1. Introduction
Intense and long-duration precipitation has caused many catastrophic flood events in Poland, such as those seen in 1970, 1997, 2001 and 2010. In addition, as [
1] indicates, the number of local flash floods resulting from heavy rainfalls has increased in Poland. The increasing urbanization process and climate changes have caused long periods of drought and then heavy rainfall, which may cause a further increase in the frequency and intensity of floods in the future. Currently, more and more emphasis is placed not only on the drainage of rainwater, but on its retention, as well as reproduction of retention lost as a result of the catchment sealing process [
2]. Because of this, accurate designing of high rainfall depths is a pressing issue.
The proper modeling of extreme precipitation in the Upper Vistula River Basin (UVB), located in the southern part of Poland, is of high importance because the region is very flood prone. In the region, the estimation of design rainfall totals for long return periods is crucial for designing storm water drainage or land drainage systems, and preparing flood risk maps, as well as planning flood-control solutions [
3]. The rationale for this study is that rivers in most of the region are very susceptible to flooding, the contribution of the surface runoff from this area to the total surface runoff of Poland is very high, and that, due to climate change, rainfall has become more and more intense in recent years.
Much attention should be given to the proper estimation of the distribution of daily rainfall totals because the right tail of the probability density function (PDF) is highly influenced by the observed high-precipitation quantiles. From the point of view of hydrology and meteorology, it is crucial to learn whether the tail of the PDF is heavy or light [
4,
5]. A heavy tail of the distribution indicates that the probability of occurrence of very high precipitation is larger than for a light tail.
The main objective of the paper was to conduct a very precise estimation of daily design rainfall depth for various return periods. The approach was not based on the commonly used annual maxima (AM) method but on the peak over threshold (POT) method with the use of Hill statistics. In the POT-based method, all sample values that exceed a certain threshold level are accounted for. The daily precipitation depth over this threshold was assumed to follow the generalized Pareto distribution (GPD). The Hill estimators of the parameters were used in the GPD fit. The estimators can accurately reflect very high rainfall values, often observed in the UVB. We also addressed the issue of the spatial associations between orography and variance of the GPD, and design rainfall depths. To assess the quality of the POT-based estimation with Hill statistics, we also performed the AM-based estimation by using the maximum likelihood and compared the results. Different distribution functions, such as the generalized extreme value (GEV), two-parameter gamma (Pearson 3, GA2), three-parameter gamma (GA3), lognormal (LOG), two-parameter Weibull (WE2), three-parameter Weibull (WE3), and Gumbel (GUM) were considered in the AM-based method in this study.
In Poland, the Bogdanowicz–Stachý probabilistic maximum precipitation model for various return periods is often used [
6,
7,
8]. This AM-based method makes use of the Weibull distribution, the parameters of which reflect some specific rainfall properties in three different regions of Poland. However, the model does not cover the southern, mountainous part of the UVB with very high precipitation totals. Moreover, recent climatic changes might also affect its suitability [
9].
The POT approach enables an increase of the sample size in comparison to the AM-based method by considering all independent peak events over threshold and the omission of low values below threshold which are not valid in the estimation of large events. This is the main advantage of the POT approach in comparison with the AM approach. The disadvantages are the inclusion of subjective judgment into the POT sample selection and the GPD estimation, and the strong sensitivity of high quantile estimates to the threshold choice. Therefore, the main difficulties in selecting the POT sample are the choice of the threshold, which produces the lowest bias of quantile estimates, and the ensured independence between successive events [
10,
11].
The GPD was used in various fields of study [
12,
13]. For instance, Madsen et al. [
14,
15,
16] demonstrated that the POT-based GPD fit leads to a more accurate estimation of high quantiles compared to the AM-based GEV fit. Van Montfort and Witter [
17] indicated that in the GPD fit, some POT series of daily rainfall show exponentially distributed peaks, with one or more outlying observations [
17]. The methodology of developing the Polish Atlas of Rains Intensities (PANDa) (see [
