1. Introduction
Black carbon (BC) is one of the by-products of the incomplete combustion of fossil fuels and biomass [
1], and it is also a global climate forcing factor with special properties. In recent years, many independent studies have shown that BC emissions from different sources have caused serious harm to the earth’s ecology [
2,
3,
4]. BC will absorb solar radiation and diffuse energy to the surrounding atmosphere, which will significantly increase the temperature [
5]. Bond et al. believe that its greenhouse effect ability is only inferior to CO
2 [
6]. BC also has strong light absorption, which can reduce the albedo of light. It settles and attaches to the ice surface, intensifying the melting of the Arctic and Himalayan glaciers [
7,
8]. The aerosols formed in the atmosphere by BC absorbs substances that are toxic to the human body, such as sulfate and organic carbon, and spread to all parts of the world with the atmospheric cycle. A large number of BC particles are suspended in the atmosphere, which can easily enter the human body through the respiratory tract, causing serious respiratory, cardiovascular and pulmonary diseases, and even inducing cancer [
9].
Today, more than 95% of all ships in the world use diesel engines as power sources, however, diesel engines have caused serious pollution to the global environment while providing a stable power output [
10]. BC is one of the main pollutants in marine diesel engine exhausts [
11]. Although the BC emissions from ships account for less than 2% of the total global BC emissions, in areas with fragile ecosystems, such as the Arctic, the BC emissions from ships have caused irreversible damage to the local environment. Compared with the mid latitude region, the impact of BC emissions in the Arctic and its adjacent sea areas on the climate is more than five times higher [
12]. In addition to the Arctic, in many busy port cities and coastal areas, BC emissions from ships have also become one of the most important environmental issues [
13]. In 2018, global ships contributed approximately one-hundred-thousand tons of BC, an increase of 12% over 89-thousand tons in 2012 [
12]. According to statistics, if effective control measures are not taken, it is estimated that the BC generated by international shipping will be more than five times that of 2010 by 2050 [
14].
In recent years, although the BC issue has been a significant concern in most countries, there is still a lack of BC emission limitation regulations and effective BC emission reduction technologies for ships. Timonmen et al. carried out a BC measurement campaign on a real ship, and the measurement results showed that the effect of exhaust gas cleaning (EGC) as a catalyst for reducing BC emissions was not obvious [
