
Application of a Hybrid CEEMD-LSTM Model Based on the Standardized Precipitation Index for Drought Forecasting: The Case of the Xinjiang Uygur Autonomous Region, China
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Data
2.2. Methods
2.2.1. Standardized Precipitation Index
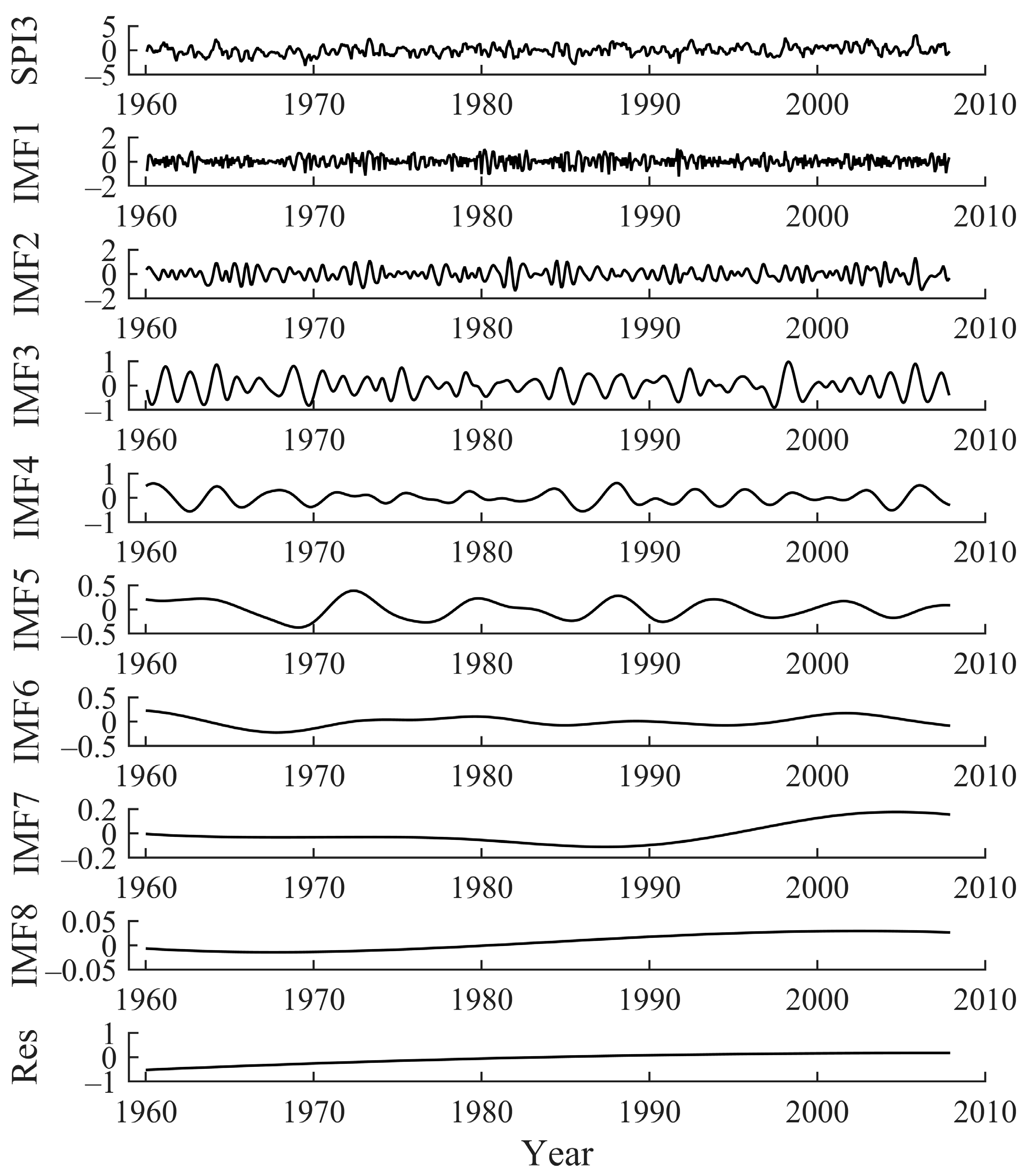
2.2.2. Complementary Ensemble Empirical Mode Decomposition
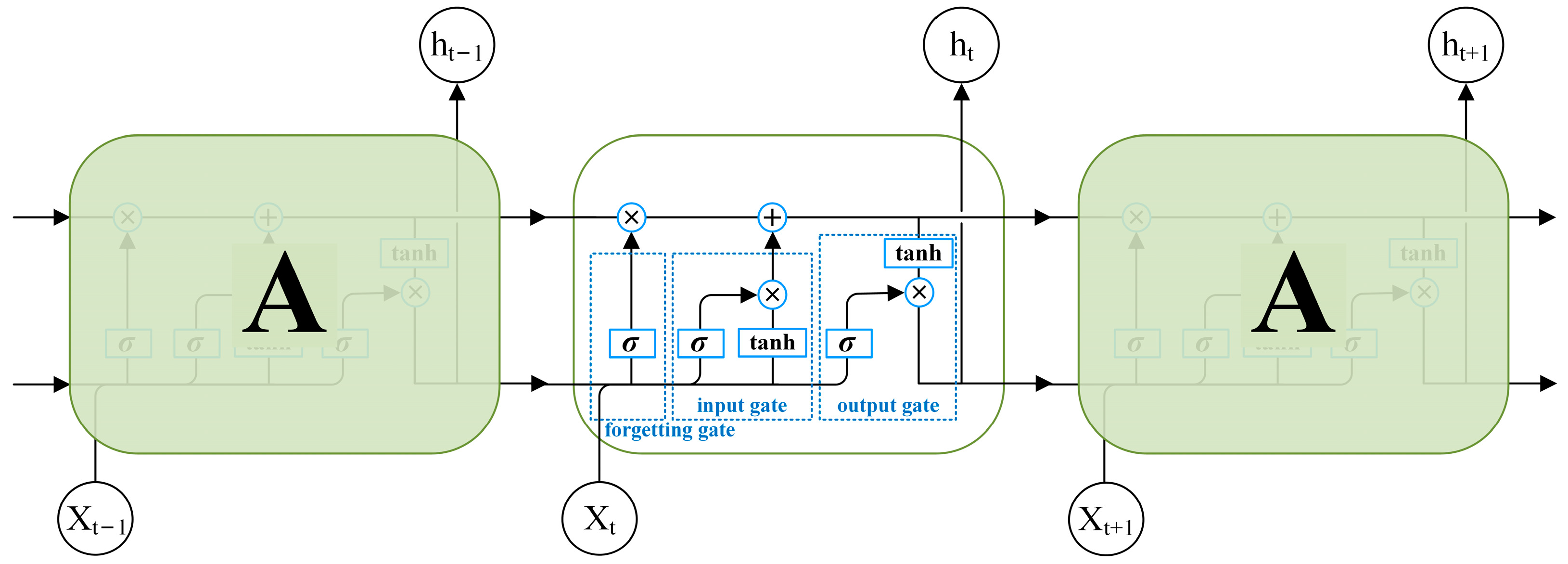
2.2.3. Long Short-Term Memory
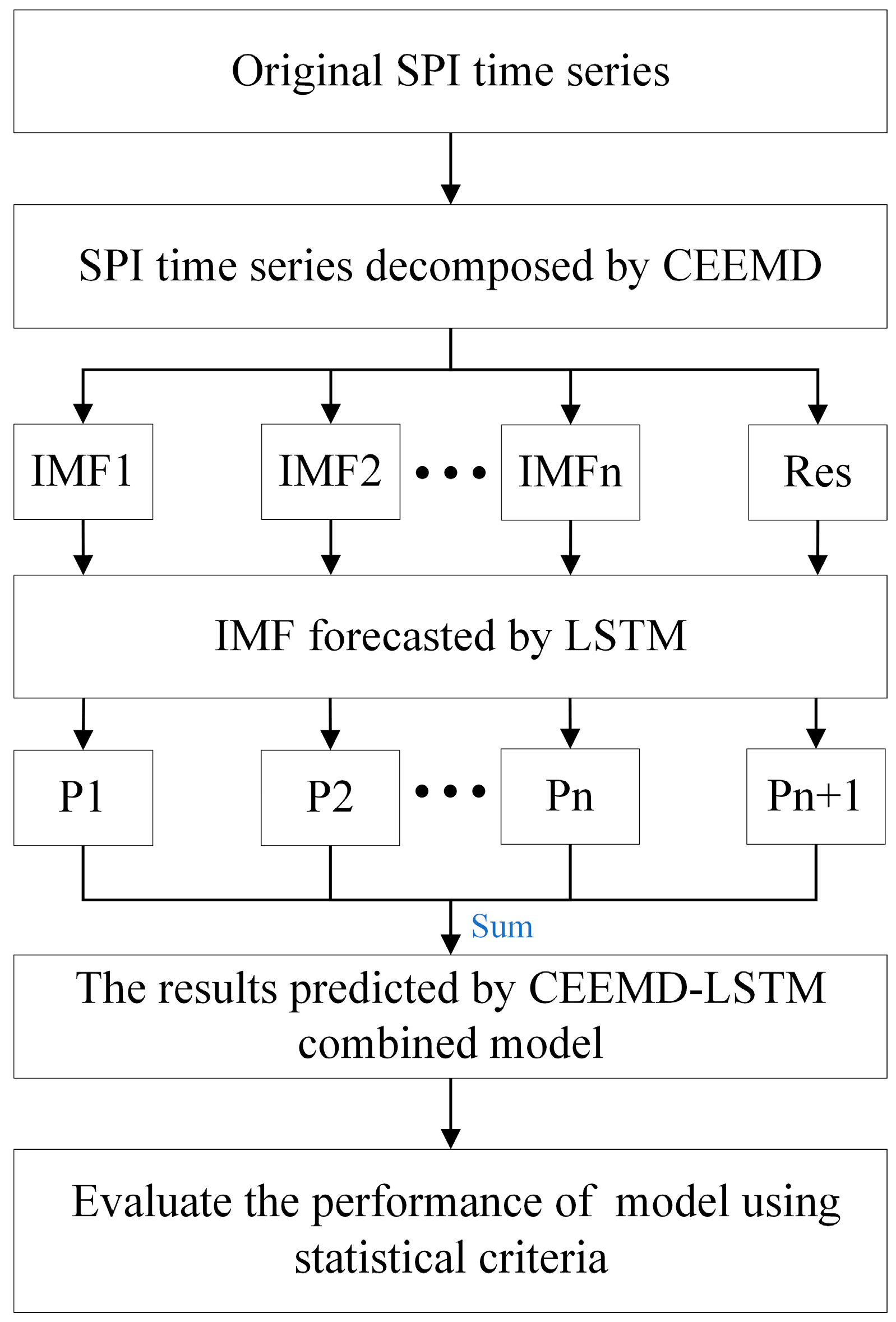
2.2.4. Framework of the Hybrid CEEMD-LSTM Model
2.2.5. Evaluation Metrics
3. Results and Discussion
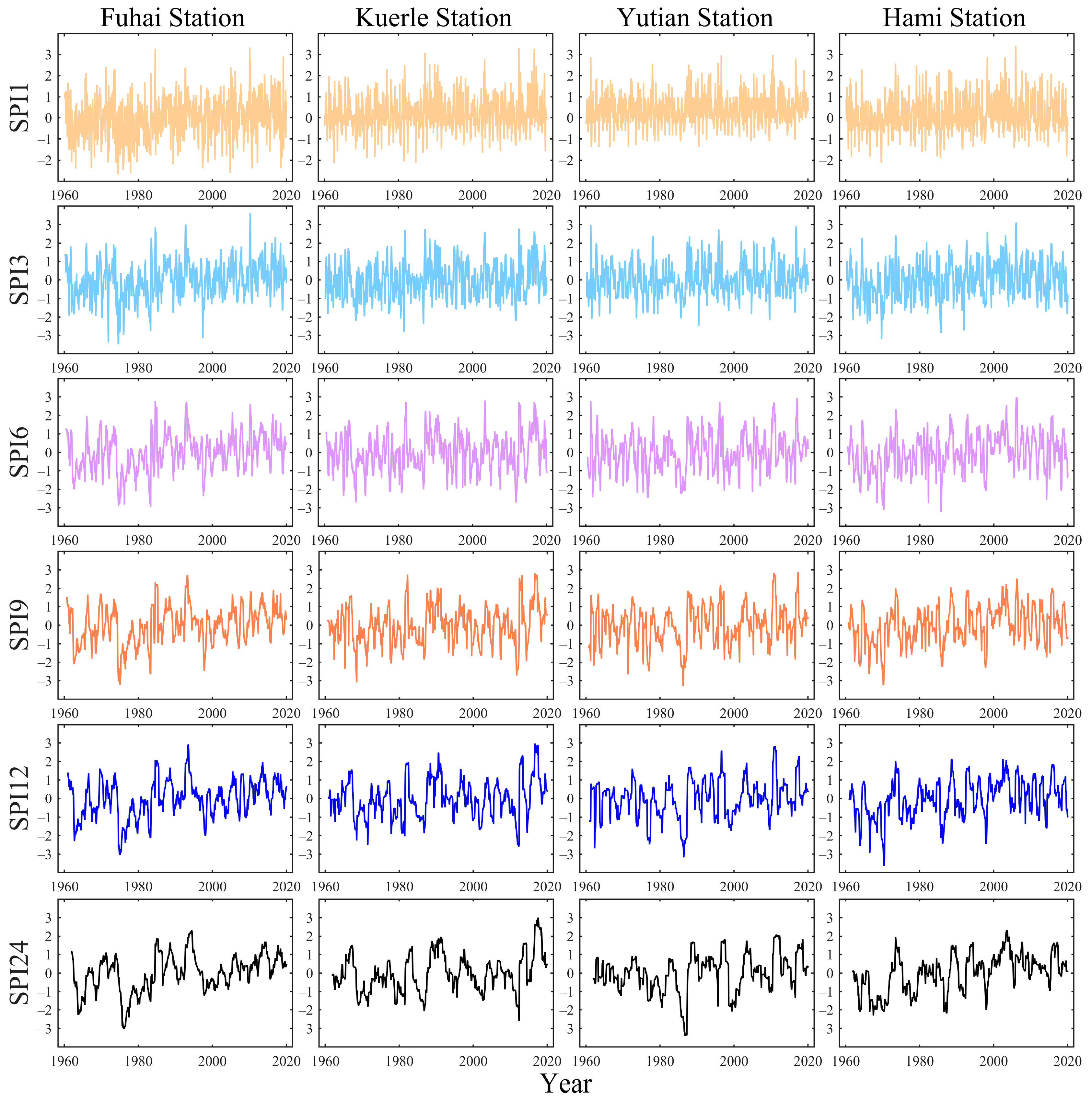
3.1. SPI Values at Different Time Scales
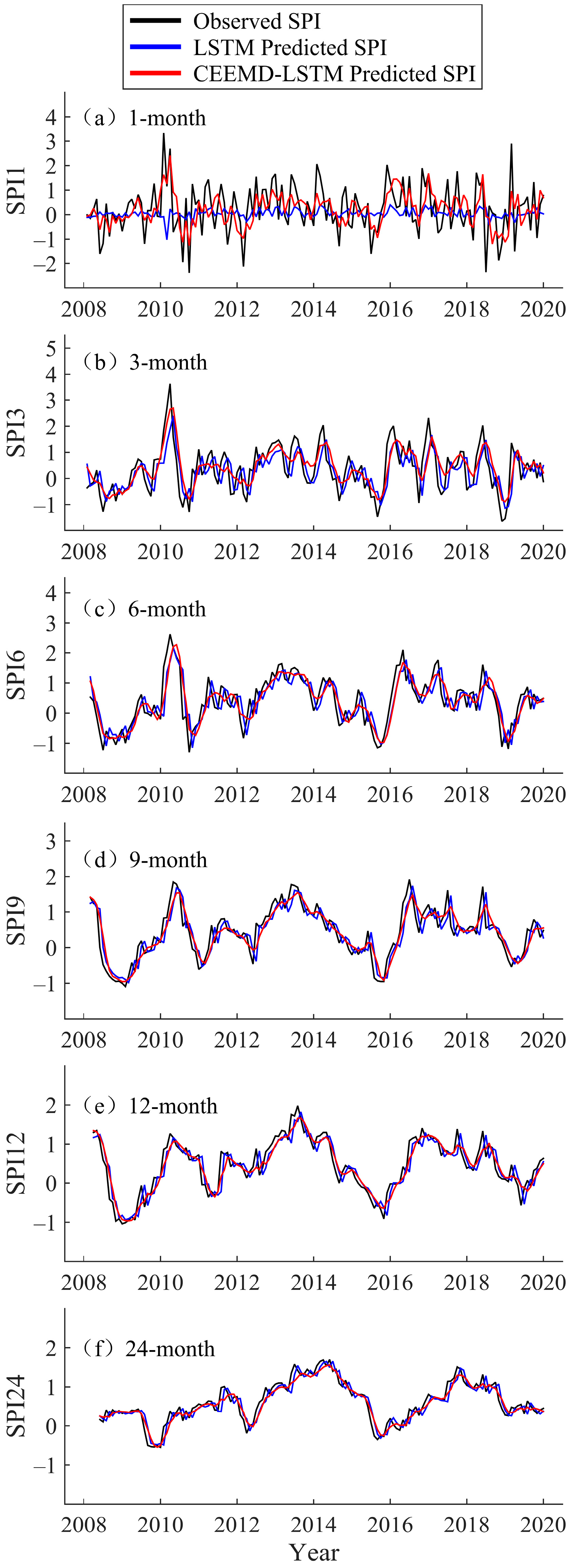
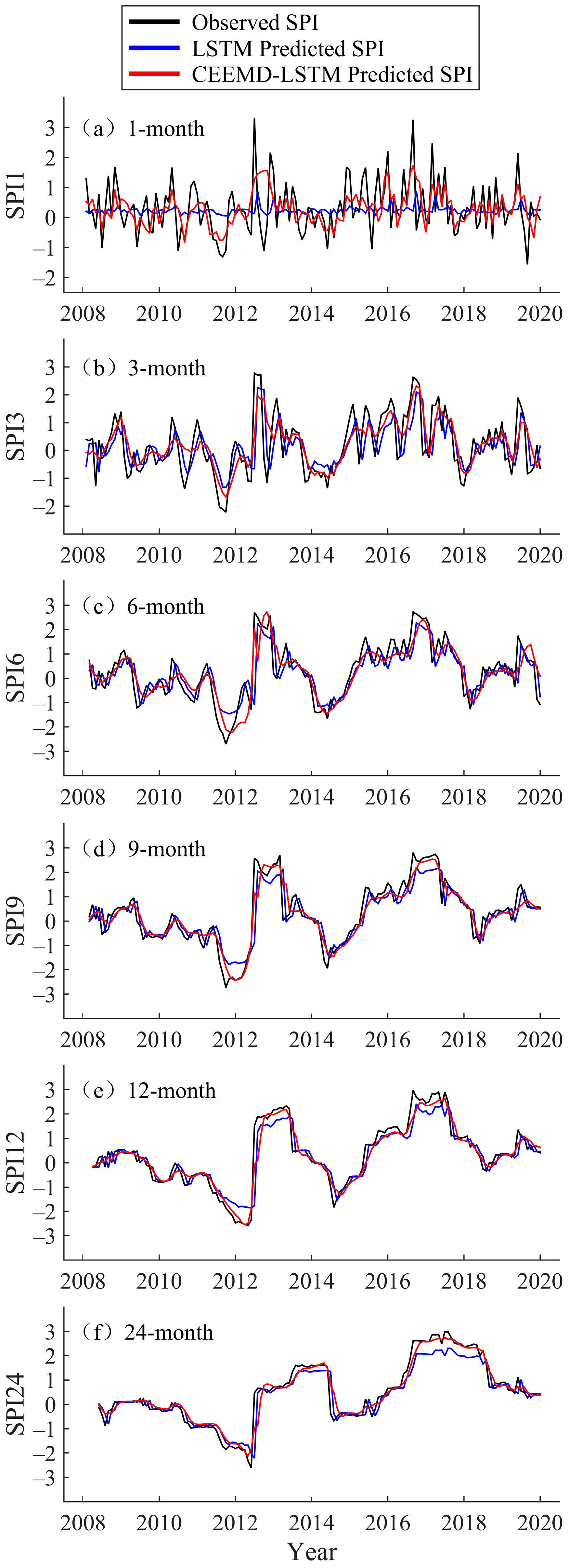
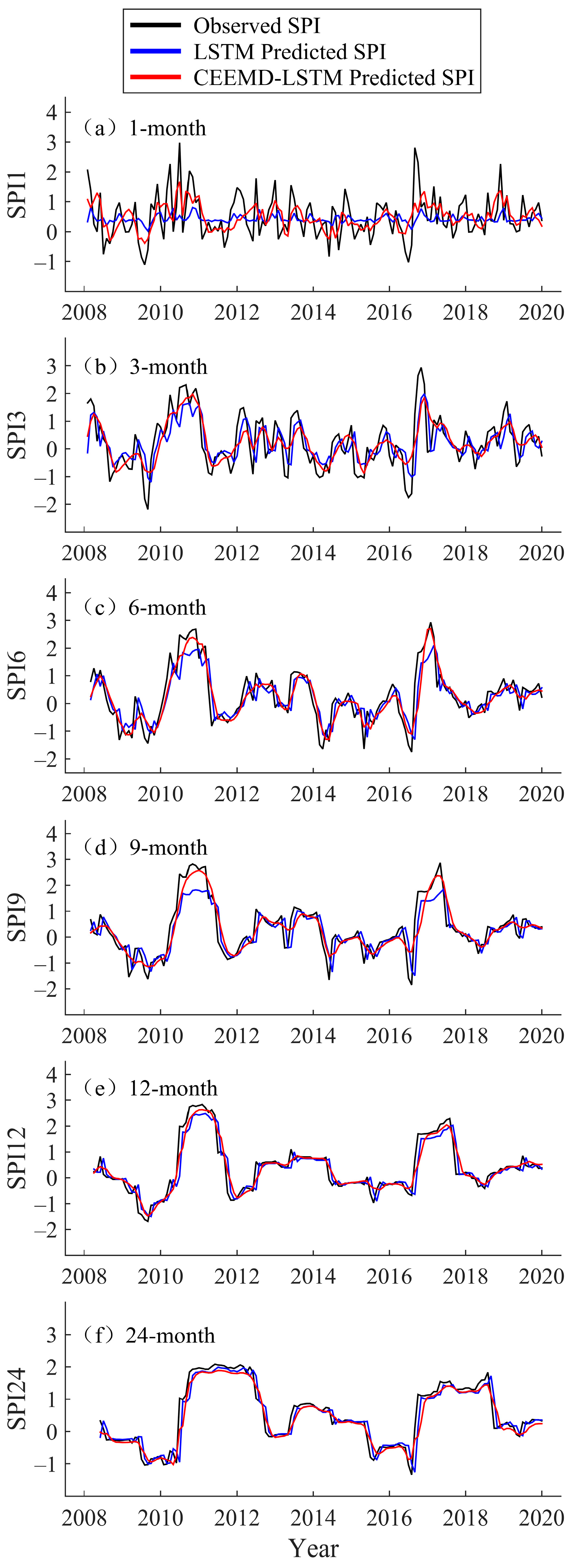
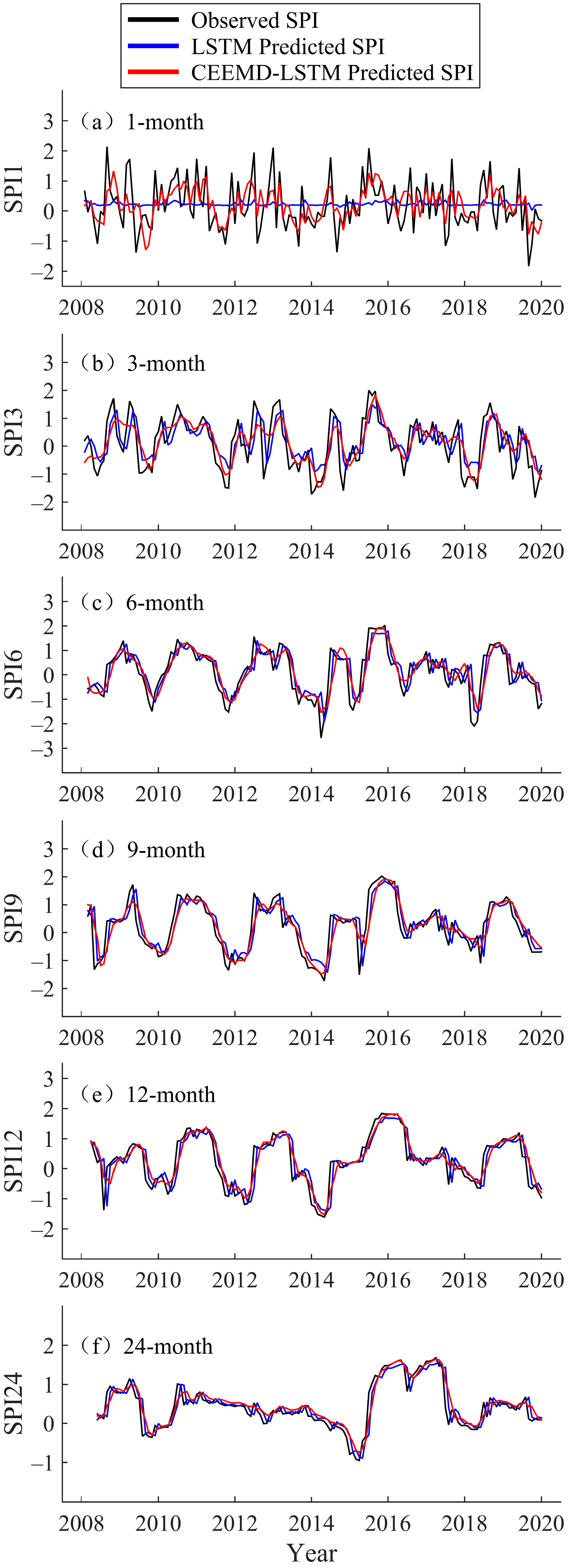
3.2. LSTM Modeling and Prediction
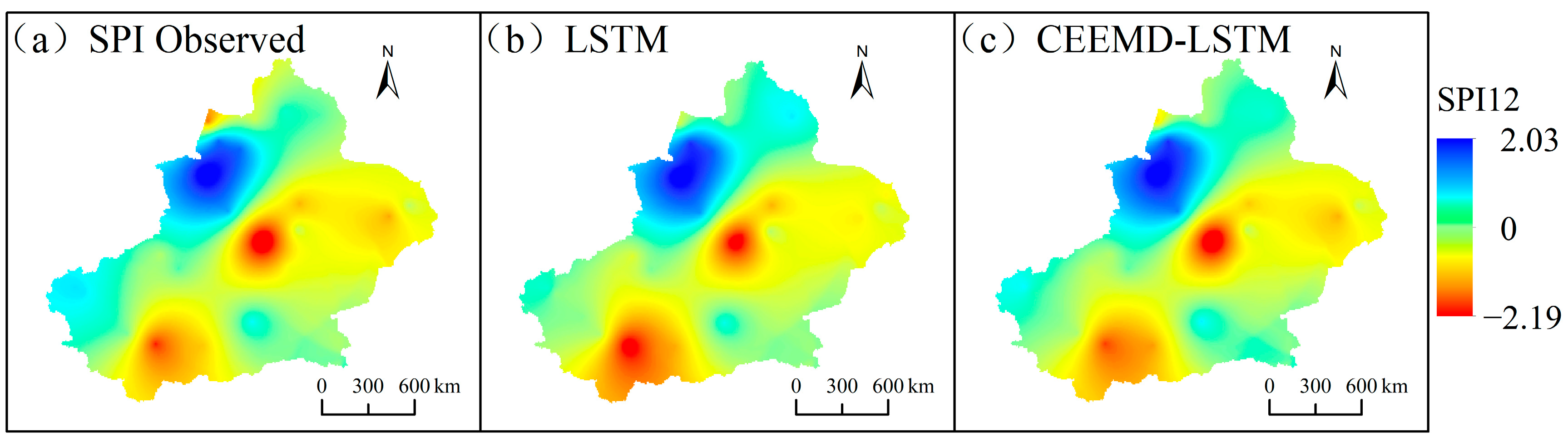
3.3. Hybrid CEEMD-LSTM Model Prediction Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| SPI | standardized precipitation index |
| SPEI | standardized precipitation evapotranspiration index |
| RDI | reconnaissance drought index |
| PDSI | Palmer drought severity index |
| EMD | empirical mode decomposition |
| EEMD | ensemble empirical mode decomposition |
| CEEMD | complementary ensemble empirical mode decomposition |
| ARMA | autoregressive and moving average |
| ANNs | artificial neural networks |
| RNNs | recurrent neural networks |
| LSTM | long short-term memory |
| NSE | Nash–Sutcliffe efficiency |
| WI | Willmott index |
| RMSE | root mean square error |
| MAE | mean absolute error |
| MSE | mean squared error |
References
- Fan, X.; Miao, C.; Duan, Q.; Shen, C.; Wu, Y. Future Climate Change Hotspots Under Different 21st Century Warming Scenarios. Earths Future 2021, 9, e2021EF002027. [Google Scholar] [CrossRef]