2]) was also based on the GDP distribution; however, the method of parameter estimation substantially differs from the method based on the Hill statistics in this paper. Various methods have been used in meteorology and hydrology to calibrate the GPD. For example, Madsen and Rosbjerg [
18] compared the method of moments, probability-weighted moments, and maximum likelihood (ML) with regard to the precision of the 100-year flood quantile estimate. Martins et al. [
19] used the ML estimates for the assessment of extreme monthly rainfall in Brazil. Singirankabo [
20] applied the ML method to daily rainfall intensity in Rwanda. Martins and Stedinger [
21] used the generalized maximum likelihood (GML) method, in which the ML and Bayesian approaches are combined, in extreme flood assessment. Yet another method of the GPD parameters’ estimation was adapted by Willems et al. to river discharges [
22]. They used the Hill estimator of the
parameter [
23,
24]. The Hill estimates were then successfully applied to river discharges and rainfall intensities in various world regions [
11,
25,
26,
27,
28]. The main advantages of the method are that (i) the calibration of the threshold is based directly on sample values, which is crucial because of the large spatial diversity of rainfalls in the UVB, and (ii) the parameter estimation is weighted toward large rainfall events that play an important role in designing extremely heavy rainfalls. This method was used in the paper.
2. Materials and Methods
2.1. Study Area and Data
The Upper Vistula River Basin (UVB) has a total surface area of 47,053.51 km
(the Polish part; see
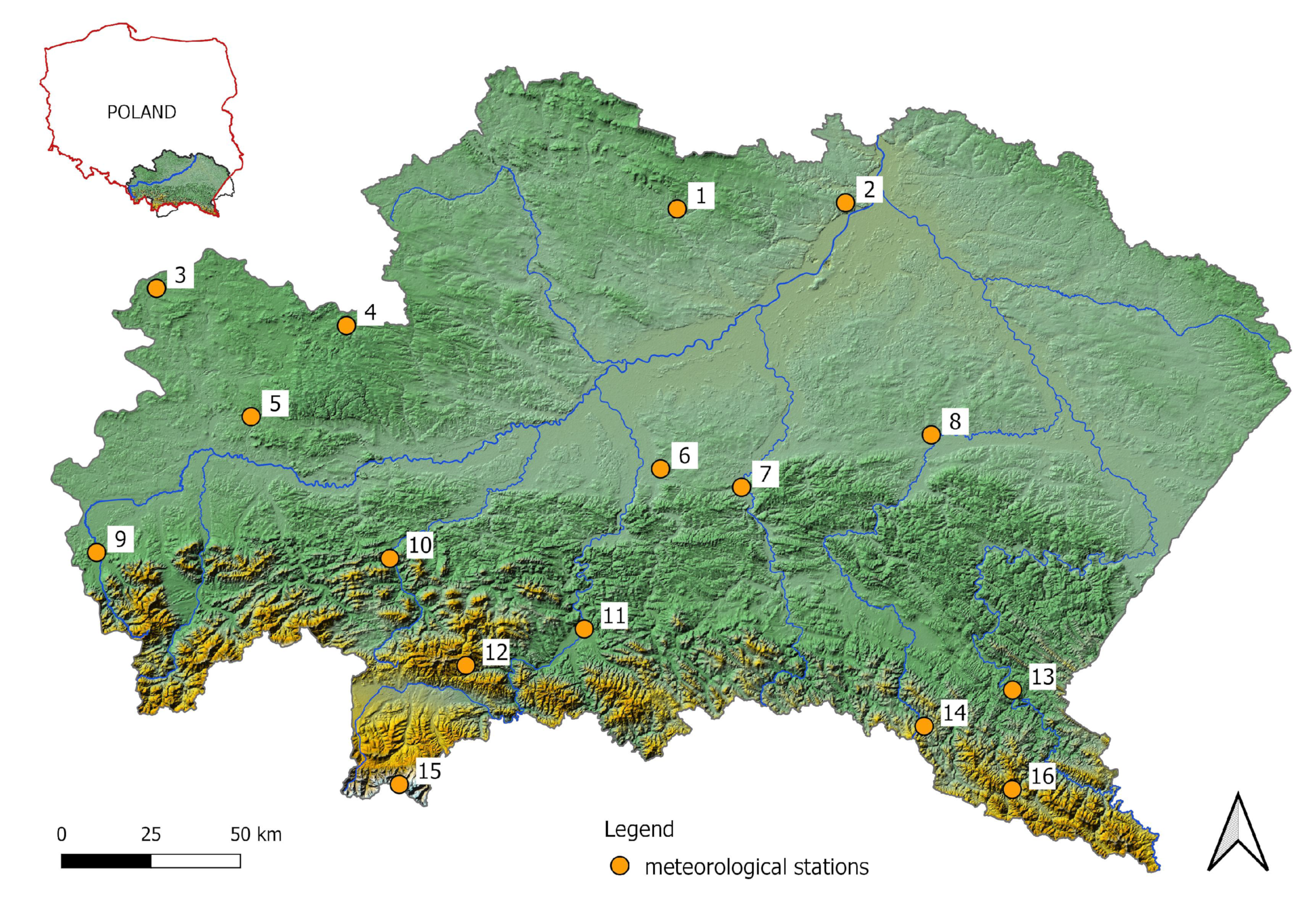
Figure 1). It is diverse in terms of altitudes and geological structure (it includes the Carpathians, a part of the Carpathian Foredeep, parts of the Lublin Basin, the Upper Silesia Basin, the Cracow Monocline, the Nida Basin, and a part of the Świętokrzyskie Mountains). The spatial distribution of precipitation varies from the lowest in the north to the highest in the south (the Tatra Mountains). The meteorological conditions are influenced by polar maritime air masses in the west and continental air masses in the east; thus the climate is transitional [
29,
30,
31]. The strong diversity in climate conditions influences the volume of precipitation and its extreme values. As indicated by Młyński et al. [
32], the occurrence of precipitation is characterized by seasonality. In the UVB, the highest rainfall most often occurs in summer (from May to September). The region is very susceptible to flooding [
33,
34]. Additionally, as the UVB makes up approximately 30% of water resources in Poland [
35], the region plays an important role in flood generation in a large part of the country [
31].
The region is heavily influenced by anthropogenic activity [
36]. It includes, e.g., a part of the Silesian urban area, which constitutes an important industrial region, as well as large cities: Kraków, Rzeszów, Tarnów, and many hydrotechnical structures (e.g. Wisła Czarne, Goczałkowice, Czorsztyn-Niedzica, Solina).
In the study, the stations located at the lowest altitudes are Rzeszów-Jasionka (200 m. a.s.l), Tarnów (209 m. a.s.l) and Pilzno (210 m. a.s.l), whereas Ochotnica Górna (620 m. a.s.l) and Kasprowy Wierch (1991 m. a.s.l, the Tatra Mountains) are at the highest altitudes (
Table 1).
The series of daily precipitation totals from the period between 1960 and 2021 from 16 meteorological stations located in the UVB were used for the analysis (
Figure 1). The data were obtained from the public database of the Institute of Meteorology and Water Management, National Research Institute (IMGW-PIB). In days with snowfall, the rainfall equivalent is provided in the data. Therefore, rainfall and precipitation are equivalent in the paper.
The mean value of the annual maximum daily rainfall total in the period between 1960 and 2021 varied from 36.14 mm (Raków) to 83.01 mm (Kasprowy Wierch) while the mean daily precipitation ranged from 1.5 mm to 2.10 mm, apart from Kasprowy Wierch, for which it was 4.89 mm (see
Table 1).
2.2. Research Methods
The POT-based method with Hill statistics was applied in the design rainfall estimation. Then, for comparative purposes, the AM-based method was also used. The superior method was selected next in the sense that a higher rating was given to the method that better estimated the highest rainfall depths. Afterward, the dependence between the distribution parameters and orographic characteristics of the region where the rainfall stations are located was found.
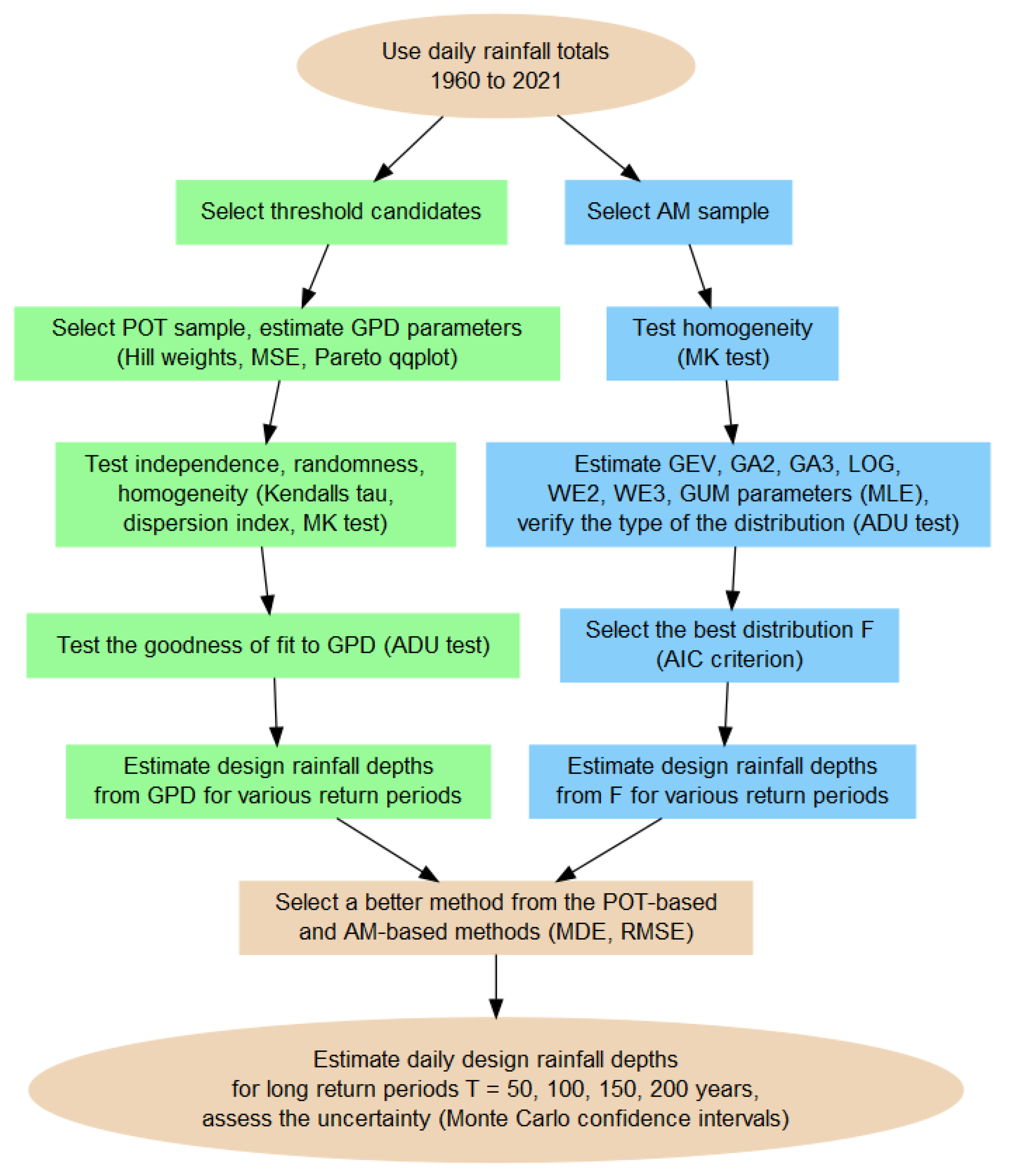
The methods were depicted in the flow diagram in
Figure 2. The shapes on the left branch refer to the steps in the POT-based estimation while the shapes on the right branch refer to the AM-based estimation. The branches join when the methods are compared, the design rainfalls and their confidence intervals are estimated, and when the GPD properties are associated with orographic characteristics. The detailed description of the methods is provided in the next sections.
