1. Introduction
The waterway water level is the primary factor to be considered for safe navigation of ships, and it is also one of the main factors affecting navigation capacity [
1,
2]. Especially for inland waterways of mountainous areas, problems such as sudden rise of water level, surge of velocity, and complex flow regime in downstream waterways occur frequently due to the irregular discharge of unsteady flow from upstream power stations and rainstorm confluence in river basins [
3,
4]. More specifically, when the river water level soars for a short time, the ships operating in ports and berthing in anchorages along the river need to be adjusted frequently according to the changes of water level. However, when the river water level drops rapidly, the navigation conditions deteriorate rapidly, which brings potential safety hazards such as stranding, hitting rocks, and even being forced to suspend navigation [
5,
6]. Therefore, water-level data are an important reference for evaluating navigation capacity, and accurate prediction of water level is of great guiding significance for flood control, reasonable stowage of ships, and especially for ensuring the safe navigation of ships [
7]. At present, by setting up hydrological observation stations and a hydrological measurement control system based on the Internet of Things, sailing ships can observe dynamic changes in water level in real time, which helps accumulate a large amount of historical hydrological data [
8]. How to further research hydrological prediction based on these data has attracted extensive attention from scholars. In recent years, the relevant research on hydrological prediction has been mainly divided into two categories including the method based on physical processes and the method based on data characteristics.
The method based on physical processes, as its name implies, involves building a model based on the actual process. There are numerous physical-process-based models, which can be classified into hydraulic models, hydrological models, and hydrological hydraulic models [
9,
10]. Typical application cases of these models include the use of the Danish Mike 21 hydrodynamic model, the American SMS hydraulic model, and the American SSARR hydrological model to explore the change of flood-water level [
11,
12,
13]. However, modeling based on physical processes typically requires the collection of numerous physical parameters from topography, land-use, and meteorological data. In practical applications, however, these hydrological and meteorological data records and geographic data records are frequently unavailable or difficult to obtain, limiting the application of such models [
14].
The method based on data feature is suitable for hydrological prediction from the data point of view by mathematical model or machine learning model to mine the relationship between data, including time-series analysis, wavelet analysis, support vector machine, and deep learning. Among them, autoregressive model (AR), autoregressive moving average model (ARMA), and autoregressive integrated moving average model (ARIMA) are often used to analyze water-level changes and runoff changes [
14]. However, this method only reveals the dependency of the series in the time domain, so the processing effect of nonlinear series is poor. Wavelet analysis performs well in the analysis of variation characteristics, so Adamowski et al., Seo et al., and Wang et al. used wavelet analysis method in combination with deep learning in water-level prediction [
15,
16,
17]. Nevertheless the selection of wavelet basis function in wavelet analysis is a thorny problem, and the prediction of water level always needs to be combined with other methods to achieve the target effect. Support vector machine (SVM) was first proposed by Cortes and Vapnik, which performs well in practical classification and regression problems [
18]. Behzad et al. compared the performance of SVM and artificial neural networks in water-level prediction of aquifers [
19]. Dai et al. used a support vector machine to calculate the ideal ecological water level of Dongting Lake [
20]. However, when solving regression problems, the selection of input features of support vector machines is more complex and time-consuming, and the effect will worsen as the amount of data increases. We therefore select the features of input data to avoid the interference caused by redundant information.
It is worth mentioning that in recent years, deep learning has made important progress in data-feature-based methods, which solves the problems that nonlinear data and large quantities of data are difficult to process in the above research methods. Because water-level data are typical nonlinear and non-stationary time-series data, the emergence of recurrent neural network (RNN) greatly promotes the development of hydrological time-series forecasting [
21,
22]. However, RNN is faced with gradient disappearance and gradient explosion, which makes it unable to cope with long-term dependence [
23,
24]. To solve these gradient problems of RNN, long short-term memory (LSTM) and the gated recurrent unit (GRU), which are excellent variation on RNN, have been proposed successively [
25,
26,
27]. Thus, due to their effectiveness in time-series prediction, LSTM and GRU have been applied to the field of hydrologic forecasting in recent years. Typically, Le et al. [
28] proposed an LSTM model suitable for flood prediction and conducted performance comparison experiments with daily runoff and rainfall data as input datasets, demonstrating the excellent performance of LSTM in flood prediction. Xu et al. [
29] proposed a water-level time-series prediction model based on GRU and LightGBM and used GRU to extract water-level data in order to develop a fundamental model for water-level data prediction. The prediction results were divided into non-flood season and flood season and then combined with environmental factors after LightGBM feature selection to establish the final model, thereby resolving the issue of accuracy loss caused by the simple superposition of the predicted values in different seasons.
A point worth emphasizing is that in terms of time-series prediction, compared with using RNN and its variants alone, some research work has combined the RNN model prediction output with the attention mechanism in deep learning. These results show that the introduction of attention mechanism can improve the accuracy of timing prediction to a large extent [
30,
31,
32]. The attention mechanism is a method for rapidly selecting high-value information from huge amounts of information. Based on this mechanism, Hu et al. [
33] developed a runoff forecasting model and predicted the runoff of the basin, and the results demonstrated that this improved method can enhance the accuracy of runoff forecasting.
However, the method combining RNN and the attention mechanism is rarely applied in the field of water-level prediction. As far as the water-level prediction, the water level is not only affected by the historical water level in the past but also by the upstream water level; that is, the river water level data are spatially and temporally related. The existing water-level-prediction models based on LSTM and GRU are facing the problem of insufficient spatial information response capacity [
34]. Moreover, the introduction of an attention mechanism based on RNN can partially solve the problem of insufficient spatial information utilization.
Thus, this paper proposes a high-accuracy water-level-prediction model based on a combination of the spatial-reduction attention and bidirectional gate recurrent unit (SRA-BiGRU) to fully utilize the valuable information contained in massive amount of hydrological data of the Wujiang river and address the deficiencies of existing water-level-prediction methods. The contribution of this model is briefly summarized below: firstly, BiGRU makes use of its strong fitting ability in capturing nonlinear characteristics and fully considers the time series of water-level data. In addition, the bidirectional GRU structure enables the modeling of the potential relationship between past and future water-level data and current data, thereby improving the accuracy of forecasts. Secondly, the introduction of spatial-reduction attention based on BiGRU can actively learn the correlation of hidden vectors of BiGRU and highlight the influence of important features on the prediction results, thereby solving the problems of insufficient utilization of spatial information and long time span in water-level-prediction tasks, which lead to the decline of prediction accuracy. Particularly, the choice of spatial-reduction attention inspired by the Pyramid vision transformer model in the field of computer vision can reduce the computational and memory overhead of the multiheaded attention mechanism due to its unique structure. Last but not least, the superiority of GRU, bidirectional RNN structure and spatial-reduction attention is gradually verified in this research by eight groups of comparative experiments based on the real-time data collected from five water-level-measurement stations in the Wujiang River, which fully proves that the SRA-BiGRU model has higher prediction accuracy in the water-level-prediction task.
