1. Introduction
With the development of industrialization and a large number of harmful gas emissions in China, air pollution has become an urgent problem to be solved. The prediction of pollutant concentration can help relevant departments to formulate reasonable prevention and control policies. Thus, it has been widely concerned with by scholars [
1,
2]. As inhalable particles in air pollutants, the higher the concentration is, the worse the air quality is. A number of studies have shown that high concentrations of
and
also increase the risk of diseases such as lung cancer [
3] and asthma [
4]. Therefore, it is of great practical significance to establish a reasonable and accurate short-term pollutant concentration early warning system. The problem of air quality seriously affects people’s health and restricts the long-term healthy development of the economy. Therefore, air quality has become a key area of in-depth attention and research by government departments and researchers. Although scholars and policymakers have made great efforts to reduce and control air pollutants in recent years,
and
have long been the main air quality pollutants in major cities in China. In response to severe air fine particulate matter (
and
) pollution, the Chinese government issued the Air Pollution Prevention and Control Action Plan in 2013 to improve the effectiveness of environmental supervision in key regions [
5].
In recent years, scholars have done a lot of research on pollutant prediction models, which are generally divided into three categories: physical models, statistical models and hybrid models. Physical models are modeled by meteorological and geographic information to simulate the diffusion and transport mechanisms of chemicals related to air pollution to predict the air quality level [
6]. At the same time, mature mathematical methods are used to calculate the temporal and spatial distribution of pollutants [
7]. The main models include the Mozart model [
8], operational street pollution model (OSPM) [
9] and community multiscale air quality (CMAQ) model [
10]. Therefore, people pay attention to the statistical model of expressing the mapping relationship between input and output through historical data. The traditional statistical methods include the regression method [
11], principal component analysis [
12], projection pursuit model [
13], autoregressive integrated moving average method [
14] and fuzzy time series analysis [
15]. Because most statistical models are single models and have defects such as a dependence on data sets or assumptions, they can not deal well with the instability and randomness of sequence data such as
or
