Yang, T.H. Analytical and Numerical Study on the Pillar Rockbursts Mechanism. Rock Mech. Rock Eng. 2006, 39, 445–467. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Wei, C. Applying Machine Learning Approaches to Evaluating Rockburst Liability: A Comparation of Generative and Discriminative Models. Pure Appl. Geophys. 2019, 176, 4503–4517. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Wang, C.; Wilson, B. Evaluation of burst liability in kimberlite using support vector machine. Acta Geophys. 2018, 66, 973–982. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Lingga, B. Rockburst prediction in kimberlite using decision tree with incomplete data. J. Sustain. Min. 2018, 17, 158–165. [Google Scholar] [CrossRef]
- Liu, Z.; Armaghani, D.-J.; Fakharian, P.; Li, D.; Ulrikh, D.-V.; Orekhova, N.-N.; Khedher, K.-M. Rock Strength Estimation Using Several Tree-Based ML Techniques. Comput. Model. Eng. Sci. 2022, 133, 799–824. [Google Scholar] [CrossRef]
- Li, G.; Xue, Y.; Qu, C.; Qiu, D.; Wang, P.; Liu, Q. Intelligent prediction of rockburst in tunnels based on back propagation neural network integrated beetle antennae search algorithm. Environ. Sci. Pollut. Res. 2022. [Google Scholar] [CrossRef]
- Kadkhodaei, M.H.; Ghasemi, E. Development of a Semi-quantitative Framework to Assess Rockburst Risk Using Risk Matrix and Logistic Model Tree. Geotech. Geol. Eng. 2022, 40, 3669–3685. [Google Scholar] [CrossRef]
- Kadkhodaei, M.H.; Ghasemi, E.; Sari, M. Stochastic assessment of rockburst potential in underground spaces using Monte Carlo simulation. Environ. Earth Sci. 2022, 81, 447. [Google Scholar] [CrossRef]
- Wang, H.; Li, Z.; Song, D.; He, X.; Sobolev, A.; Khan, M. An Intelligent Rockburst Prediction Model Based on Scorecard Methodology. Minerals 2021, 11, 1294. [Google Scholar] [CrossRef]
- Ghasemi, E.; Gholizadeh, H.; Adoko, A.C. Evaluation of rockburst occurrence and intensity in underground structures using decision tree approach. Eng. Comput. 2019, 36, 213–225. [Google Scholar] [CrossRef]
- Shaidurov, G.Y.; Kudinov, D.S.; Kokhonkova, E.A. On the possibility of creating a comprehensive system for rockburst prediction in mines and mining plants. J. Phys. Conf. Ser. 2019, 1399, 033100. [Google Scholar] [CrossRef]
- Shirani Faradonbeh, R.; Shaffiee Haghshenas, S.; Taheri, A.; Mikaeil, R. Application of self-organizing map and fuzzy c-mean techniques for rockburst clustering in deep underground projects. Neural Comput. Appl. 2020, 32, 8545–8559. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, X.-z.; Dong, L.; Hu, H.-y.; Wang, H.-y. Fisher discriminant analysis model and its application for prediction of classification of rockburst in deep-buried long tunnel. J. Coal Sci. Eng. 2010, 16, 144–149. [Google Scholar] [CrossRef]
- Li, N.; Jimenez, R. A logistic regression classifier for long-term probabilistic prediction of rock burst hazard. Nat. Hazards 2018, 90, 197–215. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Classification of Rockburst in Underground Projects: Comparison of Ten Supervised Learning Methods. J. Comput. Civ. Eng. 2016, 30, 04016003. [Google Scholar] [CrossRef]
- Zhou, J.; Guo, H.; Koopialipoor, M.; Jahed Armaghani, D.; Tahir, M.M. Investigating the effective parameters on the risk levels of rockburst phenomena by developing a hybrid heuristic algorithm. Eng. Comput. 2020, 37, 1679–1694. [Google Scholar] [CrossRef]
- Zhang, M. Prediction of rockburst hazard based on particle swarm algorithm and neural network. Neural Comput. Appl. 2021, 34, 2649–2659. [Google Scholar] [CrossRef]
- Zhang, G.; Gao, Q.; Du, J.; Li, K. Rockburst criterion based on artificial neural networks and nonlinear regression. J. Cent. South Univ. 2013, 44, 2977–2981. [Google Scholar]