2. Materials and Methods
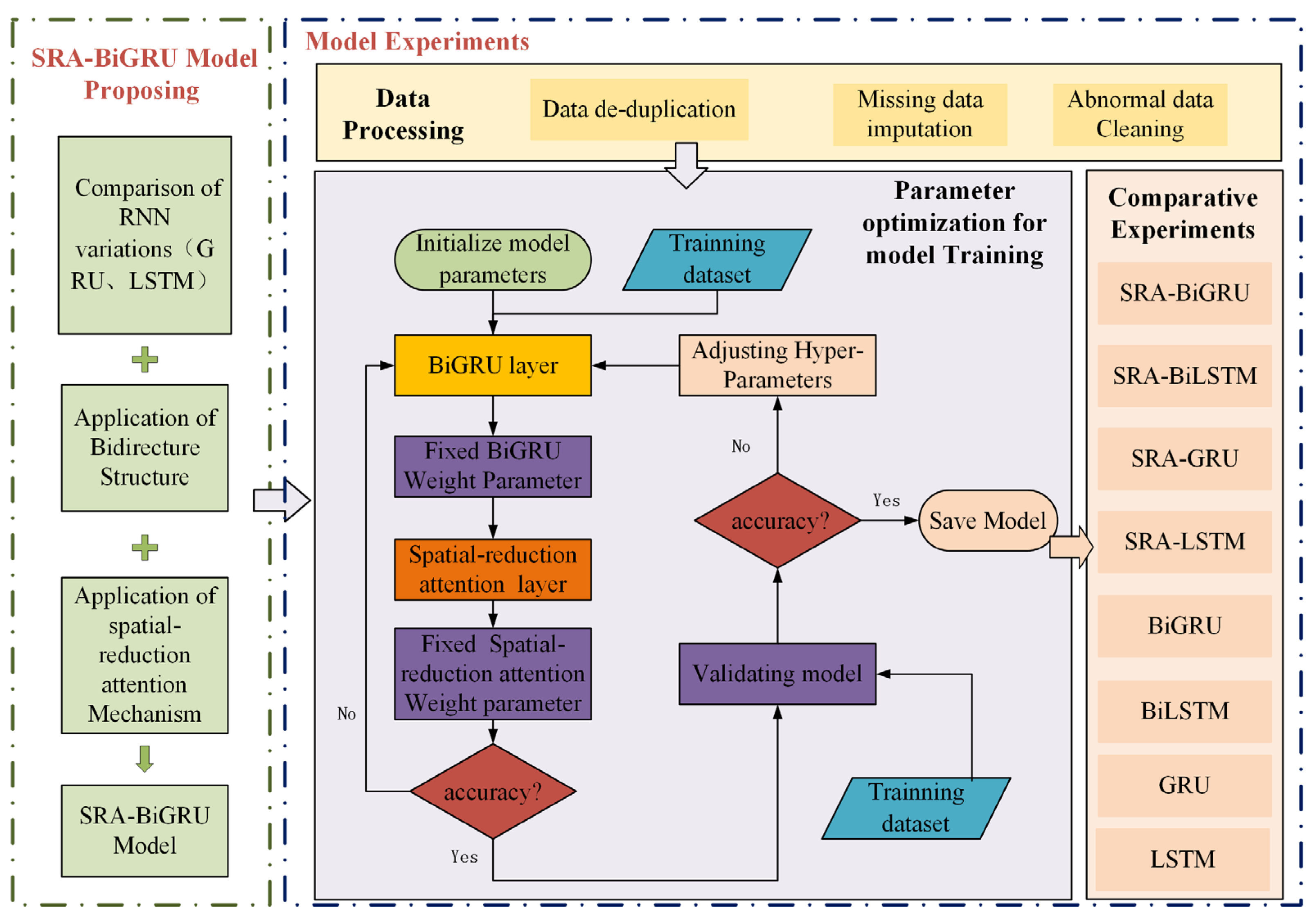
Figure 1 vividly represents the framework of this paper’s core content, which mainly consists SRA-BiGRU model proposal and model experiments. Specifically, an easy-to-use model appropriate for precise and quick water-level prediction is proposed by gradually introducing the applications of RNN variants, bidirectional RNN structure, and spatial-reduction attention. On this basis, the model experiments discuss in detail the methods of data processing and parameter optimization, which play a crucial role in enhancing the model’s accuracy, and then present the effectiveness of the proposed model through comparative experiments.
2.1. Study Area Description
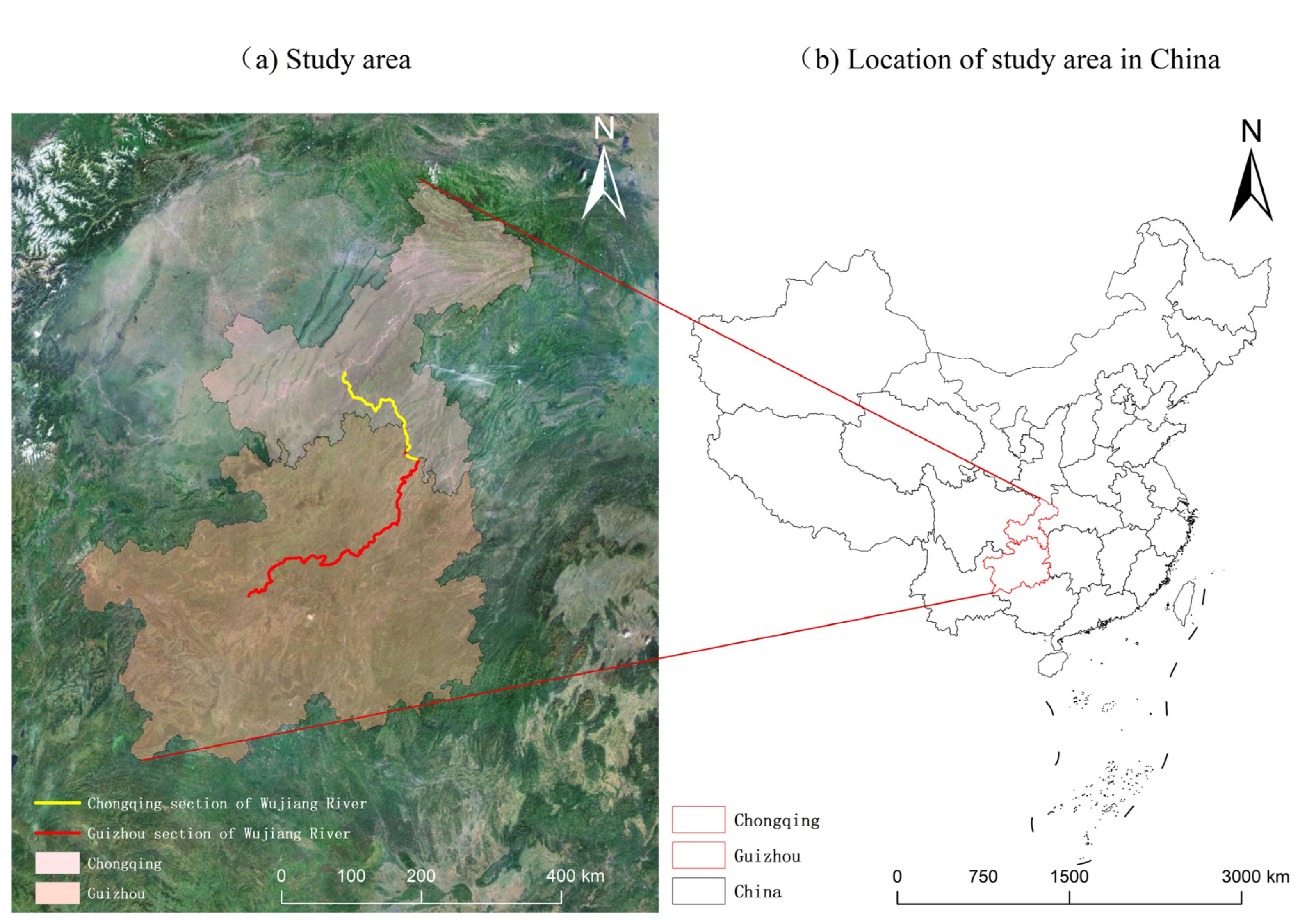
Wujiang River, originating in Guizhou Province and flowing into the Yangtze River in Chongqing City, is the largest tributary on the right bank of the upper reaches of the Yangtze River (see
Figure 2) [
35]. Heavy rainfall is the main cause of the Wujiang flood, but irregular water release from the upstream power station is also a significant contributing factor. Specifically, the Wujiang mainstream power station mainly employs multiple daily peak-shaving operations. The discharge flow of each hydropower station is non-constant and causes the water level of the channel under the dam to rise and fall sharply, with large instantaneous amplitude and frequent changes. In extreme situations, the water level can rise by up to 20 m per day [
4,
35]. When the discharge flow of the power station increases, the water level of the river under the dam rises sharply for a short time. This necessitates frequent adjustments by port operation ships and anchorage ships along the line in response to the change in water level, which poses potential safety hazards to navigable ships and berthing ships in the river section. When the discharge flow of the power station decreases, the water level of the river decreases rapidly, and the navigation conditions deteriorate rapidly. This poses potential safety hazards to transport vessels, such as running aground or being forced to stop sailing [
5,
6].