, which leads to a poor prediction performance.
In order to improve these shortcomings, scholars have proposed some artificial intelligence methods, such as the back propagation (BP) neural network [
16], artificial neural network (ANN) [
17], support vector machine (SVM) [
18], least square support vector machine and machine learning method, combined with classical statistical methods to build a better hybrid model, and have achieved some good results in various fields. As the optimization model of the support vector machine, the least squares support vector machine shows excellent performance in dealing with small samples and solving global optimization and high-dimensional feature space problems. However, the parameter selection of the least square support vector machine is often random, so scholars use intelligent algorithms to optimize the two important parameters of the least square support vector machine. Some of the most widely used algorithms include the genetic algorithm [
19], fruit fly optimization algorithm [
20], cuckoo search algorithm [
12] and gravity search algorithm [
21]. However, most of these algorithms are difficult to understand, and are easy to fall into local optimization and slow convergence, which limits their potential to combine with least squares support vector machines. The sparrow search algorithm is a new intelligent optimization algorithm [
22] proposed in 2020 based on sparrow foraging and anti-predation behavior. The SSA shows excellent performance in algorithm convergence and global optimization, which encourages us to use this algorithm to optimize the parameters of the least squares support vector machine. Some hybrid least square support vector machine models are proposed and applied to different fields, such as water quality prediction [
23], reservoir penetration rate [
24], insulator surface contamination prediction [
25] and especially
concentration [
26] and pollutant prediction [
27].
Inspired by the reference [
26,
27,
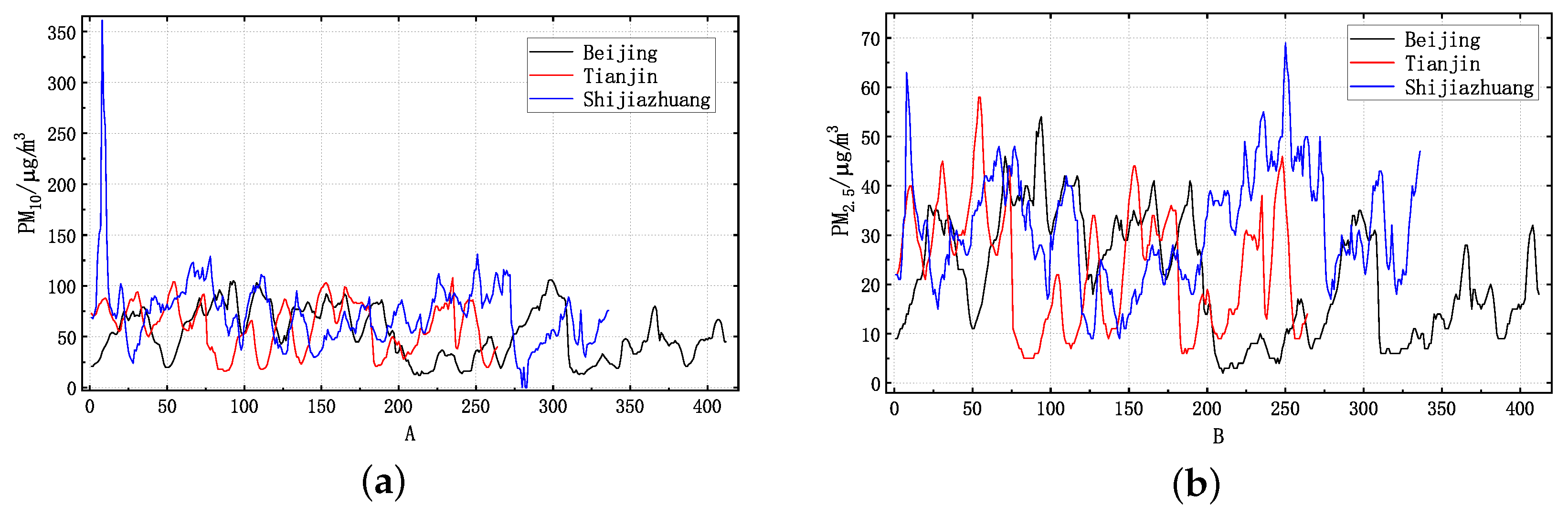
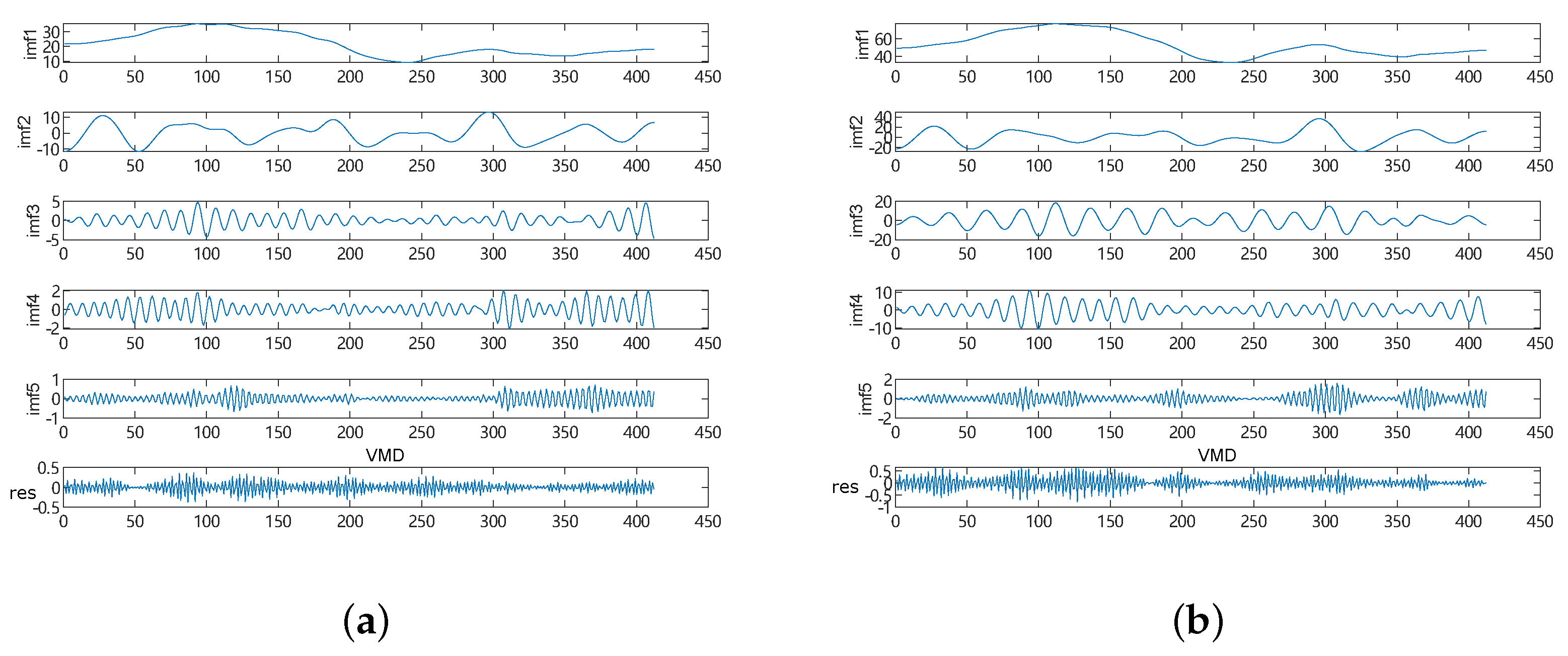
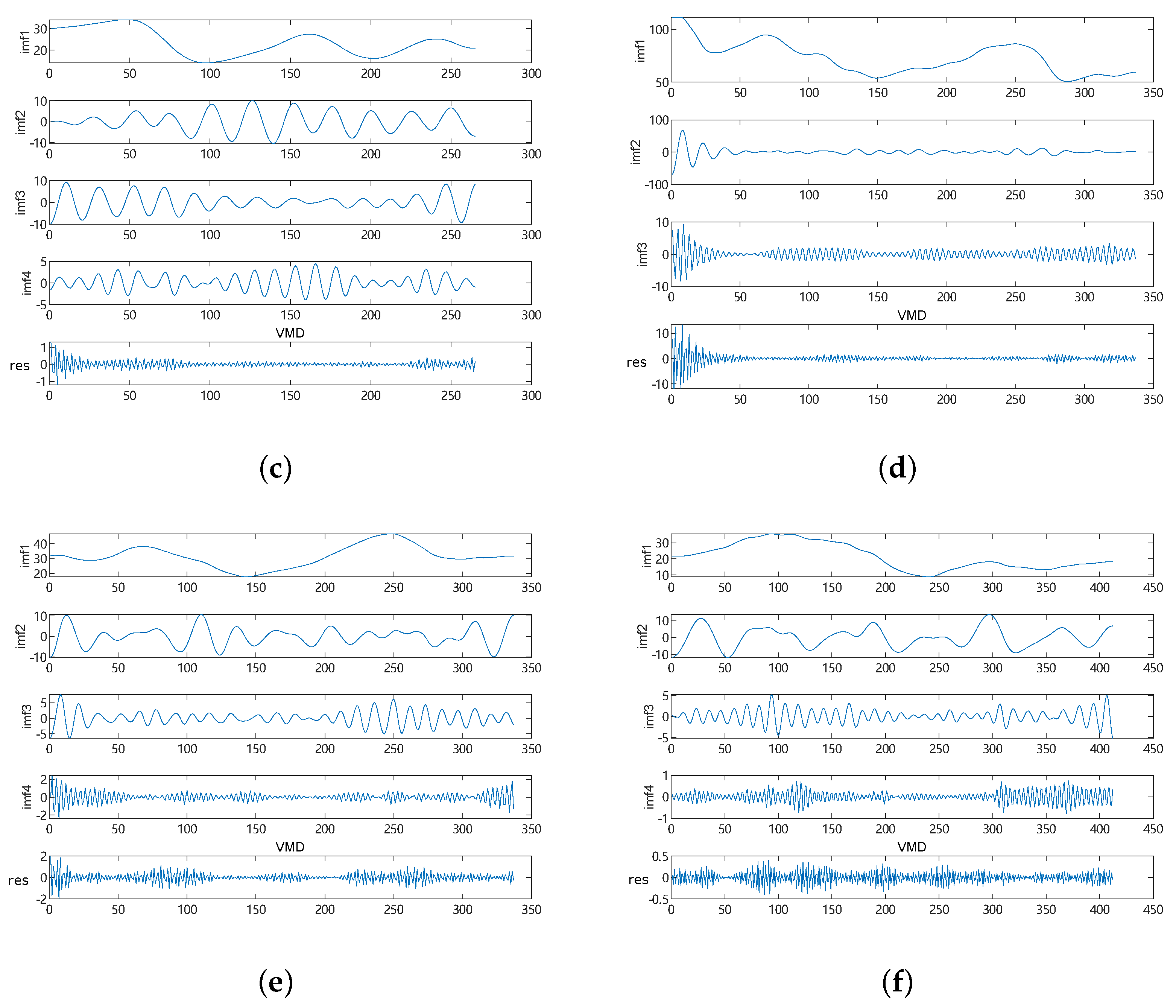
28], considering the non-linearity and non-stationarity of
and
data, which are the main pollutants affecting air quality, we introduce VMD and decompose the time series data of
and
. At the same time, in order to improve the performance of SSA-LSSVM, we introduce the reverse learning strategy-lens principle [
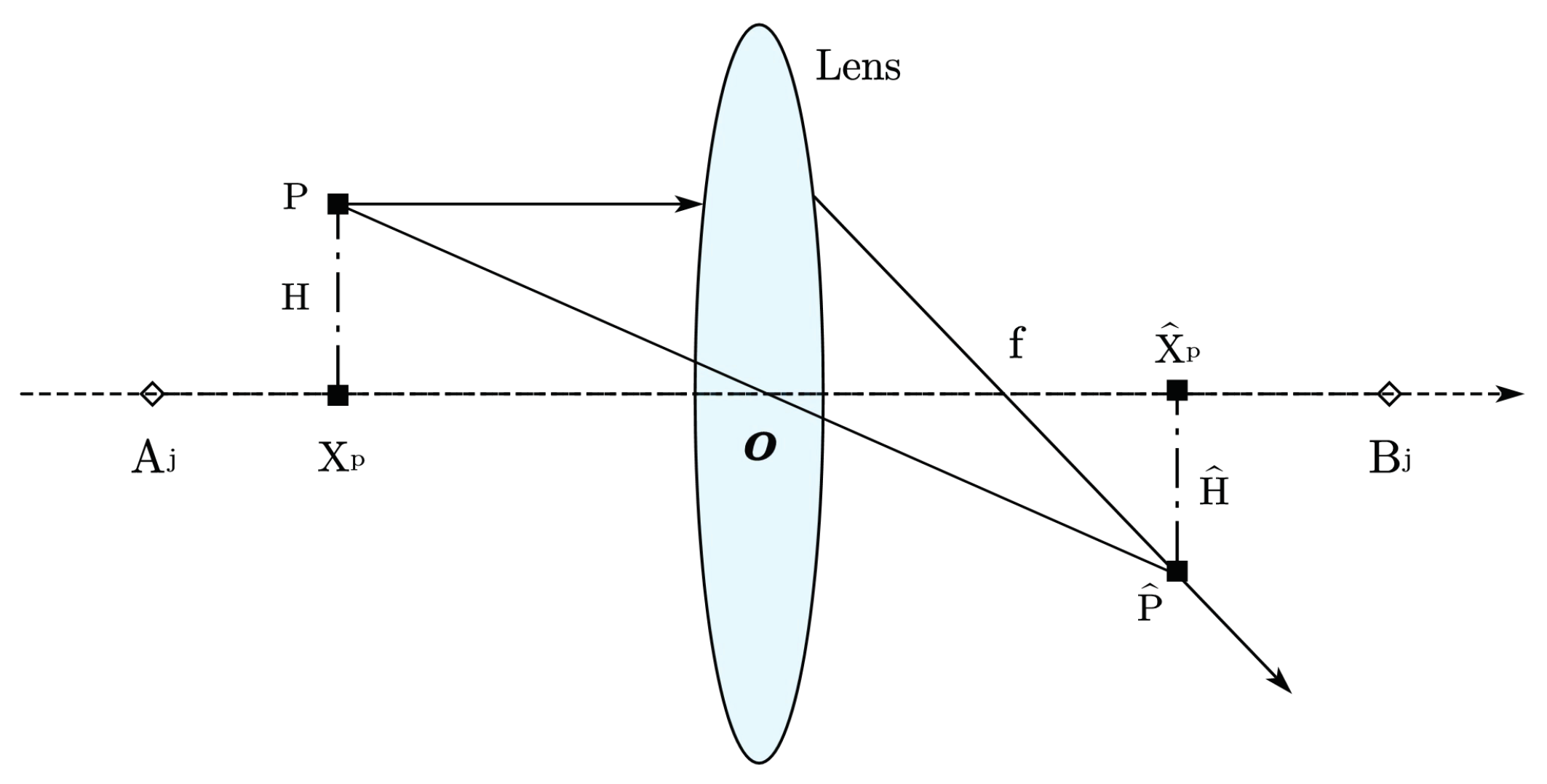
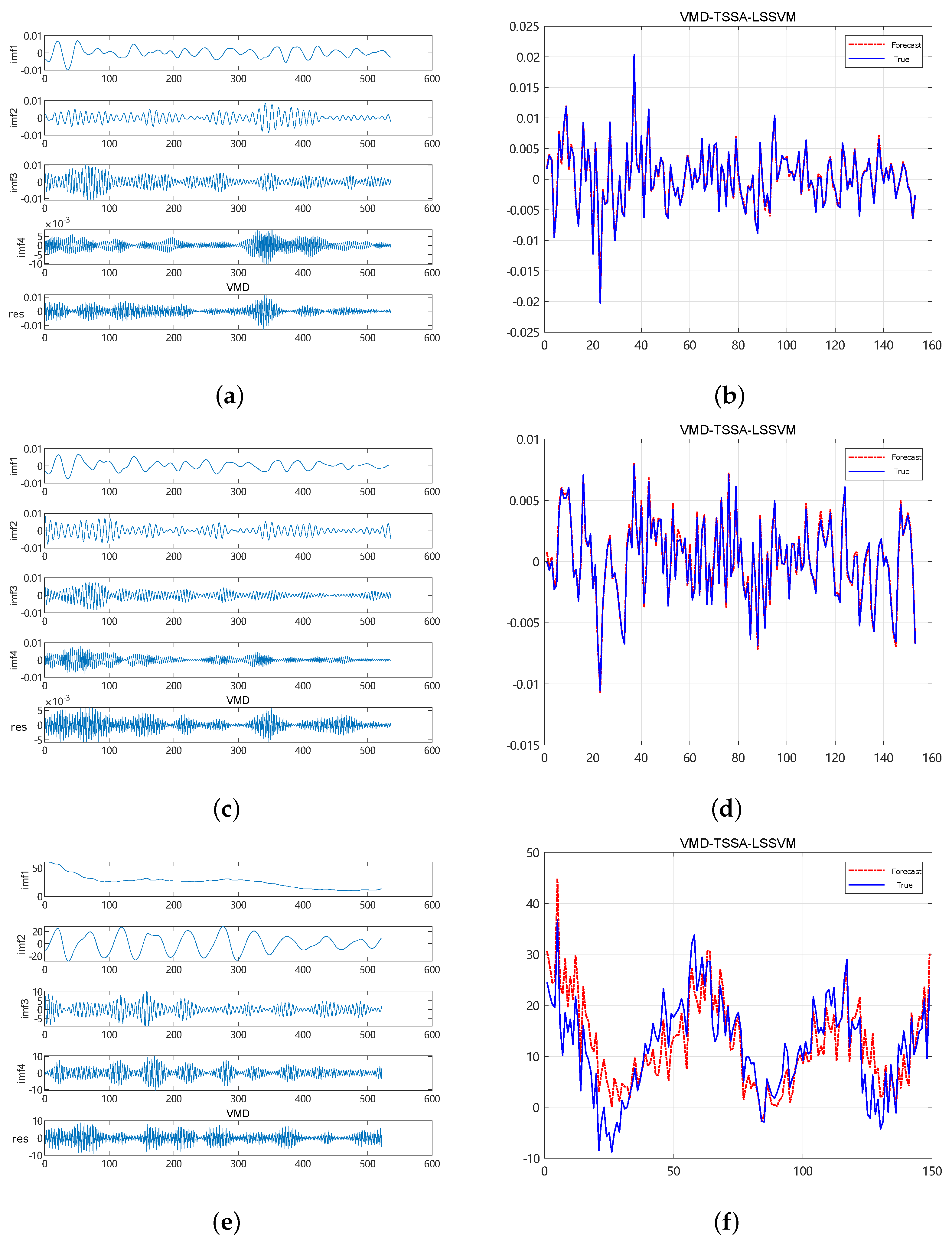
23] to optimize two important parameters of LSSVM, and establish a new model (TSSA-LSSVM) to further overcome the sensitivity of the least squares support vector machine to parameter selection.