2.3. The POT-Based Estimation
In the POT-based method, the daily rainfall depth
X over a certain threshold
(where
) is assumed to follow the generalized Pareto distribution (GPD). The GPD can cover a wide range of tail weights, and therefore it is very useful in the extreme value analysis [
10]. The cumulative distribution function (CDF) of the GPD equals
where
is the shape parameter and
is the scale parameter. The
parameter is known as the extreme value index. The scale parameter linearly depends on the threshold
, with proportionality factor equal to the shape parameter, namely
, if only
is sufficiently high [
24]. A high, positive value of the
parameter (heavy tail of the distribution) indicates that the probability of the occurrence of very high precipitation is larger than if
(light, exponential tail). The variance of GPD equals
As the values of the estimated maximum precipitation depth and their variability strongly depend on and , its precise estimation is therefore highly important, especially in the areas susceptible to heavy downpours and torrential storms.
The POT-based estimation consisted of several steps the methods of which are provided the the following subsections.
2.3.1. Selection of the POT Sample
In order to select the final POT sample, various threshold candidates had to be considered. Before this, all daily precipitation totals greater than or equal to the lowest annual maximum AM (initial value) in the period between 1960 and 2021 were selected. Subsequently, to address the issue of the serial correlation of daily rainfall totals, the Kendall’s
coefficient was tested for significance [
39] for lag = one day. At the stations where the correlation was significantly different from zero (Sandomierz, Stróża, Kasprowy Wierch), the series were then modified by taking only the days with at least one day of temporal distance. Strictly speaking, if two rainfall depths from two consecutive days were included in the first sample, the lower value was omitted. This modification enabled the selection of the series with uncorrelated elements. No modification was carried out for stations with uncorrelated rainfall events. Then, for each station, the series was ordered from the lowest to the highest,
with the lowest AM as the initial threshold value. This was the series of all threshold candidates.
Afterward, starting from the lowest element
, the threshold was successively increased and, in each step, the Hill estimate
of the shape parameter
of the GPD distribution was estimated [
40]:
The estimate
is the mean excess of the log-transformed data over the threshold
. The asymptotic mean squared error was also computed in each step [
40],
assuming the Hill weights
. The threshold
for which the series of the
achieved minimum was the final, optimal threshold. The final choice of the threshold was a tradeoff between low thresholds, which cause a high bias, and high thresholds, which cause a high variance of
; therefore the selection of
from the region of low fluctuation of
was of high importance. The final POT sample comprised of the POT events greater than or equal to the final threshold
. The appropriate choice of
was verified in the Pareto QQ plot where the points
for
—the probability of exceedance of
—should lay along the regression line with the slope equal to
if the true distribution of the rainfall depth above threshold is GPD. This is the main advantage of the Hill weights, namely that the regression line is pulled toward matching the largest rainfall events because the Hill estimation is pointed at the events with a low probability of exceedance.
If the fit in the Pareto QQ plot is poor, because the points for the highest rainfall events lie much below the regression line, this means that the tail of the empirical distribution should be fitted to the GPD with
(exponential distribution, EXP) where the estimate of the scale parameter equals [
40]
In this case, the optimal threshold
was selected based on minimizing the
[
40]:
The exponential QQ plot is
, where
, was also used to assess the goodness of fit. The method was described in [
40,
41] and applied in [
11,
22,
26].
The final estimates of the location, scale, and shape parameters of the GPD were
, where
was derived from the Equation (
3) and
, while the estimates of the location and scale parameters of the exponential distribution were
where
was derived from the Equation (
5).
2.3.2. Testing the Independence, Randomness, and Homogeneity
Many procedures for the POT series selection often suffer from some subjectivity; therefore, an objective criterion of independence, randomness, and identical distribution of the POT events should be included.
For various lags, the hypothesis that the Kendall’s
serial correlation of the POT sample is zero [
39] was verified. In order to check the randomness of the POT events, the method based on the dispersion index
was used to verify the hypothesis that the distribution of the number of exceedances over threshold per year is Poisson [
10,
42,
43]. From a theoretical point of view,
should asymptotically follow a
distribution with
degrees of freedom where
is the number of exceedances over threshold, its mean value, and the number of years, respectively.
Afterward, all final POT series were tested for homogeneity in the parameter of location by using the Mann–Kendall (MK) test for trend [
44,
45].
2.3.3. Testing the Goodness of Fit to the GPD Distribution
In order to verify the hypothesis that the distribution of rainfall depth over threshold was GPD, the Anderson–Darling (AD) test [
46] was used in its modified version which accounts for the upper tail of the probability distribution function, namely [
47],
where
G is the cumulative distribution function of the GPD (see the Equation (
1)). The critical values ADU
of the AD test were estimated by using the Monte Carlo method based on
simulations.
2.3.4. Estimating the Design Rainfall Depth
Assuming that
is the mean number of the POT elements per year, the return period of the rainfall depth
x is
. By using this equation, the design rainfall of return period
T was derived from
assuming that
.
2.4. The AM-Based Estimation
The steps were similar to those from the
Section 2.3. The difference was in the method of estimation that made use of Hill statistics in the POT-based method and the maximum likelihood estimation in the AM-based method.
2.4.1. Testing the Homogeneity of AM
The AM series was tested for trends by using the MK test. This is an important issue in order to check whether due to climate change or other circumstances the distribution of the daily annual maxima totals did not change during the observation period.
2.4.2. Parameter Estimation and Verification of the Type of the Distribution
The family of theoretical distribution function candidates,
GEV, GA2, GA3, LOG, WE2, WE3, GUM} was considered at each station where the abbreviations apply to generalized extreme value, two-parameter gamma, three-parameter gamma, lognormal, two-parameter Weibull, three-parameter Weibull, and Gumbel, respectively. The parameters were estimated by using the MLE [
48,
49]. The equations for the distribution functions are commonly used in the literature [
50,
51,
52].
For every , the null hypothesis was verified at each station by using the Anderson–Darling test (ADU test), for which the following distribution function is F.
2.4.3. Selection of the Best Distribution of the AM and Estimation of Design Rainfall Depths
For each station, the best distribution
F was selected from all distributions for which the null hypothesis was not rejected. The final selection was based on the Akaike information criterion [
53,
54], namely on the minimization of
where
L is the likelihood function and
k is the number of parameters of the theoretical distribution function. The main advantage of the use of
is that it meets the principle of parameter parsimony because it combines both the
L-based fit and the number of parameters. Thus, models with many parameters are penalized and have less of a chance to be selected.
After the best distribution, F was selected, and design rainfall depths for various return periods were estimated.
2.5. Selection of a Better Method from the POT-Based and AM-Based Methods
The comparison was performed between the results of two methods of estimation of the highest design rainfalls—the POT-based method and the AM-based method, the former using the Hill estimation of the GPD distribution from the POT sample (
Section 2.3) and the latter using the MLE of the
F distribution that was selected by using the AIC criterion (
Section 2.4). The evaluation of each method was done by using the mean deviation error (
) and the root mean squared error (
), where the observed and theoretical rainfall depths of the same return period of the GPD and
F distributions were compared. We have
where
are the observed quantiles of return period
T in the POT and AM series, respectively, while
are the estimated quantiles of the return period
T of the GPD and
F distribution, respectively. The set
S consists of various return periods and
is the number of its elements. Only long return periods were included in
S to account for the highest rainfalls, namely
years (case 1) and
years (case 2).