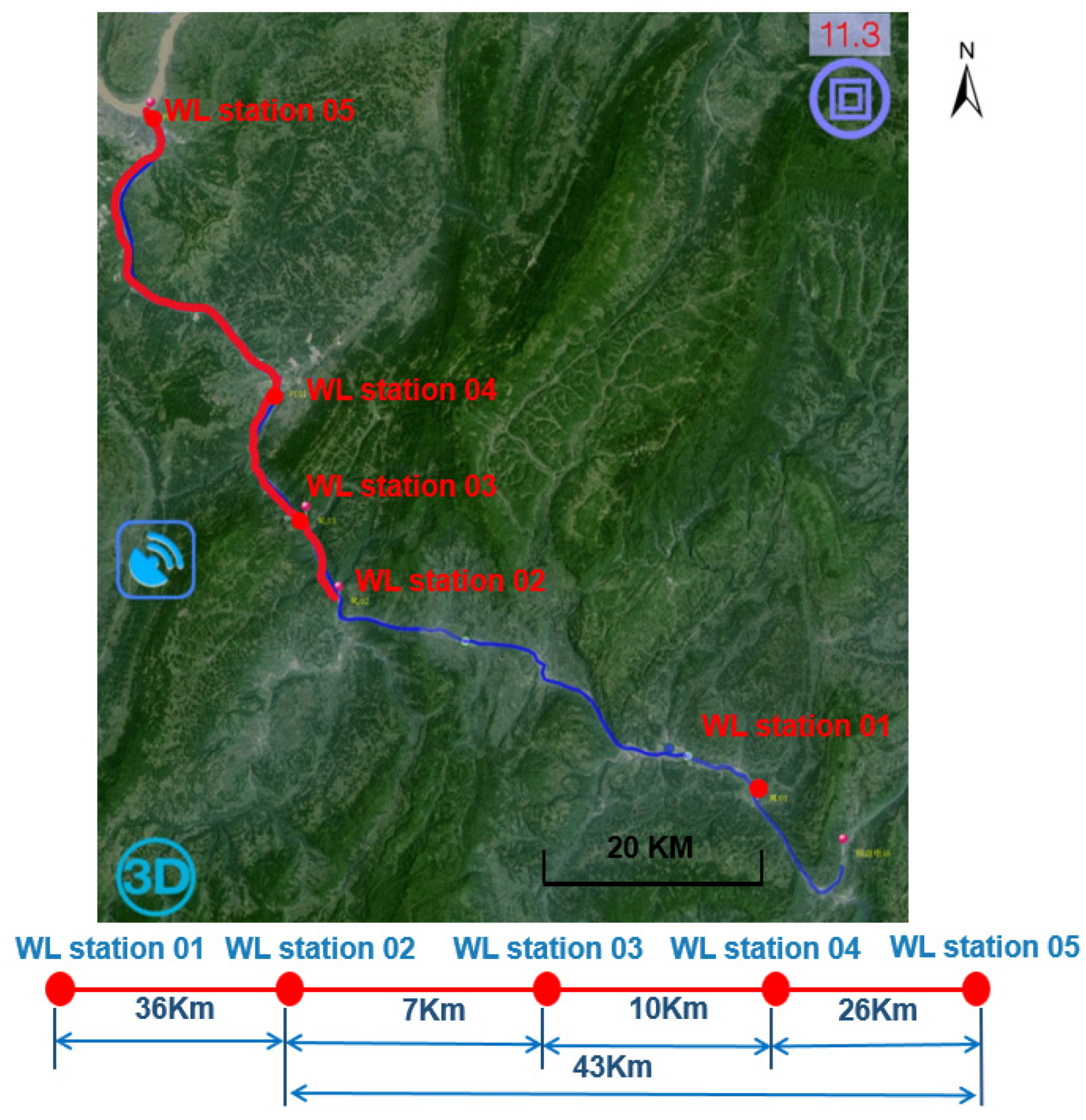
Therefore, conducting accurate water-level-prediction research on Wujiang River is of great significance for flood control, reasonable stowage, and safe navigation of ships in inland waters. Based on this, this experiment used real-time hydrological data collected from five water-level-measurement stations (WL station) built in the 79-kilometer section from Yinpan hydropower station to the Yangtze River Estuary of Wujiang River from 2018 to 2011 as the research object (see
Figure 3).
2.2. Comparison of RNN Variations
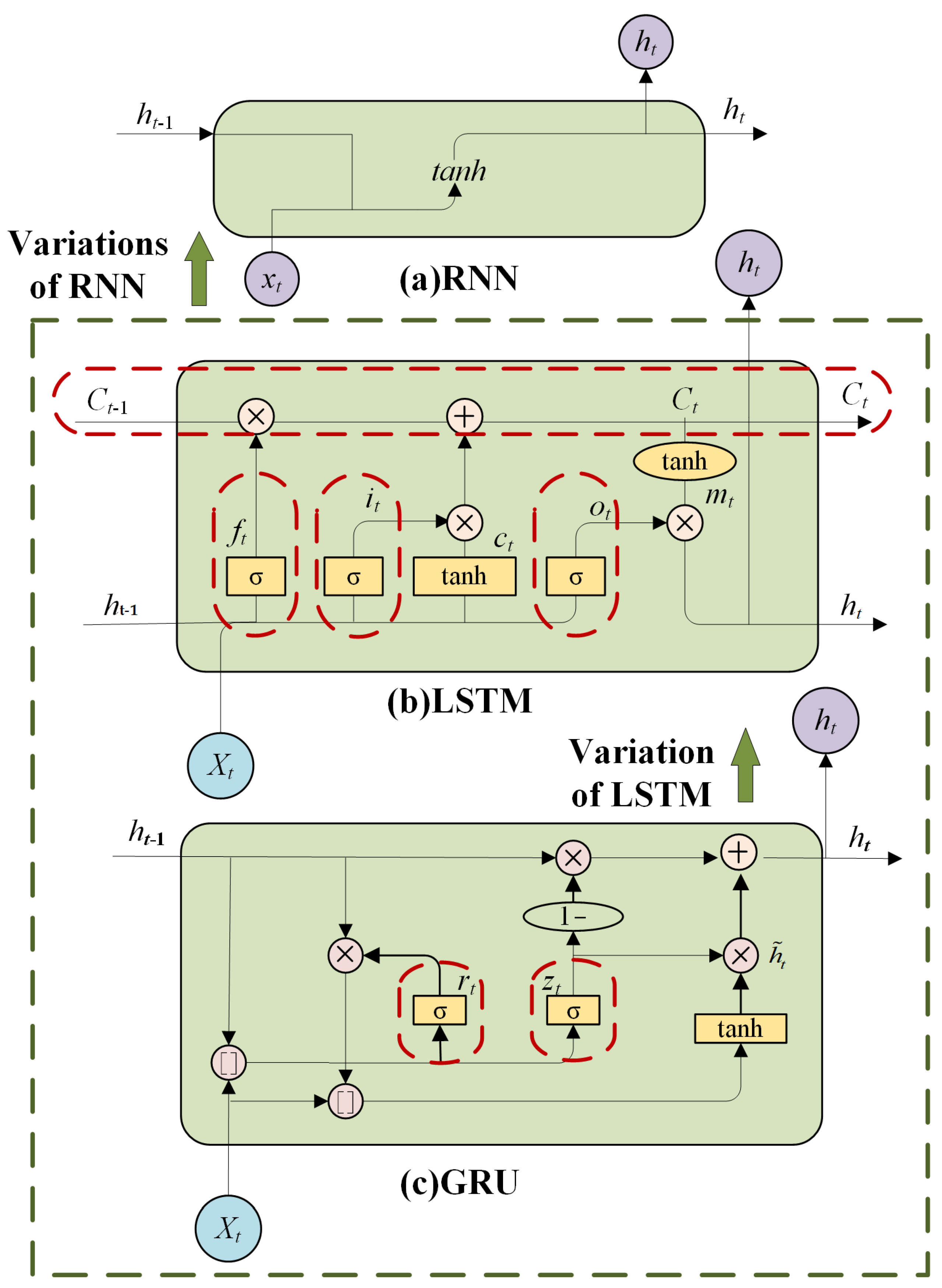
RNN has greatly contributed to the development of hydrological time-series forecasting; however, the gradient-vanishing and gradient-explosion problems of RNN lead to their inability to be applied to long-time dependent situations [
23,
24]. LSTM is one of the typical variants of RNN, which uses gate mechanism and memory unit and can solve the above gradient problem well. The gate structure in LSTM generally includes a forget gate, input gate, and output gate [
25,
26]. Additionally, GRU is a variant of LSTM, which synthesizes the forget gate and input gate of LSTM into one update gate and also mixes cell states and hidden states [
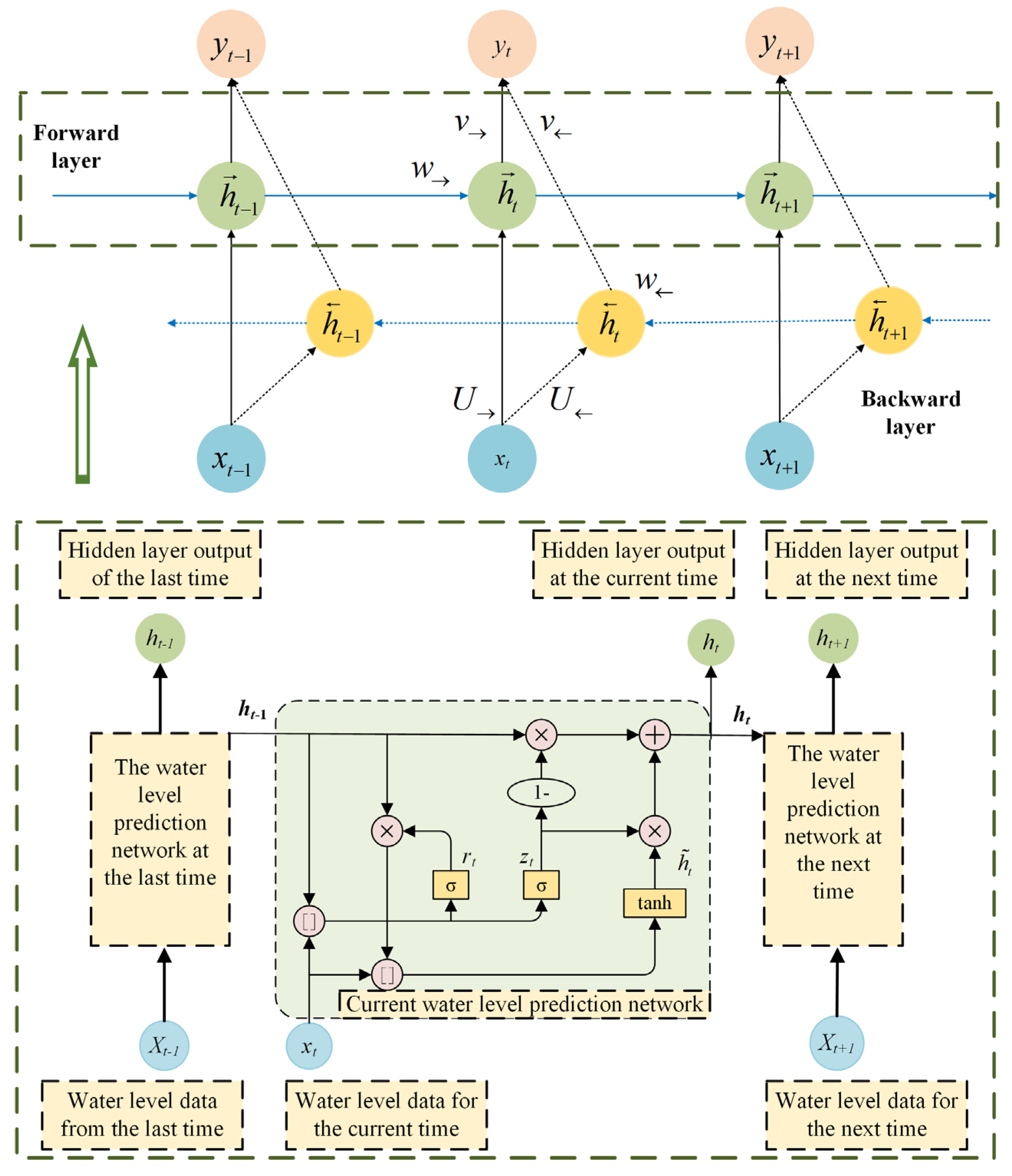
27]. Thus, fewer parameters make GRU converge faster while guaranteeing the prediction accuracy. The simplified structure of GRU is shown in
Figure 4, with only reset gate (
) and update gate (
), and the calculation procedure at each sequence index position is shown as follows:
The
controls the previous moment information with a certain probability and facilitates the obtaining of short-term dependencies in the hydrological time-series data:
Information about the state at the moment before
controls is substituted into the current state, helping to obtain long-term dependencies in the hydrological time-series data:
The implied state
is updated using the update gate
for
and
. The update gate determines the importance of the past
at the current moment as a way to solve the gradient decay problem of the RNN and to better obtain the dependencies with larger intervals in the hydrological time-series data:
where [·] means the multiplication of two vectors,
presents matrix multiplication,
demonstrates that each matrix member is multiplied correspondingly, and W and b represent the weight and bias items of the relevant gates and bias items, respectively.
is the sigmoid activation function.
Thus, as depicted in
Figure 4 [
