
A Bivariate Nonstationary Extreme Values Analysis of Skew Surge and Significant Wave Height in the English Channel

Abstract
:1. Introduction
2. Materials and Methods
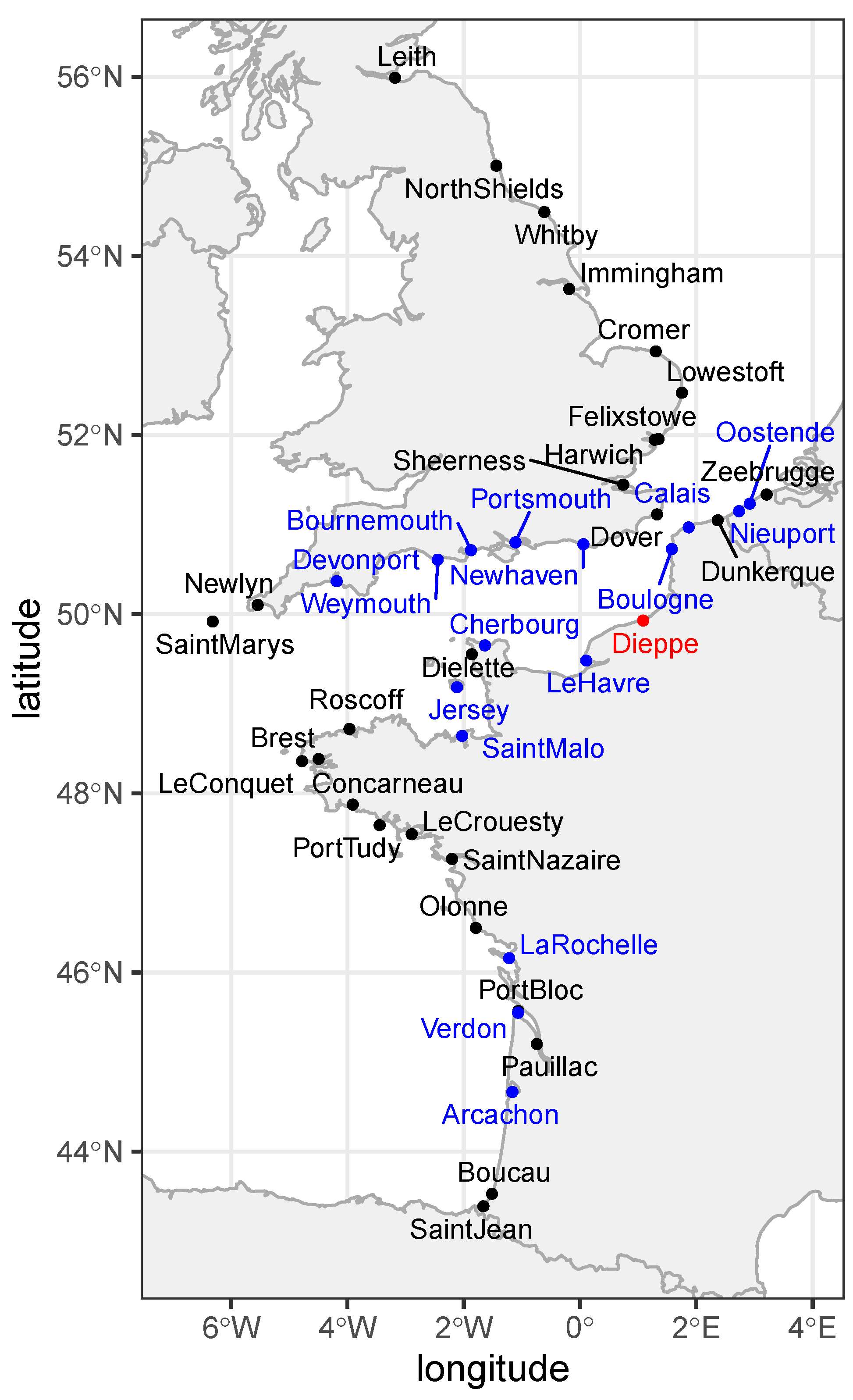
2.1. Data
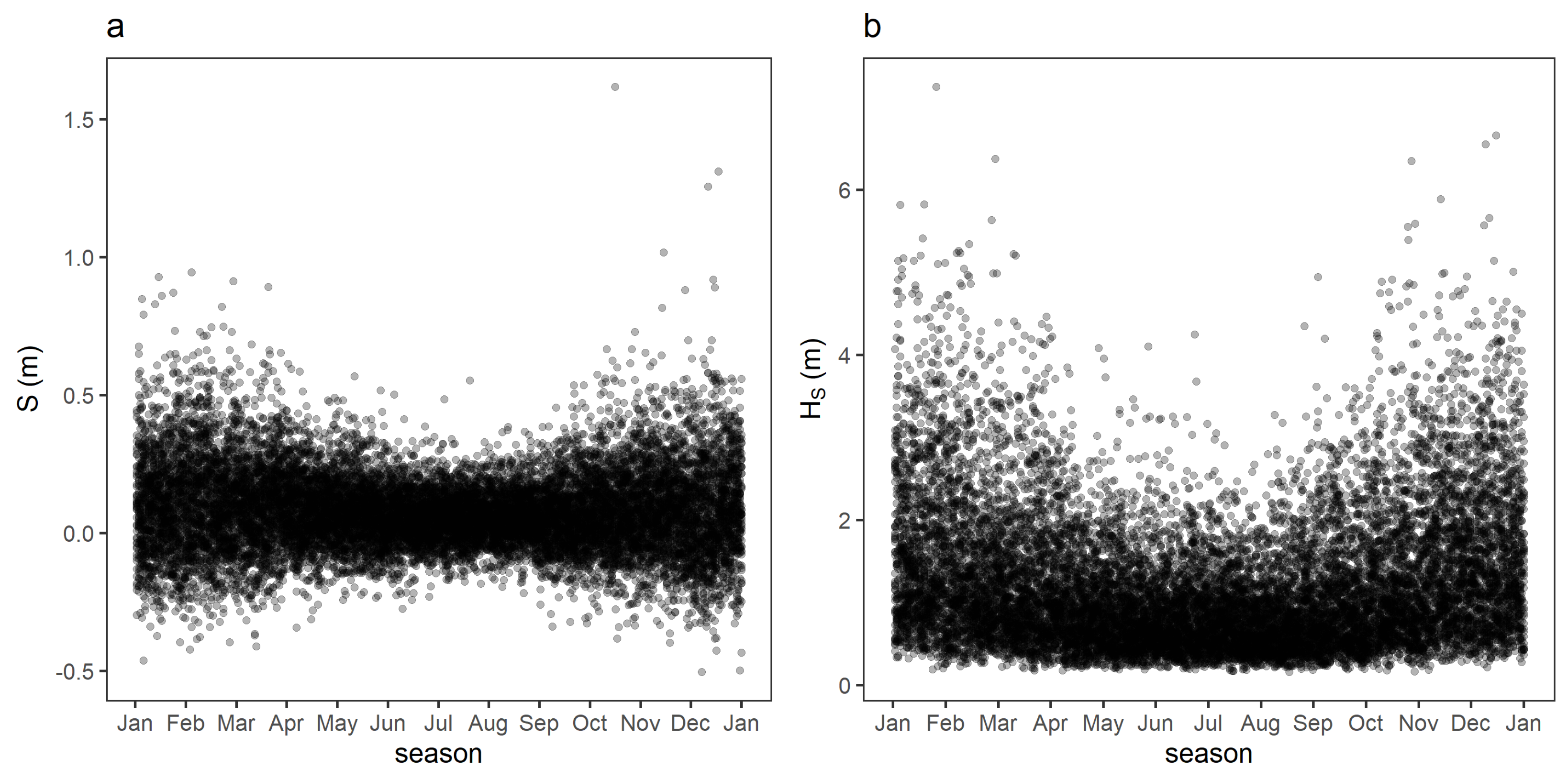
2.2. Exploratory Analysis
2.3. Modeling of S and HS Extremes
2.4. Modeling of the Dependence between S and HS
2.5. Definition of the p-Level Curves
3. Results
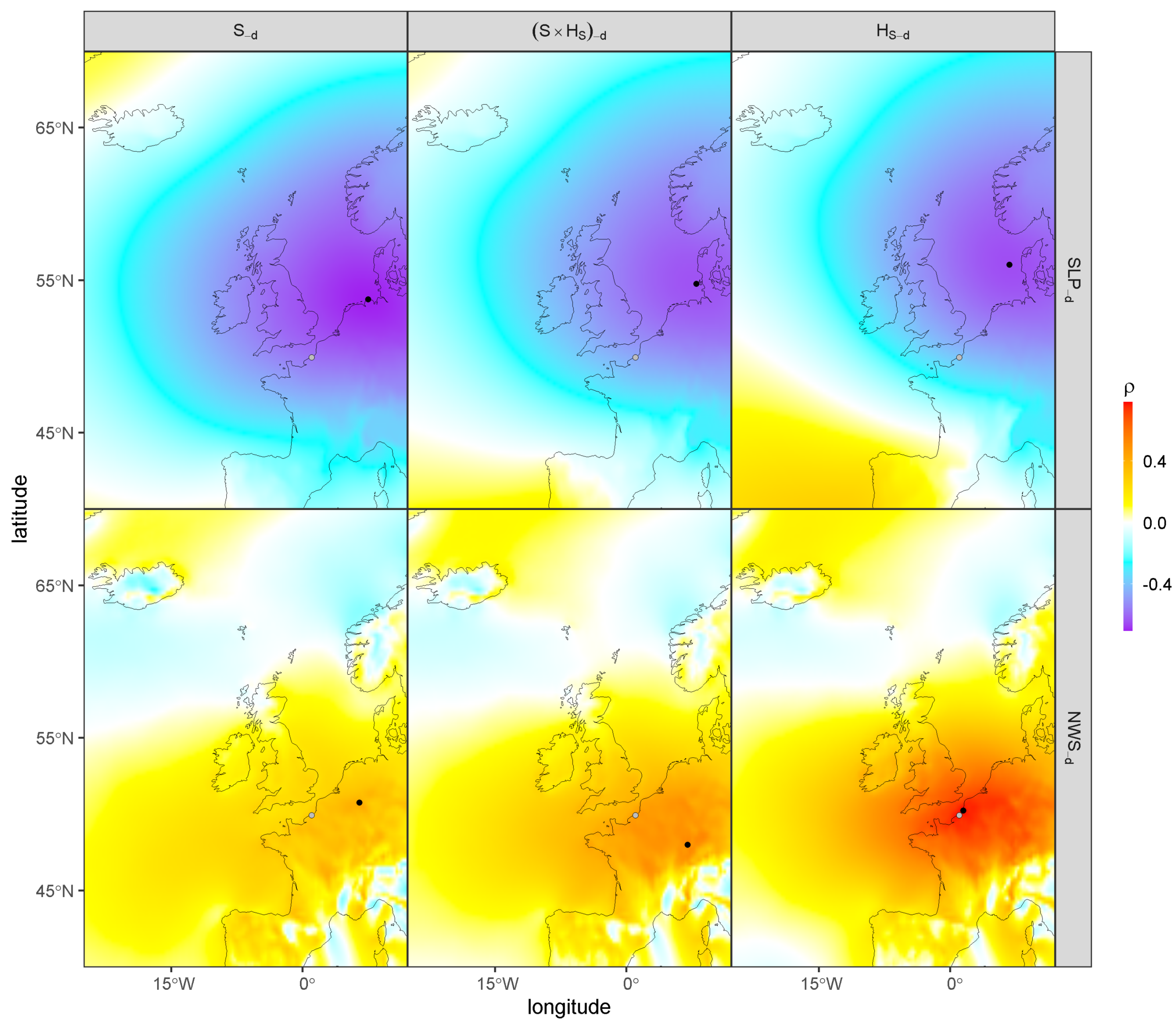
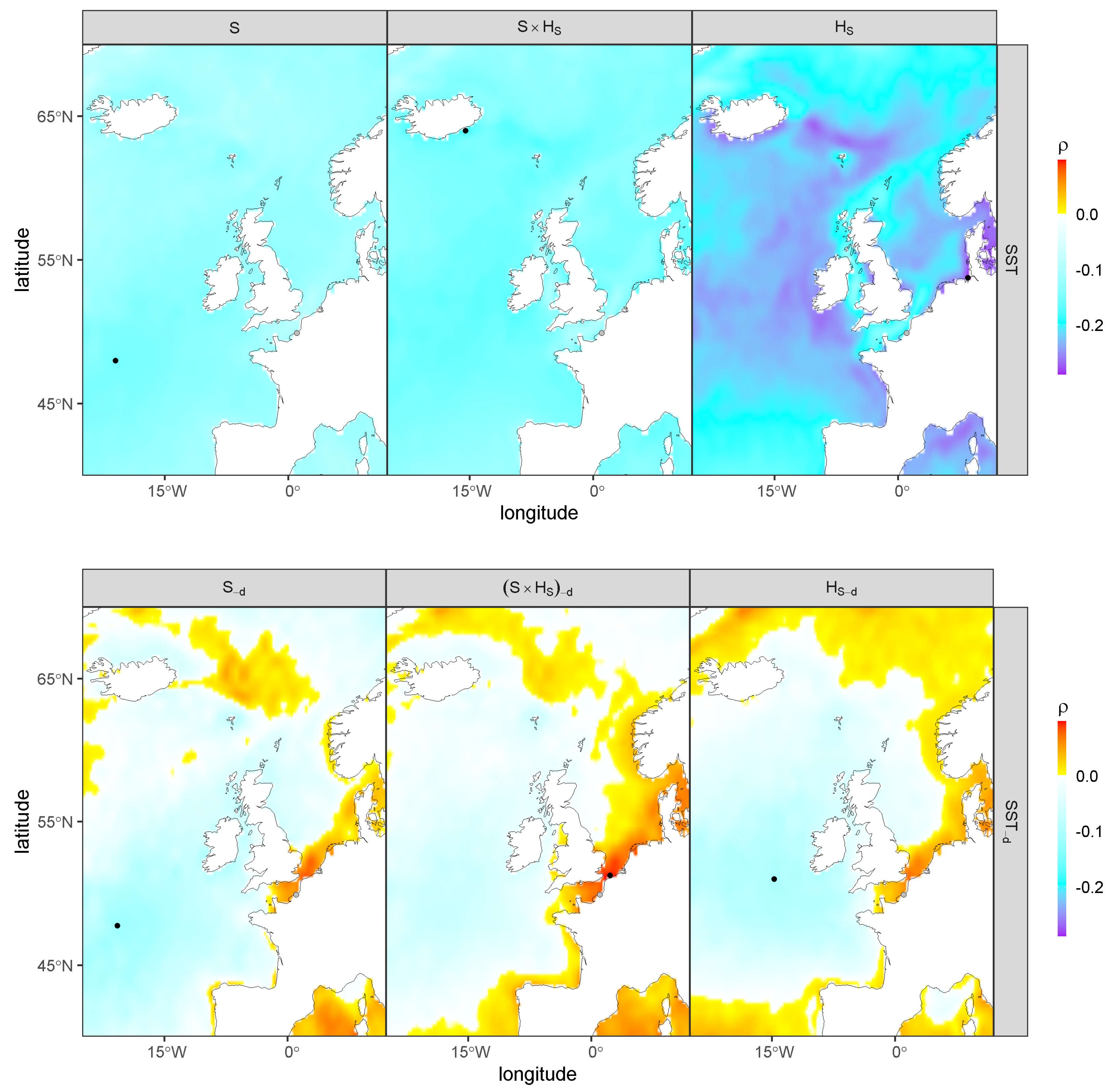
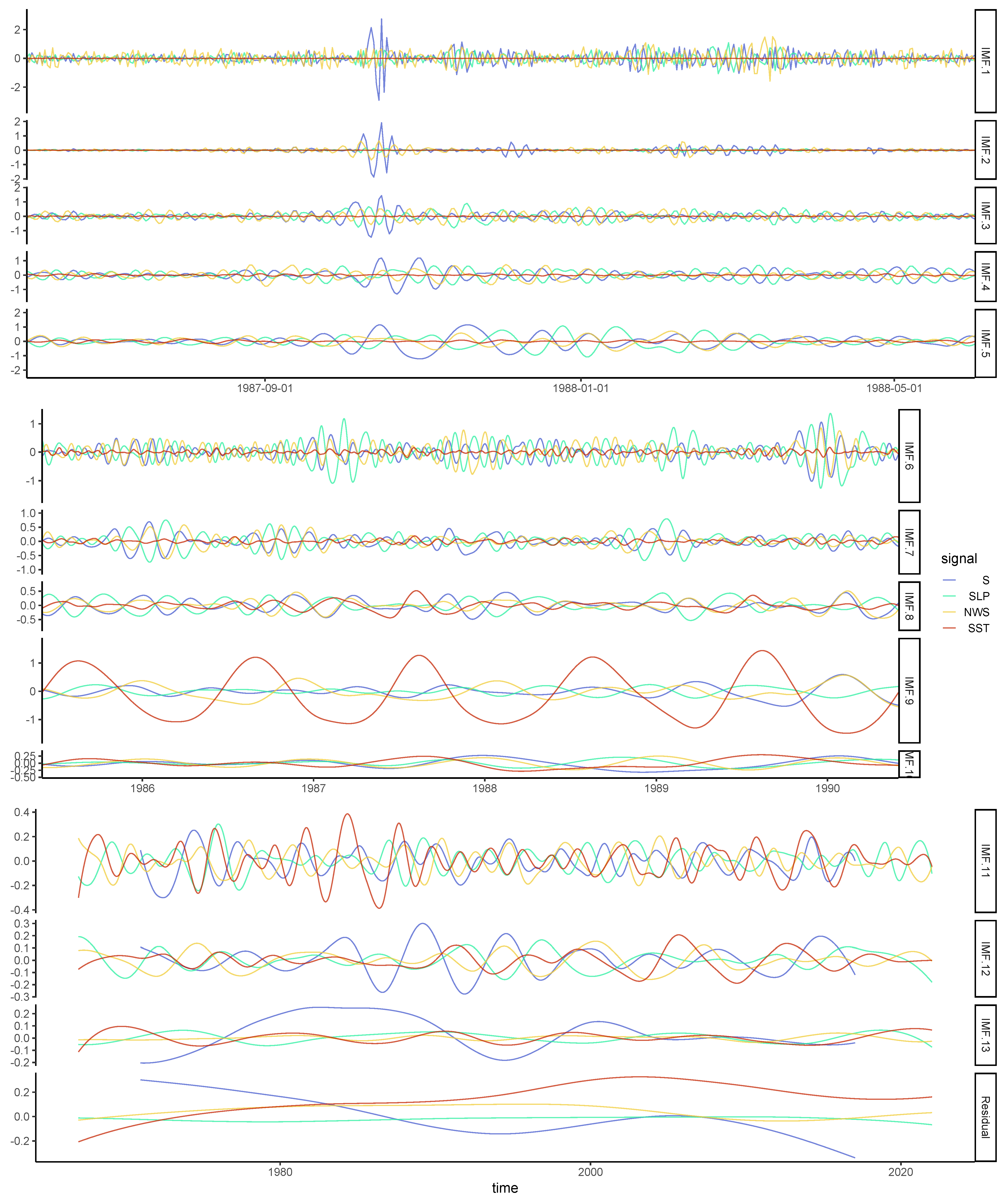
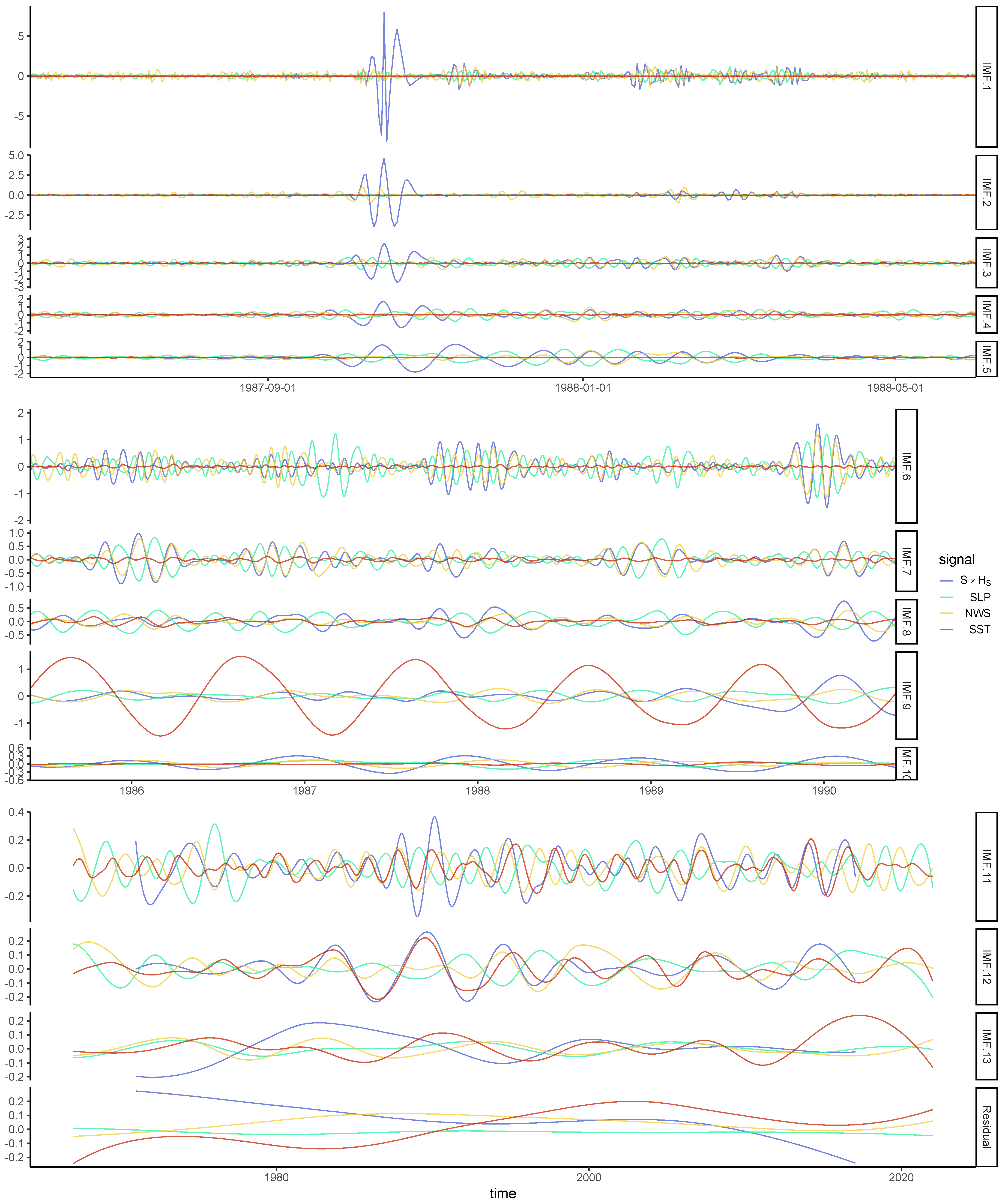
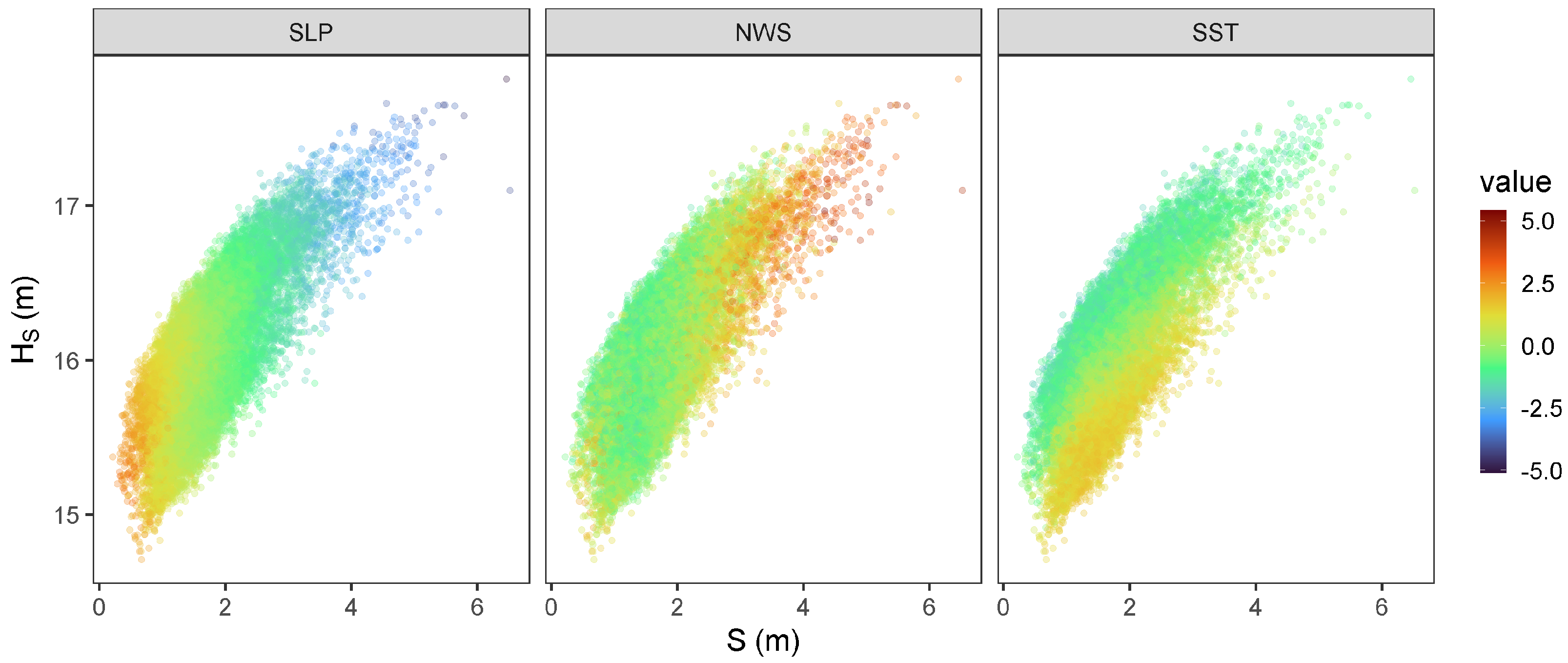
3.1. Pre-Selection of the Physical Covariates
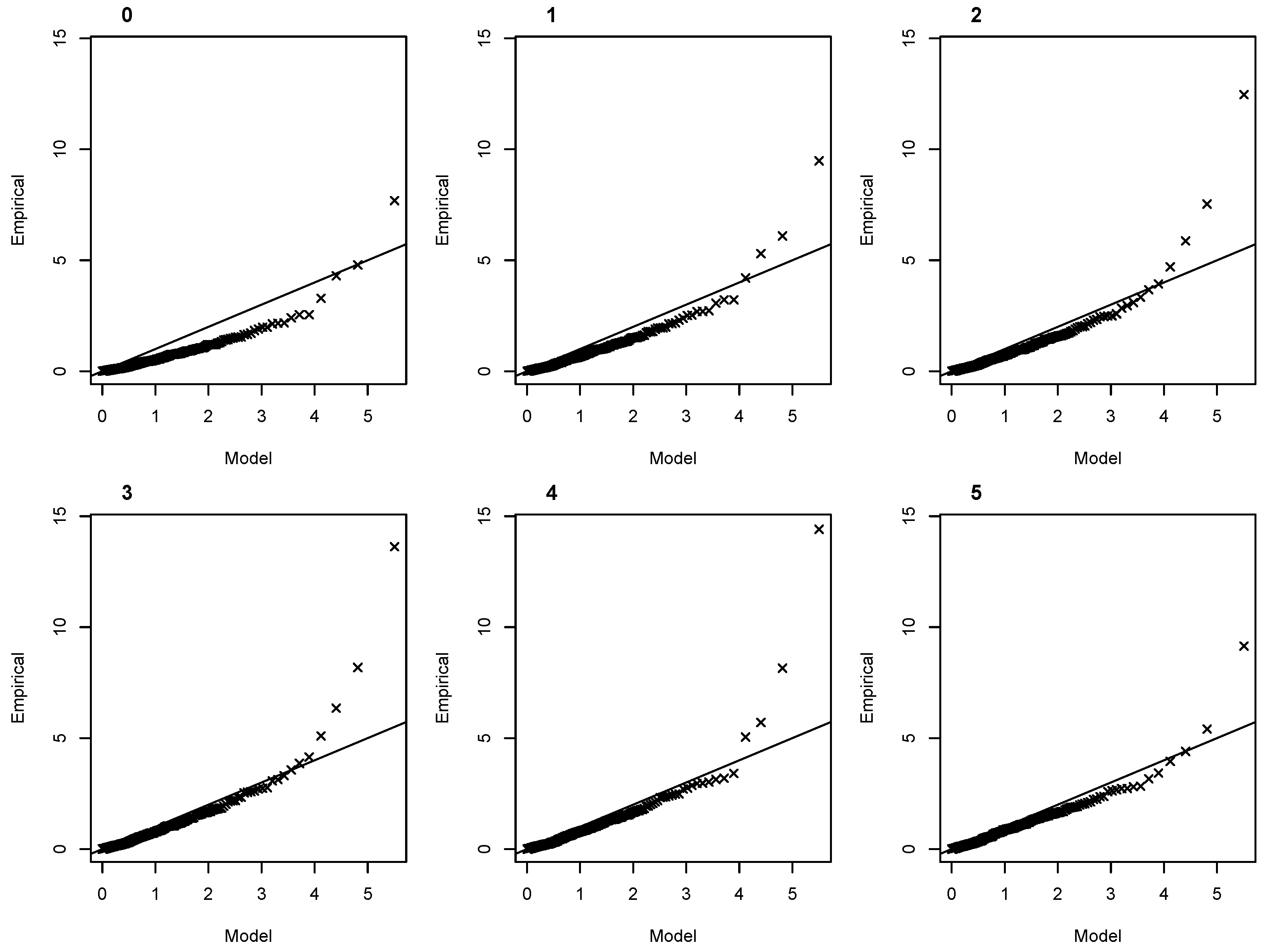
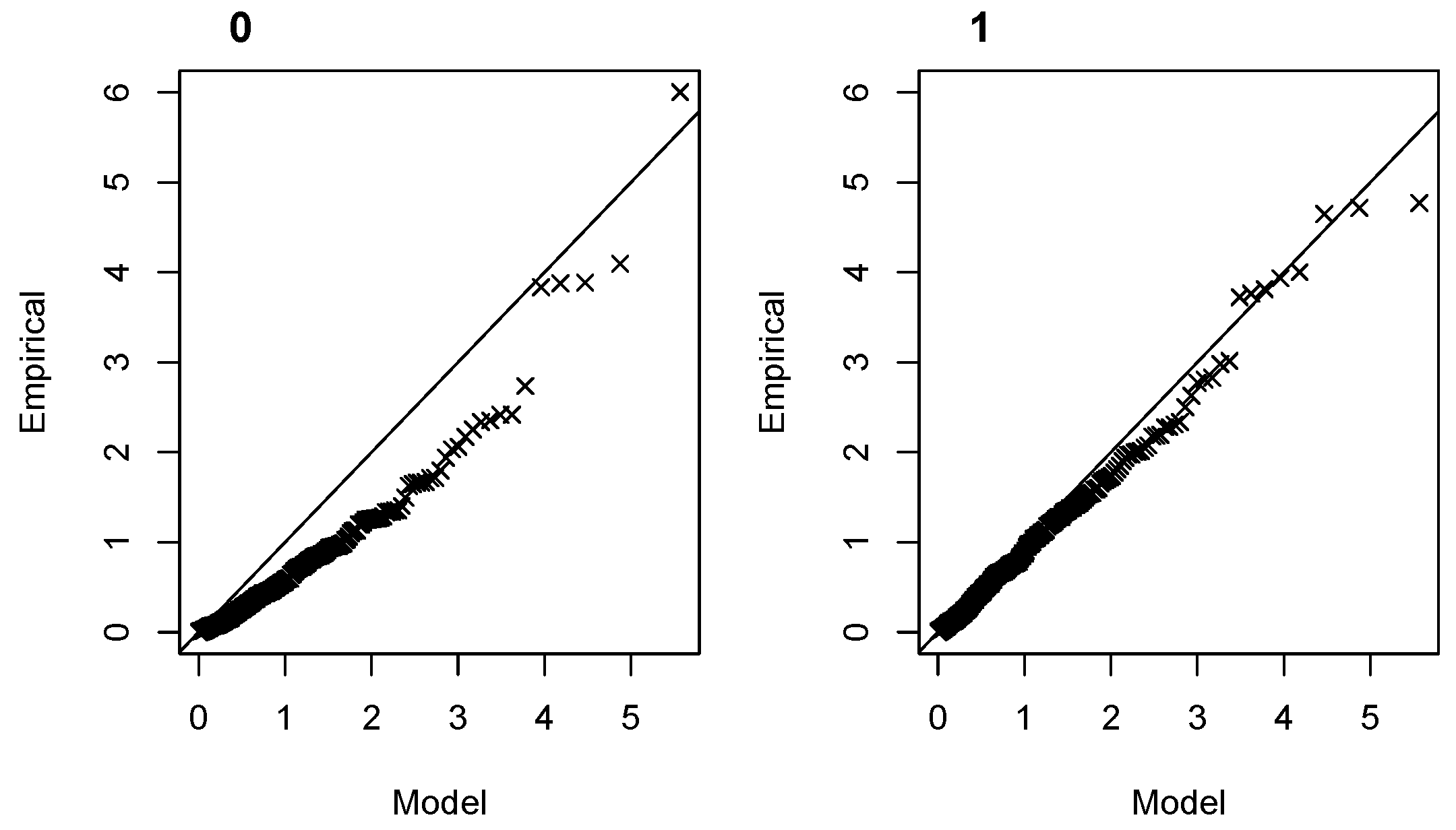
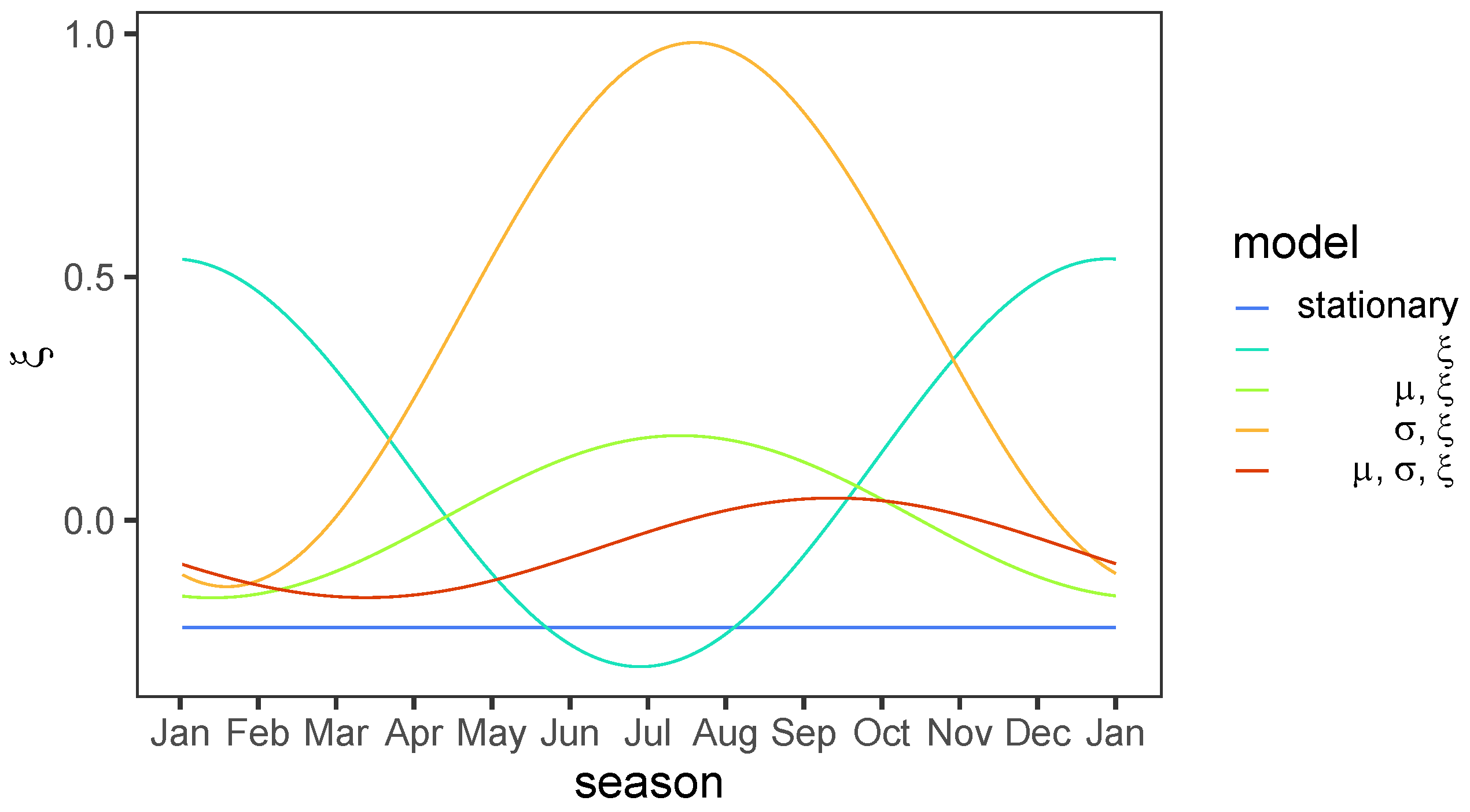
3.2. Nonstationary NHPP for S and HS Extremes
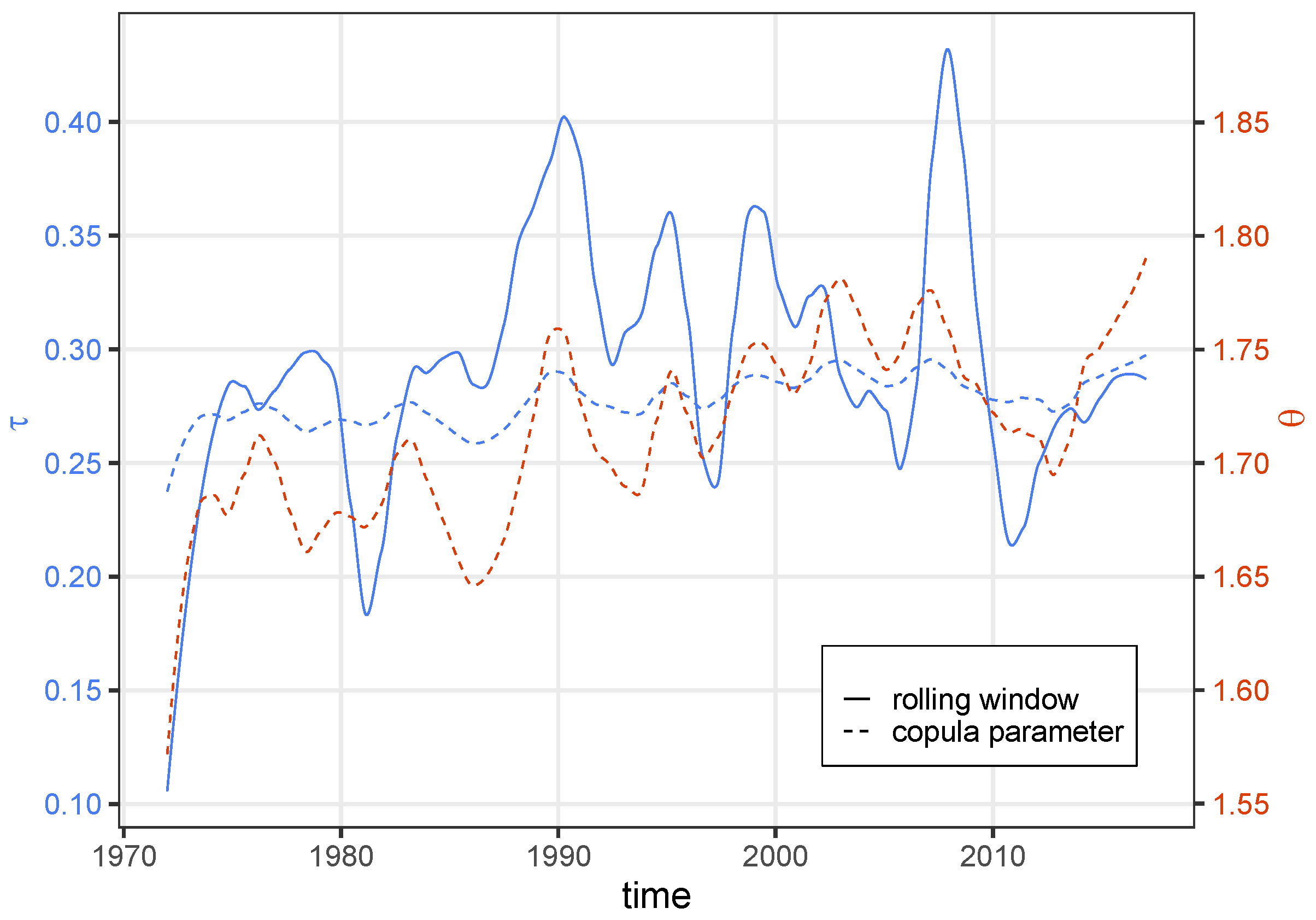
3.3. Dynamic Copula for S and HS
3.4. Climate-Dependent p-Level of S and HS