The choice of the and was due to the fact that they reflect the bias and the variance of the quantile estimators. For example, if and are near to zero, it means that the bias and variance of the estimator is low, and the design rainfall depths are estimated properly.
The POT-based and AM-based methods were assessed in the sense that the scores
were assigned first to each station
i, namely
Then, for the AM-based method and POT-based method separately, and were summarized over all stations to and . Lastly, for each method, the final score d was computed, and the higher rating was given to the method with higher d. The procedure was repeated for and .
2.6. Estimation of the Design Rainfalls for Long Return Periods and Their Confidence Intervals
The design rainfall depths for various long return periods,
years, were estimated at each station assuming that the distribution function was selected by using the methods from the
Section 2.5.
The confidence intervals for the design rainfall depths were derived next by using the Monte Carlo simulation method. For each station, artificial series representing the random variable following the distribution were selected, with parameters from a given station being randomly drawn and the design rainfall derived for each series. Then, the confidence limits were computed as the sample quantiles of order and of the design rainfalls.
2.7. Associations between Distribution Characteristics and the Station’s Altitude
The Spearman correlation coefficient
between the station’s altitude and the GDP characteristics, such as threshold
, variance (
2), and design rainfall depth (
8) was derived. Then the hypothesis that the Spearman correlation
is significantly greater than zero was verified, in order to recognize the spatial relationships across the whole region. The impact of the spatially diverse
parameter values of the GPD on design rainfalls was also analyzed. It should be noted (
Section 2.3) that
is highly responsible for the shape of the tail of the GPD, and thus it controls the values of the design rainfalls.
The level of significance
was assumed in the whole paper. All calculations were carried out in the R program [
55].
3. Results
3.1. POT-Based Method
3.1.1. Selection of the POT Sample and Estimation of the GPD Parameters
The final threshold
and the estimates
and
of the GPD parameters were derived by using the methods from
Section 2.3. The final POT sample comprised of rainfall depths greater than or equal to
. In the POT samples, the average number of events per year ranged from 1.19 for the Lesko station to 3.44 for Ochotnica Górna.
The values of
,
, and
parameters for each station are displayed in
Table 2. It can be noted that
was obtained for the stations located in the southern, mountainous parts of the UVB (Carpathians) and in the upland in the north, while
for the stations in the central part of the UVB (Northern Sub-Carpathians on the border with the Carpathians). This proves that the elevation of the station above sea level affects the properties of the distribution’s tail.
3.1.2. Testing of Homogeneity, Independence, and Randomness
The
p-values of the MK test varied from 0.054 to 0.96 among the 16 stations (see
Table 3), which means that the null hypothesis of no trend was not rejected. As evident in the results, the homogeneity of each time series can be confirmed.
The results of the hypothesis testing, that the Kendall’s
correlation coefficient for lag = 1 is zero were shown in
Table 3 in the form of the
p-values of the test. The conclusion can be drawn that the POT events are independent.
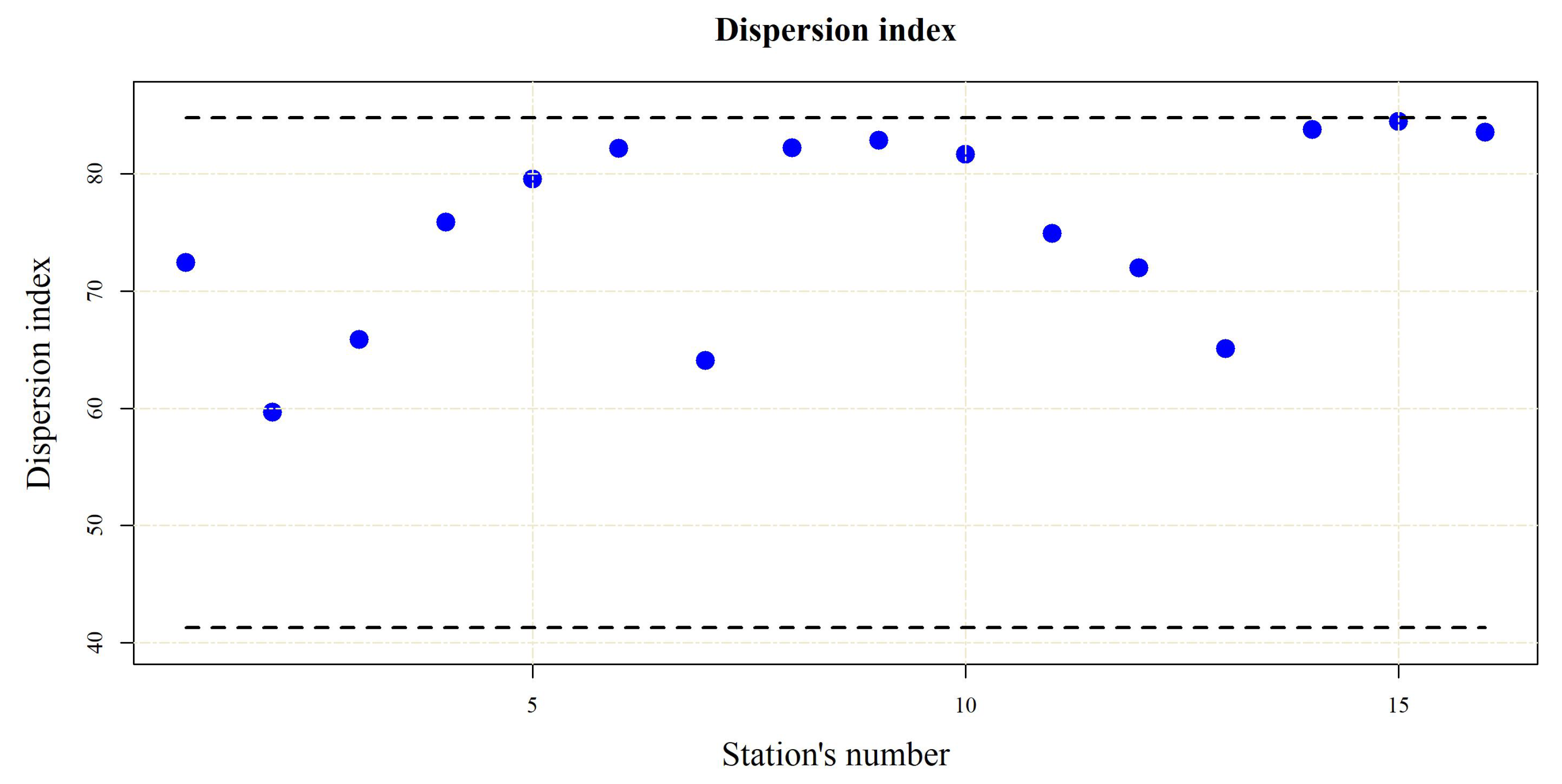
The values of the dispersion index
varied from 59.66 to 84.44. All of the index values were within the 95% confidence interval (
Figure 3). Therefore, it can be concluded that the distribution of the number of exceedances over threshold is Poisson and that the randomness of the POT events was confirmed.
3.1.3. The Anderson–Darling Test of Goodness of Fit
For each station, the ADU test statistic was lower than the critical value ADU
(
Table 4). The conclusion can be drawn that for all stations the distribution of the rainfall depth over threshold is GPD.