30], GRU and LSTM are the most representative recurrent neural networks, and both are capable of resolving problems involving long-term memory and back-propagation gradient dispersion. The GRU model and the LSTM model have indistinguishable effects on a variety of task; therefore, this paper conducts comparative experiments based on LSTM and GRU. These comparative experiments not only compare the performance of LSTM and GRU to some extent but also fully verify the effectiveness of using bidirectional RNN structure and introducing spatial-reduction attention.
2.3. Bidirectional RNN Structure
The recurrent neural network can only be extracted from previous inputs in order to predict the current state, but bidirectional recurrent neural network (BiRNN) will extract future data to enhance its accuracy [
36,
37]. BiRNN is also applicable to LSTM and GRU. Therefore, bidirectional GRU(BiGRU) will serve as an illustration for this discussion.
As shown in
Figure 5 [
30], {
,
,
} depicts the forward propagation path of BIGRU, whereas {
,
,
} depicts the reverse propagation path. To be more precise, the forward propagation learns from previous data, whereas the reverse propagation learns from future data, allowing each time step to make optimal use of upper and lower related data. Then, these two outputs are combined to form the final output of the entire BiGRU [
36,
37]. Thus, BiGRU permits the modeling of the potential relationship between previous and future water-level information with the current information, hence enhancing the accuracy of forecasts.
2.4. Spatial-Reduction Attention
Since the rapid development of deep learning, attention mechanism has been widely used in natural language processing, statistical learning, image detection, speech recognition, and other fields as well as in the processing of regression problems [
38]. For the time-series prediction, some research combines the RNN model prediction output with the attention mechanism, and its research results indicate that the addition of the attention mechanism can significantly improve prediction accuracy [
30,
31,
32]. These researchers typically use two dimensions to explain the improvement in prediction accuracy: attention mechanisms based on different times and attention mechanisms based on different characteristics. The former assigns different weights to the hidden layer outputs at different times and then uses weighted summation to obtain an RNN context vector. The latter can be thought of as assigning different attention weights to various dimensions of the output vector [
38,
39]. Thus, this paper proposes the attention mechanism based on BiGRU to address the issues of reduced prediction accuracy due to the extended time span in the water-level-prediction task and insufficient spatial information utilization in the water-level-prediction task.
