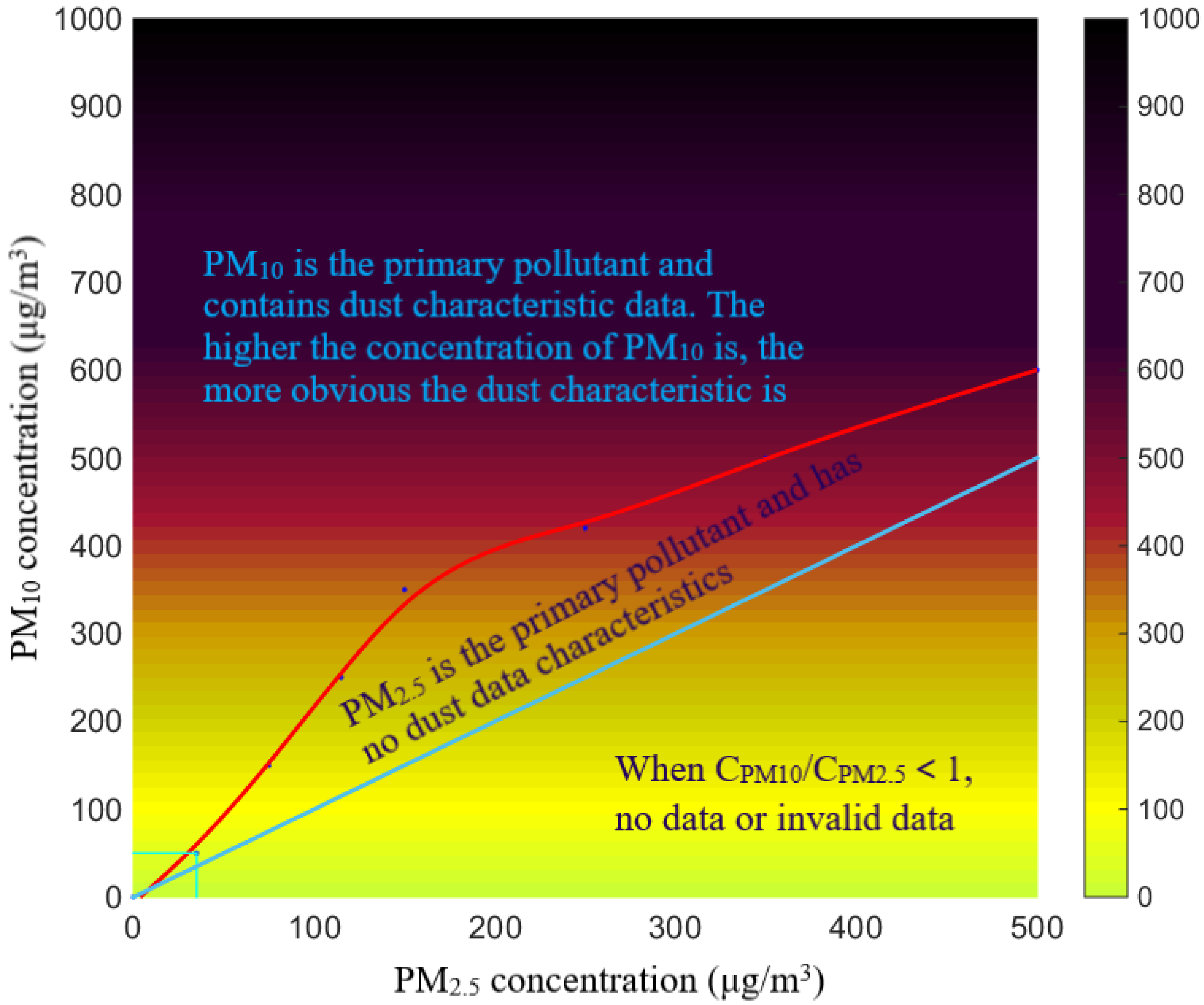
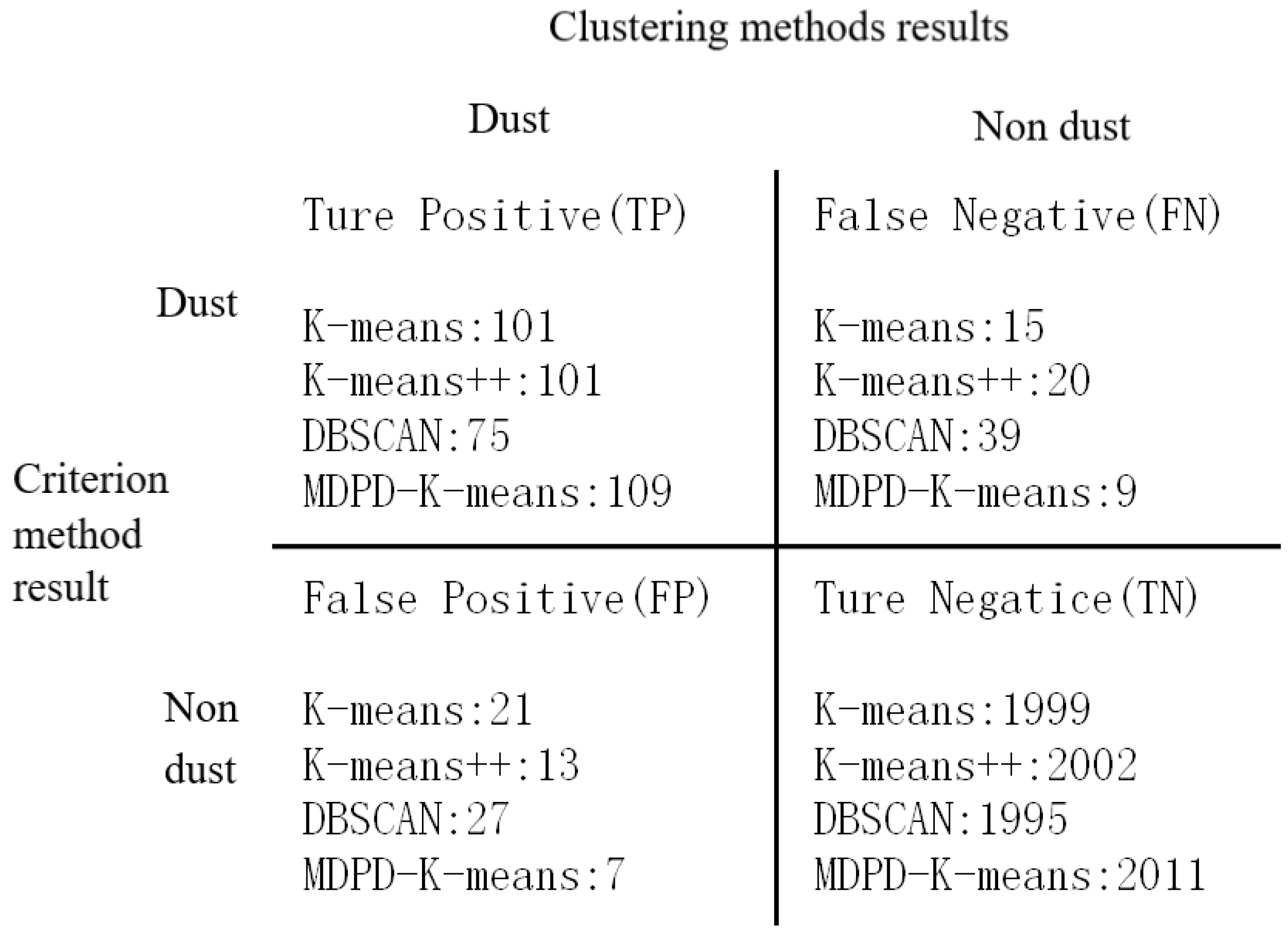
4.2. Characteristics of Data Changes
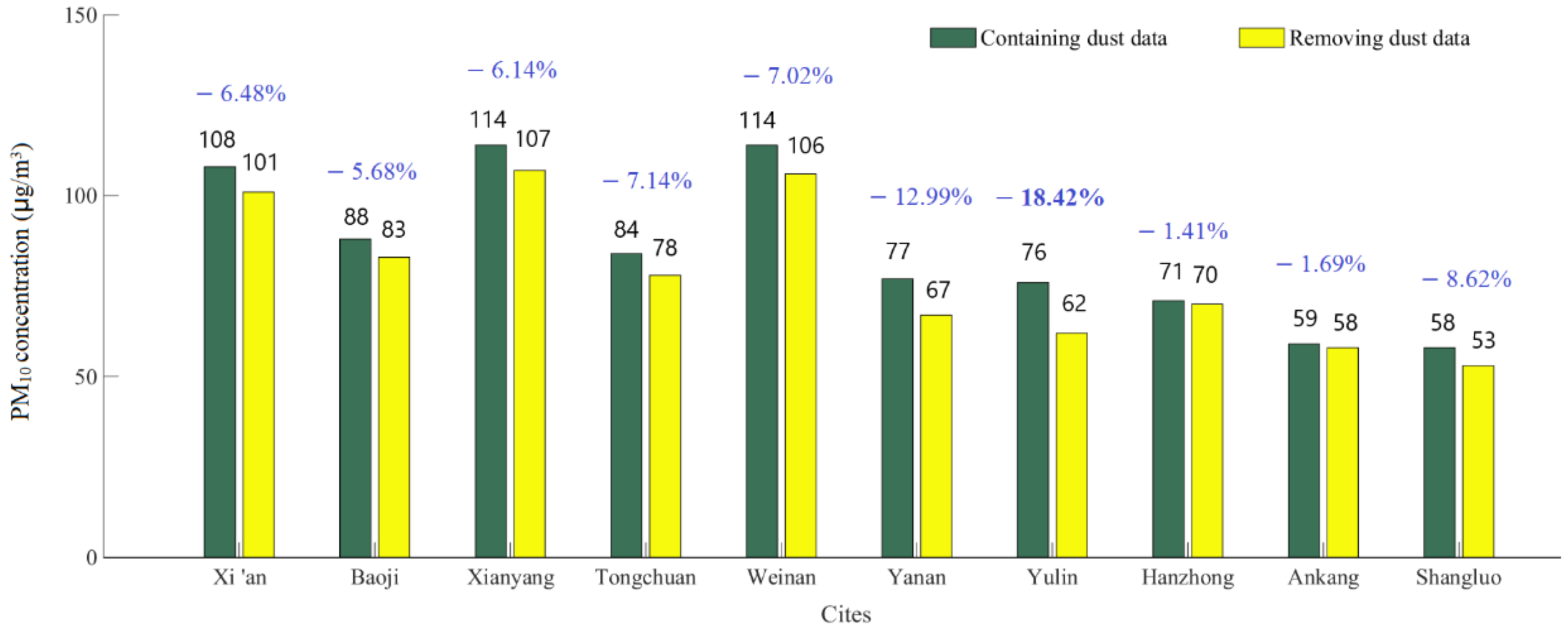
After excluding the impact of sand and dust, the annual average PM
10 concentration in 10 cities has changed to varying degrees. It can be seen from
Figure 6 that from 2016 to 2022, northern Shaanxi is heavily affected by sand and dust. Among them, Yulin is located in the transition zone between the Loess Plateau and the Inner Mongolia Plateau, and is close to the Mu Us Sand source, therefore is most seriously affected by sand and dust, with its PM
10 concentration dropping by 18.42% after excluding the impact of sand and dust. Yan’an is severely affected, with its PM
10 concentration dropping by 12.99%. Hanzhong and Ankang in southern Shaanxi are less affected by sand and dust, and their PM
10 concentrations decrease by 1.41–1.69% after excluding the impact of sand and dust. Shangluo City is at the end of the sand and dust transmission path. Due to the low background value of its urban environment, it is prominently affected by sand and dust, and its PM
10 concentration drops by 8.62% after excluding the impact of sand and dust. Cities in the Guanzhong area all belong to the area affected by sand and dust transmission. Due to the combined effect of sand and dust transmission and local fugitive dust, its PM
10 concentration decreases by 5.68–7.14% after excluding the impact of sand and dust.