15]. A research report by Germany and Finland [
16] stated that the sulfur content in the fuel was closely related to the generation of BC, and the authors believed that the increase in sulfur content would lead to the increase in BC emissions. At present, The International Maritime Organization (IMO) is committing to controlling the BC emissions of ships, including comprehensively prohibiting the use of heavy fuel oil in the Arctic region and formulating BC emission regulations [
17]. LNG is widely considered to be a clean fuel that can effectively reduce BC emissions. However, the use of this fuel will increase methane emissions [
18]. The widely recognized BC control technologies include the use of distillate fuel, exhaust gas cleaner and diesel particulate filter (DPF), however, the emission reduction effect and cost economy of these remains to be verified [
15,
17].
The research and development of BC emission control technologies requires a large number of tests on engines to determine the BC emission concentration under different working conditions. However, the current physical test still has some shortcomings that cannot be ignored, such as high cost, long cycle and easy to produce measurement errors. Therefore, it is of great practical significance to develop a model that is easy to realize, has high accuracy and a fast response to predict the BC emission concentration of marine diesel engines.
With the rapid development of data science and artificial intelligence, machine learning, as the core of the field of artificial intelligence, has gradually become one of the most important frontier technologies in biomolecular recognition [
19], weather prediction [
20], mineral exploration [
21], information security [
22,
23], automatic driving [
24] and other fields. Data-driven machine learning models have the advantages of having a fast response, high accuracy and strong generalization ability. Due to its outstanding induction and decision-making capabilities, machine learning has been gradually applied to diesel engine fault diagnosis and performance optimization [
25,
26]. Among them, the research on the prediction of diesel engine pollutants using machine learning can be traced back to the end of the last century [
27,
28]. In recent years, the leapfrog development of science and technology and the growth of public awareness of environmental protection have led to more diversified research results in this field. Achievements in this field can be divided into three categories: 1. prediction of NO
x emission concentration [