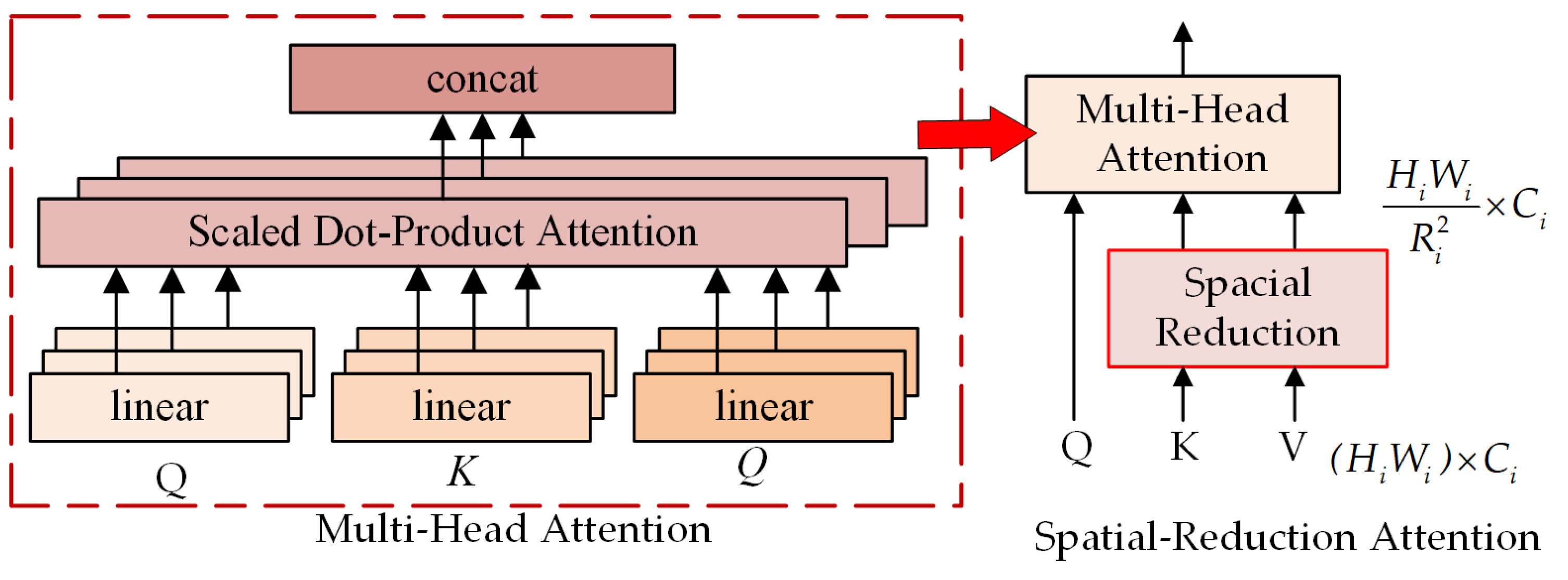
Particularly, this paper ingeniously combines the spatial-reduction attention (SRA) structure with BiGRU, inspired by the Pyramid vision transformer (PVT) model in the field of computer vision [
40,
41]. Comparable to a multi-head attention mechanism, the SRA structure receives Q, K, and V as input and outputs refined features. It refers to the fact that SRA reduces the spatial scale of K and V prior to attention operation, thereby drastically reducing the computation and memory requirements of multi-head attention mechanisms. The structure of SRA is depicted in
Figure 6 [
41], and the structure of SRA during phase
i is depicted below [
41].
where
is the operation of concatenation.
,
, and
are parameters for linear projection.
Ni is the head number of the Stage
i attention layer. Therefore, each head’s dimension is equal to
. The notation for
, which reduces the spatial dimension of the input sequence, is as follows:
is a linear projection that reduces the dimension of the input sequence to
Ci,
is the same as the original transformer, and
is calculated as follows:
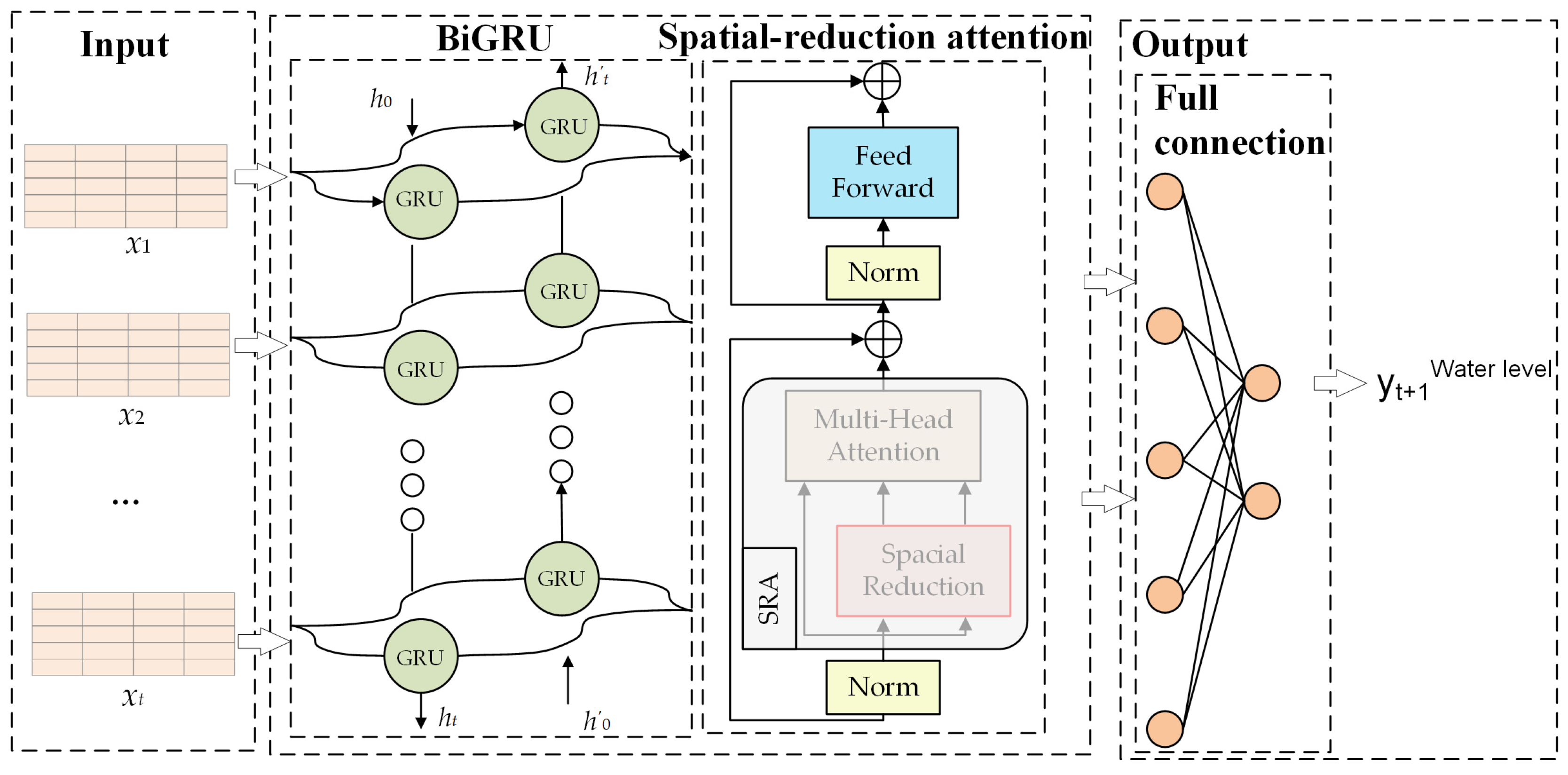
2.5. Overall Model
The SRA-BiGRU model (see
Figure 7) is proposed as an easy-to-use method for solving the problems of insufficient spatial information utilization and long time span in water-level-prediction tasks by integrating the benefits of BiGRU and spatial-reduction attention.
Specifically, because the water level is a continuously changing quantity in the time dimension and is closely related to the historical state, it is preferable to use GRU to enable the water-level information to be memorized and transmitted in time sequence, thereby realizing the concept of time series, and on this basis, the bidirectional RNN structure enables to build the prospective relationship between past water-level status and future water-level status with the current state. Therefore, BiGRU is more adaptable and can link multiple influencing factors to changes in water level.
However, in the BiGRU-based water-level-prediction model, what is used is a fixed contextual vector generated from the inputs. Due to the limited length of the vector, it is difficult to summarize the information of the whole water-level sequence, and the information entered first in BiGRU is diluted to some extent by the later inputs. Therefore, as the input sequence becomes longer, this fixed context vector becomes less and less able to reflect the real information in the water-level data. In addition, the fixed context vector alone cannot distinguish the degree of correlation between the output sequence and the hidden layer of the input sequence across time synchronization. Moreover, the water-level-prediction model based on BiGRU is affected by the inadequacy of spatial information’s response capability, so it cannot use spatial information between water-level-measurement stations.