- Sun, Q.; Miao, C.; Hanel, M.; Borthwick, A.G.L.; Duan, Q.; Ji, D.; Li, H. Global Heat Stress on Health, Wildfires, and Agricultural Crops under Different Levels of Climate Warming. Environ. Int. 2019, 128, 125–136. [Google Scholar] [CrossRef] [PubMed]
- Cai, S.; Song, X.; Hu, R.; Leng, P.; Li, X.; Guo, D.; Zhang, Y.; Hao, Y.; Wang, Y. Spatiotemporal Characteristics of Agricultural Droughts Based on Soil Moisture Data in Inner Mongolia from 1981 to 2019. J. Hydrol. 2021, 603, 127104. [Google Scholar] [CrossRef]
- Dai, M.; Huang, S.; Huang, Q.; Zheng, X.; Su, X.; Leng, G.; Li, Z.; Guo, Y.; Fang, W.; Liu, Y. Propagation Characteristics and Mechanism from Meteorological to Agricultural Drought in Various Seasons. J. Hydrol. 2022, 610, 127897. [Google Scholar] [CrossRef]
- Shi, M.; Yuan, Z.; Shi, X.; Li, M.; Chen, F.; Li, Y. Drought Assessment of Terrestrial Ecosystems in the Yangtze River Basin, China. J. Clean. Prod. 2022, 362, 132234. [Google Scholar] [CrossRef]
- Wang, S.; Li, R.; Wu, Y.; Zhao, S. Effects of Multi-Temporal Scale Drought on Vegetation Dynamics in Inner Mongolia from 1982 to 2015, China. Ecol. Indic. 2022, 136, 108666. [Google Scholar] [CrossRef]
- Ortega-Gómez, T.; Pérez-Martín, M.A.; Estrela, T. Improvement of the Drought Indicators System in the Júcar River Basin, Spain. Sci. Total Environ. 2018, 610–611, 276–290. [Google Scholar] [CrossRef]
- Sivakumar, V.L.; Ramalakshmi, M.; Krishnappa, R.R.; Manimaran, J.C.; Paranthaman, P.K.; Priyadharshini, B.; Periyasami, R.K. An Integration of Geospatial Technology and Standard Precipitation Index (SPI) for Drought Vulnerability Assessment for a Part of Namakkal District, South India. Mater. Today Proc. 2020, 33, 1206–1211. [Google Scholar]
- Zhang, Y.; Li, W.; Chen, Q.; Pu, X.; Xiang, L. Multi-Models for SPI Drought Forecasting in the North of Haihe River Basin, China. Stoch. Environ. Res. Risk Assess. 2017, 31, 2471–2481. [Google Scholar] [CrossRef]