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Kopytko, N.; Perkins, J. Climate change, nuclear power, and the adaptation–mitigation dilemma. Energy Policy 2011, 39, 318–333. [Google Scholar] [CrossRef]
- Rueda, A.; Camus, P.; Tomás, A.; Vitousek, S.; Méndez, F. A multivariate extreme wave and storm surge climate emulator based on weather patterns. Ocean Model. 2016, 104, 242–251. [Google Scholar] [CrossRef]
- Vousdoukas, M.I.; Mentaschi, L.; Voukouvalas, E.; Verlaan, M.; Jevrejeva, S.; Jackson, L.P.; Feyen, L. Global probabilistic projections of extreme sea levels show intensification of coastal flood hazard. Nat. Commun. 2018, 9, 2360. [Google Scholar] [CrossRef] [Green Version]
- Chebana, F.; Ouarda, T.B.M.J. Multivariate quantiles in hydrological frequency analysis. Environmetrics 2011, 22, 63–78. [Google Scholar] [CrossRef] [Green Version]
- Pan, X.; Rahman, A.; Haddad, K.; Ouarda, T.B.M.J. Peaks-over-threshold model in flood frequency analysis: A scoping review. Stoch. Environ. Res. Risk Assess. 2022, 36, 2419–2435. [Google Scholar] [CrossRef]
- Coles, S. An Introduction to Statistical Modeling of Extreme Values; Springer: London, UK, 2001. [Google Scholar]