- Li, D.; Liu, Z.; Xiao, P.; Zhou, J.; Jahed Armaghani, D. Intelligent rockburst prediction model with sample category balance using feedforward neural network and Bayesian optimization. Undergr. Space 2022, 7, 833–846. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Xu, H. Rockburst prediction in kimberlite with unsupervised learning method and support vector classifier. Tunn. Undergr. Space Technol. 2019, 90, 12–18. [Google Scholar] [CrossRef]
- Xue, Y.; Li, G.; Li, Z.; Wang, P.; Gong, H.; Kong, F. Intelligent prediction of rockburst based on Copula-MC oversampling architecture. Bull. Eng. Geol. Environ. 2022, 81, 209. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y.; Sun, Y.; Li, G. Strength of ensemble learning in multiclass classification of rockburst intensity. Int. J. Numer. Anal. Methods Geomech. 2020, 44, 1833–1853. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. MLear 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. MLear 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Yin, X.; Liu, Q.; Pan, Y.; Huang, X.; Wu, J.; Wang, X. Strength of Stacking Technique of Ensemble Learning in Rockburst Prediction with Imbalanced Data: Comparison of Eight Single and Ensemble Models. Nat. Resour. Res. 2021, 30, 1795–1815. [Google Scholar] [CrossRef]
- Wang, S.-m.; Zhou, J.; Li, C.-q.; Armaghani, D.J.; Li, X.-b.; Mitri, H.S. Rockburst prediction in hard rock mines developing bagging and boosting tree-based ensemble techniques. J. Cent. South Univ. 2021, 28, 527–542. [Google Scholar] [CrossRef]
- Shukla, R.; Khandelwal, M.; Kankar, P.K. Prediction and Assessment of Rock Burst Using Various Meta-heuristic Approaches. Min. Metall. Explor. 2021, 38, 1375–1381. [Google Scholar] [CrossRef]
- Li, D.; Liu, Z.; Armaghani, D.J.; Xiao, P.; Zhou, J. Novel ensemble intelligence methodologies for rockburst assessment in complex and variable environments. Sci. Rep. 2022, 12, 1844. [Google Scholar] [CrossRef]
- Li, D.; Liu, Z.; Armaghani, D.J.; Xiao, P.; Zhou, J. Novel Ensemble Tree Solution for Rockburst Prediction Using Deep Forest. Mathematics 2022, 10, 787. [Google Scholar] [CrossRef]
- Ahmad, M.; Katman, H.Y.; Al-Mansob, R.A.; Ahmad, F.; Safdar, M.; Alguno, A.C. Prediction of Rockburst Intensity Grade in Deep Underground Excavation Using Adaptive Boosting Classifier. Complexity 2022, 2022, 6156210. [Google Scholar] [CrossRef]
- Xiao, P.; Li, D.; Zhao, G.; Liu, H. New criterion for the spalling failure of deep rock engineering based on energy release. Int. J. Rock Mech. Min. Sci. 2021, 148, 104943. [Google Scholar] [CrossRef]
- Lim, S.S.; Martin, C.D. Core disking and its relationship with stress magnitude for Lac du Bonnet granite. Int. J. Rock Mech. Min. Sci. 2010, 47, 254–264. [Google Scholar] [CrossRef]
- Aljamaan, H.; Alazba, A. Software defect prediction using tree-based ensembles. In Proceedings of the 16th ACM International Conference on Predictive Models and Data Analytics in Software Engineering, Virtual Event, 8–9 November 2020; pp. 1–10. [Google Scholar]
- Yang, Y.; Chen, H.; Heidari, A.A.; Gandomi, A.H. Hunger games search: Visions, conception, implementation, deep analysis, perspectives, and towards performance shifts. Expert Syst. Appl. 2021, 177, 114864. [Google Scholar] [CrossRef]
- Russenes, B. Analysis of rock spalling for tunnels in steep valley sides. Master’s Thesis, Norwegian Institute of Technology, Department of Geology, Trondheim, Norway, 1974. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. the J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | ACC | ACC Rank | Kappa | Kappa Rank | MCC | MCC Rank | Total Rank |