- Bera, B.; Shit, P.K.; Sengupta, N.; Saha, S.; Bhattacharjee, S. Trends and Variability of Drought in the Extended Part of Chhota Nagpur Plateau (Singbhum Protocontinent), India Applying SPI and SPEI Indices. Environ. Chall. 2021, 5, 100310. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B.; Huete, A. An Improved SPEI Drought Forecasting Approach Using the Long Short-Term Memory Neural Network. J. Environ. Manag. 2021, 283, 111979. [Google Scholar] [CrossRef] [PubMed]
- Musei, S.K.; Nyaga, J.M.; Dubow, A.Z. SPEI-Based Spatial and Temporal Evaluation of Drought in Somalia. J. Arid. Environ. 2021, 184, 104296. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, Y.; Zhang, C.; Guo, H.; Hou, Y. Historical and Future Palmer Drought Severity Index with Improved Hydrological Modeling. J. Hydrol. 2022, 610, 127941. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, F.; Lai, W.; Lim, W.H.; Liu, W.; Wang, T.; Wang, P. Attributing Changes in Future Extreme Droughts Based on PDSI in China. J. Hydrol. 2019, 573, 607–615. [Google Scholar] [CrossRef]
- Asadi Zarch, M.A.; Sivakumar, B.; Sharma, A. Droughts in a Warming Climate: A Global Assessment of Standardized Precipitation Index (SPI) and Reconnaissance Drought Index (RDI). J. Hydrol. 2015, 526, 183–195. [Google Scholar] [CrossRef]
- Cheng, Q.; Gao, L.; Zhong, F.; Zuo, X.; Ma, M. Spatiotemporal Variations of Drought in the Yunnan-Guizhou Plateau, Southwest China, during 1960–2013 and Their Association with Large-Scale Circulations and Historical Records. Ecol. Indic. 2020, 112, 106041. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.; Yao, H.; Zhang, D. Multi-Timescale Assessment of Propagation Thresholds from Meteorological to Hydrological Drought. Sci. Total Environ. 2021, 765, 144232. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, X.; Hao, Z.; Singh, V.P.; Hao, F. Characterization of Agricultural Drought Propagation over China Based on Bivariate Probabilistic Quantification. J. Hydrol. 2021, 598, 126194. [Google Scholar] [CrossRef]