- Northrop, P.J.; Jonathan, P.; Randell, D. Threshold Modeling of Nonstationary Extremes. In Extreme Value Modeling and Risk Analysis: Methods and Applications; Dey, D.K., Yan, J., Eds.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2016; pp. 87–108. [Google Scholar]
- Katz, R.W.; Parlange, M.B.; Naveau, P. Statistics of extremes in hydrology. Adv. Water Resour. 2002, 25, 1287–1304. [Google Scholar] [CrossRef] [Green Version]
- Wahl, T.; Chambers, D.P. Climate controls multidecadal variability in U. S. extreme sea level records. J. Geophys. Res. Oceans 2016, 121, 1274–1290. [Google Scholar] [CrossRef] [Green Version]
- Serinaldi, F.; Kilsby, C.G. Stationarity is undead: Uncertainty dominates the distribution of extremes. Adv. Water Resour. 2015, 77, 17–36. [Google Scholar] [CrossRef] [Green Version]
- Renard, B.; Lang, M.; Bois, P. Statistical analysis of extreme events in a non-stationary context via a Bayesian framework: Case study with peak-over-threshold data. Stoch. Environ. Res. Risk Assess. 2006, 21, 97–112. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Renard, B.; Thyer, M.; Westra, S.; Lang, M. A global analysis of the asymmetric effect of ENSO on extreme precipitation. J. Hydrol. 2015, 530, 51–65. [Google Scholar] [CrossRef]
- Gilleland, E.; Katz, R.W. extRemes 2.0: An Extreme Value Analysis Package in R. J. Stat. Softw. 2016, 72, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Coles, S.; Pericchi, L. Anticipating catastrophes through extreme value modelling. J. R. Stat. Soc. Ser. C (Appl. Stat.) 2003, 52, 405–416. [Google Scholar] [CrossRef]
- Ouarda, T.B.M.J.; Charron, C. Changes in the distribution of hydro-climatic extremes in a non-stationary framework. Sci. Rep. 2019, 9, 8104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamdi, Y.; Duluc, C.M.; Bardet, L.; Rebour, V. Development of a target-site-based regional frequency model using historical information. Nat. Hazards 2019, 98, 895–913. [Google Scholar] [CrossRef]