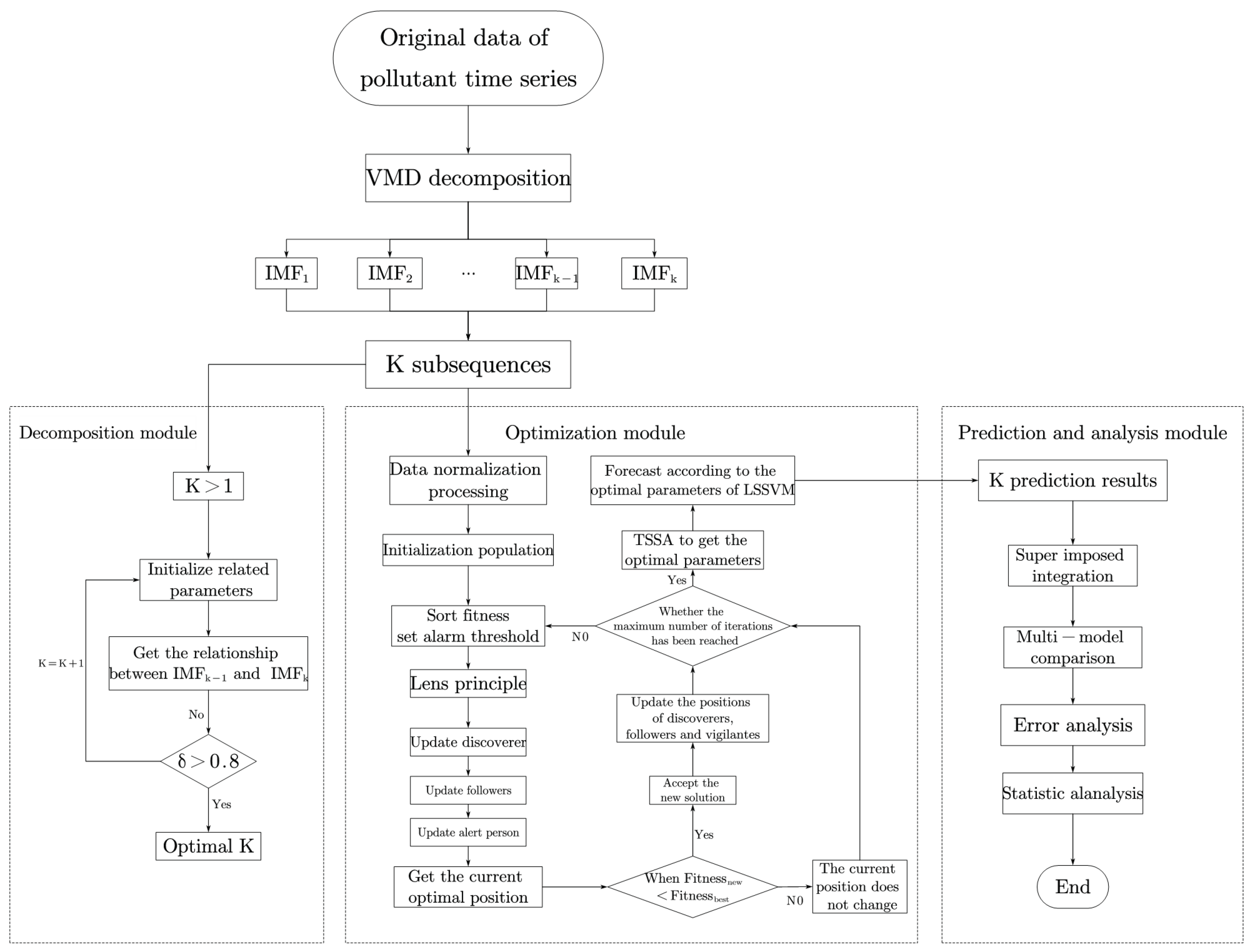
The main purpose of this paper is to improve the short-term pollutant prediction accuracy of cities in the Beijing–Tianjin–Hebei region by proposing a new hybrid model (VMD-TSSA-LSSVM) based on VMD and the machine learning method. And the major aims are as follows:
- (1)
To deal with the instability and randomness of the original data of the and time series, the VMD technique is used to decompose the original signal into multiple modes to ensure the accuracy of the decomposed signal and avoid redundancies and over-decomposition.
- (2)
The lens principle is introduced to optimize the sparrow search algorithm, the SSA shows excellent performance in algorithm convergence and global optimization and the TSSA will further improve the performance of the optimized least squares support vector machine and obtain the optimal parameters.
- (3)
To obtain effective prediction results and improve its practical application value, in the experimental stage, not only the excellent performance of the model is verified on the UCI data set, but the prediction results are also analyzed under multi-input and compared with other models to verify that the prediction accuracy of this model is better and more suitable for pollutant concentration prediction.
- (4)
Finally, based on the experimental part, we carry out a statistical analysis to further verify the effectiveness of the model.