- Seibert, M.; Merz, B.; Apel, H. Seasonal Forecasting of Hydrological Drought in the Limpopo Basin: A Comparison of Statistical Methods. Hydrol. Earth Syst. Sci. 2017, 21, 1611–1629. [Google Scholar] [CrossRef]
- Song, Y.H.; Chung, E.S.; Shahid, S. Differences in Extremes and Uncertainties in Future Runoff Simulations Using SWAT and LSTM for SSP Scenarios. Sci. Total Environ. 2022, 838, 156162. [Google Scholar] [CrossRef]
- Senanayake, S.; Pradhan, B.; Alamri, A.; Park, H.-J. A New Application of Deep Neural Network (LSTM) and RUSLE Models in Soil Erosion Prediction. Sci. Total Environ. 2022, 845, 157220. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.D.; Ding, L.; Bai, Y.L. Application of Hybrid Model Based on Empirical Mode Decomposition, Novel Recurrent Neural Networks and the ARIMA to Wind Speed Prediction. Energy Convers. Manag. 2021, 233, 113917. [Google Scholar] [CrossRef]
- Wang, W.C.; Chau, K.W.; Qiu, L.; Chen, Y.B. Improving Forecasting Accuracy of Medium and Long-Term Runoff Using Artificial Neural Network Based on EEMD Decomposition. Environ. Res. 2015, 139, 46–54. [Google Scholar] [CrossRef]
- Zhu, S.; Lian, X.; Wei, L.; Che, J.; Shen, X.; Yang, L.; Qiu, X.; Liu, X.; Gao, W.; Ren, X.; et al. PM2.5 Forecasting Using SVR with PSOGSA Algorithm Based on CEEMD, GRNN and GCA Considering Meteorological Factors. Atmos. Environ. 2018, 183, 20–32. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, N.; Wu, L.; Wang, Y. Wind Speed Forecasting Based on the Hybrid Ensemble Empirical Mode Decomposition and GA-BP Neural Network Method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Bahmani, R.; Ouarda, T.B.M.J. Groundwater Level Modeling with Hybrid Artificial Intelligence Techniques. J. Hydrol. 2021, 595, 125659. [Google Scholar] [CrossRef]
- Johny, K.; Pai, M.L.; Adarsh, S. A Multivariate EMD-LSTM Model Aided with Time Dependent Intrinsic Cross-Correlation for Monthly Rainfall Prediction. Appl. Soft Comput. 2022, 123, 108941. [Google Scholar] [CrossRef]