- Andreevsky, M.; Hamdi, Y.; Griolet, S.; Bernardara, P.; Frau, R. Regional frequency analysis of extreme storm surges using the extremogram approach. Nat. Hazards Earth Syst. Sci. 2020, 20, 1705–1717. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 Hourly Data on Single Levels from 1959 to Present; Copernicus Climate Change Service (C3S) Climate Data Store (CDS): Bologna, Italy, 2018. [Google Scholar] [CrossRef]
- Gao, B.; Huang, X.; Shi, J.; Tai, Y.; Zhang, J. Hourly forecasting of solar irradiance based on CEEMDAN and multi-strategy CNN-LSTM neural networks. Renew. Energy 2020, 162, 1665–1683. [Google Scholar] [CrossRef]
- Luukko, P.J.J.; Helske, J.; Räsänen, E. Introducing libeemd: A program package for performing the ensemble empirical mode decomposition. Comput. Stat. 2016, 31, 545–557. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Lee, T.; Ouarda, T.B. Multivariate Nonstationary Oscillation Simulation of Climate Indices with Empirical Mode Decomposition. Water Resour. Res. 2019, 55, 5033–5052. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar] [CrossRef]
- Smith, R. Statistics of Extremes, with Applications in Environment, Insurance, and Finance. In Extreme Values in Finance, Telecommunications, and the Environment, 1st ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2003; p. 78. [Google Scholar]
- Martins, E.S.; Stedinger, J.R. Generalized maximum-likelihood generalized extreme-value quantile estimators for hydrologic data. Water Resour. Res. 2000, 36, 737–744. [Google Scholar] [CrossRef]
- El Adlouni, S.; Ouarda, T.B.M.J.; Zhang, X.; Roy, R.; Bobée, B. Generalized maximum likelihood estimators for the nonstationary generalized extreme value model. Water Resour. Res. 2007, 43. [Google Scholar] [CrossRef]
- Dziak, J.J.; Coffman, D.L.; Lanza, S.T.; Li, R. Sensitivity and specificity of information criteria. Briefings Bioinform. 2020, 21, 553–565. [Google Scholar] [CrossRef] [PubMed]
- Camus, P.; Haigh, I.D.; Wahl, T.; Nasr, A.A.; Méndez, F.J.; Darby, S.E.; Nicholls, R.J. Daily synoptic conditions associated with occurrences of compound events in estuaries along North Atlantic coastlines. Int. J. Climatol. 2022, 42, 5694–5713. [Google Scholar] [CrossRef]
- Fawcett, L.; Walshaw, D. Improved estimation for temporally clustered extremes. Environmetrics 2007, 18, 173–188. [Google Scholar] [CrossRef]
- Li, X.; Genest, C.; Jalbert, J. A self-exciting marked point process model for drought analysis. Environmetrics 2021, 32, e2697. [Google Scholar] [CrossRef]
- Yan, J. Enjoy the Joy of Copulas: With a Package copula. J. Stat. Softw. 2007, 21, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Sarhadi, A.; Burn, D.H.; Ausin, M.C.; Wiper, M.P. Time-varying nonstationary multivariate risk analysis using a dynamic Bayesian copula. Water Resour. Res. 2016, 52, 2327–2349. [Google Scholar] [CrossRef]
- Chebana, F.; Ouarda, T.B.M.J. Multivariate non-stationary hydrological frequency analysis. J. Hydrol. 2021, 593, 125907. [Google Scholar] [CrossRef]
- Nagler, T.; Schepsmeier, U.; Stoeber, J.; Brechmann, E.C.; Graeler, B.; Erhardt, T. VineCopula: Statistical Inference of Vine Copulas; 2022. Available online: https://cran.r-project.org/web/packages/VineCopula/VineCopula.pdf (accessed on 9 May 2022).