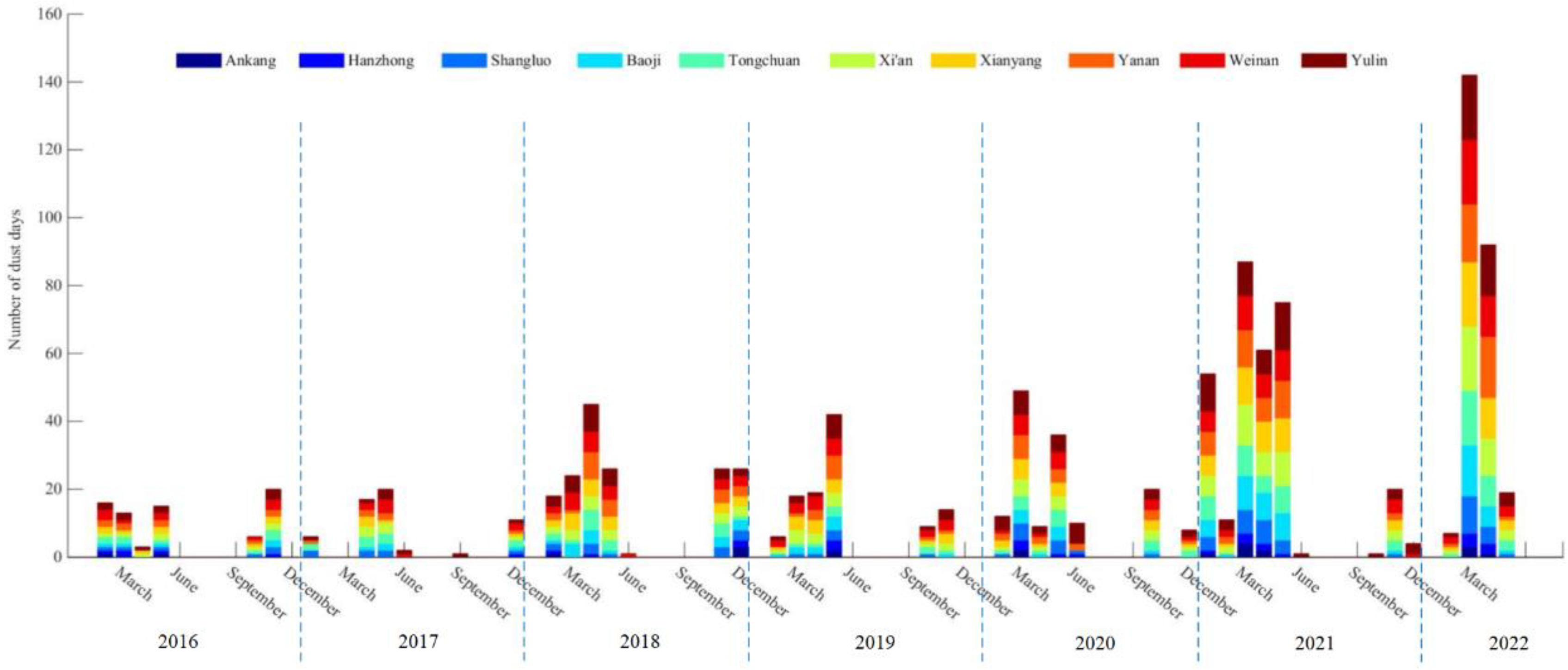
ArcGIS was used to draw the distribution map of sand and dust days in Shaanxi Province from 2016 to 2021. As shown in
Figure 7, from 2016 to 2021, 10 cities in Shaanxi Province experienced sand and dust weather to varying degrees, and the number of days with sand and dust showed an overall upward trend, while the increase was obvious in 2021. The number of times of cities affected by sand and dust gradually increased from south to north. Yulin and Yan’an were frequently affected by sand and dust, and the number of times of impact was increasing year by year. Cities in the Guanzhong region were seriously affected by sand and dust from 2018 to 2020, and the number of sand and dust days was basically the same every year, but it increased significantly in 2021. The southern Shaanxi region was less affected by sand and dust. However, located at the end of the sand and dust transmission path, the number of affected times of Shangluo was higher than that of the other two cities in southern Shaanxi.