- Mckee, T.B.; Doesken, N.J.; Kleist, J. The relationship of drought frequency and duration to time scales. In Proceedings of the 8th Conference on Applied Climatology, Anaheim, CA, USA, 17–22 January 1993; pp. 179–184. [Google Scholar]
- Svoboda, M.; Hayes, M.; Wood, D. Standardized Precipitation Index User Guide; WMO-No. 1090; World Meteorological Organization (WMO): Geneva, Switzerland, 2012. [Google Scholar]
- Huang, Y.F.; Ang, J.T.; Tiong, Y.J.; Mirzaei, M.; Amin, M.Z.M. Drought Forecasting Using SPI and EDI under RCP-8.5 Climate Change Scenarios for Langat River Basin, Malaysia. Procedia Eng. 2016, 154, 710–717. [Google Scholar] [CrossRef]
- Tsakiris, G.; Vangelis, H. Towards a Drought Watch System Based on Spatial SPI. Water Resour. Manag. 2004, 18, 1–12. [Google Scholar] [CrossRef]
- Yerdelen, C.; Abdelkader, M.; Eris, E. Assessment of Drought in SPI Series Using Continuous Wavelet Analysis for Gediz Basin, Turkey. Atmos. Res. 2021, 260, 105687. [Google Scholar] [CrossRef]
- Javed, T.; Li, Y.; Rashid, S.; Li, F.; Hu, Q.; Feng, H.; Chen, X.; Ahmad, S.; Liu, F.; Pulatov, B. Performance and Relationship of Four Different Agricultural Drought Indices for Drought Monitoring in China’s Mainland Using Remote Sensing Data. Sci. Total Environ. 2021, 759, 143530. [Google Scholar] [CrossRef] [PubMed]
- Yeh, J.R.; Shieh, J.S.; Huang, N.E. Complementary Ensemble Empirical Mode Decomposition: A Novel Noise Enhanced Data Analysis Method. Adv. Adapt. Data Anal. 2010, 2, 135–156. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ko, M.S.; Lee, K.; Kim, J.K.; Hong, C.W.; Dong, Z.Y.; Hur, K. Deep Concatenated Residual Network with Bidirectional LSTM for One-Hour-Ahead Wind Power Forecasting. IEEE Trans. Sustain. Energy 2021, 12, 1321–1335. [Google Scholar] [CrossRef]
- Vijayaprabakaran, K.; Sathiyamurthy, K. Towards Activation Function Search for Long Short-Term Model Network: A Differential Evolution Based Approach. J. King Saud Univ.-Comput. Inf. Sci. 2020, 34, 2637–2650. [Google Scholar] [CrossRef]