Consequently, introducing the spatial-reduction attention based on the BiGRU can automatically learn the correlation of each hidden vector it generates, effectively resolving the problem of accuracy degradation caused by the extended time period in the water-level-prediction task. In addition, considering that the spatial distribution of upstream water-level stations with their water level, flow velocity and climate information will have an impact on the water-level-prediction task, the attention mechanism can set the attention weight for each feature so as to calculate the impact of the information of the upstream water-level stations on the water-level prediction in the future moment with its own water-level station as the center. It is worth mentioning that the spatial-reduction attention reduces the computational and memory overhead of the multi-headed attention mechanism due to its unique structure.
4. Discussion
Most power stations in the mainstream of Wujiang River use peak-shaving operations several times a day. The unsteady flow discharged from each hydropower station causes the water level in the channel under the dam to rise and fall suddenly. The instantaneous amplitude changes frequently, even in the extreme situation where the water level rises by 20 m a day [
35]. These issues, such as abrupt changes in water level, sudden increases in velocity, and intricate flow patterns, not only extend the operational cycle of navigable ships but also increase their operational costs, posing certain risks to the safety of ship transportation and flood control of cities along the route. Consequently, the precise prediction of water level is of immense importance for flood control, rational ship stowage, and secure navigation of ships in the Wujiang River Basin. By gradually introducing the applications of GRU, bidirectional RNN structure, and spatial-reduction attention mechanism, an easy-to-use model appropriate for precise and quick water-level-prediction is proposed, and comparative experiment results further prove that the proposed SRA-BiGRU model has higher prediction accuracy in the water-level-prediction task.
GRU and LSTM, both excellent variants of the recurrent neural networks, can use their strong fitting ability in capturing nonlinear characteristics, and both fully consider the time series of water-level data [
23,
24,
25,
26,
27,
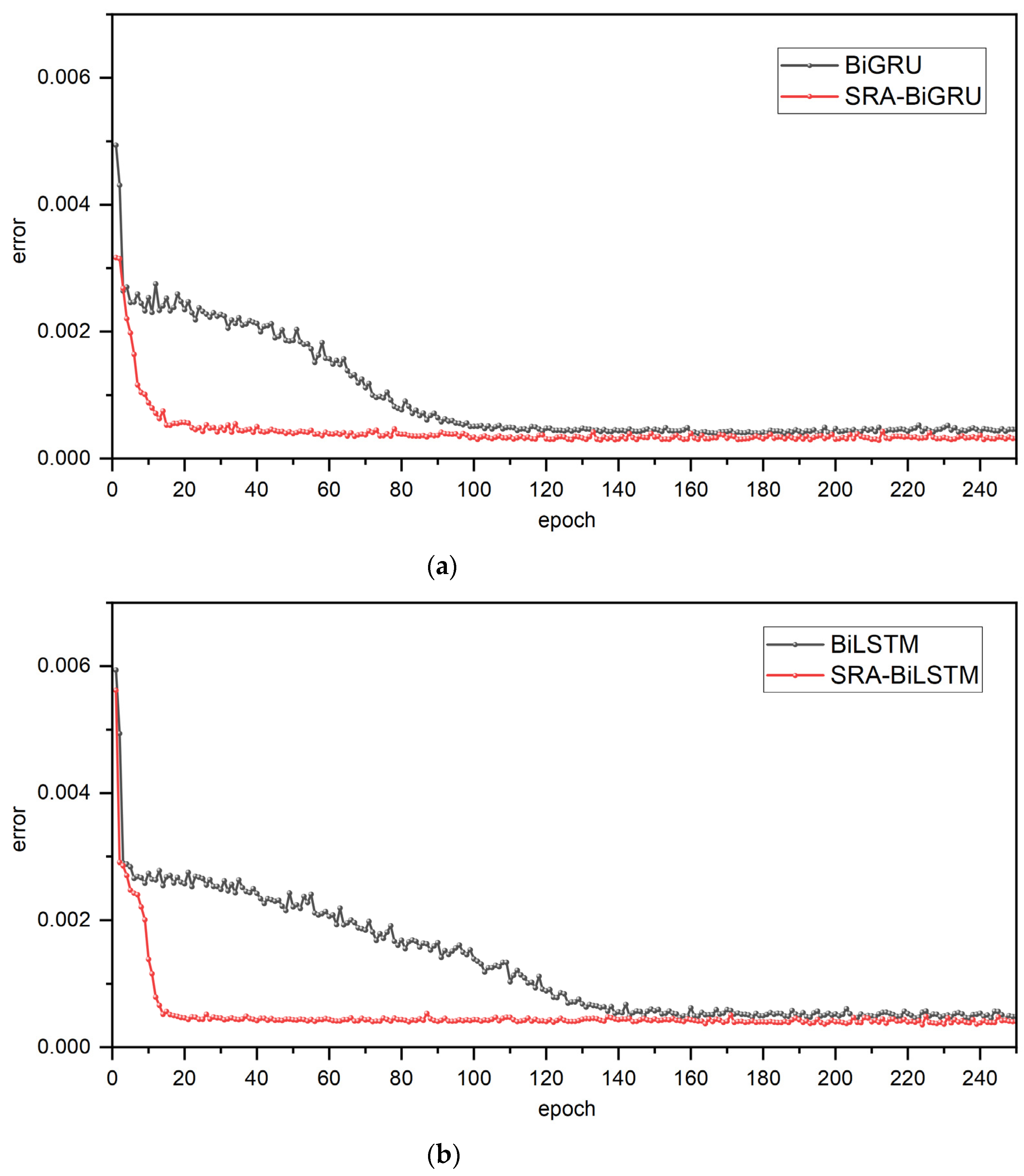
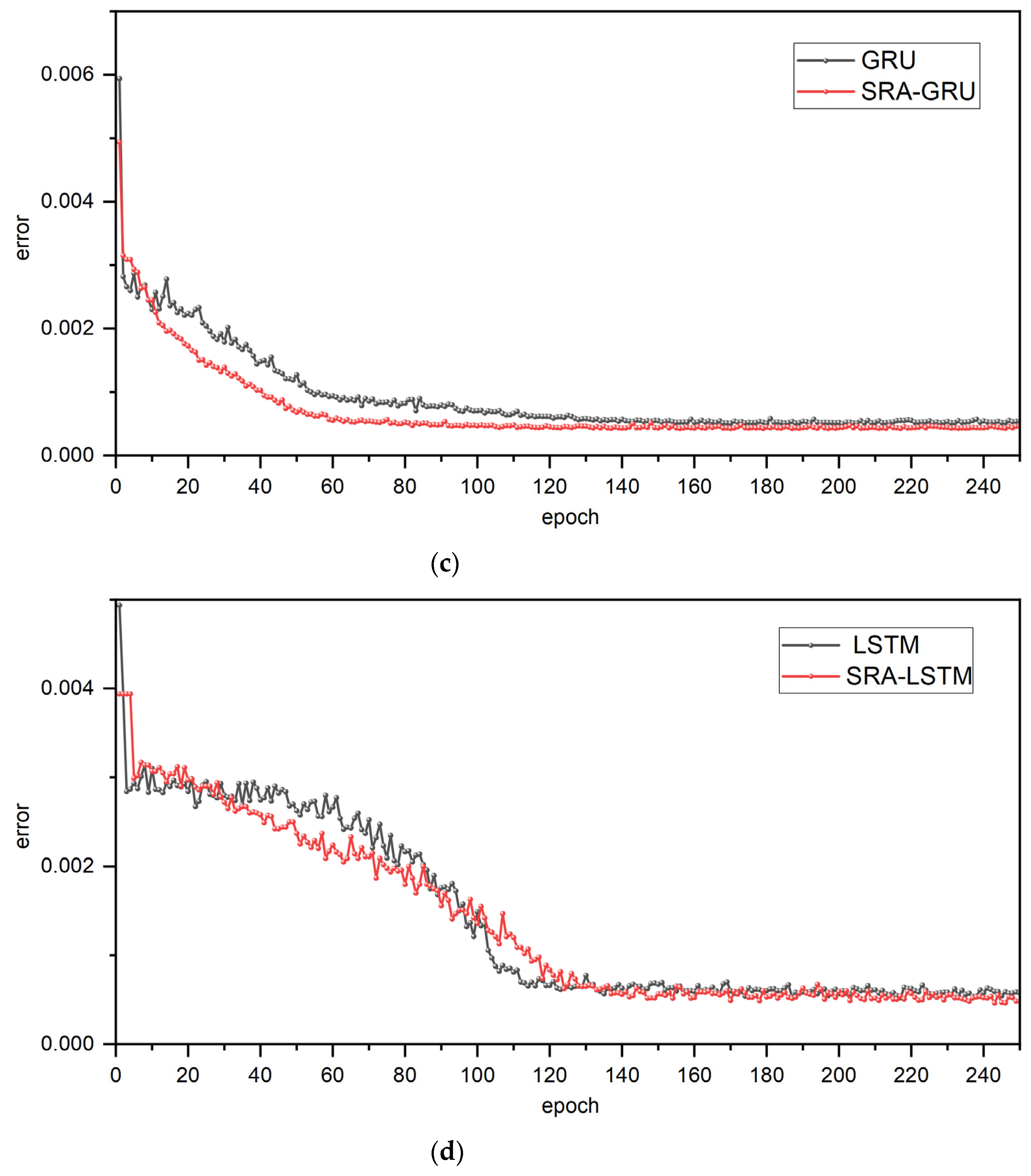
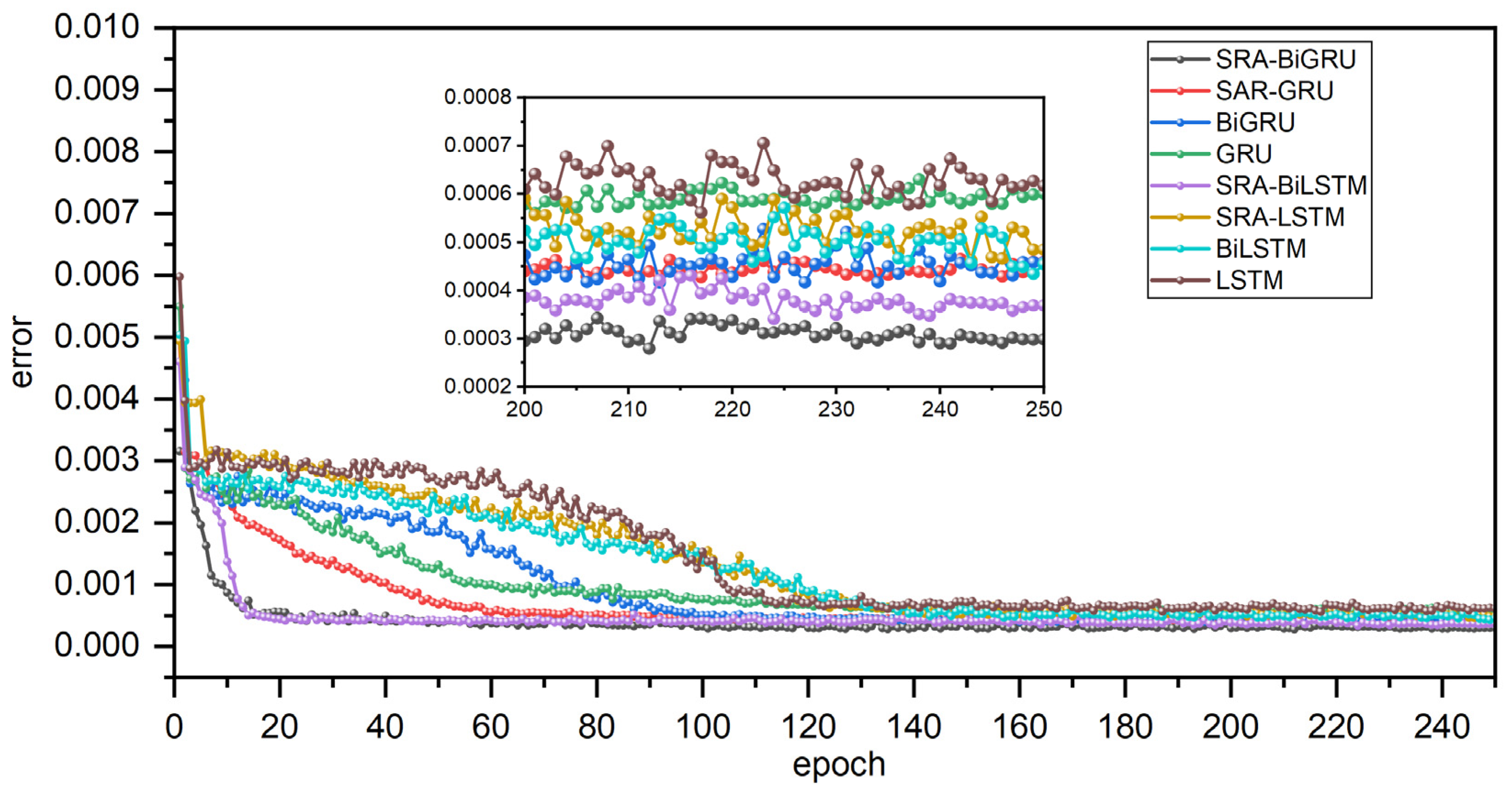
39]. Because these two models have indistinguishable effects on many tasks, this paper conducted comparative experiments using LSTM and GRU, and the results of comparative experiments indicate that GRU outperforms LSTM in terms of both efficiency and accuracy irrespective of whether the model is combined with a bidirectional RNN structure, the spatial-reduction attention mechanism, or neither. In spite of the fact that GRU outperforms LSTM in this experiment, there is no definitive conclusion as to which is superior, and the best model must be chosen based on the specific tasks and datasets at hand.