29,
30]; 2. prediction of soot emission concentration [
31,
32]; 3. prediction of emission concentrations of compression ignition engines using new fuels [
33,
34,
35]. After analyzing the above studies, we found that: (1) No research has taken BC as the prediction object; (2) The size and quality of the data set will affect the prediction accuracy of the model; (3) The types of existing research selection models are too single; (4) Feature selection is one of the keys to train an efficient model. Finding features that have strong correlation with the prediction object is the premise to improve the prediction performance of the model.
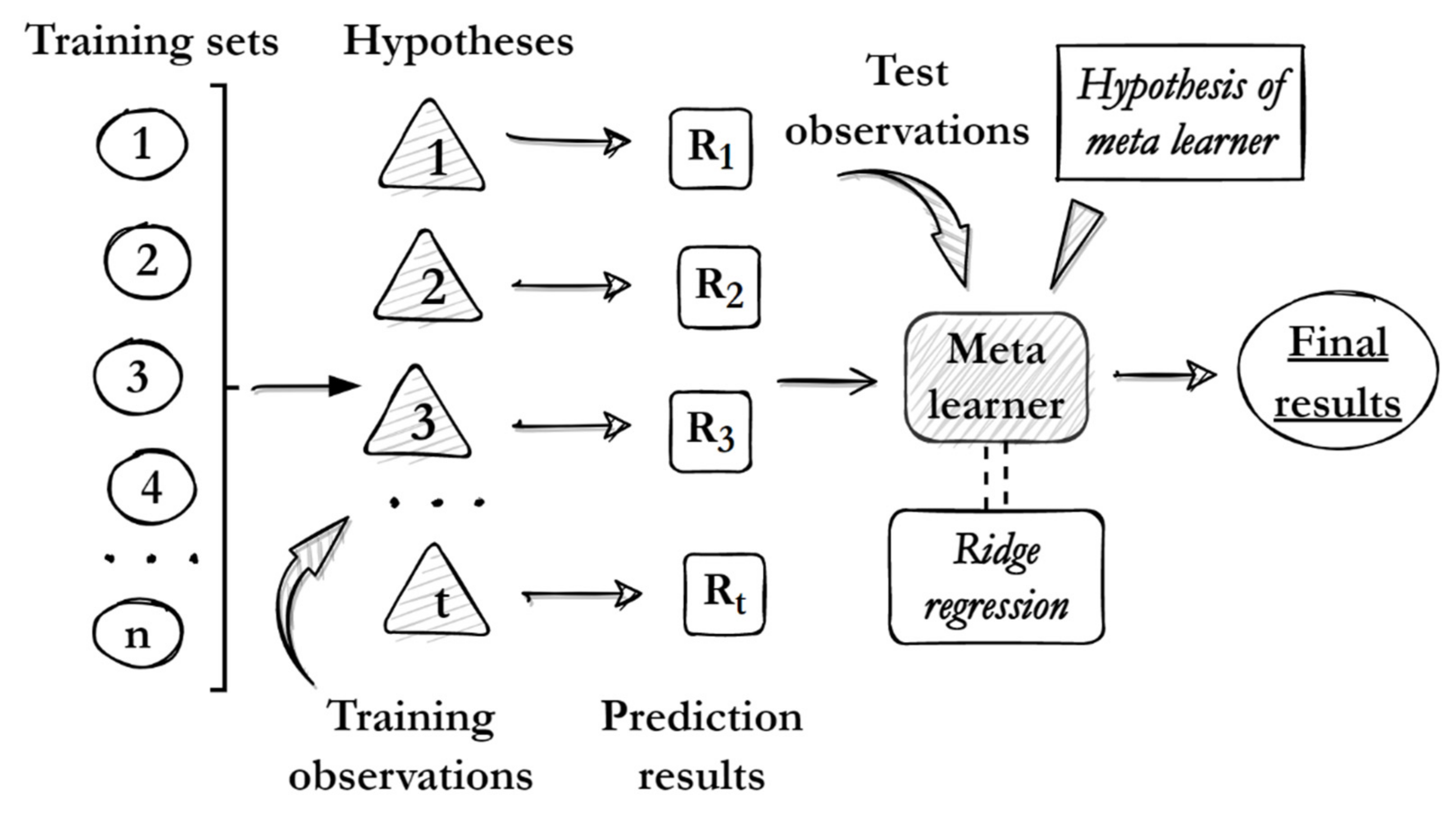
We have compared the prediction performance of various machine learning algorithms, and the results show that ensemble learning is more suitable for predicting the BC emission concentration of diesel engines under steady-state working conditions [
36]. However, in this study, we took the performance parameters of the diesel engine as the features of the models. These parameters can describe the performance of diesel engines from a macro perspective, but the correlation between them and BC is weak, and it seems that it is not enough to characterize the BC emission level under the condition of limited training samples. In addition, because