The rest of this article is organized as follows. In
Section 2, some related work is reviewed. In
Section 3, the main model is established and the relevant experimental analysis is carried out. Finally, in
Section 6, we give the conclusion of this paper.
5. Statistical Analysis
In this section, we want to use the famous Friedman test [
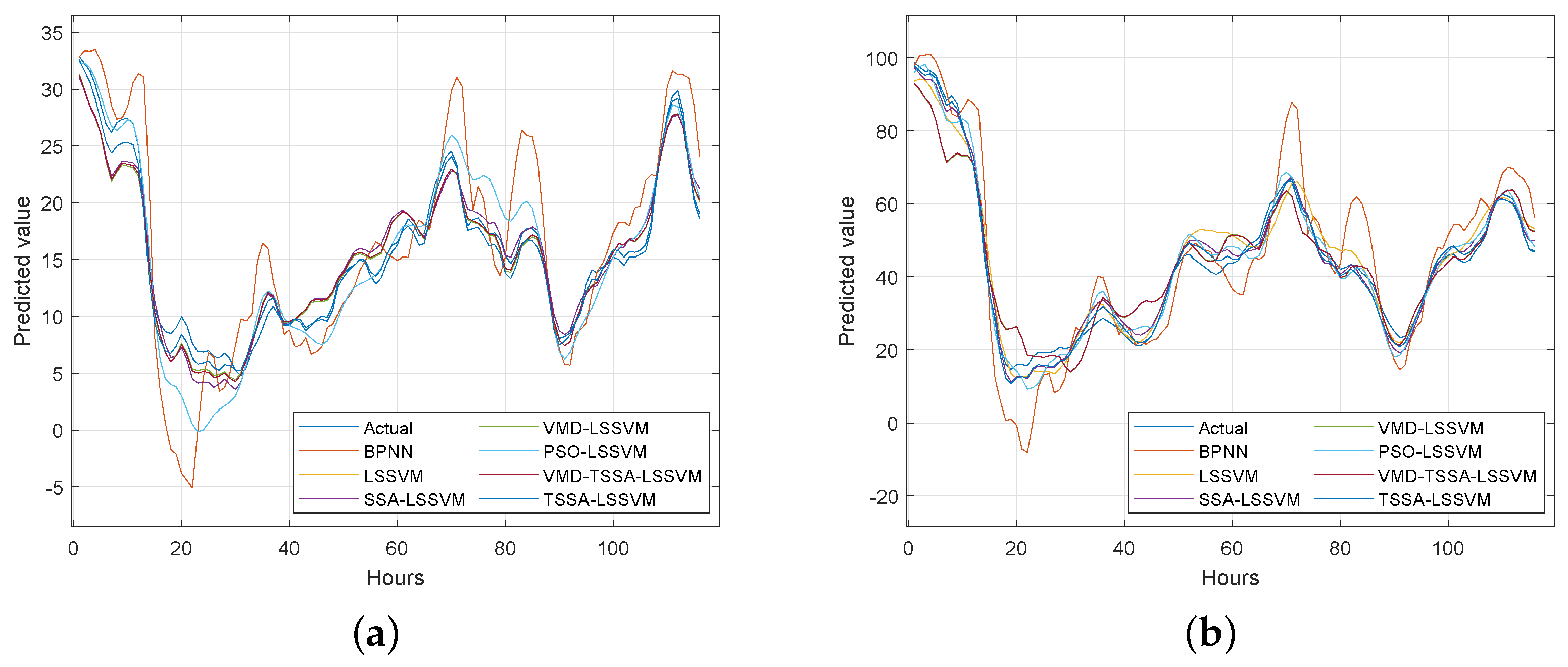
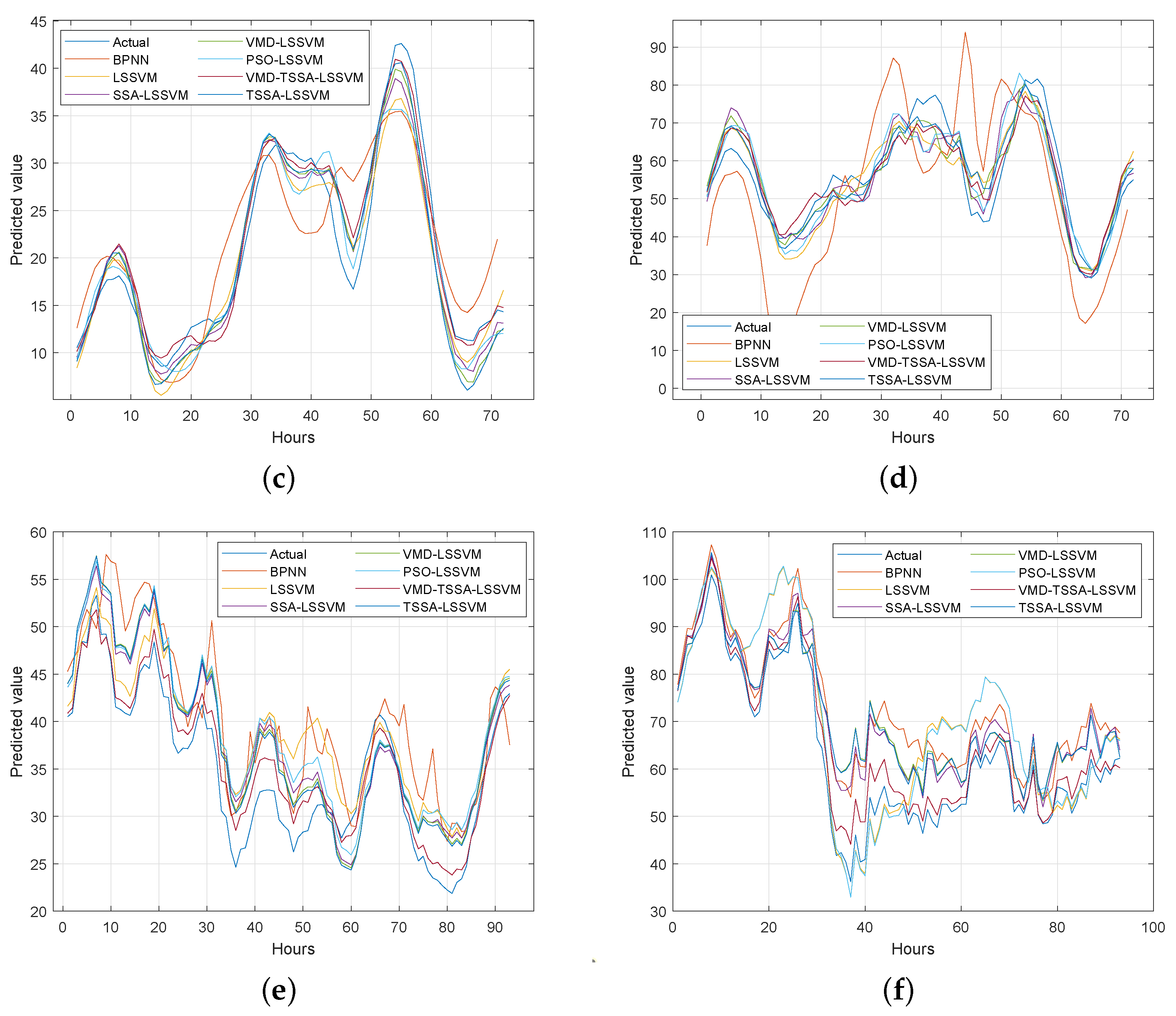
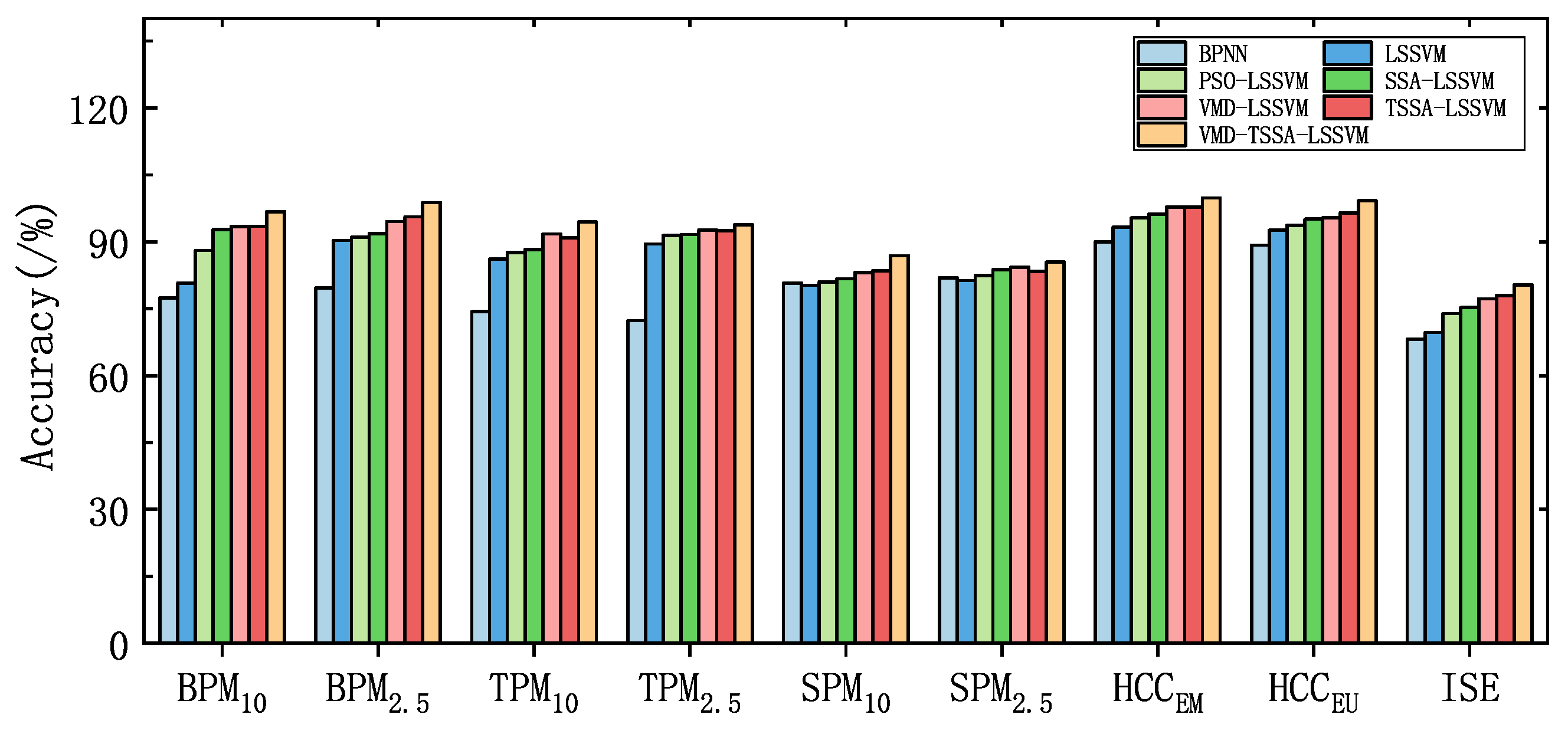
33] to analyze the differences between the seven models on the UCI data set and the pollutant data set. The Friedman test is chosen because it can make full use of the information of the original data and has the advantages of a safe and reliable nonparametric test. First of all, the prediction accuracy of the seven models on nine datasets is visually shown in
Table 6 and
Figure 7. It can be seen from the chart that the prediction accuracy of VMD-TSSA-LSSVM is higher.