However, LSTM and GRU cannot encode information from back to front and can only predict the output of the next time based on timing information from the previous time, whereas BiLSTM and BiGRU can encode information from back to front, and the output is determined by the previous and future states [
30,
36]. Due to the complex structure of the bidirectional RNN structure, its running time will increase proportionally, but it can be viewed as a technique for enhancing precision [
37]. Moreover, comparative experiments confirm the efficacy of the bidirectional structure by demonstrating that whether combined with LSTM or GRU, the bidirectional RNN structure can dramatically improve the accuracy of water-level prediction. Therefore, it gives a conclusion that BiGRU enables the modeling of the potential relationship between past and future water-level data and current data, thereby improving the accuracy of forecasts.
Targeting the time-series-prediction task, compared with using RNN and its variants alone, some research work has combined the RNN model prediction output with the attention mechanism in deep learning. These research findings indicate that this approach of rapidly selecting high-value information from a large amount of data can significantly enhance the accuracy of time-series prediction [
30,
31,
32]. However, this method is rarely applied in the field of water-level prediction. In terms of water-level prediction, the water level is affected not only by historical water levels but also by upstream water levels, indicating that river water-level data are spatially and temporally related. However, the water-level-prediction model based on BiGRU is plagued by a lack of spatial information-response capacity. Consequently, to address the issues of reduced prediction accuracy due to the extended time span in the water-level-prediction task and insufficient spatial information utilization. Particularly, the selection of spatial-reduction attention reduces the computational and memory overhead of the multihead attention mechanism owing to its distinctive structure [
41].
Furthermore, the results of comparative experiments based on the spatial-reduction attention mechanism demonstrate the benefit of combining the spatial-reduction attention mechanism with RNN and BiRNN. Therefore, it is clearly demonstrated that the incorporation of spatial-reduction attention can not only automatically capture the correlations between the hidden vectors generated by BiGRU but can also effectively address the issue of precision degradation due to the extended time span in water-level-forecasting tasks. Furthermore, it can take into account the impact of the spatial distribution of upstream water level stations on the water-level-prediction task and assign attention weights to each feature, thereby calculating the influence of upstream water-level station information on the future water-level prediction with its own water-level station as the focal point.