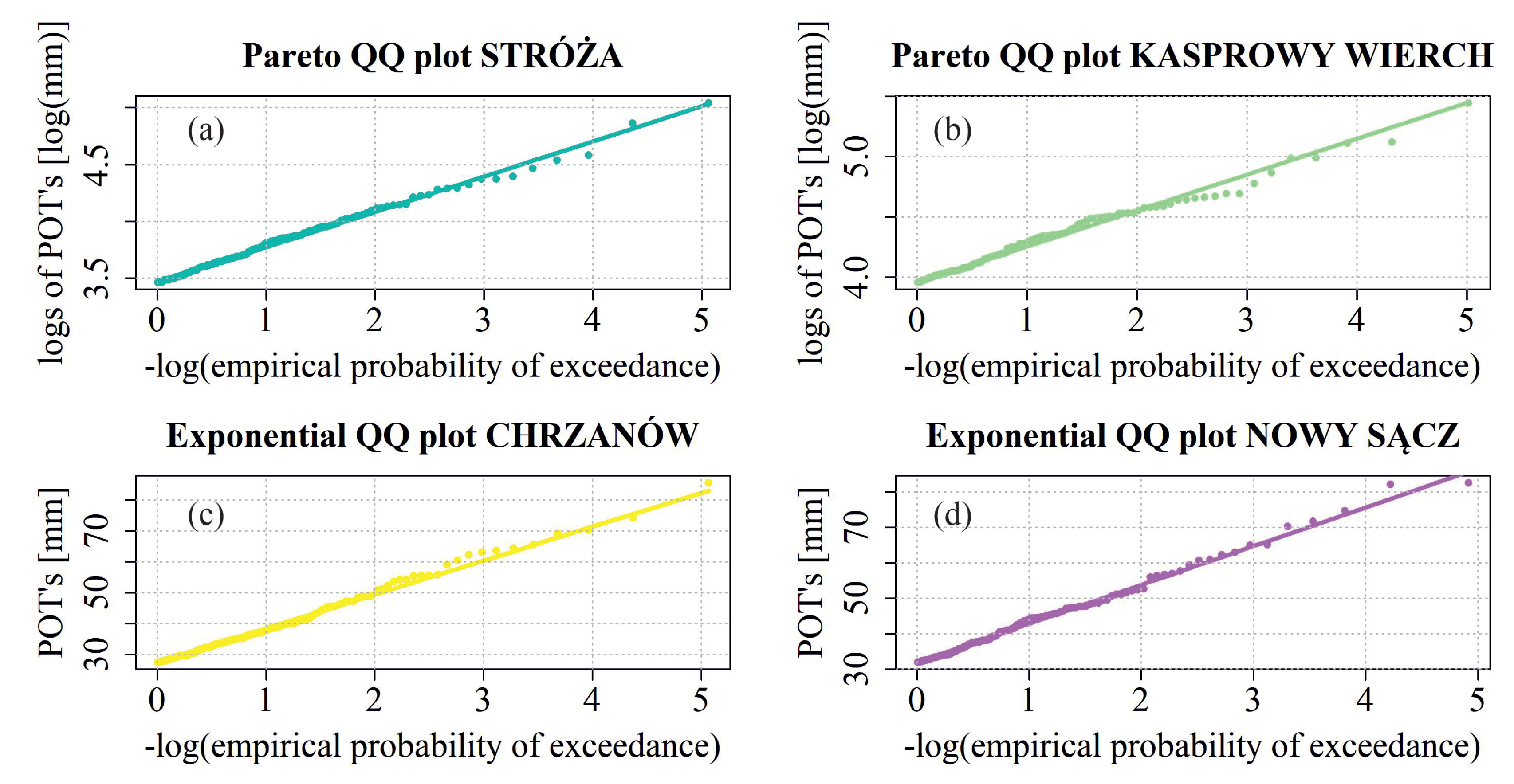
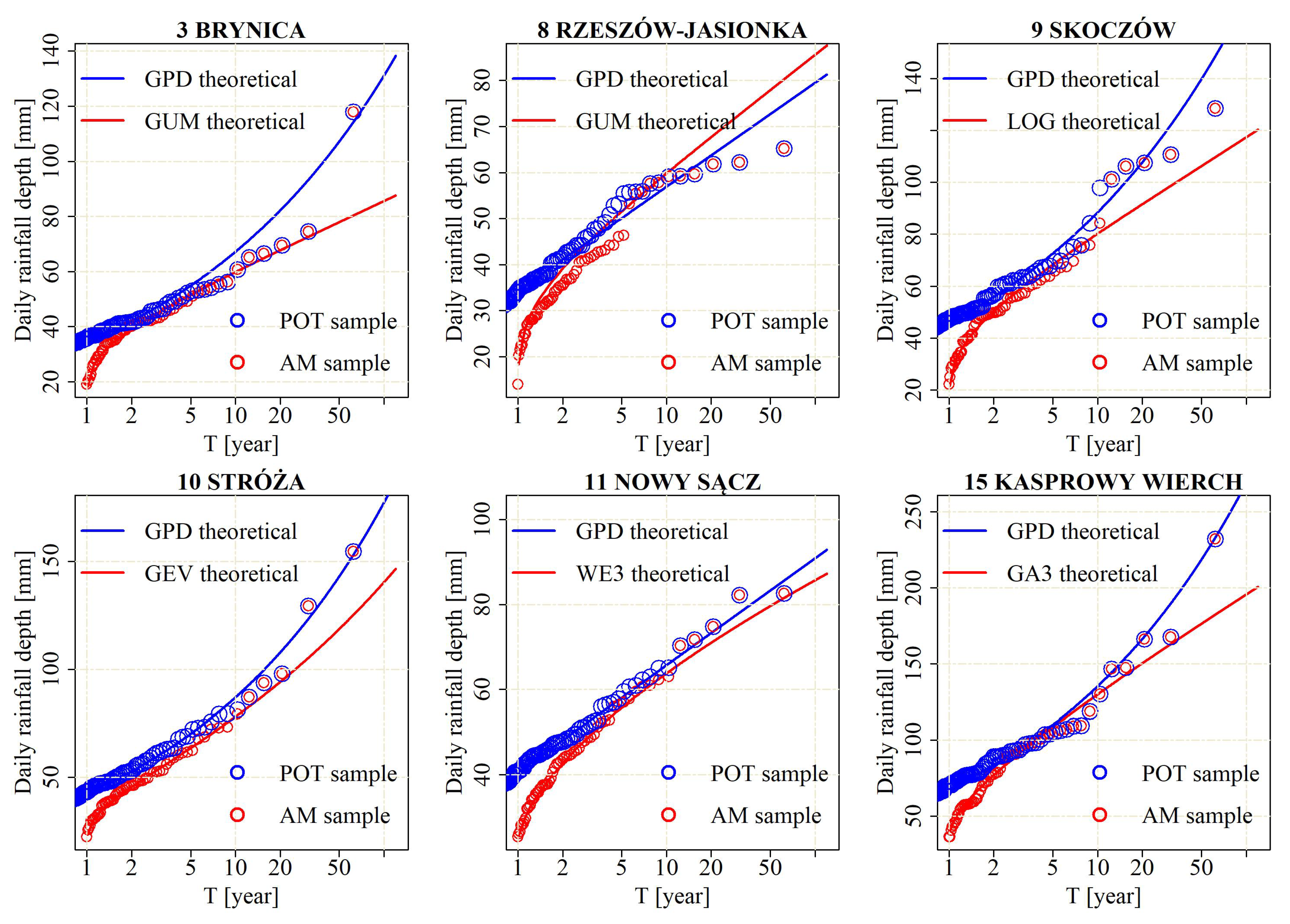
For 14 out of the 16 analysed stations, there is a good fit to the GPD or to the exponential distribution. However, in case of the Brynica and Rzeszów-Jasionka stations, the fit is weaker for higher precipitation values (the POT values are lower than the estimated values). The QQ plots for four exemplary stations (Stróża, Kasprowy Wierch, Chrzanów and Nowy Sącz) were shown in
Figure 4. The congruence between the empirical and theoretical quantiles is evident in the plots, even for high rainfall depths.