From the analysis of topography and transmission path, the sand and dust in the northwest originate from the Hexi Corridor in Gansu and enter the Guanzhong Plain from west to east through Tianshui–Baoji. At the same time, affected by the return of sand and dust in the east, sand and dust remain in Guanzhong and accumulate, causing secondary pollution to the city of Guanzhong, showing the characteristics of intermittent occurrence and decreasing intensity of sand and dust for several consecutive days. Originating from Inner Mongolia and Ningxia, the northern sand and dust travel south through Yulin and Yan’an, enter the Guanzhong Plain from north to south, resulting in a rapid increase in PM10 concentrations in cities along the way, and cross the Qinling Mountains to affect the southern Shaanxi area, mainly Shangluo, showing large-scale, high-intensity sand and dust transport characteristics. The transmission of other northern sand and dust starts from Mongolia and travels south through the Beijing–Tianjin–Hebei region. At the end of the sand and dust transmission process, it usually enters the Guanzhong Plain from Shanxi, which has a certain impact on Xi’an, Xianyang, and Weinan. Through years of sand control and soil erosion control in Shaanxi Province, the impact of local sand and dust has been basically eliminated, and the PM10 concentration has dropped significantly. However, many cities are located in the sand and dust transmission channels, and the sand and dust transmission process leads to a short-term rapid increase in PM10 concentration. Although the concentration of PM10 can be reduced through measures such as regional air pollution prevention and control, it is difficult to effectively reduce the number of sandy and dusty days.