there are many kinds of ensemble learning algorithms, choosing the best ensemble algorithm or integrating these algorithms has become a very challenging task. Therefore, in this paper, we propose a new BC emission prediction model for diesel engines, based on a stacked generalization, for the first time, which integrates XGB, LGB, RF, SVR and RR. Stacked generalization is a method to minimize the generalization error of multiple estimators, which can integrate different types of estimators in order to eliminate the bias and non-uniformity of the different algorithms [
37,
38]. At present, many studies have shown that the model after fusion using stacked generalization has stronger prediction ability than a single model [
39,
40]. Wu et al. believe that the generation of BC is related to the combustion process, and BC emissions can be reduced by improving the combustion process in the cylinders [
41], while the combustion process can usually be described and controlled by combustion characteristic parameters (CCPs) [
42,
43]. Therefore, in this paper, we have carried out a detailed analysis of the correlation between CCPs and BC emissions, and select them as the features of the prediction models.
The contributions of this paper can be summarized as follows:
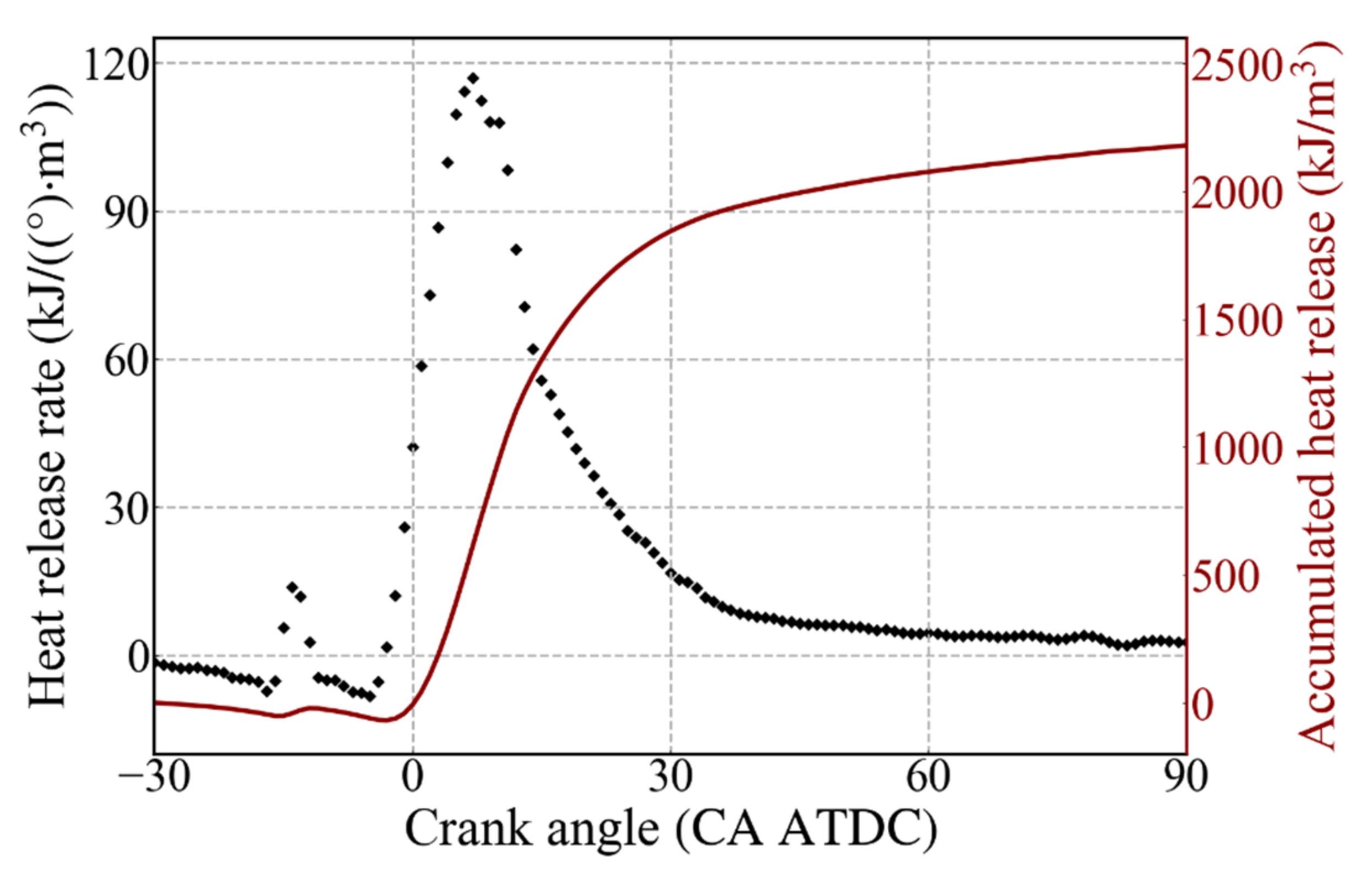