3.1.4. The Design Rainfall Depth and Its Confidence Interval
For each station, the design rainfall depth was calculated from the Equation (
8) for various return periods. The results for
and
years are presented in
Table 4. For both of the return periods, the lowest values were obtained for the Rzeszów-Jasionka station, and the highest for the Kasprowy Wierch station. The
confidence intervals of the design rainfalls were also shown in
Table 4. They reflect uncertainty of design rainfall estimates.
The visual assessment of the CIs is easier on the lollipop charts (
Figure 5) where
, and the lower and upper bounds of the CIs were depicted. A strong diversity and a high uncertainty of the estimated design rainfalls can be noted at Kasprowy Wierch, Stróża, and Skoczów stations where the CIs are widespread (see
Figure 5). In the case of the Kasprowy Wierch station, the uncertainty is approximately at the level of 20%. The narrowest confidence intervals were obtained for Rzeszów-Jasionka, Chrzanów, Tarnów, Pilzno, and Nowy Sącz stations which show the lowest uncertainty of the estimated rainfalls at these stations. It can be noted that the stations with lower altitude have lower uncertainty of design rainfall than the stations with higher altitudes. Thus, the spatial properties of the UVB are reflected in the uncertainty of design rainfall.
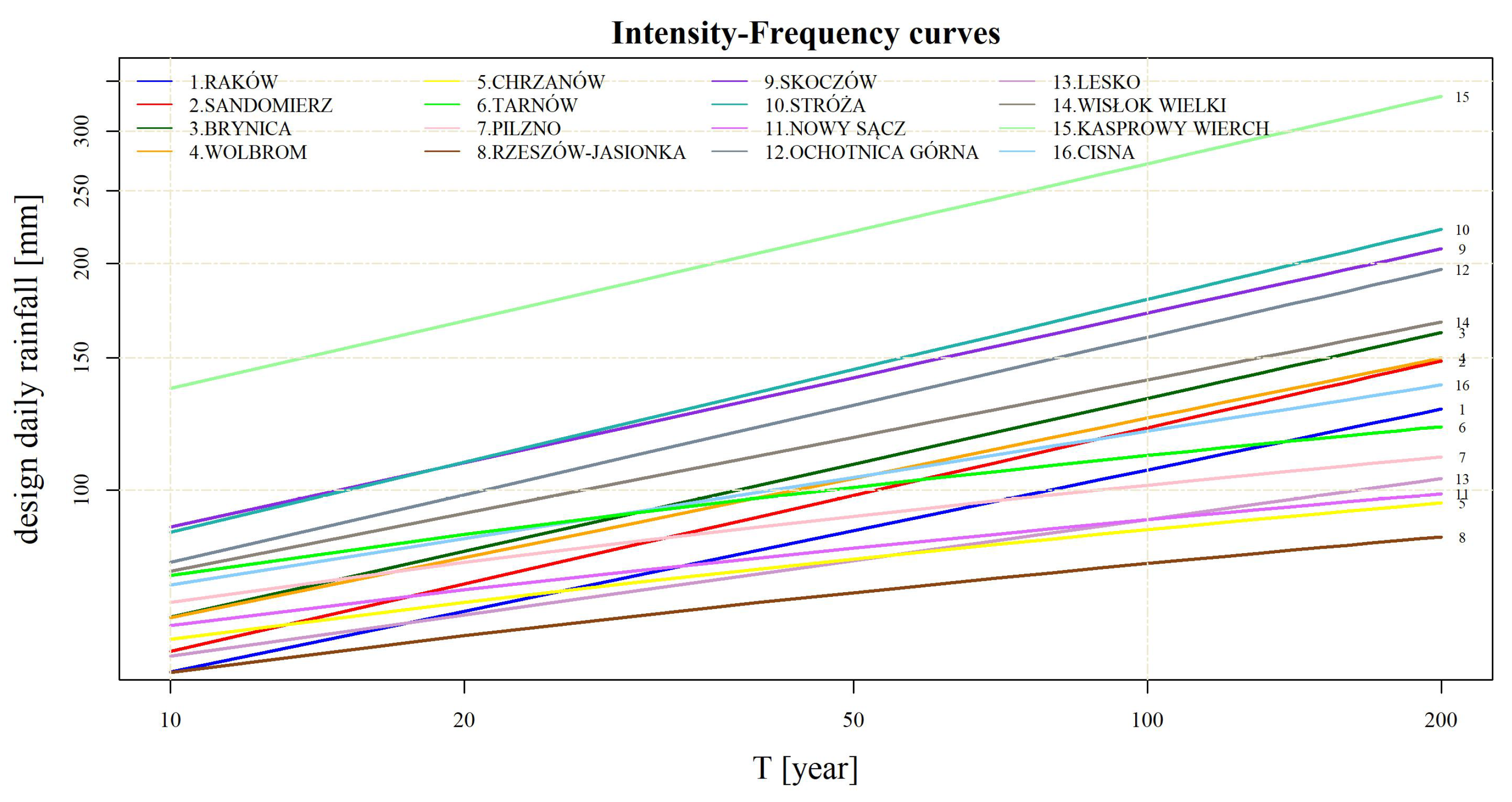
Figure 6 shows the intensity–frequency curves, where the dependence between design daily rainfall and recurrence period, as well as the comparison between design daily rainfalls for all stations, are depicted. For the Sandomierz (red line) and Raków (navy blue line) stations, in the case of short return periods (
years), the design rainfall value is relatively low. However, as the return period increases, the rainfall also increases, and for
years it exceeds 100 mm in both cases. The high values of the parameter
in the two stations are reflected in the strong increase of the intensity–requency curve. The lowest increase was obtained for the Tarnów, Chrzanów i Nowy Sącz stations, which in turn reflects a low value of the parameter
. For all return periods
, the highest values were obtained for the Kasprowy Wierch station. This station is located in the Carpathians (1991 m. a.s.l.). Meanwhile, the lowest values were found for Rzeszów-Jasionka, the station at the lowest altitude (200 m. a.s.l.). The issue of how the design rainfall depends on the altitude is discussed in detail in
Section 3.4.
3.2. AM-Based Method
3.2.1. Selection AM Sample and Testing the Homogeneity
The verification was carried out by using the Mann–Kendall test, assuming the null hypothesis about the homogeneity of the data. The p-values of the MK test varied from to . For the Wisłok Wielki station, the null hypothesis of no trend was rejected (increasing trend), and hence, because the homogeneity of the AM time series could not be confirmed, the station was omitted from further considerations. For the other 15 stations, the homogeneity of the AM series was confirmed.
3.2.2. Verification of the Type of the Distribution
The null hypothesis that the time series comes from a theoretical distribution F was verified by using the ADU test. For most stations, there were several distributions accepted by the test, e.g., the GEV, GA2, GA3, LOG, WE3, and GUM distributions. Therefore, as the hypothesis testing results were not conclusive enough in selecting the best fit, the AIC criterion was used in the next step.
3.2.3. Selection of the Best Distribution of the AM by Using the AIC Criterion
The AIC values were displayed in
Table 5. The final choices, indicated by the lowest AIC values were marked with boxes. The conclusion can be drawn that the GEV distribution turned out to provide the best fit at two stations, GA3 at four stations, LOG at three stations, WE3 at one station, and GUM at five stations. The GA2 and WE3 were not selected for any station.