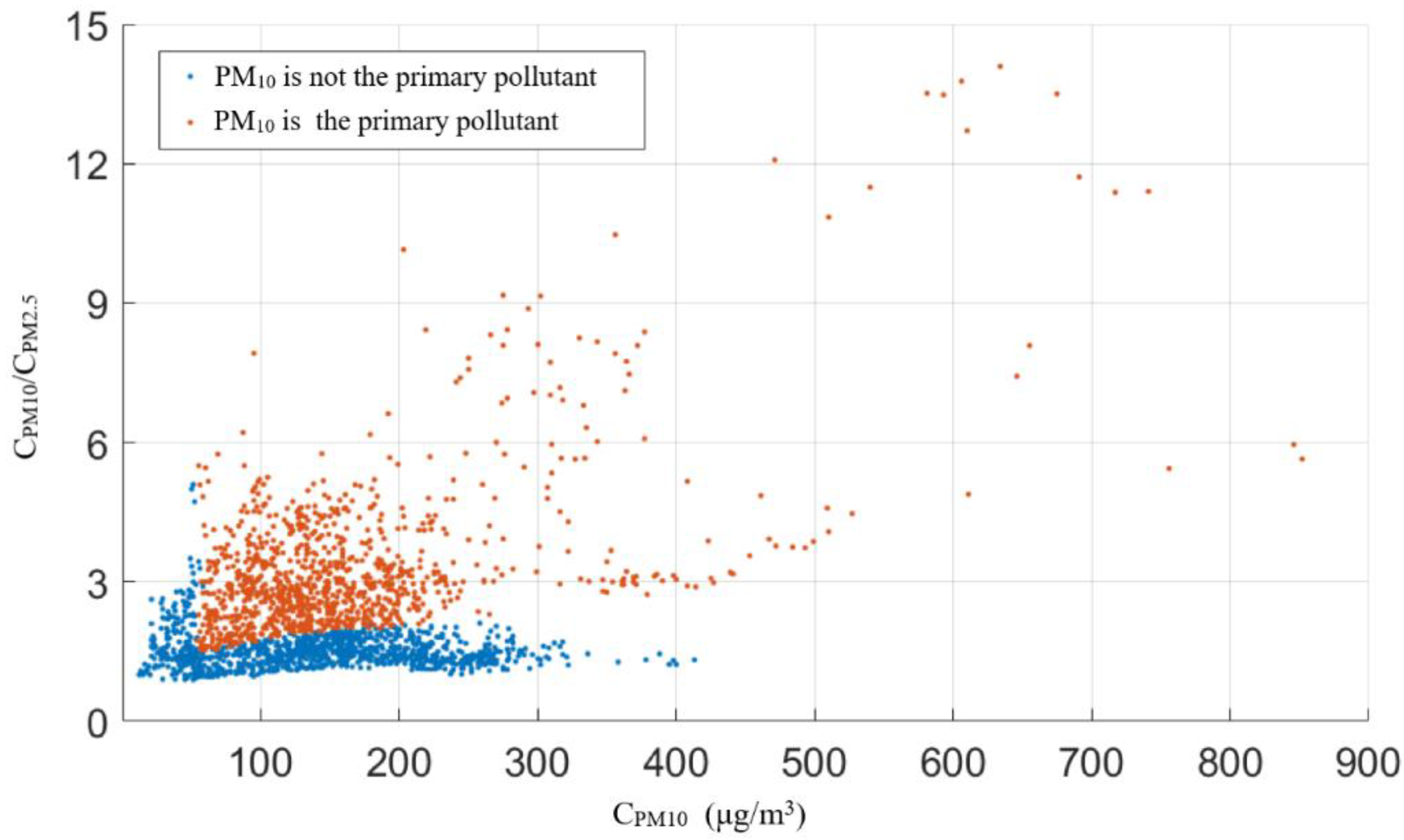
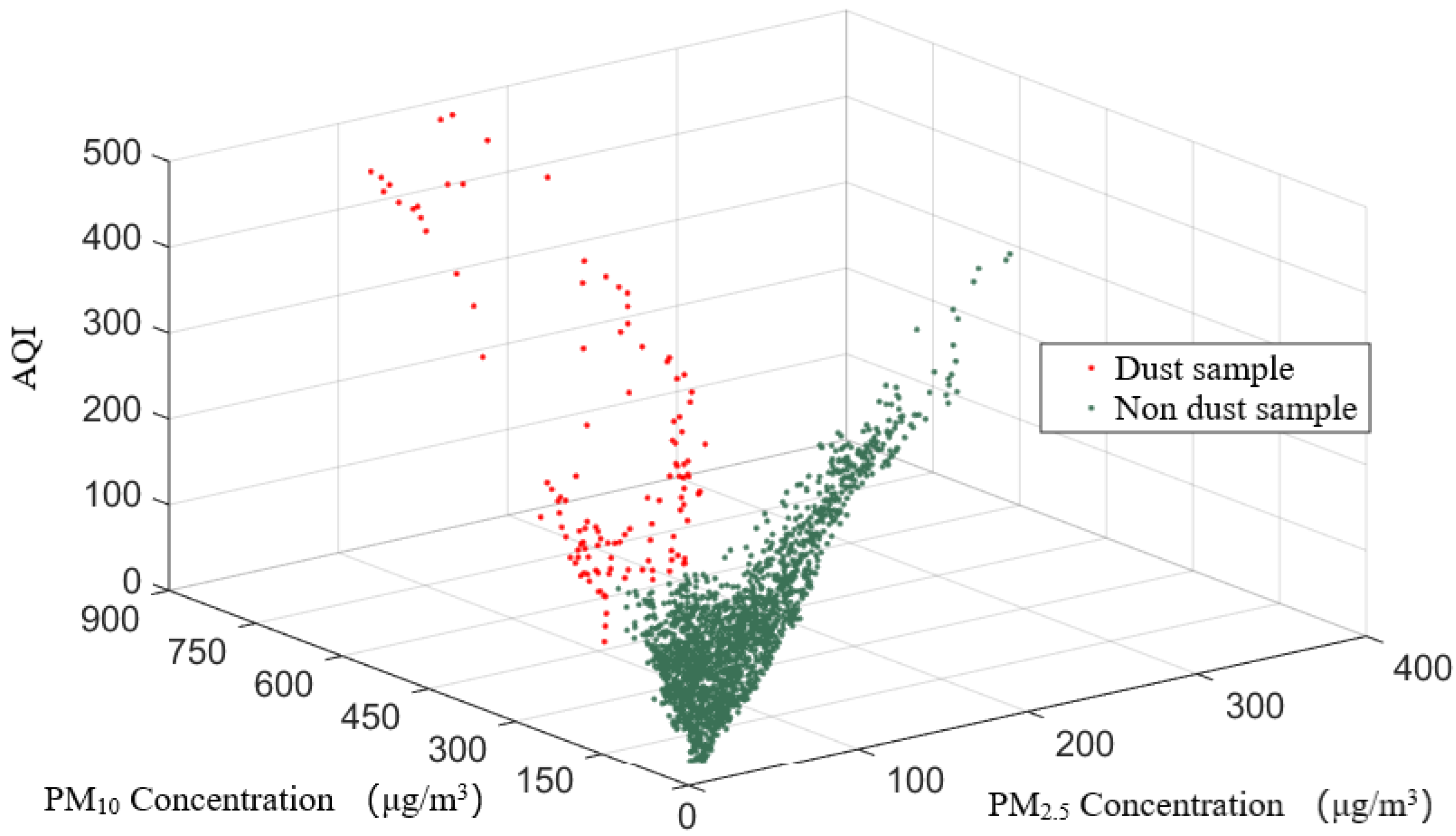
It could be seen from the frequency and distribution of sand and dust weather from 2016 to 2022 shown in
Figure 8 that Shaanxi Province was mainly affected by sand and dust from March to May, and secondarily affected by sand and dust from November to December. The transmission of sand and dust led to a rapid increase in the concentration of PM
10, with more pollution days and heavier pollution level. March was the month with the highest frequency of sand and dust occurrences, accounting for 29.7% of all sand and dust days in Shaanxi Province from 2016 to 2022. Sorting the daily average PM
10 concentration of each sand and dust process from large to small, the highest value of PM
10 daily average concentration appeared in Yulin City, which was 3673 μg/m
3 on 15 March 2021, followed by 2980 μg/m
3 of Yan’an City on 16 March. In addition, in 2021, Yulin and Yan’an had four sand and dust days with an average daily PM
10 concentration of over 1000 μg/m
3, which seriously threatened human health. In Tongchuan, Baoji, Xianyang, Weinan, Xi’an and Shangluo, the average daily concentration of PM
10 exceeded 600 μg/m
3 dust for many times, which seriously affected the ambient air quality. The one with the widest impact was the sand and dust transmission process from 12 to 14 May 2019, which affected all cities in Shaanxi Province, and the average daily PM