- Weiss Technion, G.; Goldberg, I.Y.; Yahav, E. On the Practical Computational Power of Finite Precision RNNs for Language Recognition. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 740–745. [Google Scholar]
- Adikari, K.E.; Shrestha, S.; Ratnayake, D.T.; Budhathoki, A.; Mohanasundaram, S.; Dailey, M.N. Evaluation of Artificial Intelligence Models for Flood and Drought Forecasting in Arid and Tropical Regions. Environ. Model. Softw. 2021, 144, 105136. [Google Scholar] [CrossRef]
- Chen, X.; Li, F.W.; Feng, P. A New Hybrid Model for Nonlinear and Non-Stationary Runoff Prediction at Annual and Monthly Time Scales. J. Hydro-Environ. Res. 2018, 20, 77–92. [Google Scholar] [CrossRef]
- Feng, Z.K.; Niu, W.J.; Tang, Z.Y.; Jiang, Z.Q.; Xu, Y.; Liu, Y.; Zhang, H.R. Monthly Runoff Time Series Prediction by Variational Mode Decomposition and Support Vector Machine Based on Quantum-Behaved Particle Swarm Optimization. J. Hydrol. 2020, 583, 124627. [Google Scholar] [CrossRef]
- Wen, X.; Feng, Q.; Deo, R.C.; Wu, M.; Yin, Z.; Yang, L.; Singh, V.P. Two-Phase Extreme Learning Machines Integrated with the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise Algorithm for Multi-Scale Runoff Prediction Problems. J. Hydrol. 2019, 570, 167–184. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SPI Value | Classification |
|---|---|
| −0.5+ | No drought |
| −0.5 to −0.99 | Mild drought |
| −1.0 to −1.49 | Moderate drought |
| −1.5 to −1.99 | Severe drought |
| −2.0 and less | Extreme drought |
| Example Stations | SPI Series | p Value | Trend |
|---|---|---|---|
| Fuhai | SPI1 | 2.492 × 10−5 | increasing |
| SPI3 | 3.721 × 10−10 | increasing | |
| SPI6 | 8.860 × 10−14 | increasing | |
| SPI9 | 1.665 × 10−14 | increasing | |
| SPI12 | 2.220 × 10−16 | increasing | |
| SPI24 | 0.000 | increasing | |
| Kuerle | SPI1 | 0.081 | no trend |
| SPI3 | 0.001 | increasing | |
| SPI6 | 3.329 × 10−5 | increasing | |
| SPI9 | 6.254 × 10−6 | increasing | |
| SPI12 | 8.926 × 10−7 | increasing | |