3.3. Selection of a Better Method from the POT and AM Based on the Comparison between Rainfall Depths Derived from the POT and AM Series
By using the Equation (
8) and the return periods of 2, 5, 10, 12, 15, 20, 30, and 60 years (case 1) and 15, 20, 30, and 60 years (case 2), the design daily rainfall depths were derived from the GPD (POT-based method) and the theoretical distribution selected by using the AIC (AM-based method).
Figure 7 shows the design rainfall depths obtained from the GPD estimation (the POT-based method) and the GEV/GA3/LOG/WE3/GUM estimation (the AM-based method) for six exemplary stations. It can be observed that the GPD yields a better fit to high observed values than the AM-based fit (Brynica, Skoczów, Stróża, Nowy Sącz, Kasprowy Wierch). Many highest peaks were insufficiently designed with the AM-based method while the GPD fit was more accurate. A similar situation occurred in the other stations not shown here.
To quantify the efficiency of the POT method in comparison to the AM-based method, the RMSE and MDE criteria were used to measure the forecasting errors. The comparison was conducted by using the Equations (
11) and (
12). The results are shown in
Table 6.
In case 1, the final score d was 25 and 5 for the POT-based and AM-based method, respectively. Similarly, in case 2 the final score d was 25 to 5 in favor of the POT method.
It can be concluded that from the point of view of the RMSE and MDE criteria, a higher rating was given to the POT method. Hence, the POT method with Hill estimates of the GPD is a better choice in estimating daily precipitation totals in the UVB than the AM-based method.
3.4. Associations between Distribution Characteristics and Station’s Altitude
As evident in the results (
Table 2), the parameters of the GPD differ between stations. Such differences can be also noted between design rainfall depths. Additionally, the difference is larger for longer return periods.
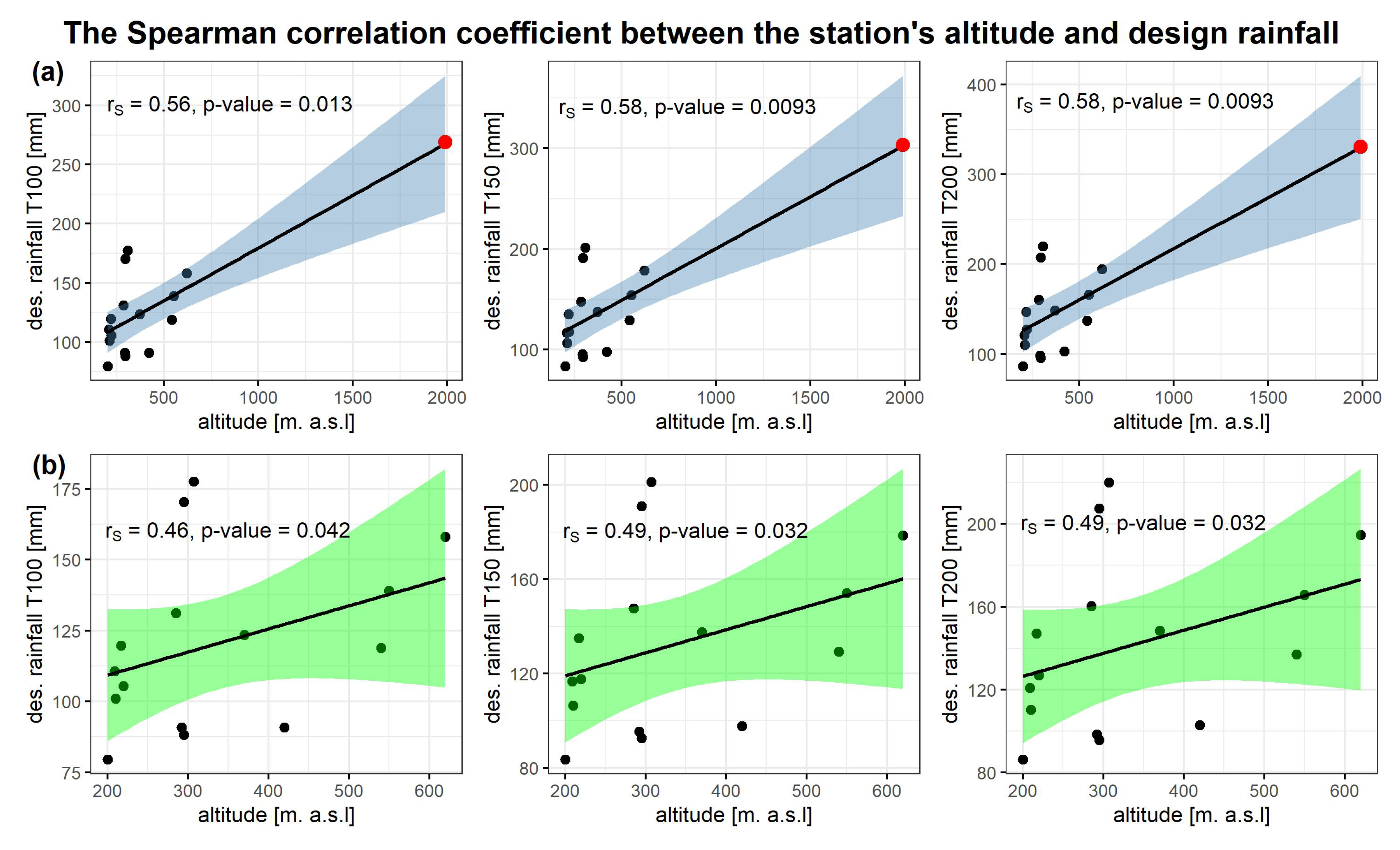
The sample Spearman correlation coefficient
between the station’s altitude and design rainfall depth for return periods of 100, 150, and 200 years was calculated first. The scatterplots were shown in
Figure 8. A deep insight into the sample values and in the scatterplot allows us to observe that after omitting the Kasprowy Wierch station (marked in red) the correlation becomes slightly weaker. As the Kasprowy Wierch station highly influences the relation, the two cases were considered next (a) with the Kasprowy Wierch and (b) without the Kasprowy Wierch station. The
values varied from 0.56 to 0.58 in (a) and dropped to 0.46–0.49 in (b). The blue and green areas represent the confidence region around the regression line at the confidence level of
.
The question was if the dependence is strong in the whole region. It was confirmed, by using hypothesis testing, that is significantly greater than zero for return periods of 100, 150, and 200 years and in both cases (a) and (b). Thus, the positive relation between the height of the station and design rainfall depth was confirmed.