Next, to facilitate the statistical analysis,
Table 7 shows the average ranking and accuracy of all models on nine data sets. It can be seen from
Table 7 that the accuracy of this model is 13.48%, 7.99%, 5.66%, 4.34%, 2.83% and 2.77% higher than that of BPNN, LSSVM, PSO-LSSVM, SSA-LSSVM, VMD-LSSVM and TSSA-LSSVM, respectively. And it is higher in the rankings.
The formula for Friedman statistical variables is as follows:
where
k is the number of algorithms in this paper, and
N is the number of selected data sets, including UCI data sets and pollutant data sets. In this paper, the values of
k and
N are 7 and 9, respectively, and
represents the average ranking of seven algorithms.
In addition, according to the
distribution with
degrees of freedom, we can obtain:
where
obeys the F-distribution, and its degree of freedom is
and
. In this paper, we choose
and we can obtain
. Obviously,
is much larger than
, so we reject the zero hypothesis.
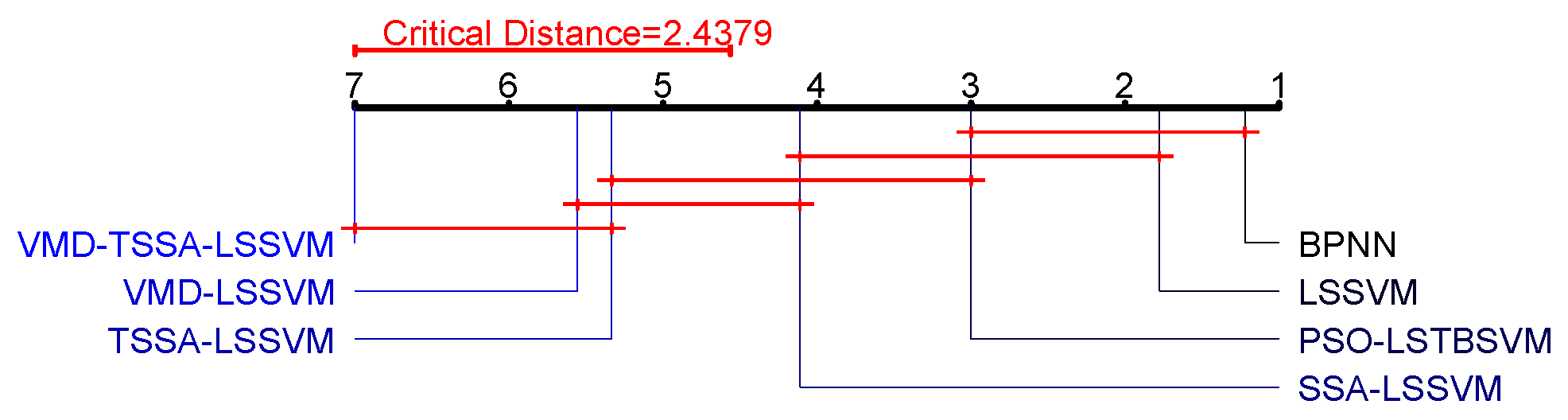
Next, through the Nemenyipost-hoctest, we can further compare the errors of the seven algorithms in this paper. Comparing the average rank difference with the critical value, the greater the numerical difference is, the more obvious the difference in algorithm performance is. Therefore, we use the following formula to calculate the critical difference (CD) and obtain
.
To better analyze the advantages of the method presented in this paper, we visualized the statistical analysis results in
Figure 8. We see that VMD-TSSA-LSSVM has significant statistical differences compared to BPNN, LSSVM, PSO-LSSVM and SSA-LSSVM, and thus our method is better than these four algorithms, because the difference between them is less than the CD value. Furthermore, we can observe that there is no significant difference between VMD-TSSA-LSSVM and TSSA-LSSVM, VMD-LSSVM, as the difference is smaller than the CD value. Therefore, based on the statistical analysis, it is safe to conclude that the VMD-TSSA-LSSVM is performs better. This shows that the prediction performance of the new hybrid model based on TSSA-LSSVM and VMD-LSSVM has been further improved.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}