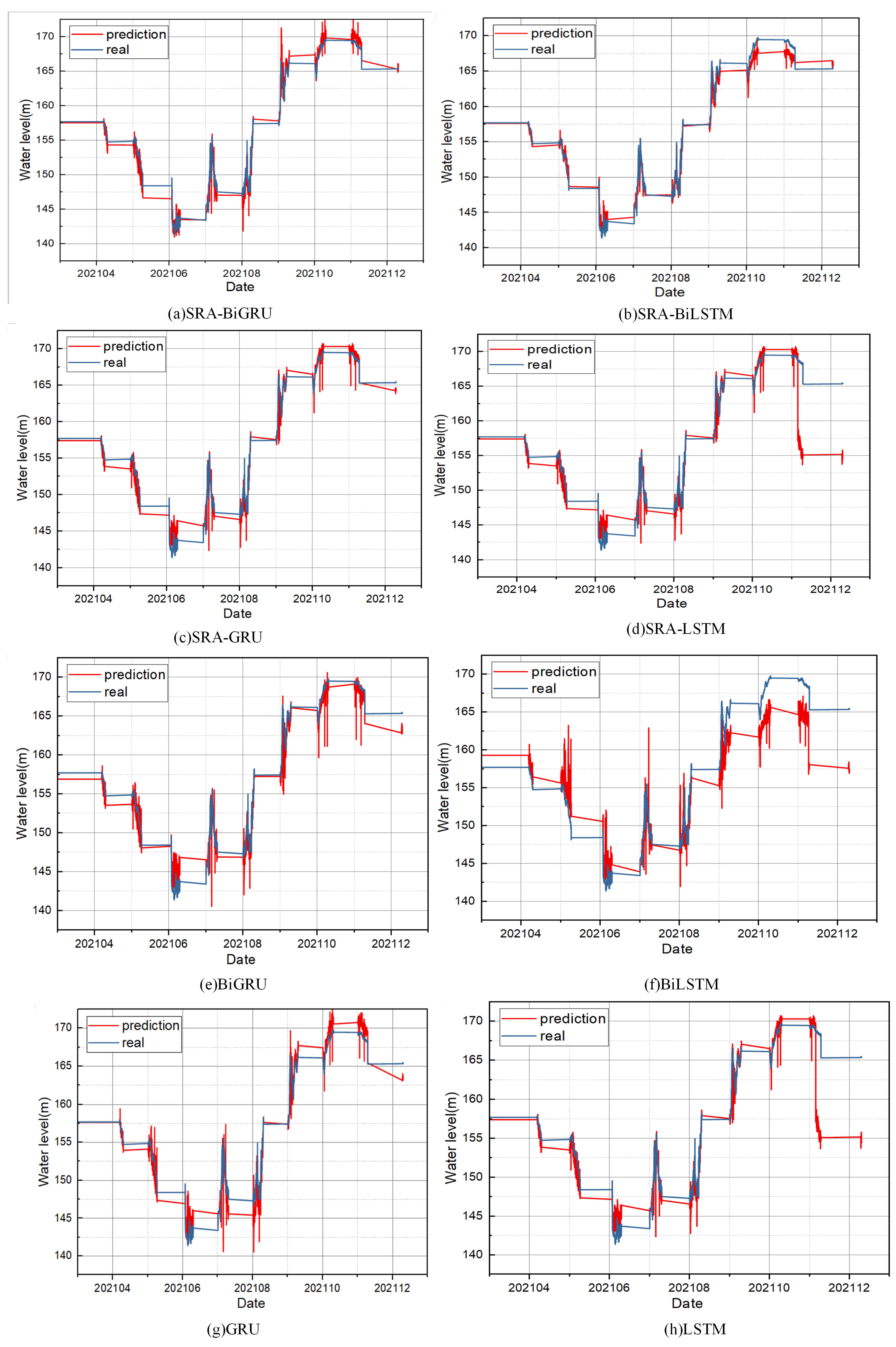
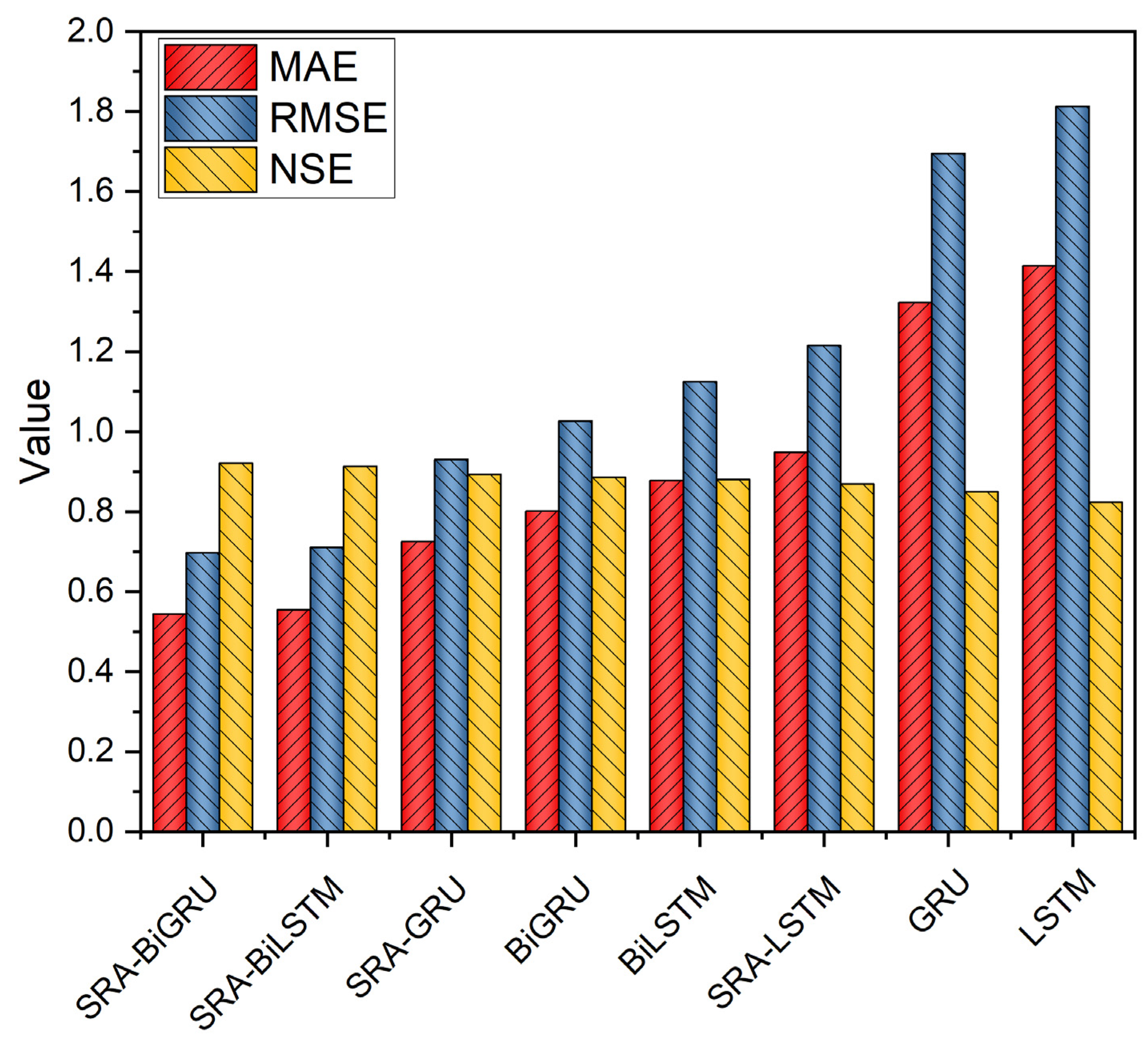
Most crucial of all, comparative experiments gradually demonstrate the superiority of GRU, BI structure, and attention mechanism, and all evaluation indices confirm that the proposed SRA-BiGRU model has higher prediction accuracy in the water-level-prediction task, indicating that it is a model with high availability, high accuracy, and high robustness.
However, this study has some weaknesses, which are embodied in the fact that it is based on the project construction of the Wujiang River water-safety-prediction system, so the dataset obtained has few characteristics and does not fully demonstrate the model’s performance, and in the subsequent step, the model can be applied to other water-level-prediction datasets, and meteorological data such as precipitation, water temperature, and temperature can be added to enhance the model’s ability to predict the water level under abnormal climate conditions.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}