10 concentrations in Shangluo on May 12 and 13 were 626 μg/m
3 and 499 μg/m
3. This sand and dust process caused the average annual concentration of PM
10 in Shangluo to increase by 2.7 μg/m
3 in 2019, while the sand dust in the whole year of 2019 caused the average annual concentration of PM
10 in Shangluo to increase by 4.0 μg/m
3 to 58 μg/m
3, causing the excess of the standard (>70 μg/m
3) of PM
10 concentration in the three cities of Yulin, Yan’an and Hanzhong, which was not conducive to air quality evaluation and national ranking. Moreover, the transmission of sand and dust greatly increased the air quality level. From 2016 to 2022, there were 142 days of severe and above pollution caused by sand and dust, accounting for 12.7% of the total number of days with sand and dust, which was not conducive to the reduction of heavily polluted weather. When there is no effective method to control the sand emission conditions in the northern sand source areas, sand prevention and dust suppression measures can be taken to reduce the superimposed pollution of sand and dust transmission and local particle sources. Based on the overall changes in air quality in 10 cities in Shaanxi Province from 2016 to 2022, it can be found that although the ambient air quality shows an overall improvement trend, with the increase in the number of sand and dust occurrences year by year, the proportion of sand and dust transmission on air quality will further increase, thereby reversing the situation of air quality improvement.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}