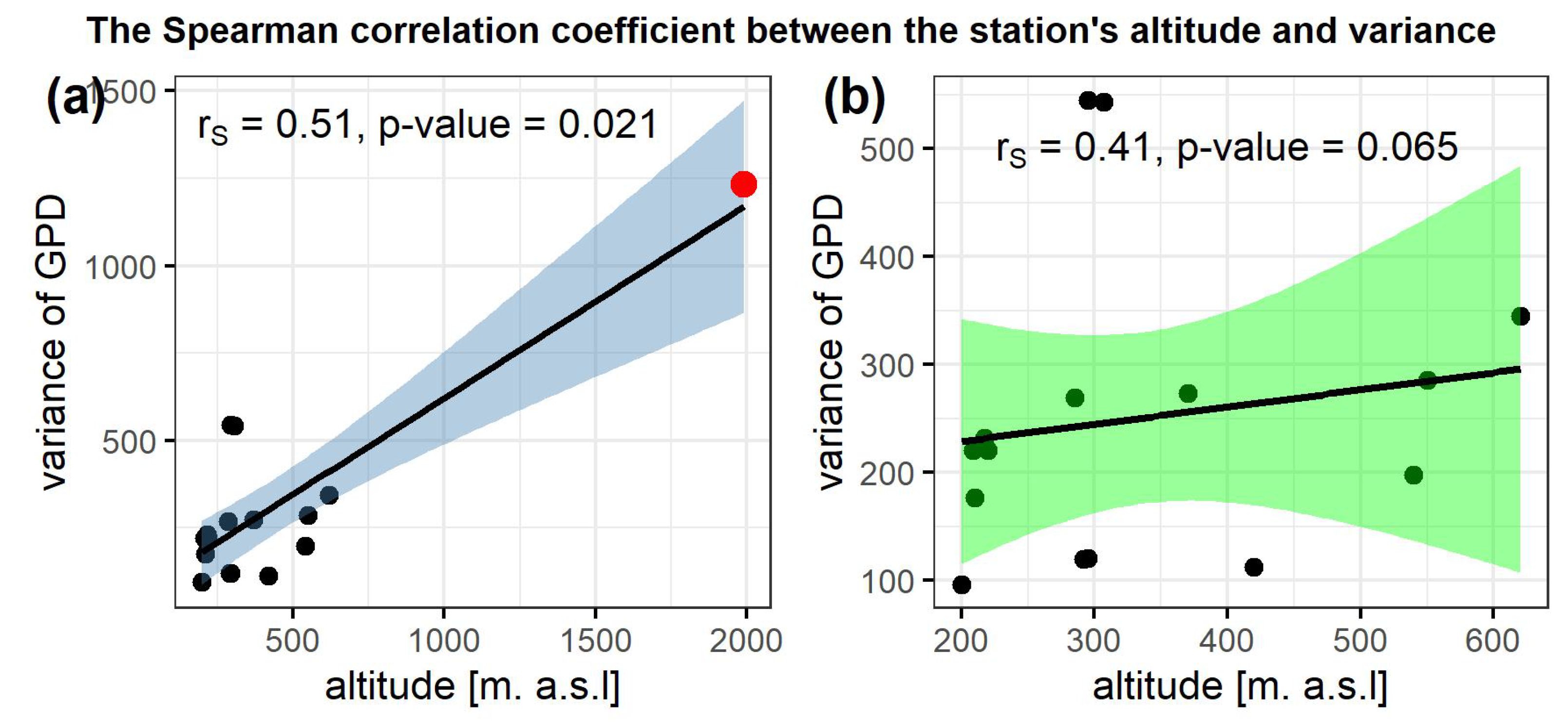
The sample correlation coefficient
between the station’s altitude and the threshold
equals 0.64 in (a) and 0.56 in (b) while between the station’s altitude and
equals 0.51 in (a) and 0.41 in (b) (see
Figure 9). It was shown, by using hypothesis testing, that the correlation between the station’s altitude and both characteristics is significantly greater than zero.
The relation between the altitude and the parameter values is also considerable because is greater than zero at the stations with higher altitude (north and south of the UVB) and equal to zero at lower altitudes (central part of the UVB). The Spearman correlation coefficient equals (case (a)) and 0.39 (case (b)). The hypothesis testing for shows that it is significantly greater than zero in (a). However, in (b) the test failed to reject the null hypothesis of no correlation.
Remembering that the uncertainty of design rainfall depth was also associated with the station’s altitude (
Section 3.1.4), this proves that the GPD properly reflects the increase in the magnitude and variability of design rainfall with the increase of each station’s altitude in the region.
The conclusion can be drawn that a strong spatial diversity can be ascribed to the GPD characteristics and to the predicted rainfalls with long return periods.
4. Discussion
To the best of our knowledge, this method has not been used in Poland so far. The novelty of the study was in the use of the Hill estimates of the GPD in a region in Poland that is very diverse with regard to rainfall pattern—ranging from moderate to torrential. The novelty also appiles to the assessment of the dependence between orography and characteristics of the GPD, which is important from the point of view of the precision of the estimates of high design rainfall totals. This is the first study in the UVB where the GPD with Hill estimates is adapted to the distribution of daily rainfall over threshold. Therefore, the comparison with other authors can be limited only to some aspects.
The drawback of all POT-based estimation methods is a lack of an unique, universal procedure of a threshold choice. However, basic guidelines that have been developed over the last several dozen years, should always be considered (see Introduction). The limitation of the POT-based method with Hill estimates is that the MSE-based optimal threshold, selected from the region of low fluctuation of , can be sometimes difficult to identify, and some experience is needed in analysing the relation between the MSE and potential thresholds. Nevertheless, the advantages of the POT-based method with the Hill estimates of the GPD, and its superiority over the AM-based method in the estimation of largest rainfall quantiles outweigh the disadvantages.
In [
2,
3,
8], the POT method was also used for stations located in Poland. A detailed description of statistical tools and exemplary stations’ analysis was provided. However, it should be highlighted that the method of parameter estimation in [
2,
8] is MLE, which differs from the method used in this paper. Based only on plots in [
8], as exact values were not provided there, it can be concluded that the design rainfalls computed by using the Hill statistics are somewhat higher than those obtained in [
8].
A similar region (UVB) was studied by Młyński et al. [
56], who chose GEV as the best distribution of the annual maximum precipitation, based on data (43 years) from 51 rainfall stations. The recommendation was based on various selection criteria (e.g., the peak-weighted root mean square error). In five stations that are common with five stations from this study, the
values obtained by the authors [
56] are similar to
values estimated in this paper.
The results of Mascaro are similar to the results obtained in this paper with regard to the gamma parameter that was greater or equal to zero in various stations. However, the seasonal approach of the POT-based method with Hill statistics in the UVB might be considered in future plans.
Onyutha and Willems [
26] derived the daily design rainfall in stations located in the Lake Victoria Basin by using the POT method and the GPD distribution and used various methods of estimation in terms of capturing the tail behaviour of the GPD and the uncertainty of the high-intensity quantiles. Some similarity between the results can be observed, namely the “normal tail” of the GPD (
near to zero) in all nine stations in [
26] and only in five stations with relatively low altitude (200–300 m. a.s.l.) in this study. However, it should be stressed that
was estimated in a majority of stations in this study, in particular in all stations with altitude greater than 300 m. a.s.l. This confirms that the inclusion of the spatial factor in rainfall estimates in upland and mountainous areas was certified.
5. Conclusions
The estimation of design rainfalls for a wide range of return periods was carried out by using the POT-based method with the GPD distribution and the Hill estimates at 16 stations located in the UVB, a spatially diverse region vulnerable to flooding. The accurate estimation of the threshold, shape, and scale parameters of the GPD was shown to be a key point in the process because their values control the tail of the GPD.
After comparison between the results of the POT-based method (Hill estimates) with the AM-based method (MLE estimates + AIC), it was found that for 80% of the stations under study the priority should be given to the former method, which shows a very good performance of the POT-based method. The results show that the characteristics (threshold, variance) of the GPD vary between stations, increase with the station’s altitude, and that the shape parameter is greater than zero for stations located in the southern, mountainous part, and in the northern, upland region, while it is mostly equal to zero in the central part with a lower altitude. This highly influenced the values of the design rainfalls that increase with the station’s altitude. This indicates that orographic enhancement increased the design rainfall depth.
The conclusions can be drawn that the method is highly competitive with other methods in designing large rainfall events and that the GPD with Hill statistics is able to properly reflect the increase in the magnitude and variability of design rainfall with the increase in each station’s altitude in the region.
With regard to future plans, considering that only mountain and upland areas were studied, it would also be worthwhile to verify whether this method will accurately estimate high precipitation totals in lowland areas, characterized by a different precipitation pattern. The next issue is seasonality, which plays an important role in temporal rainfall scheme and thus should also be considered.
Therefore the method can be recommended in water-management applications related to floods in the UVB.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}