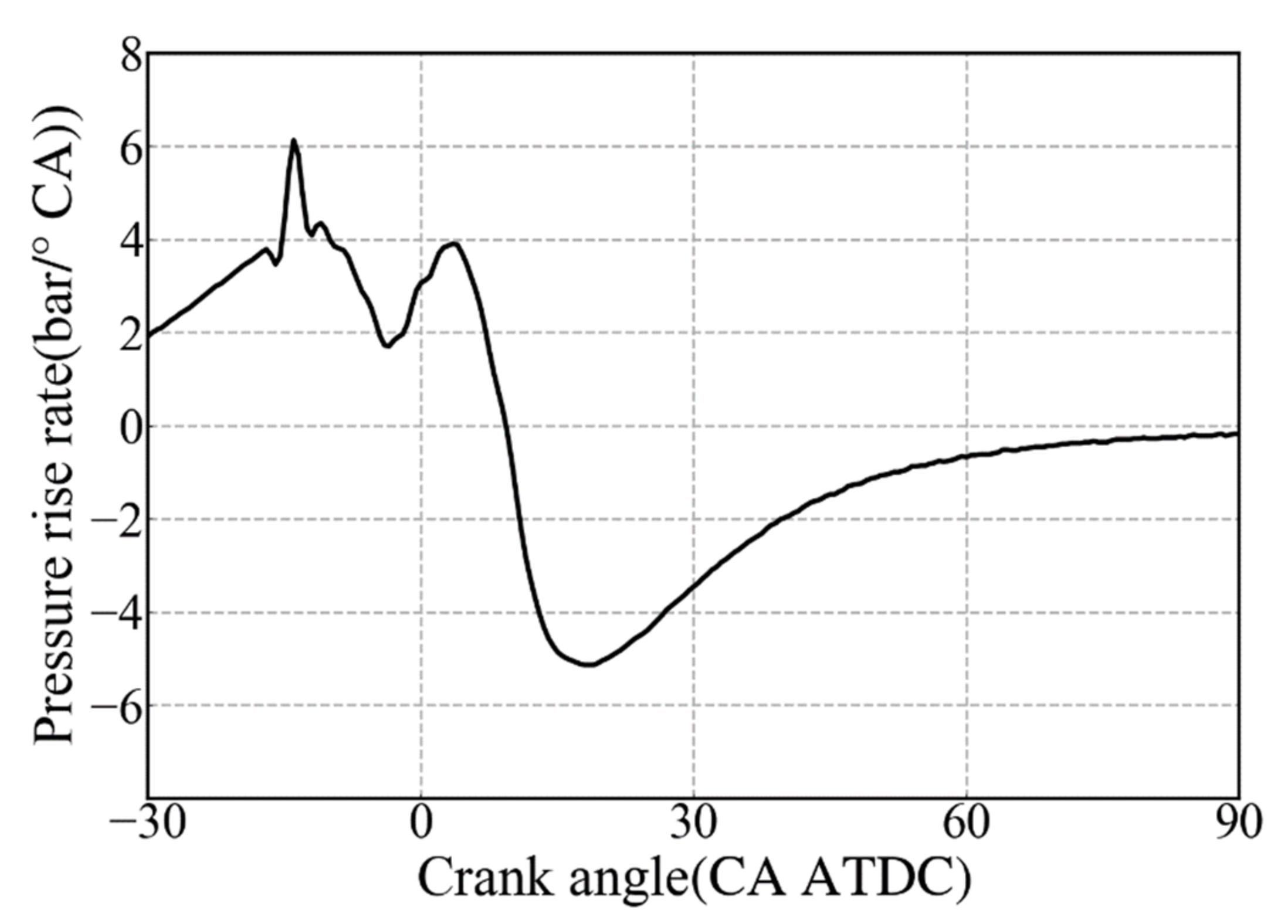
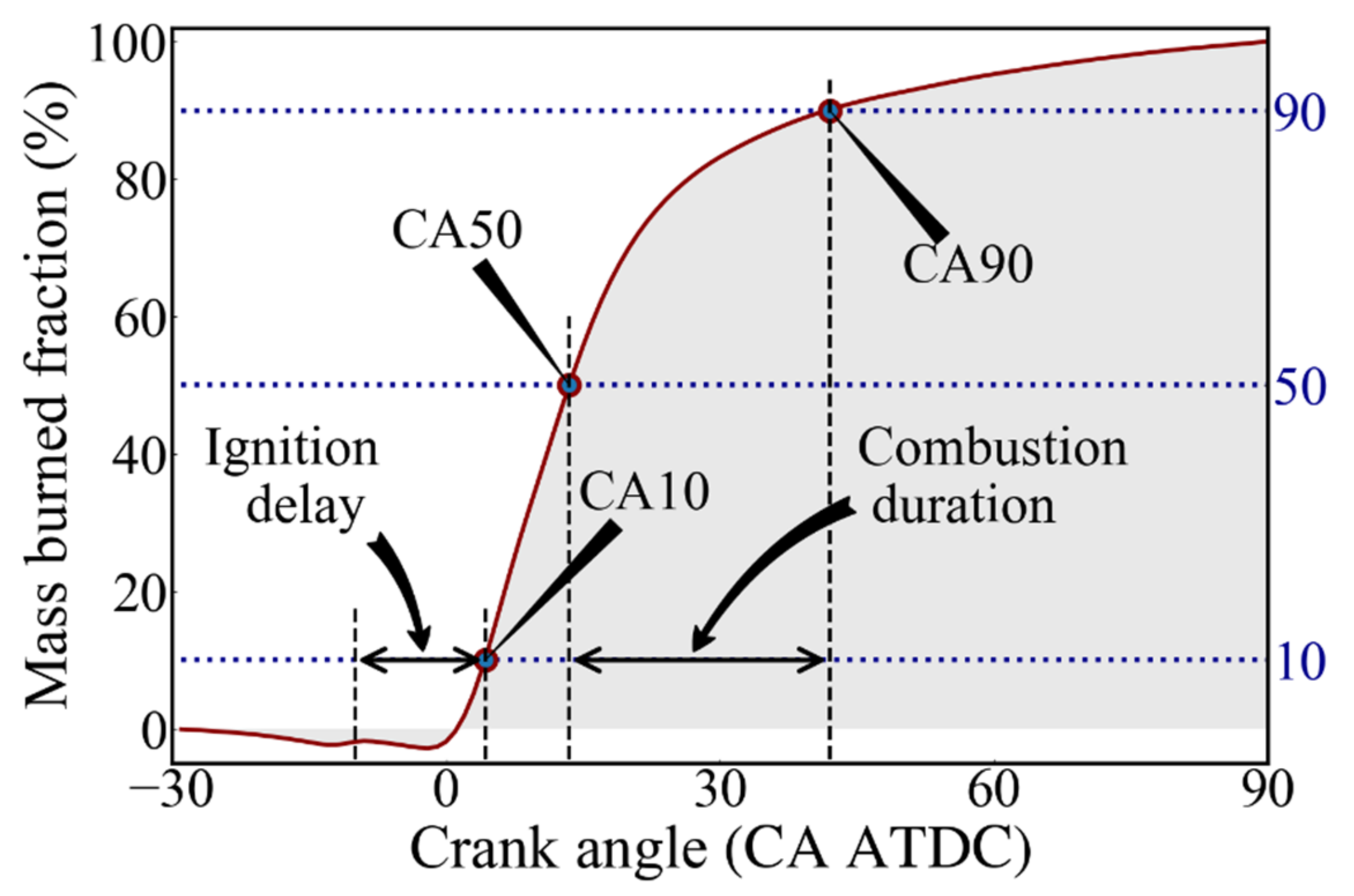
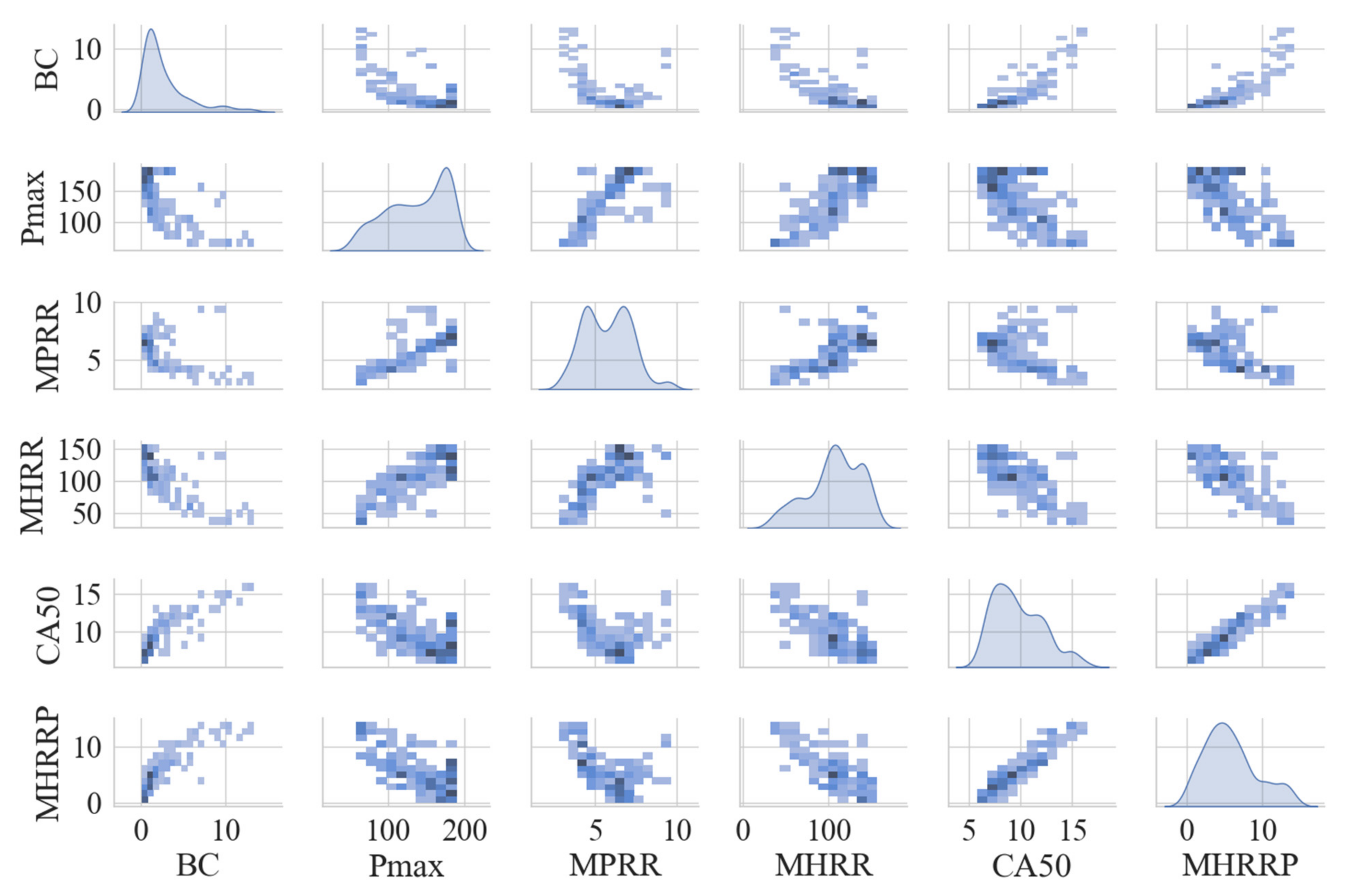
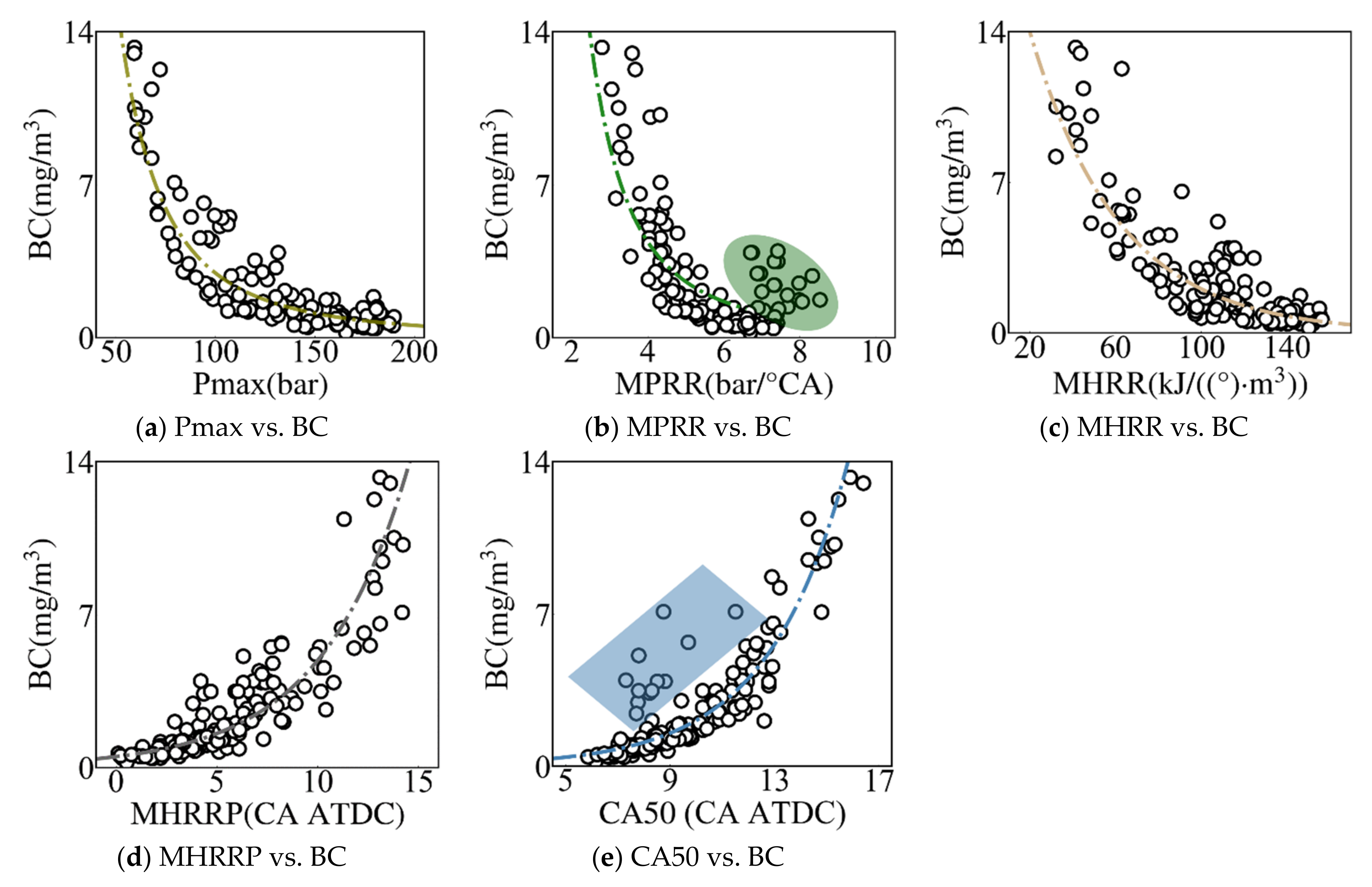
Pmax (Maximum Cylinder Pressure), MPRR (Maximum Pressure Rise Rate), MHRRP (Maximum Heat Release Rate Phase), MHRR (Maximum Heat Release Rate) and CA50 (Exothermic Center Phase) are extracted from the cylinder pressure data which acquired under different steady-state working conditions of the diesel engine, and then the influences of the changes of these CCPs on the BC emission concentration are theoretically analyzed and explained;
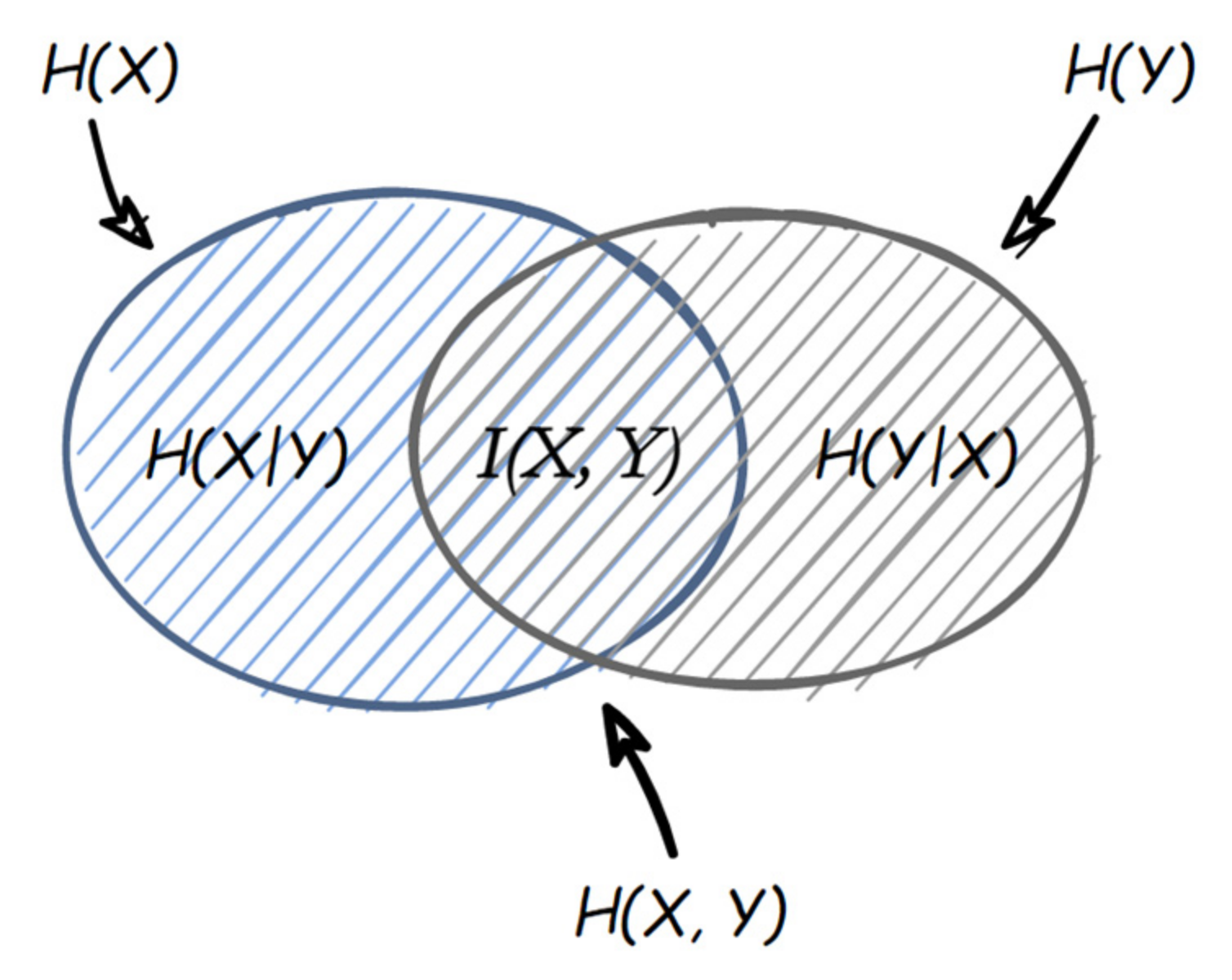
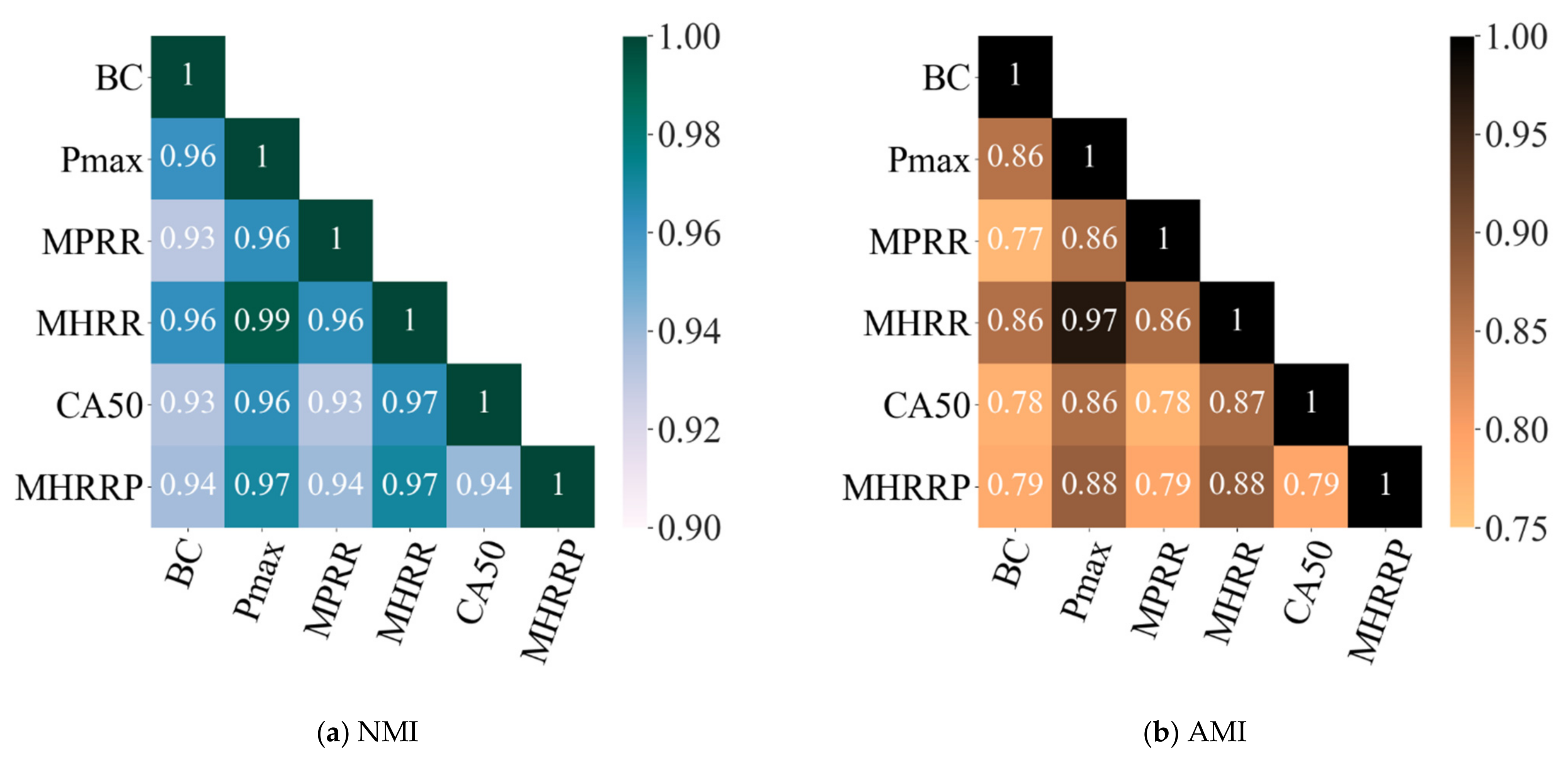
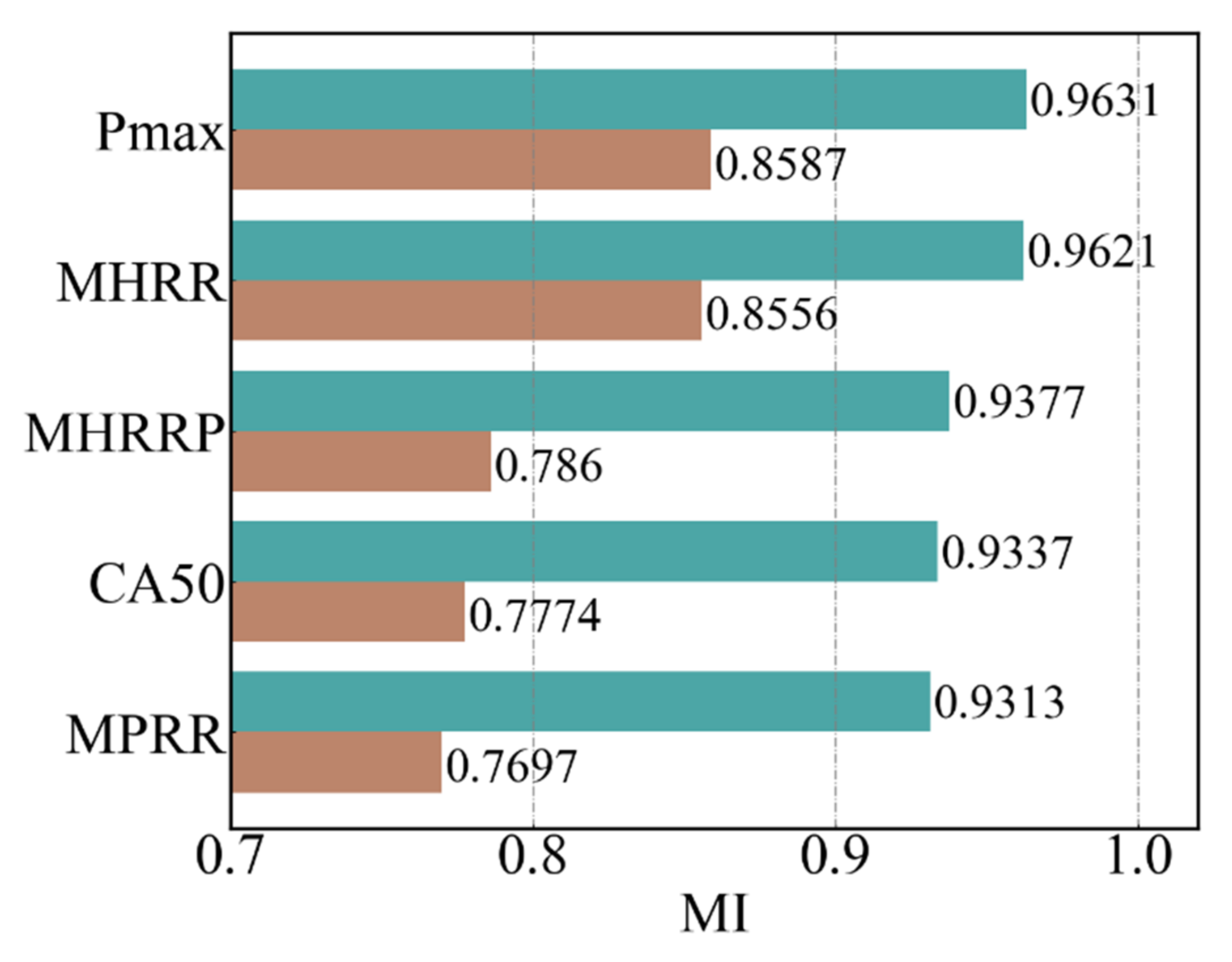
Mutual information is used to measure the correlation between the CCPs and BC emission concentration. It is found that there is a strong correlation between the CCPs and BC emission concentration. This result fully proves that suitable CCPs can be used as the features of BC emission prediction model;
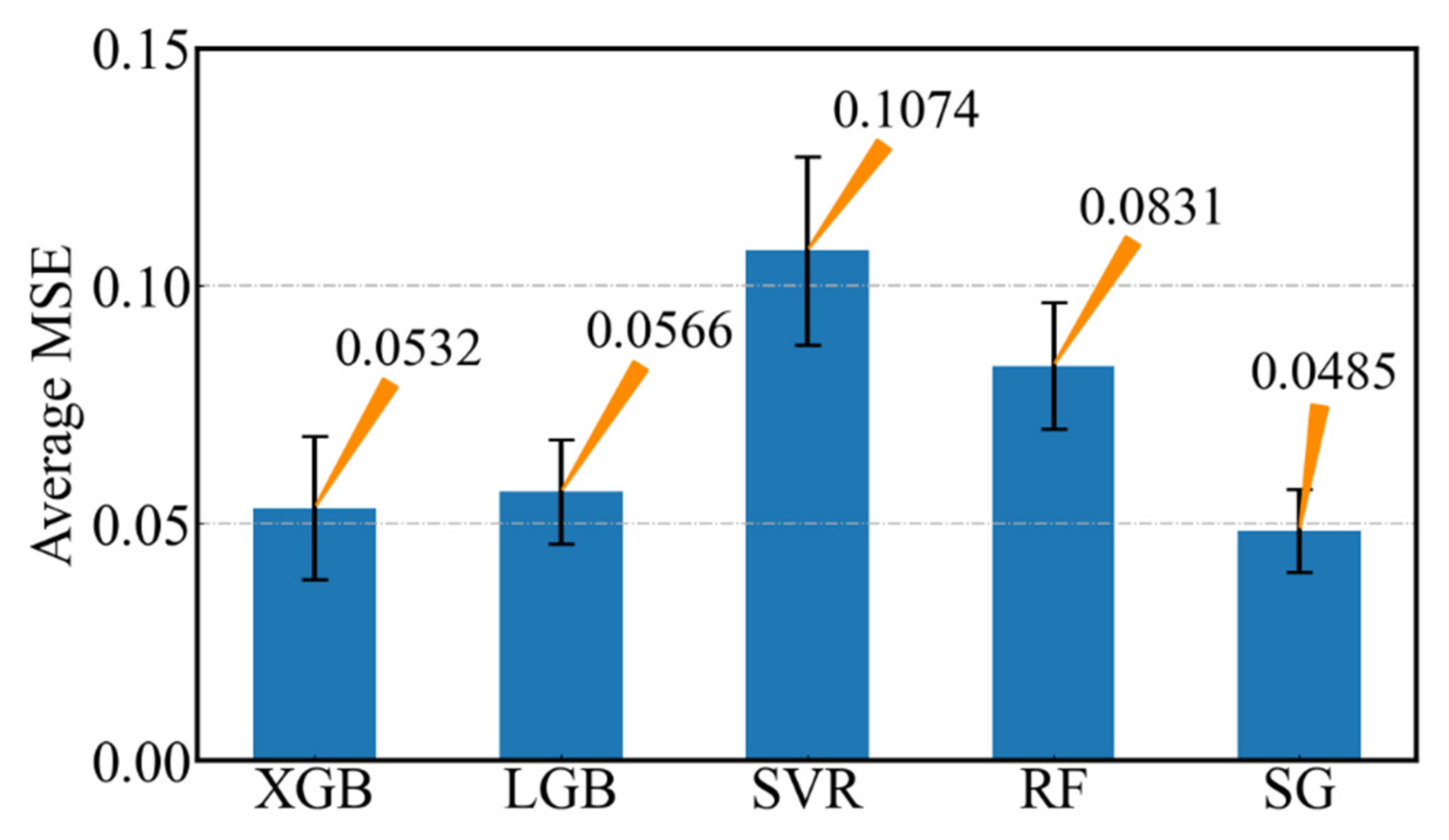
A new prediction model of diesel engine BC emissions based on SG is proposed. The stability and prediction accuracy of the SG model are higher than those of its sub models, and it can achieve higher prediction performance when the number of training samples of the model is very limited.