|---|---|---|---|---|---|---|---|
| Training | |||||||
| Swarm = 40 | 1.00 | 5 | 1.00 | 5 | 1.00 | 5 | 15 |
| Swarm = 50 | 1.00 | 5 | 1.00 | 5 | 1.00 | 5 | 15 |
| Swarm = 60 | 1.00 | 5 | 1.00 | 5 | 1.00 | 5 | 15 |
| Swarm = 70 | 1.00 | 5 | 1.00 | 5 | 1.00 | 5 | 15 |
| Swarm = 80 | 1.00 | 5 | 1.00 | 5 | 1.00 | 5 | 15 |
| Testing | |||||||
| Swarm = 40 | 0.84 | 3 | 0.78 | 3 | 0.78 | 3 | 9 |
| Swarm = 50 | 0.87 | 4 | 0.82 | 4 | 0.82 | 4 | 12 |
| Swarm = 60 | 0.87 | 4 | 0.82 | 4 | 0.82 | 4 | 12 |
| Swarm = 70 | 0.87 | 4 | 0.82 | 4 | 0.82 | 4 | 12 |
| Swarm = 80 | 0.89 | 5 | 0.84 | 5 | 0.85 | 5 | 15 |
| No. | Project | MTS/MPa | UCS/MPa | TS/MPa | BR | SCF | ESE | Rockburst Level |
|---|---|---|---|---|---|---|---|---|
| 1 | FSU Kirov mine | Nan | Nan | Nan | 20.40 | 0.30 | 5.00 | M |
| 2 | Long exploratory tunnel | Nan | Nan | Nan | 27.30 | 0.87 | 3.10 | S |
| 3 | Nan | Nan | Nan | 27.30 | 0.68 | 3.10 | M | |
| 4 | Jiangban hydropower station | 104.99 | 164.05 | Nan | Nan | 0.64 | 8.41 | S |
| 5 | 84.86 | 146.31 | Nan | Nan | 0.58 | 5.13 | M | |
| 6 | 39.56 | 131.86 | Nan | Nan | 0.30 | 4.22 | N | |
| 7 | 81.32 | 147.85 | Nan | Nan | 0.55 | 5.60 | M | |
| 8 | 55.40 | 138.50 | Nan | Nan | 0.40 | 5.38 | L | |
| 9 | 59.57 | 116.80 | Nan | Nan | 0.51 | 3.04 | L | |
| 10 | 105.88 | 168.07 | Nan | Nan | 0.63 | 7.90 | S | |
| 11 | 91.01 | 154.26 | Nan | Nan | 0.59 | 4.85 | M | |
| 12 | 55.51 | 129.10 | Nan | Nan | 0.43 | 3.41 | L | |
| 13 | 41.22 | 124.90 | Nan | Nan | 0.33 | 3.96 | N | |
| 14 | 60.58 | 140.88 | Nan | Nan | 0.43 | 4.87 | L | |
| 15 | 86.47 | 151.70 | Nan | Nan | 0.57 | 7.26 | M | |
| 16 | 47.53 | 125.07 | Nan | Nan | 0.38 | 4.08 | N | |
| 17 | 109.36 | 160.83 | Nan | Nan | 0.68 | 7.09 | M | |
| 18 | 40.45 | 130.47 | Nan | Nan | 0.31 | 3.96 | N | |
| 19 | 84.64 | 159.70 | Nan | Nan | 0.53 | 5.15 | M | |
| 20 | 118.10 | 166.34 | Nan | Nan | 0.71 | 8.32 | S | |
| 21 | 58.84 | 143.50 | Nan | Nan | 0.41 | 4.67 | L | |
| 22 | 37.39 | 128.93 | Nan | Nan | 0.29 | 4.02 | N | |
| 23 | 88.98 | 145.87 | Nan | Nan | 0.61 | 7.16 | M | |
| 24 | 39.06 | 130.21 | Nan | Nan | 0.30 | 4.21 | N | |
| 25 | 60.29 | 140.21 | Nan | Nan | 0.43 | 3.14 | L | |
| 26 | 80.96 | 137.22 | Nan | Nan | 0.59 | 3.46 | M | |
| 27 | 110.19 | 159.70 | Nan | Nan | 0.69 | 4.15 | M |
| No. | Depth/m | MTS/MPa | UCS/MPa | TS/MPa | SCF | BI | ESE | Level | Predicted Level |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 300 | 49.53 | 110.59 | 16.72 | 0.45 | 6.61 | 4.81 | L | L |
| 2 | 300 | 50.35 | 154.93 | 12.829 | 0.32 | 12.08 | 7.16 | M | M |
| 3 | 600 | 27.3 | 200.72 | 14.53 | 0.14 | 13.81 | 13.9 | M | M |
| 4 | 600 | 68.854 | 48.96 | 13.66 | 1.41 | 3.58 | 1.35 | M | M |
| 5 | 900 | 80.06 | 67.65 | 8.28 | 1.18 | 8.17 | 3.98 | M | M |
| 6 | 900 | 83.633 | 112.3 | 10.13 | 0.74 | 11.09 | 3.21 | M | M |
| 7 | 1500 | 103.82 | 206.28 | 12.1 | 0.5 | 17.05 | 6.33 | M | M |
| 8 | 1550 | 112.38 | 178.81 | 12.07 | 0.63 | 14.81 | 7.68 | S | S |
| 9 | 1900 | 120.366 | 75.21 | 9.53 | 1.6 | 7.89 | 4.15 | M | M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Zhao, G.; Xiao, P.; Yin, Y. Ensemble Tree Model for Long-Term Rockburst Prediction in Incomplete Datasets. Minerals 2023, 13, 103. https://doi.org/10.3390/min13010103
Liu H, Zhao G, Xiao P, Yin Y. Ensemble Tree Model for Long-Term Rockburst Prediction in Incomplete Datasets. Minerals. 2023; 13(1):103. https://doi.org/10.3390/min13010103
Chicago/Turabian StyleLiu, Huanxin, Guoyan Zhao, Peng Xiao, and Yantian Yin. 2023. "Ensemble Tree Model for Long-Term Rockburst Prediction in Incomplete Datasets" Minerals 13, no. 1: 103. https://doi.org/10.3390/min13010103