| SPI24 | 4.159 × 10−12 | increasing | |
| Yutian | SPI1 | 0.035 | increasing |
| SPI3 | 0.001 | increasing | |
| SPI6 | 1.649 × 10−4 | increasing | |
| SPI9 | 2.321 × 10−4 | increasing | |
| SPI12 | 4.652 × 10−4 | increasing | |
| SPI24 | 1.990 × 10−11 | increasing | |
| Hami | SPI1 | 0.006 | increasing |
| SPI3 | 9.700 × 10−7 | increasing | |
| SPI6 | 3.212 × 10−12 | increasing | |
| SPI9 | 1.332 × 10−15 | increasing | |
| SPI12 | 0.000 | increasing | |
| SPI24 | 0.000 | increasing |
| Example Stations | SPI Series | Model | MAE | RMSE | NSE | WI |
|---|---|---|---|---|---|---|
| Fuhai | SPI1 | LSTM | 0.790 | 1.028 | −32.371 | 0.255 |
| CEEMD-LSTM | 0.675 | 0.815 | −0.633 | 0.721 | ||
| SPI3 | LSTM | 0.551 | 0.681 | −0.112 | 0.781 | |
| CEEMD-LSTM | 0.474 | 0.578 | 0.247 | 0.850 | ||
| SPI6 | LSTM | 0.389 | 0.491 | 0.498 | 0.885 | |
| CEEMD-LSTM | 0.295 | 0.378 | 0.714 | 0.934 | ||
| SPI9 | LSTM | 0.275 | 0.360 | 0.682 | 0.924 | |
| CEEMD-LSTM | 0.219 | 0.291 | 0.790 | 0.951 | ||
| SPI12 | LSTM | 0.219 | 0.294 | 0.773 | 0.946 | |
| CEEMD-LSTM | 0.169 | 0.219 | 0.873 | 0.970 | ||
| SPI24 | LSTM | 0.152 | 0.198 | 0.836 | 0.960 | |
| CEEMD-LSTM | 0.119 | 0.152 | 0.895 | 0.976 | ||
| Kuerle | SPI1 | LSTM | 0.648 | 0.868 | −46.280 | 0.168 |
| CEEMD-LSTM | 0.568 | 0.739 | −0.904 | 0.688 | ||
| SPI3 | LSTM | 0.604 | 0.791 | −0.217 | 0.778 | |
| CEEMD-LSTM | 0.502 | 0.674 | 0.214 | 0.850 | ||
| SPI6 | LSTM | 0.471 | 0.660 | 0.451 | 0.890 | |
| CEEMD-LSTM | 0.412 | 0.540 | 0.717 | 0.934 | ||
| SPI9 | LSTM | 0.386 | 0.573 | 0.670 | 0.933 | |
| CEEMD-LSTM | 0.284 | 0.408 | 0.866 | 0.969 | ||
| SPI12 | LSTM | 0.308 | 0.486 | 0.794 | 0.957 | |
| CEEMD-LSTM | 0.225 | 0.342 | 0.915 | 0.981 | ||
| SPI24 | LSTM | 0.270 | 0.427 | 0.842 | 0.967 | |
| CEEMD-LSTM | 0.196 | 0.312 | 0.930 | 0.984 | ||
| Yutian | SPI1 | LSTM | 0.541 | 0.711 | −28.523 | 0.307 |
| CEEMD-LSTM | 0.509 | 0.615 | −1.257 | 0.678 | ||
| SPI3 | LSTM | 0.525 | 0.692 | −0.184 | 0.796 | |