The remainder of the paper is organized as follows: In
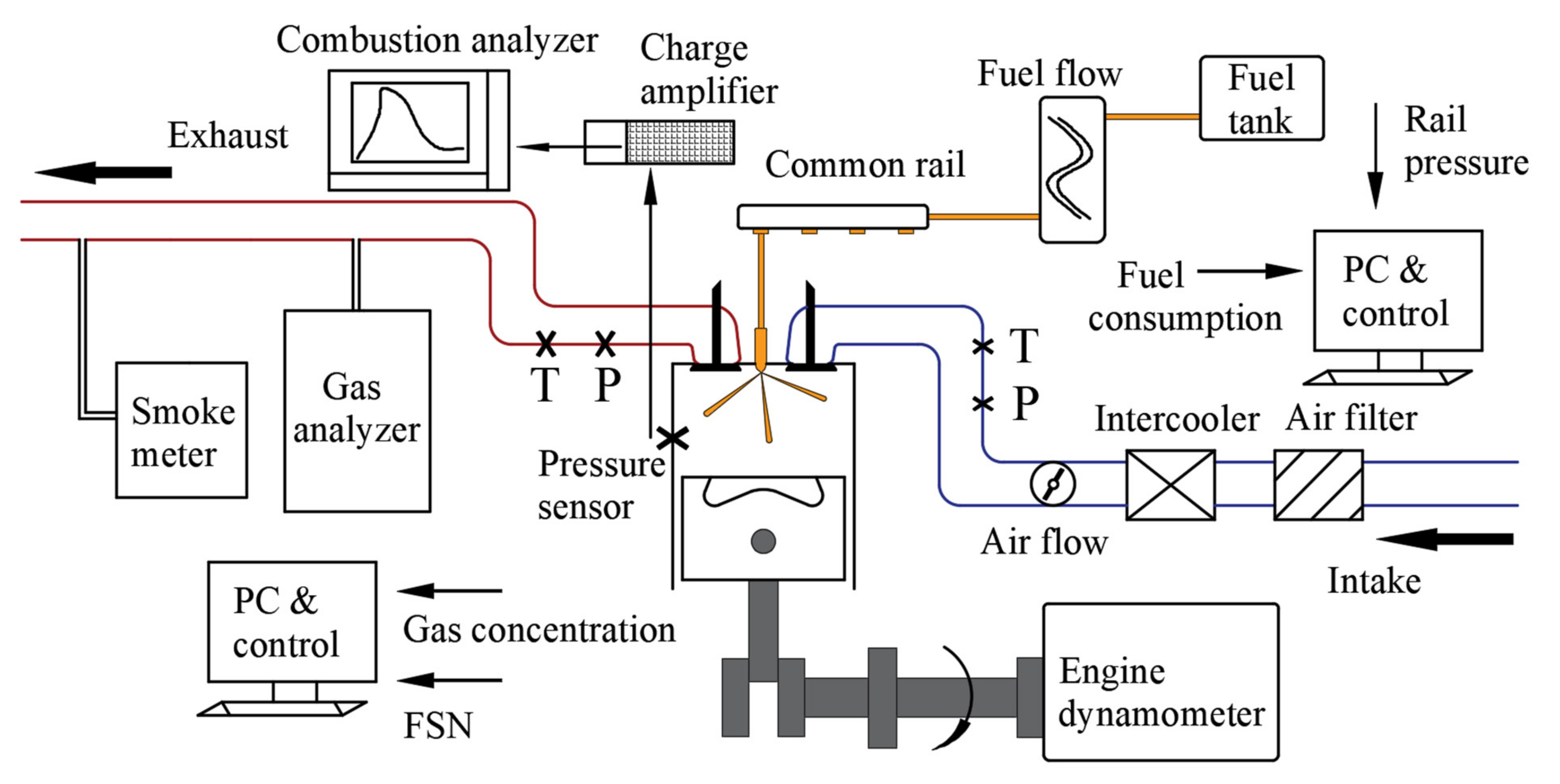
Section 2, we first describe the test instruments and test methods, then briefly introduce the definition of CCPs and the theory of the machine learning algorithms;
Section 3 analyzes the influences of the changes in CCPs on BC concentration, and calculates the correlation between them using mutual information, and then compares and evaluates the prediction performance of each sub model and SG model; In
Section 4, we draw conclusions of this paper and some follow-up research plans.
4. Conclusions
In order to accelerate the research and development process of BC emission control technology for marine diesel engines, this paper proposes an SG-based BC emission prediction model for marine diesel engines, which combines five machine learning models: XGB, LGB, RF, SVR and RR. CCPs with a high correlation with BC emissions are taken as the features of the model. Finally, by comparing the prediction results of the single model and fusion model on the same datasets, the effectiveness of the method is proved. The main research conclusions of this paper are as follows:
Due to the improvement of fuel utilization efficiency, the increase in Pmax, MPRR and MHRR will reduce the BC concentration; however, with the shortening of the ignition delay period and uneven fuel diffusion, the delay of MHRRP and CA50 led to a significant increase in BC concentration;
The correlation analysis results show that the NMI between the CCPs and BC concentrations are higher than 0.9, while the AMI are higher than 0.75, which proves that there is a strong correlation between the CCPs and BC concentrations;
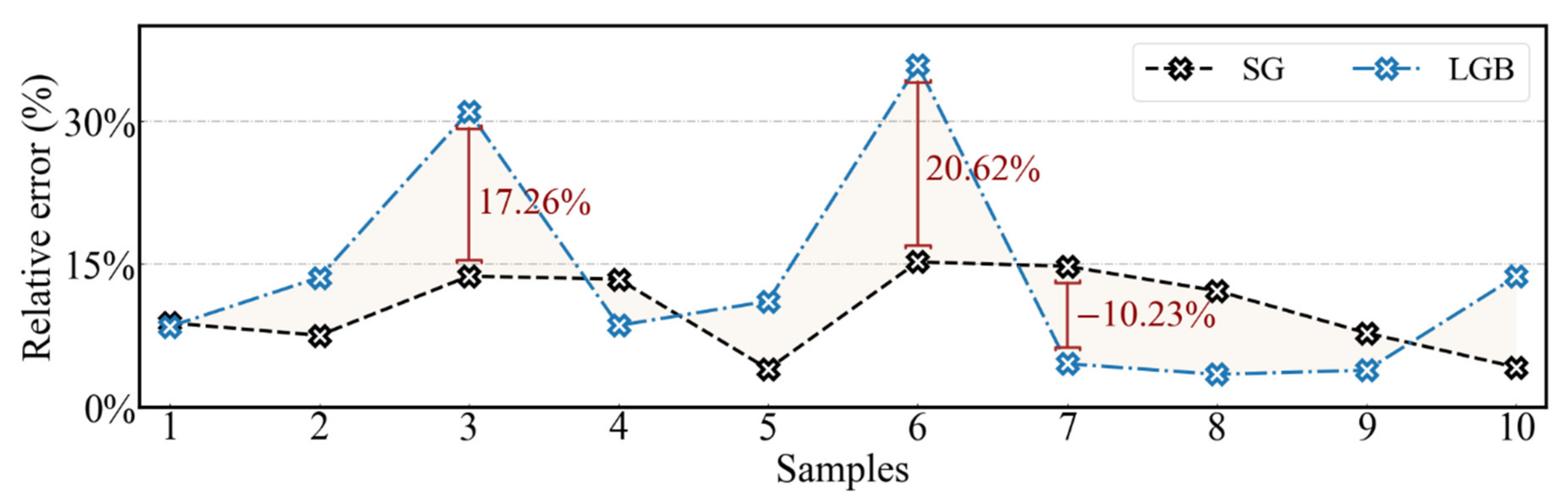
The fused model reconciles the inherent bias of a single model to data, and achieves the best prediction effect on the different data sets. The MSE and R2 of SG model for the test set are 0.0485 and 0.9983, respectively, and its average relative error for validation set is only 10.17%.
As mentioned in the introduction of this paper, machine learning is a cutting-edge data science technology, which can play a very prominent role in engine pollutant prediction. In the future, this technology can also be used to reduce the calculation cost of engine numerical simulation, adaptive control and the construction process of combustion reaction mechanism and other fields.
In addition, the limitations of the method proposed in this paper and the research that can be carried out in the future are: (1) The data used in this paper only comes from one diesel engine, and subsequent tests should be carried out on different types of diesel engines to verify the universality of the conclusions in this paper; (2) The method proposed in this paper can only be used to predict the black carbon emission concentration of engines under steady state conditions (marine engines are more often under steady state conditions), and the prediction of BC emission of diesel engine under transient condition should be discussed in the future; (3) In practical application, the available effective data may be less, so a small sample size BC emission prediction model can be developed to solve the problem.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}