- Tootoonchi, F.; Sadegh, M.; Haerter, J.O.; Räty, O.; Grabs, T.; Teutschbein, C. Copulas for hydroclimatic analysis: A practice-oriented overview. WIREs Water 2022, 9, e1579. [Google Scholar] [CrossRef]
- Serinaldi, F. Dismissing return periods! Stoch. Environ. Res. Risk Assess. 2015, 29, 1179–1189. [Google Scholar] [CrossRef] [Green Version]
- Volpi, E.; Fiori, A. Design event selection in bivariate hydrological frequency analysis. Hydrol. Sci. J. 2012, 57, 1506–1515. [Google Scholar] [CrossRef]
- Deng, K.; Azorin-Molina, C.; Minola, L.; Zhang, G.; Chen, D. Global Near-Surface Wind Speed Changes over the Last Decades Revealed by Reanalyses and CMIP6 Model Simulations. J. Clim. 2021, 34, 2219–2234. [Google Scholar] [CrossRef]
- Calafat, F.M.; Wahl, T.; Tadesse, M.G.; Sparrow, S.N. Trends in Europe storm surge extremes match the rate of sea-level rise. Nature 2022, 603, 841–845. [Google Scholar] [CrossRef] [PubMed]
- Aas, K.; Czado, C.; Frigessi, A.; Bakken, H. Pair-copula constructions of multiple dependence. Insur. Math. Econ. 2009, 44, 182–198. [Google Scholar] [CrossRef] [Green Version]
- Ahn, K.H. Streamflow estimation at partially gaged sites using multiple-dependence conditions via vine copulas. Hydrol. Earth Syst. Sci. 2021, 25, 4319–4333. [Google Scholar] [CrossRef]
- Almeida, C.; Czado, C.; Manner, H. Modeling high-dimensional time-varying dependence using dynamic D-vine models. Appl. Stoch. Model. Bus. Ind. 2016, 32, 621–638. [Google Scholar] [CrossRef]
- Saint Criq, L.; Gaume, E.; Hamdi, Y.; Ouarda, T.B.M.J. Extreme Sea Level Estimation Combining Systematic Observed Skew Surges and Historical Record Sea Levels. Water Resour. Res. 2022, 58, e2021WR030873. [Google Scholar] [CrossRef]
- Volpi, E.; Fiori, A. Hydraulic structures subject to bivariate hydrological loads: Return period, design, and risk assessment. Water Resour. Res. 2014, 50, 885–897. [Google Scholar] [CrossRef]
- Castelle, B.; Dodet, G.; Masselink, G.; Scott, T. A new climate index controlling winter wave activity along the Atlantic coast of Europe: The West Europe Pressure Anomaly. Geophys. Res. Lett. 2017, 44, 1384–1392. [Google Scholar] [CrossRef] [Green Version]
- Agilan, L.; Umamahesh, N.V. What are the best covariates for developing non-stationary rainfall Intensity-Duration-Frequency relationship? Adv. Water Resour. 2017, 101, 11–22. [Google Scholar] [CrossRef]
- Pokorná, L.; Huth, R. Climate impacts of the NAO are sensitive to how the NAO is defined. Theor. Appl. Climatol. 2015, 119, 639–652. [Google Scholar] [CrossRef]
- El Adlouni, S.; Ouarda, T.B.M.J. Joint Bayesian model selection and parameter estimation of the generalized extreme value model with covariates using birth-death Markov chain Monte Carlo. Water Resour. Res. 2009, 45. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | LR p-v. | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | - | |||||||||||||
| 1 | NWS | ≈0 | ||||||||||||
| 2 | SLP | NWS | ≈0 | |||||||||||
| 3 | SLP | NWS | SST | |||||||||||
| 4 | SLP | NWS | SST | SST | ||||||||||
| 5 | SLP | NWS | SST | SLP | SST |
| Model | LR p-v. | |||||
|---|---|---|---|---|---|---|
| 0 | - | |||||
| 1 | NWS | ≈0 |
| Model | LR p-v. | |||||||
|---|---|---|---|---|---|---|---|---|
| 0 | - | |||||||
| 1 | SST | ≈0 | ||||||
| 2 | NWS | SST | ||||||
| 3 | SLP | NWS | SST |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chapon, A.; Hamdi, Y. A Bivariate Nonstationary Extreme Values Analysis of Skew Surge and Significant Wave Height in the English Channel. Atmosphere 2022, 13, 1795. https://doi.org/10.3390/atmos13111795
Chapon A, Hamdi Y. A Bivariate Nonstationary Extreme Values Analysis of Skew Surge and Significant Wave Height in the English Channel. Atmosphere. 2022; 13(11):1795. https://doi.org/10.3390/atmos13111795
Chicago/Turabian StyleChapon, Antoine, and Yasser Hamdi. 2022. "A Bivariate Nonstationary Extreme Values Analysis of Skew Surge and Significant Wave Height in the English Channel" Atmosphere 13, no. 11: 1795. https://doi.org/10.3390/atmos13111795