| CEEMD-LSTM | 0.486 | 0.612 | 0.117 | 0.842 | ||
| SPI6 | LSTM | 0.419 | 0.560 | 0.445 | 0.889 | |
| CEEMD-LSTM | 0.324 | 0.439 | 0.740 | 0.942 | ||
| SPI9 | LSTM | 0.368 | 0.541 | 0.513 | 0.903 | |
| CEEMD-LSTM | 0.296 | 0.418 | 0.777 | 0.949 | ||
| SPI12 | LSTM | 0.239 | 0.393 | 0.805 | 0.956 | |
| CEEMD-LSTM | 0.196 | 0.300 | 0.889 | 0.975 | ||
| SPI24 | LSTM | 0.178 | 0.323 | 0.863 | 0.967 | |
| CEEMD-LSTM | 0.177 | 0.260 | 0.908 | 0.979 | ||
| Hami | SPI1 | LSTM | 0.661 | 0.806 | −194.885 | 0.115 |
| CEEMD-LSTM | 0.517 | 0.650 | −0.614 | 0.724 | ||
| SPI3 | LSTM | 0.532 | 0.673 | −0.208 | 0.787 | |
| CEEMD-LSTM | 0.470 | 0.583 | 0.231 | 0.851 | ||
| SPI6 | LSTM | 0.397 | 0.574 | 0.479 | 0.884 | |
| CEEMD-LSTM | 0.352 | 0.466 | 0.654 | 0.924 | ||
| SPI9 | LSTM | 0.342 | 0.501 | 0.578 | 0.904 | |
| CEEMD-LSTM | 0.286 | 0.406 | 0.722 | 0.937 | ||
| SPI12 | LSTM | 0.263 | 0.420 | 0.687 | 0.925 | |
| CEEMD-LSTM | 0.216 | 0.315 | 0.819 | 0.958 | ||
| SPI24 | LSTM | 0.159 | 0.244 | 0.790 | 0.950 | |
| CEEMD-LSTM | 0.139 | 0.201 | 0.852 | 0.966 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Y.; Yu, G.; Tian, R.; Sun, Y. Application of a Hybrid CEEMD-LSTM Model Based on the Standardized Precipitation Index for Drought Forecasting: The Case of the Xinjiang Uygur Autonomous Region, China. Atmosphere 2022, 13, 1504. https://doi.org/10.3390/atmos13091504
Ding Y, Yu G, Tian R, Sun Y. Application of a Hybrid CEEMD-LSTM Model Based on the Standardized Precipitation Index for Drought Forecasting: The Case of the Xinjiang Uygur Autonomous Region, China. Atmosphere. 2022; 13(9):1504. https://doi.org/10.3390/atmos13091504
Chicago/Turabian StyleDing, Yan, Guoqiang Yu, Ran Tian, and Yizhong Sun. 2022. "Application of a Hybrid CEEMD-LSTM Model Based on the Standardized Precipitation Index for Drought Forecasting: The Case of the Xinjiang Uygur Autonomous Region, China" Atmosphere 13, no. 9: 1504. https://doi.org/10.3390/atmos13091504